Иногда может понадобится найти файл, в котором содержится определённая строка или найти строку в файле, где есть нужное слово. В Linux для этого существует несколько утилит, одна из самых используемых это grep. С её помощью можно искать не только строки в файлах, но и фильтровать вывод команд, и много чего ещё.
В этой инструкции мы рассмотрим что такое команда grep Linux, подробно разберём синтаксис и возможные опции grep, а также приведём несколько примеров работы с этой утилитой.
Что такое grep?
Название команды grep расшифровывается как “search globally for lines matching the regular expression, and print them”. Это одна из самых востребованных команд в терминале Linux, которая входит в состав проекта GNU. До того как появился проект GNU, существовала утилита предшественник grep, тем же названием, которая была разработана в 1973 году Кеном Томпсоном для поиска файлов по содержимому в Unix. А потом уже была разработана свободная утилита с той же функциональностью в рамках GNU.
Grep дает очень много возможностей для фильтрации текста. Вы можете выбирать нужные строки из текстовых файлов, отфильтровать вывод команд, и даже искать файлы в файловой системе, которые содержат определённые строки. Утилита очень популярна, потому что она уже предустановлена прочти во всех дистрибутивах.
Синтаксис grep
Синтаксис команды выглядит следующим образом:
$ grep [опции] шаблон [/путь/к/файлу/или/папке…]
Или:
$ команда | grep [опции] шаблон
Здесь:
- Опции – это дополнительные параметры, с помощью которых указываются различные настройки поиска и вывода, например количество строк или режим инверсии.
- Шаблон – это любая строка или регулярное выражение, по которому будет выполняться поиск.
- Имя файла или папки – это то место, где будет выполняться поиск. Как вы увидите дальше, grep позволяет искать в нескольких файлах и даже в каталоге, используя рекурсивный режим.
Возможность фильтровать стандартный вывод пригодится, например, когда нужно выбрать только ошибки из логов или отфильтровать только необходимую информацию из вывода какой-либо другой утилиты.
Опции
Давайте рассмотрим самые основные опции утилиты, которые помогут более эффективно выполнять поиск текста в файлах grep:
- -E, –extended-regexp – включить расширенный режим регулярных выражений (ERE);
- -F, –fixed-strings – рассматривать шаблон поиска как обычную строку, а не регулярное выражение;
- -G, –basic-regexp – интерпретировать шаблон поиска как базовое регулярное выражение (BRE);
- -P, –perl-regexp – рассматривать шаблон поиска как регулярное выражение Perl;
- -e, –regexp – альтернативный способ указать шаблон поиска, опцию можно использовать несколько раз, что позволяет указать несколько шаблонов для поиска файлов, содержащих один из них;
- -f, –file – читать шаблон поиска из файла;
- -i, –ignore-case – не учитывать регистр символов;
- -v, –invert-match – вывести только те строки, в которых шаблон поиска не найден;
- -w, –word-regexp – искать шаблон как слово, отделенное пробелами или другими знаками препинания;
- -x, –line-regexp – искать шаблон как целую строку, от начала и до символа перевода строки;
- -c – вывести количество найденных строк;
- –color – включить цветной режим, доступные значения: never, always и auto;
- -L, –files-without-match – выводить только имена файлов, будут выведены все файлы в которых выполняется поиск;
- -l, –files-with-match – аналогично предыдущему, но будут выведены только файлы, в которых есть хотя бы одно вхождение;
- -m, –max-count – остановить поиск после того как будет найдено указанное количество строк;
- -o, –only-matching – отображать только совпавшую часть, вместо отображения всей строки;
- -h, –no-filename – не выводить имя файла;
- -q, –quiet – не выводить ничего;
- -s, –no-messages – не выводить ошибки чтения файлов;
- -A, –after-content – показать вхождение и n строк после него;
- -B, –before-content – показать вхождение и n строк после него;
- -C – показать n строк до и после вхождения;
- -a, –text – обрабатывать двоичные файлы как текст;
- –exclude – пропустить файлы имена которых соответствуют регулярному выражению;
- –exclude-dir – пропустить все файлы в указанной директории;
- -I – пропускать двоичные файлы;
- –include – искать только в файлах, имена которых соответствуют регулярному выражению;
- -r – рекурсивный поиск по всем подпапкам;
- -R – рекурсивный поиск включая ссылки;
Все самые основные опции рассмотрели, теперь давайте перейдём к примерам работы команды grep Linux.
Примеры использования grep
Давайте перейдём к практике. Сначала рассмотрим несколько основных примеров поиска внутри файлов Linux с помощью grep.
1. Поиск текста в файле
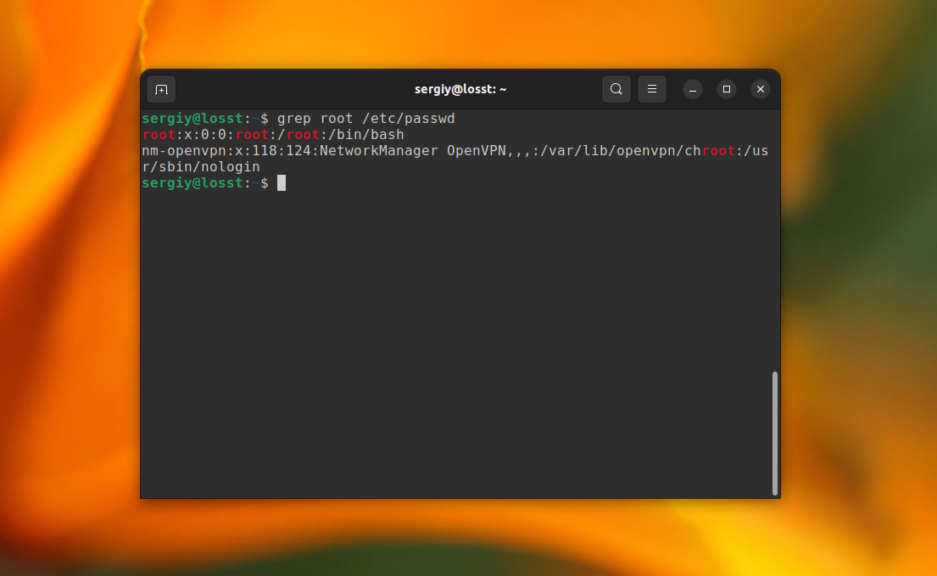
В первом примере мы будем искать информацию о пользователе root в файле со списком пользователей Linux /etc/passwd. Для этого выполните следующую команду:
grep root /etc/passwd
В результате вы получите что-то вроде этого:
С помощью опции -i можно указать, что регистр символов учитывать не нужно. Например, давайте найдём все строки содержащие вхождение слова time в том же файле:
grep -i "time" /etc/passwd
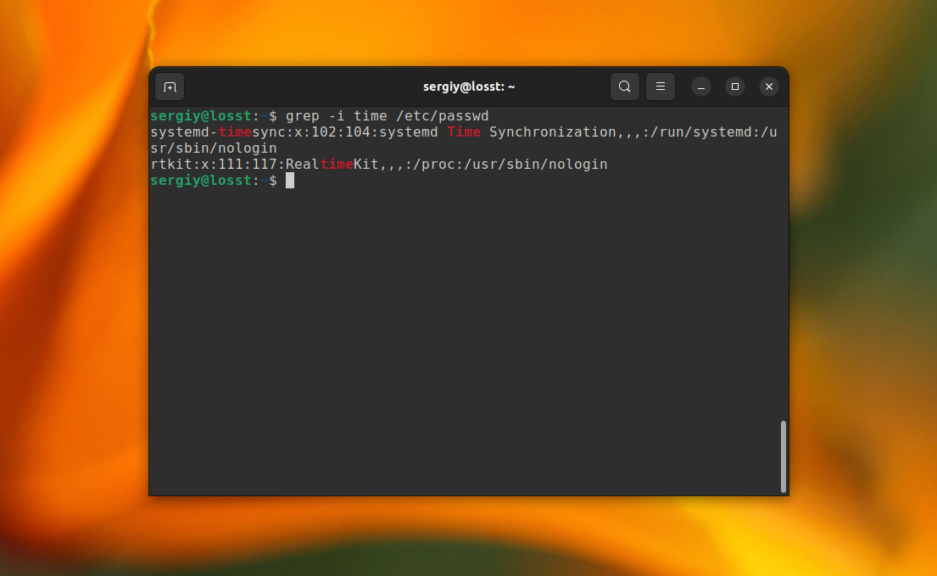
В этом случае Time, time, TIME и другие вариации слова будут считаться эквивалентными. Ещё, вы можете указать несколько условий для поиска, используя опцию -e. Например:
grep -e "root" -e "daemon" /etc/passwd
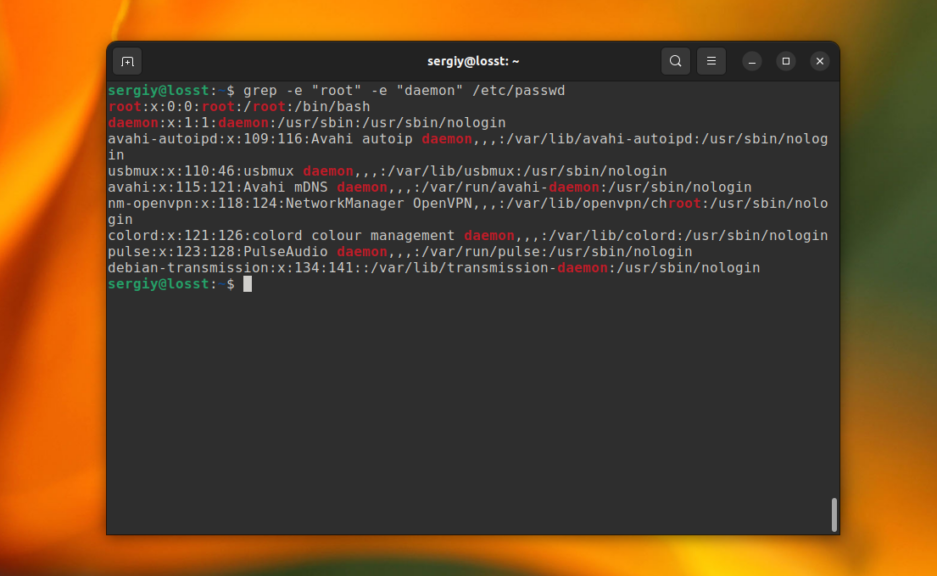
C помощью опции -n можно выводить номер строки, в которой найдено вхождение, например:
grep -n 'root' /etc/passwd
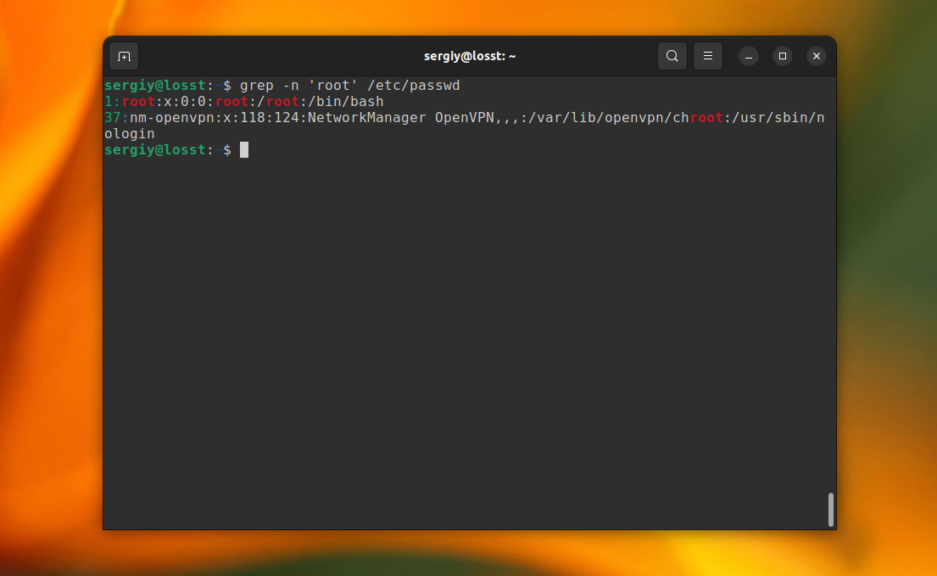
Это всё хорошо работает пока ваш поисковый запрос не содержит специальных символов. Например, если вы попытаетесь найти все строки, которые содержат символ “[” в файле /etc/grub/00_header, то получите ошибку, что это регулярное выражение не верно. Для того чтобы этого избежать, нужно явно указать, что вы хотите искать строку с помощью опции -F:
grep -F "[" /etc/grub.d/00_header
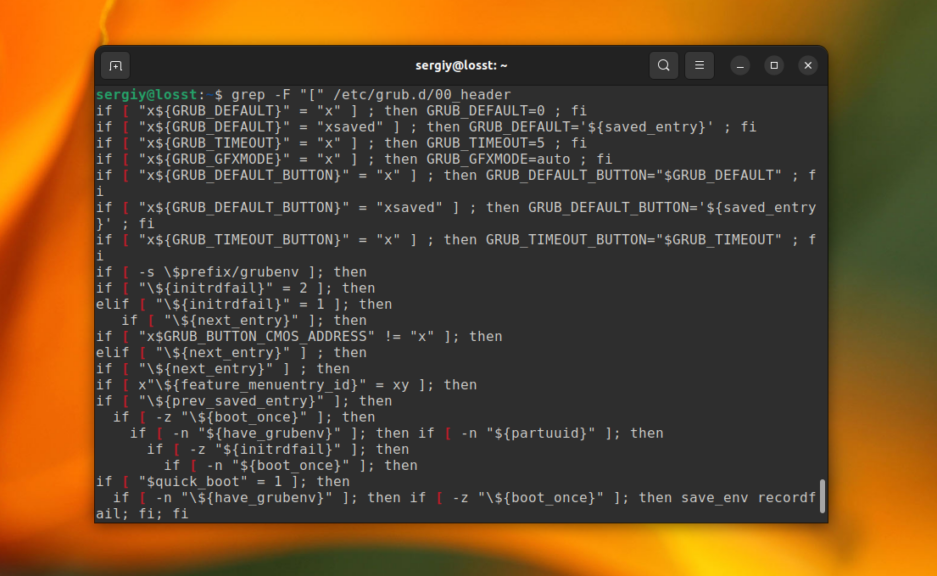
Теперь вы знаете как выполняется поиск текста файлах grep.
2. Фильтрация вывода команды
Для того чтобы отфильтровать вывод другой команды с помощью grep достаточно перенаправить его используя оператор |. А файл для самого grep указывать не надо. Например, для того чтобы найти все процессы gnome можно использовать такую команду:
ps aux | grep "gnome"
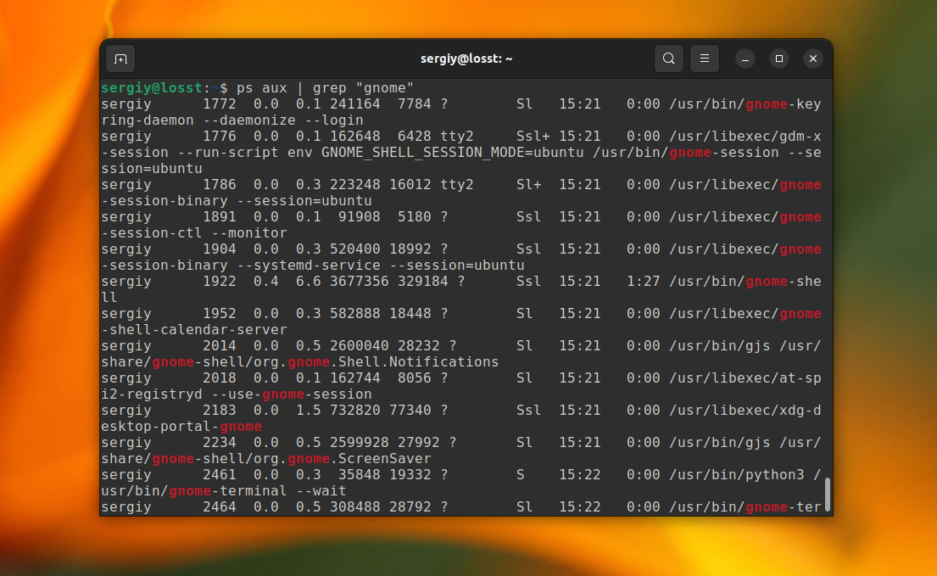
В остальном всё работает аналогично.
3. Базовые регулярные выражения
Утилита grep поддерживает несколько видов регулярных выражений. Это базовые регулярные выражения (BRE), которые используются по умолчанию и расширенные (ERE). Базовые регулярные выражение поддерживает набор символов, позволяющих описать каждый определённый символ в строке. Это: ., *, [], [^], ^ и $. Например, вы можете найти строки, которые начитаются на букву r:
grep "^r" /etc/passwd
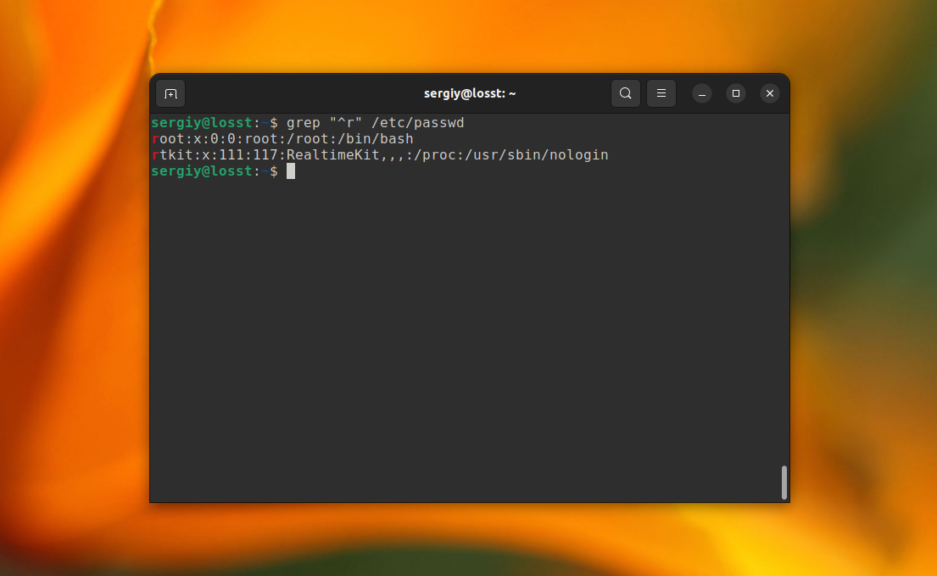
Или же строки, которые содержат большие буквы:
grep "[A-Z]" /etc/passwd
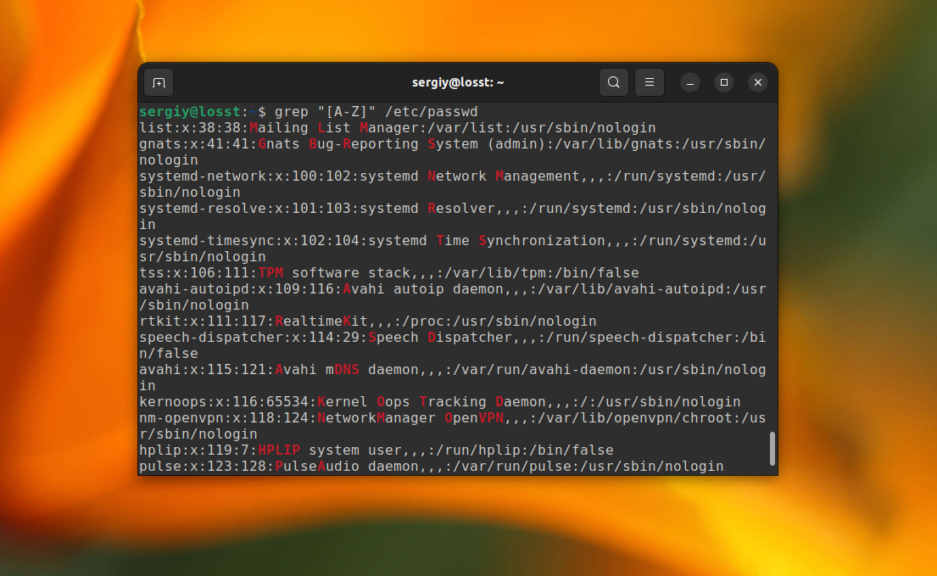
А так можно найти все строки, которые заканчиваются на ready в файле /var/log/dmesg:
grep "ready$" /var/log/dmesg
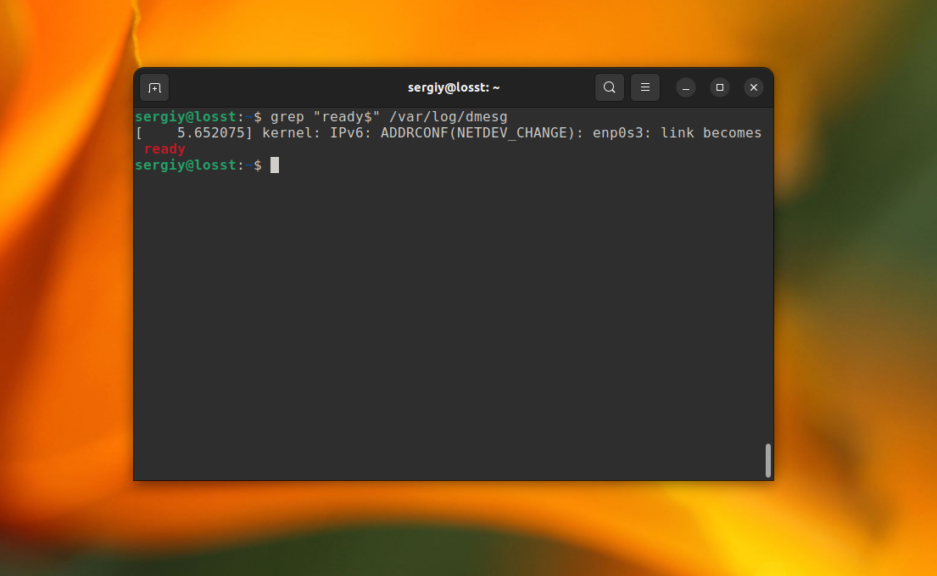
Но используя базовый синтаксис вы не можете указать точное количество этих символов.
4. Расширенные регулярные выражения
В дополнение ко всем символам из базового синтаксиса, в расширенном синтаксисе поддерживаются также такие символы:
- + – одно или больше повторений предыдущего символа;
- ? – ноль или одно повторение предыдущего символа;
- {n,m} – повторение предыдущего символа от n до m раз;
- | – позволяет объединять несколько паттернов.
Для активации расширенного синтаксиса нужно использовать опцию -E. Например, вместо использования опции -e, можно объединить несколько слов для поиска вот так:
grep -E "root|daemon" /etc/passwd
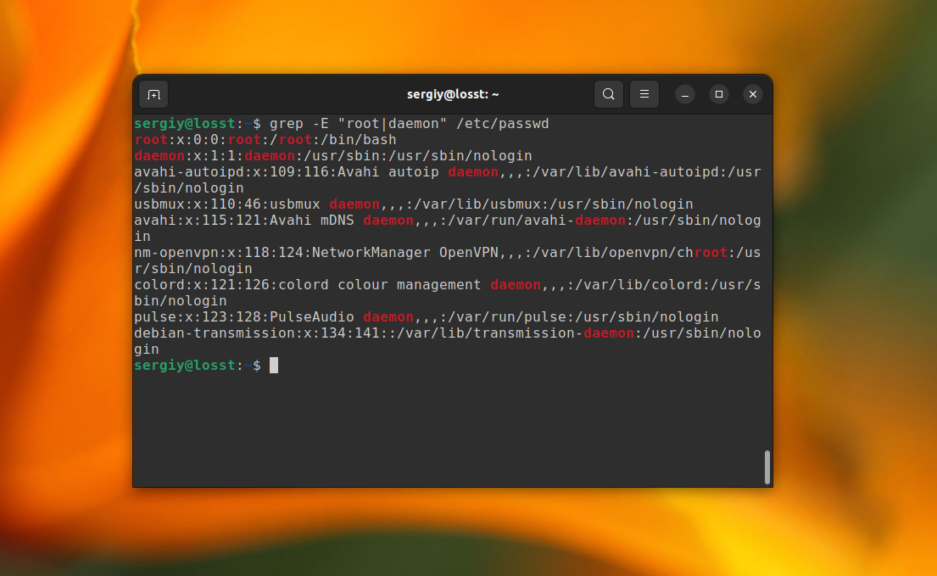
Вообще, регулярные выражения grep – это очень обширная тема, в этой статье я лишь показал несколько примеров. Как вы увидели, поиск текста в файлах grep становиться ещё эффективнее. Но на полное объяснение этой темы нужна целая статья, поэтому пока пропустим её и пойдем дальше.
5. Вывод контекста
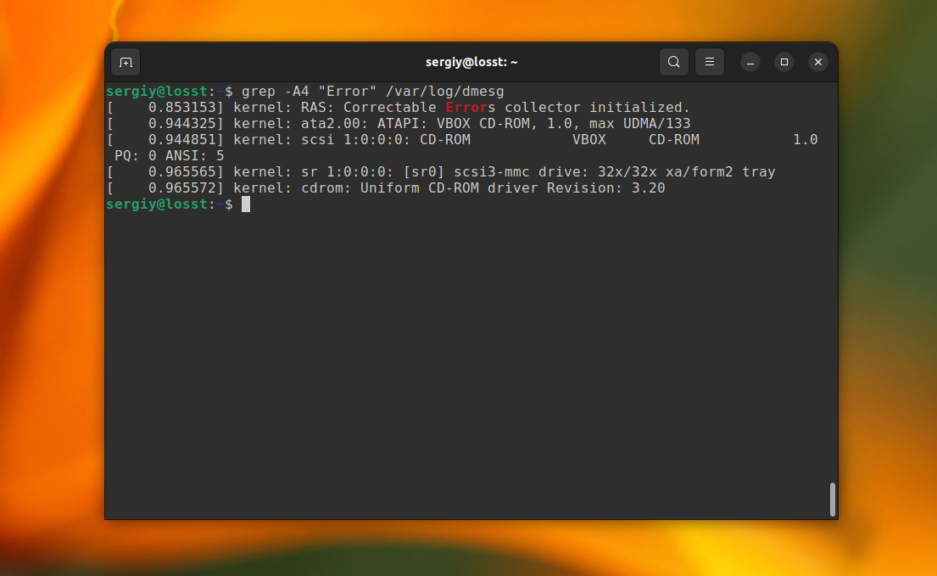
Иногда бывает очень полезно вывести не только саму строку со вхождением, но и строки до и после неё. Например, мы хотим выбрать все ошибки из лог-файла, но знаем, что в следующей строчке после ошибки может содержаться полезная информация, тогда с помощью grep отобразим несколько строк. Ошибки будем искать в /var/log/dmesg по шаблону “Error”:
grep -A4 "Error" /var/log/dmesg
Выведет строку с вхождением и 4 строчки после неё:
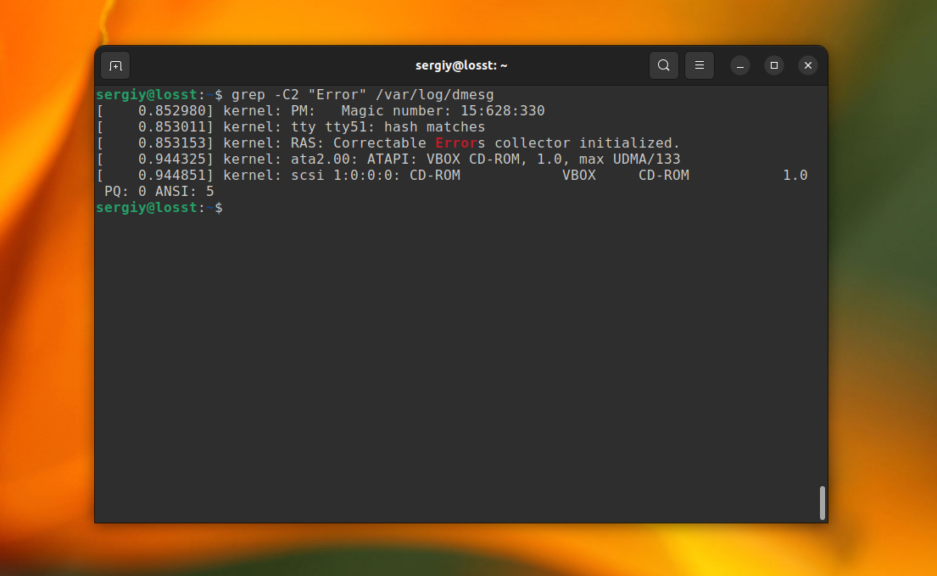
grep -B4 "Error" /var/log/dmesg
Эта команда выведет строку со вхождением и 4 строчки до неё. А следующая выведет по две строки с верху и снизу от вхождения.
grep -C2 "Error" /var/log/dmesg
6. Рекурсивный поиск в grep
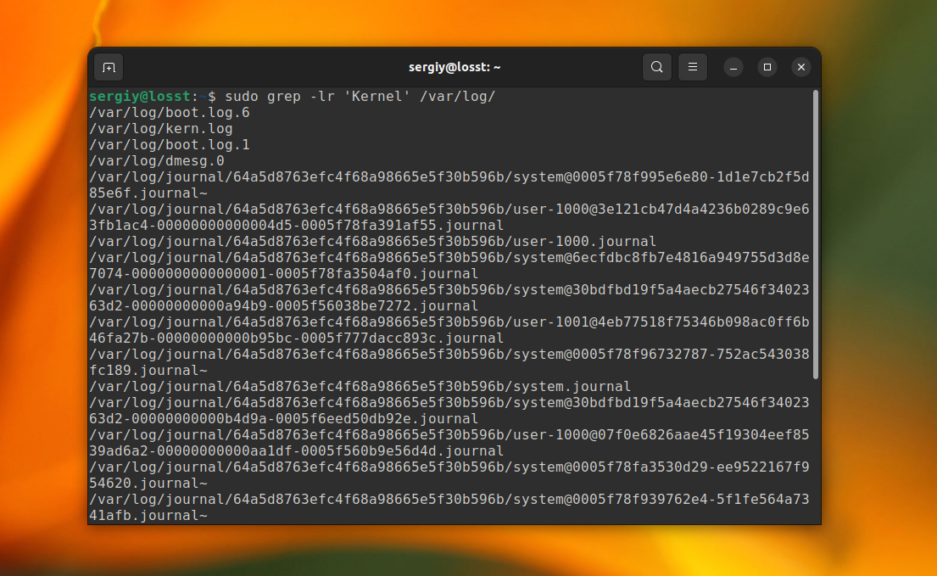
До этого мы рассматривали поиск в определённом файле или выводе команд. Но grep также может выполнить поиск текста в нескольких файлах, размещённых в одном каталоге или подкаталогах. Для этого нужно использовать опцию -r. Например, давайте найдём все файлы, которые содержат строку Kernel в папке /var/log:
grep -r "Kernel" /var/log
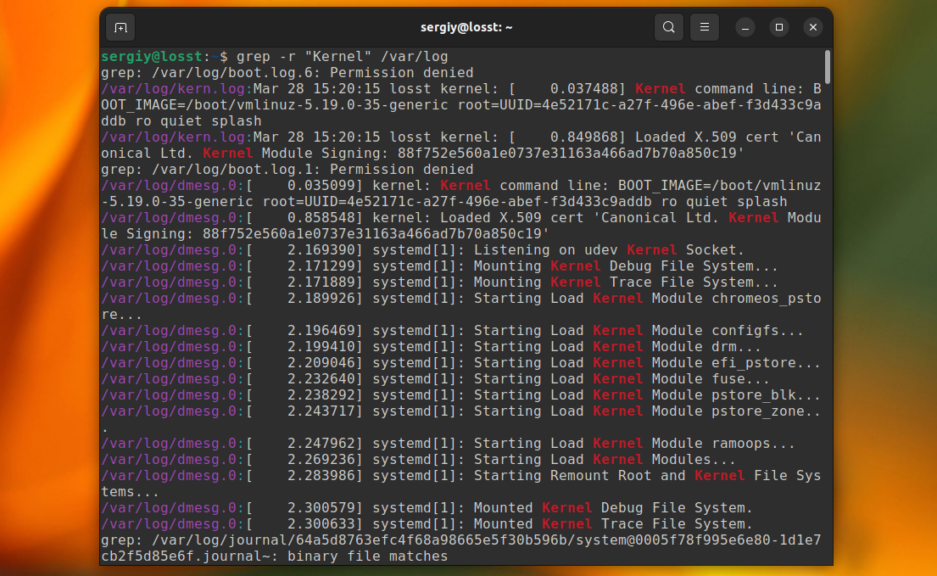
Папка с вашими файлами может содержать двоичные файлы, в которых поиск выполнять обычно не надо. Для того чтобы их пропускать используйте опцию -I:
grep -rI "Kernel" /var/log
Некоторые файлы доступны только суперпользователю и для того чтобы выполнять по ним поиск вам нужно запускать grep с помощью sudo. Или же вы можете просто скрыть сообщения об ошибках чтения и пропускать такие файлы с помощью опции -s:
grep -rIs "Kernel" /var/log
7. Выбор файлов для поиска
С помощью опций –include и –exclude вы можете фильтровать файлы, которые будут принимать участие в поиске. Например, для того чтобы выполнить поиск только по файлам с расширением .log в папке /var/log используйте такую команду:
grep -r --include="*.log" "Kernel" /var/log
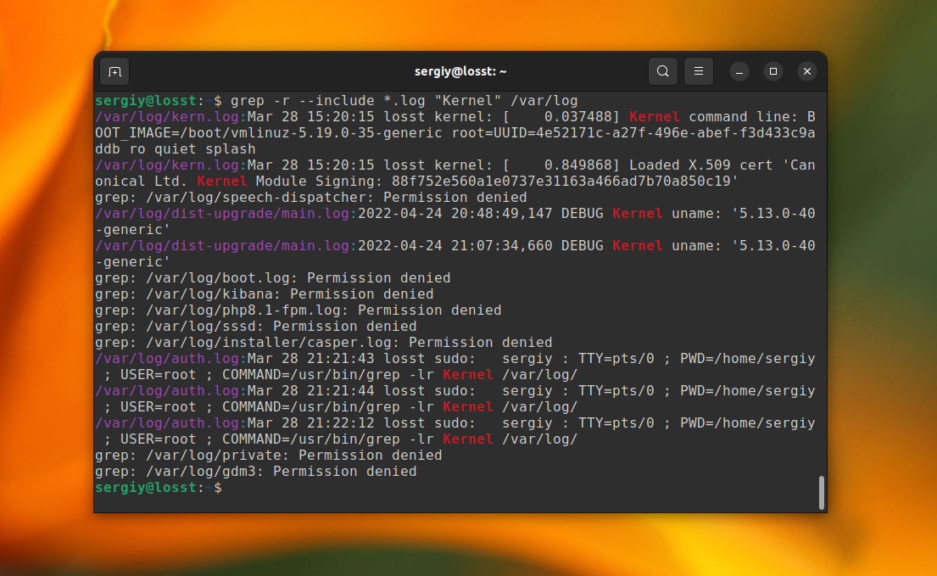
А для того чтобы исключить все файлы с расширением .journal надо использовать опцию –exclude:
grep -r --exclude="*.journal" "Kernel" /var/log
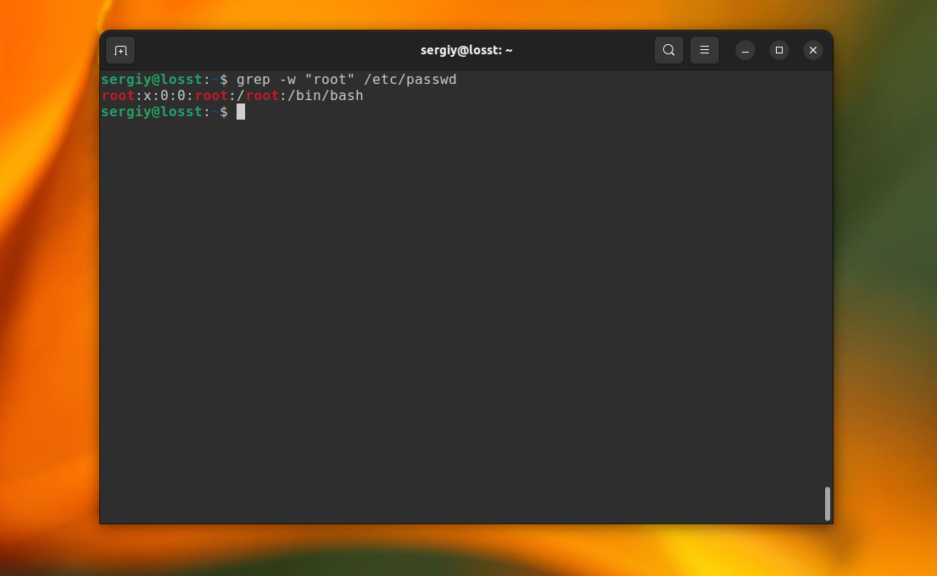
8. Поиск слов в grep
Когда вы ищете строку abc, grep будет выводить также kbabc, abc123, aafrabc32 и тому подобные комбинации. Вы можете заставить утилиту искать по содержимому файлов в Linux строки, которые включают только искомые слова полностью с помощью опции -w. Например:
grep -w "root" /etc/passwd
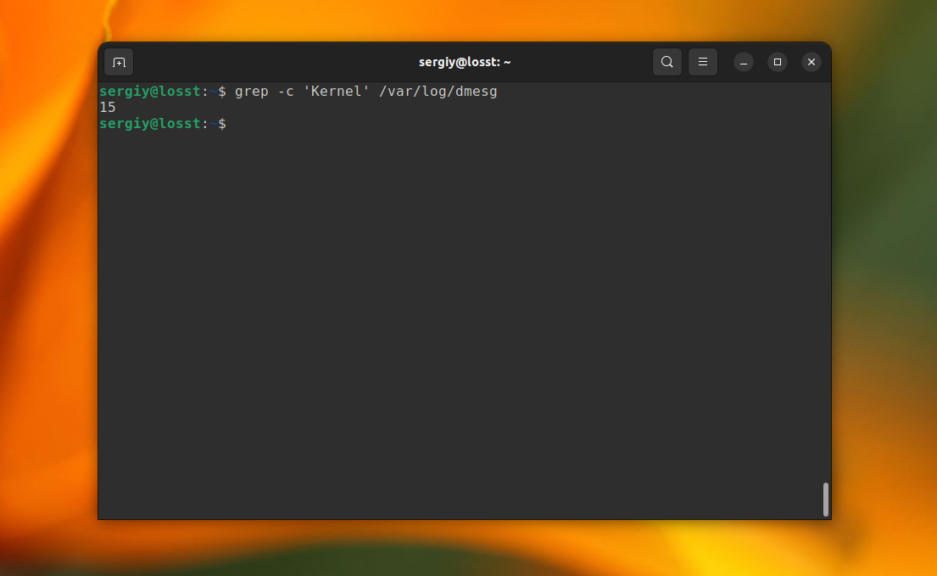
9. Количество строк
Утилита grep может сообщить, сколько строк с определенным текстом было найдено файле. Для этого используется опция -c (счетчик). Например:
grep -c 'Kernel' /var/log/dmesg
10. Инвертированный поиск
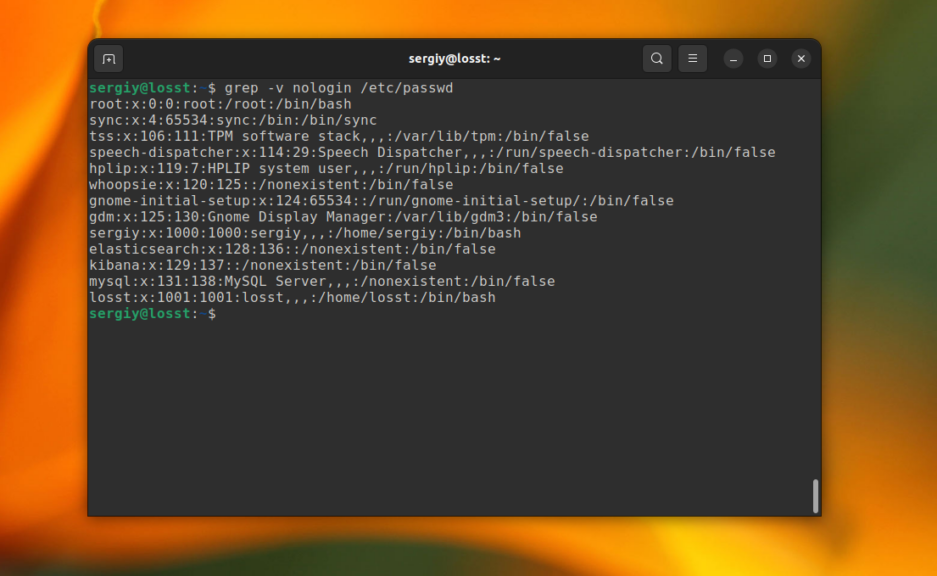
Команда grep Linux может быть использована для поиска строк, которые не содержат указанное слово. Например, так можно вывести только те строки, которые не содержат слово nologin:
grep -v nologin /etc/passwd
11. Вывод имен файлов
Вы можете указать grep выводить только имена файлов, в которых было хотя бы одно вхождение с помощью опции -l. Например, следующая команда выведет все имена файлов из каталога /var/log, при поиске по содержимому которых было обнаружено вхождение Kernel:
grep -lr 'Kernel' /var/log/
12. Цветной вывод
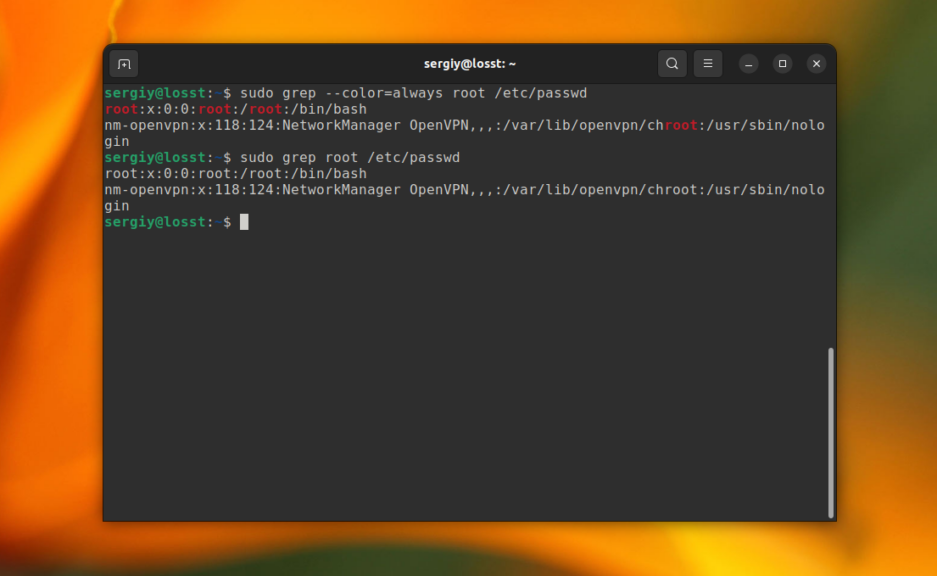
По умолчанию grep не будет подсвечивать совпадения цветом. Но в большинстве дистрибутивов прописан алиас для grep, который это включает. Однако, когда вы используйте команду c sudo это работать не будет. Для включения подсветки вручную используйте опцию –color со значением always:
sudo grep --color=always root /etc/passwd
Получится:
Выводы
Вот и всё. Теперь вы знаете что представляет из себя команда grep Linux, а также как ею пользоваться для поиска файлов и фильтрации вывода команд. При правильном применении эта утилита станет мощным инструментом в ваших руках. Если у вас остались вопросы, пишите в комментариях!
Обнаружили ошибку в тексте? Сообщите мне об этом. Выделите текст с ошибкой и нажмите Ctrl+Enter.

Статья распространяется под лицензией Creative Commons ShareAlike 4.0 при копировании материала ссылка на источник обязательна .
Команда grep означает «печать глобального регулярного выражения», и это одна из самых мощных и часто используемых команд в Linux.
grep ищет в одном или нескольких входных файлах строки, соответствующие заданному шаблону, и записывает каждую соответствующую строку в стандартный вывод. Если файлы не указаны, grep читает из стандартного ввода, который обычно является выводом другой команды.
В этой статье мы покажем вам, как использовать команду grep на практических примерах и подробных объяснениях наиболее распространенных опций GNU grep .
Командный синтаксис grep
Синтаксис команды grep следующий:
grep [OPTIONS] PATTERN [FILE...]
Пункты в квадратных скобках необязательны.
OPTIONS— Ноль или более вариантов. Grep включает ряд опций , управляющих его поведением.-
PATTERN— Шаблон поиска. -
FILE— Ноль или более имен входных файлов.
Чтобы иметь возможность искать файл, пользователь, выполняющий команду, должен иметь доступ для чтения к файлу.
Искать строку в файлах
Наиболее простое использование команды grep — поиск строки (текста) в файле.
Например, чтобы отобразить все строки, содержащие строку bash из файла /etc/passwd , вы должны выполнить следующую команду:
grep bash /etc/passwdРезультат должен выглядеть примерно так:
root:x:0:0:root:/root:/bin/bash
linuxize:x:1000:1000:linuxize:/home/linuxize:/bin/bash
Если в строке есть пробелы, вам нужно заключить ее в одинарные или двойные кавычки:
grep "Gnome Display Manager" /etc/passwdИнвертировать соответствие (исключить)
Чтобы отобразить строки, не соответствующие шаблону, используйте параметр -v (или --invert-match ).
Например, чтобы распечатать строки, не содержащие строковый nologin вы должны использовать:
grep -v nologin /etc/passwdroot:x:0:0:root:/root:/bin/bash
colord:x:124:124::/var/lib/colord:/bin/false
git:x:994:994:git daemon user:/:/usr/bin/git-shell
linuxize:x:1000:1000:linuxize:/home/linuxize:/bin/bash
Использование Grep для фильтрации вывода команды
Вывод команды может быть отфильтрован с помощью grep через конвейер, и на терминал будут напечатаны только строки, соответствующие заданному шаблону.
Например, чтобы узнать, какие процессы выполняются в вашей системе как пользовательские www-data вы можете использовать следующую команду ps :
ps -ef | grep www-datawww-data 18247 12675 4 16:00 ? 00:00:00 php-fpm: pool www
root 18272 17714 0 16:00 pts/0 00:00:00 grep --color=auto --exclude-dir=.bzr --exclude-dir=CVS --exclude-dir=.git --exclude-dir=.hg --exclude-dir=.svn www-data
www-data 31147 12770 0 Oct22 ? 00:05:51 nginx: worker process
www-data 31148 12770 0 Oct22 ? 00:00:00 nginx: cache manager process
Вы также можете объединить несколько каналов по команде. Как вы можете видеть в выходных данных выше, также есть строка, содержащая процесс grep . Если вы не хотите, чтобы эта строка отображалась, передайте результат другому экземпляру grep как показано ниже.
ps -ef | grep www-data | grep -v grepwww-data 18247 12675 4 16:00 ? 00:00:00 php-fpm: pool www
www-data 31147 12770 0 Oct22 ? 00:05:51 nginx: worker process
www-data 31148 12770 0 Oct22 ? 00:00:00 nginx: cache manager process
Рекурсивный поиск
Для рекурсивного поиска шаблона вызовите grep с параметром -r (или --recursive ). Когда используется этот параметр, grep будет искать все файлы в указанном каталоге, пропуская символические ссылки, которые встречаются рекурсивно.
Чтобы следовать по всем символическим ссылкам , вместо -r используйте параметр -R (или --dereference-recursive ).
Вот пример, показывающий, как искать строку linuxize.com во всех файлах внутри каталога /etc :
grep -r linuxize.com /etcВывод будет включать совпадающие строки с префиксом полного пути к файлу:
/etc/hosts:127.0.0.1 node2.linuxize.com
/etc/nginx/sites-available/linuxize.com: server_name linuxize.com www.linuxize.com;
Если вы используете опцию -R , grep будет следовать по всем символическим ссылкам:
grep -R linuxize.com /etcОбратите внимание на последнюю строку вывода ниже. Эта строка не печатается, когда grep вызывается с -r потому что файлы внутри каталога с sites-enabled Nginx являются символическими ссылками на файлы конфигурации внутри каталога с sites-available .
/etc/hosts:127.0.0.1 node2.linuxize.com
/etc/nginx/sites-available/linuxize.com: server_name linuxize.com www.linuxize.com;
/etc/nginx/sites-enabled/linuxize.com: server_name linuxize.com www.linuxize.com;
Показать только имя файла
Чтобы подавить вывод grep по умолчанию и вывести только имена файлов, содержащих совпадающий шаблон, используйте параметр -l (или --files-with-matches ).
Приведенная ниже команда выполняет поиск по всем файлам, заканчивающимся на .conf в текущем рабочем каталоге и выводит только имена файлов, содержащих строку linuxize.com :
grep -l linuxize.com *.confРезультат будет выглядеть примерно так:
tmux.conf
haproxy.conf
Параметр -l обычно используется в сочетании с рекурсивным параметром -R :
grep -Rl linuxize.com /tmpПоиск без учета регистра
По умолчанию grep чувствителен к регистру. Это означает, что символы верхнего и нижнего регистра рассматриваются как разные.
Чтобы игнорировать регистр при поиске, вызовите grep с параметром -i (или --ignore-case ).
Например, при поиске Zebra без какой-либо опции следующая команда не покажет никаких результатов, т.е. есть совпадающие строки:
grep Zebra /usr/share/wordsНо если вы выполните поиск без учета регистра с использованием параметра -i , он будет соответствовать как заглавным, так и строчным буквам:
grep -i Zebra /usr/share/wordsУказание «Зебра» будет соответствовать «зебре», «ZEbrA» или любой другой комбинации букв верхнего и нижнего регистра для этой строки.
zebra
zebra's
zebras
Искать полные слова
При поиске строки grep отобразит все строки, в которых строка встроена в строки большего размера.
Например, если вы ищете «gnu», все строки, в которых «gnu» встроено в слова большего размера, такие как «cygnus» или «magnum», будут найдены:
grep gnu /usr/share/wordscygnus
gnu
interregnum
lgnu9d
lignum
magnum
magnuson
sphagnum
wingnut
Чтобы вернуть только те строки, в которых указанная строка представляет собой целое слово (заключенное в символы, отличные от слов), используйте параметр -w (или --word-regexp ).
Символы слова включают буквенно-цифровые символы ( az , AZ и 0-9 ) и символы подчеркивания ( _ ). Все остальные символы считаются несловесными символами.
Если вы запустите ту же команду, что и выше, включая параметр -w , команда grep вернет только те строки, где gnu включен как отдельное слово.
grep -w gnu /usr/share/wordsgnu
Показать номера строк
Параметр -n (или --line-number ) указывает grep показывать номер строки, содержащей строку, соответствующую шаблону. Когда используется эта опция, grep выводит совпадения на стандартный вывод с префиксом номера строки.
Например, чтобы отобразить строки из файла /etc/services содержащие строку bash префиксом совпадающего номера строки, вы можете использовать следующую команду:
grep -n 10000 /etc/servicesРезультат ниже показывает нам, что совпадения находятся в строках 10423 и 10424.
10423:ndmp 10000/tcp
10424:ndmp 10000/udp
Подсчет совпадений
Чтобы вывести количество совпадающих строк в стандартный вывод, используйте параметр -c (или --count ).
В приведенном ниже примере мы подсчитываем количество учетных записей, в которых в качестве оболочки используется /usr/bin/zsh .
regular expressiongrep -c '/usr/bin/zsh' /etc/passwd
4
Бесшумный режим
-q (или --quiet ) указывает grep работать в тихом режиме, чтобы ничего не отображать на стандартном выводе. Если совпадение найдено, команда завершает работу со статусом 0 . Это полезно при использовании grep в сценариях оболочки, где вы хотите проверить, содержит ли файл строку, и выполнить определенное действие в зависимости от результата.
Вот пример использования grep в тихом режиме в качестве тестовой команды в операторе if :
if grep -q PATTERN filename
then
echo pattern found
else
echo pattern not found
fi
Основное регулярное выражение
GNU Grep имеет три набора функций регулярных выражений : базовый, расширенный и Perl-совместимый.
По умолчанию grep интерпретирует шаблон как базовое регулярное выражение, где все символы, кроме метасимволов, на самом деле являются регулярными выражениями, которые соответствуют друг другу.
Ниже приведен список наиболее часто используемых метасимволов:
-
Используйте символ
^(каретка) для сопоставления выражения в начале строки. В следующем примере строкаkangarooбудет соответствовать только в том случае, если она встречается в самом начале строки.grep "^kangaroo" file.txt -
Используйте символ
$(доллар), чтобы найти выражение в конце строки. В следующем примере строкаkangarooбудет соответствовать только в том случае, если она встречается в самом конце строки.grep "kangaroo$" file.txt -
Используйте расширение
.(точка) символ, соответствующий любому одиночному символу. Например, чтобы сопоставить все, что начинается сkanзатем имеет два символа и заканчивается строкойroo, вы можете использовать следующий шаблон:grep "kan..roo" file.txt -
Используйте
[ ](скобки) для соответствия любому одиночному символу, заключенному в квадратные скобки. Например, найдите строки, содержащиеacceptили «accent, вы можете использовать следующий шаблон:grep "acce[np]t" file.txt -
Используйте
[^ ]для соответствия любому одиночному символу, не заключенному в квадратные скобки. Следующий шаблон будет соответствовать любой комбинации строк, содержащихco(any_letter_except_l)a, напримерcoca,cobaltи т. Д., Но не будет соответствовать строкам, содержащимcola,grep "co[^l]a" file.txt
Чтобы избежать специального значения следующего символа, используйте символ (обратная косая черта).
Расширенные регулярные выражения
Чтобы интерпретировать шаблон как расширенное регулярное выражение, используйте параметр -E (или --extended-regexp ). Расширенные регулярные выражения включают в себя все основные метасимволы, а также дополнительные метасимволы для создания более сложных и мощных шаблонов поиска. Вот несколько примеров:
-
Сопоставьте и извлеките все адреса электронной почты из данного файла:
grep -E -o "b[A-Za-z0-9._%+-][email protected][A-Za-z0-9.-]+.[A-Za-z]{2,6}b" file.txt -
Сопоставьте и извлеките все действительные IP-адреса из данного файла:
grep -E -o '(25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?).(25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?).(25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?).(25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)' file.txt
Параметр -o используется для печати только соответствующей строки.
Поиск нескольких строк (шаблонов)
Два или более шаблонов поиска можно объединить с помощью оператора ИЛИ | .
По умолчанию grep интерпретирует шаблон как базовое регулярное выражение, в котором метасимволы, такие как | теряют свое особое значение, и необходимо использовать их версии с обратной косой чертой.
В приведенном ниже примере мы ищем все вхождения слов fatal , error и critical в файле ошибок журнала Nginx :
grep 'fatal|error|critical' /var/log/nginx/error.logЕсли вы используете опцию расширенного регулярного выражения -E , то оператор | не следует экранировать, как показано ниже:
grep -E 'fatal|error|critical' /var/log/nginx/error.logСтроки печати перед матчем
Чтобы напечатать определенное количество строк перед совпадающими строками, используйте параметр -B (или --before-context ).
Например, чтобы отобразить пять строк ведущего контекста перед совпадающими строками, вы должны использовать следующую команду:
grep -B 5 root /etc/passwdПечатать строки после матча
Чтобы напечатать определенное количество строк после совпадающих строк, используйте параметр -A (или --after-context ).
Например, чтобы отобразить пять строк конечного контекста после совпадающих строк, вы должны использовать следующую команду:
grep -A 5 root /etc/passwdВыводы
Команда grep позволяет искать шаблон внутри файлов. Если совпадение найдено, grep печатает строки, содержащие указанный шаблон.
Подробнее о Grep можно узнать на странице руководства пользователя Grep .
Если у вас есть какие-либо вопросы или отзывы, не стесняйтесь оставлять комментарии.
grep (GNU or BSD)
You can use grep tool to search recursively the current folder, like:
grep -r "class foo" .
Note: -r – Recursively search subdirectories.
You can also use globbing syntax to search within specific files such as:
grep "class foo" **/*.c
Note: By using globbing option (**), it scans all the files recursively with specific extension or pattern. To enable this syntax, run: shopt -s globstar. You may also use **/*.* for all files (excluding hidden and without extension) or any other pattern.
If you’ve the error that your argument is too long, consider narrowing down your search, or use find syntax instead such as:
find . -name "*.php" -execdir grep -nH --color=auto foo {} ';'
Alternatively, use ripgrep.
ripgrep
If you’re working on larger projects or big files, you should use ripgrep instead, like:
rg "class foo" .
Checkout the docs, installation steps or source code on the GitHub project page.
It’s much quicker than any other tool like GNU/BSD grep, ucg, ag, sift, ack, pt or similar, since it is built on top of Rust’s regex engine which uses finite automata, SIMD and aggressive literal optimizations to make searching very fast.
It supports ignore patterns specified in .gitignore files, so a single file path can be matched against multiple glob patterns simultaneously.
You can use common parameters such as:
-i– Insensitive searching.-I– Ignore the binary files.-w– Search for the whole words (in the opposite of partial word matching).-n– Show the line of your match.-C/--context(e.g.-C5) – Increases context, so you see the surrounding code.--color=auto– Mark up the matching text.-H– Displays filename where the text is found.-c– Displays count of matching lines. Can be combined with-H.
The grep filter searches a file for a particular pattern of characters, and displays all lines that contain that pattern. The pattern that is searched in the file is referred to as the regular expression (grep stands for global search for regular expression and print out).
Syntax:
grep [options] pattern [files]
Options Description -c : This prints only a count of the lines that match a pattern -h : Display the matched lines, but do not display the filenames. -i : Ignores, case for matching -l : Displays list of a filenames only. -n : Display the matched lines and their line numbers. -v : This prints out all the lines that do not matches the pattern -e exp : Specifies expression with this option. Can use multiple times. -f file : Takes patterns from file, one per line. -E : Treats pattern as an extended regular expression (ERE) -w : Match whole word -o : Print only the matched parts of a matching line, with each such part on a separate output line. -A n : Prints searched line and nlines after the result. -B n : Prints searched line and n line before the result. -C n : Prints searched line and n lines after before the result.
Sample Commands
Consider the below file as an input.
$cat > geekfile.txt
unix is great os. unix was developed in Bell labs. learn operating system. Unix linux which one you choose. uNix is easy to learn.unix is a multiuser os.Learn unix .unix is a powerful.
1. Case insensitive search : The -i option enables to search for a string case insensitively in the given file. It matches the words like “UNIX”, “Unix”, “unix”.
$grep -i "UNix" geekfile.txt
Output:
unix is great os. unix was developed in Bell labs. Unix linux which one you choose. uNix is easy to learn.unix is a multiuser os.Learn unix .unix is a powerful.
2. Displaying the count of number of matches : We can find the number of lines that matches the given string/pattern
$grep -c "unix" geekfile.txt
Output:
2
3. Display the file names that matches the pattern : We can just display the files that contains the given string/pattern.
$grep -l "unix" * or $grep -l "unix" f1.txt f2.txt f3.xt f4.txt
Output:
geekfile.txt
4. Checking for the whole words in a file : By default, grep matches the given string/pattern even if it is found as a substring in a file. The -w option to grep makes it match only the whole words.
$ grep -w "unix" geekfile.txt
Output:
unix is great os. unix was developed in Bell labs. uNix is easy to learn.unix is a multiuser os.Learn unix .unix is a powerful.
5. Displaying only the matched pattern : By default, grep displays the entire line which has the matched string. We can make the grep to display only the matched string by using the -o option.
$ grep -o "unix" geekfile.txt
Output:
unix unix unix unix unix unix
6. Show line number while displaying the output using grep -n : To show the line number of file with the line matched.
$ grep -n "unix" geekfile.txt
Output:
1:unix is great os. unix is free os. 4:uNix is easy to learn.unix is a multiuser os.Learn unix .unix is a powerful.
7. Inverting the pattern match : You can display the lines that are not matched with the specified search string pattern using the -v option.
$ grep -v "unix" geekfile.txt
Output:
learn operating system. Unix linux which one you choose.
8. Matching the lines that start with a string : The ^ regular expression pattern specifies the start of a line. This can be used in grep to match the lines which start with the given string or pattern.
$ grep "^unix" geekfile.txt
Output:
unix is great os. unix is free os.
9. Matching the lines that end with a string : The $ regular expression pattern specifies the end of a line. This can be used in grep to match the lines which end with the given string or pattern.
$ grep "os$" geekfile.txt
10.Specifies expression with -e option. Can use multiple times :
$grep –e "Agarwal" –e "Aggarwal" –e "Agrawal" geekfile.txt
11. -f file option Takes patterns from file, one per line.
$cat pattern.txt Agarwal Aggarwal Agrawal
$grep –f pattern.txt geekfile.txt
12. Print n specific lines from a file: -A prints the searched line and n lines after the result, -B prints the searched line and n lines before the result, and -C prints the searched line and n lines after and before the result.
Syntax:
$grep -A[NumberOfLines(n)] [search] [file] $grep -B[NumberOfLines(n)] [search] [file] $grep -C[NumberOfLines(n)] [search] [file]
Example:
$grep -A1 learn geekfile.txt
Output:
learn operating system. Unix linux which one you choose. -- uNix is easy to learn.unix is a multiuser os.Learn unix .unix is a powerful. (Prints the searched line along with the next n lines (here n = 1 (A1).) (Will print each and every occurrence of the found line, separating each output by --) (Output pattern remains the same for -B and -C respectively) Unix linux which one you choose. -- uNix is easy to learn.unix is a multiuser os.Learn unix .unix is a powerful. Unix linux which one you choose. -- uNix is easy to learn.unix is a multiuser os.Learn unix .unix is a powerful.
13. Search recursively for a pattern in the directory: -R prints the searched pattern in the given directory recursively in all the files.
Syntax
$grep -R [Search] [directory]
Example :
$grep -iR geeks /home/geeks
Output:
./geeks2.txt:Well Hello Geeks ./geeks1.txt:I am a big time geek ---------------------------------- -i to search for a string case insensitively -R to recursively check all the files in the directory.
This article is contributed by Akshay Rajput. If you like GeeksforGeeks and would like to contribute, you can also write an article using write.geeksforgeeks.org or mail your article to review-team@geeksforgeeks.org. See your article appearing on the GeeksforGeeks’ main page and help other Geeks.
Please write comments if you find anything incorrect, or you want to share more information about the topic discussed above.
Last Updated :
15 Nov, 2022
Like Article
Save Article

В статье про поиск файлов и папок мы говорили про команду find и том, как ее использовать на сервере для оптимального поиска чего-либо. Но в арсенале системного администратора Linux-сервера также имеется команда под названием grep, про которую сегодня хочу рассказать читателям и подписчикам. Давайте познакомимся с ней, поймем в чем разница между find и grep и когда лучше использовать каждую команду.
Поиск файлов и папок через терминал в Linux-дистрибутивах
Не забываем также подписаться на обновления канал Просто Код в телеграме. Так вы будете получать уведомления о новых постах быстрее, чем уведомляет об этом Дзен.
Что делает команда GREP?
GREP расшифровывается как Global Regular Expression Print, что говорит о том, что она используется для поиска строк и шаблонов в группе файлов или папок, а также среди данных, которыми оперируют другие команды и процессы на сервере. Как это часто бывает в Linux, это не просто название команды, а отдельная системная и консольная утилита. В основе работы утилиты лежит расширенный синтаксис регулярных выражений, который появился в UNIX-системах 1981 году. GREP встречается во всех дистрибутивах Linux.
Синтаксис команды
Познакомимся с синтаксисом (то есть, правилами написания) команды grep.
grep [опции] [регулярное выражение] [место поиска – файл или директория]
Но чаще всего grep используется в качестве команды, которой передают «выхлоп» (то есть, результат работы) другой команды для фильтрации и конечного вывода в терминал.
Фильтруем «выхлоп» других команд
Вспомним про команду ls, которая выводит списком содержимое директории. В тестовом примере ниже у меня есть папка Test, внутри которой есть как файлы, так и папки. Файлы имеют имя File<набор_символов>, папки названы как Folder<набор_символов>. Мне нужно показать только папки и единственное, что я помню – это то, что каждая папка имеет имя Folder. Воспользуемся командами ls и grep, чтобы реализовать задуманное
ls | grep Folder
Символ прямой черты | еще называют «трубкой», он принимает выходные данные одной команды и передает их следующей в качестве входных данных. То есть, мы передали «выхлоп» команды ls в качестве входных данных команде grep, которая отфильтровала результаты и показала только то, что содержит в имени Folder. В моем примере папок всего четыре, но представьте, если бы их было несколько десятков и сотен – тогда бы подобная фильтрация сильно сэкономила время.

В следующем примере нам нужны и файлы, и папки, которые имеют в имени какую-либо постоянную часть. Это может быть имя сервера, дата бэкапа и пр.
ls | grep ABC
Ну, и наконец, более практичный пример. Очень часто на сервере нужно посмотреть какой порт «прослушивается» каким-либо процессом или программой. Для этого тоже можно использовать команду grep, чтобы отфильтровать значения до нужных. В команде ниже я вывожу порты, которые слушает протокол ssh.
sudo netstat -lntup | grep “ssh”
Поиск строк в файлах
Представим ситуацию, что у вас есть папка с сайтом. И внутри множества файлов этого сайта нужно найти конкретное слово. Не вручную же перебирать все файлы! Для этого тоже можно использовать команду grep. Например, среди пяти файлов в папке Test попробуем найти те, где используется слово «grep»:
grep -R “grep” Test
Если нам необходимо объединить выражения и осуществить поиск нескольких строк, то нужно использовать ключ -e. Это своего рода указание «или» для утилиты. Попробуем найти среди наших файлов те, где встречаются слова «grep» или «php»:
grep -R -e “grep” -e “php” Test
Также вместо папки мы можем указать имя конкретного файла (убрав перед этим ключ -R) и попытаться найти нужные строки в нем.
grep “grep” <имя_файла>
Если в файле не будет ничего найдено, то команда вернет пустую строку.
Для расширения возможностей поиска строк в файлах можно использовать следующие ключи и так называемые якоря:
- grep -i – поиск без учета регистра
- grep -w – поиск по всему слову
- grep -v – обратный поиск (то есть, он вернет все, что не соответствует заданной после строке)
- grep -r -L – вернет имена файлов, в которых отсутствует заданный после шаблон для поиска
- grep -n – выведет не просто найденную строку, но и укажет ее номер в документе
- grep -A<количество> – выводит найденную строку и следующую строку после совпадения, количество выводимых строк можно менять
- grep -B<количество> – выводит найденную строку и предыдущую строку до совпадения, количество выводимых строк можно менять
- grep -C<количество> – выводит найденную строку и строки до и после совпадения, количество выводим строк можно менять
- grep -q – запуск команды в тихом режиме, после выполнения она просто сохранит код статуса в системной переменной $? (если 0, то совпадения есть, если 1, то совпадений нет); такой метод используют в скриптах для проверки условий, когда не нужно выводить конкретную заданную строку.
- grep “^” – якорь ^ говорит, что совпадение должно быть в начале строки
- grep “$” – якорь $ говорит, что совпадение должно быть в конце строки
- grep “<” – якорь < привязывает совпадение к началу слов
- grep “>” – якорь > привязывает совпадение к концу слов
Поиск при помощи регулярных выражений (regular expression)
По-настоящему функционал grep раскрывается при использовании регулярных выражений. Раскрыть возможности их использования в одной статье невозможно, поэтому думаю, что работе с регулярными выражениями можно посвятить отдельную статью. Давайте договоримся о том, что если такая статья вам интересна, то вы поставите этому посту лайк и как только их наберется 15 штук, я подготовлю материал по regular expression.
Отличия grep и find
Отличия между двумя командами следующие:
- команду grep лучше использовать для поиска содержимого внутри файлов и папок, тогда как find идеально подойдет если вы желаете найти сам файл или папку (она и найдет, и путь нужный выведет).
- команда find используется для поиска полных имен файлов и папок в системе, тогда как grep лучше использовать для нечеткого запроса (если уж вы все же решитесь искать файлы и папки с помощью grep)
- команда find использует для поиск стандартные (системные) шаблоны, тогда как в grep такие шаблоны может задавать пользователь
Итог
Тема использования grep обширна, на самом деле, там есть огромное количество полезных штук, лишь только часть из них я показал в рамках материала. Задача статьи – не рассказать про grep ВСЕ, а познакомить новичков с этой утилитой и мотивировать ее изучать и использовать на практике. Думаю, что в комментариях опытные подписчики и читатели смогут дополнить материал нужной информацией и конкретными примерами использования grep.
Давайте же поддержим канал подпиской, лайком и комментариями, ведь чем больше активности вы проявляете, тем чаще алгоритмы Дзена показывают посты в ленте рекомендаций.
Если не подписались на уведомления канала в Телеграм, то самое время сделать это, ведь информация о новых заметках приходит там сразу в момент публикации!
