I was trying to find all files dated and all files 3 days or more ago.
find /home/test -name 'test.log.d{4}-d{2}-d{2}.zip' -mtime 3
It is not listing anything. What is wrong with it?
asked Mar 9, 2011 at 17:32
find /home/test -regextype posix-extended -regex '^.*test.log.[0-9]{4}-[0-9]{2}-[0-9]{2}.zip' -mtime +3
-nameuses globular expressions,
aka wildcards. What you want is
-regex- To use intervals as you intend, you
need to tellfindto use Extended
Regular Expressions via the
-regextype posix-extendedflag - You need to escape out the periods
because in regex a period has the
special meaning of any single
character. What you want is a
literal period denoted by. - To match only those files that are
greater than 3 days old, you need to prefix your number with a+as
in-mtime +3.
Proof of Concept
$ find . -regextype posix-extended -regex '^.*test.log.[0-9]{4}-[0-9]{2}-[0-9]{2}.zip'
./test.log.1234-12-12.zip
answered Mar 9, 2011 at 17:34
SiegeXSiegeX
134k23 gold badges144 silver badges153 bronze badges
7
Use -regex not -name, and be aware that the regex matches against what find would print, e.g. “/home/test/test.log” not “test.log”
answered Mar 9, 2011 at 17:34
ErikErik
88k13 gold badges198 silver badges189 bronze badges
1
Start with:
find . -name '*.log.*.zip' -a -mtime +1
You may not need a regex, try:
find . -name '*.log.*-*-*.zip' -a -mtime +1
You will want the +1 in order to match 1, 2, 3 …
answered Mar 9, 2011 at 18:05
DigitalRossDigitalRoss
143k25 gold badges245 silver badges328 bronze badges
Use -regex:
From the man page:
-regex pattern
File name matches regular expression pattern. This is a match on the whole path, not a search. For example, to match a file named './fubar3', you can use the
regular expression '.*bar.' or '.*b.*3', but not 'b.*r3'.
Also, I don’t believe find supports regex extensions such as d. You need to use [0-9].
find . -regex '.*test.log.[0-9][0-9][0-9][0-9]-[0-9][0-9]-[0-9][0-9].zip'
answered Mar 9, 2011 at 17:36
![]()
dogbanedogbane
265k75 gold badges394 silver badges412 bronze badges
Just little elaboration of regex for search a directory and file
Find a directroy with name like book
find . -name "*book*" -type d
Find a file with name like book word
find . -name "*book*" -type f
answered Oct 14, 2016 at 4:41
1
grep — одна из самых полезных и мощных команд Linux для обработки текста. grep ищет в одном или нескольких входных файлах строки, соответствующие регулярному выражению, и записывает каждую совпадающую строку в стандартный вывод.
В этой статье мы собираемся изучить основы использования регулярных выражений в GNU-версии grep , которая по умолчанию доступна в большинстве операционных систем Linux.
Регулярное выражение Grep
Регулярное выражение или регулярное выражение — это шаблон, который соответствует набору строк. Шаблон состоит из операторов, конструирует буквальные символы и метасимволы, которые имеют особое значение. GNU grep поддерживает три синтаксиса регулярных выражений: базовый, расширенный и Perl-совместимый.
В своей простейшей форме, когда тип регулярного выражения не указан, grep интерпретирует шаблоны поиска как базовые регулярные выражения. Чтобы интерпретировать шаблон как расширенное регулярное выражение, используйте параметр -E (или --extended-regexp ).
В реализации grep GNU нет функциональной разницы между базовым и расширенным синтаксисами регулярных выражений. Единственная разница в том, что в базовых регулярных выражениях метасимволы ? , + , { , | , ( , и ) интерпретируются как буквальные символы. Чтобы сохранить особое значение метасимволов при использовании основных регулярных выражений, символы должны быть экранированы обратной косой чертой ( ). Мы объясним значение этих и других мета-символов позже.
Как правило, вы всегда должны заключать регулярное выражение в одинарные кавычки, чтобы избежать интерпретации и расширения метасимволов оболочкой.
Буквальные совпадения
Наиболее простое использование команды grep — поиск буквального символа или серии символов в файле. Например, чтобы отобразить все строки, содержащие строку «bash» в /etc/passwd , вы должны выполнить следующую команду:
grep bash /etc/passwdРезультат должен выглядеть примерно так:
root:x:0:0:root:/root:/bin/bash
linuxize:x:1000:1000:linuxize:/home/linuxize:/bin/bash
В этом примере строка «bash» представляет собой базовое регулярное выражение, состоящее из четырех буквальных символов. Это указывает grep искать строку, в которой сразу после grep «b» идут «a», «s» и «h».
По умолчанию команда grep чувствительна к регистру. Это означает, что символы верхнего и нижнего регистра рассматриваются как разные.
Чтобы игнорировать регистр при поиске, используйте параметр -i (или --ignore-case ).
Важно отметить, что grep ищет шаблон поиска как строку, а не слово. Итак, если вы искали «gnu», grep также напечатает строки, в которых «gnu» встроено в слова большего размера, например, «cygnus» или «magnum».
Если в строке поиска есть пробелы, вам нужно заключить ее в одинарные или двойные кавычки:
grep "Gnome Display Manager" /etc/passwdЯкорь
Якоря — это метасимволы, которые позволяют указать, где в строке должно быть найдено совпадение.
Символ ^ (каретка) соответствует пустой строке в начале строки. В следующем примере строка «linux» будет соответствовать только в том случае, если она встречается в самом начале строки.
grep '^linux' file.txtСимвол $ (доллар) соответствует пустой строке в начале строки. Чтобы найти строку, заканчивающуюся строкой «linux», вы должны использовать:
grep 'linux$' file.txtВы также можете создать регулярное выражение, используя оба якоря. Например, чтобы найти строки, содержащие только «linux», выполните:
grep '^linux$' file.txtЕще один полезный пример — шаблон ^$ , который соответствует всем пустым строкам.
Соответствующий одиночный символ
Файл . (точка) символ — это метасимвол, который соответствует любому одиночному символу. Например, чтобы сопоставить все, что начинается с «кан», затем имеет два символа и заканчивается строкой «ру», вы должны использовать следующий шаблон:
grep 'kan..roo' file.txtВыражения в скобках
Выражения в квадратных скобках позволяют сопоставить группу символов, заключив их в квадратные скобки [] . Например, найдите строки, содержащие «принять» или «акцент», вы можете использовать следующее выражение:
grep 'acce[np]t' file.txtЕсли первый символ внутри скобок — это курсор ^ , то он соответствует любому одиночному символу, не заключенному в скобки. Следующий шаблон будет соответствовать любой комбинации строк, начинающихся с «co», за которыми следует любая буква, кроме «l», за которой следует «la», например «coca», «cobalt» и т. Д., Но не будет соответствовать строкам, содержащим «cola». ”:
grep 'co[^l]a' file.txtВместо того, чтобы помещать символы по одному, вы можете указать диапазон символов внутри скобок. Выражение диапазона создается путем указания первого и последнего символов диапазона, разделенных дефисом. Например, [aa] эквивалентно [abcde] а [1-3] эквивалентно [123] .
Следующее выражение соответствует каждой строке, начинающейся с заглавной буквы:
grep '^[A-Z]' file.txtgrep также поддерживает предопределенные классы символов, заключенные в скобки. В следующей таблице показаны некоторые из наиболее распространенных классов символов:
| Квантификатор | Классы персонажей |
|---|---|
[:alnum:] |
Буквенно-цифровые символы. |
[:alpha:] |
Буквенные символы. |
[:blank:] |
Пробел и табуляция. |
[:digit:] |
Цифры. |
[:lower:] |
Строчные буквы. |
[:upper:] |
Заглавные буквы. |
Полный список всех классов персонажей можно найти в руководстве по Grep .
Квантификаторы
Квантификаторы позволяют указать количество вхождений элементов, которые должны присутствовать, чтобы совпадение произошло. В следующей таблице показаны квантификаторы, поддерживаемые GNU grep :
Символ * (звездочка) соответствует предыдущему элементу ноль или более раз. Следующее будет соответствовать «right», «sright», «ssright» и так далее:
grep 's*right'Ниже представлен более сложный шаблон, который соответствует всем строкам, которые начинаются с заглавной буквы и заканчиваются точкой или запятой. Регулярное выражение .* Соответствует любому количеству любых символов:
grep -E '^[A-Z].*[.,]$' file.txt? (знак вопроса) символ делает предыдущий элемент необязательным и может соответствовать только один раз. Следующие будут соответствовать как «ярким», так и «правильным». ? Символ экранирован обратной косой чертой, потому что мы используем базовые регулярные выражения:
grep 'b?right' file.txtВот то же регулярное выражение с использованием расширенного регулярного выражения:
grep -E 'b?right' file.txtСимвол + (плюс) соответствует предыдущему элементу один или несколько раз. Следующее будет соответствовать «sright» и «ssright», но не «right»:
grep -E 's+right' file.txtФигурные скобки {} позволяют указать точное число, верхнюю или нижнюю границу или диапазон вхождений, которые должны произойти, чтобы совпадение произошло.
Следующее соответствует всем целым числам, содержащим от 3 до 9 цифр:
grep -E '[[:digit:]]{3,9}' file.txtЧередование
Термин «чередование» представляет собой простое «ИЛИ». Оператор чередования | (pipe) позволяет вам указать различные возможные совпадения, которые могут быть буквальными строками или наборами выражений. Этот оператор имеет самый низкий приоритет среди всех операторов регулярных выражений.
В приведенном ниже примере мы ищем все вхождения слов fatal , error и critical в файле ошибок журнала Nginx :
grep 'fatal|error|critical' /var/log/nginx/error.logЕсли вы используете расширенное регулярное выражение, то оператор | не следует экранировать, как показано ниже:
grep -E 'fatal|error|critical' /var/log/nginx/error.logГруппировка
Группировка — это функция регулярных выражений, которая позволяет группировать шаблоны вместе и ссылаться на них как на один элемент. Группы создаются с помощью круглых скобок () .
При использовании основных регулярных выражений скобки должны быть экранированы обратной косой чертой ( ).
Следующий пример соответствует как «бесстрашный», так и «меньший». ? квантификатор делает группу (fear) необязательной:
grep -E '(fear)?less' file.txtСпециальные выражения обратной косой черты
GNU grep включает несколько метасимволов, которые состоят из обратной косой черты, за которой следует обычный символ. В следующей таблице показаны некоторые из наиболее распространенных специальных выражений обратной косой черты:
Следующий шаблон будет соответствовать отдельным словам «abject» и «object». Он не будет соответствовать словам, если вложен в слова большего размера:
grep 'b[ao]bjectb' file.txtВыводы
Регулярные выражения используются в текстовых редакторах, языках программирования и инструментах командной строки, таких как grep , sed и awk . Знание того, как создавать регулярные выражения, может быть очень полезным при поиске текстовых файлов, написании сценариев или фильтрации вывода команд.
Если у вас есть какие-либо вопросы или отзывы, не стесняйтесь оставлять комментарии.
Updated: 05/04/2019 by
On Unix-like operating systems, the grep command processes text line by line, and prints any lines which match a specified pattern.
This page covers the GNU/Linux version of grep.
Syntax
grep [OPTIONS] PATTERN [FILE...]
Overview
Grep, which stands for “global regular expression print,” is a powerful tool for matching a regular expression against text in a file, multiple files, or a stream of input. It searches for the PATTERN of text you specified on the command line, and outputs the results for you.
Example usage
Let’s say want to quickly locate the phrase “our products” in HTML files on your machine. Let’s start by searching a single file. Here, our PATTERN is “our products” and our FILE is product-listing.html.
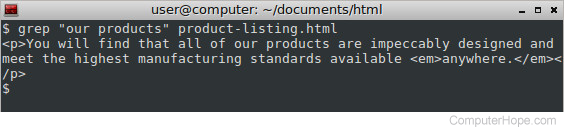
A single line was found containing our pattern, and grep outputs the entire matching line to the terminal. The line is longer than our terminal width so the text wraps around to the following lines, but this output corresponds to exactly one line in our FILE.
Note
The PATTERN is interpreted by grep as a regular expression. In the above example, all the characters we used (letters and a space) are interpreted literally in regular expressions, so only the exact phrase will be matched. Other characters have special meanings, however — some punctuation marks, for example. For more information, see: Regular expression quick reference.
Viewing grep output in color
If we use the –color option, our successful matches will be highlighted for us:

Viewing line numbers of successful matches
It will be even more useful if we know where the matching line appears in our file. If we specify the -n option, grep will prefix each matching line with the line number:

Our matching line is prefixed with “18:” which tells us this corresponds to line 18 in our file.
Performing case-insensitive grep searches
What if “our products” appears at the beginning of a sentence, or appears in all uppercase? We can specify the -i option to perform a case-insensitive match:
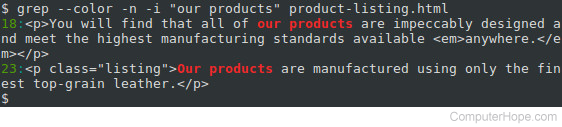
Using the -i option, grep finds a match on line 23 as well.
Searching multiple files using a wildcard
If we have multiple files to search, we can search them all using a wildcard in our FILE name. Instead of specifying product-listing.html, we can use an asterisk (“*“) and the .html extension. When the command is executed, the shell expands the asterisk to the name of any file it finds (in the current directory) which ends in “.html“.
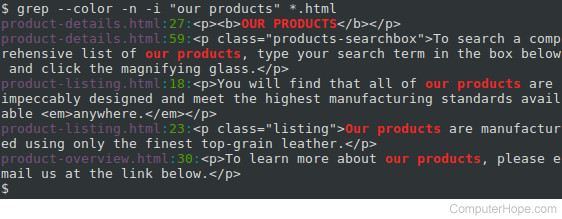
Notice that each line starts with the specific file where that match occurs.
Recursively searching subdirectories
We can extend our search to subdirectories and any files they contain using the -r option, which tells grep to perform its search recursively. Let’s change our FILE name to an asterisk (“*“), so that it matches any file or directory name, and not only HTML files:
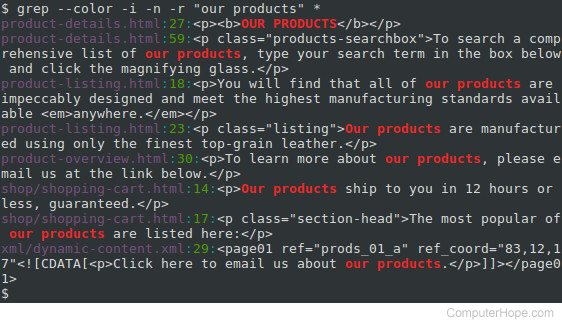
This gives us three additional matches. Notice that the directory name is included for any matching files that are not in the current directory.
Using regular expressions to perform more powerful searches
The true power of grep is that it can match regular expressions. (That’s what the “re” in “grep” stands for). Regular expressions use special characters in the PATTERN string to match a wider array of strings. Let’s look at a simple example.
Let’s say you want to find every occurrence of a phrase similar to “our products” in your HTML files, but the phrase should always start with “our” and end with “products”. We can specify this PATTERN instead: “our.*products”.
In regular expressions, the period (“.“) is interpreted as a single-character wildcard. It means “any character that appears in this place will match.” The asterisk (“*“) means “the preceding character, appearing zero or more times, will match.” So the combination “.*” will match any number of any character. For instance, “our amazing products“, “ours, the best-ever products“, and “ourproducts” will match. And because we’re specifying the -i option, “OUR PRODUCTS” and “OuRpRoDuCtS will match as well. Let’s run the command with this regular expression, and see what additional matches we can get:
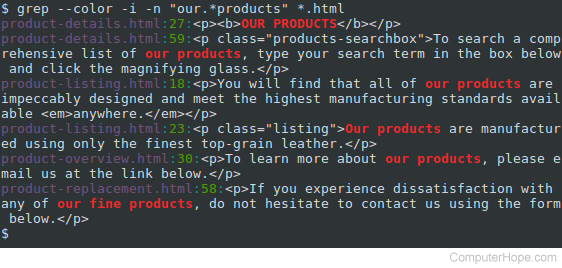
Here, we also got a match from the phrase “our fine products“.
Grep is a powerful tool to help you work with text files, and it gets even more powerful when you become comfortable using regular expressions.
Technical description
grep searches the named input FILEs (or standard input if no files are named, or if a single dash (“–“) is given as the file name) for lines containing a match to the given PATTERN. By default, grep prints the matching lines.
Also, three variant programs egrep, fgrep and rgrep are available:
- egrep is the same as running grep -E. In this mode, grep evaluates your PATTERN string as an extended regular expression (ERE). Nowadays, ERE does not “extend” very far beyond basic regular expressions, but they can still be very useful. For more information about extended regular expressions, see: Basic vs. extended regular expressions, below.
- fgrep is the same as running grep -F. In this mode, grep evaluates your PATTERN string as a “fixed string” — every character in your string is treated literally. For example, if your string contains an asterisk (“*“), grep will try to match it with an actual asterisk rather than interpreting this as a wildcard. If your string contains multiple lines (if it contains newlines), each line will be considered a fixed string, and any of them can trigger a match.
- rgrep is the same as running grep -r. In this mode, grep performs its search recursively. If it encounters a directory, it traverses into that directory and continue searching. (Symbolic links are ignored; if you want to search directories that are symbolically linked, use the -R option instead).
In older operating systems, egrep, fgrep and rgrep were distinct programs with their own executables. In modern systems, these special command names are shortcuts to grep with the appropriate flags enabled. They are functionally equivalent.
General options
| –help | Print a help message briefly summarizing command-line options, and exit. |
| -V, –version | Print the version number of grep, and exit. |
Match selection options
| -E, –extended-regexp |
Interpret PATTERN as an extended regular expression (see: Basic vs. extended regular expressions). |
| -F, –fixed-strings | Interpret PATTERN as a list of fixed strings, separated by newlines, that is to be matched. |
| -G, –basic-regexp | Interpret PATTERN as a basic regular expression (see: Basic vs. extended regular expressions). This is the default option when running grep. |
| -P, –perl-regexp | Interpret PATTERN as a Perl regular expression. This functionality is still experimental, and may produce warning messages. |
Matching control options
| -e PATTERN, –regexp=PATTERN |
Use PATTERN as the pattern to match. This can specify multiple search patterns, or to protect a pattern beginning with a dash (–). |
| -f FILE, –file=FILE | Obtain patterns from FILE, one per line. |
| -i, –ignore-case | Ignore case distinctions in both the PATTERN and the input files. |
| -v, –invert-match | Invert the sense of matching, to select non-matching lines. |
| -w, –word-regexp | Select only those lines containing matches that form whole words. The test is that the matching substring must either be at the beginning of the line, or preceded by a non-word constituent character. Or, it must be either at the end of the line or followed by a non-word constituent character. Word-constituent characters are letters, digits, and underscores. |
| -x, –line-regexp | Select only matches that exactly match the whole line. |
| -y | The same as -i. |
General output control
| -c, –count | Instead of the normal output, print a count of matching lines for each input file. With the -v, –invert-match option (see below), count non-matching lines. |
| –color[=WHEN], –colour[=WHEN] |
Surround the matched (non-empty) strings, matching lines, context lines, file names, line numbers, byte offsets, and separators (for fields and groups of context lines) with escape sequences to display them in color on the terminal. The colors are defined by the environment variable GREP_COLORS. The older environment variable GREP_COLOR is still supported, but its setting does not have priority. WHEN is never, always, or auto. |
| -L, –files-without-match |
Instead of the normal output, print the name of each input file from which no output would normally be printed. The scanning stops on the first match. |
| -l, –files-with-matches |
Instead of the normal output, print the name of each input file from which output would normally be printed. The scanning stops on the first match. |
| -m NUM, –max-count=NUM |
Stop reading a file after NUM matching lines. If the input is standard input from a regular file, and NUM matching lines are output, grep ensures that the standard input is positioned after the last matching line before exiting, regardless of the presence of trailing context lines. This enables a calling process to resume a search. When grep stops after NUM matching lines, it outputs any trailing context lines. When the -c or –count option is also used, grep does not output a count greater than NUM. When the -v or –invert-match option is also used, grep stops after outputting NUM non-matching lines. |
| -o, –only-matching | Print only the matched (non-empty) parts of a matching line, with each such part on a separate output line. |
| -q, –quiet, –silent | Quiet; do not write anything to standard output. Exit immediately with zero status if any match is found, even if an error was detected. Also see the -s or –no-messages option. |
| -s, –no-messages | Suppress error messages about nonexistent or unreadable files. |
Output line prefix control
| -b, –byte-offset | Print the 0-based byte offset in the input file before each line of output. If -o (–only-matching) is specified, print the offset of the matching part itself. |
| -H, –with-filename | Print the file name for each match. This is the default when there is more than one file to search. |
| -h, –no-filename | Suppress the prefixing of file names on output. This is the default when there is only one file (or only standard input) to search. |
| –label=LABEL | Display input actually coming from standard input as input coming from file LABEL. This is especially useful when implementing tools like zgrep, e.g., gzip -cd foo.gz | grep –label=foo -H something. See also the -H option. |
| -n, –line-number | Prefix each line of output with the 1-based line number within its input file. |
| -T, –initial-tab | Make sure that the first character of actual line content lies on a tab stop, so that the alignment of tabs looks normal. This is useful with options that prefix their output to the actual content: -H, -n, and -b. To improve the probability that lines from a single file will all start at the same column, this also causes the line number and byte offset (if present) to be printed in a minimum size field width. |
| -u, –unix-byte-offsets |
Report Unix-style byte offsets. This switch causes grep to report byte offsets as if the file were a Unix-style text file, i.e., with CR characters stripped off. This produces results identical to running grep on a Unix machine. This option has no effect unless -b option is also used; it has no effect on platforms other than MS-DOS and MS-Windows. |
| -Z, –null | Output a zero byte (the ASCII NUL character) instead of the character that normally follows a file name. For example, grep -lZ outputs a zero byte after each file name instead of the usual newline. This option makes the output unambiguous, even in the presence of file names containing unusual characters like newlines. This option can be used with commands like find -print0, perl -0, sort -z, and xargs -0 to process arbitrary file names, even those that contain newline characters. |
Context line control
| -A NUM, –after-context=NUM |
Print NUM lines of trailing context after matching lines. Places a line containing a group separator (—) between contiguous groups of matches. With the -o or –only-matching option, this has no effect and a warning is given. |
| -B NUM, –before-context=NUM |
Print NUM lines of leading context before matching lines. Places a line containing a group separator (—) between contiguous groups of matches. With the -o or –only-matching option, this has no effect and a warning is given. |
| -C NUM, –NUM, –context=NUM |
Print NUM lines of output context. Places a line containing a group separator (—) between contiguous groups of matches. With the -o or –only-matching option, this has no effect and a warning is given. |
File and directory selection
| -a, –text | Process a binary file as if it were text; this is equivalent to the –binary-files=text option. |
| –binary-files=TYPE | If the first few bytes of a file indicate that the file contains binary data, assume that the file is of type TYPE. By default, TYPE is binary, and grep normally outputs either a one-line message saying that a binary file matches, or no message if there is no match. If TYPE is without-match, grep assumes that a binary file does not match; this is equivalent to the -I option. If TYPE is text, grep processes a binary file as if it were text; this is equivalent to the -a option. Warning: grep –binary-files=text might output binary garbage, which can have nasty side effects if the output is a terminal and if the terminal driver interprets some of it as commands. |
| -D ACTION, –devices=ACTION |
If an input file is a device, FIFO or socket, use ACTION to process it. By default, ACTION is read, which means that devices are read as if they were ordinary files. If ACTION is skip, devices are silently skipped. |
| -d ACTION, –directories=ACTION |
If an input file is a directory, use ACTION to process it. By default, ACTION is read, i.e., read directories as if they were ordinary files. If ACTION is skip, silently skip directories. If ACTION is recurse, read all files under each directory, recursively, following symbolic links only if they are on the command line. This is equivalent to the -r option. |
| –exclude=GLOB | Skip files whose base name matches GLOB (using wildcard matching). A file-name glob can use *, ?, and […] as wildcards, and to quote a wildcard or backslash character literally. |
| –exclude-from=FILE | Skip files whose base name matches any of the file-name globs read from FILE (using wildcard matching as described under –exclude). |
| –exclude-dir=DIR | Exclude directories matching the pattern DIR from recursive searches. |
| -I | Process a binary file as if it did not contain matching data; this is equivalent to the –binary-files=without-match option. |
| –include=GLOB | Search only files whose base name matches GLOB (using wildcard matching as described under –exclude). |
| -r, –recursive | Read all files under each directory, recursively, following symbolic links only if they are on the command line. This is equivalent to the -d recurse option. |
| -R, –dereference-recursive |
Read all files under each directory, recursively. Follow all symbolic links, unlike -r. |
Other options
| –line-buffered | Use line buffering on output. This can cause a performance penalty. |
| –mmap | If possible, use the mmap system call to read input, instead of the default read system call. In some situations, –mmap yields better performance. However, –mmap can cause undefined behavior (including core dumps) if an input file shrinks while grep is operating, or if an I/O error occurs. |
| -U, –binary | Treat the file(s) as binary. By default, under MS-DOS and MS-Windows, grep guesses the file type by looking at the contents of the first 32 KB read from the file. If grep decides the file is a text file, it strips the CR characters from the original file contents (to make regular expressions with ^ and $ work correctly). Specifying -U overrules this guesswork, causing all files to be read and passed to the matching mechanism verbatim; if the file is a text file with CR/LF pairs at the end of each line, this causes some regular expressions to fail. This option has no effect on platforms other than MS-DOS and MS-Windows. |
| -z, –null-data | Treat the input as a set of lines, each terminated by a zero byte (the ASCII NUL character) instead of a newline. Like the -Z or –null option, this option can be used with commands like sort -z to process arbitrary file names. |
Regular expressions
A regular expression is a pattern that describes a set of strings. Regular expressions are constructed analogously to arithmetic expressions, using various operators to combine smaller expressions.
grep understands three different versions of regular expression syntax: “basic” (BRE), “extended” (ERE) and “perl” (PRCE). In GNU grep, there is no difference in available functionality between basic and extended syntaxes. In other implementations, basic regular expressions are less powerful. The following description applies to extended regular expressions; differences for basic regular expressions are summarized afterwards. Perl regular expressions give additional functionality.
The fundamental building blocks are the regular expressions that match a single character. Most characters, including all letters and digits, are regular expressions that match themselves. Any metacharacter with special meaning may be quoted by preceding it with a backslash.
The period (.) matches any single character.
Character classes and bracket expressions
A bracket expression is a list of characters enclosed by [ and ]. It matches any single character in that list; if the first character of the list is the caret ^ then it matches any character not in the list. For example, the regular expression [0123456789] matches any single digit.
Within a bracket expression, a range expression consists of two characters separated by a hyphen. It matches any single character that sorts between the two characters, inclusive, using the locale’s collating sequence and character set. For example, in the default C locale, [a-d] is equivalent to [abcd]. Many locales sort characters in dictionary order, and in these locales [a-d] is often not equivalent to [abcd]; it might be equivalent to [aBbCcDd], for example. To obtain the traditional interpretation of bracket expressions, you can use the C locale by setting the LC_ALL environment variable to the value C.
Finally, certain named classes of characters are predefined within bracket expressions, as follows. Their names are self explanatory, and they are [:alnum:], [:alpha:], [:cntrl:], [:digit:], [:graph:], [:lower:], [:print:], [:punct:], [:space:], [:upper:], and [:xdigit:]. For example, [[:alnum:]] means the character class of numbers and letters in the current locale. In the C locale and ASCII character set encoding, this is the same as [0-9A-Za-z]. (Note that the brackets in these class names are part of the symbolic names, and must be included in addition to the brackets delimiting the bracket expression.) Most metacharacters lose their special meaning inside bracket expressions. To include a literal ] place it first in the list. Similarly, to include a literal ^ place it anywhere but first. Finally, to include a literal –, place it last.
Anchoring
The caret ^ and the dollar sign $ are metacharacters that respectively match the empty string at the beginning and end of a line.
The backslash character and special expressions
The symbols < and > respectively match the empty string at the beginning and end of a word. The symbol b matches the empty string at the edge of a word, and B matches the empty string provided it’s not at the edge of a word. The symbol w is a synonym for [_[:alnum:]] and W is a synonym for [^_[:alnum:]].
Repetition
A regular expression may be followed by one of several repetition operators:
| ? | The preceding item is optional and matched at most once. |
| * | The preceding item will be matched zero or more times. |
| + | The preceding item will be matched one or more times. |
| {n} | The preceding item is matched exactly n times. |
| {n,} | The preceding item is matched n or more times. |
| {n,m} | The preceding item is matched at least n times, but not more than m times. |
Concatenation
Two regular expressions may be concatenated; the resulting regular expression matches any string formed by concatenating two substrings that respectively match the concatenated expressions.
Alternation
Two regular expressions may be joined by the infix operator |; the resulting regular expression matches any string matching either alternate expression.
Precedence
Repetition takes precedence over concatenation, which in turn takes precedence over alternation. A whole expression may be enclosed in parentheses to override these precedence rules and form a subexpression.
Back references and subexpressions
The back-reference n, where n is a single digit, matches the substring previously matched by the nth parenthesized subexpression of the regular expression.
Basic vs. extended regular expressions
In basic regular expressions the metacharacters ?, +, {, |, (, and ) lose their special meaning; instead use the backslashed versions ?, +, {, |, (, and ).
Traditional versions of egrep did not support the { metacharacter, and some egrep implementations support { instead, so portable scripts should avoid { in grep -E patterns and should use [{] to match a literal {.
GNU grep -E attempts to support traditional usage by assuming that { is not special if it would be the start of an invalid interval specification. For example, the command grep -E ‘{1’ searches for the two-character string {1 instead of reporting a syntax error in the regular expression. POSIX allows this behavior as an extension, but portable scripts should avoid it.
Environment variables
The behavior of grep is affected by the following environment variables.
The locale for category LC_foo is specified by examining the three environment variables LC_ALL, LC_foo, and LANG, in that order. The first of these variables that is set specifies the locale. For example, if LC_ALL is not set, but LC_MESSAGES is set to pt_BR, then the Brazilian Portuguese locale is used for the LC_MESSAGES category. The C locale is used if none of these environment variables are set, if the locale catalog is not installed, or if grep was not compiled with national language support (NLS).
Other variables of note:
| GREP_OPTIONS | This variable specifies default options to be placed in front of any explicit options. For example, if GREP_OPTIONS is ‘–binary- files=without-match –directories=skip‘, grep behaves as if the two options –binary-files=without-match and –directories=skip had been specified before any explicit options. Option specifications are separated by whitespace. A backslash escapes the next character, so it can specify an option containing whitespace or a backslash. | ||||||||||||||||||||||
| GREP_COLOR | This variable specifies the color used to highlight matched (non-empty) text. It is deprecated in favor of GREP_COLORS, but still supported. The mt, ms, and mc capabilities of GREP_COLORS have priority over it. It can only specify the color used to highlight the matching non-empty text in any matching line (a selected line when the -v command-line option is omitted, or a context line when -v is specified). The default is 01;31, which means a bold red foreground text on the terminal’s default background. | ||||||||||||||||||||||
| GREP_COLORS | Specifies the colors and other attributes used to highlight various parts of the output. Its value is a colon-separated list of capabilities that defaults to ms=01;31:mc=01;31:sl=:cx=:fn=35:ln=32:bn=32:se=36 with the rv and ne boolean capabilities omitted (i.e., false). Supported capabilities are as follows:
Note that boolean capabilities have no =… part. They are omitted (i.e., false) by default and become true when specified. See the Select Graphic Rendition (SGR) section in the documentation of the text terminal that is used for permitted values and their meaning as character attributes. These substring values are integers in decimal representation and can be concatenated with semicolons. grep takes care of assembling the result into a complete SGR sequence (33[…m). Common values to concatenate include 1 for bold, 4 for underline, 5 for blink, 7 for inverse, 39 for default foreground color, 30 to 37 for foreground colors, 90 to 97 for 16-color mode foreground colors, 38;5;0 to 38;5;255 for 88-color and 256-color modes foreground colors, 49 for default background color, 40 to 47 for background colors, 100 to 107 for 16-color mode background colors, and 48;5;0 to 48;5;255 for 88-color and 256-color modes background colors. |
||||||||||||||||||||||
| LC_ALL, LC_COLLATE, LANG | These variables specify the locale for the LC_COLLATE category, which determines the collating sequence used to interpret range expressions like [a-z]. | ||||||||||||||||||||||
| LC_ALL, LC_CTYPE, LANG | These variables specify the locale for the LC_CTYPE category, which determines the type of characters, e.g., which characters are whitespace. | ||||||||||||||||||||||
| LC_ALL, LC_MESSAGES, LANG | These variables specify the locale for the LC_MESSAGES category, which determines the language that grep uses for messages. The default C locale uses American English messages. | ||||||||||||||||||||||
| POSIXLY_CORRECT | If set, grep behaves as POSIX requires; otherwise, grep behaves more like other GNU programs. POSIX requires that options that follow file names must be treated as file names; by default, such options are permuted to the front of the operand list and are treated as options. Also, POSIX requires that unrecognized options be diagnosed as “illegal”, but since they are not really against the law the default is to diagnose them as “invalid”. POSIXLY_CORRECT also disables _N_GNU_nonoption_argv_flags_, described below. | ||||||||||||||||||||||
| _N_GNU_nonoption_argv_flags_ | (Here N is grep‘s numeric process ID). If the ith character of this environment variable’s value is 1, do not consider the ith operand of grep to be an option, even if it appears to be one. A shell can put this variable in the environment for each command it runs, specifying which operands are the results of file name wildcard expansion and therefore should not be treated as options. This behavior is available only with the GNU C library, and only when POSIXLY_CORRECT is not set. |
Exit status
The exit status is 0 if selected lines are found, and 1 if not found. If an error occurred the exit status is 2.
Examples
Tip
If you haven’t already seen our example usage section, we suggest reviewing that section first.
grep chope /etc/passwd
Search /etc/passwd for user chope.
grep "May 31 03" /etc/httpd/logs/error_log
Search the Apache error_log file for any error entries that happened on May 31st at 3 A.M. By adding quotes around the string, this lets you place spaces in the grep search.
grep -r "computerhope" /www/
Recursively search the directory /www/, and all subdirectories, for any lines of any files which contain the string “computerhope“.
grep -w "hope" myfile.txt
Search the file myfile.txt for lines containing the word “hope“. Only lines containing the distinct word “hope” are matched. Lines where “hope” is part of a word (e.g., “hopes”) are not be matched.
grep -cw "hope" myfile.txt
Same as previous command, but displays a count of how many lines were matched, rather than the matching lines themselves.
grep -cvw "hope" myfile.txt
Inverse of previous command: displays a count of the lines in myfile.txt which do not contain the word “hope”.
grep -l "hope" /www/*
Display the file names (but not the matching lines themselves) of any files in /www/ (but not its subdirectories) whose contents include the string “hope“.
ed — A simple text editor.
egrep — Filter text which matches an extended regular expression.
sed — A utility for filtering and transforming text.
sh — The Bourne shell command interpreter.
Иногда может понадобится найти файл, в котором содержится определённая строка или найти строку в файле, где есть нужное слово. В Linux для этого существует несколько утилит, одна из самых используемых это grep. С её помощью можно искать не только строки в файлах, но и фильтровать вывод команд, и много чего ещё.
В этой инструкции мы рассмотрим что такое команда grep Linux, подробно разберём синтаксис и возможные опции grep, а также приведём несколько примеров работы с этой утилитой.
Что такое grep?
Название команды grep расшифровывается как “search globally for lines matching the regular expression, and print them”. Это одна из самых востребованных команд в терминале Linux, которая входит в состав проекта GNU. До того как появился проект GNU, существовала утилита предшественник grep, тем же названием, которая была разработана в 1973 году Кеном Томпсоном для поиска файлов по содержимому в Unix. А потом уже была разработана свободная утилита с той же функциональностью в рамках GNU.
Grep дает очень много возможностей для фильтрации текста. Вы можете выбирать нужные строки из текстовых файлов, отфильтровать вывод команд, и даже искать файлы в файловой системе, которые содержат определённые строки. Утилита очень популярна, потому что она уже предустановлена прочти во всех дистрибутивах.
Синтаксис grep
Синтаксис команды выглядит следующим образом:
$ grep [опции] шаблон [/путь/к/файлу/или/папке…]
Или:
$ команда | grep [опции] шаблон
Здесь:
- Опции – это дополнительные параметры, с помощью которых указываются различные настройки поиска и вывода, например количество строк или режим инверсии.
- Шаблон – это любая строка или регулярное выражение, по которому будет выполняться поиск.
- Имя файла или папки – это то место, где будет выполняться поиск. Как вы увидите дальше, grep позволяет искать в нескольких файлах и даже в каталоге, используя рекурсивный режим.
Возможность фильтровать стандартный вывод пригодится, например, когда нужно выбрать только ошибки из логов или отфильтровать только необходимую информацию из вывода какой-либо другой утилиты.
Опции
Давайте рассмотрим самые основные опции утилиты, которые помогут более эффективно выполнять поиск текста в файлах grep:
- -E, –extended-regexp – включить расширенный режим регулярных выражений (ERE);
- -F, –fixed-strings – рассматривать шаблон поиска как обычную строку, а не регулярное выражение;
- -G, –basic-regexp – интерпретировать шаблон поиска как базовое регулярное выражение (BRE);
- -P, –perl-regexp – рассматривать шаблон поиска как регулярное выражение Perl;
- -e, –regexp – альтернативный способ указать шаблон поиска, опцию можно использовать несколько раз, что позволяет указать несколько шаблонов для поиска файлов, содержащих один из них;
- -f, –file – читать шаблон поиска из файла;
- -i, –ignore-case – не учитывать регистр символов;
- -v, –invert-match – вывести только те строки, в которых шаблон поиска не найден;
- -w, –word-regexp – искать шаблон как слово, отделенное пробелами или другими знаками препинания;
- -x, –line-regexp – искать шаблон как целую строку, от начала и до символа перевода строки;
- -c – вывести количество найденных строк;
- –color – включить цветной режим, доступные значения: never, always и auto;
- -L, –files-without-match – выводить только имена файлов, будут выведены все файлы в которых выполняется поиск;
- -l, –files-with-match – аналогично предыдущему, но будут выведены только файлы, в которых есть хотя бы одно вхождение;
- -m, –max-count – остановить поиск после того как будет найдено указанное количество строк;
- -o, –only-matching – отображать только совпавшую часть, вместо отображения всей строки;
- -h, –no-filename – не выводить имя файла;
- -q, –quiet – не выводить ничего;
- -s, –no-messages – не выводить ошибки чтения файлов;
- -A, –after-content – показать вхождение и n строк после него;
- -B, –before-content – показать вхождение и n строк после него;
- -C – показать n строк до и после вхождения;
- -a, –text – обрабатывать двоичные файлы как текст;
- –exclude – пропустить файлы имена которых соответствуют регулярному выражению;
- –exclude-dir – пропустить все файлы в указанной директории;
- -I – пропускать двоичные файлы;
- –include – искать только в файлах, имена которых соответствуют регулярному выражению;
- -r – рекурсивный поиск по всем подпапкам;
- -R – рекурсивный поиск включая ссылки;
Все самые основные опции рассмотрели, теперь давайте перейдём к примерам работы команды grep Linux.
Примеры использования grep
Давайте перейдём к практике. Сначала рассмотрим несколько основных примеров поиска внутри файлов Linux с помощью grep.
1. Поиск текста в файле
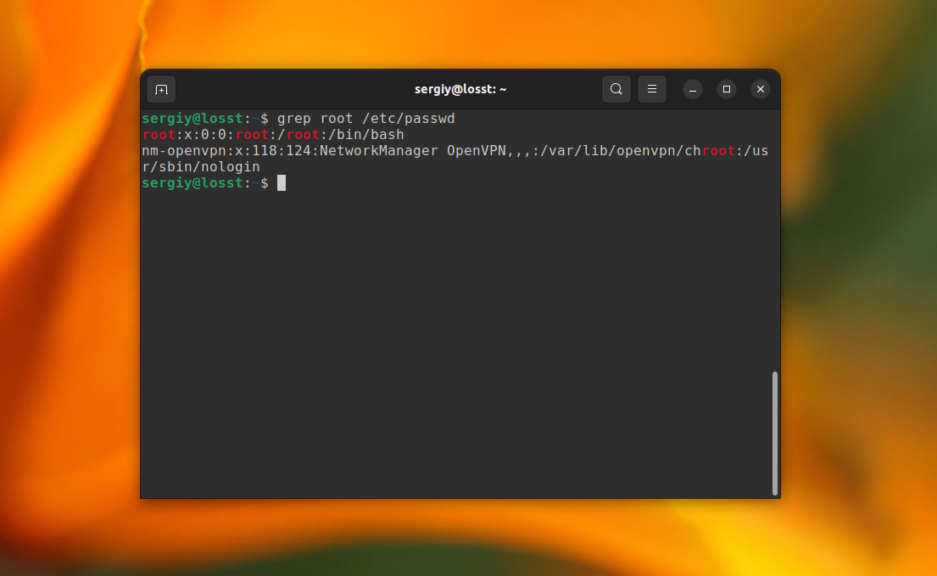
В первом примере мы будем искать информацию о пользователе root в файле со списком пользователей Linux /etc/passwd. Для этого выполните следующую команду:
grep root /etc/passwd
В результате вы получите что-то вроде этого:
С помощью опции -i можно указать, что регистр символов учитывать не нужно. Например, давайте найдём все строки содержащие вхождение слова time в том же файле:
grep -i "time" /etc/passwd
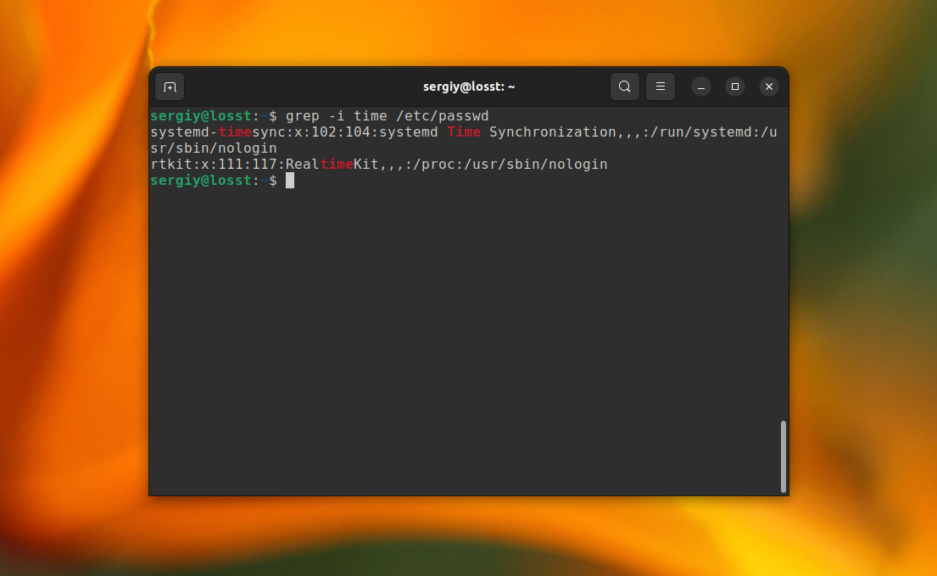
В этом случае Time, time, TIME и другие вариации слова будут считаться эквивалентными. Ещё, вы можете указать несколько условий для поиска, используя опцию -e. Например:
grep -e "root" -e "daemon" /etc/passwd
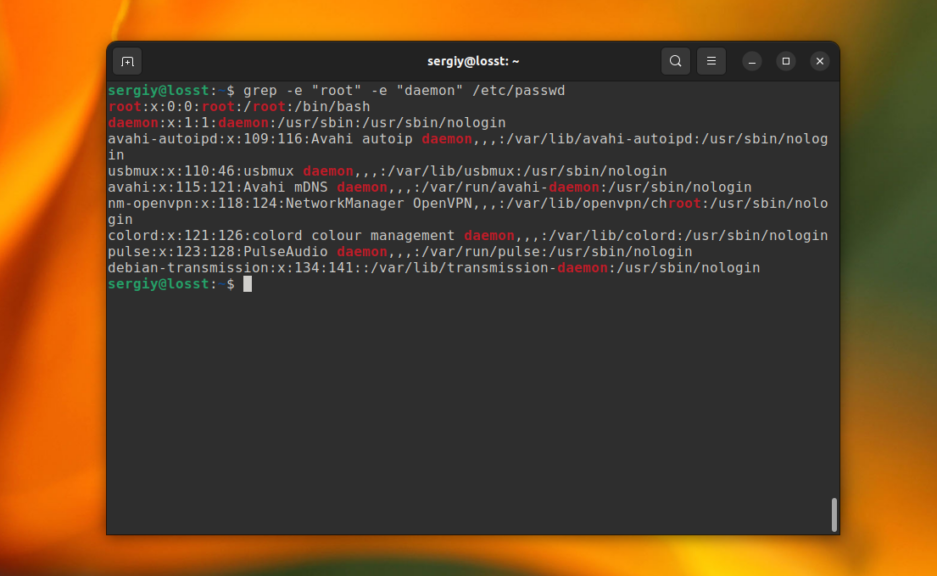
C помощью опции -n можно выводить номер строки, в которой найдено вхождение, например:
grep -n 'root' /etc/passwd
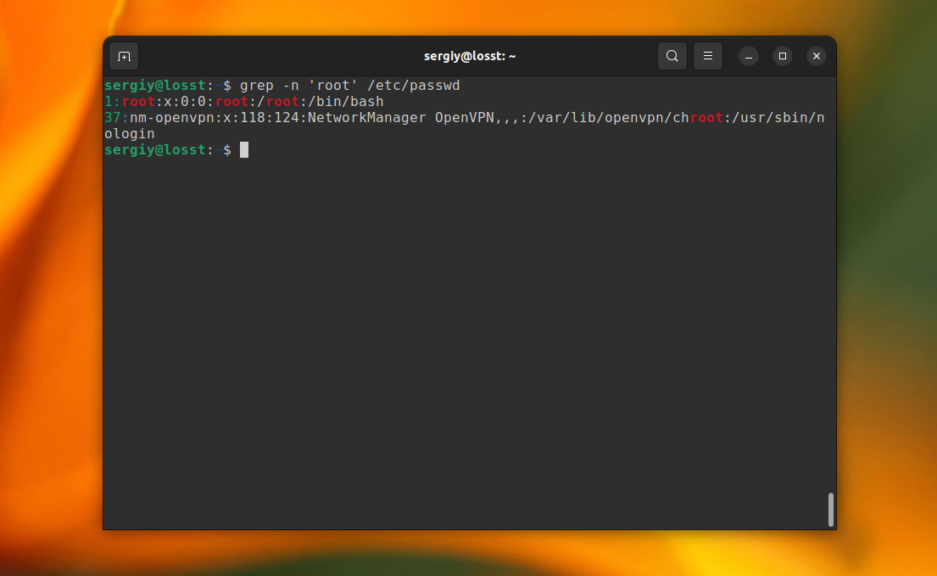
Это всё хорошо работает пока ваш поисковый запрос не содержит специальных символов. Например, если вы попытаетесь найти все строки, которые содержат символ “[” в файле /etc/grub/00_header, то получите ошибку, что это регулярное выражение не верно. Для того чтобы этого избежать, нужно явно указать, что вы хотите искать строку с помощью опции -F:
grep -F "[" /etc/grub.d/00_header
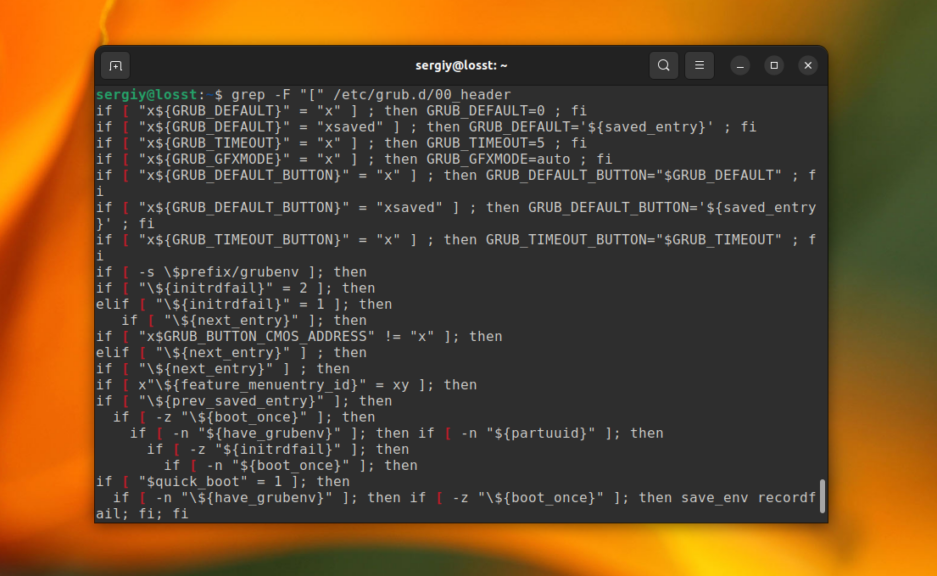
Теперь вы знаете как выполняется поиск текста файлах grep.
2. Фильтрация вывода команды
Для того чтобы отфильтровать вывод другой команды с помощью grep достаточно перенаправить его используя оператор |. А файл для самого grep указывать не надо. Например, для того чтобы найти все процессы gnome можно использовать такую команду:
ps aux | grep "gnome"
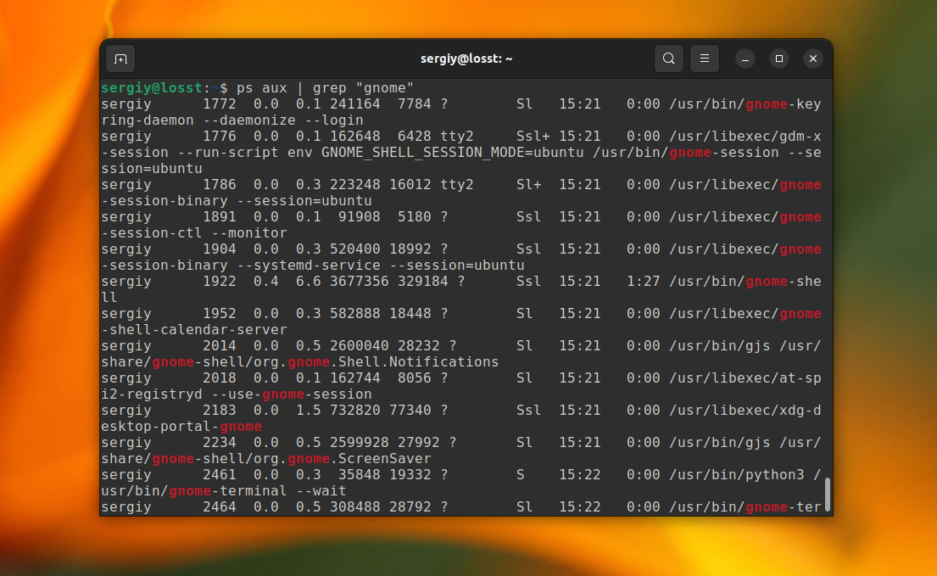
В остальном всё работает аналогично.
3. Базовые регулярные выражения
Утилита grep поддерживает несколько видов регулярных выражений. Это базовые регулярные выражения (BRE), которые используются по умолчанию и расширенные (ERE). Базовые регулярные выражение поддерживает набор символов, позволяющих описать каждый определённый символ в строке. Это: ., *, [], [^], ^ и $. Например, вы можете найти строки, которые начитаются на букву r:
grep "^r" /etc/passwd
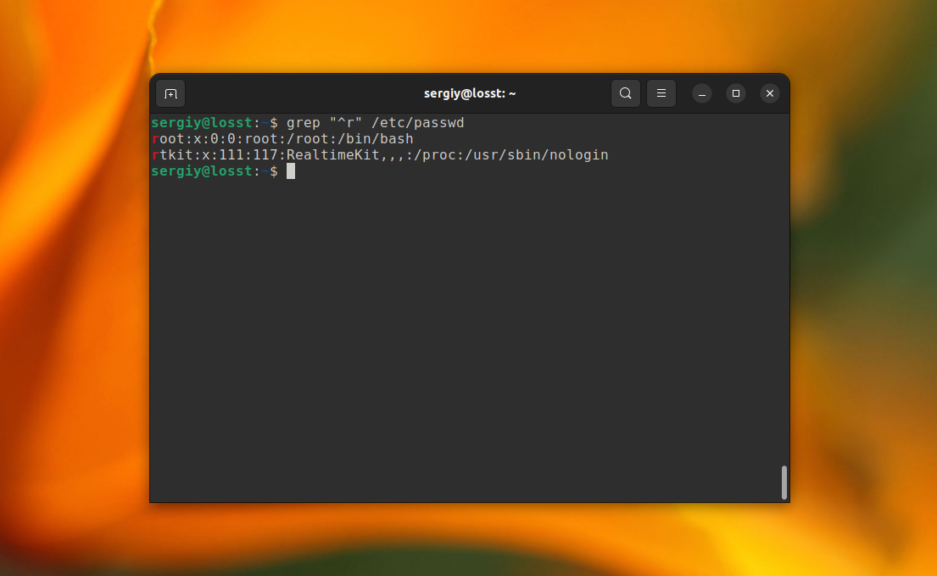
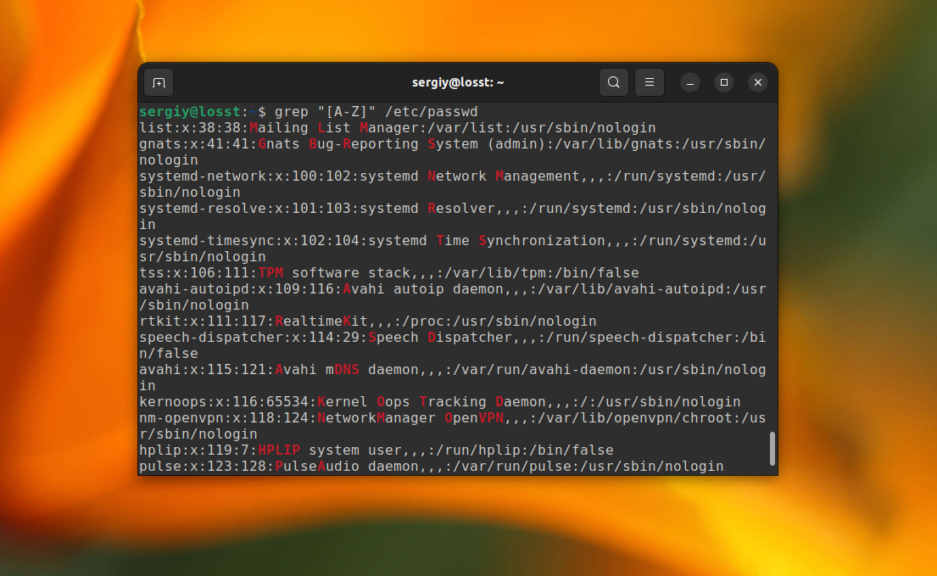
Или же строки, которые содержат большие буквы:
grep "[A-Z]" /etc/passwd
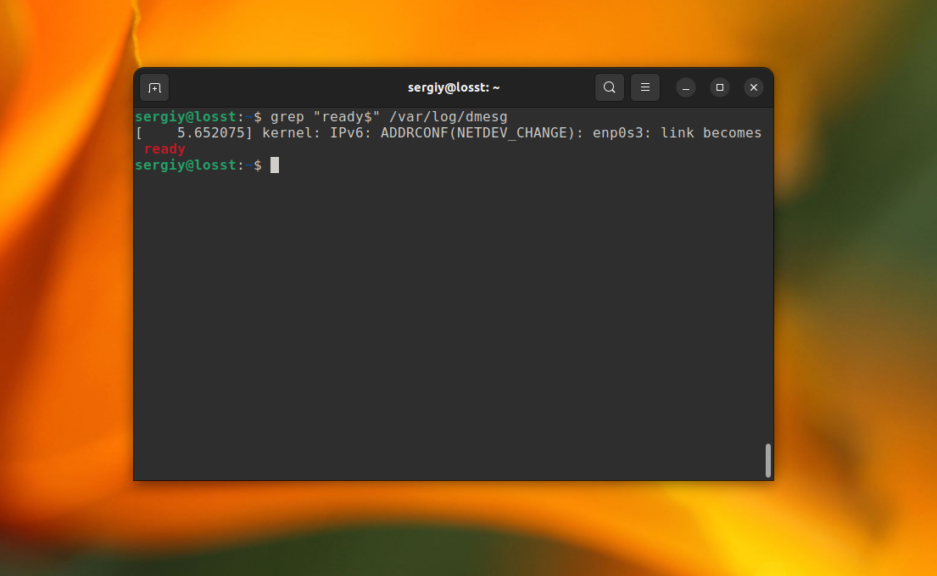
А так можно найти все строки, которые заканчиваются на ready в файле /var/log/dmesg:
grep "ready$" /var/log/dmesg
Но используя базовый синтаксис вы не можете указать точное количество этих символов.
4. Расширенные регулярные выражения
В дополнение ко всем символам из базового синтаксиса, в расширенном синтаксисе поддерживаются также такие символы:
- + – одно или больше повторений предыдущего символа;
- ? – ноль или одно повторение предыдущего символа;
- {n,m} – повторение предыдущего символа от n до m раз;
- | – позволяет объединять несколько паттернов.
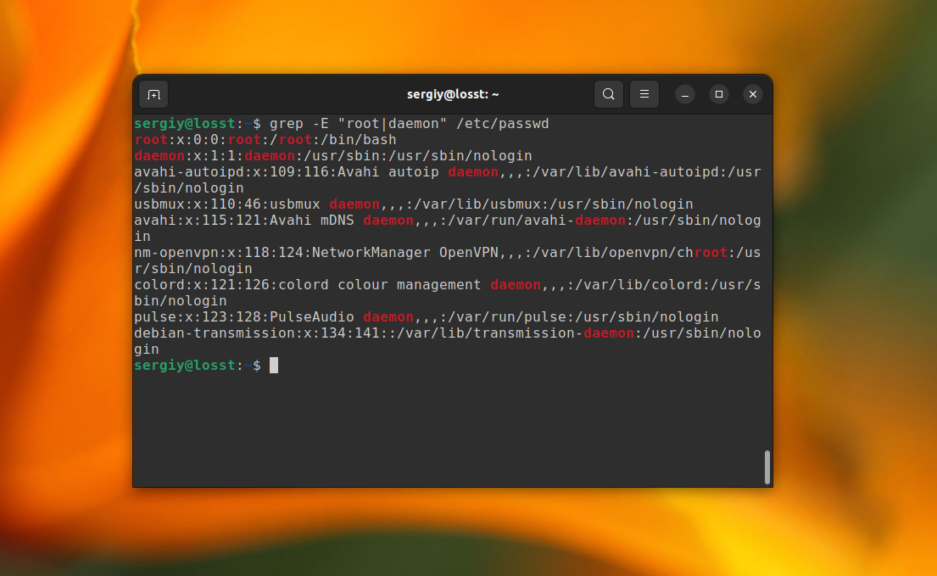
Для активации расширенного синтаксиса нужно использовать опцию -E. Например, вместо использования опции -e, можно объединить несколько слов для поиска вот так:
grep -E "root|daemon" /etc/passwd
Вообще, регулярные выражения grep – это очень обширная тема, в этой статье я лишь показал несколько примеров. Как вы увидели, поиск текста в файлах grep становиться ещё эффективнее. Но на полное объяснение этой темы нужна целая статья, поэтому пока пропустим её и пойдем дальше.
5. Вывод контекста
Иногда бывает очень полезно вывести не только саму строку со вхождением, но и строки до и после неё. Например, мы хотим выбрать все ошибки из лог-файла, но знаем, что в следующей строчке после ошибки может содержаться полезная информация, тогда с помощью grep отобразим несколько строк. Ошибки будем искать в /var/log/dmesg по шаблону “Error”:
grep -A4 "Error" /var/log/dmesg
Выведет строку с вхождением и 4 строчки после неё:
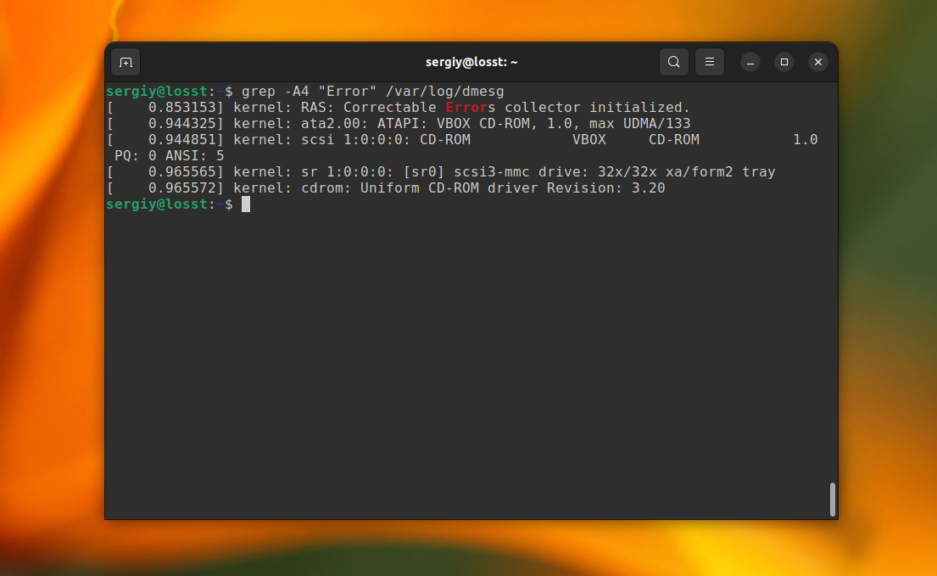
grep -B4 "Error" /var/log/dmesg
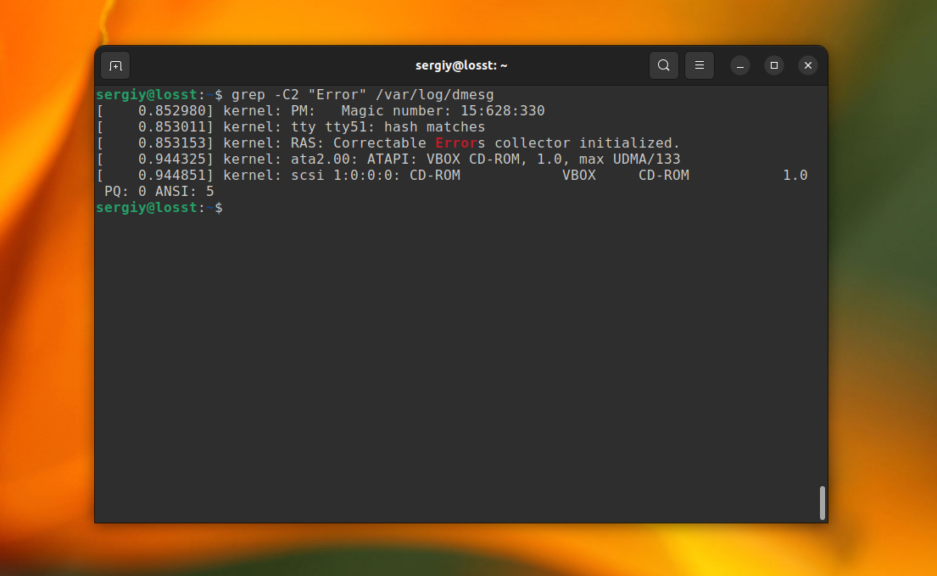
Эта команда выведет строку со вхождением и 4 строчки до неё. А следующая выведет по две строки с верху и снизу от вхождения.
grep -C2 "Error" /var/log/dmesg
6. Рекурсивный поиск в grep
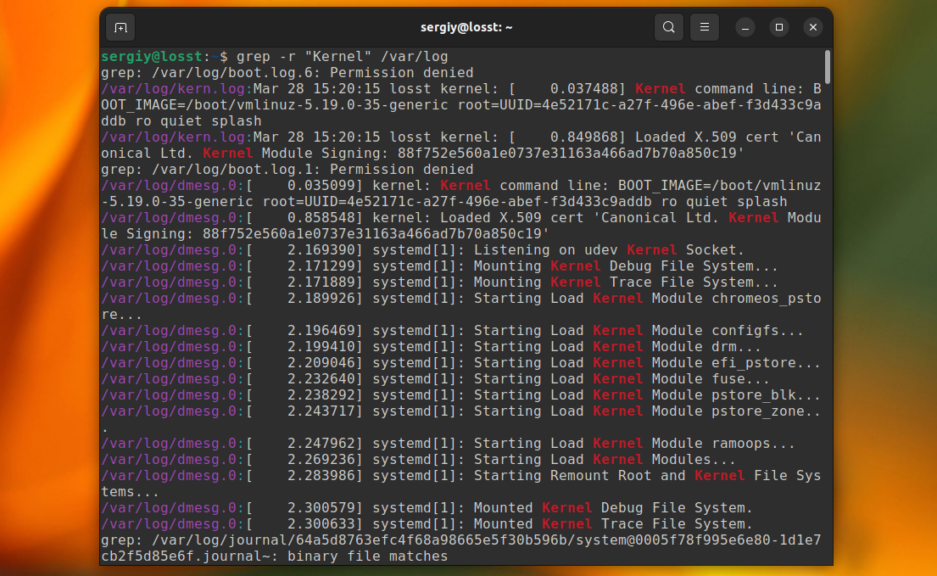
До этого мы рассматривали поиск в определённом файле или выводе команд. Но grep также может выполнить поиск текста в нескольких файлах, размещённых в одном каталоге или подкаталогах. Для этого нужно использовать опцию -r. Например, давайте найдём все файлы, которые содержат строку Kernel в папке /var/log:
grep -r "Kernel" /var/log
Папка с вашими файлами может содержать двоичные файлы, в которых поиск выполнять обычно не надо. Для того чтобы их пропускать используйте опцию -I:
grep -rI "Kernel" /var/log
Некоторые файлы доступны только суперпользователю и для того чтобы выполнять по ним поиск вам нужно запускать grep с помощью sudo. Или же вы можете просто скрыть сообщения об ошибках чтения и пропускать такие файлы с помощью опции -s:
grep -rIs "Kernel" /var/log
7. Выбор файлов для поиска
С помощью опций –include и –exclude вы можете фильтровать файлы, которые будут принимать участие в поиске. Например, для того чтобы выполнить поиск только по файлам с расширением .log в папке /var/log используйте такую команду:
grep -r --include="*.log" "Kernel" /var/log
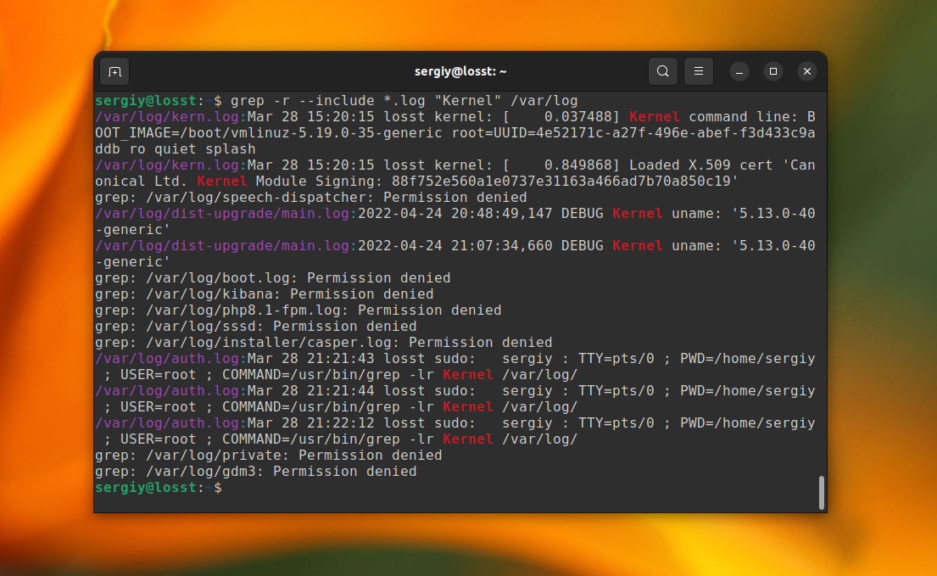
А для того чтобы исключить все файлы с расширением .journal надо использовать опцию –exclude:
grep -r --exclude="*.journal" "Kernel" /var/log
8. Поиск слов в grep
Когда вы ищете строку abc, grep будет выводить также kbabc, abc123, aafrabc32 и тому подобные комбинации. Вы можете заставить утилиту искать по содержимому файлов в Linux строки, которые включают только искомые слова полностью с помощью опции -w. Например:
grep -w "root" /etc/passwd
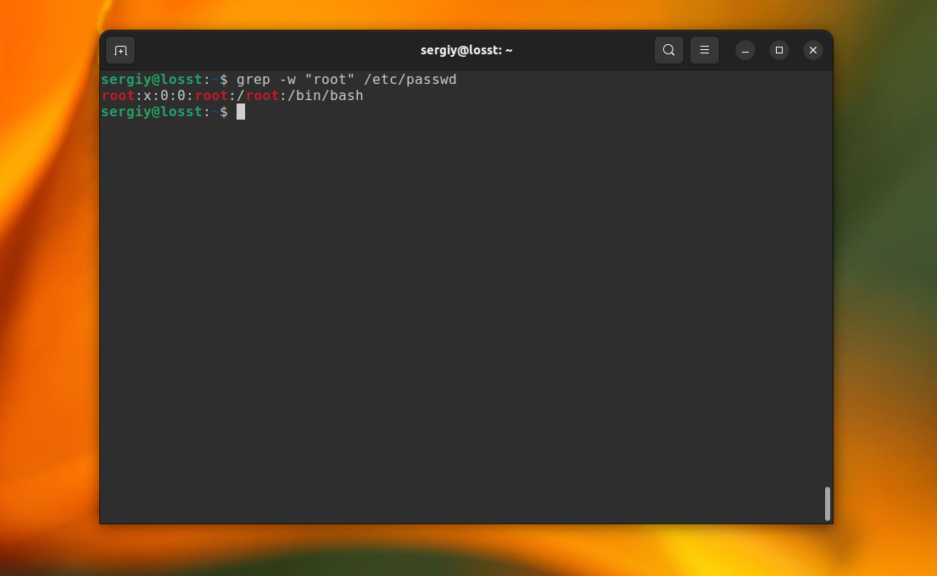
9. Количество строк
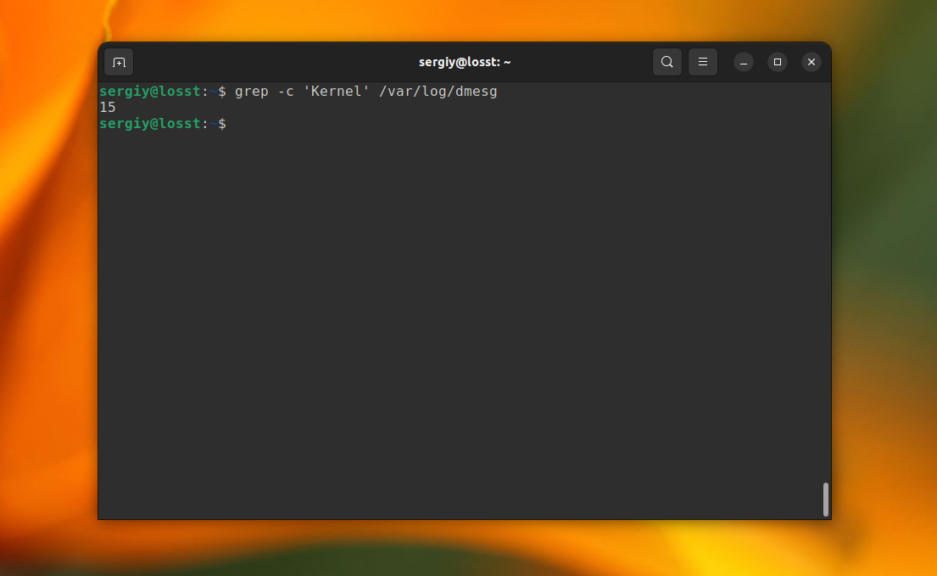
Утилита grep может сообщить, сколько строк с определенным текстом было найдено файле. Для этого используется опция -c (счетчик). Например:
grep -c 'Kernel' /var/log/dmesg
10. Инвертированный поиск
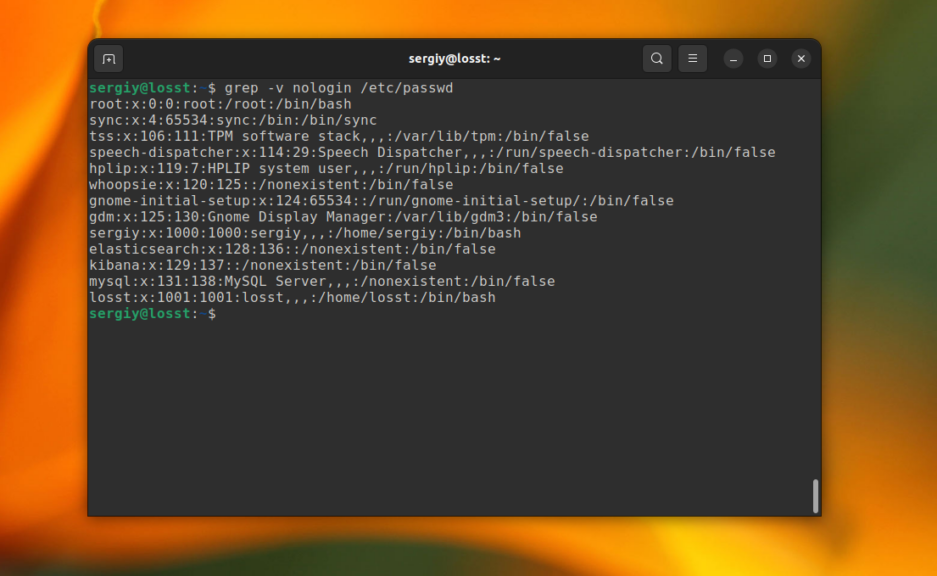
Команда grep Linux может быть использована для поиска строк, которые не содержат указанное слово. Например, так можно вывести только те строки, которые не содержат слово nologin:
grep -v nologin /etc/passwd
11. Вывод имен файлов
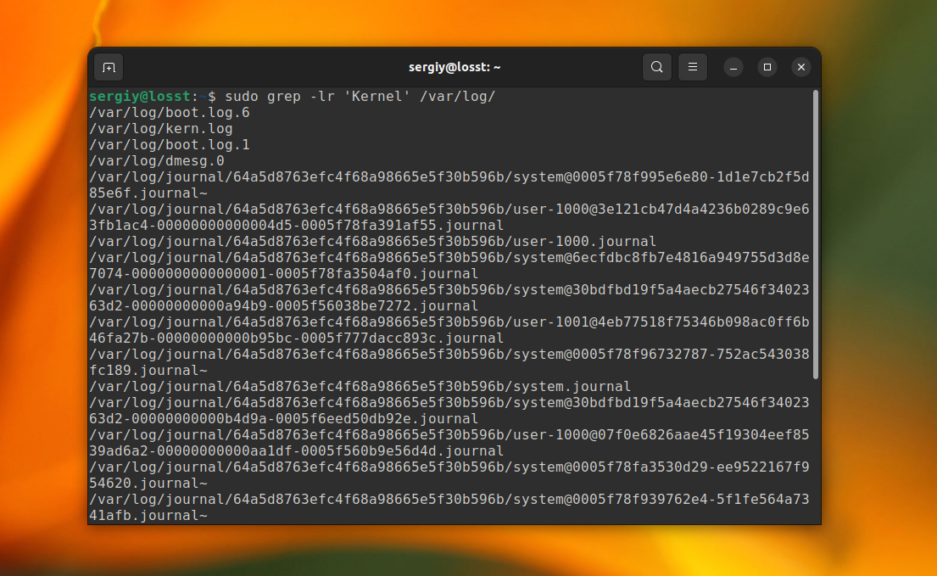
Вы можете указать grep выводить только имена файлов, в которых было хотя бы одно вхождение с помощью опции -l. Например, следующая команда выведет все имена файлов из каталога /var/log, при поиске по содержимому которых было обнаружено вхождение Kernel:
grep -lr 'Kernel' /var/log/
12. Цветной вывод
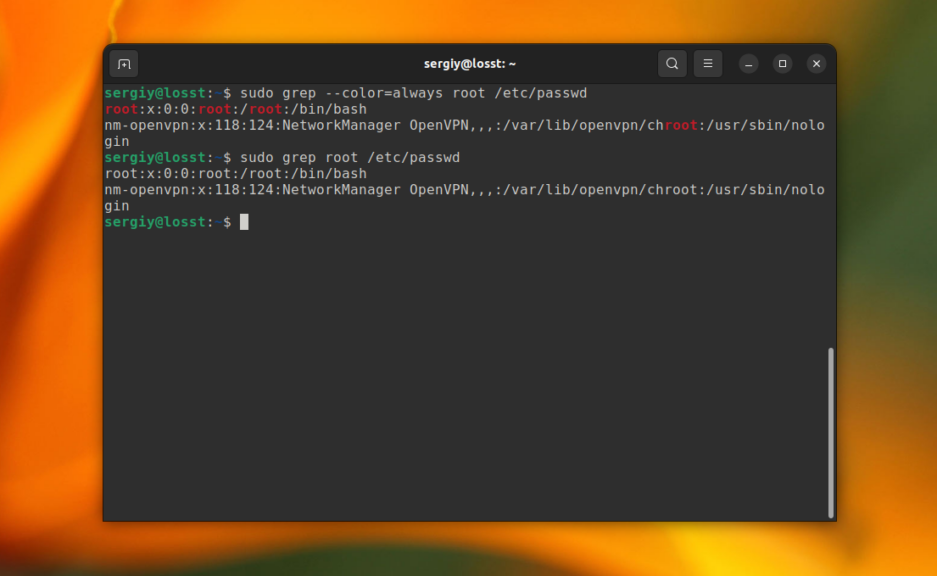
По умолчанию grep не будет подсвечивать совпадения цветом. Но в большинстве дистрибутивов прописан алиас для grep, который это включает. Однако, когда вы используйте команду c sudo это работать не будет. Для включения подсветки вручную используйте опцию –color со значением always:
sudo grep --color=always root /etc/passwd
Получится:
Выводы
Вот и всё. Теперь вы знаете что представляет из себя команда grep Linux, а также как ею пользоваться для поиска файлов и фильтрации вывода команд. При правильном применении эта утилита станет мощным инструментом в ваших руках. Если у вас остались вопросы, пишите в комментариях!
Обнаружили ошибку в тексте? Сообщите мне об этом. Выделите текст с ошибкой и нажмите Ctrl+Enter.

Статья распространяется под лицензией Creative Commons ShareAlike 4.0 при копировании материала ссылка на источник обязательна .
