Искать символы Unicode обычно неудобно: приходится отвлекаться от основной работы. Программа SymbSearch упрощает этот процесс, задействуя горячие клавиши.

Unicode — это стандарт кодирования символов, который позволяет использовать знаки почти всех письменных языков. Если вы пользуетесь нестандартными его обозначениями, то неудобной таблице символов Windows и поиску в Google появилась неплохая альтернатива — SymbSearch. Это бесплатная утилита с открытым программным кодом, которая поможет быстро находить символы Unicode при помощи горячих клавиш, не отвлекаясь от рабочего процесса.
Программа пока не имеет инсталлятора. Чтобы установить её, достаточно разархивировать папку в нужном месте на жёстком диске. После этого запустите SymbSearch.exe, и SymbSearch окажется в фоновых процессах. Она занимает 105 МБ на жёстком диске и 64 МБ в оперативной памяти.
SymbSearch ориентирована на использование клавиатуры. Когда вы печатаете текст, нажмите Ctrl + Alt + W для запуска приложения. Найдите нужный символ, выберите его при помощи стрелок на клавиатуре и нажмите Enter. Значение будет скопировано в буфер обмена. Затем SymbSearch самостоятельно закроется, а вы вернётесь в активное окно текста, практически не оторвавшись от написания. Всё, что останется, — вставить символ при помощи сочетания клавиш Ctrl + V.
Изначальный список символов огромен, но не пугайтесь. SymbSearch фильтрует знаки по 11 категориям: греческий алфавит, латинский, математика, стрелки и другие. Чтобы быстро переключаться между категориями, используйте клавишу Alt.
Если вы уже знаете, какой конкретно символ нужен для текста или формулы, можно вбить его в поисковую строку.
Пользоваться мышью в программе неудобно. SymbSearch не понимает кликов. Чтобы скопировать символ, необходимо его выделить и нажать Ctrl + C.
Программа SymbSearch находится в активной разработке, но её уже можно использовать. Версия 0.4.0 пока не включает такой необходимой функции, как загрузка при запуске системы, поэтому придётся добавлять утилиту в автозагрузку вручную или запускать её каждый раз, когда это необходимо.
Разработчики SymbSearch отмечают, что в планах — поддержка Linux и macOS, настройка горячих клавиш, инсталлятор для программы и возможность автозагрузки.
Скачать SymbSearch →
Уровень сложности
Средний
Время на прочтение
14 мин
Количество просмотров 4K
Unicode – это набор символов, целью которого является определение всех символов и глифов всех человеческих языков, живых и мертвых. Поскольку всё больше и больше программ должны поддерживать несколько языков или просто любой язык, юникод в последние годы приобретает всё большую популярность. Использование различных наборов символов для разных языков может быть слишком обременительным для программистов и пользователей.
К сожалению, юникод привносит свои требования и подводные камни, когда речь заходит о регулярных выражениях.
Поддержка юникод-совместимых регулярных выражений
Из всех движков регулярных выражений, обсуждаемых здесь, Java, XML и .NET используют движки поддерживающие юникод. Perl поддерживает юникод, начиная с версии 5.6. PCRE может быть опционально скомпилирован с поддержкой юникод. Обратите внимание, что PCRE гораздо менее гибок в том, что он позволяет делать для p, несмотря на своё название “Perl-совместимый”. Функции PHP preg, основанные на PCRE, поддерживают юникод, если к регулярному выражению добавлена опция /u. Ruby поддерживает категории юникода в регулярных выражениях начиная с версии 1.9. XRegExp привносит поддержку категорий юникода в JavaScript.
Regex-движок RegexBuddy полностью совместим с юникодом, начиная с версии 2.0.0. RegexBuddy 1.x.x не поддерживал юникод вообще. PowerGREP использует regex-движок с поддержкой юникода, начиная с версии 3.0.0. Более ранние версии конвертировали Unicode файлы в ANSI перед выполнением поиска с помощью 8-битного (т.е. не-Unicode) regex движка. EditPad Pro поддерживает юникод, начиная с версии 6.0.0.
Символы, коды и графемы, или как юникод вносит беспорядок
Большинство людей считают à одним символом. К сожалению, это не так, в зависимости от значения слова “символ”.
Все regex-движки с поддержкой юникода, обсуждаемые здесь, рассматривают любой отдельный Unicode код как отдельный символ. Когда говорится, что . соответствует любому отдельному символу, это переводится на язык Unicode как “. соответствует любому отдельному коду Unicode”. В юникоде символ à может быть представлен через два кода: U+0061 (a), за которым следует U+0300 (гравис). В этой ситуации ., примененная к à, будет соответствовать a без грависа.^.$ не будет соответствовать данной строке, так как она состоит из двух кодов, в то время как ^..$ соответствует.
Код U+0300 (гравис) является комбинируемым символом. За любым кодом, который не является комбинируемым символом, может следовать любое количество комбинируемых. Эта последовательность, как и U+0061 U+0300 выше, отображается на экране как одна графема.
à также может быть представлен единственным кодом U+00E0 (a с грависом). Причина такой двойственности в том, что многие исторические наборы символов кодируют “a с грависом” как один символ. Разработчики юникода решили, что будет полезно иметь сопоставление один к одному с популярными историческими наборами символов, в дополнение к способу юникода разделять знаки и базовые буквы (что делает возможными произвольные комбинации, не поддерживаемые историческими наборами символов).
Как сопоставить одну графему Юникода
В Perl, PCRE, PHP, Boost, Ruby 2.0, Java 9 и приложениях Just Great Software сопоставление одной графемы, будь она закодирована как одним кодом или несколькими с помощью комбинируемых знаков, очень просто: просто используйте X. Вы можете считать X юникод-версией .. Но есть одно отличие: X всегда соответствует символам перевода строки, в то время как . не соответствует им, если только вы не включите режим соответствия . новой строке.
В .NET, Java 8 и ниже, а также Ruby 1.9 вы можете использовать P{M}p{M}*+ или (?>P{M}p{M}*) в качестве достаточно близкой замены. Чтобы подобрать любое количество графем, используйте (?>P{M}p{M}*)+ как замену X+.
Как сопоставить конкретный код Юникода
Чтобы сопоставить конкретный код, используйте uFFFF, где FFFF – шестнадцатеричный код, который вы хотите сопоставить. Вы всегда должны указывать все 4 шестнадцатеричных разряда. Например, u00E0 соответствует à, при представлении одним кодом U+00E0.
Особенности в разных движках
Perl, PCRE, Boost и std::regex не поддерживают синтаксис uFFFF. Вместо него они используют x{FFFF}. Вы можете опустить ведущие нули в фигурных скобках. Поскольку x сам по себе не является допустимым символом регулярного выражения, x{1234} никогда не может быть перепутано с x 1234 раза. Это всегда соответствует коду U+1234. x{1234}{5678} будет сопоставляться с кодом U+1234 ровно 5678 раз.
В Java uFFFF соответствует только указанному коду, даже если вы включили каноническую эквивалентность. Однако тот же синтаксис uFFFF также используется для вставки символов юникода в литеральные строки в исходном коде Java. Pattern.compile("u00E0") будет соответствовать как однокодовому, так и двухкодовому варианту à, в то время как Pattern.compile("\u00E0") соответствует только однокодовой версии. Помните, что при записи regex как строкового литерала Java, обратные слэши должны быть экранированы. Первый код Java компилирует regex à, а второй компилирует u00E0. В зависимости от того, что вы делаете, разница может быть существенной.
JavaScript, который не предлагает никакой поддержки Unicode через свой класс RegExp, поддерживает uFFFF для соответствия одному коду.
XML Schema и XPath не имеют regex токенов для сопоставления кодов Unicode. Однако вы можете легко использовать такие XML-сущности, как  для вставки явных кодов в ваше регулярное выражение.
Категории в Юникоде
В дополнение к сложностям, Unicode также приносит и новые возможности. Одна из них заключается в том, что каждый символ юникода принадлежит к определенной категории. Вы можете сопоставить один символ, принадлежащий к категории “буква”, с p{L}, или не принадлежащий к ней, с P{L}.
Опять же, “символ” на самом деле означает “код юникод-символа”. p{L} соответствует одному коду в категории “буква”. Если входная строка à закодирована как U+0061 U+0300, она соответствует a без грависа. Если входная строка à закодирована как U+00E0, она соответствует à с грависом. Причина в том, что коды U+0061 (a) и U+00E0 (à) относятся к категории “буква”, а U+0300 – к категории “знак”.
Теперь вы должны понять, почему P{M}p{M}*+ эквивалентно X. P{M} соответствует коду, который не является комбинируемым знаком, в то время как p{M}*+ соответствует нулю или более кодов, которые являются комбинируемыми. Чтобы найти букву, включая все диакритические знаки, используйте p{L}p{M}*+. Последний regex всегда будет соответствовать à, независимо от того, как это закодировано. Possessive квантификатор гарантирует, что поиск с возвратом не приведет к тому, что P{M}p{M}*+ будет соответствовать не-знаку без комбинируемых символов, которые следуют за ним, чего X никогда не сделает.
PCRE, PHP и .NET чувствительны к регистру при проверке части между фигурными скобками лексемы p. p{Zs} будет соответствовать любому символу пробела, в то время как p{zs} выдаст ошибку. Все другие regex-движки, описанные здесь, будут соответствовать пробелу в обоих случаях, игнорируя регистр категории между фигурными скобками. Тем не менее, рекомендуется взять за привычку использовать ту же комбинацию прописных и строчных букв, как в списке категорий ниже. Это позволит вашим регулярным выражениям работать со всеми regex-движками поддерживающими Unicode.
В дополнение к стандартной нотации p{L}, Java, Perl, PCRE, движок JGsoft и XRegExp 3 позволяют использовать сокращение pL. Это сокращение работает только с однобуквенными категориями Unicode. pLl не является эквивалентом p{Ll}. Это эквивалент p{L}l, который соответствует Al или àl или любой букве юникода, за которой следует буква l.
Perl, XRegExp и движок JGsoft также поддерживают длиннобуквенный p{Letter}. Полный список всех категорий Unicode приведен ниже. Вы можете опустить подчёркивания или использовать вместо них дефисы или пробелы.
[прим.: * – ссылки на сторонний ресурс, с указанием кодов, принадлежащих к конкретной подкатегории, для наглядности]
-
p{L}илиp{Letter}– любой вид любой буквы на любом языке.-
p{Ll}илиp{Lowercase_Letter}– буква в нижнем регистре, которая имеет вариант в верхнем. * -
p{Lu}илиp{Uppercase_Letter}– буква в верхнем регистре, которая имеет вариант в нижнем. * -
p{Lt}илиp{Titlecase_Letter}– диграф единым символом (кодом) в начале слова, когда заглавной является только его первая часть. * -
p{L&}илиp{Cased_Letter}– буква, которая существует в строчном и прописном вариантах (сочетаниеLl,LuиLt). -
p{Lm}илиp{Modifier_Letter}– специальный символ, который используется как буква. * -
p{Lo}илиp{Other_Letter}– буква или идеограмма, не имеющая строчных и прописных вариантов. *
-
-
p{M}илиp{Mark}– символ, предназначенный для сочетания с другим символом.-
p{Mn}илиp{Non_Spacing_Mark}– символ, предназначенный для сочетания с другим символом, не занимая дополнительного места (например, ударения, умляуты и т.д.). * -
p{Mc}илиp{Spacing_Combining_Mark}– символ, предназначенный для сочетания с другим символом, занимающий дополнительное место (как знаки гласных во многих восточных языках). * -
p{Me}илиp{Enclosing_Mark}– символ, который окружает символ, с которым он сочетается (круг, квадрат и т.д.). *
-
-
p{Z}илиp{Separator}– любые пробельные символы или невидимые разделители.-
p{Zs}илиp{Space_Separator}– символ пробела, который невидим, но занимает место. * -
p{Zl}илиp{Line_Separator}– разделитель строкU+2028. -
p{Zp}илиp{Paragraph_Separator}– разделитель параграфовU+2029.
-
-
p{S}илиp{Symbol}– математические символы, знаки валют, дингбаты, символы для рисования и т.д.-
p{Sm}илиp{Math_Symbol}– любой математический символ. * -
p{Sc}илиp{Currency_Symbol}– любой символ валюты. * -
p{Sk}илиp{Modifier_Symbol}– объединяющий символ (знак) как самостоятельный полный символ. * -
p{So}илиp{Other_Symbol}– различные символы, не относящиеся к прошлым подкатегориям. *
-
-
p{N}илиp{Number}– любой числовой символ любой письменности.-
p{Nd}илиp{Decimal_Digit_Number}– цифра от нуля до девяти в любой письменности, кроме идеографической. * -
p{Nl}илиp{Letter_Number}– число, которое выглядит как буква, например, римская цифра. * -
p{No}илиp{Other_Number}– надстрочная или подстрочная цифра, или число, не являющееся цифрой 0-9 (исключая числа из идеографических письменностей). *
-
-
p{P}orp{Punctuation}– любой символ пунктуации.-
p{Pd}илиp{Dash_Punctuation}– любой вид дефиса или тире. * -
p{Ps}илиp{Open_Punctuation}– любой вид открывающей скобки. * -
p{Pe}илиp{Close_Punctuation}– любой вид закрывающей скобки. * -
p{Pi}илиp{Initial_Punctuation}– любой вид открывающей кавычки. * -
p{Pf}илиp{Final_Punctuation}– любой вид закрывающей кавычки. * -
p{Pc}илиp{Connector_Punctuation}– символ пунктуации, такой как подчёркивание, который соединяет слова. * -
p{Po}илиp{Other_Punctuation}– любой знак препинания, не относящийся к прошлым подкатегориям. *
-
-
p{C}илиp{Other}– невидимые управляющие символы и неиспользуемые коды.-
p{Cc}илиp{Control}– управляющие ASCII или Latin-1 символы:0x00–0x1Fи0x7F–0x9F. * -
p{Cf}илиp{Format}– невидимый индикатор форматирования. * -
p{Co}илиp{Private_Use}– любой код, зарезервированный для частного использования. -
p{Cs}илиp{Surrogate}– одна половина суррогатной пары в кодировке UTF-16. -
p{Cn}илиp{Unassigned}– любой код, которому не присвоен ни один символ.
-
Письменности в Юникоде
Стандарт Unicode помещает каждый назначенный код (символ) в одну категорию письменности. Некоторые категории, например Thai, соответствуют одному человеческому языку. Другие категории, например Latin, относятся к нескольким языкам.
Некоторые языки состоят из нескольких письменностей. Японской письменности в юникоде не существует. Вместо этого юникод предлагает хира́гану, ката́кану, китайское письмо и латиницу, из которых обычно состоят японские документы.
Особой категорией является Common script. Здесь содержатся всевозможные символы, которые являются общими для широкого числа письменностей. Категория включает в себя всевозможные знаки препинания, пробелы и различные прочие символы.
Все назначенные коды являются частью ровно одной категории письменности. Все неназначенные коды (те, которые соответствуют p{Cn}) не являются частью какой-либо категории письменности вообще.
Движки JGsoft, Perl, PCRE, PHP, Ruby 1.9, Delphi и XRegExp могут сопоставлять категории письменности юникода.
Список письменностей
-
p{Common} -
p{Arabic} -
p{Armenian} -
p{Bengali} -
p{Bopomofo} -
p{Braille} -
p{Buhid} -
p{Canadian_Aboriginal} -
p{Cherokee} -
p{Cyrillic} -
p{Devanagari} -
p{Ethiopic} -
p{Georgian} -
p{Greek} -
p{Gujarati} -
p{Gurmukhi} -
p{Han} -
p{Hangul} -
p{Hanunoo} -
p{Hebrew} -
p{Hiragana} -
p{Inherited} -
p{Kannada} -
p{Katakana} -
p{Khmer} -
p{Lao} -
p{Latin} -
p{Limbu} -
p{Malayalam} -
p{Mongolian} -
p{Myanmar} -
p{Ogham} -
p{Oriya} -
p{Runic} -
p{Sinhala} -
p{Syriac} -
p{Tagalog} -
p{Tagbanwa} -
p{TaiLe} -
p{Tamil} -
p{Telugu} -
p{Thaana} -
p{Thai} -
p{Tibetan} -
p{Yi}
Perl и JGsoft позволяют использовать p{IsLatin} вместо p{Latin}. Синтаксис Is полезен для различения письменностей и блоков, как объясняется в следующем разделе. PCRE, PHP и XRegExp не поддерживают префикс Is.
Java 7 добавляет поддержку категорий письменностей. В отличие от прочих, Java 7 требует префикс Is.
Блоки Юникода
Стандарт Unicode делит карту символов на различные блоки или диапазоны кодов. Каждый блок используется для определения символов конкретной письменности, например, “тибетское письмо” или относящихся к определенной группе, например, “шрифт Брайля”. Большинство блоков включают нераспределённые коды, зарезервированные для будущего расширения стандарта.
Обратите внимание, что блоки юникода не совпадают на 100% с категориями письменностей. Существенное различие между блоками и данными категориями заключается в том, что блок – это один непрерывный диапазон кодов, как указано ниже. Категории письменностей состоят из символов, взятых со всей карты символов юникода. Блоки могут включать неназначенные коды (т.е. коды, соответствующие p{Cn}). Категории письменностей никогда не включают неназначенные коды. Обычно, если вы не уверены, использовать ли категорию письменности или блок юникода, используйте категорию письменности.
Например, блок Currency не включает символы доллара и йены. Вместо этого они находятся в блоках Basic_Latin и Latin-1_Supplement, несмотря на то, что оба символа являются валютными, а символ йены не является латинским символом. Это объясняется историческими причинами, поскольку стандарт ASCII включает знак доллара, а стандарт ISO-8859 – знак йены. Не следует слепо использовать любой из перечисленных ниже блоков, основываясь на их названиях. Вместо этого посмотрите на диапазоны символов, которым они фактически соответствуют. В этом может помочь такой инструмент, как RegexBuddy. Категория p{Sc} или p{Currency_Symbol} будет лучшим выбором, чем блок p{InCurrency_Symbols}, когда вы пытаетесь найти все символы валюты.
Блоки юникода
-
p{InBasic_Latin}: U+0000–U+007F -
p{InLatin-1_Supplement}: U+0080–U+00FF -
p{InLatin_Extended-A}: U+0100–U+017F -
p{InLatin_Extended-B}: U+0180–U+024F -
p{InIPA_Extensions}: U+0250–U+02AF -
p{InSpacing_Modifier_Letters}: U+02B0–U+02FF -
p{InCombining_Diacritical_Marks}: U+0300–U+036F -
p{InGreek_and_Coptic}: U+0370–U+03FF -
p{InCyrillic}: U+0400–U+04FF -
p{InCyrillic_Supplementary}: U+0500–U+052F -
p{InArmenian}: U+0530–U+058F -
p{InHebrew}: U+0590–U+05FF -
p{InArabic}: U+0600–U+06FF -
p{InSyriac}: U+0700–U+074F -
p{InThaana}: U+0780–U+07BF -
p{InDevanagari}: U+0900–U+097F -
p{InBengali}: U+0980–U+09FF -
p{InGurmukhi}: U+0A00–U+0A7F -
p{InGujarati}: U+0A80–U+0AFF -
p{InOriya}: U+0B00–U+0B7F -
p{InTamil}: U+0B80–U+0BFF -
p{InTelugu}: U+0C00–U+0C7F -
p{InKannada}: U+0C80–U+0CFF -
p{InMalayalam}: U+0D00–U+0D7F -
p{InSinhala}: U+0D80–U+0DFF -
p{InThai}: U+0E00–U+0E7F -
p{InLao}: U+0E80–U+0EFF -
p{InTibetan}: U+0F00–U+0FFF -
p{InMyanmar}: U+1000–U+109F -
p{InGeorgian}: U+10A0–U+10FF -
p{InHangul_Jamo}: U+1100–U+11FF -
p{InEthiopic}: U+1200–U+137F -
p{InCherokee}: U+13A0–U+13FF -
p{InUnified_Canadian_Aboriginal_Syllabics}: U+1400–U+167F -
p{InOgham}: U+1680–U+169F -
p{InRunic}: U+16A0–U+16FF -
p{InTagalog}: U+1700–U+171F -
p{InHanunoo}: U+1720–U+173F -
p{InBuhid}: U+1740–U+175F -
p{InTagbanwa}: U+1760–U+177F -
p{InKhmer}: U+1780–U+17FF -
p{InMongolian}: U+1800–U+18AF -
p{InLimbu}: U+1900–U+194F -
p{InTai_Le}: U+1950–U+197F -
p{InKhmer_Symbols}: U+19E0–U+19FF -
p{InPhonetic_Extensions}: U+1D00–U+1D7F -
p{InLatin_Extended_Additional}: U+1E00–U+1EFF -
p{InGreek_Extended}: U+1F00–U+1FFF -
p{InGeneral_Punctuation}: U+2000–U+206F -
p{InSuperscripts_and_Subscripts}: U+2070–U+209F -
p{InCurrency_Symbols}: U+20A0–U+20CF -
p{InCombining_Diacritical_Marks_for_Symbols}: U+20D0–U+20FF -
p{InLetterlike_Symbols}: U+2100–U+214F -
p{InNumber_Forms}: U+2150–U+218F -
p{InArrows}: U+2190–U+21FF -
p{InMathematical_Operators}: U+2200–U+22FF -
p{InMiscellaneous_Technical}: U+2300–U+23FF -
p{InControl_Pictures}: U+2400–U+243F -
p{InOptical_Character_Recognition}: U+2440–U+245F -
p{InEnclosed_Alphanumerics}: U+2460–U+24FF -
p{InBox_Drawing}: U+2500–U+257F -
p{InBlock_Elements}: U+2580–U+259F -
p{InGeometric_Shapes}: U+25A0–U+25FF -
p{InMiscellaneous_Symbols}: U+2600–U+26FF -
p{InDingbats}: U+2700–U+27BF -
p{InMiscellaneous_Mathematical_Symbols-A}: U+27C0–U+27EF -
p{InSupplemental_Arrows-A}: U+27F0–U+27FF -
p{InBraille_Patterns}: U+2800–U+28FF -
p{InSupplemental_Arrows-B}: U+2900–U+297F -
p{InMiscellaneous_Mathematical_Symbols-B}: U+2980–U+29FF -
p{InSupplemental_Mathematical_Operators}: U+2A00–U+2AFF -
p{InMiscellaneous_Symbols_and_Arrows}: U+2B00–U+2BFF -
p{InCJK_Radicals_Supplement}: U+2E80–U+2EFF -
p{InKangxi_Radicals}: U+2F00–U+2FDF -
p{InIdeographic_Description_Characters}: U+2FF0–U+2FFF -
p{InCJK_Symbols_and_Punctuation}: U+3000–U+303F -
p{InHiragana}: U+3040–U+309F -
p{InKatakana}: U+30A0–U+30FF -
p{InBopomofo}: U+3100–U+312F -
p{InHangul_Compatibility_Jamo}: U+3130–U+318F -
p{InKanbun}: U+3190–U+319F -
p{InBopomofo_Extended}: U+31A0–U+31BF -
p{InKatakana_Phonetic_Extensions}: U+31F0–U+31FF -
p{InEnclosed_CJK_Letters_and_Months}: U+3200–U+32FF -
p{InCJK_Compatibility}: U+3300–U+33FF -
p{InCJK_Unified_Ideographs_Extension_A}: U+3400–U+4DBF -
p{InYijing_Hexagram_Symbols}: U+4DC0–U+4DFF -
p{InCJK_Unified_Ideographs}: U+4E00–U+9FFF -
p{InYi_Syllables}: U+A000–U+A48F -
p{InYi_Radicals}: U+A490–U+A4CF -
p{InHangul_Syllables}: U+AC00–U+D7AF -
p{InHigh_Surrogates}: U+D800–U+DB7F -
p{InHigh_Private_Use_Surrogates}: U+DB80–U+DBFF -
p{InLow_Surrogates}: U+DC00–U+DFFF -
p{InPrivate_Use_Area}: U+E000–U+F8FF -
p{InCJK_Compatibility_Ideographs}: U+F900–U+FAFF -
p{InAlphabetic_Presentation_Forms}: U+FB00–U+FB4F -
p{InArabic_Presentation_Forms-A}: U+FB50–U+FDFF -
p{InVariation_Selectors}: U+FE00–U+FE0F -
p{InCombining_Half_Marks}: U+FE20–U+FE2F -
p{InCJK_Compatibility_Forms}: U+FE30–U+FE4F -
p{InSmall_Form_Variants}: U+FE50–U+FE6F -
p{InArabic_Presentation_Forms-B}: U+FE70–U+FEFF -
p{InHalfwidth_and_Fullwidth_Forms}: U+FF00–U+FFEF -
p{InSpecials}: U+FFF0–U+FFFF
Не все regex-движки с поддержкой юникода используют одинаковый синтаксис для сопоставления блоков. Java, Ruby 2.0 и XRegExp используют синтаксис p{InBlock}, как указано выше. В .NET и XML вместо этого используется p{IsBlock}. Perl и JGsoft поддерживают обе нотации. Рекомендуется использовать нотацию In, если ваш regex-движок поддерживает её. In можно использовать только для блоков Unicode, в то время как Is можно использовать для общих категорий и категорий письменностей, в зависимости от используемого вами шаблона регулярных выражений. При использовании In очевидно, что вы сопоставляете блок, а не общую категорию или письменность с аналогичным названием.
В .NET и XML вы должны опустить подчёркивание, но сохранить дефисы в именах блоков. Например, используйте p{IsLatinExtended-A} вместо p{InLatin_Extended-A}. В Java вы должны опустить дефисы. .NET и XML также сравнивают имена с учетом регистра, в то время как Perl, Ruby и JGsoft сравнивают их без учета регистра. Java 4 чувствительна к регистру. Java 5 и более поздние версии учитывают регистр для префикса Is, но не для самих имен блоков.
Фактические имена блоков одинаковы во всех движках регулярных выражений. Имена блоков определены в стандарте Unicode. PCRE и PHP не поддерживают блоки, хотя они поддерживают категории письменностей.
Нужно ли вам беспокоиться о различных кодировках?
Хотя вы всегда должны помнить о подводных камнях, создаваемых различными способами кодирования комбинированных символов, вам не всегда нужно беспокоиться об этом. Если вы знаете, что ваша входная строка и ваше регулярное выражение используют один и тот же подход, то вам вообще не нужно беспокоиться об этом. Этот процесс называется нормализацией Unicode. Все языки программирования со встроенной поддержкой Unicode, такие как Java, C# и VB.NET, имеют функции библиотек для нормализации строк. Если вы нормализуете и объект, и регулярное выражение перед попыткой сопоставления, никаких несоответствий не возникнет.
Если вы используете Java, вы можете передать флаг CANON_EQ в качестве второго параметра в Pattern.compile(). Это указывает движку регулярных выражений Java считать канонически эквивалентные символы идентичными. Символ à, закодированный как U+00E0, соответствует à, закодированному как U+0061 U+0300, и наоборот. Ни один из других regex-движков в настоящее время не поддерживает каноническую эквивалентность при сопоставлении.
Если набрать на клавиатуре клавишу à, все известные нам текстовые процессоры вставят в файл код U+00E0. Таким образом, если вы работаете с текстом, который вы набрали сами, любое регулярное выражение, который вы набрали сами, будет соответствовать таким же образом.
Наконец, если вы используете PowerGREP для поиска в текстовых файлах, закодированных с помощью традиционной кодовой страницы Windows (часто называемой “ANSI”) или ISO-8859, PowerGREP всегда использует подстановку один к одному. Поскольку все кодовые страницы Windows или ISO-8859 представляют комбинированные символы одним кодом, почти все программы используют один код для каждого символа при преобразовании файла в юникод.
Нашли опечатку или неточность в переводе? Выделите и нажмите
CTRL/⌘+Enter
Читайте также
Identify Unicode characters that force text messages into Unicode format.
How to Use the Unicode Character Detector
With this simple tool, you can instantly identify GSM characters and Unicode symbols in your text messages. Characters in the GSM charset will be grey, while Unicode special characters will be highlighted in red.
-
Step #1 Copy and paste a text message into the empty box. Characters will automatically be displayed in the results box.
-
Step #2 Identify the different symbols in your SMS message. GSM characters will be displayed in grey, Unicode characters will appear in red and escape characters will be displayed in orange.
-
Step #3 The tool also calculates the number of characters in the text and the number of parts of a split message, thus allowing you to control concatenation.
Why you should use the Unicode character detector
As you probably already know, text messages are limited to 160 characters if they are all from the GSM character set. However, if your text contains Unicode symbols, it will be limited to 70 characters instead of 160.
Of course, messages longer than 70 characters can still be sent, but they will become multipart. This means that a 160-character SMS message will be split into three text messages if they have Unicode symbols. This can be extremely frustrating. What is even more frustrating is when your client’s phone crashes due to the Unicode character strings (this has actually happened on several occasions).
By using the Unicode character detector, you can identify and replace symbols that aren’t part of the 7-bit GSM charset to avoid splitting text messages into multiple segments.
Why we built this tool
Unicode characters not only break up text, but sometimes they do not show up at all, or they appear as the dreaded □ □ □. To ensure that the information is passed correctly to the SMS gateway, text messages must be properly encoded. The problem is that many characters are extremely difficult to encode, and because the GSM 3.38 charset is almost impossible to support, many providers have decided to quit altogether.
We created the Unicode character detector tool to help our clients avoid the problems listed above and to ensure that your messages are delivered as intended.
Benefits of using the Unicode character detector
Here are the main benefits of using our Unicode character detection tool:
-
Identify GSM and Unicode characters in your text messages.
-
Identify the number of characters and parts in a text.
-
Based on the number of Unicode characters, find out if the text will be segmented.
-
Remove Unicode symbols and replace them with GSM characters.
-
Preview your text messages before sending them to customers.
-
Control how a text message will be split if it contains Unicode.
Why are text messages that contain Unicode segmented?
When you try to send a text message with symbols that fall outside the GSM character set, you have to use Unicode, which assigns a unique code to every character that isn’t part of the standard charset. Because several GSM characters are used to describe a Unicode character, you will only be able to send text messages of 35–70 characters.
Can I avoid text message segmentation and still use Unicode?
To avoid SMS segmentation and to convert Unicode symbols to Latin only, you can use our Text Transliterator.
GSM describes the protocols for second-generation cellular networks and mobile devices. Presently, it is the standard for mobile communications, holding over 90% of the market share. Therefore, all messages sent to such devices must respect the standard GSM charset.
When a text message contains non-GSM characters, it will be limited to 70 characters. The only solution to avoid having your texts split is to check for Unicode characters and to replace them with their equivalent in the GSM charset (if such an equivalent exists).
What characters are part of the GSM charset?
The standard GSM character set contains the letters of the English alphabet, digits and some special characters, including a few Greek ones.
GSM character list: here
What characters are part of the Unicode charset?
The Unicode character list contains symbols from the Cyrillic, Chinese, Arabic, Korean and Hangul alphabets. It also contains several special symbols (such as emoticons, emoji and kanji).
Unicode character list: here
Во время серфинга в Интернете (или даже в автономном режиме) вы, вероятно, встретите множество символов. Некоторые из них являются обычными, но для других вам, вероятно, понадобится помощь в идентификации символа.
К счастью, в Интернете есть множество ресурсов по идентификаторам символов, которые могут вам помочь. Мы покажем вам, как узнать, что означает символ, с помощью различных методов.
1. Определите символы с помощью Symbols.com

Удачно названный Symbols.com – отличное место для начала поиска. Наряду с избранными подборками и категориями на домашней странице вы можете использовать его поисковую систему по символам, чтобы найти то, что вы ищете. Просто введите запрос вверху, и вы увидите соответствующие ему символы.
Это замечательно, если вы хотите найти символ по тексту (например, поиск символа «кошерный»). Но во многих случаях вы увидите символ и задаетесь вопросом, каково его значение. К счастью, на сайте есть и другие способы определения символа.
В нижнем левом углу страницы вы увидите раздел « Графический указатель ». Это позволяет искать символ на основе его характеристик. Он предоставляет несколько простых раскрывающихся списков, позволяющих указать, является ли форма открытой или закрытой, имеет ли она цвета, изогнутые ли линии или прямые и т. Д.
Введите как можно больше информации, затем нажмите « Поиск», чтобы найти символы, соответствующие вашим критериям. Если это не поможет вам найти то, что вы ищете, вы можете использовать категории символов для просмотра по группам, таким как знаки валюты , предупреждающие символы и другие.
Если это не поможет, вы можете выполнить поиск по алфавиту, используя буквы в верхней части экрана. Если вы не ищете ничего особенного, кнопка « Случайно» поможет вам узнать что-то новое.
2. Нарисуйте символ, чтобы узнать его значение.

Если вас озадачило то, что вы видели в офлайне, имеет смысл найти символ по картинке. Вы найдете несколько сайтов, которые предлагают функцию рисования символа и узнаете, что он означает.
Один из них – Shapecatcher . Просто нарисуйте символ, который хотите найти, с помощью мыши или сенсорного экрана и нажмите кнопку « Распознать» . Сервис вернет символы, соответствующие вашему рисунку.
Если вы не видите совпадения, нарисуйте его еще раз и попробуйте еще раз. На сайте используются только бесплатные шрифты Unicode, поэтому на нем могут быть не все возможные символы. Попробуйте Mausr для аналогичной альтернативы рисования символов, если она вам не подходит.
3. Поиск символов с помощью Google

Если вы натолкнулись на незнакомый значок во время просмотра веб-страниц, вам не нужно беспокоиться о поиске его на сайте с идентификатором символа. Просто запустите поиск символов с помощью Google, и вы получите ответ в течение нескольких секунд.
В Chrome, как и в большинстве других браузеров, вы можете легко искать в Google любой текст. Просто выделите его на странице, щелкните правой кнопкой мыши и выберите « Искать в Google по запросу [термин]» . Это откроет новую вкладку с поиском Google по запросу. Если в вашем браузере по какой-то причине этого нет, вы можете просто скопировать символ, как любой другой текст, и вставить его в Google.
В любом случае Google должен указать вам правильное направление, чтобы узнать значение этого символа.
4. Просмотрите список символов.

Юникод (стандарт кодирования текста) поддерживает ряд общих символов, благодаря чему они могут выглядеть как стандартный текст. Хотя у них нет выделенных клавиш на стандартной клавиатуре, вместо этого вы можете использовать несколько методов для ввода иностранных символов .
Если вы не смогли найти искомый символ с помощью любого из вышеперечисленных методов, возможно, вы сможете найти его, просмотрев все символы, поддерживаемые Unicode. Взгляните на список Compart “других символов” Unicode-символов, и вы можете найти тот, который вам интересен. Если вы предпочитаете альтернативу, посмотрите таблицу Unicode-символов .
Конечно, в Юникоде поддерживаются не все символы. Дорожные знаки, религиозные символы и повседневные потребительские символы не входят в его состав. Возможно, вам придется покопаться на странице списка символов в Википедии для поиска таких значков или просмотреть список символов Ancient-Symbols для менее техничных символов.
5. Изучите символы Emoji.

Хотя вы можете утверждать, что с технической точки зрения это не символы, смайлики часто сбивают с толку людей. В конце концов, есть сотни смайлов, которые нужно отслеживать, плюс постоянно появляются изменения в дизайне и новые.
Во-первых, мы рекомендуем ознакомиться с нашим руководством по значениям смайликов . Это поможет вам быстрее освоить некоторые из наиболее распространенных.
Если у вас все еще есть вопросы о символах эмодзи, загляните в Emojipedia . Здесь вы можете искать определенный смайлик, просматривать по категориям и читать новости об эмодзи. Страница каждого смайлика сообщает вам не только его официальное значение, но и то, для чего он часто используется.

Мы завершаем обсуждение раскрытия значений символов упоминанием финансовых символов. Они явно отличаются от символов, упомянутых выше, но они по-прежнему являются символом, который вы можете захотеть найти.
MarketWatch , один из наших любимых финансовых сайтов, позволяющих не отставать от рынка , предлагает удобный инструмент поиска символов. Если вы знаете интересующий вас символ, введите его, чтобы увидеть подробную информацию об этой компании. Если вы не уверены, что это, введите название компании, и вы увидите совпадения для него.
Зайдя на страницу компании, вы можете увидеть все виды данных, такие как тенденции, новости и конкуренты.
Легко узнать, что означает любой символ
Теперь вы знаете, куда обращаться, если встретите незнакомый символ. Выполняете ли вы быстрый поиск в Google или рисуете символ, который видели офлайн, вам больше не нужно гадать, что означают эти значки.
Между тем, у многих платформ и сервисов есть свои символы, о которых вам также следует знать.
Как узнать Unicode нужного символа?
Чтобы в любой момент узнать десятичный Unicode уже введен
ного символа, надо:
1. В окне открытого документа поставить курсор ввода текста справа от нужного символа.
2. Использовать сочетание клавиш Alt+X.
3. Знак будет заменен соответствующим кодом.
4. Чтобы вернуть отображение символа, достаточно снова на
жать клавиши Alt+X.
Чтобы узнать каков Unicode любого (даже не введенного в до
кумент) символа, надо:
1. В окне открытого документа перейти к вкладке «Вставка».
2. В группе «Символы» выбрать кнопку «Символ».
3. В меню «Символ» выбрать пункт «Другие символы».
4. В окне «Символ» в окошке с таблицей символов найти нуж
ный.
5. В графе «Из» выбрать кодировку – шестнадцатеричную или десятичную.
6. В графе «Код знака» отобразится код выбранного символа в нужной кодировке.
Автозамена
Некоторые часто используемые символы можно вводить в текст в режиме автозамены, то есть при наборе определенных знаков произойдет замена на нужный символ.
Как включить режима автозамены?
Чтобы включить режим автозамены, выполните следующие действия:
1. В левом верхнем углу окна программы щелкните по кнопке
«Office».
2. В меню типичных задач выберите кнопку «Параметры Word».
3. В окне «Параметры Word» выберите вкладку «Правописа
ние».
4. В поле окна щелкните кнопку «Параметры автозамены.
5. В окне «Автозамена: русский» включите пункт «Заменять при вводе».
Примеры автозамены: (с) = ©;
( r ) =®;
> =
Как создать способы автозамены?
Кроме стандартного набора знаков для преобразования в рас пространенные символы, можно организовать собственные спосо бы автозамены.
1. В окне открытого документа переходим к вкладке «Вставка».
2. В группе «Символы» выбираем кнопку «Символ».
3. В меню «Символ» выбираем пункт «Другие символы».
4. В окне «Символ» на вкладке «Символы» или «Специальные знаки» выбираем нужный символ или знак, для которого будет создаваться автозамена. Например, символ (±).
5. Щелкаем кнопку «Автозамена».
6. В окне «Автозамена: русский» на вкладке «Автозамена» в графе «На» отобразится выбранный ранее символ.
7. В графе «Заменить» набираем нужную последовательность знаков или букв, которая должна автоматически заменяться выбранным символом. Например, последовательность (/ / / /).
8. Щелкаем кнопку «Добавить».
9. Закрываем окно кнопкой «ОК».
10. Теперь после набора определенной последовательности зна ков в месте размещения курсора ввода текста появится нуж ный символ.
Примечание. Если необходимо добавить в нужном месте документа тек стовое пояснение или замечание по ходу работы с документом, необходимо воспользоваться вставкой примечания. При выводе документа на печать вне сенные примечания также могут быть распечатаны.
Источник: Игорь Пащенко – Word 2007 (Шаг за шагом) – 2008
Как узнать ASCII-код символа?
Как узнать ASCII-код символа?
-
Мне в свое время нужно было знать ASCII-код в первую очередь в Ворде. Для того, чтобы узнавать в Ворде ASCII-код символа у меня есть специальный макрос. Насколько мне известно, встроенного сочетания клавиш для этого нет.
Кстати, Unicode код символа в Ворде узнать очень просто. Для этого достаточно поставить курсор после интересующего вас символа и нажать quot;Alt+xquot;. Чтобы вернуть символ обратно опять жмите quot;Alt+xquot;.
Но в Ворде есть диалог вставки символа – Вставка -> Символ…
В не можно выбрать символ, а также в выпадающем меню quot;ASCII (дес.)quot;, и Ворд покажет в окошке слева код символа. Его, кстати, можно вставить при помощи клавиши Alt. например, чтобы вставить русские кавычки необходимо набрать сначала quot;Alt+0171quot;, затем quot;Alt+0187quot;. Цифры нужно набирать на цифровой клавиатуре справа.
-
Во многих средствах разработки приложений есть стандартные функции, чтобы узнать ASCII-код символа.
Например, в postgesSQL (он у меня сейчас открыт) можно ASCII-код узнать запросом (в окне query):
select ascii(lt;тут пишете символ или строку в кавычках, код которой нужен>), например ascii(A)
enter и табуляцию quot;проглотилоquot;:
ASCII-код enter – 13;
ASCII-код табуляции – 9;
а escape и backspace – нет, поскольку это управляющие клавиши. Их коды:
ASCII 8 BackSpace – 8 (= Ctrl + H)
ASCII 27 Escape – 27 (=Ctrl + )
Остальные коды вы без особого труда можете узнать тут.
Там же есть и про символы Windows (для разных кодировок). Ещ можно здесь посмотреть (про функциональные клавиши и прочие расширенные символы).
❶ Как определить символ
Инструкция
Используйте компонент «Таблица символов». С ее помощью вы сможете узнать код интересующего вас символа. Перейдите в меню «Пуск». Затем выберите пункт «Все программы», далее «Стандартные», затем «Служебные» и наконец «Таблица символов». Если вы хотите быстрее определить символ, то нажмите сочетание клавиш Win+R. Откроется диалоговое окно запуска программ. Введите в командной строке charman. Затем нажмите кнопку Ок.
Найдите интересующий вас символ в появившейся таблице. Кликните по нему левой кнопкой мыши. В левом нижнем углу таблицы появится Юникод символа в шестнадцатеричной кодировке. Также, через двоеточие в том же месте вы обнаружите название этого же символа, но на английском языке. Чтобы узнать символ и его порядковый номер, посмотрите в правый нижний угол окна. После префикса Alt+ размещается порядковый номер данного символа в ASCII-таблице.
Запуcтите текстовый редактор Microsoft Word, чтобы найти символ. В этом редакторе есть таблица, аналогичная той, что была рассмотрена выше. Чтобы ее запустить, на панели инструментов выберите пункт меню «Вставка», затем «Символ». Появится таблица. Чтобы узнать код символа, выделите его и посмотрите его в поле «Код знака».
Используйте таблицы символов, размещенные в интернете. Это достаточно эффективное альтернативное программное средство для установления кода символов, не вошедших в стандартные наборы операционной системы. Как правило, эти таблицы ориентированы для предоставления кода символов, которые в последствие будут размещены на веб-страницах. Также, в интернете можно найти готовые к вставке исходные проекты HTML-страниц. Если отбросить ненужные префиксы в прописанном программном коде, то можно получить кодировку более чем десяти тысяч символов.
Специальные символы Windows – все способы ввода
Ввод специальных символов — все способы.
Специальные символы можно вводить несколькими способами — правильный подход зависит от того, что это за символ. Специальные символы для программы Word, также рассмотрим в этой статье.
Системное средство ввода произвольных символов.
В операционной системе Windows имеется специальная служебная программа – Таблица символов, с помощью которой можно вставлять любые символы любых шрифтов в любые программы. Программа запускается командой Пуск > Программы > Стандартные > Служебные > Таблица символов. Ее рабочее окно показано на ниже.
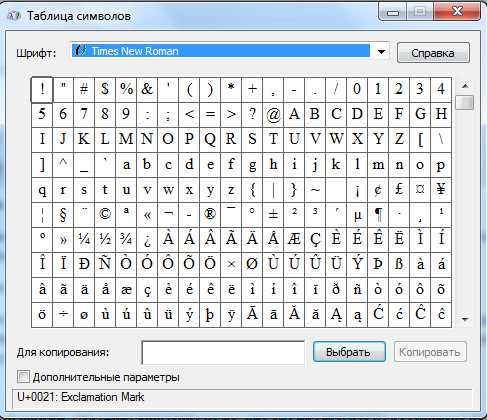
1. В поле Шрифт выберите нужный шрифт. Обратите внимание на то, что эта программа не рассчитана на работу со шрифтами формата Unicode и потому в ней различные шрифтовые наборы одного шрифта Unicode представлены как бы разными шрифтами. Получается, что вместо нескольких наборов одного шрифта Times New Roman мы имеем несколько разных шрифтов: Times New Roman Cyr (кириллица), просто Times New Roman (латиница) и Times New Roman СЕ (символы шрифтов стран Центральной Европы).
2. Выберите в таблице нужный символ и нажмите кнопку Выбрать — символ появится в поле Копировать символы (Для копирования в Word 2007).
3. После этого нажмите кнопку Копировать — символ переместится в буфер обмена Windows.
4. Сверните, не закрывая, окно программы Таблица символов и откройте свой документ. Разместите курсор там, где должен быть вставлен символ, и дайте команду вставки CTRL + V или Правка > Вставить.
5. Если символ одного шрифта вставляется в строку символов другого шрифта, то он меняет изображение, хотя его код остается правильным. Чтобы восстановить правильный вид символа, его необходимо выделить и вручную сменить шрифт.
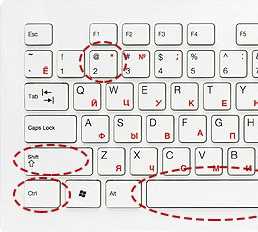
Ввод символов с помощью дополнительной цифровой панели клавиатуры.
Работая с программой — Таблица символов, обратите внимание на то, что когда какой-то символ выбран в таблице, в правом нижнем углу окна программы отображается запись, подсказывающая, за какой клавишей этот символ закреплен. Если же он не закреплен ни за какой клавишей, то здесь может показываться его альтернативный код: например для знака «§» — код ALT + 0167, а для символа «°» (градус) — ALT + 0176 и т. п.
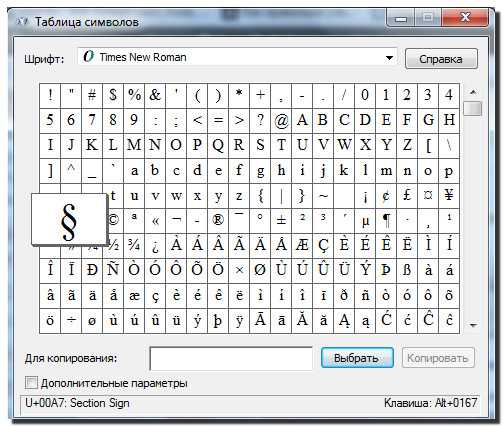 Специальные символы Windows
Специальные символы Windows
Зная альтернативный код любого символа, можно ввести любой символ с помощью дополнительной панели клавиатуры, но предварительно должна быть включена клавиша Num Lock. Ввод символов по альтернативному коду выполняют следующим образом:
♦ включите режим Num Lock и убедитесь, что зажегся соответствующий индикатор клавиатуры; ♦ нажмите клавишу ALT и не отпускайте; ♦ на дополнительной панели последовательно наберите цифры кода: 0-1-6-7;
♦ отпустите клавишу ALT — символ будет вставлен.
Как всегда, если символ одного шрифта вставляется в строку символов другого шрифта, то он при этом меняет изображение — надо его выделить и задать правильный шрифт.
Ввод специальных символов с помощью дополнительной клавиатуры осуществляется намного быстрее, чем выбором из программы Таблица символов. Поэтому имеет смысл запомнить коды нескольких символов, встречающихся в ваших документах достаточно часто.
Word и Специальные символы.
Программа имеет несколько специальных символов-разделителей, например:
♦ длинное (полиграфическое) тире; ♦ короткое тире; ♦ мягкий перенос (применяется, когда надо перейти на новую строку, не завершив предыдущую, но при этом нельзя начать новый абзац клавишей ENTER; ♦ пробелы разной ширины (так называемые шпации);
♦ неразрывный пробел (применяется между словами в тех случаях, когда они не должны оказаться на разных строках).
Для вставки специального символа-разделителя установите в нужное место курсор и дайте команду Вставка > Символ > Специальные символы. Выберите нужный символ в открывшемся диалоговом окне и нажмите кнопку Вставить.
Чтобы всякий раз, когда нужен специальный символ, не открывать это окно, посмотрите, какая комбинация клавиш закреплена за этим символом. Например, длинное тире вводят одновременным нажатием трех клавиш: CTRL + ALT + клавиша «-» на дополнительной цифровой панели клавиатуры. Если за символом не закреплена никакая комбинация клавиш, создайте собственную комбинацию с помощью кнопки Клавиша или Сочетание клавиш.
Встроенное средство ввода специальных символов в Word.
В том же диалоговом окне Символ на вкладке Символы (Другие символы для версии Word 2007) можно найти таблицу, в которой приведены символы, входящие в комплекты шрифтов Unicode.
Шрифты формата Unicode могут содержать до 65 ООО символов в отличие от обычных шрифтов, в которых символов не более 256. Формат Unicode поддерживается программой Word, начиная с версии Word 97 и до самой последней, существующей версии.
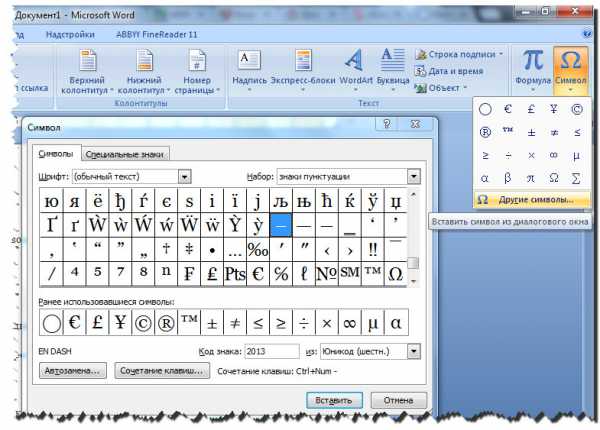
Для обеспечения совместимости с другими программами, не способными работать со шрифтами формата Unicode, комплект символов шрифта представляется в виде нескольких символьных наборов. Чтобы выбрать нужный символ, укажите сначала шрифт, например Times New Roman, а потом набор, например Кириллица. Щелчком мыши отметьте нужный символ и вставьте его в текст нажатием кнопки Вставить. Если символ используется очень часто, закрепите его за избранной комбинацией клавиш с помощью кнопки — Сочетание клавиш.

Смотрите также
-

Границы в css
-
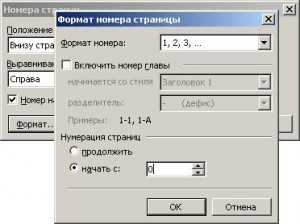
Word 2007 как не ставить номер на первой странице
-
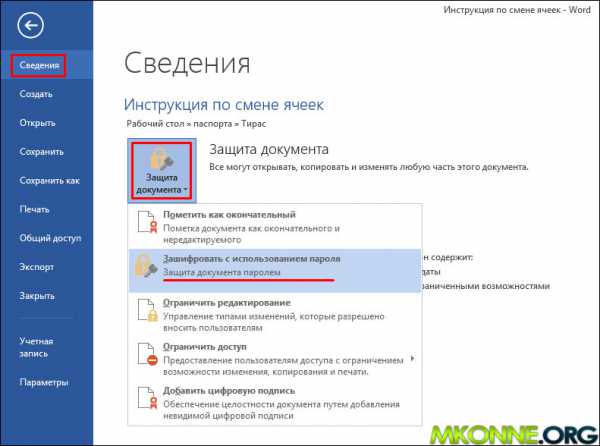
Как установить пароль на word документ
-
Иконки в css
-
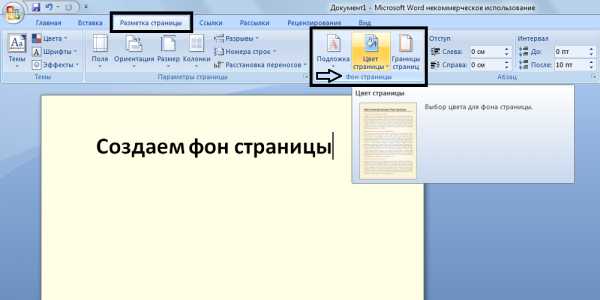
Как в word сделать фон страницы
-
Как в word 2007 по умолчанию сделать шрифт
-
Как создать шаблон документа в word 2010
-
Как в word сделать титульный лист
-
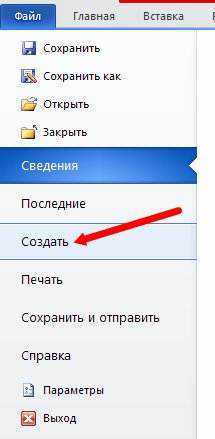
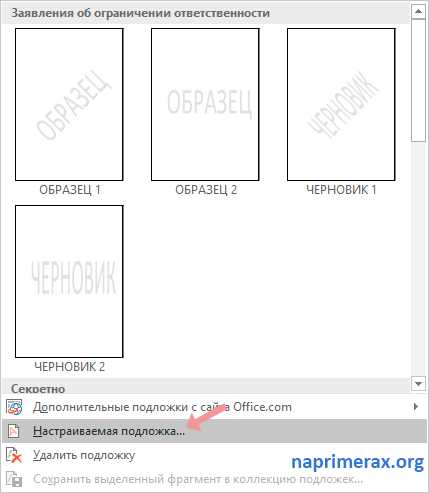
Как word убрать подложку в
-
Как в word поставить знак градуса
-
Комментарии в css коде