![]()
Загрузить PDF
![]()
Загрузить PDF
В статистике абсолютная частота показывает, какое количество раз конкретное значение появляется в наборе данных. В отличие от нее, накопительная частота показывает сумму (или нарастающий итог) всех частот вплоть до текущей точки в наборе данных. Не беспокойтесь, если поначалу это кажется не совсем понятным: возьмите ручку и лист бумаги, и вы быстро во всем разберетесь!
-

1
Отсортируйте набор данных. «Набор данных» — это просто изучаемый вами список числовых значений. Отсортируйте его так, чтобы числа располагались по возрастанию.[1]
- Пример: предположим, список чисел представляет собой количество книг, которые каждый студент прочитал за последний месяц. После сортировки у вас получился следующий набор чисел: 3, 3, 5, 6, 6, 6, 8.
-
2
Посчитайте абсолютную частоту каждой величины. Частота значения показывает, сколько раз данное значение появляется в наборе данных. Это число можно называть абсолютной частотой, чтобы не путать его с накопительной частотой. Наиболее простой способ заключается в том, чтобы составить таблицу. Вверху левой колонки напишите «Значение» (или укажите, что измеряется данными числами). Вверху второй колонки напишите «Частота». Заполните таблицу для всех значений из списка.[2]
- Пример: вверху левой колонки напишите «Количество книг», а вверху правой колонки — «Частота».
- Во второй строке напишите первое количество прочитанных книг, то есть число 3.
- Посчитайте, сколько раз число 3 встречается в списке данных. В списке есть два числа 3, поэтому во второй строке колонки «Частота» запишите цифру 2.
- Повторите данную процедуру для всех значений списка, пока не заполните таблицу:
- 3 | Ч = 2
- 5 | Ч = 1
- 6 | Ч = 3
- 8 | Ч = 1
-
3
Найдите накопительную частоту для первого значения. Накопительная частота отвечает на вопрос «сколько раз встречается в списке данное значение или меньшая величина?». Всегда начинайте с наименьшего значения в наборе данных. Поскольку в нашем примере нет меньших значений, для данной величины накопительная частота равна абсолютной.[3]
-
Пример: наименьшее значение равно 3. Количество прочитавших 3 книги студентов составляет 2. Никто из студентов не прочитал меньшее число книг, поэтому накопительная частота равна 3. Впишите это значение в третью колонку таблицы:
- 3 | F = 2 | НЧ=2
-
Пример: наименьшее значение равно 3. Количество прочитавших 3 книги студентов составляет 2. Никто из студентов не прочитал меньшее число книг, поэтому накопительная частота равна 3. Впишите это значение в третью колонку таблицы:
-
4
Найдите накопительную частоту для следующей величины. Перейдите к следующему значению списка. Выше мы определили, сколько раз встречается в списке наименьшая величина. Чтобы определить накопительную частоту для второго значения списка, необходимо прибавить его абсолютную частоту к накопительной частоте предыдущего значения. Иными словами, следует взять последнюю накопительную частоту и прибавить к ней абсолютную частоту данной величины.[4]
-
Пример:
- 3 | Ч = 2 | НЧ = 2
- 5 | Ч = 1 | НЧ = 2+1 = 3
-
Пример:
-
5
Повторите процедуру для остальных значений. Постепенно продвигайтесь к более высоким числам. При этом каждый раз прибавляйте текущую абсолютную частоту к последней накопительной частоте.
-
Пример:
- 3 | Ч = 2 | НЧ = 2
- 5 | Ч = 1 | НЧ = 2 + 1 = 3
- 6 | Ч = 3 | НЧ = 3 + 3 = 6
- 8 | Ч = 1 | НЧ = 6 + 1 = 7
-
Пример:
-
6
Проверьте полученные результаты. В итоге вы сложите абсолютные частоты всех значений списка. Конечная накопительная частота должна соответствовать числу значений в списке. Есть два способа проверить, так ли это:
- Сложите абсолютные частоты всех значений: 2 + 1 + 3 + 1 = 7, в результате у вас получится накопительная частота.
- Посчитайте число значений в наборе данных. В нашем примере список имел следующий вид: 3, 3, 5, 6, 6, 6, 8. В этом списке семь величин, и итоговая накопительная частота также равна 7.
Реклама






-
1
Поймите разницу между дискретными и непрерывными данными. Дискретные данные можно посчитать, они не дробятся на более мелкие составляющие. Непрерывные данные часто не поддаются конечному счету, между двумя произвольными величинами обязательно найдутся другие возможные значения. Ниже приведена пара примеров:[5]
- Количество собак является дискретным множеством. Нет такого понятия, как половина собаки.
- Глубина снега представляет собой непрерывное множество. Она возрастает постепенно и непрерывно, а не на дискретные величины. Если вы измерите глубину снега в сантиметрах, то точное значение может оказаться, например, 20,6 сантиметра.
-
2
Разбейте непрерывные данные на интервалы. Наборы непрерывных данных часто имеют большое количество значений. Если попробовать представить такой набор описанным выше методом, таблица получится слишком длинной и малопонятной. В этом случае удобно разбить данные на отдельные интервалы. Эти интервалы должны быть одинаковой длины (например, 0—10, 11–20, 21–30 и так далее) независимо от того, сколько значений попадает в каждый интервал. Ниже приведена возможная таблица для непрерывного набора данных:[6]
- Набор данных: 233, 259, 277, 278, 289, 301, 303
- Таблица (в первой колонке интервал значений, во второй частота, в третьей накопительная частота):
- 200–250 | 1 | 1
- 251–300 | 4 | 1 + 4 = 5
- 301–350 | 2 | 5 + 2 = 7
-
3
Постройте линейный график. После того как вы рассчитаете накопительную частоту, возьмите лист миллиметровой бумаги. Отложите по горизонтальной оси (ось x) значения из набора данных, а по вертикальной (ось y) — накопительную частоту, и постройте график. Это значительно облегчит последующие вычисления.[7]
- Например, если набор данных включает числа от 1 до 8, отложите по горизонтальной оси 8 делений. Над каждым делением отметьте точкой соответствующее ему значение накопительной частоты. Соедините получившиеся точки линией.
- Если какое-либо значение не встречается, его абсолютная частота составляет 0. В этом случае прибавьте 0 к последней величине накопительной частоты и поставьте точку на том же уровне, что и в предыдущий раз.
- Поскольку накопительная частота всегда растет с продвижением к большим значениям, с перемещением вправо линия будет оставаться на той же самой высоте или подниматься. Если в какой-то точке линия опустилась вниз, значит, вы допустили ошибку (например, вместо накопительной частоты взяли абсолютную).
-
4
Найдите по графику медиану. Медиана — это значение, расположенное точно посередине набора данных. Половина значений находится выше медианы, а вторая половина расположена ниже нее. Медиану можно найти по графику следующим образом:
- Посмотрите на последнее значение в самом правом конце графика. Для него величина y соответствует суммарной накопительной частоте, которая равна общему числу точек в наборе данных. Предположим, эта величина равна 16.
- Умножьте эту величину на ½ и найдите соответствующее значение на оси y. В нашем примере получится 8. Найдите число 8 на оси y.
- Найдите точку на линии графика, значение y которой соответствует найденной величине. Проведите от цифры 8 на оси y горизонтальную прямую и определите точку ее пересечения с линией графика. Именно эта точка делит набор данных точно пополам.
- Найдите значение x в данной точке. Проведите из точки вертикальную прямую до пересечения с осью x. Точка пересечения определит медиану для изучаемого набора данных. Например, если получилось 65, значит половина данных расположена ниже 65, а вторая половина лежит выше этого значения.
-
5
Найдите по графику квартили. Квартили делят набор данных на четыре части. Эта процедура очень похожа на определение медианы. Единственное различие заключается в нахождении значений y:
- Чтобы определить величину y для нижнего квартиля, умножьте максимальное значение накопительной частоты на ¼. В результате вы получите значение x, ниже которого будет лежать ровно ¼ всех данных.
- Чтобы найти величину y для верхнего квартиля, умножьте максимальное значение накопительной частоты на ¾. В результате вы получите значение x, ниже которого будет лежать ¾, а выше — ¼ всех данных.
Реклама





Советы
- С помощью интервалов можно представлять любые большие, в том числе и дискретные наборы данных.
Реклама
Об этой статье
Эту страницу просматривали 72 751 раз.
Была ли эта статья полезной?
Расчет накопленных частот и процентной суммы накопленных частот
|
Классы группировки |
Точные границы классов |
Частоты данных |
Накопленные частоты (cum) |
Процентная сумма накопленных частот |
|
10 9 8 7 6 5 4 3 2 1 |
54,5-59,5 49,5-54,5 44,5-49,5 39,5-44,5 34,5-39,5 29,5-34,5 24,5-29,5 19,5-24,5 14,5-19,5 9,5-14,5 |
1 1 3 4 6 7 12 6 8 2 |
50 49 48 45 41 35 28 16 10 2 |
1,00100=100 0,98100=98 0,96100=96 0,90100=90 0,82100=82 0,70100=70 0,56100=56 0,32100=32 0,20100=20 0,04100=4 |
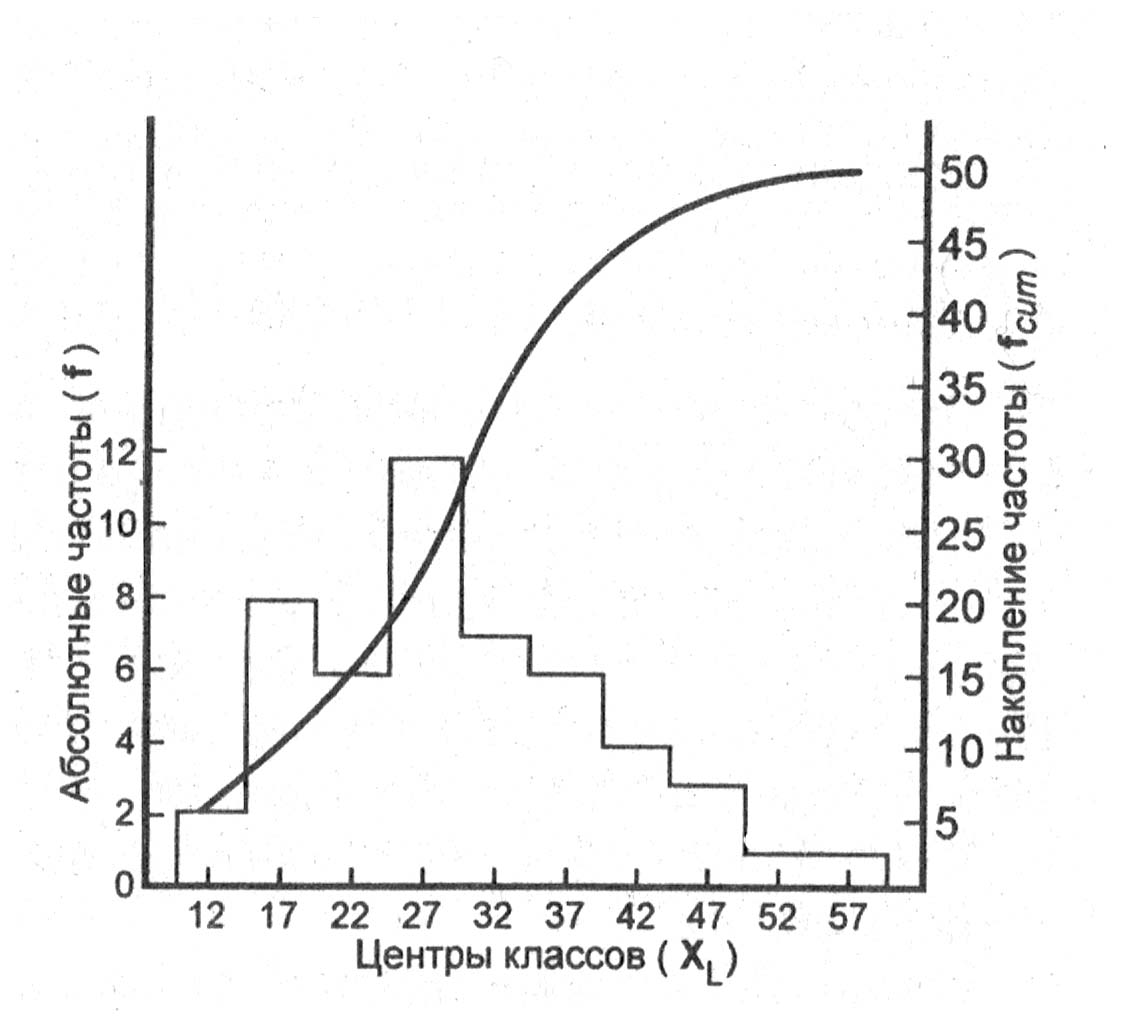
Рис.
1.1.6. Гистограмма
и кривая накопленных частот первичных
результатов
исследования
выборки (см. табл. 1.1.5).
На
основе описанного только что метода
представления первичных результатов
– табличного и графического – может быть
произведен расчет статистических
показателей. Цель этих расчетов в том,
чтобы с помощью простых показателей
дать математическую оценку результатов
эксперимента или наблюдения. Наиболее
часто используемыми статистическими
показателями распределения являются
меры центральной тенденции и меры
рассеивания.
Меры
центральной тенденции. Среди множества
мер центральной тенденции для обработки
результатов психологических исследований
чаще всего используют среднюю
арифметическую величину (М) и медиану
(Me).
В случае
небольшого числа первичных результатов
и отсутствия предварительной их
группировки значение средней арифметической
получают путем последовательного
суммирования исходных величин (X) с
последующим делением этой суммы на
общее количество исходных данных (N):
![]()
.
Если
массив первичных данных был подвергнут
предварительной группировке, то для
вычисления средней арифметической
величины проделывают следующие операции.
Для каждого класса группировки определяют
произведение частоты класса (f)
на центр группировки класса (X), а
затем суммируют эти произведения и
полученную величину делят на общее
количество исходных данных N:
![]()
.
Так,
для примера, приведенного в табл. 1.1.4,
мы имеем: 57+52+141+ +168+222+224+324+132+136+24 =1480 и
![]()
= 29,60, т. е. М = 29,60.
Второй
мерой центральной тенденции, особенно
для порядковых величин, является медиана.
Медиана – это точка на измерительной
шкале, выше которой находится точно
половина наблюдений и ниже которой –
также точно половина наблюдений. В этом
определении важно подчеркнуть, что
медиана – это точка на шкале, а не отдельное
измерение или наблюдение. На примере
данных табл. 1.1.4 продемонстрируем этапы
вычисления медианы на основе сгруппированных
данных.
-
Находим половину
наблюдений в массиве данных т. е. N/2.
В нашем примере: 50:2 = 25,0. -
Суммируем частоты,
начиная с минимального класса группировки,
до класса, содержащего половину
необходимых наблюдений т. е. медиану.
Для нашего примера, в котором N
=50, половиной наблюдений будет 25.
Итак, по данным табл. 1.1.4 это: 2 + 8 + 6 + 12 =
28. Отсюда очевидно, что медиана
предположительно расположена в 4-м
классе группировки, точные границы
которого 24,5 и 29,5. -
Определяем, сколько
же наблюдений из класса, содержащего
медиану, необходимо для того, чтобы
найти ее. Поскольку сумма накопленных
частот из предыдущих трех классов равна
16 (см. табл. 1.1.5), то ясно, что из медианного
класса необходимо еще 9 наблюдений, а
именно 25-16 =9. -
Вычисляем ту долю
интервала на шкале, которая позволит
определить точное положение медианы.
Если в медианном классе имеем 12 наблюдений
и наблюдения в пределах класса
распределены равномерно, то при ширине
класса, равной 5 единицам, получаем:
9/125 = 3,75. -
Прибавляем полученный
результат к нижней точной границе
класса группировки, содержащего медиану:
24,5+3,75 = 28,25. Это и есть ее значение: Mе
= 28,25.
Существует
аналитическая формула для интерполяции
медианы:

,
где l – нижняя точная граница класса
группировки содержащего медиану; Fb
– сумма частот классов* ниже l;
fp – сумма частот класса,
содержащего медиану; N – число
наблюдении или измерений; i
– ширина класса группировки.
*
Величина Fb
в данной формуле соответствует по своему
смыслу величине накопленных частот
(fcum),
расчет которой был продемонстрирован
выше.
Как
видно из нашего примера, когда распределение
первичных результатов наблюдений или
измерений отличается от нормального,
то величины средней арифметической и
медианы не совпадают: 29,6028,25.
Меры
изменчивости. В качестве мер изменчивости
результатов, характеризующих степень
рассеивания отдельных величин вокруг
средней арифметической, используются
разные меры в зависимости от примененных
шкал измерения. Для характеристики
рассеивания величин интервальных шкал
и шкал отношений пользуются значением
среднеквадратичного отклонения ().
Для величин порядковых шкал используют
значения полуквартильных отклонений
(1,
и 3).
При
несгруппированных данных произведем
расчет так называемого стандартного
отклонения, обозначаемого S.
Понятие стандартного отклонения (S)
на практике чаще всего используется
как синоним среднего квадратичного
отклонения ().
Расчет делается следующим образом:
1. Рассчитаем среднюю
арифметическую величину (М).
2. Находим отклонение
(х) каждого результата измерения
(X) от средней арифметической величины:
х=Х-М.
3. Возводим найденное
значение отклонения каждого результата
от среднего в квадрат: x2.
4. Суммируем значения
квадратов отклонений всех результатов:
x2.
5. Делим сумму квадратов
отклонений на общее число наблюдений
(N) и получаем величину,
называемую дисперсией (D):
![]()
6. Извлекаем корень
квадратный из дисперсии и получаем
величину, называемую стандартным
отклонением (S),
или среднеквадратичное отклонение
():
![]()
,
=![]()
.
Таблица
1.1.6
Расчет
дисперсии (D) и
стандартного отклонения (S) (при N=10)
-
Х
х
х2
13
17
15
11
13
11
17
13
11
11
0,2
-3,8
-1,8
2,2
0,2
2,2
-3,8
0,2
2,2
2,2
0,04
14,44
3,24
4,84
0,04
4,84
14,44
0.04
4,84
4,84
х2 = 51,60
Таким
образом: D![]()
и S![]()
.
Приведем
все описанные расчеты для конкретного
примера и определим дисперсию и
стандартное отклонение для выборки,
состоящей из результатов 10 измерений:
13; 17; 15; 11; 13; 11; 17; 13; 11; 11. Для начала
рассчитаем среднюю арифметическую
величину: она оказывается равна 13,2. Для
облегчения дальнейших расчетов составляем
табл. 1.1.6. В 1 -и графе таблицы записываем
первичные данные (X), во 2-й – отклонения
их значений от средней арифметической
(х) и в 3-й – квадраты отклонений (х2).
При
сгруппированных данных формула расчета
дисперсии приобретает следующий вид:
![]()
,
где f – частота
каждого из классов группировки; Xi
– центр каждого из классов группировки;
М – средняя арифметическая величина,
а N – число измерений.
Различают
два полуквартильных отклонения – для
левой и правой сторон распределения
экспериментальных данных. Каждое из
полуквартильных отклонений представляет
собой величину, соответствующую половине
области распределения центральных 50%
данных на шкале измерений. Очевидно,
что любое распределение экспериментальных
данных может быть разделено на четыре
равные части, каждая из которых охватывает
25% наблюдений. Если отсчитывать наблюдения,
начиная от минимальной величины на
измерительной шкале, то точка 1
, отделяющая первые 25% наблюдений от
остальных, определит границу первого
квартиля. Та же самая процедура счета,
производимая от максимальной величины,
отделяет последний, т. е. четвертый,
квартиль; сама же точка на шкале
обозначается как 3
. Наконец медиана, согласно ее
определению, позволяет идентифицировать
второй и третий квартили: точка их
разделения на шкале и соответствует
медиане. Она получила обозначение 2.
Половина же интервала на измерительной
шкале, заключенного между точками 1
и 3 и есть
полуквартильные отклонения. Только в
случае нормального, т. е. симметричного,
распределения данных точка 2
совпадает с местоположением медианы.
Следовательно, с помощью полуквартильных
отклонений можно определять рассеивание
экспериментальных данных вокруг медианы.
Обратимся
снова к табл. 1.1.4 и расчету мер центральной
тенденции. Ранее для приведенных там
данных мы рассчитали, что Me
= 28,25, и таким образом определили точку
2. Теперь
нам предстоит найти точки 1
и 3.
В случае нормального, т. е. строго
симметричного, распределения данных
точки 1и
3 можно
рассматривать в качестве медиан: 1
– для левого интервала (от начала шкалы
измерений до точки 2),
a 3
– для правого интервала (от конца шкалы
до той же точки 2).
Поэтому дальнейшие процедуры расчетов
значений 1
и 3 будут
аналогичны той, которую мы рассматривали
при вычислении медианы. То есть мы имели
право воспользоваться приведенной выше
аналитической формулой для интерполяции
медианы, а именно

.
-
Прежде всего укажем,
что значение i – ширины класса
группировки – нам известно, из задания:
i = 5 (как для левого интервала, так
и для правого). -
Что касается N –
числа измерений, то согласно определению
медианы вообще, а в нашем случае точки
3
в частности, оно должно быть одинаковым
в обоих рассматриваемых интервалах:
Nл = Nпр = 25 при общем числе
измерений, равном 50. Отсюда
![]()
-
Анализируя группировку
данных, приведенную в табл. 1.1.4, нетрудно
заметить, что классом группировки,
предположительно содержащим половину
наблюдений левого интервала, является
3-й класс, а таким же классом для правого
интервала – 6-й класс. Исходя из этого,
по табл. 1.1.4 легко определить, что
для
левого интервала l
=19,5; Fb=10; fp= 6;
для
правого интервала l
=39,5; Fb = 9; fp = 6.
-
Пользуясь найденными
значениями величин, производим
необходимые расчеты медиан обоих
интервалов:
для
левого 1=19,5
+
![]()
5
= 21,58,
для
правого 3 =
39,5-![]()
5
= 36,58.
-
Согласно определению
квартального отклонения следует, что
![]()
,
т. е. в
нашем примере
=
![]()
.
-
Однако этот результат
получен нами для нормального распределения
данных. На самом же деле, как показывает
табл. 1.1.4, в нашем примере мы имеем дело
с явно асимметричным распределением.
Поэтому истинные полуквартильные
отклонения в данном случае необходимо
было рассчитывать с учетом вычисленного
значения для медианы (или 2),
a именно, что Mе = 28,25.
Тогда мы получаем
для
левого интервала 2
– 1 =
28,25-21,58 = 6,67,
для
правого интервала 3
– 2 =
36,58-28,25 = 8,33.
С помощью
данного приема можно очень легко
определить право- и левостороннюю
асимметрию любого распределения:
если
3 – 1
> 2
– 1 то
имела место правосторонняя асимметрия;
если
3 – 2
< 2 –
1,
то – левосторонняя.
И только
при равенстве указанных разностей можно
говорить о строго симметричном
распределении.
Для
каких целей служат меры центральной
тенденции (М или Me)
и меры изменчивости (D,
S, ,
)? Во-первых, эти
меры используются для интерпретации
первичных результатов. На основе
полученных значений мер центральной
тенденции можно, например, предвидеть
наиболее вероятные результаты аналогичного
исследования другой выборки. На основе
же мер изменчивости можно оценить
точность проведенных измерений, т. е.
выявить случайные ошибки измерения.
Во-вторых, та или иная из вышеназванных
мер необходима для проверки статистической
значимости различий (см. с. 274, Приложение
I: t-критерий Стьюдента)
между результатами исследования двух
разных выборок, а также для вычисления
так называемых коэффициентов корреляции,
о которых сейчас пойдет речь.
Меры
взаимосвязи. Коэффициентами корреляции
пользуются для того, чтобы выяснить,
существует ли взаимосвязь между двумя
переменными, и определить ее степень,
т. е. тесноту взаимосвязи. Значение
коэффициента корреляции изменяется от
-1 до +1. Величины, лежащие в этих пределах,
отражают максимально возможную
взаимосвязь сравниваемых переменных.
Когда коэффициент корреляции равен
нулю, то это означает, что взаимосвязь
отсутствует. Положительная корреляционная
связь указывает на прямо пропорциональное
отношение между двумя переменными, а
отрицательная – на обратно пропорциональную
взаимосвязь. Чем больше абсолютное
значение коэффициента корреляции, тем
теснее связь между изучаемыми переменными.
При значениях коэффициентов ± 1 можно
говорить об отношении тождественности
между переменными.
При
сравнении порядковых величин пользуются
коэффициентом ранговой корреляции по
Ч. Спирмену (), при
сравнении интервальных величин –
коэффициентом корреляции произведений
по К. Пирсону (r). Рассмотрим
кратко способы расчета этих коэффициентов.
Допустим,
что с помощью двух опросников (X и
Y), требующих
альтернативных ответов «да» или «нет»,
были получены первичные результаты –
ответы 15 испытуемых (N =15). Результаты
представлены в виде сумм баллов за
утвердительные ответы («да») для каждого
испытуемого отдельно для опросника Х
и опросника Y. Требуется определить,
измеряют ли опросники Х и Y похожие
личностные качества испытуемых, или не
измеряют. Можно предположить, что если
опросники по содержанию и формулировкам
мало отличаются друг от друга, то сумма
баллов, набранная каждым из испытуемых
по опроснику X, будет близка к сумме
баллов, набранных по опроснику Y.
Полученные
в эксперименте первичные результаты
представляют собой два ряда порядковых
величин для переменной Х и для
переменной Y. Для установления
взаимосвязи между каждой парой порядковых
величин применяют коэффициент порядковой
корреляции Спирмена ().
Для расчета величины
известна следующая формула:
=
![]()
,
где N – число
сравниваемых пар величин двух переменных
и d2 –
квадрат разностей рангов этих величин.
Для
вычисления предстоит проделать ряд
операций. Прежде всего надлежит
табулировать все первичные результаты
(табл. 1.1.7). В 1-й графе записывают номер
испытуемого, а во 2-й и 3-й – полученные
им суммы баллов по первой методике
(переменная X) и по второй (переменная
Y).
Таблица
1.1.7
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #

Содержание
- Формулы
- Прочие накопленные частоты
- Как получить накопленную частоту?
- Как заполнять частотную таблицу
- Таблица частотности
- Кумулятивное частотное распределение
- пример
- Предлагаемое упражнение
- Ответить
- Ссылки
В накопленная частота представляет собой сумму абсолютных частот f, от самой низкой до той, которая соответствует определенному значению переменной. В свою очередь, абсолютная частота – это количество раз, когда наблюдение появляется в наборе данных.
Очевидно, переменная исследования должна быть сортируемой. А поскольку накопленная частота получается сложением абсолютных частот, получается, что накопленная частота до последних данных должна совпадать с их суммой. В противном случае в расчетах будет ошибка.

Обычно накопленная частота обозначается как Fя (или иногда nя), чтобы отличить ее от абсолютной частоты fя и важно добавить для него столбец в таблице, с помощью которой организованы данные, известной как таблица частот.
Это упрощает, среди прочего, отслеживание того, сколько данных было подсчитано до определенного наблюдения.
А Фя он также известен как абсолютная совокупная частота. Если разделить на общие данные, мы получим относительная совокупная частота, окончательная сумма которых должна быть равна 1.
Формулы
Кумулятивная частота данного значения переменной Xя представляет собой сумму абсолютных частот f всех значений, меньших или равных ей:
Fя = f1 + f2 + f3 +… Fя
Путем сложения всех абсолютных частот получается общее количество данных N, то есть:
F1 + F2 + F3 +…. + Fп = N
Предыдущая операция кратко записывается с помощью символа суммирования ∑:
∑ Fя = N
Прочие накопленные частоты
Также могут накапливаться следующие частоты:
-Относительная частота: получается делением абсолютной частоты fя между общими данными N:
Fр = fя / N
Если относительные частоты сложить от самой низкой к той, которая соответствует определенному наблюдению, мы получим совокупная относительная частота. Последнее значение должно быть равно 1.
-Процент кумулятивной относительной частоты: накопленная относительная частота умножается на 100%.
F% = (fя / N) x 100%
Эти частоты полезны для описания поведения данных, например, при нахождении показателей центральной тенденции.
Как получить накопленную частоту?
Чтобы получить накопленную частоту, необходимо упорядочить данные и организовать их в таблице частот. Процедура иллюстрируется следующей практической ситуацией:
-В интернет-магазине, который продает сотовые телефоны, отчет о продажах определенного бренда за март месяц показал следующие значения за день:
1; 2; 1; 3; 0; 1; 0; 2; 4; 2; 1; 0; 3; 3; 0; 1; 2; 4; 1; 2; 3; 2; 3; 1; 2; 4; 2; 1; 5; 5; 3
Переменная – это количество телефонов, проданных за день и это количественно. Данные, представленные таким образом, не так легко интерпретировать, например, владельцы магазина могут быть заинтересованы в том, чтобы узнать, есть ли какая-либо тенденция, например, дни недели, когда продажи этого бренда выше.
Подобную информацию и многое другое можно получить, представив данные в упорядоченном виде и указав частоты.
Как заполнять частотную таблицу
Для расчета накопленной частоты данные сначала упорядочиваются:
0; 0; 0; 0; 1; 1; 1; 1; 1; 1; 1; 1; 2; 2; 2; 2; 2; 2; 2; 2; 3; 3; 3; 3; 3; 3; 4; 4; 4; 5; 5
Затем строится таблица со следующей информацией:
-Первый столбец слева с количеством проданных телефонов от 0 до 5 в порядке возрастания.
-Второй столбец: абсолютная частота, то есть количество дней, в течение которых было продано 0 телефонов, 1 телефон, 2 телефона и т. Д.
-Третий столбец: накопленная частота, состоящая из суммы предыдущей частоты и частоты данных, которые необходимо учитывать.
Этот столбец начинается с первых данных в столбце абсолютной частоты, в данном случае это 0. Для следующего значения сложите его с предыдущим. Это продолжается до тех пор, пока не будут достигнуты последние накопленные данные частоты, которые должны совпадать с общими данными.
Таблица частотности
В следующей таблице показаны переменная «количество телефонов, проданных за день», ее абсолютная частота и подробный расчет накопленной частоты.
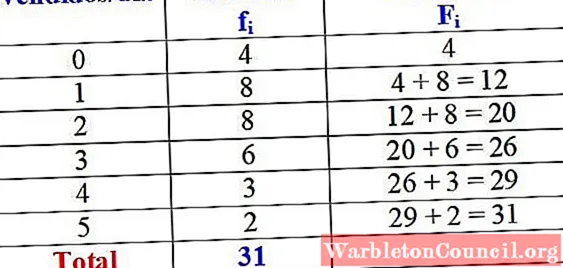
На первый взгляд, можно сказать, что у рассматриваемого бренда один или два телефона почти всегда продаются в день, поскольку максимальная абсолютная частота составляет 8 дней, что соответствует этим значениям переменной. Только за 4 дня месяца они не продали ни одного телефона.
Как уже отмечалось, таблицу легче изучить, чем изначально собранные индивидуальные данные.
Кумулятивное частотное распределение
Кумулятивное распределение частот – это таблица, в которой показаны абсолютные частоты, совокупные частоты, совокупные относительные частоты и совокупные процентные частоты.
Хотя есть преимущество организации данных в таблице, подобной предыдущей, если количество данных очень велико, может оказаться недостаточно для их организации, как показано выше, потому что, если частот много, их все равно трудно интерпретировать.
Проблему можно решить, построив Распределение частоты по интервалам, полезная процедура, когда переменная принимает большое количество значений или если это непрерывная переменная.
Здесь значения сгруппированы в интервалы равной амплитуды, называемые класс. Классы характеризуются наличием:
-Предел класса: – крайние значения каждого интервала, их два, верхний предел и нижний предел. Как правило, верхняя граница относится не к интервалу, а к следующему, а нижняя – к.
-Классовый знак: является средней точкой каждого интервала и принимается в качестве его репрезентативного значения.
-Ширина класса: Он рассчитывается путем вычитания значения самого высокого и самого низкого данных (диапазона) и деления на количество классов:
Ширина класса = Диапазон / Количество классов
Подробное описание частотного распределения приведено ниже.
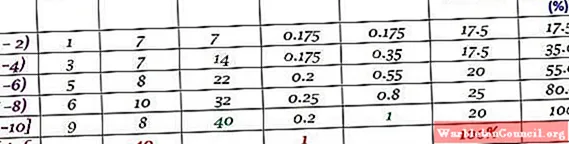
пример
Этот набор данных соответствует 40 баллам за тест по математике по шкале от 0 до 10:
0; 0;0; 1; 1; 1; 1; 2; 2; 2; 3; 3; 3; 3; 4; 4; 4; 4; 5; 5; 5; 5; 6; 6; 6; 6; 7; 7; 7; 7; 7; 7; 8; 8; 8; 9; 9; 9;10; 10.
Распределение частот может быть выполнено с определенным количеством классов, например 5 классами. Следует иметь в виду, что при использовании многих классов данные нелегко интерпретировать, и смысл группировки теряется.
А если, наоборот, они сгруппированы в очень немногие, то информация размывается и часть ее теряется. Все зависит от количества имеющихся у вас данных.
В этом примере рекомендуется иметь две оценки в каждом интервале, поскольку будет 10 оценок и будет создано 5 классов. Ранг – это вычитание между высшим и низшим классом, ширина класса составляет:
Ширина класса = (10-0) / 5 = 2
Слева интервалы закрыты, а справа открыты (кроме последнего), что обозначено скобками и круглыми скобками соответственно. Все они одинаковой ширины, но это не обязательно, хотя и является наиболее распространенным.
Каждый интервал содержит определенное количество элементов или абсолютную частоту, а в следующем столбце – накопленная частота, с которой переносится сумма. В таблице также указана относительная частота fр (абсолютная частота между общим количеством данных) и относительная частота в процентах fр ×100%.
Предлагаемое упражнение
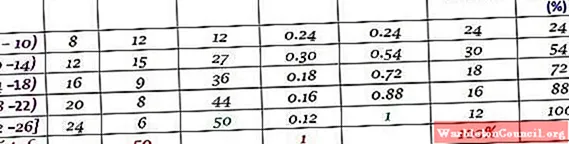
Одна компания ежедневно звонила своим клиентам в течение первых двух месяцев года. Данные следующие:
6, 12, 7, 15, 13, 18, 20, 25, 12, 10, 8, 13, 15, 6, 9, 18, 20, 24, 12, 7, 10, 11, 13, 9, 12, 15, 18, 20, 13, 17, 23, 25, 14, 18, 6, 14, 16, 9, 6, 10, 12, 20, 13, 17, 14, 26, 7, 12, 24, 7
Сгруппируйте по 5 классам и составьте таблицу с частотным распределением.
Ответить
Ширина класса:
(26-6)/5 = 4
Пожалуйста, попытайтесь понять это, прежде чем увидите ответ.
Ссылки
- Беренсон, М. 1985. Статистика для управления и экономики. Interamericana S.A.
- Деворе, Дж. 2012. Вероятность и статистика для техники и науки. 8-е. Издание. Cengage.
- Левин, Р. 1988. Статистика для администраторов. 2-й. Издание. Прентис Холл.
- Вероятность и статистика. Ширина интервала классов. Получено с: pedroprobabilidadyestadistica.blogspot.com.
- Шпигель, М. 2009. Статистика. Серия Шаум. 4-й Издание. Макгроу Хилл.
- Уолпол, Р. 2007. Вероятность и статистика для инженерии и науки. Пирсон.
Интервальный вариационный ряд и его характеристики
- Построение интервального вариационного ряда по данным эксперимента
- Гистограмма и полигон относительных частот, кумулята и эмпирическая функция распределения
- Выборочная средняя, мода и медиана. Симметрия ряда
- Выборочная дисперсия и СКО
- Исправленная выборочная дисперсия, стандартное отклонение выборки и коэффициент вариации
- Алгоритм исследования интервального вариационного ряда
- Примеры
п.1. Построение интервального вариационного ряда по данным эксперимента
Интервальный вариационный ряд – это ряд распределения, в котором однородные группы составлены по признаку, меняющемуся непрерывно или принимающему слишком много значений.
Общий вид интервального вариационного ряда
| Интервалы, (left.left[a_{i-1},a_iright.right)) | (left.left[a_{0},a_1right.right)) | (left.left[a_{1},a_2right.right)) | … | (left.left[a_{k-1},a_kright.right)) |
| Частоты, (f_i) | (f_1) | (f_2) | … | (f_k) |
Здесь k – число интервалов, на которые разбивается ряд.
Размах вариации – это длина интервала, в пределах которой изменяется исследуемый признак: $$ F=x_{max}-x_{min} $$
Правило Стерджеса
Эмпирическое правило определения оптимального количества интервалов k, на которые следует разбить ряд из N чисел: $$ k=1+lfloorlog_2 Nrfloor $$ или, через десятичный логарифм: $$ k=1+lfloor 3,322cdotlg Nrfloor $$
Скобка (lfloor rfloor) означает целую часть (округление вниз до целого числа).
Шаг интервального ряда – это отношение размаха вариации к количеству интервалов, округленное вверх до определенной точности: $$ h=leftlceilfrac Rkrightrceil $$
Скобка (lceil rceil) означает округление вверх, в данном случае не обязательно до целого числа.
Алгоритм построения интервального ряда
На входе: все значения признака (left{x_jright}, j=overline{1,N})
Шаг 1. Найти размах вариации (R=x_{max}-x_{min})
Шаг 2. Найти оптимальное количество интервалов (k=1+lfloorlog_2 Nrfloor)
Шаг 3. Найти шаг интервального ряда (h=leftlceilfrac{R}{k}rightrceil)
Шаг 4. Найти узлы ряда: $$ a_0=x_{min}, a_i=1_0+ih, i=overline{1,k} $$ Шаг 5. Найти частоты (f_i) – число попаданий значений признака в каждый из интервалов (left.left[a_{i-1},a_iright.right)).
На выходе: интервальный ряд с интервалами (left.left[a_{i-1},a_iright.right)) и частотами (f_i, i=overline{1,k})
Заметим, что поскольку шаг h находится с округлением вверх, последний узел (a_kgeq x_{max}).
Например:
Проведено 100 измерений роста учеников старших классов.
Минимальный рост составляет 142 см, максимальный – 197 см.
Найдем узлы для построения соответствующего интервального ряда.
По условию: (N=100, x_{min}=142 см, x_{max}=197 см).
Размах вариации: (R=197-142=55) (см)
Оптимальное число интервалов: (k=1+lfloor 3,322cdotlg 100rfloor=1+lfloor 6,644rfloor=1+6=7)
Шаг интервального ряда: (h=lceilfrac{55}{5}rceil=lceil 7,85rceil=8) (см)
Получаем узлы ряда: $$ a_0=x_{min}=142, a_i=142+icdot 8, i=overline{1,7} $$
| (left.left[a_{i-1},a_iright.right)) cм | (left.left[142;150right.right)) | (left.left[150;158right.right)) | (left.left[158;166right.right)) | (left.left[166;174right.right)) | (left.left[174;182right.right)) | (left.left[182;190right.right)) | (left[190;198right]) |
п.2. Гистограмма и полигон относительных частот, кумулята и эмпирическая функция распределения
Относительная частота интервала (left.left[a_{i-1},a_iright.right)) – это отношение частоты (f_i) к общему количеству исходов: $$ w_i=frac{f_i}{N}, i=overline{1,k} $$
Гистограмма относительных частот интервального ряда – это фигура, состоящая из прямоугольников, ширина которых равна шагу ряда, а высота – относительным частотам каждого из интервалов.
Площадь гистограммы равна 1 (с точностью до округлений), и она является эмпирическим законом распределения исследуемого признака.
Полигон относительных частот интервального ряда – это ломаная, соединяющая точки ((x_i,w_i)), где (x_i) – середины интервалов: (x_i=frac{a_{i-1}+a_i}{2}, i=overline{1,k}).
Накопленные относительные частоты – это суммы: $$ S_1=w_1, S_i=S_{i-1}+w_i, i=overline{2,k} $$ Ступенчатая кривая (F(x)), состоящая из прямоугольников, ширина которых равна шагу ряда, а высота – накопленным относительным частотам, является эмпирической функцией распределения исследуемого признака.
Кумулята – это ломаная, которая соединяет точки ((x_i,S_i)), где (x_i) – середины интервалов.
Например:
Продолжим анализ распределения учеников по росту.
Выше мы уже нашли узлы интервалов. Пусть, после распределения всех 100 измерений по этим интервалам, мы получили следующий интервальный ряд:
| i | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| (left.left[a_{i-1},a_iright.right)) cм | (left.left[142;150right.right)) | (left.left[150;158right.right)) | (left.left[158;166right.right)) | (left.left[166;174right.right)) | (left.left[174;182right.right)) | (left.left[182;190right.right)) | (left[190;198right]) |
| (f_i) | 4 | 7 | 11 | 34 | 33 | 8 | 3 |
Найдем середины интервалов, относительные частоты и накопленные относительные частоты:
| (x_i) | 146 | 154 | 162 | 170 | 178 | 186 | 194 |
| (w_i) | 0,04 | 0,07 | 0,11 | 0,34 | 0,33 | 0,08 | 0,03 |
| (S_i) | 0,04 | 0,11 | 0,22 | 0,56 | 0,89 | 0,97 | 1 |
Построим гистограмму и полигон:

Построим кумуляту и эмпирическую функцию распределения: 

Эмпирическая функция распределения (относительно середин интервалов): $$ F(x)= begin{cases} 0, xleq 146\ 0,04, 146lt xleq 154\ 0,11, 154lt xleq 162\ 0,22, 162lt xleq 170\ 0,56, 170lt xleq 178\ 0,89, 178lt xleq 186\ 0,97, 186lt xleq 194\ 1, xgt 194 end{cases} $$
п.3. Выборочная средняя, мода и медиана. Симметрия ряда
Выборочная средняя интервального вариационного ряда определяется как средняя взвешенная по частотам: $$ X_{cp}=frac{x_1f_1+x_2f_2+…+x_kf_k}{N}=frac1Nsum_{i=1}^k x_if_i $$ где (x_i) – середины интервалов: (x_i=frac{a_{i-1}+a_i}{2}, i=overline{1,k}).
Или, через относительные частоты: $$ X_{cp}=sum_{i=1}^k x_iw_i $$
Модальным интервалом называют интервал с максимальной частотой: $$ f_m=max f_i $$ Мода интервального вариационного ряда определяется по формуле: $$ M_o=x_o+frac{f_m-f_{m-1}}{(f_m-f_{m-1})+(f_m+f_{m+1})}h $$ где
(h) – шаг интервального ряда;
(x_o) – нижняя граница модального интервала;
(f_m,f_{m-1},f_{m+1}) – соответственно, частоты модального интервала, интервала слева от модального и интервала справа.
Медианным интервалом называют первый интервал слева, на котором кумулята превысила значение 0,5. Медиана интервального вариационного ряда определяется по формуле: $$ M_e=x_o+frac{0,5-S_{me-1}}{w_{me}}h $$ где
(h) – шаг интервального ряда;
(x_o) – нижняя граница медианного интервала;
(S_{me-1}) накопленная относительная частота для интервала слева от медианного;
(w_{me}) относительная частота медианного интервала.
Расположение выборочной средней, моды и медианы в зависимости от симметрии ряда аналогично их расположению в дискретном ряду (см. §65 данного справочника).
Например:
Для распределения учеников по росту получаем:
| (x_i) | 146 | 154 | 162 | 170 | 178 | 186 | 194 | ∑ |
| (w_i) | 0,04 | 0,07 | 0,11 | 0,34 | 0,33 | 0,08 | 0,03 | 1 |
| (x_iw_i) | 5,84 | 10,78 | 17,82 | 57,80 | 58,74 | 14,88 | 5,82 | 171,68 |
$$ X_{cp}=sum_{i=1}^k x_iw_i=171,68approx 171,7 text{(см)} $$ На гистограмме (или полигоне) относительных частот максимальная частота приходится на 4й интервал [166;174). Это модальный интервал.
Данные для расчета моды: begin{gather*} x_o=166, f_m=34, f_{m-1}=11, f_{m+1}=33, h=8\ M_o=x_o+frac{f_m-f_{m-1}}{(f_m-f_{m-1})+(f_m+f_{m+1})}h=\ =166+frac{34-11}{(34-11)+(34-33)}cdot 8approx 173,7 text{(см)} end{gather*} На кумуляте значение 0,5 пересекается на 4м интервале. Это – медианный интервал.
Данные для расчета медианы: begin{gather*} x_o=166, w_m=0,34, S_{me-1}=0,22, h=8\ \ M_e=x_o+frac{0,5-S_{me-1}}{w_me}h=166+frac{0,5-0,22}{0,34}cdot 8approx 172,6 text{(см)} end{gather*} begin{gather*} \ X_{cp}=171,7; M_o=173,7; M_e=172,6\ X_{cp}lt M_elt M_o end{gather*} Ряд асимметричный с левосторонней асимметрией.
При этом (frac{|M_o-X_{cp}|}{|M_e-X_{cp}|}=frac{2,0}{0,9}approx 2,2lt 3), т.е. распределение умеренно асимметрично.
п.4. Выборочная дисперсия и СКО
Выборочная дисперсия интервального вариационного ряда определяется как средняя взвешенная для квадрата отклонения от средней: begin{gather*} D=frac1Nsum_{i=1}^k(x_i-X_{cp})^2 f_i=frac1Nsum_{i=1}^k x_i^2 f_i-X_{cp}^2 end{gather*} где (x_i) – середины интервалов: (x_i=frac{a_{i-1}+a_i}{2}, i=overline{1,k}).
Или, через относительные частоты: $$ D=sum_{i=1}^k(x_i-X_{cp})^2 w_i=sum_{i=1}^k x_i^2 w_i-X_{cp}^2 $$
Выборочное среднее квадратичное отклонение (СКО) определяется как корень квадратный из выборочной дисперсии: $$ sigma=sqrt{D} $$
Например:
Для распределения учеников по росту получаем:
| $x_i$ | 146 | 154 | 162 | 170 | 178 | 186 | 194 | ∑ |
| (w_i) | 0,04 | 0,07 | 0,11 | 0,34 | 0,33 | 0,08 | 0,03 | 1 |
| (x_iw_i) | 5,84 | 10,78 | 17,82 | 57,80 | 58,74 | 14,88 | 5,82 | 171,68 |
| (x_i^2w_i) – результат | 852,64 | 1660,12 | 2886,84 | 9826 | 10455,72 | 2767,68 | 1129,08 | 29578,08 |
$$ D=sum_{i=1}^k x_i^2 w_i-X_{cp}^2=29578,08-171,7^2approx 104,1 $$ $$ sigma=sqrt{D}approx 10,2 $$
п.5. Исправленная выборочная дисперсия, стандартное отклонение выборки и коэффициент вариации
Исправленная выборочная дисперсия интервального вариационного ряда определяется как: begin{gather*} S^2=frac{N}{N-1}D end{gather*}
Стандартное отклонение выборки определяется как корень квадратный из исправленной выборочной дисперсии: $$ s=sqrt{S^2} $$
Коэффициент вариации это отношение стандартного отклонения выборки к выборочной средней, выраженное в процентах: $$ V=frac{s}{X_{cp}}cdot 100text{%} $$
Подробней о том, почему и когда нужно «исправлять» дисперсию, и для чего использовать коэффициент вариации – см. §65 данного справочника.
Например:
Для распределения учеников по росту получаем: begin{gather*} S^2=frac{100}{99}cdot 104,1approx 105,1\ sapprox 10,3 end{gather*} Коэффициент вариации: $$ V=frac{10,3}{171,7}cdot 100text{%}approx 6,0text{%}lt 33text{%} $$ Выборка однородна. Найденное значение среднего роста (X_{cp})=171,7 см можно распространить на всю генеральную совокупность (старшеклассников из других школ).
п.6. Алгоритм исследования интервального вариационного ряда
На входе: все значения признака (left{x_jright}, j=overline{1,N})
Шаг 1. Построить интервальный ряд с интервалами (left.right[a_{i-1}, a_ileft.right)) и частотами (f_i, i=overline{1,k}) (см. алгоритм выше).
Шаг 2. Составить расчетную таблицу. Найти (x_i,w_i,S_i,x_iw_i,x_i^2w_i)
Шаг 3. Построить гистограмму (и/или полигон) относительных частот, эмпирическую функцию распределения (и/или кумуляту). Записать эмпирическую функцию распределения.
Шаг 4. Найти выборочную среднюю, моду и медиану. Проанализировать симметрию распределения.
Шаг 5. Найти выборочную дисперсию и СКО.
Шаг 6. Найти исправленную выборочную дисперсию, стандартное отклонение и коэффициент вариации. Сделать вывод об однородности выборки.
п.7. Примеры
Пример 1. При изучении возраста пользователей коворкинга выбрали 30 человек.
Получили следующий набор данных:
18,38,28,29,26,38,34,22,28,30,22,23,35,33,27,24,30,32,28,25,29,26,31,24,29,27,32,24,29,29
Постройте интервальный ряд и исследуйте его.
1) Построим интервальный ряд. В наборе данных: $$ x_{min}=18, x_{max}=38, N=30 $$ Размах вариации: (R=38-18=20)
Оптимальное число интервалов: (k=1+lfloorlog_2 30rfloor=1+4=5)
Шаг интервального ряда: (h=lceilfrac{20}{5}rceil=4)
Получаем узлы ряда: $$ a_0=x_{min}=18, a_i=18+icdot 4, i=overline{1,5} $$
| (left.left[a_{i-1},a_iright.right)) лет | (left.left[18;22right.right)) | (left.left[22;26right.right)) | (left.left[26;30right.right)) | (left.left[30;34right.right)) | (left.left[34;38right.right)) |
Считаем частоты для каждого интервала. Получаем интервальный ряд:
| (left.left[a_{i-1},a_iright.right)) лет | (left.left[18;22right.right)) | (left.left[22;26right.right)) | (left.left[26;30right.right)) | (left.left[30;34right.right)) | (left.left[34;38right.right)) |
| (f_i) | 1 | 7 | 12 | 6 | 4 |
2) Составляем расчетную таблицу:
| (x_i) | 20 | 24 | 28 | 32 | 36 | ∑ |
| (f_i) | 1 | 7 | 12 | 6 | 4 | 30 |
| (w_i) | 0,033 | 0,233 | 0,4 | 0,2 | 0,133 | 1 |
| (S_i) | 0,033 | 0,267 | 0,667 | 0,867 | 1 | – |
| (x_iw_i) | 0,667 | 5,6 | 11,2 | 6,4 | 4,8 | 28,67 |
| (x_i^2w_i) | 13,333 | 134,4 | 313,6 | 204,8 | 172,8 | 838,93 |
3) Строим полигон и кумуляту

Эмпирическая функция распределения: $$ F(x)= begin{cases} 0, xleq 20\ 0,033, 20lt xleq 24\ 0,267, 24lt xleq 28\ 0,667, 28lt xleq 32\ 0,867, 32lt xleq 36\ 1, xgt 36 end{cases} $$ 4) Находим выборочную среднюю, моду и медиану $$ X_{cp}=sum_{i=1}^k x_iw_iapprox 28,7 text{(лет)} $$ На полигоне модальным является 3й интервал (самая высокая точка).
Данные для расчета моды: begin{gather*} x_0=26, f_m=12, f_{m-1}=7, f_{m+1}=6, h=4\ M_o=x_o+frac{f_m-f_{m-1}}{(f_m-f_{m-1})+(f_m+f_{m+1})}h=\ =26+frac{12-7}{(12-7)+(12-6)}cdot 4approx 27,8 text{(лет)} end{gather*}
На кумуляте медианным является 3й интервал (преодолевает уровень 0,5).
Данные для расчета медианы: begin{gather*} x_0=26, w_m=0,4, S_{me-1}=0,267, h=4\ M_e=x_o+frac{0,5-S_{me-1}}{w_{me}}h=26+frac{0,5-0,4}{0,267}cdot 4approx 28,3 text{(лет)} end{gather*} Получаем: begin{gather*} X_{cp}=28,7; M_o=27,8; M_e=28,6\ X_{cp}gt M_egt M_0 end{gather*} Ряд асимметричный с правосторонней асимметрией.
При этом (frac{|M_o-X_{cp}|}{|M_e-X_{cp}|} =frac{0,9}{0,1}=9gt 3), т.е. распределение сильно асимметрично.
5) Находим выборочную дисперсию и СКО: begin{gather*} D=sum_{i=1}^k x_i^2w_i-X_{cp}^2=838,93-28,7^2approx 17,2\ sigma=sqrt{D}approx 4,1 end{gather*}
6) Исправленная выборочная дисперсия: $$ S^2=frac{N}{N-1}D=frac{30}{29}cdot 17,2approx 17,7 $$ Стандартное отклонение (s=sqrt{S^2}approx 4,2)
Коэффициент вариации: (V=frac{4,2}{28,7}cdot 100text{%}approx 14,7text{%}lt 33text{%})
Выборка однородна. Найденное значение среднего возраста (X_{cp}=28,7) лет можно распространить на всю генеральную совокупность (пользователей коворкинга).
Содержание:
В результате статистической обработки материалов, полученных при измерении величины явления, можно подсчитать число единиц, обладающих конкретным значением того или иного признака.
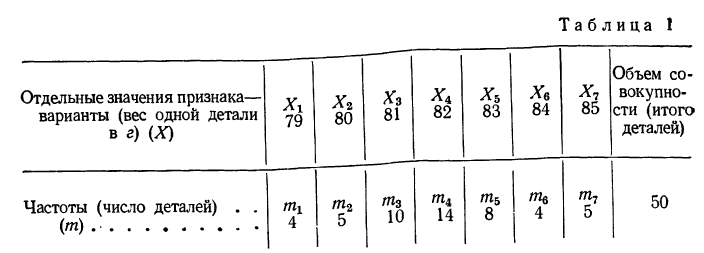
Допустим, что в качестве изучаемого признака взят вес детали. Будем обозначать этот признак X. Измерения веса, например, 50 деталей дали следующие результаты (в г): 83, 85, 81, 82, 84, 82, 79, 84, 80, 81, 82, 82, 80, 82, 80, 82, 83, 84, 79, 79, 83, 82, 83, 85, 82, 82, 81, 80, 82, 82, .83,80, 82, 85, 81, 83, 81, 81, 83, 82, 81, 85, 83, 79, 81, 85, 81, 84, 81, 82.
Условились каждое отдельное значение признака обозначать 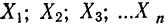
Если мы расположим отдельные значения признака (варианты) в возрастающем или убывающем порядке и укажем относительно каждого варианта, как часто он встречался в данной совокупности, то получим распределение признака, или вариационный ряд.
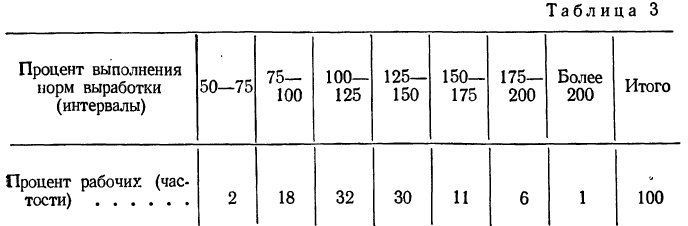
Вариационные ряды и их характеристики
Построим вариационный ряд для приведенного выше примера. Для этого находим наименьший вариант, равный 79 г, и, располагая варианты в возрастающем порядке, подсчитываем их частоту. Так, вариант 79 г встречается 4 раза, вариант 80 г — 5 раз и т. д. Расположим полученные варианты следующим образом (см. табл. 1).
Такой ряд называется вариационным рядом; он характеризует изменение (варьирование) какого-нибудь количественного признака (в нашем примере варьирование веса деталей). Следовательно, вариационный ряд представляет собой две строки (или колонки). В одной из них приводятся варианты, а в другой частоты.
Виды вариации
Вариация признака может быть дискретной и непрерывной. Дискретной вариацией признака называется такая, при которой отдельные значения признака (варианты) отличаются друг от друга на некоторую конечную величину (обычно целое число), т. е. даны в виде прерывных чисел. Непрерывной называется вариация, при которой значения признака могут отличаться одно от другого на сколь угодно малую величину. В качестве примера можно привести: для дискретной вариации признака — число станков, обслуживаемых одним рабочим, число семян в 1 кг и т. д.; для непрерывной вариации признака— процент выполнения рабочим нормы выработки, вес одного семени и т. д.
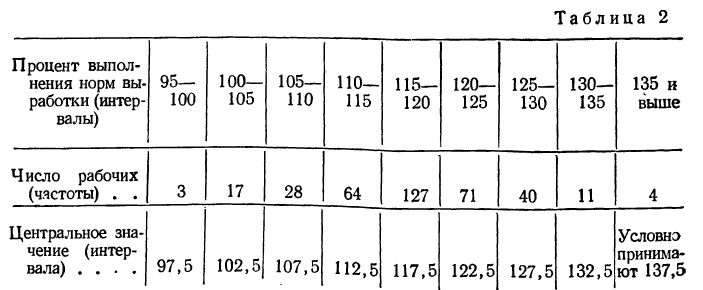
При непрерывной вариации распределение признака называется интервальным. Частоты относятся не к отдельному значению признака, как это бывает при дискретной вариации, а ко всему интервалу. Часто за значение интервала принимают его середину, т. е. центральное значение. В качестве примера можно привести интервальный вариационный ряд по проценту выполнения норм выработки.
Пример 1.
Распределение рабочих по проценту выполнения норм выработки.
Частость
Нередко вместо абсолютных значений. частот используют относительные величины. Для этой цели можно использовать долю частоты того или иного варианта (а также интервала) в сумме всех частот. Такая величина называется частостью и обозначается 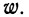
Мы имеем частоты 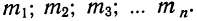
Для получения суммы всех частот их нужно сложить
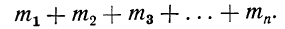
В математике используется знак 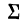 (греческая буква сигма заглавная), означающий суммирование.
(греческая буква сигма заглавная), означающий суммирование.
Следовательно, можно записать:
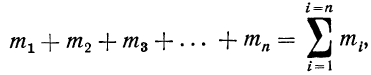
где значки 1=1 и i=n под и над 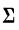 показывают, что суммированию подлежат все
показывают, что суммированию подлежат все 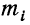 при условии, что i принимает все целые значения от 1 до n.
при условии, что i принимает все целые значения от 1 до n.
В дальнейшем в подобных случаях (т. е. при суммировании по подстрочному номеру i) мы не будем записывать значения, принимаемые i, но будем помнить смысл записи 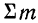 (уже без указания значений, принимаемых i).
(уже без указания значений, принимаемых i).
Для получения частости каждого варианта или интервала-нужно его частоту разделить на 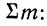
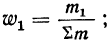
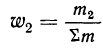 и т.д.,
и т.д.,
где 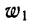 — частость первого варианта или интервала,
— частость первого варианта или интервала, 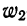 — второго и т. д.
— второго и т. д.
Вычислим частости, используя данные табл. 1: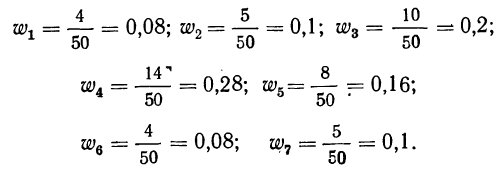
Сумма всех частостей равна 1:
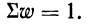
В нашем примере
0,08+0,1+0,2+0,28+0,16+0,08+0,1 = 1,00.
Частости можно выражать и в процентах (тогда сумма всех частостей равна 100%).
Границы интервалов
В интервальном вариационном ряду в каждом интервале различают нижнюю и верхнюю границы интервала:
- нижняя граница интервала
- верхняя граница интервала
- величина интервала
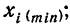
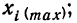
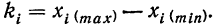
При построении интервальных вариационных рядов в каждый интервал включаются варианты, числовые значения которых больше нижней границы и меньше или равны верхней грани це. Так, в табл.12 в интервал 95—100% попадают все рабочие, выполнившие нормы выработки от 95 до 100% включительно. Рабочие, выполнившие план на 100,01%, попадают в следующий интервал. Разумеется надо стремиться строить интервалы так, чтобы избегать попадания значительного числа случаев на границы интервалов.
Интервальные вариационные ряды бывают с одинаковыми и неодинаковыми интервалами. В последнем случае чаще всего встречаются интервалы последовательно увеличивающиеся.
Пример 2.
Вариационный ряд с равными интервалами:
Пример 2а.
Вариационный ряд с последовательно увеличивающимися интервалами:
Свойства сумм
Как видно (и из дальнейшего изучения материала), нам приходится иметь дело с суммами. Рассмотрим некоторые свойства сумм.
1) Сумма ограниченного числа слагаемых, имеющих одну и ту же величину (сумма постоянной), равна произведению величины слагаемых на их число: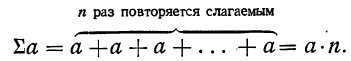
2) Постоянный множитель может быть вынесен из-под знака суммы и введен под знак суммы:
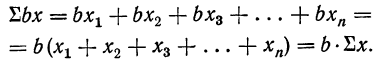
3) Сумма алгебраической суммы нескольких переменных равна алгебраической сумме сумм каждой переменной:
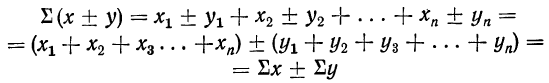
(легко обобщается на большее число слагаемых).
Величина интервала
Для выбора оптимальной величины интервала, т. е. такой величины интервала, при которой вариационный ряд не будет очень громоздким и в нем не исчезнут особенности явления, можно рекомендовать формулу:
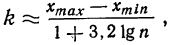
где n — число единиц в совокупности.
Так, если в совокупности 200 единиц наибольший вариант равен 49,961, а наименьший — 49,918, то
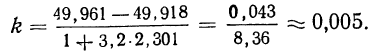
Следовательно, в данном случае оптимальной величиной интервала может служить величина 0,005.
Плотность распределения
В качестве характеристики ряда распределения применяют плотность распределения, которую вычисляют как отношение-частот или частостей к величине интервала.
Различают абсолютную плотность распределения:
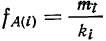
и относительную плотность распределения:
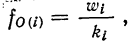
где 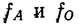 -— плотности распределения, абсолютная (со значком А) и относительная (со значком О).
-— плотности распределения, абсолютная (со значком А) и относительная (со значком О).
Пример 3.
По данным примера 2 вычислим относительную плотность распределения. Для первого интервала
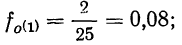
для второго интервала
Расщепление интервалов
Часто возникает необходимость в расщеплении интервалов. Для этой цели можно воспользоваться следующим методом для интервальных вариационных рядов с равными интервалами.
Расщепление производится при предположении, что плотность вариационного ряда изменяется по параболе второго порядка. Имеется в виду, что весь интервал разбивается на две части: первую, составляющую долю  в величине интервала, и вторую 1—
в величине интервала, и вторую 1—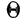 . Соответственно частость расщепляемого интервала F распадается на
. Соответственно частость расщепляемого интервала F распадается на  В этом случае:
В этом случае:
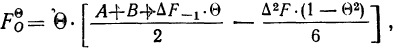
где А — частость интервала, предшествующего расщепляемому;
В — частость расщепляемого интервала;
С — частость интервала, последующего за расщепляемым;
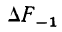 — приращение частости интервала, предшествующего расщепляемому (
— приращение частости интервала, предшествующего расщепляемому (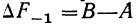 );
);
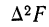 — второе приращение частостей
— второе приращение частостей 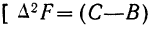 — (В—А)=С—2В+А].
— (В—А)=С—2В+А].
Пример 4.
По данным примера 2 произведем расщепление интервала 100—125% на две части, выделим часть интервала 100—120% и определим удельный вес рабочих, выполняющих норму выработки от 100 до 120%.
Имеем: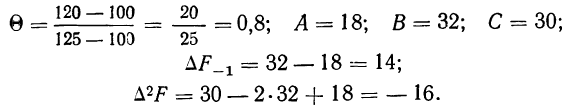
Получаем частость по соответствующей формуле: 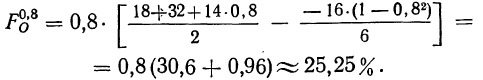
В случае неравных интервалов вычисление усложняется.
Графические методы изображения вариационных рядов
Большое значение для наглядного представления вариационного ряда имеют графические методы его изображения. Вариационный ряд графически может быть изображен в виде полигона, гистограммы, кумуляты и огивы.
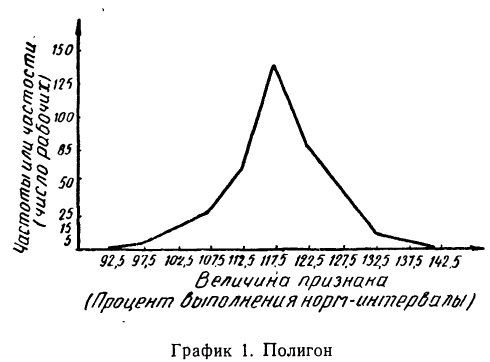
Полигон распределения (Дословно – многоугольник распределения) строится в прямоугольной системе координат. Величина признака откладывается на оси абсцисс, частоты или частости (точнее — плотности распределения) — по оси ординат.
На оси абсцисс отмечаются точки, соответствующие, величине вариантов, и из них восстанавливаются ординаты (перпендикуляры), длина которых соответствует численности этих вариантов. Вершины ординат соединяются прямыми линиями. Чаще всего полигоны применяются для изображения дискретных вариационных рядов, но могут быть применены и для интервальных рядов. В этом случае ординаты, пропорциональные частоте или частости интервала, восстанавливаются перпендикулярно оси абсцисс в точке, соответствующей середине данного интервала. Для замыкания крайние ординаты соединяются с •серединой интервалов, в которых частоты или частости равны нулю.
Пример 5.
По данным примера 1 строим полигон.
Гистограмма распределения строится аналогично полигону в прямоугольной системе координат. В отличие от полигона при построении гистограммы на оси абсцисс берутся не точки, а отрезки, изображающие интервал, а вместо ординат, соответствующих частотам или частостям отдельных вариантов, строят прямоугольники с высотой, пропорциональной частотам или частостям интервала.
В случае неравенства интервалов гистограмма распределения строится не по частотам или частостям, а по плотности интервалов (абсолютной или относительной). При этом общая площадь гистограммы равна численности совокупности, если построение производится по абсолютной плотности, или единице, если гистограмма построена по относительной плотности.
Если соединить прямыми линиями середины верхних сторон прямоугольников, то получим полигоны распределения.
Разбивая интервалы на несколько частей и исходя из того, что вся площадь гистограммы должна остаться при этом неизменной, можно получить мелкоступенчатую гистограмму, которая в пределе (за счет уменьшения величины интервала) перейдет в плавную кривую, называемую кривой распределения.
Пример 6.
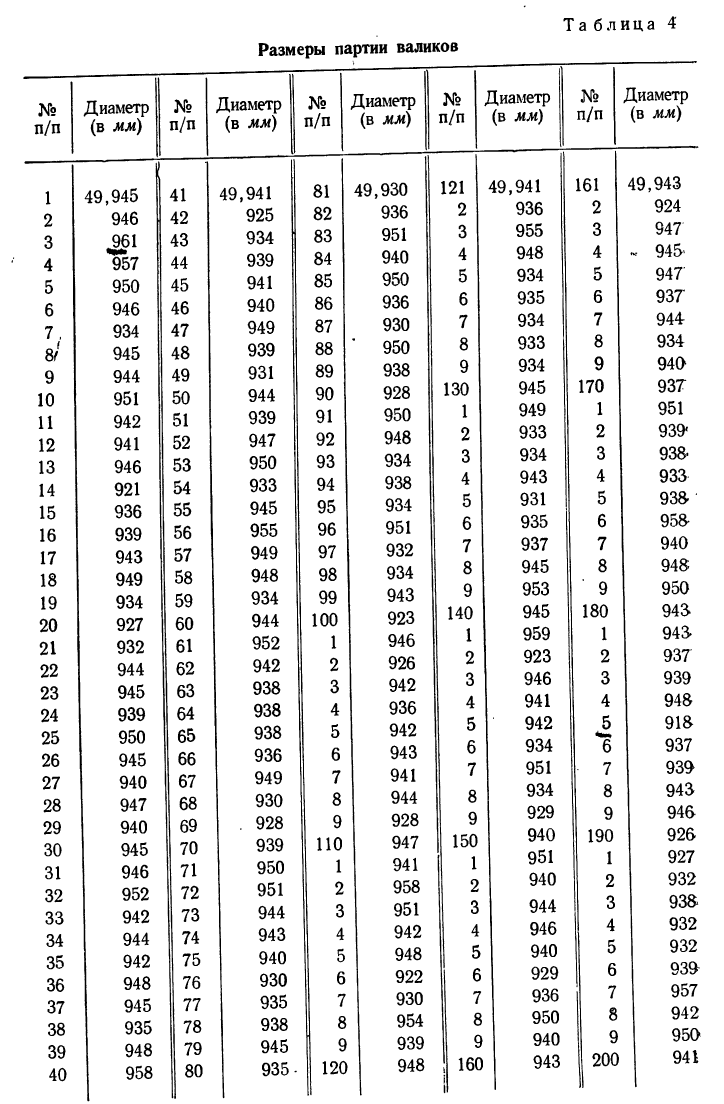
Имеются данные о диаметре 200 валиков (см. табл. 4).
Чтобы по этим данным построить вариационный ряд с равными интервалами, изобразить его с помощью гистограммы, а затем превратить ее в мелкоступенчатую, производим следующие действия:
а) Выбираем наименьший вариант, а затем наибольший и находим между ними разность. Делим полученную разность на число проектируемых интервалов и получаем величину каждого интервала.
Так, наименьший интервал 49,918, наибольший — 49,961. Разность 49,961—49,918=0,043.
Допустим, мы хотим получить пять интервалов, тогда величина каждого интервала равна
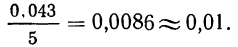
Следовательно, будем иметь такие интервалы:
49,918—49,928; 49,928—49,938 и т. д.
Строим рабочую таблицу, в которой подсчитываем численность каждого интервала путём . разноски данных из табл. 4 в рабочую табл. 5 и проставления черточек, соответствующих единице счета. По мере накопления четырех черточек перечеркиваем их одной чертой и ведем счет пятками (см. табл. 5).
На основании рабочей таблицы получаем следующий вариационный ряд (см. табл. 6).
б) По полученному вариационному ряду строим гистограмму распределения: на оси абсцисс откладываем диаметры валиков, начиная с 49,918 до 49,968, а на оси ординат проставляем масштаб; далее строим прямоугольники с высотой, пропорциональной количеству валиков в каждом интервале.
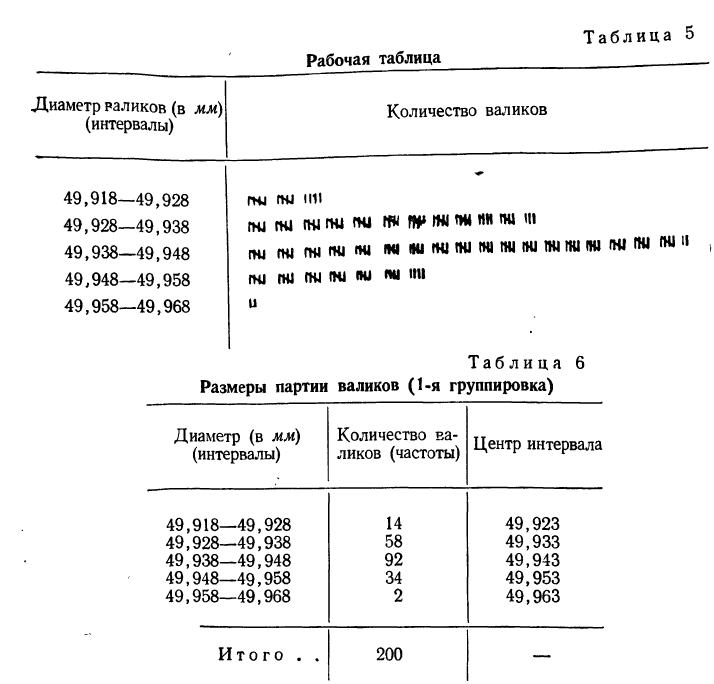
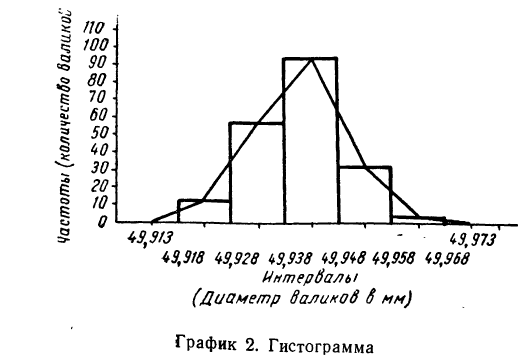
Соединяем прямыми линиями середины верхних сторон прямоугольников и получаем полигон (см. график 2).
Для получения мелкоступенчатой гистограммы разбиваем интервалы на две равные части и получаем:
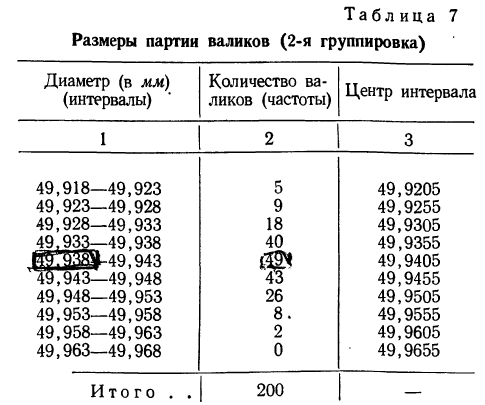
Если построить гистограмму по новому вариационному ряду, с уменьшенными интервалами, то получим гистограмму с более мелкими ступенями. Учет требования о неизменности площади гистограммы приводит к необходимости увеличить масштаб оси ординат вдвое.
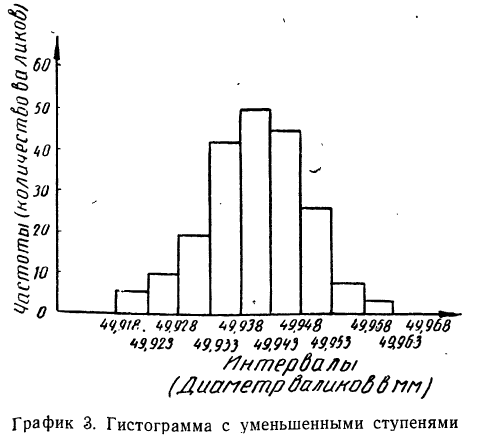
Можно продолжить процесс расчленения интервалов и дальше, получая все более и более мелкоступенчатую гистограмму.
Кумулятивная кривая (кривая сумм — кумулята) получается при изображении вариационного ряда с накопленными частотами или частостями в прямоугольной системе координат. При построении кумуляты дискретного признака на ось абсцисс наносятся значения признака (варианты). Ординатами служат вертикальные отрезки, длина которых пропорциональна накопленной частоте или частости того или иного варианта. Соединением вершин ординат прямыми линиями получаем ломаную (кривую) кумуляту.
Пример 7.
По данным табл. 4 построить кумуляту.
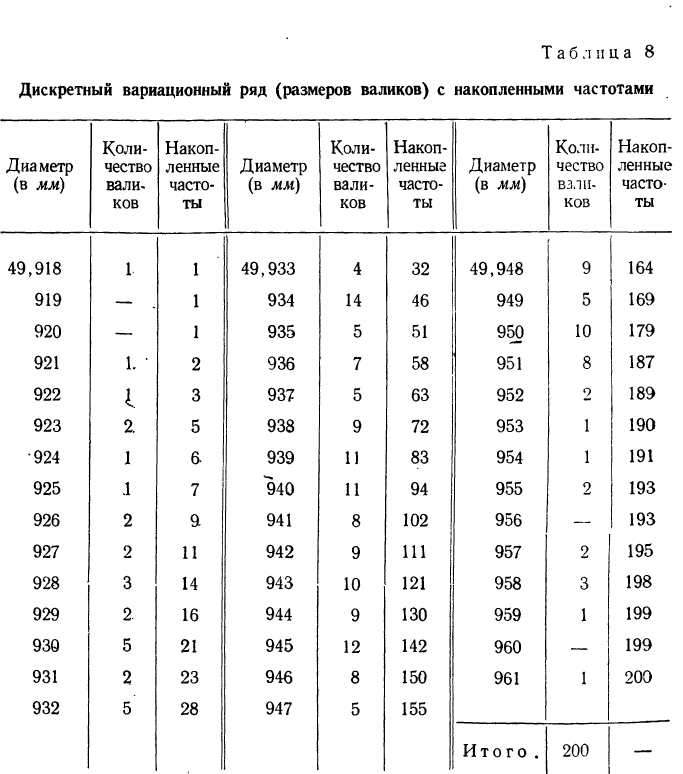
Составляем дискретный вариационный ряд с накопленными частотами (при наличии частостей можно для построения кумуляты пользоваться ими; см. табл. 8).
Накопленная частота определенного варианта получается суммированием всех частот вариантов, предшествующих данному, с частотой этого варианта.
Используя накопленные частоты, строим кумуляту.
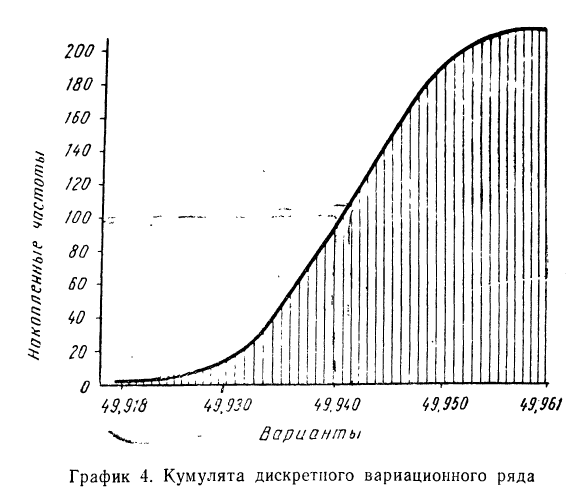
При построении кумуляты- интервального вариационного ряда нижней границе первого интервала соответствует частота, равная нулю, а верхней границе — вся частота интервала. Верхней границе второго интервала соответствует накопленная частота первых двух интервалов (т. е. сумма частот этих интервалов) и т. д. Верхней границе последнего (максимального) интервала соответствует накопленная частота, равная сумме всех частот.
Пример 8.
По данным табл. 7 построить кумуляту.
Составляем интервальный вариационный ряд с накопленными частотами (см. табл. 9). По полученным накопленным частотам строим кумуляту (см. график 5).
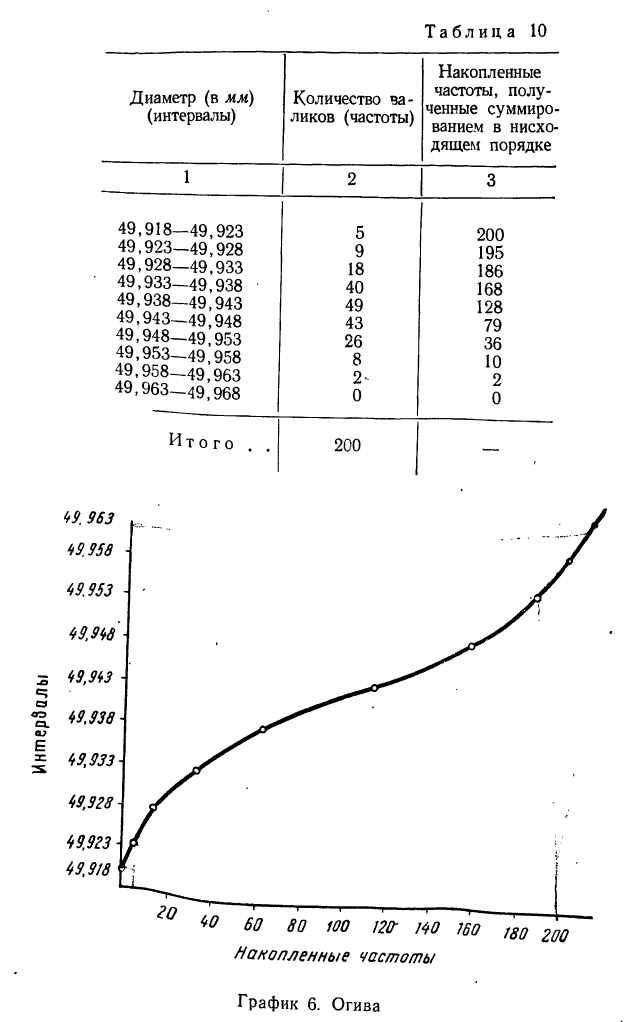
Огива строится аналогично кумуляте с той лишь разницей, что на ось абсцисс наносят накопленные частоты, а на ось ординат — значения признака. Если лист бумаги, на котором изображена кумулята, повернуть на 90° и посмотреть на него с обратной стороны на свет, то можно увидеть огиву.
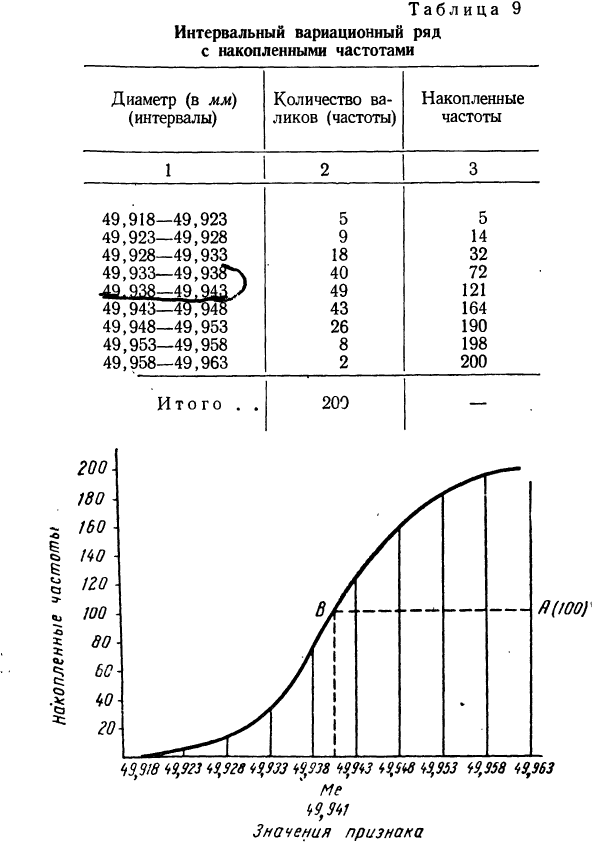
График 5. Кумулята интервального вариационного ряда
Пример 9. По данным табл. 9 построим огиву (см. график 6)-
Накопленные частоты можно получать не только в восходящем порядке, но и в нисходящем, тогда частоты вариантов суммируются снизу вверх.
Пример 10.
По данным табл. 7. вычислить накопленные частоты в нисходящем порядке.
Средние величины
В качестве одной из важнейших характеристик вариационного ряда применяют среднюю величину. Математическая статистика различает ряд типов средних величин: арифметическую, геометрическую, гармоническую, квадратическую, кубическую и др. Все перечисленные типы средних могут быть исчислены для случаев, когда каждый из вариантов вариационного ряда встречается только один раз, — тогда средняя называется простой или невзвешенной, — и для случаев, когда варианты или интервалы повторяются различное число раз. При этом число повторений вариантов или интервалов называют частотой или статистическим весом, а среднюю, вычисленную с учетом статистического веса, —взвешенной средней.
Выбор одного из перечисленных типов средних для характеристики вариационного ряда производится не произвольно, а в зависимости от особенностей изучаемого явления и цели, для которой средняя исчисляется.
Практически при выборе того или другого типа средней следует исходить из принципа осмысленности результата при суммировании или при взвешивании. Только тогда средняя применена правильно, когда в результате взвешивания или суммирования получаются величины, имеющие реальный смысл.
Обычно затруднения при выборе типа средней возникают лишь в использовании средней арифметической или гармонической. Что же касается геометрической и квадратической средних, то их применение ограничено особыми случаями (см. далее).
Следует иметь в виду, что средняя только в том случае является обобщающей характеристикой, если она применяется к однородной совокупности., В случае использования средней для неоднородных совокупностей можно прийти к неверным выводам. Научной – основой статистического анализа является метод статистических группировок, т. е. расчленения совокупности на качественно однородные группы.
Степенная средняя
Все указанные типы средних величин могут быть получены из формул степенной средней. Если имеются варианты 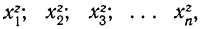 то средняя из вариант тов может быть исчислена по формуле простой невзвешенной степенной средней порядка z
то средняя из вариант тов может быть исчислена по формуле простой невзвешенной степенной средней порядка z
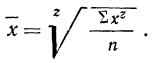
При наличии соответствующих частот  средняя исчисляется по формуле взвешенной степенной средней
средняя исчисляется по формуле взвешенной степенной средней
где 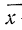 — степенная средняя;
— степенная средняя;
z — показатель степени, определяющий тип средней;
х — варианты;
m — частоты или статистические веса вариантов.
Средняя арифметическая получается из формулы степенной средней при подстановке z=1
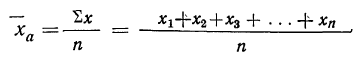
средняя арифметическая невзвешенная и
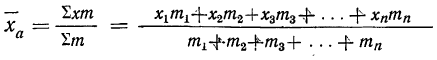
средняя арифметическая взвешенная.
Пример 11.
Измерения 20 единиц продукции дали следующие результаты (колонки 1 и 2):
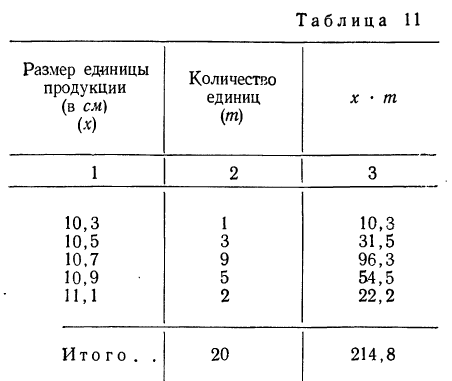
Вычислить средний размер единицы продукции.
Находим среднюю арифметическую. Для этого исчисляем в табл. 11 колонку 3
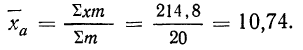
Здесь умножение значения признака на вес и суммирование этих произведений дает общий размер продукции, т. е. имеет реальный смысл.
Средняя гармоническая получается при подстановке в формулу степенной средней значения z =—1.
Средняя гармоническая простая
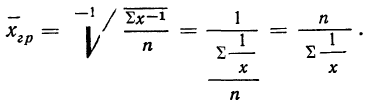
Средняя гармоническая взвешенная
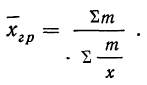
Средняя гармоническая вычисляется в тех случаях, когда средняя предназначается для расчета сумм слагаемых, обратно пропорциональных величине данного признака, т. е. когда суммированию подлежат не сами варианты, а обратные им величины
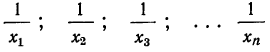
или
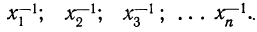
Пример 12.
По следующим данным о работе 22 рабочих в течение 6 часов вычислить среднюю гармоническую взвешенную.
В данном случае взвешивание состоит в делении по каждой группе количества рабочих (m) на затраты времени по изготовлению одной детали (х). Для проверки правильности выбора типа средней осмыслим результат взвешивания. Исходя из того, что все рабочие работали по 6 часов, количество рабочих можно рассматривать как величину, определяющую общие затраты времени. Тогда результат деления представит вполне осмысленную величину:
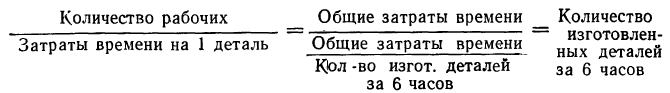
Таким образом, средняя гармоническая в данном примере применена правильно. При использовании средней гармонической для упрощения расчетов целесообразно пользоваться таблицами обратных чисел (см. приложение VIII).
Средняя квадратическая получается из формулы степенной средней при подстановке z=2
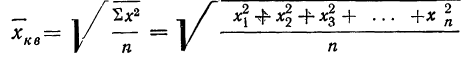
средняя квадратическая невзвешенная и
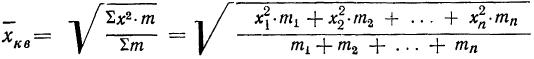
средняя квадратическая взвешенная.
Средняя квадратическая используется только в тех случаях, когда варианты представляют собой отклонения фактических величин от их средней арифметической или от заданной нормы.
Пример 13.
Имеются результаты измерения отклонений фактической длины изделий от заданной нормы.

Вычислим среднюю величину отклонений.
Находим среднюю квадратическую взвешенную; для этого исчисляем в табл. 13 колонки 3 и 4:
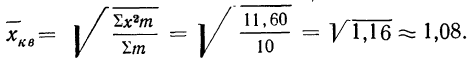
Значит, средняя величина отклонений фактической длины изделий от заданной нормы составляет 1,08 мм. В данном случае средняя арифметическая была бы непригодна, так как в результате мы получили бы нуль
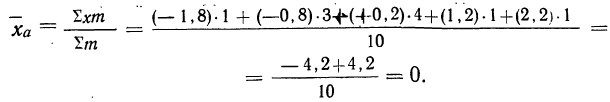
Средняя геометрическая получается из формулы степенной средней при подстановке z=0:
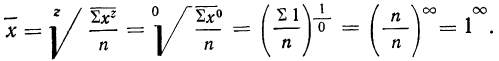
Для раскрытия неопределенности этого вида прологарифмируем обе части равенства: 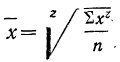
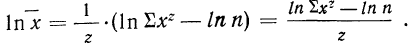
Теперь при подстановке z в правую часть равенства получаем неопределенность вида 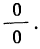 Используя правило Лопиталя и дифференцируя отдельно числитель и знаменатель по переменной z, получаем:
Используя правило Лопиталя и дифференцируя отдельно числитель и знаменатель по переменной z, получаем:
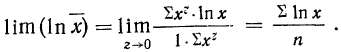
Таким образом:
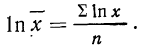
Потенцируя, находим среднюю:
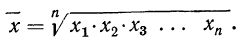
Это и есть формула средней геометрической невзвешенной, которая записывается сокращенно так:
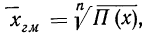
где П — знак произведения;
n — число вариантов.
Если использовать частоты (m), то средняя геометрическая взвешенная примет следующий вид:
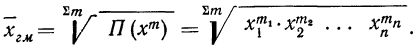
Вычисления средней геометрической в значительной мере упрощаются применением логарифмирования. Для невзвешенной средней геометрической 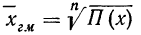 получаем:
получаем:
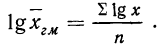
Для взвешенной средней геометрической:
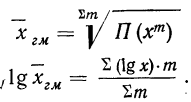
Таким образом, логарифм средней геометрической есть средняя арифметическая, из логарифмов вариантов (см. формулы средней арифметической).
Средняя геометрическая используется главным образом при изучении динамики (см. раздел II).
Расчет средних коэффициентов и темпов. роста производится по формулам средней геометрической.
Пример 14.
Выпуск промышленной продукции производился предприятием в следующих размерах:

Чтобы найти средний месячный коэффициент и темп роста промышленной продукции, определяем помесячные коэффициенты роста 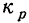 , которые в данном случае и являются вариантами:
, которые в данном случае и являются вариантами:
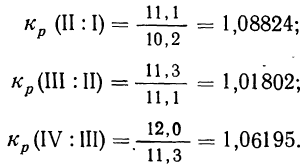
Из найденных трех помесячных коэффициентов роста (вариантов) определяем средний месячный коэффициент роста 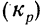 по формуле средней геометрической. Для этого найденные коэффициенты роста перемножаются и из произведения извлекается корень третьей степени
по формуле средней геометрической. Для этого найденные коэффициенты роста перемножаются и из произведения извлекается корень третьей степени
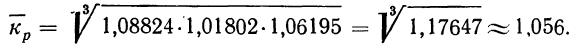
Из разобранного примера можно сделать два вывода: во-первых, что произведение трех найденных коэффициентов роста можно получить без их предварительного исчисления путем деления апрельского объема продукции (12,0) на январский объем (10,2):
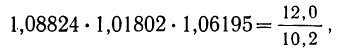
и, во-вторых, что показатель степени корня, равный трем (число коэффициентов роста), можно получить вычитанием единицы из числа приведенных в примере месяцев (четыре).
Таким образом, наиболее удобной для исчисления среднего коэффициента роста следует считать формулу:
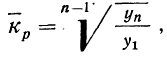
где n — число приведенных дат или периодов;
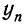 — последний член ряда;
— последний член ряда;
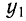 — первый член ряда.
— первый член ряда.
Математические свойства средней арифметической
Из вышеуказанных средних наиболее часто применяется средняя арифметическая. Знание свойств средней арифметической позволяет упрощенно ее вычислять.
Математические свойства средней арифметической:
1) Средняя постоянной величины равна этой же постоянной
величине.
2) Сумма отклонений от средней, умноженных на веса (частоты), равна нулю:
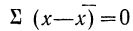 (если все веса равны единице)
(если все веса равны единице)
или
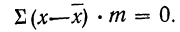
Докажем это свойство для средней взвешенной.
Имеем: варианты 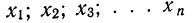
частоты 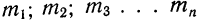
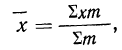 откуда
откуда 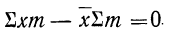
и 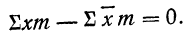
Подводя под общий знак суммы, получаем:
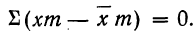
Следовательно, 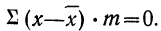
Пример 15.
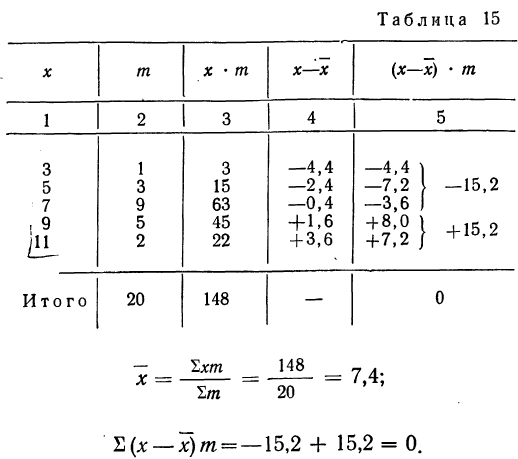
Вычислить среднюю (по колонкам 1 и 2) и убедиться в правильности выведенной формулы.
3) Если у всех вариантов х частоты m равны друг другу, то средняя арифметическая взвешенная равна средней арифметической невзвешенной.
Имеем 
Тогда:
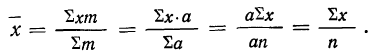
4) Если из всех вариантов (х) вычесть постоянную величину 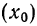 и из результатов вычитания, т. е. из отклонений вариантов от этой постоянной величины
и из результатов вычитания, т. е. из отклонений вариантов от этой постоянной величины 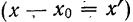 вычислить среднюю
вычислить среднюю 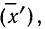 то она окажется меньше искомой средней на эту постоянную величину
то она окажется меньше искомой средней на эту постоянную величину 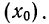 Поэтому, чтобы получить среднюю из вариантов
Поэтому, чтобы получить среднюю из вариантов 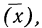 нужно к найденной средней
нужно к найденной средней  прибавить ту же постоянную величину:
прибавить ту же постоянную величину:
если 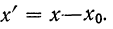
Доказательство.
Имеем отклонения от постоянной величины 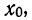 обозначенные
обозначенные 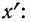
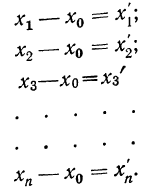
Находим среднюю из 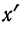
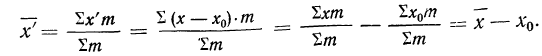
Откуда 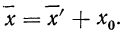
Пример 16.
Вычислить среднюю путем вычитания 1000 из всех вариантов по следующим данным (колонки 1 и 2).
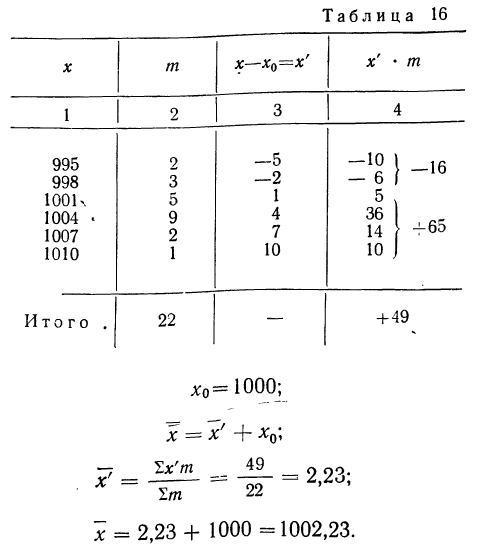 .
.
Пример 17.
Используя данные прёдыдущего примера, можно убедиться, что если за  взять не 1000, а 1004, то величина средней не изменится.
взять не 1000, а 1004, то величина средней не изменится.
5) Если все варианты (х) уменьшить в одно и то же число раз, т. е. разделить на постоянную величину (k), и из частных  вычислить среднюю, то онa окажется уменьшенной в такое же число раз, а поэтому, чтобы получить среднюю из вариантов
вычислить среднюю, то онa окажется уменьшенной в такое же число раз, а поэтому, чтобы получить среднюю из вариантов  нужно найденную среднюю
нужно найденную среднюю 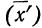 умножить на ту же постоянную величину (k):
умножить на ту же постоянную величину (k):
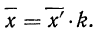
Доказательство.
Имеем частные от деления вариантов х на постоянную величину k, обозначенные х’:
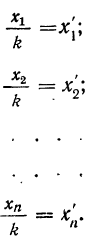
Находим среднюю из 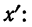
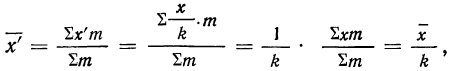
откуда 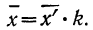
Пример 18.
Вычислить среднюю путем деления всех вариантов на 100 по следующим данным (колонки 1 и 2):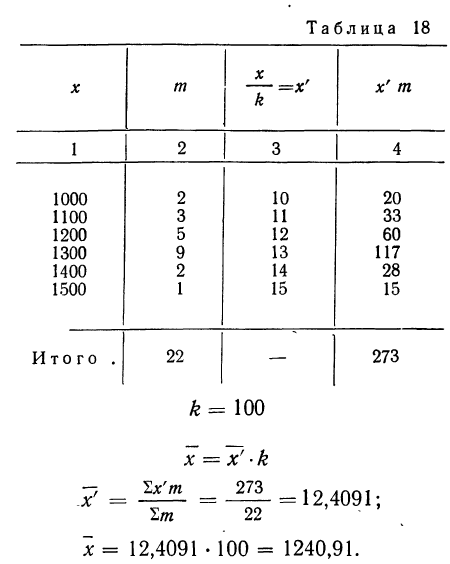
6) При вычислении средней вместо абсолютных значений весов (m) можно использовать относительные величины структуры (частости), т. е. удельные веса отдельных частот в общей сумме всех частот (см. § 4), или относительные величины координации, которые получаются путем отношения частот всех вариантов к одной из частот, принятой за единицу
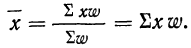
Если же удельные веса частот выражены в процентах, то
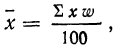
где 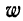 — частость, т. е. доля частоты варианта в общей сумме частот.
— частость, т. е. доля частоты варианта в общей сумме частот.
Доказательство.
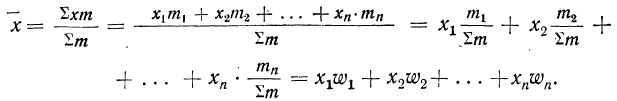
Значит 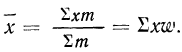
Пример 19.
Вычислить средний размер детали по следующим данным (колонки 1 и 2):
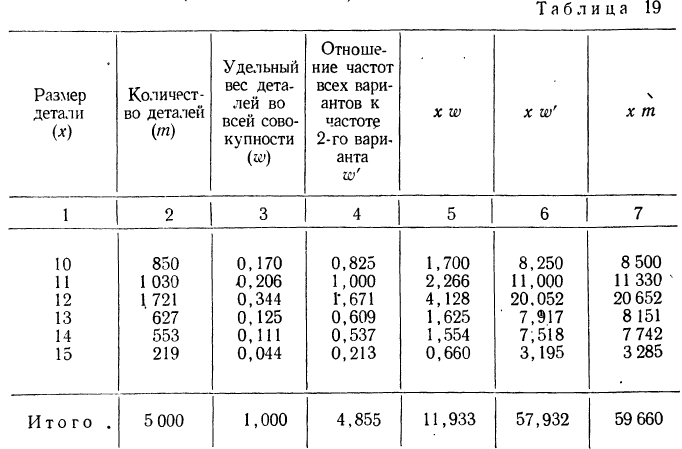
Предварительно найдем относительные величины структуры (колонка 3), а затем вычислим средний размер детали, используя их в качестве весов:
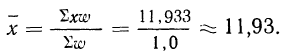
Если теперь вычислить средний размер детали, используя в качестве весов частоты, то получим:
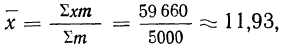
что согласуется с результатом, полученным ранее.
Для вычисления средней можно было использовать колонку 4 : 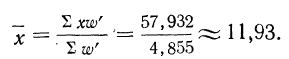
7) Если в частотах (m) имеется общий множитель (A), то его можно при вычислении средней не принимать во внимание т. е. взвешивание производить по сокращенным частотам 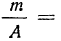
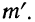 Численное значение средней от замены частот (m) на сокращенные частоты
Численное значение средней от замены частот (m) на сокращенные частоты 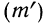 не изменится
не изменится
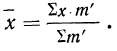
Доказательство.
Имеем: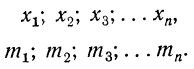
Разделим частоты на общий множитель А, содержащийся в них:
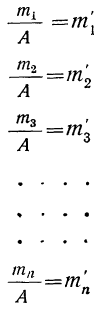
Тогда
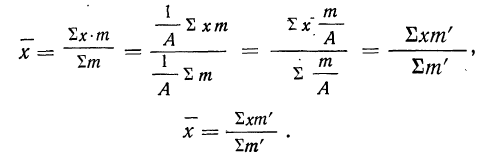
Пример 20.
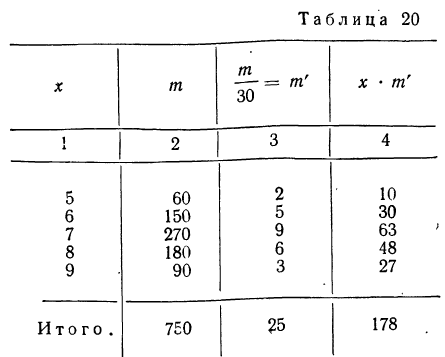
Вычислить среднюю по данным табл. 20 (колонки 1 и 2), произведя взвешивание вариантов по сокращенным весам.
Вычисляем среднюю по указанной формуле, предварительно сократив веса и заполнив колонки 3 и 4.
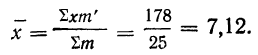
8) Общая средняя равна-.-взвешенной средней из частных средних:
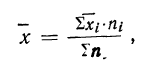
где 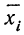 — частные средние, т. е. средние для отдельных групп совокупности;
— частные средние, т. е. средние для отдельных групп совокупности;
 — средняя из вариантов первой группы;
— средняя из вариантов первой группы;
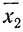 — средняя из вариантов второй группы и т. д.;
— средняя из вариантов второй группы и т. д.;
 — частоты отдельных групп;
— частоты отдельных групп;
 — частота первой группы;
— частота первой группы;
 — частота второй группы и т. д.
— частота второй группы и т. д.
Доказательство.
Пусть имеются частные средние:
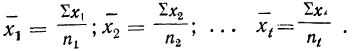
Найдем среднюю для всей совокупности:
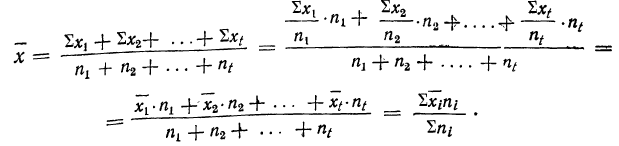
Пример 21.
В трех, партиях продукции численностью 1000, 2000 и 500 единиц найден средний вес детали (в кг): 3,3; 3,1; 3,7. Вычислить средний вес детали во всех трех партиях
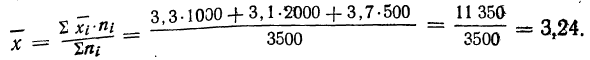
9) Сумма квадратов отклонений от средней меньше суммы квадратов отклонений от произвольной величины (В) на величину поправки С, равной произведению объема совокупности на квадрат разности между средней и данной произвольной величиной:
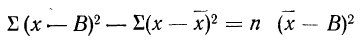
для случая невзвешенной средней или
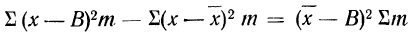
для случая взвешенной средней.
Доказательство для случая невзвешенной средней.
Имеем:
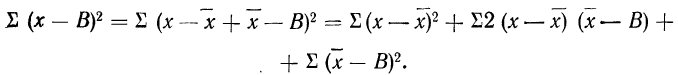
Пользуясь свойствами сумм (см. стр. 11), производим преобразования:
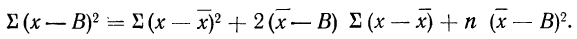
На основании второго свойства средней арифметической 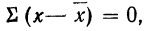 а поэтому
а поэтому
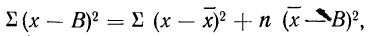
откуда
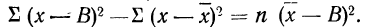

Пример 22.
По данным табл. 21 (колонки 1 и 2) убедиться в правильности указанных соотношений.
Вычисляем колонки 3, 4, 5, 6, 7, 8, 9 и находим:
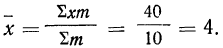
Подставляя полученные результаты в формулу
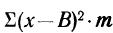
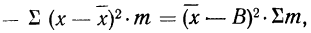 имеем:
имеем:
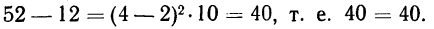
Метод отсчета от условного нуля
Упрощенное вычисление средней, состоящее в использовании ряда ее свойств, называется методом отсчета от условного нуля и предполагает:
- вычитание из всех вариантов начала отсчета или «ложного нуля»
- деление всех вариантов или отклонений вариантов от начала отсчета на общий множитель, содержащийся в них (k);
- условное принятие центра интервала за значение признака всех единиц в данном интервале.
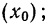
Кроме того, в качестве весов используют сокращенные частоты 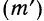 или относительные величины (структуры или координации).
или относительные величины (структуры или координации).
Формула исчисления средней методом отсчета от условного нуля:
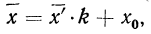
где 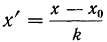 , т. е. отклонение от начала отсчета делится на общий множитель, а исчисление средней из
, т. е. отклонение от начала отсчета делится на общий множитель, а исчисление средней из 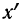 в зависимости от того, какими весами мы располагаем, производится по одной из следующих формул:
в зависимости от того, какими весами мы располагаем, производится по одной из следующих формул:
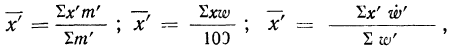
где 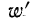 — относительные величины координации (см. табл. 19).
— относительные величины координации (см. табл. 19).
Пример 23.
Вычислить средний вес зерен (на 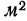 ) по данным колонок 1 и 2 табл. 22 (см. стр. 38), используя метод отсчета от условного нуля.
) по данным колонок 1 и 2 табл. 22 (см. стр. 38), используя метод отсчета от условного нуля.
Используем формулу 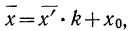 предварительно заполнив колонки 3, 4, 5 и 6 табл. 22:
предварительно заполнив колонки 3, 4, 5 и 6 табл. 22:
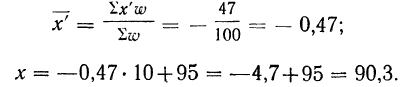

Метод стандартизации средних
Часто сравниваемые совокупности неоднородны по своему составу, и выводы при использовании средних для подобных сравнений могут оказаться неправильными. Чтобы .этого избежать, используют метод стандартизации.
Метод стандартизации средних наиболее разработан в статистике населения (демографической) и медицинской статистике, когда производится сравнение совокупностей с различными Структурами. Стандартизация достигается элиминированием (устранением) влияния различия в структурах совокупностей. Результат сравнения характеризует различие в средних при условии, что структура сравниваемых совокупностей одинакова.
Рассмотрим применение метода стандартизации на примере из медицинской статистики. Имеются данные о двух больницах А и Б по отделениям и в целом.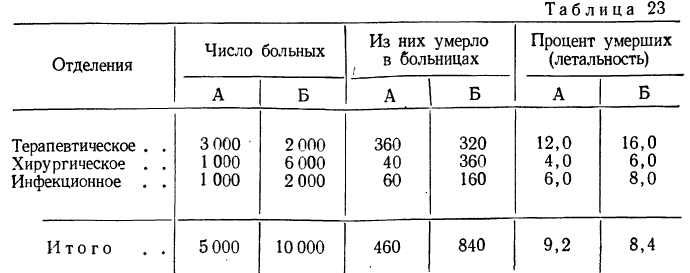
Получается парадоксальное положение, при котором по больнице Б итоговая (общая) летальность (8,4%) ниже, чем в больнице А (9,2%), хотя по всем отделениям летальность в больнице Б выше (см. последние две колонки).
Причиной этого парадокса является отличие удельных весов разных отделений в больницах. Доля терапевтического отделения (по числу больных) с самой высокой летальностью составляет в больнице А 60%„ а в больнице Б — 20%, а доля хирургического отделения, с самой низкой летальностью, в больнице А — 20%, а в больнице Б — 60%.
Устраним влияние различия в структурах и стандартизуем распределение больных по отделениям. В качестве стандарта можно взять распределение больных по отделениям в любой больнице или привлечь данные о распределении больных нескольких других больниц. Возьмем за стандарт распределение больных в больнице А. Тогда по больнице А общая летальность (9,2%) останется без изменения. По больнице Б произведем пересчет.
Находим среднюю стандартизованную летальность больных больницы Б:
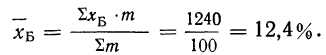
Таким образом, после стандартизации летальность в больнице Б оказалась значительно выше,, чем в больнице А:
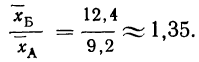
Следует иметь в виду, что полученное значение стандартизованной средней может служить только для сравнительных целей, абсолютное же ее значение принимать во внимание не следует.
Если за стандарт принять распределение больных в больнице Б, то получим следующую стандартизованную летальность для больницы А:
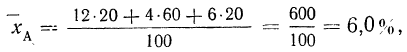
а отношение стандартизованных средних почти не изменится:
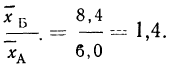
Мажорантность средних
Если вычислить различные типы средних для одного и того же вариационного ряда, то численные их значения будут отличаться друг от друга. При этом средние по своей величине расположатся в определенном порядке. Наименьшей из перечисленных средних окажется средняя гармоническая, затем геометрическая и т. д., наибольшей — средняя квадратическая. Порядок возрастания средних при этом определяется показателем степени z в формуле степенной средней и вытекает из «правила мажорантности».
Так,
при z= —1 получаем среднюю гармоническую,
при z= 0 »» геометрическую,
при z= 1 »» арифметическую,
при z= 2 »» квадратическую:
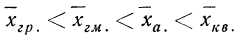
Подробное выяснение общего условия мажорантности впервые было произведено А. Я. Боярским, доказавшим, что если две средние должны удовлетворять соответственно уравнениям
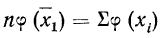
и
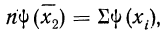
то первая из них  мажорантна в отношении
мажорантна в отношении  если при любом значении аргумента
если при любом значении аргумента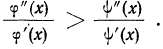
Для степенной средней порядка z имеем:
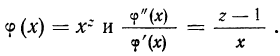
Это отношение для положительных значений с показателем x растет вместе с показателем z.
Пример 24.
Вычислить различные типы средних,по следующим данным (колонки 1 и 2) и убедиться в правильности порядка возрастания средних:
Заполняем колонки с 3-й по 8-ю и по соответствующим формулам исчисляем средние взвешенные:

Порядок средних определился в соответствии с правилом мажорантности:
17,41 < 18,14 < 18,8< 19,37.
Медиана
В качестве характеристики вариационного ряда применяется медиана ( ), т. е. такое значение варьирующего признака, которое приходится на середину упорядоченного вариационного ряда. Если в вариационном ряде 2m + 1 случаев, то значение признака у случая m + 1 будет медианным. Если в ряду четное число 2m случаев, то медиана равна средней арифметической из двух срединных значений.
), т. е. такое значение варьирующего признака, которое приходится на середину упорядоченного вариационного ряда. Если в вариационном ряде 2m + 1 случаев, то значение признака у случая m + 1 будет медианным. Если в ряду четное число 2m случаев, то медиана равна средней арифметической из двух срединных значений.
Формулы для исчисления медианы при нечетном и четном числе вариантов:
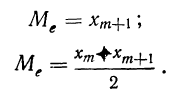
Пример 25.
Дано девять вариантов признака х, расположенных в возрастающем порядке:
Вычислить медиану.
Имеем нёчетное число вариантов:
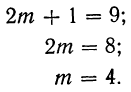
Находим медиану
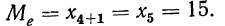
Пример 26.
Дано 12 вариантов признака х, расположенных в возрастающем порядке:
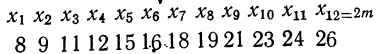
Ищем медиану.
Имеем четное число вариантов:
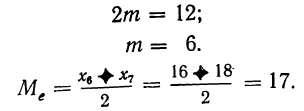
При исчислении медианы интервального вариационного ряда сначала находят интервал, содержащий медиану, путем использования накопленных частот или частостей. Медианному интервалу соответствует первая из накопленных частот или частостей, превышающая половину всего объема совокупности.
Для нахождения медианы при постоянстве плотности внутри интервала, содержащего медиану, используют следующую формулу:
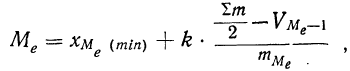
где  —нижняя граница медианного интервала;
—нижняя граница медианного интервала;
k — интервальная разность;
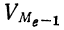 — накопленная частота интервала, предшествующего медианному;
— накопленная частота интервала, предшествующего медианному;
 — частота медианного интервала.
— частота медианного интервала.
Пример 27.
По данным табл. 7 вычислить медиану.
Используем табл. 9, в которой дана колонка накопленных частот. Так как вариационный ряд содержит 200 единиц, то медиана будет 100-й единицей, входящей в интервал 49,938— 49,943 (определяется из колонки 3 табл. 9 по накопленной частоте 121, первой из накопленных частот, которая превышает половину всего объема вариационного ряда). Следовательно:
Вычислим медиану:
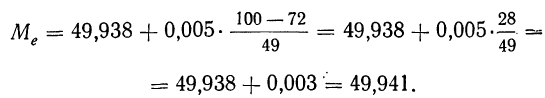
Медиана может быть определена и графически по кумуляте или огиве. Для определения медианы по кумуляте последнюю ординату, пропорциональную сумме всех частот или частостей, делят пополам. Из полученной точки восстанавливают перпендикуляр до пересечения с кумулятой. Абсцисса точки пересечения и дает значение медианы.
П р и м е р 28. По графику 5 определить медиану.
Последняя ордината, как видно из графика, равна 200. Деление этой ординаты пополам дает точку А (100). Перпендикуляр из точки А до пересечения с кумулятой дает точку В. Абсцисса точки В, равная 49,941, и будет медианой.
Медиана обладает тем свойством, что сумма абсолютных величин отклонений вариантов от медианы меньше, чем от любой другой величины (в том числе и от средней арифметической).
Доказательство. Допустим, что в упорядоченном вариационном ряду, состоящем из n вариантов, в качестве начала отсчета отклонений взят вариант, расположенный так, что число вариантов меньше его m, а больше n—m.
Найденную сумму абсолютных величин отклонений от этого варианта обозначим 
Если теперь передвинуть начало отсчета на один вариант вверх так, чтобы вариантов, величина которых меньше начала отсчета, было m—1, а больше n—m+1, то при этом сумма абсолютных величин отклонений вариантов меньших, чем начало отсчета, от начала отсчета уменьшится на m • с, где с — разность между старым и новым началами отсчета.
В то же время сумма абсолютных величин отклонений больших вариантов от нового начала отсчета отклонений увеличится на (n—m) • с. Новая сумма абсолютных отклонений окажется равной
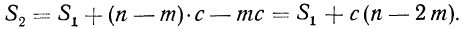
Следовательно, при таком передвижении начала отсчета вверх новая сумма абсолютных отклонений будет уменьшаться до тех пор, пока 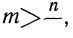 т. е. пока m больше половины n.
т. е. пока m больше половины n.
При 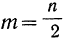 сумма абсолютных отклонений будет, следовательно, наименьшей, а затем при дальнейшем передвижении начала отсчета начнет увеличиваться.
сумма абсолютных отклонений будет, следовательно, наименьшей, а затем при дальнейшем передвижении начала отсчета начнет увеличиваться.
Теперь следует учесть, что n-й вариант, расположенный в середине вариационного ряда, и есть медиана.
Таким образом, минимальное свойство медианы будет доказано.
Это свойство медианы может быть использовано при проектировке расположения трамвайных и троллейбусных остановок, бензоколонок, ссыпных пунктов и т. д.
Например, на шоссе длиной 100 км имеется 10 гаражей. Для проектирования строительства бензоколонки были собраны данные о числе предполагаемых ездок на заправку с каждого гаража. Результаты обследования представлены в табл, на стр. 45.
Нужно поставить бензоколонку так, чтобы общий пробег автомашин на заправку был наименьшим.
Решение: Вариант 1. Если бензоколонку поставить на середине шоссе, т. е. на 50-м километре, то пробеги с учетом числа ездок составят:
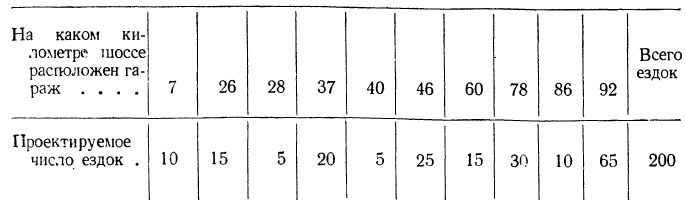
а) в одном направлении: 43 • 10 + 24 • 15 + 22 • 5 + 13 • 20 +
+ 10-5 + 4-25 = 1310 км;
б) в противоположном направлении: 10-15 + 28-30 + 36-10 +
+ 42-65 = 4080 км.
Общий пробег в оба направления окажется равным 5390 км.
Вариант 2. Уменьшения пробега можно достигнуть, если бензоколонку поставить на 63,85-м километре (средний участок шоссе с учетом числа ездок).
В этом случае пробеги составят:
а) в одном направлении: 56,85-10 + 37,85-15 + 35,85-5 + 26,85 -20 + 23,85-5+17,85 • 25 + 3,85 -15 = 2475,75 км;
б) в противоположном направлении: 14,15-30 + 22,15-10 + 28,15-65 = 2475,75 км.
Общий пробег в оба направления составит 4951,5 км и окажется меньше, чем при первом варианте, на 438,5 км.
Вариант 3. Наилучший результат, т. е. минимальный общий пробег, будет получен в том случае, если мы поставим бензоколонку на 78-м километре, что будет соответствовать медиане.
Тогда пробеги составят:
а) в одном направлении: 71 • 10 + 52 • 15 + 50 • 5 + 41 • 20 + 38-5 + 32-25+ 18-15 = 3820 км;
б) в противоположном направлении: 8 • 10+14 • 65 = 990 км.
Общий пробег равен 4810 км, т. е. он оказался меньше общих пробегов, рассчитанных по предыдущим вариантам.
Мода
Модой ( ) называется вариант, наиболее часто, встречающийся в данном вариационном ряду. Для дискретного ряда мода, являющаяся характеристикой вариационного ряда, определяется по частотам вариантов и соответствует варианту с наибольшей частотой.
) называется вариант, наиболее часто, встречающийся в данном вариационном ряду. Для дискретного ряда мода, являющаяся характеристикой вариационного ряда, определяется по частотам вариантов и соответствует варианту с наибольшей частотой.
В случае интервального распределения с равными интервалами модальный интервал (т. е. содержащий моду) определяется пр наибольшей частоте, а при неравных интервалах — по наибольшей плотности.
Вычисление моды производится по следующей формуле:
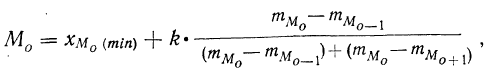
где
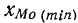 – нижняя граница модального интервала;
– нижняя граница модального интервала;
k—интервальная разность;
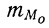 — частота модального интервала;
— частота модального интервала;
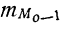 — частота интервала, предшествующего модальному;
— частота интервала, предшествующего модальному;
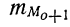 — частота интервала, последующего за модальным.
— частота интервала, последующего за модальным.
Пример 29.
По данным табл. 7 находим моду.
Наибольшая частота, равная 49 (колонка 2, табл. 7), соответствует интервалу 49,938—49,943, который и будет модальным.
Следовательно:
Подставляя в формулу найденные значения, вычислим моду
Как видно из разобранного примера и примера 27, для данного вариационного ряда мода и медиана очень близки друг к другу.
Симметричные вариационные ряды
Вариационные ряды, в которых частоты вариантов, равно отстоящих от средней, равны между собой, называются симметричными. Особенностью симметричных вариационных рядов является равенство трех характеристик: средней арифметической, моды и медианы:
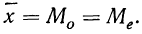
Этим пользуются для распознания симметричности вариации в тех случаях, когда она затушевана тем, что средняя приходится не на середину интервала и не на границу между двумя интервалами, т. е. в результате сдвига интервалов группировки ряд частот как таковых оказывается не вполне симметричным.
Пример 30.
По данным табл. 7 определить среднюю и сопоставить с модой и медианой, вычисленными по этим же данным в примерах 27 и 29.
Вычисляем среднюю (см. табл. 26):
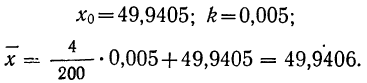

Найденную среднюю сопоставляем с модой и медианой, вычисленными ранее:
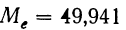 (из примера 27);
(из примера 27);
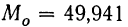 (из примера 29);
(из примера 29);
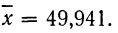
Полученные характеристики по своей величине близки друг к другу, что дает нам основание считать данный вариационный ряд не очень отклоняющимся от симметричного.
Асимметричные вариационные ряды
Вариационные ряды, в которых расположение вариантов вокруг средней неодинаково, т. е. частоты по обе стороны от средней изменяются по-разному, называются асимметричными или скошенными. Различают левостороннюю и правостороннюю асимметрию.
Меры колеблемости (вариации) признака
Средние величины, характеризуя вариационный ряд одним числом, не учитывают вариацию признака, между тем эта вариация существует. Для измерения вариации признака математическая статистика применяет ряд способов.
Вариационный размах (R) (или широта распределения) есть разность между экстремальными (крайними) значениями вариационного ряда. Он представляет собой величину неустойчивую, чрезвычайно зависящую от случайных обстоятельств; применяется в качестве приблизительной оценки вариации.
В последнее время вариационный размах стал применяться в ряде отраслей промышленности при статистическом изучении качества продукции.
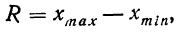
где 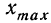 — наибольший вариант вариационного ряда;
— наибольший вариант вариационного ряда;
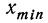 — наименьший вариант вариационного ряда.
— наименьший вариант вариационного ряда.
Среднее линейное отклонение или простое среднее отклонение (р —ро) представляет собой среднюю арифметическую из абсолютных значений отклонений вариантов от средней.
В зависимости от отсутствия или наличия частот вычисляют среднее линейное отклонение невзвешенное или взвешенное:
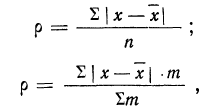
где прямые скобки, в которых заключены разности между вариантами и средней, показывают, что непосредственное суммирование и суммирование после взвешивания производится без учета знаков.
Средний квадрат отклонения — дисперсия (обычно обозначаемый 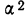 или
или 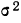 ) наиболее часто применяется и в теории и на практике в качестве меры колеблемости признака. Если дисперсию вычисляют для всей совокупности, то ее обозначают а и называют общей дисперсией:
) наиболее часто применяется и в теории и на практике в качестве меры колеблемости признака. Если дисперсию вычисляют для всей совокупности, то ее обозначают а и называют общей дисперсией:
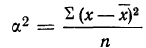
Дисперсия невзвешенная
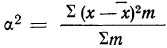
Дисперсия взвешенная
Таким образом, общая дисперсия есть средняя арифметическая из квадратов отклонений вариантов от их средней арифметической.
Среднее квадратическое отклонение (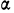 или
или  ) представляет собой квадратный корень из дисперсии:
) представляет собой квадратный корень из дисперсии:
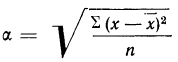
Среднее квадратическое отклонение невзвешенное
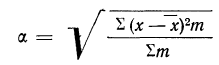
Среднее квадратическое отклонение взвешенное
Достоинством этого показателя по сравнению со средним линейным отклонением ( ) является то, что при его вычислении никакого условного допущения о необходимости суммирования отклонений вариантов от средней без учета их знаков мы не делаем, а используем формулу средней квадратической (см. формулу на стр. 25), по которой при возведении отклонений в квадрат их знак безразличен.
) является то, что при его вычислении никакого условного допущения о необходимости суммирования отклонений вариантов от средней без учета их знаков мы не делаем, а используем формулу средней квадратической (см. формулу на стр. 25), по которой при возведении отклонений в квадрат их знак безразличен.
Учитывая, что среднее линейное отклонение и среднее квадратическое отклонение представляют собой абсолютные величины, выраженные в тех же единицах измерения, что и варианты, для характеристики колеблемости признака используют относительные показатели – коэффициенты вариации (V), представляющие собой отношение среднего линейного отклонения или среднего квадратического отклонения к средней, выраженное в процентах (или в долях единицы):
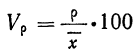
Коэффициент вариации по среднему линейному отклонению
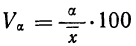
Коэффициент вариации по среднему квадратическому отклонению
Видоизмененный показатель коэффициента вариации по среднему линейному отклонению (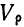 ) представляет собой показатель неровноты (Н). Он применяется в текстильной промышленности в. качестве меры колеблемости при изучении неровноты пряжи (по толщине, весу и другим показателям)
) представляет собой показатель неровноты (Н). Он применяется в текстильной промышленности в. качестве меры колеблемости при изучении неровноты пряжи (по толщине, весу и другим показателям)
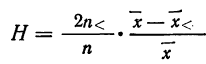
Показатель неровноты невзвешенный
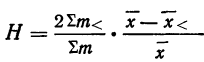
Показатель неровноты взвешенный
 — общая средняя;
— общая средняя;
 — количество вариантов, величина которых меньше, чем общая средняя;
— количество вариантов, величина которых меньше, чем общая средняя;
n — объем вариационного ряда;
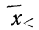 —средняя из вариантов меньших, чем общая средняя;
—средняя из вариантов меньших, чем общая средняя;
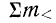 — сумма частот вариантов, меньших общей средней;
— сумма частот вариантов, меньших общей средней;
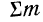 —сумма частот всех вариантов.
—сумма частот всех вариантов.
Доказательство (для показателя неровноты невзвешенного) .
Подставляя в формулу 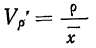 вместо
вместо 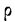 его значение
его значение 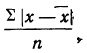
получаем:
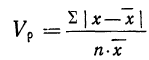 (без умножения на 100).
(без умножения на 100).
Разделим весь вариационный ряд на две части. Пусть в первую часть включены варианты меньшие, чем общая средняя, а во вторую — большие, чем общая средняя.
Тогда
где
 —сумма отклонений вариантов, больших, чем общая средняя, от общей средней дает положительную величину;
—сумма отклонений вариантов, больших, чем общая средняя, от общей средней дает положительную величину;
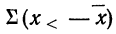 — сумма отклонений вариантов меньших, чем общая средняя, от общей средней дает отрицательную величину.
— сумма отклонений вариантов меньших, чем общая средняя, от общей средней дает отрицательную величину.
Но так как 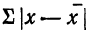 представляет сумму абсолютных значений отклонений, перед вторым слагаемым ставим знак минус. Наос-новании свойства средней арифметической о том, что
представляет сумму абсолютных значений отклонений, перед вторым слагаемым ставим знак минус. Наос-новании свойства средней арифметической о том, что 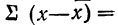 0, делаем вывод, что
0, делаем вывод, что 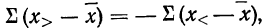 и следовательно,
и следовательно,
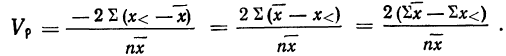
Учитывая, что под знаком суммы слагаемых будет  выносим
выносим 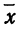 из-под знака суммы:
из-под знака суммы:
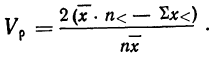
Делим и умножаем числитель на 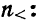
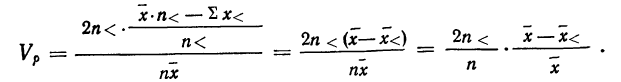
Пример 31.
По данным табл. 27 о крепости одиночной нити (в г) вычислим показатели вариации признака: вариационный размах, показатель неровноты, коэффициенты вариации по среднему линейному отклонению и среднему квадратическому отклонению.
Вычисляем R:
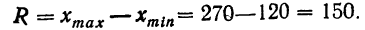
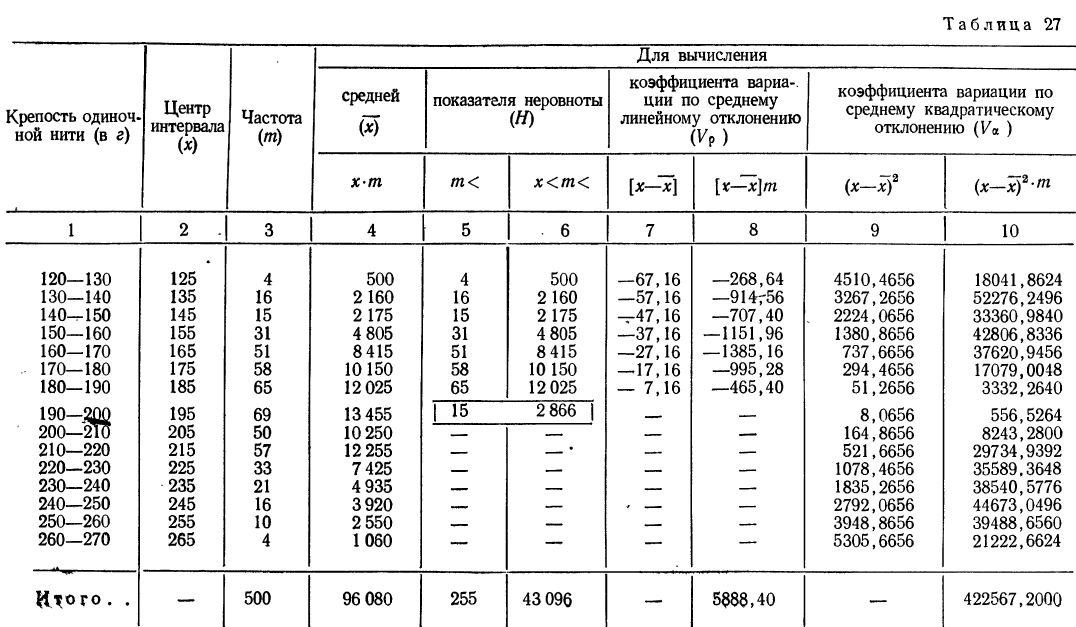
Находим среднюю: 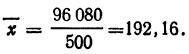
Находим Н. Интервал 190—200 расчленяем на две части: 190—192,16 и 192,16—200.
Аналогично поступаем с частотами: так как вся частота данного интервала равна 69, то, предполагая равномерное распределение признака внутри интервала, получим, что на величину, равную единице интервала, приходится 6,9 единицы частот (абсолютная плотность); на новый интервал (190—192,16), в котором интервальная разность равна 2,16, придется 6,9*2,16 = 14,9 единицы частот. Для простоты возьмем 15. Суммируя частоты вариантов, меньших общей средней, получим 255 (см. колонку 5 табл. 27). Суммируя произведения х
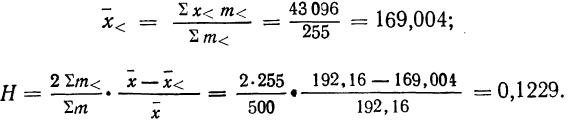
Вычисляем  и
и  .
.
Учитывая одно из свойств средней, а именно, что сумма отклонений от средней, соответствующим образом взвешенных, равна нулю, практически поступают следующим образом. В колонке 7 табл. 27, несмотря на знак прямых скобок, указывающих на абсолютную величину отклонений, для отрицательных отклонений от средней знак минус оставляют и ведут вычисление только до перемены знака на плюс. Взвешивают отрицательные отклонения от средней (колонка 8 табл. 27) и, так как сумма взвешенных положительных отклонений от средней должна быть равна сумме взвешенных отрицательных отклонений от средней, для определения общей суммы взвешенных отклонений найденную сумму удваивают.
Получаем:
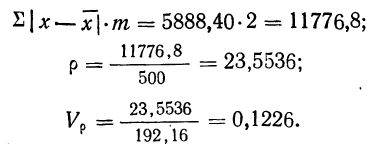
Вычисляем 
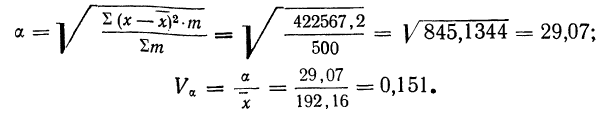
Между средним квадратическим отклонением 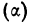 и средним линейным отклонением
и средним линейным отклонением 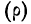 существует определенное соотношение (такое же соотношение, как между
существует определенное соотношение (такое же соотношение, как между 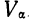 и
и  ). По свойству мажорантности
). По свойству мажорантности  всегда больше
всегда больше 
Если объем совокупности достаточно большой и распределение признака в вариационном ряде близко к нормальному (см. раздел IV), то связь между  и
и 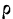 определяется по формуле:
определяется по формуле: 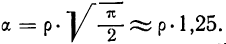
Отклонения  от 125 в обе стороны зависят от близости распределения к нормальному.
от 125 в обе стороны зависят от близости распределения к нормальному.
Пример 32.
По данным примера 31. найти соотношение между  и
и 
Имеем:
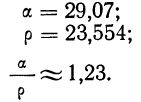
Это отношение не намного отличается от теоретического (1,25), что косвенно свидетельствует о близости взятого распределения к нормальному.
Свойства дисперсии
Средний квадрат отклонения — дисперсия — обладает рядом свойств, которые позволяют упростить вычисления.
1) Дисперсия постоянной величины равна нулю:
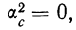
где с — постоянная величина;
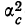 — дисперсия постоянной величины.
— дисперсия постоянной величины.
2) Если все значения вариантов признака х уменьшить на постоянную величину, то дисперсия не изменится. Это позволяет вычислить дисперсию вариационного ряда путем вычитания из вариантов начала отсчета 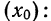
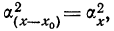
где 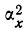 — дисперсия вариантов х;
— дисперсия вариантов х;
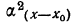 —дисперсия вариантов, уменьшенных вычитанием
—дисперсия вариантов, уменьшенных вычитанием 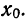
Доказательство для невзвешенной дисперсии
Имеем: 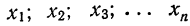 со средней
со средней 
 со средней
со средней
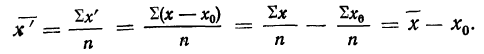
Тогда
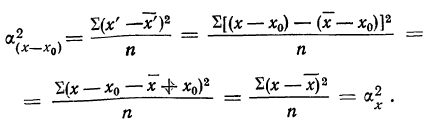
3) Дисперсия алгебраической суммы независимых случайных величин (см. стр. 115 и далее) равна сумме их дисперсий:
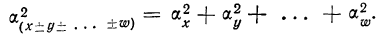
4) Если все значения вариантов х уменьшить в k раз, то дисперсия уменьшится в 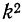 раз:
раз:
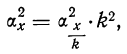
где 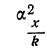 —дисперсия из частных, полученных в результате деления вариантов на постоянную величину k.
—дисперсия из частных, полученных в результате деления вариантов на постоянную величину k.
Доказательство для невзвешенной дисперсии
Имеем: 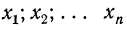 со средней
со средней 
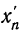 со средней
со средней 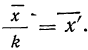 Тогда:
Тогда:
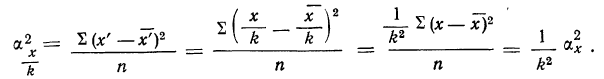
Отсюда: 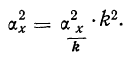
5) Дисперсия суммы двух случайных величин, связанных корреляционной зависимостью, равна сумме их дисперсий плюс удвоенное произведение среднеквадратических отклонений на коэффициент корреляции между этими случайными величинами
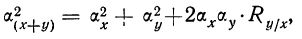
где 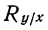 — коэффициент корреляции между величинами у и х, определяемый по формуле
— коэффициент корреляции между величинами у и х, определяемый по формуле 
(Значение его как меры тесноты связи см. раздел «Корреляция».)
Пример 33.
Даны случайные величины у и х, связанные корреляционной зависимостью так, что  =0,5.
=0,5.
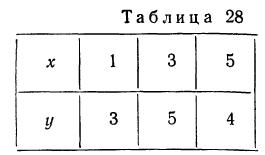
Найти дисперсию суммы этих случайных величин (для простоты дан пример без взвешивания).
Находим средние: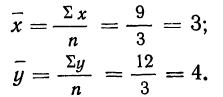
Определяем дисперсии:
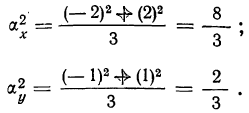
Используя рассматриваемую формулу, имеем:
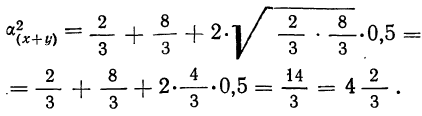
Убедимся, что если х + у = z, то получаем три значения z: 4, 8 и 9.
Находим: среднюю
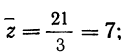
дисперсию
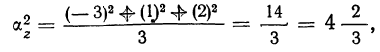
т. е.
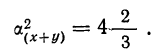
Результаты вычисления, произведенные по непосредственным данным и суммированным, совпадают.
6) Дисперсия суммы двух случайных величин, связанных Линейной функциональной зависимостью (см. раздел «Корреляция»), равна сумме их дисперсий плюс или минус удвоенное произведение среднеквадратических отклонений:
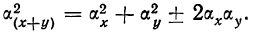
В данной формуле знак плюс или минус определяется характером связи. При прямолинейной связи у с х 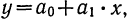 знак, о котором идет речь, совпадает со знаком
знак, о котором идет речь, совпадает со знаком 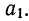 Если
Если  то в формуле берем знак плюс, если
то в формуле берем знак плюс, если  то берем знак минус.
то берем знак минус.
Пример 34.
Даны две случайные величины х и у, связанные уравнением у=2+Зх.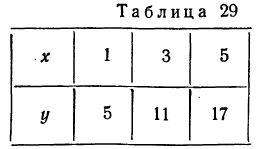
Найти дисперсию суммы этих случайных величин. Находим средние:
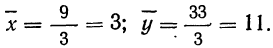
Определяем дисперсии по формуле:
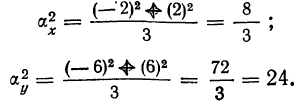
Используем рассматриваемую формулу. В данном случае берем знак плюс:
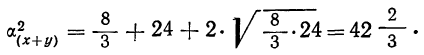
Убеждаемся, что если х + у = z, то получаем три значения z: 6, 14 и 22.
Находим: среднюю
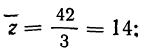
дисперсию
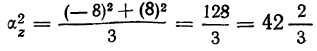
т. е.
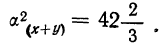
Вычисление дисперсии методом отсчета от условного нуля
Практически расчет дисперсии производят по формуле, упрощающей вычисления. Эта формула получена с учетом свойств дисперсии, а расчет по ней называется отсчетом от условного нуля:
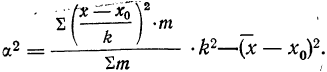
Доказательство. Возьмем выражение 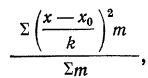 произведем некоторые преобразования и получим:
произведем некоторые преобразования и получим:
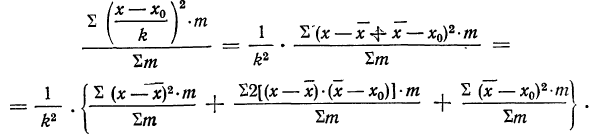
Так как второе слагаемое в фигурной скобке равно нулю: 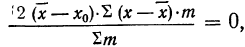 то, продолжая преобразования, получаем:
то, продолжая преобразования, получаем:
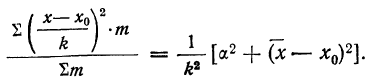
Отсюда:
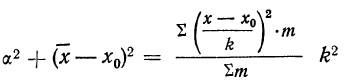
и
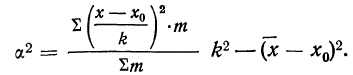
Пример 35.
По данным табл. 27 (колонки 2 и 3) рассчитать дисперсию, используя формулу, упрощающую вычисления. Располагаем данные, необходимые для ее вычисления, в таблице (см. табл. 30).
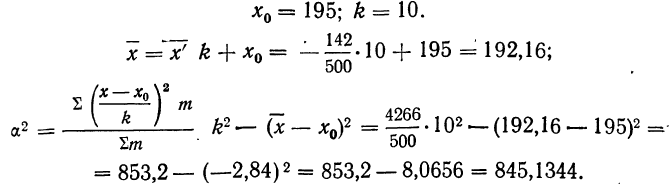
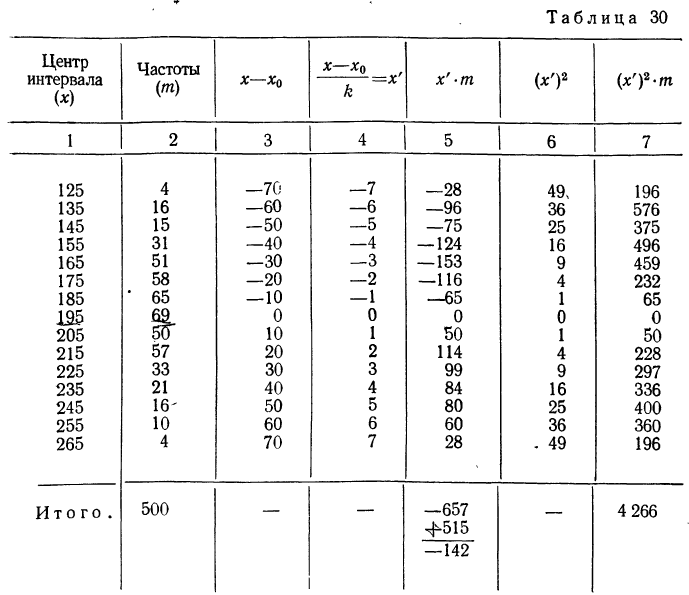
Величина дисперсии совпадает с величиной, полученной в примере 31, но в данном случае вычисления в значительной мере упрощены.
Из формулы 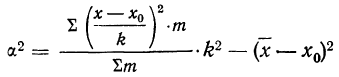 вытекает еще одна формула дисперсии.
вытекает еще одна формула дисперсии.
При  получаем:
получаем:
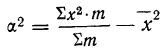
или
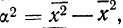
где 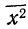 — средняя из квадратов вариантов.
— средняя из квадратов вариантов.
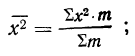
 — квадрат средней
— квадрат средней
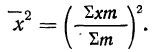
Так, если вычислить дисперсию по данным табл. 27, пользуясь этой формулой, то получим: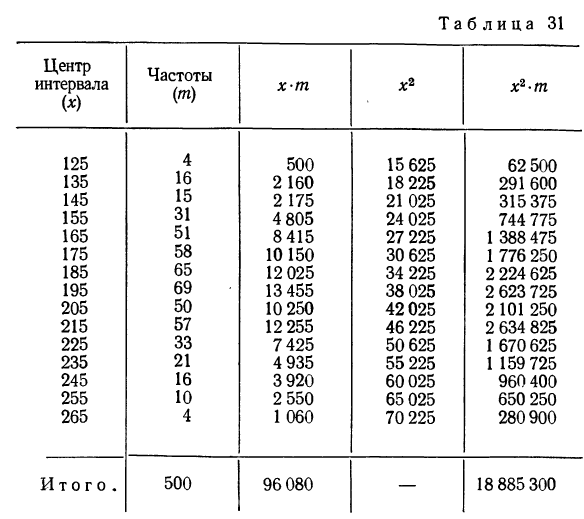
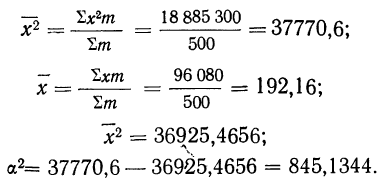
Результат совпадает с дисперсией, полученной по этим данным в примере 31.
Частные дисперсии
Для каждой группы вариантов вариационного ряда может быть исчислена наряду с частной средней и дисперсия, которая называется частной дисперсией или внутригрупповой, 
 (невзвешенная);
(невзвешенная);
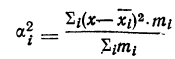 (взвешенная),
(взвешенная),
Где 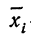 — частная средняя i-й группы;
— частная средняя i-й группы;
 —частная дисперсия i-й группы.
—частная дисперсия i-й группы.
( означает суммирование по i-й части совокупности).
означает суммирование по i-й части совокупности).
Средняя из частных дисперсий
Из частных, т. е.
внутригрупповых, дисперсий может быть найдена средняя, которая обозначается 
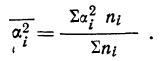
Средняя из частных дисперсий служит для характеристики среднего рассеяния признака внутри групп.
Межгрупповая дисперсия
Частные средние по группам 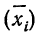 могут не совпадать с общей средней
могут не совпадать с общей средней 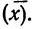 Мерой колеблемости частных средних вокруг общей средней является меж-
Мерой колеблемости частных средних вокруг общей средней является меж-
групповая дисперсия  — дельта квадрат в среднем
— дельта квадрат в среднем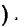
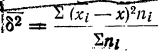
Правило сложения вариаций
Между общей дисперсией, средней из частных дисперсий и межгрупповой дисперсией “существует такая связь:
Это — правило сложения вариации (или дисперсий).
Доказательство.
Пусть общая совокупность состоит из t групп численностью 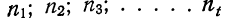 и
и 
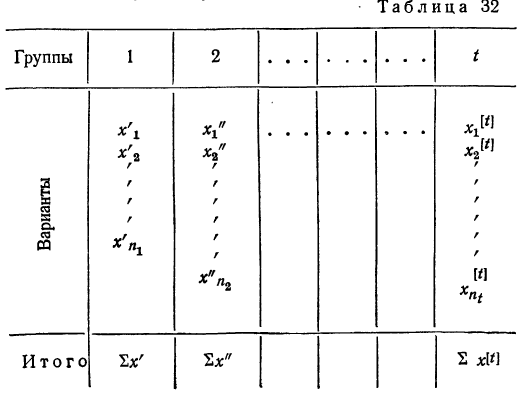
Частные средние  общая средняя
общая средняя 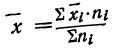 и дисперсия
и дисперсия
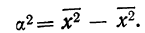
Частные дисперсии можно записать следующим образом.
откуда
Суммируя 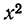 для всей совокупности, получаем:
для всей совокупности, получаем: 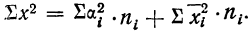
Умножим обе части этого равенства на 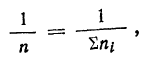 тогда
тогда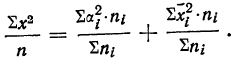
Вычитая из обеих частей равенства  получим:
получим:
Левая часть равенства представляет собой общую дисперсию, т. е. 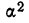 . В правой части первое слагаемое есть средняя из частных дисперсий, т. е.
. В правой части первое слагаемое есть средняя из частных дисперсий, т. е. 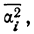 а разность двух последних выражений— межгрупповая дисперсия
а разность двух последних выражений— межгрупповая дисперсия 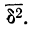 Тогда:
Тогда:
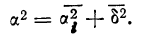
Пример 36.
Используя данные табл. 27 и расчленяя вариационный ряд на две группы (1-я группа с интервала 120—130 до интервала 190—200 включительно, а 2-я группа с •интервала 200—210 до интервала 260—270), исчислить частные дисперсии, среднюю из частных дисперсий и межгрупповую дисперсию.
Начинаем расчет с 1-й группы (см. табл. 33):
 = 195; k= 10;
= 195; k= 10;

Для 2-й группы получаем (по тем же формулам):
Вычисляем среднюю из частных дисперсий:
Находим межгрупповую дисперсию, используя общую среднюю для всего вариационного ряда, найденную в примере 31 и равную 192,16
Для получения общей дисперсии используем правило сложения вариации:
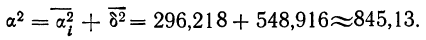
Результат совпадает с дисперсией, вычисленной в примере 31 по табл. 27 без расчленения вариационного ряда на две группы.
Вариация альтернативного признака
Наряду с количественной вариацией признака может иметь место и качественная вариация. Если, имеются два взаимно исключающих друг друга варианта, то вариация признака называется альтернативной.
Так, например, рассмотрение выпущенной продукции с точки зрения ее качества, т. е. пригодности к дальнейшему использованию, дает альтернативный признак. Обозначая наличие признака 1, а отсутствие — 0 и долю вариантов, обладающих данным признаком, — р, а долю вариантов, не обладающий им, — q
и замечая, что p + q=1, получаем сначала среднюю: 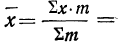
 , а затем дисперсию альтернативного признака:
, а затем дисперсию альтернативного признака:
Следовательно, 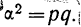
§ 35. Из дисперсии альтернативного признака извлечением корня находится среднее квадратическое отклонение:
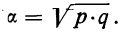
Пример 37.
Совокупность состоит из 10000 электрических, лампочек, включающих в свой состав 20 бракованных. Найти дисперсию признака и среднее квадратическое отклонение.
Находим долю брака и долю доброкачественных лампочек:
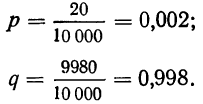
По формуле  вычислим дисперсию:
вычислим дисперсию:
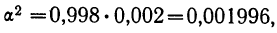
а затем среднее квадратическое отклонение:
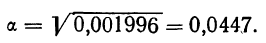
Попытки измерить колеблемость признака путем нахождения средней арифметической из квадратов разностей вариантов во всех возможных их попарных сочетаниях не вносят-ничего принципиально нового.
Можно доказать, что этот показатель  представляет собой дисперсию, умноженную на 2, т. е.
представляет собой дисперсию, умноженную на 2, т. е.
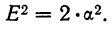
Пусть, например, имеются варианты:
1; 3; 5; 6; 10.
Исчислим среднюю и дисперсию:
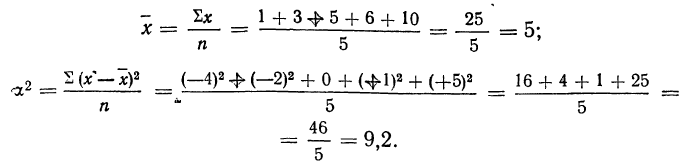
Вычислим абсолютные разности всех возможных попарных сочетаний, включая и сочетания каждого варианта с ним же:
1) Разности попарных сочетаний с первым вариантом
1 — 1=0; 3—1=2; 5—1=4; 6—1 = 5; 10—1=9.
2) Разности попарных сочетаний со вторым вариантом
3 — 3 = 0; 3—1 =2; 3 —5 = 2; 3 — 6 = 3; 3—10 = 7
и далее:
5 —5 = 0; 5—1 =4; 5 —3 = 2; 5 —6= 1; 5—10 = 5;
6 — 6 = 0; 6—1 =5; 6 — 3 = 3; 6 — 5= 1; 6—10 = 4;
10 — 10 = 0; 10 — 1 = 9; 10 —3 = 7; 10 —5 = 5; 10 —6 = 4.
Находим сумму квадратов 25 разностей и делением на 25 — среднюю арифметическую из квадратов разностей: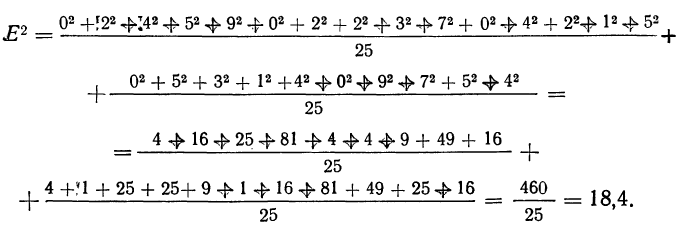
Замечаем, что этот же результат можно получить умножением дисперсии (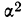 ) на 2:
) на 2:
9,2*2=18,4.
Квартили и децили
Как уже было показано, медиана — это вариант, который делит упорядоченный вариационный ряд на две равные по объему группы. В каждой группе аналогично можно найти также вариант, делящий ее на две подгруппы. Такие варианты называются квартилями.
Различают нижний и верхний квартили. Иногда вычисляют и децили, т.е. такие варианты, которые делят вариационный ряд на 10 равных по объему групп.
При отношении объема двух подгрупп, как 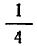 к
к 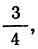 имеем нижний квартиль
имеем нижний квартиль 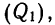 при отношении объемов подгрупп
при отношении объемов подгрупп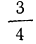 к
к 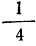 верхний квартиль
верхний квартиль  а при отношениях объемов групп
а при отношениях объемов групп 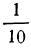 к
к 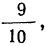
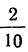 к
к 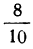 и т.д. —децили.
и т.д. —децили.
Формулы для расчетов в интервальном ряду:
нижнего квартиля
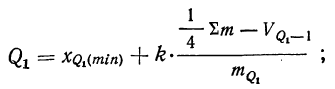
верхнего квартиля
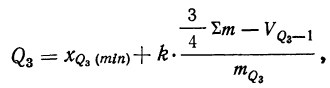
где 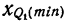 — минимальная граница интервала, содержащего нижний квартиль (определяется по накопленным частотам);
— минимальная граница интервала, содержащего нижний квартиль (определяется по накопленным частотам);
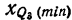 —то же, для верхнего квартиля;
—то же, для верхнего квартиля;
k — интервальная разность;
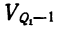 —накопленная частота интервала, предшествующего интервалу, содержащему нижний квартиль;
—накопленная частота интервала, предшествующего интервалу, содержащему нижний квартиль;
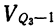 —то же, для верхнего квартиля;
—то же, для верхнего квартиля;
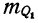 —частота интервала, содержащего нижний квартиль;
—частота интервала, содержащего нижний квартиль;
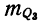 —то же, для верхнего квартиля.
—то же, для верхнего квартиля.
Вычисление децилей ничем принципиально не отличается от вычисления медианы и квартилей. Так, первый и второй децили могут быть вычислены по формулам:
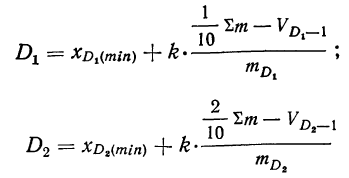
и т.д.
Пример 38.
По данным табл. 7 вычислить нижний и верхний квартили (рекомендуется предварительно вспомнить вычисление медианы).
Используем табл. 9, в которой дана колонка накопленных частот. Нижний квартиль рассчитывается по соответствующей формуле 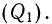 Из итога колонки 2 табл. 9 видно, что численность совокупности для этого ряда равна 200 единицам. Следовательно, нижний квартиль соответствует 50-й единице. По колонке накопленных частот (3) видим, что нижний квартиль содержится в интервале 49,933—49,938, потому что первая из накопленных частот, превышающих 50, — это накопленная частота данного интервала.
Из итога колонки 2 табл. 9 видно, что численность совокупности для этого ряда равна 200 единицам. Следовательно, нижний квартиль соответствует 50-й единице. По колонке накопленных частот (3) видим, что нижний квартиль содержится в интервале 49,933—49,938, потому что первая из накопленных частот, превышающих 50, — это накопленная частота данного интервала.
Следовательно:
Находим нижний квартиль:
Верхний квартиль отвечает 150-й единице и содержится в интервале 49,943-49,948 (так как первая из накопленных частот, превышающая 150, равна 164 и соответствует данному интервалу).
Находим верхний квартиль:
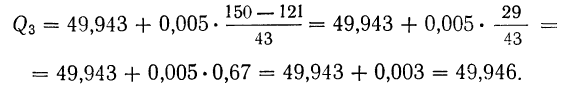
Квартиль
В качестве характеристики колеблемости вариационного ряда применяется относительный показатель, подобный коэффициенту вариации, но для вычисления которого используются нижний и верхний квартили и медиана. Этот показатель называют квартилем 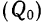 без добавления слова нижний или верхний. Он исчисляется по формуле:
без добавления слова нижний или верхний. Он исчисляется по формуле:
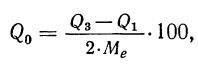
где 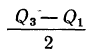 — половина межквартильного расстояния.
— половина межквартильного расстояния.
Пример 39.
По результатам исчисления медианы, а также нижнего и верхнего квартилей по табл. 7 (см. примеры 27 и 38) найти квартиль.
Имеем:
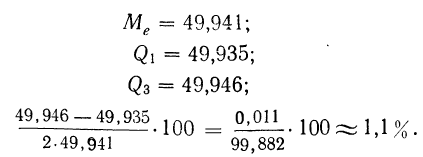
Интересно, что величина коэффициента вариации, по данным табл. 7, довольно близка к полученной величине квартиля:
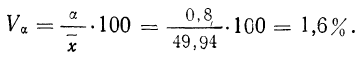
Моменты распределения
Обобщающими характеристиками вариационных рядов являются моменты распределения. Характер распределения может быть определен с помощью небольшого числа моментов. Способ моментов был разработан русским математиком П. Л. Чебышевым и успешно применен А. А. Марковым для рассмотрения возможностей использования закона нормального распределения при изучении сумм: большого, но конечного числа независимых случайных величин.
Средняя из k-x степеней-отклонений вариантов х от некоторой постоянной величины А называется моментом k-гo порядка:
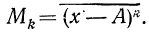
При исчислении средней в качестве весов могут быть использованы частоты, частости или вероятности (см. раздел II). При использовании в качестве весов частот или частостей моменты называются эмпирическими, а при использовании вероятностей — теоретическими.
Порядок момента определяется величиной k. Эмпирический момент k-гo порядка находится как отношение суммы произведений k-x степеней отклонений вариантов от постоянной величины А на частоты к сумме частот:
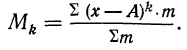
В зависимости от выбора постоянной величины А различают следующие моменты:
1) Если постоянная величина А равна нулю (А=0), то моменты называются начальными. Приводим формулу всех начальных моментов:
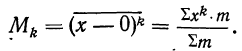
Тогда:
при k = 0 получаем
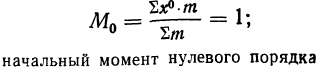
при k=1
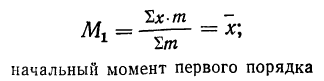
при k=2
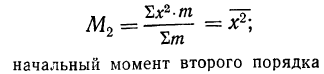
при k = 3
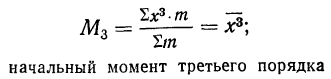
при k = 4
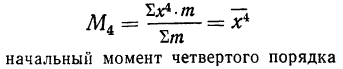
и т. д. Практически используют моменты первых четырех порядков.
Пример 40.
Вычислить начальные моменты первых четырех порядков, если варианты х имеют как отрицательные, так и положительные значения.
Располагаем все расчеты в таблицу:
Вычисляем моменты:
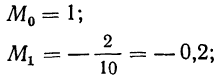
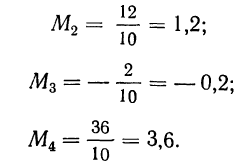
2) Если А не равно нулю, а некоторой произвольной величине  (начало отсчета), то моменты называются начальными относительно
(начало отсчета), то моменты называются начальными относительно  и обозначаются
и обозначаются 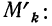
При подстановке различных значений k получаем начальные моменты относительно 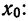
при k=0
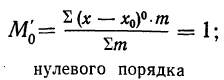
при k=1
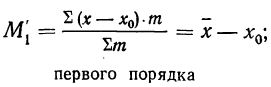
при k=2
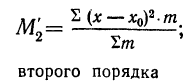
при k=3
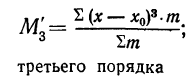
при k=4
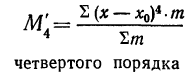
и т.д.
Из формулы момента первого порядка вытекает, что 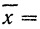
 т. е. средняя арифметическая равна началу отсчета плюс начальный момент первого порядка относительно начала отсчета. Если отклонения х от
т. е. средняя арифметическая равна началу отсчета плюс начальный момент первого порядка относительно начала отсчета. Если отклонения х от  имеют общий множитель С, то на него можно разделить отклонения, а по окончании вычислений полученный момент умножить на этот множитель в соответствующей степени, т. е.
имеют общий множитель С, то на него можно разделить отклонения, а по окончании вычислений полученный момент умножить на этот множитель в соответствующей степени, т. е.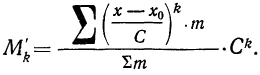
Отсюда следует, что 
При сравнении с вычислением средней методом отсчета от условного нуля видно, что  (см. стр. 37) и
(см. стр. 37) и 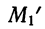 тождественны. Поэтому вычисление средней методом отсчета от условного нуля иногда называют методом моментов.
тождественны. Поэтому вычисление средней методом отсчета от условного нуля иногда называют методом моментов.
Пример 41.
Вычислить начальные моменты относительно 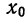 = 20 первых четырех порядков по данным колонок 1 и 2 табл. 35.
= 20 первых четырех порядков по данным колонок 1 и 2 табл. 35.
Располагаем все расчеты в таблицу:
Таблица 35

Возьмем в качестве  вариант, равный 20, вычислим колонку 3, разделим все отклонения от начала отсчета на общий множитель С, равный 2, и получим значения
вариант, равный 20, вычислим колонку 3, разделим все отклонения от начала отсчета на общий множитель С, равный 2, и получим значения  в колонке 4, для которых начальные моменты вычислены в примере 40.
в колонке 4, для которых начальные моменты вычислены в примере 40.
Для получения  нужно найденные в примере 40 начальные моменты умножить на С, равное 2, в соответствующей степени:
нужно найденные в примере 40 начальные моменты умножить на С, равное 2, в соответствующей степени:
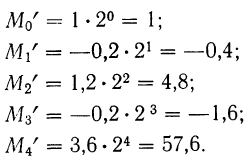
Практически при нахождении начальных моментов относительно 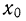 поступают следующим образом:
поступают следующим образом:
из всех вариантов вычитают начало отсчета и находят отклонения 
делят эти отклонения на общий множитель 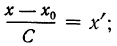
находят начальные моменты для 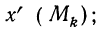
путем умножения найденных начальных моментов на 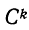 получают начальные моменты относительно
получают начальные моменты относительно 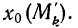
3) Если за постоянную величину А взять среднюю 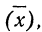 то моменты называются центральными и обозначаются
то моменты называются центральными и обозначаются 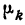
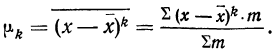
Тогда:
при k = 0
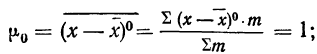
центральный момент нулевого порядка равен единице
при k=1
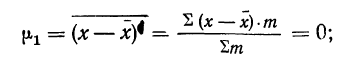
центральный момент первого порядка равен нулю
при k = 2
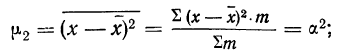
центральный момент второго порядка равен дисперсии и служит мерой колеблемости признака
при k = 3
центральный момент третьего порядка служит мерой асимметрии распределения признака. Если распределение симметрично, то 
При k = 4
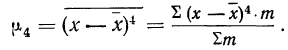
центральный момент четвертого порядка
Пример 42.
Вычислим центральные,моменты первых четырех порядков по данным табл. 36 (колонки 1, 2).
Располагаем все расчеты в таблицу (см. табл. 36). Получаем:
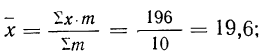

§ 40. Существует связь между начальными моментами первых четырех порядков вариантов 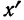 и начальным моментом 4-го порядка вариантов
и начальным моментом 4-го порядка вариантов 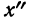 для случая, когда варианты
для случая, когда варианты 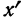 меньше вариантов
меньше вариантов 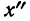 на единицу:
на единицу:
где  — четвертый начальный момент вариантов
— четвертый начальный момент вариантов 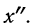
В правой части формулы все начальные моменты (от нулевого порядка до четвертого порядка) вариантов 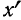 .
.
Практически данная формула используется для проверки
вычисления начальных моментов первых четырех порядков вариантов 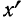 путем вычисления начального момента 4-го порядка новых вариантов
путем вычисления начального момента 4-го порядка новых вариантов 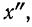 полученных прибавлением к вариантам
полученных прибавлением к вариантам 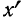 единицы.
единицы.
Если исчисления  непосредственно из данных по формуле
непосредственно из данных по формуле
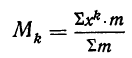
и по формуле связи между моментами дают тождественные результаты, то это свидетельствует о правильности всех начальных моментов первых четырех порядков, вычисленных для вариантов 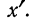
Пример 43.
Проверим правильность начальных моментов первых четырех порядков, вычисленных в примере 40.
Располагаем все расчеты в таблицу: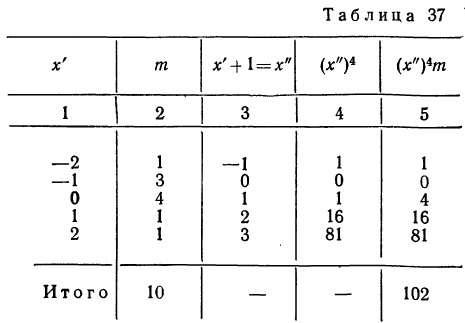
В колонке 3 записываем новые варианты  путем прибавления к старым вариантам
путем прибавления к старым вариантам  единицы.
единицы.
Получаем по формуле:
Для расчетов 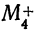 по формуле связи между моментами привлекаем данные из примера 40:
по формуле связи между моментами привлекаем данные из примера 40:
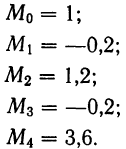
Получаем:
Результаты совпадают, следовательно, начальные моменты первых четырех порядков в примере 40 вычислены правильно.
Вычисление центральных моментов, привлекаемых в качестве характеристик вариационного ряда, по формуле
 с точки зрения вычислительной техники довольно громоздко. Поэтому сначала вычисляют начальные моменты-относительно
с точки зрения вычислительной техники довольно громоздко. Поэтому сначала вычисляют начальные моменты-относительно 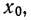 а для нахождения центральных моментов используют формулу перехода от начальных моментов, вычисленных относительно
а для нахождения центральных моментов используют формулу перехода от начальных моментов, вычисленных относительно 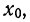 к центральным:
к центральным:
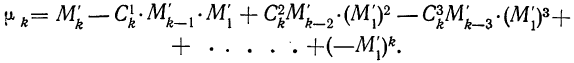
Знаки в формуле чередуются.
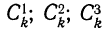 и т. д. обозначают числа сочетаний из: k по 1; k по 2; k по 3 и т. д.
и т. д. обозначают числа сочетаний из: k по 1; k по 2; k по 3 и т. д.
Полагая в этой формуле k равным 0, 1, 2, 3, 4 и т. д., можем получить центральные моменты различных порядков:
Для вычисления центральных моментов высших порядков по найденным центральным моментам низших порядков и начальным моментам относительно  подставляем в формулу третьего центрального момента величину
подставляем в формулу третьего центрального момента величину 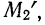 найденную из формулы второго центрального момента:
найденную из формулы второго центрального момента:
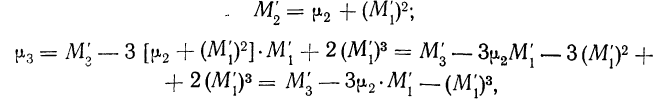
т. е.
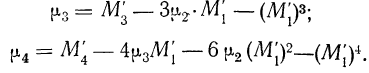
Пример 44.
Используя данные примера 41, где вычислены начальные моменты относительно 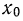 = 20, вычислим центральные моменты первых четырех порядков по соответствующим формулам и сверим полученные результаты с центральными моментами, вычисленными в примере 42.
= 20, вычислим центральные моменты первых четырех порядков по соответствующим формулам и сверим полученные результаты с центральными моментами, вычисленными в примере 42.
Из примера 41 имеем:
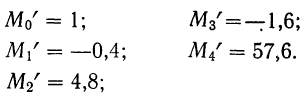
По формулам центральных моментов получаем, используя начальные моменты:
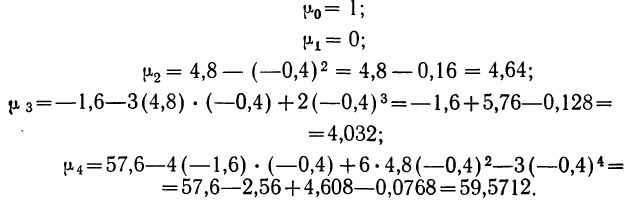
Сравнивая центральные моменты первых четырех порядков, вычисленные по указанным формулам, с центральными моментами, вычисленными в примере 42 непосредственно по формуле  убеждаемся в сравнительной простоте исчисления центральных моментов по приведенным в этом параграфе формулам.
убеждаемся в сравнительной простоте исчисления центральных моментов по приведенным в этом параграфе формулам.
Аналогично используются и формулы центральных моментов высших порядков по центральным моментам низших порядков.
Вычислим третий центральный момент по второму центральному моменту и начальным относительно  моментам:
моментам:
Вычислим и четвертый центральный момент по третьему и второму центральным моментам и начальным относительно  моментам:
моментам:
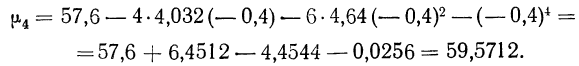
Исчисление центральных моментов сводится к:
- нахождению начальных моментов и их проверке:
- нахождению начальных моментов относительно произвольно выбранного начала отсчета
- использованию формул перехода от начальных моментов относительно произвольно выбранного начала отсчета к центральным моментам
 и их проверке:
и их проверке: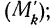
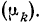
Пример 45.
По данным табл. 38 (колонки 1, 2 и 3) вычислить центральные моменты первых четырех порядков:
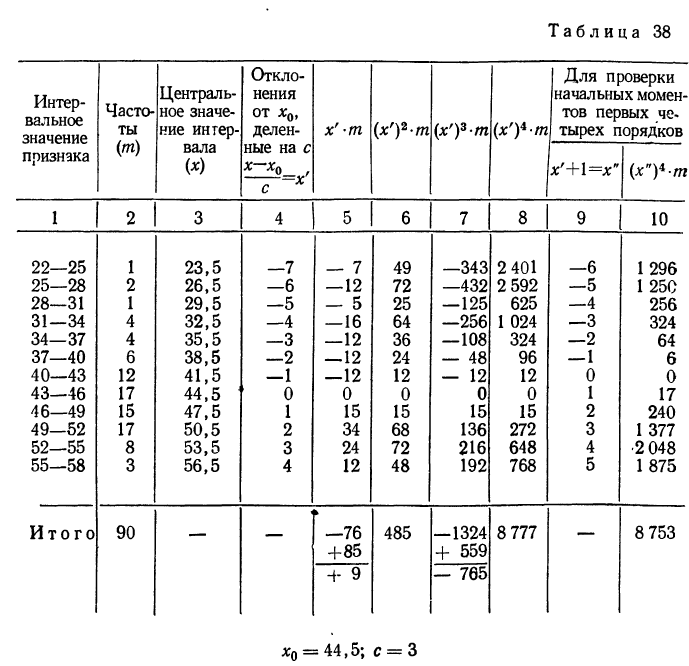
Начнем с вычисления начальных моментов. Для этого выбираем 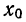 = 44,5, находим отклонения вариантов х от
= 44,5, находим отклонения вариантов х от 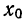 и делим эти отклонения на общий множитель с=3.
и делим эти отклонения на общий множитель с=3.
Все действия производим в табл. 38 и получаем колонку 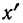 (колонка 4). Далее, произведя расчеты по формуле
(колонка 4). Далее, произведя расчеты по формуле 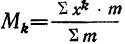 находим начальные моменты. Для этого рассчитываем колонки 5, 6, 7 и 8.
находим начальные моменты. Для этого рассчитываем колонки 5, 6, 7 и 8.
Для простоты расчета числа колонки 5 получают перемножением чисел, расположенных в колонках 2 и 4, числа колонки 6 получают перемножением чисел колонок 4 и 5, числа колонки 7— перемножением чисел колонок 4 и 6 и т. д.
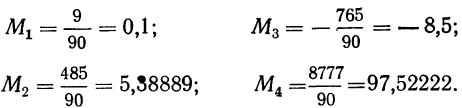
Проверяем вычисление начальных моментов первых четырех порядков. Для этого вычисляем колонки 9 и 10.
Числа колонки 9 получают прибавлением к числам колонки 4 единицы. Числа колонки 10 (а можно и 8) получают, используя таблицу, имеющую следующий вид:
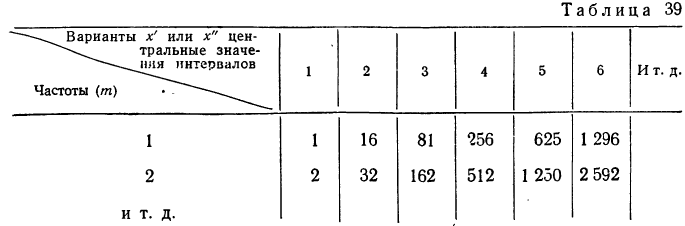
В колонке 1 таблицы указаны частоты (m) от 1 до 50, а в верхнем заголовке — числа х’ или х”. Произведения  или
или  находятся на пересечении соответствующей строки и столбца.
находятся на пересечении соответствующей строки и столбца.
Так, если 
если 
и т. д. (см. приложение VII).
Используя формулу 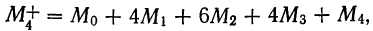 получаем:
получаем:
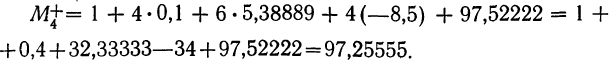
Исчисляя  непосредственно по формуле
непосредственно по формуле  получаем:
получаем:
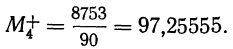
Результаты вычисления 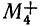 по двум формулам совпадают, что свидетельствует о правильности расчета первых четырех начальных моментов.
по двум формулам совпадают, что свидетельствует о правильности расчета первых четырех начальных моментов.
Находим начальные моменты первых четырех порядков относительно выбранного начала отсчета 44,5 по формуле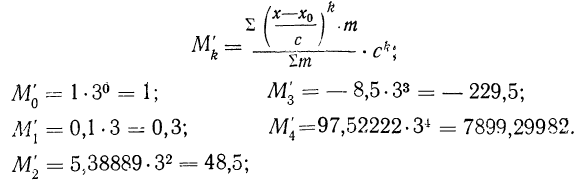
Находим центральные моменты, используя формулы перехода от начальных моментов, вычисленных относительно 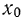
Вычисление моментов способом сумм
Вычисление моментов при равно отстоящих значениях признака может производиться двумя способами: 1) способом произведений, использованным нами ранее во всех случаях вычислений моментов, и 2) способом сумм, являющимся более упрощенным.
Таблица, в которой производятся все подготовительные расчеты для вычисления начальных четырех моментов, включает в себя колонки х и m и, кроме этого, 4 нумерованные колонки.
Рассмотрим пример вычисления начальных моментов способом сумм по данным табл. 38 (см. табл. 40).
Вся таблица делится на две части чертой, проведенной против частости, соответствующей  В каждой части таблицы суммирование частот производится отдельно. Для верхней части таблицы в колонке 1 идут накопленные частоты начиная сверху, а для нижней части таблицы — начиная снизу. В остальных колонках накопление производится так же и заканчивается на одну клетку раньше, чем в предыдущей колонке.
В каждой части таблицы суммирование частот производится отдельно. Для верхней части таблицы в колонке 1 идут накопленные частоты начиная сверху, а для нижней части таблицы — начиная снизу. В остальных колонках накопление производится так же и заканчивается на одну клетку раньше, чем в предыдущей колонке.
Для получения  ( —) суммируются числа верхней части таблицы, а для
( —) суммируются числа верхней части таблицы, а для  ( + ) —нижней части таблицы.
( + ) —нижней части таблицы.
Величины S и D получаются сложением и вычитанием (—) и
(—) и  ( + ). Так: S =
( + ). Так: S = (-) +
(-) +  ( + ), a D =
( + ), a D = (—) —
(—) —  ( + ).
( + ).
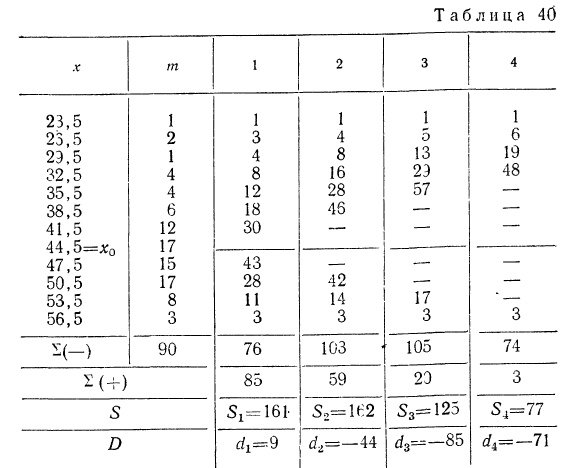
Для вычисления начальных моментов по способу сумм используют следующие формулы:
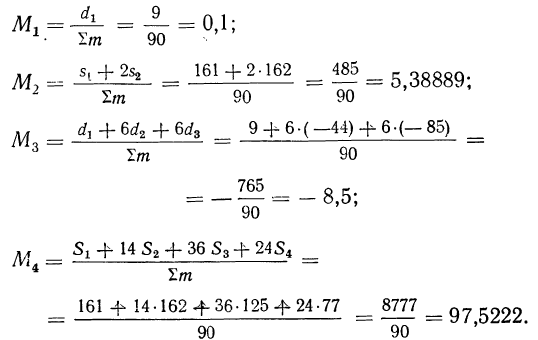
Как видим, результаты вычислений по способу сумм совпадают с результатами примера 45.
Нормированные моменты
Второй центральный момент равен дисперсии, т. е.  Если среднее квадратическое отклонение
Если среднее квадратическое отклонение  т. е. корень из дисперсии, иначе говоря, корень из второго центрального момента
т. е. корень из дисперсии, иначе говоря, корень из второго центрального момента 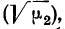 принять за стандарт, то отношение центрального момента k-гo порядка к стандарту в k-й степени сбудет называться нормированным моментом и обозначаться
принять за стандарт, то отношение центрального момента k-гo порядка к стандарту в k-й степени сбудет называться нормированным моментом и обозначаться 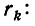
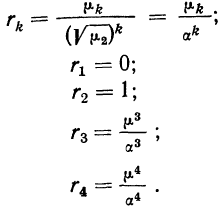
Пример 46. По найденным в примере 45 центральным моментам найти нормированные моменты первых четырех порядков.
Из примера 45 имеем:
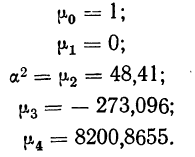
Находим сначала стандарт:
а затем нормированные моменты:
Использование нормированных моментов
Нормированные моменты используются при изучении вариационных рядов. Третий нормированный момент 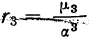 называется мерой или. косости вариационного ряда.Знак перед
называется мерой или. косости вариационного ряда.Знак перед 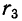 указывает на направление асимметрии ряда. Если
указывает на направление асимметрии ряда. Если  то вариационный ряд будет с левосторонней скошенностью, а если
то вариационный ряд будет с левосторонней скошенностью, а если  — с правосторонней скошенностью. В симметричном ряде
— с правосторонней скошенностью. В симметричном ряде 
Четвертый нормированный момент  называется мерой крутости.
называется мерой крутости.
Если 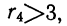 то распределение высоковершинное, если
то распределение высоковершинное, если  то распределение низковершинное, если
то распределение низковершинное, если  то распределение близко к нормальному (см. раздел IV).
то распределение близко к нормальному (см. раздел IV).
По результатам вычисления нормированных моментов в примере 46 видно, что  отрицателен (—0,81), т. е. распределение с незначительной правосторонней скошенностью, а
отрицателен (—0,81), т. е. распределение с незначительной правосторонней скошенностью, а 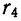 больше 3. Это указывает на высоковершинность данного распределения. В целом данное распределение не очень сильно отличается от нормального.
больше 3. Это указывает на высоковершинность данного распределения. В целом данное распределение не очень сильно отличается от нормального.
Коэффициент асимметрии
В качестве показателя отклонения вариационного ряда от симметрии применяется простой эмпирический коэффициент асимметрии 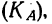 представляющий собой отношение разности между средней арифметической и модой к среднему квадратическому отклонению:
представляющий собой отношение разности между средней арифметической и модой к среднему квадратическому отклонению:
Если  то скошенность левосторонняя;
то скошенность левосторонняя;
если 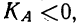 то скошенность правосторонняя;
то скошенность правосторонняя;
если 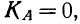 то вариационный ряд симметричен.
то вариационный ряд симметричен.
Пример 47.
По данным примера 31 (табл. 27) вычислим коэффициент асимметрии.
Имеем: 
Вычислим моду по формуле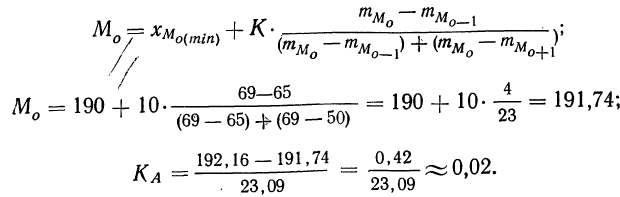
В данном случае асимметрия небольшая и скошенность левосторонняя.
- Законы распределения случайных величин
- Дисперсионный анализ
- Математическая обработка динамических рядов
- Корреляция – определение и вычисление
- Статистическая проверка гипотез
- Статистические оценки
- Теория статистической проверки гипотез
- Линейный регрессионный анализ
