Генеральным
средним называется среднее арифметическое
значений признака Х в генеральной
совокупности (обозначение
 ).
).
Выборочным средним называется среднее
арифметическое значение признака Х в
выборочной совокупности:

Выборочное
среднее является оценкой для генерального
среднего или является оценкой неизвестного
математического ожидания с.в., если
выборка получена в результате наблюдения
над некоторой случайной величиной.
Генеральной
дисперсией называется дисперсия признака
Х в генеральной совокупности. Выборочной
дисперсией называется дисперсия признака
Х в выборочной совокупности:

Для
вычисления дисперсии используют формулу:

Дисперсия
равняется среднему квадратов без
квадрата среднего. Выборочная дисперсия
является оценкой неизвестной генеральной
дисперсии, или, ели наблюдается некоторая
с.в., то выборочная дисперсия служит
оценкой для неизвестной дисперсии.
Пример на вычисление выборочного
среднего и выборочной дисперсии см.
ниже в разделе ”Выборочное уравнение
регрессии”.
Во
многих случаях мы располагаем информацией
о виде закона распределения случайной
величины (нормальный, бернуллиевский,
равномерный и т. п.), но не знаем параметров
этого распределения, таких как M,
D.
Для определения этих параметров
применяется выборочный метод.
Пусть
выборка объема n представлена в виде
вариационного ряда. Назовем выборочной
средней
величину

Величина
 называетсяотносительной
называетсяотносительной
частотой
значения признака xi.
Если значения признака, полученные из
выборки не группировать и не представлять
в виде вариационного ряда, то для
вычисления выборочной средней нужно
пользоваться формулой
 .
.
Естественно
считать величину
 выборочной оценкой параметра M.
выборочной оценкой параметра M.
Выборочная оценка параметра, представляющая
собой число, называется
точечной оценкой.
Выборочную
дисперсию

можно
считать точечной оценкой дисперсии D
генеральной совокупности.
Приведем
еще один пример точечной оценки. Пусть
каждый объект генеральной совокупности
характеризуется двумя количественными
признаками x и y. Например, деталь может
иметь два размера – длину и ширину.
Можно в различных районах измерять
концентрацию вредных веществ в воздухе
и фиксировать количество легочных
заболеваний населения в месяц. Можно
через равные промежутки времени
сопоставлять доходность акций данной
корпорации с каким-либо индексом,
характеризующим среднюю доходность
всего рынка акций. В этом случае
генеральная совокупность представляет
собой двумерную случайную величину ,
.
Эта случайная величина принимает
значения x, y на множестве объектов
генеральной совокупности. Не зная закона
совместного распределения случайных
величин
и ,
мы не можем говорить о наличии или
глубине корреляционной связи между
ними, однако некоторые выводы можно
сделать, используя выборочный метод.
Выборку
объема n в этом случае представим в виде
таблицы, где
i-тый отобранный объект
(i= 1,2,…n) представлен парой чисел xi,
yi
:
|
x1 |
x2 |
… |
xn |
|
y1 |
y2 |
… |
yn |
Выборочный
коэффициент корреляции рассчитывается
по формуле

Здесь
 ,
, ,
,
 .
.
Выборочный
коэффициент корреляции можно рассматривать
как точечную оценку коэффициента
корреляции ,
характеризующего генеральную совокупность.
Выборочные
параметры
 или любые другие зависят от того, какие
или любые другие зависят от того, какие
объекты генеральной совокупности попали
в выборку и различаются от выборки к
выборке. Поэтому они сами являются
случайными величинами.
Пусть
выборочный параметр
рассматривается как выборочная оценка
параметра
генеральной совокупности и при этом
выполняется равенство
M
=.
Такая
выборочная оценка называется несмещенной.
Для
доказательства несмещённости некоторых
точечных оценок будем рассматривать
выборку объема n как систему n независимых
случайных величин 1,
2,…
n
, каждая из которых имеет тот же закон
распределения с теми же параметрами,
что и случайная величина ,
представляющая генеральную совокупность.
При таком подходе становятся очевидными
равенства: Mxi = Mi =M;
Dxi
= Di
=D
для всех k = 1,2,…n.
Теперь
можно показать, что выборочная средняя
 есть несмещенная оценка средней
есть несмещенная оценка средней
генеральной совокупности или , что то
же самое, математического ожидания
интересующей нас случайной величины
:
 .
.
Выведем
формулу для дисперсии выборочной
средней:
 .
.
Найдем
теперь, чему равно математическое
ожидание выборочной дисперсии 2.
Сначала преобразуем 2
следующим образом:



Здесь
использовано преобразование:


Теперь,
используя полученное выше выражение
для величины 2,
найдем ее математическое ожидание.
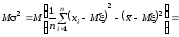

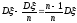 .
.
Так
как M 2 D,
выборочная
дисперсия не является несмещенной
оценкой дисперсии генеральной
совокупности.
Чтобы
получить несмещенную оценку дисперсии
генеральной совокупности, нужно умножить
выборочную дисперсию на
 .
.
Тогда получится величина ,
,
называемаяисправленной
выборочной
дисперсией.

Пусть
имеется ряд несмещенных точечных оценок
одного и того же параметра генеральной
совокупности. Та оценка, которая имеет
наименьшую дисперсию, называется
эффективной.
Полученная
из выборки объема n точечная оценка n
параметра
генеральной совокупности называется
состоятельной,
если она сходится по вероятности к .
Это означает, что для любых положительных
чисел
и
найдется такое число n
, что для всех чисел n, удовлетворяющих
неравенству n > n
выполняется условие .
. и
и являются несмещёнными, состоятельными
являются несмещёнными, состоятельными
и эффективными оценками величинM
и D.
17 авг. 2022 г.
читать 2 мин
Точечная оценка представляет собой число, которое мы вычисляем на основе выборочных данных для оценки некоторого параметра совокупности. Это служит нашей наилучшей возможной оценкой того, каким может быть истинный параметр населения.
В следующей таблице показана точечная оценка, которую мы используем для оценки параметров совокупности:
| Измерение | Параметр населения | Балльная оценка | | — | — | — | | Иметь в виду | μ (среднее значение населения) | х (выборочное среднее) | | Доля | π (доля населения) | p (пропорция выборки) |
Хотя точечная оценка представляет собой наше лучшее предположение о параметре совокупности, не гарантируется, что она точно соответствует истинному параметру совокупности.
По этой причине мы также часто рассчитываем доверительные интервалы — интервалы, которые могут содержать параметр генеральной совокупности с определенным уровнем достоверности.
В следующих примерах показано, как рассчитать точечные оценки и доверительные интервалы в Excel.
Пример 1. Точечная оценка среднего значения генеральной совокупности
Предположим, нас интересует вычисление среднего веса популяции черепах. Для этого мы собираем случайную выборку из 20 черепах:

Наша точечная оценка среднего значения населения — это просто среднее значение выборки, которое оказывается равным 300,3 фунта:

Затем мы можем использовать следующую формулу для расчета 95% доверительного интервала для среднего значения генеральной совокупности:
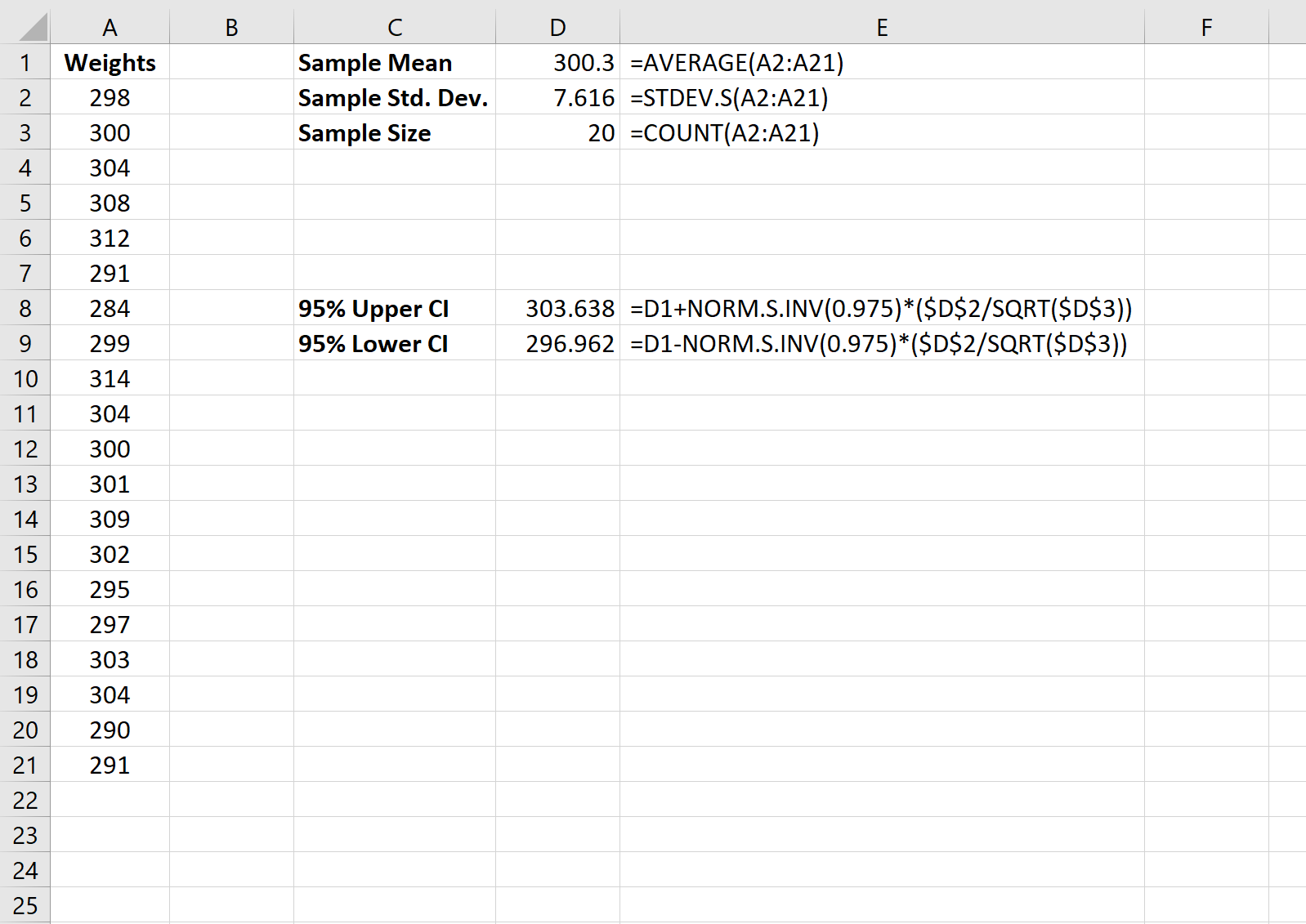
Мы на 95% уверены, что истинный средний вес черепах в этой популяции находится в диапазоне [296,96, 303,64] .
Мы можем подтвердить эти результаты, используя калькулятор доверительного интервала .
Пример 2: Точечная оценка доли населения
Предположим, нам нужно рассчитать долю черепах в популяции, имеющих пятна на панцире. Для этого мы собираем случайную выборку из 20 черепах и обнаруживаем, что у 13 из них есть пятна.
Наша точечная оценка доли черепах с пятнами составляет 0,65 :

Затем мы можем использовать следующую формулу для расчета 95% доверительного интервала для доли населения:

Мы на 95% уверены, что истинная доля черепах в этой популяции с пятнами находится в диапазоне [0,44, 0,86] .
Мы можем подтвердить эти результаты, используя калькулятор доверительного интервала для пропорции .
Дополнительные ресурсы
Как рассчитать доверительные интервалы в Excel
Как рассчитать интервал прогнозирования в Excel
Как рассчитать погрешность в Excel
Статистические оценки параметров генеральной совокупности
Определение статистической оценки. Точечные статистические оценки: смещенные и несмещенные, эффективные и состоятельные. Интервальные статистические оценки. Точность и надежность оценки; определение доверительного интервала; построение доверительных интервалов для средней при известном и неизвестном среднеквадратическом отклонении.
Определение статистической оценки
Пусть требуется изучить количественный признак генеральной совокупности. Допустим, что из теоретических соображений удалось установить, какое именно распределение имеет признак. Возникает задача оценки параметров, которыми определяется это распределение. Например, если известно, что изучаемый признак распределен в генеральной совокупности по нормальному закону, то необходимо оценить математическое ожидание и среднеквадратическое отклонение, так как эти два параметра полностью определяют нормальное распределение. Если имеются основания считать, что признак имеет распределение Пуассона, то необходимо оценить параметр , которым это распределение определяется. Обычно имеются лишь данные выборки, полученные в результате
наблюдений:
. Через эти данные и выражают оцениваемый параметр. Рассматривая
как значения независимых случайных величин
можно сказать, что найти статистическую оценку неизвестного параметра теоретического распределения означает найти функцию от наблюдаемых случайных величин, которая и дает приближенное значение оцениваемого параметра.
Точечные статистические оценки
Статистической оценкой неизвестного параметра теоретического распределения называют функцию от наблюдаемых случайных величин. Статистическая оценка неизвестного параметра генеральной совокупности одним числом называется точечной. Рассмотрим следующие точечные оценки: смещенные и несмещенные, эффективные и состоятельные.
Для того чтобы статистические оценки давали хорошие приближения оцениваемых параметров, они должны удовлетворять определенным требованиям. Укажем эти требования. Пусть есть статистическая оценка неизвестного параметра
теоретического распределения. Допустим, что по выборке объема
найдена оценка
. Повторим опыт, т. е. извлечем из генеральной совокупности другую выборку того же объема и по ее данным найдем оценку
и т. д. Получим числа
, которые будут различаться. Таким образом, оценку
можно рассматривать как случайную величину, а числа
— как возможные ее значения.
Если оценка дает приближенное значение
с избытком, то найденное по данным выборок число
будет больше истинного значения
. Следовательно, и математическое ожидание (среднее значение) случайной величины
будет превышать
, то есть
. Если
дает приближенное значение
с недостатком, то
.
Использование статистической оценки, математическое ожидание которой не равно оцениваемому параметру, приводит к систематическим ошибкам. Поэтому нужно потребовать, чтобы математическое ожидание оценки было равно оцениваемому параметру. Соблюдение требования
устраняет систематические ошибки.
Несмещенной называют статистическую оценку , математическое ожидание которой равно оцениваемому параметру
, то есть
.
Смещенной называют статистическую оценку , математическое ожидание которой не равно оцениваемому параметру.
Однако ошибочно считать, что несмещенная оценка всегда дает хорошее приближение оцениваемого параметра. Действительно, возможные значения могут быть сильно рассеяны вокруг своего среднего значения, т. е. дисперсия величины
может быть значительной. В этом случае найденная по данным одной выборки оценка, например
, может оказаться удаленной от своего среднего значения
, а значит, и от самого оцениваемого параметра
. Приняв
в качестве приближенного значения
, мы допустили бы ошибку. Если потребовать, чтобы дисперсия величины
была малой, то возможность допустить ошибку будет исключена. Поэтому к статистической оценке предъявляются требования эффективности.
Эффективной называют статистическую оценку, которая (при заданном объеме выборки ) имеет наименьшую возможную дисперсию. При рассмотрении выборок большого объема к статистическим оценкам предъявляется требование состоятельности.
Состоятельной называют статистическую оценку, которая при стремится по вероятности к оцениваемому параметру. Например, если дисперсия несмещенной оценки при
стремится к нулю, то такая оценка оказывается также состоятельной.
Рассмотрим вопрос о том, какие выборочные характеристики лучше всего в смысле несмещённости, эффективности и состоятельности оценивают генеральную среднюю и дисперсию.
Пусть изучается дискретная генеральная совокупность относительно количественного признака. Генеральной средней называется среднее арифметическое значений признака генеральной совокупности. Она вычисляется по формуле
или
где — значения признака генеральной совокупности объема
;
— соответствующие частоты, причем
Пусть из генеральной совокупности в результате независимых наблюдений над количественным признаком извлечена выборка объема со значениями признака
. Выборочной средней называется среднее арифметическое значений признака выборочной совокупности и вычисляется по формуле
или
где — значения, признака в выборочной совокупности объема
;
— соответствующие частоты, причем
Если генеральная средняя неизвестна и требуется оценить ее по данным выборки, то в качестве оценки генеральной средней принимают выборочную среднюю, которая является несмещенной и состоятельной оценкой. Отсюда следует, что если по нескольким выборкам достаточно большого объема из одной и той же генеральной совокупности будут найдены выборочные средние, то они будут приближенно равны между собой. В этом состоит свойство устойчивости выборочных средних.
Если дисперсии двух совокупностей одинаковы, то близость выборочных средних к генеральным не зависит от отношения объема выборки к объему генеральной совокупности. Она зависит- от объема выборки: чем больше объем выборки, тем меньше выборочная средняя отличается от генеральной.
Для того чтобы охарактеризовать рассеяние значений количественного признака генеральной совокупности вокруг своего среднего значения, вводят сводную характеристику — генеральную дисперсию. Генеральной дисперсией
называется среднее арифметическое квадратов отклонений значений признака генеральной совокупности от их среднего значения
, которое вычисляется по формуле
или
Для того чтобы охарактеризовать рассеяние наблюденных значений количественного признака выборки вокруг своего среднего значения хв, вводят сводную характеристику — выборочную дисперсию. Выборочной дисперсией называется среднее арифметическое квадратов отклонений наблюденных значений признака от их среднего значения
, которое вычисляется по формуле
или
Кроме дисперсии для характеристики рассеяния значений признака генеральной (выборочной) совокупности вокруг своего среднего значения используют сводную характеристику — среднее квадратическое отклонение. Генеральным средним квадратическим отклонением называют квадратный корень из генеральной дисперсии: . Выборочным средним квадратическим отклонением называют квадратный корень из выборочной дисперсии:
.
Пусть из генеральной совокупности в результате независимых наблюдений над количественным признаком
извлечена выборка объема
. Требуется по данным выборки оценить неизвестную генеральную дисперсию
. Если в качестве оценки генеральной дисперсии принять выборочную дисперсию, то эта оценка приведет к систематическим ошибкам, давая заниженное значение генеральной дисперсии. Объясняется это тем, что выборочная дисперсия является смещенной оценкой
. Другими словами, математическое ожидание выборочной дисперсии не равно оцениваемой генеральной дисперсии, а равно
.
Легко исправить выборочную дисперсию так, чтобы ее математическое ожидание было равно генеральной дисперсии. Для этого нужно умножить на дробь
. В результате получим исправленную дисперсию
, которая будет несмещенной оценкой генеральной дисперсии:
Интервальные оценки
Наряду с точечным оцениванием, статистическая теория оценивания параметров занимается вопросами интервального оценивания. Задачу интервального оценивания можно сформулировать так: по данным выборки построить числовой интервал, относительно которого с заранее выбранной вероятностью можно сказать, что внутри него находится оцениваемый параметр. Интервальное оценивание особенно необходимо при малом количестве наблюдений, когда точечная оценка малонадежна.
Доверительным интервалом для параметра
называется такой интервал, относительно которого с заранее выбранной вероятностью
, близкой к единице, можно утверждать, что он содержит неизвестное значение параметра
, то есть
. Чем меньше для выбранной вероятности число
, тем точнее оценка неизвестного параметра
. И, наоборот, если это число велико, то оценка, проведенная с помощью данного интервала, малопригодна для практики. Так как концы доверительного интервала зависят от элементов выборки, то значения
и
могут изменяться от выборки к выборке. Вероятность
принято называть доверительной (надежностью). Обычно надежность оценки задается наперед, причем в качестве
берут число, близкое к единице. Выбор доверительной вероятности не является математической задачей, а определяется конкретной решаемой проблемой. Наиболее часто задают надежность, равную 0,95; 0,99; 0,999.
Доверительный интервал для генеральной средней при известном значении среднего квадратического отклонения и при условии, что случайная величина (количественный признак ) распределена нормально, задается выражением
где — наперед заданное число, близкое к единице, а значения функции
приведены в таблице прил. 2.
Смысл этого соотношения заключается в следующем: с надежностью можно утверждать, что доверительный интервал
покрывает неизвестный параметр
, точность оценки
. Число
определяется из равенства
, или
. По прил. 2 находят аргумент
, которому соответствует значение функции Лапласа, равное
.
Пример 1. Случайная величина имеет нормальное распределение с известным средним квадратическим отклонением
. Найти доверительные интервалы для оценки неизвестной генеральной средней по выборочным средним, если объем выборок
и надежность оценки
.
Решение. Найдем . Из соотношения
получим, что
. По прил. 2 находим
. Найдем точность оценки
. Доверительные интервалы будут таковы:
. Например, если
, то доверительный интервал имеет следующие доверительные границы:
. Таким образом, значения неизвестного параметра
, согласующиеся с данными выборки, удовлетворяют неравенству
.
Доверительный интервал для генеральной средней нормального распределения признака при неизвестном значении среднего квадратического отклонения задается выражением
Отсюда следует, что с надежностью можно утверждать, что доверительный интервал
покрывает неизвестный параметр
.
Существуют таблицы (прил. 4), пользуясь которыми, по заданным и
находят вероятность
и, наоборот, по заданным
и
находят
.
Пример 2. Количественный признак генеральной совокупности распределен нормально. По выборке объема
найдены выборочная средняя
и исправленное среднеквадратическое отклонение
. Оценить неизвестную генеральную среднюю с помощью доверительного интервала с надежностью
.
Решение. Найдем . Пользуясь прил. 4 по
и
находим
. Найдем доверительные границы:
Итак, с надежностью неизвестный параметр
заключен в доверительном интервале
.
Математический форум (помощь с решением задач, обсуждение вопросов по математике).
Если заметили ошибку, опечатку или есть предложения, напишите в комментариях.
Реферат
на тему «Точечные оценки»
по учебной дисциплине
«ОСНОВЫ МАТЕМАТИЧЕСКОЙ ОБРАБОТКИ ИНФОРМАЦИИ»
Выполнил(а):
Савкина Юлия Камильевна
2022 г
Оглавление
Введение
Статистика есть наука о том, как,
не умея мыслить и понимать,
заставить делать это цифры.
В. О. Ключевский
Математическая статистика – это наука, изучающая методы сбора и обработки статистической информации для получения научных и практических выводов.
Одной из центральных задач математической статистики является задача оценивания теоретического распределения случайной величины на основе выборочных данных. При этом часто предполагается, что вид закона распределения генеральной совокупности известен, но неизвестны параметры этого распределения, такие как математическое ожидание, дисперсия и др. Требуется найти приближенные значения этих параметров, то есть получить статистические оценки указанных параметров.
Основным методом математической статистики является выборочный метод, его суть состоит в исследовании представительной выборочной совокупности – для достоверной характеристики совокупности генеральной. Данный метод экономит временные, трудовые и материальные затраты, поскольку исследование всей совокупности зачастую затруднено или невозможно.
Для нахождения вида функции оценивания того или иного параметра используют один из следующих методов: 1) метод максимального правдоподобия; 2) метод моментов; 3) оценивание с помощью метода наименьших квадратов
Числовые характеристики, полученные по выборкам, называют статистическими оценками параметров. Различают два вида оценок параметров точечные и интервальные.
В данной работе речь пойдет именно о точечных оценках.
Глава 1. Основная часть
Основные понятия математической статистики
Введем основные понятия, связанные с выборками. Генеральной совокупностью называется совокупность объектов, из которых производится выборка. Выборочной совокупностью (выборкой) называется совокупность случайно отобранных объектов из генеральной совокупности. Число объектов в совокупности называется ее объемом.
Числовые характеристики всей генеральной совокупности называются параметрами. Так как всю генеральную совокупность изучить достаточно часто не представляется возможным, о параметрах судят по выборочным характеристикам. На основании выборочных данных можно получить лишь приближенное значение параметра, которое является его оценкой.
Выборочная характеристика, используемая в качестве приближенного значения неизвестного параметра генеральной совокупности, называется точечной оценкой, т.к представляет собой число или точку на числовой оси.
Числовые характеристики выборки
По результатам выборочных наблюдений вычисляются такие статистические выборочные характеристики, как выборочные средняя, дисперсия, среднее квадратичное отклонение, коэффициент корреляции и т.д. Эти характеристики определяют соответствующие параметры генеральной совокупности.
Пусть x1, x2, …, xn – выборка из генеральной совокупности объёма n.
Выборочной средней (или средним значение выборки) называется среднее арифметическое значение признака выборочной совокупности.
Генеральная средняя для изучаемого количественного признака Х по генеральной совокупности
 и выборочная средняя
и выборочная средняя

Если все значения x1, x2, …, xn признака выборки объема n различны, то среднее значение выборки оценивается по формуле:
 .
.
Для обозначения среднего значения выборки чаще всего используются обозначения  и
и 
Если значения признака Х1, X2, …, Хk в выборке имеют соответственно частоты n1, n2, …, nk, то последнюю формулу можно переписать в виде

Математическое ожидание характеризует среднее значение случайной величины и определяется по формулам:
|
|
(1.1) |

где mx обозначает число, полученное после вычислений по формуле (1.1); M[X] – оператор математического ожидания, ДСВ – дискретная случайная величина, НСВ – непрерывная случайная величина. Как видно из (1.1), в качестве математического ожидания используется «среднее взвешенное значение», причем каждое из значений случайной величины учитывается с «весом», пропорциональным вероятности этого значения.
Начальный момент k-го порядка случайной величины X есть математическое ожидание k-й степени этой случайной величины:
|
|
(1.2) |

При k=0 значение α0(x) = M[X0] = M [1] = 1; при k=1 — α1(x) = M[X1] = M [Х] = mx – математическое ожидание; при k=2 — α2(x) = M[X2].
Центрированной случайной величиной Х° называется случайная величина, математическое ожидание которой находится в начале координат (в центре числовой оси), т.е. M[X°] = 0. Операция центрирования (переход от нецентрированной величины Х к центрированной X°) имеет вид X° =X − mX .
Центральный момент порядка k случайной величины X есть математическое ожидание k-й степени центрированной случайной величины X:
|
|
(1.3) |

При k=0 значение 0(x)=M [X°0]=M [1]=1; при k=1 — 1(x)=M [X°1]=M [Х°] = 0; при k=2 — 2 (x)=M[X°2]= M [(X – mx)2]=M[X 2] – 2mx M [X ]+ mx2= α2 – mx2=Dx – дисперсия.
Дисперсия случайной величины характеризует степень рассеивания (разброса) значений случайной величины относительно ее математического ожидания и определяется по формулам:
|
|
(1.4) |

Дисперсия выборки или выборочная дисперсия оценивается по (слегка измененной) формуле:
 , где m*– среднее значение выборки.
, где m*– среднее значение выборки.
Дисперсия случайной величины имеет размерность квадрата случайной величины, поэтому для анализа диапазона значений величины Х дисперсия не совсем удобна. Этого недостатка лишено среднее квадратическое отклонение (СКО), размерность которого совпадает с размерностью случайной величины. Выборочным средним квадратичным отклонением (стандартом) называют квадратный корень из выборочной дисперсии:
|
|
(1.5) |

Мода случайной величины равна ее наиболее вероятному значению, т.е. то значение, для которого вероятность pi (для дискретной случайной величины) или f(x) (для непрерывных случайной величины) достигает максимума: f (Mo) = max, p(X = Mo) = max.
Медиана случайной величины X равна такому ее значению, для которого выполняется условие p { X < Me } = p { X Me }. Медиана, как правило, существует только для непрерывных случайных величин. Значение Me может быть определено как решение одного из следующих уравнений:
|
|
(1.6) |

В точке Me площадь, ограниченная кривой распределения делится пополам.Медиана вычисляется следующим образом. Изучаемая выборка упорядочивается в порядке возрастания (N – объем выборки). Получаемая последовательность ak, где k=1,…, N называется вариационным рядом или порядковыми статистиками.
Если число наблюдений N нечетно, то медиана оценивается как m = aN+1/2
Если число наблюдений N четно, то медиана оценивается как m = ( aN/2 + aN/2+1 ) / 2
Квантиль хp случайной величины X – это такое ее значение, для которого выполняется условие
|
p { X < xp } = F(xp)= p. (1.7) |
(1.7) |
Очевидно, что медиана – это квантиль x0,5.
Свойства точечных оценок
Статистической оценкой Qˆ неизвестного параметра Q теоретического распределения называется приближенное значение параметра, вычисленное по результатам эксперимента (по выборке). Статистические оценки делятся на точечные и интервальные. Точечной называется оценка, определяемая одним числом. Точечная оценка Qˆ параметра Q случайной величины X в общем случае равна
|
Qˆ= (x1, x2, …, xn), где xi – значения выборки. |
(1.8) |
Очевидно, что оценка Qˆ – это случайная величина, так как она является функцией от n-мерной случайной величины (Х1, …, Хn), где Хi, – значение величины Х в i-м опыте, и значения будут изменяться от выборки к выборке случайным образом. Чтобы точечная оценка была наилучшей с точки зрения точности, необходимо, чтобы она была состоятельной, несмещенной и эффективной.
Оценка Qˆ называется состоятельной, если при увеличении объема выборки n она сходится по вероятности к значению параметра Q:
|
|
(1.9) |

Состоятельность – это минимальное требование к оценкам.
Оценка Qˆ называется несмещенной, если ее математическое ожидание точно равно параметру Q для любого объема выборки:
Несмещенная оценка Qˆ является эффективной, если ее дисперсия минимальна по отношению к дисперсии любой другой оценки этого параметра:
|
|
(1.11) |

Первые два требования к оценке являются обязательными, выполнение последнего требования – желательно.
Точечная оценка математического ожидания. На основании теоремы Чебышева в качестве состоятельной оценки математического ожидания может быть использовано среднее арифметическое значений выборки  , называемое выборочным средним:
, называемое выборочным средним:
Определим числовые характеристики оценки .
 т.е. оценка несмещенная.
т.е. оценка несмещенная.
Оценка (1.12) является эффективной, т.е. ее дисперсия минимальна, если величина X распределена по нормальному закону.
Состоятельная оценка начального момента k-го порядка определяется по формуле
Точечная оценка дисперсии. В качестве состоятельной оценки дисперсии может быть использовано среднее арифметическое квадратов отклонений значений выборки от выборочного среднего:
Определим математическое ожидание оценки S2. Так как дисперсия не зависит от того, где выбрать начало координат, выберем его в точке mX, т.е. перейдем к центрированным величинам:

Ковариация Kij =0, так как опыты, а, следовательно, и Хi − значение величины Х в i‑м опыте − независимы. Таким образом, величина является смещенной оценкой дисперсии, а несмещенная состоятельная оценка дисперсии равна:
Дисперсия величины S02 равна:
Для нормального закона распределения величины X формула (1.17) примет вид
Для равномерного закона распределения –
Состоятельная несмещенная оценка среднеквадратического отклонения определяется по формуле: (1.20)
Состоятельная оценка центрального момента k-го порядка равна:
Точечная оценка вероятности. На основании теоремы Бернулли несмещенная состоятельная и эффективная оценка вероятности случайного события A в схеме независимых опытов равна частоте этого события:
где m – число опытов, в которых произошло событие A; n – число проведенных опытов. Числовые характеристики оценки вероятности p*(A) = p* равны:
Среднее арифметическое х, выборочная дисперсия Дх, частость р – это точечные статистические оценки соответственно математического ожидания (генерального среднего) МХ, дисперсии (генеральной дисперсии) ДХ, истиной (генеральной) вероятности р. Чтобы не заблудиться в этом многообразии, удобно пользоваться таблицей 1, представленной ниже [3].
Методы построения точечных оценок
Выше мы рассматривали точечные оценки основных генеральных характеристик: математического ожидания, дисперсии, вероятности и др. Однако осталось неясным, каким образом получены эти оценки. В математической статистике разработано большое число методов оценивания неизвестных параметров по данным случайной выборки, из которых наиболее часто используются:
метод моментов1;
метод максимального правдоподобия2;
метод наименьших квадратов;
графический метод (или метод номограмм).
Рассмотрим первые два из них.
Метод моментов. Пусть имеется выборка {x1, …, xn} независимых значений случайной величины с известным законом распределения f(x, Q1 , …, Qm) и m неизвестными параметрами Q1, …, Qm. Необходимо вычислить оценки Qˆ1, …, Qˆm параметров Q1, …, Qm. Последовательность вычислений следующая:
Вычислить значения m начальных и/или центральных теоретических моментов
Определить m соответствующих выборочных начальных αkˆ(x) и/или центральных µkˆ(x) моментов по формулам (1.14, 1.21).
Составить и решить относительно неизвестных параметров Q1, …, Qm систему из m уравнений, в которых теоретические моменты приравниваются к выборочным моментам. Каждое уравнение имеет вид αk(x) =αkˆ(x) или µ k(x) = µ kˆ(x). Найденные корни являются оценками Q1ˆ, …, Qmˆ неизвестных параметров.
Замечание. Часть уравнений может содержать начальные моменты, а оставшаяся часть – центральные.
Метод максимального правдоподобия. Согласно данному методу оценки Qˆ1, …, Qˆm получаются из условия максимума по параметрам Q1, …, Qm положительной функции правдоподобия L ( x1, …, xn, Q1, …, Qm). Если случайная величина X непрерывна, а значения xi независимы, то функция правдоподобия равна

Если случайная величина X дискретна и принимает независимые значения xi с вероятностями p (X=xi) = pi ( xi, Q1, …, Qm), то функция правдоподобия равна

Система уравнений согласно этому методу может записываться в двух видах:
или
Найденные корни выбранной системы уравнений являются оценками Q1ˆ, …, Qmˆ неизвестных параметров Q1, …, Qm.
Как правило оценка максимального правдоподобия эффективнее оценки, полученной методом моментов, и более того, если существует несмещенная эффективная оценка параметра, то она будет получена методом максимального правдоподобия.
Глава 2. Практическая часть
Примеры вычисления точечных оценок
Пример 1. Найдем оценку для вероятности P наступления события A по данному числу m появления этого события в n испытаниях.
Решение. Воспользуемся методом максимального правдоподобия: в этом случае функция правдоподобия L равна L = Cnm P m (1–P) n–m.
Тогда ln (L) = ln Cnm + m ln (P) + (n–m) ln (1 – P).
Уравнение для определения оценки:

Значит, оценкой методом максимального правдоподобия вероятности наступления события будет его относительная частота w.

Пример 2. Случайная величина X (число появлений события А в t независимых испытаниях) подчинена биномиальному закону распределения с неизвестным параметром р. Ниже приведено эмпирическое распределение числа появлений события в 10 опытах по 5 испытаний в каждом (в первой строке указано число xi появлений события А в одном опыте; во второй строке указана частота ni — количество опытов, в которых наблюдалось столько появлений события А).
Найти методом моментов точечную оценку параметра р биномиального распределения. Оценить вероятность p0=P(X=0).
Решение. Математическое ожидание биномиального распределения известно: MX = m p. Приравняв математическое ожидание к выборочному среднему, получим уравнение:  , откуда
, откуда  . Для рассматриваемого примера имеем:
. Для рассматриваемого примера имеем:
|
|
(05+12+21+31+41) / 10=1,1; |
||
|
|
= 1,1/5=0,22; |
|

Если распределение определяется двумя параметрами, то для построения их оценок два теоретических момента приравнивают двум соответствующим эмпирическим моментам тех же порядков (обычно первым двум).
Пример 3. Для изучения генеральной совокупности относительно некоторого количественного признака была извлечена выборка:
Найти несмещенные оценки генеральной средней и генеральной дисперсии.
Решение. Несмещенной оценкой генеральной средней является выборочная средняя: .
.
Несмещенной оценкой генеральной дисперсии является исправленная выборочная дисперсия:
 Ответ: 50; 2,57.
Ответ: 50; 2,57.
Пример 4. По выборке объема N=41 найдена смещенная оценка генеральной дисперсии DB=3. Найти несмещенную оценку дисперсии генеральной совокупности.
Решение. Смещенной оценкой генеральной дисперсии служит выборочная дисперсия

Несмещенной оценкой генеральной дисперсии является «исправленная дисперсия»
 или
или 
Таким образом, мы получаем искомую несмещенную оценку дисперсии генеральной совокупности:

Пример 5. Для анализа лингвистических терминологических систем взято 7 фрагментов по 250 терминоупотреблений из русских лингвистических текстов. После подсчёта в каждом фрагменте числа употреблений слова «лицо» получен следующий вариационный ряд: 1,1,3,4,9,10,12.
1) Определите по выборке несмещённую и состоятельную оценку математического ожидания М(Х) и дисперсии D(X) случайной величины Х – «число употреблений слова «лицо» в русских лингвистических текстах.
2) Найдите несмещённую, состоятельную и эффективную оценку вероятности события А= «слово лицо использовано более 5 раз».
Решение
1) Несмещённая и состоятельная оценка М(Х) есть среднее выборочное.

Несмещённая и состоятельная оценка D(X) есть исправленная выборочная дисперсия: 

2) Несмещённой, состоятельной и эффективной оценкой вероятности события А= «слово лицо использовано более 5 раз» является частота этого события Р(А): 
Пример 6. Выборка задана таблицей распределения

Найти выборочные характеристики: среднюю, дисперсию и среднее квадратическое отклонение.
Решение. Cначала находим  в:
в:

Затем по формулам находим две другие искомые величины:

Пример 7. Из 1500 деталей отобрано 250, распределение которых по размеру Х задано в таблице:
|
xi |
7,8-8,0 |
8,0-8,2 |
8,2-8,4 |
8,4-8,6 |
8,6-8,8 |
8,8-9,0 |
|
ni |
5 |
20 |
80 |
95 |
40 |
10 |
Найти точечные оценки для среднего и дисперсии, а также дисперсию оценки среднего при повторном и бесповторном отборах.
Решение. Вычислим по формулам (используем середины интервалов сi, число интервалов r=6, объем выборки n=250):
|
сi |
7,9 |
8,1 |
8,3 |
8,5 |
8,7 |
8,9 |
|
|
ni |
5 |
20 |
80 |
95 |
40 |
10 |
n=250 |





Вычислим дисперсию оценки среднего:
для повторной выборки:

для бесповторной выборки

Пример 8. Выборочно обследовали партию кирпича. Из 100 проб в 12 случаях кирпич оказался бракованным. Найти оценку доли бракованного кирпича и дисперсию этой оценки.
Решение. По условию задачи, число бракованных изделий m=12, объем выборки n=100, тогда оценкой доли бракованных является выборочная доля

Дисперсия этой оценки для повторной выборки равна

А среднее квадратическое отклонение этой оценки равно 
Задачи подобраны таким образом, чтобы показать их разнообразную тематику и способы решений. Это и доказательство свойств точечной оценки, представление выборок разными способами и вычисление точечных оценок. Чтобы облегчить свою работу, можно воспользоваться таблицей 1 (см Приложение 1).
Заключение
Точечная оценка параметра – это оценка, которая характеризуется одним конкретным числом (например, математическим ожиданием, дисперсией, средним квадратичным отклонением и т.д.). Точечные оценки параметров генеральной совокупности могут быть приняты в качестве ориентировочных, первоначальных результатов обработки выборочных данных. Их основной недостаток заключается в том, что неизвестно, с какой точностью оценивается параметр. Если для выборок большого объема точность обычно бывает достаточной (при условии несмещенности, эффективности и состоятельности оценок), то для выборок небольшого объема вопрос точности становится очень важным. По этой причине при небольшом объеме выборки следует пользоваться интервальными оценками.
Решение задач математической статистики обусловливает существенный объем вычислений. Во избежание ошибок, можно воспользоваться инженерным калькулятором или выполнить вычисления с помощью офисного пакета MS Excel, в котором есть различные статистические функции и надстройки, в том числе и возможность решить задачи по теме «Анализ данных»
Список литературы
- Гмурман, В. Е. Теория вероятностей и математическая статистика: учебник для прикладного бакалавриата / В. Е. Гмурман. — 12-е изд. — Москва: Издательство Юрайт, 2019. — 479 с. — (Бакалавр. Прикладной курс). — Текст: электронный // ЭБС Юрайт [сайт]. — URL: https://biblio-online.ru/bcode/431095.
- Гмурман, В. Е. Руководство к решению задач по теории вероятностей и математической статистике: учебное пособие для бакалавриата и специалитета / В. Е. Гмурман. — 11-е изд., перераб. и доп. — Москва: Издательство Юрайт, 2019. — 406 с. — (Бакалавр и специалист). — Текст: электронный // ЭБС Юрайт [сайт]. — URL: https://biblio-online.ru/bcode/431094.
- Малугин, В. А. Теория вероятностей и математическая статистика: учебник и практикум для вузов / В. А. Малугин. — Москва: Издательство Юрайт, 2022. — 470 с. — (Высшее образование). — Текст: электронный // ЭБС Юрайт [сайт]. — URL: https://urait.ru/viewer/teoriya-veroyatnostey-i-matematicheskaya-statistika-493318
- Малугин, В. А. Математическая статистика: учебное пособие для бакалавриата и магистратуры / В. А. Малугин. — Москва: Издательство Юрайт, 2019. — 218 с. — (Бакалавр и магистр. Академический курс). — Текст: электронный // ЭБС Юрайт [сайт]. — URL: https://biblio-online.ru/bcode/441413.
- Энатская, Н. Ю. Математическая статистика и случайные процессы: учебное пособие для вузов / Н. Ю. Энатская. — Москва: Издательство Юрайт, 2022. — 201 с. — (Высшее образование). — Текст: электронный // ЭБС Юрайт [сайт]. — URL: https://urait.ru/viewer/matematicheskaya-statistika-i-sluchaynye-processy-490096
Приложение 1
Таблица 1. Точечные оценки случайных величин

окончание таблицы 1
Таблица1. Точечные оценки случайных величин

1 Метод моментов был впервые предложен английским ученым, основателем математической статистики К. Пирсоном (1857-1936) в 1894 году.
2 Метод максимального правдоподобия разработал английский статистик Р. Фишер, который в 1921 г доказал, что ММ-оценки чаще всего не эффективны.
Задача 55. Из генеральной совокупности извлечена выборка объема N, заданная вариантами ХI и соответствующими им частотами. Найти несмещенную оценку генеральной средней.
|
Варианта ХI |
2 |
5 |
7 |
10 |
|
Частота Ni |
16 |
12 |
8 |
14 |
Решение. Множество всех объектов, подлежащих изучению, называется Генеральной совокупностью. Множество случайно отобранных объектов называется выборочной совокупностью или Выборкой.
Для оценки неизвестных параметров теоретического распределения служат статистические оценки. Статистическая оценка, определяемая одним числом, называется Точечной оценкой.
Точечная статистическая оценка, математическое ожидание которой равно оцениваемому параметру при любом объеме выборки, называется Несмещенной оценкой. Статистическая оценка, математическое ожидание которой не равно оцениваемому параметру является Смещенной.
Несмещенной оценкой генеральной средней (математического ожидания) служит выборочная средняя
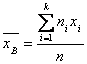 (1),
(1),
Где ХI – варианта выборки (элемент выборки); Ni – частота варианты ХI (число наблюдений варианты ХI); ![]() – объем выборки (число элементов совокупности).
– объем выборки (число элементов совокупности).
Объем данной выборки равен ![]() .
.
Далее по формуле (1) вычисляем несмещенную оценку генеральной средней:
![]()
Задача 56. По выборке объема N=41 найдена смещенная оценка генеральной дисперсии ![]() . Найти несмещенную оценку дисперсии генеральной совокупности.
. Найти несмещенную оценку дисперсии генеральной совокупности.
Решение. Смещенной оценкой генеральной дисперсии служит выборочная дисперсия
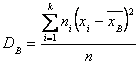
Несмещенной оценкой генеральной дисперсии является «исправленная дисперсия»
![]() или
или 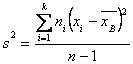
Таким образом, мы получаем искомую несмещенную оценку дисперсии генеральной совокупности:
![]()
Задача 57. Найти доверительный интервал для оценки с надежностью P=0,95 неизвестного математического ожидания A нормально распределенного признака Х генеральной совокупности, если даны генеральное среднее квадратическое отклонение S=5, выборочная средняя ![]() , а объем выборки N=25.
, а объем выборки N=25.
Решение. Интервальной оценкой называется интервал, покрывающий оцениваемый параметр. Доверительным интервалом является интервал, который с данной надежностью покрывает оцениваемый параметр.
Для оценки математического ожидания A нормально распределенного количественного признака Х по выборочной средней ![]() при известном среднем квадратическом отклонении s генеральной совокупности служит доверительный интервал
при известном среднем квадратическом отклонении s генеральной совокупности служит доверительный интервал
![]() ,
,
Где ![]() – точность оценки, T – значение аргумента функции Лапласа
– точность оценки, T – значение аргумента функции Лапласа ![]() (приложение, таблица 2).
(приложение, таблица 2).
В данной задаче T находим из условия ![]() . По таблице 2 определяем
. По таблице 2 определяем ![]() . Таким образом, T=1,96.
. Таким образом, T=1,96.
Далее получаем
![]()
Или ![]()
Задача 58. По данным N=9 независимых равноточных измерений некоторой физической величины найдены среднее арифметическое результатов измерений ![]() и исправленное среднее квадратическое отклонение S=6. Оценить истинное значение измеряемой величины при помощи доверительного интервала с надежностью
и исправленное среднее квадратическое отклонение S=6. Оценить истинное значение измеряемой величины при помощи доверительного интервала с надежностью ![]() =0,99.
=0,99.
Решение. Оценкой математического ожидания A нормально распределенного количественного признака Х в случае неизвестного среднего квадратического отклонения является доверительный интервал
![]() .
.
По таблице 3 приложения, по заданным N и ![]() находим
находим ![]() =3,36.
=3,36.
Таким образом
![]()
Окончательно получаем
![]()
Задача 59. Из генеральной совокупности извлечена выборка объема N. Оценить с надежностью ![]() =0,95 математическое ожидание A нормально распределенного признака Х генеральной совокупности по выборочной средней с помощью доверительного интервала.
=0,95 математическое ожидание A нормально распределенного признака Х генеральной совокупности по выборочной средней с помощью доверительного интервала.
|
Значение признака ХI |
-2 |
1 |
1 |
3 |
4 |
5 |
|
Частота Ni |
2 |
1 |
2 |
2 |
2 |
1 |
Решение. Объем данной выборки равен ![]()
![]()
По данным задачи находим выборочную среднюю:
![]()
Далее находим исправленное среднее квадратическое отклонение S:
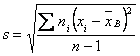
![]()
Для оценки математического ожидания A нормально распределенного количественного признака Х в случае неизвестного среднего квадратического отклонения служит доверительный интервал
![]() .
.
По таблице 3 приложения по заданным N и ![]() находим
находим ![]() =2,26.
=2,26.
Таким образом
![]()
Окончательно получаем
![]()
Задача 60. Построить полигон частот и эмпирическую функцию по данному распределению выборки:
|
Варианты ХI |
-3 |
0 |
1 |
4 |
6 |
7 |
|
Частоты Ni |
3 |
6 |
1 |
2 |
5 |
1 |
Решение. Полигоном частот называют ломаную, отрезки которой соединяют точки ![]() ;
; ![]() ;…;
;…;![]() , где ХI – варианты выборки, Ni – соответствующие им частоты.
, где ХI – варианты выборки, Ni – соответствующие им частоты.
Полигон частот для данного распределения изображен на рисунке 15.

Рис. 15
Эмпирической функцией распределения (функцией распределения выборки) называют функцию ![]() , определяющую для каждого значения X относительную частоту события
, определяющую для каждого значения X относительную частоту события ![]() :
:
![]() ,
,
Где ![]() – число вариант, меньших Х; N – объем выборки.
– число вариант, меньших Х; N – объем выборки.
Из определения следует, что ![]() .
.
Найдем эмпирическую функцию распределения.
Объем данной выборки равен ![]() =18.
=18.
Если ![]() , то
, то ![]() =0 (так как -3 – наименьшая варианта). Если
=0 (так как -3 – наименьшая варианта). Если ![]() , то значение
, то значение ![]() , а именно
, а именно ![]() наблюдалось 3 раза, следовательно,
наблюдалось 3 раза, следовательно, ![]() . При
. При ![]() значения
значения ![]() , а именно
, а именно ![]() и
и ![]() наблюдались 3+6=9 раз, следовательно,
наблюдались 3+6=9 раз, следовательно, ![]() .
.
Аналогично получаем, что при ![]() функция распределения
функция распределения ![]() ; при
; при ![]() функция распределения
функция распределения ![]() ; при
; при ![]() функция распределения
функция распределения ![]() . Далее, если
. Далее, если ![]() , то
, то ![]() (так как 7 – наибольшая варианта).
(так как 7 – наибольшая варианта).
Таким образом, эмпирическая функция распределения равна:

График полученной эмпирической функции распределения изображен на рисунке 16.
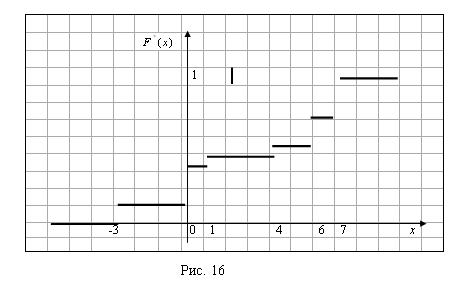
Задача 61. Найти методом сумм асимметрию и эксцесс по заданному распределению выборки объема N=100:
|
Варианта ХI |
48 |
52 |
56 |
60 |
64 |
68 |
72 |
76 |
80 |
84 |
|
Частота Ni |
2 |
4 |
6 |
8 |
12 |
30 |
18 |
8 |
7 |
5 |
Решение. Асимметрия ![]() эмпирического распределения определяется равенством:
эмпирического распределения определяется равенством:
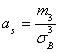 ,
,
Где ![]() – центральный эмпирический момент третьего порядка, вычисляемый по формуле:
– центральный эмпирический момент третьего порядка, вычисляемый по формуле: 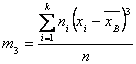
Эксцесс ![]() эмпирического распределения определяется равенством:
эмпирического распределения определяется равенством:
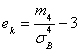 ,
,
Где ![]() – центральный эмпирический момент четвертого порядка, вычисляемый по формуле:
– центральный эмпирический момент четвертого порядка, вычисляемый по формуле: 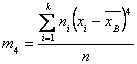
Асимметрия и эксцесс служат для оценки отклонения эмпирического распределения от нормального. Для нормального распределения эти характеристики равны нулю. Поэтому, если для изучаемого распределения асимметрия и эксцесс имеют небольшие значения, то можно предположить близость этого распределения к нормальному. Наоборот, большие значения асимметрии и эксцесса указывают на значительное отклонение от нормального. Кроме того, если эксцесс положительный, то распределение будет островершинным; если отрицательный, то распределение будет плосковершинным по сравнению с нормальным распределением.
Для практического расчета асимметрии и эксцесса непосредственно пользоваться вышеуказанными формулами довольно затруднительно, поэтому воспользуемся методом сумм. Составим расчетную таблицу 1, для этого:
1) Запишем варианты в первый столбец.
2) Запишем частоты во второй столбец; сумму частот (100) поместим в нижнюю клетку столбца.
3) В качестве ложного нуля С выберем варианту (68), которая имеет наибольшую частоту (в качестве С можно взять любую варианту, расположенную примерно в середине столбца); в клетках строки, содержащей ложный нуль, запишем нули; в четвертом столбце над и под уже помещенным нулем запишем еще по одному нулю.
4) В оставшихся незаполненными над нулем клетках третьего столбца (исключая самую верхнюю) запишем последовательно накопленные частоты:
2; 2+4=6; 6+6=12; 12+8=20; 20+12=32.
Сложив все накопленные частоты, получим число B1=72, которое поместим в верхнюю клетку третьего столбца. В оставшихся незаполненными под нулем клетках третьего столбца (исключая самую нижнюю) запишем последовательно накопленные частоты:
5; 5+7=12; 12+8=20; 20+18=38.
Сложив все накопленные частоты, получим число A1=75, которое поместим в нижнюю клетку третьего столбца.
5) Аналогично заполняется четвертый столбец, причем суммируют частоты третьего столбца. Сложив все накопленные частоты, расположенные над нулем, получим число B2=70, которое поместим в верхнюю клетку четвертого столбца. Сумма накопленных частот, расположенных под нулем, равна числу A2=59, которое поместим в нижнюю клетку четвертого столбца.
6) Для заполнения столбца 5 запишем нуль в клетке строки, содержащей ложный нуль (68); над этим нулем и под ним поставим еще по два нуля. В клетках над нулями запишем накопленные частоты, для чего просуммируем частоты столбца 4 сверху вниз; в итоге будем иметь следующие накопленные частоты:
2; 2+8=10; 10+20=30.
Сложив накопленные частоты, получим число B3=42, которое поместим в верхнюю клетку пятого столбца. В клетках под нулями запишем накопленные частоты, для чего просуммируем частоты столбца 4 снизу вниз; в итоге будем иметь следующие накопленные частоты:
5; 5+17=22.
Сложив накопленные частоты, получим число A3=27, которое поместим в нижнюю клетку пятого столбца.
7) Аналогично заполняется столбец 6, причем суммируют частоты столбца 5.
В итоге получим расчетную таблицу 1:
Расчетная таблица 1
|
1 |
2 |
3 |
4 |
5 |
6 |
|
ХI |
Ni |
B1=72 |
B2=70 |
B3=42 |
B4=14 |
|
48 |
2 |
2 |
2 |
2 |
2 |
|
52 |
4 |
6 |
8 |
10 |
12 |
|
56 |
6 |
12 |
20 |
30 |
0 |
|
60 |
8 |
20 |
40 |
0 |
0 |
|
64 |
12 |
32 |
0 |
0 |
0 |
|
68 |
30 |
0 |
0 |
0 |
0 |
|
72 |
18 |
38 |
0 |
0 |
0 |
|
76 |
8 |
20 |
37 |
0 |
0 |
|
80 |
7 |
12 |
17 |
22 |
0 |
|
84 |
5 |
5 |
5 |
5 |
5 |
|
N=100 |
A1=75 |
A2=59 |
A3=27 |
A4=5 |
Теперь найдем Di (I=1, 2, 3) и si (I=1, 2, 3, 4):
![]() ;
; ![]() ;
; ![]() ;
;
![]() ;
; ![]() ;
;
![]() ;
; ![]() .
.
Найдем условные моменты первого, второго, третьего и четвертого порядков:
![]() ;
; ![]() ;
;
![]() ;
;
![]() .
.
Найдем далее центральные эмпирические моменты третьего и четвертого порядков, учитывая, что шаг ![]() (разность между двумя соседними вариантами):
(разность между двумя соседними вариантами):
![]() ;
;

Так как дисперсия ![]() , то выборочное среднее квадратическое отклонение
, то выборочное среднее квадратическое отклонение ![]() .
.
Учитывая определения асимметрии и эксцесса, окончательно получаем:
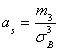
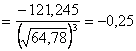 ;
; 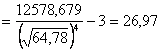 .
.
| < Предыдущая | Следующая > |
|---|
