Поиск значений в списке данных
Excel для Microsoft 365 Excel для Интернета Excel 2021 Excel 2019 Excel 2016 Excel 2013 Excel 2010 Excel 2007 Еще…Меньше
Предположим, что вы хотите найти расширение телефона сотрудника, используя его номер эмблемы или правильную ставку комиссионных за объем продаж. Вы можете искать данные для быстрого и эффективного поиска определенных данных в списке, а также для автоматической проверки правильности данных. После поиска данных можно выполнить вычисления или отобразить результаты с возвращаемой величиной. Существует несколько способов поиска значений в списке данных и отображения результатов.
Что необходимо сделать
-
Точное совпадение значений по вертикали в списке
-
Подыыывка значений по вертикали в списке с помощью приблизительного совпадения
-
Подстановка значений по вертикали в списке неизвестного размера с использованием точного совпадения
-
Точное совпадение значений по горизонтали в списке
-
Подыыывка значений по горизонтали в списке с использованием приблизительного совпадения
-
Создание формулы подступа с помощью мастера подметок (только в Excel 2007)
Точное совпадение значений по вертикали в списке
Для этого можно использовать функцию ВLOOKUP или сочетание функций ИНДЕКС и НАЙТИПОЗ.
Примеры ВРОТ

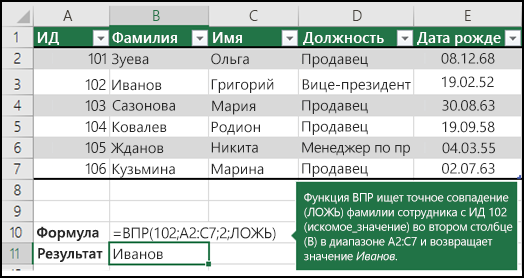
Дополнительные сведения см. в этой информации.
Примеры индексов и совпадений
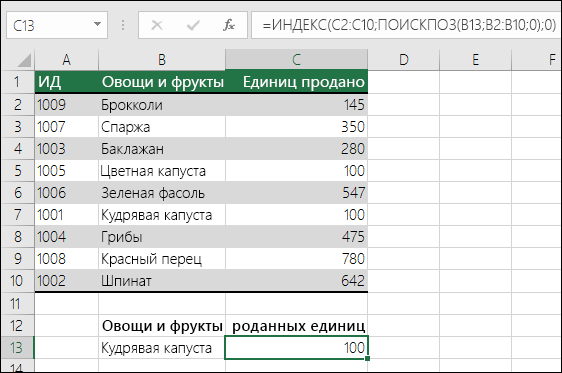
Что означает:
=ИНДЕКС(нужно вернуть значение из C2:C10, которое будет соответствовать ПОИСКПОЗ(первое значение “Капуста” в массиве B2:B10))
Формула ищет в C2:C10 первое значение, соответствующее значению “Ольга” (в B7), и возвращает значение в C7(100),которое является первым значением, которое соответствует значению “Ольга”.
Дополнительные сведения см. в функциях ИНДЕКС иФУНКЦИЯ MATCH.
К началу страницы
Подыыывка значений по вертикали в списке с помощью приблизительного совпадения
Для этого используйте функцию ВЛВП.
Важно: Убедитесь, что значения в первой строке отсортировали в порядке возрастания.
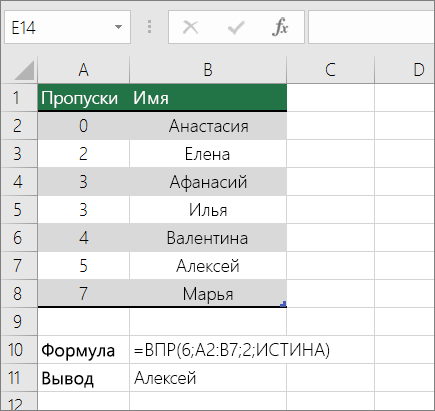
В примере выше ВРОТ ищет имя учащегося, у которого 6 просмотров в диапазоне A2:B7. В таблице нет записи для 6 просмотров, поэтому ВРОТ ищет следующее самое высокое совпадение меньше 6 и находит значение 5, связанное с именем Виктор,и таким образом возвращает Его.
Дополнительные сведения см. в этой информации.
К началу страницы
Подстановка значений по вертикали в списке неизвестного размера с использованием точного совпадения
Для этого используйте функции СМЕЩЕНИЕ и НАЙТИВМЕСЯК.
Примечание: Используйте этот подход, если данные в диапазоне внешних данных обновляются каждый день. Вы знаете, что цена находится в столбце B, но вы не знаете, сколько строк данных возвращает сервер, а первый столбец не отсортировали по алфавиту.
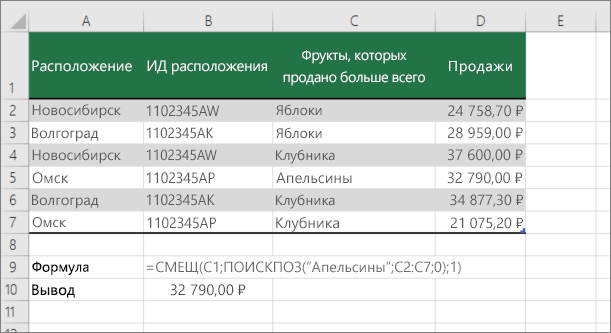
C1 — это левые верхние ячейки диапазона (также называемые начальной).
MATCH(“Оранжевая”;C2:C7;0) ищет “Оранжевые” в диапазоне C2:C7. В диапазон не следует включать запускаемую ячейку.
1 — количество столбцов справа от начальной ячейки, из которых должно быть возвращено значение. В нашем примере возвращается значение из столбца D, Sales.
К началу страницы
Точное совпадение значений по горизонтали в списке
Для этого используйте функцию ГГПУ. См. пример ниже.
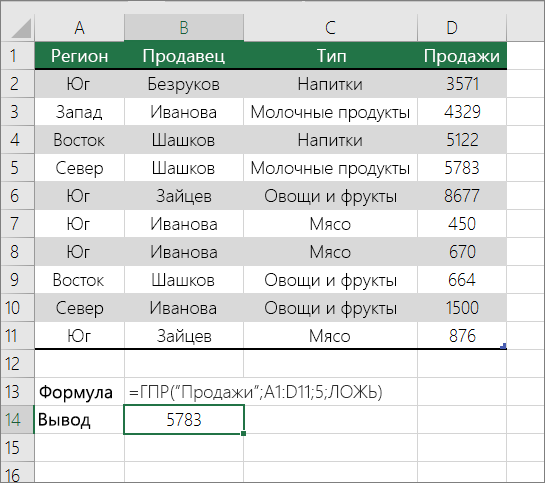
Г ПРОСМОТР ищет столбец “Продажи” и возвращает значение из строки 5 в указанном диапазоне.
Дополнительные сведения см. в сведениях о функции Г ПРОСМОТР.
К началу страницы
Подыыывка значений по горизонтали в списке с использованием приблизительного совпадения
Для этого используйте функцию ГГПУ.
Важно: Убедитесь, что значения в первой строке отсортировали в порядке возрастания.
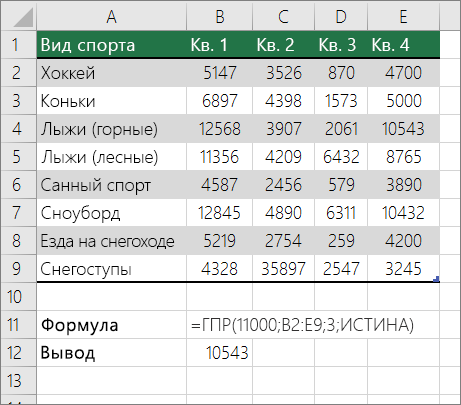
В примере выше ГЛЕБ ищет значение 11000 в строке 3 указанного диапазона. Она не находит 11000, поэтому ищет следующее наибольшее значение меньше 1100 и возвращает значение 10543.
Дополнительные сведения см. в сведениях о функции Г ПРОСМОТР.
К началу страницы
Создание формулы подступа с помощью мастера подметок (толькоExcel 2007 )
Примечание: В Excel 2010 больше не будет надстройки #x0. Эта функция была заменена мастером функций и доступными функциями подменю и справки (справка).
В Excel 2007 создается формула подытов на основе данных на основе данных на основе строк и столбцов. Если вы знаете значение в одном столбце и наоборот, мастер под поисков помогает находить другие значения в строке. В формулах, которые он создает, используются индекс и MATCH.
-
Щелкните ячейку в диапазоне.
-
На вкладке Формулы в группе Решения нажмите кнопку Под поиск.
-
Если команда Подытов недоступна, вам необходимо загрузить мастер под надстройка подытогов.
Загрузка надстройки “Мастер подстройок”
-
Нажмите кнопку Microsoft Office
 , выберите Параметры Excel и щелкните категорию Надстройки.
, выберите Параметры Excel и щелкните категорию Надстройки. -
В поле Управление выберите элемент Надстройки Excel и нажмите кнопку Перейти.
-
В диалоговом окне Доступные надстройки щелкните рядом с полем Мастер подстрок инажмите кнопку ОК.
-
Следуйте инструкциям мастера.
К началу страницы
Нужна дополнительная помощь?
Нужны дополнительные параметры?
Изучите преимущества подписки, просмотрите учебные курсы, узнайте, как защитить свое устройство и т. д.
В сообществах можно задавать вопросы и отвечать на них, отправлять отзывы и консультироваться с экспертами разных профилей.
Колонки сравнивают для того, чтобы, например, в отчетах не было дубликатов. Или, наоборот, для проверки правильности заполнения — с поиском непохожих значений. И проще всего выполнять сравнение двух столбцов на совпадение в Excel — для этого есть 6 способов.

1 Сравнение с помощью простого поиска
При наличии небольшой по размеру таблицы заниматься сравнением можно практически вручную. Для этого достаточно выполнить несколько простых действий.
- Перейти на главную вкладку табличного процессора.
- В группе «Редактирование» выбрать пункт поиска.
- Выделить столбец, в котором будет выполняться поиск совпадений — например, второй.
- Вручную задавать значения из основного столбца (в данном случае — первого) и искать совпадения.
Если значение обнаружено, результатом станет выделение нужной ячейки. Однако с помощью такого способа можно работать только с небольшими столбцами. И, если это просто цифры, так можно сделать и без поиска — определяя совпадения визуально. Впрочем, если в колонках записаны большие объемы текста, даже такая простая методика позволит упростить поиск точного совпадения.

2 Операторы ЕСЛИ и СЧЕТЕСЛИ
Еще один способ сравнения значений в двух столбцах Excel подходит для таблиц практически неограниченного размера. Он основан на применении условного оператора ЕСЛИ и отличается от других методик тем, что для анализа совпадений берется только указанная в формуле часть, а не все значения массива. Порядок действий при использовании методики тоже не слишком сложный и подойдет даже для начинающего пользователя Excel.
- Сравниваемые столбцы размещаются на одном листе. Не обязательно, чтобы они находились рядом друг с другом.
- В третьем столбце, например, в ячейке J6, ввести формулу такого типа: =ЕСЛИ(ЕОШИБКА(ПОИСКПОЗ(H6;$I$6:$I$14;0));»;H6)
- Протянуть формулу до конца столбца.
Результатом станет появление в третьей колонке всех совпадающих значений. Причем H6 в примере — это первая ячейка одного из сравниваемых столбцов. А диапазон $I$6:$I$14 — все значения второй участвующей в сравнении колонки. Функция будет последовательно сравнивать данные и размещать только те из них, которые совпали. Однако выделения обнаруженных совпадений не происходит, поэтому методика подходит далеко не для всех ситуаций.
Еще один способ предполагает поиск не просто дубликатов в разных колонках, но и их расположения в пределах одной строки. Для этого можно применить все тот же оператор ЕСЛИ, добавив к нему еще одну функцию Excel — И. Формула поиска дубликатов для данного примера будет следующей: =ЕСЛИ(И(H6=I6); «Совпадают»; «») — ее точно так же размещают в ячейке J6 и протягивают до самого низа проверяемого диапазона. При наличии совпадений появится указанная надпись (можно выбрать «Совпадают» или «Совпадение»), при отсутствии — будет выдаваться пустота.
Тот же способ подойдет и для сравнения сразу большого количества колонок с данными на точное совпадение не только значения, но и строки. Для этого применяется уже не оператор ЕСЛИ, а функция СЧЕТЕСЛИ. Принцип написания и размещения формулы похожий.
Она имеет вид =ЕСЛИ(СЧЕТЕСЛИ($H6:$J6;$H6)=3; «Совпадают»;») и должна размещаться в верхней части следующего столбца с протягиванием вниз. Однако в формулу добавляется еще количество сравниваемых колонок — в данном случае, три.
Если поставить вместо тройки двойку, результатом будет поиск только тех совпадений с первой колонкой, которые присутствуют в одном из других столбцов. Причем, тройные дубликаты формула проигнорирует. Так же как и совпадения второй и третьей колонки.
3 Формула подстановки ВПР
Принцип действия еще одной функции для поиска дубликатов напоминает первый способ использованием оператора ЕСЛИ. Но вместо ПОИСКПОЗ применяется ВПР, которую можно расшифровать как «Вертикальный Просмотр». Для сравнения двух столбцов из похожего примера следует ввести в верхнюю ячейку (J6) третьей колонки формулу =ВПР(H6;$I$6:$I$15;1;0) и протянуть ее в самый низ, до J15.
С помощью этой функции не просто просматриваются и сравниваются повторяющиеся данные — результаты проверки устанавливаются четко напротив сравниваемого значения в первом столбце. Если программа не нашла совпадений, выдается #Н/Д.
4 Функция СОВПАД
Достаточно просто выполнить в Эксель сравнение двух столбцов с помощью еще двух полезных операторов — распространенного ИЛИ и встречающейся намного реже функции СОВПАД. Для ее использования выполняются такие действия:
- В третьем столбце, где будут размещаться результаты, вводится формула =ИЛИ(СОВПАД(I6;$H$6:$H$19))
- Вместо нажатия Enter нажимается комбинация клавиш Ctr + Shift + Enter. Результатом станет появление фигурных скобок слева и справа формулы.
- Формула протягивается вниз, до конца сравниваемой колонки — в данном случае проверяется наличие данных из второго столбца в первом. Это позволит изменяться сравниваемому показателю, тогда как знак $ закрепляет диапазон, с которым выполняется сравнение.
Результатом такого сравнения будет вывод уже не найденного совпадающего значения, а булевой переменной. В случае нахождения это будет «ИСТИНА». Если ни одного совпадения не было обнаружено — в ячейке появится надпись «ЛОЖЬ».
Стоит отметить, что функция СОВПАД сравнивает и числа, и другие виды данных с учетом верхнего регистра. А одним из самых распространенных способом использования такой формулы сравнения двух столбцов в Excel является поиска информации в базе данных. Например, отдельных видов мебели в каталоге.

5 Сравнение с выделением совпадений цветом
В поисках совпадений между данными в 2 столбцах пользователю Excel может понадобиться выделить найденные дубликаты, чтобы их было легко найти. Это позволит упростить поиск ячеек, в которых находятся совпадающие значения. Выделять совпадения и различия можно цветом — для этого понадобится применить условное форматирование.
Порядок действий для применения методики следующий:
- Перейти на главную вкладку табличного процессора.
- Выделить диапазон, в котором будут сравниваться столбцы.
- Выбрать пункт условного форматирования.
- Перейти к пункту «Правила выделения ячеек».
- Выбрать «Повторяющиеся значения».
- В открывшемся окне указать, как именно будут выделяться совпадения в первой и второй колонке. Например, красным текстом, если цвет остальных сообщений стандартный черный. Затем указать, что выделяться будут именно повторяющиеся ячейки.
Теперь можно снять выделение и сравнить совпадающие значения, которые будут заметно отличаться от остальной информации. Точно так же можно выделить, например, и уникальную информацию. Для этого следует выбрать вместо «повторяющихся» второй вариант — «уникальные».
6 Надстройка Inquire
Начиная с версий MS Excel 2013 табличный процессор позволяет воспользоваться еще одной методикой — специальной надстройкой Inquire. Она предназначена для того, чтобы сравнивать не колонки, а два файла .XLS или .XLSX в поисках не только совпадений, но и другой полезной информации.
Для использования способа придется расположить столбцы или целые блоки информации в разных книгах и удалить все остальные данные, кроме сравниваемой информации. Кроме того, для проверки необходимо, чтобы оба файла были одновременно открытыми.
Процесс использования надстройки включает такие действия:
- Перейти к параметрам электронной таблицы.
- Выбрать сначала надстройки, а затем управление надстройками COM.
- Отметить пункт Inquire и нажать «ОК».
- Перейти к вкладке Inquire.
- Нажать на кнопку Compare Files, указать, какие именно файлы будут сравниваться, и выбрать Compare.
- В открывшемся окне провести сравнения, используя показанные совпадения и различия между данными в столбцах.
У каждого варианта сравнения — свое цветовое решение. Так, зеленым цветом на примере выделены отличия. У совпадающих данных отсутствует выделение. А сравнение расчетных формул показало, что результаты отличаются все — и для выделения использован бирюзовый цвет.
Читайте также:
- 5 программ для совместной работы с документами
-
Как в Экселе протянуть формулу по строке или столбцу: 5 способов
При анализе данных с помощью Excel очень часто приходится искать некоторые значения по определенным критериям и подставлять их в другие таблицы. В таких задачах на помощью приходит функция ВПР, но у нее есть два существенных недостатка. Во-первых, функция ВПР возвращает только первое найденное значение. Например, у меня есть перечень заказов и необходимо получить номера всех заказов, которые оформил конкретный менеджер. Фамилия менеджера выбирается из выпадающего списка (выделено желтым) и ниже должны выводиться соответствующие номера заказов (зеленая область).
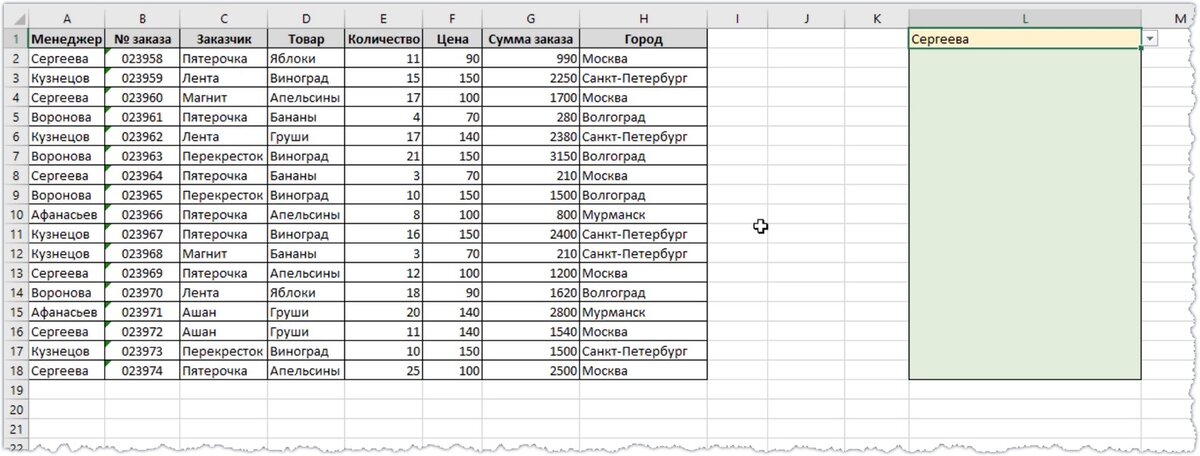
Если использовать стандартную функцию ВПР, то она найдет первый подходящий заказ и вернет ТОЛЬКО его номер.
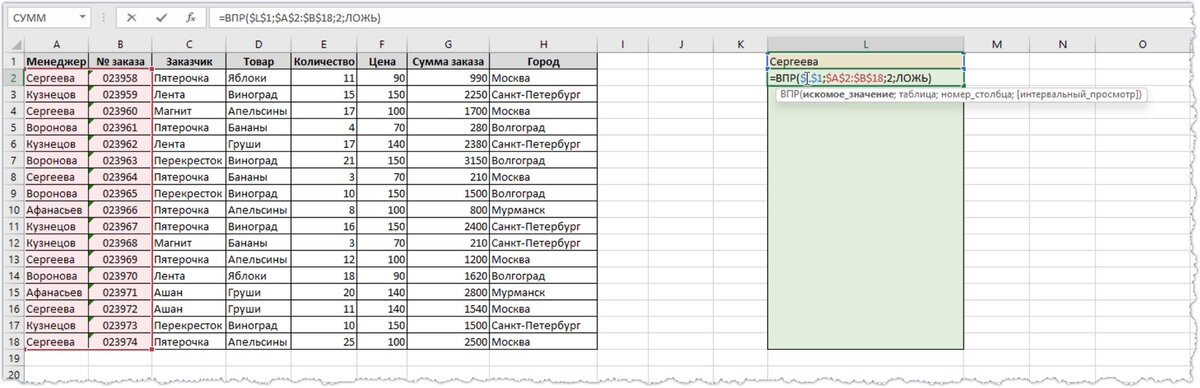
Еще одним недостатком функции ВПР является то, что она ищет значения только в левом крайнем столбце выделенного диапазона. То есть если бы столбец с фамилиями менеджеров находился правее столбца с номерами заказов, то функцию ВПР вообще не удалось бы использовать.
Этот недостаток устраняется с помощью сочетания функций ИНДЕКС и ПОИСКПОЗ, которые являются более гибкой альтернативой функции ВПР, но и эти функции не решают поставленную задачу.
Как же быть, если нужно вернуть все значения, соответсвующие определенному критерию? В этом также поможет функция ИНДЕКС.
Напомню, что функция ИНДЕКС возвращает значение, которое находится в указанном номере строки выделенного диапазона. То есть мы должны выбрать некоторый диапазон значений и вторым аргументом указать номер строки в этом диапазоне. Подчеркиваю, не номер строки листа Эксель, а номер строки выделенного диапазона значений.
Функция ИНДЕКС может возвращать не только одно значение, а массив значений. И именно это нам и нужно. Чтобы функция вернула массив значений, мы должны в нее подставить массив номеров нужным нам строк. Поэтому основной задачей для нас сейчас как раз и будет получение этого массива.
Давайте рассмотрим упрощенную таблицу, чтобы в ней не было отвлекающей информации. У нас есть таблица, состоящая из двух столбцов – Менеджер и Номер заказа. Также есть выпадающий список с фамилиями менеджеров и некоторая область листа, в которую мы будем выводить все заказы, связанные с выбранным менеджером.
Итак, сначала мы должны определить все строки в основной таблице, относящиеся к выбранному в списке менеджеру. Давайте сделаем это с помощью вспомогательного столбца и функции ЕСЛИ.
Если значение из текущей ячейки первого столбца таблицы (А2) равно значению, выбранному в выпадающем списке (L1), то определим номер строки, в котором это значение находится. Для этого воспользуемся функцией СТРОКА, которая как раз и предназначена для решения этой задачи. Так как формулу мы будем протягивать по диапазону, то не забываем зафиксировать ссылку на ячейку с выпадающем списком.
Протягиваем формулу.
Так как мы не указали в функции ЕСЛИ значение, которое появится в случае невыполнения условия, то в соответствующих ячейках выводится логическое выражение ЛОЖЬ. Это неважно, так как нас будут интересовать только цифры.
Мы получили номера строк листа Эксель, но в функцию ИНДЕКС необходимо подставить номер строки в выделенном диапазоне. В данном примере основная таблица располагается в верху листа и в первой строке находится шапка с названиями столбцов, поэтому, чтобы получить необходимые значения, мы можем откорректировать формулу и отнять единицу от полученного значения. В итоге во вспомогательном столбце появится массив необходимых нам чисел.
Если же таблица находится в другой части листа, то нужно будет либо вручную прописать необходимое корректировочное значение (то есть отступ от первой строки листа), либо можно автоматизировать этот процесс с помощью все той же функции СТРОКА, но об этом я расскажу чуть позже, чтобы сейчас не усложнять формулу.
Итак, теперь нам нужно отсортировать столбец, чтобы в начале были цифры. Сделать это можно, например, с помощью функции НАИМЕНЬШИЙ, которая возвращает указанное по счету наименьшее значение в выбранном диапазоне.
Выбираем диапазон (С2:С18) и затем необходимо указать цифру, определяющую, какое по порядку наименьшее число нужно вывести. Если укажем 1, то получим первое наименьшее значение в диапазоне, если 2, то второе, и так далее. Именно таким образом мы и сможем отсортировать полученный список с помощью формулы. Создадим вспомогательный столбец со значениями по порядку и подставим эти значения в функцию НАИМЕНЬШИЙ.
Мы получили необходимый нам перечень номеров строк и можем вернуться к функции ИНДЕКС. Фактически нам нужно подтянуть значения из второго столбца основной таблицы, поэтому в качестве диапазона указываем его. В качестве строки, соответственно, только что рассчитанные значения.
Чтобы избавиться от ошибки ЧИСЛО! воспользуемся функцией ЕСЛИОШИБКА. Обернем ей полученную функцию и в случае ошибки выведем пустоту.
Мы достигли необходимого результата, но для этого пришлось создать несколько вспомогательных столбцов. Давайте свернем все промежуточные вычисления в одну формулу, но это будет не простая формула, а формула массива, поэтому нам нужно будет поменять некоторые ссылки на диапазоны, к которым они относятся. А если точнее, то в функции ЕСЛИ нужно будет заменить относительные ссылки на ячейки столбца А соответствующим диапазоном и не забываем зафиксировать его. Также не забываем сделать формулу формулой массива, нажав сочетание клавиш Ctrl + Shift + Enter. Растянем формулу на весь зарезервированный диапазон таблицы и получаем необходимый результат.
Все вспомогательные столбцы, кроме столбца с нумерацией (столбец F) можно удалить. Давайте сделаем так, чтобы и этот столбец был не нужен. Значения столбца F используются в функции НАИМЕНЬШИЙ и нам нужно сделать так, чтобы подобный ряд чисел создавался автоматически и не зависел от того, где находится таблица с формулами. Для этого можно воспользоваться функцией СТРОКА и определить номер строки листа Эксель первой ячейки основной таблицы. Затем этот номер будем вычитать из номера последующих строк. Чтобы значения «не сползали» при протягивании формулы, зафиксируем ссылку на первую ячейку диапазона.
Все отлично, кроме того, что все значения нужно увеличить на единицу. Дополним формулу и получим нужный нам результат.
Осталось скопировать формулу и подставить ее в формулу массива, после чего и последний вспомогательный столбец можно будет удалить.
Ну и по аналогии можно решить проблему зависимости формулы от расположения исходной таблицы. Сейчас ее заголовки расположены в первой строке листа и поэтому формула четко привязана к этому положению.
Мы можем внести в функцию ЕСЛИ аналогичную формулу с двумя функциями СТРОКА. То есть отнимем от уже имеющейся функции СТРОКА со всем диапазоном столбца номер строки первой ячейки этого диапазона и прибавим единицу.
Теперь формула никак не привязана к положению исходной таблице на листе и она выполняет поставленную задачу – возвращает все искомые значения из указанного диапазона.
Ссылки на мои ресурсы по Excel
★ YouTube-канал по Excel
★ Телеграм
★ Серия видеокурсов “Microsoft Excel Шаг за Шагом”
★ Авторские книги и курсы
Функция ПОИСКПОЗ в Excel используется для поиска точного совпадения или ближайшего (меньшего или большего заданному в зависимости от типа сопоставления, указанного в качестве аргумента) значения заданному в массиве или диапазоне ячеек и возвращает номер позиции найденного элемента.
Примеры использования функции ПОИСКПОЗ в Excel
Например, имеем последовательный ряд чисел от 1 до 10, записанных в ячейках B1:B10. Функция =ПОИСКПОЗ(3;B1:B10;0) вернет число 3, поскольку искомое значение находится в ячейке B3, которая является третьей от точки отсчета (ячейки B1).
Данная функция удобна для использования в случаях, когда требуется вернуть не само значение, содержащееся в искомой ячейке, а ее координату относительно рассматриваемого диапазона. В случае использования для констант массивов, которые могут быть представлены как массивы элементов «ключ» – «значение», функция ПОИСКПОЗ возвращает значение ключа, который явно не указан.
Например, массив {“виноград”;”яблоко”;”груша”;”слива”} содержит элементы, которые можно представить как: 1 – «виноград», 2 – «яблоко», 3 – «груша», 4 – «слива», где 1, 2, 3, 4 – ключи, а названия фруктов – значения. Тогда функция =ПОИСКПОЗ(“яблоко”;{“виноград”;”яблоко”;”груша”;”слива”};0) вернет значение 2, являющееся ключом второго элемента. Отсчет выполняется не с 0 (нуля), как это реализовано во многих языках программирования при работе с массивами, а с 1.
Функция ПОИСКПОЗ редко используется самостоятельно. Ее целесообразно применять в связке с другими функциями, например, ИНДЕКС.
Формула для поиска неточного совпадения текста в Excel
Пример 1. Найти позицию первого частичного совпадения строки в диапазоне ячеек, хранящих текстовые значения.
Вид исходной таблицы данных:
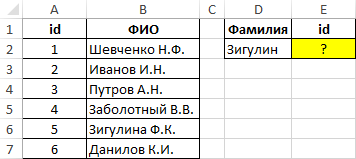
Для нахождения позиции текстовой строки в таблице используем следующую формулу:
=ПОИСКПОЗ(D2&”*”;B:B;0)-1
Описание аргументов:
- D2&”*” – искомое значение, состоящее и фамилии, указанной в ячейке B2, и любого количества других символов (“*”);
- B:B – ссылка на столбец B:B, в котором выполняется поиск;
- 0 – поиск точного совпадения.
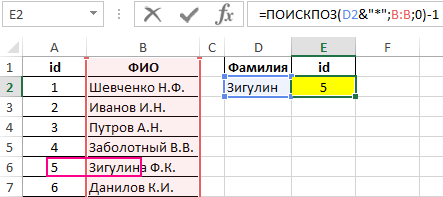
Из полученного значения вычитается единица для совпадения результата с id записи в таблице.
Пример поиска:
Сравнение двух таблиц в Excel на наличие несовпадений значений
Пример 2. В Excel хранятся две таблицы, которые на первый взгляд кажутся одинаковыми. Было решено сравнить по одному однотипному столбцу этих таблиц на наличие несовпадений. Реализовать способ сравнения двух диапазонов ячеек.
Вид таблицы данных:
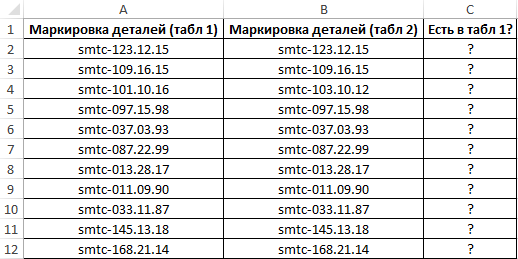
Для сравнения значений, находящихся в столбце B:B со значениями из столбца A:A используем следующую формулу массива (CTRL+SHIFT+ENTER):
Функция ПОИСКПОЗ выполняет поиск логического значения ИСТИНА в массиве логических значений, возвращаемых функцией СОВПАД (сравнивает каждый элемент диапазона A2:A12 со значением, хранящимся в ячейке B2, и возвращает массив результатов сравнения). Если функция ПОИСКПОЗ нашла значение ИСТИНА, будет возвращена позиция его первого вхождения в массив. Функция ЕНД возвратит значение ЛОЖЬ, если она не принимает значение ошибки #Н/Д в качестве аргумента. В этом случае функция ЕСЛИ вернет текстовую строку «есть», иначе – «нет».
Чтобы вычислить остальные значения «протянем» формулу из ячейки C2 вниз для использования функции автозаполнения. В результате получим:
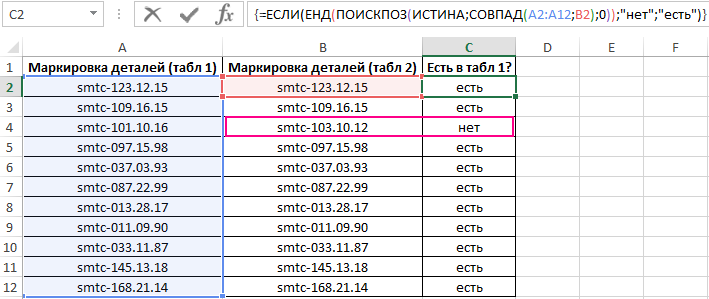
Как видно, третьи элементы списков не совпадают.
Поиск ближайшего большего знания в диапазоне чисел Excel
Пример 3. Найти ближайшее меньшее числу 22 в диапазоне чисел, хранящихся в столбце таблицы Excel.
Вид исходной таблицы данных:
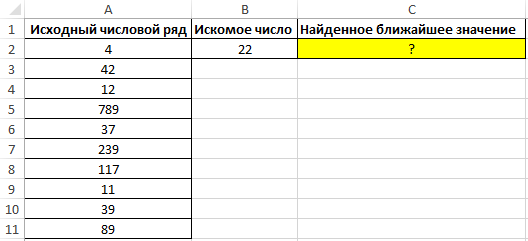
Для поиска ближайшего большего значения заданному во всем столбце A:A (числовой ряд может пополняться новыми значениями) используем формулу массива (CTRL+SHIFT+ENTER):
Функция ПОИСКПОЗ возвращает позицию элемента в столбце A:A, имеющего максимальное значение среди чисел, которые больше числа, указанного в ячейке B2. Функция ИНДЕКС возвращает значение, хранящееся в найденной ячейке.
Результат расчетов:
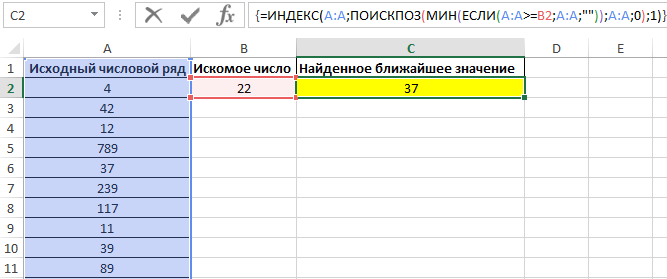
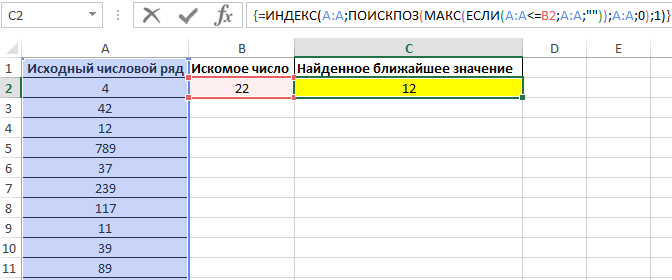
Для поиска ближайшего меньшего значения достаточно лишь немного изменить данную формулу и ее следует также ввести как массив (CTRL+SHIFT+ENTER):
Результат поиска:
Особенности использования функции ПОИСКПОЗ в Excel
Функция имеет следующую синтаксическую запись:
=ПОИСКПОЗ(искомое_значение;просматриваемый_массив;[тип_сопоставления])
Описание аргументов:
- искомое_значение – обязательный аргумент, принимающий текстовые, числовые значения, а также данные логического и ссылочного типов, который используется в качестве критерия поиска (для сопоставления величин или нахождения точного совпадения);
- просматриваемый_массив – обязательный аргумент, принимающий данные ссылочного типа (ссылки на диапазон ячеек) или константу массива, в которых выполняется поиск позиции элемента согласно критерию, заданному первым аргументом функции;
- [тип_сопоставления] – необязательный для заполнения аргумент в виде числового значения, определяющего способ поиска в диапазоне ячеек или массиве. Может принимать следующие значения:
- -1 – поиск наименьшего ближайшего значения заданному аргументом искомое_значение в упорядоченном по убыванию массиве или диапазоне ячеек.
- 0 – (по умолчанию) поиск первого значения в массиве или диапазоне ячеек (не обязательно упорядоченном), которое полностью совпадает со значением, переданным в качестве первого аргумента.
- 1 – Поиск наибольшего ближайшего значения заданному первым аргументом в упорядоченном по возрастанию массиве или диапазоне ячеек.
Скачать примеры ПОИСКПОЗ для поиска совпадения значений в Excel
Примечания:
- Если в качестве аргумента искомое_значение была передана текстовая строка, функция ПОИСКПОЗ вернет позицию элемента в массиве (если такой существует) без учета регистра символов. Например, строки «МоСкВа» и «москва» являются равнозначными. Для различения регистров можно дополнительно использовать функцию СОВПАД.
- Если поиск с использованием рассматриваемой функции не дал результатов, будет возвращен код ошибки #Н/Д.
- Если аргумент [тип_сопоставления] явно не указан или принимает число 0, для поиска частичного совпадения текстовых значений могут быть использованы подстановочные знаки («?» – замена одного любого символа, «*» – замена любого количества символов).
- Если в объекте данных, переданном в качестве аргумента просматриваемый_массив, содержится два и больше элементов, соответствующих искомому значению, будет возвращена позиция первого вхождения такого элемента.
Ссылка на это место страницы:
#title
- Получить первое не пустое значение в списке
- Получить первое текстовое значение в списке
- Получить первое текстовое значение с ГПР
- Получить позицию последнего совпадения
- Получить последнее совпадение содержимого ячейки
- Получить n-е совпадение
- Получить n-ое совпадение с ИНДЕКС/ПОИСКПОЗ
- Получить n-ое совпадение с ВПР
- Если ячейка содержит одну из многих вещей
- Поиск первой ошибки
- Поиск следующего наибольшего значения
- Несколько совпадений в списке, разделенных запятой
- Частичное совпадение чисел с шаблоном
- Частичное совпадение с ВПР
- Положение первого частичного совпадения
- Скачать файл
Ссылка на это место страницы:
#punk01
{ = ИНДЕКС( диапазон ; ПОИСКПОЗ( ЛОЖЬ; ЕПУСТО ( диапазон ); 0 )) }
{ = INDEX( диапазон ; MATCH( FALSE; ISBLANK ( диапазон ); 0 )) }

Если вам нужно получить первое не пустое значение (текст или число) в диапазоне в одной колонке вы можете использовать формулу массива на основе функций ИНДЕКС, ПОИСКПОЗ и ЕПУСТО.
В данном примере мы используем эту формулу:
{ = ИНДЕКС( B3: B11; ПОИСКПОЗ( ЛОЖЬ; ЕПУСТО ( B3: B11 ); 0 )) }
{ = INDEX( B3:B11; MATCH( FALSE; ISBLANK ( B3:B11 ); 0 )) }
Таким образом, суть проблемы заключается в следующем: мы хотим получить первую не пустую ячейку, но для этого нет конкретной формулы в Excel. Мы могли бы использовать ВПР с шаблоном *, но это будет работать только для текста, а не для чисел.
Таким образом, нам нужно строить функциональные возможности для нужных нам формул. Способ сделать это состоит в использовании функции массива, которая “тестирует” ячейки и возвращает массив истина/ложь значения, которые мы можем сопрягать с ПОИСКПОЗ.
Работая изнутри, ЕПУСТО оценивает ячейки в диапазоне В3: В11 и возвращает результат и массив, который выглядит следующим образом:
{ИСТИНА; ЛОЖЬ; ИСТИНА; ЛОЖЬ; ЛОЖЬ; ИСТИНА; ИСТИНА; ИСТИНА; ИСТИНА}
Каждая ЛОЖЬ представляет собой ячейку в диапазоне, который не является пустой.
Далее, ПОИСКПОЗ ищет ЛОЖЬ внутри массива и возвращает позицию первого наденного совпадения, в этом случае 2. На данный момент, формула в примере теперь выглядит следующим образом:
{ = ИНДЕКС( B3: B11; 2; 0 )) }
{ = INDEX( B3:B11; 2; 0 )) }
И, наконец, функция ИНДЕКС выводит значение в положении 2 в массиве, в этом случае число 10.
Ссылка на это место страницы:
#punk02
= ВПР ( “*”; диапазон; 1; ЛОЖЬ)
= VLOOKUP ( “*”; диапазон; 1; FALSE)
Если вам нужно получить первое текстовое значение в списке (диапазон один столбец), вы можете использовать функцию ВПР, чтобы установить точное соответствие, с шаблонным символом для поиска.

В данном примере формула в D7 является:
= ВПР ( “*” ; B5: B11 ; 1 ; ЛОЖЬ)
= VLOOKUP ( “*” ; B5:B11 ; 1 ; FALSE)
Групповой символ звездочка (*) соответствует любому текстовому значению.
Ссылка на это место страницы:
#punk03
= ГПР ( “*”; диапазон; 1; ЛОЖЬ)
= HLOOKUP ( “*”; диапазон; 1; FALSE)

Для поиска и получения первого текстового значения во всем диапазоне столбцов, вы можете использовать функцию ГПР с групповым символом. В примере формула в F5 является:
= ГПР ( “*”; диапазон; 1; ЛОЖЬ)
= HLOOKUP ( “*”; диапазон; 1; FALSE)
Значение поиска является “*”, групповым символом, который соответствует одному или более текстовому значению.
Ссылка на это место страницы:
#punk04
= ГПР ( “*”; диапазон; 1; ЛОЖЬ)
= HLOOKUP ( “*”; диапазон; 1; FALSE)
Для того, чтобы получить позицию последнего совпадения (т.е. последнего вхождения) от значения поиска, вы можете использовать формулу, основанную на ЕСЛИ, СТРОКА, ИНДЕКС, ПОИСКПОЗ и MAКС функций.

=МАКС(ЕСЛИ(B4:B11=G5;СТРОКА(B4:B11)-СТРОКА(ИНДЕКС(B4:B11;1;1))+1))
=MAX(IF(B4:B11=G5;ROW(B4:B11)-ROW(INDEX(B4:B11;1;1))+1))
Суть этой формулы состоит в том, что мы строим список номеров строк для данного диапазона, соответствующие по значению, а затем используем функцию MAКС, чтобы получить наибольшее количество строк, что соответствует последнему значению соответствия.
Ссылка на это место страницы:
#punk05
=МАКС(ЕСЛИ(B4:B11=G5;СТРОКА(B4:B11)-СТРОКА(ИНДЕКС(B4:B11;1;1))+1))
=MAX(IF(B4:B11=G5;ROW(B4:B11)-ROW(INDEX(B4:B11;1;1))+1))
Чтобы проверить ячейку для одной из нескольких вещей, и вернуть последнее совпадение, найденное в списке, вы можете использовать формулу, основанную на ПРОСМОТР и ПОИСК функций. В случае нескольких найденных совпадений, формула вернет последнее совпадение из списка «вещей».

=ПРОСМОТР(2;1/ПОИСК($E$4:$E$7;B4);$E$4:$E$7)
=LOOKUP(2;1/SEARCH($E$4:$E$7;B4);$E$4:$E$7)
Ссылка на это место страницы:
#punk06
= НАИМЕНЬШИЙ( ЕСЛИ( логический тест; СТРОКА( список ) – МИН( СТРОКА( список )) + 1 ); n )
= SMALL( IF( логический тест; СТРОКА( список ) – MIN( ROW( список )) + 1 ); n )
Для того, чтобы получить позицию n-го совпадения (например, второе значение соответствия заданному, третье значение соответствия и т.д.), вы можете использовать формулу, основанную на функции НАИМЕНЬШИЙ.
= НАИМЕНЬШИЙ( ЕСЛИ( список = E5 ; СТРОКА( список ) – МИН( СТРОКА( список )) + 1 ); F5 )
= SMALL( IF( список = E5 ; ROW( список ) – MIN( ROW( список )) + 1 ); F5 )
Эта формула возвращает позицию второго появления “красных” в списке.
Сутью этой формулы является функция НАИМЕНЬШИЙ, которая просто возвращает n-е наименьшее значение в списке значений, которое соответствует номеру строки. Номера строк были “отфильтрованы” функцией ЕСЛИ, которая применяет логику для совпадения.
Ссылка на это место страницы:
#punk07
{ = ИНДЕКС( массив; НАИМЕНЬШИЙ( ЕСЛИ( величины = знач ; СТРОКА ( величины ) – СТРОКА ( ИНДЕКС( величины; 1 ; 1 )) + 1 ); n-й )) }
{ = INDEX( массив; SMALL( IF( величины = знач ; ROW ( величины ) – ROW ( INDEX( величины; 1 ; 1 )) + 1 ); n-й )) }

Эта формула возвращает позицию второго появления “красных” в списке.
Сутью этой формулы является функция НАИМЕНЬШИЙ, которая просто возвращает n-е наименьшее значение в списке значений, которое соответствует номеру строки. Номера строк были “отфильтрованы” функцией ЕСЛИ, которая применяет логику для совпадения.
Ссылка на это место страницы:
#punk08
= ВПР( id_формулы; стол; 4; 0 )
= VLOOKUP( id_формулы; стол; 4; 0 )
Чтобы получить n-ое совпадение с ВПР, вам необходимо добавить вспомогательный столбец в таблицу , которая строит уникальный идентификатор , который включает счетчик.

Эта формула зависит от вспомогательного столбца, который добавляется в качестве первого столбца таблицы исходных данных.
Вспомогательный столбец содержит формулу, которая строит уникальное значение взгляда вверх от существующего идентификатора и счетчика. Счетчик подсчитывает сколько раз уникальный идентификатор появился в таблице данных.
В примере, формула ячейки J6 вспомогательного столбца выглядит следующим образом:
=ВПР(J3&”-“&I6;B4:G11;4;0)
=VLOOKUP(J3&”-“&I6;B4:G11;4;0)
Ссылка на это место страницы:
#punk09
{ = ИНДЕКС( результаты ;ПОИСКПОЗ( ИСТИНА ; ЕЧИСЛО( ПОИСК( вещи ; A1 )); 0 )) }
{ = INDEX( результаты ;MATCH( TRUE ; ISNUMBER( SEARCH( вещи ; A1 )); 0 )) }
Чтобы проверить ячейку для одной из нескольких вещей, и вернуть пользовательский результат для первого найденного совпадения, вы можете использовать формулу ИНДЕКС/ПОИСКПОЗ, основанную на функции поиска.
{ = ИНДЕКС( результаты ; ПОИСКПОЗ( ИСТИНА ; ЕЧИСЛО( ПОИСК ( вещи ; B5 )); 0 )) }
= INDEX( результаты ; MATCH( TRUE ; ISNUMBER( SEARCH ( вещи ; B5 )); 0 ))
Эта формула использует два названных диапазона: E5: E8 называется “вещи” и F5: F8 называется “Результаты”. Убедитесь, что вы используете диапазоны имен с одинаковыми именами (на основе ваших данных). Если вы не хотите использовать именованные диапазоны, используйте абсолютные ссылки вместо этого.
Ссылка на это место страницы:
#punk10
{ = ПОИСКПОЗ( ИСТИНА ; ЕОШИБКА(диап ); 0 ) }
{ = MATCH( TRUE ; ISERROR(диап ); 0 ) }
Если вам нужно найти первую ошибку в диапазоне ячеек, вы можете использовать формулу массива, основанную на ПОИСКПОЗ и ЕОШИБКА функциях.

В приведенном примере формула:
{ = ПОИСКПОЗ( ИСТИНА ; ЕОШИБКА( B4: B11 ); 0 ) }
{ = MATCH( TRUE ; ISERROR( B4:B11 ); 0 ) }
Работая изнутри, функция ЕОШИБКА возвращает значение ИСТИНА, если значение является признанной ошибкой, и ЛОЖЬ, если нет.
Когда дается диапазон ячеек (массив ячеек) функция ЕОШИБКА будет возвращать массив истина/ложь значений. В примере, это результирующий массив выглядит следующим образом:
{ЛОЖЬ; ЛОЖЬ; ЛОЖЬ; ЛОЖЬ; ЛОЖЬ; ИСТИНА; ЛОЖЬ; ЛОЖЬ}
Обратите внимание, что 6-е значение (что соответствует 6-й ячейке в диапазоне) истинно, так как ячейка В9 содержит #Н/A.
Ссылка на это место страницы:
#punk11
=ИНДЕКС ( данные; ПОИСКПОЗ( поиск ; значения ) + 1 )
=INDEX ( данные; MATCH( поиск ; значения ) + 1 )

Для того, чтобы найти “следующее наибольшее” значение в справочной таблице, можно использовать формулу, основанную на ИНДЕКС и ПОИСКПОЗ. В примере формула в F6 является:
=ИНДЕКС ( данные; ПОИСКПОЗ( поиск ; значения ) + 1 )
=INDEX ( данные; MATCH( поиск ; значения ) + 1 )
Ссылка на это место страницы:
#punk12
{ = ОБЪЕДИНИТЬ ( “;” ; ИСТИНА ; ЕСЛИ( диапазон1 = E5 ; диапазон2 ; “” )) }
{ = ОБЪЕДИНИТЬ ( “;” ; TRUE ; IF( диапазон1 = E5 ; диапазон2 ; “” )) }
Для поиска и извлечения нескольких совпадений, разделенных запятыми (в одной ячейке), вы можете использовать функцию ЕСЛИ с функцией ОБЪЕДИНИТЬ.
{ = ОБЪЕДИНИТЬ( “;” ; ИСТИНА ; ЕСЛИ( группа = E5 ; имя ; “” )) }
Эта формула использует “имя” – именованный диапазон (B5: B11) и “группа” – (C5: C11).
Ссылка на это место страницы:
#punk13
{ = ПОИСКПОЗ( “*” & номер & “*” ; ТЕКСТ( диапазон ; “0” ); 0 ) }
{ = MATCH( “*” & номер & “*” ; TEXT( диапазон ; “0” ); 0 ) }
Для того, чтобы выполнить частичное совпадение (подстроки) против чисел, вы можете использовать формулу массива, основанную на ПОИСКПОЗ и ТЕКСТ.

Excel поддерживает символы подстановки “*” и “?”. Тем не менее, если вы используете специальные символы с номером, вы будете преобразовывать числовое значение в текстовое значение. Другими словами, “*” & 99 & “*” = “* 99 *” (текстовая строка).
Если попытаться найти текстовое значение в диапазоне чисел, совпадение завершится неудачно.
Одно из решений заключается в преобразовании чисел в диапазоне поиска для текстовых значений, а затем сделать нормальный поиск с ПОИСКПОЗ, ВПР и т.д.
Другой способ, чтобы преобразовать числа в текст, чтобы сцепить пустую строку. Эта формула работает так же, как выше формуле:
= ПОИСКПОЗ ( “*” & Е5 & “*” ; В5: В10 & “” ; 0 )
= MATCH ( “*” & Е5 & “*” ; В5: В10 & “” ; 0 )
Ссылка на это место страницы:
#punk14
Если вы хотите получить информацию из таблицы на основе частичного совпадения, вы можете сделать это с помощью ВПР в режиме точного соответствия, и групповые символы.

В примере формула ВПР выглядит следующим образом:
=ВПР($H$2&”*”;$B$3:$E$12;2;0)
=VLOOKUP($H$2&”*”;$B$3:$E$12;2;0)
В этой формуле, значение представляет собой именованный диапазон, который относится к Н2, а также данные , представляет собой именованный диапазон , который относится к B3: E102. Без названных диапазонов, формула может быть записана следующим образом:
Ссылка на это место страницы:
#punk15
= ПОИСКПОЗ ( “* текст *” ; диапазон; 0 )
= MATCH ( “* текст *” ; диапазон; 0 )
Для того, чтобы получить позицию первого частичного совпадения (то есть ячейку, которая содержит текст, который вы ищете), вы можете использовать функцию ПОИСКПОЗ со специальными символами.

=ПОИСКПОЗ(“*”&E6&”*”;B5:B10;0)
=MATCH(“*”&E6&”*”;B5:B10;0)
Функция ПОИСКПОЗ возвращает позицию или “индекс” в первом совпадении на основании значения поиска в диапазоне.
ПОИСКПОЗ поддерживает подстановочное согласование со звездочкой “*” (один или несколько символов) или знаком вопроса “?” (один символ), но только тогда, когда третий аргумент, тип_сопоставления, установлен в ЛОЖЬ или ноль.
Ссылка на это место страницы:
#punk16
Файлы статей доступны только зарегистрированным пользователям.
1. Введите свою почту
2. Нажмите Зарегистрироваться
3. Обновите страницу
Вместо этого блока появится ссылка для скачивания материалов.

Привет! Меня зовут Дмитрий. С 2014 года Microsoft Cretified Trainer. Вместе с командой управляем этим сайтом. Наша цель – помочь вам эффективнее работать в Excel.
Изучайте наши статьи с примерами формул, сводных таблиц, условного форматирования, диаграмм и макросов. Записывайтесь на наши курсы или заказывайте обучение в корпоративном формате.

Подписывайтесь на нас в соц.сетях:
