Improve Article
Save Article
Like Article
Improve Article
Save Article
Like Article
Let’s discuss how to get unique values from a column in Pandas DataFrame.
Create a simple dataframe with dictionary of lists, say columns name are A, B, C, D, E with duplicate elements.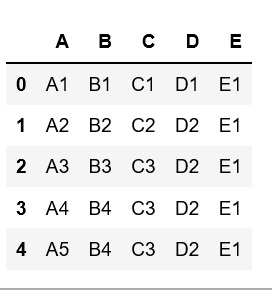
Now, let’s get the unique values of a column in this dataframe.
Example #1: Get the unique values of ‘B’ column
import pandas as pd
data = {
'A':['A1', 'A2', 'A3', 'A4', 'A5'],
'B':['B1', 'B2', 'B3', 'B4', 'B4'],
'C':['C1', 'C2', 'C3', 'C3', 'C3'],
'D':['D1', 'D2', 'D2', 'D2', 'D2'],
'E':['E1', 'E1', 'E1', 'E1', 'E1'] }
df = pd.DataFrame(data)
df.B.unique()
Output:![]()
Example #2: Get the unique values of ‘E’ column
import pandas as pd
data = {
'A':['A1', 'A2', 'A3', 'A4', 'A5'],
'B':['B1', 'B2', 'B3', 'B4', 'B4'],
'C':['C1', 'C2', 'C3', 'C3', 'C3'],
'D':['D1', 'D2', 'D2', 'D2', 'D2'],
'E':['E1', 'E1', 'E1', 'E1', 'E1'] }
df = pd.DataFrame(data)
df.E.unique()
Output:![]()
Example #3: Get number of unique values in a column
import pandas as pd
data = {
'A':['A1', 'A2', 'A3', 'A4', 'A5'],
'B':['B1', 'B2', 'B3', 'B4', 'B4'],
'C':['C1', 'C2', 'C3', 'C3', 'C3'],
'D':['D1', 'D2', 'D2', 'D2', 'D2'],
'E':['E1', 'E1', 'E1', 'E1', 'E1'] }
df = pd.DataFrame(data)
df.C.nunique(dropna = True)
Output:![]()
Last Updated :
10 Dec, 2018
Like Article
Save Article
I have a pandas dataframe. I want to print the unique values of one of its columns in ascending order. This is how I am doing it:
import pandas as pd
df = pd.DataFrame({'A':[1,1,3,2,6,2,8]})
a = df['A'].unique()
print a.sort()
The problem is that I am getting a None for the output.
![]()
ivanleoncz
8,7706 gold badges56 silver badges48 bronze badges
asked Aug 18, 2015 at 12:10
![]()
2
import pandas as pd
df = pd.DataFrame({'A':[1,1,3,2,6,2,8]})
a = df['A'].unique()
print(sorted(a))
OUTPUT
[1, 2, 3, 6, 8]
![]()
Paul P
3,0712 gold badges11 silver badges24 bronze badges
answered Aug 18, 2015 at 12:18
![]()
1
sort sorts inplace so returns nothing:
In [54]:
df = pd.DataFrame({'A':[1,1,3,2,6,2,8]})
a = df['A'].unique()
a.sort()
a
Out[54]:
array([1, 2, 3, 6, 8], dtype=int64)
So you have to call print a again after the call to sort.
Eg.:
In [55]:
df = pd.DataFrame({'A':[1,1,3,2,6,2,8]})
a = df['A'].unique()
a.sort()
print(a)
[1 2 3 6 8]
answered Aug 18, 2015 at 12:12
![]()
EdChumEdChum
371k198 gold badges804 silver badges560 bronze badges
1
You can also use the drop_duplicates() instead of unique()
df = pd.DataFrame({'A':[1,1,3,2,6,2,8]})
a = df['A'].drop_duplicates()
a.sort()
print a
answered Aug 18, 2015 at 12:24
![]()
MelounMeloun
13.3k17 gold badges64 silver badges92 bronze badges
2
Fastest code
for large data frames:
df['A'].drop_duplicates().sort_values()
answered Aug 25, 2021 at 9:08
![]()
Serge StroobandtSerge Stroobandt
27.6k9 gold badges104 silver badges100 bronze badges
2
Came across the question myself today. I think the reason that your code returns ‘None’ (exactly what I got by using the same method) is that
a.sort()
is calling the sort function to mutate the list a. In my understanding, this is a modification command. To see the result you have to use print(a).
My solution, as I tried to keep everything in pandas:
pd.Series(df['A'].unique()).sort_values()
answered Oct 19, 2018 at 20:21
![]()
Bowen LiuBowen Liu
1,0511 gold badge10 silver badges23 bronze badges
1
I prefer the oneliner:
print(sorted(df['Column Name'].unique()))
answered Mar 19, 2018 at 16:37
![]()
MDMoore313MDMoore313
3,2031 gold badge23 silver badges37 bronze badges
I would suggest using numpy’s sort, as it is anyway what pandas is doing in background:
import numpy as np
np.sort(df.A.unique())
But doing all in pandas is valid as well.
answered Aug 18, 2015 at 12:24
![]()
ChallensoisChallensois
5222 silver badges10 bronze badges
Another way is using set data type.
Some characteristic of Sets: Sets are unordered, can include mixed data types, elements in a set cannot be repeated, are mutable.
Solving your question:
df = pd.DataFrame({'A':[1,1,3,2,6,2,8]})
sorted(set(df.A))
The answer in List type:
[1, 2, 3, 6, 8]
answered Dec 8, 2018 at 7:27
![]()
0
Surprised no one suggested this:
df['A'].sort_values().unique()
answered Apr 6 at 21:18
![]()
2
Pandas
17 авг. 2022 г.
читать 1 мин
Самый простой способ получить список уникальных значений в столбце pandas DataFrame — использовать функцию unique() .
В этом руководстве представлено несколько примеров использования этой функции со следующими пандами DataFrame:
import pandas as pd
#create DataFrame
df = pd.DataFrame({'team': ['A', 'A', 'A', 'B', 'B', 'C'],
'conference': ['East', 'East', 'East', 'West', 'West', 'East'],
'points': [11, 8, 10, 6, 6, 5]})
#view DataFrame
df
team conference points
0 A East 11
1 A East 8
2 A East 10
3 B West 6
4 B West 6
5 C East 5
Найти уникальные значения в одном столбце
Следующий код показывает, как найти уникальные значения в одном столбце DataFrame:
df.team.unique ()
array(['A', 'B', 'C'], dtype=object)
Мы видим, что уникальные значения в столбце команды включают «A», «B» и «C».
Найти уникальные значения во всех столбцах
Следующий код показывает, как найти уникальные значения во всех столбцах DataFrame:
for col in df:
print(df[col]. unique ())
['A' 'B' 'C']
['East' 'West']
[11 8 10 6 5]
Поиск и сортировка уникальных значений в столбце
Следующий код показывает, как найти и отсортировать уникальные значения в одном столбце DataFrame:
#find unique points values
points = df.points.unique ()
#sort values smallest to largest
points. sort ()
#display sorted values
points
array([ 5, 6, 8, 10, 11])
Найти и подсчитать уникальные значения в столбце
В следующем коде показано, как найти и подсчитать появление уникальных значений в одном столбце DataFrame:
df.team.value_counts ()
A 3
B 2
C 1
Name: team, dtype: int64
Дополнительные ресурсы
Как выбрать уникальные строки в Pandas DataFrame
Как найти уникальные значения в нескольких столбцах в Pandas
Example
In [15]: df = pd.DataFrame({"A":[1,1,2,3,1,1],"B":[5,4,3,4,6,7]})
In [21]: df
Out[21]:
A B
0 1 5
1 1 4
2 2 3
3 3 4
4 1 6
5 1 7
To get unique values in column A and B.
In [22]: df["A"].unique()
Out[22]: array([1, 2, 3])
In [23]: df["B"].unique()
Out[23]: array([5, 4, 3, 6, 7])
To get the unique values in column A as a list (note that unique() can be used in two slightly different ways)
In [24]: pd.unique(df['A']).tolist()
Out[24]: [1, 2, 3]
Here is a more complex example. Say we want to find the unique values from column ‘B’ where ‘A’ is equal to 1.
First, let’s introduce a duplicate so you can see how it works. Let’s replace the 6 in row ‘4’, column ‘B’ with a 4:
In [24]: df.loc['4', 'B'] = 4
Out[24]:
A B
0 1 5
1 1 4
2 2 3
3 3 4
4 1 4
5 1 7
Now select the data:
In [25]: pd.unique(df[df['A'] == 1 ]['B']).tolist()
Out[25]: [5, 4, 7]
This can be broken down by thinking of the inner DataFrame first:
df['A'] == 1
This finds values in column A that are equal to 1, and applies True or False to them. We can then use this to select values from column ‘B’ of the DataFrame (the outer DataFrame selection)
For comparison, here is the list if we don’t use unique. It retrieves every value in column ‘B’ where column ‘A’ is 1
In [26]: df[df['A'] == 1]['B'].tolist()
Out[26]: [5, 4, 4, 7]
Время чтения 3 мин.
Метод Pandas unique() имеет преимущество перед numpy.unique, поскольку здесь мы также можем иметь значения NA, и она сравнительно быстрее. Функция unique() основана на хеш-таблице. Уникальные значения возвращаются в порядке их появления в наборе данных.
Содержание
- Что такое функция Series unique() вPandas?
- Синтаксис
- Параметры
- Возвращаемое значение
- Пример
- Неупорядоченный категориальный список
- Упорядоченный категориальный список
- Массив кортежей
- Pandas unique() с NaN и None
Что такое функция Series unique() в Pandas?
Функция Pandas unique() извлекает уникальные данные из набора данных. Метод unique() не принимает никаких параметров и возвращает пустой массив уникальных значений в этом конкретном столбце.
Когда мы много раз анализируем набор данных, и нам нужно, чтобы уникальные данные решали проблемы такого типа, мы используем метод Pandas unique(), который возвращает уникальные данные из заданного набора данных.
Синтаксис
Параметры
Функция unique() не принимает никаких параметров, но ее следует применять к одномерному массиву.
Возвращаемое значение
Функция unique() возвращает массив уникальных значений в этом конкретном столбце.
Возвращаемое значение может быть:
- Index: когда вход является индексом.
- Categorical: когда вход является категориальным типом.
- ndarray: когда в качестве входных данных используется Series/ndarray.
Пример
 | Pandas.Series.unique в Python")
- Напишем программу, показывающую работу метода unique() в Python.
|
import pandas as pd dataset = { ‘Name’: [‘Rohit’, ‘Arun’, ‘Sohit’, ‘Arun’, ‘Shubh’], ‘Roll no’: [’01’, ’02’, ’03’, ’04’, ’05’], ‘maths’: [’93’, ’63’, ’74’, ’94’, ’83’], ‘science’: [’88’, ’55’, ’66’, ’94’, ’35’], ‘english’: [’93’, ’74’, ’84’, ’92’, ’87’]} df = pd.DataFrame(dataset) group = df[“Name”].unique() print(group) |
Выход:
|
[‘Rohit’ ‘Arun’ ‘Sohit’ ‘Shubh’] |
В этом примере мы видим, что мы пытались найти все уникальные элементы столбца «Name». Здесь мы видим, что Arun повторяется в столбце дважды; следовательно, с помощью функции unique() мы извлекли только уникальные имена.
- Напишем программу, которая использует unique() для элементов списка и возвращает уникальные элементы из этого списка.
В этом примере мы будем использовать серию Pandas и находить уникальные предметы из последовательности.
|
import pandas as pd print(pd.unique(pd.Series([1, 2, 3, 4, 5, 6, 7, 7, 7, 7, 8]))) |
Выход:
В этом коде мы напечатали все уникальные элементы серии.
Неупорядоченный категориальный список
Если наш ввод является неупорядоченным категориальным типом dtype, мы получим следующий вывод.
|
import pandas as pd print(pd.unique(pd.Series(pd.Categorical(list(‘tenet’))))) |
Выход:
|
[t, e, n] Categories(3, object): [t, e, n] |
Упорядоченный категориальный список
Если наш ввод является упорядоченным категориальным типом dtype, мы получим следующий вывод.
|
import pandas as pd print(pd.unique(pd.Series(pd.Categorical(list(‘tenet’), categories=list(‘ent’), ordered=True)))) |
Выход:
|
[t, e, n] Categories(3, object): [e < n < t] |
Массив кортежей
Давайте передадим массив кортежей функции pd.unique() и посмотрим на результат.
|
import pandas as pd print(pd.unique([(‘x’, ‘y’),(‘y’, ‘x’),(‘x’, ‘z’),(‘y’, ‘x’)])) |
Выход:
|
[(‘x’, ‘y’)(‘y’, ‘x’)(‘x’, ‘z’)] |
В этом примере мы передали(‘y’, ‘x’) два раза, но в выводе отображается только один раз. Это означает, что функция pd.unique() отфильтровала повторяющийся кортеж. Помните одну вещь: метод unique() работает только с сериями, а не с DataFrames.
Если вы вызовете метод unique() для DataFrame, он выдаст следующую ошибку.
|
AttributeError: ‘DataFrame’ object has no attribute ‘unique’ |

Pandas unique() с NaN и None
Метод pd.unique() включает значение NULL, None или NaN в качестве уникального значения.
Если вы еще не установили numpy, установите и импортируйте numpy в файл.
|
import pandas as pd import numpy as np print(pd.unique([(‘x’, ‘y’),(‘y’, ‘x’),(‘x’, ‘z’), np.nan, None, np.nan])) |
Выход:
|
[(‘x’, ‘y’)(‘y’, ‘x’)(‘x’, ‘z’) nan None] |
В этом примере мы взяли значения np.nan два раза, но на выходе они возвращаются только один раз.
