Мне бы хотелось точнее понимать значение в вопросе слова вытащить, но допустим это будет в значении вывести в консоль.
words = ['он', 'отпер', 'а', 'дверь', 'своим', 'а', 'ключом', 'и', 'вошел', 'а', 'следом', 'в']
Срез списка
list()[begin_index : end_index]. Рассматривайте end_index как условие остановки добавления элементов в срез. То есть все элементы начиная с end_index не будут добавлены в срез.
Выводим срез списка words с 0-го по 9-й элемент (индексы).
for item in words[ :10 ]:
print(item)
Аналогичная запись:
print(*words[ :10 ], sep='n')
Звездочкой мы указываем, что элементы среза мы передаем функции print как аргументы. В этом случае стандартно он разделяет их пробелом, но мы указываем разделителем символ перехода на новую строку.
Счетчик
Определяем внутри цикла, когда нам следует остановить вывод элементов.
enumerate каждым элементом возвращает кортеж (индекс элемента, элемент).
for item_index, item in enumerate(words):
if item_index == 10:
break
print(item)
Аналогичная запись:
item_index = int()
for item in words:
if item_index == 10:
break
print(item)
item_index += 1
Выпадающий список с быстрым поиском
Классический выпадающий список в ячейке листа Excel, сделанный через Данные – Проверка (Data – Validation) – простая и удобная штука, которую ежедневно применяют очень многие пользователи. Однако, у этого списка есть один весьма серьезный недостаток – в нём нет быстрого поиска по первым символам, т.е. фильтрации (отбора) только тех значений, куда введённый фрагмент входит как подстрока. Это серьезно ухудшает удобство пользования даже если в списке всего пара-тройка десятков позиций, а при нескольких сотнях убивает юзабилити напрочь.
Давайте рассмотрим как всё же реализовать подобный трюк. В качестве подопытного кролика возьмём список 250 лучших фильмов по версии IMDb:

Конечная цель – создать выпадающий список (ячейка G3), в котором можно будет быстро находить нужные фильмы, введя только жанр, год или фрагмент названия, например “гамп”.
Шаг 1. Определяем, кто нам нужен
Сначала нам нужно понять, какие из исходных ячеек нужно показывать в списке, т.е. определить содержится ли введённый в выпадающем списке текст (например, жанр “детектив”) в названии фильма. Для этого добавим слева от исходных данных еще один столбец с функцией ПОИСК (SEARCH), которая ищет заданную подстроку в тексте и выдает либо порядковый номер символа, где он был обнаружен, либо ошибку, если его там нет:

Теперь завернем нашу формулу в функцию проверки ЕЧИСЛО (ISNUMBER), которая превратит числа в логическую ИСТИНУ (TRUE), а ошибки – в ЛОЖЬ (FALSE):

Теперь сделаем так, чтобы ЛОЖЬ превратилась в 0, а вместо ИСТИНА в столбце появились последовательно возрастающие индексы-числа 1,2,3… и т.д. Это можно сделать с помощью добавления к нашей же формуле ещё парочки функций:

Здесь функция ЕСЛИ (IF) проверяет что мы имеем (ИСТИНУ или ЛОЖЬ), и
- если была ИСТИНА, то выводит максимальное значение из всех вышестоящих чисел + 1
- если была ЛОЖЬ, то выводит 0
Шаг 2. Отбираем в отдельный список
Дальше – проще. Теперь банальной функцией ВПР (VLOOKUP) просто выведём все найденные названия (я добавил столбец с порядковыми номерами для удобства):

После этого можно поиграться, вводя в жёлтую ячейку G2 разные слова и фразы и понаблюдать за тем, как наши формулы отбирают только подходящие фильмы:

Шаг 3. Создаем именованный диапазон
Теперь создадим именованный диапазон, который будет ссылаться на отобранные фильмы. Для этого выбрем на вкладке Формулы команды Диспетчер имен – Создать (Formulas – Name Manager – Create):

Имя диапазона может быть любым (например, Фильмы), а самое главное – это функция СМЕЩ (OFFSET), которая и делает всю работу. Напомню её синтаксис, если вы подзабыли:
=СМЕЩ(начальная_ячейка; сдвиг_вниз; сдвиг_вправо; высота; ширина)

У нас:
- В качестве начальной ячейки задаём первую ячейку списка отобранных элементов (E2).
- Сдвиги вниз и вправо у нас отсутствуют, т.е. равны нулю.
- Высота диапазона у нас соответствует максимальному значению индекса из столбца А.
- Ширина диапазона – 1 столбец.
Осталось сделать выпадающий список.
Шаг 4. Создаем выпадающий список
Выделим жёлтую ячейку (G2) и выберем на вкладке Данные команду Проверка данных (Data – Validation). В открывшемся окне выбрем Список (List) в поле Тип данных (Allow), а в качестве источника введем имя нашего созданного диапазона со знаком равно перед ним:

Чтобы Excel не ругался при вводе на неточное совпадение наших фраз с исходным списком, на вкладке Сообщение об ошибке (Error Alert) в этом окне нужно выключить флажок Выводить сообщение об ошибке (Show error alert):

Вот и всё. Можно жать на ОК и наслаждаться результатом:

Для пущего удобства при вводе с клавиатуры можно использовать Ctrl+Enter вместо Enter после ввода текста (так активная ячейка не уходит вниз) и сочетание клавиш Alt+стрелка вниз, чтобы развернуть выпадающий список без мыши.
P.S.
В принципе, можно было бы и не продолжать, но недавно Microsoft выкатила обновление вычислительного движка Excel, который теперь поддерживает динамические массивы и имеет специальные функции для работы с ними. Большинству пользователей они станут доступны в ближайшие месяцы, но даже если пока этих возможностей в вашем Excel нет – грех не показать как элементарно с их помощью решается наша задача.

Всё, что мы делали на Шагах 1-3 заменяется одной(!) формулой, где новая функция ФИЛЬТР (FILTER) отбирает из исходного диапазона A2:A251 только те фильмы, которые содержат заданную подстроку.
А дальше останется при создании выпадающего списка указать в качестве источника первую ячейку диапазона отобранных фильмов (C2) и добавить к ней знак #, чтобы получить ссылку на весь динамический массив:

И всё. Никаких именованных диапазонов и медленных СМЕЩ, никаких танцев с дополнительными столбцами и формулами. Песня!
Ссылки по теме
- Что такое динамические массивы в Excel
- Разбор трех основных функций динамических массивов: СОРТ, ФИЛЬТР и УНИК
- 4 способа создать выпадающий список на листе Excel
Выпадающие списки в Excel – это тема, которая интересует многих пользователей программы, ведь с помощью таких списков можно существенно облегчить ввод информации в таблицу или создать удобный интерфейс для доступа к данным. Но если выпадающий список имеет слишком много элементов, то быстро найти нужный из них становится затруднительным. В этой ситуации будет полезен выпадающий список с возможностью поиска.
Например, нужно по имени человека выводить его номер телефона.
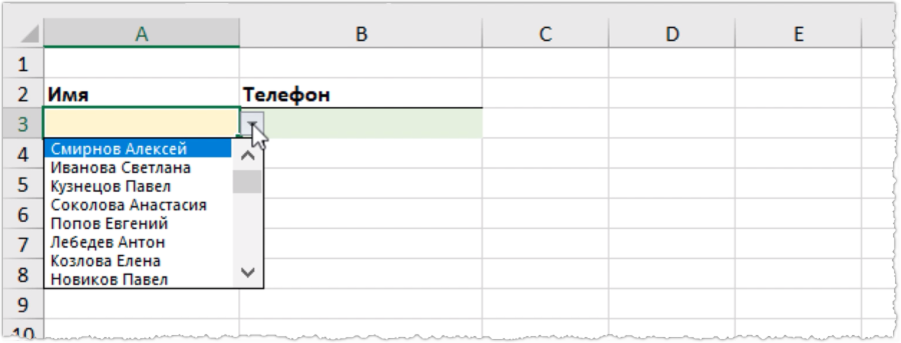
В обычном выпадающем списке будут перечислены все имена из телефонной книги (таблицы с данными) и быстро найти нужного человека не так-то просто. Однако если список имеет возможность поиска, то можно ввести какой-то набор символов и в списке отобразятся только те данные, в которых этот набор символов встречается, причем неважно в какой части.
Как и многое в Excel создать такой список можно разными способами. У каждого из них есть свои плюсы и минусы.
Excel постоянно совершенствуется и в нем появляются инструменты, которые позволяют существенно упростить ряд задач, поэтому я расскажу о двух способах создания выпадающего списка с быстрым поиском.
Файлы с примерами можно скачать здесь.
Первый вариант выпадающего списка с поиском (динамические массивы)
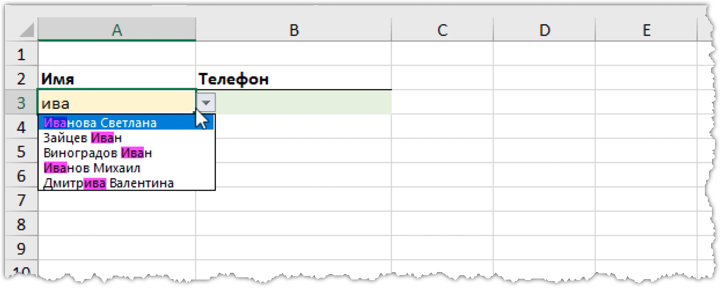
Итак, есть исходная таблица в два столбца. Первый содержит список имен, а второй телефоны. В еще одну из ячеек первой строки введем набор символов, который мы хотим найти, то есть смоделируем поисковое поле (введем “сми“).
Ниже этой ячейки мы должны сформировать список только из тех данных исходной таблицы, которые содержат введенные выше символы.
Поможет в этом функция ПОИСК (SEARCH), которая ищет заданный набор символов и выдает либо порядковый номер первого символа в тексте, либо ошибку, если символы обнаружены не были.
В качестве искомого текста указываем ссылку на ячейку выше, а искать мы будем в первой ячейке столбца с именами. Последний аргумент функции необязателен и в нашем случае указывать его не будем.
Что мы получили в итоге?
Цифра “1” указывает нам позицию введенных символов в выбранном нами тексте (строка начинается с этих символов).
Если введем «але», то получим цифру 9, которая указывает на девятую позицию. Именно девятым будет первый символ искомого текста в этом имени (пробел также учитывается).
Если же введем «ива», то получим ошибку ЗНАЧ!, которая указывает на то, что такой комбинации символов в тексте не найдено.
Так работает функция ПОИСК и нам лишь остается указать весь диапазон, на который она должна распространяться. Для этого откорректируем формулу и подставим сюда весь диапазон – выбираем первую его ячейку (А2), а затем нажимаем сочетание клавиш Ctrl + Shift + стрелка вниз. Будет выбран весь неразрывный диапазон значений. В моем случае А2:А30. Нажимаем Enter и получаем диапазон значений, который представляет собой динамический массив. На это также указывает синий контур, обрамляющий значения.
Динамические массивы в Excel появились несколько лет назад, но до сих пор они доступны лишь пользователям Microsoft Office 365 и в онлайн-версии офисного пакета. В других версиях и редакциях Excel динамических массивов пока нет и вряд ли они там появится. Скорее всего в коробочной редакции Excel их стоит ждать лишь в следующей версии офисного пакета в 22-ом году.
Тем не менее, динамические массивы и функции с ними связанные очень сильно расширяют возможности Excel и я уверен, что в дальнейшем они получат еще более широкий функционал. По этой причине, хоть данный способ пока и не универсален, но он максимально прост, удобен и в перспективе будет востребован. Поэтому я детально рассмотрю весь процесс создания выпадающего списка с помощью динамических массивов и их функций.
Итак, мы получили динамический массив. Если в его ячейках отражается любая цифра, то это означает, что искомая комбинация символов была найдена, а ошибка свидетельствует об обратном.
Фактически нас интересуют только ячейки с числами, при этом сами значения неважны. Поэтому можем переконвертировать полученные значения в формат ИСТИНА/ЛОЖЬ.
Для этого воспользуемся функцией ЕЧИСЛО (ISNUMBER) и обернем ей созданную ранее формулу. В результате если в ячейке будет находиться число, то функция выдаст ИСТИНУ, иначе ЛОЖЬ.
Осталось лишь отфильтровать значения, ведь нас интересует только ИСТИНА. Воспользуемся функцией ФИЛЬТР (FILTER), которая позволяет работать с динамическими массивами.
Обернем созданную ранее формулу функцией ФИЛЬТР.
Первый аргумент функции – массив. Укажем диапазон с именами А2:А30. Далее нужно указать то, что нужно включить в новый диапазон, а это вычисляет ранее созданная формула. В качестве третьего аргумента зададим значение, которое будет выводиться в случае отсутствия искомых символов в тексте. Например, напишем «не найдено».
Все, формула готова!
Вот так просто мы получили список из имен, которые удовлетворяют условиям поиска. Осталось лишь создать выпадающий список. Для этого откорректируем формулу и подставим в функцию ПОИСК ссылку на ячейку, в которой будет выпадающий список. В моем примере эти ячейки находятся на втором листе.
Теперь на вкладке Данные откроем окно проверки и создадим список.
В качестве источника данных укажем первую ячейку динамического массива и добавим к ней знак решетки, что позволит нам получить ссылку на весь динамический массив.
Если мы теперь введем что-то новое в поисковую строку, то получим ошибку, так как мы вводим неточное совпадение, которое отсутствует в списке.
Чтобы отключить это сообщение вновь вызовем окно проверки и на вкладке Сообщение об ошибке уберем флажок Выводить сообщение об ошибке.
Теперь при введении нового значения ошибка возникать не будет, а в выпадающем списке будут только нужные вхождения.
При работе с таким списком удобнее использовать не Enter, а сочетание Ctrl + Enter так как после ввода текста табличный курсор не будет смещаться вниз.
Осталось лишь подставить номер телефона по имени и сделать это можно различными способами, например, с помощью функции ВПР или связки функций ИНДЕКС и ПОИСКПОЗ. Однако, если уж мы говорим о динамических массивах и функциях по работе с ними, то решим эту задачу с помощью все той же функции ФИЛЬТР.
В качестве массива данных укажем диапазон с телефонами, затем напишем небольшое условие – данные из диапазона с именами должны соответствовать информации из соответствующей ячейки, в которой находится выпадающий список. Ну а третий аргумент определяет, что нужно выводить в случае отсутствия данных, укажем пустоту.
В итоге получаем нужный нам результат.
Ну и чтобы можно было автоматически расширять данные в выпадающем списке нужно преобразовать исходные данные с именами и телефонами в умную таблицу, например, с помощью сочетания клавиш Ctrl + T.
После этого вновь добавленные в таблицу данные будут автоматически “подхватываться” выпадающим списком.
Функции СОРТ (SORT) и УНИК (UNIQUE)
Ну и если уж речь зашла о динамических массивах, то нельзя не сказать о функциях СОРТ и УНИК.
Например, мы хотим, чтобы данные в выпадающем списке были отсортированы по алфавиту. Просто оборачиваем формулу функцией СОРТ и получаем результат – данные будут отсортированы в динамическом массиве, а значит и в выпадающем списке.
Ну а если данные в исходной таблице дублируются, а нужно получить только уникальные значения, то можно воспользоваться функцией УНИК. Эта функция убирает повторы и в результате мы получаем список без дубликатов.
Итак, мы получили выпадающий список с поиском в одной ячейке. Но как сделать так, чтобы его можно было использовать для заполнения данных в таблице?
Об этом в следующей заметке.
Поиск данных в списке
Поиск
необходимых данных в списке можно
осуществлять также при помощи команды
Найти
(как
в текстовом редакторе Word).
Эта команда позволяет быстро отыскать
любое сочетание символов, слов или цифр.
Предположим, нам нужно найти
номера телефонов, которые начинаются
цифрами 234. Активизируйте команду
Правка/Найти,
внесите
символы 234-
в
поле Что
диалогового
окна Найти
(рис.
15), а затем нажмите кнопку Найти
далее. Вызвать
это диалоговое окно Можно также
посредством комбинации клавиш [Сtгl
+ F].
После
ввода в поле, Что
значения
234-
вам
поочередно будут предложены к рассмотрению
все телефоны, которые начинаются этими
цифрами. Если же в данное поле
ввести слово «Иван», то будут найдены
все Иваны, Ивановы и Ивановичи.
Чтобы
заменить найденные значения, нужно
нажать кнопку Заменить
диалогового
окна Найти.
После
этого название диалогового окна изменится
с Найти
на
Заменить,
и
в нем появится дополнительное поле
ввода Заменить
на. Введите
в это
поле фрагмент данных, которыми следует
заменить фрагмент, указанный в поле
Что.
Замену
найденного фрагмента можно произвести,
нажав кнопку Заменить.
Если же все элементы в списке можно
заменить без предварительной проверки,
воспользуйтесь кнопкой Заменить
все.

Рис.
15.
Диалоговое
окно Найти
с
внесенными начальными цифрами
искомого
телефонного номера

Рис.
16.
Диалоговое
окно Заменить
с
начальными цифрами телефонного номера,
который
нужно найти, и цифрами для замены
начальных.
Диалоговое окно форма
В
Ехсеl
имеется специальное диалоговое окно
(рис. 17), которое обеспечивает удобный
способ ввода и просмотра данных в списке.
Для вызова этого окна необходимо
поместить табличный курсор в любую
ячейку списка и выполнить команду
Данные/Форма.
С
помощью встроенной формы, нажимая на
соответствующие
кнопки, вы можете вводить, редактировать
и удалять записи табличной базы
данных.
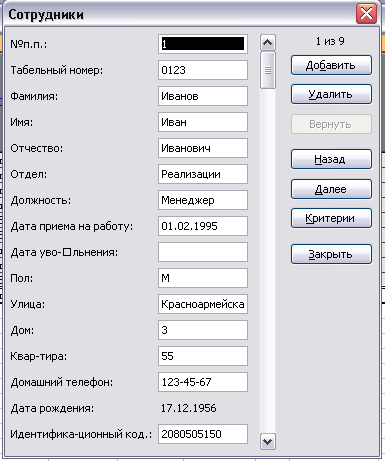
Рис.
17.
В
диалоговом окне формы отображаются
данные выбранного
Сотрудника
Изменение имени листа
По
умолчанию рабочим листам присваиваются
имена Лист1,
Лист2 и
т. д. Конечно,
такие имена никак не отражают тип
выполняемых на листе расчетов. Выработайте
привычку присваивать листам информативные
имена, иначе через некоторое
время вы просто перестанете ориентироваться
в своих данных. Что касается нашей
задачи, то давайте присвоим рабочему
листу с табличной базой данных имя
Сотрудники.
Это
можно сделать несколькими способами:
-
путем
вызова команды Формат/Лист/Переименовать; -
посредством
щелчка правой кнопкой мыши на ярлыке
листа и выбора в появившемся
контекстном меню команды Переименовать; -
двойным
щелчком мышью на ярлыке листа.
После
выполнения любого из этих действий имя
листа на ярлыке будет выделено черным
цветом, и вам останется только ввести
новое имя листа с клавиатуры.
Удаление листов
По
умолчанию новая книга содержит три
листа. Однако во многих случаях данные
занимают только один или два листа.
Кроме того, часто при расчетах приходится
применять промежуточные листы, на
которых производится отладка алгоритма
обработки данных. Когда такие листы
становятся ненужными, их следует удалить.
Лишние листы рекомендуется удалить и
накануне пересылки файла по электронной
почте.
Перейдите
на лист, подлежащий удалению, и вызовите
команду Правка/Удалить
лист
или щелкните правой кнопкой мыши на
ярлыке этого листа и выберите в контекстном
меню команду Удалить.
Ехсе1
отобразит окно с предупреждением, что
отменить операцию удаления листов
невозможно. Вы должны подтвердить свое
намерение, нажав кнопку ОК.
Чтобы
удалить несколько листов сразу, отметьте
их ярлыки мышью, удерживая нажатой
клавишу [Ctrl]
или [Shift].
При помощи клавиши [Ctrl]
можно выделить отдельные
листы, а при помощи клавиши [Shift]
— несколько листов, расположенных
рядом.
Соседние файлы в папке контрольная работа
- #
28.01.201421.5 Кб351.xls
- #
28.01.2014586.75 Кб1910.doc
- #
28.01.2014198.14 Кб2912.xls
- #
28.01.201427.14 Кб25Задача 5.xls
- #
- #
28.01.2014190.57 Кб26Информатика.ods
- #
28.01.201435.33 Кб26итог.xls
Содержание:развернуть
- Что такое список
-
Как списки хранятся в памяти?
- Базовая работа со списками
-
Объявление списка
-
Обращение к элементу списка в Python
-
Добавление в список
-
Добавление в список на указанную позицию
-
Изменение элементов списка
-
Удаление элемента из списка
-
Как проверить наличие элемента в списке
-
Объединение списков
-
Копирование списка Python
-
Цикл по списку
- Методы списков
- Вложенные списки
- Срезы
- Генераторы списков
- Best Practices
-
Как получить список в обратном порядке
-
Как перевести список в другой формат?
-
Как узнать индекс элемента в списке?
-
Как посчитать количество уникальных элементов в списке?
-
Как проверить список на пустоту?
-
Как создать список числовых элементов с шагом
Создание списка в Python может понадобиться для хранения в них коллекции объектов. Списки могут хранить объекты всех типов в одном, в отличие от массива в другом языке программирования. Также размер списка доступен к изменению.
Ниже разберёмся, как устроены списки, как с ними работать и приведём 6 примеров из практики.
Что такое список
Список (list) — тип данных, предназначенный для хранения набора или последовательности разных элементов.
[1, 33, 6, 9] # литерал списка в Python
Его можно сравнить со списком покупок для магазина: точно так же вносятся элементы, их тоже можно добавлять и корректировать.
Как списки хранятся в памяти?
Базовая C-структура списков в Python (CPython) выглядит следующим образом:
typedef struct {
PyObject_VAR_HEAD
PyObject **ob_item;
Py_ssize_t allocated;
} PyListObject;
Когда мы создаём список, в памяти под него резервируется объект, состоящий из 3-х частей:
PyObject_VAR_HEAD— заголовок;ob_item— массив указателей на элементы списка;allocated— количество выделенной памяти под элементы списка.
Объект списка хранит указатели на объекты, а не на сами объекты
Python размещает элементы списка в памяти, затем размещает указатели на эти элементы. Таким образом, список в Python — это массив указателей.
Базовая работа со списками
Объявление списка
Объявление списка — самый первый и главный этап его создания. Для объявления списка в Python существует несколько способов.
Вариант №1: Через литерал (выражение, создающее объект):
>>> elements = [1, 3, 5, 6]
>>> type(elements)
<class 'list'>
>>> print(elements)
[1, 3, 5, 6]
В данном примере мы создали список с заранее известными данными. Если нужен пустой список, в квадратных скобках ничего не указывается — elements = [].
Вариант №2: Через функцию list():
>>> elements = list()
>>> type(elements)
<class 'list'>
>>> print(elements)
[]
В этом примере создается пустой список.
Обращение к элементу списка в Python
Чтобы обратиться к элементу списка, достаточно указать его индекс:
>>> elements = [1, 2, 3, 'word']
>>> elements[3]
'word'
Индекс — это порядковый номер элемента в списке. В примере выше индексы (позиции в списке) соответственно будут: 0, 1, 2, 3.
Нумерация элементов списка в Python начинается с нуля
Существует также отрицательный индекс, рассмотрим на примере:
>>> elements = [1, 2, 3, 'word']
>>> elements[-4]
1
>>> elements[-1]
'word'
Отрицательные индексы работают справа налево (то есть индекс значения ‘1’ — -4, а отрицательный индекс ‘word’ — -1.
💡 Отрицательным индексом удобно пользоваться, когда необходимо обратиться к последнему элементу в списке, не высчитывая его номер. Любой конечный элемент будет с индексом, равным -1.
Добавление в список
В списках доступно добавление, изменение, удаление элементов. Рассмотрим каждый способ изменения элементов на примерах.
Для того чтобы добавить новый элемент в список, используется list.append(x), где list — список, x — нужное значение.
>>> elements = [1, 2, 3, 'word']
>>> elements.append('meow')
>>> print(elements)
[1, 2, 3, 'word', 'meow']
Для простого примера, рассмотрим создание списка с нуля с помощью метода append() :
>>> elements = []
>>> elements.append(1)
>>> elements.append('word')
>>> elements.append('meow')
>>> print(elements)
[1, 'word', 'meow']
Добавление в список на указанную позицию
Немаловажно обратить внимание на метод list.insert(i, x), где list — список, i — позиция, x — нужное значение.
>>> elements = [1, 2, 4]
>>> print(elements)
[1, 2, 4]
>>> elements.insert(2, 3)
>>> print(elements)
[1, 2, 3, 4]
Изменение элементов списка
Изменение элементов списка происходит следующим образом: нужно выбрать элемент по индексу (порядковому номеру элемента) и присвоить новое значение.
>>> elements = [2, 4, 6]
>>> elements[2] = 8
>>> print(elements)
[2, 4, 8]
В примере выше мы заменили 6 на 8.
Не забывайте, что счёт начинается с нуля, и в данном списке цифра 6 это 2-й элемент
Удаление элемента из списка
Для удаление из списка используют инструкцию del list[i], где list — список, i — индекс (позиция) элемента в списке:
>>> elements = [1, "test", 5, 7]
>>> del elements[1]
>>> print(elements)
[1, 5, 7]
Удалять можно как из текущего списка, так и из вложенных списков:
>>> my_list = ["hello", "world", "!"]
>>> elements = [1, my_list, "ok"]
>>> del elements[1][2]
>>> print(elements)
[1, ['hello', 'world'], 'ok']
Можно удалять целыми диапазонами:
>>> elements = [2, 4, 6, 8, 12]
>>> del elements[2:] # удаляем все элементы после 2-го элемента (включительно)
>>> print(elements)
[2, 4]
>>> elements = [2, 4, 6, 8, 12]
>>> del elements[:3] # удаляем все элементы до 3-го элемента
>>> print(elements)
[8, 12]
>>> elements = [2, 4, 6, 8, 12]
>>> del elements[1:3] # удаляем от 1-го элемента включительно до 3-го элемента
>>> print(elements)
[2, 8, 12]
Еще один способ удаления из списка — list.remove(x), где list — список, x — значение, которое нужно удалить:
>>> elements = [2, "test", 4]
>>> elements.remove("test")
>>> print(elements)
[2, 4]
Как проверить наличие элемента в списке
Для того чтобы проверить существование какого-либо элемента в списке, нужно воспользоваться оператором in. Рассмотрим на примере:
>>> elements = ['слон', 'кот', 'лошадь', 'змея', 'рыба']
>>> if 'кот' in elements:
print('meow')
meow
Объединение списков
Списки в Python можно объединять с помощью оператора + или метода extend . Выглядит это так:
>>> a = [1, 3, 5]
>>> b = [1, 2, 4, 6]
>>> print(a + b)
[1, 3, 5, 1, 2, 4, 6]
>>> hello = ["h", "e", "l", "l", "o"]
>>> world = ["w", "o", "r", "l", "d"]
>>> hello.extend(world) # extends не возвращает новый список, а дополняет текущий
>>> print(hello)
['h', 'e', 'l', 'l', 'o', 'w', 'o', 'r', 'l', 'd']
Копирование списка Python
Если вы захотите скопировать список оператором =, вы скопируете не сам список, а только его ссылку.
>>> a = [1, 2, 3]
>>> b = a # переменной b присваивается не значение списка a, а его адрес
>>> print(id(a), id(b))
56466376 56466376 # a и b ссылаются на один и тот же список
>>> b.append(4)
>>> print(a, b)
[1, 2, 3, 4] [1, 2, 3, 4]
Для копирования списков можно использовать несколько вариантов:
elements.copy()— встроенный метод copy (доступен с Python 3.3);list(elements)— через встроенную функциюlist();copy.copy(elements)— функцияcopy()из пакета copy;elements[:]— через создание среза (устаревший синтаксис).
Рассмотрим на примере каждый из этих способов:
>>> a = ["кот", "слон", "змея"]
>>> b = a.copy()
>>> print(id(a), id(b), a, b)
56467336 56467016 ['кот', 'слон', 'змея'] ['кот', 'слон', 'змея']
>>> d = list(a)
>>> print(id(a), id(d), a, d)
56467336 60493768 ['кот', 'слон', 'змея'] ['кот', 'слон', 'змея']
>>> import copy
>>> e = copy.copy(a) #
>>> print(id(a), id(e), a, e)
56467336 60491304 ['кот', 'слон', 'змея'] ['кот', 'слон', 'змея']
>>> f = copy.deepcopy(a)
>>> print(id(a), id(f), a, f)
56467336 56467400 ['кот', 'слон', 'змея'] ['кот', 'слон', 'змея']
>>> c = a[:] # устаревший синтаксис
>>> print(id(a), id(c), a, c)
56467336 60458408 ['кот', 'слон', 'змея'] ['кот', 'слон', 'змея']
Важно: copy.copy(a) делает поверхностное копирование. Объекты внутри списка будут скопированы как ссылки на них (как в случае с оператором =). Если необходимо рекурсивно копировать всех элементов в списке, используйте copy.deepcopy(a)
Скопировать часть списка можно с помощью срезов. Есть несколько вариантов использования:
>>> a = ["кот", "слон", "змея"]
>>> b = a[2:] # с 2-го элемента (включительно) до конца списка
>>> print(b)
['змея']
>>> c = a[:2] # с начала списка по 2-й элемент
>>> print(c)
['кот', 'слон']
>>> d = a[1:2] # с 1-го элемента (включительно) по 2-й элемент
>>> print(d)
['слон']
>>> a = [1, 2, 3, 4, 5, 6, 7, 8]
>>> e = a[0:8:2] # c 0-го элемента по 8-й элемент с шагом 2
>>> print(e)
[1, 3, 5, 7]
Цикл по списку
Для перебора списков в Python есть два цикла: for и while.
elements = [1, 2, 3, "meow"]
for el in elements:
print(el)
Результат выполнения:
1
2
3
meow
Попробуем построить цикл while. Он выполняется, когда есть какое-либо определённое условие:
elements = [1, 2, 3, "meow"]
elements_len = len(elements)
i = 0
while i < elements_len:
print(elements[i])
i += 1
Результат выполнения:
1
2
3
meow
Из примеров выше можем сделать вывод, что конструкция for выглядит заметно компактнее, чем while.
Методы списков
list.append(x)— позволяет добавлять элемент в конец списка;list1.extend(list2)— предназначен для сложения списков;list.insert(i, x)— служит для добавления элемента на указанную позицию(i— позиция,x— элемент);list.remove(x)— удаляет элемент из списка (только первое вхождение);list.clear()— предназначен для удаления всех элементов (после этой операции список становится пустым []);list.copy()— служит для копирования списков.list.count(x)— посчитает количество элементовxв списке;list.index(x)— вернет позицию первого найденного элементаxв списке;list.pop(i)— удалит элемент из позицииi;list.reverse()— меняет порядок элементов в списке на противоположный;list.sort()— сортирует список.
Пример использования методов:
# append
>>> a = [1, 2, 3]
>>> a.append(4)
print(a)
[1, 2, 3, 4]
# extend
>>> elements = [1, 2, 3, "meow"]
>>> elements.extend([4, 5, "gaf"])
>>> print(elements)
[1, 2, 3, 'meow', 4, 5, 'gaf']
# insert
>>> a = [1, 3, 4]
>>> a.insert(1, 2) # insert добавит на позицию 1 цифру 2
>>> print(a)
[1, 2, 3, 4]
# remove
>>> elements = [1, "meow", 3, "meow"]
>>> elements.remove("meow") # remove удалит только первое вхождение
>>> print(elements)
[1, 3, 'meow']
# clear
>>> a = [1, 2, 3]
>>> a.clear()
>>> print(a)
[]
# copy
>>> a = [1, 2, 3]
>>> b = a.copy()
>>> print(id(a), id(b), a, b)
60458408 60491880 [1, 2, 3] [1, 2, 3]
# count
>>> elements = ["one", "two", "three", "one", "two", "one"]
>>> print(elements.count("one"))
3
# index
>>> elements = ["one", "two", "three", "one", "two", "three"]
>>> print(elements.index("three")) # index вернет первый найденный индекс
2
# pop (положительный индекс)
>>> elements = [1, "meow", 3, "wow"]
>>> elements.pop(1) # удаляет элемент с индексом 1
'meow' # pop возвращает удаленный элемент списка
>>> print(elements)
[1, 3, 'wow']
# pop (отрицательный индекс) [удаление с конца списка, начиная с -1]
elements = ["hello", "world", "!"]
elements.pop(-2)
'world'
>>> print(elements)
['hello', '!']
# pop (без индекса) [удалит из списка последний элемент]
>>> elements = [1, 2, 3]
>>> elements.pop() # по умолчанию, в методе pop индекс равен -1
3
>>> print(elements)
[1, 2]
# reverse
>>> a = [1, 2, 3]
>>> a.reverse()
>>> print(a)
[3, 2, 1]
# sort (по возрастанию)
>>> elements = [3, 19, 0, 3, 102, 3, 1]
>>> elements.sort()
>>> print(elements)
[0, 1, 3, 3, 3, 19, 102]
# sort (по убыванию)
>>> elements = [3, 19, 0, 3, 102, 3, 1]
>>> elements.sort(reverse = True)
>>> print(elements)
[102, 19, 3, 3, 3, 1, 0]
Вложенные списки
Список может содержать объекты разных типов: числовые, буквенные, а также списки. Список списков выглядит следующим образом:
>>> elements = [1, 2, [0.1, 0.2, 0.3]]
Для обращения к элементу вложенного списка нужно использовать два индекса: первый указывает на индекс главного списка, второй — индекс элемента во вложенном списке. Вот пример:
>>> elements = [["яблоки", 50], ["апельсины", 190], ["груши", 100]]
>>> print(elements[0])
['яблоки', 50]
>>> print(elements[1][0])
апельсины
Срезы
Срезы (slices) — это подмножества элементов списка. Срезу нужны, когда необходимо извлечь часть списка из полного списка.
У них есть свой собственный синтаксис. Записывается срез так же, как обращение к элементу, используя индекс. Пример:
elements[START:STOP:STEP]
В этом случае берётся срез от номера start (включительно) до stop (не включая его), а step — это шаг. По умолчанию start и stop равны 0, step равен 1.
>>> elements = [0.1, 0.2, 1, 2, 3, 4, 0.3, 0.4]
>>> int_elements = elements[2:6] # с 2-го элемента включительно по 6-й элемент
>>> print(id(elements), id(int_elements)) # elements и int_elements - 2 разных списка
53219112 53183848
>>> print(elements)
[0.1, 0.2, 1, 2, 3, 4, 0.3, 0.4] # срез не модифицирует исходный список
>>> print(int_elements)
[1, 2, 3, 4]
Генераторы списков
Генератором списка называется способ построения списка с применением выражения к каждому элементу, входящему в последовательность. Есть схожесть генератора списка и цикла for. На этом примере мы рассмотрим простейший генератор списков:
>>> c = [c * 3 for c in 'list']
>>> print(c)
['lll', 'iii', 'sss', 'ttt']
Таким образом мы получили отдельно взятые утроенные буквы слова, введённого в кавычки. Есть множество вариантов применения генератора списков.
Пример генератора списка:
>>> nums = [i for i in range(1, 15)]
>>> print(nums)
[1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14]
Пример посложнее:
>>> c = [c + d for c in 'list' if c != 'i' for d in 'spam' if d != 'a']
>>> print(c)
['ls', 'lp', 'lm', 'ss', 'sp', 'sm', 'ts', 'tp', 'tm']
Это усложнённая конструкция генератора списков, в которой мы сделали все возможные наборы сочетаний букв из введённых слов. Буквы-исключения видны по циклу, где стоит знак != для одной переменной и другой.
Best Practices
Последние абзацы статьи будут посвящены лучшим решениям практических задач, с которыми так или иначе сталкивается Python-разработчик.
Как получить список в обратном порядке
Изменить порядок размещения элементов в списке помогает функция list.reverse():
>>> elements = [1, 2, 3, 4, 5, 6]
>>> elements.reverse()
>>> print(elements)
[6, 5, 4, 3, 2, 1]
Как перевести список в другой формат?
Иногда требуется перевести список в строку, в словарь или в JSON. Для этого нужно будет вывести список без скобок.
Перевод списка в строку осуществляется с помощью функции join(). На примере это выглядит так:
>>> fruits = ["яблоко", "груша", "ананас"]
>>> print(', '.join(fruits))
яблоко, груша, ананас
В данном случае в качестве разделителя используется запятая.
Словарь в Python — это такая же встроенная структура данных, наряду со списком. Преобразование списка в словарь — задача тоже несложная. Для этого потребуется воспользоваться функцией dict(). Вот пример преобразования:
>>> elements = [['1', 'a'],['2', 'b'],['3', 'c']]
>>> my_dict = dict(elements)
>>> print(my_dict)
{'1': 'a', '2': 'b', '3': 'c'}
JSON — это JavaScript Object Notation. В Python находится встроенный модуль json для кодирования и декодирования данных JSON. С применением метода json.dumps(x) можно запросто преобразовать список в строку JSON.
>>> import json
>>> json.dumps(['word', 'eye', 'ear'])
'["word", "eye", "ear"]'
Как узнать индекс элемента в списке?
Узнать позицию элемента в последовательности списка бывает необходимым, когда элементов много, вручную их не сосчитать, и нужно обращение по индексу. Для того чтобы узнать индекс элемента, используют функцию list.index(x).
>>> elements = [1, 3, 6, 9, 55]
>>> print(elements.index(9))
3
В качестве аргумента передаем значение, а на выходе получаем его индекс.
Как посчитать количество уникальных элементов в списке?
Самый простой способ — приведение списка к set (множеству). После этого останутся только уникальные элементы, которые мы посчитаем функцией len():
>>> words = ["one", "two", "one", "three", "one"]
>>> len(set(words))
3
Как проверить список на пустоту?
>>> a = []
>>> if not a:
print("список пуст!")
список пуст!
Как создать список числовых элементов с шагом
Создание списка числовых элементов с шагом может понадобиться не так и часто, но мы рассмотрим пример построения такого списка.
Шагом называется переход от одного элемента к другому. Если шаг отрицательный, произойдёт реверс массива, то есть отсчёт пойдёт справа налево. Вот так выглядит список с шагом.
>>> elements = [1, 2, 3, 4, 5, 8, 9, 10, 11, 14, 20]
>>> print(elements[0:11:2])
[1, 3, 5, 9, 11, 20]
Еще один вариант — воспользоваться генератором списков:
>>> elements = [c for c in range(0, 10, 2)] # от 0 (включительно) до 10 с шагом 2
>>> print(elements)
[0, 2, 4, 6, 8]
При разработке на языке Python, списки встречаются довольно часто. Знание основ работы со списками поможет быстро и качественно писать программный код 😉.
