Поиск и удаление повторений
Excel для Microsoft 365 Excel 2021 Excel 2019 Excel 2016 Excel 2013 Excel 2010 Excel 2007 Excel Starter 2010 Еще…Меньше
В некоторых случаях повторяющиеся данные могут быть полезны, но иногда они усложняют понимание данных. Используйте условное форматирование для поиска и выделения повторяющихся данных. Это позволит вам просматривать повторения и удалять их по мере необходимости.
-
Выберите ячейки, которые нужно проверить на наличие повторений.
Примечание: В Excel не поддерживается выделение повторяющихся значений в области “Значения” отчета сводной таблицы.
-
На вкладке Главная выберите Условное форматирование > Правила выделения ячеек > Повторяющиеся значения.

-
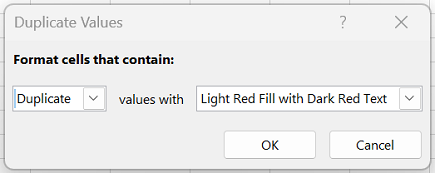
В поле рядом с оператором значения с выберите форматирование для применения к повторяющимся значениям и нажмите кнопку ОК.
Удаление повторяющихся значений
При использовании функции Удаление дубликатов повторяющиеся данные удаляются безвозвратно. Чтобы случайно не потерять необходимые сведения, перед удалением повторяющихся данных рекомендуется скопировать исходные данные на другой лист.
-
Выделите диапазон ячеек с повторяющимися значениями, который нужно удалить.
-
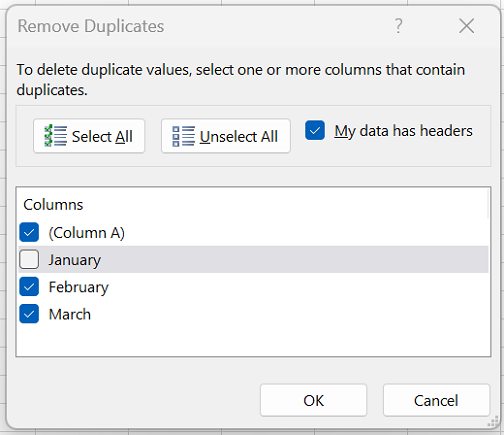
На вкладке Данные нажмите кнопку Удалить дубликаты и в разделе Столбцы установите или снимите флажки, соответствующие столбцам, в которых нужно удалить повторения.
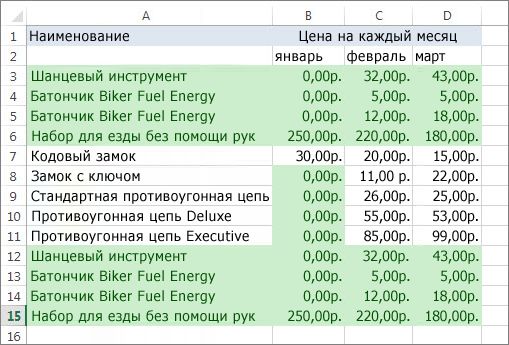
Например, на данном листе в столбце “Январь” содержатся сведения о ценах, которые нужно сохранить.
Поэтому флажок Январь в поле Удаление дубликатов нужно снять.
-
Нажмите кнопку ОК.
Примечание: Количество повторяющихся и уникальных значений, заданных после удаления, может включать пустые ячейки, пробелы и т. д.
Дополнительные сведения

Нужна дополнительная помощь?
Нужны дополнительные параметры?
Изучите преимущества подписки, просмотрите учебные курсы, узнайте, как защитить свое устройство и т. д.
В сообществах можно задавать вопросы и отвечать на них, отправлять отзывы и консультироваться с экспертами разных профилей.
- Найти и выделить цветом дубликаты в Excel
- Формула проверки наличия дублей в диапазонах
- Внутри диапазона
- !SEMTools, поиск дублей внутри диапазона
- Найти дубли ячеек в столбце, кроме первого
- Найти в столбце дубли ячеек, включая первый
- Найти дубли в столбце без учета лишних пробелов
Найти повторяющиеся значения в столбцах Excel — на поверку не такая уж и простая задача. Есть пара встроенных инструментов, таких как условное форматирование и инструмент удаления дубликатов, но они не всегда подходят для решения реальных задач.
Поиск дублей в Excel может быть очень разным, и, в зависимости от вводных, производиться тоже будет по-разному.
Ключевых моментов несколько:
- Какие конкретно повторяющиеся значения — повторы слов в ячейках, сами повторяющиеся ячейки или повторяющиеся строки?
- Если ячейки, то:
- Какие ячейки мы готовы считать дубликатами — все кроме первой или включая ее?
- Считаем ли дублями строки, отличающиеся только пробелами до/после слов или лишними пробелами между словами?
- Где мы будем искать дубли — в одном столбце, в двух столбцах или в нескольких?
- А может, нам нужно найти неявные дубли?
Сначала рассмотрим простые примеры.
Для выделения дубликатов ячеек подходит инструмент условное форматирование. В процедуре есть ряд готовых правил, в том числе и для повторяющихся значений.
Найти инструмент можно на вкладке программы “Главная”:
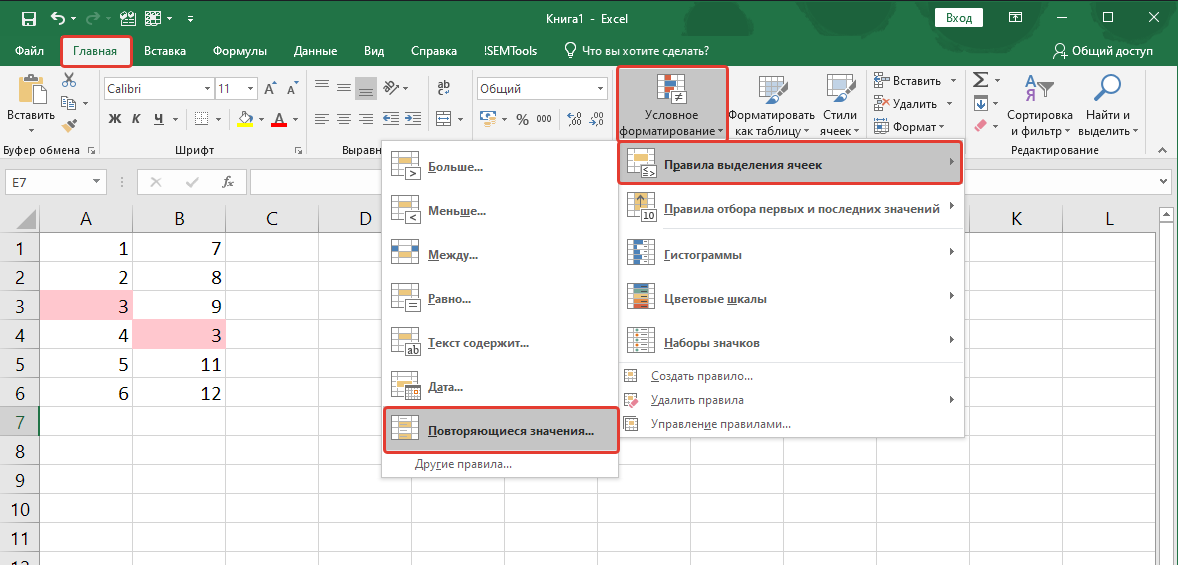
Процедура интуитивно понятна:
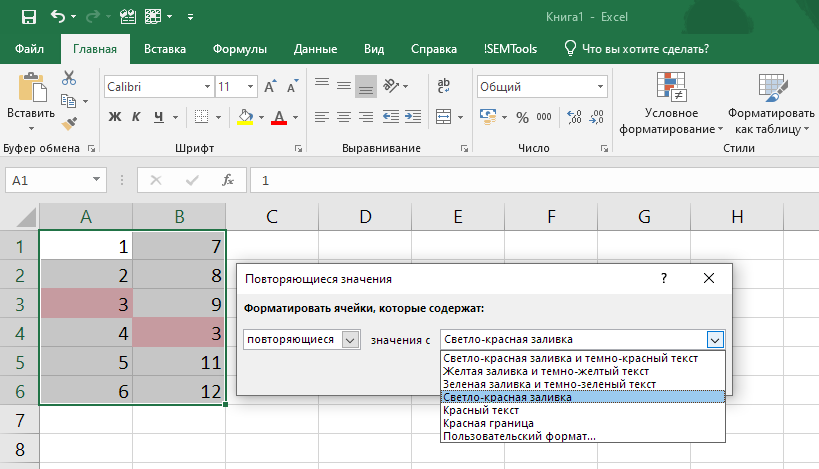
- Выделяем диапазон, в котором хотим найти дубликаты.
- Вызываем процедуру.
- Выбираем форматирование для отобранных ячеек (есть предустановленные форматы или же можно задать свой вариант).
Важно понимать, что процедура находит дубликаты внутри всего диапазона и поэтому может не быть применима для сравнения двух столбцов. Достаточно иметь дубликаты внутри одного столбца — и процедура подсветит их оба, хотя во втором их не будет:
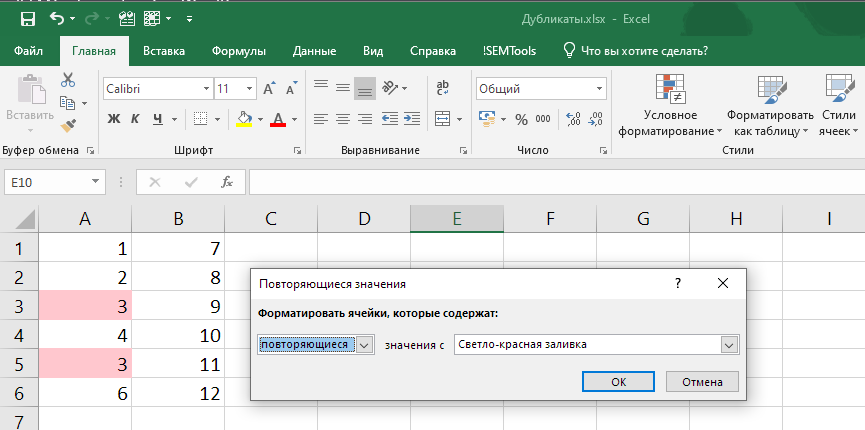
Данное поведение является неочевидным, и об этом факте часто забывают. Если дальше вы планируете удалять повторы, можете потерять оба варианта в одном столбце.
Как избежать подобной ситуации, если хочется найти именно дубли в другом столбце? Простейшее решение: удалить дубли внутри каждого столбца перед применением условного форматирования.
Но есть и другие решения. О них дальше.
Формула проверки наличия дублей в диапазонах
Использование собственной формулы для проверки дубликатов в списке или диапазоне имеет ряд преимуществ, единственная задача — составление такой формулы. Но её я возьму на себя.
Внутри диапазона
Чтобы проверить, есть ли в диапазоне повторяющиеся значения, можно использовать такую формулу массива:
=СУММПРОИЗВ(СЧЁТЕСЛИ(диапазон;тот-же-диапазон)-1)>0
Так выглядит на практике применение формулы:

В чем же преимущество такой формулы, ведь она полностью дублирует опцию условного форматирования, спросите вы.
А дело все в том, что формулу несложно видоизменить и улучшить.
Например, можно улучшить эффективность формулы, добавив в нее функцию СЖПРОБЕЛЫ .Это позволит находить дубликаты, отличающиеся незаметными лишними пробелами:
=СУММПРОИЗВ(--(СЖПРОБЕЛЫ(ячейка)=СЖПРОБЕЛЫ(диапазон)))>1
Эта формула слегка отличается, так как проверяет встречаемость в диапазоне значения одной ячейки.
Если внести ее как правило отбора условного форматирования, она позволит выявлять неявные дубли. Ниже демонстрация того, как работает формула:
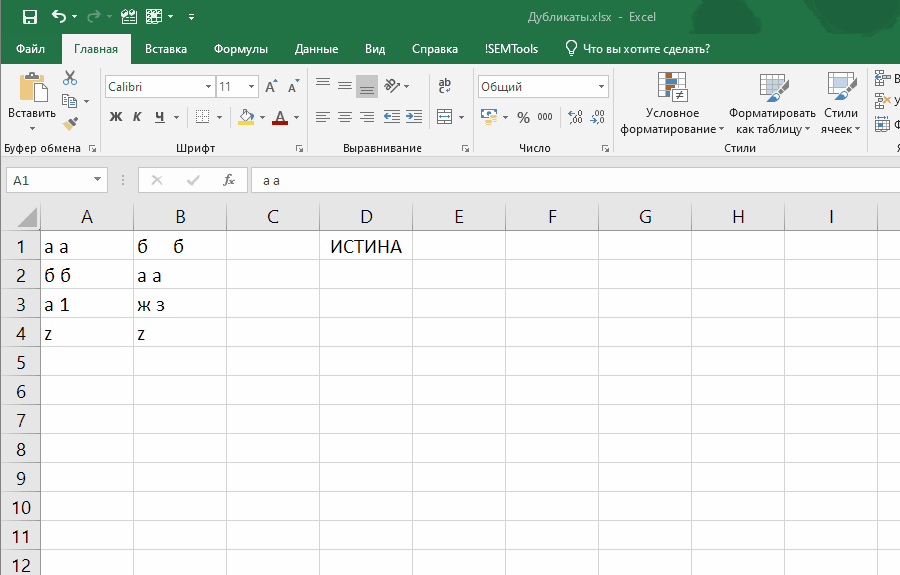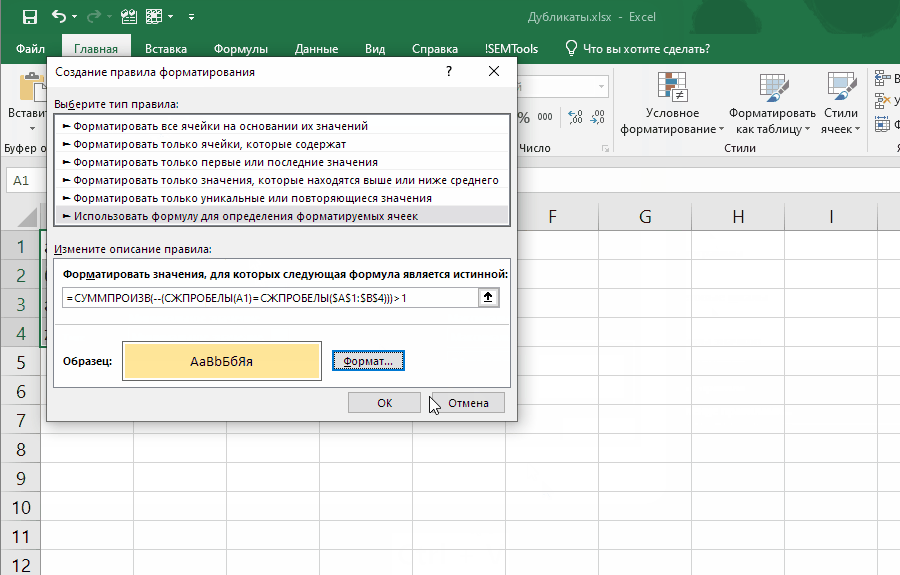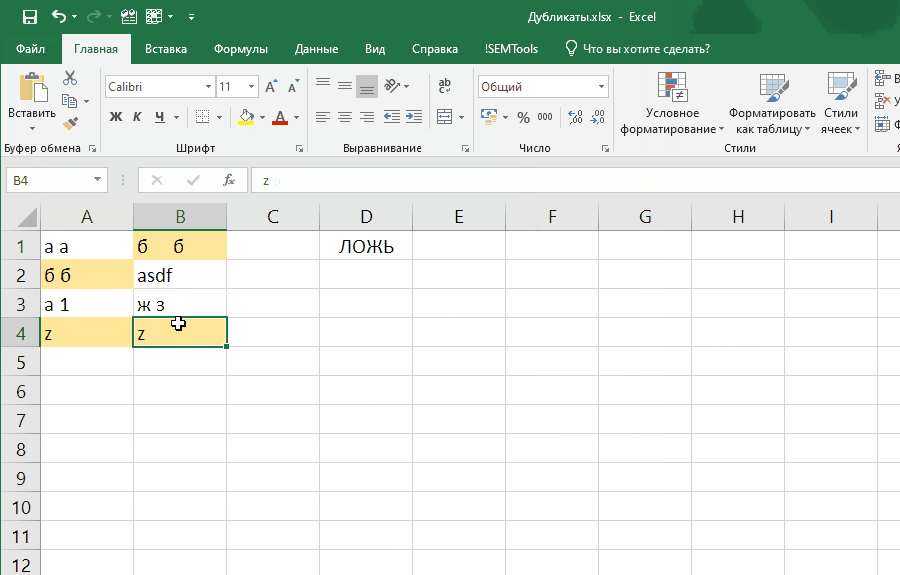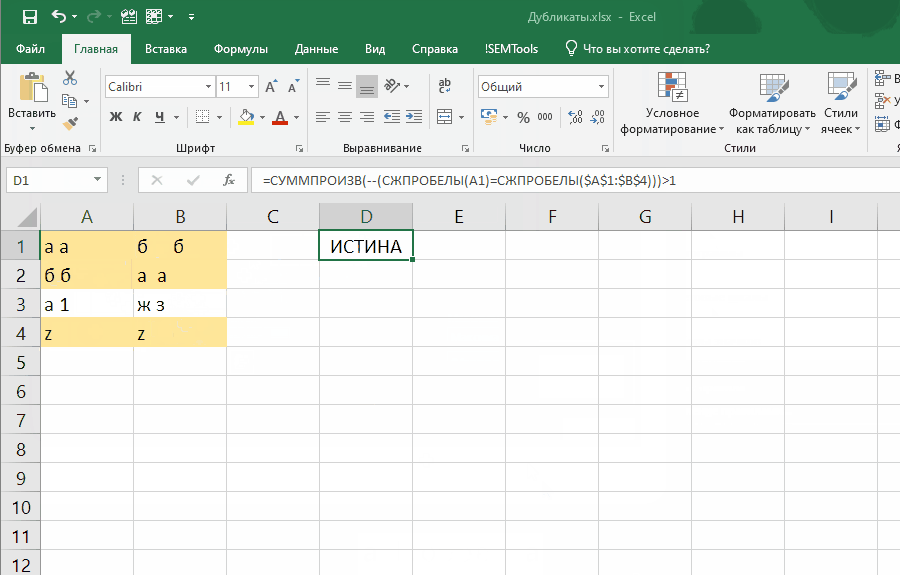
Обратите внимание на один момент в этой демонстрации: диапазон закреплен ($A$1:$B$4), а искомая ячейка (A1) нет. Именно это позволяет условному форматированию находить все дубликаты в диапазоне.
!SEMTools, поиск дублей внутри диапазона
Когда-то я потратил немало времени, пользуясь перечисленными выше методами поиска повторяющихся значений. Все они мне не нравились. Причина была одна: это попросту медленно. Поэтому я решил сделать отдельные процедуры для поиска и удаления дубликатов в Excel в своей надстройке.
Давайте покажу, как они работают.
Найти дубли ячеек в столбце, кроме первого
Процедура позволяет выделить все вторые, третьи и т.д. повторяющиеся значения в столбце.

Найти в столбце дубли ячеек, включая первый
Зачастую нужно найти в столбце все повторяющиеся ячейки, включая первую, для того, чтобы далее отфильтровать их все.

Найти дубли в столбце без учета лишних пробелов
Если мы считаем дубликатами фразы, отличающиеся количеством пробелов между словами или после, наша задача — сначала избавиться от лишних пробелов, и далее произвести тот же поиск дубликатов.
Для первой операции есть отдельный инструмент «Удалить лишние пробелы»:

Найти повторяющиеся значения в Excel и решить сотни других задач поможет надстройка !SEMTools.
Скачайте прямо сейчас и убедитесь сами!
Смотрите также:
- Удалить дубли без смещения строк;
- Удалить неявные дубли;
- Найти повторяющиеся слова в Excel;
- Удалить повторяющиеся слова внутри ячеек.
При совместной работе с таблицами Excel или большом числе записей накапливаются дубли строк. Ста…
При совместной работе с
таблицами Excel или большом числе записей
накапливаются дубли строк. Статья
посвящена тому, как выделить
повторяющиеся значения в Excel,
удалить лишние записи или сгруппировать,
получив максимум информации.

Поиск
одинаковых значений в Excel
Выберем
одну из ячеек в таблице. Рассмотрим, как
в Экселе найти повторяющиеся значения,
равные содержимому ячейки, и выделить
их цветом.
На
рисунке – списки писателей. Алгоритм
действий следующий:
- Выбрать
ячейку I3
с записью «С. А. Есенин». - Поставить
задачу – выделить цветом ячейки с
такими же записями. - Выделить
область поисков. - Нажать
вкладку «Главная». - Далее
группа «Стили». - Затем
«Условное форматирование»; - Нажать
команду «Равно».
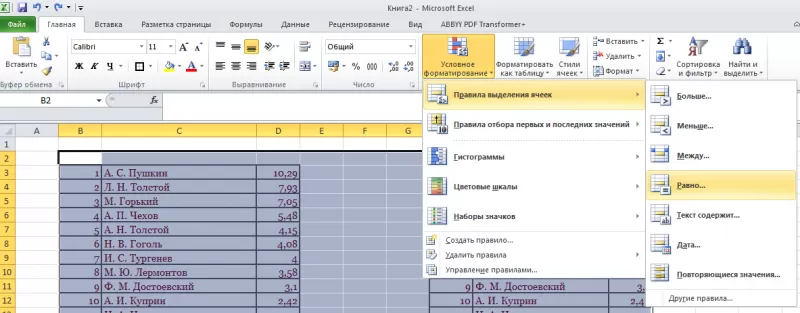
- Появится
диалоговое окно:
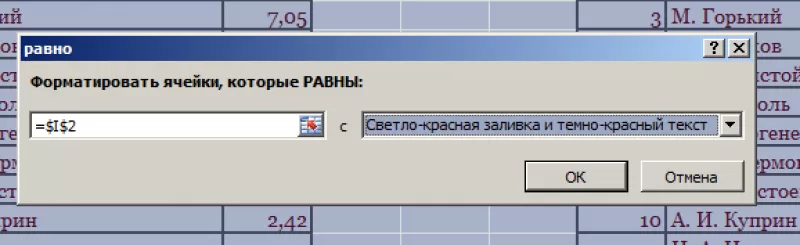
- В
левом поле указать ячейку с I2,
в которой записано «С. А. Есенин». - В
правом поле можно выбрать цвет шрифта. - Нажать
«ОК».
В
таблицах отмечены цветом ячейки, значение
которых равно заданному.
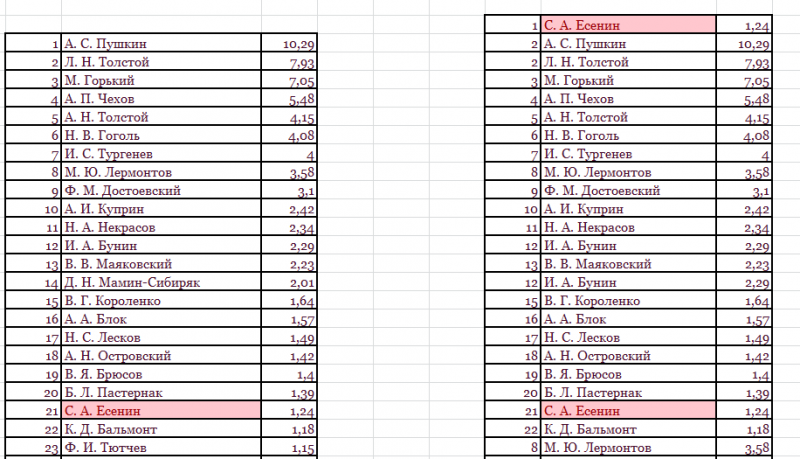
Несложно
понять, как
в Экселе найти одинаковые значения в
столбце.
Просто выделить перед поиском нужную
область – конкретный столбец.
Ищем в таблицах Excel
все повторяющиеся значения
Отметим
все неуникальные записи в выделенной
области. Для этого нужно:
- Зайти
в группу «Стили». - Далее
«Условное форматирование». - Теперь
в выпадающем меню выбрать «Правила
выделения ячеек». - Затем
«Повторяющиеся значения».
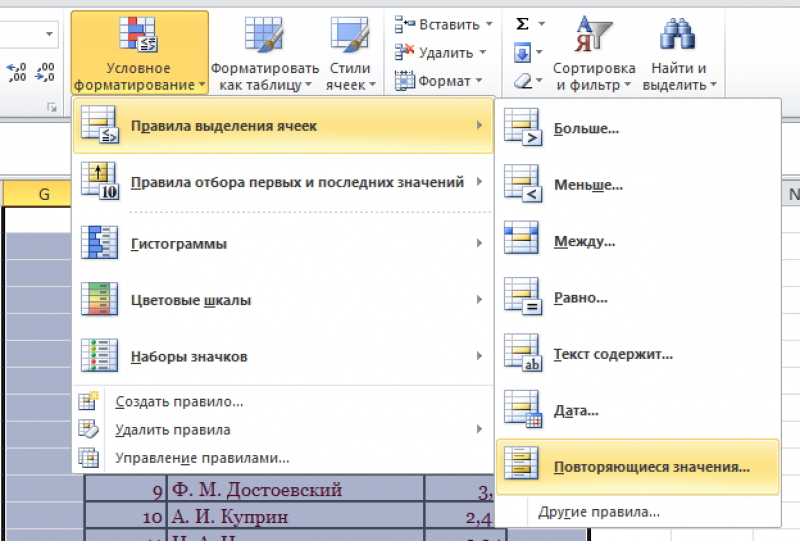
- Появится
диалоговое окно:
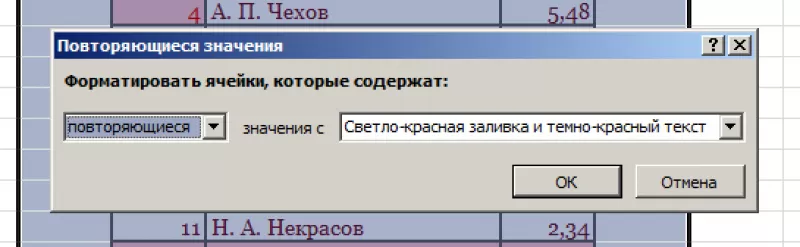
- Нажать
«ОК».
Программа
ищет повторения во всех столбцах.
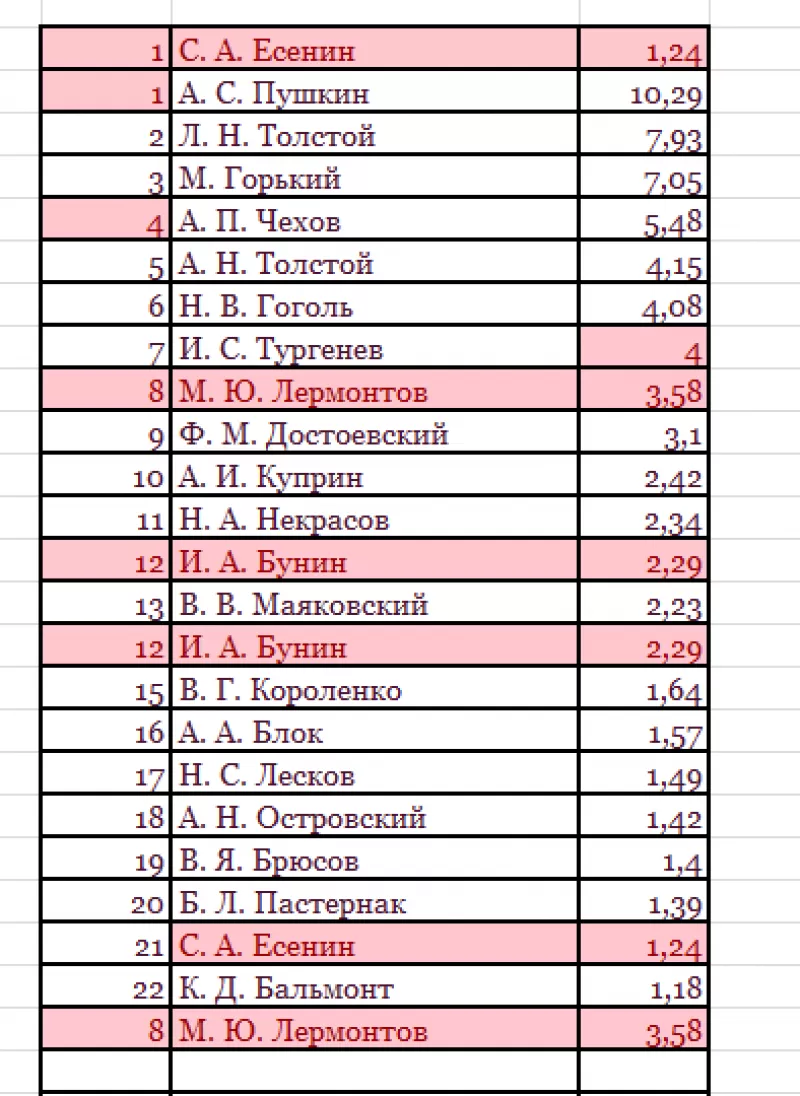
Если
в таблице много неуникальных записей,
то информативность такого поиска
сомнительна.
Удаление одинаковых значений
из таблицы Excel
Способ
удаления неуникальных записей:
- Зайти
во вкладку «Данные». - Выделить
столбец, в котором следует искать
дублирующиеся строки. - Опция
«Удалить дубликаты».
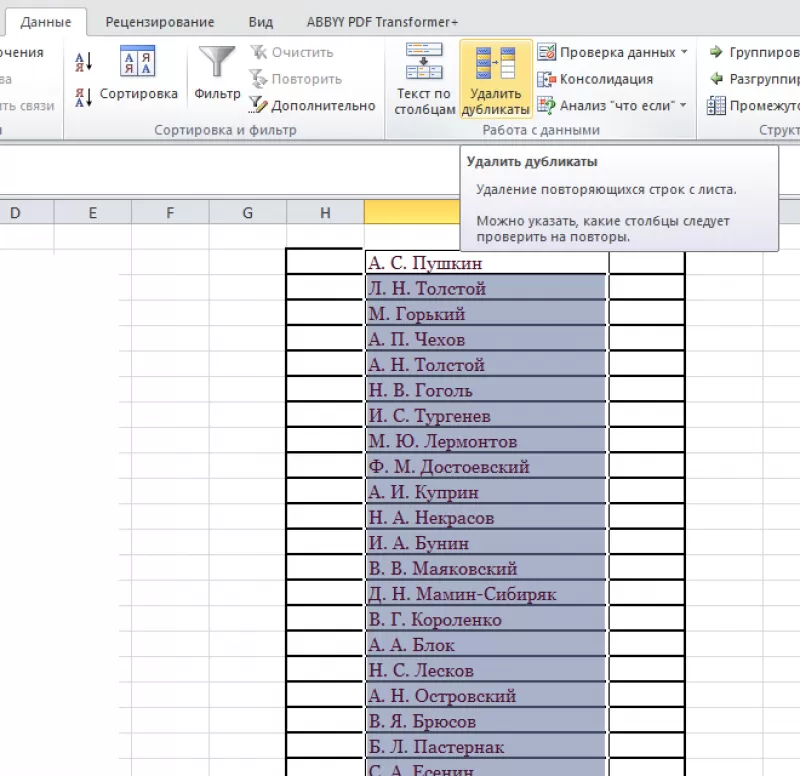
В
результате получаем список, в котором
каждое имя фигурирует только один раз.
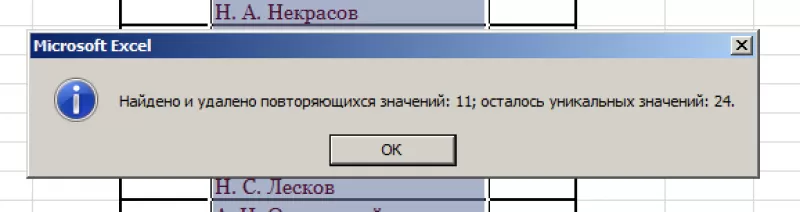
Список
с уникальными значениями:

Расширенный фильтр: оставляем
только уникальные записи
Расширенный
фильтр – это инструмент для получения
упорядоченного списка с уникальными
записями.
- Выбрать
вкладку «Данные». - Перейти
в раздел «Сортировка и фильтр». - Нажать
команду «Дополнительно»:
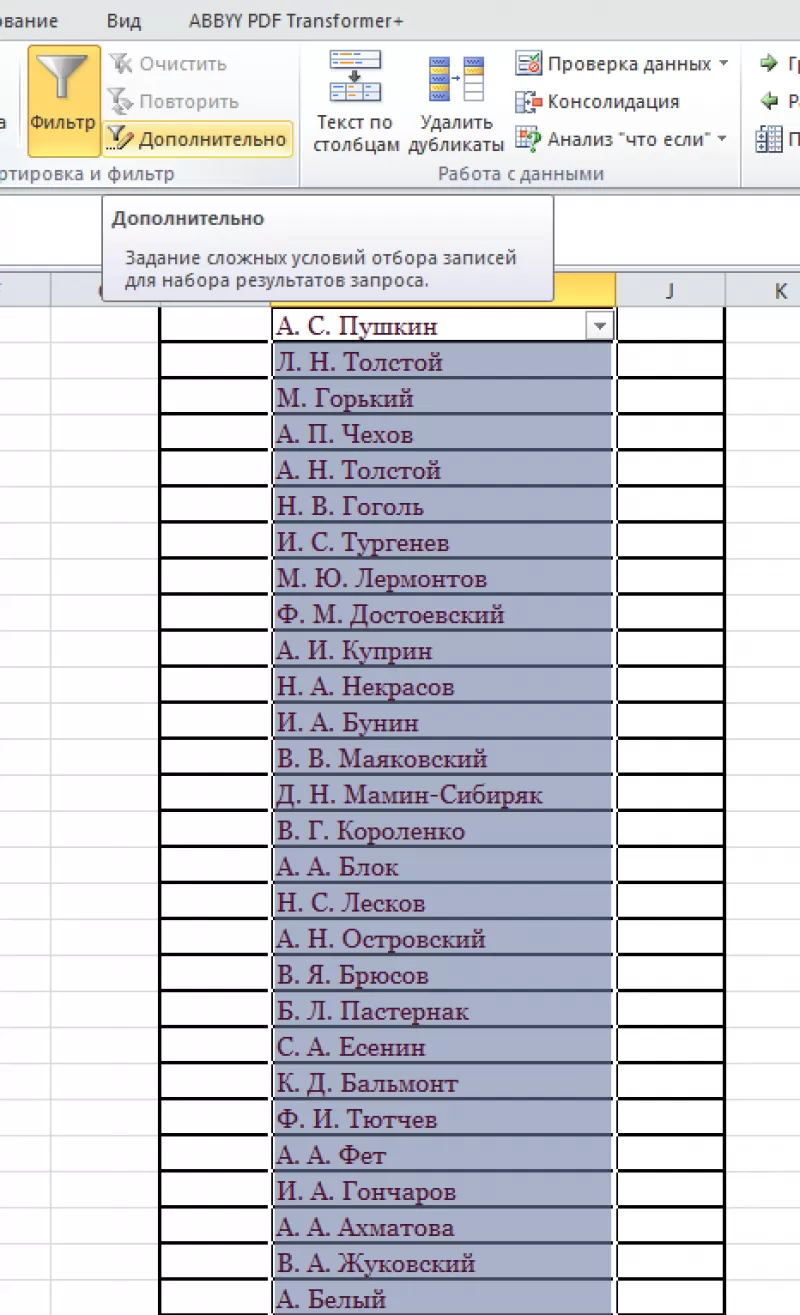
- В
появившемся диалоговом окне ставим
флажок «Только уникальные записи». - Нажать
«OK»
– уникальный список готов.
Поиск дублирующихся значений
с помощью сводных таблиц
Составим
список уникальных строк, не теряя данные
из других столбцов и не меняя исходную
таблицу. Для этого используем инструмент
Сводная таблица:
Вкладка
«Вставка».
Пункт
«Сводная таблица».
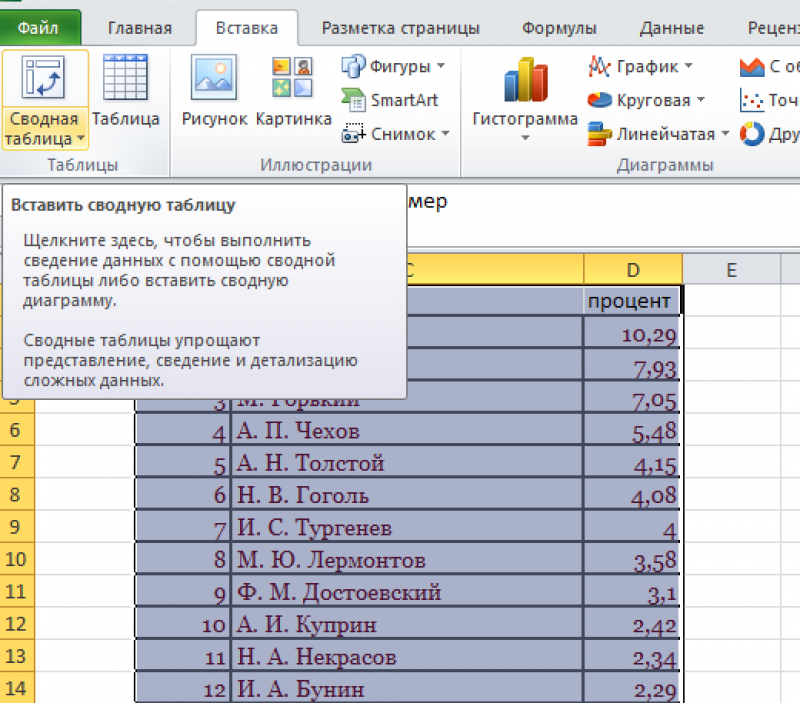
В
диалоговом окне выбрать размещение
сводной таблицы на новом листе.
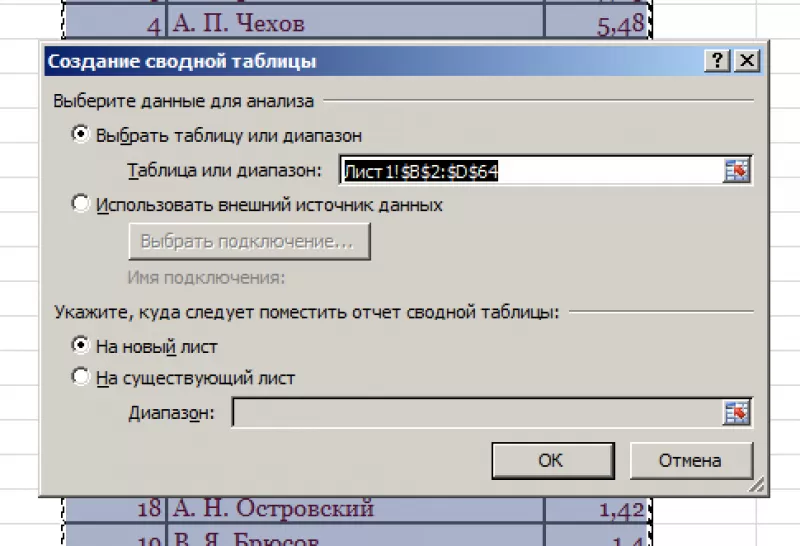
В
открывшемся окне отмечаем столбец, в
котором содержатся интересующие нас
значений.
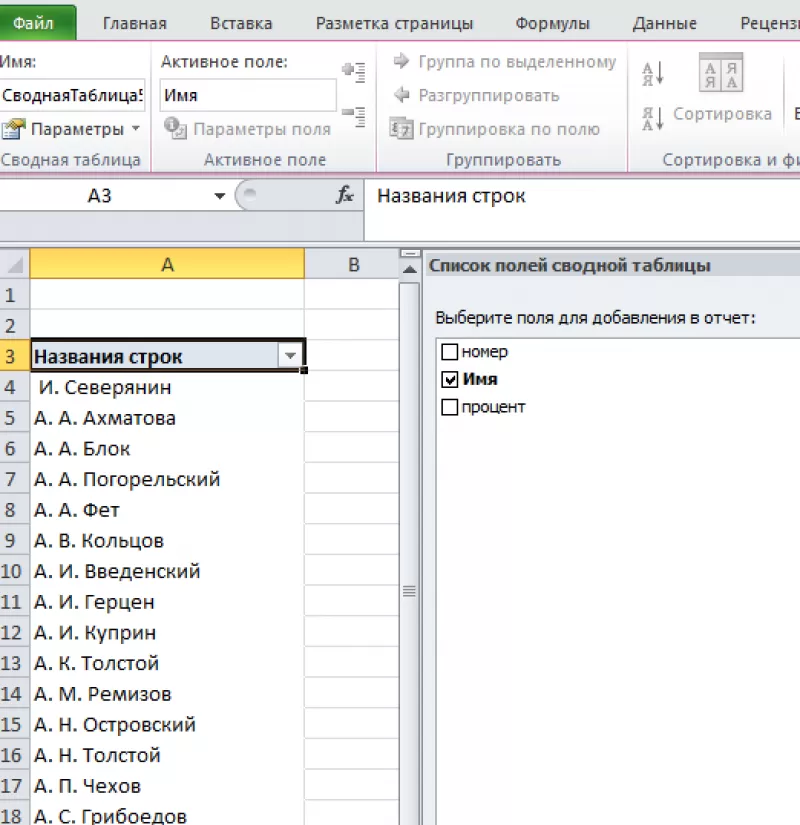
Получаем
упорядоченный список уникальных строк.

В прошлой статье мы начали изучать функцию ЕСЛИ, посмотрели как она работает с числовыми, а также с текстовыми значениями. Сегодня разовьём тему работы с текстами. Приступим к следующим примерам.
Пример 3: Точное совпадение текста
В прошлый раз мы говорили, что функция ЕСЛИ не чувствительна к регистру текста, то есть ей всё равно используете вы заглавные или строчные буквы. В большинстве случаев этого будет достаточно для наших задач. Но что, если нам всё-таки понадобится учитывать регистр?
Вернёмся к нашим покупателям из прошлых примеров. Вы также можете скачать файл с готовыми новыми примерами по ссылке. Или пробуйте всё делать своими руками.
Допустим, покупатели заходили на наш сайт и вводили разные промокоды (например, XY, XX, xx). Нам нужно выбрать тех покупателей, которые ввели промокод XX, чтобы, например, одобрить им членство в закрытом клубе покупателей с дополнительными привилегиями.
Как же нам это сделать, если функция ЕСЛИ игнорирует регистр и когда мы с помощью неё будем искать XX, она также будет принимать и xx? На помощь нам придёт ещё одна функция – СОВПАД.
Функция СОВПАД сравнивает две текстовые строки и если они полностью совпадают, включая регистр, то возвращает ИСТИНА, а если нет, то ЛОЖЬ.
Это очень простая функция, вам нужно только указать её для сравнения две текстовые строки:
=СОВПАД(текст1; текст2)
Попробуйте сами используя в связке функции ЕСЛИ и СОВПАД сделать формулу, которая бы выбирала только код XX и в столбце “Одобрение” возвращала бы “Да” в случае одобрения и “Нет” в случае отказа. Давайте проверим, правильно ли у вас получилось.
В ячейку C2 введём следующую формулу:
=ЕСЛИ(СОВПАД(B2;”XX”);”ДА”;”Нет”)
Расшифруем: если текст в ячейке B2 полностью совпадает с текстом “XX”, то пишем “Да”, иначе пишем “Нет”.
Вот что у нас получилось:
Теперь давайте усложним задачу.
Пример 4: Частичное совпадение текста
А что если нам надо сопоставить только часть текста из ячейки?
У нас есть список кодов заказов, который состоит из наборов цифр и символов. Буквенные символы указывают, кто сделал заказ (XX – участник нашего клуба покупателей, XY – внешний покупатель). В столбце B нам нужно расшифровать тип заказчика: “Участник” или “Внешний”.
На первый взгляд задача нетривиальная. Как вы думаете, что нам мешает использовать ранее изученные функции для её решения?
Во-первых, это циферно-буквенная смесь. Во-вторых, длина строк разная, то есть количество символов в каждой ячейке отличается. И, в-третьих, нужный нам буквенный код в каждом случае “бегает” по строке. Обычный пользователь Excel махнул бы рукой и начал бы вручную смотреть какой код в строке и заполнять столбец B.
Но мы ведь с вами собираемся стать продвинутыми пользователями, правда? Поэтому ручной метод – это не наш путь. Что, если таких кодов тысячи и десятки тысяч? Благо Excel очень мощная программа, которая позволяет с лёгкостью автоматизировать даже такие непростые на первый взгляд задачи.
Многие функции в Excel, такие как ВПР или СЧЁТЕСЛИМН, позволяют использовать символы подстановки (* звездочку, ? вопросительный знак и ~ тильду) для фильтрации данных в строке. Но функция ЕСЛИ не позволяет использовать эти символы. Поэтому о них мы поговорим позднее. а пока нам надо придумать альтернативный способ.
Для поиска буквенного кода в строке мы будем использовать, как ни странно, функцию ПОИСК. Задача функции ПОИСК – найти текст внутри другой текстовой строки у казать его местоположение в этой строке.
У функции ПОИСК три аргумента:
=ПОИСК(искомый_текст; текст_для_поиска; [нач_позиция])
- Искомый текст: Какой текст вы ищете.
- Текст для поиска: Где искать данный текст.
- [Начальная позиция]: С какой позиции (заданной номером индекса) в строке текст_для_поиска начинать поиск. Если этот аргумент опущен, то поиск начнётся с первого символа.
Введём в ячейку B2 и протянем формулу, которая будет искать местоположение кода “XX”:
=ПОИСК(“XX”;A2)
Вот что у нас получилось:
Смотрите, там где в коде заказа было “XX”, формула вернула номер позиции, с которой начинается в строке искомый код. Например, в “XX2962” с первого знака, а в “485XX” с четвёртого. А там, где “XX” не встречается, формула возвращает ошибку #ЗНАЧ! Кстати, обо всех ошибках формул Excel вы можете прочитать здесь.
Небольшая дополнительная информация. Можно также использовать функцию НАЙТИ. Разница между НАЙТИ и ПОИСК заключается в том, что НАЙТИ чувствительна к регистру текста, а ПОИСК – нет. Но более подробно о всех функциях работы с текстом мы поговорим позднее.
Итак, с помощью функции ПОИСК мы нашли индексный номер первого символа кода “XX” там где он есть.
Затем мы используем ещё одну новую функцию ЕЧИСЛО, для того, чтобы преобразовать полученную информацию в ИСТИНУ или ЛОЖЬ. ЕЧИСЛО проверяет, является ли значение число, и если да, то возвращает ИСТИНА, если нет – ЛОЖЬ.
Доработаем нашу формулу:
=ЕЧИСЛО(ПОИСК(“XX”;A2))
Расшифровка: если в ячейке A2 находится строка “XX” и возвращается в виде числа номер позиции с которой она начинается, то ИСТИНА, иначе ЛОЖЬ.
Но для простого восприятия нам проще работать с обычными словами, как, например, “Участник” или “Внешний”, а не с логическими переменными ИСТИНА и ЛОЖЬ. Поэтому мы добавим в нашу формулу функцию ЕСЛИ:
=ЕСЛИ(ЕЧИСЛО(ПОИСК(“XX”;A2));”Участник”;”Внешний”)
Расшифровка: если в ячейке A2 находится строка “XX” и возвращается в виде числа номер позиции с которой она начинается, то ИСТИНА, иначе ЛОЖЬ. Если ИСТИНА, то пишем “Участник”, если ЛОЖЬ, то пишем “Внешний”.
Уффф, какая сложная многоуровневая формула. Давайте проверим, работает ли она?
Всё работает идеально!
Предлагаю сделать паузу. Сегодня мы продолжили изучать тонкости функции ЕСЛИ, а также познакомились с несколькими новыми: СОВПАД, ПОИСК, НАЙТИ и ЕЧИСЛО. Скажу без иронии, уже с таким арсеналом знаний вы стали намного более продвинутым пользователем Excel, чем многие ваши коллеги. Что же будет, если вы подпишетесь и продолжите изучение дальше? 😉
В следующий раз мы продолжим изучать функцию ЕСЛИ и посмотрим, как с помощью неё проверять значения даты, а также пустые и незаполненные ячейки.
Не переключайтесь;)
На чтение 10 мин Просмотров 15.5к. Опубликовано 31.07.2020
Содержание
- 5 thoughts on “ «ВПР» по частичному совпадению ”
- Проверяем условие для полного совпадения текста.
- ЕСЛИ + СОВПАД
- Использование функции ЕСЛИ с частичным совпадением текста.
- ЕСЛИ + ПОИСК
- ЕСЛИ + НАЙТИ
- Примеры использования функции ПОИСКПОЗ в Excel
- Формула для поиска неточного совпадения текста в Excel
- Сравнение двух таблиц в Excel на наличие несовпадений значений
- Поиск ближайшего большего знания в диапазоне чисел Excel
- Особенности использования функции ПОИСКПОЗ в Excel
Спустя катастрофически большой промежуток времени с момента публикации моего последнего поста, решил поделиться супер крутой, на мой взгляд, Excel-формулой, узнав о которой, начинаешь удивляться, как же раньше-то я жил без нее. Но, должен сказать, авторство ее создания не мое, а вероятнее всего принадлежит англоязычному ресурсу, о котором я скажу ниже.
Кто более-менее часто работает с массивами данных в Excel почти наверняка знает про функцию ВПР (см. мою статью) или ИНДЕКС+ПОИСКПОЗ, которые решают достаточно частую задачу по объединению двух наборов данных по каким-либо совпадающим значениям. И действительно, использование этих функций решает задачи по сопоставлению и объединению данных в 90% случаев. Если бы не одно но — данные, по которым производится объединение, действительно должны именно совпадать. Но бывают случаи, когда требуется сопоставление по частичному совпадению. Да, в ВПР есть поиск по приблизительному совпадению, но работает он не совсем прозрачно, а потому предугадать, почему было подобрано одно похожее слово, а не другое, может быть невозможно не просто. Как вы поняли, эту прелюдию я затеял не просто так, а для того, чтобы рассказать, как же решить такую задачу при помощи Excel.
Предположим, у нас есть список товаров, которые надо как-то сгруппировать:





5 thoughts on “ «ВПР» по частичному совпадению ”
На форуме SQL.ru мне подсказали еще одно очень изящное решение этой задачи, посмотреть его можно здесь:
http://www.sql.ru/forum/actualutils.aspx?action=gotomsg&t > Спасибо большое, Казанский (автор совета)!
Игорь, спасибо Вам огромное за эту «бронебойную» формулу. Весь интернет «перелопатила» в поиске решения своей задачи и только Вы мне помогли на 100%. Всё работает как часики. Удачи Вам, успешной работы и ещё больше таких гениальных решений.
Ольга, спасибо большое за Ваш комментарий! Справедливости ради надо сказать, что идея этой формулы не моя, а обнаружил я ее на сайте Exceljet
Игорь, добрый день!
Формула прекрасная, но есть ли какая-нибудь ее вариация, которая может находить и подставлять несколько значений сразу?
Например, в строке указаны два производителя холодильников, LG и Samsung
Можно ли вывести их в ячейку через запятую?
Добрый день, Артём!
Спасибо за ваш комментарий и прошу прощения за медленный ответ. Вопрос интересный, но с ходу у меня на него ответа, увы, нет, а по времени довольно сильно ограничен. Если будет свободное время, попробую поломать голову на эту тему
Рассмотрим использование функции ЕСЛИ в Excel в том случае, если в ячейке находится текст.
Будьте особо внимательны в том случае, если для вас важен регистр, в котором записаны ваши текстовые значения. Функция ЕСЛИ не проверяет регистр – это делают функции, которые вы в ней используете. Поясним на примере.
Проверяем условие для полного совпадения текста.
Проверку выполнения доставки организуем при помощи обычного оператора сравнения «=».
=ЕСЛИ(G2=”выполнено”,ИСТИНА,ЛОЖЬ)
При этом будет не важно, в каком регистре записаны значения в вашей таблице.

Если же вас интересует именно точное совпадение текстовых значений с учетом регистра, то можно рекомендовать вместо оператора «=» использовать функцию СОВПАД(). Она проверяет идентичность двух текстовых значений с учетом регистра отдельных букв.
Вот как это может выглядеть на примере.

Обратите внимание, что если в качестве аргумента мы используем текст, то он обязательно должен быть заключён в кавычки.
ЕСЛИ + СОВПАД
В случае, если нас интересует полное совпадение текста с заданным условием, включая и регистр его символов, то оператор “=” нам не сможет помочь.
Но мы можем использовать функцию СОВПАД (английский аналог — EXACT).
Функция СОВПАД сравнивает два текста и возвращает ИСТИНА в случае их полного совпадения, и ЛОЖЬ — если есть хотя бы одно отличие, включая регистр букв. Поясним возможность ее использования на примере.
Формула проверки выполнения заказа в столбце Н может выглядеть следующим образом:

Как видите, варианты “ВЫПОЛНЕНО” и “выполнено” не засчитываются как правильные. Засчитываются только полные совпадения. Будет полезно, если важно точное написание текста — например, в артикулах товаров.
Использование функции ЕСЛИ с частичным совпадением текста.
Выше мы с вами рассмотрели, как использовать текстовые значения в функции ЕСЛИ. Но часто случается, что необходимо определить не полное, а частичное совпадение текста с каким-то эталоном. К примеру, нас интересует город, но при этом совершенно не важно его название.
Первое, что приходит на ум – использовать подстановочные знаки «?» и «*» (вопросительный знак и звездочку). Однако, к сожалению, этот простой способ здесь не проходит.
ЕСЛИ + ПОИСК
Нам поможет функция ПОИСК (в английском варианте – SEARCH). Она позволяет определить позицию, начиная с которой искомые символы встречаются в тексте. Синтаксис ее таков:
=ПОИСК(что_ищем, где_ищем, начиная_с_какого_символа_ищем)
Если третий аргумент не указан, то поиск начинаем с самого начала – с первого символа.
Функция ПОИСК возвращает либо номер позиции, начиная с которой искомые символы встречаются в тексте, либо ошибку.
Но нам для использования в функции ЕСЛИ нужны логические значения.
Здесь нам на помощь приходит еще одна функция EXCEL – ЕЧИСЛО. Если ее аргументом является число, она возвратит логическое значение ИСТИНА. Во всех остальных случаях, в том числе и в случае, если ее аргумент возвращает ошибку, ЕЧИСЛО возвратит ЛОЖЬ.
В итоге наше выражение в ячейке G2 будет выглядеть следующим образом:
Еще одно важное уточнение. Функция ПОИСК не различает регистр символов.

ЕСЛИ + НАЙТИ
В том случае, если для нас важны строчные и прописные буквы, то придется использовать вместо нее функцию НАЙТИ (в английском варианте – FIND).
Синтаксис ее совершенно аналогичен функции ПОИСК: что ищем, где ищем, начиная с какой позиции.
Изменим нашу формулу в ячейке G2

То есть, если регистр символов для вас важен, просто замените ПОИСК на НАЙТИ.
Итак, мы с вами убедились, что простая на первый взгляд функция ЕСЛИ дает нам на самом деле много возможностей для операций с текстом.
Функция ПОИСКПОЗ в Excel используется для поиска точного совпадения или ближайшего (меньшего или большего заданному в зависимости от типа сопоставления, указанного в качестве аргумента) значения заданному в массиве или диапазоне ячеек и возвращает номер позиции найденного элемента.
Примеры использования функции ПОИСКПОЗ в Excel
Например, имеем последовательный ряд чисел от 1 до 10, записанных в ячейках B1:B10. Функция =ПОИСКПОЗ(3;B1:B10;0) вернет число 3, поскольку искомое значение находится в ячейке B3, которая является третьей от точки отсчета (ячейки B1).
Данная функция удобна для использования в случаях, когда требуется вернуть не само значение, содержащееся в искомой ячейке, а ее координату относительно рассматриваемого диапазона. В случае использования для констант массивов, которые могут быть представлены как массивы элементов «ключ» — «значение», функция ПОИСКПОЗ возвращает значение ключа, который явно не указан.
Например, массив <“виноград”;”яблоко”;”груша”;”слива”>содержит элементы, которые можно представить как: 1 – «виноград», 2 – «яблоко», 3 – «груша», 4 – «слива», где 1, 2, 3, 4 – ключи, а названия фруктов – значения. Тогда функция =ПОИСКПОЗ(“яблоко”;<“виноград”;”яблоко”;”груша”;”слива”>;0) вернет значение 2, являющееся ключом второго элемента. Отсчет выполняется не с 0 (нуля), как это реализовано во многих языках программирования при работе с массивами, а с 1.
Функция ПОИСКПОЗ редко используется самостоятельно. Ее целесообразно применять в связке с другими функциями, например, ИНДЕКС.
Формула для поиска неточного совпадения текста в Excel
Пример 1. Найти позицию первого частичного совпадения строки в диапазоне ячеек, хранящих текстовые значения.
Вид исходной таблицы данных:
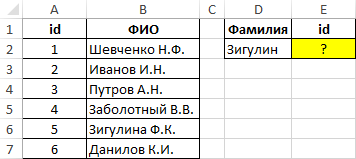
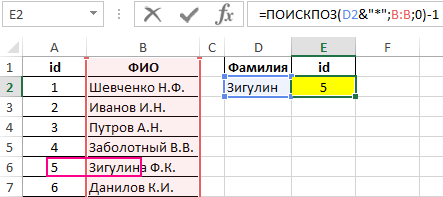
Для нахождения позиции текстовой строки в таблице используем следующую формулу:
Из полученного значения вычитается единица для совпадения результата с id записи в таблице.
Сравнение двух таблиц в Excel на наличие несовпадений значений
Пример 2. В Excel хранятся две таблицы, которые на первый взгляд кажутся одинаковыми. Было решено сравнить по одному однотипному столбцу этих таблиц на наличие несовпадений. Реализовать способ сравнения двух диапазонов ячеек.
Вид таблицы данных:
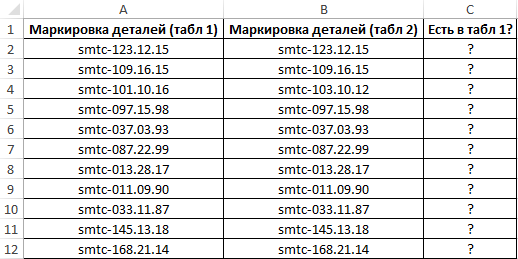
Для сравнения значений, находящихся в столбце B:B со значениями из столбца A:A используем следующую формулу массива (CTRL+SHIFT+ENTER):
Функция ПОИСКПОЗ выполняет поиск логического значения ИСТИНА в массиве логических значений, возвращаемых функцией СОВПАД (сравнивает каждый элемент диапазона A2:A12 со значением, хранящимся в ячейке B2, и возвращает массив результатов сравнения). Если функция ПОИСКПОЗ нашла значение ИСТИНА, будет возвращена позиция его первого вхождения в массив. Функция ЕНД возвратит значение ЛОЖЬ, если она не принимает значение ошибки #Н/Д в качестве аргумента. В этом случае функция ЕСЛИ вернет текстовую строку «есть», иначе – «нет».
Чтобы вычислить остальные значения «протянем» формулу из ячейки C2 вниз для использования функции автозаполнения. В результате получим:
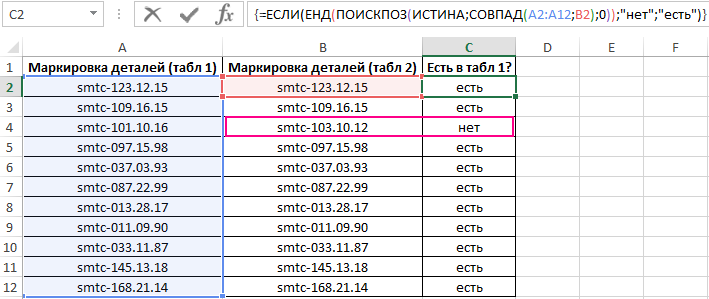
Как видно, третьи элементы списков не совпадают.
Поиск ближайшего большего знания в диапазоне чисел Excel
Пример 3. Найти ближайшее меньшее числу 22 в диапазоне чисел, хранящихся в столбце таблицы Excel.
Вид исходной таблицы данных:
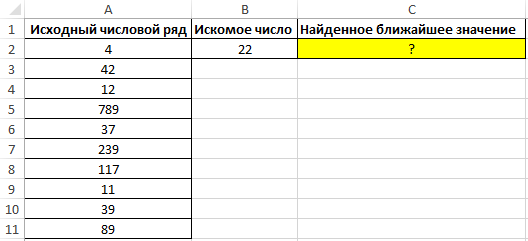
Для поиска ближайшего большего значения заданному во всем столбце A:A (числовой ряд может пополняться новыми значениями) используем формулу массива (CTRL+SHIFT+ENTER):
Функция ПОИСКПОЗ возвращает позицию элемента в столбце A:A, имеющего максимальное значение среди чисел, которые больше числа, указанного в ячейке B2. Функция ИНДЕКС возвращает значение, хранящееся в найденной ячейке.
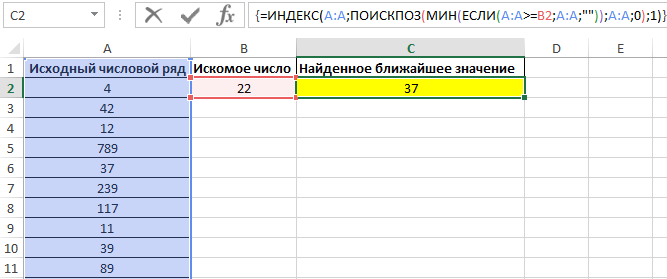
Для поиска ближайшего меньшего значения достаточно лишь немного изменить данную формулу и ее следует также ввести как массив (CTRL+SHIFT+ENTER):
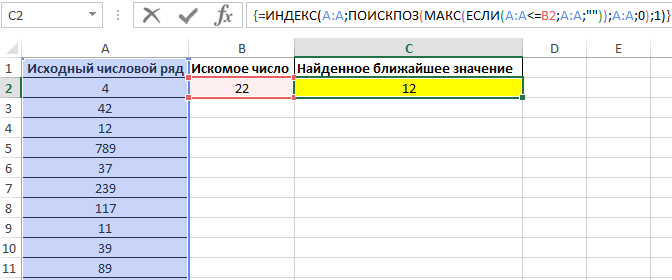
Особенности использования функции ПОИСКПОЗ в Excel
Функция имеет следующую синтаксическую запись:
=ПОИСКПОЗ( искомое_значение;просматриваемый_массив; [тип_сопоставления])
- искомое_значение – обязательный аргумент, принимающий текстовые, числовые значения, а также данные логического и ссылочного типов, который используется в качестве критерия поиска (для сопоставления величин или нахождения точного совпадения);
- просматриваемый_массив – обязательный аргумент, принимающий данные ссылочного типа (ссылки на диапазон ячеек) или константу массива, в которых выполняется поиск позиции элемента согласно критерию, заданному первым аргументом функции;
- [тип_сопоставления] – необязательный для заполнения аргумент в виде числового значения, определяющего способ поиска в диапазоне ячеек или массиве. Может принимать следующие значения:
- -1 – поиск наименьшего ближайшего значения заданному аргументом искомое_значение в упорядоченном по убыванию массиве или диапазоне ячеек.
- 0 – (по умолчанию) поиск первого значения в массиве или диапазоне ячеек (не обязательно упорядоченном), которое полностью совпадает со значением, переданным в качестве первого аргумента.
- 1 – Поиск наибольшего ближайшего значения заданному первым аргументом в упорядоченном по возрастанию массиве или диапазоне ячеек.
- Если в качестве аргумента искомое_значение была передана текстовая строка, функция ПОИСКПОЗ вернет позицию элемента в массиве (если такой существует) без учета регистра символов. Например, строки «МоСкВа» и «москва» являются равнозначными. Для различения регистров можно дополнительно использовать функцию СОВПАД.
- Если поиск с использованием рассматриваемой функции не дал результатов, будет возвращен код ошибки #Н/Д.
- Если аргумент [тип_сопоставления] явно не указан или принимает число 0, для поиска частичного совпадения текстовых значений могут быть использованы подстановочные знаки («?» — замена одного любого символа, «*» — замена любого количества символов).
- Если в объекте данных, переданном в качестве аргумента просматриваемый_массив, содержится два и больше элементов, соответствующих искомому значению, будет возвращена позиция первого вхождения такого элемента.
