В этом уроке по подготовке к ЕГЭ по информатике 2022 разберём задание номер 10.
Это задание, как и предыдущее, решается с помощью компьютера. Нужно будет провести поиск в тексте по определённому критерию и ответить на поставленный вопрос.
Информационный поиск нужно сделать с помощью текстового редактора. Мы в наших задачах будем использовать текстовый редактор Word от компании Microsoft.
Задача (Классическая)
С помощью текстового редактора определите, сколько раз встречается слово «рад» или «Рад» в тексте А.С. Пушкина «Руслан и Людмила».Такие слова как «радостный», «радость» и т.д., учитывать не следует. В ответе укажите только
число.
Решение:
После открытия файла нужно открыть окно “Расширенный поиск“.
На вкладке “Главная” находится кнопка “Найти“. Кликаем по чёрному треугольнику возле этой кнопки и выбираем “Расширенный поиск“.
")
Далее, нажимаем кнопку “Больше>>“.
")
Теперь у нас есть все инструменты, чтобы решить 10 задание из ЕГЭ по информатике 2022.
В поле “Найти” пишем наше слово “рад”.
")
Рассмотрим некоторые параметры, которые присутствуют в этом окне.
Учитывать регистр. Если не ставить эту галочку, то программа будет игнорировать регистр. Т.е. не важно, как мы написали в строке поиске, программа будет искать слова с большими буквами и с маленькими буквами. Нам в этой задаче не нужно ставить эту галочку.
Только слово целом. Если поставить эту галочку, то программа будет игнорировать слова, куда наше искомое слово входит. Это то, что нам нужно в этой задаче. Поставим галочку в этой задаче.
После того, как мы сделали нужные настройки нажимаем на кнопку “Найти в” (В некоторых версиях Word эта кнопка может называться “Область поиска” или как-то ещё.) и нажимаем “Основной документ“.
")
После того, как мы это сделаем, нам программа напишет ответ к нашей задаче.
![]()
Ответ: 2.
Ещё одна задача при подготовке к 10 заданию ЕГЭ по информатике 2022.
Задача (Разные падежи)
Определите, сколько раз в тексте произведения А. С. Пушкина «Капитанская дочка» встречается имя Емельян в любом падеже.
Источник задачи: https://inf-ege.sdamgia.ru/
Решение:
Вобьём в строку поиска слово Емельян. Будем нажимать на кнопку Найти далее и по очереди проверим каждый случай.
Первый случай не подходит, т.к. это слово находится в аннотации до основного произведения А.С. Пушкина. Нас просили найти именно слова, которые в тексте самого произведения.
Остальные случаи подходят. Всего получается два слова.
Ответ: 2
Ещё один пример из примерных задач ЕГЭ по информатике 2022, где мы составим маску для поиска.
Задача (Маска поиска)
С помощью текстового редактора определите, сколько раз, не считая сносок, встречается слово, которое начинается на букву “С” или на “с” в предложенном файле. Предлог “C” или “с” учитывать не нужно. В ответе укажите только число.
Решение:
Эту задачу можно решить с помощью “Подстановочных знаков“, чтобы можно было использовать маску (шаблон).
Ставим галочку “Подстановочные знаки”.
Основные правила для составления маски в программе Word:
| Спец. знаки | Что обозначают | Пример строки поиска | Что будет находить |
| ? | Один любой символ | р?к | рак, рок, рик, рык и т.д. |
| * | Любое число любых символов | р*к | риск, рок, ребёнок и т.д. |
| [] | Один из указанных символов | б[аоу]к | бак, бок, бук |
| [-] | Один символ из диапазона. Диапазон должен быть указан в порядке возрастания кодов символов. |
[а-яё] | Любая строчная русская буква |
| [А-ЯЁ] | Любая прописная русская буква |
||
| [0-9] | Любая цифра буква |
||
| [!] | Один любой символ не указанный после восклицательного знака |
б[!ы]к | бак, бок и т. п., но не бык |
| [!x-z] | Один любой символ, не входящий в диапазон указанный после восклицательного знака | [!а-яё]ок | Бок, Док и т. п., но не бок, док |
| [!0-9] | Любой символ кроме цифр | ||
| {n} | Строго n штук предыдущего символа или выражения. Выражением является все то, что заключено в круглые скобки. Выражение может состоять как из конкретных символов, так и содержать спец. знаки. |
10{3} | 1000, но не 100, 10000 |
| 10(20){2} | 102020, но не 1020, 10202020 |
||
| {n;} | n и более штук предыдущего символа или выражения |
10{3;} | 1000, 10000, 100000 и т. д., но не 100 |
| {n;m} | От n до m штук предыдущего символа или выражения |
10{3;4} | 1000, 10000, но не 100, 100000 |
| @ | Один или более штук предыдущего символа или выражения |
10@ | 10, 100, 1000, 10000 и т. д. |
| < | Начало слова | <бок | боксер, но не колобок |
| > | Конец слова | бок> | колобок, но не боксер |
Сначала в поле “Найти” в нашей задаче нужно написать следующую маску:
<[Сс][а-яё]@>
Знак “<” обозначает начало слова. Затем должна идти большая или маленькая буква “С”, затем должна идти хотя бы одна маленькая буква русского алфавита. Знак “>” обозначает конец слова.
В этой задачке нужно игнорировать сноски, поэтому нажмём “Найти в” -> “Основной документ“. Это даст возможность не искать в сносках.
")
Нашлось 287 слов.
Ответ: 287
Счастливых экзаменов!
С подстановочными знаками можно поэкспериментировать. Все они перечислены на странице поддержки MS Office в разделе о работе с Word.
Если ввести в форму поиска пять вопросительных знаков “?????”, то система выдаст очень плачевную картину, потому что во-первых, без указания границ слова результат выделит слова с этими пятью знаками в середине слова и во-вторых, среди вопросительных знаков могут быть пробелы. Даже если по краям установить угловые скобки “<?????>”, то избежать попадания пробела в середину слова не удастся. Так что поиск с вопросительными знаками отметаем.
Тогда нужно брать подстановочные знаки.
Границы слова отметить нужно обязательно – “<” и “>”. Далее можно попробовать ввести любой символ в диапазоне от “а” до “я” пять раз. Получим вот такую формулу: “<[а-я][а-я][а-я][а-я][а-я]>”.
Есть и более экономичный вариант, если указать количество символов (кроме пробелов) после заданного знака с помощью фигурных скобок. А этот заданный знак в диапазоне от “а” до “я”. (Если указать просто знак, то количество этих повторяющихся знаков будет 5 и нет гарантий, что в тексте есть слово с одинаковыми пятью буквами). И не забудем про границы слова
Итак, формула – “<[а-я]{5}>”. Количество букв в слове будет равно 5, а буква может быть любой в диапазоне от “а” до “я”.
У Word есть мощные возможности поиска, которые позволяют искать вам текст, числа, форматы, параграфы, разрывы страниц, использовать подстановочные символы, коды полей и многое другое. Используя подстановочные символы, вы можете искать просто всё что угодно в вашем документе. Поскольку функция поиска совмещена с заменой, то вы можете также выполнять весьма замысловатые преобразования текста.
Прежде чем мы приступим, поясню пару терминов, которые могут быть не совсем понятными для вас.
Регулярное выражение — это условное обозначение критериев, которым должна соответствовать искомая строка. С помощью регулярных выражений можно найти множество строк или слов, соответствующих заданным условиям.
Подстановочные символы (wildcards) — это * (звёздочка), . (точка) и ? (знак вопроса), которые имеют в регулярных выражениях специальное значение. Например, символ * (звёздочка) обозначает любое количество любых символов, а ? (знак вопроса) означает любой один символ.
Давайте начнём знакомство с продвинутыми возможностями поиска в Word!
Как использовать подстановочные символы в продвинутом поиске
В ленте Word переключитесь на вкладку «Главная» и нажмите кнопку «Заменить»:

В окне «Найти и заменить» кликните «Больше >>», чтобы развернуть диалоговое окно и увидеть дополнительные опции. Если вы увидели кнопку «<< Меньше», значит всё прошло удачно.
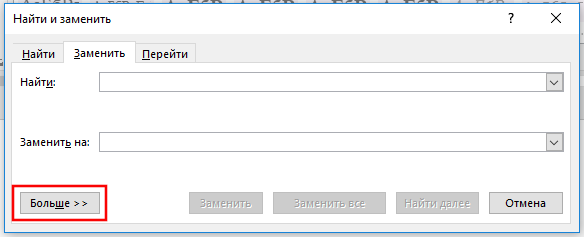
В раскрывшемся окне для показа опций поиска, включите флажок «Подстановочные знаки».

Обратите внимание, что после того, как вы включили опцию «Подстановочные знаки», Word сразу под полем «Найти:» показывает, что эта опция включена. Также когда выбран флажок «Подстановочные знаки», некоторые опции становятся недоступными для включения, а именно: «Учитывать регистр», «Только слово целиком», «Учитывать префикс», «Учитывать суффикс».
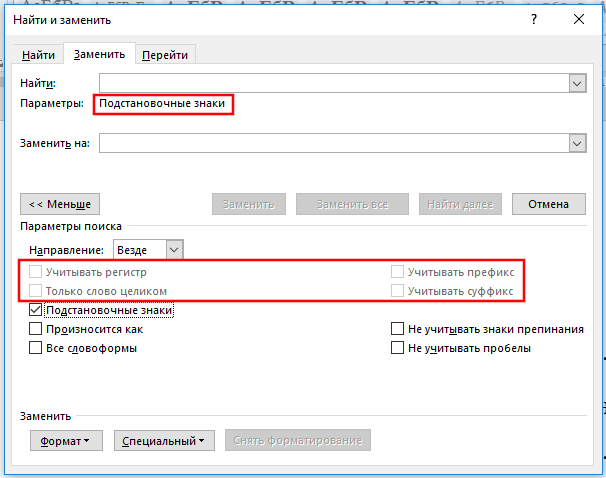
Теперь нажмите кнопку «Специальный» для просмотра списка подстановочных знаков.
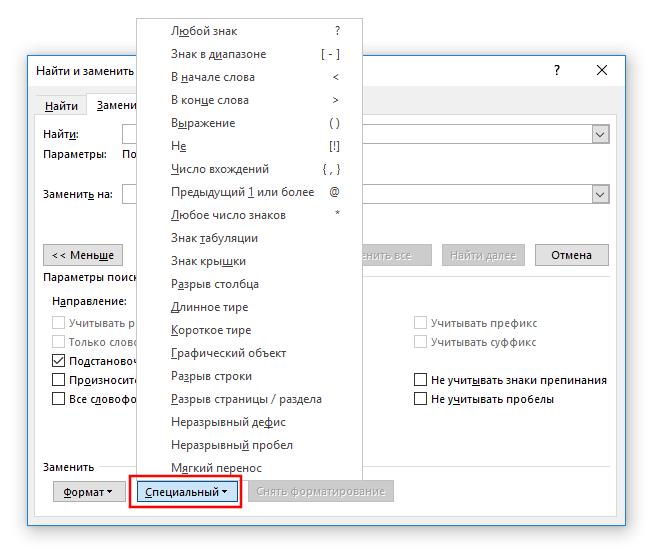
В Word доступны следующие подстановочные символы:
| Символ | Значение |
|---|---|
| ? | Любой знак |
| [-] | Символ в диапазоне |
| < | В начале слова |
| > | В конце слова |
| () | Выражение – единая последовательность символов. Также применяется для обратных ссылок |
| [!] | Не |
| {;} | Число вхождений |
| @ | Предыдущий 1 или более |
| * | Любое число знаков |
| ^t | Знак табуляции |
| ^^ | Знак крышки |
| ^n | Знак столбца |
| ^+ | Длинное тире |
| ^= | Короткое тире |
| ^g | Графический объект |
| ^l | Разрыв строки |
| ^m | Разрыв страницы / раздела |
| ^~ | Неразрывный дефис |
| ^s | Неразрывный пробел |
| ^- | Мягкий перенос |
Наконец выберите подстановочный символ для вставки в ваши критерии поиска. После выбора подстановочного знака, символ добавляется в строку поиска. Когда запомните значения, вы также можете использовать клавиатуру для ввода символов вместо вставки их путём выбора из списка. Меню «Специальный» работает как справка в случае если вы не помните, какие доступны специальные символы и их значения.
Готовые увидеть как работают подстановочные символы? Давайте ознакомимся с конкретными примерами использования регулярных выражений и подстановочных символов в Word.
Для чего используются подстановочные символы?
В меню «Специальный» содержит много специальных символов, которые вы можете использовать для поиска по документу Word, но на самом деле не все они являются подстановочными символами. Большинство из них нужны для поиска каких-то специфичных и, иногда, скрытых символов Word, таких как пробелы, разного вида тире, разрывы страницы.
Здесь мы заострим внимание в первую очередь на подстановочных знаках, которые означают один или более символов текста или модифицируют поиск на основе другого символа в вашем поиске.
Использование звёздочки для указания любого количества символов
Скорее всего, самым часто используемым подстановочным символом для вас станет звёздочка. Она означает, что вы хотите найти любое количество символов. Например, чтобы найти все слова, начинающиеся с «отм», напечатайте «отм*» в строке поиска и затем кликните кнопку «Найти далее». Наше регулярное выражение означает любое количество букв (* звёздочка), следующих после «отм».
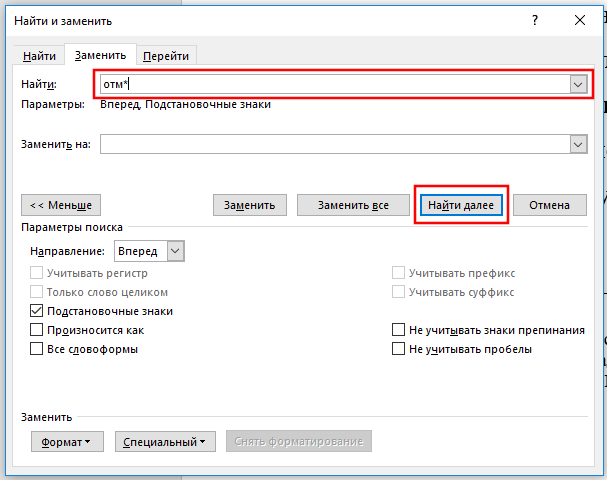
В качестве альтернативы ввода символа звёздочки с клавиатуры, вы можете использовать выбор специального символа из списка подстановочных знаком. Вначале наберите «отм» в строке «Найти». Поставьте галочку «Подстановочные знаки». Затем кликните кнопку «Специальный» и выберите «Любое число символов». После этого нажмите кнопку «Найти далее»:
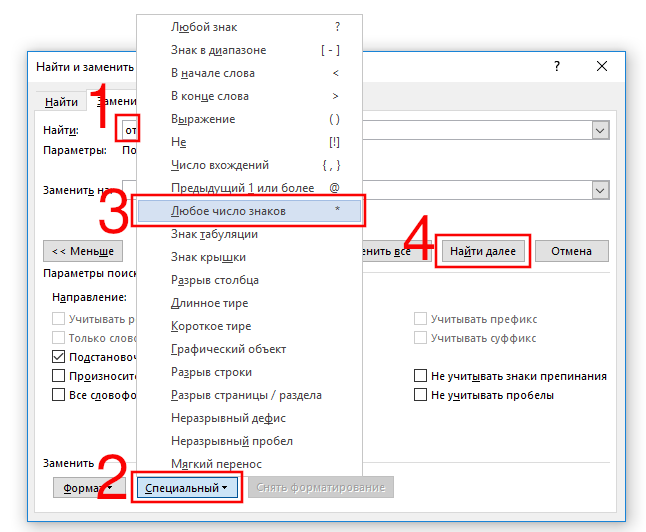
Word оценивает поиск и показывает вам первое вхождение, которое он найдёт в документе. Продолжайте кликать «Найти далее», чтобы найти все части текста, которые соответствуют вашему поисковому термину.
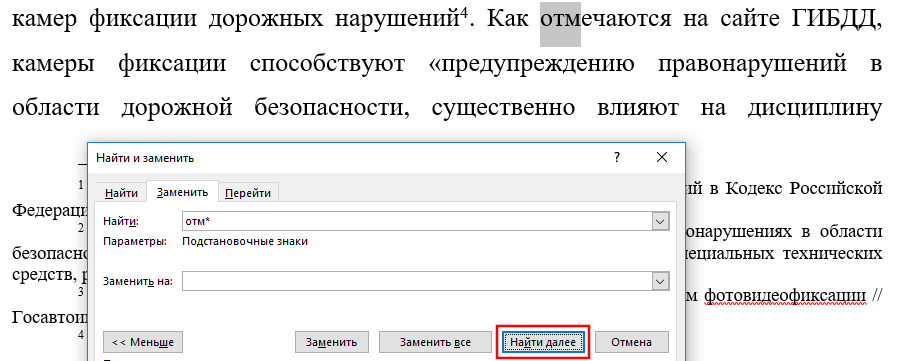
Вы должны помнить важную вещь: при включении подстановочных знаков, поиск автоматически становится чувствительным к регистру (такова особенность регулярных выражений, частью которых являются подстановочные символы). Поэтому поиск «отм*» и «Отм*» даст различные результаты.
Использование знака вопроса для поиска определённого количества символов
В то время как звёздочка означает любое количество символов, знак вопроса в регулярном выражении означает единичный (один) символ. Например, если «отм*» будет искать строки начинающиеся с «отм» за которыми идёт любое количество символов, то «отм?» будет искать строки, начинающиеся с «отм», за которой идёт только один символ.
Как и звёздочку, знак вопроса можно использовать в любой части слова — в том числе в начале и в середине.
Также можно использовать вместе несколько знаков вопроса вместе, тогда они будут обозначать несколько букв.
Например, регулярное выражение для поиска «о?о?о» оно означает букву «о», за которой идёт любой символ, затем снова идёт буква «о», затем опять любой символ и затем опять буква «о» найдёт следующие слова:
- потоков
- многополосных
- многополосных
- которое
- правового
- такового
- такого основания
Можно найти слова с четырьмя буквами «о», шаблон «о?о?о?о»:
- которого
- многополосных
Или с тремя буквами «а», шаблон «а?а?а»:
- наказания
- задача
- аппарата
- высказана
- началах
Необязательно использовать одинаковые буквы — составляйте выражения под ваши задачи.
Например, чтобы найти слова, в которых первая буква «з», затем идёт любой другой символ, а затем буква «к» и вновь любой символ, шаблон для поиска «з?к?» найдёт:
- закономерности
- законодательно
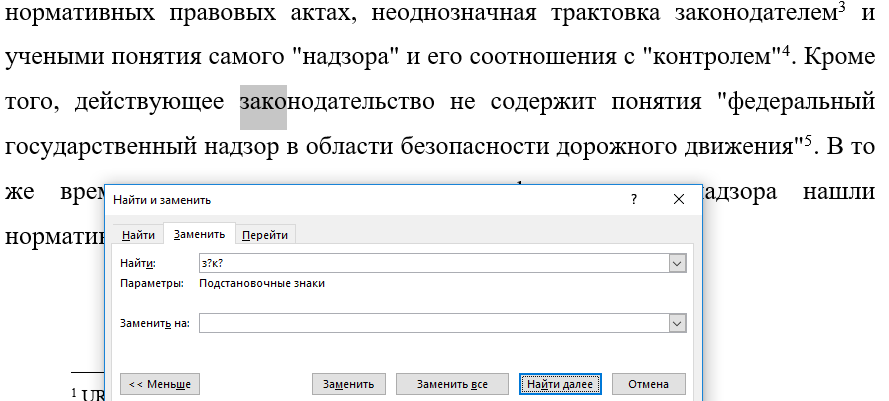
Использование знака собачка (@) и фигурных скобок ({ and}) для поиска вхождений предыдущего символа
Вы можете использовать знак собачка (@) для указания одного или более вхождения предыдущего символа. Например, «ro@t» найдёт все слова, которые начинаются на «ro» и заканчиваются на «t» и которые имеют любое количество букв «o» между этими частями. Поэтому по этим условиям поиска будут найдены слова «rot», «root» и даже «roooooot».
Для большего контроля поиска предыдущих символов, вы можете использовать фигурные скобки, внутри которые укажите точное число вхождений предыдущего символа, который вы хотите найти. Например, поиск «ro{2}t» найдёт «root», но не найдёт «rot» или «roooooot».
Также поддерживает синтаксис вида {n;} – означает искать количество вхождений символа более n раз; {;m} – означает искать количество вхождений символа менее m раз; {n;m} – означает искать количество вхождений символа более n раз, но менее m раз.
Чтобы показать более практический пример, немного забежим вперёд, следующий поиск использует набор символов (будут рассмотрены в этой статье чуть ниже), в результате, будут найдены все слова, в которых подряд идут четыре согласных буквы:
[бвгджзйклмнпрстфхцчшщ]{4}
Использование угловых скобок (< и >) для обозначения начала и конца слова
Думаю, вы заметили, особенно когда составляли поисковые запросы со звёздочкой, что пробел считается за обычный символ и могут быть найдены довольно неожиданные фрагменты большого размера, либо фрагменты, состоящие из двух слов. Вы можете использовать угловые скобки (символы «больше чем» и «меньше чем») для обозначения начала и конца слова поиска. Например, вы можете искать «<но>» и Word найдёт все вхождения «но», но не найдёт слова вроде «новости», «законодатель».
Это довольно полезно, но эта техника становится более мощной, когда вы комбинируете её с другими подстановочными символами. Например, с помощью «<з????>» вы можете найти все слова, которые начинаются на «з» и состоят ровно из пяти букв.
Вам необязательно использовать обе угловые скобки в паре. Вы можете обозначить просто только начало или конец слова, используя только одну соответствующую скобку. Например «ство>» найдёт слова
- руководство
- множество
- средство
- количество
Использование квадратных скобок ([ и ]) для поиска определённых символов или диапазонов символов
Вы можете использовать квадратные скобки для указания любых символов или диапазонов символов. Например «[а]» будет искать любые вхождения буквы «а».
В следующем примере, будет искаться строка, которая начинается на «р», затем идёт любая гласная, а затем снова буква «р»: «р[аеиоуэюя]р»
Далее аналогичный пример, но между буквами «р» должно быть две любых гласных: «р[аеиоуэюя]{2}р», будет найдено, к примеру, слово «приоритет».
Вы также можете искать квадратные скобки для поиска диапазонов символов, например «[a-z]» найдёт любую из этих букв в нижнем регистре. Поиск «[0-9]» найдёт любую из этих цифр.
Пример р[а-и]{2}р найдёт строку, которая начинается и заканчивается на букву «р» между которыми две любые буквы из указанного диапазона.
Следующий пример довольно сложный, но при этом и довольно интересный:
[А-Я]{1}[а-я0-9 ,-]{1;}.

В начале строки должна стоят любая заглавная буква ([А-Я]) ровно один раз ({1}). Затем должны идти маленькие буквы, цифры, пробелы, запятые и тире ([а-я0-9 ,-]) хотя бы один раз и более ({1;}), в самом конце должна стоять точка (.)
Думаю вы догадались, что это регулярное выражение которое будет искать предложения. Перечислены не все возможные символы, поэтому не будут найдены предложения, содержащие кавычки и некоторые другие символы, а также вопросительные и восклицательные предложения.
То есть вы можете комбинировать подстановочные символы и дополнять их кванторами количества, а затем это всё комбинировать любое количество раз, пока не получите желаемый результат. На самом деле, это довольно сложно — почти как программирование, поскольку требует абстрактного мышления.
Использование скобок для группировки поисковых терминов в последовательности
Вы можете использовать круглые скобки в вашем поиске для группировки последовательностей символов.
Можно использовать довольно простые шаблоны, например «(го){3;}» найдёт строки, в которых «го» встречается три и более раза подряд.
Но настоящую силу эта конструкция покажет при использовании в операциях поиска и замены.
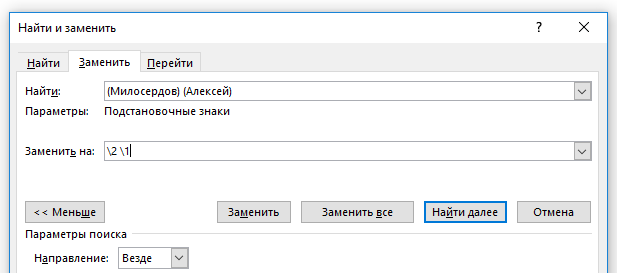
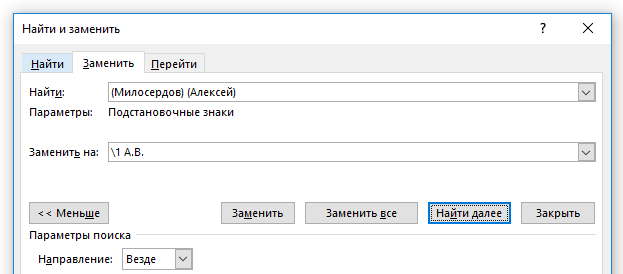
Показанная далее техника называется «обратные ссылки». Начнём с конкретного примера, чтобы было проще понять. Предположим, нам нужно во всём документе поменять местами два слова, допустим, имя и фамилию. К примеру, во всём тексте множество раз упоминается «Милосердов Алексей», а нам нужно, чтобы было «Алексей Милосердов».
Для этого в строке поиска мы вставляем «(Милосердов) (Алексей)», а в строке «Заменить на» пишем «2 1».
Скобки не участвуют в поиске, то есть в результате будет искаться фраза «Милосердов Алексей» При этом то, что было найдено в первых скобках, будет присвоено как значение «1», а то, что было найдено во вторых скобках, станет значением «2». При этом найденная строка заменится на «Алексей Милосердов».
Можно сделать по-другому, допустим вместо фамилии и имени, я хочу заменить на фамилию и инициалы, тогда в строке поиска я ищу «(Милосердов) (Алексей)», а в строке «Заменить на» пишу «1 А.В.».
В скобках можно писать не только слова, там могут использоваться подстановочные символы в разных сочетаниях, а также кванторы количества. Когда находится целая фраза, то Word автоматически пронумеровывает эти группы слева направо (это происходит «под капотом» – мы это не видим), поэтому в поле «Заменить на» мы можем использовать эти группы по их номеру, перед которым нужно поставить обратный слэш.
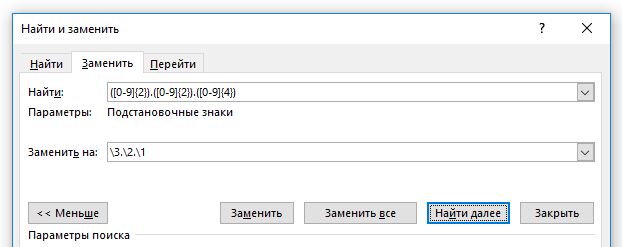
Рассмотрим более жизненный пример. Допустим, у нас по всему документу имеются даты вида 31.12.2019 (то есть в формате день.месяц.год), а мы хотим чтобы все эти даты были в формате 2019.12.31 (то есть год.месяц.день).
Тогда для поиска любых дат составляем регулярное выражение с подстановочными символами:
«[0-9]{2}.[0-9]{2}.[0-9]{4}»
«[0-9]» – это диапазон, обозначающий все цифры, «{2}» – это квантор количества, который говорит, что предыдущий символ должен встречаться ровно два раза. То есть будет искаться строка длиной ровно два символа, состоящая из цифр. Затем идёт точка, затем снова аналогичная строка и точка, и в конце строка из четырёх цифр.
Строка подходит для поиска, но чтобы были созданы обратные ссылки, мы заключаем нужные нам элементы в круглые скобки: «([0-9]{2}).([0-9]{2}).([0-9]{4})» – она будет работать точно также, как и предыдущая.
Теперь составляем строку «Заменить на». В начале идёт год, то есть третья группа, она обозначается как «3», затем точка, затем вторая группа, затем опять точка и затем первая группа, получаем «3.2.1».
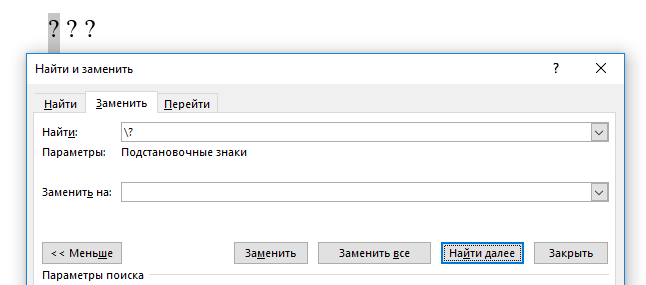
Используйте обратный слэш () если вам нужно искать символы, которые являются подстановочными знаками
А что если вам нужно найти в документе символ, который используется как подстановочный? Например, если вам нужно найти звёздочку? Если просто её вставите, то она сработает как подстановочный знак и будет найдено всё что угодно. Есть два способа искать символы в их буквальном значении.
Первый способ, это снять галочку с опции «Подстановочные знаки» перед выполнением поиска. Но если вы не хотите это делать, вы можете использовать обратный слэш () перед этим символом. Например, чтобы найти буквальный знак вопроса при включённых «Подстановочных знаках», введите в поле Поиск «?».
Заключение
Вы можете делать весьма сложные поиски и замены комбинируя подстановочные символы в ваших поисках в Word, поэтому продолжайте пробовать с ними. После того, как вы действительно разберётесь, какой потенциал несут регулярные выражения, вы сможете увеличить вашу продуктивность. Нам только следует порекомендовать вам не делать большие операции поиска и замены одновременно для всего документа, если у вас нет полной уверенности что ваши подстановочные символы делают именно то, что вы задумали. Также рекомендуется для этого использовать тестовые копии документов.
Связанные статьи:
- Как в Microsoft Word сделать массовую замену или удаление текста (74%)
- Как убрать лишние пробелы в Microsoft Word (74%)
- Как выделить текст цветом в Word (66.3%)
- Как вставить музыкальный символ, ноты в Word (57.7%)
- Как напечатать диапазон страниц документа Word из нескольких разделов (57.7%)
- Как остановить спам в Календаре Google (RANDOM – 26.1%)
Skip to content
В этом кратком руководстве показано, как можно быстро извлекать число из различных текстовых выражений в Excel с помощью формул или специального инструмента «Извлечь».
Проблема выделения числа из текста возникает достаточно часто, особенно когда вы работаете с данными, полученными из других программ. К примеру, нужно вытащить почтовый индекс из адреса, номенклатурный номер из строки с наименованием товара, номер счета из платежного документа. Нужное нам число может находиться в любом месте текста — в начале, в середине или в конце.
Вот что мы рассмотрим в этой статье:
- Как извлечь число в конце текста
- Получаем число из начала текста
- Как извлечь все числа из текста
- Извлекаем числа без формул при помощи Ultimate Suite
Когда дело доходит до извлечения части текстового значения заданной длины, Эксель предоставляет три текстовых функции (ЛЕВСИМВ, ПРАВСИМВ и ПСТР) для быстрого выполнения этой задачи. А вот когда дело доходит до извлечения числа из буквенно-цифровой строки, Microsoft Excel … не предоставляет ничего.
Чтобы извлечь число из текста в Excel, требуется немного изобретательности, немного терпения и множество различных функций, вложенных друг в друга.
Или вы можете запустить инструмент «Извлечь (Extract)» из надстройки Ablebits Ultimate Suite и выполнить эту операцию одним щелчком мыши. Ниже вы найдете полную информацию обо всех этих методах.
Как извлечь число из конца текстовой строки.
Если у вас есть столбец буквенно-цифровых значений, в котором число всегда идет после текста, вы можете использовать одну из следующих формул, чтобы вытащить из них числа.
Важное замечание! В приведенных ниже формулах извлечение выполняется с помощью функций ПРАВСИМВ и ЛЕВСИМВ, которые относятся к категории текстовых функций. Эти функции всегда возвращают текст. В нашем случае результатом будет числовая подстрока, которая с точки зрения Excel также является текстом, а не числом. Если вам нужно, чтобы результат был числом (которое можно использовать в дальнейших вычислениях), оберните соответствующую формулу в функцию ЗНАЧЕН, или выполните с ней простейшую математическую операцию (например, двойное отрицание).
Чтобы извлечь число из строки «текстовое число», первое, что вам нужно знать, — это с какой позиции начать операцию. Итак, давайте определим положение первой цифры с помощью этой общего выражения:
=МИН(ПОИСК({0;1;2;3;4;5;6;7;8;9}; ячейка &”0123456789″))
О логике вычислений мы поговорим чуть позже. На данный момент просто замените слово «ячейка» ссылкой на позицию, содержащую исходный текст (в нашем случае A2), и запишите получившееся выражение в любую пустую клетку той же строки, скажем, в B2:
=МИН(ПОИСК({0;1;2;3;4;5;6;7;8;9};A2&”0123456789″))
Хотя формула содержит константу массива, это обычное выражение, которое вводится обычным способом: нажатием клавиши Enter.
Как только позиция первой цифры определена, можно использовать функцию ПРАВСИМВ для извлечения числа. Чтобы узнать, сколько символов нужно извлечь, вы вычитаете позицию первой цифры из общей длины строки и добавляете единицу к результату, потому что первая цифра также должна быть включена:
=ПРАВСИМВ(A2;ДЛСТР(A2)-B2+1)
Где A2 – исходная ячейка, а B2 – позиция первой цифры.
На следующем скриншоте показаны результаты:

Чтобы исключить вспомогательный столбец, содержащий позицию первой цифры, вы можете встроить формулу МИН непосредственно в функцию ПРАВСИМВ следующим образом:
=ПРАВСИМВ(A2;ДЛСТР(A2)-МИН(ПОИСК({0;1;2;3;4;5;6;7;8;9};A2&”0123456789″))+1)
Чтобы формула возвращала именно число, а не числовую строку, вложите ее в функцию ЗНАЧЕН:
=ЗНАЧЕН(ПРАВСИМВ(A2;ДЛСТР(A2)-МИН(ПОИСК({0;1;2;3;4;5;6;7;8;9};A2&”0123456789″))+1))
Или просто примените двойное отрицание, использовав два знака «минус»:
=–ПРАВСИМВ(A2;ДЛСТР(A2)-МИН(ПОИСК({0;1;2;3;4;5;6;7;8;9};A2&”0123456789″))+1)
Другой способ извлечь число из конца строки — использовать вот такое выражение:
=ПРАВСИМВ( ячейка ;СУММ(ДЛСТР( ячейка ) – ДЛСТР(ПОДСТАВИТЬ( ячейка ; {“0″;”1″;”2″;”3″;”4″;”5″;”6″;”7″;”8″;”9″};””))))
Используя исходный текст в A2, вы записываете приведенную ниже формулу в B2 или любую другую пустую ячейку в той же строке, а затем копируете её вниз по столбцу:
=ПРАВСИМВ(A2;СУММ(ДЛСТР(A2) – ДЛСТР(ПОДСТАВИТЬ(A2; {“0″;”1″;”2″;”3″;”4″;”5″;”6″;”7″;”8″;”9″};””))))

Примечание. Эти формулы предназначены для случая, когда числа находятся только в конце текстовой строки. Если некоторые цифры также находятся в середине или в начале, то ничего не будет работать.
Этих недостатков не имеет третья формула, которая извлекает только последнее число в тексте, игнорируя все предыдущие:
=ПРАВСИМВ(A2; ДЛСТР(A2) – МАКС(ЕСЛИ(ЕЧИСЛО(ПСТР(A2; СТРОКА(ДВССЫЛ( “1:”&ДЛСТР(A2))); 1) *1)=ЛОЖЬ; СТРОКА(ДВССЫЛ( “1:”&ДЛСТР(A2))); 0)))
На скриншоте ниже вы видите результат ее работы.

Как видите, цифры в начале или в середине текста игнорируются. Также обратите внимание, что результатом, как и в предыдущих формулах, является число, записанное в виде текста. Как превратить его в нормальное число, мы уже рассмотрели выше в этой статье.
Примечание. Если вы используете Excel 2019 или более ранние версии, нужно использовать формулу массива, нажав при вводе комбинацию Ctrl+Shift+Enter. Если у вас Office365, вводите как обычно, через Enter.
Как извлечь число из начала текстовой строки
Если вы работаете со строками, в которых текст находится после числа, решение для извлечения числа будет аналогично описанному выше. С той только разницей, что вы используете функцию ЛЕВСИМВ для извлечения из левой части текста:
=ЛЕВСИМВ( ячейка ;СУММ(ДЛСТР( ячейка )-ДЛСТР(ПОДСТАВИТЬ( ячейка ;{“0″;”1″;”2″;”3″;”4″;”5″;”6″;”7″;”8″;”9″};””))))
Используя этот метод для A2, извлекаем число при помощи такого выражения:
=ЛЕВСИМВ(A2;СУММ(ДЛСТР(A2)-ДЛСТР(ПОДСТАВИТЬ(A2;{“0″;”1″;”2″;”3″;”4″;”5″;”6″;”7″;”8″;”9″};””))))

Это решение работает для текстовых выражений, которые содержат числа только в начале. Если некоторые цифры также находятся в середине или в конце строки, формула не будет работать.
Если вы хотите извлечь только числа слева и игнорировать остальные, воспользуйтесь другой формулой:
=ЛЕВСИМВ(A2;ПОИСКПОЗ(ЛОЖЬ;ЕЧИСЛО(–ПСТР(A2;СТРОКА($1:$94);1));0)-1)
Или чуть модифицируем, чтобы ускорить расчеты:
=ЛЕВСИМВ(A2; ПОИСКПОЗ(ЛОЖЬ; ЕЧИСЛО(ПСТР(A2; СТРОКА(ДВССЫЛ( “1:”&ДЛСТР(A2)+1)); 1) *1); 0) -1)

Если у вас Excel 2019 и ниже, вводите ее как формулу массива, используя Ctrl+Shift+Enter. В Office365 и выше можно вводить как обычно.
Примечание. Как и в случае с функцией ПРАВСИМВ, функция ЛЕВСИМВ также возвращает числовую подстроку, которая технически является текстом, а не числом.
Как получить число из любой позиции в тексте
Если ваша задача подразумевает извлечение числа из любого места строки, вы можете использовать следующую формулу:
=СУММПРОИЗВ(ПСТР(0&A2; НАИБОЛЬШИЙ(ИНДЕКС(ЕЧИСЛО(–ПСТР(A2; СТРОКА(ДВССЫЛ(“1:”&ДЛСТР(A2))); 1)) * СТРОКА(ДВССЫЛ(“1:”&ДЛСТР(A2))); 0); СТРОКА(ДВССЫЛ(“1:”&ДЛСТР(A2))))+1; 1) * 10^СТРОКА(ДВССЫЛ(“1:”&ДЛСТР(A2)))/10)
Где A2 – исходная текстовая строка.
Для пояснения, как это работает, потребуется отдельная статья. Поэтому вы можете просто скопировать на свой рабочий лист, чтобы убедиться, что это действительно работает 🙂

Обратите внимание, что в этом случае в тексте могут находиться несколько чисел. Все они будут извлечены и объединены в единое целое.
Однако, изучив результаты, вы можете заметить один незначительный недостаток: если исходный текст в ячейке не содержит числа, формула возвращает ноль, как в строке 7 на скриншоте выше. Чтобы исправить это, вы можете заключить формулу в оператор ЕСЛИ, который проверит, содержит ли исходный текст какое-либо число. Если это так, формула извлекает это число, в противном случае возвращает пустую строку:
=ЕСЛИ(СУММ(ДЛСТР(A2)-ДЛСТР(ПОДСТАВИТЬ(A2;{“0″;”1″;”2″;”3″;”4″;”5″;”6″;”7″;”8″;”9″};””)))>0; СУММПРОИЗВ(ПСТР(0&A2; НАИБОЛЬШИЙ(ИНДЕКС(ЕЧИСЛО(–ПСТР(A2; СТРОКА(ДВССЫЛ(“1:”&ДЛСТР(A2))); 1)) * СТРОКА(ДВССЫЛ(“1:”&ДЛСТР(A2))); 0); СТРОКА(ДВССЫЛ(“1:”&ДЛСТР(A2))))+1; 1) * 10^СТРОКА(ДВССЫЛ(“1:”&ДЛСТР(A2)))/10);””)
В отличие от всех предыдущих примеров, результатом этих формул является число. Чтобы убедиться в этом, просто обратите внимание на выровненные по правому краю значения в столбце B и усеченные ведущие нули (например, 88 вместо 088).
Если число, которое вы хотите извлечь, ограничено какими-то знаками-разделителями, то можно использовать функцию ПСТР. Рассмотрим пример, как получить номер счета из текста платежа.
Мы будем искать позицию знака «№» и позицию следующего за ним первого пробела. То, что находится между ними, как раз и будет номером счёта:
=ПСТР(ПОДСТАВИТЬ(A2;” “;””);НАЙТИ(“№”;ПОДСТАВИТЬ(A2;” “;””))+1;НАЙТИ(” “;A2;НАЙТИ(“№”;A2;1))-НАЙТИ(“№”;A2;1)-1)
На скриншоте ниже вы видите, как это работает.

Вот еще один возможный вариант вынимания числа из текста. Необходимо извлечь первое встретившееся число из текста.
Используем формулу
=ПРОСМОТР(2^64;–ЛЕВСИМВ(ПСТР(A1&”_0″;МИН(НАЙТИ({0;1;2;3;4;5;6;7;8;9};A1&”_0123456789″));15); {1;2;3;4;5;6;7;8;9;10;11;12;13;14;15}))
или заменяем список цифр функцией:
=ПРОСМОТР(2^64;–ЛЕВСИМВ(ПСТР(A1&”_0″;МИН(НАЙТИ({0;1;2;3;4;5;6;7;8;9};A1&”_0123456789″));15); СТРОКА($A$1:$IV$16)))
Как видите, получаем только первое число, независимо от его расположения:

И еще один пример. Давайте попробуем достать все числа из текста, разграничив их каким-то разделителем. Например, дефисом “-“.
В этом случае придется использовать формулу массива:
{=ПОДСТАВИТЬ(СЖПРОБЕЛЫ(СЦЕП(ЕСЛИ(ЕЧИСЛО(–ПСТР(A2;СТРОКА($1:$94);1));ПСТР(A2;СТРОКА($1:$94);1);” “)));” “;”-“)}
Мы нашли все числа в тексте, как вы видите на скриншоте ниже:

Откорректировав эту формулу, вы можете использовать любой другой разделитель.
Поскольку между ними есть разделители, то вы легко можете распределить эти числа в отдельные ячейки. Как это сделать — читайте в материале 8 способов разделить ячейку Excel на две или несколько.
Как выделить число из текста с помощью Ultimate Suite
Как вы только что видели, не существует простой и понятной формулы Excel для извлечения чисел из текстовой строки. Если у вас есть трудности с пониманием формул или их настройкой для ваших наборов данных, вам может понравиться этот простой способ получить число из текста в Excel.
С надстройкой Ultimate Suite, добавленной на вашу ленту Excel, вы можете быстро получить число из любой буквенно-цифровой строки:
- Перейдите на вкладку Ablebits Data > Text и нажмите Извлечь (Extract) :

- Выделите все ячейки с данными, которые нужно обработать.
- На панели инструмента «Извлечь (Extract)» установите переключатель «Извлечь числа (Extract numbers)».
- В зависимости от того, хотите ли вы, чтобы результаты были формулами или значениями, выберите поле «Вставить как формулу (Insert as formula)» или оставьте его пустым (по умолчанию).
Я советую активировать это поле, если вы хотите, чтобы извлеченные числа обновлялись автоматически, как только в исходные значения вносятся какие-либо изменения. Если нужно, чтобы результаты не зависели от будущих изменений (например, если вы планируете удалить исходные данные позже), не используйте эту опцию.
- Нажмите кнопку «Вставить результаты (Insert Results)». Готово!

Как и в предыдущем примере, результаты извлечения являются числами. Это означает, что вы можете подсчитывать, суммировать, усреднять или выполнять любые другие вычисления с ними.
Если установлен флажок «Вставить как формулу», вы увидите выражение в строке формул. Любопытно узнать, какое именно? Просто скачайте пробную версию Ultimate Suite и убедитесь сами 🙂
Если вы хотите иметь это, а также еще более 60 полезных инструментов в Excel, воспользуйтесь этой надстройкой.
Я постарался дать вам максимально полные рекомендации, какими способами можно извлечь число из текста. Конечно, они не могут охватить все возможные случаи. Поэтому если встретилось что-то особенно заковыристое — не стесняйтесь писать в комментариях. Постараюсь помочь по мере сил.
 Как быстро посчитать количество слов в Excel – В статье объясняется, как подсчитывать слова в Excel с помощью функции ДЛСТР в сочетании с другими функциями Excel, а также приводятся формулы для подсчета общего количества или конкретных слов в…
Как быстро посчитать количество слов в Excel – В статье объясняется, как подсчитывать слова в Excel с помощью функции ДЛСТР в сочетании с другими функциями Excel, а также приводятся формулы для подсчета общего количества или конкретных слов в…  Как умножить число на процент и прибавить проценты – Ранее мы уже научились считать проценты в Excel. Рассмотрим несколько случаев, когда известная нам величина процента помогает рассчитать различные числовые значения. Чему равен процент от числаКак умножить число на процентКак…
Как умножить число на процент и прибавить проценты – Ранее мы уже научились считать проценты в Excel. Рассмотрим несколько случаев, когда известная нам величина процента помогает рассчитать различные числовые значения. Чему равен процент от числаКак умножить число на процентКак…  Как считать проценты в Excel — примеры формул – В этом руководстве вы познакомитесь с быстрым способом расчета процентов в Excel, найдете базовую формулу процента и еще несколько формул для расчета процентного изменения, процента от общей суммы и т.д.…
Как считать проценты в Excel — примеры формул – В этом руководстве вы познакомитесь с быстрым способом расчета процентов в Excel, найдете базовую формулу процента и еще несколько формул для расчета процентного изменения, процента от общей суммы и т.д.…  Функция ПРАВСИМВ в Excel — примеры и советы. – В последних нескольких статьях мы обсуждали различные текстовые функции. Сегодня наше внимание сосредоточено на ПРАВСИМВ (RIGHT в английской версии), которая предназначена для возврата указанного количества символов из крайней правой части…
Функция ПРАВСИМВ в Excel — примеры и советы. – В последних нескольких статьях мы обсуждали различные текстовые функции. Сегодня наше внимание сосредоточено на ПРАВСИМВ (RIGHT в английской версии), которая предназначена для возврата указанного количества символов из крайней правой части…  Функция ЛЕВСИМВ в Excel. Примеры использования и советы. – В руководстве показано, как использовать функцию ЛЕВСИМВ (LEFT) в Excel, чтобы получить подстроку из начала текстовой строки, извлечь текст перед определенным символом, заставить формулу возвращать число и многое другое. Среди…
Функция ЛЕВСИМВ в Excel. Примеры использования и советы. – В руководстве показано, как использовать функцию ЛЕВСИМВ (LEFT) в Excel, чтобы получить подстроку из начала текстовой строки, извлечь текст перед определенным символом, заставить формулу возвращать число и многое другое. Среди…  5 примеров с функцией ДЛСТР в Excel. – Вы ищете формулу Excel для подсчета символов в ячейке? Если да, то вы, безусловно, попали на нужную страницу. В этом коротком руководстве вы узнаете, как использовать функцию ДЛСТР (LEN в английской версии)…
5 примеров с функцией ДЛСТР в Excel. – Вы ищете формулу Excel для подсчета символов в ячейке? Если да, то вы, безусловно, попали на нужную страницу. В этом коротком руководстве вы узнаете, как использовать функцию ДЛСТР (LEN в английской версии)…  Как быстро сосчитать количество символов в ячейке Excel – В руководстве объясняется, как считать символы в Excel. Вы изучите формулы, позволяющие получить общее количество символов в диапазоне и подсчитывать только определенные символы в одной или нескольких ячейках. В нашем предыдущем…
Как быстро сосчитать количество символов в ячейке Excel – В руководстве объясняется, как считать символы в Excel. Вы изучите формулы, позволяющие получить общее количество символов в диапазоне и подсчитывать только определенные символы в одной или нескольких ячейках. В нашем предыдущем…
Бесплатный сервис поиска слов Адвего покажет онлайн все вхождения ключевых слов, стоп-слов и слов по заданному образцу. Поиск фраз и наборов символов на любом языке.
Как работает поиск слов и фраз в тексте
Скопируйте в первое поле проверяемый текст, а во втором поле укажите все слова и фразы по одной на строку, после чего нажмите кнопку “Найти”. Чтобы найти слова в документе или на странице сайта, скопируйте весь текст в поле для проверки.
По умолчанию система ищет только точные совпадения с указанной строкой (с учетом знаков препинания).
Например, по строке “номер” будет найдено слово “номер”, но не будут найдены слова “номерной” или “госномер”. Аналогично, при поиске по фразе “легкий завтрак” будет найдена только фраза “легкий завтрак”, но не будут найдены фразы “легким завтраком” или “легкий, завтрак”.
Чтобы задать поиск по маске, используйте символ звездочки * в начале, в конце или с обеих сторон каждого слова:
ра*— будут найдены все слова, начинающиеся на “ра”, в том числе слово “ра”: работа, разный, рад.*ет— будут найдены все слова, заканчивающиеся на “ет”, в том числе слово “ет”: работает, полет, нет.*ой*— будут найдены все слова, содержащие буквосочетание “ой” в любом месте: ойкнул, водопой, спокойствие.
Маску можно указать для одного или нескольких слов во фразе, правила будут применяться последовательно:
ра* *ет— будут найдены фразы только из двух рядом стоящих слов, первое из которых начинается на “ра”, а второе заканчивается на “ет”: рабочий совет, но не будут найдены фразы “свет комет” или “равная опора”.
Также можно найти все вхождения любой заданной последовательности символов в тексте — для этого необходимо добавить символ ! в начале и конце строки.
Например, по запросу !дом! будут найдены вхождения этого буквосочетания в словах “дом”, “домашний”, “одомашненный” и т. д., но выделены будут именно вхождения, а не слова целиком, в отличие от режима поиска по маске с символом *.
Чтобы выделить все вхождения конкретного слова или фразы в тексте, нажмите на строку с ними в таблице совпадений. Чтобы выделить все совпадения, нажмите на строку с общим количеством совпадений.
Проверять текст можно неограниченное количество раз — после его редактирования или изменения списка слов нажмите повторно кнопку “Найти” и система покажет результаты новой проверки.
Возможности сервиса:
- поиск заданных слов и фраз (ключевых, стоп-слов);
- поиск по фразе целиком или по ее части;
- поиск необходимого слова или фразы в документе;
- поиск одинаковых и повторяющихся слов;
- поиск однокоренных слов по маске;
- поиск любых последовательностей символов;
- поиск в английском тексте и на любом языке.
