Как искать нужное слово или фразу в тексте?
Mrs. Creative
Ученик
(190),
на голосовании
11 лет назад
Например на сайте очень длинный текст, а искать определённое предложение долго то как его быстро найти. Помню что как то делала с помощью каких то сочетаний клавиш.
Голосование за лучший ответ
Jhojitan
Мудрец
(15002)
11 лет назад
ctrl плюс f
Игорь Максимов
Просветленный
(39618)
11 лет назад
Правка – найти на этой странице, или Ctrl+F
The Demon
Просветленный
(23591)
11 лет назад
В меню правка как правило есть кнопка поиск. В 2007 и 2010 офисе на вкладке главная есть кнопка поиск
Оксана Панюхина
Ученик
(122)
5 лет назад
Очень просто, нажать кнопку F3 ( находится наверху клавиатуры) чуть выше цифр, выпадает окно, вставить нужное слово или фразу, поиск автоматически всё найдёт.
Horri Horriovna
Ученик
(145)
4 года назад
Ctrl+F или F3
Aya Urkenkyzy
Ученик
(110)
1 год назад
Нужно найти цитаты в тексте конь с розовый гривой
Похожие вопросы
Бесплатный сервис поиска слов Адвего покажет онлайн все вхождения ключевых слов, стоп-слов и слов по заданному образцу. Поиск фраз и наборов символов на любом языке.
Как работает поиск слов и фраз в тексте
Скопируйте в первое поле проверяемый текст, а во втором поле укажите все слова и фразы по одной на строку, после чего нажмите кнопку “Найти”. Чтобы найти слова в документе или на странице сайта, скопируйте весь текст в поле для проверки.
По умолчанию система ищет только точные совпадения с указанной строкой (с учетом знаков препинания).
Например, по строке “номер” будет найдено слово “номер”, но не будут найдены слова “номерной” или “госномер”. Аналогично, при поиске по фразе “легкий завтрак” будет найдена только фраза “легкий завтрак”, но не будут найдены фразы “легким завтраком” или “легкий, завтрак”.
Чтобы задать поиск по маске, используйте символ звездочки * в начале, в конце или с обеих сторон каждого слова:
ра*— будут найдены все слова, начинающиеся на “ра”, в том числе слово “ра”: работа, разный, рад.*ет— будут найдены все слова, заканчивающиеся на “ет”, в том числе слово “ет”: работает, полет, нет.*ой*— будут найдены все слова, содержащие буквосочетание “ой” в любом месте: ойкнул, водопой, спокойствие.
Маску можно указать для одного или нескольких слов во фразе, правила будут применяться последовательно:
ра* *ет— будут найдены фразы только из двух рядом стоящих слов, первое из которых начинается на “ра”, а второе заканчивается на “ет”: рабочий совет, но не будут найдены фразы “свет комет” или “равная опора”.
Также можно найти все вхождения любой заданной последовательности символов в тексте — для этого необходимо добавить символ ! в начале и конце строки.
Например, по запросу !дом! будут найдены вхождения этого буквосочетания в словах “дом”, “домашний”, “одомашненный” и т. д., но выделены будут именно вхождения, а не слова целиком, в отличие от режима поиска по маске с символом *.
Чтобы выделить все вхождения конкретного слова или фразы в тексте, нажмите на строку с ними в таблице совпадений. Чтобы выделить все совпадения, нажмите на строку с общим количеством совпадений.
Проверять текст можно неограниченное количество раз — после его редактирования или изменения списка слов нажмите повторно кнопку “Найти” и система покажет результаты новой проверки.
Возможности сервиса:
- поиск заданных слов и фраз (ключевых, стоп-слов);
- поиск по фразе целиком или по ее части;
- поиск необходимого слова или фразы в документе;
- поиск одинаковых и повторяющихся слов;
- поиск однокоренных слов по маске;
- поиск любых последовательностей символов;
- поиск в английском тексте и на любом языке.
Как найти что-то в тексте
Время на прочтение
8 мин
Количество просмотров 5.5K
Найти объект или распознать понятие в тексте — с этого начинается решение большинства NLP задач. Если вы проектируете поисковую систему, создаете голосового помощника или классифицируете пользовательские запросы, прежде всего вы должны разобрать входной текст и попытаться найти в нем именованные сущности, которые могут быть универсальными, такими как даты, страны и города, или специфичными для конкретной модели. Обратите внимание, мы сейчас говорим лишь о тех видах задач, для которых заранее известно, что именно вы ищете или что может встретиться в тексте.
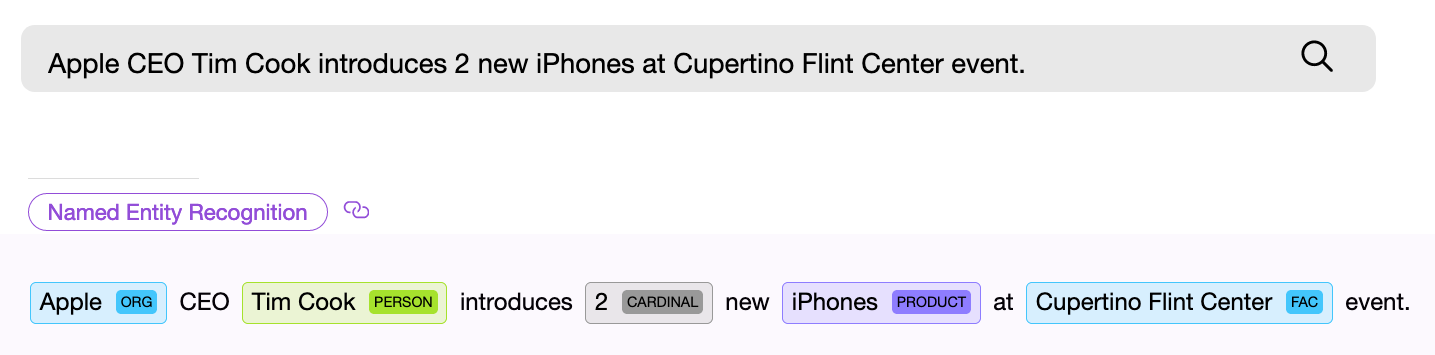
NER (named entity recognition) компонент, то есть программный компонент для поиска именованных сущностей, должен найти в тексте объект и по возможности получить из него какую-то информацию. Пример — “Дайте мне двадцать две маски”. Числовой NER компонент находит в приведенном тексте словосочетание “двадцать две” и извлекает из этих слов числовое нормализованное значение — “22”, теперь это значение можно использовать.
NER компоненты могут базироваться на нейронных сетях или работать на основе правил и каких-либо внутренних моделях. Универсальные NER компоненты часто используют второй способ.
Рассмотрим несколько готовых решений по поиску стандартных сущностей в тексте. В данной заметке мы остановимся на бесплатных или бесплатных с ограничениями библиотеках, а также расскажем о том, что сделано в проекте Apache NlpCraft в рамках данной проблематики. Представленный ниже список не является подробным и обстоятельным обзором, которых и так достаточное количество в сети, а скорее кратким описанием основных особенностей, плюсов и минусов использования этих библиотек.
Провайдеры NER компонентов
Apache OpenNlp
Apache OpenNlp предоставляет для английского языка достаточно стандартный набор NER компонентов, работающих с датами, временем, географией, организациями, числовыми процентами и персонами. Имеется небольшой набор и для других языков (испанский, голландский).
Поставка:
Java библиотека. Apache OpenNlp не поставляет модели вместе с основным проектом. Они доступны для скачивания отдельно.
Плюсы:
Apache лицензия. Модели протестированы на множестве внедрений.
Минусы:
Судя по всему, модели недаром вынесены из основного проекта. Складывается впечатление, что работа над ними или остановлена или идет в удручающе неторопливом темпе, так как новых моделей или изменений в существующих не видно уже довольно давно. Так как пользователи Apache OpenNlp могут создавать и тренировать свои собственные модели, возможно эта задача фактически полностью переложена на них.
Stanford Nlp
Stanford NLP — живой, постоянно развивающийся продукт отличного качества и широких возможностей. Для английского языка добавлена поддержка распознавания следующих сущностей: person, location, organization, misc, money, number, ordinal, percent, date, time, duration, set. Кроме того встроенный Regex NER компонент позволяет находить с высокой степенью точности такие сущности как: email, url, city, state_or_province, country, nationality, religion, (job) title, ideology, criminal_charge, cause_of_death, handle. Подробнее по ссылке. Заявлена поддержка ограниченного набора NER для немецкого, испанского и китайского языков. Качество распознавания можно попробовать с помощью онлайн демо.
Поставка:
Java библиотека. Модели можно загрузить из мавен вместе с проектом.
Я нигде не нашел перечня и детального описания NER компонентов для языков отличных от английского. По ссылкам 1, 2 — приведены примеры процесса тренировки собственных NER компонентов для разных языков. Проще говоря, возможность использовать другие языки заявлена, но придется повозиться.
Плюсы:
Ощущение от работы с проектом в целом и с готовыми моделями самое позитивное, проект живет и развивается, качество распознавания хорошее (”хорошее” — понятие условное, существуют метрики, характеризующие качество распознавания NER компонентов, но данный вопрос выходит за рамки статьи).
Минусы:
Помимо некоторого хаоса с документаций, они небольшие. Кому это важно, обратите внимание на лицензию. GNU General Public License отличается от Apache, так, например, вы не можете добавить продукт с данной лицензией в продукты, лицензируемые под Apache и т. д.
Google Language API
Google language API для английского языка поддерживает следующий список сущностей: person, location, organization, event, work_of_art, consumer_good, other, phone_number, address, date, number, price.
Платформа:
REST API, SaaS. Доступны готовые клиентские библиотеки над REST (Java, C#, Python, Go и т. д.).
Плюсы:
Большой набор NER компонентов, развитие и качество обеспечивается всем известным интернет гигантом.
Минусы:
Начиная с определенных объемов, использование платное.
Spacy
Данная библиотека предоставляет один из наиболее широких наборов поддерживаемых для распознавания сущностей, по ссылке список поддерживаемых.
Платформа:
Python.
К сожалению отсутствие личного опыта промышленного использования не позволяет мне добавить реальное описание плюсов и минусов данной библиотеки. К тому же подробный обзор питоновских NLP решений уже опубликован на habr.
Все вышеперечисленные библиотеки позволяют обучать собственные модели. Также все из них (кроме Apache OpenNlp) позволяют извлекать нормализованные значения из найденных сущностей, то есть, например, получить число “173“ из найденной в запросе числовой сущности “сто семьдесят три“.
Как мы видим вариантов решения задачи нахождения именованных сущностей представлено множество, направление их развития очевидно — расширение списка поддерживаемых языков и набора распознаваемых сущностей, улучшение качества распознавания.
Ниже описано, что привнес проект Apache NlpCraft в данную, уже широко проработанную область.
Дополнительные возможности предоставляемые NlpCraft
- Собственные NER компоненты для новых сущностей, улучшенные варианты решения для некоторых уже существующих.
- Интеграция NER компонентов всех вышеперечисленных библиотек в рамках использования продукта.
- Поддержка “составных сущностей“, что дает пользователям простую возможность создания новых собственных компонентов на основе уже имеющихся.
Теперь обо всем этом чуть подробнее.
Собственные NER компоненты
Собственные NER компоненты Apache NlpCraft — это компоненты распознавания дат, чисел, географии, координат, сортировки и сопоставления разных сущностей. Часть из них уникальна, часть — лишь улучшенная реализация существующих решений (повышена точность распознавания, добавлены дополнительные поля значений и т. д.).
Интеграция существующих решений
Все перечисленные выше решения интегрированы для использования в Apache NlpCraft.
При работе с проектом пользователю достаточно подключить нужный модуль и указать в конфигурации какие именно NER компоненты должны быть задействованы при поиске сущностей конкретной модели.
Ниже приведен пример конфигурации, для которой при поиске в тексте используется четыре различных NER компонента от двух провайдеров:
"enabledBuiltInTokens": [
"nlpcraft:num",
"nlpcraft:coordinate",
"google:organization",
"google:phone_number"
]
Подробнее об использовании Apache NlpCraft написано здесь. Для использования Google Language API необходим действующий Google developer account.
Поддержка составных сущностей
Поддержка составных сущностей — самая интересная из вышеперечисленных возможностей, остановимся на ней немного подробнее.
Составная сущность — это сущность определенная на основе другой. Рассмотрим пример. Пусть вы разрабатываете NLP систему управления, основанную на интентах (см. Alexa, Google Dialogflow, Алиса, Apache NlpСraft и т. д.), и пусть ваша модель работает с географией, но только для США. Вы можете взять любой компонент для поиска географии, например ”nlpcraft:city”, и использовать его напрямую.
Далее, при срабатывании интента, вы в соответствующей ему функции (callback), должны проверить значение поля ”country”, и если оно не удовлетворяет требуемым условиям, завершить работу функции, предотвращая ложное срабатывание. Далее вы должны вернуться к матчингу и попытаться выбрать другую, более подходящую функцию.
Что не так в данном подходе:
- Вы значительно усложняете работу с вызываемыми функциями, передавая управление из них в основной рабочий поток и обратно. Кроме того стоит учесть, что подобным функционалом передачи управления обладают далеко не все диалоговые системы.
- Вы размазываете логику матчинга между интентом и кодом исполняемого метода.
Хорошо… Вы можете с нуля создать свой собственный NER компонент по поиску американских городов, но эта задача решается не за пять минут.
Попробуем иначе. Вы можете усложнить интент (в тех системах где это возможно) и искать города, дополнительно отфильтрованные по стране. Но, повторюсь, возможность сложной фильтрации по полям элементов предоставляют далеко не все системы, кроме того вы усложняете интенты, которые должны быть максимально понятными и простыми, особенно если их много в проекте.
Apache NlpCraft предлагает механизм определения собственных NER компонентов на основе уже существующих. Ниже приведен пример конфигурации (полный синтаксис DSL доступен по ссылке, пример создания элементов — тут):
"elements": [
{
"id": "custom:city:usa",
"description": "Wrapper for USA cities",
"synonyms": [
"^^id == 'nlpcraft:city' && lowercase(~city:country) == 'usa')^^"
]
}
]
В данном примере мы описываем новую именованную сущность “американский город“ — “custom:city:usa”, основанную на уже существующей “nlpcraft:city”, отфильтрованной по определенному критерию.
Теперь вы можете создавать интенты, опирающиеся на созданный новый элемент, а встреченные в тексте города за пределами США не вызовут нежелательного срабатывания ваших интентов.
Еще пример:
"macros": [
{
"name": "<AIRPORT>",
"macro": "{airport|aerodrome|airdrome|air station}"
}
],
"elements": [
{
"id": "custom:airport:usa",
"description": "Wrapper for USA airports",
"synonyms": [
"<AIRPORT> {of|for|*} ^^id == 'nlpcraft:city' &&
lowercase(~city:country) == 'usa')^^"
]
}
]
В данном примере мы определили именованную сущность “городской аэропорт в США“ — “custom:airport:usa”. При определении этого элемента мы не только отфильтровали города по признаку принадлежности к государству, но и задали дополнительное правило, по которому названию города должен предшествовать какой-либо синоним, определяющий понятие “аэропорт”. (Подробнее о создании синонимов элементов через макросы — тут).
Составные элементы могут быть определены с любой степенью вложенности, то есть при необходимости вы можете спроектировать новые элементы на базе только что созданного “custom:airport:usa”. Также обратите внимание на то, что все нормализованные значения родительских сущностей, в данном случае базового элемента “nlpcraft:city”, доступны также в элементе “custom:airport:usa”, и могут быть использованы в теле функции сработавшего интента.
Разумеется, “составные элементы“ можно определять не только для всех поддерживаемых стандартных компонентов от OpenNlp, Stanford, Google, Spacy и NlpCraft, но и для пользовательских NER компонентов, расширяя их возможности и позволяя переиспользовать уже имеющиеся программные наработки.
Обратите внимание, фактически вы не плодите новые компоненты для каждой новой задачи, а просто конфигурируете их или “подмешиваете” их функционал в собственные элементы.
Таким образом, используя “составные сущности“ разработчик может:
- Значительно упростить логику построения интентов путем ее частичного переноса в переиспользуемые составные элементы.
- С помощью изменений конфигурации получить NER компоненты с новым поведением без обучения моделей или кодирования.
- Переиспользовать уже готовые решения с ожидаемым качеством, опираясь на существующие тесты или метрики.
Заключение
Надеюсь, что краткий обзор плюсов и минусов существующих NER компонентов будет полезен читателям, а понимание того, как с помощью Apache NlpCraft можно существенно расширить их возможности и адаптировать имеющиеся решения для новых задач, ускорит процесс разработки ваших проектов.
Открываем Google, пишем то, что нужно найти в специальную строку и жмем Enter. «Все просто, чему вы меня учить собрались», — думаете вы. Ага, не тут-то было, друзья.
После сегодняшней статьи большинство из вас поймет, что делали это неправильно. Но этот навык – один из самых важных для продуктивного сотрудника. Потому что в 2021 году дергать руководство по вопросам, которые, как оказалось, легко гуглятся, — моветон.
Ну и на форумах не даст вам упасть лицом в грязь, чего уж там.
Затягивать не будем, ниже вас ждут фишки, которые облегчат вам жизнь.
Кстати, вы замечали, что какую бы ты ни ввёл проблему в Google, это уже с кем-то было? Серьёзно, даже если ввести запрос: «Что делать, если мне кинули в лицо дикобраза?», то на каком-нибудь форуме будет сидеть мужик, который уже написал про это. Типа, у нас с женой в прошлом году была похожая ситуация.
Ваня Усович, Белорусский и российский стендап-комик и юморист
Фишка 1
Если вам нужно найти точную цитату, например, из книги, возьмите ее в кавычки. Ниже мы отыскали гениальную цитату из книги «Мастер и Маргарита».
Фишка 2
Бывает, что вы уже точно знаете, что хотите найти, но гугл цепляет что-то схожее с запросом. Это мешает и раздражает. Чтобы отсеять слова, которые вы не хотите видеть в выдаче, используйте знак «-» (минус).
Вот, например, поисковой запрос ненавистника песочного печенья:
Фишка 3
Подходит для тех, кто привык делать всё и сразу. Уже через несколько долей секунд вы научитесь вводить сразу несколько запросов.
*барабанная дробь*
Для этого нужна палочка-выручалочка «|». Например, вводите в поисковую строку «купить клавиатуру | компьютерную мышь» и получаете страницы, содержащие «купить клавиатуру» или «купить компьютерную мышь».
Совет: если вы тоже долго ищете, где находится эта кнопка, посмотрите над Enter.
Фишка 4
Выручит, если вы помните первое и последнее слово в словосочетании или предложении. А еще может помочь составить клевый заголовок. Короче, знак звездочка «*» как бы говорит гуглу: «Чувак, я не помню, какое слово должно там быть, но я надеюсь, ты справишься с задачей».
Фишка 5
Если вы хотите найти файл в конкретном формате, добавьте к запросу «filetype:» с указанием расширения файла: pdf, docx и т.д., например, нам нужно было отыскать PDF-файлы:
Фишка 6
Чтобы найти источник, в котором упоминаются сразу все ключевые слова, перед каждым словом добавьте знак «&». Слов может быть много, но чем их больше, тем сильнее сужается зона поиска.
Кстати, вы еще не захотели есть от наших примеров?
Фишка 7
Признавайтесь, что вы делаете, когда нужно найти значение слова. «ВВП что такое» или «Шерофобия это». Вот так пишете, да?
Гуглить значения слов теперь вам поможет оператор «define:». Сразу после него вбиваем интересующее нас слово и получаем результат.
— Ты сильный?!
— Я сильный!
— Ты матерый?!
— Я матерый!
— Ты даже не знаешь, что такое сдаваться?!
— Я даже не знаю, что такое «матерый»!
Фишка 8
Допустим, вам нужно найти статью не во всём Интернете, а на конкретном сайте. Для этого введите в поисковую строку «site:» и после двоеточия укажите адрес сайта и запрос. Вот так все просто.
Фишка 9
Часто заголовок полностью отображает суть статьи или материалов, которые вам нужны. Поэтому в некоторых случаях удобно пользоваться поиском по заголовку. Для этого введите «intitle:», а после него свой запрос. Получается примерно так:
Фишка 10
Чтобы расширить количество страниц в выдаче за счёт синонимов, указывайте перед запросом тильду «~». К примеру, загуглив «~cтранные имена», вы найдете сайты, где помимо слова «странные» будут и его синонимы: «необычные, невероятные, уникальные».
Ну и, конечно, не забывайте о расширенных инструментах, которые предлагает Google. Там вы можете установить точный временной промежуток для поиска, выбирать язык и даже регион, в которым был опубликован материал.
В комментариях делитесь, о каких функциях вы знали, а о каких услышали впервые 🙂
Кстати, еще больше интересных фишек в области онлайн-образования, подборки с полезными ресурсами и т.д., вы найдете в нашем Telegram-канале. Присоединяйтесь!
|
При поиске в интернете зачастую выдаются страницы с большим количеством информации. Подскажите, как быстро в тексте найти нужное слово?
Это очень просто сделать. Для поиска нужного слова или фразы на Web-странице нужно набрать на клавиатуре комбинацию клавиш Ctrl и F. Это стандартная комбинация, которая работает во многих браузерах, в редакторах документов и других программах. Появится окно поиска, в которое нужно ввести слово или фрагмент текста, который вас интересует. Нажимаем Enter. После этого браузер подсчитает количество вхождений заданного ключевого слова в текст. Если это число больше нуля, то можно будет по очереди переходить к каждому из вхождений. Все вхождения будут подсвечиваться определённым цветом в браузере (например, зелёным).
автор вопроса выбрал этот ответ лучшим Яна 2015 7 лет назад Найти слово или фразу на странице в интернете можно точно так же, как и в текстовом документе. Нажимаете сочетание Ctrl F (одинаковое для всех браузеров) – вверху появляется строка поиска. Вписываете туда текст, который нужно найти. В некоторых браузерах после этого нужно нажать “Найти” или Enter, в других поиск происходит автоматически. Результаты поиска выделяются в тексте цветом. Переходить от результата к результату поиска можно клавишей Enter или стрелками в строке поиска. Enough 6 лет назад Найти нужное слово на сайте в интернете можно с помощью строки поиска. Вызвать строку поиска текста можно сочетанием клавиш Ctrl + F. Обычно в правом верхнем углу появляется строка для ввода искомого фрагмента текста. Если слово или фраза, которую нужно найти на сайте, уже скопированы в памяти, то достаточно установить мышкой курсор в строке поиска и нажать Ctrl+V или правой клавишей мыши, потом выбрать “Вставить”. Также можно начинать вводить нужное слово по буквам. В правой части строки будет указано количество найденных вариантов. Нажимая клавишу ввода (Enter) курсор будет переходить от слова к слову (если таких вариантов найдено несколько).
Для того чтобы найти нужное слово или словосочетание на интернет странице в браузере нужно нажать клавиши на клавиатуре. Нажимаем на Ctrl+F и справа в верхней части браузера появится окно куда и вводим нужное для поиска слово. Затем нажимаем Enter и смотрим. Показаны все упоминания данного слова в тексте которые выделены другим цветом. Alexsandr82 5 лет назад Для поиска нужной фразы или слова на интернет странице можно использовать два способа: во-первых, можно использовать горячие клавиши для поиска, они задаются по умолчанию в каждом браузере(обычно для поиска используется комбинация ctrl+F, если она не срабатывает то скорее всего в вашем браузере задана другая комбинация горячих клавиш для поиска), в этом случае необходимо изучить настройки браузера (так как в разных браузерах настроить горячие клавиши нужно по разному), нужно искать пункт меню “горячие клавиши”, там вы сможете просмотреть действующие комбинации и изменить их на другие. Во-вторых, любой браузер в меню содержит возможность поиска по странице, это как раз то что нужно, если в меню браузера вы нашли этот пункт нажимайте на него, появится окно для ввода искомого текста, вводите туда то что нужно найти и нажимаете поиск. Если искомая фраза илислово встречается на странице несколько раз то сначало браузер переместит вас на то место где фраза упоминается в первые а затем при нажатии кнопки далее он будет переходить к следующему упоминанию нужного слова. MaxFer 7 лет назад Это очень просто. Обычно большинство браузеров содержит функцию “поиск на странице”. Прост ее нужно поискать в настройках или еще где-нибудь. Но есть и более удобный способ вызова поиска слов – это хитрое сочетание клавиш при открытом браузере: ctrl+”F”. То есть нажав и удерживая клавишу “ctrl” нужно нажат на клавишу “F” (видимо, потому что с нее начинается слово find – найти). Тогда откроется поле для ввода искомого слова/словосочетания. Универсальность данного сочетания клавиш заключается еще в том, что с их помощью можно искать нужные слова не только в браузерах, но и в ВОРД, ЕКСЕЛЬ, ПОВЕРПОЙНТ и др.
moreljuba 6 лет назад Раньше я тоже задавалась этим вопросом, ведь порой откроешь страничку, а там столько написано, а нужно выделить что-то конкретное и не знаешь как. Так вот для этого есть возможность использовать комбинацию клавиш “ctrl” плюс “F”. После нажатия появлется маленькая строчка, где можно вбить искомую фразу или слово и нажать на Enter. после чего все такие же комбинации будут выделены для удобства отбора цветом.
Любопытство 5 лет назад Для этого необходимо на Web-странице на клавиатуре найти Ctrl и F. Запасной вариант – F3. Нажимаем – появилось окошко поиска. Впечатываем слово, которое нас интересует, или фразу, после чего находим на клавиатуре справа слово Enter. Нажимаем. Всё. Можно искать то, что хотели. Mozgo-go 6 лет назад Искать слова, фразы, части слов, да и вообще открывать форму поиска, горячим сочетанием клавиш “ctrl-F” это уже повсеместный стандарт. Работает в любом приложении и на любой платформе. Не только на веб-страницах.
К сожалению, не во всех браузерах работает вариант для поиска слова Ctrl + F. Есть еще кнопка F3 – если вы нажмете на нее,то всегда откроется окошечко в браузере с поиском, с помощью которого можно найти нужное слово или фразу на страничке. Знаете ответ? |












