Скрыть содержимое сайта от индексирования можно с помощью файла robots.txt, HTML-разметки или авторизации на сайте.
- Запретить индексирование сайта, раздела или страницы
- Запретить индексирование части текста страницы
- Скрыть от индексирования ссылку на странице
Если какие-то страницы или разделы сайта не должны индексироваться (например, со служебной или конфиденциальной информацией), ограничьте доступ к ним следующими способами:
-
В файле robots.txt укажите директиву Disallow.
-
В HTML-коде страниц сайта укажите метатег robots с директивой noindex или none. Подробнее см. в разделе Метатег robots и HTTP-заголовок X-Robots-Tag.
-
Используйте авторизацию на сайте. Рекомендуем этот способ, чтобы скрыть от индексирования главную страницу сайта. Если главная страница запрещена в файле robots.txt, но на нее ведут ссылки с других сайтов, страница может попасть в результаты поиска.
Примечание. Чтобы неавторизованные пользователи не попадали на закрытые страницы, настройте для таких страниц HTTP-код ответа сервера 404 Not Found, 403 Forbidden или 410 Gone.
Скрыть от индексирования часть текста можно несколькими способами:
-
В HTML-код страницы добавьте элемент noindex. Например:
<noindex>текст, индексирование которого нужно запретить</noindex>Элемент не чувствителен к вложенности — может находиться в любом месте HTML-кода страницы. Если на странице отсутствует закрывающий тег, скрытым считается весь контент страницы. Не создавайте множественную вложенность тегов noindex — разметка будет учитываться только до первого закрывающего тега.
При необходимости сделать код сайта валидным возможно использование тега в следующем формате:
<!--noindex-->текст, индексирование которого нужно запретить<!--/noindex--> -
В HTML-код страницы добавьте элемент noscript. Например:
<noscript>текст, индексирование которого нужно запретить</noscript>Элемент noscript, как и noindex, запрещает индексирование, но при этом скрывает содержимое сайта от пользователя, если его браузер поддерживает технологию JavaScript.
Примечание. JavaScript поддерживают все популярные браузеры, если эта функция не отключена пользователем специально.
Посмотреть отчет о наличии JavaScript можно в Яндекс Метрике .
Рекомендуем использовать атрибут rel. Разные значения атрибута указывают на тип ссылки, что помогает поисковой системе лучше распознавать содержимое сайта.
-
rel=”ugc”. Используйте, если на вашем сайте есть форум или возможность оставить отзыв и вы не уверены в качестве ссылок, которые оставляют посетители.
-
rel=”sponsored”. Используйте, если ссылка носит рекламный характер, указывает на рекламное место или размещение в рамках партнерской программы с другим сайтом.
-
rel=”nofollow”. Указывайте, чтобы робот не проходил по ссылке, не зависимо от ее типа.
Можно комбинировать несколько значений. Пример:
<a href="url" rel="nofollow,sponsored">текст ссылки</a>
или
<a href="url" rel="nofollow sponsored">текст ссылки</a>Значения атрибута rel воспринимаются роботом как рекомендация не принимать ссылку во внимание.
Чтобы скрыть от индексирования все ссылки на странице, укажите в HTML-коде страницы метатег robots с директивой nofollow. Робот не перейдет по ссылкам при обходе сайта, но может узнать о них из других источников. Например, на других страницах или сайтах.
При использовании любого из перечисленных указаний ссылка может быть обработана роботом и отобразиться в Вебмастере как внутренняя или внешняя. Само отображение или отсутствие ссылки в Вебмастере не указывает на то, что поисковые алгоритмы учитывают ее.
noindex – это правило, которое задается с помощью тега <meta> или заголовка HTTP-ответа и запрещает индексирование контента поисковыми системами, поддерживающими noindex, например Google. Обнаружив такой тег или заголовок во время сканирования страницы, робот Googlebot проигнорирует ее, даже если на нее ссылаются другие сайты.
Директива noindex позволяет управлять доступом к отдельным страницам сайта. Это может быть полезно, если у вас нет доступа к корневому каталогу на сервере.
Как внедрять правило noindex
Внедрить правило noindex можно двумя способами: как тег <meta> или как заголовок HTTP-ответа. Они работают одинаково, поэтому выбор подходящего способа будет зависеть от вашего сайта и типа контента, расположенного на нем. Google не поддерживает указание правила noindex в файле robots.txt.
noindex можно объединять с другими правилами, которые управляют индексированием. Например, можно объединить атрибут nofollow и правило noindex: <meta name="robots" content="noindex, nofollow" />.
Тег <meta>
Чтобы ни одна поисковая система, поддерживающая правило noindex, не могла проиндексировать страницу вашего сайта, поместите следующий тег <meta> в раздел <head>:
<meta name="robots" content="noindex">
Если вы хотите закрыть доступ к странице только роботам Google, используйте следующий код:
<meta name="googlebot" content="noindex">
Учитывайте, что некоторые поисковые системы могут по-другому интерпретировать правило noindex и показывать в результатах поиска страницу, на которой оно используется.
Подробнее о теге <meta> с атрибутом noindex…
Вместо тега <meta> можно возвращать HTTP-заголовок X-Robots-Tag со значением noindex или none в ответе.
Вы можете использовать этот способ для файлов, формат которых отличается от HTML, например PDF, видео и изображений. Ниже приведен пример HTTP-ответа с заголовком X-Robots-Tag, запрещающим поисковым системам индексировать страницу:
HTTP/1.1 200 OK (...) X-Robots-Tag: noindex (...)
Подробнее о заголовках ответов с директивой noindex…
Устранение проблем с правилом noindex
Чтобы обнаружить теги <meta> и HTTP-заголовки, мы должны просканировать вашу страницу. Если страница продолжает появляться в результатах поиска, вероятно, мы ещё не обработали ее после добавления правила noindex. Робот Googlebot может повторно посетить страницу только спустя несколько месяцев. Воспользуйтесь инструментом проверки URL, чтобы запросить повторное сканирование страницы роботом Google.
Если вам нужно быстро убрать страницу сайта из результатов поиска Google, ознакомьтесь с документацией по удалению.
Другая возможная причина: файл robots.txt запрещает роботу Googlebot доступ к URL и не дает ему обнаружить метатег. Чтобы предоставить роботам Google доступ к вашей странице, вам необходимо изменить файл robots.txt.
Это можно сделать с помощью специального инструмента.
Наконец, убедитесь, что правило noindex доступно роботу Googlebot. Проверьте, корректно ли внедрено правило noindex: воспользуйтесь инструментом проверки URL, чтобы увидеть HTML, который робот Googlebot получил при сканировании страницы.
Вы можете также использовать отчет об индексировании страниц в Search Console, чтобы отслеживать страницы сайта, из которых робот Googlebot извлек правило noindex.
Тег <noindex> используется для запрета индексации служебных участков текста. Данный тег может находиться в любом участке HTML-кода страницы, учитывается он только Яндексом. Google и другие поисковые системы будут его игнорировать.
Работает этот элемент аналогично МЕТА-тегу noindex, но распространяется исключительно на текстовый контент, который размещен на странице, то есть, закрыть от индексации ссылки с его помощью не получится.
Приведем пример использования:
<noindex>служебный текст, который не нужно индексировать</noindex>
И еще один верный вариант:
<!--noindex-->служебный текст, который не нужно индексировать<!--/noindex-->
В каких случаях можно употреблять
При ответе на этот вопрос важно уточнить, что же такое индексация. Это процесс анализа информации на web-ресурсе и последующее добавление ее в индекс (базу данных поисковых систем) для формирования поисковой выдачи по релевантным запросам. Соответственно, тегом noindex мы советуем закрывать ту информацию, которая не должна участвовать в процессе ранжирования и отображаться в поисковой выдаче, но при этом не содержит ничего, за что можно получить санкции от Яндекса. Например, это может быть мобильный номер телефона, который не должен отображаться в выдаче, но нужен пользователям на страницах сайта.
Нужно учитывать еще один важный фактор – тег noindex запрещает Яндексу индексировать участок текста, но не устанавливает запрет на его чтение. То есть, применять данный элемент для сокрытия скопированных с других ресурсов текстов не получится, так как плагиат все равно будет обнаружен, и сайт подвергнется пессимизации.
Как обнаружить страницы с этим тегом на сайте
При продвижении очень важно знать, на каких страницах вашего сайта употребляется этот атрибут, поскольку часть важной информации могла быть закрыта от индексации или другие оптимизаторы использовали этот тег не по назначению.
Сервис Labrika предлагает удобный отчет по страницам с тегом <noindex>. Найти его можно в подразделе “Страницы с тегом noindex” раздела “SEO-аудит” в левом боковом меню:

В этом отчете содержится информация обо всех страницах вашего сайта, на которых находится тег <noindex>. Выглядит он следующим образом:
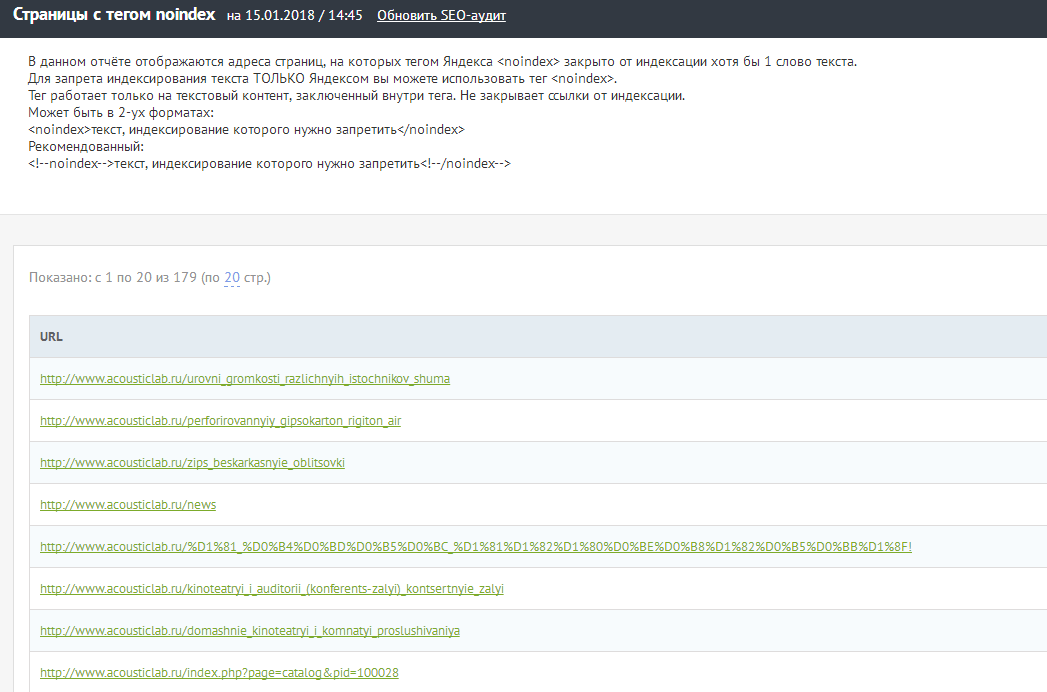
Для того, чтобы воспользоваться отчетом и получить актуальную на данный момент информацию, необходимо обновить SEO-аудит. Сделать это можно с помощью соответствующей кнопки прямо на странице отчета:

 Тег noindex служит для обозначения фрагментов текста, запрещенных для индексирования поисковой системой Яндекс.
Тег noindex служит для обозначения фрагментов текста, запрещенных для индексирования поисковой системой Яндекс.
Тег введен в оборот системой яндекс и используется только ей и, возможно, Рамблер.
Google его не понимает и никак не учитывает.
Содержание
- Передача веса закрытой ссылке
- Метатег noindex
- Сообщение — url запрещен к индексированию тегом noindex
Первоначально, чтобы закрыть часть текста от индексации, нужно было обернуть его, как указано ниже:
|
<noindex>текст, закрытый от индексации</noindex> |
Поскольку тег не является частью утвержденных стандартов, возникают проблемы валидации страницы при ее проверке в любом сервисе проверки валидностью кода html.
Из-за этого яндекс ввел другую версию тега вида <!—noindex—>неиндексируемый текст<!—/noindex—>. При таком использовании страница нормально проходит проверку. Первый вариант также до сих пор работает, но более правильно использовать второй вариант.
Применять данный тег можно, например, чтобы закрыть счетчики, комментарии. Но нет смысла закрывать, например, меню в целях перераспределения ссылочного веса на сайте.
Передача веса закрытой ссылке
Тег закрывает от индексации только текст, заключенный в него, но не влияет на индексирование ссылок внутри этого текста и передачу веса по ним. Для закрытия ссылки нужно использовать атрибут rel=»nofollow», как писал здесь.
Метатег в коде страницы вида:
|
<meta name=“robots” content=“noindex,nofollow”/> |
запрещает от индексации содержимое всей страницы (за это отвечает noindex), а также индексацию ссылок на этой страницы (за это отвечает nofollow).
Для массового проставления данного метатега, например, для архивов и других таксономий в wordpress можно использовать плагин Yoast SEO. В нем можно прописать метатеги в том числе и для отдельных страниц.
В robots.txt тег noindex не работает и не используется.
Сообщение — url запрещен к индексированию тегом noindex
В некоторых случаев вебмастер яндекс выдает сообщение, что адрес страницы, например, главной запрещен от индексации. Это значит, что на странице появился обнаружен этот метатег. Чаще всего такое бывает в двух случаях. Когда создавали сайт, то указали настройку «Попросить поисковые системы не индексировать сайт» на время разработки. Теперь нужно просто убрать эту пометку и отправить сайт в вебмастере на перепроверку. Или второй вариант — у вас стоит SEO плагин вроде Yoast Seo, в настройках которого вы указали запрет индексации, соответственно теперь его нужно убрать.
Время чтения 2 мин.Просмотры 378Опубликовано 04.08.2019Обновлено 18.08.2022
Опубликовано: 14.04.2018. Обновлено: 18.10.2019 1 056 0
Полезный контент может быть закрыт тегом noindex по ошибке, например, вебмастер забыл поставить закрывающий тег. Теги nofollow могут быть поставлены также по ошибке на внутренние ссылки сайта.
Поиск noindex на всём сайте
Контент может оказаться внутри тегов

Для проверки в Компарсере перед началом сканирования нажимаем кнопку “Поиск кода” и в открывшемся окне забиваем “noindex”:

После этого с обычными настройками сканируем сайт:

Затем в верхней панели выбираем “Экспорт” — “Экспорт данных краулера”. В результатах экспорта крайняя правая колонка:

Если фрагмент noindex обнаружен на странице, то в колонке — значение “1”. Если фрагмента нет — “0”.
Поиск nofollow на всём сайте
Аналогичным образом нужно проверить наличие атрибута nofollow в ссылках. Как поступать, если обнаружен:
- во внутренней перелинковке — удаляем.
- в исходящих ссылках — оставляем.
