Как найти что-то в тексте
Время на прочтение
8 мин
Количество просмотров 5.5K
Найти объект или распознать понятие в тексте — с этого начинается решение большинства NLP задач. Если вы проектируете поисковую систему, создаете голосового помощника или классифицируете пользовательские запросы, прежде всего вы должны разобрать входной текст и попытаться найти в нем именованные сущности, которые могут быть универсальными, такими как даты, страны и города, или специфичными для конкретной модели. Обратите внимание, мы сейчас говорим лишь о тех видах задач, для которых заранее известно, что именно вы ищете или что может встретиться в тексте.
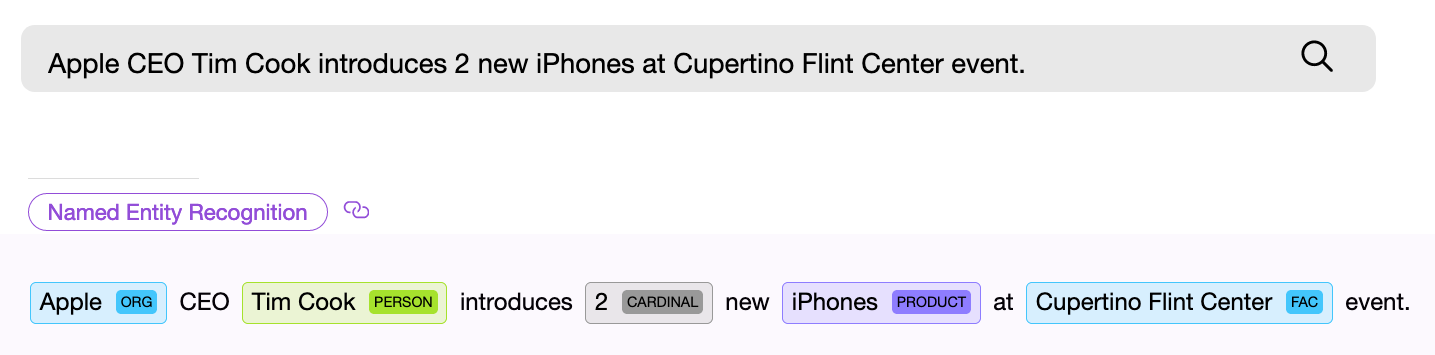
NER (named entity recognition) компонент, то есть программный компонент для поиска именованных сущностей, должен найти в тексте объект и по возможности получить из него какую-то информацию. Пример — “Дайте мне двадцать две маски”. Числовой NER компонент находит в приведенном тексте словосочетание “двадцать две” и извлекает из этих слов числовое нормализованное значение — “22”, теперь это значение можно использовать.
NER компоненты могут базироваться на нейронных сетях или работать на основе правил и каких-либо внутренних моделях. Универсальные NER компоненты часто используют второй способ.
Рассмотрим несколько готовых решений по поиску стандартных сущностей в тексте. В данной заметке мы остановимся на бесплатных или бесплатных с ограничениями библиотеках, а также расскажем о том, что сделано в проекте Apache NlpCraft в рамках данной проблематики. Представленный ниже список не является подробным и обстоятельным обзором, которых и так достаточное количество в сети, а скорее кратким описанием основных особенностей, плюсов и минусов использования этих библиотек.
Провайдеры NER компонентов
Apache OpenNlp
Apache OpenNlp предоставляет для английского языка достаточно стандартный набор NER компонентов, работающих с датами, временем, географией, организациями, числовыми процентами и персонами. Имеется небольшой набор и для других языков (испанский, голландский).
Поставка:
Java библиотека. Apache OpenNlp не поставляет модели вместе с основным проектом. Они доступны для скачивания отдельно.
Плюсы:
Apache лицензия. Модели протестированы на множестве внедрений.
Минусы:
Судя по всему, модели недаром вынесены из основного проекта. Складывается впечатление, что работа над ними или остановлена или идет в удручающе неторопливом темпе, так как новых моделей или изменений в существующих не видно уже довольно давно. Так как пользователи Apache OpenNlp могут создавать и тренировать свои собственные модели, возможно эта задача фактически полностью переложена на них.
Stanford Nlp
Stanford NLP — живой, постоянно развивающийся продукт отличного качества и широких возможностей. Для английского языка добавлена поддержка распознавания следующих сущностей: person, location, organization, misc, money, number, ordinal, percent, date, time, duration, set. Кроме того встроенный Regex NER компонент позволяет находить с высокой степенью точности такие сущности как: email, url, city, state_or_province, country, nationality, religion, (job) title, ideology, criminal_charge, cause_of_death, handle. Подробнее по ссылке. Заявлена поддержка ограниченного набора NER для немецкого, испанского и китайского языков. Качество распознавания можно попробовать с помощью онлайн демо.
Поставка:
Java библиотека. Модели можно загрузить из мавен вместе с проектом.
Я нигде не нашел перечня и детального описания NER компонентов для языков отличных от английского. По ссылкам 1, 2 — приведены примеры процесса тренировки собственных NER компонентов для разных языков. Проще говоря, возможность использовать другие языки заявлена, но придется повозиться.
Плюсы:
Ощущение от работы с проектом в целом и с готовыми моделями самое позитивное, проект живет и развивается, качество распознавания хорошее (”хорошее” — понятие условное, существуют метрики, характеризующие качество распознавания NER компонентов, но данный вопрос выходит за рамки статьи).
Минусы:
Помимо некоторого хаоса с документаций, они небольшие. Кому это важно, обратите внимание на лицензию. GNU General Public License отличается от Apache, так, например, вы не можете добавить продукт с данной лицензией в продукты, лицензируемые под Apache и т. д.
Google Language API
Google language API для английского языка поддерживает следующий список сущностей: person, location, organization, event, work_of_art, consumer_good, other, phone_number, address, date, number, price.
Платформа:
REST API, SaaS. Доступны готовые клиентские библиотеки над REST (Java, C#, Python, Go и т. д.).
Плюсы:
Большой набор NER компонентов, развитие и качество обеспечивается всем известным интернет гигантом.
Минусы:
Начиная с определенных объемов, использование платное.
Spacy
Данная библиотека предоставляет один из наиболее широких наборов поддерживаемых для распознавания сущностей, по ссылке список поддерживаемых.
Платформа:
Python.
К сожалению отсутствие личного опыта промышленного использования не позволяет мне добавить реальное описание плюсов и минусов данной библиотеки. К тому же подробный обзор питоновских NLP решений уже опубликован на habr.
Все вышеперечисленные библиотеки позволяют обучать собственные модели. Также все из них (кроме Apache OpenNlp) позволяют извлекать нормализованные значения из найденных сущностей, то есть, например, получить число “173“ из найденной в запросе числовой сущности “сто семьдесят три“.
Как мы видим вариантов решения задачи нахождения именованных сущностей представлено множество, направление их развития очевидно — расширение списка поддерживаемых языков и набора распознаваемых сущностей, улучшение качества распознавания.
Ниже описано, что привнес проект Apache NlpCraft в данную, уже широко проработанную область.
Дополнительные возможности предоставляемые NlpCraft
- Собственные NER компоненты для новых сущностей, улучшенные варианты решения для некоторых уже существующих.
- Интеграция NER компонентов всех вышеперечисленных библиотек в рамках использования продукта.
- Поддержка “составных сущностей“, что дает пользователям простую возможность создания новых собственных компонентов на основе уже имеющихся.
Теперь обо всем этом чуть подробнее.
Собственные NER компоненты
Собственные NER компоненты Apache NlpCraft — это компоненты распознавания дат, чисел, географии, координат, сортировки и сопоставления разных сущностей. Часть из них уникальна, часть — лишь улучшенная реализация существующих решений (повышена точность распознавания, добавлены дополнительные поля значений и т. д.).
Интеграция существующих решений
Все перечисленные выше решения интегрированы для использования в Apache NlpCraft.
При работе с проектом пользователю достаточно подключить нужный модуль и указать в конфигурации какие именно NER компоненты должны быть задействованы при поиске сущностей конкретной модели.
Ниже приведен пример конфигурации, для которой при поиске в тексте используется четыре различных NER компонента от двух провайдеров:
"enabledBuiltInTokens": [
"nlpcraft:num",
"nlpcraft:coordinate",
"google:organization",
"google:phone_number"
]
Подробнее об использовании Apache NlpCraft написано здесь. Для использования Google Language API необходим действующий Google developer account.
Поддержка составных сущностей
Поддержка составных сущностей — самая интересная из вышеперечисленных возможностей, остановимся на ней немного подробнее.
Составная сущность — это сущность определенная на основе другой. Рассмотрим пример. Пусть вы разрабатываете NLP систему управления, основанную на интентах (см. Alexa, Google Dialogflow, Алиса, Apache NlpСraft и т. д.), и пусть ваша модель работает с географией, но только для США. Вы можете взять любой компонент для поиска географии, например ”nlpcraft:city”, и использовать его напрямую.
Далее, при срабатывании интента, вы в соответствующей ему функции (callback), должны проверить значение поля ”country”, и если оно не удовлетворяет требуемым условиям, завершить работу функции, предотвращая ложное срабатывание. Далее вы должны вернуться к матчингу и попытаться выбрать другую, более подходящую функцию.
Что не так в данном подходе:
- Вы значительно усложняете работу с вызываемыми функциями, передавая управление из них в основной рабочий поток и обратно. Кроме того стоит учесть, что подобным функционалом передачи управления обладают далеко не все диалоговые системы.
- Вы размазываете логику матчинга между интентом и кодом исполняемого метода.
Хорошо… Вы можете с нуля создать свой собственный NER компонент по поиску американских городов, но эта задача решается не за пять минут.
Попробуем иначе. Вы можете усложнить интент (в тех системах где это возможно) и искать города, дополнительно отфильтрованные по стране. Но, повторюсь, возможность сложной фильтрации по полям элементов предоставляют далеко не все системы, кроме того вы усложняете интенты, которые должны быть максимально понятными и простыми, особенно если их много в проекте.
Apache NlpCraft предлагает механизм определения собственных NER компонентов на основе уже существующих. Ниже приведен пример конфигурации (полный синтаксис DSL доступен по ссылке, пример создания элементов — тут):
"elements": [
{
"id": "custom:city:usa",
"description": "Wrapper for USA cities",
"synonyms": [
"^^id == 'nlpcraft:city' && lowercase(~city:country) == 'usa')^^"
]
}
]
В данном примере мы описываем новую именованную сущность “американский город“ — “custom:city:usa”, основанную на уже существующей “nlpcraft:city”, отфильтрованной по определенному критерию.
Теперь вы можете создавать интенты, опирающиеся на созданный новый элемент, а встреченные в тексте города за пределами США не вызовут нежелательного срабатывания ваших интентов.
Еще пример:
"macros": [
{
"name": "<AIRPORT>",
"macro": "{airport|aerodrome|airdrome|air station}"
}
],
"elements": [
{
"id": "custom:airport:usa",
"description": "Wrapper for USA airports",
"synonyms": [
"<AIRPORT> {of|for|*} ^^id == 'nlpcraft:city' &&
lowercase(~city:country) == 'usa')^^"
]
}
]
В данном примере мы определили именованную сущность “городской аэропорт в США“ — “custom:airport:usa”. При определении этого элемента мы не только отфильтровали города по признаку принадлежности к государству, но и задали дополнительное правило, по которому названию города должен предшествовать какой-либо синоним, определяющий понятие “аэропорт”. (Подробнее о создании синонимов элементов через макросы — тут).
Составные элементы могут быть определены с любой степенью вложенности, то есть при необходимости вы можете спроектировать новые элементы на базе только что созданного “custom:airport:usa”. Также обратите внимание на то, что все нормализованные значения родительских сущностей, в данном случае базового элемента “nlpcraft:city”, доступны также в элементе “custom:airport:usa”, и могут быть использованы в теле функции сработавшего интента.
Разумеется, “составные элементы“ можно определять не только для всех поддерживаемых стандартных компонентов от OpenNlp, Stanford, Google, Spacy и NlpCraft, но и для пользовательских NER компонентов, расширяя их возможности и позволяя переиспользовать уже имеющиеся программные наработки.
Обратите внимание, фактически вы не плодите новые компоненты для каждой новой задачи, а просто конфигурируете их или “подмешиваете” их функционал в собственные элементы.
Таким образом, используя “составные сущности“ разработчик может:
- Значительно упростить логику построения интентов путем ее частичного переноса в переиспользуемые составные элементы.
- С помощью изменений конфигурации получить NER компоненты с новым поведением без обучения моделей или кодирования.
- Переиспользовать уже готовые решения с ожидаемым качеством, опираясь на существующие тесты или метрики.
Заключение
Надеюсь, что краткий обзор плюсов и минусов существующих NER компонентов будет полезен читателям, а понимание того, как с помощью Apache NlpCraft можно существенно расширить их возможности и адаптировать имеющиеся решения для новых задач, ускорит процесс разработки ваших проектов.
Все постепенно превращаются в операторов машинного производства. И переводческая отрасль — не исключение. Лингвистам требуется непрерывно держать руку на пульсе технологических достижений, чтобы оставаться успешными. Новые программы, новые сервисы, новые тенденции…
В современных быстроменяющихся условиях автоматизация различных процессов играет весьма большую, порой решающую роль. Чем больше автоматических операций, тем больше преимуществ в конкурентной борьбе. Все постепенно превращаются в операторов машинного производства. И переводческая отрасль — не исключение. Лингвистам требуется непрерывно держать руку на пульсе технологических достижений, чтобы оставаться успешными. Новые программы, новые сервисы, новые тенденции… Революций пока не происходит, но эволюция стремительна. И под нее нужно подстраиваться. Данная статья посвящена всего лишь одному аспекту переводческой деятельности — терминологии. Правильность и согласованность терминологии являются одними из ключевых показателей качества любого перевода. Все начинается с отдельных слов и словосочетаний, и сколь бы грамотным ни был текст и каким бы красивым ни был стиль, неверно или неточно переведенные термины способны «убить» любой перевод.
Когда речь идет о небольшом тексте, проблем с терминологией, как правило, не возникает. Однако по мере роста его объема даже опытные переводчики нередко «грешат» несогласованностью терминологии. При этом перевод отдельных терминов порой может занимать больше времени, чем перевод объемного текста, поскольку требуется «погружаться» в тематику, изучать контекст, вникать в его особенности и т. п. А если над проектом работает целая группа, то обеспечить согласованный перевод терминов без глоссариев практически невозможно. Говоря языком законов Мерфи, если термин может быть переведен по-разному, он точно будет переведен по-разному. Таким образом, глоссарии нужны, глоссарии важны (разумеется, если требуется качество). И весь вопрос в том, как их составлять.
Самый простой способ — искать и извлекать термины вручную. Для опытного специалиста это не проблема. Но данная операция весьма трудоемка, а лишние затраты времени в переводческом деле не приветствуются. И все-таки… Многие по-прежнему создают глоссарии вручную, хотя средства для автоматического извлечения терминов присутствуют на рынке уже достаточно давно. Так в чем же проблема? В нежелании разбираться в новых инструментах, привычке или неэффективности этих инструментов?
Для данного исследования были отобраны несколько средств из разных категорий. Во-первых, это memoQ и SDL MultiTerm Extract, которые представляют самые популярные в отрасли CAT-системы, а значит уже есть у многих переводчиков и переводческих компаний. Во-вторых, это отдельная программа SynchroTerm 2014 от компании Terminotix, которая разрабатывалась специально для извлечения терминологии, не входит в состав каких-либо программных пакетов и имеет ряд весьма положительных отзывов на просторах Интернета. SynchroTerm 2014 является платной программой, поэтому интересно узнать, насколько целесообразно ее приобретение, учитывая наличие так или иначе более доступных решений. В-третьих, были проанализированы два представителя облачных решений для извлечения терминологии, а именно сервисы Prospector («Старатель») от компании Logrus Global и Tilde Terminology от компании Tilde. Разумеется, это далеко не исчерпывающий перечень возможных решений. И в каждой из категорий можно найти еще массу вариантов, причем, возможно, какой-то «алмаз» окажется упущенным из виду. Однако все объять весьма сложно, поэтому данный перечень представляется достаточно показательным срезом для рассматриваемой области.
Исследование проводилось на примере файла технического характера в формате .doc. Файл был достаточно объемным (более 250 страниц), имел сложное форматирование и содержал чрезвычайно много разнообразных терминов. В конце файла присутствовал указатель с наиболее важными терминами, который мог послужить базой для извлечения. Кроме того, для этого файла уже существовал глоссарий, содержащий более 500 терминов, который составлялся вручную опытными переводчиками и использовался как основа для анализа результатов. При этом, чтобы не усложнять исследование, извлечение производилось только на одном языке (без использования переведенного файла и базы перевода), несмотря на то что некоторые инструменты поддерживают двуязычное извлечение. Поскольку английский язык наиболее популярен в переводческой отрасли, именно он и был выбран для анализа.
1. Средства для извлечения терминологии, встроенные в CAT-системы. SDL MultiTerm Extract и memoQ
SDL Multiterm Extract и memoQ входят в состав, пожалуй, самых популярных на рынке CAT-систем. И если MemoQ то и дело обгоняют конкуренты (например, по данным ресурса Translation Rating в России системы Memsource и Smartcat более популярны среди переводческих компаний), то продукты SDL являются безоговорочными лидерами по популярности практически во всех исследованиях. А это означает, что у многих компаний и переводчиков уже есть под рукой средства, способные автоматически извлекать терминологию. Насколько они полезны?
memoQ
В системе memoQ (данный анализ проводился в версии memoQ 8.2) извлечение терминов производится внутри проектов. Эта функция встроена в систему и не предоставляется в виде отдельного решения. После создания проекта и загрузки туда необходимых файлов на панели инструментов становится доступной команда Extract Terms. Данная команда позволяет запустить процесс извлечения терминов из документов проекта. При этом поддерживается извлечение как из файлов, так из баз перевода. Перечень настроек типичен для подобных инструментов (см. ниже). Можно задать максимальное количество слов, минимальное число знаков в слове для однословных терминов, минимальную частоту встречаемости терминов и т. д. Также можно добавить список игнорируемых слов, в том числе выбрать список по умолчанию. Никаких настроек для качества извлечения не предусмотрено.

Результат извлечения получился неплохим и в то же время не впечатляющим (см. примеры ниже). Для контрольного файла программа предложила чуть более 4 тыс. потенциальных терминов, среди которых оказалось немало «мусора». Причем игра с настройками никаких качественных улучшений внести не позволила. Отфильтровать подобный список и выделить приемлемые термины среди множества вариантов — задача непростая. Очевидно, что программа не использует лингвистический анализ, а извлекает термины на базе статистического метода. Соответственно, наличие указателя на ситуацию никак не влияло. Если тот или иной термин встречался достаточно часто, то есть превышался заданный нижний порог частоты встречаемости, программа его извлекала. В противном случае термин оставался «за кадром». Также необходимо отметить, что в список потенциальных терминов, извлеченных memoQ, попали далеко не все термины, выявленные вручную. Учитывая вышесказанное, этого и следовало ожидать.

Таким образом, функция извлечения терминологии в memoQ хоть и может быть полезной, но носит исключительно вспомогательный характер и не позволяет создать полноценный глоссарий. Скорее, она подходит, чтобы быстро отобрать некоторое множество терминов, бегло пролистав результаты и не сильно углубляясь в содержимое переводимых файлов, и составить на их основе некоторый базовый глоссарий. Вполне возможно, что кто-то вообще сочтет эту функцию декоративной и предпочтет работать по старинке, то есть вручную.
SDL MultiTerm Extract
В SDL избрали другой путь и создали целую отдельную программу SDL MultiTerm Extract. Причем эта программа регулярно меняет цифры в названии: 2014, 2015, 2017… Такой подход внушает уважение и создает впечатление, что продукт совершенствуется. Что же он может на данный момент, то есть в версии 2017?
На первом этапе SDL MultiTerm Extract предлагает выбрать способ извлечения терминов (см. окно ниже). По существу, таких способа два — одноязычное излечение и двуязычное извлечение, причем для второго способа доступны несколько вариантов. Поскольку двуязычное извлечение не является предметом настоящего обзора, двуязычный режим рассматриваться не будет.

Для одноязычного извлечения предлагается следующий набор настроек.

Можно отметить, что данный набор беднее, чем в memoQ, и, наверное, это плюс, так как в случае memoQ лишние настройки практически не способствуют более эффективному извлечению. Итак, SDL MultiTerm Extract позволяет только задать минимальное и максимальное число слов в терминах, ограничить количество извлекаемых терминов и установить уровень качества, то есть некое соотношение «сигнал/шум», которое призвано уменьшить объем «мусора» в результатах. По умолчанию предлагается среднее соотношение (некий оптимум с точки зрения разработчиков), но его можно менять в довольно широких пределах. Также программа дает возможность загрузить список игнорируемых слов, причем для многих языков, включая русский, такие списки уже есть.
Что же получается на выходе?
Например, при настройках по умолчанию для контрольного файла SDL MultiTerm Extract выдает 2086 потенциальных терминов (см. фрагмент с результатами ниже).

Объем «мусора» примерно такой же, как в memoQ, а термины также содержат относительно много обрывков фраз типа «following references are used» независимо от заданного максимального числа слов в терминах.
При изменении уровня качества число извлекаемых терминов в данном примере варьируется от 447 до 7186. Однако сказать, что результаты как-то качественно улучшаются, нельзя. Возникает ощущение, что в зависимости от настройки просто отбрасывается или добавляется часть результатов, причем как «хороших», так и «плохих», так как даже при максимально уровне относительный объем «мусора» остается значительным. Другими словами, уровень качества влияет больше на количество, чем на качество. Поэтому что означают границы уровня «мусора» «Silence» и «Noise» с точки зрения разработчиков, понять так и не удалось.
Таким образом, SDL MultiTerm Extract справляется с своей задачей примерно так же, как memoQ. Указатель отрабатывается не полностью, многие термины из составленного вручную глоссария отсутствуют. А значит все выводы, сделанные для memoQ, применимы и к этой программе.
2. Программа SynchroTerm 2014
SynchroTerm 2014 — единственная программа в данном обзоре, которая создавалась специально для извлечения терминологии, причем программа платная. Логично предположить, что качество извлечения в ней должно быть выше, чем в более многофункциональных средствах, иначе смысла приобретать отдельный продукт нет. В чем же ее преимущества?
Набор настроек в SynchroTerm 2014 (см. ниже) богаче, чем в memoQ и MultiTerm Extract, но основные настройки практически такие же, как в memoQ. Отдельно можно выделить лишь режим «Delta Extraction», возможность интеграции с CAT-системой LogiTerm и возможность извлечения только существительных. Причем режим «Delta Extraction», который позволяет извлекать только те термины, которых еще нет в базе терминов, для данного исследования бесполезен, так как не вносит никаких качественных улучшений в процесс извлечения. А CAT-система LogiTerm слишком редко используется в отрасли, чтобы имело смысл анализировать еще и ее. Едва ли кто-то станет приобретать дополнительную CAT-систему, если ему требуется просто создавать глоссарии. Таким образом, в контексте данного исследования в плюсы можно занести лишь возможность извлечения только существительных, которая может оказаться весьма полезной, учитывая, что большинство терминов являются именно существительными, а значит такая функций способна сократить объем «мусора» в результатах.

Примеры результатов, выданных программой, представлены ниже.

Программа SynchroTerm 2014 извлекла из выбранного для анализа файла примерно 4 тыс. потенциальных терминов, то есть продемонстрировала показатель на уровне memoQ. При этом в извлеченных терминах также присутствовали «мусор» и обрывки фраз. Однако следует отметить, что качество терминов оказалось значительно выше, чем в memoQ и SDL MultiTerm Extract, поскольку именно терминов SynchroTerm 2014 предложила намного больше. Причем сделала это весьма корректно. Например, в термин «still pipe array antenna» встречался в одном из документов 23 раза. И memoQ, и SDL MultiTerm Extract (при уровнях «мусора» ближе к максимальным в понимании разработчиков), разумеется, не смогли не добавить столь частотный термин в результаты. А в SynchroTerm 2014 «still pipe» и «array antenna» попали только по отдельности. И это логично, так как значение термина «still pipe array antenna» просто складывается из значений терминов «still pipe» и «array antenna» и включать его в глоссарий дополнительно смысла нет. Это явный пример лингвистической обработки текста. Правда, что любопытно, термин «array antenna of the still pipe» на удивление все-таки попал в результаты.
Практически все термины, включенные в глоссарий, который был составлен вручную, попали в список результатов. То есть в отличие от рассмотренных ранее средств задача здесь сводится к тому, чтобы профильтровать результаты. Беспокоиться о том, что что-то важное осталось за пределами внимания, практически не нужно. К тому же интерфейс программы субъективно более удобен для работы с терминологией. В нем проще анализировать контекст, отбирать надлежащие термины и добавлять их в глоссарий. Есть даже удобная функция смены регистра знаков, которая дает возможность нажатием одной кнопки воспроизвести регистр из исходного текста, если он был изменен в процессе извлечения.
Итак, SynchroTerm 2014 эффективнее и memoQ, и SDL MultiTerm Extract. Общая доля «мусора» в этой программе меньше, а количество извлекаемых терминов больше. Соответственно, на подготовку глоссариев требуется меньше времени. Кроме того, необходимо отметить, что SynchroTerm 2014 поддерживает как одноязычное, так и двуязычное извлечение. Причем двуязычное извлечение также осуществляется намного эффективнее, чем, например, в SDL MultiTerm Extract (хоть это и не является предметом настоящего исследования, данный режим тоже рассматривался). Стоит ли приобретать программу, сказать сложно. Да, она лучше справляется с задачей извлечения, чем штатные средства популярных CAT-программ. Но если учесть ее цену, а это 550 канадских долларов, то выгода представляется не такой уж однозначной. Наверное, если задачу составления глоссариев приходится решать часто, то приобретение такой программы целесообразно. Если такие задачи возникают разово, то можно обойтись и без нее.
3. Облачные сервисы
Облачный сектор, пожалуй, является одним из самых бурно развивающихся. Многие программы так или иначе переносятся в «облака». Создаются все новые и новые самостоятельные облачные сервисы. Их можно любить или не любить, но повлиять на их рост невозможно. Не могли они не затронуть и «извлечение терминологии». В Интернете можно найти немало различных сайтов со встроенными инструментами для извлечения терминологии, как платных, так и бесплатных. Наша задача не состояла в том, чтобы охватить все это разнообразие. Поэтому весьма вероятно, что где-то существует скромное, но почти идеальное решение. Например, когда-то таким же образом, то есть совершенно случайно, при поиске средств для распознавания речи удалось найти сервис Go Transcribe, который наголову превосходил всех конкурентов. Сейчас мы решили остановиться на двух представителях облачных решений — на сервисе Prospector («Старатель»), просто потому что он позиционируется как одно из лучших решений на рынке, и сервисе Tilde Terminology, поскольку он имеет несколько неплохих отзывов, но все же скорее был выбран по случайному принципу.
Tilde Terminology
Сервис Tilde Terminology является узкоспециализированным и ориентирован именно на извлечение терминологии. От таких монофункциональных решений обычно ожидаешь чего-то особенного. И учитывая результаты, которые продемонстрировала программа SynchroTerm 2014, что-нибудь неординарное могло скрываться и здесь.
Сервис имеет несколько тарифных планов. Тарифный план «Free» является бесплатным и вполне подходит для целей исследования. Он охватывает 25 языков и включает в себя почти все, что есть в платных тарифах. Исключение составляют лишь ограниченная поддержка и возможность работы только с одним проектом (впрочем, можно в любое время удалить текущий проект и создать абсолютно другой). В платном тарифе «Premium» (стоимостью от 8 до 9,95 евро в месяц в зависимости от срока подписки) уже можно работать одновременно с 20 проектами и возможна поддержка в режиме онлайн. Доступны также индивидуальные тарифные планы, стоимость которых согласуется отдельно.
В процессе создания проекта сервис предлагает выбрать тематику (см. ниже). Это интересная особенность, которую ранее встречать не удавалось. Извлечение терминов с учетом тематики вполне может быть более эффективным. Впрочем, когда документ находится на стыке тематик или относится одновременно к нескольким тематикам, такой тематический подход уже создает сложности. Кроме того, Tilde Terminology предлагает режим «Enable semantic data», что подразумевает работу со смыслом, а не только со статистическими данными. В общем, только на этапе предварительной настройки можно предположить, что качество извлечения не должно быть посредственным.

В ходе загрузки документа выяснилась одна неприятная особенность — размер одного документа не может превышать 1 МБ. В принципе, это ограничение не так сложно обойти, поскольку для извлечения терминов «тяжеловесные» объекты не нужны, однако для сокращения размера обрабатываемых файлов требуются дополнительные действия. Кстати, в случае сохранения, например, документа .doc в формате .txt для уменьшения его размера необходимо уделить внимание кодировке. В частности, для файла .txt в кодировке ANSI выданный список терминов оказался пустым.
Предварительная настройка (см. ниже), по существу, сводится только к выбору уровня качества. Следует отметить, что сервис также поддерживает двуязычное извлечение и в таком режиме предлагает на выбор еще набор источников для поиска перевода. Но так как данный обзор посвящен одноязычному извлечению, сервис анализировался исключительно в режиме «Source».

Tilde Terminology оказался самым медленным инструментом. В нашем случае извлечение заняло более 20 минут (если отключить вспомогательную функцию визуализации, то около 5 минут). В результате для контрольного файла было извлечено примерно 3 тыс. терминов. В основном извлекаются одно- и трехсловные термины. Никаких длинных обрывков фраз в результатах обнаружено не было. Для приведенного выше примера «still pipe array antenna» в список результатов, как и в SynchroTerm 2014, попали только «still pipe» и «array antenna». Откровенного «мусора» программа не выдает совсем. Встречаются лишь малоперспективные словосочетания типа «support need», «cover in order» или «actual Dielectric». Неприятным моментом стало то, что сервис оказался чувствительным к регистру, то есть в результаты, например, попали три варианта одного и того же термина «Verification pin», «Verification Pin» и «verification pin». Кроме того, некоторые термины все-таки не попадают в список. Например, термин «Hold Off Distance» не попал в результаты извлечения ни при одной из трех настроек качества. Вообще сложилось впечатление, что сервис идеально настроен на извлечение двухсловных терминов. Не удалось найти ни одного термина из двух слов, который не попал бы в список результатов. А вот с терминами, содержащими три и более слов могут возникнуть проблемы. То есть существует шанс что-нибудь упустить. SynchroTerm 2014 в этом смысле предпочтительнее, так как этой программе удается извлечь больше терминов. Впрочем, справедливости ради, и «мусора» она извлекает тоже больше.
Итак, сервис Tilde Terminology безусловно более пригоден для извлечения терминологии, чем встроенные средства CAT-систем. Но результаты его работы неоднозначны. Если сравнивать с SynchroTerm 2014, то «мусора» на выходе меньше, но и собственно терминов тоже меньше. По субъективным ощущениям работать с программой SynchroTerm 2014 удобнее, она извлекает больше терминов и делает это в разы быстрее, для нее не требуется дополнительно обрабатывать большие файлы. Плюсами Tilde Terminology являются очень качественное извлечение двухсловных терминов, поддержка автоматического перевода терминологии на базе различных источников, а также возможность бесплатного использования (впрочем, и платная версия стоит намного меньше, чем SynchroTerm). Последнее может вполне перевесить все недостатки.
Prospector («Старатель»)
Сервис Prospector от компании Logrus Global — единственный инструмент в данном обзоре, который является сугубо одноязычным. Он позволяет работать исключительно с файлами на английском языке. Другими словами, это самое узкоспециализированное средство. По утверждению разработчиков процесс извлечения построен на базе самого крупного в мире корпуса английского языка, поддерживаемого профессором Brigham Young University, извлекает много терминов, мало «мусора» и выдает на выходе глоссарий в файле Excel. А что еще надо для счастья в нашем контексте?
Использовать сервис можно бесплатно, но чтобы получить к нему доступ, необходимо подать заявку. Причем заявка обрабатывается не автоматически. Зарегистрироваться самостоятельно, как в Tilde Terminology, не получится.
Процесс извлечения предельно прост. Сначала выбирается подлежащий обработке файл (поддерживаются форматы .txt, .html, .htm, .doc и .docx), а затем нажимается кнопка «ПОЛУЧИТЬ ТЕРМИНОЛОГИЮ». Никаких настроек не предлагается. Это весьма удобно.
Стоит отметить, что первоначально сервис выдал сообщение о внутренней ошибке при попытке извлечь терминологию из файла .doc. Никакие манипуляции с этим файлом устранить ошибку не помогли. В результате пришлось пересохранить его в формате .docx, после чего процесс извлечения запустился без каких-либо проблем.
Собственно процесс извлечения в отличие от Tilde Terminology занимает считанные секунды. После его завершения создается файл Excel с несколькими вкладками. В нашем примере файл содержал следующие 6 вкладок:

Из контрольного файла Prospector извлек 2496 терминов (см. фрагмент с результатами ниже) без учета дополнительных листов.

Явного «мусора» в результатах действительно не оказалось. Большинство извлеченных терминов действительно можно считать терминами. Причем смещения в сторону двухсловных терминов, характерного для Tilde Terminology, замечено не было. Prospector способен выдать и четырехсловные, и даже шестисловные термины. Обрывков фраз, как и ожидалось, в результатах практически нет (за некоторыми исключениями типа «Function Block processes field device measurement», процент которых ничтожно мал). Впрочем, выбранный выше в качестве примера лингвистической обработки термин «still pipe array antenna» вошел в список вместе со своими составляющими «still pipe» и «array antenna», то есть найденные термины дублируются. В этом моменте Prospector, как выяснилось, уступил и Tilde Terminology, и SynchroTerm 2014. Однако, например, упущенный сервисом Tilde Terminology термин «Hold Off Distance» был извлечен, причем не один, а вместе с «Used Hold Off Distance». Вообще говоря, дублирование в том или ином виде терминов представляется основной проблемой рассматриваемого сервиса. Тот же вышеупомянутый «still pipe» вошел в довольно большое число составных терминов, например:

Это явная избыточность, тем более что некоторые другие средства, как мы знаем, смогли избежать подобного дублирования.
Также следует отметить, что в таблицу терминов попала строка типа «Witnessed calibration certificate Calibration certificate witness». Именно такого сочетания слов в исходном документе конечно же нет. Подобный результат обнаружился всего один раз, хотя мог быть и не единичным, так как тщательной проверки всех извлеченных терминов не производилось. Что явилось для сервиса побудительным мотивом в данном случае, сказать сложно. Возможно, некоторые термины интерпретируются как синонимы и объединяются (хотя это сомнительно, учитывая их эпизодический характер). Возможно, просто происходят сбои в алгоритмах обработки. Впрочем, из-за ничтожно малого количества таких элементов можно считать их несущественными.
Основное достоинство сервиса Prospector состоит в том, что он действительно находит практически все термины. В этом данный сервис вполне на уровне SynchroTerm 2014. Однако он значительно впереди с точки зрения объема «мусора», которого практически нет. Поэтому в целом его использование значительно эффективнее. Собственно, по совокупности показателей можно определенно сказать, что Prospector обеспечивает пусть и не идеальное, на наиболее качественное извлечение терминологии.
Что касается дополнительных листов, которые содержат получаемые файлы Excel, то некоторые из них в нашем случае оказались абсолютно бесполезными. Например, лист Cities содержал следующее:

Наверное, все эти аббревиатуры имеют некие географические расшифровки, но в данном документе они точно имели иной смысл. Все прочие дополнительные листы также не представляли особой пользы в нашем примере. С другой стороны, вполне вероятно, что в каких-то ситуациях они могут оказаться полезными.
Итак, сервис Prospector наиболее эффективен в плане извлечения терминологии в сравнении с другими изученными средствами. Вместе с тем он работает всего с одним языком и не поддерживает двуязычное извлечение, что серьезно ограничивает область его применения.
Заключение
В данном обзоре рассмотрены всего 5 средств для извлечения терминологии. Однако все они представляют отдельные категории и служат неким срезом для них.
В CAT-системах функция извлечения терминов реализована весьма посредственно. Здесь представлены результаты исследования только для двух наиболее популярных систем memoQ и SDL Trados Studio. Разумеется, подобные средства есть и в других системах, например, в Memsource и Déjà Vu (Лексикон). Однако практика показывает, что в настоящее время все CAT-системы находятся более или менее на одном уровне. А значит едва ли стоит ожидать от какой-либо из них прорыва в сфере извлечения терминологии.
Специализированные программы и сервисы, как и ожидалось, намного лучше справляются с задачей извлечения. Преимущество сервисов помимо прочего состоит в том, что среди них нередко встречаются бесплатные решения. А некоторые из них оказываются к тому же еще и самыми эффективными. В частности, сервис Prospector определенно можно считать лучшим средством для извлечения терминологии из англоязычных документов на данный момент. Однако он также не идеален, а другие решения демонстрируют, в каком направлении можно еще продвинуться. Остается надеяться, что извлечение терминологии еще не достигло своего пика.
Бесплатный сервис поиска слов Адвего покажет онлайн все вхождения ключевых слов, стоп-слов и слов по заданному образцу. Поиск фраз и наборов символов на любом языке.
Как работает поиск слов и фраз в тексте
Скопируйте в первое поле проверяемый текст, а во втором поле укажите все слова и фразы по одной на строку, после чего нажмите кнопку “Найти”. Чтобы найти слова в документе или на странице сайта, скопируйте весь текст в поле для проверки.
По умолчанию система ищет только точные совпадения с указанной строкой (с учетом знаков препинания).
Например, по строке “номер” будет найдено слово “номер”, но не будут найдены слова “номерной” или “госномер”. Аналогично, при поиске по фразе “легкий завтрак” будет найдена только фраза “легкий завтрак”, но не будут найдены фразы “легким завтраком” или “легкий, завтрак”.
Чтобы задать поиск по маске, используйте символ звездочки * в начале, в конце или с обеих сторон каждого слова:
ра*— будут найдены все слова, начинающиеся на “ра”, в том числе слово “ра”: работа, разный, рад.*ет— будут найдены все слова, заканчивающиеся на “ет”, в том числе слово “ет”: работает, полет, нет.*ой*— будут найдены все слова, содержащие буквосочетание “ой” в любом месте: ойкнул, водопой, спокойствие.
Маску можно указать для одного или нескольких слов во фразе, правила будут применяться последовательно:
ра* *ет— будут найдены фразы только из двух рядом стоящих слов, первое из которых начинается на “ра”, а второе заканчивается на “ет”: рабочий совет, но не будут найдены фразы “свет комет” или “равная опора”.
Также можно найти все вхождения любой заданной последовательности символов в тексте — для этого необходимо добавить символ ! в начале и конце строки.
Например, по запросу !дом! будут найдены вхождения этого буквосочетания в словах “дом”, “домашний”, “одомашненный” и т. д., но выделены будут именно вхождения, а не слова целиком, в отличие от режима поиска по маске с символом *.
Чтобы выделить все вхождения конкретного слова или фразы в тексте, нажмите на строку с ними в таблице совпадений. Чтобы выделить все совпадения, нажмите на строку с общим количеством совпадений.
Проверять текст можно неограниченное количество раз — после его редактирования или изменения списка слов нажмите повторно кнопку “Найти” и система покажет результаты новой проверки.
Возможности сервиса:
- поиск заданных слов и фраз (ключевых, стоп-слов);
- поиск по фразе целиком или по ее части;
- поиск необходимого слова или фразы в документе;
- поиск одинаковых и повторяющихся слов;
- поиск однокоренных слов по маске;
- поиск любых последовательностей символов;
- поиск в английском тексте и на любом языке.
Голосование за лучший ответ
Артур Петрусь
Мудрец
(18889)
5 лет назад
термин это определение чего либо
Екатерина Кущева
Знаток
(333)
5 лет назад
Термин — это когда ты что-то объясняшь. Кстати, это тоже можно считать термином)))
ae5yrgae srethaerУченик (71)
5 лет назад
Спартак – это термин?
Екатерина Кущева
Знаток
(333)
Нет. Тогда так: Спартак — это фк. То есть должно стоять тире)))
⠀ ⠀ ⠀ ⠀ ⠀ ⠀ ⠀ ⠀
Гуру
(2541)
5 лет назад
Это любое слово в тексте, имеющее значение/определение. Напр. (Аксиома — исходное положение какой-либо теории).
Даниил Копосов
Мыслитель
(6482)
5 лет назад
Слово “термин” означает уникальную номинацию – то, у чего не может быть синонимов. например, слово “хомяк” – термин. Или слово “унитаз”. Или слово “скальпель”. Если не торопиться и внимателшшьно читать текст, найдёте. Удачи!
Существует множество систем
извлечения терминов, основанные на
правилах, такие, как система DEFINDER
[Klavans,
Muresan
2000], позволяющая извлекать термины из
медицинских текстов, LSPL
[http://www.lspl.ru/]. –
язык, предназначенный для формального
описания конструкций русского языка,
система ACABIT
[Daille
1994], которая использует не только
статистические данные, но и правила для
извлечения терминов. Некоторые из этих
систем мы рассмотрим более подробно в
следующем разделе.
Кроме того, существуют системы,
которые можно использовать для написания
собственных правил. Такие системы
разрабатываются в основном для извлечения
информации, и могут так же быть использованы
для извлечения терминов.
Например, Томита-парсер
компании «Яндекс». [https://tech.yandex.ru]
«Томита-парсер создан для извлечения
структурированных данных из текста на
естественном языке. Вычленение фактов
происходит при помощи контекстно-свободных
грамматик и словарей ключевых слов.
Парсер позволяет писать свои грамматики
и добавлять словари для нужного языка».
[https://tech.yandex.ru/tomita/]
С помощью парсера можно извлекать
термины. Приведем пример правила на
языке Tomita:
Такое правило извлечет все
конструкции типа область
желтого пятна, где главное
слово – существительное в именительном
падеже, от него зависит именное
словосочетание в родительном падеже
(gnc-agr
– параметр,
обозначающий согласование в роде (g),
числе (n)
и
падеже (c)).
Подобные грамматики можно писать
и, например, в системе Sketch
Engine
[https://www.sketchengine.co.uk/].
Смешанные подходы
автоматическому определению терминов
является сочетанием статистических и
лингвистических методов, то есть,
например, использование шаблонов для
выделения терминов и одного из
статистических критериев (или их
комбинации) для фильтрации. Такие подходы
наиболее популярны на данный момент,
так как они позволяют уменьшить уровень
«шума» и повысить качество автоматического
извлечения терминов. Примером смешанного
подхода является системам ACABIT
[Daille
1994], которая использует как статистические,
так и лингвистические данные. Подробное
описание этой системы содержится в
разделе 2.4.2.
В этом разделе мы рассмотрим
несколько систем автоматического
извлечения терминологии и проанализируем
их особенности.
«Язык LSPL (Lexico-Syntactic
Pattern Language) предназначен для формального
описания конструкций (выражений) русского
языка с целью их представления в системах
извлечения информации из текстов
(Information Extraction Systems)» [http://www.lspl.ru/]. Работа
над созданием LSPL
была начата в 2007 г. в МГУ им. Ломоносова.
LSPL
создавался как язык описания лексических
и грамматических свойств конструкций,
характерных для русского языка. Такие
конструкции выделялись на основе
морфологического и синтаксического
анализа и описывались в виде
лексико-синтаксических шаблонов. Язык
был создан для автоматизации некоторых
задач анализа научно-технических
текстов.
В этой системе
существует набор шаблонов и основанные
на этих шаблонах алгоритмы выделения
терминов. Шаблон языка LSPL
задает последовательность слов, из
которых может состоять соответствующая
конструкция и описывает условия
согласования этих слов. Например, шаблон
A
N
<A=N>
описывает
словосочетания прилагательное +
существительное с согласованием по их
общим морфологическим характеристикам
(сахарный
диабет, первичная глаукома).
Для элементов могут задаваться не только
части речи, но и их морфологические
характеристики. В шаблоне так же может
определяться повторяемость элементов,
их обязательность/необязательность,
альтернативные элементы. Шаблоны
подразделяются на несколько групп. Ниже
приводится таблица, содержащая группы
шаблонов, их примеры и примеры употребления.
Таблица 1. Лексико-синтаксические шаблоны
[Ефремова, Большакова, Носков, Антонов
2010]
Описываемое исследование было
проведено на основании корпуса текстов
по физике и информатике. Для каждого из
этих шаблонов разработан алгоритм
распознавания соответствующего
терминоупотребления в тексте.
Дополнительные алгоритмы отвечают за
вычисление частоты употребления термина
в тексте. С большой вероятностью среди
так называемых терминов-кандидатов
могут оказаться общенаучные термины,
которые не должны выделяться. Если
необходимо найти варианты термина, на
вход программе поступают не только
текст и набор шаблонов, но и термины,
для которых надо найти варианты и список
слов и словосочетаний, среди которых
нужно искать варианты. После тестирования
работы программы на корпусе текстов
результаты сравнивались с результатами
работы экспертов, оценивались точность
и полнота. Результаты представлены в
таблице.
Таблица 2. Полнота и точность процедур
[Ефремова, Большакова, Носков, Антонов
2010]
Авторы приходят к выводу, что
полноту можно повысить, увеличивая
количество шаблонов, но от этого будет
страдать точность. Кроме того, была
разработана схема сочетания нескольких
процедур для того, чтобы одна процедура
могла учитывать результаты работы
другой. Эти комбинации дали значительные
результаты: для оценки использовалась
F-мера,
ее прирост при использовании комбинации
алгоритмов для выделения терминов
составил 19,8%, для выделения терминоупотреблений
15,5%. [Ефремова, Большакова,
Носков, Антонов 2010]
Система была разработана в 1994
г. [Enguehard, Pantéra 1995]
Поскольку система должна работать
как с письменными, так и с устными
текстами, она не может использовать
синтаксические структуры, так как они
часто видоизменяются в устной речи.
Кроме того, в устной речи чаще встречаются
неологизмы. Помимо этого, в системе
используется количественный критерий:
слова, состоящие из менее 3-х букв, не
считаются терминами. Авторы используют
функцию взаимной информации (mutual
information)
как меру связи между словами. Чтобы
избежать использования лингвистических
характеристик, была разработана концепция
«гибкого распознавания строк», которая
порождает математическую функцию для
определения степени сходства между
словами. Система включает в себя две
части: модуль сходства и модуль
распознавания. Первый модуль делит
слова на три группы:
Второй модуль отвечает за
извлечение новых терминов на основании
уже имеющихся. Из связи между выделенными
словами автоматически создается
семантическая сеть. Эта часть основана
на совместной встречаемости слов,
возможны три варианта сочетания слов:
Система рекурсивно ищет элементы
в этих трех вариантах сочетания до тех
пор, пока не находит новый термин. Авторы
протестировали систему на корпусе
(25 000 слов), 29 терминов. Процент ошибки:
25%. [Enguehard, Pantéra 1995] [Cabré
et
al.
2001]
Система была разработана в 1994
г. [Daille
1994] В основе этой системы лежит сочетание
лингвистических и статистических
методов. На вход программе должен
подаваться морфологически размеченный
корпус. На основании синтаксических
шаблонов создается список терминов-кандидатов,
который впоследствии фильтруется
статическими методами.
Программа создана для выделения
терминов французского языка. Для
французского языка важнейшим шаблоном
являются N1
PREP
(DET)
N2
и N
ADJ
PREP
à (DET)
N2
(Сущим
Предл (Определитель) Сущрод
и Сущ
Прил Предл à
(Определитель) Сущрод
). К этим
шаблонам применяются статистические
алгоритмы. Для выделения сочетаний,
соответствующих шаблонам, используется
алгоритм конечных состояний. Алгоритм
конечных состояний представляется
подмножеством грамматических тэгов, к
которым добавляются леммы, словоформы
и знаки пунктуации. Таким образом, этот
алгоритм рассматривается как
лингвистический фильтр, который выбирает
определенные шаблоны, устанавливая при
этом частоту их встречаемости и выделяя
их различные вариации.
Корпус анализируется статистически
с помощью множества статистических
мер, которые можно разделить на следующие
четыре группы: меры частоты, критерии
ассоциации, критерии сходства и меры
расстояния. В первую очередь рассматриваются
пары лемм, входящие в один шаблон как
две переменные, для которых подсчитывается
степень зависимости. Данные представляются
в таблице сопряженности.
Для установления степени
независимости переменных в таблице
применяются 18 мер, среди которых,
например, частота и функция правдоподобия.
Система показывает достаточно
хорошие результаты. При этом появляется
некоторое количество «шума», связанного
с ошибками в морфологической разметке
или с наличием сочетаний, не являющихся
устойчивыми, но встречающимися достаточно
часто. [Cabré
et
al.
2001]
Система разработана в 1996 г.
[Jacquemin
1996] Она направлена на извлечение вариантов
терминов по имеющемуся списку терминов
(может использоваться и для извлечения
терминологии). Эти термины могут
содержаться в базе данных или поставляться
специализированной программой.
Первый этап работы алгоритма –
анализ списка терминов и составление
списка правил. Парсер отвечает за
применение этих правил. Варианты терминов
извлекаются с помощью метаграмматики,
которая генерируется динамически.
Следующим этапом из нескольких метаправил
генерируются новые правила, чтобы
описать все возможные варианты каждого
термина в списке.
Метаграмматика изначально
включает 73 правила образования вариантов
терминов: 25 правил соединения, 31 правило
трансформации и 17 правил вставки. Каждое
из этих правил связано со своей частью
синтаксического анализатора, что
увеличивает скорость работы системы.
Lexicalization
– действие, активирующее работу правила.
Таким образом, правило для слова «serum»
запускается с помощью предыдущего
правила, когда это слово встречается в
предложении.
Каждое правило представляет
конкретную структуру и конкретный
шаблон. В метаправиле могут содержаться
определенные ограничения.
Процесс выделения терминов
длится до тех пор, пока не выделятся все
возможные термины. Для английского
языка метаграмматика содержит 73 правила:
25 правил соединения, 17 вставки и 31 правило
замены.
Автор описывает эксперимент,
проведенный на корпусе медицинских
текстов (1,5 млн. слов) и списке из 70 000
терминов. После 15 итераций было выделено
17 000 терминов, из которых 5 000 были
новые. Но, когда список изначальных
терминов был уменьшен до 6 000, программа
находит всего 3 800 новых терминов.
Данные, зависимые от выбранного языка
хранятся в отдельном текстовом файле,
что позволяет использовать программу
для разных языков. FASTR
была применена для японского, английского
и испанского языков.
Алгоритм включает в себя два
этапа: лингвистический анализ и инструмент
выделения терминов. Лингвистический
анализ включает в себя несколько частей:
Программа выделения терминов
состоит из нескольких частей: модуль
запросов к корпусу (CQP), модуль языка
запросов и модуль выделения ключевых
слов из контекста (KWIC). Язык запросов
имеет сложную структуру, для разных
типов терминов существуют разные
запросы. Например, для терминов, состоящих
из одного слова, запросы формируются
из морфем или типичных компонентов,
образующих дериваты.
Этот инструмент был применен к
корпусу текстов по автомобилестроению
на немецком языке (35 000 словоупотреблений).
Корпус был проанализирован вручную
перед началом автоматического анализа.
Результаты:
Использование тематических
моделей для автоматического выделения
терминов направлено в первую очередь
на повышение точности выделения
терминологии. Был проведен эксперимент,
результаты которого представлены в
статье [Нокель, Лукашевич 2013] Так как
большинство терминов относятся к
какой-либо подтеме предметной области,
авторы предлагают использовать
тематические модели для определения
подтем текста и тем самым улучшить
качество автоматического извлечения
терминов.
Статистические тематические
модели коллекции текстов с помощью
статистических методов устанавливают
принадлежности текста из коллекции к
определенной подтеме и выделяют список
слов, образующих каждую подтему. Авторы
приводят примеры подтем для русских
текстов по банковской тематике.
Обычно в тематический моделях
используется модель мешка слов, при
которой текст представляется как набор
слов, в нем содержащихся. Для этого
исследования так же была проведена
предобработка: из текста были выбраны
прилагательные и существительные, так
как ими покрывается основная часть
терминов.
В ходе эксперимента авторы
сначала выбрали наилучшую тематическую
модель. Были проанализированы тематические
модели, основанные на методах кластеризации
текстов К-средних, иерархическая
агломеративная кластеризация,
неотрицательная матричная факторизация
(NMF),
вероятностные тематические модели
(PLSI,
LDA).
Среди всех этих методов лучший результат
был получен при использовании NMF.
Далее авторами было проведено
сравнение результатов работы алгоритмов
извлечения терминологии без тематических
признаков и с тематическими признаками.
Для коллекции русских текстов
точность возросла с 54.6% до 56.3%, для
коллекции английских текстов с 50.4% до
51.4%. [Нокель, Лукашевич 2013]
Результаты работы системы по сравнению
с результатами других систем можно
назвать средними. Это может быть связано
с тем, что тематические слова не всегда
однозначно соотносятся с терминами, а
многие термины, наоборот, не являются
тематическими слова. В связи с этим
падает точность и полнота работы системы.
Целью данной работы было создание
программы автоматического поиска
терминов на основании деривационных
преобразований терминоэлементов. В
этой главе мы опишем проведенный
эксперимент.
Программа нацелена на выделение
однословных узко специальных терминов.
В рамки нашего исследования не будет
входить поиск терминов-аббревиатур
и многословных терминов. В связи с этим
вне нашего анализа останутся такие
характерные для медицины типы терминов,
как двухсловные термины образованные
с использованием имен собственных
(болезнь Гиппеля – Линдау)
или трехсловные термины с главным словом
существительным (область
желтого пятна). Так же за
рамками нашего исследования останутся
латинские термины, употребляющиеся без
перевода и записывающиеся латиницей.
Такие термины в основном используются
на практике (в историях болезни, справках),
но достаточно редко используются в
медицинской литературе.
Наш эксперимент состоит из двух
основных частей: предварительная
подготовка, в рамках которой были
выделены характерные для офтальмологии
деривационные модели и словообразовательные
форманты и собственно эксперимент.
Для проведения исследования был
создан корпус текстов на материале
статей по офтальмологии из журнала
«Офтальмологические ведомости» за
2008, 2009, 2010, 2011 и 2012 годы (см. Список
использованных материалов) и статей из
журнала «Современная оптометрия» за
2008 и журналов «Эффективная фармакотерапия.
Эндокринология», «Эндокринология:
новости, мнения, обучение», «ФАРМАТЕКА»,
«Consilium Medicum» за 2012 и 2014 годы. Часть этого
корпуса – подкорпус, содержащий 70 000
словоупотреблений – использовалась
для определения начального списка
аффиксов и опорных основ (которые
впоследствии использовались для
выделения терминоэлементов). Вторая
часть – собственно тестовый подкорпус
на 30 000 словоупотреблений.
Оценка результатов производилась
двумя экспертами: врачом-офтальмологом
и врачом-эндокринологом, хорошо знакомым
с выбранной узкой областью медицины.
Работа экспертов состояла из двух
частей: сначала проверяли термины,
выделенные при предварительной обработке
текста, после этого проверялись результаты
работы программы.
Наша программа состоит их двух
частей: на первом этапе на основе списков
аффиксов и опорных основ выделяются
терминоэлементы; вторым этапом является
выделение терминов на основе выделенных
терминоэлементов. Далее мы подробно
опишем нашу программу и алгоритм ее
работы.
-
Предварительная подготовка: анализ
текста, выделение аффиксов и опорных
основ
В ходе предварительной подготовки
было сделано следующее:
-
морфологический анализ;
-
проверка слов на предмет
отсутствия анализа; -
для непроанализированных слов
были выделены основы и аффиксы; -
были составлены списки опорных
основ и основных деривационных моделей.
Для анализа текста использовался
морфологический анализатор Mystem компании
«Яндекс». [https://tech.yandex.ru/mystem/] Эта программа
работает на основе словаря, но может
строить гипотетические разборы новых
слов. Корпус был проанализирован с
помощью Mystem,
в отдельный файл были записаны слова,
которые программа посчитала новыми и
для которых сформировала гипотетический
анализ. Пример гипотетического анализа,
выполненного программой Mystem:
хориоретинопатии{хориоретинопатия?}
нейросенсорного{нейросенсорный?}
хориоретинопатией{хориоретинопатия?}
хориоретинопатию{хориоретинопатия?}
ретинопатия{ретинопатия?}
хориоретинопатии{хориоретинопатия?}
хориоретинопатии{хориоретинопатия?}
биомикроскопия{биомикроскопия?}
диоптрийности{диоптрийность?}
хориоретинопатия{хориоретинопатия?}
хориоретинопатия{хориоретинопатия?}
хориоретинопатии{хориоретинопатия?}
неоваскуляризации{неоваскуляризация?}
биомикроскопии{биомикроскопия?}
эпителиопатией{эпителиопатия?}
субконъюнктивальный{субконъюнктивальный?}
рецидивирующем{рецидивирующий?|рецидивировать?}
хориоретинопатии{хориоретинопатия?}
нелеченными{нелечивать?}
На основе такого анализа был
создан список необработанных слов
(список необработанных слов см. Приложение
1). В список входят более 600 слов. Для
каждого были построены деривационные
модели. Списки деривационных моделей
были отсортированы по части речи
мотивированного слова. После этого был
создан список основных (наиболее
частотных) моделей и составлен список
опорных основ, списки суффиксов и
префиксов. Пример наиболее частотных
деривационных моделей для нашего
корпуса:
-
суффиксация
-
глаголы
N+ирова
-
существительные
Adj+ость
N+ст
-
прилагательные
N+тивн
V+ан/анн
N+альн
-
префиксация (образование
существительных)
-
авто+N
-
ауто+N
-
био+N
-
гипер+N
-
гипо+N
-
де+N
-
дис+N
-
ин+N
-
интра+N
-
микро+N
-
не+N
-
нео+N
-
пан+N
-
поли+N
-
пре+N
-
ре+N
-
суб+N
-
опорные основы
-
вазо-
-
витрео-
-
нейро-
-
хорио-
-
инсулино-
-
офтальмо-
-
кислород-
-
-патия
-
-логия
-
-скопия
-
-стомия.
Списки опорных основ, суффиксов
и префиксов используются в программе
автоматического извлечения терминов.
-
Программа по автоматическому извлечению
терминов
Как было сказано выше, наша
программа состоит из двух частей. На
первом этапе работы программы производится
поиск терминоэлементов в тексте. На
основе списков опорных основ, префиксов
и суффиксов, сформированных на этапе
предварительной подготовки, программа
выделяет терминоэлементы.
При разработке алгоритма
автоматического извлечения терминов
мы исходили из того, что в рамках одного
текста часто встречаются целые
деривационные цепочки терминов. Можно
предположить, что, если один и тот же
терминоэлемент встречается в нескольких
соседних предложениях текста, значит,
его значение имеет отношение к тематике
текста и, соответственно, к терминологической
системе этой области знания. Мы часто
можем встретить подобные деривационные
ряды в научной литературе, например,
макула, макулярный, макулодистрофия.
На стадии предварительной
подготовки мы выделили ряд терминоэлементов,
характерных для текстов по выбранной
нами тематике. Большинство этих
терминоэлементов общенаучного или
общелитературного характера. В ходе
эксперимента будет осуществляться
поиск слов, содержащих эти терминоэлементы.
В найденных словах терминоэлементы из
списка будут отрезаться и, как мы
предполагаем, оставшуюся часть тоже
можно считать терминоэлементом. Далее
осуществляется поиск оставшихся
терминоэлементов в ближайших нескольких
предложениях, и, если один и тот же
терминоэлемент встречается пределах
нескольких предложений более одного
раза, слова, соответствующие ему,
выделяются.
Опишем алгоритм работы этой
части программы:
-
На вход программе подается текст
в формате .txt,
размеченный с помощью морфологического
анализатора Mystem
с сохранением предложений и три списка
в формате .txt:
список опорных основ, список префиксов
и список суффиксов (списки
опорных основ, суффиксов и префиксов
см. Приложение 2). Для того
чтобы сохранить деление на предложения
в тексте, используется специальная
опция морфоанализатора, позволяющая
сохранять исходный текст при выводе. -
Программа осуществляет поиск
элементов из списков по документу.
Сначала осуществляется поиск префиксов,
затем суффиксов, после этого опорных
основ. -
Когда программа находит
соответствующий элемент списка, она
удаляет его из данного слова. -
В результате получается список
терминоэлементов.
Рассмотрим пример работы этой
части программы.
На вход поступает фрагмент
текста, проанализированного с помощью
морфологического анализатора. Анализ
производится для того, чтобы привести
все слова к начальной форме, таким
образом, программа сможет распознать
окончания (по списку) и отрезать их.
После того, как программа отрежет
окончания, начнется стадия выделения
терминоэлементов.
На вход программе поступает
следующий текст:
Возрастная{возрастной}
макулярная{макулярный?}
дегенерация{дегенерация} это{это}
хроническое{хронический}
прогрессирующее{прогрессировать}
заболевание{заболевание},
характеризующееся{характеризоваться}
поражением{поражение} центральной{центральный}
зоны{зона} сетчатки{сетчатка}
(области{область} желтого{желтый}
пятна{пятно} макулы{макула?}). {s}В{в}
литературе{литература} можно{можно}
встретить{встречать} и{и} другие{другой}
термины{термин}, обозначающие{обозначать}
эту{этот} патологию{патология}:
инволюционная{инволюционный}
центральная{центральный}
хориоретинальная{хориоретинальный?}
дистрофия{дистрофия},
склеротическая{склеротический}
макулодистрофия{макулодистрофия?},
возрастная{возрастной} макулярная{макулярный?}
дистрофия{дистрофия}, сенильная{сенильный}
макулярная{макулярный?} дистрофия{дистрофия},
возрастная{возрастной} макулопатия{макулопатия?},
связанная{связывать} с{с} возрастом{возраст}
макулярная{макулярный?} дегенерация{дегенерация}.
На выходе получаем текст с
выделенными в нем терминоэлементами
из списка. Поиск самих терминоэлементов
происходит по словам, приведенным к
начальной форме (словам в фигурных
скобках), но, чтобы сохранить исходный
текст, на выходе программа возвращает
исходные слова. Итак, на выходе программа
записывает к .txt
файл следующий текст:
Возра-ст-ная
макул-яр-ная
де-генерация
– это хроническое прогрессиру-ющ-ее
заболевание, характеризу-ющ-ееся
поражением центр-альн-ой
зоны сетчатки (области желтого пятна
макулы).
В литературе можно
встретить и другие термины, обозначающие
эту пато-лог-ию
: ин-волюционная
центр-альн-ая
хориоретинальная дистрофия,
склеротическая макулодистрофия ,
возра-ст-ная
макул-яр-ная
дис-трофия
, сенильная макул-яр-ная
дистрофия , возра-ст-ная
макуло-патия
, связанная с возрастом макул-яр-ная
де-генерация.
Вторая часть работы программы
отвечает за выделение терминов:
-
Программа осуществляет поиск
выделенных на первом этапе
терминоэлементов в документе. -
Если терминоэлемент найден,
то проверяется, если ли такой же
терминоэлемент в нескольких соседних
предложениях текста (это число можно
настраивать; в нашей работе приведены
результаты с n=10). -
Когда программа находит один
и тот же терминоэлемент в нескольких
соседних предложениях текста она
выделяет слова содержащие этот
терминоэлемент. Предполагается,
что это слово является термином.
Параметр n
ближайших предложений введен для того,
чтобы исключить возможность случайного
попадания в список выделенных терминов
слов общелитературного языка, общенаучных
терминов, общемедицинских терминов.
Изначально для нашей программы установлено
n=2,
но в ходе работы над программой этот
параметр был изменен несколько раз на
основе анализа текстов входящих в
корпус. Результаты будут представлены
ниже.
Рассмотрим работу этой части
программы на примере.
На предыдущем примере было
показано, какие терминоэлементы выделила
наша программа. На этом этапе на основе
этих терминоэлементов программа выделяет
другие терминоэлементы и осуществляет
их поиск по документу.
Возра-ст-ная
макул-яр-ная
де-генерация
– это хроническое
прогрессиру-ющ-ее
заболевание, характеризу-ющ-ееся
поражением центр-альн-ой
зоны
сетчатки (области желтого пятна макулы).
В литературе можно
встретить и другие термины, обознача-ющ-ие
эту пато-лог-ию
: ин-волюционная
центр-альн-ая
хориоретинальная
дистрофия,
склеротическая макулодистрофия
, возра-ст-ная
макул-яр-ная
дис-трофия
, сенильная
макул-яр-ная
дис-трофия
, возра-ст-ная
макуло-патия
, связанная с возрастом макул-яр-ная
де-генерация.
На примере мы видим, как происходит
выделение терминоэлементов к рамках
двух соседних предложениях. Красным
отмечены те термины, которые не были
выделены программой. Другими цветами
отмечены повторяющиеся терминоэлементы
и, соответственно, слова, которые были
выделены в качестве терминов. Следует
обратить внимание на некоторые слова,
в которых были найдены терминоэлементы
из списка, но, при этом, они не были
выделены в качестве терминов, так
соответствующий им терминоэлемент
встречается в рамках двух предложений
только один раз (например, пато-лог-ию).
В следующем разделе мы подробно
опишем разные этапы разработки программы
и результаты ее работы на разных этапах.
Кроме того, будут проанализированы
причины ошибок в работе программы и
приведены идеи по улучшению качества
работы программы.
-
Анализ результатов эксперимента
В этом разделе будут описаны
результаты проведенного эксперимента.
В ходе анализа работы программы на
разных стадиях мы пришли к выводу, что
результаты зависят от того, в рамках
какого фрагмента текста происходит
поиск терминов. Здесь будут представлены
результаты для различных настроек
программы.
Для анализа результатов работы
программы мы использовали такие метрики,
как точность и полнота.
Точность
рассчитывается по формуле: ![]()
Полнота
рассчитывается по формуле:![]() ,
,
где A —
количество правильно выделенных
терминов; B —
количество ошибочно выделенных терминов;
C —
количество ошибочно невыделенных
терминов.
Результаты. Этап 1.
На первом этапе разработки
программы было принято решение выделять
термины в пределах двух соседних
предложений и только в пределах одного
абзаца. Как было описано выше, программа
производила поиск терминоэлементов и
проверяла, есть ли такие же терминоэлементы
в двух следующих предложениях (n
= 2). Если такие терминоэлементы были
найдены, она выделяла их и продолжала
поиск для следующего найденного
термоэлемента.
Здесь следует снова обратиться
к нашему примеру.
Возра-ст-ная
макул-яр-ная
де-генерация
– это хроническое
прогрессиру-ющ-ее
заболевание, характеризу-ющ-ееся
поражением центр-альн-ой
зоны
сетчатки (области желтого пятна макулы).
В литературе можно
встретить и другие термины, обознача-ющ-ие
эту пато-лог-ию
: ин-волюционная
центр-альн-ая
хориоретинальная
дистрофия,
склеротическая макулодистрофия
, возра-ст-ная
макул-яр-ная
дис-трофия
, сенильная
макул-яр-ная
дис-трофия
, возра-ст-ная
макуло-патия
, связанная с возрастом макул-яр-ная
де-генерация.
Так выглядели результаты работы
программы для данного отрывка, когда
поиск осуществлялся в пределах одного
абзаца в двух соседних предложениях.
Мы видим, что большинство терминов не
были выделены, потому что соответствующие
им терминоэлементы повторялись уже в
следующем абзаце.
Для такого варианта настройки
программы результаты выглядят
неудовлетворительно. Всего было выделено
32% терминов. Точность составила при этом
0,91, а полнота 0,33. В связи с получением
неудовлетворительных результатов на
первом этапе было принято решение
изменить конфигурации программы.
Результаты. Этап 2.
На втором этапе разработки
программы было принято решение удалить
из программы ограничение на поиск в
пределах одного абзаца. Несмотря на то,
что чаще всего деление на абзацы связано
с тема-рематическим членением, и,
возможно, могло быть достаточно удобным
фильтром для выделения какой-либо
информации из общелитературных текстов,
она не подходит в качестве фильтра для
выделение терминологической лексики
в связи с тем, что один и тот же узко
специальный термин (и однокоренные
термины) встречается, как правило, не
только в рамках одного абзаца.
Итак, результаты работы программы
при удалении фильтра по абзацу с
сохранением поиска по ближайшим двум
предложениям.
Для такого варианта настройки
программы результаты резко изменились,
но удовлетворительными их считать
нельзя. Всего было выделено 46% терминов.
Точность составила при этом так же 0,91,
а полнота 0,47. На следующем этапе мы
снова изменили конфигурации программы
для улучшения качества ее работы.
Результаты. Этап 3.
На этом этапе было принято решение
расширить поиск до n
= 5. Здесь результаты выглядят более
убедительно, хотя, все еще остаются
термины, которые могли быть выделены
нашим алгоритмом, но не выделяются
именно из-за фильтра в 5 ближайших
предложений.
Итак, всего программой было
выделено 50% терминов. Точность составила
при этом так же 0,91, а полнота выросла до
0,51.
Результаты. Этап 4.
На этом этапе работы программы
поиск осуществлялся по ближайшим 10
предложениям. Мы получили следующие
результаты: всего программой было
выделено 53% терминов. Точность составила
при этом так же 0,89, а полнота выросла до
0,54. Как мы видим, при такой конфигурации
программы упала точность извлечения
терминов, это связано с тем, что вероятность
появления случайных слов (и, соотвественно,
нетерминов) в пределах большего числа
предложений выше, чем для, например, n
= 2.
Далее мы приводим сводную таблицу
результатов для всех этапов разработки
программы.
|
Этап 1 |
Этап 2 |
Этап 3 |
Этап 4 |
|
|
% |
32% |
46% |
50% |
53% |
|
P |
0,91 |
0,91 |
0,91 |
0,89 |
|
R |
0,33 |
0,47 |
0,51 |
0,54 |
Таблица 3. Результаты работы программы
по автоматическому извлечению терминологии
на разных этапах разработки
Как видно из таблицы от первого
к последнему этапу результаты работы
программы значительно улучшились. Но,
несмотря на это, остается ряд терминов,
которые наша программа не выделяет.
Такие ошибки принято называть ошибками
первого рода или ложноположительным
срабатыванием. Далее мы рассмотрим
причины возникновения ошибок.
Существует несколько причин
ошибочной работы программы, то есть
выделения слов, не являющихся терминами:
-
Морфологическое сходство
терминов и нетерминов -
Высокая частота появления в
текстах некоторых терминов других
наук, не относящихся к медицинской
терминологии.
Рассмотрим эти причины. Под
морфологическим сходством подразумевается
то, что, как уже было упомянуто выше,
термины образуются по тем же правилам
и, достаточно часто, с использованием
тех же словообразовательных элементов,
что и слова общелитературного языка. В
связи с этим в структуре термина часто
встречаются аффиксы, характерные так
же и для общелитературного языка. Помимо
этого, проблема возникает и при
разграничении узко специальной
терминологии и общенаучной терминологии,
терминологии разных наук, поскольку
часть деривационных формантов используются
во многих областях знания.
Исправить такие ошибки работы
программы можно более детальной
проработкой списка аффиксов, и, возможно,
усовершенствованием инструмента
выделения терминоэлементов. Например,
выделять не один, а несколько
терминоэлементов в каждом слове.
Рассмотрим вторую проблему:
выделение высокочастотных нетерминов
в качестве терминов. Чем шире рамки
поиска мы задавали в программе, тем
больше «шума» мы получали на выходе.
Эта проблема достаточно стандартна для
такого рода программ, в большинстве
случаев выделяется какое-то количество
высокочастотного «шума». Исправить
такие ошибки так же поможет более
детальная проработка списков аффиксов
и опорных основ (наша программа выделяет
некоторые нетермины в связи с тем, что
в списке присутствует ряд аффиксов,
характерных для общелитературного
языка). Кроме того, возможно введение
статистических метрик для фильтрации
терминов-кандидатов.
Гораздо более серьезной проблемой
по сравнению с ошибочным выделением
нетерминов является невыделение
терминов. Такие ошибки обычно называют
ошибками второго рода или пропуском
события (ложноотрицательным срабатыванием).
Анализируя таблицу с результатами
работы программы, можно заметить, что
показатель полноты не достаточно высокий
для всех этапов разработки программы,
особенно, для этапа 1 и этапа 2.
Рассмотрим две основные причины
невыделения некоторых терминов.
-
Отсутствие аффиксов и опорных
основ в списке для выделения
незаимствованных терминов -
Невыделение многословных
терминов и, как следствие, невыделение
некоторых однословных терминов,
являющихся производными от этих терминов
или сокращениями этих терминов (например,
кровеносные сосуды
часто называют просто сосудами).
Первая проблема очень важна,
потому что достаточное количество
незаимствованных терминов типа сетчатка
не выделяются нашей программой. Для
устранения этих ошибок нужно разработать
инструмент анализа незаимствованных
слов и сделать отдельный список аффиксов
и опорных основ.
Единственным логичным способом
решения второй проблемы является
разработка инструмента выделения
многословных терминов и выделения на
их основе однословных терминов. Мы
планируем разработку такого инструмента
в будущем.
Заключение
В ходе нашей работы был проведен
анализ основных понятий словообразования,
рассмотрены различные определения
понятия «термин», составлен список
основных характеристик термина и описаны
особенности медицинской терминологии.
Были выполнены поставленные
перед нами цели и задачи: результатом
нашей работы стала программа по
автоматическому извлечению однословных
терминов из медицинских текстов.
При создания программы по
автоматическому извлечению терминологии
были предприняты следующие шаги: был
создан корпус медицинских текстов по
офтальмологической тематике, который
впоследствии был разбит на два подкорпуса
(тренировочный и тестовый подкорпусы);
для обоих подкорпусов был проведен
автоматический морфологический анализ
с помощью морфологического анализатора;
на основе проведенного морфологического
анализа слов тренировочного подкорпуса
были созданы списки префиксов, опорных
основ и аффиксов; с помощью этих списков
в дальнейшем проводилось собственно
извлечение медицинской терминологии.
В ходе реализации алгоритма
автоматического извлечения терминов
мы столкнулись с рядом сложностей,
некоторые из которых удалось решить в
ходе работы, другие планируется решить
в дальнейшем. Одной из проблем, которую
нам удалось решить, была проблема
лемматизации (приведения слов текста
к начальной форме) для того, чтобы можно
было удалить окончание и работать только
с основой слова (это касается
прилагательных). Проблема была решена
применением специальной опции
морфологического анализатора, позволяющей
приводить в скобках лемму или гипотетическую
лемму. Таким образом, поиск производился
не по словоформам из текста, а по
соответствующим леммам.
Как уже было упомянуто ранее,
актуальность нашей работы обуславливается
тем, то на данный момент существует
потребность в создании системы по
автоматическому извлечению терминологии
из медицинских текстов. Появление такого
инструмента способствовало бы дальнейшему
развитию методов по созданию
баз данных по медицинской тематике,
автоматизированному составлению
медицинских словарей и энциклопедий,
способствовало бы улучшению качества
поиска по медицинским текстам, и, как
следствие, позволило бы усовершенствовать
инструменты для автоматического
заполнения медицинской документации
и прочих структурированных форм по
данной тематике.
В нашей работе была представлена
реализация алгоритма выделения
однословных терминов. В дальнейшем
планируется расширить и модифицировать
созданную нами программу для извлечения
многословных терминов.
Список литературы
-
Cabré
Castellví M. Teresa, Rosa Estopà Bagot, Jordi Vivaldi Palatresi
Automatic
term detection: a review of current systems -
Enguehard, C., Pantéra, L., Automatic Natural
Acquisition of a Terminology // Journal of Quantitative Linguistics,
vol.2, n°1, p.27-32, 1995. -
Heid U., Jauss S., Krueger K., Hohmann A. Term
extraction with standard tools for corpus exploration. Experience
from German 1996 // Terminology and Knowledge Engineering, 139-150.
Berlin: Indeks Verlag -
Jacquemin C. FASTR: A unification based front-end to
automatic indexing 1994 -
Klavans,
Muresan DEFINDER: Rule-based Methods for the Extraction of Medical
Terminology and their Associated Definitions from On-line Text 2000 -
Sanja S.
Comparative Analysis of Automatic Term and Collocation Extraction.
2009 -
Seljan S.;
Gašpar A. First Steps in Term and Collocation Extraction from
English-Croatian Corpus // Proceedings of 8th International
Conference on Terminology and Artificial Intelligence, Toulouse,
France, 2009 -
Арнольд И. В. Лексикология
современного английского языка. М.:
Высшая школа, 1986. -
Ахманова О. С. Терминология
лингвистическая // Лингвистический
энциклопедический словарь. -
Ахманова, О. С. Словарь
лингвистических терминов. М.: Сов.
Энциклопедия, 1966. -
Браславский П.И.,
Соколов Е.А. Cравнение
пяти методов извлечения терминов
произвольной длины // По
материалам ежегодной Международной
конференции «Диалог», 2008 -
Винокур Г. О. О некоторых явлениях
словообразования в русской технической
терминологии. // Тр. Моск. ин-та истории,
философии и литературы. Филологический
ф-т. Т. 5. М., 1939. -
Винокур Г.О. Заметки по русскому
словообразованию // Избранные работы
по русскому языку. М., 1959 -
Герд A. C. Формирование
терминологической структуры русского
биологического текста. Л.: Изд-во ЛГУ,
1981. 112 с. -
Герд А. С. Введение
в изучение ЯСЦ, 2011 -
Герд А. С. Формирование
терминологической структуры русского
биологического текста 1981 -
Головин Б. Н Лингвистические
основы учения о терминах. М.: Высшая
школа, 1987. 103с. -
Головин Б. Н., Кобрин Р. Ю.
Лингвистические основы учения о
терминах. М.: Высшая школа, 1987. -
Гринев C. B. Введение в терминоведение.
М.: Московский лицей, 1993. 309 с. -
Даниленко В. П. Лингвистический
аспект стандартизации терминологии.
М.: Наука, 1993. -
Даниленко В. П. Русская терминология:
опыт лингвистического описания. М.:
Наука, 1977 -
Ефремова Н.Э., Большакова Е.И.,
Носков А.А., Антонов В.Ю. Терминологический
анализ текста на основе лексико-синтаксических
шаблонов // Компьютерная лингвистика
и интеллектуальные технологии: По
материалам ежегодной Международной
конференции «Диалог» М.: Изд-во РГГУ,
2010, с. 124-129. -
Евгеньева А. П. Словарь русского
языка: В 4-х т. — М.: Русский язык, 1981—1984 -
Ефремова Т.Ф. Новый
толково-словообразовательный словарь
русского языка. М., 2000. -
Захаров В.П., Хохлова
М.В. Автоматическое извлечение терминов
из специальных текстов с использованием
дистрибутивно-статистического метода
как инструмент создания тезаурусов //
Структурная и прикладная лингвистика.
Выпуск 9. СПб, 2012 .
С. 222-233. -
Земская Е. А. Активные процессы
современного словопроизводства //
Русский язык конца XX столетия (1985—1995).
— М.: Языки русской культуры, 1996. — С.
90-141. -
Земская Е.А., Кубрякова Е.С.
Проблемы словообразования на современном
этапе // Вопросы языкознания, 1978, № 6. -
Земская.Е. А. Современный русский
язык. Словообразование, М., 1973 -
Канделаки Т. Л. Значения терминов
и системы значений научно-технических
терминологий // Проблемы языка науки и
техники. Логические, лингвистические
и историко-научные аспекты терминологии.
— Москва: Наука, 1970 -
Кияк Т. Р. Лингвистические аспекты
терминоведения. Киев: УМКВО, 1989. 103 с. -
Кубрякова Е.С., Деривация,
транспозиция, конверсия // Вопросы
языкознания, 1974, № 5. -
Кубрякова Е.С., Теория номинации
и словообразование. Монография. Изд.
3-е. – М., 2009. -
Кубрякова Е.С., Типы языковых
значений. Семантика производного слова,
М., 1981. -
Курилович Е. Очерки по лингвистике.
М., 1962. -
Лейчик В. M. Применение системного
подхода для анализа терминосистем //
Терминоведение. № 1–2, 1993. М.: Московский
лицей, 1993. С. 23–26. -
Лейчик В.
М. Терминоведение:
предмет, методы, структура. — М.,
КомКнига, 2006 -
Лейчик В.М. Особенности терминологии
общественных наук и сферы ее использования
// Язык и стиль научного изложения.
Лингвометодические исследования. М.:
Наука, 1983. – С. 70-88. -
Лейчик В.М., Шелов
С.Д. Лингвистические проблемы терминологии
и научно-технический перевод. Вып.18,
ч.2. — М., 1991. — 78 с. -
Лотте Д. С. Вопросы заимствования
и упорядочения иноязычных терминов и
терминоэлементов. — М., 1982. -
Лотте Д. С. Некоторые
принципиальные вопросы отбора и
построения научно-технических терминов.
М.; Л., 1941. -
Лотте Д. С. Основы
построения научно-технической
терминологии. М.: АН СССР, 1961 -
Марусенко М.А. Об
основном понятии терминоведения
научно-техническом термине //
Научно-техническая информация. Сер.2.
1981. С. 1-6. -
Покровский В.И. Энциклопедический
словарь медицинских терминов M.:
Медицина, 2005. — 1592 с. -
Реформатский A. A. О сопоставительном
методе // Русский язык в национальной
школе №5. М., 1962 -
Реформатский А. А. Введение в
языковедение. М.: Аспект-Пресс, 1997. -
Суперанская A. B. Общая терминология:
вопросы теории. М.: Наука, 1989. 246 с. -
Суперанская А. В., Подольская Н.
В., Васильева Н. В. Общая терминология.
Вопросы теории. М.: Наука, 2012 -
Теньер Л., Основы структурного
синтаксиса, пер. с франц., М., 1988 -
Шведова Н. Ю. (гл. ред.), Русская
грамматика. Т. 1 // М., 1980. -
Шелов С.Д. Еще раз об определении
понятия термин // Вестник Нижегородского
университета им. Н.И. Лобачевского,
2010, № 4 (2), с. 795–799. -
Штунь А. И. Латинский
язык для медиков. М.: Эксмо, 2008. – 160 с. -
Щерба Л. В. Опыт общей теории
лексикографии. Л.: Изд-во ЛГУ, 1971. -
Ярцев В.Н. (гл. ред.), Лингвистический
энциклопедический словарь., М., 1990.
Приложение 1. Фрагмент списка необработанных
программой Mystem слов
абиотрофию{абиотрофия?}
ангиогенез{ангиогенез?}
антипролиферативные{антипролиферативный?}
биодеградации{биодеградация?}
биомикроофтальмоскопии{биомикроофтальмоскопия?}
биомикроскопией{биомикроскопия?}
вазопролиферативного{вазопролиферативный?}
вакуумэкстракция{вакуумэкстракция?}
вентрикулостомия{вентрикулостомия?}
гемангибластомы{гемангибластома?}
гематоретинального{гематоретинальный?}
гемоглобинсодержащих{гемоглобинсодержащий?}
демиелинизации{демиелинизация?}
диабетический{диабетический?}
диабетология{диабетология?}
диоптрийности{диоптрийность?}
идеопатической{идеопатический?}
иммунофлюоресценции{иммунофлюоресценция?}
катаракты{катаракт?}
кератэктомия{кератэктомия?}
кислородиндуцированной{кислородиндуцированный?|кислородиндуцировать?}
лазеркоаугляция{лазеркоаугляция?}
липоатрофией{липоатрофия?}
макулодистрофии{макулодистрофия?}
макулопатия{макулопатия?}
макулярный{макулярный?}
мезангия{мезангия?|мезангий?}
метаморфопсии{метаморфопсия?}
невральной{невральный?}
неинвазивность{неинвазивность?}
оптометрия{оптометрия?}
открытоугольной{открытоугольный?}
офтальмогипертензией{офтальмогипертензия?}
папиллитом{папиллит?}
псевдогипопион{псевдогипопион?}
реабсорбировать{реабсорбировать?}
реоофтальмографии{реоофтальмография?}
саркоидозе{саркоидоз?}
сенсомоторной{сенсомоторный?}
сердечнососудистые{сердечнососудистый?}
транспупиллярной{транспупиллярный?}
трансретинальное{трансретинальный?}
тробоцитов{тробоцит?}
фибринолиза{фибринолиз?}
фиброваскулярная{фиброваскулярный?}
Флуорометрические{флуорометрический?}
Хориоидальная{хориоидальный?}
хориоретинальной{хориоретинальный?}
цилиарного{цилиарный?}
цитокины{цитокин?|цитокина?}
экстравазального{экстравазальный?}
эндотелиоцитов{эндотелиоцит?}
Приложение 2. Список префиксов, опорных
основ и суффиксов
|
Префиксы |
Опорные основы |
Суффиксы |
|
авто ауто био гипер гипо де пара дис витрео нейро интра пери микро нео пан поли полу пре про рео ре суб стерео не вазо хорио инсулино офтальмо имплант ин антиген кардио кислород иммуно ангио визо лазер много моно липо вакуум гонио беза гемо вентри |
логия патия скопия стомия метрия терапия продукция ст сульфат фосфат излияние графия эктомия вирус цит фибрат трофия фосфо липид флюор фено фарм трофия вид |
ярн анн иальн ирова ость тивн ющ ем альн ия н ние арн |
