Новичку очень трудно найти нужный символ или слово в массе кода, однако это делается очень быстро и просто. Если не знаете как, то читайте дальше.
В следующей статье, мы приступим к редактированию шаблона, и нам придётся находить нужные элементы в коде темы.
Если кто-то ещё не видел, что из себя представляет код шаблона, то зайдите в Консоль — Внешний вид — Редактор.
Перед Вами откроется код файла style.css. Покрутите его вниз, и первое, что придёт Вам в голову будет: ё-моё, как же в этой массе английских слов, цифр и символов, найти то, что нам будет нужно.
Для полноты ощущения, можно открыть один из php файлов, которые расположены в колонке справа от поля редактора.
Только сразу отгоните мысль типа: «Я в этом до самой смерти не разберусь». Разберётесь, и я Вам в этом помогу.
Рассмотрим два варианта, в зависимости от начальных условий, нахождения нужного элемента в коде.
Вариант 1.
Условие: мы точно знаем то, что нам нужно найти.
Для примера возьмём код страницы.
Комбинация клавиш Contrl-F откроет окно поиска в правом верхнем углу, в которое можно ввести искомый элемент кода. Элемент и все его повторения подсветятся.
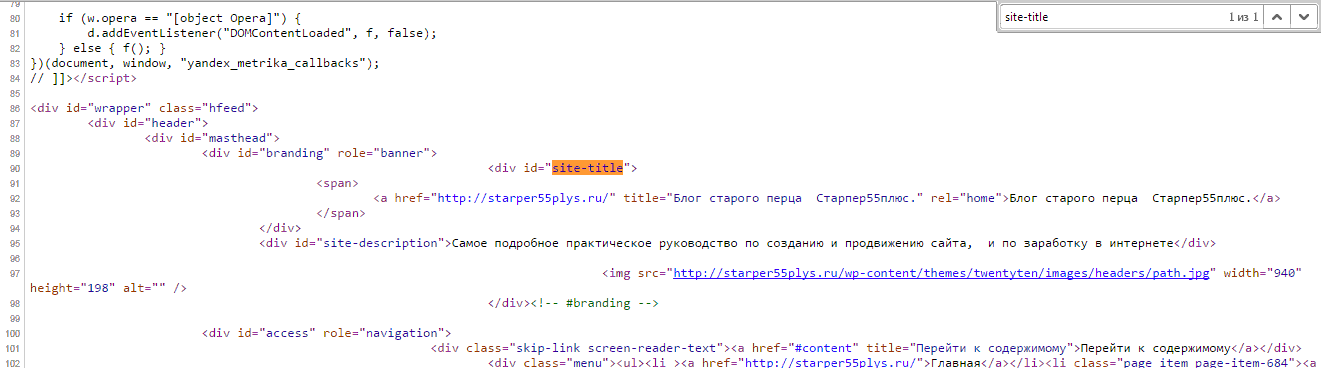
Этот поиск работает абсолютно для любого кода, открытого в браузере, то есть на странице.
Вариант 2.
Условие: мы видим элемент на странице, но не знаем ни его html, ни css.
В этом случае потребуется web-инспектор, или по другому Инструмент разработчика.
Инструмент разработчика есть во всех браузерах и открыть его можно или клавишей F12, или правой клавишей мыши, выбрав “Просмотреть код” или “Исследовать элемент”. В разных браузерах по разному.
Главное не выбирайте “Просмотреть код страницы”. Похоже, но не то.
После этого появится web-инспектор. Его интерфейс в разных браузерах немного отличается, но принцип действия везде одинаковый.
Я покажу на примере web-инспектора Chrome.
Заходим на страницу и открываем web-инспектор. По умолчанию он откроется в двух колонках, в левой будет html код всех элементов, находящихся на странице, а в правой — css оформление.
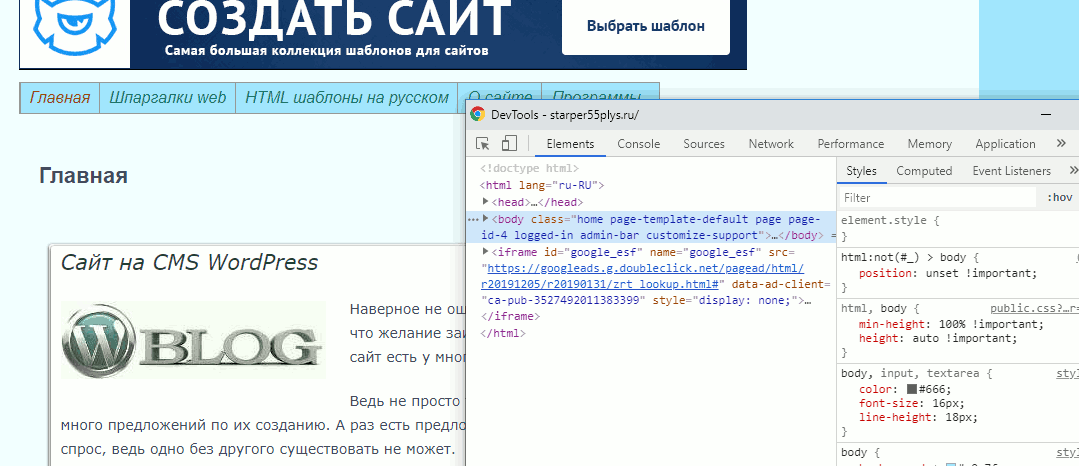
Изначально, код откроется в сложенном виде, то есть будут видны только основные элементы страницы, но если щёлкнуть по треугольничку в начале строки, то откроются все вложения, находящиеся в элементе.
И вот так, открывая вложение за вложением, можно добраться практически до любого элемента, находящегося на странице.
Определить, какой код, какому элементу соответствует, очень просто.
Надо просто вести по строкам курсором, и как только курсор оказывается на строке с кодом, так тут-же элемент, которому соответствует этот код, подсвечивается.
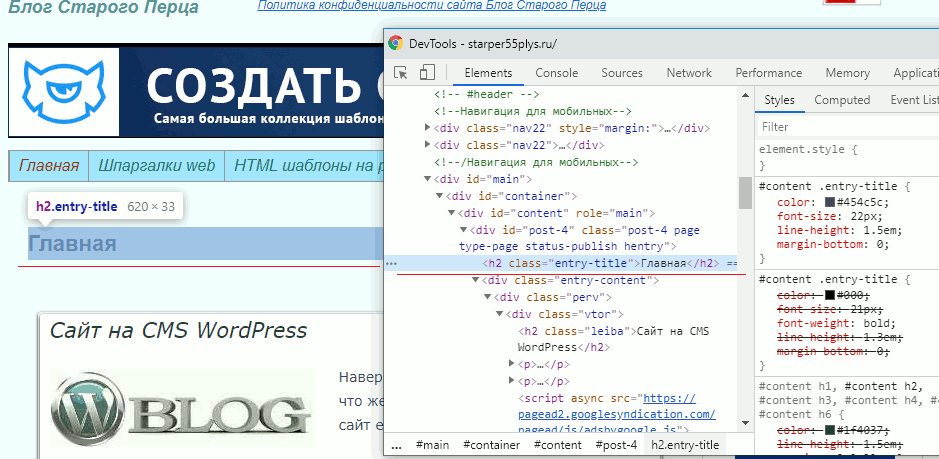
Теперь найдём css этого элемента. Для этого надо один раз щёлкнуть левой клавишей по строке с html, и в правой колонке отобразятся все стили, которые ему заданы, а так-же стили, влияющие на элемент, от родительских элементов.

Теперь, зная class или id элемента, можно спокойно идти в файл style.css, найти в нём нужный селектор, с помощью Поиска (Ctrl+F), и править внешний вид элемента.
Желаю творческих успехов.
Неужели не осталось вопросов? Спросить

Перемена
— Мам, ну почему ты думаешь, что если я была на дне рождения, то сразу пила?!
— Дочь а нечего что я папа?
Объявление в метро: «при обнаружении подозрительных предметов сделайте подозрительное лицо.
В раздел > > > Исправляем шаблон WordPress. Веб-инспектор
Содержание
- Как найти элемент в коде
- Организация поиска по веб-странице на JavaScript (без jQuery)
- Поиск готового решения
- Почему скрипт работал некорректно?
- Итак пишем скрипт с нуля
- Окей, двигаемся дальше. Переходим к JavaScript
- Будем считать, что вы уже создали и подключили js файл к DOM.
- Как найти нужный фрагмент кода в плагине или шаблоне
- Проект: собственный поиск по странице на jQuery
- Общая идея
- Готовим каркас
- Добавляем форму поиска и текст
- Общая идея
- Настраиваем стили
- Пишем скрипт
- Как можно улучшить
- Поиск на сайте своими руками
- Принцип работы
- Подготовка
- Морфологический анализатор
- Механизм ранжирования на уровне морфологии
- Индексирование содержимого сайта
- Хранение индексированных данных
- Benchmark
- Реализация поиска
- Реализация поиска на примере интернет-магазина
- Заключение
Как найти элемент в коде
Новичку очень трудно найти нужный символ или слово в массе кода, однако это делается очень быстро и просто. Если не знаете как, то читайте дальше.
В следующей статье, мы приступим к редактированию шаблона, и нам придётся находить нужные элементы в коде темы.
Если кто-то ещё не видел, что из себя представляет код шаблона, то зайдите в Консоль — Внешний вид — Редактор.
Для полноты ощущения, можно открыть один из php файлов, которые расположены в колонке справа от поля редактора.
Только сразу отгоните мысль типа: «Я в этом до самой смерти не разберусь». Разберётесь, и я Вам в этом помогу.
Рассмотрим два варианта, в зависимости от начальных условий, нахождения нужного элемента в коде.
Условие: мы точно знаем то, что нам нужно найти.
Для примера возьмём код страницы.
Комбинация клавиш Contrl-F откроет окно поиска в правом верхнем углу, в которое можно ввести искомый элемент кода. Элемент и все его повторения подсветятся.
Этот поиск работает абсолютно для любого кода, открытого в браузере, то есть на странице.
Условие: мы видим элемент на странице, но не знаем ни его html, ни css.
В этом случае потребуется web-инспектор, или по другому Инструмент разработчика.
Инструмент разработчика есть во всех браузерах и открыть его можно или клавишей F12, или правой клавишей мыши, выбрав «Просмотреть код» или «Исследовать элемент». В разных браузерах по разному.
Главное не выбирайте «Просмотреть код страницы». Похоже, но не то.
После этого появится web-инспектор. Его интерфейс в разных браузерах немного отличается, но принцип действия везде одинаковый.
Я покажу на примере web-инспектора Chrome.
Заходим на страницу и открываем web-инспектор. По умолчанию он откроется в двух колонках, в левой будет html код всех элементов, находящихся на странице, а в правой — css оформление.
Изначально, код откроется в сложенном виде, то есть будут видны только основные элементы страницы, но если щёлкнуть по треугольничку в начале строки, то откроются все вложения, находящиеся в элементе.
И вот так, открывая вложение за вложением, можно добраться практически до любого элемента, находящегося на странице.
Определить, какой код, какому элементу соответствует, очень просто.
Надо просто вести по строкам курсором, и как только курсор оказывается на строке с кодом, так тут-же элемент, которому соответствует этот код, подсвечивается.
Теперь найдём css этого элемента. Для этого надо один раз щёлкнуть левой клавишей по строке с html, и в правой колонке отобразятся все стили, которые ему заданы, а так-же стили, влияющие на элемент, от родительских элементов.
Теперь, зная class или id элемента, можно спокойно идти в файл style.css, найти в нём нужный селектор, с помощью Поиска (Ctrl+F), и править внешний вид элемента.
Желаю творческих успехов.
Перемена
— Мам, ну почему ты думаешь, что если я была на дне рождения, то сразу пила?!
— Дочь а нечего что я папа?
Объявление в метро: «при обнаружении подозрительных предметов сделайте подозрительное лицо.
Источник
Организация поиска по веб-странице на JavaScript (без jQuery)
Пару дней назад получил тестовое задание от компании на вакансию Front-end dev. Конечно же, задание состояло из нескольких пунктов. Но сейчас речь пойдет только об одном из них — организация поиска по странице. Т.е. банальный поиск по введенному в поле тексту (аналог Ctrl+F в браузере). Особенность задания была в том, что использование каких-либо JS фреймворков или библиотек запрещено. Все писать на родном native JavaScript.
(Для наглядности далее буду сопровождать всю статью скринами и кодом, чтоб мне и вам было понятнее, о чем речь в конкретный момент)
Поиск готового решения
Первая мысль: кто-то уже точно такое писал, надо нагуглить и скопипастить. Так я и сделал. За час я нашел два неплохих скрипта, которые по сути работали одинаково, но были написаны по-разному. Выбрал тот, в коде которого лучше разобрался и вставил к себе на старничку.
Если кому интересно, код брал тут.
Почему скрипт работал некорректно?
Все просто. Скрипт работает следующим образом. Сперва в переменную записываем все содержимое тега body, затем ищем совпадения с регулярным выражением (задает пользователь при вводе в текстовое поле) и затем заменяем все совпадения на следующий код:
А затем заменяем текущий тег body на новый полученный. Разметка обновляется, меняются стили и на экране подсвечиваются желтым все найденные результаты.
Вы уже наверняка поняли, в чем проблема, но я все же объясню подробней. Представьте, что в поле поиска ввели слово «div». Как вы понимаете, внутри body есть множество других тегов, в том числе и div. И если мы всем к «div» применим стили, указанные выше, то это уже будет не блок, а непонятно что, так как конструкция ломается. В итоге после перезаписи разметки мы получим полностью сломанную веб-страницу. Выглядит это так.
Было до поиска:  Просмореть полностью
Просмореть полностью
Стало после поиска: Просмореть полностью
Как видите, страница полностью ломается. Короче говоря, скрипт оказался нерабочим, и я решил написать свой с нуля, чему и посвящается эта статья.
Итак пишем скрипт с нуля
Как все у меня выглядит.
Сейчас нас интересует форма с поиском. Обвел ее красной линией.
Давайте немного разберемся. Я это реализовал следующим образом (пока чистый HTML). Форма с тремя тегами.
Первый — для ввода текста;
Второй — для для отмены поиска (снять выделение);
Третий — для поиска (выделить найденные результаты).
Итак, у нас есть поле для ввода и 2 кнопки. JavaScript буду писать в файле js.js. Предпложим, что его вы уже создали и подключили.
Первое, что сделаем: пропишем вызовы функции при нажатии на кнопку поиска и кнопку отмены. Выглядеть будет так:
Давайте немного поясню что тут и зачем нужно.
Полю с текстом даем id=«text-to-find» (по этому id будем обращатсья к элементу из js).
Кнопке отмены даем такие атрибуты: type=«button» onclick=«javascript: FindOnPage(‘text-to-find’,false); return false;»
— Тип: button
— При нажатии вызывается функция FindOnPage(‘text-to-find’,false); и передает id поля с текстом, false
Кнопке поиска даем такие атрибуты: type=«button» onclick=«javascript: FindOnPage(‘text-to-find’,true); return false;»
— Тип: submit (не кнопка потому, что тут можно юзать Enter после ввода в поле, а так можете и button использовать)
— При нажатии вызывается функция FindOnPage(‘text-to-find’,true); и передает id поля с текстом, true
Вы наверняка заметили еще 1 атрибут: true/false. Его будем использовать для определения, на какую именно кнопку нажали (отменить поиск или начать поиск). Если жмем на отмену, то передаем false. Если жмем на поиск, то передаем true.
Окей, двигаемся дальше. Переходим к JavaScript
Будем считать, что вы уже создали и подключили js файл к DOM.
Прежде, чем начнем писать код, давайте отвлечемся и сперва обсудим, как все должно работать. Т.е. по сути пропишем план действий. Итак, нам надо, чтоб при вводе текста в поле шел поиск по странице, но нельзя затрагивать теги и атрибуты. Т.е. только текстовые объекты. Как этого достичь — уверен есть много способов. Но сейчас будем использовать регулярные выражения.
Итак, следующее регулярное выражение будет искать только текст след. вида: «>… текст.
Источник
Как найти нужный фрагмент кода в плагине или шаблоне
Здравствуйте. Периодически нужно найти и откорректировать какой-то фрагмент кода, но искать его на хостинге по всем папкам и файлам очень долго. Есть ли какой-то более быстрый способ поиска?
В этой заметке я вам покажу: как найти нужный блок в исходном коде и в каком файле он вызывается.
Как пример возьмем вот этот блок: 
Что мы знаем о этой странице?
В вордпресс ее выводит плагин WP-Recall. А сама страница выводится шорткодом productlist с атрибутом type=slab
Инспектируем:
В браузере жмем F12. Открывается консоль разработки. В верхнем углу, слева, в этой панели кнопка «Инспектировать» (иконка курсор с прямоугольником) жмем по ней и тыкаем на искомый элемент на странице: 
— ок. Имя дива мы знаем. Это product-metas
Теперь плагин WP-Recall (ведь именно он выводит этот контент в нашем случае) копируем на ПК, и ищем по всем файлам этого плагина (ctrl + shift + F в notepad++)
Находим: 
три файла. Один — таблица стилей. Два — темплейты. Этот блок я выводил шорткодом slab. Значит мой вариант — файл product-slab.php
Буквально за 2 минуты мы нашли то что искали. Это даже быстрей чем написать свой вопрос на форуме.
Удачного вам обучения юные вебмастера, веб программисты и просто те, кто настраивает себе свой персональный блог. Эти простые основы помогут вам быстро разобраться в внутреннем устройстве плагинов.
p.s. один знающий товарищ написал:
Всё, что выше написал коллеги касается файлов темы, но не движка или плагинов, потому как корректировать их код ненужно и может быть опасно.
но есть случаи не для правки (мой ответ):
не всегда чтобы что-то найти ищут именно для изменения. Мне часто надо просто глянуть исходники и найти за что зацепиться чтобы решить свою задачу — т.к. у 99% плагинов нет технического описания их api. Вот и изучаю самостоятельно.
т.е. так я могу найти нужную мне функцию (чтобы вывести какой либо блок в произвольном месте, или посмотреть аргументы функции и зависимости), посмотреть есть ли в ней хуки и фильтры или посмотреть кто же еще вызывает эту функцию.
Источник
Проект: собственный поиск по странице на jQuery
Потому что почему бы и нет.
Недавно мы говорили о библиотеках и фреймворках — и обещали, что попробуем что-нибудь на них собрать. Настало время.
Сегодня мы возьмём популярную библиотеку jQuery и сделаем на её основе поиск по странице. Браузеры это умеют делать встроенными инструментами, но с помощью нашего метода можно будет более тонко всё настроить и сделать поле поиска видимым и удобным.
Общая идея
У нас есть сайт с неким текстом, и нам нужно быстро находить в нём нужные слова или части слов. Для этого мы в самом начале страницы делаем поле ввода, куда будем писать наши слова для поиска, и кнопку, которая этот поиск запускает.
Дальше скрипт берёт весь текст, находит в нём нужные фрагменты и подсвечивает их. Если он ничего не находит — пишет сообщение о том, что таких слов в тексте нет.
Готовим каркас
Добавляем форму поиска и текст
Наша форма поиска — это поле ввода и кнопка, которая запускает скрипт. Мы не будем сильно настраивать внешний вид формы, при желании вы можете сделать это сами — все нужные знания для этого у вас уже есть. Если что-то забыли — посмотрите, как мы настраивали вид поля ввода в статье про планировщик задач.
Добавим код формы сразу после тега :
Осталось добавить сам текст в блок
Общая идея
У нас есть сайт с неким текстом, и нам нужно быстро находить в нём нужные слова или части слов. Для этого мы в самом начале страницы делаем поле ввода, куда будем писать наши слова для поиска, и кнопку, которая этот поиск запускает.
Дальше скрипт берёт весь текст, находит в нём нужные фрагменты и подсвечивает их. Если он ничего не находит — пишет сообщение, что таких слов в тексте нет.
Сохраняем, открываем в браузере:


Настраиваем стили
Стили отвечают за внешний вид всех элементов на странице. Главное, что нам нужно сделать, — нормальный внешний вид формы поиска и выбрать подсветку для найденных результатов. Это мы настроим в блоке в начале страницы:
Сохраняем и обновляем страницу — теперь форма выглядит лучше:

Пишем скрипт
Задача скрипта — пробежаться по всему содержимому текста и сравнить все слова с тем, что мы ввели в строке поиска. Всю работу за нас сделает плагин highlight, нам остаётся только вывести количество найденных совпадений и очистить страницу от предыдущих результатов поиска.
Как можно улучшить
Можно убрать кнопку «Найти» и запускать поиск при вводе текста в поле.
Можно сделать два поля ввода, подсвечивая найденное по каждому разными цветами. Это полезно, например, если нужно проанализировать, каких слов в тексте больше.
Регулярные выражения! О них отдельно напишем, это же просто праздник какой-то.
Источник
Поиск на сайте своими руками

Наверное, многие когда-нибудь задумывались, как сделать поиск на сайте? Безусловно, для крупных сайтов с большим количеством контента поиск является просто незаменимой вещью. В большинстве случаев пользователь, впервые посетив Ваш сайт в поисках чего-либо важного, не станет разбираться в навигационных панелях, выпадающих меню и прочих элементах навигации, а в спешке попытается найти что-нибудь похожее на поисковую строку. И если такой роскоши на сайте не окажется, либо он не справится с поисковым запросом, то посетитель просто закроет вкладку. Но статья не о значении поиска для сайта и не о психологии посетителей. Я расскажу, как реализовать небольшой алгоритм полнотекстового поиска, который, надеюсь, избавит начинающих разработчиков от головной боли.
У читателя может возникнуть вопрос: зачем писать все с нуля, если все уже давно написано? Да, у крупных поисковиков есть API, есть такие клевые проекты, как Sphinx и Apache Solr. Но у каждого из этих решений есть свои преимущества и недостатки. Пользуясь услугами поисковиков, типа Google и Яндекс, Вы получите множество плюшек, таких как мощный морфологический анализ, исправление опечаток и ошибок в запросе, распознавание неверной раскладки клавиатуры, однако без ложки дегтя тут не обойдется. Во первых, такой поиск не интегрируется в структуру сайта — он внешний, и Вы не сможете указать ему, какие данные наиболее важны, а какие не очень. Во вторых, содержимое сайта индексируется только с определенным интервалом, который зависит от выбранного поисковика, так что если на сайте что-нибудь обновится, придется дожидаться момента, когда эти изменения попадут в индекс и станут доступными в поиске. У Sphinx и Apache Solr дела с интеграцией и индексированием гораздо лучше, но не каждый хостинг позволит из запустить.
Ничто не мешает написать поисковый механизм самостоятельно. Предполагается, что сайт работает на PHP в связке с каким-нибудь сервером баз данных, например MySQL. Давайте сначала определимся, что требуется от поиска на сайте?
В конце статьи будет показан пример реализации поиска на примере простого интернет-магазина. Тем, кому лень все это изучать и просто нужен готовый поисковик, можно смело забирать движок из репозитория GitHub FireWind.
Принцип работы
Подготовка
Задача поставлена, теперь можно перейти к делу. Я использую Linux в качестве рабочей ОС, однако постараюсь не использовать ее экзотических возможностей, чтобы любители Windows смогли «собрать» поисковый движок по аналогии. Все, что Вам нужно — это знание основ PHP и умение обращаться с MySQL. Поехали!
Наш проект будет состоять из ядра, где будут собраны все жизненно необходимые функции, а также модуля морфологического анализа и обработки текста. Для начала создадим корневую папку проекта firewind, а в ней создадим файл core.php — он и будет ядром.
Теперь вооружаемся своим любимым текстовым редактором и подготавливаем каркас:
Тут мы создали основной класс, который можно будет использовать на Ваших сайтах. На этом подготовительная часть заканчивается, пора двигаться дальше.
Морфологический анализатор
Русский язык — довольно сложная штука, которая радует своим разнообразием и шокирует иностранцев конструкциями, типа «да нет, наверное». Научить машину понимать его, да и любой другой язык, — довольно непростая задача. Наиболее успешны в этом плане поисковые компании, типа Google и Яндекс, которые постоянно улучшают свои алгоритмы и держат их в секрете. Придется нам сделать что-то свое, попроще. К счастью, колесо изобретать не придется — все уже сделано за нас. Встречайте, phpMorphy — морфологический анализатор, поддерживающий русский, английский и немецкий языки. Более подробную информацию можно получить тут, однако нас интересуют только две его возможности: лемматизация, то есть получение базовой формы слова, и получение грамматической информации о слове (род, число, падеж, часть речи и т.д.).
Нужна библиотека и словарь для нее. Все это добро можно найти тут. Библиотека находится в одноименной папке «phpmorphy», словари расположены в «phpmorphy-dictionaries». Скачиваем последние версии в корневую папку проекта и распаковываем:
Отлично! Библиотека готова к использованию. Пришло время написать «оболочку», которая абстрагирует работу с phpMorphy. Для этого создадим еще один файл morphyus.php в корневой директории:
Пока реализовано только два метода. get_words разбивает текст на массив слов, фильтруя при этом HTML-теги и сущности типа » «. Метод lemmatize возвращает массив лемм слова, либо false, если таковых не нашлось.
Механизм ранжирования на уровне морфологии
Давайте остановимся на такой единице языка, как предложение. Наиболее важной частью предложения является основа в виде подлежащего и/или сказуемого. Чаще всего подлежащее выражается существительным, а сказуемое глаголом. Второстепенные члены в основном употребляются для уточнения смысла основы. В разных предложениях одни и те же части речи порой имеют совершенно разное значение, и наиболее точно оценить это значение в контексте текста сегодня может только человек. Однако программно оценить значение какого-либо слова все-таки можно, хоть и не так точно. При этом алгоритм ранжирования должен опираться на так называемый профиль текста, который определяется его автором. Профиль представляет из себя ассоциативный массив, ключами которого являются части речи, а значениями соответственно ранг (или вес) каждой из них. Пример профиля я покажу в заключении, а пока попробуем перевести эти размышления на язык PHP, добавив еще один метод к классу morphyus:
Индексирование содержимого сайта

Как уже говорилось выше, индексирование заметно ускоряет выполнение поискового запроса, так как поисковому движку не нужно обрабатывать контент каждый раз заново — поиск выполняется по индексу. Но что же все-таки происходит при индексировании? Если по порядку, то:
В результате получается объект следующего формата:
Пишем инициализатор и первый метод ядра поискового движка:
Теперь при добавлении или изменении данных в таблицах достаточно просто вызвать данную функцию, чтобы проиндексировать их, но это не обязательно: индексирование может быть и отложенным. Первым аргументом метода make_index является исходный текст, вторым — коэффициент значимости индексируемых данных. Ранг каждого слова, кстати, расчитывается по формуле:
Хранение индексированных данных
Очевидно, что индекс нужно где-нибудь хранить, да еще и привязать к исходным данным. Наиболее подходящим местом для них будет база данных. Если индексируется содержимое файлов, то можно создать отдельную таблицу в базе данных, которая будет содержать индекс название каждого файла, а для содержимого, которое уже хранится в базе, можно добавить еще одно поле типа в структуру таблиц. Такой подход позволит разделять типы содержимого при поиске, например, названия и описание статей в случае блога.
Нерешенным остался лишь вопрос формата индексированного содержимого, ведь make_index возвращает объект, и так просто в базу данных или файл его не запишешь. Можно использовать JSON и хранить его в полях типа LONGTEXT, можно BSON или CBOR, используя тип данных LONGBLOB. Два последних формата позволяют представлять данные в более компактном виде, чем первый.
Как говорится, «хозяин — барин», так-что решать, где и как все будет храниться, Вам.
Benchmark
Давайте проверим, что у нас получилось. Я взял текст своей любимой статьи «Темная материя интернета», а именно содержимое узла #content html_format и сохранил его в отдельный файл.
На моей машине с конфигурацией:
CPU: Intel Core i7-4510U @ 2.00GHz, 4M Cache
RAM: 2×4096 Mb
OS: Ubuntu 14.04.1 LTS, x64
PHP: 5.5.9-1ubuntu4.5
Индексирование заняло около секунды:
Думаю, вполне неплохой результат.
Реализация поиска
Остался последний и самый главный метод, метод поиска. В качестве первого аргумента метод принимает индекс поискового запроса, в качестве второго — индекс содержимого, в котором выполняется поиск. В результате выполнения возвращается суммарный ранг, рассчитанный на основе ранга найденных слов, либо 0, если ничего не нашлось. Это позволит сортировать поисковую выдачу.
Все! Поисковый движок готов к использованию. Но есть одно но… На самом деле это не джин-волшебник, и просто закинув его на свой сайт Вы не получите ничего. Его нужно интегрировать, причем этот процесс во многом зависит от архитектуры Вашего сайта. Рассмотрим этот процесс на примере небольшого интернет магазина.
Реализация поиска на примере интернет-магазина
Допустим, информация о продаваемой продукции хранится в таблице production:
А описание в таблице description:
Поле production.keywords будет содержать индекс ключевых слов продукта, description.index будет содержать индексированное описание. И все это будут храниться в формате JSON.
Вот пример функции добавления нового продукта:
Здесь поисковый механизм был интегрирован в функцию добавления нового продукта магазина. А теперь обработчик поисковых запросов:
Данный сценарий принимает поисковый запрос в виде GET-параметра query и выполняет поиск. В результате выводятся найденные продукты магазина.
Заключение
В статье был описан один из вариантов реализации поиска для сайта. Это самая первая его версия, поэтому буду только рад узнать Ваши замечания, мнения и пожелания. Присоединяйтесь к моему проекту на Github: https://github.com/axilirator/firewind. В планах добавить туда еще кучу всяких возможностей, вроде кэширования поисковых запросов, подсказок при вводе поискового запроса и алгоритма побуквенного сравнения, который поможет бороться с опечатками.
Всем спасибо за внимание, ну и с днем информационной безопасности!
Источник
При вводе строки по CTRL+F в коде надо помнить, что внутри строчки не должно быть никаких тегов, например изменения шрифта или стиля, иначе строчка может и не найтись в поиске по тексту HTML кода.
Например текст на странице такой:
2х2=4
Это же самое в HTML коде выглядит так:
2х2=<strong>4</strong>
Поиск ничего не даст
Такое бывает в тех случаях когда внутри строки используются теги; в этом случае надо найти и скопировать строчку на экране, затем преобразовать в HTML (фрагмент кода для преобразования приведен в ответе на вопрос Какие есть толковые способы перевести doc в html?) и только потом, зная как закодирована строчка, можно искать этот код в коде HTML.

how can i search an html page for a word fast?
and how can i get the html tag that the word is in? (so i can work with the entire tag)
asked Apr 14, 2009 at 16:08
Chen KinnrotChen Kinnrot
20.5k17 gold badges79 silver badges139 bronze badges
To find the element that word exists in, you’d have to traverse the entire tree looking in just the text nodes, applying the same test as above. Once you find the word in a text node, return the parent of that node.
var word = "foo",
queue = [document.body],
curr
;
while (curr = queue.pop()) {
if (!curr.textContent.match(word)) continue;
for (var i = 0; i < curr.childNodes.length; ++i) {
switch (curr.childNodes[i].nodeType) {
case Node.TEXT_NODE : // 3
if (curr.childNodes[i].textContent.match(word)) {
console.log("Found!");
console.log(curr);
// you might want to end your search here.
}
break;
case Node.ELEMENT_NODE : // 1
queue.push(curr.childNodes[i]);
break;
}
}
}
this works in Firefox, no promises for IE.
What it does is start with the body element and check to see if the word exists inside that element. If it doesn’t, then that’s it, and the search stops there. If it is in the body element, then it loops through all the immediate children of the body. If it finds a text node, then see if the word is in that text node. If it finds an element, then push that into the queue. Keep on going until you’ve either found the word or there’s no more elements to search.
answered Apr 14, 2009 at 16:15
3
You can iterate through DOM elements, looking for a substring within them. Neither fast nor elegant, but for small HTML might work well enough.
I’d try something recursive, like: (code not tested)
findText(node, text) {
if(node.childNodes.length==0) {//leaf node
if(node.textContent.indexOf(text)== -1) return [];
return [node];
}
var matchingNodes = new Array();
for(child in node.childNodes) {
matchingNodes.concat(findText(child, text));
}
return matchingNodes;
}
answered Apr 14, 2009 at 16:14
vartecvartec
130k36 gold badges217 silver badges244 bronze badges
0
You can try using XPath, it’s fast and accurate
http://www.w3schools.com/Xpath/xpath_examples.asp
Also if XPath is a bit more complicated, then you can try any javascript library like jQuery that hides the boilerplate code and makes it easier to express about what you want found.
Also, as from IE8 and the next Firefox 3.5 , there is also Selectors API implemented. All you need to do is use CSS to express what to search for.
answered Apr 14, 2009 at 16:16
AzderAzder
4,6787 gold badges37 silver badges57 bronze badges
2
You can probably read the body of the document tree and perform simple string tests on it fast enough without having to go far beyond that – it depends a bit on the HTML you are working with, though – how much control do you have over the pages? If you are working within a site you control, you can probably focus your search on the parts of the page likely to be different page from page, if you are working with other people’s pages you’ve got a tougher job on your hands simply because you don’t necessarily know what content you need to test against.
Again, if you are going to search the same page multiple times and your data set is large it may be worth creating some kind of index in memory, whereas if you are only going to search for a few words or use smaller documents its probably not worth the time and complexity to build that.
Probably the best thing to do is to get some sample documents that you feel will be representative and just do a whole lot of prototyping based around the approaches people have offered here.
answered Apr 14, 2009 at 16:19
glenatronglenatron
10.9k13 gold badges63 silver badges109 bronze badges
form.addEventListener("submit", (e) => {
e.preventDefault();
var keyword = document.getElementById("search_input");
let words = keyword.value;
var word = words,
queue = [document.body],
curr;
while (curr = queue.pop()) {
if (!curr.textContent.toUpperCase().match(word.toUpperCase())) continue;
for (var i = 0; i < curr.childNodes.length; ++i) {
switch (curr.childNodes[i].nodeType) {
case Node.TEXT_NODE: // 3
if (curr.childNodes[i].textContent.toUpperCase().match(word.toUpperCase())) {
console.log("Found!");
console.log(curr);
curr.scrollIntoView();
}
break;
case Node.ELEMENT_NODE: // 1
queue.push(curr.childNodes[i]);
break;
}
}
}
});
answered Dec 18, 2020 at 17:39
how can i search an html page for a word fast?
and how can i get the html tag that the word is in? (so i can work with the entire tag)
asked Apr 14, 2009 at 16:08
Chen KinnrotChen Kinnrot
20.5k17 gold badges79 silver badges139 bronze badges
To find the element that word exists in, you’d have to traverse the entire tree looking in just the text nodes, applying the same test as above. Once you find the word in a text node, return the parent of that node.
var word = "foo",
queue = [document.body],
curr
;
while (curr = queue.pop()) {
if (!curr.textContent.match(word)) continue;
for (var i = 0; i < curr.childNodes.length; ++i) {
switch (curr.childNodes[i].nodeType) {
case Node.TEXT_NODE : // 3
if (curr.childNodes[i].textContent.match(word)) {
console.log("Found!");
console.log(curr);
// you might want to end your search here.
}
break;
case Node.ELEMENT_NODE : // 1
queue.push(curr.childNodes[i]);
break;
}
}
}
this works in Firefox, no promises for IE.
What it does is start with the body element and check to see if the word exists inside that element. If it doesn’t, then that’s it, and the search stops there. If it is in the body element, then it loops through all the immediate children of the body. If it finds a text node, then see if the word is in that text node. If it finds an element, then push that into the queue. Keep on going until you’ve either found the word or there’s no more elements to search.
answered Apr 14, 2009 at 16:15
3
You can iterate through DOM elements, looking for a substring within them. Neither fast nor elegant, but for small HTML might work well enough.
I’d try something recursive, like: (code not tested)
findText(node, text) {
if(node.childNodes.length==0) {//leaf node
if(node.textContent.indexOf(text)== -1) return [];
return [node];
}
var matchingNodes = new Array();
for(child in node.childNodes) {
matchingNodes.concat(findText(child, text));
}
return matchingNodes;
}
answered Apr 14, 2009 at 16:14
vartecvartec
130k36 gold badges217 silver badges244 bronze badges
0
You can try using XPath, it’s fast and accurate
http://www.w3schools.com/Xpath/xpath_examples.asp
Also if XPath is a bit more complicated, then you can try any javascript library like jQuery that hides the boilerplate code and makes it easier to express about what you want found.
Also, as from IE8 and the next Firefox 3.5 , there is also Selectors API implemented. All you need to do is use CSS to express what to search for.
answered Apr 14, 2009 at 16:16
AzderAzder
4,6787 gold badges37 silver badges57 bronze badges
2
You can probably read the body of the document tree and perform simple string tests on it fast enough without having to go far beyond that – it depends a bit on the HTML you are working with, though – how much control do you have over the pages? If you are working within a site you control, you can probably focus your search on the parts of the page likely to be different page from page, if you are working with other people’s pages you’ve got a tougher job on your hands simply because you don’t necessarily know what content you need to test against.
Again, if you are going to search the same page multiple times and your data set is large it may be worth creating some kind of index in memory, whereas if you are only going to search for a few words or use smaller documents its probably not worth the time and complexity to build that.
Probably the best thing to do is to get some sample documents that you feel will be representative and just do a whole lot of prototyping based around the approaches people have offered here.
answered Apr 14, 2009 at 16:19
glenatronglenatron
10.9k13 gold badges63 silver badges109 bronze badges
form.addEventListener("submit", (e) => {
e.preventDefault();
var keyword = document.getElementById("search_input");
let words = keyword.value;
var word = words,
queue = [document.body],
curr;
while (curr = queue.pop()) {
if (!curr.textContent.toUpperCase().match(word.toUpperCase())) continue;
for (var i = 0; i < curr.childNodes.length; ++i) {
switch (curr.childNodes[i].nodeType) {
case Node.TEXT_NODE: // 3
if (curr.childNodes[i].textContent.toUpperCase().match(word.toUpperCase())) {
console.log("Found!");
console.log(curr);
curr.scrollIntoView();
}
break;
case Node.ELEMENT_NODE: // 1
queue.push(curr.childNodes[i]);
break;
}
}
}
});
answered Dec 18, 2020 at 17:39
