Лексико-грамматический поиск
С помощью лексико-грамматического поиска можно искать последовательность лексем и/или словоформ, обладающих определенными грамматическими и/или семантическими характеристиками.
В новом интерфейсе блоки, относящиеся к отдельным словам, в лексико-грамматическом поиске идут не сверху вниз, а слева направо.
По-умолчанию в форме показано только одно Слово, при желании пользователь может добавить дополнительные Слова или удалить ненужные Слова самостоятельно, нажав плюсик или крестик справа .
В блоке показан набор условий, который можно варьировать: убрать ненужные условия или добавить дополнительные условия, которые не входят в набор условий, отображающихся по умолчанию, или были ранее удалены пользователем.
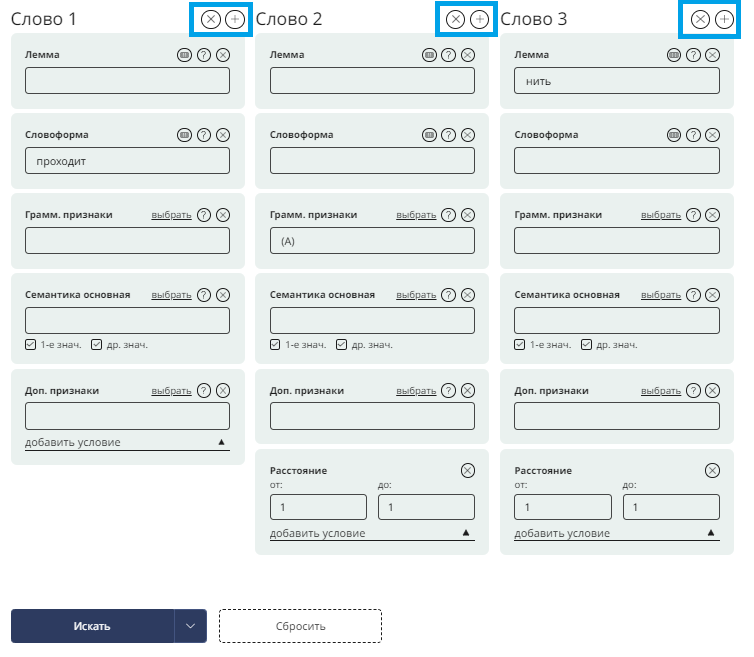
Условия на расстояние между словами доступны начиная со Слова 2 и задают расстояние между текущим словом и предыдущим, находящимся в форме поиска левее.
В наборе условий присутствуют отдельные поля Лемма и Слово, что позволяет задавать условия на словоформу без ввода спецсимволов-кавычек. В поле Лемма для уточнения запроса можно использовать специальные операторы.
В основном корпусе и в корпусе региональных СМИ в специальных полях Лемма с рег. выражениями и Слово с рег. выражениями можно задавать условия поиска с помощью регулярных выражений.
Для ряда полей доступны два способа ввода значений. Большинству пользователей будет легче воспользоваться выбором опций во всплывающем окне.

Для дополнительного удобства пользователей в ходе выбора условий одновременно формируется и отображается формула значений для поля.
Для опытных пользователей доступен ввод формулы в поле вручную. Однако при таком способе ввода недоступно редактирование значений через всплывающее окно и не гарантируется наличие примеров.

При нажатии кнопки Искать откроются результаты поиска. Продвинутые пользователи могут выбрать предпочтительный вид выдачи, который будет выводиться по умолчанию.
lingdata
Сайт курса «Лингвистические данные», бакалавры 1 курс НИУ ВШЭ
View the Project on GitHub olesar/lingdata
Цель этого практикума – ознакомиться с языком запросов и типами лингвистической информации, доступными при поиске по Основному корпусу.
1. Точный поиск
примеры запросов: подыми, надо же было, расти, опал и др.
(скриншот)
Страница результатов: количество документов и вхождений
Статистика вхождений – сколько раз слово встречается в корпусе. Количество документов – в скольких текстах встречается слово.
В блоке ниже после двоеточия запишите статистику по документам и вхождениям для слова подыми, а также ответьте на вопрос 1.3.
# 1.1 Количество документов:
# 1.2 Количество вхождений:
# 1.3 Почему количество документов меньше количества вхождений? Ответ:
2. Разборы у слов в корпусе
Кликнув мышкой на любом слове, вы откроете всплывающее окошко с его характеристиками: начальной формой (леммой), грамматическими показателями, семантическими признаками и т.д.
# 2.1 К какой части речи принадлежит форма _подыми_ в первом предложении выдачи? Запишите ее помету:
3. Лексико-грамматический поиск
В поле Слово введите лемму слова (например, “поднять” для всех форм типа “поднял”, “поднимет” и т. д.).
Обратите внимание, у лексико-грамматического поиска своя кнопка Искать.
Специальные символы
* : нач* задаст поиск всех лемм типа начало, начать, начинать, начинить. *ча задаст поиск всех лемм типа чукча, буча, молча
- (НЕ) : минус перед словом исключает его из запроса. Пример: *вед -швед (все слова на *вед, кроме швед)
Неправильно: “*вед – швед” (никогда не ставьте пробел после минуса)
| : сидя | лежа | стоя найдет все три наречия (но только в тех текстах, где они размечены, как наречия)
& или просто пробел (И) : достичь достигнуть найдет в корпусе все формы, размеченные двумя леммами
"словоформа" : в поле Слово строка без кавычек задает поиск по всем формам слова (задается начальная форма), строка в кавычках задает поиск по точной словоформе)
Другие примеры запросов: посол -"после", трудно* -трудно -трудност*.
Задание 3.1 Впишите количество вхождений слов, начинающихся на цы-, но не цыган, цыпочки, цыпленок, цыц
Настройки сортировки: по дате создания, по правому контексту. Формат выдачи KWIQ.
Задание 3.2-3.3 Укажите год создания самого раннего текста Основного корпуса, включающего слова из запроса 3.1, а также лемму первого по времени вхождения.
# 3.2 Первое вхождение (год):
# 3.3 Первое вхождение (лемма):
Задание 3.4 Мы уже предлагали поискать словосочетание баба с возу с помощью точного поиска. Почему строка баба с возу (набранная вместе в поле Слово лексико-грам. поиска) не будет найдена в корпусе?
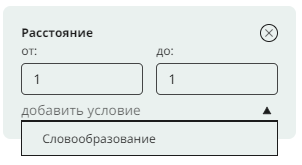
4. Поиск по грамматическим признакам
См. всплывающее окно по ссылке “выбрать” над полем Грамм. признаки.
Найдите все употребления аномальных форм повелительного наклонения глагола в ед. числе, отсортируйте по найденным формам по алфавиту.
Подсказка: задать грамматические признаки глагол, повелительное наклонение, ед. число, аномальная форма; отсортировать по правому или левому контексту с учетом найденного слова
# 4.1 Самая последняя по алфавитному порядку словоформа:
5. Задать подкорпус: Корпус со снятой лексико-грамматической омонимией.
В этом корпусе (“снятнике”) у грамматически неоднозначных форм (типа стали, белка) были удалены нерелевантные грамматические разборы.
Запишите объем этого корпуса на момент поиска:
6. “Вторые” падежи и другие “дополнительные” грамматические формы
См. пометы падежей в разделе Морфология
Примеры запросов: словоформа “лесу” как предложный2, “сахару” как родительный 2, все формы императива2.
Задание 6.1 Сколько уникальных лемм имеют счетную форму?
# 6.1 Лемм со счетной формой:
7. Поиск по нескольким словам: добавление 3-го и т.д. слов стрелочкой справа. Расстояние между словами. Поиск по дополнительным признакам.
Найдите (в подкорпусе со снятой омонимией) все предложения, похожие по структуре на “Мама мыла раму”. Сравните число вхождений с общим количеством предложений в подкорпусе.
Подсказка:
Слово1, грам.признаки: сущ., одуш., ед. ч., им. падеж
Слово2, грам.признаки: глагол, прош. вр., ед. число
Слово3: грам.признаки: сущ., неодуш., ед. ч., вин. падеж
Дополнительные признаки:
Слово1 – в начале предложения, с заглавной буквы
Слово3 – в конце предложения, перед точкой
Чтобы исключить шум: Слово2 – выбрать доп. признаки перед любым знаком препинания + после любого знака препинания, затем перед каждым поставить “минус”: -amark -bmark
Cбросить подкорпус
через “Задать подкорпус” -> Очистить подкорпус (кнопка внизу страницы)
8. Поиск по семантическим признакам (классы слов, выделенные по общему значению).
Примеры запросов:
а) найти все глаголы речи
б) найти имена лиц с уменьшительно-ласкательным значением, но не на -чка, -нька
(подсказка)
Запишите фамилию самого юного автора, в тексте которого встречается имя лица с уменьшительно-ласкательным значением, но не на -чка, -нька
9. Случайная выдача (Настройки -> Упорядочить…). Выгрузка результатов в оффлайн.
Если примеров много, будут выданы в случайно отсортированном порядке примеры из первых нескольких тысяч результатов поиска.
Для выгрузки результатов перейдите по ссылке Скачать несколько первых результатов выдачи в формате Excel. Откройте файл в редакторе таблиц, изучите содержание столбцов.
10. Поиск по словообразовательным признакам
Примеры заданий: найти слова с приставкой вс-. Сравнить с результатами простого запроса со звездочкой вс*, без учета словообразовательных признаков.
Подсказка: Откройте всплывающее окно выбора словообр. признаков.
__Текст___: вс
__статус__: префикс
Полезная информация
- На сайте корпуса изучите основную информацию о составе корпуса и включенных в него материалах:
- что такое корпус?
- состав и структура корпуса
-
Откройте раздел “поиск в корпусе”
- Инструкция по работе с корпусом
- ссылка “Инструкция” на страницах поиска
- см. также всплывающие подсказки (?) на странице поиска
- На страницах Морфология, Семантика и др. (в меню главной страницы корпуса) можно узнать расшифровку корпусных помет
Автор: Участник:Улитин Борис
С конца 80-х годов прошлого века в русском языкознании получила свое развитие корпусная лингвистика, и сегодня русисты имеют в своем распоряжении Национальный корпус русского языка (НКРЯ).
Первоначальные корпусные лингвистические исследования решали проблемы лингвостатистики – сводились к подсчету частот встречаемости различных языковых элементов: слов, графем, морфем, словосочетаний.
Приведем пример такого запроса. Предположим, нам необходима статистика употребления Л.Н.Толстым слов «война» и «мир» в своих произведениях. Последовательность действий пользователя представлена в презентации. Отметим, что возможность задания подкорпуса является чрезвычайно мощным инструментом, так как позволяет отобрать нужные тексты по таким критериям, как автор, название, год создания и др. Но для такого типа запросов в НКРЯ, к сожалению, отсутствуют средства графической интерпретации, поэтому приходится использовать внешние программы, например, EXCEL MS Office или такие on-line интернет-сервисы, как Canva, Infogram, Pictochart.

Для проведения диахронических исследований, в разделе НКРЯ «графики» имеется возможность сравнить хронологическое распределение частот употребления словоформ в Основном корпусе. Результаты иллюстрируются двумерными графиками.

Особенность поисковой системы НКРЯ состоит в том, что в ней на общем корпусе учитываются прежде всего морфологические свойства слов, синтаксические же характеристики легли в основу синтаксической разметки небольшого по объему материала, о чем свидетельствует таблица.
| Подкорпус | Число текстов | Число предложений | Число предложений |
| Основной корпус | 76 882 | 17 574 752 | 209 198 275 |
| в том числе со снятой омонимией | 2 147 | 516 852 | 5 944 188 |
Поэтому при определенных исследовательских работах необходимо самим составлять сводные списки признаков, отличающих языковые объекты. Затем, опираясь на эти признаки, составлять поисковые запросы к НКРЯ. Наиболее интересными в этом случае оказывается работа с омонимами, принадлежащими к разным грамматическим классам (например, вводные слова, слова категории состояния, наречия, краткие прилагательные).
Рассмотрим пример. Среди отличительных признаков вводных слов можно отметить следующий – возможность разворачивания слова в предикативную единицу – вербализованную модусную рамку с подчинительным союзом что – с сохранением смысла. Данный признак можно эффективно использовать для отбора предложений, содержащих заданное слово в позиции вводного. Описание такого запроса содержится в презентации.
Приведенные в статье поисковые запросы показывают, что аппарат поиска информации в НКРЯ достаточно эффективен, при условии, что пользователь обладает знанием морфологических норм, правил употребления синтаксических конструкций.

кандидат филологических наук, доцент кафедры русской литературы и журналистики Петрозаводского государственного университета
Эксперт: Центра современных образовательных технологий, сертифицированный старший тьютор программы “Intel: Обучение для будущего”, Google certified teacher
Чтение художественного текста не может ограничиваться простым считыванием смыслов. Но как изумить ученика? Как показать ему высоту мастерства писате-
ля? Как открыть ему достоинства классических текстов?
Одним из таких способов является перечитывание.
Существуют различные методики перечитывания текста, но большинство из них отличается высокой трудозатратностью (при тотальном перечитывании) или низкой эффективностью (при беглом прочтении). Современные информационные системы дают возможность сделать даже кратковременные возвращения к прочитанному тексту одновременно интересными и эффективными.
Одним из таких инструментов может быть назван Национальный корпус русского языка, разрабатываемый группой российских ученых при поддержке компании Яндекс.
Что такое Национальный корпус русского языка
Корпус – это информационно-справочная система, основанная на собрании текстов на некотором языке в электронной форме. Национальный
корпус представляет данный язык на определенном этапе (или этапах) его существования и во всём многообразии жанров, стилей, территориальных и
социальных вариантов и т. п.
Важно понимать, что Национальный корпус – это не электронная библиотека, а средство поиска слов, словосочетаний, грамматических и синтаксических конструкций и т.д.
В настоящее время Национальный корпус русского языка состоит из 12 корпусов:
- основной;
- синтаксический;
- газетный;
- параллельные корпуса;
- диалектный;
- поэтический;
- обучающий;
- устной речи;
- акцентологический;
- мультимедийный;
- мультипарк;
- исторический.
Несмотря на свое предназначение для лингвистов, исследующих историю слов и грамматических конструкций, корпус представляет ценность для
всех исследователей русской культуры, выразителем которой является язык.
Как искать в Национальном корпусе русского языка?
В рамках общего образования акцент обычно делается на прочтении, пересказе, обсуждении и анализе на уровне проблематики и композиционных приемов.
Между тем, литература – это искусство слова, поэтому очень важно, чтобы учащиеся видели словесную ткань и осознавали, каким образом она
взаимосвязана со смыслами и ощущениями, рождаемыми текстом.
По заглавию
Заглавие текста не только выражает его основную мысль или направляет восприятие текста в определенное русло, оно также может находиться в очень сложных отношениях с самим текстом.
Например, заглавие «Гроза» в тексте пьесы А. Н. Островского.
Для исследования вопроса нам необходимо зайти на страницу основного корпуса (http://ruscorpora.ru/search-main.html) и выбрать гиперссылку
«задать подкорпус» (вверху справа). В открывшемся окне «Выбор подкорпуса», в графе «Название» мы вводим без кавычек название пьесы, а в графе
«Автор текста» фамилию и инициалы имени и отчества ее автора (без точек, разделяя пробелами). Затем нажимаем кнопку «Далее» внизу страницы.

После этого нужно проверить, правильно ли выбран текст, который войдет в подкорпус, и сохранить его (кнопка «Сохранить подкорпус и перейти к странице поиска»).Теперь мы создали подкорпус, включающий в себя только текст «Грозы». Хотя страница поиска будет идентична странице поиска в основном корпусе, дальнейший поиск будет осуществляться исключительно в тексте пьесы.
Итогом поиска являются 17 примеров (если ввести слово гроза – 15 примеров), один из которых мы исключаем, т. к. он взят из заглавия.
По именам и наименованиям
Корпус дает возможность выявить внутритекстовые словесные взаимосвязи. Но надо понимать, что они присущи далеко не всем именам, т. е.
этот метод не является ни исчерпывающим, ни универсальным, он актуален только в единичных случаях, но именно в тех, когда другие методы не срабатывают.
Например, попробуем рассмотреть отражение в романе фамилии Раскольникова.
Очевидно, что фамилия Раскольникова отсылает нас к семантике раскола. Но как это отражено в романе?
Техническая трудность подобного поиска состоит в том, что эта фамилия упоминается в романе очень часто, и в выдаче мы можем не заметить другие слова. В корпусе подобные ситуации предусмотрены, нам нужно ввести фамилию Раскольников в список исключений. Для решения проблемы нам необходимо в графе «Слово» лексико-грамматического поиска ввести сначала «раскол*», а затем, после пробела,«-раскольников*» (здесь мы тоже ставим звездочку, чтобы исключить упоминания как Родиона Раскольникова, так и Дуни Раскольниковой), причем, между дефисом и фамилией героя пробел ставить нельзя. Запрос будет выглядеть следующим образом: раскол* -раскольников*.

В итоге мы получаем единственный пример – это «расколотое блюдечко», где Раскольников берет «кусочек мыла», чтобы отмыть себе руки
после преступления. Расколотое блюдечко становится одной из тех «мелочей», к которой «прилепляется» герой, «забывая о главном», т. е. о своем ужасном плане.
Перед нами одна из важных деталей, с помощью которой автор ведет диалог с читателем, выражая свое отношение к мыслям и поступкам героя, и эта де-
таль напрямую коррелирует с фамилией героя.
По идее или концепту
Наименования идей и концептов, многократно повторяющиеся в разных контекстуальных ситуациях, могут раскрывать авторское отношение к самим идеям и концептам.
В основе теории Раскольникова лежит деление людей на «право имеющих» и «тварей дрожащих». Попробуем рассмотреть функционирование в романе первого из приведенных словосочетаний.
Форма лексико-грамматического поиска предполагает введение слов в начальной форме. Введем в качестве первого слова право, в качестве второго – иметь. Если мы зададим эти параметры, то обнаружим в результатах поиска 9 примеров. Но тогда сюда не попадут примеры с отрицательной частицей («права не имею») и с другими словами, вклинивающимися в это словосочетание («право такое иметь», «право, наконец, имеешь») и др.)
Также надо учитывать, что в тексте встречается обратный порядок слов (не только «право иметь», но и «иметь право»), поэтому мы должны составить запрос так, чтобы обратный порядок слов тоже учитывался. Для учета подобных факторов на странице поиска предусмотрены окна, позволяющие настроить расстояние между словами внутри словосочетания, причем, обратный порядок слов задается отрицательным
числом.

По деталям
Роль художественной детали в понимании художественного текста очень велика. Халат Обломова, сирень, которую он дарит Ольге Ильинской,
шляпа Раскольников, бинокль Червякова и т. д. Корпус позволяет преодолеть границы отдельного эпизода и рассмотреть функционирование детали
во всем тексте или в творчестве писателя.
Например, через серию упоминаний халата в романе «Обломов» можно проследить эволюцию главного героя. Для этого мы создадим подкорпус
с текстом романа и сформируем запрос для лексико-грамматического поиска – введем слово халат.
Как интерпретировать результаты
Когда мы работаем только с языковой спецификой (например, выясняя цвет сумерек в русской поэзии), то представленных фрагментов, как правило, будет достаточно – мы легко выделим и сможем систематизировать обнаруженные нами цветовые характеристики. Но для литературоведа чаще всего очень важен широкий контекст слова – его место в сюжете и в системе образов произведения.
К сожалению, фрагмента, приведенного в результатах поиска, иногда оказывается недостаточно, чтобы понять, из какой части текста он взят, кому принадлежит прямая речь, на какие слова отвечает герой и т. д. Поэтому для привлечения контекста целесообразно обращаться к полной версии произведения.
Корпус не дает готовых ответов, но он дает почву для размышлений. Он бесполезен, если не прочитан текст, но он может стать стимулом к его прочтению.
Как организовать работу с корпусом языка
- Фронтальная работа, когда все ученики выполняют одинаковые задания.
Такая работа может быть оправдана только на этапе ознакомления с корпусом, т. к. позволит учителю оперативно выявлять и устранять пробелы
и проблемы в понимании учениками законов функционирования корпуса.
Например, устройте состязание, кто из учеников (или какая группа, т. к. за компьютером, вероятнее всего, будут сидеть 2-3 человека) быстрее всех и
точнее всех выяснит, для каких героев романа «Преступление и наказание» характерна дрожь.
- Распределение работы по группам или по индивидуальным исполнителям с последующим обсуждением полученных результатов и обменом опытом.
Первый сценарий предполагает распределение единого задания, когда это задание разбивается на части, и группе поручается выполнить определенную часть.
При всей привлекательности такого сценария технически осуществить его очень трудно.
Второй сценарий предполагает, что у каждой группы или индивидуального исполнителя будет свое задание, разработанное учителем.
Например, выясняя употребление в романе сочетаний «право + иметь», «иметь + право» и слов с корнем «дрож*» можно прийти к сходным выводам о незаметном, но отчетливом выражении авторского отношения к героям, состоящего в опровержении через детали теории Раскольникова.
Однако,как и в первом сценарии, у нас возникает проблема неравномерности количества примеров в разных заданиях.
Третий сценарий, когда группы или индивидуальные исполнители сами формируют и выполняют свои задания, потому что в наибольшей степени возможностям корпуса соответствует проектно-исследовательская работа учащихся, которая легко может перерасти в полноценное научное исследование.
В третьем сценарии тоже встает вопрос о временной организации, но здесь уже будет больше вариантов, и они будут выбираться совместно учителем и учащимися.
Результатом такой работы может быть исследовательский тупик, если задание сформулировано неправильно или неудачно, в таком случае, учите-
лю придется выяснять и объяснять причины обнаружившегося тупика и совместно с учащимися искать выход из положения.
Другим неожиданным развитием событий может быть научное открытие. Поскольку корпус является новым исследовательским инструментом,
он дает возможность посмотреть на художественные тексты под таким углом зрения, под каким раньше на них никто не смотрел.
Статьи по теме
- Игра-мастерская «Магисториум-университет мудрости» на уроке литературы в школе
- Технологическая карта образовательного квеста на примере литературного моноквеста: «Гоголь путешествует во времени»
- Система заданий к урокам изучения поэмы М.Ю. Лермонтова «МЦЫРИ»
- 6 компетентностно-ориентированных заданий по литературе (на примере басен И.А. Крылова)
2019. № 1, 99-108
Светлана Олеговна Савчук, Институт русского языка им. В. В. Виноградова РАН (Москва, Россия), savsvetlana@mail.ru
Аннотация:
Национальный корпус русского языка — это не просто большое собрание самых разных текстов, но и разнообразная лингвистическая информация, сопровождающая тексты, и средства поиска информации. Однако многие неподготовленные пользователи не подозревают о богатых возможностях этого лингвистического ресурса и к тому же не любят читать инструкции, поэтому используют его только для простого поиска слов. Для таких пользователей корпуса мы предлагаем серию заметок, в которых разработчики НКРЯ на примерах конкретных поисковых задач будут знакомить читателей с корпусными инструментами и приемами их использования. В настоящей заметке рассказывается о средстве, позволяющем осуществлять поиск по части словоформы или лексемы, а также о способе установления фильтров на ненужные единицы, что позволяет получать более точные результаты.
