There are 4 methods you can use:
- DISTINCT
- GROUP BY
- Subquery
- Common Table Expression (CTE) with ROW_NUMBER()
Consider the following sample TABLE with test data:
/** Create test table */
CREATE TEMPORARY TABLE dupes(word text, num int, id int);
/** Add test data with duplicates */
INSERT INTO dupes(word, num, id)
VALUES ('aaa', 100, 1)
,('bbb', 200, 2)
,('ccc', 300, 3)
,('bbb', 400, 4)
,('bbb', 200, 5) -- duplicate
,('ccc', 300, 6) -- duplicate
,('ddd', 400, 7)
,('bbb', 400, 8) -- duplicate
,('aaa', 100, 9) -- duplicate
,('ccc', 300, 10); -- duplicate
Option 1: SELECT DISTINCT
This is the most simple and straight forward, but also the most limited way:
SELECT DISTINCT word, num
FROM dupes
ORDER BY word, num;
/*
word|num|
----|---|
aaa |100|
bbb |200|
bbb |400|
ccc |300|
ddd |400|
*/
Option 2: GROUP BY
Grouping allows you to add aggregated data, like the min(id), max(id), count(*), etc:
SELECT word, num, min(id), max(id), count(*)
FROM dupes
GROUP BY word, num
ORDER BY word, num;
/*
word|num|min|max|count|
----|---|---|---|-----|
aaa |100| 1| 9| 2|
bbb |200| 2| 5| 2|
bbb |400| 4| 8| 2|
ccc |300| 3| 10| 3|
ddd |400| 7| 7| 1|
*/
Option 3: Subquery
Using a subquery, you can first identify the duplicate rows to ignore, and then filter them out in the outer query with the WHERE NOT IN (subquery) construct:
/** Find the higher id values of duplicates, distinct only added for clarity */
SELECT distinct d2.id
FROM dupes d1
INNER JOIN dupes d2 ON d2.word=d1.word AND d2.num=d1.num
WHERE d2.id > d1.id
/*
id|
--|
5|
6|
8|
9|
10|
*/
/** Use the previous query in a subquery to exclude the dupliates with higher id values */
SELECT *
FROM dupes
WHERE id NOT IN (
SELECT d2.id
FROM dupes d1
INNER JOIN dupes d2 ON d2.word=d1.word AND d2.num=d1.num
WHERE d2.id > d1.id
)
ORDER BY word, num;
/*
word|num|id|
----|---|--|
aaa |100| 1|
bbb |200| 2|
bbb |400| 4|
ccc |300| 3|
ddd |400| 7|
*/
Option 4: Common Table Expression with ROW_NUMBER()
In the Common Table Expression (CTE), select the ROW_NUMBER(), partitioned by the group column and ordered in the desired order. Then SELECT only the records that have ROW_NUMBER() = 1:
WITH CTE AS (
SELECT *
,row_number() OVER(PARTITION BY word, num ORDER BY id) AS row_num
FROM dupes
)
SELECT word, num, id
FROM cte
WHERE row_num = 1
ORDER BY word, num;
/*
word|num|id|
----|---|--|
aaa |100| 1|
bbb |200| 2|
bbb |400| 4|
ccc |300| 3|
ddd |400| 7|
*/
Запросы
Последнее обновление: 16.05.2018
С помощью оператора DISTINCT можно выбрать уникальные данные по определенным столбцам.
К примеру, разные товары могут иметь одних и тех же производителей, и, допустим, у нас следующая таблица товаров:
USE productsdb;
DROP TABLE IF EXISTS Products;
CREATE TABLE Products
(
Id INT AUTO_INCREMENT PRIMARY KEY,
ProductName VARCHAR(30) NOT NULL,
Manufacturer VARCHAR(20) NOT NULL,
ProductCount INT DEFAULT 0,
Price DECIMAL NOT NULL
);
INSERT INTO Products (ProductName, Manufacturer, ProductCount, Price)
VALUES
('iPhone X', 'Apple', 3, 71000),
('iPhone 8', 'Apple', 3, 56000),
('Galaxy S9', 'Samsung', 6, 56000),
('Galaxy S8', 'Samsung', 2, 46000),
('Honor 10', 'Huawei', 3, 26000);
Выберем всех производителей:
SELECT Manufacturer FROM Products;
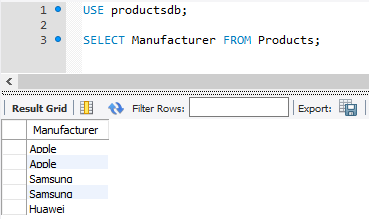
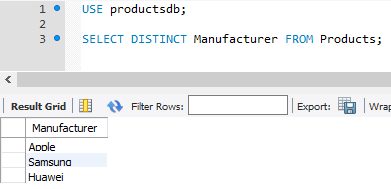
Однако при таком запросе производители повторяются. Теперь применим оператор DISTINCT для выборки уникальных значений:
SELECT DISTINCT Manufacturer FROM Products;
Также мы можем задавать выборку уникальных значений по нескольким столбцам:
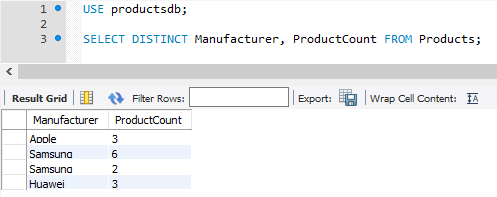
SELECT DISTINCT Manufacturer, ProductCount FROM Products;
В данном случае для выборки используются столбцы Manufacturer и ProductCount. Из пяти строк только для двух строк эти столбцы имеют повторяющиеся значения.
Поэтому в выборке будет 4 строки:
В этом учебном материале вы узнаете, как использовать SQL оператор DISTINCT с синтаксисом и примерами.
Описание
SQL оператор DISTINCT используется для удаления дубликатов из результирующего набора оператора SELECT.
Синтаксис
Синтаксис для оператора DISTINCT в SQL:
SELECT DISTINCT expressions
FROM tables
[WHERE conditions];
Параметры или аргументы
- expressions
- Столбцы или расчеты, которые вы хотите получить.
- tables
- Таблицы, из которых вы хотите получить записи. В предложении FROM должна быть указана хотя бы одна таблица.
- WHERE conditions
- Необязательный. Условия, которые должны быть выполнены для записей, которые будут выбраны.
Примечание
- Если в операторе DISTINCT указано только одно выражение, запрос возвратит уникальные значения для этого выражения.
- Если в операторе DISTINCT указано несколько выражений, запрос извлекает уникальные комбинации для перечисленных выражений.
- В SQL оператор DISTINCT не игнорирует значения NULL. Поэтому при использовании DISTINCT в вашем операторе SQL ваш результирующий набор будет содержать значение NULL в качестве отдельного значения.
Пример – поиск уникальных значений в столбце
Давайте посмотрим, как использовать оператор DISTINCT для поиска уникальных значений в одном столбце таблицы.
В этом примере у нас есть таблица suppliers со следующими данными:
| supplier_id | supplier_name | city | state |
|---|---|---|---|
| 100 | Yandex | Moscow | Russia |
| 200 | Lansing | Michigan | |
| 300 | Oracle | Redwood City | California |
| 400 | Bing | Redmond | Washington |
| 500 | Yahoo | Sunnyvale | Washington |
| 600 | DuckDuckGo | Paoli | Pennsylvania |
| 700 | Qwant | Paris | Ile de France |
| 800 | Menlo Park | California | |
| 900 | Electronic Arts | San Francisco | California |
Давайте найдем все уникальные значения в таблице suppliers. Введите следующий SQL оператор:
|
SELECT DISTINCT state FROM suppliers ORDER BY state; |
Будет выбрано 6 записей. Вот результаты, которые вы должны получить:
| state |
|---|
| Russia |
| Ile de France |
| Pennsylvania |
| California |
| Washington |
| Michigan |
В этом примере возвращаются все уникальные значения состояния из таблицы поставщиков и удаляются все дубликаты из набора результатов. Как видите, штат Калифорния в наборе результатов отображается только один раз, а не четыре раза.
Пример – поиск уникальных значений в нескольких столбцах
Далее давайте рассмотрим, как использовать SQL DISTINCT для удаления дубликатов из более чем одного поля в операторе SELECT.
Используя ту же таблицу suppliers из предыдущего примера, введите следующий SQL оператор:
|
SELECT DISTINCT city, state FROM suppliers ORDER BY city, state; |
Будет выбрано 8 записей. Вот результаты, которые вы получите:
| city | state |
|---|---|
| Moscow | Russian |
| Lansing | Michigan |
| Redwood City | California |
| Redmond | Washington |
| Sunnyvale | Washington |
| Paoli | Pennsylvania |
| Paris | France |
| Menlo Park | California |
В этом примере будет возвращаться каждая уникальная комбинация city и state. В этом случае DISTINCT применяется к каждому полю, указанному после ключевого слова DISTINCT. Как видите, ‘Redwood City’, ‘California’ в наборе результатов отображается только один раз, а не дважды.
Пример – как DISTINCT обрабатывает значения NULL
Наконец, считает ли оператор DISTINCT NULL уникальным значением в SQL? Ответ – да. Давайте рассмотрим это дальше.
В этом примере у нас есть таблица products со следующими данными:
| product_id | product_name | category_id |
|---|---|---|
| 1 | Pear | 50 |
| 2 | Banana | 50 |
| 3 | Orange | 50 |
| 4 | Apple | 50 |
| 5 | Bread | 75 |
| 6 | Sliced Ham | 25 |
| 7 | Kleenex | NULL |
Теперь давайте выберем уникальные значения из поля category_id, которое содержит значение NULL. Введите следующий запрос SQL:
|
SELECT DISTINCT category_id FROM products ORDER BY category_id; |
Будет выбрано 4 записи. Вот результаты, которые вы должны получить:
| category_id |
|---|
| NULL |
| 25 |
| 50 |
| 75 |
В этом примере запрос вернет уникальные значения, найденные в столбце category_id. Как видно из первой строки в наборе результатов, NULL – это уникальное значение, которое возвращается оператором DISTINCT.
В некоторых ситуациях SQL запрос на выборку может возвращать повторяющиеся строки данных.
Например, давайте выведем поле class из таблицы Student_in_class из базы данных, в которой организовано хранение информации о расписании занятий в школе.

SELECT class FROM Student_in_class;Поскольку в одном классе возможно нахождение нескольких студентов, то не удивительно, что при выводе мы можем наблюдать одинаковые значения.
Чтобы при выборке избежать такого дублирования, есть оператор DISTINCT.Синтаксис оператора
SELECT [DISTINCT] поля_таблиц FROM наименование_таблицы;То есть в нашем случае запрос на получение уникальных классов, в которых есть хотя бы один студент, будет выглядеть следующим образом:
SELECT DISTINCT class FROM Student_in_class;DISTINCT для нескольких колонок
При использовании оператора DISTINCT для двух и более колонок будут удаляться записи, которые имеют одинаковые значения по всем полям.
То есть для такой таблицы
запрос с оператором DISTINCT вернул бы все сочетания имён и фамилий кроме дублирующихся «John Scott».
SELECT DISTINCT first_name, last_name FROM User;
Для случая если Вам надо найти несколько равенств и несколько неравенств, можно использовать следующий запрос (корректно для MySQL и Oracle, для других СУБД не проверял):
select hash
from alldata T1
where (name_var,value) in (('number','5'),('abcd','xyz'))
and not exists(
select 1 from alldata T2
where T2.hash=T1.hash
and (T2.name_var,T2.value) in (('text','hello'),('text','apple'),('param','2'))
)
group by hash
having count(1)=2
Данный запрос даст все hash для которых есть строки с number=5 И abcd='xyz' при этом для которых не существует ни одной записи c: text='hello' или text='apple' или param!='2'.
Число 2 в строке having count(1)=2 – это количество условий которые должны совпасть в первой части sql запроса. Оно должно точно соответствовать количеству различных name_var, упомянутых в первой части запроса.
В первой части нельзя в in указывать проверку одного и того же поля на несколько разных значений. Если такое встречается, то in, написанный для удобства, надо разворачивать в полноценные проверки. Например в первой части для выбора number=5 или number=6 нельзя написать (name_var,value) in (('number','5'),('number','6'),('abcd','xyz')) т.к. в этом случае count(1) даст неверный результат. В таком случае надо писать что то типа ( (name_var='number' and (value='5' or value='6') ) OR (name_var='abcd' and 'value'='xyz') )
Напротив, во вложенном запросе (который в not exists) можно перечислять любые недопустимые значения, что и показано в основном примере.
