Материал из MachineLearning.
Перейти к: навигация, поиск
Содержание
- 1 Полином в каноническом виде
- 2 Способ вычисления полинома в точке
- 3 Анализ метода
- 3.1 Сложность вычислений
- 3.2 Погрешность интерполяции
- 3.3 Выбор узлов интерполяции
- 4 Вычислительный эксперимент
- 4.1 Пример: Интерполяция синуса
- 5 Рекомендации программисту
- 5.1 Предварительные настойки
- 5.2 Использование программы
- 6 Вывод
- 7 Прикреплённые файлы
- 8 Литература
- 9 Смотри также
- 10 Ссылки
Интерполяция — приближение одной функции другой функцией.
С самого начала хотелось бы заметить, что мы занимаемся интерполяцией функций, а не узлов. Разумеется, интерполяция будет проводиться в конечном числе точек, но выбирать их мы будем сами.
В настоящем исследовании будет изучена проблема интерполяции функции одной переменной полиномом каноническим полиномом, будет рассмотрен вопрос точности приближения, и как, варьируя узлы, через которые пройдёт полином, достигнуть максимальной точности интерполяции.
Полином в каноническом виде
Известно, что любая непрерывная на отрезке [a,b] функция f(x) может быть хорошо приближена некоторым полиномом Pn(x).
Справедлива следующая Теорема (Вейерштрасса): Для любого >0 существует полином Pn(x) степени
, такой, что
В качестве аппроксимирующей функции выберем полином степени n в каноническом виде:
Коэффициенты полинома определим из условий Лагранжа
,
, что с учётом предыдущего выражения даёт систему линейных алгебраических уравнений с n+1 неизвестными:
Обозначим систему таких уравнений символом (*) и перепишем её следующим образом:
или в матричной форме: где
– вектор-столбец, содержащий неизвестные коэффициенты
,
– вектор-столбец, составленный из табличных значений функции
, а матрица
имеет вид:
Система линейных алгебраических уравнений (*) относительно неизвестных иметь единственное решение, если определитель матрицы
отличен от нуля.
Определитель матрицы называют определителем Вандермонда, его можно вычислить по следующей формуле:
Число узлов интерполяционного полинома должно быть на единицу больше его степени. Это понятно из интуитивных соображений: через 2 точки можно провести единственную прямую, через 3 – единственную параболу и т.д. Но полином может получиться и меньшей степени. Т.е. если 3 точки лежат на одной прямой, то через них пройдёт единственный полином первой степени (но это ничему не противоречит: просто коэффициент при старшей степени равен нулю).
При достаточной простоте реализации метода он имеет существенный недостаток: число обусловленности матрицы быстро растёт с увеличением числа узлов интерполяции, что можно показать на следующем графике
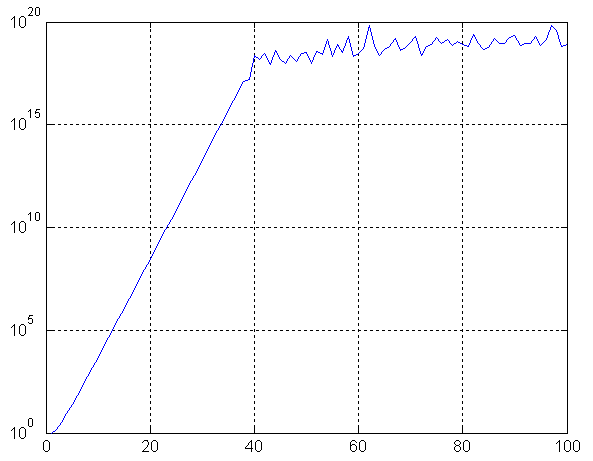
Из-за плохой обусловленности матрицы рекомендуется применять другие методы интерполяции (например, интерполяция полиномами Лагранжа). При этом важно понимать, что при теоретическом применении различных методов они приводят к одинаковому результату, т.е. мы получим один и тот же полином.
Однако при практической реализации мы получим полиномы различной точности аппроксимации из-за погрешности вычислений аппаратуры.
Способ вычисления полинома в точке
Чтобы изобразить графически аппроксимирующий полином, необходимо вычислить его значение в ряде точек. Это можно сделать следующими способами.
Первый способ. Можно посчитать значение a1x и сложить с a0. Далее найти a2x2, сложить с полученным результатом, и так далее. Таким образом, на j-ом шаге вычисляется значение ajxj и складывается с уже вычисленной суммой .
Вычисление значения ajxj требует j операций умножения. Т.е. для подсчёта многочлена в заданной точке требуется (1 + 2 + … + n) = n(n+1)/2 операций умножения и n операций сложения. Всего операций в данном случае: Op1 = n(n+1)/2 + n.
Второй способ. Полином можно также легко вычислить с помощью так называемой схемы Горнера:
Для вычисления значения во внутренних скобках anx + an-1 требуется одна операция умножения и одна операция сложения. Для вычисления значения в следующих скобках (anx + an-1)x + an-2 требуется опять одна операция умножения и одна операция сложения, т.к. anx + an-1 уже вычислено, и т.д.
Тогда в этом способе вычисление Pn(x) потребует n операций умножения и n операций сложения, т.е. сложность вычислений Op2 = n+n = 2n.
Ясно, что Op2 << Op1.
Анализ метода
Сложность вычислений
Оценка сложности интерполирования функции складывается из количества операций для решения системы линейных алгебраических уравнений (СЛАУ) и нахождения значения полинома в точке.
Сложность решения СЛАУ, например, методом Гаусса для матрицы размера nxn: 2n3/3, т.е. O(n3).
Для нахождения полинома в заданной точке требуется n умножений и n сложений. В результате сложность метода: O(n3).
Погрешность интерполяции
Предположим, что на отрезке интерполирования [a,b] функция f(x) n раз непрерывно-дифференцируема. Погрешность интерполяции складывается из погрешности самого метода и ошибок округления.
Ошибка приближения функции f(x) интерполяционным полиномом n-ой степени Pn(x) в точке x определяется разностью: Rn(x) = f(x) – Pn(x).
Погрешность Rn(x) определяется следующим соотношением:
Здесь – производная (n+1)-го порядка функции f(x) в некоторой точке
а функция
определяется как
Если максимальное значение производной fn+1(x) равно то для погрешности интерполяции следует оценка:
При реализации данного метода на ЭВМ ошибкой интерполяции En(x) будем считать максимальное уклонение полинома от исходной функции на выбранном промежутке:
Выбор узлов интерполяции
Ясно, что от выбора узлов интерполируемой функции напрямую зависит, насколько точно многочлен будет являться её приближением.
Введём следующее определение: полиномом Чебышева называется многочлен вида
Tk(x) = cos(k arccos x), |x|≤1.
Известно (см. ссылки литературы), что если узлы интерполяции x0, x1,…,xn являются корнями полинома Чебышева степени n+1, то величина принимает наименьшее возможное значение по сравнению с любым другим выбором набора узлов интерполяции.
Очевидно, что в случае k = 1 функция T1(x), действительно, является полиномом первой степени, поскольку T1(x) = cos(arccos x) = x.
В случае k = 2 T2(x) тоже полином второй степени. Это нетрудно проверить. Воспользуемся известным тригонометрическим тождеством: cos2θ = 2cos²θ – 1, положив θ = arccos x.
Тогда получим следующее соотношение: T2(x) = 2x² – 1.
С помощью тригонометрического тождества cos(k + 1)θ = 2cosθcoskθ – cos(k – 1) легко показать, что для полиномов Чебышева справедливо реккурентное соотношение:
Tk+1(x) = 2xTk(x) – Tk-1(x)
При помощи данного соотношения можно получить формулы для полиномов Чебышева любой степени.
Корни полинома Чебышева легко находятя из уравнения: Tk(x) = cos(k arccos x) = 0. Получаем, что уравнение имеет k различных корней, расположенных на отрезке [-1,1]: которые и следует выбирать в качестве узлов интерполирования.
Нетрудно видеть, что корни на [-1,1] расположены симметрично и неравномерно – чем ближе к краям отрезка, тем корни расположены плотнее. Максимальное значение модуля полинома Чебышева равно 1 и достигается в точках
Если положить то для того, чтобы коэффициент при старшей степени полинома ωk(x) был равен 1,
Известно, что для любого полинома pk(x) степени k с коэффициентом, равным единице при старшей производной верно неравенство т.е. полиномы Чебышева являются полиномами, наименее уклоняющимися от нуля.
Вычислительный эксперимент
Для реализации поставленной задачи была написана программа на языке С++, которая по заданной функции приближает её каноническим полиномом. Разумеется, необходимо указать узлы, через которые полином пройдёт, и значения функции в этих узлах.
Далее строится СЛАУ, которая решается методом Гаусса. На выходе получаем коэффициенты для полинома и ошибку аппроксимации.
Как было показано выше, и в чём мы убедимся в дальнейшем, от выбора узлов зависит точность, с которой полином будет приближать функцию.
Пример: Интерполяция синуса
Попробуем интерполировать функцию y = sin(x) на отрезке [1, 8.5]. Выберем узлы интерполяции: {1.1, 2, 4.7, 7.5, 8.5}
Полученный в результате интерполяции полином отображён на рисунке (синим цветом показан график y = sin(x), красным – интерполяционного полинома)
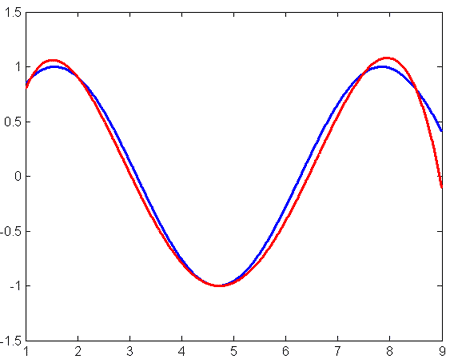
Ошибка интерполяции в этом случае: 0.1534
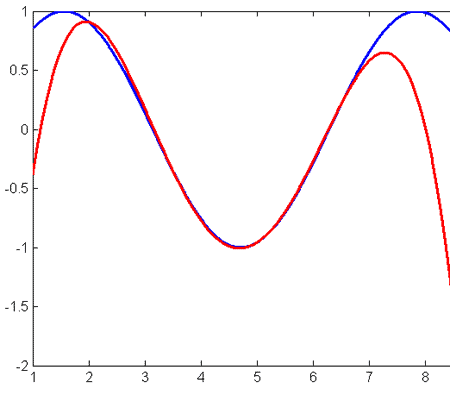
Давайте посмотрим, что произойдёт, если выбрать равномерно стоящие узлы {2, 3.5 5, 6.5, 8} для той же функции на том же отрезке.
На отрезке [3, 6] приближение, бесспорно, стало лучше. Однако разброс на краях очень большой. Ошибка интерполяции: 2.3466.
Наконец, выберем узлы интерполяции в соответствии с Чебышевским алгоритмом. Получим их по следующей формуле (просто сделаем замену переменной):
В нашем случае [a,b] – отрезок [1, 8.5], y = cosx, n+1 – количество узлов.
Остаётся открытым вопрос, какое количество узлов выбрать.
- При значении n меньше 3 ошибка аппроксимации получается более 10.6626.
- При n = 4: приближение лучше (ошибка равна 1.0111),
- при n = 5: ошибка аппроксимации 0.2797
График функций при n = 4 выглядит следующим образом:
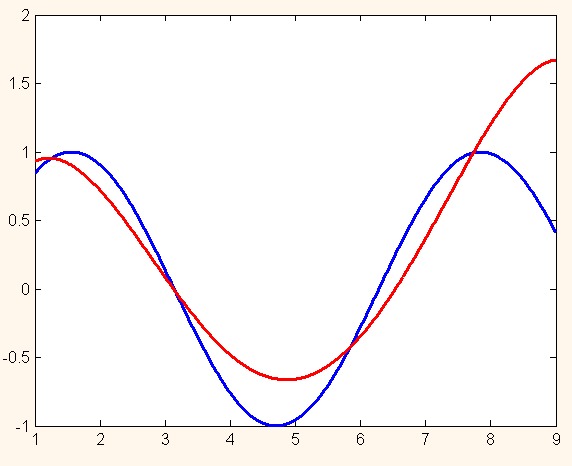
Продолжим исследования.
- n = 6: ошибка аппроксимации 1.0233.
При n = 7 ошибка аппроксимации принимает наименьшее из полученных ранее значений (для данного промежутка): 0.0181. График синуса (обозначен синим цветом) и аппроксимационного полинома (обозначен красным цветом) представлены на следующем графике:
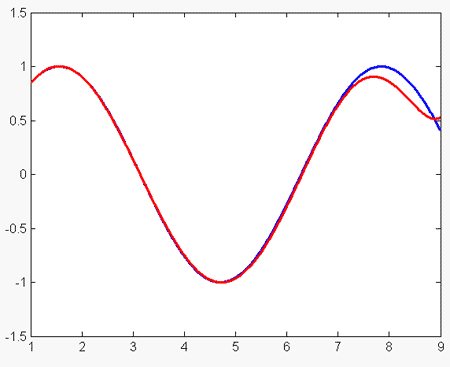
Что интересно, если при этом же количестве узлов выбирать их на отрезке [1, 8], то ошибка аппроксимации становится ещё меньше : 0.0124. График в этом случае выглядит так:
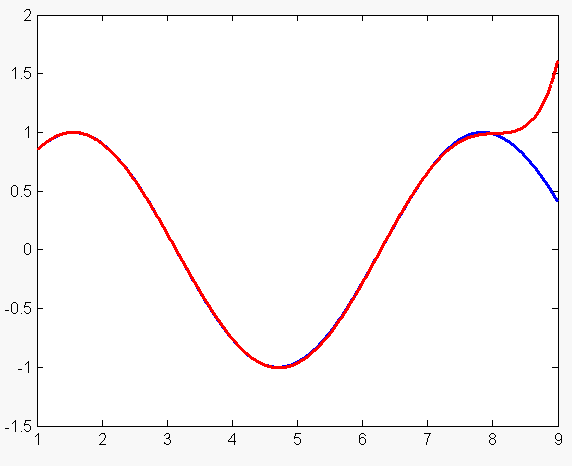
При выборе большего количества узлов ситуация ухудшается: мы стараемся слишком точно приблизить исходную функцию:
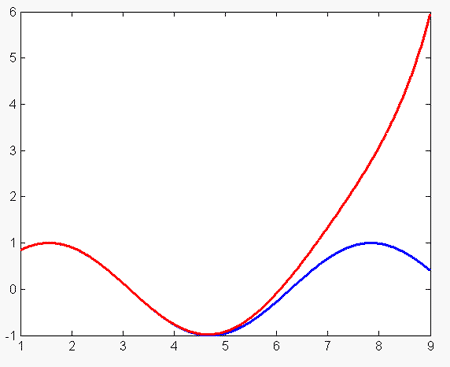
Ошибка аппроксимации будет только расти с увеличением числа узлов.
Как видим, наилучшее приближение получается при выборе узлов по методу Чебышева. Однако рекомендаций, какое количество узлов является оптимальным, нет – это определяется только экспериментальным путём.
Рекомендации программисту
Программа написана на языке C++ с использованием библиотеки линейной алгебры UBlas, которая является частью собрания библиотек Boost. Скачать исходный текст программы можно здесь [2.55Кб].
Предварительные настойки
Чтобы воспользоваться программой, необходимо сделать следующее:
1. Определиться с функцией, которую вы собираетесь интерполировать
2. Создать текстовый файл (например, vec.txt), в первой строчке которого через пробел размещены узлы интерполяции, а во второй – значения выбранной функции в этих узлах.
Например, функция y = sin(x):
0.74 2 -3.5 0.6743 0.9093 0.351
3. В .cpp файле программы в функцию double f(double x) вместо строки return прописать возвращаемое исходной функцией значение. Например, для функции y = sin(x):
return sin(x);
4. В функции int main() исходного кода присвоить переменной char* flname путь к входному файлу с данными. В нашем случае char* flname = “vec.txt”;
Использование программы
В программе реализованы следующие основные функции:
- double f(double x), описание которой было дано выше
- int load(char *filename, vector<double> &x, vector<double> &y) – загрузка узлов интерполяции в переменную x и значения функции в этих узлах в переменную y текстового файла filename. В случае удачной загрузки данных из файла функция возвращает 0.
- void matrix2diag(matrix<double> &A, vector<double> &y) – приводит матрицу A к треугольному виду. y – столбец правой части (также изменяется вместе с матрицей A).
- void SolveSystem(matrix<double> &A, vector<double> &y, vector<double> &coef) – решить СЛАУ (A – треугольная матрица, y – столбец правой части, coef – в этот вектор заносится решение СЛАУ)
- double errapprox(vector<double> coef, double a, double b, double h) – возвращает ошибку аппроксимации полиномом исходной функции.
На вход функции подаются следующие параметры:
-
- vector coef – вектор коэффициентов интерполяционного полинома, который получается в ходе решения СЛАУ
- double a, double b – границы промежутка интерполяции [a, b]
- double h – шаг, с которым «пробегаем» промежуток [a, b]
- int outpolyn(char** filename, vector<double> coef) – сохраняет коэффициенты полинома coef в файл filename. В случае удачного сохранения функция возвращает ‘0’.
После запуска программы на экране появляются коэффициенты интерполяционного полинома и ошибка аппроксимации.
Вывод
Был исследован и программно реализован метод интерполяции функции каноническим полиномом. В ходе исследований установлено, что ошибка интерполяции получается как из-за ошибок компьютерных вычислений, так и из-за ошибок метода.
Также замечено, что от выбора узлов интерполяции напрямую зависит качество интерполяции. Минимальная ошибка интерполяции достигается при выборе «чебышевских» узлов.
Прикреплённые файлы
Программная реализация на языке С++ (исходный текст) [2.55Кб]
Литература
- Н.С. Бахвалов, Н.П. Жидков, Г.М. Кобельков. Численные методы. Изд-во “Лаборатория базовых знаний”. Москва. 2003.
- И.С. Березин, Н.П. Жидков. Методы вычислений. Изд. ФизМатЛит. Москва. 1962.
- Дж. Форсайт, М.Мальком, К. Моулер. Машинные методы математических вычислений. Изд-во “Мир”. Москва. 1980.
Смотри также
- Проблема выбора узлов для интерполяции
- Ошибки вычислений
- Метод наименьших квадратов
- Интерполяционный многочлен Лагранжа
- Практикум ММП ВМК, 4й курс, осень 2008
Ссылки
- Собрание библиотек Boost
Алгоритм построения интерполяционного многочлена Ньютона
Для
построения интерполяционного многочлена
Ньютона необходимо вычислить ряд
разделенных разностей, входящих в
интерполяционную формулу Ньютона
(4.2.5). Но на самом деле, наряду с этими
разделенными разностями, придется
вычислить и другие разности, которые
непосредственно в формулу (4.2.5) не входят,
но через которые вычисляются и другие
разности нужные нам. Поместим все
разделенные разности, необходимые для
построения многочлена Ньютона в таблицу.
Приведем такую таблицу для случая
![]() (табл. 4.1).
(табл. 4.1).
Таблица 4.1
|
|
|
|
|
|
|
|
|
|
||||
|
|
|||||
|
|
|
|
|||
|
|
|
||||
|
|
|
|
|
||
|
|
|
||||
|
|
|
|
|||
|
|
|||||
|
|
|
Интерполяционный
многочлен Ньютона в этом случае примет
вид
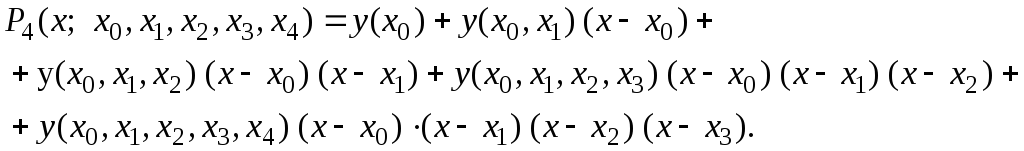
Для
построения интерполяционного многочлена
Ньютона нам понадобятся только
подчеркнутые в табл.4.1 разности, но
вычислять необходимо все. Вести вычисления
следует слева направо. Вначале вычисляются
все разности первого порядка, затем –
второго, и так далее.
Пример
Требуется
построить для функции
![]()
интерполяционный многочлен Ньютона
третьего порядка с узлами
![]() .
.
Требуемый
интерполяционный многочлен Ньютона
имеет вид
![]()
Пользуясь
определением, вычислим значения
разделенных разностей и поместим их в
табл. 4.2
![]() ,
,
![]() ,
,
![]() ,
,
![]() ,
,
![]() ,
,
![]() .
.
Таблица
4.2
|
|
|
|
|
|
|
|
|
|||
|
|
||||
|
|
|
|
||
|
|
|
|||
|
|
|
|
||
|
|
||||
|
|
|
Осталось составить
интерполяционный многочлен
![]() .
.
Построенный
интерполяционный многочлен в рассмотренном
примере совпал с исходной функцией
![]() .
.
Это не случайно и непосредственно
следует из единственности интерполяционного
многочлена.
4.3. Кратные узлы интерполяции. Интерполяционный многочлен Эрмита Кратные узлы интерполяции. Формулировка задачи интерполяции с кратными узлами
Иногда
оказываются известными значения функции
![]() в заданных точках и значения ее
в заданных точках и значения ее
производных. Эту дополнительную
информацию можно использовать при
построении интерполяционного многочлена.
В результате чего получается
интерполяционный многочлен Эрмита.
Пусть
заданы табличные значения функции
![]() и ее производных в заданных точках
и ее производных в заданных точках![]() ,
,
причем известными считаются значения
![]()
![]()
(4.3.1)
…………………………….
![]()
Здесь
![]() ,
,![]() .
.
Введем величину
![]() .
.
(4.3.2)
Будем
искать алгебраический многочлен n-й
степени
![]() такой, что
такой, что
![]()
![]()
(4.3.3)
………………………………………….…………………………..
![]()
Точки
![]() называютсяузлами
называютсяузлами
интерполяции,
а искомый многочлен
![]()
интерполяционным
многочленом Эрмита.
Если
![]() ,
,
то узел![]() называетсяпростым,
называетсяпростым,
или однократным,
а если
![]() ,
,
то узел![]() называетсякратным,
называетсякратным,
причем величина
![]() называетсякратностью
называетсякратностью
узла
![]() .
.
Условия
(4.3.3) называются условиями
интерполяции с кратными узлами.
В
дальнейшем будем использовать для
многочлена Эрмита, наряду с введенным
кратким обозначением, развернутое
обозначение. В нем указываются узлы
интерполяции в качестве параметров,
причем количество повторений узла в
обозначении многочлена Эрмита совпадает
с его кратностью:
![]() .
.
(4.3.4)
Теорема.
Может
существовать только один многочлен
Эрмита.
Доказательство.
Доказательство
будем вести от противного. Пусть
существуют два разных алгебраических
многочлена n-й
степени
![]() и
и![]() ,
,
удовлетворяющие условиям интерполяции
(4.3.3). Тогда их разность![]() будет представлять собой алгебраический
будет представлять собой алгебраический
многочлен степени не вышеn,
не равный тождественно нулю, причем для
него будут выполнены условия
![]()
![]()
(4.3.5)
………………………………………….…..
![]()
Таким
образом, многочлен
![]() имеетm
имеетm
корней суммарной кратности
![]() .
.
Полученное противоречие доказывает
наше утверждение.
Соседние файлы в папке ВМ_УЧЕБНИК
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
Мы уже говорили, что сетки могут быть равномерными и неравномерными. Возникает естественный вопрос: существует ли оптимальное распределение узлов на отрезке ![]() при интерполяции полиномами? То есть существует ли распределение узлов, при котором погрешность интерполяции полиномами минимальна при фиксированном n?
при интерполяции полиномами? То есть существует ли распределение узлов, при котором погрешность интерполяции полиномами минимальна при фиксированном n?
Отметим, что во многих задачах вычислительной математики введение неравномерной сетки позволяет уменьшить погрешность или сделать ее минимальной. Таким образом в вычислительной математике существует общий прием – введение неравномерной сетки.
Рассмотрим применение этого приема при интерполяции полиномами. Рассмотрим оценку погрешности:
![]() .
.
Первые два сомножителя не зависят от ![]() .
.
От ![]() зависит третий сомножитель
зависит третий сомножитель ![]() , полином степени
, полином степени ![]() . То есть нужно решить задачу:
. То есть нужно решить задачу:
![]() .
.
Если в качестве ![]() рассмотреть отрезок
рассмотреть отрезок ![]() , то мы получим задачу, которая решается с помощью полиномов Чебышева. Оптимальным распределением узлов интерполяции на отрезке [-1, 1] являются нули полинома Чебышева
, то мы получим задачу, которая решается с помощью полиномов Чебышева. Оптимальным распределением узлов интерполяции на отрезке [-1, 1] являются нули полинома Чебышева ![]() .
.
Полиномы Чебышева определяются следующим образом:
![]() ,
, ![]() .
.
Запишем полиномы Чебышева степени 0 и степени 1: ![]() ,
, ![]() . Полиномы более высокой степени вычисляются по рекуррентной формуле:
. Полиномы более высокой степени вычисляются по рекуррентной формуле:
![]() .
.
Найдем нули полинома Чебышева степени n:.
![]() ,
, ![]() ,
, ![]()
![]() ,
, ![]() .
.
Запишем формулу для нулей полинома Чебышева степени n таким образом, чтобы ![]() вычислялись в порядке возрастания:
вычислялись в порядке возрастания:
![]() ,
, ![]() .
.
Точки ![]() являются оптимальными узлами сетки размерности n при интерполяции полиномами на отрезке [-1, 1]. Из формулы для нулей полинома Чебышева вытекает, что
являются оптимальными узлами сетки размерности n при интерполяции полиномами на отрезке [-1, 1]. Из формулы для нулей полинома Чебышева вытекает, что ![]() для любого i, то есть
для любого i, то есть ![]() на отрезке [-1, 1] имеет n вещественных корней.
на отрезке [-1, 1] имеет n вещественных корней.
Если интерполирование производится на отрезке [a, b], то линейной заменой переменных
![]()
переводим отрезок [a, b] в отрезок [-1, 1].
Отметим два свойства полиномов Чебышева:
1) старший коэффициент ![]() равен
равен![]() ;
;
2) ![]() – это ортогональные полиномы на отрезке [-1, 1] с весом
– это ортогональные полиномы на отрезке [-1, 1] с весом ![]() , т.е.
, т.е.
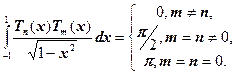
Теорема Чебышева
Из всех полиномов ![]() n-й степени со старшим коэффициентом, равным единице, для полинома
n-й степени со старшим коэффициентом, равным единице, для полинома ![]() выполнено неравенство:
выполнено неравенство:
![]() ,
,
то есть полиномы ![]() – это полиномы, наименее уклоняющиеся от нуля в равномерной норме на отрезке [-1, 1].
– это полиномы, наименее уклоняющиеся от нуля в равномерной норме на отрезке [-1, 1].
Сформируем два важных утверждения, связанных с оптимальным выбором узлов интерполяции.
Первое утверждение – это оценка погрешности для оптимального распределения узлов. Второе утверждение – это теорема о сходимости интерполяционных полиномов при оптимальном распределении узлов.
Теорема (оценка погрешности)
Если в качестве узлов интерполяции на отрезке [-1, 1] выбраны нули полинома Чебышева ![]() степени n + 1, то для интерполяционного полинома
степени n + 1, то для интерполяционного полинома ![]() , построенного по соответствующей интерполяционной таблице, справедлива оценка погрешности:
, построенного по соответствующей интерполяционной таблице, справедлива оценка погрешности:
![]() .
.
Если же интерполяция проводится на отрезке [a, b] и в качестве узлов интерполяции выбраны точки, соответствующие нулям полинома Чебышева на отрезке [-1, 1], то справедлива оценка:
![]() .
.
Теорема (о сходимости)
Если функция![]() является непрерывно дифференцируемой на отрезке [–1, 1], то интерполяционный полином
является непрерывно дифференцируемой на отрезке [–1, 1], то интерполяционный полином ![]() , совпадающий с
, совпадающий с ![]() в нулях полинома Чебышева степени n + 1, сходится к
в нулях полинома Чебышева степени n + 1, сходится к ![]() при
при ![]() для любой точки x из отрезка [-1, 1].
для любой точки x из отрезка [-1, 1].
Практический вывод. Если интерполяция может выполняться с произвольным выбором узлов на отрезке [-1, 1], то целесообразно в качестве узлов выбрать нули полинома Чебышева.
Геометрический смысл. Для отрезка [a, b] точки, соответствующие нулям полинома Чебышева на отрезке[-1, 1], получаются построением на отрезке [a, b] полукруга,
делением этого полукруга на n равных дуг и проецированием середин каждой из дуг на данный отрезок (рис. 5.4). Нули полинома Чебышева сгущаются к концам отрезка.
Кратко остановимся на главных моментах темы интерполяции полиномами.
Если в интерполяционной таблице все ![]() различны (
различны (![]() при
при ![]() ), то существует единственный интерполяционный полином, степень которого на единицу меньше, чем размерность интерполяционной таблицы.
), то существует единственный интерполяционный полином, степень которого на единицу меньше, чем размерность интерполяционной таблицы.
Известны разные формы записи одного и того же интерполяционного полинома (форма Лагранжа, форма Ньютона, форма Стирлинга).

Рис. 5.4. Нули полинома Чебышева ![]()
Существует оптимальное распределение узлов интерполяции на отрезке [-1,1], а именно нули полинома Чебышева, использование которых для непрерывно дифференцируемых функций обеспечивает сходимость интерполяционных полиномов.
С ростом степени интерполяционного полинома требуется существование у ![]() производных все более высокого порядка.
производных все более высокого порядка.
При неоптимальном распределении узлов интерполяции на отрезке [a, b] возможно увеличение погрешности с ростом степени интерполяционного полинома и возникновение осцилляции на концах отрезка.
Объем арифметических действий, необходимых для построения полинома Лагранжа – ![]() , полинома Ньютона –
, полинома Ньютона – ![]() . Объем памяти –
. Объем памяти – ![]() .
.
Макеты страниц
Как мы видели, отклонение  от
от  определяется величиной
определяется величиной  Если о первой величине мы можем иногда сказать, в каких пределах она заключена, то вторую мы можем в некоторых случаях менять по нашему желанию, изменяя точки х. Поставим следующую задачу: как нужно выбрать узлы
Если о первой величине мы можем иногда сказать, в каких пределах она заключена, то вторую мы можем в некоторых случаях менять по нашему желанию, изменяя точки х. Поставим следующую задачу: как нужно выбрать узлы  для того, чтобы
для того, чтобы  была наименьшей. Для ответа на этот вопрос нам придется использовать многочлены Чебышева.
была наименьшей. Для ответа на этот вопрос нам придется использовать многочлены Чебышева.
Многочлен Чебышева  определяется так:
определяется так:

При

При

Далее, из тождества

полагяя  получим:
получим:

Таким образом,  действительно являются многочленами, причем коэффициент при старшей степени х равен
действительно являются многочленами, причем коэффициент при старшей степени х равен  Из рекуррентной формулы последовательно находим:
Из рекуррентной формулы последовательно находим:

 как многочлен степени
как многочлен степени  имеет ровно
имеет ровно  корней. Из
корней. Из  следует
следует

Давая  значения
значения  получим
получим  различных корней, причем все они оказываются заключенными между
различных корней, причем все они оказываются заключенными между  Заметим также, что
Заметим также, что  на отрезке
на отрезке  равен 1
равен 1
и достигается в  точках
точках  Если в качестве отрезка интерполирования
Если в качестве отрезка интерполирования  взять
взять  и в качестве узлов интерполирования — корни многочлена Чебышева
и в качестве узлов интерполирования — корни многочлена Чебышева  то
то  Покажем, что какой бы многочлен
Покажем, что какой бы многочлен  степени
степени  со старшим коэффициентом 1 мы ни взяли,
со старшим коэффициентом 1 мы ни взяли,  Действительно, если бы это было не так, то разность
Действительно, если бы это было не так, то разность  представляла бы собой многочлен степени
представляла бы собой многочлен степени  принимающий в
принимающий в  точках
точках  попеременно то положительные, то отрицательные значения. Следовательно, он должен иметь по крайней мере
попеременно то положительные, то отрицательные значения. Следовательно, он должен иметь по крайней мере  корней, что невозможно.
корней, что невозможно.
Таким образом, если ограничиться рассмотрением отрезка  то
то  будет иметь наименьшее возможное значение
будет иметь наименьшее возможное значение  при условии, что в качестве узлов интерполирования взяты корни многочлена Чебышева, и в этом случае, наша оценка примет вид
при условии, что в качестве узлов интерполирования взяты корни многочлена Чебышева, и в этом случае, наша оценка примет вид

Если интерполирование производится на произвольном отрезке  то линейной заменой переменного
то линейной заменой переменного

его можно перевести в  При этом корни многочлена
При этом корни многочлена  перейдут в
перейдут в

Оценка для этого случая будет такова:

Полученные нами результаты дают наилучшую оценку в целом по всему отрезку  Мы воспользовались тем свойством многочленов
Мы воспользовались тем свойством многочленов  что для них
что для них  имеет
имеет  меньшее значение среди всех многочленов степени
меньшее значение среди всех многочленов степени  с коэффициентом при старшей степени, равным единице. Благодаря этому свойству многочлены
с коэффициентом при старшей степени, равным единице. Благодаря этому свойству многочлены  получили название многочленов, наименее
получили название многочленов, наименее
отклоняющихся от нуля. Можно поставить и другую задачу: при фиксированных узлах интерполирования изучить, для каких промежутков изменения остаточный член будет принимать большие значения и для каких меньшие. Для решения этой задачи нам нужно изучить поведение функции  при фиксированных
при фиксированных  Многочлен
Многочлен  обращается в нуль в точках
обращается в нуль в точках  меняет знак, переходя через каждое из этих значений, и где-то в промежутках между ними принимает попеременно то максимальное, то минимальное значение (рис. 19).
меняет знак, переходя через каждое из этих значений, и где-то в промежутках между ними принимает попеременно то максимальное, то минимальное значение (рис. 19).

Рис. 19.
Абсолютные значения этих экстремумов будут равны друг другу только в том случае, если  являются корнями многочлена
являются корнями многочлена

В остальных случаях они будут различны. При интерполировании вблизи больших по абсолютной величине экстремумов можно ожидать большей погрешности, там же, где эти экстремумы будут принимать меньшие значения, следует ожидать меньшей погрешности. Исследование общего случая  при произвольном распределении узлов интерполяции довольно затруднительно. Поэтому мы ограничимся случаем равноотстоящих узлов, т. е. будем предполагать, что
при произвольном распределении узлов интерполяции довольно затруднительно. Поэтому мы ограничимся случаем равноотстоящих узлов, т. е. будем предполагать, что

Опять введем  при помощи соотношения
при помощи соотношения  Тогда
Тогда

и нам следует изучить поведение функции

при различных значениях  Прежде всего заметим, что эта функция будет четной или нечетной относительно точки
Прежде всего заметим, что эта функция будет четной или нечетной относительно точки  в зависимости от четности
в зависимости от четности  Действительно, если произвести замену
Действительно, если произвести замену  то получим:
то получим:

Правая часть этого равенства будет четной функцией  если
если  нечетно, и будет нечетной функцией
нечетно, и будет нечетной функцией  если
если  четно. Далее, заметим, что
четно. Далее, заметим, что

Таким образом, если разбить отрезок  на части [0, 1], [1, 2],
на части [0, 1], [1, 2],  то значение функции в отрезке
то значение функции в отрезке  будет получаться из соответствующего значения функции в предыдущем отрезке путем умножения его на
будет получаться из соответствующего значения функции в предыдущем отрезке путем умножения его на  Последний множитель всегда отрицателен при изменении
Последний множитель всегда отрицателен при изменении  от
от  до
до  Поэтому знаки значений функции будут чередоваться при переходе от одного интервала к следующему. Абсолютная величина этого множителя будет меньше 1 на отрезке
Поэтому знаки значений функции будут чередоваться при переходе от одного интервала к следующему. Абсолютная величина этого множителя будет меньше 1 на отрезке  Таким образом, экстремальные значения
Таким образом, экстремальные значения  будут убывать по абсолютной величине до середины отрезка
будут убывать по абсолютной величине до середины отрезка  и затем в силу симметрии снова возрастать.
и затем в силу симметрии снова возрастать.

Рис. 20.
Вне пределов отрезка  функция
функция  быстро возрастает по абсолютной величине. Итак, графики функции будут следующих двух типов (рис. 20). Какие же выводы можно сделать о точности интерполирования из приведенного нами анализа? Во-первых, оценка остаточного члена формулы Лагранжа
быстро возрастает по абсолютной величине. Итак, графики функции будут следующих двух типов (рис. 20). Какие же выводы можно сделать о точности интерполирования из приведенного нами анализа? Во-первых, оценка остаточного члена формулы Лагранжа  будет особенно велика для значений х, лежащих вне отрезка
будет особенно велика для значений х, лежащих вне отрезка  Поэтому следует
Поэтому следует
ожидать, что если мы производим вычисления по интерполяционной формуле для значений х, лежащих вне отрезка  или, как принято говорить, производим экстраполирование, то погрешности будут очень велики. Во-вторых, при интерполировании для значений х, лежащих не близко к узлам интерполирования, точность будет больше для средних отрезков
или, как принято говорить, производим экстраполирование, то погрешности будут очень велики. Во-вторых, при интерполировании для значений х, лежащих не близко к узлам интерполирования, точность будет больше для средних отрезков  и меньше для крайних.
и меньше для крайних.
Интерполя́ция алгебраи́ческими многочле́нами функции 
![[a,b]](https://wikimedia.org/api/rest_v1/media/math/render/svg/9c4b788fc5c637e26ee98b45f89a5c08c85f7935)





Система линейных алгебраических уравнений, определяющих коэффициенты 

Её определителем является определитель Вандермонда.

Он отличен от нуля при всяких попарно различных значениях 
Применение[править | править код]
Полученную интерполяционную формулу 


![{displaystyle xin left[a,bright]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/7c4dd3adabf0430c82fd37cb45576a1df8c60002)
![{displaystyle xnot in left[a,bright]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/aa8e7512a92b9d9164a2f11e0035411ecea3cbf5)
Задача интерполяции в пространстве[править | править код]
Пусть в пространстве заданы 

Задача интерполяции состоит в построении кривой, проходящей через указанные точки
в указанном порядке.
Решение задачи[править | править код]
Через фиксированный упорядоченный набор точек можно провести бесконечное число кривых, поэтому задача интерполяции произвольной функцией не имеет единственного решения. Для единственности решения необходимо наложить определённые ограничения на вид функции.
Будем строить кривые в виде 

![[a, b]](https://wikimedia.org/api/rest_v1/media/math/render/svg/5be2db1121262d7d81c3fefaef1a359117682bc3)
.
Введем на отрезке 




Введение параметризации и сетки может быть выполнено различными способами. Обычно выбирают либо равномерную сетку, полагая





Одним из распространенных способов интерполяции является использование кривой в виде многочлена от 

Многочлен имеет 
Эти условия приводят к системе линейных уравнений для коэффициентов

Обратим внимание, что для отыскания коэффициентов, например, в трёхмерном пространстве нужно решить три системы уравнений: для 



называется определителем Вандермонда. Если узлы сетки не совпадают, он отличен от нуля и система уравнений имеет единственное решение.
Кроме прямого обращения матрицы, имеются несколько других способов вычисления
интерполяционного многочлена. В силу единственности многочлена речь идет о различных формах его записи.
Преимущества[править | править код]
- Для заданного набора точек и сетки параметра кривая строится однозначно.
- Кривая является интерполяционной, то есть проходит через все заданные точки.
- Кривая имеет непрерывные производные любого порядка.
Недостатки[править | править код]
Пример[править | править код]

Интерполяция на последовательности сеток. Пример осцилляций Рунге.
Классическим примером (Рунге), показывающим возникновение осцилляций у интерполяционного многочлена, служит интерполяция на равномерной сетке значений функции

Введем на отрезке ![{displaystyle [-5,5]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/f6e33603930f175fbb5b1bb25c0a106f4564cb47)





На рисунке представлены графики самой функции (штрих-пунктирная линия) и трех интерполяционных кривых при 
- интерполяция на сетке
— квадратичная парабола;
- интерполяция на сетке
— многочлен четвёртой степени;
- интерполяция на сетке
— многочлен восьмой степени.
Значения интерполяционного многочлена даже для гладких функций в промежуточных точках, не совпадающих с узлами интерполяции, могут сильно уклоняться от значений самой функции, такое поведение многочлена называют осцилляциями.
См. также[править | править код]
- Интерполяционный многочлен Лагранжа
- Интерполяционный многочлен Ньютона
- Вейвлет
