Перейти к содержанию
Как в браузере Яндекс добавить сайт в доверенные
На чтение 2 мин Просмотров 38.4к. Обновлено 16.10.2020
Яндекс браузер – это удобный браузер для повседневного серфинга и скачивания пользовательских файлов в виде картинок, видео, аудио или документов в электронных форматах. Разработчики же дают возможность доверять определенным сайтам на уровне поисковой системы.
Поэтому сегодня мы поговорим о том, как добавить сайт в надежные узлы в Яндекс браузере, что это такое и зачем нужно.
Надежные узлы в Yandex Browser
Добавление сайтов в доверенные – это возможность задать особые правила обработки данных для отдельных ресурсов.
Следуйте дальнейшей инструкции:
- На главной страничке Яндекс.Браузера жмем на кнопку в виде трех горизонтальных полос в правом верхнем углу.
- В выпадающем списке выбираем «Настройки».
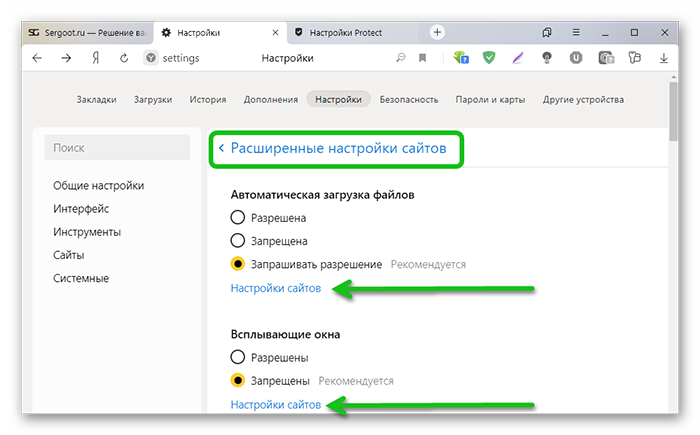
- Слева в панели инструментов переходим на вкладку «Сайты».
- Пролистываем страничку до надписи «Расширенные…».

- Здесь поочерёдно открываем «Настройки сайта» и добавляем требуемый ресурс в доверенные. Например, если нужно разрешить или запретить всплывающие окна на сайте, настроить доступ к камере или местоположению.
- Чтобы добавить сайт, в отдельном разделе кликаем в правом верхнем углу «Добавить» и копируем URL ресурса из буфера обмена.


Аналогичным образом можно добавить сайт в список запрещенных, чтобы функционал веб ресурсов не ограничивал работу пользователей.

Заключение
Добавление сайтов в доверенные yandex browser – это хорошая возможность не блокировать часть пользовательских данных. Разработчики предусмотрели такую возможность в системных настройках поисковика.
Некоторые вебсайты не проходят проверку безопасности в Yandex.Browser, из-за чего они работают некорректно или не загружаются полностью. Чтобы исправить ситуацию, расскажем, как добавить сайт в надежные узлы Яндекс Браузер, избавившись от любых ограничений.
Все окно разбито на подразделы. На какие из них необходимо обратить внимание :
Исходя из названия — обозреватель расценивает добавленные в перечень ресурсы как проверенные. Добавлять в списки стоит безопасной ресурсы, с защитой в виде TSL или SSL-протокола. Последние выявляют по иконке замка, размещенного рядом со ссылкой на ресурс. 
Добавление надежных узлов в Яндекс Браузере открывает отмеченным ресурсам доступ к той или иной функции обозревателя.
Яндекс браузер – это удобный браузер для повседневного серфинга и скачивания пользовательских файлов в виде картинок, видео, аудио или документов в электронных форматах. Разработчики же дают возможность доверять определенным сайтам на уровне поисковой системы.
Поэтому сегодня мы поговорим о том, как добавить сайт в надежные узлы в Яндекс браузере, что это такое и зачем нужно.
Добавление сайтов в доверенные – это возможность задать особые правила обработки данных для отдельных ресурсов.
Аналогичным образом можно добавить сайт в список запрещенных, чтобы функционал веб ресурсов не ограничивал работу пользователей.
Заключение
Добавление сайтов в доверенные yandex browser – это хорошая возможность не блокировать часть пользовательских данных. Разработчики предусмотрели такую возможность в системных настройках поисковика.
Источник
Как добавить сайт в исключения в Яндекс Браузере?
Серфинг по интернету не всегда безопасен, поэтому стоит отдельно отмечать в настройках надежные узлы в Яндекс браузере, чтобы не нанести вред компьютеру. Опция защитит программы и файлы от заражения вирусами, а пользователя – от использования программ слежения и перехвата конфиденциальной информации.
Как добавить сайт
Перед началом работы нужно создать список ресурсов, посещение которых необходимо разрешить. Добавить сайт в исключения браузера Яндекс несложно, для этого необходимо сначала проверить, открывается ли запрашиваемая страница в других браузерах. Если в доступе отказывает несколько поисковиков, страница может действительно причинить вред компьютеру. Далее потребуется составить список сайтов для добавления с их электронными адресами.
Для некоторых ресурсов может потребоваться вносить адреса отдельных страниц.
Выполнить операцию можно только на компьютере или ноутбуке, для мобильных устройств функция не поддерживается. Алгоритм работы выглядит следующим образом:
- открыть меню настроек поисковика, кликнув по трем полоскам в правом верхнем углу экрана;
- войти в раздел «Настройки»;
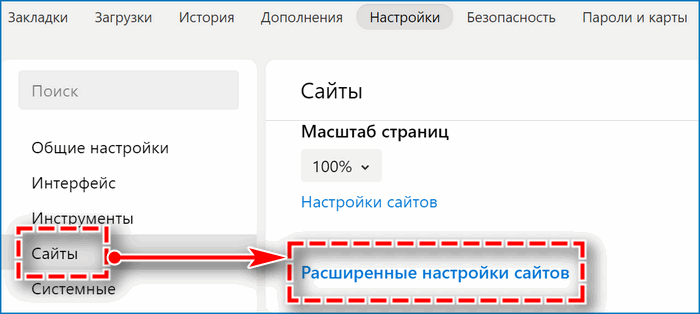
- выбрать в левой вертикальной колонке подраздел «Сайты»;
- кликнуть по строчке «Расширенные настройки сайтов»;

- выбрать настройки, которые необходимы, например, включить cookie-файлы;
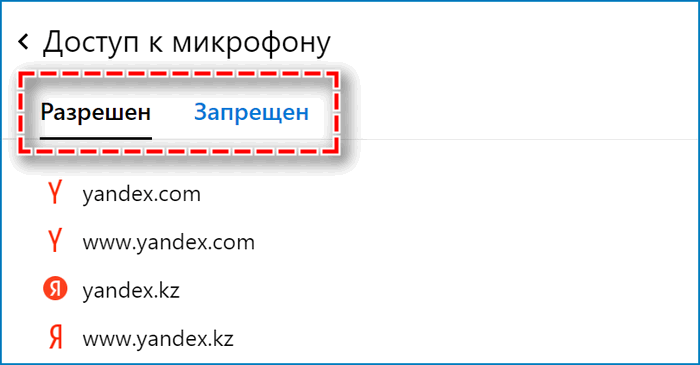
- открыть подраздел «Разрешено». Ввести вручную url-адрес сайта, который необходимо добавить в доверенные, нажать на кнопку «Добавить».

Если потребность в ресурсе исчерпана, его вновь можно внести в перечень запрещенных. Чтобы обеспечить полностью комфортное пользование сайтом, необходимо выбрать опцию «Разрешить» для каждого вида активности. Потребуется вручную разрешить загрузку картинок и видео, обработку протоколов, файлы cookie, flash и JavaScript.
Виды исключений
Яндекс Браузер позволяет гибко настраивать перечень сайтов и контента, для которых делаются исключения. Можно выбрать из следующего списка:
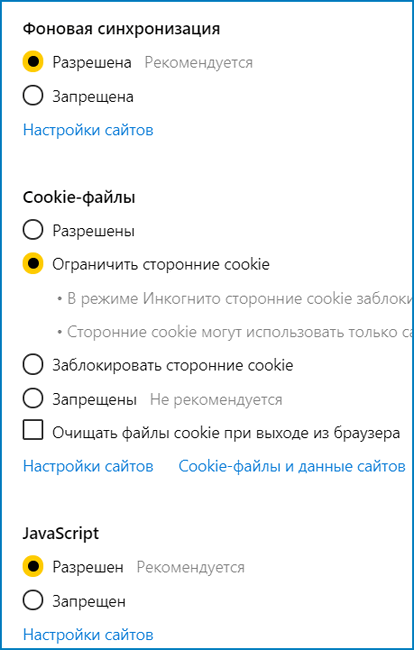
- Файлы cookie. На многих сайтах они собирают информацию об активности пользователей. Протокол безопасности может быть настроен так, чтобы блокировать порталы с такими файлами, придется разрешать их загрузку для каждого ресурса. Иногда следящие программы могут оказаться опасными, отслеживая местонахождение устройства. Пример такой настройки – запрет на автоматический запрос местоположения при посещении интернет-магазинов.
- Отдельные скрипты, сценарии выполнения задач. Ошибки в первичном коде могут помешать корректной загрузке страницы. Запрет запуска JavaScript на конкретном сайте обезопасит от неожиданно всплывающих окон или флеш-игр. Некоторые сценарии могут содержать вредоносные программы, блокировать страницы.
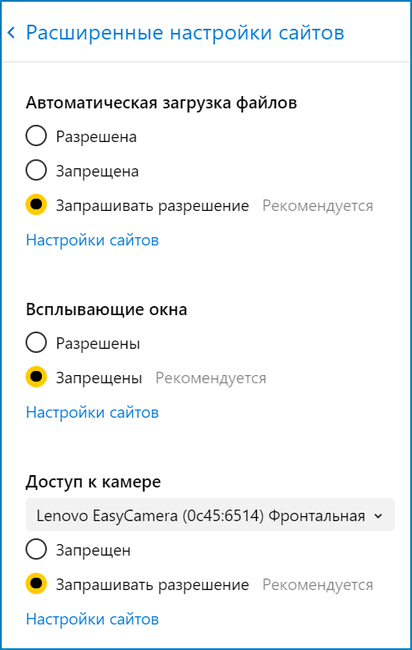
- Всплывающие окна, реклама. Если они не блокируются файерволом, необходимо вручную запретить выполнение этих операций.
- Автоматическая загрузка файлов и документов. Они могут содержать вирусы, поэтому операцию следует запретить.
- Плагины. Некоторые приложения следует заблокировать, они мешают корректной работе сайта.
- Картинки и видео. Блокировка их загрузки воспроизведен на экране пустые места, но снизит расход трафика. Предусмотрена опция показывать все картинки, не показывать их.
- Опция «Во весь экран». Отключение разрешения снизит число случаев перехода в полноэкранный режим без запроса пользователя.
Настройки поисковика позволяют оптимизировать серфинг по интернету, сокращая время загрузки страниц и расход трафика. Каждый элемент следует настраивать постепенно, проверяя изменения в качестве загрузки страниц ресурса. Блокировка может настраиваться на постоянной основе или на один конкретный сеанс работы в сети.
Политика безопасности
Иногда необходимо добавить сайт в доверенные или, наоборот, в заблокированные, особенно это важно при фильтрации контента страниц, посещаемых детьми. Существует большой перечень страниц, которые желательно отключить, а настройки доверенных сайтов смогут гарантировать информационную безопасность.
Различные политики безопасности иногда произвольно исключают страницу из рекомендуемых к посещению, это может быть следствием ошибки. Опция, позволяющая создать список сайтов, подтвердивших надежность, окажется удачным решением. Настройки браузера по «умолчанию» создают единый режим для всех сайтов.
Некоторые программы, например, тайм-трекеры, используемые работодателями для контроля времени работы сотрудников, уже имеют готовый список из 100-200 сайтов, его можно скопировать в собственные настройки.
Возможность добавить сайт в надежные узлы снимет проблему информационной безопасности, оградит компьютер от заражения, если страница не несет угрожающего контента. При этом настроенный список доверенных ресурсов позволит получать нужную информацию, не ожидая долгой загрузки.
Источник
Как добавить сайт в надежные Яндекс Браузер
Время от времени Яндекс браузер может не открывать вполне безопасные сайты. Связано это с тем, что алгоритм по каким-то причинам считает открываемую страницу потенциально опасным сайтом для пользователя. Если вы уже с этим сталкивались или столкнулись на днях и не знаете как с этим бороться, то читайте далее. Мы рассмотрим, как добавить сайт в надежные списки Яндекс браузер, чтобы обойти возможную блокировку страницы.
На компьютер
Прежде чем переходить к инструкции, убедитесь, что заблокированный сайт открывается в других браузерах, так как проблема может быть далеко не в Яндекс браузере. Если же страница открывается в другом веб-обозревателе, то можете смело переходить к нижеуказанной инструкции.
Для того, чтобы добавить сайт в надежные списки Яндекс браузера, воспользуемся следующей инструкцией:
- Запускаем Яндекс браузер на компьютере и переходим в раздел настроек. Для этого нажимаем на три параллельные линии, расположенные в верхнем правом углу, и кликаем по кнопке «Настройки».
- В отобразившемся окне открываем меню «Сайты» и далее переходим во вкладку «Расширенные настройки сайтов».
- Далее нам потребуется добавить сайт в надежный список. Для этого потребуется обратиться к опции «Настройки сайтов», которая есть у каждого пункта в открывшемся разделе. Я лишь покажу как это сделать для первого пункта, после чего вы сможете проделать аналогичные шаги для всех остальных пунктов.
- Итак, под блоком «Автоматическая загрузка файлов» нажимаем на кнопку «Настройки сайтов». В отобразившейся вкладке в верхнем правом углу кликаем по кнопке добавить и вписываем сайт, к которому закрыт доступ. Далее кликаем еще раз по кнопке «Добавить».




Не забудьте выполнить указанное действие для оставшихся пунктов и проверить работоспособность сайта, к которому был закрыт доступ в Яндекс браузере.
На телефоне

Теперь вы знаете как добавить сайт в доверенные списки Яндекс браузер. Для этого необходимо открыть параметры Яндекса и запустить расширенные настройки сайтов, в которые нужно добавить заблокированный сайт.
Источник
Как добавить сайт в надежные Яндекс Браузер
Время от времени Яндекс браузер может не открывать вполне безопасные сайты. Связано это с тем, что алгоритм по каким-то причинам считает открываемую страницу потенциально опасным сайтом для пользователя. Если вы уже с этим сталкивались или столкнулись на днях и не знаете как с этим бороться, то читайте далее. Мы рассмотрим, как добавить сайт в надежные списки Яндекс браузер, чтобы обойти возможную блокировку страницы.
На компьютер
Прежде чем переходить к инструкции, убедитесь, что заблокированный сайт открывается в других браузерах, так как проблема может быть далеко не в Яндекс браузере. Если же страница открывается в другом веб-обозревателе, то можете смело переходить к нижеуказанной инструкции.
Для того, чтобы добавить сайт в надежные списки Яндекс браузера, воспользуемся следующей инструкцией:
- Запускаем Яндекс браузер на компьютере и переходим в раздел настроек. Для этого нажимаем на три параллельные линии, расположенные в верхнем правом углу, и кликаем по кнопке «Настройки».
- В отобразившемся окне открываем меню «Сайты» и далее переходим во вкладку «Расширенные настройки сайтов».
- Далее нам потребуется добавить сайт в надежный список. Для этого потребуется обратиться к опции «Настройки сайтов», которая есть у каждого пункта в открывшемся разделе. Я лишь покажу как это сделать для первого пункта, после чего вы сможете проделать аналогичные шаги для всех остальных пунктов.
- Итак, под блоком «Автоматическая загрузка файлов» нажимаем на кнопку «Настройки сайтов». В отобразившейся вкладке в верхнем правом углу кликаем по кнопке добавить и вписываем сайт, к которому закрыт доступ. Далее кликаем еще раз по кнопке «Добавить».




Не забудьте выполнить указанное действие для оставшихся пунктов и проверить работоспособность сайта, к которому был закрыт доступ в Яндекс браузере.
На телефоне
К сожалению, на телефоне добавить сайт в надежные Яндекс браузера у вас не получится. Данная функция не предусмотрена для телефонной версии обозревателя.
Теперь вы знаете как добавить сайт в доверенные списки Яндекс браузер. Для этого необходимо открыть параметры Яндекса и запустить расширенные настройки сайтов, в которые нужно добавить заблокированный сайт.
Бич XXI века – вирусы и все, что с ними связано. Каждый пользователь не раз сталкивался с рекламными баннерами или всплывающими окнами, а об попытках фишинга и говорить не приходится. С каждым годом становится все меньше интернет-площадок, которым можно доверять.
Сегодня мы поговорим о том, как добавить сайт в исключения Гугл Хром, также в процессе повествования рассмотрим удобный способ достижения желаемого.
От слов к делу
Разработчики предусмотрели несколько способов ограничить круг сайтов, которым пользователь может доверять. Системно это выражается в снятии всех защитных редутов перед исходным кодом рассматриваемой платформы.
Другие же сайты попадают под блокировки, что вполне оправдано.
Для претворения задуманного в жизнь воспользуемся следующей пошаговой инструкцией:
- Открываем браузер и кликаем на троеточие в правом верхнем углу пользовательского интерфейса (для перехода в системное меню).
- Здесь выбираем раздел «Настройки», прокручиваем открывшуюся страницу до пункта «Дополнительные».
- Здесь находим блок «Настройки контента», где кликаем ЛКМ по вкладке «Файлы cookies».




Для добавления сайта в перечень «доверенных» можно воспользоваться всплывающими подсказками при переходе на непроверенную платформу.
Подведем итоги
Существует несколько способов ограничить количество площадок, которые будут доступны в Интернете. Такие ограничения связаны с большим количеством вирусного контента и повышенной опасностью подцепить что-то мерзкое.
Практически у каждого пользователя интернета есть свои любимые сайты, которые вы часто посещаете, которым вы полностью доверяете, да и полностью уверены в том, что они будут безопасны для вашего компьютера.
Но зачастую, при стандартных настройках браузера, IE всячески мешает вам работать на таких сайтах. Он начинает выдавать кучи уведомлений, предупреждений, запрещает выполнять некоторые действия, ссылаясь на недостаточную безопасность. Иногда это имеет смысл, однако, в большинстве случаев, всё это безосновательно, а посещение и работа с сайтом не принесут вам никакого вреда.
Думаю, мало кому хочется, чтобы браузер всячески ограничивал вас: мешал скачивать файлы, переходить по ссылкам, выдавал ошибки безопасности, либо же ошибки сертификатов. Чтобы этого не происходило, вам следует добавить сайты в доверенные сайты Interent Explorer. Важно отметить тот факт, что некоторые сайты, для их корректной работы, требуют добавления в доверенные узлы.
Итак, разобравшись с тем, что такое доверенные узлы, мы переходим к самому важному вопросу. Как добавить сайт в Internet Explorer?
Для этого необходимо нажать на шестеренку в верхнем правом углу браузера, выбрать “Свойства браузера, перейти в раздел “Безопасность”, нажать “Надежные сайты” и кликнуть по кнопке “Сайты”

В этом разделе вы можете добавить надёжный сайт в Internet Explorer. После этого сайт получит расширенные полномочий и сможет функционировать без каких – либо ограничений. Однако стоит помнить, что следует выбирать такие сайты очень осторожно. Помимо этого, сайты могут подвергаться хаккерским атакам. Но если он окажется у вас в списке доверенных, то его посещение, как и работа с ним, могут повредить вашей безопасности. Поэтому стоит с осторожностью пользоваться этой функцией.
Источник
При помощи DOM вы можете получить доступ к каждому узлу в XML-документе.
Получить доступ к узлу можно тремя способами:
- Используя метод getElementsByTagName()
- Путем перебора (обхода) дерева узлов
- Путем обхода дерева узлов, используя отношения между узлами.
Метод getElementsByTagName()
Метод getElementsByTagName() возвращает все элементы с указанным именем тега.
Синтаксис:
узел.getElementsByTagName(“имя_тега“);
В следующем примере возвращаются все элементы <title>, содержащиеся в элементе x:
x.getElementsByTagName("title");
Обратите внимание, что приведенный выше пример возвращает только те элементы <title>, которые находятся внутри узла x. Чтобы получить все элементы <title>, находящиеся в XML-документе, следует использовать:
xmlDoc.getElementsByTagName("title");
где xmlDoc – это сам документ (узел документа).
Список узлов DOM
Метод getElementsByTagName() возвращает список узлов. Список узлов – это массив узлов.
x = xmlDoc.getElementsByTagName("title");
Доступ к элементам <title> в узле x можно получить по номеру индекса. Для доступа к третьему <title> можно написать:
y = x[2];
Внимание! Нумерация индексов начинается с 0.
Подробнее о списках узлов будет рассказано в следующей главе этого руководства.
Длина списка узлов DOM
Свойство length определяет длину списка узлов (количество узлов).
Используя свойство length, можно пройтись по всему списку узлов:
var x = xmlDoc.getElementsByTagName("title");
for (i = 0; i < x.length; i++) {
// что-то делаем с каждым узлом
}
Типы узлов
Свойство documentElement XML-документа содержит корневой узел.
Свойство nodeName узла содержит имя узла.
Свойство nodeType узла содержит тип узла.
Подробнее о свойствах узла будет рассказано в следующей главе этого руководства.
Обход узлов
В следующем примере мы в цикле обходим дочерние узлы корневого узла, которые также являются узлами-элементами:
txt = "";
x = xmlDoc.documentElement.childNodes;
for (i = 0; i < x.length; i++) {
// Обрабатываем только узлы элементов (тип 1)
if (x[i].nodeType == 1) {
txt += x[i].nodeName + "<br>";
}
}
Объяснение примера:
- Предположим, вы загрузили файл books.xml в xmlDoc
- Получаем дочерние узлы корневого элемента (xmlDoc)
- Для каждого дочернего узла проверяем тип узла. Если тип узла “1”, это узел элемента.
- Выводим имя узла, если это узел элемента
Перемещаемся по узлам, используя отношения между ними
В следующем примере мы в цикле обходим дерево узлов, используя отношения между узлами:
x = xmlDoc.getElementsByTagName("book")[0];
xlen = x.childNodes.length;
y = x.firstChild;
txt = "";
for (i = 0; i < x len; i++) {
// Обрабатываем только узлы элементов (тип 1)
if (y.nodeType == 1) {
txt += y.nodeName + "<br>";
}
y = y.nextSibling;
}
Объяснение примера:
- Предположим, вы загрузили файл books.xml в xmlDoc
- Получаем дочерние узлы первого элемента book
- Поместим в переменную “y” первый дочерний узел первого элемента book.
- Для каждого дочернего узла (начиная с первого дочернего узла в переменной “y”):
- Проверяем тип узла. Если тип узла “1”, это узел элемента.
- Выводим имя узла, если это узел элемента
- Помещаем в переменную “y” следующего одноуровневый узел и снова выполняем цикл.
4 января, 2018 12:10 пп
2 409 views
| Комментариев нет
Java
В предыдущем мануале – Доступ к элементам в DOM – вы узнали, как использовать встроенные методы объекта document для доступа к элементам HTML по идентификатору, классу, имени тега и селекторам запросов. Как вы уже знаете, DOM структурирован как дерево узлов: в корне находится узел document, а остальные узлы (включая элементы, комментарии и текстовые узлы) представляют ветки.
Читайте также: Дерево и узлы DOM
Часто вам нужно будет перемещаться по DOM без предварительного указания каждого элемента. Умение перемещаться вверх и вниз по дереву DOM и переходить от ветки к ветке необходимо для понимания того, как работать с JavaScript и HTML.
В этом мануале речь пойдет о навигации по DOM с помощью свойств родительских, дочерних и соседних узлов.
Подготовка
Для начала создайте файл nodes.html и добавьте в него такой код:
<!DOCTYPE html>
<html>
<head>
<title>Learning About Nodes</title>
<style>
* { border: 2px solid #dedede; padding: 15px; margin: 15px; }
html { margin: 0; padding: 0; }
body { max-width: 600px; font-family: sans-serif; color: #333; }
</style>
</head>
<body>
<h1>Shark World</h1>
<p>The world’s leading source on <strong>shark</strong> related information.</p>
<h2>Types of Sharks</h2>
<ul>
<li>Hammerhead</li>
<li>Tiger</li>
<li>Great White</li>
</ul>
</body>
<script>
const h1 = document.getElementsByTagName (‘h1’)[0];
const p = document.getElementsByTagName (‘p’)[0];
const ul = document.getElementsByTagName (‘ul’)[0];
</script>
</html>
Загрузите эту страницу в браузере и убедитесь, что она работает.
На этом тестовом сайте есть HTML-документ с несколькими элементами. Некоторые базовые CSS добавлены в тег style, чтобы каждый элемент был явно видимым, а несколько переменных были созданы в script для удобства доступа к нескольким элементам. Поскольку для h1, p и ul существует только один элемент, вы можете получить доступ к первому индексу каждого соответствующего свойства getElementsByTagName.
Корневые узлы
Объект document является корнем для каждого узла в DOM. Этот объект фактически является свойством объекта window, который является глобальным объектом верхнего уровня, представляющим вкладку в браузере. Объект window имеет доступ к такой информации, как панель инструментов, высота и ширина окна, подсказки и предупреждения. Документ состоит из того, что находится внутри объекта window.
В этой таблице перечислены корневые элементы, которые будет содержать каждый документ. Даже если в браузер загружен пустой HTML-файл, эти узлы будут добавлены и проанализированы в DOM.
| Свойство | Узел | Тип узла |
| document | #document | DOCUMENT_NODE |
| document.documentElement | html | ELEMENT_NODE |
| document.head | head | ELEMENT_NODE |
| document.body | body | ELEMENT_NODE |
Поскольку элементы html, head и body очень распространены, они имеют свои собственные свойства в документе.
Откройте консоль в DevTools и проверьте каждое из этих четырех свойств. Вы также можете проверить h1, p и ul, которые возвратят элементы благодаря переменным, которые добавлены в тег script.
Родительские узлы
Узлы в DOM бывают родительскими, дочерними и соседними в зависимости от их отношения к другим узлам. Родительским называется узел, который находится на уровень выше других узлов (или ближе к document в иерархии DOM). Существует два свойства для получения родительских узлов – parentNode и parentElement.
| Свойство | Результат |
| parentNode | Родительский узел |
| parentElement | Узел родительского элемента |
В файле nodes.html:
- html – родитель узлов head, body и script.
- body – родитель h1, h2, p и ul, но не li, поскольку li находится на два уровня ниже body.
Чтобы узнать, какой узел является родительским узлом элемента р, используйте свойство parentNode. Переменная р происходит из пользовательской декларации document.getElementsByTagName(‘p’)[0].
p.parentNode;
► <body>...</body>
Родительским узлом р является body, но как узнать родителя более высокого уровня? Для этого можно соединить свойства:
p.parentNode.parentNode;
► <html>...</html>
Используя parentNode дважды, вы можете получить родительский узел p более высокого порядка.
Есть два свойства для извлечения родительского узла, но между ними есть одно небольшое различие, как показано в этом фрагменте:
// Assign html object to html variable
const html = document.documentElement;
console.log(html.parentNode); // > #document
console.log(html.parentElement); // > null
Родителем почти любого узла будет узел элемента, поскольку текстовый узел и узел комментария не могут быть родителями других узлов. Однако родительский элемент html является узлом документа, поэтому parentElement возвращает значение null. Как правило, при обходе DOM используется parentNode.
Дочерние узлы
Дочерними называются узлы, которые находятся на уровень ниже. Любые узлы, находящиеся за пределами одного уровня вложения, обычно называются дочерними.
| Свойство | Результат |
| childNodes | Дочерние узлы |
| firstChild | Первый дочерний узел |
| lastChild | Последний дочерний узел |
| children | Дочерние узлы элемента |
| firstElementChild | Первый дочерний узел элемента |
| lastElementChild | Последний дочерний узел элемента |
Свойство childNodes возвращает живой список дочерних узлов. кажется, что элемент ul получит три дочерних элемента li. Давайте проверим эту догадку.
ul.childNodes;
► (7) [text, li, text, li, text, li, text]
В дополнение к трем элементам li он также получает четыре текстовых узла. Это потому, что вы написали собственный HTML (он не был сгенерирован JavaScript), а отступы между элементами подсчитываются в DOM как текстовые узлы. Это неочевидно, так как вкладка Elements в DevTools удаляет узлы пробелов.
Если вы попробуете изменить цвет фона первого дочернего узла с помощью свойства firstChild, он вернет ошибку, потому что первым узлом является текст.
ul.firstChild.style.background = 'yellow';
Uncaught TypeError: Cannot set property 'background' of undefined
Свойства children, firstElementChild и lastElementChild существуют в подобных ситуациях только для извлечения узлов элемента. ul.children вернет только три элемента li.
Используя firstElementChild, вы можете изменить цвет фона первого li в ul.
ul.firstElementChild.style.background = 'yellow';
После запуска этого кода страница в браузере обновится и изменит цвет фона соответствующего узла.
При выполнении основных операций с DOM (как в этом примере) чрезвычайно полезны специфичные свойства элемента. В веб-приложениях, сгенерированных JavaScript, с большей вероятностью будут использоваться свойства, которые охватывают все узлы, поскольку в этом случае не будет новых строк и отступов.
Цикл for…of может итерировать все элементы children.
for (let element of ul.children) {
element.style.background = 'yellow';
}
После этого на странице изменится цвет фона всех дочерних элементов.
Элемент р имеет как текст, так и другие элементы, и свойство childNodes поможет извлечь эти данные:
for (let element of p.childNodes) {
console.log(element);
}
"The world's leading source on "
<strong>shark</strong>
" related information."
childNodes и children не возвращают массивы со всеми свойствами и методами, но они ведут себя аналогично массивам JavaScript. Вы можете получить доступ к узлам по номеру индекса или найти их свойство length.
Читайте также:
- Работа с массивами в JavaScript
- Методы массивов в JavaScript: модификаторы
document.body.children[3].lastElementChild.style.background = 'fuchsia';
Вышеприведенный код найдет последний элемент child (li) четвертого дочернего элемента (ul) для body и применит стиль.
Используя свойства родительских и дочерних узлов, вы можете получить любой узел в DOM.
Соседние узлы
Соседними называются узлы, которые находятся на одном уровне дерева DOM. Соседние узлы не обязательно должны быть узлами одного типа – текстовые узлы, узлы элементов и комментариев могут считаться соседними.
| Свойство | Результат |
| previousSibling | Предыдущий соседний узел |
| nextSibling | Следующий соседний узел |
| previousElementSibling | Предыдущий соседний узел элемента |
| nextElementSibling | Следующий соседний узел элемента |
Свойства соседних узлов работают так же, как и дочерние узлы, поскольку тут существует набор свойств для навигации по всем узлам и набор свойств только для узлов элемента. previousSibling и nextSibling выводят предыдущий или последующий узел относительно указанного узла, а previousElementSibling и nextElementSibling выводят только узлы элемента.
В файле nodes.html попробуйте выбрать средний элемент ul:
const tiger = ul.children[1];
Поскольку этот DOM был создан с нуля и не как веб-приложение JavaScript, для доступа к предыдущему и следующему узлам элемента нужно использовать свойства соседних узлов (так как в DOM есть пробел).
tiger.nextElementSibling.style.background = 'coral';
tiger.previousElementSibling.style.background = 'aquamarine';
Запустив этот код, вы измените цвет фона Hammerhead и Great White.
Заключение
Теперь вы умеете обращаться к корневым узлам каждого HTML-документа и перемещаться по DOM с помощью свойств родительских, дочерних и соседних узлов.
Читайте также: Доступ к элементам в DOM
Tags: DOM
В предыдущем разделении мы кратко представим BOM и DOM, и он также узнает, как JavaScript связывается с браузером через методы, которые они предоставляют.
Когда в браузере загружается в браузер, браузер сначала проанализирует этот HTML-документ, а затем разрешает его в DOM (модель объекта документа, модель объекта файла) в соответствии с этим содержимым HTML.
И DOM является нормой, чтобы сформулировать W3C, что является стандартным в постоянном и языке. Другими словами, до тех пор, пока такие спецификации, независимо от того, какая платформа или какой язык разработан, вы можете управлять контентом, структурой и стилем DOM через API, предоставляемую DOM.
Итак, Дом является фундаментом веб-страницы, знаяControl DOM может управлять всей веб-страницей, сделать хороший интерактивный опыт。
Таким образом, в сегодняшнем обмене мы будем продолжать вводить метод поиска узла поиска API DOM.
Предисловие: где та метка сценария?
против<script>Где этикетка, эта тема на самом деле нет стандартного ответа, обычно вы увидите две версии:
- Вставить
<head> ... </head>между - Вставить
</body>До
Некоторые люди скажут почему<head> ... </head>Не существует ли никакого эффекта в JavaScript? Я думаю, что это сказано иметь доступ, здесь мы просто говорим о проблеме.
Тогда давайте попробуем предыдущее введение, сначалаdocument.querySelectorПолучатьid="hello"Узел, затем пройтиtextContentИзменять контент.
Попробуйте сначала сначала<script>Этикетка</body>До. Сделайте это сразу в Jsbin, кажется, очень хорошо!
Тогда мы попробовали<script>Этикетка<head> ... </head>между:
Хм? Что у тебя было что-нибудь? И отсутствует сообщение об ошибке, JavaScript действительно нравится все, это очень мусор?
Спокойствие, позвольте мне объяснить.
Как упоминалось ранее, когда веб-страница загружается в браузер, браузер впервые проанализирует этот HTML-документ, а парсер читается в порядке:
Таким образом, в приведенном выше примере JSBIN, когда браузер<head> ... </head>Вмешательство<script>Когда метка мечена, страница разборки приостановлена, а такженемедленновоплощать в жизнь<script>Содержание до тех пор, пока сценарий не будет выполнен, продолжайте разрешать веб.
когда<head> ... </head>внутренний<script>Хочу попытаться найти<div id="hello">Эта этикетка, но потому что нет разрешения тела веб-страницы, нет приобретения.
Не браузер плохой, ни JavaScript слишком шлак, но потому что мыНедопонимание, вызванное принципами выполнения браузера。
Вот браузер загружен один<script> Что случилось на веб-сайте этикетки:
- Возьмите HTML-страницу
- Начните анализ HTML
- Разрешить
<script>Файл сценария готовят после получения метки. - Браузер получает файл сценария. В то же время HTML-анализ прерывается иБлокироватьАнализ другого HTML на странице.
- Через некоторое время сценарий скачан ивоплощать в жизнь。
- Продолжайте разбирать другие части HTML-документа (разрешение HTML-кода после скрипта)
Шаг 4 приводит к очень плохому пользователю, пока файлы сценариев не будут загружены до завершения завершения, и HTML не может быть проанализирован.
Итак, когда мы положили<script>Этикетка</body>До конца, потому что DOM проанализировал,document.querySelectorПриходить гладкоid="hello"Узел и положить'HELLO'Строка размещается на веб-странице!
Это сказано,<script>Этикетка не подходит для<head> ... </head>Что это?
Я не могу сказать, что я могу использовать целое, чтобы объяснить это серьезно.
Выбор узлов DOM
Предыдущая статья сказала,Объект документаЯвляется корневым узлом дерева DOM, поэтому, когда мы должны получить доступ к HTML,documentОбъект начинается. И тип узла DOM, кромеУзел элемента HTML(Узлы элемента)Текстовый узел(text nodes)、Примечание узлаКомментарий узлы и т. Д.
И общие методы выбора DOM имеют следующее:
/ / В соответствии с входящим значением, найдите элемент в DOM 'XXX'.
document.getElementById('xxx');
// Для данного имени тега верните все квалифицированные объекты odelist (коллекция узлов)
document.getElementsByTagName('xxx');
// Возвращает все квалифицированные коллекции узлов для данного имени класса
document.getElementsByClassName('xxx');
// для данного условия селектора, верните первый или все соответствующие коллекции узла
document.querySelector('xxx');
document.querySelectorAll('xxx');
Копировать кодТип узлов DOM
Дом Обычно используемые типы узлов имеют следующее:
Его можно судить по постоянной типе узла или соответствующее значение:
document.nodeType === Node.DOCUMENT_NODE; //true
document.nodeType === 9; //true
Копировать кодДругое необычное или было заброшено, можно упомянуть:MDN Node.nodeTypeодин период.
Найти Travers между узлами DOM (пересекающие)
Поскольку узел DOM имеет иерархическую концепцию, отношения между узлами и узлами, мы обычно можем быть разделены на два типа:
- Отец и детские отношения:Кроме
documentКроме того, каждый узел будет иметь верхний узел, который обычно называется «родительский узел», а относительно, от узла, принадлежащего нижний слой, он называется «узел дочернего узела» (узел ребенка). - Братство: Существует узел того же «родительского узла», то они являются «узлом братьев и сестер» между ними.
Узлы отсека в основном не связаны напрямую.
Соседний узел в горизонтальном направлении на рисунке является родительским и дочерним отношениям, один и тот же уровень слоя в вертикальном направлении – братья.
Node.childNodes
Все объекты NOM узлов имеютchildNodesАтрибуты, и такие атрибуты не могут быть изменены.
Мы можем пройтиNode.hasChildNodes()Чтобы проверить, имеет ли узел DOM для ребенка.
var node = document.querySelector('#hello');
// Если есть подэлемент в узле
if( node.hasChildNodes() ) {
/ / Вы можете получить соответствующий узел у Node.childnodes [n] (n для цифрового индекса)
// Обратите внимание, что объект объекта odelist - это набор мгновенных обновлений.
for (var i = 0; i < node.childNodes[i].length; i++) {
// ...
};
}
Копировать кодNode.childNodesБудут эти типы, которые будут возвращены:
- Узел элемента HTML (узлы элемента)
- Текстовые узлы, включая пробелы
- Комментарий узлов
Node.firstChild
Node.firstChildМожет получитьNodeУзелПервыйДетский узел, возвращение, если нет детского узлаnull。
Следует отметить, что узел ребенка включает в себя пустой узел, как описано ниже:
<p>
<span>span 1</span>
<span>span 2</span>
<span>span 3</span>
</p>
<script>
var p = document.querySelector('p');
// свойство Tagname может получить имя тега узла
console.log(p.firstChild.tagName); // undefined
</script>
Копировать кодПотому что это<p>Первый<span>В середине персонажа обертки, такp.firstChild.tagNameБыть полученнымundefinedОтказ Так что изменилось на это:
<p><span>span 1</span><span>span 2</span><span>span 3</span></p>
<script>
var p = document.querySelector('p');
// свойство Tagname может получить имя тега узла
console.log(p.firstChild.tagName); // "SPAN"
</script>
Копировать кодСнимите среднюю обертку и пробел, его ожидается."SPAN"Отказ
Node.lastChild
Node.lastChildМожет получитьNodeПоследний ребенок узел узела, возвращает, если нет детского узлаnull。
иNode.firstChildТо же самое заключается в том, что узел ребенка также включает в себя пустые узлы, так понравилось:
<p>
<span>span 1</span>
<span>span 2</span>
<span>span 3</span>
</p>
<script>
var p = document.querySelector('p');
// Свойство TextContent может получить контент текста в узле
console.log(p.lastChild.textContent); // «» (КНР)
</script>
Копировать кодПолученный в результате будет нулевая строка характера обертка.
Удалить дополнительный пробел между узлами:
<p><span>span 1</span><span>span 2</span><span>span 3</span></p>
<script>
var p = document.querySelector('p');
// Свойство TextContent может получить контент текста в узле
console.log(p.lastChild.textContent); // "span 3"
</script>
Копировать кодВывод будет правильным «промежутком 3».
Node.parentNode
По сравнению с детской сериалой,parentNodeПросто.
пройти черезNode.parentNodeМожет использоваться для получения родительского элемента, возвращаемое значение может представлять собой элементный узел, целевой узел или узел DocumentFragment.
<p><span>span 1</span><span>span 2</span><span>span 3</span></p>
<script>
var el = document.querySelector('span');
console.log( el.parentNode.nodeName ); // "P"
</script>
Копировать кодNode.previousSibling
После прочтения отца Дома и ребенка, затем посмотрите на узел братьев.
пройти черезNode.previousSiblingВы можете получить предыдущий узел между тем же уровнем, если узел уже является первым узлом, и нет узла, то вернутьnull。
<p><span>span 1</span><span>span 2</span><span>span 3</span></p>
<script>
var el = document.querySelector('span');
console.log( el.previousSibling ); // null
// Document.QuerySereCtionAllAll все получит все квалифицированную коллекцию,
// и document.queryselectorall («SPIN») [2] относится к «третьему» подходящему элементу.
var el2 = document.querySelectorAll('span')[2];
console.log( el2.previousSibling.textContent ); // "span 2"
</script>
Копировать кодNode.nextSibling
иNode.previousSiblingПохоже, пройтиNode.nextSiblingВы можете получить следующий узел между тем же уровнем, если узел уже последний узел, то вернитеnull。
<p><span>span 1</span><span>span 2</span><span>span 3</span></p>
<script>
// document.queryselector получит первый подходящий элемент
var el = document.querySelector('span');
console.log( el.nextSibling.textContent ); // "span 2"
</script>
Копировать кодВо время документа .QuerySelector / Document.QuerySelectionall Различия
Я поделился множеством способов выбора из DOM и найти обход.document.getElementByIdа такжеdocument.querySelectorПотому что есть только один элемент / узел, не будетindexиlengthАтрибуты.
иdocument.getElementsBy**(Примечание, есть S) иdocument.querySelectorAllЗатем верните HTMLCollection и NodeList соответственно.
Оба из них на самом деле немного отличаются, и HTMLcollection собирает только узел HTML-элемента, и NodeList также включает в себя текстовые узлы, узлы атрибута и т. Д. В дополнение к узлу HTML-элемента. Конечно, у обоих есть похожие места, хотя они не могут использовать массив метода, эти два могут получить доступ к контенту с индексом массива, то есть псевдо-массивом.
Другое место для обращения внимания, заключается в том, что HTMLCollection / NodeList в большинстве случаевМгновенное обновлениеНо сквозьdocument.querySelector/document.querySelectorAllПолученный узелСтатическийиз.
Что ты имеешь в виду? Например:
<div id="outer">
<div id="inner">inner</div>
</div>
<script>
// <div id="outer">
var outerDiv = document.getElementById('outer');
// все <div> теги
var allDivs = document.getElementsByTagName('div');
console.log(allDivs.length); // 2
/ / Пустой <div id = "внешний"> под узлом
outerDiv.innerHTML = '';
// потому что узел под <div id = "@">, только внешние останки
console.log(allDivs.length); // 1
</script>
Копировать кодЕсли это измененоdocument.querySelectorПисьмо:
<div id="outer">
<div id="inner">inner</div>
</div>
<script>
// <div id="outer">
var outerDiv = document.getElementById('outer');
// все <div> теги
var allDivs = document.querySelectorAll('div');
console.log(allDivs.length); // 2
/ / Пустой <div id = "внешний"> под узлом
outerDiv.innerHTML = '';
// document.queryselector Возвращает статический odelist, не затронутый внешней
console.log(allDivs.length); // 2
</script>
Копировать кодТак выше, то, что вы хотите представить сегодня.
В последующих статьях будет продолжать объяснять часть API DOM к новому / удалению / изменению узла, добро пожаловать внимание.
Если вы думаете, что статья помогла вам, добро пожаловатьМой блог GitHubСайт и внимание, я благодарен!
