Голосование за лучший ответ
Артур Петрусь
Мудрец
(18889)
5 лет назад
термин это определение чего либо
Екатерина Кущева
Знаток
(333)
5 лет назад
Термин — это когда ты что-то объясняшь. Кстати, это тоже можно считать термином)))
ae5yrgae srethaerУченик (71)
5 лет назад
Спартак – это термин?
Екатерина Кущева
Знаток
(333)
Нет. Тогда так: Спартак — это фк. То есть должно стоять тире)))
⠀ ⠀ ⠀ ⠀ ⠀ ⠀ ⠀ ⠀
Гуру
(2541)
5 лет назад
Это любое слово в тексте, имеющее значение/определение. Напр. (Аксиома — исходное положение какой-либо теории).
Даниил Копосов
Мыслитель
(6482)
5 лет назад
Слово “термин” означает уникальную номинацию – то, у чего не может быть синонимов. например, слово “хомяк” – термин. Или слово “унитаз”. Или слово “скальпель”. Если не торопиться и внимателшшьно читать текст, найдёте. Удачи!
Как найти что-то в тексте
Время на прочтение
8 мин
Количество просмотров 5.5K
Найти объект или распознать понятие в тексте — с этого начинается решение большинства NLP задач. Если вы проектируете поисковую систему, создаете голосового помощника или классифицируете пользовательские запросы, прежде всего вы должны разобрать входной текст и попытаться найти в нем именованные сущности, которые могут быть универсальными, такими как даты, страны и города, или специфичными для конкретной модели. Обратите внимание, мы сейчас говорим лишь о тех видах задач, для которых заранее известно, что именно вы ищете или что может встретиться в тексте.
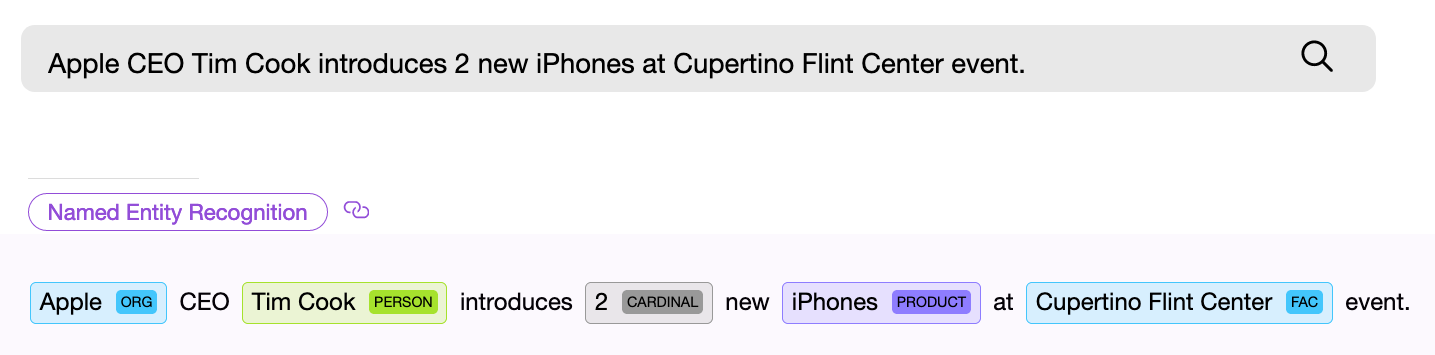
NER (named entity recognition) компонент, то есть программный компонент для поиска именованных сущностей, должен найти в тексте объект и по возможности получить из него какую-то информацию. Пример — “Дайте мне двадцать две маски”. Числовой NER компонент находит в приведенном тексте словосочетание “двадцать две” и извлекает из этих слов числовое нормализованное значение — “22”, теперь это значение можно использовать.
NER компоненты могут базироваться на нейронных сетях или работать на основе правил и каких-либо внутренних моделях. Универсальные NER компоненты часто используют второй способ.
Рассмотрим несколько готовых решений по поиску стандартных сущностей в тексте. В данной заметке мы остановимся на бесплатных или бесплатных с ограничениями библиотеках, а также расскажем о том, что сделано в проекте Apache NlpCraft в рамках данной проблематики. Представленный ниже список не является подробным и обстоятельным обзором, которых и так достаточное количество в сети, а скорее кратким описанием основных особенностей, плюсов и минусов использования этих библиотек.
Провайдеры NER компонентов
Apache OpenNlp
Apache OpenNlp предоставляет для английского языка достаточно стандартный набор NER компонентов, работающих с датами, временем, географией, организациями, числовыми процентами и персонами. Имеется небольшой набор и для других языков (испанский, голландский).
Поставка:
Java библиотека. Apache OpenNlp не поставляет модели вместе с основным проектом. Они доступны для скачивания отдельно.
Плюсы:
Apache лицензия. Модели протестированы на множестве внедрений.
Минусы:
Судя по всему, модели недаром вынесены из основного проекта. Складывается впечатление, что работа над ними или остановлена или идет в удручающе неторопливом темпе, так как новых моделей или изменений в существующих не видно уже довольно давно. Так как пользователи Apache OpenNlp могут создавать и тренировать свои собственные модели, возможно эта задача фактически полностью переложена на них.
Stanford Nlp
Stanford NLP — живой, постоянно развивающийся продукт отличного качества и широких возможностей. Для английского языка добавлена поддержка распознавания следующих сущностей: person, location, organization, misc, money, number, ordinal, percent, date, time, duration, set. Кроме того встроенный Regex NER компонент позволяет находить с высокой степенью точности такие сущности как: email, url, city, state_or_province, country, nationality, religion, (job) title, ideology, criminal_charge, cause_of_death, handle. Подробнее по ссылке. Заявлена поддержка ограниченного набора NER для немецкого, испанского и китайского языков. Качество распознавания можно попробовать с помощью онлайн демо.
Поставка:
Java библиотека. Модели можно загрузить из мавен вместе с проектом.
Я нигде не нашел перечня и детального описания NER компонентов для языков отличных от английского. По ссылкам 1, 2 — приведены примеры процесса тренировки собственных NER компонентов для разных языков. Проще говоря, возможность использовать другие языки заявлена, но придется повозиться.
Плюсы:
Ощущение от работы с проектом в целом и с готовыми моделями самое позитивное, проект живет и развивается, качество распознавания хорошее (”хорошее” — понятие условное, существуют метрики, характеризующие качество распознавания NER компонентов, но данный вопрос выходит за рамки статьи).
Минусы:
Помимо некоторого хаоса с документаций, они небольшие. Кому это важно, обратите внимание на лицензию. GNU General Public License отличается от Apache, так, например, вы не можете добавить продукт с данной лицензией в продукты, лицензируемые под Apache и т. д.
Google Language API
Google language API для английского языка поддерживает следующий список сущностей: person, location, organization, event, work_of_art, consumer_good, other, phone_number, address, date, number, price.
Платформа:
REST API, SaaS. Доступны готовые клиентские библиотеки над REST (Java, C#, Python, Go и т. д.).
Плюсы:
Большой набор NER компонентов, развитие и качество обеспечивается всем известным интернет гигантом.
Минусы:
Начиная с определенных объемов, использование платное.
Spacy
Данная библиотека предоставляет один из наиболее широких наборов поддерживаемых для распознавания сущностей, по ссылке список поддерживаемых.
Платформа:
Python.
К сожалению отсутствие личного опыта промышленного использования не позволяет мне добавить реальное описание плюсов и минусов данной библиотеки. К тому же подробный обзор питоновских NLP решений уже опубликован на habr.
Все вышеперечисленные библиотеки позволяют обучать собственные модели. Также все из них (кроме Apache OpenNlp) позволяют извлекать нормализованные значения из найденных сущностей, то есть, например, получить число “173“ из найденной в запросе числовой сущности “сто семьдесят три“.
Как мы видим вариантов решения задачи нахождения именованных сущностей представлено множество, направление их развития очевидно — расширение списка поддерживаемых языков и набора распознаваемых сущностей, улучшение качества распознавания.
Ниже описано, что привнес проект Apache NlpCraft в данную, уже широко проработанную область.
Дополнительные возможности предоставляемые NlpCraft
- Собственные NER компоненты для новых сущностей, улучшенные варианты решения для некоторых уже существующих.
- Интеграция NER компонентов всех вышеперечисленных библиотек в рамках использования продукта.
- Поддержка “составных сущностей“, что дает пользователям простую возможность создания новых собственных компонентов на основе уже имеющихся.
Теперь обо всем этом чуть подробнее.
Собственные NER компоненты
Собственные NER компоненты Apache NlpCraft — это компоненты распознавания дат, чисел, географии, координат, сортировки и сопоставления разных сущностей. Часть из них уникальна, часть — лишь улучшенная реализация существующих решений (повышена точность распознавания, добавлены дополнительные поля значений и т. д.).
Интеграция существующих решений
Все перечисленные выше решения интегрированы для использования в Apache NlpCraft.
При работе с проектом пользователю достаточно подключить нужный модуль и указать в конфигурации какие именно NER компоненты должны быть задействованы при поиске сущностей конкретной модели.
Ниже приведен пример конфигурации, для которой при поиске в тексте используется четыре различных NER компонента от двух провайдеров:
"enabledBuiltInTokens": [
"nlpcraft:num",
"nlpcraft:coordinate",
"google:organization",
"google:phone_number"
]
Подробнее об использовании Apache NlpCraft написано здесь. Для использования Google Language API необходим действующий Google developer account.
Поддержка составных сущностей
Поддержка составных сущностей — самая интересная из вышеперечисленных возможностей, остановимся на ней немного подробнее.
Составная сущность — это сущность определенная на основе другой. Рассмотрим пример. Пусть вы разрабатываете NLP систему управления, основанную на интентах (см. Alexa, Google Dialogflow, Алиса, Apache NlpСraft и т. д.), и пусть ваша модель работает с географией, но только для США. Вы можете взять любой компонент для поиска географии, например ”nlpcraft:city”, и использовать его напрямую.
Далее, при срабатывании интента, вы в соответствующей ему функции (callback), должны проверить значение поля ”country”, и если оно не удовлетворяет требуемым условиям, завершить работу функции, предотвращая ложное срабатывание. Далее вы должны вернуться к матчингу и попытаться выбрать другую, более подходящую функцию.
Что не так в данном подходе:
- Вы значительно усложняете работу с вызываемыми функциями, передавая управление из них в основной рабочий поток и обратно. Кроме того стоит учесть, что подобным функционалом передачи управления обладают далеко не все диалоговые системы.
- Вы размазываете логику матчинга между интентом и кодом исполняемого метода.
Хорошо… Вы можете с нуля создать свой собственный NER компонент по поиску американских городов, но эта задача решается не за пять минут.
Попробуем иначе. Вы можете усложнить интент (в тех системах где это возможно) и искать города, дополнительно отфильтрованные по стране. Но, повторюсь, возможность сложной фильтрации по полям элементов предоставляют далеко не все системы, кроме того вы усложняете интенты, которые должны быть максимально понятными и простыми, особенно если их много в проекте.
Apache NlpCraft предлагает механизм определения собственных NER компонентов на основе уже существующих. Ниже приведен пример конфигурации (полный синтаксис DSL доступен по ссылке, пример создания элементов — тут):
"elements": [
{
"id": "custom:city:usa",
"description": "Wrapper for USA cities",
"synonyms": [
"^^id == 'nlpcraft:city' && lowercase(~city:country) == 'usa')^^"
]
}
]
В данном примере мы описываем новую именованную сущность “американский город“ — “custom:city:usa”, основанную на уже существующей “nlpcraft:city”, отфильтрованной по определенному критерию.
Теперь вы можете создавать интенты, опирающиеся на созданный новый элемент, а встреченные в тексте города за пределами США не вызовут нежелательного срабатывания ваших интентов.
Еще пример:
"macros": [
{
"name": "<AIRPORT>",
"macro": "{airport|aerodrome|airdrome|air station}"
}
],
"elements": [
{
"id": "custom:airport:usa",
"description": "Wrapper for USA airports",
"synonyms": [
"<AIRPORT> {of|for|*} ^^id == 'nlpcraft:city' &&
lowercase(~city:country) == 'usa')^^"
]
}
]
В данном примере мы определили именованную сущность “городской аэропорт в США“ — “custom:airport:usa”. При определении этого элемента мы не только отфильтровали города по признаку принадлежности к государству, но и задали дополнительное правило, по которому названию города должен предшествовать какой-либо синоним, определяющий понятие “аэропорт”. (Подробнее о создании синонимов элементов через макросы — тут).
Составные элементы могут быть определены с любой степенью вложенности, то есть при необходимости вы можете спроектировать новые элементы на базе только что созданного “custom:airport:usa”. Также обратите внимание на то, что все нормализованные значения родительских сущностей, в данном случае базового элемента “nlpcraft:city”, доступны также в элементе “custom:airport:usa”, и могут быть использованы в теле функции сработавшего интента.
Разумеется, “составные элементы“ можно определять не только для всех поддерживаемых стандартных компонентов от OpenNlp, Stanford, Google, Spacy и NlpCraft, но и для пользовательских NER компонентов, расширяя их возможности и позволяя переиспользовать уже имеющиеся программные наработки.
Обратите внимание, фактически вы не плодите новые компоненты для каждой новой задачи, а просто конфигурируете их или “подмешиваете” их функционал в собственные элементы.
Таким образом, используя “составные сущности“ разработчик может:
- Значительно упростить логику построения интентов путем ее частичного переноса в переиспользуемые составные элементы.
- С помощью изменений конфигурации получить NER компоненты с новым поведением без обучения моделей или кодирования.
- Переиспользовать уже готовые решения с ожидаемым качеством, опираясь на существующие тесты или метрики.
Заключение
Надеюсь, что краткий обзор плюсов и минусов существующих NER компонентов будет полезен читателям, а понимание того, как с помощью Apache NlpCraft можно существенно расширить их возможности и адаптировать имеющиеся решения для новых задач, ускорит процесс разработки ваших проектов.
1. Большую роль в исследованиях строения и свойств электронных оболочек атомов сыграли лучи, открытые в 1895 г. В. Рентгеном и названные в его честь рентгеновскими лучами. Рентгеновские лучи возникают при торможении веществом быстрых электронов. Для получения рентгеновских лучей служат специальные электровакуумные приборы — рентгеновские трубки, состоящие из вакуумированного стеклянного или металлического корпуса, в котором на некотором расстоянии друг от друга находятся катод и анод, включенные в цепь высокого напряжения. В рентгеновских трубках катод служит источником электронов, а анод (антикатод) — источником рентгеновских лучей. Между катодом и анодом создается сильное электрическое поле, разгоняющее электроны до энергий 104—105 эВ. Для получения электронов столь высоких энергий в рентгеновских трубках создается вакуум ~10-6 мм рт. ст. В современных ускорительных установках (бетатронах и синхротронах) (см. т. II, §18.5 и 21.2) рентгеновские лучи возникают при торможении электронов с энергиями порядка 103 МэВ и более.
2. Рентгеновские лучи возникают в результате преобразования кинетической энергии быстрых электронов в энергию электромагнитного излучения и представляют собой электромагнитные волны с длиной волны порядка от 0,01 А до 800 А. (Напомним, что длина волн наиболее короткого из воспринимаемого глазом фиолетового излучения равна 4000 А.) Волновая электромагнитная природа рентгеновских лучей полностью доказывается опытами по дифракции рентгеновских лучей (см. §6.4). Кроме того, с рентгеновскими лучами были осуществлены интерференционные и дифракционные опыты, аналогичные опытам с зеркалами Френеля и дифракции на щели, хотя малая длина волны рентгеновских лучей сильно затрудняла осуществление этих экспериментов. Тем не менее, эти опыты были осуществлены и волновая электромагнитная природа рентгеновских лучей была твердо установлена.
3. Для обнаружения рентгеновского излучения используются различные их действия. Рентгеновское излучение в сильной степени действует на фотопластинку, обладает высокой способностью ионизировать газы, вызывает флуоресцентное свечение в так называемых люминофорах. (Явление флуоресценции рассмотрено в §15.8.) Для измерения интенсивности рентгеновских лучей используются главным образом их фотохимическое и ионизирующее действия. В специальных ионизационных камерах интенсивность рентгеновского излучения измеряется по силе тока насыщения, возникшего в результате ионизации газа, заключенного в камере. Сила этого тока пропорциональна интенсивности рентгеновского излучения.
Ионизационные камеры и другие методы обнаружения ионизирующих излучений рассмотрены в ядерной физике (см. § 17.4).
4. Экспериментальные исследования показали, что существуют два типа рентгеновского излучения. При энергиях электронов, не превышающих некоторого критического, зависящего от материала антикатода, возникает рентгеновское излучение со сплошным спектром, подобным спектру белого света. Такое рентгеновское излучение называется белым. Белое рентгеновское излучение, как показали подробные исследования, вызывается торможением быстрых электронов при их движении в веществе. Поэтому белое излучение называют также тормозным.
Таким образом, этот тип рентгеновского излучения испускается самими электронами, движущимися в веществе. Согласно классической теории излучения, при торможении движущегося заряда должно действительно возникать излучение с непрерывным спектром. Однако рентгеновский сплошной спектр отличается важнейшей особенностью — он ограничен со стороны малых длин волн некоторой границей λмин, называемой границей сплошного спектра (Детлаф А. А., Яворский Б. М. Курс физики (в трех томах): учебное пособие. М.: Высшая школа, 1979. – Т. 3: Волновые процессы. Оптика. Атомная и ядерная физика. – С. 317-318).

ЛЕКСИЧЕСКИЕ СРЕДСТВА.
ПОДСКАЗКА.
Задание № 26. Как легко найти лексические средства в предложении?
Лексика – это словарный запас языка.
Лексические средства выразительности – это такие средства, которые связаны с лексикой. Давайте вспомним их.
Лексические средства выразительности.
Антонимы — это слова, противоположные по своему лексическому значению.
Примеры:
Друг — враг, горячий — холодный, убеждать — разубеждать.
Контекстные антонимы – это слова, которые являются антонимами лишь в данном контексте.
Примеры:
один день – вся жизнь, волки — овцы, поэт – стихотворец.
Архаизмы — это устаревшие слова, которые в современном языке заменены синонимами.
Примеры:
ланиты (щёки), чело (лоб), зело (очень).
Диалектизмы — слова, употребляемые лишь жителями определённой местности.
Примеры:
гуторить (говорить), балка (овраг), бучило (глубокая яма с весенней водой).
Жаргонизмы – слова, отличные от общего языка, употребляемые в речи определённой социальной группы.
Примеры:
Предки – родители, хвост (несданный экзамен, слежка), общага – общежитие.
Заимствованные слова – слова, пришедшие в русский язык из других языков.
Примеры:
вуаль, такси, ландшафт, либретто, трюмо, афиша.
Историзмы — это устаревшие слова, обозначающие предметы и понятия, не существующие в наше время, их используют чаще всего для характеристики той или иной эпохи.
Примеры:
Боярин, царь, стрельцы, лакей, треуголка, зипун, грош, волость и др.
Книжная лексика – слова, которые употребляются преимущественно в письменной речи.
Примеры:
воздвигнуть, низвергнуть, генезис, адресат, аргументировать, аналогичный, дифференцировать, гуманизм.
Просторечные слова – слова, употребляемые в разговорной речи и имеющие оттенок грубости, также слова, не соответствующие литературным нормам языка.
Примеры:
шарахнуть – ударить, башка – голова , притащиться – прийти , траНвай – траМвай, квАртал – квартАл, вовнутрь, задаром, покамест, умаяться.
Профессионализмы – слова, употребляющиеся только в определенной профессиональной среде.
Примеры:
синтаксис, морфология(лингвистика), штурвал, каюта (морская терминология).
Разговорные слова – слова, использующиеся в устной речи, часто в бытовом общении.
Примеры:
хвастунишка, читалка, задира, работяга, многовато.
Синонимы — это слова, различные по звучанию и написанию, но имеющие одинаковое или очень близкое лексическое значение.
Примеры:
Кавалерия — конница; большой — огромный, громадный; бояться — робеть, страшиться; жара — зной.
Контекстные синонимы – это слова, которые являются синонимами лишь в данном контексте.
Пример:
по характеру это была добрая, мягкая женщина.
Синонимы данных слов вне текста:
Добрый — сердечный, душевный, жалостливый, человечный и др.
Мягкий — пухлый, пластичный, эластический, пушистый.
Термины – слова, употребляемые в различных отраслях знаний для точного определения того или иного понятия.
Примеры:
термины в литературоведении: рассказ, роман, литературный герой, классицизм и др.
Фразеологизмы – устойчивые сочетания слов, которые по значению равны одному слову.
Примеры:
работать засучив рукава (работать усердно), броситься очертя голову (не раздумывая), как снег на голову (неожиданно), работать и день и ночь (очень много).
Эмоционально-экспрессивная лексика – слова, которые носят оценочный характер.
Примеры:
детина, бабуля, солнышко, чудесный, подхалим, малюсенький.
РЕКОМЕНДАЦИИ.
- Если по заданию нужно в тексте найти лексические средства, то сначала прочитайте СПИСОК ТЕРМИНОВ, найдите в нём лексические средства (их будет не больше 2-3).
- Таким образом вы сократите количество терминов, которые нужно искать.
- Внимательно прочитайте «подсказки» – это слова, данные в скобках. Часто по ним уже можно определить, что это за лексическое средство.
- В любом случае, обязательно прочитайте предложения, убедитесь, что в них данные слова являются именно теми средствами, о которых вы думаете.
Все постепенно превращаются в операторов машинного производства. И переводческая отрасль — не исключение. Лингвистам требуется непрерывно держать руку на пульсе технологических достижений, чтобы оставаться успешными. Новые программы, новые сервисы, новые тенденции…
В современных быстроменяющихся условиях автоматизация различных процессов играет весьма большую, порой решающую роль. Чем больше автоматических операций, тем больше преимуществ в конкурентной борьбе. Все постепенно превращаются в операторов машинного производства. И переводческая отрасль — не исключение. Лингвистам требуется непрерывно держать руку на пульсе технологических достижений, чтобы оставаться успешными. Новые программы, новые сервисы, новые тенденции… Революций пока не происходит, но эволюция стремительна. И под нее нужно подстраиваться. Данная статья посвящена всего лишь одному аспекту переводческой деятельности — терминологии. Правильность и согласованность терминологии являются одними из ключевых показателей качества любого перевода. Все начинается с отдельных слов и словосочетаний, и сколь бы грамотным ни был текст и каким бы красивым ни был стиль, неверно или неточно переведенные термины способны «убить» любой перевод.
Когда речь идет о небольшом тексте, проблем с терминологией, как правило, не возникает. Однако по мере роста его объема даже опытные переводчики нередко «грешат» несогласованностью терминологии. При этом перевод отдельных терминов порой может занимать больше времени, чем перевод объемного текста, поскольку требуется «погружаться» в тематику, изучать контекст, вникать в его особенности и т. п. А если над проектом работает целая группа, то обеспечить согласованный перевод терминов без глоссариев практически невозможно. Говоря языком законов Мерфи, если термин может быть переведен по-разному, он точно будет переведен по-разному. Таким образом, глоссарии нужны, глоссарии важны (разумеется, если требуется качество). И весь вопрос в том, как их составлять.
Самый простой способ — искать и извлекать термины вручную. Для опытного специалиста это не проблема. Но данная операция весьма трудоемка, а лишние затраты времени в переводческом деле не приветствуются. И все-таки… Многие по-прежнему создают глоссарии вручную, хотя средства для автоматического извлечения терминов присутствуют на рынке уже достаточно давно. Так в чем же проблема? В нежелании разбираться в новых инструментах, привычке или неэффективности этих инструментов?
Для данного исследования были отобраны несколько средств из разных категорий. Во-первых, это memoQ и SDL MultiTerm Extract, которые представляют самые популярные в отрасли CAT-системы, а значит уже есть у многих переводчиков и переводческих компаний. Во-вторых, это отдельная программа SynchroTerm 2014 от компании Terminotix, которая разрабатывалась специально для извлечения терминологии, не входит в состав каких-либо программных пакетов и имеет ряд весьма положительных отзывов на просторах Интернета. SynchroTerm 2014 является платной программой, поэтому интересно узнать, насколько целесообразно ее приобретение, учитывая наличие так или иначе более доступных решений. В-третьих, были проанализированы два представителя облачных решений для извлечения терминологии, а именно сервисы Prospector («Старатель») от компании Logrus Global и Tilde Terminology от компании Tilde. Разумеется, это далеко не исчерпывающий перечень возможных решений. И в каждой из категорий можно найти еще массу вариантов, причем, возможно, какой-то «алмаз» окажется упущенным из виду. Однако все объять весьма сложно, поэтому данный перечень представляется достаточно показательным срезом для рассматриваемой области.
Исследование проводилось на примере файла технического характера в формате .doc. Файл был достаточно объемным (более 250 страниц), имел сложное форматирование и содержал чрезвычайно много разнообразных терминов. В конце файла присутствовал указатель с наиболее важными терминами, который мог послужить базой для извлечения. Кроме того, для этого файла уже существовал глоссарий, содержащий более 500 терминов, который составлялся вручную опытными переводчиками и использовался как основа для анализа результатов. При этом, чтобы не усложнять исследование, извлечение производилось только на одном языке (без использования переведенного файла и базы перевода), несмотря на то что некоторые инструменты поддерживают двуязычное извлечение. Поскольку английский язык наиболее популярен в переводческой отрасли, именно он и был выбран для анализа.
1. Средства для извлечения терминологии, встроенные в CAT-системы. SDL MultiTerm Extract и memoQ
SDL Multiterm Extract и memoQ входят в состав, пожалуй, самых популярных на рынке CAT-систем. И если MemoQ то и дело обгоняют конкуренты (например, по данным ресурса Translation Rating в России системы Memsource и Smartcat более популярны среди переводческих компаний), то продукты SDL являются безоговорочными лидерами по популярности практически во всех исследованиях. А это означает, что у многих компаний и переводчиков уже есть под рукой средства, способные автоматически извлекать терминологию. Насколько они полезны?
memoQ
В системе memoQ (данный анализ проводился в версии memoQ 8.2) извлечение терминов производится внутри проектов. Эта функция встроена в систему и не предоставляется в виде отдельного решения. После создания проекта и загрузки туда необходимых файлов на панели инструментов становится доступной команда Extract Terms. Данная команда позволяет запустить процесс извлечения терминов из документов проекта. При этом поддерживается извлечение как из файлов, так из баз перевода. Перечень настроек типичен для подобных инструментов (см. ниже). Можно задать максимальное количество слов, минимальное число знаков в слове для однословных терминов, минимальную частоту встречаемости терминов и т. д. Также можно добавить список игнорируемых слов, в том числе выбрать список по умолчанию. Никаких настроек для качества извлечения не предусмотрено.

Результат извлечения получился неплохим и в то же время не впечатляющим (см. примеры ниже). Для контрольного файла программа предложила чуть более 4 тыс. потенциальных терминов, среди которых оказалось немало «мусора». Причем игра с настройками никаких качественных улучшений внести не позволила. Отфильтровать подобный список и выделить приемлемые термины среди множества вариантов — задача непростая. Очевидно, что программа не использует лингвистический анализ, а извлекает термины на базе статистического метода. Соответственно, наличие указателя на ситуацию никак не влияло. Если тот или иной термин встречался достаточно часто, то есть превышался заданный нижний порог частоты встречаемости, программа его извлекала. В противном случае термин оставался «за кадром». Также необходимо отметить, что в список потенциальных терминов, извлеченных memoQ, попали далеко не все термины, выявленные вручную. Учитывая вышесказанное, этого и следовало ожидать.

Таким образом, функция извлечения терминологии в memoQ хоть и может быть полезной, но носит исключительно вспомогательный характер и не позволяет создать полноценный глоссарий. Скорее, она подходит, чтобы быстро отобрать некоторое множество терминов, бегло пролистав результаты и не сильно углубляясь в содержимое переводимых файлов, и составить на их основе некоторый базовый глоссарий. Вполне возможно, что кто-то вообще сочтет эту функцию декоративной и предпочтет работать по старинке, то есть вручную.
SDL MultiTerm Extract
В SDL избрали другой путь и создали целую отдельную программу SDL MultiTerm Extract. Причем эта программа регулярно меняет цифры в названии: 2014, 2015, 2017… Такой подход внушает уважение и создает впечатление, что продукт совершенствуется. Что же он может на данный момент, то есть в версии 2017?
На первом этапе SDL MultiTerm Extract предлагает выбрать способ извлечения терминов (см. окно ниже). По существу, таких способа два — одноязычное излечение и двуязычное извлечение, причем для второго способа доступны несколько вариантов. Поскольку двуязычное извлечение не является предметом настоящего обзора, двуязычный режим рассматриваться не будет.

Для одноязычного извлечения предлагается следующий набор настроек.

Можно отметить, что данный набор беднее, чем в memoQ, и, наверное, это плюс, так как в случае memoQ лишние настройки практически не способствуют более эффективному извлечению. Итак, SDL MultiTerm Extract позволяет только задать минимальное и максимальное число слов в терминах, ограничить количество извлекаемых терминов и установить уровень качества, то есть некое соотношение «сигнал/шум», которое призвано уменьшить объем «мусора» в результатах. По умолчанию предлагается среднее соотношение (некий оптимум с точки зрения разработчиков), но его можно менять в довольно широких пределах. Также программа дает возможность загрузить список игнорируемых слов, причем для многих языков, включая русский, такие списки уже есть.
Что же получается на выходе?
Например, при настройках по умолчанию для контрольного файла SDL MultiTerm Extract выдает 2086 потенциальных терминов (см. фрагмент с результатами ниже).

Объем «мусора» примерно такой же, как в memoQ, а термины также содержат относительно много обрывков фраз типа «following references are used» независимо от заданного максимального числа слов в терминах.
При изменении уровня качества число извлекаемых терминов в данном примере варьируется от 447 до 7186. Однако сказать, что результаты как-то качественно улучшаются, нельзя. Возникает ощущение, что в зависимости от настройки просто отбрасывается или добавляется часть результатов, причем как «хороших», так и «плохих», так как даже при максимально уровне относительный объем «мусора» остается значительным. Другими словами, уровень качества влияет больше на количество, чем на качество. Поэтому что означают границы уровня «мусора» «Silence» и «Noise» с точки зрения разработчиков, понять так и не удалось.
Таким образом, SDL MultiTerm Extract справляется с своей задачей примерно так же, как memoQ. Указатель отрабатывается не полностью, многие термины из составленного вручную глоссария отсутствуют. А значит все выводы, сделанные для memoQ, применимы и к этой программе.
2. Программа SynchroTerm 2014
SynchroTerm 2014 — единственная программа в данном обзоре, которая создавалась специально для извлечения терминологии, причем программа платная. Логично предположить, что качество извлечения в ней должно быть выше, чем в более многофункциональных средствах, иначе смысла приобретать отдельный продукт нет. В чем же ее преимущества?
Набор настроек в SynchroTerm 2014 (см. ниже) богаче, чем в memoQ и MultiTerm Extract, но основные настройки практически такие же, как в memoQ. Отдельно можно выделить лишь режим «Delta Extraction», возможность интеграции с CAT-системой LogiTerm и возможность извлечения только существительных. Причем режим «Delta Extraction», который позволяет извлекать только те термины, которых еще нет в базе терминов, для данного исследования бесполезен, так как не вносит никаких качественных улучшений в процесс извлечения. А CAT-система LogiTerm слишком редко используется в отрасли, чтобы имело смысл анализировать еще и ее. Едва ли кто-то станет приобретать дополнительную CAT-систему, если ему требуется просто создавать глоссарии. Таким образом, в контексте данного исследования в плюсы можно занести лишь возможность извлечения только существительных, которая может оказаться весьма полезной, учитывая, что большинство терминов являются именно существительными, а значит такая функций способна сократить объем «мусора» в результатах.

Примеры результатов, выданных программой, представлены ниже.

Программа SynchroTerm 2014 извлекла из выбранного для анализа файла примерно 4 тыс. потенциальных терминов, то есть продемонстрировала показатель на уровне memoQ. При этом в извлеченных терминах также присутствовали «мусор» и обрывки фраз. Однако следует отметить, что качество терминов оказалось значительно выше, чем в memoQ и SDL MultiTerm Extract, поскольку именно терминов SynchroTerm 2014 предложила намного больше. Причем сделала это весьма корректно. Например, в термин «still pipe array antenna» встречался в одном из документов 23 раза. И memoQ, и SDL MultiTerm Extract (при уровнях «мусора» ближе к максимальным в понимании разработчиков), разумеется, не смогли не добавить столь частотный термин в результаты. А в SynchroTerm 2014 «still pipe» и «array antenna» попали только по отдельности. И это логично, так как значение термина «still pipe array antenna» просто складывается из значений терминов «still pipe» и «array antenna» и включать его в глоссарий дополнительно смысла нет. Это явный пример лингвистической обработки текста. Правда, что любопытно, термин «array antenna of the still pipe» на удивление все-таки попал в результаты.
Практически все термины, включенные в глоссарий, который был составлен вручную, попали в список результатов. То есть в отличие от рассмотренных ранее средств задача здесь сводится к тому, чтобы профильтровать результаты. Беспокоиться о том, что что-то важное осталось за пределами внимания, практически не нужно. К тому же интерфейс программы субъективно более удобен для работы с терминологией. В нем проще анализировать контекст, отбирать надлежащие термины и добавлять их в глоссарий. Есть даже удобная функция смены регистра знаков, которая дает возможность нажатием одной кнопки воспроизвести регистр из исходного текста, если он был изменен в процессе извлечения.
Итак, SynchroTerm 2014 эффективнее и memoQ, и SDL MultiTerm Extract. Общая доля «мусора» в этой программе меньше, а количество извлекаемых терминов больше. Соответственно, на подготовку глоссариев требуется меньше времени. Кроме того, необходимо отметить, что SynchroTerm 2014 поддерживает как одноязычное, так и двуязычное извлечение. Причем двуязычное извлечение также осуществляется намного эффективнее, чем, например, в SDL MultiTerm Extract (хоть это и не является предметом настоящего исследования, данный режим тоже рассматривался). Стоит ли приобретать программу, сказать сложно. Да, она лучше справляется с задачей извлечения, чем штатные средства популярных CAT-программ. Но если учесть ее цену, а это 550 канадских долларов, то выгода представляется не такой уж однозначной. Наверное, если задачу составления глоссариев приходится решать часто, то приобретение такой программы целесообразно. Если такие задачи возникают разово, то можно обойтись и без нее.
3. Облачные сервисы
Облачный сектор, пожалуй, является одним из самых бурно развивающихся. Многие программы так или иначе переносятся в «облака». Создаются все новые и новые самостоятельные облачные сервисы. Их можно любить или не любить, но повлиять на их рост невозможно. Не могли они не затронуть и «извлечение терминологии». В Интернете можно найти немало различных сайтов со встроенными инструментами для извлечения терминологии, как платных, так и бесплатных. Наша задача не состояла в том, чтобы охватить все это разнообразие. Поэтому весьма вероятно, что где-то существует скромное, но почти идеальное решение. Например, когда-то таким же образом, то есть совершенно случайно, при поиске средств для распознавания речи удалось найти сервис Go Transcribe, который наголову превосходил всех конкурентов. Сейчас мы решили остановиться на двух представителях облачных решений — на сервисе Prospector («Старатель»), просто потому что он позиционируется как одно из лучших решений на рынке, и сервисе Tilde Terminology, поскольку он имеет несколько неплохих отзывов, но все же скорее был выбран по случайному принципу.
Tilde Terminology
Сервис Tilde Terminology является узкоспециализированным и ориентирован именно на извлечение терминологии. От таких монофункциональных решений обычно ожидаешь чего-то особенного. И учитывая результаты, которые продемонстрировала программа SynchroTerm 2014, что-нибудь неординарное могло скрываться и здесь.
Сервис имеет несколько тарифных планов. Тарифный план «Free» является бесплатным и вполне подходит для целей исследования. Он охватывает 25 языков и включает в себя почти все, что есть в платных тарифах. Исключение составляют лишь ограниченная поддержка и возможность работы только с одним проектом (впрочем, можно в любое время удалить текущий проект и создать абсолютно другой). В платном тарифе «Premium» (стоимостью от 8 до 9,95 евро в месяц в зависимости от срока подписки) уже можно работать одновременно с 20 проектами и возможна поддержка в режиме онлайн. Доступны также индивидуальные тарифные планы, стоимость которых согласуется отдельно.
В процессе создания проекта сервис предлагает выбрать тематику (см. ниже). Это интересная особенность, которую ранее встречать не удавалось. Извлечение терминов с учетом тематики вполне может быть более эффективным. Впрочем, когда документ находится на стыке тематик или относится одновременно к нескольким тематикам, такой тематический подход уже создает сложности. Кроме того, Tilde Terminology предлагает режим «Enable semantic data», что подразумевает работу со смыслом, а не только со статистическими данными. В общем, только на этапе предварительной настройки можно предположить, что качество извлечения не должно быть посредственным.

В ходе загрузки документа выяснилась одна неприятная особенность — размер одного документа не может превышать 1 МБ. В принципе, это ограничение не так сложно обойти, поскольку для извлечения терминов «тяжеловесные» объекты не нужны, однако для сокращения размера обрабатываемых файлов требуются дополнительные действия. Кстати, в случае сохранения, например, документа .doc в формате .txt для уменьшения его размера необходимо уделить внимание кодировке. В частности, для файла .txt в кодировке ANSI выданный список терминов оказался пустым.
Предварительная настройка (см. ниже), по существу, сводится только к выбору уровня качества. Следует отметить, что сервис также поддерживает двуязычное извлечение и в таком режиме предлагает на выбор еще набор источников для поиска перевода. Но так как данный обзор посвящен одноязычному извлечению, сервис анализировался исключительно в режиме «Source».

Tilde Terminology оказался самым медленным инструментом. В нашем случае извлечение заняло более 20 минут (если отключить вспомогательную функцию визуализации, то около 5 минут). В результате для контрольного файла было извлечено примерно 3 тыс. терминов. В основном извлекаются одно- и трехсловные термины. Никаких длинных обрывков фраз в результатах обнаружено не было. Для приведенного выше примера «still pipe array antenna» в список результатов, как и в SynchroTerm 2014, попали только «still pipe» и «array antenna». Откровенного «мусора» программа не выдает совсем. Встречаются лишь малоперспективные словосочетания типа «support need», «cover in order» или «actual Dielectric». Неприятным моментом стало то, что сервис оказался чувствительным к регистру, то есть в результаты, например, попали три варианта одного и того же термина «Verification pin», «Verification Pin» и «verification pin». Кроме того, некоторые термины все-таки не попадают в список. Например, термин «Hold Off Distance» не попал в результаты извлечения ни при одной из трех настроек качества. Вообще сложилось впечатление, что сервис идеально настроен на извлечение двухсловных терминов. Не удалось найти ни одного термина из двух слов, который не попал бы в список результатов. А вот с терминами, содержащими три и более слов могут возникнуть проблемы. То есть существует шанс что-нибудь упустить. SynchroTerm 2014 в этом смысле предпочтительнее, так как этой программе удается извлечь больше терминов. Впрочем, справедливости ради, и «мусора» она извлекает тоже больше.
Итак, сервис Tilde Terminology безусловно более пригоден для извлечения терминологии, чем встроенные средства CAT-систем. Но результаты его работы неоднозначны. Если сравнивать с SynchroTerm 2014, то «мусора» на выходе меньше, но и собственно терминов тоже меньше. По субъективным ощущениям работать с программой SynchroTerm 2014 удобнее, она извлекает больше терминов и делает это в разы быстрее, для нее не требуется дополнительно обрабатывать большие файлы. Плюсами Tilde Terminology являются очень качественное извлечение двухсловных терминов, поддержка автоматического перевода терминологии на базе различных источников, а также возможность бесплатного использования (впрочем, и платная версия стоит намного меньше, чем SynchroTerm). Последнее может вполне перевесить все недостатки.
Prospector («Старатель»)
Сервис Prospector от компании Logrus Global — единственный инструмент в данном обзоре, который является сугубо одноязычным. Он позволяет работать исключительно с файлами на английском языке. Другими словами, это самое узкоспециализированное средство. По утверждению разработчиков процесс извлечения построен на базе самого крупного в мире корпуса английского языка, поддерживаемого профессором Brigham Young University, извлекает много терминов, мало «мусора» и выдает на выходе глоссарий в файле Excel. А что еще надо для счастья в нашем контексте?
Использовать сервис можно бесплатно, но чтобы получить к нему доступ, необходимо подать заявку. Причем заявка обрабатывается не автоматически. Зарегистрироваться самостоятельно, как в Tilde Terminology, не получится.
Процесс извлечения предельно прост. Сначала выбирается подлежащий обработке файл (поддерживаются форматы .txt, .html, .htm, .doc и .docx), а затем нажимается кнопка «ПОЛУЧИТЬ ТЕРМИНОЛОГИЮ». Никаких настроек не предлагается. Это весьма удобно.
Стоит отметить, что первоначально сервис выдал сообщение о внутренней ошибке при попытке извлечь терминологию из файла .doc. Никакие манипуляции с этим файлом устранить ошибку не помогли. В результате пришлось пересохранить его в формате .docx, после чего процесс извлечения запустился без каких-либо проблем.
Собственно процесс извлечения в отличие от Tilde Terminology занимает считанные секунды. После его завершения создается файл Excel с несколькими вкладками. В нашем примере файл содержал следующие 6 вкладок:

Из контрольного файла Prospector извлек 2496 терминов (см. фрагмент с результатами ниже) без учета дополнительных листов.

Явного «мусора» в результатах действительно не оказалось. Большинство извлеченных терминов действительно можно считать терминами. Причем смещения в сторону двухсловных терминов, характерного для Tilde Terminology, замечено не было. Prospector способен выдать и четырехсловные, и даже шестисловные термины. Обрывков фраз, как и ожидалось, в результатах практически нет (за некоторыми исключениями типа «Function Block processes field device measurement», процент которых ничтожно мал). Впрочем, выбранный выше в качестве примера лингвистической обработки термин «still pipe array antenna» вошел в список вместе со своими составляющими «still pipe» и «array antenna», то есть найденные термины дублируются. В этом моменте Prospector, как выяснилось, уступил и Tilde Terminology, и SynchroTerm 2014. Однако, например, упущенный сервисом Tilde Terminology термин «Hold Off Distance» был извлечен, причем не один, а вместе с «Used Hold Off Distance». Вообще говоря, дублирование в том или ином виде терминов представляется основной проблемой рассматриваемого сервиса. Тот же вышеупомянутый «still pipe» вошел в довольно большое число составных терминов, например:

Это явная избыточность, тем более что некоторые другие средства, как мы знаем, смогли избежать подобного дублирования.
Также следует отметить, что в таблицу терминов попала строка типа «Witnessed calibration certificate Calibration certificate witness». Именно такого сочетания слов в исходном документе конечно же нет. Подобный результат обнаружился всего один раз, хотя мог быть и не единичным, так как тщательной проверки всех извлеченных терминов не производилось. Что явилось для сервиса побудительным мотивом в данном случае, сказать сложно. Возможно, некоторые термины интерпретируются как синонимы и объединяются (хотя это сомнительно, учитывая их эпизодический характер). Возможно, просто происходят сбои в алгоритмах обработки. Впрочем, из-за ничтожно малого количества таких элементов можно считать их несущественными.
Основное достоинство сервиса Prospector состоит в том, что он действительно находит практически все термины. В этом данный сервис вполне на уровне SynchroTerm 2014. Однако он значительно впереди с точки зрения объема «мусора», которого практически нет. Поэтому в целом его использование значительно эффективнее. Собственно, по совокупности показателей можно определенно сказать, что Prospector обеспечивает пусть и не идеальное, на наиболее качественное извлечение терминологии.
Что касается дополнительных листов, которые содержат получаемые файлы Excel, то некоторые из них в нашем случае оказались абсолютно бесполезными. Например, лист Cities содержал следующее:

Наверное, все эти аббревиатуры имеют некие географические расшифровки, но в данном документе они точно имели иной смысл. Все прочие дополнительные листы также не представляли особой пользы в нашем примере. С другой стороны, вполне вероятно, что в каких-то ситуациях они могут оказаться полезными.
Итак, сервис Prospector наиболее эффективен в плане извлечения терминологии в сравнении с другими изученными средствами. Вместе с тем он работает всего с одним языком и не поддерживает двуязычное извлечение, что серьезно ограничивает область его применения.
Заключение
В данном обзоре рассмотрены всего 5 средств для извлечения терминологии. Однако все они представляют отдельные категории и служат неким срезом для них.
В CAT-системах функция извлечения терминов реализована весьма посредственно. Здесь представлены результаты исследования только для двух наиболее популярных систем memoQ и SDL Trados Studio. Разумеется, подобные средства есть и в других системах, например, в Memsource и Déjà Vu (Лексикон). Однако практика показывает, что в настоящее время все CAT-системы находятся более или менее на одном уровне. А значит едва ли стоит ожидать от какой-либо из них прорыва в сфере извлечения терминологии.
Специализированные программы и сервисы, как и ожидалось, намного лучше справляются с задачей извлечения. Преимущество сервисов помимо прочего состоит в том, что среди них нередко встречаются бесплатные решения. А некоторые из них оказываются к тому же еще и самыми эффективными. В частности, сервис Prospector определенно можно считать лучшим средством для извлечения терминологии из англоязычных документов на данный момент. Однако он также не идеален, а другие решения демонстрируют, в каком направлении можно еще продвинуться. Остается надеяться, что извлечение терминологии еще не достигло своего пика.
