Основные характеристики блоковых корректирующих кодов
К основным
характеристикам блоковых корректирующих
кодов относятся следующие:
1. Разрядность кода
Под разрядностью
![]() корректирующего кода понимается длина
корректирующего кода понимается длина
его кодовых комбинаций, выраженная в
числе символов.
2. Число информационных символов.
Пусть корректирующим
кодом необходимо закодировать N
сообщений. Вначале эти сообщения
кодируются равномерным двоичным
нормальным кодом. Минимальное число
разрядов k,
которое может содержать такой код,
определяется из неравенства.
![]() . (5)
. (5)
Затем выполним
кодирование N
сообщений корректирующим кодом
разрядности nk.
Построить комбинации такого кода можно
двумя способами:
а) к символам каждой
k-разрядной
комбинации нормального двоичного кода,
которым и выполнено первичное кодирование
N
сообщений, добавляется еще r
символов, значения которых находятся
в соответствии с некоторым законом.
Разрядность получаемого кода n=k+r.
б) каждому из N
сообщений
сразу ставится в соответствие некоторая
кодовая комбинация n-разрядного
кода, причем в эту комбинацию не входит
составной частью комбинация нормального
двоичного кода, которой первично может
кодироваться данное сообщение. Основные
k
символов, которые входят в комбинации
корректирующего кода, построенного по
первому способу, называются информационными,
а r
символов, которые добавляются к
информационным символам, называются
проверочными.
k
= kэ
символов, которые необходимы для
кодирования N
сообщений нормальным двоичным кодом
при втором способе построения
корректирующего кода называются
эквивалентными информационными
символами, а rэ=n−kэ
символов при этом способе – эквивалентными
проверочными символами.
Коды, построенные
по первому способу называются разделимыми,
по второму способу – неразделимыми.
3. Относительная скорость передачи.
Относительная
скорость передачи q
характеризует степень использования
в корректирующем коде информационных
возможностей двоичных последовательностей
длины n.
Относительная скорость передачи
определяется как
![]() (6)
(6)
В частном случае,
когда N=2k,
![]() (7)
(7)
4. Избыточность кода
Под избыточностью
корректирующего кода понимается степень
выполнения неравенства (2) N<N0.
Оценку избыточности будем проводить
при помощи коэффициента избыточности
χ,
определяемого как
![]() (8)
(8)
Такое определение
коэффициента избыточности является
универсальным, так как в этой форме он
может быть использован для оценки
избыточности любого кода, удовлетворяющего
неравенству (2), при любом способе
построения его комбинаций. Когда N=N0,
т.е. избыточности нет,
![]() ,
,
если N=const,
а N0
→∞, то
![]() .
.
При N0
= 2n
и N=2k
![]() . (9)
. (9)
5. Минимальное хэммингово расстояние кода, кодовое расстояние.
Хэмминговым
расстоянием между двумя кодовыми
комбинациями называют число разрядов,
в которых эти комбинации имеют разные
символы в соответствующих одноименных
разрядах.
Хэммингово
расстояние между двумя кодовыми
комбинациями удобно находить, используя
операцию сложения по mod2,
так как результат сложения по mod2
только тогда равен 1, когда складываемые
символы различаются. Учитывая это, можно
определить расстояние между любыми
двумя комбинациями n-разрядного
кода Vi=(a1a2…an)
и Vj=(b1b2…bn)
следующим образом:
![]() . (10)
. (10)
Это расстояние
можно трактовать и несколько иначе, а
именно, как число единиц в той комбинации,
которая получается в результате
поразрядного сложения по mod2
двух исходных комбинаций: VΣ=V1V2.
Например, суммой
по mod2
комбинаций V1=1110
и V2=0100
является комбинация V=1010.
Число единиц в
комбинации двоичного кода называют
весом комбинации. Если обозначить вес
комбинации V
через
w(V),
то сказанное можно выразить следующим
равенством:
d
(V1,
V2)=w(V). (11)
Кодовое расстояние,
определяется как минимальное Хэммингово
расстояние, взятое по всем возможным
парам комбинаций
![]() , (12)
, (12)
где dij
вычисляется в соответствии с (10).
Код длины
n,
состоящий из N
комбинаций, называется оптимальным по
d,
если он имеет максимально возможное
d=dмакс,
то есть если из N0
=2n
комбинаций нормального кода длины n
не может быть составлен никой другой
код с N
комбинациями, имеющий d=dмакс.
Обычно при заданных n
и N
существует несколько кодов, оптимальных
по d.
Общие сведения
Как известно, для передачи информации ее представляют в форме сообщения, например текста. При этом сообщение формируется из некоторого набора символов (букв). Набор символов, из которого формируется сообщение, называется первичным алфавитом. Первичный алфавит обычно содержит большое число символов, например, в русском языке первичный алфавит составляет 33 символа (буквы). При передаче сообщения на него воздействуют помехи, что приводит к изменению символов сообщения, а поскольку количество символов сравнительно большое и вероятность появления их одинакова, то восстановить исходное сообщение довольно сложно. Поэтому осуществляют переход от первичного алфавита с большим количеством символов к вторичному алфавиту с малым числом символов. Так как количество символов вторичного алфавита меньше, то и восстановить исходное сообщение становится легче. Таким образом, можно сказать, что, вторичный алфавит это набор символов, с помощью которого осуществляется отображение символов первичного алфавита. Процесс перехода от первичного алфавита к его вторичному отображению называется кодированием. Набор элементов и правило, в соответствии с которым осуществляется переход от первичного алфавита ко вторичному отображению называется кодом. В процессе кодирования каждому символу первичного алфавита соответствует некоторый набор символов вторичного алфавита. Последовательность символов вторичного алфавита соответствующая одному символу первичного алфавита называется кодовой комбинацией. Для того чтобы правильно восстановить закодированное исходное сообщение необходимо, чтобы кодовые комбинации различных символов первичного алфавита не повторялись.
Основными задачами кодированияявляются повышение помехоустойчивости передаваемых сообщений, удаление избыточности из закодированных сообщений и защита информации от несанкционированного доступа (постороннего прослушивания).
Автоматическое кодирование осуществляется в устройстве называемом кодером, а обратный процесс декодирование происходит в декодере. Устройство, объединяющее кодер и декодер называется кодек.
Система передачи сообщений с кодированием представлена на рисунке 1.

Рисунок 1 – Структурная схема системы передачи с кодированием сигналов
Источник сообщения (ИС) формирует сообщение, которое преобразуется в сигнал в преобразователе сообщения в сигнал (ПСС1). Аналоговый сигнал из ПСС1 поступает в аналого-цифровой преобразователь (АЦП) где аналоговый сигнал преобразуется в цифровой. Цифровой сигнал поступает в кодер источника. В кодере источника из закодированного сообщения удаляют избыточность, что позволяет увеличить скорость передачи информации в канале. Полученная на выходе кодера кодовая последовательность Аi поступает в кодер канала. В кодере канала осуществляется кодирование с целью повышения помехоустойчивости сигнала. Для этого кодирования используются корректирующие (помехоустойчивые) коды. Полученная в кодере канала последовательность Bip поступает в канал связи. Под действием помех N(t), воздействующих в канале возможны искажения принимаемого сигнала, проявляющиеся в изменении элементов кодовой последовательности. Принимаемая из канала последовательность Bip’ поступает в кодер канал. В нем осуществляется декодирование и исправление (коррекция) ошибок. Полученная на выходе последовательность Ai’ поступает в декодер источника, в котором восстанавливается избыточность закодированного сообщения. Затем сигнал поступает в цифро-аналоговый преобразователь (ЦАП), где осуществляется преобразование цифрового сигнала в аналоговый. Затем сигнал поступает в преобразователь сигнала в сообщение (ПСС2), где он преобразуется в форму удобную для получателя. Полученное сообщение воспринимается получателем (ПС).
Параметры кодов
Основание кода (m) — соответствует количеству элементов, из которых состоит вторичный алфавит, соответствует системе счисления. Например в двоичном коде символы могут принимать два значения «0» и «1» или «.» и «-».
Разрядность кодовой комбинации (n) — соответствует количеству элементов, из которых состоит кодовая комбинация. Например, для кодовой комбинации 100110 разрядность составляет 6.
Емкость кода (N0) — соответствует количеству возможных кодовых комбинаций при заданном основании и разрядности:
N0 = mn.
Данный показатель применяют к равномерным кодам.
Количество сообщений, которые необходимо закодировать Nа — соответствует количеству символов первичного алфавита. Например для русского алфавита Nа = 33.
Для корректирующих кодов вводятся следующие параметры.
Вес кодовой комбинации (W) — соответствует количеству ненулевых элементов в кодовой комбинации. Например, для кодовой комбинации 11011 вес равен W = 4.
Расстояние Хэмминга (dij) — показывает, на сколько разрядов одна кодовая комбинация отличается от другой. Данный параметр определяется как вес кодовой комбинации полученной в результате сложения по модулю два двух рассматриваемых комбинаций
 Кодовое расстояние (d0) — это наименьшее расстояние Хэмминга для заданного кода. Для его определения d0 производится определение расстояния Хэмминга для всех возможных пар кодовых комбинаций кода, после чего выбирается наименьшее. Например, для кода состоящего из трех кодовых комбинаций 100101, 011010, 100011 кодовое расстояние будет равно
Кодовое расстояние (d0) — это наименьшее расстояние Хэмминга для заданного кода. Для его определения d0 производится определение расстояния Хэмминга для всех возможных пар кодовых комбинаций кода, после чего выбирается наименьшее. Например, для кода состоящего из трех кодовых комбинаций 100101, 011010, 100011 кодовое расстояние будет равно

Относительная скорость кода (Rк) — показывает относительное число разрешенных комбинаций кода.
Rк = log2Na/log2N0.
Избыточность кода (cк) — показывает относительное число запрещенных комбинации кода.
cк = 1 – Rк.
Корректирующая способность кода — определяется кратностями обнаруживаемых (qо ош) и исправляемых (qи ош) ошибок, под которыми понимают гарантированное число обнаруживаемых и исправляемых ошибок в кодовых комбинациях кодом. Например, если qо ош = 1, то код способен обнаружить ошибку в любом разряде принятой комбинации, при условии, что она одна, а если qи ош = 1 то код способен исправить одну ошибку в любом разряде принятой комбинации, при условии, что она одна.
Классификация кодов
Общая классификация кодов представлена схемой (рисунок 2).
Двоичные — это коды, основание которых равно двум (m=2), примерами таких кодов может являться код Морзе, линейный двоичный код.
Многопозиционные — это коды, основание которых больше двух (m>2).
Равномерные — это коды, все кодовые комбинации которых имеют одинаковую разрядность (n=const), примерами таких кодов могут являться циклические коды, МТК-3.
Неравномерные — это коды, кодовые комбинации которых имеют различную разрядность (n?const), примерами таких кодов могут являться код Шеннона-Фано, код Хафмена, код Морзе.
Простые — это коды, в которых все возможные кодовые комбинации используются для передачи сообщения (N0=Na). Такие коды не обладают способностью обнаруживать и исправлять ошибки в кодовых комбинациях.

Рисунок 2 – Классификация кодов
Избыточные — это коды, в которых часть кодовых комбинаций используется для передачи сообщений (разрешенные комбинации), а остальные комбинации не используется для передачи сообщений (запрещенные комбинации), т. е. у таких кодов N0>Na. Такие коды способны обнаруживать и исправлять ошибки в кодовых комбинациях.
Последовательные — это коды, разряды кодовых комбинаций которых передаются последовательно друг за другом. Такие коды используются для передачи сообщений в каналы связи (код Морзе, МТК-3, HDB-3).
Параллельные — это коды, разряды кодовых комбинаций которых передаются одновременно. Такие коды используются в микропроцессорной технике, а также к ним можно отнести многочастотные коды, используемые в координатных АТС.
Примеры задач с решениями
Задача 1. Приняты две кодовые комбинации: 0001 и 1111. Определить значность кодовых комбинаций, их вес и кодовое расстояние между комбинациями.
Решение. 1. Значность кодовых комбинаций соответствует количеству разрядов — п. В принятых кодовых комбинациях пх = п2 = 4.
- 2. Вес определяется по количеству «1» в комбинации. В принятых кодовых комбинациях Vx = 1; V2 =4.
- 3. Кодовое расстояние между комбинациями определяется как вес суммы по модулю 2 кодовых комбинаций. В принятых кодовых комбинациях d = 000101111 = 1110 = 3.
Задача 2. Принята кодовая комбинация 101011. Известно, что вектор ошибки ё = 101000 . Найти исходную кодовую комбинацию.
Решение. Для нахождения исходной кодовой комбинации определим сумму по модулю 2 для принятой комбинации и вектора ошибки, т.е. «’ = 101011, ё = 101000 , получим « = «’0ё = 1О1О1101О1ООО = ОООО11.
Задача 3. Передана кодовая комбинация 1100. Известно, что вес вектора ошибки V- =2. Найти возможные варианты искаженных комбинаций и кодовое расстояние, необходимое для обнаружения и устранения всех ошибок.
Решение. 1. Возможные варианты искаженных комбинаций состоят из тех комбинаций, которые отличаются от исходной двумя позиционными местами, так как те = 2. Возможные варианты искаженных комбинаций: 1010, 1001, ОНО, 0101, 0000.
Проверим комбинации, сложив их по модулю 2 с исходной комбинацией,т.е. ё = а®а‘.Получим ёх =110001010 = 0110; е2 =110001001 = 0101; ё3 =110000110 = 1010; ё4 =110000101 = 1001; ё5 = 110000000 = 1100.
2. Для обнаружения и устранения всех ошибок необходимо, чтобы кодовое расстояние составляло d > t + 6 -г 1, где Г — обнаруживаемые ошибки; б — исправляемые ошибки. При разрядности нашего числа
п = 4 могут возникнуть четырехкратные ошибки. Следовательно, для их исправления и обнаружения необходимо, чтобы кодовое расстояние удовлетворяло условию 4 + 4 +1 > 9 , т.е. необходимо увеличить разрядность кода.
Задача 4. Определить корректирующую способность кода, имеющего разрешенные комбинации 00000, 01110, 10101 и 11011.
Код Рида-Соломона

Важной задачей кодологии при обработке информационных потоков кодированных сообщений в каналах систем связи и компьютерных является разделение потоков и селектирование их по заданным признакам. Выделенный поток расчленяется на отдельные сообщения и для каждого из них выполняется углубленный анализ с целью установления кода и его характеристик с последующим декодированием и доступом к семантике сообщения.
Так, например, для определенного Рида-Соломона кода (РС-кода) необходимо установить:
- длину n кодового слова (блока);
- количество k информационных и N-k проверочных символов;
- неприводимый многочлен р(х), задающий конечное поле GF(2 r );
- примитивный элемент α конечного поля;
- порождающий многочлен g(x);
- параметр j кода;
- используемое перемежение;
- последовательность передачи кодовых слов или символов в канал и еще некоторые другие.
Здесь в работе рассматривается несколько другая частная задача — моделирование собственно РС-кода, являющаяся центральной основной частью названной выше задачи анализа кода.
Описание РС-кода и его характеристик
Для удобства и лучшего уяснения сущности устройства РС-кода и процесса кодирования вначале приведем основные понятия и термины (элементы) кода.
Рида – Соломона коды (РС-код) можно интерпретировать как недвоичные коды БЧХ (Боуза – Чоудхури – Хоквингема), значения кодовых символов которых взяты из поля GF(2 r ), т. е. r информационных символов отображаются отдельным элементом поля. Коды Рида – Соломона – это линейные недвоичные систематические циклические коды, символы которых представляют собой r-битовые последовательности, где r – целое положительное число, большее 1.
Коды Рида – Соломона (n, k) определены на r-битовых символах при всех n и k, для которых:
0 r + 2, где
k – число информационных символов, подлежащих кодированию,
n – число кодовых символов в кодируемом блоке.
Для большинства (n, k)-кодов Рида – Соломона; (n, k) = (2 r –1, 2 r –1–2∙t), где
t – количество ошибочных символов, которые может исправить код, а
n–k = 2t – число контрольных символов.
Код Рида – Соломона обладает наибольшим минимальным расстоянием (числом символов, которыми отличаются последовательности), возможным для линейного кода. Для кодов Рида – Соломона минимальное расстояние определяется следующим образом: dmin = n–k +1.
Определение. РС-кодом над полем GF(q=р m ), с длиной блока n = q m -1, исправляющим t ошибок, является множество всех кодовых слов u(n) над GF(q), для которых 2t последовательных компонентов спектра с номерами равны 0.
Тот факт, что 2t последовательных степеней α — корни порождающего многочлена g(x) или что спектр содержит 2t последовательных нулевых компонентов, является важным свойством кода, позволяющим исправлять t ошибок.
Информационный многочлен Q. Задает текст сообщения, которое делится на блоки (слова) постоянной длины и оцифровывается. Это то, что подлежит передаче в системе связи.
Порождающий многочлен g(x) РС-кода — многочлен, который преобразует информационные многочлены (сообщения) в кодовые слова путем перемножения Q·g(x)= С =u(n) над GF(q).
Проверочный многочлен h(x) позволяет устанавливать наличие искаженных символов в слове.
Синдромный многочлен S(z). Многочлен, содержащий компоненты соответствующие ошибочным позициям. Вычисляется для каждого принятого декодером слова.
Многочлен ошибок E. Многочлен с длиной равной кодовому слову, с нулевыми значениями во всех позициях, кроме тех, что содержат искажения символов кодового слова.
Многочлен локаторов ошибок Λ(z) обеспечивает нахождение корней, указывающих позиции ошибок в словах, принятых приемной стороной канала связи (декодером). Корни его могут быть найдены методом проб и ошибок, т.е. путем подстановки по очереди всех элементов поля, пока Λ(z) не станет равным нулю.
Многочлен значений ошибок Ω(z)≡Λ(z)·S(z) (modz 2t ) сравним по модулю z 2t с произведением многочлена локаторов ошибок на синдромный многочлен.
Неприводимый многочлен поля р(x). Конечные поля существуют не при любом числе элементов, а только в случае, если число элементов является простым числом р или степенью q=р m простого числа. В первом случае поле называется простым (его элементы-вычеты чисел по модулю простого числа р), во втором-расширением соответствующего простого поля (его q элементов-многочленов степени m-1 и менее — это вычеты многочленов по модулю неприводимого над простым полем многочлена р(x) степени m)
Примитивный многочлен. Если корнем неприводимого многочлена поля является примитивный элемент α, то р(x) называют неприводимым примитивным многочленом.
В ходе изложения действий с РС-кодом нам потребуется неоднократно обращение к полю Галуа, поэтому сразу здесь поместим рабочую таблицу с элементами этого поля при разных представлениях элементов (десятичным числом, двоичным вектором, многочленом, степенью примитивного элемента).
Таблица П — Характеристики элементов конечного поля расширения GF(2 4 ), неприводимый многочлен p(x) = x 4 +x+1, примитивный элемент α =0010= 210
Пример 1. Над конечным полем GF(2 4 ), задан неприводимый многочлен поля p(x) = x 4 + x + 1, примитивный элемент α =2, и задан (n, k)- код Рида-Соломона (РС-код). Кодовое расстояние этого кода равно d = n — k + 1 = 7. Такой код может исправлять до трёх ошибок в блоке (кодовом слове) сообщения.
Порождающий многочлен g(z) кода имеет степень m =n-k = 15-9 = 6 (его корнями являются 6 элементов поля GF(2 4 ) в десятичном представлении, а именно элементы 2, 3, 4, 5, 6, 7) и определяется соотношением, т.е. многочленом от z с коэффициентами (элементами) из GF(2 4 ) в десятичном представлении при i = 1(1)6. В рассматриваемом РС-коде 2 9 = 512 кодовых слов.
Кодирование сообщений РС-кодом
В таблице П эти корни имеют и степенное представление .
Здесь z- абстрактная переменная, а α -примитивный элемент поля, через его степени выражены все (16) элементы поля. Многочленное представление элементов поля использует переменную х.
Вычисление порождающего многочлена g(x)=А·В РС-кода выполним частями (по три скобки):
Векторное представление (через коэффициенты g(z) элементами поля в десятичном представлении) порождающего многочлена имеет вид
g(z) = G = (1, 11, 15, 5, 7, 10, 7).
После формирования порождающего многочлена РС-кода, ориентированного на обнаружение и исправление ошибок, задается сообщение. Сообщение представляется в цифровом виде (например, ASCII- кодом), от которого переходят к многочленному или векторному представлению.
Информационный вектор (слово сообщения) имеет k — компонентов из (n, k). В примере k = 9, вектор получается 9-компонентный, все компоненты – это элементы поля GF(2 4 ) в десятичном представлении Q = (11, 13, 9, 6, 7, 15, 14, 12, 10).
Из этого вектора формируется кодовое слово u — вектор с 15 компонентами. Кодовые слова, как и сами коды, бывают систематическими и несистематическими. Несистематическое кодовое слово получают умножением информационного вектора Q на вектор, соответствующий порождающему многочлену
После преобразований получаем несистематическое кодовое слово (вектор) в виде
Q·g = .
При систематическом кодировании сообщение (информационный вектор) представляют многочленом Q(z) в форме Q(z)=q(z)·g(z) + R(z), где степень degR(z) n — k (в примере Z n — k = Z 6 ) и выполняют после сдвига деление Q(z)·Z n — k на g(z). В результате находят остаток от деления R(z). Все операции выполняют над полем GF(2 4 )
(11, 13, 9, 6, 7, 15, 14, 12, 10, 0, 0, 0, 0, 0, 0) =
=(1, 11, 15, 5, 7, 10, 7)·(11, 15, 9, 10,12,10,10,10, 3) + (1, 2, 3, 7, 13, 9) = G·S + R.
Остаток при делении многочленов вычисляется обычным способом (уголком см.здесь Пример 6). Деление выполняется по образцу: Пусть Q = 26, g(z) = 7 тогда 26 = 7·3 +R(z), R(z)=26 -7·3 =26-21 = 5. Вычисление остатка R(z) от деления многочленов. Приписываем к вектору Q справа остаток R.
Получаем u — кодовое слово в систематическом виде. Этот вид явно содержит информационное сообщение в k старших разрядах кодового слова
u = (11,13,9,6,7,15,14,12,10; 1, 2, 3, 7, 13, 9)
Разряды вектора нумеруются справа налево от 0(1)14. Шесть младших разрядов справа являются проверочными.
Декодирование кодов Рида-Соломона
После получения блока декодер обрабатывает каждый блок (кодовое слово) и исправляет ошибки, которые возникли во время передачи или хранения. Декодер делит полученный многочлен на порождающий многочлен кода РС. Если остаток равен нулю, то ошибок не обнаружено, в противном случае — имеют место ошибки.
Типичный РС-декодер выполняет пять этапов в цикле декодирования, а именно:
- Вычисление синдромного многочлена (его коэффициентов ), обнаруживаются ошибки.
- Решается ключевое уравнение Падэ — вычисление значений ошибок и их позиций соответствующих местоположений.
- Реализуется процедура Ченя — нахождение корней многочлена локатора ошибок.
- Используется алгоритм Форни для вычисления значения ошибки.
- Вносятся корректирующие поправки в искаженные кодовые слова;
Завершается цикл извлечением сообщения из кодовых слов (снятие кода).
Генерация синдрома из принятого кодового слова является первым этапом процесса
декодирования. Здесь вычисляются синдромы и определяется, есть ли ошибки в полученном кодовом слове или нет
Декодирование кодовых слов РС – кода может быть организовано разными способами. К классическим способам относится декодирование с привлечением алгоритмов, работающих во временной или в частотной области, которые используют вычисление синдрома, либо не используют. Не углубляясь в теорию этого вопроса, остановим свой выбор на декодировании с вычислением синдромов кодовых слов во временной области.
Обнаружение искажений
Синдромный , где вектор последовательно определяется для каждого из полученных декодером на его входе кодовых слов. При нулевых значениях компонентов вектора синдрома , декодер считает, что в принятом слове ошибки нет. Если же хотя бы для одного , то декодер делает вывод о наличии ошибок в кодовом векторе и приступает к их выявлению, что является 1-м шагом работы декодера.
Вычисление синдромного многочлена
Умножение на приемной стороне кодового слова С на проверочную матрицу Н может давать в результате два исхода:
- синдромный вектор S=0, что соответствует отсутствию ошибок в векторе C;
- синдромный вектор S≠0, что означает наличие ошибок (одной или более) в компонентах вектора C.
Интерес представляет второй случай.
Кодовый вектор с ошибками представлен в виде C(E) =C + E, E– вектор ошибок. Тогда
Компоненты Sj синдрома определяются либо соотношением суммирования
для n = q-1 и j = 1(1)m = n-k, либо схемой Горнера:
Пример 2. Пусть вектор ошибок имеет вид Е = . Он искажает в кодовом векторе символы на 3-й и 10-й позициях. Значения ошибок соответственно 8 и 12 — эти значения также являются элементами поля GF(2 4 ) и заданы в десятичном (табл. П) представлении. В векторе Е нумерация позиций от младших справа налево, начиная с 0(1)14.
Сформируем теперь кодовый вектор с двумя ошибками в 3-ем разряде и в 10-ом со значениями 8 и 12 соответственно. Это осуществляется суммированием в поле GF(2 4 ) по правилам арифметики этого поля. Суммирование элементов поля с нулем не изменяет их значения. Ненулевые значения (элементы поля) суммируются после преобразования их к многочленному представлению, как обычно суммируются многочлены, но коэффициенты при неизвестной приводятся по mod 2.
После получения результата суммирования они вновь преобразуются к десятичному представлению, пройдя предварительно через степенное представление
Ниже показано вычисление искажённых ошибками значений в 10 и 3 позициях кодового слова:
Декодер вычисления выполняет по общей формуле для компонентов Sj, j=1(1)m. Здесь (в модели) используем соотношение , так как E задаём (моделируем) в программе сами, то ненулевые слагаемые получаются только при i = 3 и i = 10.
Специально ниже покажем вычисления по этой формуле в развернутом виде.
Проверочная матрица РС – кода
Как только сформулирован порождающий многочлен кода, появляется возможность построения проверочной матрицы для кодовых слов, а также определение количества исправляемых ошибок (см.здесь, декодер ). Построим вспомогательную матрицу [7×15], из которой могут быть получены две разные проверочные матрицы: первые шесть строк – одна и последние шесть строк – другая.
Сама матрица формируется специальным образом. Первые две строки очевидны, третья строка и все последующие получены вычитанием из предыдущей (второй) строки отрезка чисел натурального ряда 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15 по mod 15. При возникновении нулевого значения оно заменяется числом 15, отрицательные вычеты преобразуются в положительные.
Каждая матрица соответствует своему порождающему многочлену для систематического и несистематического кодирования.
Определение коэффициентов синдромного многочлена
Далее будем определять коэффициенты синдромного многочлена при j=1(1)6.
Относительно кодового слова с длиной , поступающего на вход декодера мы допускаем, что оно искажено ошибками.
Относительно вектора ошибок для его выявления необходимо знать следующее:
- количество искаженных позиций у кодового слова
- ;
- номера (положение) искаженных позиций в кодовом слове ;
- значения (величины) искажений .
Как вычисляется и используется далее синдромный вектор (многочлен) S? Его роль при декодировании кодовых слов очень значительна. Покажем это с иллюстрацией на числовом примере.
Пример 3. (Вычисление компонентов синдромного вектора >$” data-tex=”inline”/> )
то в итоге имеем >=(S_1,S_2,S_3,S_4,S_5,S_6)$” data-tex=”inline”/> =
Для дальнейшего рассмотрения введем новые понятия. Величину будем называть локатором ошибок, здесь искаженный символ кодового слова на позиции , α – примитивный элемент поля GF(2 4 ).
Множество локаторов ошибок конкретного кодового слова рассматривается далее как коэффициенты многочлена локаторов ошибок σ(z), корнями которого являются значения , обратные локаторам.
При этом выражения обращаются в нуль.
всегда свободный член уравнения всегда свободный член уравнения .
Степень многочлена локаторов ошибок равна v – количеству ошибок и не превышает величины .
Все искаженные символы находятся на разных позициях слова, следовательно, среди локаторов , не может быть повторяющихся элементов поля, а многочлен σ(z)=0 не имеет кратных корней.
Величины ошибок для удобства записи переобозначим символом . Для коэффициентов синдромного многочлена ранее рассматривались нелинейные уравнения. В нашем случае v=1 начало отсчета компонентов синдрома.
где — неизвестные величины, а — известные, вычисляемые на первом этапе декодирования, параметры (компоненты синдромного вектора).
Методы решения подобных систем нелинейных уравнений неизвестны, но решения отыскивают, используя ухищрения (обходные пути). Выполняется переход к Ганкелевой (теплицевой) системе линейных уравнений относительно коэффициентов многочлена локаторов.
Преобразование к системе линейных уравнений
В уравнение многочлена локаторов ошибок подставляется значение его корней . При этом многочлен обращается в нуль. Образуется тождество, обе части которого умножаем на , получаем:
.
Таких равенств получаем
Суммируем эти равенства по всем , при которых эти равенства выполняются. Так как многочлен σ(z) имеет v корней , раскроем скобки и перенесем коэффициенты за знак суммы:
В этом равенстве согласно системе нелинейных уравнений, приведенной
ранее, каждая сумма равна одному из компонентов вектора синдрома. Отсюда заключает, что относительно коэффициентов можно выписать систему уже линейных уравнений.
Знаки «–» при вычислениях над двоичным полем опускаются, так как со-ответствуют «+». Полученная система линейных уравнений является ганкелевой и ей соответствует матрица с размерами бит.
Эта матрица не вырождена, если число ошибок в кодовом слове C(E) строго равно , т.е. способность помехоустойчивости данного кода не нарушилась.
Решение системы линейных уравнений
Полученная система линейных уравнений в качестве неизвестных содержит коэффициенты многочлена локаторов ошибок для кодового слова C(E). Известными считаются вычисленные ранее компоненты синдромного вектора . Здесь t – количество ошибок в слове, m – количество проверочных позиций в слове.
Существуют разные методы решения сформированной системы.
Отметим, что матрица (ганкелева) не вырождена для размерностей, ограниченных количеством допустимым в отдельном слове (меньшем 0.5m) ошибок. При этом система уравнений однозначно разрешается, а задача может быть сведена просто к обращению ганкелевой матрицы. Желательно было бы снять ограничение на размерность матриц, т.е. над бесконечным полем.
Над бесконечными полями известны методы решения ганкелевой системы линейных уравнений:
- итеративный метод Тренча – Берлекэмпа — Месси (ТБМ-метод); (1)
- прямой детерминированный Питерсона — Горенштейна — Цирлера; (ПГЦ — метод); (2)
- метод Сугиямы, использующий алгоритм Евклида для нахождения НОД (С-метод).(3)
Не рассматривая других методов, остановим свой выбор на ТБМ-методе. Мотивировка выбора следующая.
Метод (ПГЦ) прост и хорош, но для малого количества исправляемых ошибок, С-метод сложен для реализации на ЭВМ и ограниченно опубликован (освещен) в источниках, хотя С-метод как и ТБМ-метод по известному многочлену синдромов S(z) обеспечивает решение уравнения Падэ над полем Галуа. Это уравнение сформировано для многочлена локаторов ошибок σ(z) и многочлена ω(z), в теории кодирования называется ключевым уравнением Падэ:
.
Решением ключевого уравнения является совокупность корней многочлена σ(z), и соответственно локаторов , т.е. позиции ошибок. Значения (величины) ошибок определяются из формулы Форни в виде
где и — значения многочленов σ(z) и ω(z) в точке , обратной корню многочлена σ(z);
i — позиция ошибки; — формальная производная многочлена σ(z) по z;
Формальная производная многочлена в конечном поле
Имеются различия и сходство для производной по переменной в поле вещественных чисел и формальной производной в конечном поле. Рассмотрим многочлен
– это элементы поля, i = 1(1)n
Элементы поля. Задан код над вещественным полем GF(2 4 ). Производная по z имеет вид:
В бесконечном вещественном поле операции умножить на n и суммировать n раз совпадают. Для конечных полей производная определяется иначе.
Производная по аналогии определяется соотношением:
где ((i)) = 1+1+. +1, (i) раз, суммируемых по правилам конечного поля: знак + обозначает операцию «суммировать столько-то раз», т.е. элемент повторить 2 раза, элемент повторить 3 раза, элемент повторить n раз.
Ясно, что эта операция не совпадает с операции умножения в конечном поле. В частности, в полях GF(2 r ) сумма четного числа одинаковых слагаемых берется по mod2 и обнуляется, а нечетного – равна самому слагаемому без изменений. Следовательно, в поле GF(2 r ) производная получает вид
вторая и старшие четные производные в этом поле равны нулю.
Из алгебры известно, если многочлен имеет кратные корни (кратность р ), то производная многочлена будет иметь этот же корень, но с кратностью р-1. Если р = 1, то f(z) и f ‘(z) не имеет общего корня. Следовательно, если многочлен и его производная имеют общий делитель, то существует кратный корень. Все корни производной f ‘(z) эти корни кратные в f(z).
Метод решения ключевого уравнения
ТМБ (Тренча-Берлекэмпа-Месси) — метод решения ключевого уравнения. Итеративный алгоритм обеспечивает определение многочленов σ(z) и ω(z), и решение уравнения Падэ (ключевого).
Исходные данные: коэффициенты многочлена степени n-1.
Цель. Определение в явном (аналитическом) виде многочленов σ(z) и ω(z).
В алгоритме используются обозначения: j — номер шага, — степень многочлена, — разложение многочлена по степеням и — промежуточные переменные и функции на j-м шаге алгоритма;
Начальные условия необходимо задавать, так как здесь используется рекурсия.
Пример 4. Выполнение итеративного алгоритма для вектора
S=(8,13,7,13,15,15). Определяются многочлены и .
Таблица 2 – Расчет многочленов локаторов ошибок
Итак , =7z+8.
Многочлен локаторов ошибок σ(z) над полем GF(2 4 ) с неприводимым многочленом p(x) = x 4 + x + 1 имеет корни
и , в этом легко убедиться непосредственной проверкой, т.е. и 13=4^<-1>$” data-tex=”inline”/>. Подстановка корней в
=
=;
=
=.
Взяв формальную производную от σ(z), получаем σ_2(z) =2·14+13 =13, так как 14z берется в сумме 2 раза и по mod 2 обращается в нуль.
С использованием формулы Форни найдем выражения для расчета величин ошибок .
Подстановкой значений i = 3 и i = 10 позиций в последнее выражение
находим
= =8$” data-tex=”inline”/>;
= =12$” data-tex=”inline”/>.
Архитектура построения программного комплекса
Для построения программного комплекса предлагается использовать следующее архитектурное решение. Программный комплекс реализуется в виде приложения с графическим интерфейсом пользователя.
Исходными данными для программного комплекса является цифровой поток информации, выгруженной с помощью дампа из файла. Для удобства анализа и наглядности работы комплекса предполагается использование .txt файлов.
Загруженный цифровой поток представляется в виде массивов данных, в ходе работы комплекса над которыми применяются различные вычислительные действия.
На каждом этапе работы комплекса предоставляется возможность наглядного представления промежуточных результатов работы.
Результаты работы программного комплекса представляются в виде числовых данных, отображающихся в таблицах.
Сохранение промежуточных и окончательных результатов анализа производится в файлы.
Схема функционирования программного комплекса
Работа с комплекса начинается с загрузки цифрового потока с помощью дампа из файла. После загрузки пользователю предоставляется возможность визуального представления двоичного содержимого файла и его текстового содержимого.
В рамках данного интерфейса должны реализовываться следующие функциональные задачи:
- Загрузка исходного сообщения;
- Преобразование сообщения в дамп;
- Кодирование сообщения;
- Моделирование перехваченного сообщения
- Построение спектров полученных кодовых слов с целью анализа их визуального представления;
- Вывод на экран параметров кода.
Описание работы программного комплекса
При запуске исполняемого файла программы на экране появляется окно представленное на рисунке 2, в котором отображён основной интерфейс программы.
На вход программы подается файл, который нужно передать по каналу связи. Для его передачи по реальным каналам связи требуется кодирование – добавление к нему проверочных символов, необходимых для однозначного декодирования слова на источнике-получателе. Для начала работы комплекса необходимо с помощью кнопки “Загрузить файл” выбрать нужный текстовый файл. Его содержимое будет отображено в нижнем поле главного окна программы.
Двоичное представление сообщения будет представлено в соответствующем поле, двоичное представление информационных слов – в поле “Двоичное представление информационных слов”.
Число бит исходного сообщения и общее число слов в нем отображаются в полях “Количество бит в передаваемом сообщении” и “Количество слов в передаваемом сообщении”.
Сформированные информационные и кодовые слова отображаются в таблицах в правой части основного окна программы.
Окно программы с промежуточными результатами представлено на рисунке 3.
Рисунок 3 – Промежуточное представление результатов работы программного комплекса
Рисунок 4. Результаты загрузки файла сообщения
Рисунок 5. Результаты кодирования файла
Рисунок 6. Вывод сообщения с внесенными в него ошибками.
Рисунок 7. Вывод результатов декодирования и сообщения с внесенными в него ошибками
Рисунок 8. Вывод декодированного сообщения.
Заключение
АНБ США является главным оператором глобальной системы перехвата «Эшелон». «Эшелон» располагает разветвлённой инфраструктурой, включающей в себя станции наземного слежения, расположенные по всему миру. Отслеживаются практически все мировые информационные потоки.
Исследование возможностей получения доступа к семантике кодированных информационных сообщений в настоящее время активной информационной борьбы как в области технологий, так и в политике — стало очередным вызовом и одной из актуальных и востребованных задач современности.
В подавляющем большинстве кодов кодирование и декодирование сообщений (информации) реализуется на строгой математической основе конечных расширенных полей Галуа. Работа с элементами таких полей отличается от общепринятых в арифметике и требует при использовании вычислительных средств написания специальных процедур манипулирования с элементами полей.
Предлагаемая вниманию читателей работа слегка приоткрывает завесу тайны над подобной деятельностью на уровне фирм, компаний и государств в целом.
Найти кодовые векторы по информационным блокам
В обычном равномерном непомехоустойчивом коде число разрядов n в кодовых комбинациях определяется числом сообщений и основанием кода.
Коды, у которых все кодовые комбинации разрешены, называются простыми или равнодоступными и являются полностью безызбыточными. Безызбыточные коды обладают большой «чувствительностью» к помехам. Внесение избыточности при использовании помехоустойчивых кодов связано с увеличением n – числа разрядов кодовой комбинации. Таким образом, все множество комбинаций можно разбить на два подмножества: подмножество разрешенных комбинаций, обладающих определенными признаками, и подмножество запрещенных комбинаций, этими признаками не обладающих.
Помехоустойчивый код отличается от обычного кода тем, что в канал передаются не все кодовые комбинации N, которые можно сформировать из имеющегося числа разрядов n, а только их часть Nk , которая составляет подмножество разрешенных комбинаций. Если при приеме выясняется, что кодовая комбинация принадлежит к запрещенным, то это свидетельствует о наличии ошибок в комбинации, т.е. таким образом решается задача обнаружения ошибок. При этом принятая комбинация не декодируется (не принимается решение о переданном сообщении). В связи с этим помехоустойчивые коды называют корректирующими кодами. Корректирующие свойства избыточных кодов зависят от правила их построения, определяющего структуру кода, и параметров кода (длительности символов, числа разрядов, избыточности и т. п.).
Первые работы по корректирующим кодам принадлежат Хеммингу, который ввел понятие минимального кодового расстояния dmin и предложил код, позволяющий однозначно указать ту позицию в кодовой комбинации, где произошла ошибка. К информационным элементам k в коде Хемминга добавляется m проверочных элементов для автоматического определения местоположения ошибочного символа. Таким образом, общая длина кодовой комбинации составляет: n = k + m.
Метричное представление n,k-кодов
В настоящее время наибольшее внимание с точки зрения технических приложений уделяется двоичным блочным корректирующим кодам. При использовании блочных кодов цифровая информация передается в виде отдельных кодовых комбинаций (блоков) равной длины. Кодирование и декодирование каждого блока осуществляется независимо друг от друга.
Почти все блочные коды относятся к разделимым кодам, кодовые комбинации которых состоят из двух частей: информационной и проверочной. При общем числе n символов в блоке число информационных символов равно k, а число проверочных символов:
К основным характеристикам корректирующих кодов относятся:
– число разрешенных и запрещенных кодовых комбинаций;
– избыточность кода;
– минимальное кодовое расстояние;
– число обнаруживаемых или исправляемых ошибок;
– корректирующие возможности кодов.
Для блочных двоичных кодов, с числом символов в блоках, равным n, общее число возможных кодовых комбинаций определяется значением
Число разрешенных кодовых комбинаций при наличии k информационных разрядов в первичном коде:
Очевидно, что число запрещенных комбинаций:
а с учетом отношение будет
где m – число избыточных (проверочных) разрядов в блочном коде.
Избыточностью корректирующего кода называют величину
Эта величина показывает, какую часть общего числа символов кодовой комбинации составляют информационные символы. В теории кодирования величину Bk называют относительной скоростью кода. Если производительность источника информации равна H символов в секунду, то скорость передачи после кодирования этой информации будет
поскольку в закодированной последовательности из каждых n символов только k символов являются информационными.
Если число ошибок, которые нужно обнаружить или исправить, значительно, то необходимо иметь код с большим числом проверочных символов. Чтобы при этом скорость передачи оставалась достаточно высокой, необходимо в каждом кодовом блоке одновременно увеличивать как общее число символов, так и число информационных символов.
При этом длительность кодовых блоков будет существенно возрастать, что приведет к задержке информации при передаче и приеме. Чем сложнее кодирование, тем длительнее временная задержка информации.
Минимальное кодовое расстояние – dmin. Для того чтобы можно было обнаружить и исправлять ошибки, разрешенная комбинация должна как можно больше отличаться от запрещенной. Если ошибки в канале связи действуют независимо, то вероятность преобразования одной кодовой комбинации в другую будет тем меньше, чем большим числом символов они различаются.
Если интерпретировать кодовые комбинации как точки в пространстве, то отличие выражается в близости этих точек, т. е. в расстоянии между ними.
Количество разрядов (символов), которыми отличаются две кодовые комбинации, можно принять за кодовое расстояние между ними. Для определения этого расстояния нужно сложить две кодовые комбинации «по модулю 2» и подсчитать число единиц в полученной сумме. Например, две кодовые комбинации xi = 01011 и xj = 10010 имеют расстояние d(xi,xj) , равное 3, так как:
Здесь под операцией ⊕ понимается сложение «по модулю 2».
Заметим, что кодовое расстояние d(xi,x0) между комбинацией xi и нулевой x0 = 00. 0 называют весом W комбинации xi, т.е. вес xi равен числу «1» в ней.
Расстояние между различными комбинациями некоторого конкретного кода могут существенно отличаться. Так, в частности, в безызбыточном первичном натуральном коде n = k это расстояние для различных комбинаций может изменяться от единицы до величины n, равной разрядности кода. Особую важность для характеристики корректирующих свойств кода имеет минимальное кодовое расстояние dmin, определяемое при попарном сравнении всех кодовых комбинаций, которое называют расстоянием Хемминга.
В безызбыточном коде все комбинации являются разрешенными и его минимальное кодовое расстояние равно единице – dmin=1. Поэтому достаточно исказиться одному символу, чтобы вместо переданной комбинации была принята другая разрешенная комбинация. Чтобы код обладал корректирующими свойствами, необходимо ввести в него некоторую избыточность, которая обеспечивала бы минимальное расстояние между любыми двумя разрешенными комбинациями не менее двух – dmin ≥ 2..
Минимальное кодовое расстояние является важнейшей характеристикой помехоустойчивых кодов, указывающей на гарантируемое число обнаруживаемых или исправляемых заданным кодом ошибок.
Число обнаруживаемых или исправляемых ошибок
При применении двоичных кодов учитывают только дискретные искажения, при которых единица переходит в нуль («1» → «0») или нуль переходит в единицу («0» → «1»). Переход «1» → «0» или «0» → «1» только в одном элементе кодовой комбинации называют единичной ошибкой (единичным искажением). В общем случае под кратностью ошибки подразумевают число позиций кодовой комбинации, на которых под действием помехи одни символы оказались замененными на другие. Возможны двукратные (g = 2) и многократные (g > 2) искажения элементов в кодовой комбинации в пределах 0 ≤ g ≤ n.
Минимальное кодовое расстояние является основным параметром, характеризующим корректирующие способности данного кода. Если код используется только для обнаружения ошибок кратностью g0, то необходимо и достаточно, чтобы минимальное кодовое расстояние было равно dmin ≥ g0 + 1.
В этом случае никакая комбинация из go ошибок не может перевести одну разрешенную кодовую комбинацию в другую разрешенную. Таким образом, условие обнаружения всех ошибок кратностью g0 можно записать
Чтобы можно было исправить все ошибки кратностью gu и менее, необходимо иметь минимальное расстояние, удовлетворяющее условию dmin ≥ 2gu
В этом случае любая кодовая комбинация с числом ошибок gu отличается от каждой разрешенной комбинации не менее чем в gu+1 позициях. Если условие не выполнено, возможен случай, когда ошибки кратности g исказят переданную комбинацию так, что она станет ближе к одной из разрешенных комбинаций, чем к переданной или даже перейдет в другую разрешенную комбинацию. В соответствии с этим, условие исправления всех ошибок кратностью не более gи можно записать:
Из и следует, что если код исправляет все ошибки кратностью gu, то число ошибок, которые он может обнаружить, равно go = 2gu. Следует отметить, что эти соотношения устанавливают лишь гарантированное минимальное число обнаруживаемых или исправляемых ошибок при заданном dmin и не ограничивают возможность обнаружения ошибок большей кратности. Например, простейший код с проверкой на четность с dmin = 2 позволяет обнаруживать не только одиночные ошибки, но и любое нечетное число ошибок в пределах go 3 = 8). Нулевой синдром (000) указывает на то, что ошибки при приеме отсутствуют или не обнаружены. Всякому ненулевому синдрому соответствует определенная конфигурация ошибок, которая и исправляется. Классические коды Хемминга имеют число синдромов, точно равное их необходимому числу (что позволяет исправить все однократные ошибки в любом информативном и проверочном символах) и включают один нулевой синдром. Такие коды называются плотноупакованными.
Усеченные коды являются неплотноупакованными, так как число синдромов у них превышает необходимое. Так, в коде (9,5) при четырех проверочных символах число синдромов будет равно 2 4 =16, в то время как необходимо всего 10. Лишние 6 синдромов свидетельствуют о неполной упаковке кода (9,5).
Рис. 2 Декодер для (7, 4)-кода Хемминга
Для рассматриваемого кода (7,4) в табл. 2 представлены ненулевые синдромы и соответствующие конфигурации ошибок.
Таким образом, (7,4)-код позволяет исправить все одиночные ошибки. Простая проверка показывает, что каждая из ошибок имеет свой единственный синдром. При этом возможно создание такого цифрового корректора ошибок (дешифратора синдрома), который по соответствующему синдрому исправляет соответствующий символ в принятой кодовой группе. После внесения исправления проверочные символы ri можно на выход декодера (рис. 2) не выводить. Две или более ошибок превышают возможности корректирующего кода Хемминга, и декодер будет ошибаться. Это означает, что он будет вносить неправильные исправления и выдавать искаженные информационные символы.
Идея построения подобного корректирующего кода, естественно, не меняется при перестановке позиций символов в кодовых словах. Все такие варианты также называются (7,4)- кодами Хемминга.
Циклические коды
Своим названием эти коды обязаны такому факту, что для них часть комбинаций, либо все комбинации могут быть получены путем циклическою сдвига одной или нескольких базовых комбинаций кода.
Построение такого кода основывается на использовании неприводимых многочленов в поле двоичных чисел. Такие многочлены не могут быть представлены в виде произведения многочленов низших степеней подобно тому, как простые числа не могут быть представлены произведением других чисел. Они делятся без остатка только на себя или на единицу.
Для определения неприводимых многочленов раскладывают на простые множители бином х n -1. Так, для n = 7 это разложение имеет вид:
(x 7 )=(x-1)(x 3 +x 2 )(x 3 +x-1)
Каждый из полученных множителей разложения может применяться для построения корректирующего кода.
Неприводимый полином g(x) называют задающим, образующим или порождающим для корректирующего кода. Длина n (число разрядов) создаваемого кода произвольна. Кодовая последовательность (комбинация) корректирующего кода состоит из к информационных разрядов и n – к контрольных (проверочных) разрядов. Степень порождающего полинома r = n – к равна количеству неинформационных контрольных разрядов.
Если из сделанного выше разложения (при n = 7) взять полипом (х – 1), для которого r=1, то k=n-r=7-1=6. Соответствующий этому полиному код используется для контроля на чет/нечет (обнаружение ошибок). Для него минимальное кодовое расстояние D0 = 2 (одна единица от D0 – для исходного двоичного кода, вторая единица – за счет контрольного разряда).
Если же взять полином (x 3 +x 2 +1) из указанного разложения, то степень полинома r=3, а k=n-r=7-3=4.
Контрольным разрядам в комбинации для некоторого кода могут быть четко определено место (номера разрядов). Тогда код называют систематическим или разделимым. В противном случае код является неразделимым.
Способы построения циклических кодов по заданному полиному.
1) На основе порождающей (задающей) матрицы G, которая имеет n столбцов, k строк, то есть параметры которой связаны с параметрами комбинаций кода. Порождающую матрицу строят, взяв в качестве ее строк порождающий полином g(x) и (k – 1) его циклических сдвигов:
Пример; Определить порождающую матрицу, если известно, что n=7, k=4, задающий полином g(x)=x 3 +х+1.
Решение: Кодовая комбинация, соответствующая задающему полиному g(x)=x 3 +х+1, имеет вид 1011. Тогда порождающая матрица G7,4 для кода при n=7, к=4 с учетом того, что k-1=3, имеет вид:
Порождающая матрица содержит k разрешенных кодовых комбинаций. Остальные комбинации кода, количество которых (2 k – k) можно определить суммированием по модулю 2 всевозможных сочетаний строк матрицы Gn,k. Для матрицы, полученной в приведенном выше примере, суммирование по модулю 2 четырех строк 1-2, 1-3, 1-4, 2-3, 2-4, 3-4 дает следующие кодовые комбинации циклического кода:
Другие комбинации искомого корректирующего кода могут быть получены сложением трех комбинаций, например, из сочетания строк 1-3-4, что дает комбинацию 1111111, а также сложением четырех строк 1-2-3-4, что дает комбинацию 1101001 и т.д.
Ряд комбинаций искомого кода может быть получено путем дальнейшего циклического сдвига комбинаций порождающей матрицы, например, 0110001, 1100010, 1000101. Всего для образования искомого циклического кода требуется 2 k =2 4 =16 комбинаций.
2) Умножение исходных двоичных кодовых комбинаций на задающий полином.
Исходными комбинациями являются все k-разрядные двоичные комбинации. Так, например, для исходной комбинации 1111 (при k = 4) умножение ее на задающий полином g(x)=x 3 +х+1=1011 дает 1101001. Полученные на основе двух рассмотренных способов циклические коды не являются разделимыми.
3) Деление на задающий полином.
Для получения разделимого (систематического) циклического кода необходимо разделить многочлен x n-k *h(x), где h(x) – исходная двоичная комбинация, на задающий полином g(x) и прибавить полученный остаток от деления к многочлену x n-k *h(x).
Заметим, что умножение исходной комбинации h(x) на x n-k эквивалентно сдвигу h(x) на (n-к) разрядов влево.
Пример: Требуется определить комбинации циклического разделимого кода, заданного полиномом g(x)=x 3 +х+1=1011 и имеющего общее число разрядов 7, число информационных разрядов 4, число контрольных разрядов (n-k)=3.
Решение: Пусть исходная комбинация h(x)=1100. Умножение ее на x n-k =x 3 =1000 дает x 3 *(x 3 +x 2 )=1100000, то есть эквивалентно сдвигу исходной комбинации на 3 разряда влево. Деление комбинации 1100000 на комбинацию 1011, эквивалентно задающему полиному, дает:
Полученный остаток от деления, содержащий x n-k =3 разряда, прибавляем к полиному, в результате чего получаем искомую комбинацию разделимого циклического кода: 1100010. В ней 4 старших разряда (слева) соответствуют исходной двоичной комбинации, а три младших разряда являются контрольными.
Следует сделать ряд указаний относительно процедуры деления:
1) При делении задающий полином совмещается старшим разрядом со старшим «единичными разрядом делимого.
2) Вместо вычитания по модулю 2 выполняется эквивалентная ему процедура сложения по модулю 2.
3) Деление продолжается до тех пор, пока степень очередного остатка не будет меньше степени делителя (задающего полинома). При достижении этого полученный остаток соответствует искомому содержанию контрольных разрядов для данной искомой двоичной комбинации.
Для проверки правильности выполнения процедуры определения комбинации циклического кода необходимо разделить полученную комб1шацию на задающий полином с учетом сделанных выше замечаний. Получение нулевого остатка от такого деления свидетельствует о правильности определения комбинации.
Логический код 4В/5В
Логический код 4В/5В заменяет исходные символы длиной в 4 бита на символы длиной в 5 бит. Так как результирующие символы содержат избыточные биты, то общее количество битовых комбинаций в них больше, чем в исходных. Таким образом, пяти-битовая схема дает 32 (2 5 ) двухразрядных буквенно-цифровых символа, имеющих значение в десятичном коде от 00 до 31. В то время как исходные данные могут содержать только четыре бита или 16 (2 4 ) символов.
Поэтому в результирующем коде можно подобрать 16 таких комбинаций, которые не содержат большого количества нулей, а остальные считать запрещенными кодами (code violation). В этом случае длинные последовательности нулей прерываются, и код становится самосинхронизирующимся для любых передаваемых данных. Исчезает также постоянная составляющая, а значит, еще более сужается спектр сигнала. Но этот метод снижает полезную пропускную способность линии, так как избыточные единицы пользовательской информации не несут, и только “занимают эфирное время”. Избыточные коды позволяют приемнику распознавать искаженные биты. Если приемник принимает запрещенный код, значит, на линии произошло искажение сигнала.
Итак, рассмотрим работу логического кода 4В/5В. Преобразованный сигнал имеет 16 значений для передачи информации и 16 избыточных значений. В декодере приемника пять битов расшифровываются как информационные и служебные сигналы.
Для служебных сигналов отведены девять символов, семь символов – исключены.
Исключены комбинации, имеющие более трех нулей (01 – 00001, 02 – 00010, 03 – 00011, 08 – 01000, 16 – 10000). Такие сигналы интерпретируются символом V и командой приемника VIOLATION – сбой. Команда означает наличие ошибки из-за высокого уровня помех или сбоя передатчика. Единственная комбинация из пяти нулей (00 – 00000) относится к служебным сигналам, означает символ Q и имеет статус QUIET – отсутствие сигнала в линии.
Такое кодирование данных решает две задачи – синхронизации и улучшения помехоустойчивости. Синхронизация происходит за счет исключения последовательности более трех нулей, а высокая помехоустойчивость достигается приемником данных на пяти-битовом интервале.
Цена за эти достоинства при таком способе кодирования данных – снижение скорости передачи полезной информации. К примеру, В результате добавления одного избыточного бита на четыре информационных, эффективность использования полосы частот в протоколах с кодом MLT-3 и кодированием данных 4B/5B уменьшается соответственно на 25%.
Схема кодирования 4В/5В представлена в таблице.
Итак, соответственно этой таблице формируется код 4В/5В, затем передается по линии с помощью физического кодирования по одному из методов потенциального кодирования, чувствительному только к длинным последовательностям нулей – например, в помощью цифрового кода NRZI.
Символы кода 4В/5В длиной 5 бит гарантируют, что при любом их сочетании на линии не могут встретиться более трех нулей подряд.
Буква ^ В в названии кода означает, что элементарный сигнал имеет 2 состояния – от английского binary – двоичный. Имеются также коды и с тремя состояниями сигнала, например, в коде 8В/6Т для кодирования 8 бит исходной информации используется код из 6 сигналов, каждый из которых имеет три состояния. Избыточность кода 8В/6Т выше, чем кода 4В/5В, так как на 256 исходных кодов приходится 36=729 результирующих символов.
Как мы говорили, логическое кодирование происходит до физического, следовательно, его осуществляют оборудование канального уровня сети: сетевые адаптеры и интерфейсные блоки коммутаторов и маршрутизаторов. Поскольку, как вы сами убедились, использование таблицы перекодировки является очень простой операцией, поэтому метод логического кодирования избыточными кодами не усложняет функциональные требования к этому оборудованию.
Единственное требование – для обеспечения заданной пропускной способности линии передатчик, использующий избыточный код, должен работать с повышенной тактовой частотой. Так, для передачи кодов 4В/5В со скоростью 100 Мб/с передатчик должен работать с тактовой частотой 125 МГц. При этом спектр сигнала на линии расширяется по сравнению со случаем, когда по линии передается чистый, не избыточный код. Тем не менее, спектр избыточного потенциального кода оказывается уже спектра манчестерского кода, что оправдывает дополнительный этап логического кодирования, а также работу приемника и передатчика на повышенной тактовой частоте.
В основном для локальных сетей проще, надежней, качественней, быстрей – использовать логическое кодирование данных с помощью избыточных кодов, которое устранит длительные последовательности нулей и обеспечит синхронизацию сигнала, потом на физическом уровне использовать для передачи быстрый цифровой код NRZI, нежели без предварительного логического кодирования использовать для передачи данных медленный, но самосинхронизирующийся манчестерский код.
Например, для передачи данных по линии с пропускной способностью 100М бит/с и полосой пропускания 100 МГц, кодом NRZI необходимы частоты 25 – 50 МГц, это без кодирования 4В/5В. А если применить для NRZI еще и кодирование 4В/5В, то теперь полоса частот расширится от 31,25 до 62,5 МГц. Но тем не менее, этот диапазон еще “влазит” в полосу пропускания линии. А для манчестерского кода без применения всякого дополнительного кодирования необходимы частоты от 50 до 100 МГц, и это частоты основного сигнала, но они уже не будут пропускаться линией на 100 МГц.
Скрэмблирование
Другой метод логического кодирования основан на предварительном “перемешивании” исходной информации таким образом, чтобы вероятность появления единиц и нулей на линии становилась близкой.
Устройства, или блоки, выполняющие такую операцию, называются скрэмблерами (scramble – свалка, беспорядочная сборка) .
При скремблировании данные перемешиваються по определенному алгоритму и приемник, получив двоичные данные, передает их на дескрэмблер, который восстанавливает исходную последовательность бит.
Избыточные биты при этом по линии не передаются.
Суть скремблирования заключается просто в побитном изменении проходящего через систему потока данных. Практически единственной операцией, используемой в скремблерах является XOR – “побитное исключающее ИЛИ”, или еще говорят – сложение по модулю 2. При сложении двух единиц исключающим ИЛИ отбрасывается старшая единица и результат записывается – 0.
Метод скрэмблирования очень прост. Сначала придумывают скрэмблер. Другими словами придумывают по какому соотношению перемешивать биты в исходной последовательности с помощью “исключающего ИЛИ”. Затем согласно этому соотношению из текущей последовательности бит выбираются значения определенных разрядов и складываются по XOR между собой. При этом все разряды сдвигаются на 1 бит, а только что полученное значение (“0” или “1”) помещается в освободившийся самый младший разряд. Значение, находившееся в самом старшем разряде до сдвига, добавляется в кодирующую последовательность, становясь очередным ее битом. Затем эта последовательность выдается в линию, где с помощью методов физического кодирования передается к узлу-получателю, на входе которого эта последовательность дескрэмблируется на основе обратного отношения.
Например, скрэмблер может реализовывать следующее соотношение:
где Bi – двоичная цифра результирующего кода, полученная на i-м такте работы скрэмблера, Ai – двоичная цифра исходного кода, поступающая на i-м такте на вход скрэмблера, Bi-3 и Bi-5 – двоичные цифры результирующего кода, полученные на предыдущих тактах работы скрэмблера, соответственно на 3 и на 5 тактов ранее текущего такта, ⊕ – операция исключающего ИЛИ (сложение по модулю 2).
Теперь давайте, определим закодированную последовательность, например, для такой исходной последовательности 110110000001.
Скрэмблер, определенный выше даст следующий результирующий код:
B1=А1=1 (первые три цифры результирующего кода будут совпадать с исходным, так как еще нет нужных предыдущих цифр)
Таким образом, на выходе скрэмблера появится последовательность 110001101111. В которой нет последовательности из шести нулей, п рисутствовавшей в исходном коде.
После получения результирующей последовательности приемник передает ее дескрэмблеру, который восстанавливает исходную последовательность на основании обратного соотношения.
Существуют другие различные алгоритмы скрэмблирования, они отличаются количеством слагаемых, дающих цифру результирующего кода, и сдвигом между слагаемыми.
Главная проблема кодирования на основе скремблеров – синхронизация передающего (кодирующего) и принимающего (декодирующего) устройств. При пропуске или ошибочном вставлении хотя бы одного бита вся передаваемая информация необратимо теряется. Поэтому, в системах кодирования на основе скремблеров очень большое внимание уделяется методам синхронизации.
На практике для этих целей обычно применяется комбинация двух методов:
а) добавление в поток информации синхронизирующих битов, заранее известных приемной стороне, что позволяет ей при ненахождении такого бита активно начать поиск синхронизации с отправителем,
б) использование высокоточных генераторов временных импульсов, что позволяет в моменты потери синхронизации производить декодирование принимаемых битов информации “по памяти” без синхронизации.
Существуют и более простые методы борьбы с последовательностями единиц, также относимые к классу скрэмблирования.
Для улучшения кода ^ Bipolar AMI используются два метода, основанные на искусственном искажении последовательности нулей запрещенными символами.
Рис. 3 Коды B8ZS и HDB3
На этом рисунке показано использование метода ^ B8ZS (Bipolar with 8-Zeros Substitution) и метода HDB3 (High-Density Bipolar 3-Zeros) для корректировки кода AMI. Исходный код состоит из двух длинных последовательностей нулей (8- в первом случае и 5 во втором).
Код B8ZS исправляет только последовательности, состоящие из 8 нулей. Для этого он после первых трех нулей вместо оставшихся пяти нулей вставляет пять цифр: V-1*-0-V-1*. V здесь обозначает сигнал единицы, запрещенной для данного такта полярности, то есть сигнал, не изменяющий полярность предыдущей единицы, 1* – сигнал единицы корректной полярности, а знак звездочки отмечает тот факт, что в исходном коде в этом такте была не единица, а ноль. В результате на 8 тактах приемник наблюдает 2 искажения – очень маловероятно, что это случилось из-за шума на линии или других сбоев передачи. Поэтому приемник считает такие нарушения кодировкой 8 последовательных нулей и после приема заменяет их на исходные 8 нулей.
Код B8ZS построен так, что его постоянная составляющая равна нулю при любых последовательностях двоичных цифр.
Код HDB3 исправляет любые 4 подряд идущих нуля в исходной последовательности. Правила формирования кода HDB3 более сложные, чем кода B8ZS. Каждые четыре нуля заменяются четырьмя сигналами, в которых имеется один сигнал V. Для подавления постоянной составляющей полярность сигнала V чередуется при последовательных заменах.
Кроме того, для замены используются два образца четырехтактовых кодов. Если перед заменой исходный код содержал нечетное число единиц, то используется последовательность 000V, а если число единиц было четным – последовательность 1*00V.
Таким образом, применение логическое кодирование совместно с потенциальным кодированием дает следующие преимущества:
Улучшенные потенциальные коды обладают достаточно узкой полосой пропускания для любых последовательностей единиц и нулей, которые встречаются в передаваемых данных. В результате коды, полученные из потенциального путем логического кодирования, обладают более узким спектром, чем манчестерский, даже при повышенной тактовой частоте.
Линейные блочные коды
При передаче информации по каналам связи возможны ошибки вследствие помех и искажений сигналов. Для обнаружения и исправления возникающих ошибок используются помехоустойчивые коды. Упрощенная схема системы передачи информации при помехоустойчивом кодировании показана на рис. 4
Кодер служит для преобразования поступающей от источника сообщений последовательности из k информационных символов в последовательность из n cимволов кодовых комбинаций (или кодовых слов). Совокупность кодовых слов образует код.
Множество символов, из которых составляется кодовое слово, называется алфавитом кода, а число различных символов в алфавите – основанием кода. В дальнейшем вследствие их простоты и наибольшего распространения рассматриваются главным образом двоичные коды, алфавит которых содержит два символа: 0 и 1.
Рис. 4 Система передачи дискретных сообщений
Правило, по которому информационной последовательности сопоставляется кодовое слово, называется правилом кодирования. Если при кодировании каждый раз формируется блок А из k информационных символов, превращаемый затем в n-символьную кодовую комбинацию S, то код называется блочным. При другом способе кодирования информационная последовательность на блоки не разбивается, и код называется непрерывным.
С математической точки зрения кодер осуществляет отображение множества из 2 k элементов (двоичных информационных последовательностей) в множество, состоящее из 2 n элементов (двоичных последовательностей длины n). Для практики интересны такие отображения, в результате которых получаются коды, обладающие способностью исправлять часть ошибок и допускающие простую техническую реализацию кодирующих и декодирующих устройств.
Дискретный канал связи – это совокупность технических средств вместе со средой распространения радиосигналов, включенных между кодером и декодером для передачи сигналов, принимающих конечное число разных видов. Для описания реальных каналов предложено много математических моделей, с разной степенью детализации отражающих реальные процессы. Ограничимся рассмотрением простейшей модели двоичного канала, входные и выходные сигналы которого могут принимать значения 0 и 1.
Наиболее распространено предположение о действии в канале аддитивной помехи. Пусть S=(s1,s2. sn) и Y=(y1,y2. yn) соответственно входная и выходная последовательности двоичных символов. Помехой или вектором ошибки называется последовательность из n символов E=(e1,e2. en), которую надо поразрядно сложить с переданной последовательностью, чтобы получить принятую:
Таким образом, компонента вектора ошибки ei=0 указывает на то, что 2-й символ принят правильно (yi=si), а компонента ei=1 указывает на ошибку при приеме (yi≠si).Поэтому важной характеристикой вектора ошибки является число q ненулевых компонентов, которое называется весом или кратностью ошибки. Кратность ошибки – дискретная случайная величина, принимающая целочисленные значения от 0 до n.
Классификация двоичных каналов ведется по виду распределения случайного вектора E. Основные результаты теории кодирования получены в предположении, что вероятность ошибки в одном символе не зависит ни от его номера в последовательности, ни от его значения. Такой канал называется стационарным и симметричным. В этом канале передаваемые символы искажаются с одинаковой вероятностью P, т.е. P(ei=1)=P, i=1,2. n.
Для симметричного стационарного канала распределение вероятностей векторов ошибки кратности q является биноминальным:
которая показывает, что при P j является убывающей функцией q, т.е. в симметричном стационарном канале более вероятны ошибки меньшей кратности. Этот важный факт используется при построении помехоустойчивых кодов, т.к. позволяет обосновать тактику обнаружения и исправления в первую очередь ошибок малой кратности. Конечно, для других моделей канала такая тактика может и не быть оптимальной.
Декодирующее устройство (декодер) предназначено оценить по принятой последовательности Y=(y1,y2. yn) значения информационных символов A ‘ =(a ‘ 1,a ‘ 2. a ‘ k,). Из-за действия помех возможны неправильные решения. Процедура декодирования включает решение двух задач: оценивание переданного кодового слова и формирование оценок информационных символов.
Вторая задача решается относительно просто. При наиболее часто используемых систематических кодах, кодовые слова которых содержат информационные символы на известных позициях, все сводится к простому их стробированию. Очевидно также, что расположение информационных символов внутри кодового слова не имеет существенного значения. Удобно считать, что они занимают первые k позиций кодового слова.
Наибольшую трудность представляет первая задача декодирования. При равновероятных информационных последовательностях ее оптимальное решение дает метод максимального правдоподобия. Функция правдоподобия как вероятность получения данного вектора Y при передаче кодовых слов Si, i=1,2. 2 k на основании Y=S+E определяется вероятностями появления векторов ошибок:
Очевидно, вероятность P(Y/Si) максимальна при минимальном qi. На основании принципа максимального правдоподобия оценкой S ‘ является кодовое слово, искажение которого для превращения его в принятое слово Y имеет минимальный вес, т. е. в симметричном канале является наиболее вероятным (НВ):
Если несколько векторов ошибок Ei имеют равные минимальные веса, то наивероятнейшая ошибка EHB определяется случайным выбором среди них.
В качестве расстояния между двумя кодовыми комбинациями принимают так называемое расстояние Хэмминга, которое численно равно количеству символов, в которых одна комбинация отлична от другой, т.е. весу (числу ненулевых компонентов) разностного вектора. Расстояние Хэмминга между принятой последовательностью Y и всеми возможными кодовыми словами 5, есть функция весов векторов ошибок Ei:
Поэтому декодирование по минимуму расстояния, когда в качестве оценки берется слово, ближайшее к принятой последовательности, является декодированием по максимуму правдоподобия.
Таким образом, оптимальная процедура декодирования для симметричного канала может быть описана следующей последовательностью операций. По принятому вектору Y определяется вектор ошибки с минимальным весом EHB, который затем вычитается (в двоичном канале – складывается по модулю 2) из Y:
Наиболее трудоемкой операцией в этой схеме является определение наи-вероятнейшего вектора ошибки, сложность которой существенно возрастает при увеличении длины кодовых комбинаций. Правила кодирования, которые нацелены на упрощение процедур декодирования, предполагают придание всем кодовым словам технически легко проверяемых признаков.
Широко распространены линейные коды, называемые так потому, что их кодовые слова образуют линейное подпространство над конечным полем. Для двоичных кодов естественно использовать поле характеристики p=2. Принадлежность принятой комбинации Y известному подпространству является тем признаком, по которому выносится решение об отсутствии ошибок (EHB=0).
Так как по данному коду все пространство последовательностей длины n разбивается на смежные классы, то для каждого смежного класса можно заранее определить вектор ошибки минимального веса, называемый лидером смежного класса. Тогда задача декодера состоит в определении номера смежного класса, которому принадлежит Y, и формировании лидера этого класса.
[spoiler title=”источники:”]
http://habr.com/ru/post/518120/
http://garick58.narod2.ru/content/KR/io.html
[/spoiler]
Уведомления
- Начало
- » Python для экспертов
- » Оприделить “вес” комбинации. Опять нужен алгоритм.
#1 Июль 4, 2008 15:43:45
Оприделить “вес” комбинации. Опять нужен алгоритм.
Доброго времени суток.
Есть колода карт. Есть несколько игроков. У каждого есть 7 карт из которых надо выбрать лучшую комбинацию , состоящую из 5 карт.
выигрывает лучшая комбинация из всех.
Вопрос 1: как из 7 карт выбрать лучшую возможную?
Вопрос 2: Как сравнить эти 2 комбинации?
Немного рабочей инфы (для тех, кто не знаком с покером):
Масти карт:
d – diamonds (бубна)
h – hearts (черва)
s – spades (пик)
с – clubs (трефа)
Карты:
A – туз
K – король
Q – дама
J – валет
T – 10
9 … 2 – все остальные
Всего групп комбинаций – 10 (с примерами):
Самая сильная – Флеш-рояль: A K Q J T одной масти
Стрит флеш: (A 2 3 4 5 ) или (K Q J T 9) одной масти
каре: (2 2 2 2 <любая карта>) или (A A A A <любая карта>)
фулл хаус или просто фулл: (2 2 2 5 5) или (A A A Q Q) в общем 3 карты одного достоинства и 2 другого
Флеш: 5 любых карт одной масти ( As Ts 9s 6s 2s )
Стрит: 5 карт подряд разных мастей (As Kd Qh Js Tc)
Тройка или трипс: 3 карты одного достоинства (2 2 2 <любая карта> <любая карта>)
Две пары: 2 пары карт одинакового достоинства: (A A 4 4 <любая карта>)
Пара: Просто пара карт (A A <любая карта> <любая карта> <любая карта>)
И пустая комбинация, то есть когда нет ничего из вышеперечисленного.
Сравнение идет просто: Любая комбинация бьет ту, что ниже ее.. то есть фулл бьет трипсу, а флеш-рояль бьет вообще все.
Если 2 игрока имеют комбинации одинакового ранга, то сравнивается достоинство “главных карт” комбинации. Например если у одного стрит от 9 до K а у другого от 6 до T то выигрвает первый. Если оба собрали, допустим, по паре тузов, то дальше смотрятся их остальные карты (кикеры). Пример: 1: (A A T 6 7) 2: (A A J 2 3) – выигрывает второй или 1: (A A J 3 2 ) 2: (A A J 6 2) – выигрывает второй, так как 6 > 3.
Если 2 комбинации пустые, то побеждает та, у которой самая высшая карта из неодинаковых (она же кикер).
Теперь к питону:
У меня есть списки карт
например
['Ks', 'Qs', '7c', 'Jc', 'Td', 'Ah', 'Ad']
надо эти списки сравнить и найти максимальный.
PS: задача эта “для себя”. Просто хочу понять алгоритм.
Идея как составить максимальную комбинацию из 7, вроде есть – просто пройти вниз по возможным комбинациям (от флеш рояля до пары) и найти ту, которая соответствует какой-то группе.
Но вот как сравнить 2 комбинации мой гуманитарный мозг отказывается придумывать 🙁
PPS: Может кому еще задача интересной покажется 🙂
Отредактировано (Июль 4, 2008 15:51:29)
Офлайн
- Пожаловаться
#2 Июль 4, 2008 15:52:32
Оприделить “вес” комбинации. Опять нужен алгоритм.
Просто как валенок. Введите коефициенты для комбинаций и считайте их для каждого набора.
Офлайн
- Пожаловаться
#3 Июль 4, 2008 15:57:28
Оприделить “вес” комбинации. Опять нужен алгоритм.
Ferroman
Введите коефициенты для комбинаций и считайте их для каждого набора.
не понял.
то есть, например пустая комбинация – 0, пара – 1 и тд?
Офлайн
- Пожаловаться
#4 Июль 4, 2008 16:02:17
Оприделить “вес” комбинации. Опять нужен алгоритм.
Да, верно. При чём можно сделать так, что бы одинаковые комбинации имели разный вес в зависимости от карт.
Офлайн
- Пожаловаться
#5 Июль 4, 2008 16:12:24
Оприделить “вес” комбинации. Опять нужен алгоритм.
Ferroman
При чём можно сделать так, что бы одинаковые комбинации имели разный вес в зависимости от карт.
Вот как это сделать?
Я сначала придумал, что вес карты – число 2=2 3=3 A=13
Но тут есть нюанс:
туз может быть самой старшей картой в комбинации стрит и самой младшей. то есть
A 2 3 4 5 – стрит
и A K Q J T – тоже стрит, но уже больше, чем первый. Вот в этом основная загвоздка.
Вообще в этом загвоздка и при выделении комбинации из 7 карт.
и еще пример
2 2 2 A A фулл и 3 3 3 K K – фулл, второй – больше чем первый.
У меня есть класс – рука. в ней как раз список из 7 карт. мне нужно сравнить 2 экземпляра этого класса.
грубо говоря:
if hand1 > hand2: ... победил первый elif hand1 < hand2: ... победил второй else: ... ничья
Отредактировано (Июль 4, 2008 16:12:58)
Офлайн
- Пожаловаться
#6 Июль 4, 2008 16:24:50
Оприделить “вес” комбинации. Опять нужен алгоритм.
Вы не считайте только вес карт. Вы считайте вес комбинаций. А вес карт считайте отдельно.
Тогда у вас получится 2 числа – одно вес комбинации в руке, а второе – вес карт в каждой комбинации (грубо – сумма веса каждой карты).
То есть для каждой “руки” – пара (вес комбинации, вес карт).
Да, по скольку есть ещё и масти, то можно ещё добавлять дополнительные баллы, там, где это имеет значение. Или подсчитывать отдельный коэффициент для этого, как будет проще.
Отредактировано (Июль 4, 2008 16:27:19)
Офлайн
- Пожаловаться
#7 Июль 4, 2008 17:15:27
Оприделить “вес” комбинации. Опять нужен алгоритм.
Ferroman
(грубо – сумма веса каждой карты).
То есть для каждой “руки” – пара (вес комбинации, вес карт).
вот в этом вся загвоздка.
222AA в сумме дают 32
33344 дают 17
или
A2345 = 27
23456 = 20
но второй случай – больше первого.
или какая другая сумма имелась ввиду?
Суммы я с самого начала пытался приделать.
PS: пока писал придумал вот что:
>>> [3, 3, 3, 2, 2] > [2, 2, 2, 13, 13] True
на сколько этот вариант быстр и корректен? может действительно можно одно число получить, чтобы сравнивать не листы, а числа, что, мне кажется, быстрее.
—-
ну это вроде как становится ясно. Теперь бы придумать как выделить из семи – пятерку лучшего варианта. Идея с перебором всего возможного кажется слишком тормозной.
Офлайн
- Пожаловаться
#8 Июль 4, 2008 17:26:31
Оприделить “вес” комбинации. Опять нужен алгоритм.
Вы не читаете посты. Вес комбинации и сумма весов карт – разные цифры.
222AA – даёт список с 2-мя парами – ((8,3),(2,26))
33344 – даёт список с 2-я другими парами – ((8,6)(2,6))
Вот эти списки и сравнивайте. Ну или можно по-другому – сразу учитывая возможные комбинации пар (2 пары, пара+3) и рассматривать их как отдельные комбинации со своими весами.
Обращаю внимание что “вес” “тройки” я взял от балды – “8”, а пару посчитал как “2”. В примере карта “2” имеет вес “1” (как наименьшая), “3” – “2”, “4”-“3” а “А” – “13”. У Вас могут быть другие “весы”.
Такое сравнение как у Вас в посте – некоректно, поскольку не всегда даст правильный результат. Например если тройка и пара будут идти в обратном порядке, чем у Вас.
PS. Я прошу прощения, но я в покере не силён.
Отредактировано (Июль 4, 2008 17:27:55)
Офлайн
- Пожаловаться
#9 Июль 4, 2008 17:38:01
Оприделить “вес” комбинации. Опять нужен алгоритм.
Да, а зачем Вам скорость? Вы разницу заметите только если будуте сравнивать 1000 комбинаций.
Офлайн
- Пожаловаться
#10 Июль 4, 2008 17:44:34
Оприделить “вес” комбинации. Опять нужен алгоритм.
Вы не читаете посты. Вес комбинации и сумма весов карт – разные цифры.
Сорри, очевидно не так понял.
Такое сравнение как у Вас в посте – некоректно, поскольку не всегда даст правильный результат. Например если тройка и пара будут идти в обратном порядке, чем у Вас.
порядок не имеет значения. его можно и поменять. если это фулл, то сначала можно и даже нужно поставить трипс. Думаю, это будет решаться на стадии выделения комбинации из семерки.
Офлайн
- Пожаловаться
- Начало
- » Python для экспертов
- » Оприделить “вес” комбинации. Опять нужен алгоритм.
МИНИСТЕРСТВО ОБРАЗОВАНИЯ И
НАУКИ
РЕСПУБЛИКИ КАЗАХСТАН
Алматинский институт энергетики и связи
Кафедра автоматической электросвязи
А.Д. Джангозин, К.С. Чежимбаева
ПОМЕХОУСТОЙЧИВЫЕ ЦИКЛИЧЕСКИЕ КОДЫ
Учебное пособие
Алматы 2006
УДК 621.37:378 (075.8)
ББК 32.84 я 7
Д 40
Джангозин А.Д., Чежимбаева К.С.
Помехоустойчивые циклические коды: Учебное пособие – Алматы: АИЭС,
2006.- 78с.
В пособии даётся классификация
разновидностей, характеристик и параметров корректирующих кодов, изложены
принципы построения, формирования и обработки помехоустойчивых циклических
кодов, их определение, свойства и эффективность, а также реализация кодирующих
и декодирующих устройств этих кодов на базе
линейных переключательных схем. Приводятся примеры применения
циклических кодов и линейных переключательных схем в радиотехнических системах при выполнении курсовых проектов. А также дан перечень рекомендуемой литературы.
Пособие предназначено для студентов
всех форм обучения специальностей 380140 – Сети связи и системы коммутации и
380240 – Многоканальные телекоммуникационные системы.
Ил.21, табл.17, библиогр.- 20назв.
Рецензент: канд. техн. наук, доцент
кафедры АТМ, КазНТУ, Бейсембаев А.А., канд. техн. наук, доцент АИЭС Туманбаева К.Х.
Печатается по дополнительному плану
издания министерство Образование и Науки Республики Казахстан на 2006 г.
![]()
ISBN 9965-708-47-9
ãАлматинский
институт энергетики и связи, 2006г.
Введение
Динамичный переход нашей
технологической цивилизации на цифровые системы обработки и передачи информации
создает много проблем при проектировании современных систем информатики и
телекоммуникации
В настоящее время, в связи с
многократно возросшими объёмами передаваемой и сохраняемой информации,
ужесточились требования к её достоверности. Одним из самых перспективных
методов решения этой проблемы является помехоустойчивые кодирование на основе
корректирующих кодов. В последнее время коды, исправляющие ошибки, нашли применение
во многих системах передачи и хранения информации. Наиболее известные из них –
это сотовые системы связи, различные
системы спутниковой телефонной связи, накопители информации на магнитных
дисках, система звукозаписи на компакт – дисках и др. Во всех вышеприведенных
примерах систем с помехозащищённой обработкой информации используются наиболее
простые и эффективные циклические корректирующие коды, которые, наряду с
простотой кодирования и декодирования, отличаются достаточно большой
корректирующей способностью.
1 Классификация корректирующих кодов
Все корректирующие коды можно разделить на два класса:
блочные и непрерывные.
Блочные коды — коды, в которых каждому сообщению (или
элементу) сопоставляется блок из n символов (кодовый вектор длиной n). Операции кодирования и декодирования в
каждом блоке производятся отдельно.
Непрерывные коды представляют собой непрерывную
последовательность символов, не подразделяемую на блоки. Такие коды называются
также рекуррентными, цепными, свёрточными, конволюционными. Процессы
кодирования и декодирования осуществляются непрерывно. Передаваемая
последовательность образуется путем размещения в определённом порядке
проверочных символов между информационными символами исходной
последовательности.
Как блочные, так и
непрерывные коды делятся на разделимые и неразделимые.
Разделимые коды предусматривают возможность чёткого
разграничения информационных и проверочных символов.
Неразделимые коды не предусматривают такой возможности и к
ним относятся, например, коды с постоянным весом (КПВ).
Разделимые коды делятся, в свою очередь, на систематические
(линейные или групповые) и несистематические (нелинейные).
Систематические
коды характеризуются тем, что сумма по модулю 2
двух разрешённых кодовых комбинаций кодов этого класса снова даёт разрешённую
кодовую комбинацию.
Кроме того, в систематических кодах информационные символы,
как правило, не изменяются при кодировании и занимают определённые заранее
заданные места. Проверочные символы вычисляются как линейная комбинация
информационных, откуда и возникло другое наименование этих кодов — линейные.
Для систематических кодов принимается обозначение [n, k] – код, где k — число информационных символов в
кодовой комбинации, n —
общее число символов в коде.
Несистематические
коды не обладают отмеченными выше свойствами и
применяются значительно реже, чем систематические, в частности, в несимметричных
каналах связи. К этому классу кодов относятся такие, например, коды, как КПВ,
итеративные, комбинационные и антифединговые [3].
Циклические
коды составляют большую группу наиболее широко
используемых на практике линейных, систематических кодов. Их основное свойство,
давшее им название, состоит в том, что каждый вектор, получаемый из исходного
кодового вектора путём циклической перестановки его символов, также является
разрешённым кодовым вектором. Принято описывать циклические коды (ЦК) при
помощи порождающих полиномов ![]() степени
степени ![]() , где
, где ![]() – число проверочных символов в кодовом слове.
– число проверочных символов в кодовом слове.
В связи с этим ЦК относятся к разновидности полиномиальных кодов.
Операции кодирования и декодирования ЦК сводятся к
известным процедурам умножения и деления полиномов. Для двоичных кодов эти
операции легко реализуются технически с помощью линейных переключательных схем
(ЛПС), при этом получаются относительно простые схемы кодеков, в чём состоит
одно из практических достоинств ЦК.
Коды Файра могут исправлять пакет ошибок длиной ![]()
![]() и обнаруживать пакет ошибок длиной
и обнаруживать пакет ошибок длиной![]() .[заметим, что в кодах Файра понятие кодового расстояния d не используется]
.[заметим, что в кодах Файра понятие кодового расстояния d не используется]
Среди циклических кодов особое место занимает класс кодов,
предложенных Боузом и Чоудхури и независимо от них Хоквингемом. Коды Боуза—Чоудхури-Хоквингема
получили сокращённое наименование БЧХ- коды.
БЧХ- коды являются
обобщением кодов Хемминга на случай исправления нескольких независимых ошибок
(qи >1). Частными случаями БЧХ- кодов
являются коды Файра, предназначенные для обнаружения и исправления серийных
ошибок (“пачек” ошибок), код Голея – код, исправляющий одиночные,
двойные и тройные ошибки (dmin=7), коды Рида-Соломона (РС- коды), у
которых символами кода являются многоразрядные двоичные числа.
1.1
Полиномиальное
определение циклических кодов и операции
с ними
Циклические коды являются частным случаем систематических,
линейных [n, k]-кодов. Название ЦК получили из-за своего
основного свойства: циклическая перестановка символов разрешённой кодовой
комбинации даёт также разрешённую кодовую комбинацию. При циклической
перестановке символы кодового слова перемещаются слева направо на одну позицию,
причем крайний справа символ переносится на место крайнего левого.
Если, например, А1 – 101100, то разрешённой
кодовой комбинацией будет и А2
– 010110, полученная циклической перестановкой. Отметим, что перестановка производится
вместе с проверочными символами, и по правилам линейных кодов сумма по модулю 2 двух
разрешённых кодовых комбинаций даёт также очередную разрешённую кодовую
комбинацию.
Описание ЦК связано с представлением кодовых комбинаций в
виде полиномов (многочленов) фиктивной переменной “X“. Для примера переведём кодовое слово А1 = 101100 в полиномиальный
вид
|
i |
6 |
5 |
4 |
3 |
2 |
1 |
|
код |
1 |
0 |
1 |
1 |
0 |
0 |
При этом А1
(Х) = 1 ![]() X5 + 0
X5 + 0 ![]() X4
X4
+ 1 ![]() X3
X3
+ 1 ![]() X2
X2
+ 0![]() X1 + 0
X1 + 0 ![]() Х° = X5 + X3 + X2.
Х° = X5 + X3 + X2.
Действия с кодовыми векторами, представленными в виде
полиномов, производятся по правилам арифметики по модулю 2, в которой
вычитание равносильно сложению. Так, из равенства Хn -1 =0 получаем Хn =1. Прибавив к левой и правой частям по
единице, имеем Хn + 1=1![]() 1=0. Таким образом, вместо двучлена Хn -1 можно ввести бином Хn +1 или 1 + Хn, из чего следует, что Хk
1=0. Таким образом, вместо двучлена Хn -1 можно ввести бином Хn +1 или 1 + Хn, из чего следует, что Хk ![]() Хk = Хk (1
Хk = Хk (1 ![]() 1) = 0 и при последующих
1) = 0 и при последующих
операциях с полиномами необходимо вычёркивать пары фиктивных переменных X с одинаковыми степенями.
Приведём далее порядок суммирования (вычитания), умножения
и деления полиномов с учётом того, что операция суммирования осуществляется по
модулю 2. В примерах используем вышеприведённые кодовые комбинации А1(Х) = X5
+ X3+ X2 и А2(Х)
= X4 + Х2+ X.
Суммирование (вычитание):
А1 +А2
= А1 – А2= X5 + X4+ X3
+Х2+ Х2+ Х = Х5+Х4+ Х3+ X
или
А1
101100
![]()
А2
010110
![]()
111010 = Х5+Х4+ Х3+ X
Умножение:
А1 хА2 = (Х5+ Х3+ Х2)![]() (Х4+ Х2+X)= Х9+Х7 + Х6
(Х4+ Х2+X)= Х9+Х7 + Х6
+Х7+ Х5+Х4 + Х6+ Х4+Х3
= Х9+Х5+ Х3=1000101000
Деление:![]()
![]()
![]()
X5 + X3 + X2
X4 + X2 + X
– X
X5 + Х3+ Х2
0 0
0 – остаток при делении ![]() = 0.
= 0.
Из последнего примера следует, что при циклическом сдвиге
вправо на один разряд необходимо исходную кодовую комбинацию поделить на X, а умножение на X эквивалентно сдвигу влево на один
символ.
На основании того, что
будет сказано далее о ЦК, нельзя установить теоретически те или иные свойства
этих кодов, ряд приводимых ниже результатов придётся принять без
соответствующих доказательств на веру. Однако, рассмотрев приведённые далее
примеры, можно понять и освоить специфику и идеологию формирования и обработки
ЦК.
1.2
Порождающие
полиномы циклических кодов
Формирование разрешённых кодовых комбинаций ЦК В1(X) основано на предварительном выборе так
называемого порождающего (образующего) полинома G(Х), который обладает важным отличительным признаком: все
комбинации В1(X) делятся на порождающий полином G(Х) без остатка, т. е.
![]() = Аi(Х)
= Аi(Х)
(при остатке R(Х) = 0), (1.1)
где Аi(Х)
— информативный
полином (кодовая комбинация первичного кода, преобразуемого в корректирующий
ЦК).
Поскольку, как отмечалось выше, ЦК относятся к классу
блочных разделимых кодов, у которых при общем числе символов n число информационных символов в Аi(Х) равно k, то степень порождающего полинома определяет число проверочных
символов r =n – k.
Из этого свойства следует сравнительно простой способ
формирования разрешённых кодовых комбинаций ЦК — умножение комбинаций
информационного кода Аi(Х) на порождающий полином ![]()
![]() Вi(Х).
Вi(Х).
(1.2)
В теории циклических кодов доказывается, что порождающими
могут быть только такие полиномы, которые являются делителями двучлена
(бинома) Хn +1
![]() = Н(Х)
= Н(Х)
(при остатке R(Х) = 0). (1.3)
Возможные порождающие полиномы, найденные с помощью ЭВМ,
сведены в обширные таблицы. Так, в [6] приведены таблицы G(Х) с записью полиномов в восьмеричной
системе счисления (при mod 8). В этом случае весовые коэффициенты ki представляют три двоичных знака в
соответствии со следующим кодом
 . (1.4)
. (1.4)
Двоичные символы являются весовыми коэффициентами
порождающих полиномов, коэффициенты восьмеричной системы счисления расположены
слева от них с учётом того, что 0![]() ki
ki![]() 7 (при mod 8). Например, 3425 обозначает многочлен 10-й степени. В двоичной
7 (при mod 8). Например, 3425 обозначает многочлен 10-й степени. В двоичной
записи числу 3425 (mod
8) эквивалентно число 011100010101, и соответствующий многочлен равен X10
+ X9 + X8 + X4
+ X2 + 1. Как видно из этого примера, восьмеричная система
счисления для записи многочленов выбрана, в частности, из соображений экономии
длины записи (бумаги) в три раза при больших объёмах табулированных значений,
что подчёркивает известный недостаток двоичной системы счисления.
Некоторые из порождающих полиномов приведены в таблице 1.
Следует отметить, что с увеличением максимальной степени
порождающих полиномов г резко увеличивается их количество. Так, при r=3 имеется всего два полинома, а при r = 10 их уже несколько десятков.
Первый порождающий полином минимальной степени r=1, удовлетворяющий условию (1.3),
формирует код с проверкой на чётность при двух информативных символах и одном
проверочном, обеспечивающем обнаружение однократной ошибки, поскольку
минимальное кодовое расстояние dmin=2. В общем случае коэффициент избыточности
КПЧ минимален
![]() (1.5)
(1.5)
а относительная скорость
кода – максимальна и равна
![]() (1.6)
(1.6)
В связи с этим КПЧ иногда называют быстрым кодом.
Таблица 1 –
Некоторые порождающие полиномы
|
r-степень полинома |
Порождающий |
Запись |
Запись |
n |
k |
Примечание |
|
1 |
Х+1 |
11 |
3 |
3 |
2 |
Код с |
|
2 |
Х2+X+1 |
111 |
7 |
3 |
1 |
Код с |
|
3 |
Х3+Х2+1 |
1101 |
13 15 |
7 7 |
4 4 |
Классический |
|
4 |
Х4+Х3+1 Х4+Х+1 Х4+Х2+X+1 Х4+Х3+Х2+1 |
11001 |
31 23 27 35 |
15 15 7 7 |
11 11 3 3 |
Классический |
|
5 |
Х5+Х2+1 Х5+Х3+1 ….. |
100101 |
45 51 |
31 31 |
26 26 |
Классический |
|
6 |
….. Х6+Х5+Х4+ ….. …. |
1111111 |
177 |
7 |
1 |
Код с |
Второй порождающий полином степени r =2, являющийся «партнёром» первого ![]() =
= ![]() при разложении бинома
при разложении бинома
с n = 3, определяет код
с повторением единственного информативного символа к =1 (“0” или
“1”).
Отметим, что ЦК принадлежат к классу линейных кодов, у
которых кодовые комбинации “000 … 00” и “111… 11 ”
являются разрешёнными.
У кода с повторением возможности обнаружения и исправления
ошибок безграничны, поскольку число повторений l [1] определяет минимальное кодовое расстояние
dmin=l. (1.7)
В общем случае коэффициент избыточности кодов с повторением
кодовых комбинаций является максимально возможным:
![]()
и при увеличении l приближается к 1, а скорость (1.6) – минимальна
![]() . (1.8)
. (1.8)
Таким образом, коды с проверкой на чётность и коды с
повторением – до некоторой степени антиподы. Первый код очень быстр (всего
один дополнительный символ), но зачастую “легкомыслен”. Возможности
второго кода с повторением по исправлению ошибок теоретически безграничны, но
он крайне “медлителен” [7].
Следующие порождающие полиномы в таблице 1 со степенью r = 3 позволяют сформировать набор
классических корректирующих кодов Хемминга (7, 4). Коды Хемминга также
принадлежат к классу ЦК, однако при этом группа проверочных символов кода
получается сразу “в целом” при делении информативной кодовой группы
на порождающий полином, а не “поэлементно”. Отметим, что два
варианта, порождающих полиномов кода Хемминга (7,4), с записью по модулю 2 в
виде 1101 и 1011 представляют собой так называемые двойственные многочлены (полиномы).
Двойственные
многочлены определяются следующим образом: если задан
полином в виде
h(Х) = h0 +h1(Х) + h2Х2 + … + hr Хr,
то двойственным к нему полиномом является
![]() = h0 Хr +h1 Хr-1 +…+h, (1.9)
= h0 Хr +h1 Хr-1 +…+h, (1.9)
т. е. весовые коэффициенты исходного полинома, зачитываемые
слева направо, становятся весовыми коэффициентами двойственного полинома при
считывании их справа налево. Говоря образно, набор весовых коэффициентов
“вывёртывается наизнанку”.
Обратим внимание на то, что в полных таблицах, порождающих
ЦК полиномов, двойственные полиномы, как правило, не приводятся [6].
Наряду с тем, что порождающие полиномы кода Хемминга (7,4)
являются двойственными друг другу, они также являются неприводимыми.
Неприводимые
полиномы не делятся ни на какой другой полином
степени меньше r,
поэтому их называют ещё неразложимыми, простыми и примитивными.
Далее в таблице 1 при значениях r = 4 и 5 попадают следующие классические
коды Хемминга (15, 11) и (31, 26). Порождающие их полиномы также являются
двойственными друг к другу и неприводимыми. Напомним, что к классическим кодам
Хемминга относятся коды, у которых n = 2r-1, а k= 2r-1-r [3], с минимальным кодовым расстоянием dmin=3, позволяющим исправлять однократные ошибки и обнаруживать
двойные.
При значениях
r = 4 в таблице 1
попадают двойственные порождающие многочлены кода Абрамсона (7, 3), являющиеся
частным случаем кодов Файра, порождающие полиномы для которых имеют вид
![]() , (1.10)
, (1.10)
где р(Х) – неприводимый полином.
Коды Абрамсона совпадают с кодами Файра, если положить с
= 1. Число проверочных символов r = 4 определяет общее число символов в коде (значность кода), поскольку
для этих кодов n =
2 r-1– 1. Эти коды исправляют все одиночные и
смежные двойные ошибки (т.е. серии длиной 2). Помещённые в таблице 1 коды
Абрамсона (7,3) являются первыми циклическими кодами, исправляющими серийные
ошибки (пакеты ошибок). В этом применении ЦК оказываются особенно эффективными.
Обратим внимание на то, что при с =1 в (1.10) порождающими полиномами р(Х) являются
двойственные полиномы X3 + Х2+ 1 и X3 + Х+ 1, образующие код Хемминга (7,4) при r = 3.
Серийные ошибки возникают в результате воздействия в канале
передачи сообщений помех импульсного характера, длительность которых больше
длительности одного символа. При этих условиях ошибки уже не независимы, а
возникают пачками, общая длительность которых соответствует длительности
помехи.
В заключение на основании данных таблице 1 приведём все
возможные порождающие полиномы для кодовых комбинаций с числом символов n = 7.
В соответствии со свойством (1.3) порождающих полиномов ![]() бином X7 +1 раскладывается на три неприводимых полинома
бином X7 +1 раскладывается на три неприводимых полинома
![]() , (1.11)
, (1.11)
каждый из которых является
порождающим для следующих кодов
![]() – код с проверкой на
– код с проверкой на
чётность, КПЧ (7, 6);
![]() – первый вариант кода Хемминга (7,4);
– первый вариант кода Хемминга (7,4);
![]() – двойственный
– двойственный ![]() (X)
(X)
второй вариант кода Хемминга.
Кроме того, различные вариации произведений G1,2,3(Х) дают возможность получить остальные
порождающие полиномы:
![]() – код Абрамсона (7,3);
– код Абрамсона (7,3);
![]() -двойственный
-двойственный ![]() ;
;
![]() – код с повторением (7,1).
– код с повторением (7,1).
Таким образом, для постоянного заданного значения п все
возможные порождающие полиномы ЦК размещаются между кодами с проверкой на
чётность (n, n-1) (r =1) и кодами с повторением (n, 1) (r =n -1), которые правомерно и называют
“кодами антиподами”.
При выборе применяемых в системах связи корректирующих
кодов необходимо позаботиться о том, чтобы, во-первых, избыточность кода была
минимальной, т. е. относительная скорость кода или эффективность кода была
максимальной, а, во-вторых, техника кодирования и декодирования была по
возможности проста.
1.3 Принципы формирования и обработки
разрешённых кодовых комбинаций циклических кодов
На основании материалов предыдущего раздела можно дать
следующее определение циклических кодов.
Циклические коды (ЦК) составляют множество многочленов Вi(Х) степени n-1 и менее (до r
=n
– k, где r – число
проверочных символов), кратных порождающему (образующему) полиному G(Х) степени r, который, в свою
очередь, должен быть делителем бинома Xn + 1, т. е. остаток после деления бинома на G(Х) должен равняться нулю.
Учитывая, что ЦК принадлежат к классу линейных, групповых
кодов, сформулируем ряд основных свойств, им присущих:
а) сумма разрешённых кодовых комбинаций ЦК образует
разрешённую кодовую комбинацию
Вi(Х)![]() Вj(Х)=
Вj(Х)=
Вk(Х); (1.12)
б) поскольку к числу разрешённых кодовых комбинаций ЦК
относится нулевая комбинация 000…00, то минимальное кодовое расстояние dmin для ЦК определяется минимальным весом
разрешённой кодовой комбинации
Dmin
=Wmin. (1.13)
в) циклический код не обнаруживает только такие искажённые
помехами кодовые комбинации, которые приводят к появлению на стороне приёма
других разрешённых комбинаций этого кода из набора Nо;
г) значения проверочных элементов r =n – k для ЦК могут определяться путем суммирования по модулю 2 ряда
определённых информационных символов кодовой комбинации Аi(Х). Например, для кода Хемминга (7,4) с
порождающим полиномом G(Х)=Х3+Х+1 алгоритм получения проверочных символов
будет следующим [3]
r1 = i1![]() i2
i2![]() i3;
i3;
r2 = i2![]() i3
i3![]() i4 ;
i4 ;
(1.14)
r3 = i1![]() i2
i2![]() i4.
i4.
Эта процедура
свидетельствует о возможности “поэлементного” получения проверочной
группы для каждой кодовой комбинации Аi(Х). В соответствии с (1.14) могут строиться
кодирующие устройства для ЦК [3];
д) как было показано на примере в подразделе 1.1, умножение
полинома на X приводит к
сдвигу членов полинома на один разряд влево, а при умножении на Хr соответственно,
на г разрядов влево с заменой r младших разрядов полинома
“нулями”. Умножение полинома на X свидетельствует о том, что при этой процедуре X является “оператором сдвига”. Деление полинома на X приводит к соответствующему сдвигу членов полинома вправо с
уменьшением показателей членов на 1. Процедура сдвига позволяет исходной кодовой комбинации Аi(Х) после домножения её на Хr дописать справа г проверочных символов;
е) поскольку
разрешённые кодовые слова
ЦК Вi(Х)
без остатка делятся на порождающий полином G(Х) с получением итога в виде информационной комбинации Ai(Х) (1.1), то имеется возможность формировать
Вi(Х) на стороне передачи (кодирующее устройство) простым методом
умножения (1.2).
Два последних свойства ЦК позволяют осуществить построение
кодеров ЦК двумя методами: методом умножения и методом деления полиномов.
Рассмотрим достоинства и недостатки этих методов с учётом вариантов построения
декодеров ЦК, соответствующих этим методам.
Метод умножения позволяет при формировании разрешённых
кодовых комбинаций по алгоритму (1.2) использовать любой порождающий полином,
лишь бы его максимальная степень была равна числу необходимых проверочных
символов r.
Однако этот метод обладает двумя существенными
недостатками.
Во-первых, при формировании ЦК методом умножения в
полученной комбинации Вi(Х) в явном виде не содержатся информационные
символы. Код получается неразделимым с “перетасованными”
информативными и проверочными символами, что затрудняет его декодирование, так
как это приводит к необходимости применять метод максимального правдоподобия в
декодирующем устройстве (ДУ).
Метод
максимального правдоподобия (ММП) предполагает
при исправлении ошибок принимаемую кодовую комбинацию отождествлять с той
разрешённой, к которой принятая находится ближе всего. При таком
непосредственном способе декодирования в памяти запоминающего устройства (ЗУ)
декодера необходимо хранить все разрешённые кодовые комбинации Nо, что требует на стороне приёма больших объёмов ЗУ и большого
времени обработки при декодировании. Эти обстоятельства являются вторым
недостатком метода умножения при кодировании ЦК.
Исследования показывают [5-8], что хороший циклический
корректирующий код с кратностью исправляемых ошибок gu![]() 5 при
5 при
относительной скорости кода Вk > 0,5, т. е. коэффициенте избыточности
k < 0,5, должен
иметь число информационных символов k > 40 . Это значение и приводит к техническим трудностям
при процедуре декодирования по ММП, сводящейся к сравнению принятой кодовой комбинации
со всеми Nо
разрешёнными.
Для примера определим время декодирования Тдк
принятой кодовой комбинации, если число информационных символов в ней k= 40 и для сравнения используется ЭВМ со
скоростью 107 операций в секунду. Будем полагать, что для сравнения
принятой кодовой комбинации с одной из разрешённых достаточно одной операции
на ЭВМ. Тогда для проведения
Nо = 2k = 240 сравнений потребуется
время декодирования
Тдк ![]() .
.
Как видно из примера, задача декодирования простым
перебором и сравнением непосильна даже для современных ЭВМ.
В соответствии с этим
основным направлением в теории кодирования является поиск таких кодов и
алгоритмов их формирования и обработки, для которых не требуется хранение в ЗУ
разрешённых кодовых комбинаций. Эти задачи решаются, в частности, при
построении кодеров на основе деления полиномов, а при декодировании — на основе
синдромного метода декодирования (СМД).
Метод деления полиномов позволяет представить разрешённые к
передаче кодовые комбинации в виде разделённых информационных Ai(Х) и проверочных Ri(Х) символов, т. е. получить блочный код.
Поскольку число проверочных символов равно r, то для компактной их записи в последние
младшие разряды кодового слова надо предварительно к Ai(Х) справа приписать r “нулей”, что эквивалентно
умножению Ai(Х) на оператор сдвига Хr (свойство
(д) ЦК).
На практике предпочитают использование метода деления
полиномов при построении кодеков, поскольку при этом имеется возможность
представить кодовую комбинацию в виде разделённых информационных и проверочных
символов
Вi(Х)= Ai(Х)Хr +Ri(Х)
,
(1.15)
где Ri(Х)
— остаток от деления Ai(Х) Хr /G(Х).
В алгоритме (1.15) можно выделить три этапа формирования
разрешённых кодовых комбинаций в кодирующем устройстве:
а) к комбинации первичного кода Ai(Х) дописывается справа г нулей, что эквивалентно умножению Ai(Х)
на Хr;
б)
произведение ![]() делится на
делится на
соответствующий порождающий полином G(Х) и определяется остаток Ri(Х), степень которого не превышает r -1, этот остаток и даёт группу проверочных
символов;
в) вычисленный остаток присоединяется справа к ![]() .
.
Пример 1. Рассмотрим процедуру кодирования по алгоритму
(1.15): для кодовой комбинации А=1001 сформировать
кодовую комбинацию циклического кода (7,4).
В заданном ЦК n=7, k = 4, r =
3 и из таблицы 1.1 выберем порождающий полином G(Х) = X3 + X + 1 (код
Хемминга). Выполним три необходимые операции для получения кодовой
комбинации ЦК согласно алгоритму (1.15)
![]() ~ X3 + 1 , (знак ” ~ ” – тильда – означает соответствие).
~ X3 + 1 , (знак ” ~ ” – тильда – означает соответствие).
а) ![]() = (Х3 + 1)
= (Х3 + 1) ![]() Х3 = Х6+Х3 ~
Х3 = Х6+Х3 ~
1001000, (n=7);
![]() б)
б)
Ai(Х)
![]() Хr /G(Х) = X6
Хr /G(Х) = X6
+ X3
X3 + X + 1
![]() + X3 + X
+ X3 + X
![]() X6 + X4 + X3
X6 + X4 + X3
X4
+
X 4 + Х2+ X
Х2+Х – остаток Рi(Х)=
Х2+Х ~110;
в) Вi(Х) = Ai(Х)
![]() Хr
Хr
+Ri(Х)= 1001110-итоговая комбинация ЦК.
Синдромный
метод декодирования (СМД) предполагает в ДУ принятую кодовую
комбинацию поделить на порождающий полином. Если принятая комбинация является
разрешённой, т. е. не искажена помехами в канале связи, то остаток от деления
будет нулевым. Ненулевой остаток свидетельствует о наличии в принятой кодовой
комбинации ошибок, остаток от деления и называется синдромом.
Термин “синдром” заимствован из медицинской
практики (от греч. вместе бегущий) и означает сочетание (комплекс) симптомов
болезни, характерное для определённого заболевания. В теории кодирования
синдром, который также называют опознавателем ошибки, обозначает совокупность
признаков, характерных для определённой ошибки. Для исправления ошибки на
стороне приёма необходимо знать не только факт её существования, но и её
местонахождение, которое определяется по установленному виду вектора ошибки z(Х).
После передачи по каналу с помехами принимается кодовое
слово
Вi(Х) =Вi(Х) + z(Х), (1.16)
где Вi(Х) – передаваемая кодовая комбинация; z(Х) — полином (вектор) ошибки, имеющий степень от 1 до n -1.
При декодировании принятое кодовое слово делится на G(Х)
![]() , (1.17)
, (1.17)
где остаток от деления Si(X) и является синдромом.
Если при делении получается нулевой остаток Si
(Х) = 0, то выносится
решение об отсутствии ошибки z(Х) = 0. Если остаток (синдром) ненулевой Si(Х)![]() 0, то выносится решение о наличии ошибки и определяется
0, то выносится решение о наличии ошибки и определяется
шумовой вектор (полином) z(Х), а затем -передаваемое кодовое слово,
поскольку из (1.16) следует
Вi(Х) = Вi(Х) +z(Х). (1.18)
Всякому ненулевому синдрому соответствует определённое
расположение (конфигурация) ошибок. Взаимосвязь между видом синдрома и
местоположением ошибочного символа находится довольно просто. Достаточно в
любую разрешённую кодовую комбинацию ввести ошибку и выполнить деление на G(Х). Полученный
остаток (1.17) – синдром и будет указывать на ошибку в этом символе.
В качестве примера для ЦК Хемминга (7,4), позволяющего
исправлять однократную ошибку при dmin= 3 (таблица 1), взаимосвязь между
синдромом и ошибочным символом для двух возможных порождающих полиномов кода
(7,4) приведена в таблице 2. Пользуясь этой таблицей, можно найти
местоположение ошибки и исправить её.
Для параметров рассмотренного ранее примера 1, где была
показана процедура кодирования кодовой комбинации Ai = 1001 при использовании порождающего
полинома G(Х)
= X3 + X +1 для кода Хемминга (7,4), исправляющего однократную ошибку, приведём
в примере 2 процедуру декодирования принятой с помехой кодовой комбинации.
Пример 2. Принятая кодовая комбинация ЦК (7,4) имеет вид Вi‘(Х)=1011110. Определить и исправить ошибку в Вi(X), если она имеется.
Выполним три необходимые операции, проводимые при
декодировании:
Таблица 2
|
Номер символа комбинации со старшего разряда |
Ошибочный |
Синдром G(Х)=X3 +Х+1 |
Синдром |
Шумовой вектор z(Х) |
|
7 6 5 4 3 2 1 |
X6 X5 X4 X3 X2 X1 X0 |
cм. 1.29 |
см. 1.29 |
1000000 0100000 0010000 0001000 0000100 0000010 0000001 |
|
Нет ошибки |
000 |
000 |
0000000 |
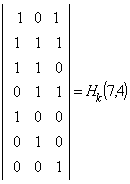
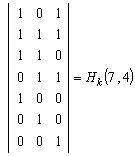
а) в соответствии с алгоритмом (1.17)
производим деление
![]() Bi(X)/ G(Х) = X6 + X4 +
Bi(X)/ G(Х) = X6 + X4 +
X3+X2 +X
X3+X +1
X6 + X4 + Х3 X3
![]()
Х2 +
Х – остаток R(Х) = Х2 + Х~110,
отметим, что совпадение остатков в примере 1 и 2 — чисто
случайное, в примере 1 остаток являлся проверочной группой кода, а в примере 2
– синдромом;
б) по полученному
синдрому 110 в соответствующем
опознавателе синдрома (дешифраторе
синдрома, локаторе ошибки)
определяем вид шумового
вектора z(Х)
0010000 (таблица 2);
в) воспользовавшись алгоритмом (1.18),
исправляем принятую кодовую комбинацию Вi‘
(X) и получаем переданную комбинацию Вi(X):
Вi (X) = Вi (X) + z(Х) =
1011110
+
0010000
1001110 – исправленная
комбинация на выходе ДУ с инвертированием неверно принятого символа.
Число проверочных символов r =n – k определяет число
исправляемых ошибок. Значение r должно быть достаточным для получения необходимого числа синдромов
![]() (опознавателей ошибок). Так, для исправления всех одиночных
(опознавателей ошибок). Так, для исправления всех одиночных
(однократных) ошибок необходимо ![]() = n +1
= n +1
синдромов, так как шумовой вектор может принимать следующие n значений:
000…01, 000…10,…, 001…00, 010…00, 100…00,
кроме того, необходим один синдром для определения факта
безошибочного приёма кодовой комбинации Sо = 000…00. Таким образом, для двоичных
кодов при необходимости исправления всех однократных ошибок требуется
выполнение соотношения
![]() = 2n–k = 2r = n+1
= 2n–k = 2r = n+1
,
(1.19)
поскольку синдром
формируется на месте г проверочных разрядов кода.
Плотноупакованные коды – такое название получили коды, у которых
соблюдаются точное равенство в (1.19) числа необходимых синдромов для
исправления ошибок заданной кратности. Вследствие уникальности таких кодов
плотноупакованные коды называют также “совершенными” или “оптимальными”.
К таким кодам относятся коды Хемминга, которые при минимальном кодовом
расстоянии dmin =3 обеспечивают
исправление всех однократных ошибок, поскольку у классических кодов
Хемминга число символов n= 2r-1 удовлетворяет условию (1.19).
В общем случае при необходимости исправления всех
независимых ошибок кратности до qи
включительно требуемое число синдромов определяется выражением
![]() ,
,
(1.20)
где ![]() – число сочетаний из n по
– число сочетаний из n по
I, причем ![]() , так как 0!=1.
, так как 0!=1.
С учетом (1.19) и (1.20), можно получить выражение для
оценки числа проверочных символов r при
необходимости исправления qи –
кратных ошибок в принятых кодовых комбинациях
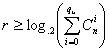 . (1.21)
. (1.21)
Занимаясь поиском плотноупакованных кодов (“код без
потерь”), М. Голей заметил ( опубликовано
в1949 году), что
![]() ,
,
а это означало, что может существовать плотноупакованный
двоичный (23,12) код, удовлетворяющий условию (1.20), исправляющий все кодовые
комбинации с тремя или менее ошибками. Он показал, что такой код действительно
существует, и в дальнейшем этот код получил его имя.
Код Голея относится к классу ЦК с порождающими
двойственными (дуальными) полиномами (4.9)
G(Х) = Х11+Х10+Х6 +Х5+Х4+Х2+1; (1.22)
![]() (Х) = Х11+Х9+Х7
(Х) = Х11+Х9+Х7
+Х6+Х5+Х+1.
Простыми вычислением проверяется, что
![]() ,
,
в связи с чем в качестве порождающего полинома ЦК Голея
(23,12) можно использовать как G(Х), так и ![]() (Х).
(Х).
Код Голея, гарантированно исправляющий ошибки с кратностью
не менее трех включительно, обладает минимальным кодовым расстоянием dmin=2qu+1=7, что, как правило, указывается в
маркировке кода (23,12,7). Добавление к этому коду общей проверки на четность
по всем позициям увеличивает на единицу как общую длину кода, так и минимальное
кодовое расстояние dmin=8.
Расширенный код Голея, имеющий маркировку (24,12,8),
состоит из 12 информационных символов и 12 проверочных, т.е. представляет собой
код, обладающий скоростью ½ и избыточностью, также равной ½.
Обратим внимание на
то, что плотноупакованные коды Хемминга и Голея – циклические, которые
принадлежат классу двоичных линейных кодов. Общим для линейных двоичных кодов
является наличие в качестве разрешенного нулевого кодового слова 000…00, что
приводит к тому, что минимальный вес wmin ненулевого разрешенного кодового слова
равен минимальному кодовому расстоянию dmin (1.13).
В общем случае вес кодовых комбинаций может принимать
различные значения, и совокупность чисел кодовых комбинаций с постоянным весом Nw определяют как распределение весов кода
или как спектр весов кода. Распределение весов в коде Голея (23,12,7) следующее
![]() ;
; ![]() ;
; ![]() ;
; ![]() ,
,
а в расширенном коде Голея –
![]() ;
; ![]() ;
; ![]() .
.
(1.23)
Кодовые слова с весом 12,8 и 16, выделенные из кода (24,12,8), образуют КПВ максимальной мощности.
К сожалению, кроме кодов Хемминга (dmin=3, qи=1) и кода Голея (23, 12, 7), пока не найдено других совершенных,
плотноупакованных кодов, число синдромов у которых точно соответствует
требуемому значению для гарантированного исправления ошибок заданной кратности.
1.3.1
Построение
порождающих и проверочных матриц
циклических кодов
Наряду с полиномиальным
способом задания кода, структуру построения кода можно определить с помощью
матричного представления. При этом в ряде случаев проще реализуется построение
кодирующих и декодирующих устройств ЦК.
Рассмотрим варианты формирования и обработки ЦК, заданных в
виде порождающих и проверочных матриц, на конкретном примере ЦК Хемминга
(7,4), воспользовавшись выражением (1.11), в котором определены двойственные
(дуальные) порождающие полиномы кода
Х7+1
= (X
+1) ![]() (Х3+Х+1)
(Х3+Х+1) ![]() (Х3+Х2+1),
(Х3+Х2+1),
что соответствует кодам (7, 6); (7, 4); (7, 4).
Пример 3. Задан ЦК (7,4) дуальными порождающими полиномами
G(7,4) = Х3+Х+1
и ![]() (7,4) = X3
(7,4) = X3
+Х2+1.
Составить порождающие матрицы для формирования разрешённых
кодовых комбинаций и проверочные матрицы для получения синдромов.
Первой строкой в матрице записывается порождающий полином
(в двоичном представлении) с доумножением его на оператор сдвига Хr для
резервирования места под запись r = 3 проверочных символов. Следующие
k -1 строк матриц получаются путём последовательного
циклического сдвига базового кодового слова матрицы G и ![]() на одну позицию
на одну позицию
вправо, поскольку при этом по определению ЦК также получаются разрешённые к
передаче кодовые комбинации
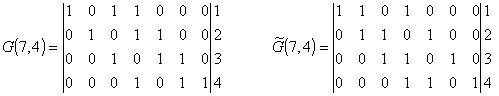 (1.24)
(1.24)
Однако в таком виде эти порождающие матрицы размерностью k х n (n столбцов, k строк) могут образовать только неразделимый
ЦК, т. е. код, у которого не определены жёстко места информационных и
проверочных элементов. Для построения порождающей матрицы, формирующей
разделимый блочный код, необходимо матрицу преобразовать к каноническому виду
путём простых линейных операций над строками.
С учётом свойства ЦК (1.12) каноническую форму матрицы
можно получить путём сложения ряда разрешённых кодовых комбинаций.
Каноническая матрица должна в левой части порождающей ЦК матрицы содержать
единичную диагональную квадратную подматрицу порядка”k” для получения в итоге блочного ЦК.
С этой целью для получения первой строки канонической матрицы Gk(7,4)
необходимо сложить по модулю 2 строки с номерами 1, 3 и 4 матрицы G(7, 4), а для матрицы ![]() (7,4); —строки с номерами 1, 2 и 3 матрицы
(7,4); —строки с номерами 1, 2 и 3 матрицы ![]() (7,4). В этом случае в матрицах (1.24) в первых строках остаются
(7,4). В этом случае в матрицах (1.24) в первых строках остаются
“1” только на первых позициях, а остальные “k-1″ символов заменяются
“0”, что и соответствует первым строкам единичных подматриц порядка
“k“. Нормирование
последующих трёх строк канонических матриц производится путём соответствующего
суммирования строк матриц (1.24).
В итоге имеем следующий вид дуальных канонических матриц
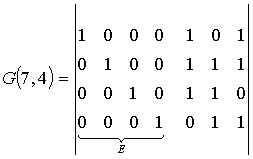
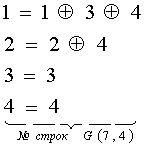
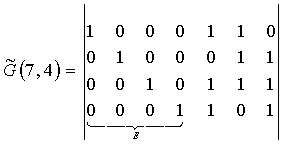
 (1.25)
(1.25)
Процесс кодирования первичных кодов на стороне источника
сообщений сводится к умножению информационных посылок, представленных в виде
векторов ![]() (Х), на соответствующую
(Х), на соответствующую
порождающую каноническую матрицу
![]() . (1.26)
. (1.26)
Эта процедура позволяет получить блочные коды Хемминга
“в целом”, т, е. получить проверочную группу символов r1, r2, r3 сразу после выполнения операции (1.26). Наряду с этим, имеется
возможность формировать символы проверочной группы поэлементно, где 3
проверочных символов задавались следующими равенствами проверки на чётность
r1 = i1![]() i2
i2![]() i3; r1 = i1
i3; r1 = i1![]() i3
i3![]() i4;
i4;
r2 = i2![]() i3
i3![]() i4; r2 = i1
i4; r2 = i1![]() i2
i2![]() i3; (1.27)
i3; (1.27)
r3 = i1![]() i2
i2![]() i4; r3 = i2
i4; r3 = i2![]() i3
i3![]() i4.
i4.
Обратим внимание на то, что
алгоритм (1.27) просто получается из рассмотрения порождающих коды Хемминга
матриц (1.25), в которых проверочные подматрицы, содержащие 3 столбца (r-1, r2, rз),
имеют символы” 1″ в тех строках, номера которых совпадают с
маркировкой информационных символов i в равенствах
(1.27) ((1.14)).
При матричном варианте обработки принятых кодов на стороне
получателя сообщений для получения синдрома необходимо принятую, возможно
искажённую в канале, кодовую комбинацию ![]() умножить на
умножить на
проверочную матрицу Н(Х)
![]() =
=![]() -Н(Х). (1.28)
-Н(Х). (1.28)
Процедура построения проверочной матрицы Н достаточно
подробно рассмотрена в [3]. Заметим, что матрица Н с размерностью n х r может быть получена из порождающей
матрицы канонического вида (1.25) путём дополнения проверочной подматрицы
единичной матрицей размерности r х r,
что даёт следующий вид дуальных проверочных матриц
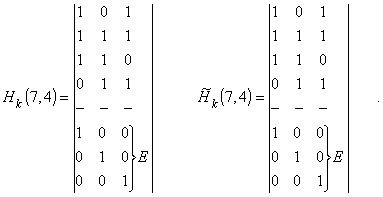 (1.29)
(1.29)
По определённому с помощью полученного синдрома (1.28)
соответствующему шумовому вектору исправляются ошибки (1.18).
Интересно отметить, что в таблице 2, в которой рассмотрена
связь между синдромом и шумовым вектором для кода (7,4), колонки с синдромами
дуальных порождающих полиномов полностью совпадают с (1.29).
В ЦК Хемминга (n , k) все проверочные r = n – k разряды размещаются в конце кодовой
комбинации и, как отмечалось, формируются «в целом». При поэлементном
получении проверочных символов (1.27) целесообразно, чтобы каждый синдром
представлял собой двоичное число, указывающее на номер разряда, в котором
произошла ошибка. Коды, в которых синдромы (опознаватели) соответствуют
указанному принципу, и предложил впервые Хемминг. В этом случае для кода (7, 4)
проверочные символы r1,, r2, r3 (таблица 2) размещаются на первой, второй и четвертой позициях
кодовой комбинации, отсчитываемых справа налево. Такое построение кодов
упрощает декодирующее устройство на стороне получателя сообщений.
1.4 Укороченные циклические коды
Поскольку ЦК порождаются
делителями бинома Хn +1 (1.3), то
для большей части значений n и k имеется относительно мало
кодов, удовлетворяющих всем свойствам, присущим ЦК (подраздел 1.3). Поэтому
естественно попытаться найти среди линейных кодов такие, которые хотя и не
являются в действительности циклическими, обладают похожей математической
структурой и столь же легко реализуются.
При разработке систем передачи
информаций, работающих с дискретными сигналами в предположении необходимости
исправления (обнаружения) ошибок, число информативных символов kΣ выбирают, как правило, таким, чтобы оно было кратным длине
первичного кода k1
![]() , где
, где ![]()
а значение ![]() где число проверочных символов должно удовлетворять заданному
где число проверочных символов должно удовлетворять заданному
значению кратности обнаруживаемых и исправляемых ошибок. В частности, ЭВМ
обычно обмениваются машинными словами в виде байтов, состоящих из восьми
символов (k1=8).
При этом nΣ и kS часто не совпадают с
табулированными в [6] ЦК. В этом случае по таблице [6] находят ЦК, который
соответствует обоснованному значению r = n–k для
классического, табулированного ЦК, а затем уменьшают n и kS до n – ℓ и
kS = k – ℓ, получая
укороченный ЦК.
Укороченные циклические коды (УЦК) получают
из полных ЦК, используя для передачи информаций только кодовые комбинаций
полного кода, содержащие слева ℓ нулей. Это дает возможность построить
УЦК (n – ℓ, k – ℓ) путем исключения первых ℓ столбцов
и ℓ
строк из порождающей матрицы (1.24). Полученный код не будет строго циклическим, так как циклический
сдвиг не всегда будет приводить к получению очередной разрешённой кодовой
комбинации. Поэтому укороченные (усечённые) ЦК часто называют
псевдоциклическими или квазициклическими.
Укороченные ЦК сохраняют
основные свойства классических ЦК
(подраздел 1.3), к числу которых относятся следующие:
а) УЦК образуются делителями
бинома Хn +1, порождающими
полиномами G(X), такими
же, как у полных ЦК;
б) УЦК
относятся к классу линейных (групповых) кодов, для которых сумма разрешённых
кодовых комбинаций УЦК также являются разрешённой кодовой комбинацией (4.12);
в) УЦК
обладает таким же минимальным (конструктивным) кодовым расстоянием, как у
исходного ЦК, и таким же числом проверочных символов (4.21), но не может быть
плотноупакованным;
г) УЦК
исправляет такое же число ошибок, что и ЦК, т.е. имеет такую же кратность
обнаруживаемых и исправляемых ошибок;
д) при
построении кодеков УЦК используются те же схемы, что и для классических ЦК, при
условии, что каждому усечённому коду спереди приписывается ℓ нулей.
Специфику построения УЦК рассмотрим на
следующем примере
Пример 4. Передаче подлежит сообщение,
закодированное стандартным кодом МТК-2 с числом информационных символов k=2.
Обеспечить у получателя сообщений исправление однократной ошибки в кодовом
слове.
Однократная ошибка исправляется при минимальном
кодовом расстоянии dmin=3, этому значению удовлетворяют коды Хемминга (7,4),
(15,11), (31,26)…(таблица 1). Код (7,4) с числом информационных символов k=4
не удовлетворяет условию примера при необходимости передачи k=5. Этому условию
удовлетворяет следующий по порядку код Хемминга (15,11), если из общего числа
символов n=15 и числа информативных символов k=11 вычесть одно и то же число
е=6 (исключение первых e столбцов и е строк порождающей код матрицы с
размерностью k x n), получаем УЦК (9,5), удовлетворяющий условию примера k=5,
dmin=3,с числом проверочных символов r=4.
Для опорного ЦК (15,11) бином Хn+1
раскладывается на следующие неприводимые полиномы
![]() ,
,
из которых для построения кода r=4
можно выбрать любой из трёх последних. Выберем в качестве порождающего полинома
G(X) = X4+X+1 и на основе матрицы этого ЦК (15,11) покажем, как осуществляется
отсечка
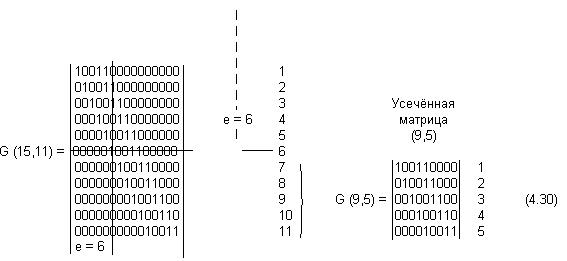
Приведём усечённую матрицу G(9,5) к
каноническому виду путём соответствующего суммирования строк по аналогии с
проводимыми преобразованиями с матрицами (1.24) и (1.25) и получим
соответствующие равенства проверки на чётность при поэлементном формировании
усечённого кода (9,5) (см. (1.27) в качестве аналога
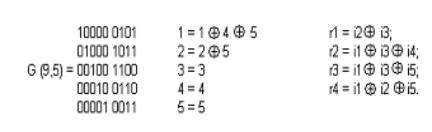
Таким образом, УЦК (9,5) полностью удовлетворяет условиям примера 4.
1.5 Структурный состав линейных переключательных схем
Цикличность перестановок при формировании разрешенных
кодовых комбинаций ЦК лежит в основе техники построения кодирующих устройств
(КУ) и декодирующих устройств (ДУ) циклических кодов. Эта техника применяет
сдвигающие регистры (СР) в виде триггерных цепочек с теми или иными обратными
связями. Такие СР называют также многотактными линейными переключателями
схемами (ЛПС) и линейными кодовыми фильтрами Хаффмана, который первым начал
изучение ЛПС с точки зрения линейных фильтров. Кстати, Д.Хаффман является и
автором принципа, состоящего в том, что «две точки зрения лучше, чем одна»,
получившего широкое применение в настоящее компромиссное время.
При построении ЛПС используется 3 вида элементарных
устройств:
а) сумматор, имеющий, как правило, два входа и один
выход, причем для двоичных кодов суммирование осуществляется по модулю 2;
б) ЗУ, имеющее один вход и один выход и представляющее
собой одну тригерную ячейку (один разряд) СР;
в) устройство умножения на постоянную величину,
имеющее один вход и один выход. Эти устройства изображаются на схемах так, как
показано на рисунке 1.




Рисунок 1
Линейными переключательными
схемами с
конечным числом состояний называются любые схемы, содержащие конечное число
сумматоров, устройств памяти и устройств умножения на константу, соединённых
любым допустимым способом.
В бинарном случае сумматор (равно как и вычитатель)
представляет собой логический элемент «исключающее ИЛИ», а устройство памяти
является устройством задержки (D-триггером). Устройства
задержки, включенные последовательно, составляют СР, в ячейках которого
выходной символ совпадает с входным символом в предшествующий момент времени. К
СР подводится шина сдвига, с помощью которой тактовыми пульсами (ТИ)
осуществляется продвижение по разрядам СР записанной кодовой информации. Как
правило, шина сдвига не показывается на схемах с изображениями ЛПС.
При формировании и обработке
двоичных ЦК введение в схему ЛПС умножителя на константу, равную 1, эквивалентно
введению дополнительного соединения, а умножитель на константу, равную 0,
соответствует отсутствию такого соединения.
Предполагается, что на вход
СР, входящего в состав ЛПС, кодовая комбинация подается последовательно, с
периодичностью, равной периоду следования ТИ в шине сдвига. Аналогично,
последовательно во времени появляются кодовые символы на выходе СР. когда
входом или выходом является многочлен, представляющий при двоичной обработке
набор «1» и «0», то на входном или на выходном конце СР появляются только
коэффициенты («1» или «0»), начиная с коэффициентов высших порядков. Это
обуславливается тем, что при делении у делителя сначала должны быть обработаны
коэффициенты высших порядков.
В последующих разрядах
описываются схемы, используемые для умножения и деления любых многочленов на
некоторый фиксированный, в частности, порождающий полином.
1.6 Умножение полиномов на
базе ЛПС
Cхема, изображенная на рисунке 2, используется для
умножения любого полинома на входе
![]() .
.
На фиксированный полином, в частности, порождающий:
![]()
предполагается, что первоначально все разряды СР
содержат нули, а на вход коэффициенты полинома А(Х) поступают, начиная с коэффициентов высших порядков (со старших
разрядов), после чего следует r нулей.
Первый
вариант ЛПС для умножения полиномов
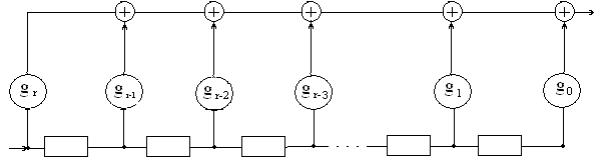
Рисунок 2
Произведение
полиномов
![]() . (1.32)
. (1.32)
Когда
на входе ЛПС появляется первый (старший) коэффициент полинома А(Х), то он
умножится в первом устройстве умножения на gr и появится на выходе уже как результат перемножения акgr, проследовав «транзитом» через все схемы суммирования
по модулю 2. Кроме того, ак запишется в первом разряде СР, а все
остальные разряды СР будут содержать нули. Спустя единицу времени, с появлением
в шины сдвига второго ТИ на входе появится ак-1, который
перемножится с gr и сложится в
первой схеме суммирования по модулю 2 с акgr-1,
сформировав на выходе сумму ак-1gr+akgr-1;
т.е. второй коэффициент произведения А(Х)G(X). Дальнейшие
операции производятся аналогичным образом. После r+k сдвигов СР
полностью обнуляется и на выходе появляются значения a0g0, равные первому коэффициенту произведения (1.32), так
что произведение на выходе ЛПС последовательно получается в полном составе.
Второй
вариант умножения полиномов показан на рисунке3.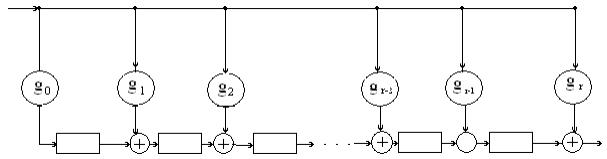
Рисунок 3
Коэффициенты произведения формируются
непосредственно в СР после того, как первый символ подаётся на вход, на выходе
появляется последний коэффициент (1.32) акgr, а разряды СР содержат
только нули. После одного сдвига ячейки СР содержат элементы akg0,,
akg1, … , akgr-1, а вход равен ak-1.
При этом выход СР равен akgr-1 + ak-1gr, т.е. равен второму коэффициенту (1.32), после появления среднего ТИ в
шине сдвига (не показана на рисунке 2 и 3) на выходе появляется третий
коэффициент (1.32), дальнейшие операции проводятся аналогичным образом.
Схемы умножения могут иметь
более чем один вход, если добавить к ЛПС, изображенной на рисунке 3, вторую
шину с цепочкой устройств умножения, связанных с соответствующими схемами
суммирования по модулю 2, тогда схема будет реализовывать процедуру суммирования
произведений двух пар полиномов, причем ЗУ в виде СР будет только одно.
![]() .
.
(1.33)
Пример 5. Составить две
схемы кодирующих устройств ЦК Хемминга (7,4) на базе двух рассмотренных
вариантов ЛПС для умножения полиномов (рисунок 4). В качестве порождающего
полинома использовать полином
![]() (примеры 1 и 3).
(примеры 1 и 3).
 Рисунок 4
Рисунок 4
Напомним (подраздел 1.3),
что применение в кодерах метода умножения приводит, к сожалению, к формированию
неразделимых ЦК.
1.7 Деление полиномов на
базе ЛПС
Схема для деления
полинома ![]() на полином
на полином ![]() представлена на рисунке 5. Динамическое ЗУ в
представлена на рисунке 5. Динамическое ЗУ в
виде СР вначале должно содержать все нули. Для деления полиномов СР охвачен
обратной связью, т.е. выход СР соединяется со входом. Для подчеркивания
противоположного направления шины обратной связи коэффициент умножителя
обозначается как gr-1, однако для двоичных кодов
результат умножения и деления на единицу одинаков, поэтому указанное
обозначение в дальнейшем использоваться не будет.
Первый
вариант ЛПС для деления полиномов.
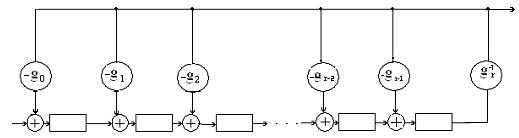
Рисунок 5
Для первых r –
сдвигов, т.е. до тех пор, пока первый входной символ не достигнет конца РС,
выход принимает значения, равные «0». После этого на выходе появляется первый
нулевой выход, который равен akgr-1 – первому коэффициенту
частного. Для каждого коэффициента частного gj необходимо вычесть из
делимого полином G(X). Это вычитание производится
с помощью обратной связи. После k сдвигов на выходе появится
частное от деления, а остаток от деления будет находиться в РС.
Работу схемы легче всего
понять с помощью примеров построения КУ и ДКУ на базе ЛПС.
Второй
вариант ЛПС с делением на генераторный полином.
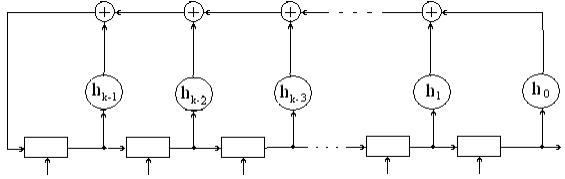
Рисунок 6
При построении КУ ЦК, а
также генераторов различных кодов последовательностей, в частности,
последовательностей максимальной длины (М – последовательностей), применяется в
ряде случаев так называемый генераторный полином ![]() . Этот полином называют также проверочным, если он получается
. Этот полином называют также проверочным, если он получается
при делении бинома ![]() на порождающий
на порождающий
полином G(X
![]() . (1.34)
. (1.34)
При использовании этой схемы
в качестве КУ ЦК исходную кодовую комбинацию А(Х) параллельно, одновременно записывают в k
разрядов СР.
С первым тактом на выход
будет выдан коэффициент bn-1 = ak-1, произойдет сдвиг в право в
СР, и в освободившуюся ячейку памяти будет записано вычисленное значение
проверочного бита ![]() . Со вторым тактом на выход будет считан коэффициент bn-2 =
. Со вторым тактом на выход будет считан коэффициент bn-2 =
ak-2, произойдет сдвиг, и в освободившуюся первую ячейку
СР запишется второй проверочный бит ![]() , через n–k тактов будут вычислены все n–k
, через n–k тактов будут вычислены все n–k
проверочных символов ![]() и записаны в СР.
и записаны в СР.
После к тактов, т.е. после вывода на выход всех информационных символов, станут
выводиться проверочные символы в том же порядке, в каком они вычислялись. На
выходе получается блочный код. После к тактов процесс кодирования одной
комбинации Аi(Х)
заканчивается, и СР принимает исходное состояние. Для кодирования следующей
комбинации необходимо стереть Аi(Х),
ввести в СР новую Аj(Х)
и повторит ь цикл из n тактов.
Рассмотрим более конкретную
работу этой схемы на примере использования её в качестве КУ с привязкой
начальных к данным предыдущих примеров 1,2 и 3.
Пример 6.
Построить схему КУ, обеспечивающего кодирование ЦК Хемминга (7,4) с порождающим
полиномом ![]() путем вычисления
путем вычисления
блока проверочных символов «в целом», используя проверочный полином Н(Х). Проследить по тактам процесс
кодирования и состояния элементов схемы при кодировании исходной комбинации 1001~![]() .
.
Построение
схемы КУ определяется проверочным полиномом (1.34)
![]() .
.
Так как к=4,
то число разрядов СР равно четырем. По виду проверочного полинома определяем,
что ![]()
![]() .
.
Схема КУ для условий примера
приведена на рисунке 7, состояние ячеек СР и выхода схемы по тактам – в
таблице 4.
В исходном положении в триггерные ячейки СР
записываются информационные символы ![]() ~1001, учитывая
~1001, учитывая
наличие обратной связи в СР с выхода на вход, суммирование по модулю 2 выходов
ячеек Х1, Х2 и Х3 даст символ записи в ячейку
Х0. После первого сдвига в Х0 будет записан символ
проверочной группы r1, который при последующих сдвигах продефилирует на
выход СР. Из таблицы 4 видно, что после n=7 тактов на выходе
образуется комбинация 0111001 (старшим разрядом вперед), такая
же, как в примерах 1 и 2.
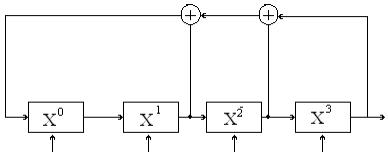
|
|
|
|
|
|||||||
|
|
||||||||||
Ai(X)
Рисунок 7
Таблица 4
|
Номер такта |
Состояние ячеек |
выход |
|||
|
Х0 |
Х1 |
Х2 |
Х3 |
||
|
А(Х) |
1 |
0 |
0 |
1 |
— |
|
1 2 3 4 5 6 7 |
1 1 0 1 0 0 1 |
1 1 1 0 1 0 0 |
0 1 1 1 0 1 0 |
0 0 1 1 1 0 1 |
1 0 0 1 1 1 0 |
При этом триггерные ячейки
СР принимают исходное значение 1001, при необходимости возможно повторение
процедуры кодирования этой же кодовой комбинации А(Х) путем подачи очередных,
следующих n=7 тактов. Таким образом, этот способ кодирования
так же, как и первый вариант схемы для деления полиномов, обеспечивает
получение кодовой комбинации разделимого, блочного ЦК. Кроме того,
подобная ЛПС может быть
использована для генерации определенной кодовой
комбинации, в частности, М – последовательности.
Рассмотрение вариантов
построения ЛПС, выполняющих операции умножения и деления полиномов, с целью
использования в кодеках УК, позволяет сделать следующие выводы:
а) в КУ ЦК процедура
умножения полиномов приводит к получению неразделимых кодов, что усложняет их
последующее декодирование. Поэтому операция умножения редко используется в
устройствах формирования и обработки ЦК;
б) при делении на
порождающий полином G(X)
код на выходе КУ получается разделимым и СР содержит r разрядов. Так как в
большинстве случаев используется ЦК, у которых число проверочных символов r
существенно меньше числа информационных (r<k), то СР в этом случае будет
иметь меньшее число разрядов, чем при делении на генераторный полином;
в) при делении в КУ исходной
кодовой комбинации на генераторный многочлен ЦК также получается разделимым, но
в СР требуется использовать не r, а k разрядов, которых как
правило больше.
Применение этого способа
более целесообразно в тех случаях, когда одна и так же кодовая комбинация
передаётся по каналу связи многократно, например, при передаче формата
сообщения с аварийных буев в системах поиска и спасения терпящих бедствие
объектов.
Линейные переключательные
схемы широко применяются как при формировании и обработке ЦК, так и при
генерировании кодированных последовательностей, в частности, М –
последовательностей. Рассмотрим ряд характерных примеров применения ЛПС в
технике связи.
1.8 Циклические коды,
обнаруживающие и исправляющие
пакеты ошибок (коды Файра)
Под
пакетом ошибок длиной b понимают такой вид комбинации помехи, в
которой между крайними разрядами, пораженными помехами, содержится b
– 2 разряда. Например, при b = 5 комбинации помехи, т. е. пакет ошибок, могут иметь
следующий вид: 10001 (поражены только два
крайних символа), 11111 (поражены все символы), 10111, 11101, 11011 (не поражен лишь один символ), 10011, 11001,
10101 (поражены три символа). При
любом варианте непременным условием пакета данной длины является поражение крайних символов.
Коды
Файра могут исправлять пакет ошибок длиной bs и обнаруживать пакет ошибок длиной br [заметим, что в кодах
Файра понятие кодового расстояния d, а следовательно, и
уравнение d = r+s+1 не используются].
Образующий
многочлен кода Файра Р(Х)ф определяется
из выражения
![]() (1.35)
(1.35)
где Р(Х) — неприводимый многочлен степени ![]() .
.
Из
принципа построения кода следует, что
![]() (1.36)
(1.36)
![]() (1.37)
(1.37)
При этом
с не должно делиться нацело на число
е, где
![]() (1.38)
(1.38)
Неприводимый
многочлен Р(Х) выбирают из таблицы 5,
согласно уравнению (1.33), но так, чтобы удовлетворялось условие (1.38). Длина слова п равна наименьшему общему кратному чисел с и е,
так как только в этом случае многочлен Хn + 1 делится на Р(Х)Ф
без остатка [при п'<.п никакой многочлен Хn’+1 не делится на Р(Х)Ф]
![]() . (1.39)
. (1.39)
Число
контрольных символов
![]() (1.40)
(1.40)
Таблица 5 – Неприводимые многочлены и их
эквиваленты
|
P( P(X2)=X2 +X+1 P(X3)=X3 +X+1 P(X3)=X3 + X2+1 P(X4)=X4 +X+1 P(X4)=X4 + X3+1 P(X4)=X4 + X3+ X2
P(X5)=X5 + X2+1 P(X5)=X5 + X3+1 |
P(X5)=X5 + X3+ X2 P(X5)=X5 + X4+ X2 P(X5)=X5 + X4+ X3 P(X5)=X5 + X4+ X3 P(X6)=X6 + X+1 P(X7)=X7 + X3 +1 P(X8)=X8 + X4+ X3
P(X9)=X9 + X4+1 P(X10)=X10 + X3 +1 |
Для кода Файра приведем два примера.
Пример 7. Согласно статистическим характеристикам помех, bs = 5 и br = 6. По этим данным требуется построить
код Файра.
На основании (1.36) и (1.37)
![]()
![]() .
.
По таблице 5
находим неприводимый многочлен пятой степени
Р(Х)= Х5 + Х2+
1.
Согласно
(1.35), образующий многочлен
Р(Х)Ф = (Х5 + Х2+ 1)(
Х10 +1)==X15 + X12+ X10+ X5+ X2+1.
Согласно (1.38), е
= 25 — 1 = 31. Поэтому длина кода n = НОК(31,10)=310. Из (1.40) число
контрольных и проверочных символов
k=n–m=310-15=295;
m = 10 + 5= 15, т. е. в данном случае оно
равно степени образующего многочлена. В итоге получаем код (310,
295).Избыточность такого кода, если учитывать его исправляющую способность,
невелика: И=m/n= 15/310
= 0,048
Представляет интерес сравнение избыточности кода той же
длины при исправлении того же числа ошибок, но не сгруппированных в пакет, т.
е. рассеянных по всей длине слова. Если воспользоваться для этой цели кодами
БЧХ и близким значением n=127, то при s=4 можно по изложенной методике подсчитать, что число контрольных
символов m=28,
т.е. получен код (127,99). Избыточность такого кода И = 28/127 = 0,22, т.е.
значительно выше, чем у кода Файра. Это очевидно: исправить четыре ошибки,
находящиеся в одном месте, проще, чем ошибки, рассредоточенные по всей длине
комбинации.
Заметим, что существует следующее правило: если циклический
код рассчитан на обнаружение независимых ошибок, он может обнаружить также
пакет ошибок длиной т.
При делении кодовой комбинации G(X)=1000000…………..000
на образующий полином вида 1001010000100101 получаем остаток
100101000010010.
Пример 8. Согласно статистическим характеристикам
помех, bs =4 и br = 5. По этим данным требуется построить
код Файра.
Исправить пакет bs=4—значит исправить одну из следующих
комбинаций ошибок, пораженных помехами: 1111, 1101, 1011 и 1001. В то же время
этот код может обнаружить одну из комбинаций в пять символов, рассмотренных
ранее (10001, 11111 и т. д.).
На основании (1.36) и (1.37) с≥8 и l≥4.
По таблицам 5 находим неприводимый многочлен четвертой степени Р(Х)= Х4 + Х+ 1.
Согласно
(1.35), образующий многочлен будет равен
Р(Х)Ф = (Х4 + Х+ 1)( Х8
+1)=X12 + X9+ X8 + X4+ X+1.
Согласно (1.38), е
= 24 – 1 = 15. Поэтому длина кода n= НОК (15,8) =120. Из (1.40) число
контрольных проверочных символов
k=n–m=120-12=108;
m = 8 + 4= 12, т. е. в данном случае оно
равно степени образующего многочлена. В итоге получаем код (120, 108)
Избыточность такого кода, если учитывать его исправляющую способность,
невелика: И— 12/120 = 0,1
Представляет интерес сравнение избыточности кода той же
длины при исправлении того же числа ошибок, но не сгруппированных в пакет, т.
е. рассеянных по всей длине слова. Если воспользоваться для этой цели кодами
БЧХ и близким значением n=127, то при s=4 можно по изложенной методике подсчитать, что число контрольных
символов m=28,
т.е. получен код (127,99). Избыточность такого кода И = 28/127 = 0,22, т.е.
значительно выше, чем у кода Файра. Это очевидно: исправить четыре ошибки,
находящиеся в одном месте, проще, чем ошибки, рассредоточенные по всей длине
комбинации.
Заметим, что существует следующее правило: если циклический
код рассчитан на обнаружение независимых ошибок, он может обнаружить также
пакет ошибок длиной т.
При делении кодовой комбинации G(X)=1000000…………..000 на образующий полином вида
11001000011001 получаем остаток 110010001100.
1.9
Декодирование кодов Файра
Рассмотрев
код, исправляющий единичные и двойные смежные ошибки, мы установили
необходимость двух схем в детекторе ошибок, настроенных на два выделенных
синдрома. При большом числе выделенных синдромов, как это имеет место, например, в случае кодов,
исправляющих пакеты ошибок значительной
длины, такой подход неприемлем, так как декодирующее устройство оказывается
чрезвычайно сложным.
В связи
с этим разработаны коды, в схемах декодирования которых детектор ошибки
автоматически настраивается
на нужный выделенный синдром. Осуществляется
это за счет схемы деления на второй соответствующим образом подобранный многочлен. Образующий многочлен таких кодов, следовательно, представляет
собой произведение двух многочленов
![]() (1.41)
(1.41)
В
качестве примера рассмотрим класс кодов Файра с образующим многочленом
![]() (1.42)
(1.42)
где р(х)—
неприводимый многочлен степени m ³ b,
принадлежащий
показателю степени е = 2m – 1;
b – длина корректируемого
пакета ошибок.
Поступающую
из канала связи кодовую комбинацию h{x) представляем суммой по модулю два, неискаженной комбинации кода f{x) и вектора,
соответствующего пачке ошибок В(х)
![]() (1.43)
(1.43)
где ![]() – характеризует положение пачки ошибок В(х) в векторе ошибки. Вектор f(x) делится на каждый из многочленов g1(х) и g2(x) без остатка. Поэтому процесс декодирования можно
– характеризует положение пачки ошибок В(х) в векторе ошибки. Вектор f(x) делится на каждый из многочленов g1(х) и g2(x) без остатка. Поэтому процесс декодирования можно
анализировать, ограничиваясь вектором xjВ(х). Отметим, что при выбранном нами соотношении числа разрядов в
пакете ошибок и степени образующего многочлена т = b совокупность
различных исправляемых пакетов
ошибок является одновременно совокупностью остатков,
получаемых при делении на р(х).
В качестве остатка на n-м
такте (выделенного синдрома) при пакете ошибок в старших разрядах h(x) желательно иметь сам многочлен ошибки.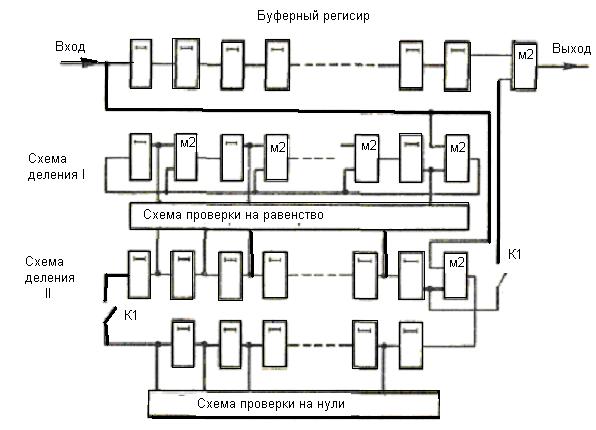
Рисунок 8
Тогда на следующих тактах, выводя его в узел коррекции синхронно с
последовательностью h(x) из буферного регистра, легко исправить искаженные символы.
Остаток
на n-м такте мы
получим только в том случае,
если будем использовать схему, обеспечивающую деление
с первого такта и требующую домножения h(x) на хm.
Для случая поступления
кодовых комбинаций, разнесенных во времени,
схема декодирующего устройства для
кодов Файра представлена на рисунке 8.
При
поступлении h(x) в схему деления I [на многочлен р(х)] в ней
начинается закономерное чередование остатков. В(х),
являющийся одним из остатков, появляется в первый раз на (2m – 1)-м такте. Следовательно,
для того чтобы он появился на
n-м такте, общее число
разрядов должно быть кратно 2m – 1.
В
процессе деления h(x) на многочлен х2b-1+1, принадлежащий показателю
(2b – 1), образуется (2b
– 1) остатков. Вектор типа В(х)хb-1 является одним из остатков.
Он возникает впервые на (2b – 1)-м такте, и затем
его
появление циклически повторяется с периодом (2b – I)
тактов.
Если мы
желаем выставить этот остаток в детекторе ошибки, т. е. получить его также на n-м такте, то п должно быть кратно (2b – 1). Чтобы детектор ошибки
не
сработал раньше, числа 2m-1 и 2b – 1 должны быть взаимно простыми, а n — наименьшим кратным
этих чисел.
Равенство
остатков В(х) в регистрах двух схем
деления,
а также равенство нулю остальных (b—1) разрядов в схеме деления II
(на многочлен х2b-1 + 1) являются условиями возможности
исправления обнаруженного пакета ошибок и устанавливаются схемным путем.
После фиксации условий,
допускающих исправление пакета, ключ К1
замыкается, а ключ K2 размыкается. На схему коррекции
(сумматор по модулю два) одновременно
начинают выводиться символы В(х) как с буферного
регистра, так и со схемы деления II. При этом пакет
ошибок В(х) в векторе h(x)
устраняется.
В общем
случае, когда В(х) начинается не со
старшего
разряда, а с j-го, для обеспечения равенства остатков,
полученных
на n-ы такте, нужно проводить последовательные домножения
их на х с приведением по модулю р(х) в одной схеме и по модулю (х2b-1 + 1) – в другой.
Если пачка начинается с j-го разряда, то необходимо сделать дополнительно (n
— j) тактов, прежде чем остатки в регистрах сравняются, причем с учетом домножения h(x) на xmj может принимать
значения от 1 до n.
За (n – /) дополнительных сдвигов содержимое буферного регистра сместится, и ошибочные символы
снова окажутся непосредственно перед схемой коррекции.
Если за
время вывода h(x) из буферного регистра условия возможности проведения коррекции
не были выполнены, то обнаружена неисправимая
ошибка.
Пример
9 – Рассмотреть процесс
исправления пакетов ошибок кодом Файра с образующим многочленом
![]()
(1.42)
Код может
исправлять пакеты ошибок, состоящие из трех символов (где b=bs = 3). Длина кодовой комбинации равна n
= (2b – 1)![]() (2
(2![]() b -1) = (23 -1)
b -1) = (23 -1) ![]() (2
(2![]() 3-1)=35. Предположим, что в трех старших разрядах
3-1)=35. Предположим, что в трех старших разрядах
нулевой кодовой комбинации возникла пачка
ошибок типа В(х) = 101.
При
делении В(х) на g1(x) = х3 + х2 + 1 остаток В(х) будет появляться в регистре с
периодом 7 тактов. Действительно,
Чередование
остатков B(x) xb-1
при делений B(x) на g2 (x) = x5 +1 происходит с периодом 5 тактов:
Условия возможности исправления пакета
ошибок выполняются на 35-ом такте. За последующие три такта при выводе кодовой
комбинации из буферного регистра на схему коррекции пачка ошибок устраняется.
Пример 10.Образующий многочлен таких кодов
представляет собой произведение двух многочленов
g(x)= g1(x) ![]() g2(x)=
g2(x)=
Рф(х)
Рф(х) =
(х5+х2+1)(х10+1)
g1(x)
= (х5+х2+1) = 100101
g2(x)= = (х10+1)
= 10000000001
Длина кодовой комбинации
n=(2b-1) ![]() (2
(2![]() b-1)=(25-1)(2*5-1)=279
b-1)=(25-1)(2*5-1)=279
Предположим, что при делении В(х) на g2(х) остаток В(х) будет появляться в регистре с периодом 9 тактов.
Таблица 6 – Остатки от деления В(х) на g1(х)
и g2(х).
|
Номер |
Остаток |
Остаток |
|
1 2 . . . 9 . . . 31 . . . 279 |
0100000001 1100000001 . . . 1010000000 . . . . . . . 1010000000 |
01101 11111 11010 . . . . . . 10100 . . . 10100 |
Условия возможности исправления пакета
ошибок выполняются на 279-ом такте. За последующие три такта при выводе кодовой
комбинации из буферного регистра на схему коррекции пачка ошибок устраняется.
1.10 Циклические коды Боуза -Чоудхури -Хоквингема
Коды Боуза –
Чоудхури – Хоквингема (БЧХ)
представляют собой обширный класс кодов, способных исправлять несколько ошибок
и занимающих заметное место в теории и практике кодирования. Интерес к кодам
БЧХ определяется по меньшей мере тремя следующими обстоятельствами:
а) среди кодов
БЧХ при небольших
длинах существуют хорошие
(но, как правило, не лучшие из
известных) коды;
б) известны
относительно простые и конструктивные методы их кодирования и декодирования;
в) полное понимание
построения кодов БЧХ является
наилучшей отправной точкой для изучения многих других классов кодов.
Коды БЧХ независимо открыли Хоквингем (1959) и Боуз и
Рой-Чоудхури (1960), которые доказали ряд теорем, устанавливающих существование
таких ЦК, у которых минимизируется число проверочных символов, а также
указывающих пути нахождения порождающих полиномов для этих кодов.
Корректирующие свойства ЦК могут быть
определены на основании следующей теоремы: для любых значений m и gu существует ЦК длиной n = 2m-1, исправляющий все ошибки кратности gu и менее (gu <m) и содержащий не более n –k < gu проверочных символов. Так, например, при n = 15, m= 4 и различных gu число проверочных символов будет равно: gu =1, n – k = m gu = 4*1= 4; gu = 2, mgu = 4*2 = 8; gu = 3, m gu = 4*3 = 12. Соответствующие коды (n, к) будут (15,11), (15,7), (15,3).
Напомним, что минимальное кодовое расстояние dmin=2gu+1, и применительно к ЦК оно чаще называется
конструктивным расстоянием. Если величины gu или d выбрать слишком большими, то
получившийся в результате код будет тривиальным — в нём будет лишь один либо
(при r > n) ни одного информационного символа.
В таблице 7 даны параметры и порождающие полиномы некоторых
кодов БЧХ. Полиномы приведены в восьмеричной форме записи, старшая степень
расположена слева.
Например, коду (15,7) соответствуют двоичное представление
111010001 и многочлен G(Х)
= X8 + X7 + X6
+ X4 +1. Подробные таблицы порождающих полиномов циклических кодов БЧХ приведены в [6].
Таблица 7
|
m |
n |
k |
r |
gu |
G(X)-mod 8 |
m |
k |
R |
gu |
G(X)-mod 8 |
|
|
3 4 5 6 |
7 15 31 63 |
4 11 7 26 21 16 11 57 51 45 39 36 |
3 4 8 5 10 15 20 6 12 18 24 27 |
1 1 2 1 2 3 5 1 2 3 4 5 |
13 23 721 45 3551 107657 5423325 103 12471 1701317 166623567 1033500423 |
7 8 |
127 225 |
120 113 106 99 92 247 239 231 223 215 |
7 14 21 28 35 8 16 24 32 40 |
1 2 3 4 5 1 2 3 4 5 |
211 41567 11554743 3447023271 624730022327 435 267543 156720665 75626641375 23157564726421 |
Коды БЧХ с длиной 2m -1 называют примитивными кодами БЧХ. К
ним, в частности, относятся классические коды Хемминга, исправляющие
однократные ошибки. К кодам БЧХ относятся также коды, длина n которых является делителем 2m -1. Например, код Голея (23, 12, 7)
(подраздел 1.3) также принадлежит классу кодов БЧХ, поскольку при m = 11 примитивный код БЧХ имеет длину n=211 -1 = 2047, причём это значение
без остатка делится на длину кода Голея n = 23 (2047 : 23 = 89), который относится
к непримитивным БЧХ- кодам [5, 6].
Как отмечалось выше, все примитивные коды БЧХ обладают
конструктивным расстоянием dmin =2![]() +1. Расстояние можно увеличить до 2
+1. Расстояние можно увеличить до 2![]() + 2. Для этого нужно основной порождающий полином БЧХ –
+ 2. Для этого нужно основной порождающий полином БЧХ –
кода домножить на бином Х+1, т.е. G1(Х)
= (Х+1) х GБЧХ(Х), что повлечёт за собой прибавление к коду одного проверочного
символа, обеспечивающего проверку на чётность всех символов кода БЧХ. Таким
образом получается расширенный код БЧХ.
Адекватно можно получить укороченный (усечённый) БЧХ – код,
следуя алгоритму, изложенному в подразделе 1.4.
Коды Рида—Соломона
(РС) являются важным и широко используемым подмножеством кодов
БЧХ. Двоичный код Рида—Соломона получится, если взять основание кода q=2s. Это означает, что каждый символ кода заменяется
s – значной двоичной
последовательностью. Если исходный код с основанием q исправляет ошибки кратности <![]() , то полученный из него двоичный код имеет 2
, то полученный из него двоичный код имеет 2![]() s
s
проверочных символов (по 2![]() на каждый блок из символов) из общего числа n =s -(2s – 1). Код может исправлять серийные
на каждый блок из символов) из общего числа n =s -(2s – 1). Код может исправлять серийные
ошибки (пакеты ошибок) длиной ≤b = s * (![]() -1 )+1 .
-1 )+1 .
Коды РС, наряду с
кодами Файра (1.10), являются наиболее подходящими для исправления серийных
ошибок, а также в каскадных системах кодирования в качестве внешних кодов.
Построение кодеров и декодеров ЦК основывается на
применении ЛПС, содержащих сдвигающие регистры. Как отмечает Р. Блейхут [5],
ЛПС «были сразу использованы большинством исследователей и вошли в литературу
без всяких фанфар».
1.6.1
Циклические коды с d³5. Эти коды,
разработанные Боузом, Чоудхури и Хоквинхемом (сокращенно коды БЧХ), позволяют
обнаруживать и исправлять любое число ошибок. Заданными при кодировании является число ошибок s,
которое следует исправить, и общее число символов, посылаемых в линию, т.
е. длина слова п. Числа информационных символов к и контрольных символов т, а
также состав контрольных символов подлежат определению.
Методика
кодирования такова:
а) коды
БЧХ для исправления ошибок.
1. Выбор длины слова. При кодировании по
методу БЧХ нельзя выбирать произвольную длину слова n.
Первым ограничением является то, что слово может иметь только нечетное число
символов. Однако даже при этом не все нечетные числа могут составлять длину
слова. Здесь могут быть два случая:
1) по
заданному n находят такое число h, чтобы удовлетворялось равенство 2h – 1=п. Например, при n = 7 h
= 3, при n=15 h = 4, при n = 31 h =5, при n=63 h =6 и т. д.;
2) находят такое число h, чтобы
удовлетворялось равенство
(2h-1)/g=n, (1.45)
где h>0— целое число, a g – нечетное положительное число, при
делении на
которое n получается целым нечетным числом.
Разлагая
2n – 1
на сомножители, получаем следующие числа n и g:
7=23-1=7 255=28-1=17x5x3
15=24-1=5x3 511=29-1=73x7
31=25-1=31 1023=210-1=31x11x3
63 = 26-1=7x3x3=21x3 2047=211-1=89x23
127 = 27 -1=127 4095=212-1=3x3x5x7x13
Так, из
четвертой строки следует, что при h = 6 длина слова может
быть
равна не только 63 (первый случай), но и 21
(q=3).
2.
Определение кодового расстояния. Кодовое расстояние определяют, согласно d
= 2s+l.
3.
Определение образующего многочлена Р(Х).
Образующий
многочлен есть наименьшее общее кратное (НОК) так называемых минимальных
многочленов М(X) до порядка 2s-1 включительно, причем образующий
многочлен составляется из произведения
некоторого числа нечетных минимальных многочленов
P(X)=HOK[M1 (X) M3 (X)… M2S-1 (X)]… (1.46)
Минимальные
многочлены являются простыми неприводимыми многочленами, метод определения которых
дается в [26]. Заметим, что если среди минимальных многочленов окажутся два
одинаковых, то один из них исключается.
4.
Определение числа минимальных многочленов L.
Из уравнения (1.46) следует, что порядок минимальных многочленов определяется как
2S – 1. Если учесть, что этот образующий
многочлен состоит только
из нечетных минимальных многочленов,
то числа их определяется просто. Например, если
s = 3, то 2s
— 1 =5. Это значит, что в уравнении (1.46) будут записаны минимальные
многочлены М1(Х),
М3(Х) и М5(х),
т.е L=3. Если s
= 8, то 2s-1 =15, и в уравнении будут
использованы минимальные многочлены M1(Х),
M3 (Х), M5(Х), M7(Х), M9(Х), M11(Х), M13(Х), M15(Х), т.е. L=8. Таким образом, число минимальных
многочленов равно числу исправляемых ошибок
L=s (1.47)
5. Определение
старшей степени l минимального многочлена. Степень l есть такое наименьшее целое число, при
котором 2l–1 нацело
делится на n или ng,
т.е. n=2l–1 или 2l–1=2l–1.
Отсюда
следует, что
l = h. (1.48)
6. Выбор минимальных многочленов. После того как
определены
число минимальных многочленов L и степень старшего
многочлена
l, многочлены
выписывают из таблицы 8. При этом НОК
может быть составлено не только из многочленов старшей степени l.
Это, в частности, касается многочленов четвертой и шестой степеней.
7. Определение степени β образующего многочлена Рb(Х). Степень образующего многочлена зависит от НОК и не
превышает
произведения ls или lL, так как L=s. После нахождения всех минимальных
многочленов образующий многочлен
находят по уравнению (1.46).
Таблица 8
|
Номер М(Х) |
Минимальные |
|||||||
|
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
|
|
M1(Х) M3(Х) M5(Х) M7(Х) M9(Х) M11(Х) M13(Х) |
111 |
1011 1101 |
10011 11111 111 11001 |
100101 111101 110111 101111 110111 111011 |
1000011 1010111 1100111 1001001 1101 1101101 |
10001001 10001111 10011101 11110111 10111111 11010101 10000011 |
100011101 101110111 111110011 101101001 110111101 111100111 100101011 |
1000010001 1001011001 1100110001 1010011001 1100010011 1000101101 1001110111 |
8. Определение числа контрольных символов. Так как число контрольных
символов m
равно степени образующего многочлена, то в коде длины n.
b = m £ ls. (1.49)
9. Определение числа информационных символов. Его производят обычным
порядком из равенства k=n–m. Дальнейшие этапы
кодирования аналогичны рассмотренным для циклических кодов c d < 4, т. е. находят дополнительную
матрицу, составляют образующую матрицу, по которой рассчитывают все кодовые
комбинации;
б) коды БЧХ для обнаружения ошибок. Их строят следующим
образом. Если необходимо образовать код с обнаружением четного числа ошибок, то по заданному числу r согласно d=r+1, т.е. r=d-1
и d=2s+1, т.е. s=(d-1)/2, находят значения d и s. Дальнейшее кодирование выполняют, как и
ранее. Если требуется обнаружить нечетное число ошибок, то находят ближайшее
меньшее целое число s и
кодирование производят так же, как и в предыдущем случае, с той лишь разницей,
что найденный согласно (1.46) образующий многочлен дополнительно умножают на
двучлен (Х+1). Например, требуется построить код БЧХ, обнаруживающий
семь ошибок при n=15.
Находим, что d=8,
а ближайшее меньшее
значение s=3.
Далее определяем многочлен Р(Х)
и умножаем его на двучлен (Х+1), Таким образом построен код БЧХ .
Пример 11. Даны следующие параметры: s=2, n= 31.
Методика кодирования:
а) определим кодовое расстояние
d=2![]() s+1=2
s+1=2![]() 2+1=5.
2+1=5.
Для
исправления sи.ош.![]() 2 необходимо
2 необходимо
иметь d0![]() 2
2![]() sи.ош+1,
sи.ош+1,
длина кодовой комбинации должна удовлетворять условию:
(2h-1)/g=n,
где h>0— целое число, a g – нечетное положительное число, при
делении на
которое n получается целым нечетным числом;
б) определение минимального количества многочленов
L=S, значит L=2;
в) определение
старшей степени l минимального многочлена
n=2l-1, 31=2l-1, l=5,
зная l, выбираем из таблицы 8 минимальные
многочлены:
M1=x5+x2+1,
M3=x5+x4+
x3+ x2 +1;
г) определение образующего
многочлена Р(Х)
P(Х)=HOK[M1(Х),M3(Х),…,M2s-1(x)],
P(Х)=M1(Х)![]() M3(Х).
M3(Х).
Минимальные многочлены являются простыми
непроводимыми многочленами, метод определения которых дается в [ 26].
Заметим что, если среди минимальных
многочленов окажутся два одинаковых, то один из них исключается.
Р(Х)= Х10+Х9+ Х8 +
Х6 + Х5 + Х3 + 1;
д) определение степени β образующего многочлена Рb(Х)
b = 10;
е) определение числа контрольных символов. Так как
число контрольных символов m равно степени образующего многочлена, то в
коде длины n.
b = m £ ls, m=10;
ж) определение
числа информационных символов. Его
производят обычным порядком из равенства k=n–m=31-10=21.
Получаем код БЧХ
(31,21) с s=2.
При делении кодовой
комбинации
G(X)![]() Хr=1000000000000000000000000000000 на
Хr=1000000000000000000000000000000 на
образующий полином вида Р(Х)=11101101001 получаем остаток R(X)=1010010011.
Пример 12. Кодирование кода БЧХ (с обнаружением).
12.1 Расчет параметров кодирующего устройства
Для построения структурной схемы
кодирующего устройства кода БЧХ необходимо рассчитать следующие параметры:
Исходные
данные:
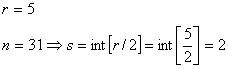
Решение :
а) определение кодового расстояния.
d= r+1=5+1=6;
б) определение минимального количества многочленов
L=S,
L=2;
в) определение
старшей степени l минимального многочлена
n=2l-1, 31=2l-1, l=5
Зная l, выбираем из таблицы 8 минимальные
многочлены:
M1=x5+x2+1,
M3=x5+x4+
x3+ x2 +1;
г) определение
образующего многочлена Р(Х):
P(Х)=HOK[M1(Х),M3(Х),…,M2s-1(x)]
P(Х)=M1(Х)![]() M3(Х).
M3(Х).
Если необходимо образовать код
обнаружением четного числа ошибок, кодирование выполняют, как ранее. Если
обнаруживать нечетное число ошибок, то находят ближайшее число [s], лишь образующий полином умножается на
(Х+1).
Р(Х)= (Х10+Х9+ Х8
+ Х6 + Х5 + Х3 + Х + 1)+(Х+1)= Х11+ Х8 + Х7
+ Х5 + Х4 +Х3 + Х + 1;
д) определение
степени β образующего многочлена
Рb(Х). Степень образующего многочлена зависит от НОК и не
превышает
произведения ls или lL, так как L=s.
b = 11;
е) определение числа контрольных символов. Так как
число контрольных символов m равно степени образующего многочлена, то в
коде длины n
b = m £ ls, m = 11;
ж) определение числа
информационных символов
k=n–m=31-11=20.
Получим
код БЧХ [31;20].
1.11 Декодирование циклических кодов
БЧХ с обнаружением и исправлением нескольких ошибок
1.11.1 Рассмотрим схемную реализацию декодирования
комбинации 100000011101000, искаженной двумя ошибками и принявшей вид
111000011101000. Декодер состоит (рисунок 9) из делителя, выполненного для
деления на многочлен Р(Х)= Х8 + Х7 + Х6
+ Х4 + 10 и запоминающего устройства, представляющего собой регистр с
сумматором символов k. Комбинация
поступает одновременно на делитель и запоминающее устройство, начиная со
старшего разряда. Искаженные символы в комбинации отмечены точками. В начале
ключ К1 замкнут, а ключ К2 разомкнут. В таблице 9
показан процесс деления, начиная с такта 8, так как в первые семь тактов
происходит заполнение делителя и обратная связь не проявляется. В такте 15 синдром
(остаток от деления) оказывается записанным в ячейках регистра (01001110).
Однако его вес W=4 больше числа исправляемых ошибок s, поэтому делитель делает еще один шаг (такт
первый), в процессе которого снова осуществляется деление на многочлен Р(Х).
Синдром 10011100 опять имеет вес W=4. Только
после третьего такта W=2=s. В этот момент ключ К1 размыкается, а ключ К2 замыкается, и синдром с делителя
начинает поступать на сумматор запоминающего устройства, у которого ключ К3
замкнут, а ключ К4 разомкнут. Это устройство в такте 15 первого
этапа полностью заполнилось. А на втором этапе его работы начался циклический
сдвиг записанной информации (таблица 10). Так, в такте 1 единица из ячейки Х6
информационных символов переместилась в ячейку Х0 контрольных
символов m. В такте 2 эта
единица передвинулась в ячейку Х1, а её место в ячейке заняла
следующая единица и т.д. Первые шесть нулей синдрома не влияют на работу
запоминающего устройства. Лишь в тактах 10 и 11 две единицы синдрома,
складываясь по модулю 2 с двумя ошибочными единицами символов k (обозначены точками), «уничтожают» их, т.е.
исправляют ошибки. Регистр ЗУ продолжает переключаться до окончания второго
цикла (этапа) его работы. После такта
15 ключи К2 и К3 размыкаются, а ключи К1 и К4 замыкаются:
начинается считывание исправленной комбинации и одновременная запись новой.
Таким образом,
декодирование состоит из двух этапов. На первом этапе осуществляется нахождение
остатка и запись кодовой комбинации, на втором – её исправление и расстановка
символов k и m на свои места.
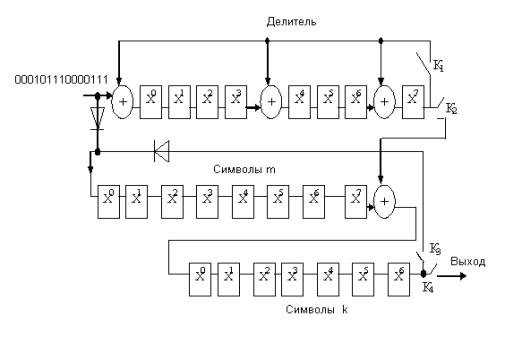
Рисунок 10
Таблица 9
|
Номер такта |
Делимое |
Состояние ячеек делителя |
Вес остатка |
|||||||
|
X0 |
X1 |
X2 |
X3 |
X4 |
X5 |
X6 |
X7 |
|||
|
VIII |
1 |
1 |
0 |
0 |
0 |
0 |
i |
i |
1 |
|
|
IX |
1 |
0 |
1 |
0 |
0 |
1 |
0 |
0 |
0 |
|
|
X |
1 |
1 |
0 |
1 |
0 |
0 |
1 |
0 |
0 |
|
|
XI |
0 |
0 |
1 |
0 |
1 |
0 |
0 |
1 |
0 |
|
|
XII |
1 |
1 |
0 |
1 |
0 |
1 |
0 |
0 |
1 |
|
|
XIII |
0 |
1 |
1 |
0 |
1 |
1 |
1 |
1 |
1 |
|
|
XIV |
0 |
1 |
1 |
1 |
0 |
0 |
1 |
0 |
0 |
|
|
XV |
0 |
0 |
1 |
1 |
1 |
0 |
0 |
1 |
0 |
4 |
|
I |
0 |
0 |
1 |
1 |
1 |
0 |
0 |
1 |
4 |
|
|
II |
1 |
0 |
0 |
1 |
0 |
1 |
1 |
1 |
5 |
|
|
III |
1 |
1 |
0 |
0 |
0 |
0 |
0 |
0 |
2 |
Таблица 10 – Работа ЗУ
|
Номер такта |
Символы m |
Символы k |
||||||||||||||
|
X0 |
X1 |
X2 |
X3 |
X4 |
X5 |
X6 |
X7 |
X0 |
X1 |
X2 |
X3 |
X4 |
X5 |
X6 |
||
|
XV |
0 |
0 |
0 |
1 |
0 |
1 |
1 |
1 |
0 |
0 |
0 |
0 |
i |
i |
1 |
|
|
I |
1 |
0 |
0 |
0 |
1 |
0 |
1 |
1 |
1 |
0 |
0 |
0 |
0 |
i |
i |
|
|
II |
i |
1 |
0 |
0 |
0 |
1 |
0 |
1 |
1 |
1 |
0 |
0 |
0 |
0 |
i |
|
|
III |
i |
i |
1 |
0 |
0 |
0 |
1 |
0 |
1 |
1 |
1 |
0 |
0 |
0 |
0 |
|
|
Cиндром
|
||||||||||||||||
|
IV |
0 |
i |
i |
1 |
0 |
0 |
0 |
1 |
0 |
1 |
1 |
1 |
0 |
0 |
0 |
|
|
V |
0 |
0 |
i |
i |
1 |
0 |
0 |
0 |
1 |
0 |
1 |
1 |
1 |
0 |
0 |
|
|
VI |
0 |
0 |
0 |
i |
i |
1 |
0 |
0 |
0 |
1 |
0 |
1 |
1 |
1 |
0 |
|
|
VII |
0 |
0 |
0 |
0 |
i |
i |
1 |
0 |
0 |
0 |
1 |
0 |
1 |
1 |
1 |
|
|
VIII |
1 |
0 |
0 |
0 |
0 |
i |
i |
1 |
0 |
0 |
0 |
1 |
0 |
1 |
1 |
|
|
1IX |
1 |
1 |
0 |
0 |
0 |
0 |
i |
i |
1 |
0 |
0 |
0 |
1 |
0 |
1 |
|
|
X |
1 |
1 |
1 |
0 |
0 |
0 |
0 |
i |
0 |
1 |
0 |
0 |
0 |
1 |
0 |
|
|
XI |
0 |
1 |
1 |
1 |
0 |
0 |
0 |
0 |
0 |
0 |
1 |
0 |
0 |
0 |
1 |
|
|
XII |
1 |
0 |
1 |
1 |
1 |
0 |
0 |
0 |
0 |
0 |
0 |
1 |
0 |
0 |
0 |
|
|
XIII |
0 |
1 |
0 |
1 |
1 |
1 |
0 |
0 |
0 |
0 |
0 |
0 |
1 |
0 |
0 |
|
|
XIV |
0 |
0 |
1 |
0 |
1 |
1 |
1 |
0 |
0 |
0 |
0 |
0 |
0 |
1 |
0 |
|
|
XV |
0 |
0 |
0 |
1 |
0 |
1 |
1 |
1 |
0 |
0 |
0 |
0 |
0 |
0 |
1 |
1.11.2
Рассмотрим процесс исправления единичной ошибки при использований кода (7,4) с
образующим многочленом ![]() и применений в
и применений в
декодирующем устройстве схем деления за n и k тактов.
Определим
опознаватели ошибок и выделенный синдром для случая использования схемы деления
за n тактов:

Детектор ошибки, обеспечивающий формирование на выходе
сигнала только в случае появления в схеме деления остатка 110, можно
реализовать посредством двух логических элементов НЕ и одного логического
элемента ИЛИ – НЕ.
На рисунке 11 приведена схема соответствующего
декодирующего устройства. В таблице 11 представлен процесс исправления ошибки
для случая, когда кодовая комбинация 1001011 (таблица 11) поступила на вход
декодирующего устройства с искаженным символом в 4-м разряде (1000011).
После n (в данном
случае 7) тактов в схему деления II
переписывается
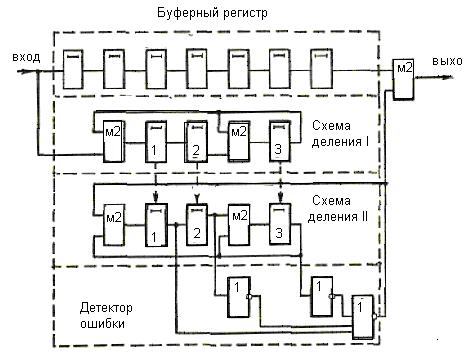
Рисунок 11
Таблица 11
|
Номер такта |
Вход |
Состояние ячеек схем деления |
Выход после коррекций |
||
|
1 |
2 |
3 |
|||
|
1 |
1 |
1 |
0 |
0 |
|
|
2 |
0 |
0 |
1 |
0 |
|
|
3 |
0 |
0 |
0 |
0 |
|
|
4 |
0 |
1 |
0 |
1 |
|
|
5 |
0 |
1 |
1 |
1 |
|
|
6 |
1 |
0 |
1 |
0 |
|
|
7 |
1 |
1 |
0 |
1 |
|
|
Переписывается в схему деления II |
|||||
|
8 |
0 |
1 |
1 |
1 |
1 |
|
9 |
0 |
1 |
1 |
0 |
01 |
|
10 |
0 |
0 |
1 |
1 |
001 |
|
11 |
0 |
0 |
0 |
0 |
1001 |
|
12 |
0 |
0 |
0 |
0 |
01001 |
|
13 |
0 |
0 |
0 |
0 |
1101001 |
|
14 |
0 |
0 |
0 |
0 |
. |
опознаватель
ошибки 101. На каждом последующем
такте, на выходе буферного регистра появляется неискаженный символ
корректируемой кодовой комбинации, а в схеме деления II – новый остаток. Выделенный синдром появится в схеме
деления на 10-м такте, когда искаженный символ займет крайнюю правую ячейку
регистра. На следующем такте он попадает в корректирующий сумматор и будет там
исправлен импульсом, поступающим с выхода детектора ошибки. Этот же импульс по
цепи обратной связи приводит ячейки схемы деления II в нулевое состояние (корректирует выделенный
синдром).
При использований схемы деления за k тактов соответствие между векторами ошибок и
остатками на n-м такте иное.
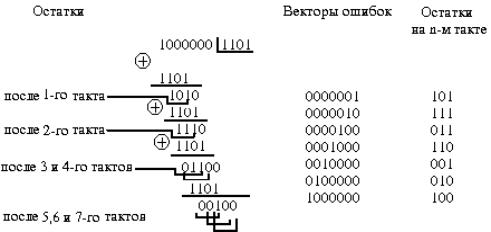
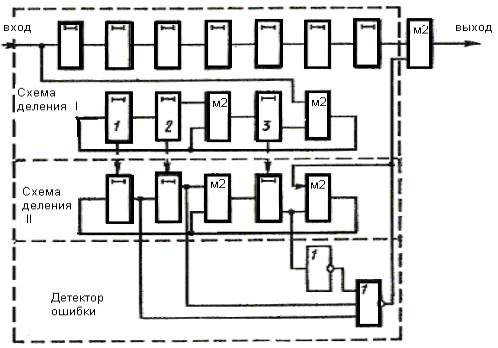
Рисунок 12
Детектор для выделенного синдрома 100 можно построить
из одного логического элемента НЕ и одного элемента ИЛИ – НЕ.
На рисунке 6.20 представлена схема декодирующего
устройства для этого случая.
Таблица 12 позволяет проследить по тактам процесс
исправления ошибки в кодовой комбинации 1000011 (искажен символ в 4-ом
разряде).
Таблица 12
|
Номер такта |
Вход |
Состояние ячеек схем деления |
Выход после коррекций |
||
|
1 |
2 |
3 |
|||
|
1 |
1 |
1 |
0 |
1 |
|
|
2 |
0 |
1 |
1 |
1 |
|
|
3 |
0 |
1 |
1 |
0 |
|
|
4 |
0 |
0 |
1 |
1 |
|
|
5 |
0 |
1 |
0 |
0 |
|
|
6 |
1 |
1 |
1 |
1 |
|
|
7 |
1 |
0 |
1 |
1 |
|
|
Переписывается в схему деления II |
|||||
|
8 |
0 |
1 |
0 |
0 |
1 |
|
9 |
0 |
0 |
1 |
0 |
01 |
|
10 |
0 |
0 |
0 |
1 |
001 |
|
11 |
0 |
0 |
0 |
0 |
1001 |
|
12 |
0 |
0 |
0 |
01001 |
|
|
13 |
0 |
0 |
0 |
0 |
101001 |
|
14 |
0 |
0 |
0 |
0 |
1101001 |
Сравнение показывает, что использование в декодирующем
устройстве схемы деления за k тактов
предпочтительно, так как выделенный синдром в этом случае при любом объеме кода
содержит единицу в старшем и нули во всех остальных разрядах, что приводит к
более простому детектору ошибки.
1.12 Код Хэмминга
На практике широко используется код Хэмминга. Код
Хэмминга предназначен для исправления ошибок и имеет кодовое расстояние d0=3.
Покажем на примере (7,4) кода, используя, можно обеспечить исправление одиночных
ошибок. Кодовые комбинации (7,4) кода в общем случае имеют вид а = (а1,
а2, а3, а4, b1, b2, b3).
Правила формирования проверочных элементов должны быть такими, чтобы в
результате проверок на четность числа единиц в группах информационных элементов
можно было указать на порядковый номер искаженного элемента. Для этого каждый
информационный элемент должен участвовать, как минимум, в двух проверках из
трех (r=3). Например, для кода (7,4) можно записать
![]() а1
а1![]() а2
а2 ![]() а1
а1![]() b1=0;
b1=0;
![]() а2
а2![]() а3
а3 ![]() а4
а4![]() b2=0; (1.50)
b2=0; (1.50)
а1![]() а2
а2 ![]() а4
а4![]() b3=0.
b3=0.
Возможны и другие варианты выбора групп проверочных
элементов. Если все уравнения (1.50) удовлетворяются, это свидетельствует об
отсутствии ошибок в принимаемой комбинации либо о наличии необнаруживаемой
ошибки. Невыполнение первого и третьего уравнений свидетельствует об ошибочном
приеме а1 всех трех уравнении
а2, первого и второго – а3, второго и третьего его
– а4.
Результат проверок на четность удобно записывать в
виде r– разрядного двоичного проверочного числа, называемого
синдромом. Например, при искажении элемента а4 синдром S=011, а при отсутствии ошибок S=000. Очевидно, что в общем случае число различных
синдромов 2r должно быть меньше всех
вариантов ошибок.
На рисунке 13 и 14 приведены схемы кодирующего и
декодирующего устройств (7,4) кода Хэмминга. Единичные элементы комбинации
первичного кода, поступающие из кодера оконечного устройства в параллельный
код, записываются в ячейки 1 – 4 регистра. Одновременно группы информационных
элементов поступают на три сумматора по модулю 2, с помощью которых формируются
проверочные элементы b1, b2 и b3,
записываемые в ячейке 5 – 7 регистра. Под воздействием продвигающих импульсов на
выходе регистра формируется в последовательном коде комбинация избыточного
кода.
Комбинация, поступающая из канала, записывается в
течение семи тактов в регистр 1, (рисунок 14), после чего с помощью сумматоров
по
модулю 2 проверяется на четность число единиц в
группах элементов в соответствии с (1.50). Если синдром, поступающий от
сумматоров на вход дешифратора, отличен от нуля, то на одном из выходов
дешифратора появляется сигнал 1, который записывается в ячейку регистра 2,
порядковый номер которого соответствует порядковому номеру искаженного
элемента. Далее под воздействием тактовых импульсов искаженный разряд в
регистре 1 и единица в регистре 2 продвигаются параллельно и одновременно
появляются на выходах регистров. В устройстве исправления ошибок (УИО), функцию
которого выполняет также сумматор по модулю 2, искаженный элемент заменяется
противоположным.
Регистр 1
Регистр
|
|
6 |
5 |
4 |
3 |
2 |
1 |
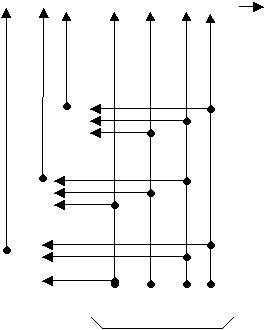
|
7 |
6 |
5 |
4 |
3 |
2 |
1 |
b1
![]()
![]()
![]()
![]()
![]()
b2
![]()
b3
|
7 |
6 |
5 |
4 |
3 |
2 |
1 |
 а4 а3 а2 а1
а4 а3 а2 а1
Рисунок 14 – Декодирующее устройство кода
Хэмминга
Комбинация
первичного кода
Рисунок 13 – Кодирующее устройство кода Хэмминга
1.13
Применение
кода Рида – Соломона
Выше мы рассматривали основные двоичные коды,
исправляющие ошибки, очевиден недостаток этих кодов – малая загруженность линии
связи. Действительно, через линию связи проходит только два сигнала: сигнал
“0” и сигнал “1”, в то время как возможности линии
допускают гораздо меньшую дискретность и большее количество дискретных уровней.
Наличие ошибок, обусловленных помехами в каналах
передачи, а так- же физическими повреждениями носителей в каналах хранения,
требует введения избыточности в информацию, подлежащей передаче и хранению. Помехоустойчивая
обработка двоичной информации кодов с основанием ![]() позволяет получить
позволяет получить
достаточно простые реализации кодирующих и декодирующих устройств при высокой
исправляющей и обнаруживающей способностях, как в отношении независимых, так и
корректированных ошибок. К ним относятся линейные блоковые коды с основанием ![]() .
.
Общая характеристика и способы кодирования
Если каждому из ![]() недвоичных векторов длиной “а” сопоставить один из
недвоичных векторов длиной “а” сопоставить один из
символов недвоичного алфавита, то вместо двоичной последовательности длиной k·a
можно рассматривать эквивалентную двоичную последовательность длиной
“k”. Помеха устойчивости обработки такой информации возможна с
помощью различных кодов с основанием k =![]() .
.
В случае линейных блоковых кодов (n, k) преобразование
исходного информационного вектора ![]() длиной k в кодовый
длиной k в кодовый
вектор ![]() , длиной n > k осуществляется с помощью линейной операции
, длиной n > k осуществляется с помощью линейной операции
 , (1.51)
, (1.51)
где ![]() – строки порождающей матрицы G размерностью
– строки порождающей матрицы G размерностью
k и n, являющимися базисными векторами кода. Эти векторы должны быть линейно
независимыми, чтобы любая их сумма не была базисным вектором
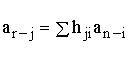 ,
, ![]() , (1.52)
, (1.52)
коэффициенты ![]() составляют матрицу
составляют матрицу ![]() размерностью
размерностью ![]() , так что
, так что ![]() .
.
С учетом соотношений (1.51) выражения для ![]() можно записать в
можно записать в
канонической форме
![]() , (1.53)
, (1.53)
где ![]() – единичная матрица
– единичная матрица
размерностью ![]() . Кроме того, матрица R входит в состав проверочной матрицы
. Кроме того, матрица R входит в состав проверочной матрицы
H, которая в канонической форме соответствует соотношению (1.52) и имеет вид:
![]() , (1.54)
, (1.54)
где ![]() – единичная матрица
– единичная матрица
размерностью ![]() .
.
Кодовые векторы (кодовые слова) A составляют нулевое
пространство матрицы H, так как
![]() , (1.55)
, (1.55)
коэффициенты ![]() так же является
так же является
символами рассматриваемого недвоичного алфавита объемом, ![]() , которым соответствуют двоичные векторы длиной “а”
, которым соответствуют двоичные векторы длиной “а”
или многочлены фиктивной переменной x с двоичными коэффициентами.
Например, вектору (010111) соответствует многочлен ![]() .
.
Сложение недвоичного алфавита. Операция сложения
символов недвоичного алфавита выполняется путем поразрядного (по модулю два)
сложения соответствующих векторов. Например,
(1011) + (0110) = (1101).
Все k символы недвоичного алфавита образует
мультипликативную группу, включающую в себя нулевой элемент 0, которому
соответствует вектор (00…0), единичный элемент, которому соответствует вектор
(00…010), а также все целые положительные степени ![]() до k-2 включительно.
до k-2 включительно.
Кроме того, на всю мультипликативную группу
накладывается требование цикличности
![]() .
.
Перемножение недвоичного алфавита.
Перемножение элементов группы для сохранения длины
эквивалентных векторов выполняется как перемножение соответствующих многочленов
по модулю некоторого многочлена F(x) степени а, т.е. ![]() . Для
. Для ![]() многочлены даны в
многочлены даны в
таблице 12. То есть правило
перемножения необходимы для того, чтобы разрядность кода не переполнялась, так
как
![]() ,
,
то,
деление на ![]() эквивалентно
эквивалентно
умножению ![]() .
.
Для построения мультипликативной группы рассмотрим
пример.
Построим мультипликативную группу для ![]() ,
, ![]() .
.
Операция по модулю F(x) означает, что ![]() , следовательно, элементу
, следовательно, элементу ![]() соответствует
соответствует
многочлен ![]() и вектор (11),
и вектор (11),
значения отдельных элементов (символов недвоичного алфавита) представлены в
таблице 13.
Таблица 12 – Многочлены F(x) для ![]()
|
|
F(x) в виде многочлена |
F(x) в виде числа |
|
2 |
|
111 |
|
3 |
|
1011 |
|
4 |
|
10011 |
|
5 |
|
100101 |
|
6 |
|
1000011 |
|
7 |
|
10000011 |
|
8 |
|
100001111 |
|
9 |
|
1000010001 |
|
10 |
|
10000001001 |
Расстояния Хемминга между векторами определяется как
число различий в отдельных элементах. Например, расстояние между векторами ![]() и
и ![]() равно двум.
равно двум.
Минимальное расстояние Хемминга по всему множеству кодовых векторов называется
кодовым расстоянием d. С помощью такого кода может быть гарантировано,
исправлено t ошибок и восстановлено y стираний, если d>2t+y.
Таблица 13 – Значение отдельных
элементов недвоичного алфавита
|
Элементы |
Элементы |
Элементы |
|
0 |
– |
00 |
|
1 |
1 |
01 |
|
|
|
10 |
|
|
|
11 |
Прохождение вектора ![]() (кода) через канал
(кода) через канал
может быть представлено как
![]() , (1.56)
, (1.56)
где ![]() – вектор на выходе
– вектор на выходе
канала, причем
![]() .
.
Существуют различные способы декодирования полученных
из канала векторов ** (по минимуму расстояние, мажоритарное, синдромное
декодирование). Наиболее распространенный способ синдромного декодирования,
основанный на вычислении синдромов **, являющихся векторами длинны r
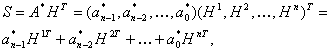 (1.57)
(1.57)
где
![]() – векторы столбцы
– векторы столбцы
матрицы H.
![]() . (1.58)
. (1.58)
Значение синдрома S зависит от вектора ошибок и вида
проверочной матрицы. ![]() означает, что векторы
означает, что векторы ![]() и
и ![]() кодовые (т.е.
кодовые (т.е.
информация получена без ошибок). ![]() означает, что из
означает, что из
канала получен некодовый вектор, т.е. информация получена с ошибкой. В этом
случае можно ограничиться обнаружением d – 1 ошибки, и принятый вектор просто
отбросить (декодирование с обнаружением ошибок). Ошибки можно исправить, если
каждому их образцу будет однозначно соответствовать свой вид синдрома.
Так, если ошибочно принят один из
символов ![]() , то
, то ![]() , и чтобы эти синдромы были различными для каждого образца
, и чтобы эти синдромы были различными для каждого образца
ошибок, необходимо различие всех ![]() для
для ![]() и
и ![]() . Таким образом, общее число синдромов
. Таким образом, общее число синдромов ![]() должно быть
должно быть
достаточным для исправления любого из ![]() образцов ошибок на
образцов ошибок на
любой из n – позиции, полученных из
канала вектора им для выявления факта ошибок
![]() . (1.59)
. (1.59)
Отсюда максимальная длина кода для гарантированного
исправления одной ошибки ![]() .
.
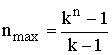 . (1.60)
. (1.60)
Рассмотрим пример.
Для ![]()
![]() и
и ![]() максимальная длина
максимальная длина
кода ![]() , следовательно, можно построить (5,3) линейный код для
, следовательно, можно построить (5,3) линейный код для
гарантированного исправления одной ошибки. Проверочная матрица ![]() должна иметь
должна иметь
размерность ![]() . В качестве первого столбца произвольно выберем
. В качестве первого столбца произвольно выберем
 ,
,
поэтому
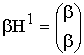 ,
, 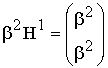 ,
,
так как ![]() ,
, ![]() , то произвольно выбираем
, то произвольно выбираем 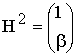 , тогда
, тогда 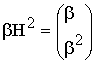 ,
, 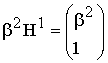 . Далее поскольку
. Далее поскольку ![]() ,
, ![]() ,
, ![]() , то выберем произвольно
, то выберем произвольно 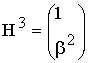 и далее возьмем
и далее возьмем 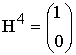 и
и ![]() , и проверочная матрица будет иметь каноническую форму.
, и проверочная матрица будет иметь каноническую форму.
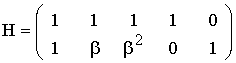 ,
,
(1.61)
где
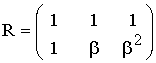 .
.
Пусть ![]() , тогда
, тогда ![]() получим выражение
получим выражение
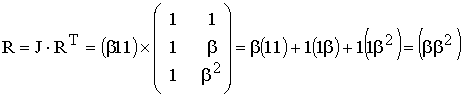 ,
,
и
![]() .
.
Вообще для ![]()
![]() и проверочная матрица
и проверочная матрица
имеет вид
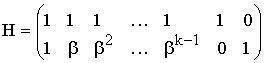 .
.
Кодирующие преобразователи.
Кодовый вектор ![]() может быть переведен
может быть переведен
в двоичную форму.
![]() .
.
Преобразуем матрицу в двоичную форму с учетом выше
рассмотренных результатов
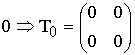 ,
,
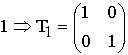 ,
,
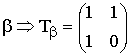 ,
,
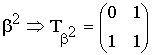 ,
,
где ![]() – это матрица
– это матрица
размерностью ![]() .
.
Проверочная и порождающая матрицы будут иметь вид.
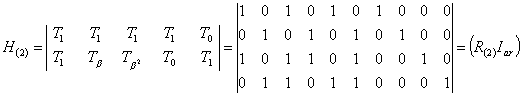
Порождающая матрица
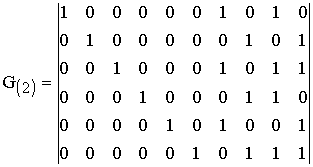 .
.
Информационному вектору ![]() соответствует двоичный
соответствует двоичный
вектор ![]() . Кодовый вектор в двоичной форме можно получить как
. Кодовый вектор в двоичной форме можно получить как
![]() ,
,
что соответствует ![]() и совпадает с
и совпадает с
результатом примера два.
Декодирующие преобразователи с исправлением ошибок.
Наиболее простые алгоритмы разработаны для исправления
одиночной ошибки с помощью линейных кодов с основанием k=2a и с d=3. Можно, например, предусмотреть
выполнение следующих операций:
–
вычислить ![]() ;
;
–
если S=0, то получателю
выдать вектор ![]() ;
;
–
если ![]() , то для
, то для ![]() вычислить
вычислить ![]() ;
;
–
так как значение j, при
котором ![]() , в случае одной ошибки соответствует ее образцу
, в случае одной ошибки соответствует ее образцу ![]() , произвести коррекцию:
, произвести коррекцию: ![]() ;
;
–
выдать получателю
скорректированный информационный вектор: ![]() .
.
Пример.
Для (5,3) кода, декодируем вектор, принятый из канала ![]() .
.
В соответствии с рассмотренным алгоритмом:
1 ![]() ;
;
2 ![]() ,
, ![]() ,
, ![]() ;
;
3 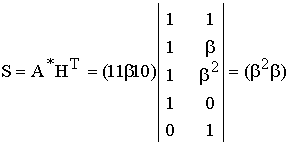 ;
;
4 en-3=e2=b 2, a*n-3=a*2=b, ![]() ;
;
5 ![]() ,
, ![]() .
.
Для исправления одиночных ошибок с помощью кодов с
двумя проверочными символами, имеющими проверочные матрицы вида:
 ,
,
не обязательно хранить в памяти матрицу H.
1.14 Общая характеристика
кодов Рида – Соломона
Кодами Рида – Соломона называют циклические коды у
которых основание равно не двум, как обычно, а некоторому числу ![]() .
.
![]() ,
, ![]() .
.
Таким образом, число символов алфавита также будет
равно 2а, что дает возможность в “а” раз повысить скорость
прохождения информации через линии связи, потому что вместо двоичных последовательностей
длиной ![]() , мы будем иметь последовательность длиной
, мы будем иметь последовательность длиной ![]() . Алфавитом кода является мультипликативная группа, в которой
. Алфавитом кода является мультипликативная группа, в которой
существует элемент “0”, элемент “1” и примитивный элемент b, а также все целые положительные степени b от двух до k-2
включительно.
В такой группе обязательно должны определяться
сложения и умножения.
Сложение элементов мультипликативной группы
осуществляется как сложение соответствующих им двоичных векторов или
многочленов с фиктивной переменной по модулю два.
Все k символы
недвоичного алфавита образуют мультипликативную группу, включающую в себя
нулевой элемент 0, которому соответствует вектор (00…0), единичный элемент
цифрой 1, которому соответствует (элемент) вектор(00…01), примитивный элемент
b, которому соответствует
вектор (00…10), а также все целые положительные степени b до k-2
включительно.
Группа является циклической, так что ![]() .
.
Длина кода Рида – Соломона равна ![]() , порождаемая многочленом
, порождаемая многочленом
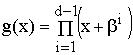 ,
,
где d– кодовое расстояние (нечетное), а b – примитивный элемент мультипликативной группы,
объединяющий все k символы недвоичного алфавита.
Очевидно, что
![]() ,
, ![]()
является корнями g(x), т.е. ![]() .
.
Как для любого циклического кода, число контрольных
символов равно степени порождающего много члена
![]() .
.
Число информационных символов ![]() . Коды Рида – Соломона обладают всеми свойствами линейных
. Коды Рида – Соломона обладают всеми свойствами линейных
кодов, следовательно, можно построить порождающие и проверочные матрицы. Их
находят путем деления единицы с нулями на выбранный многочлен ![]() и выписывания всех
и выписывания всех
промежуточных остатков. При этом должны быть соблюдены условия:
– число остатков должно быть равно числу
информационных символов k;
-для проверочной матрицы пригодны лишь остатки весом W, не меньшим числа обнаруживаемых ошибок r, т.е. не меньшим двух.
1.15 Выбор числа символов и
образующего многочлена
Рассмотрим такой
пример, что на некотором объекте существует система телемеханики с линиями
связи, в которых дискретность уравнения равна восьми, при этом необходимо,
чтобы была возможность обнаружить двойные и исправлять одиночные ошибки, т.е.
кодовое расстояние должно быть не менее трех
![]() .
.
С другой стороны, для того, что бы работать с
восьмиуровневой системой информации; необходимо чтобы
![]() , т.е.
, т.е. ![]() ,
,
тогда
![]() .
.
Следующий этап построения кода является нахождение
символов недвоичного алфавита, для ![]() из таблицы 3 .1
из таблицы 3 .1
находим
![]() .
.
Итак, первым элементом группы должен быть ноль, т.е.
(000). Второй элемент-единица, т.е. (001). Третий элемент – ![]() . Четвертый элемент –
. Четвертый элемент – ![]() . Пятый элемент синтезируется из условия
. Пятый элемент синтезируется из условия
![]() ,
,
так как
![]() ,
,
![]() ,
,
![]() ,
,
![]() .
.
После нахождения элементов алфавита сведем их в
таблицу 14.
Теперь необходимо построить многочлен, пользуясь
формулой порождающего многочлена
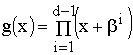 .
.
Итак,
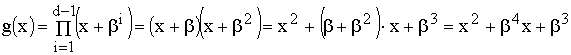 .
.
Таким образом
![]() .
.
После нахождения ![]() можно приступить к
можно приступить к
кодированию.
Таблица 14 – Недвоичный алфавит Рида –
Соломона
|
Символ |
Многочлен |
Вектор |
|
0 |
– |
000 |
|
1 |
1 |
001 |
|
b |
|
010 |
|
|
|
100 |
|
|
|
011 |
|
|
|
110 |
|
|
|
111 |
|
|
|
101 |
1.16 Кодирование кодов Рида – Соломона
Как было указано ранее, для аппаратной реализации
наиболее удобен способ кодирования, в котором получаются разделимые коды (кодирования, деления на порождающий
многочлен) т.е. исходную комбинацию умножить на ![]() , а затем прибавить к полученной комбинации остаток от
, а затем прибавить к полученной комбинации остаток от
деления.
![]() .
.
То есть ![]() делим на
делим на ![]() . В нижерассматриваемом примере будет показано осуществление
. В нижерассматриваемом примере будет показано осуществление
аппаратного кодирования.
Пример.
Пусть дана исходная комбинация 10000. Умножим на ![]() и получим комбинацию
и получим комбинацию
1000000.
Теперь эту комбинацию делим на порождающий многочлен,
и мы найдем контрольные символы
![]() ,
,
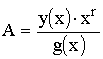 ,
,
получим
![]()
![]()
![]()
![]()
![]()
![]()
![]()
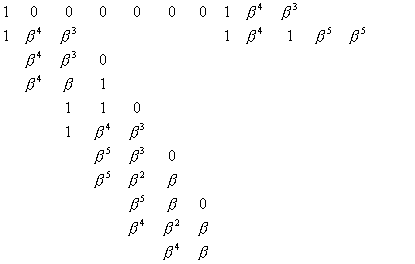
Таким образом, мы нашли контрольные символы: ![]() , и тогда вся комбинация примет вид
, и тогда вся комбинация примет вид
![]() .
.
Отсюда легко получить
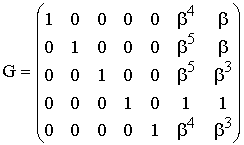 ,
,
например, для
![]() ,
,
![]() .
.
1.17 Декодирование
Декодирование кодов Рида – Соломона производится
аналогично декодированию циклических кодов, то есть принятая комбинация делится
на образующий многочлен ![]() .
.
Если остаток от деления отсутствует, то это означает,
что в принятом коде ошибки нет (т.е. не искажен). Для вышеприведенного примера
эта будет выглядеть таким образом
![]()
![]()
![]()
![]()
![]()
![]()
![]()

Исправление ошибки происходит следующим образом.
Многочлен ![]() , принятый из линии связи, делится на
, принятый из линии связи, делится на ![]() – образующий
– образующий
многочлен, при этом к ![]() с каждым шагом
с каждым шагом
дописывается ![]() . При получении остатка вида
. При получении остатка вида ![]() ,
, ![]() , где
, где ![]() – это номер позиции,
– это номер позиции,
где произошла ошибка, а ![]() – вид ошибки. Ее
– вид ошибки. Ее
можно исправить
![]() .
.
В примере, приведенном ниже, мы можем наглядно
удостовериться, каким образом это происходит.
Предположим, что
в выше построенной комбинации произошла одна ошибка в четвертом символе,
т.е. вместо ![]() была принята
была принята
комбинация ![]() .
.
Осуществим деление полученной комбинации на
порождающий многочлен
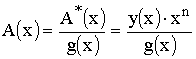 ,
,
.
Отсюда видно, что ошибка произошла, в четвертом
символе исходный символ был “0”, так как ![]() . Если остаток содержит более двух символов, то это говорит о
. Если остаток содержит более двух символов, то это говорит о
том, что произошло больше одной ошибки, значит исправление невозможно.
1.18 Понятие о сверточном кодировании
Кодирование и декодирование сверточных кодов осуществляется
непрерывно, без деления информационной последовательности на блоки. Сверточные
коды являются частным случай непрерывных (рекуррентных) кодов. В основу их
построения положен принцип формирования проверочных разрядов путем суммирования
по модулю 2 каждого информационного разряда с некоторым разрядом наоборот
предыдущих разрядов. Примеры простейших сверточных кодеров приведены на рисунке
15 (а). Входящая информационная последовательность u1, u2, u3,…., ut поступает в регистр многотактного фильтра (N=3), некоторые из ячеек которого связаны с двумя сумматорами по модулю 2.На
контакт 1 коммутатора К подан информационный символ, на контакты 2 и 3 –
проверочные символы. После поступления каждого информационного символа
коммутатор осуществляет считывание трех символов (информационного и двух
проверочных) и передает их в канал. Поскольку в рассматриваемом случае в канал
подается как информационный, так и проверочные символы, то выходная кодовая
последовательность является систематической. Однако выход с первой ячейки на
контакт 1 может отсутствовать или на этот контакт могут быть поданы и выходы
других ячеек, в результате чего код будет несистематическим. В общем случае
сверточный кодер имеет вид, представленный на рисунке 15 (б). Считывание
выходных символов коммутатором осуществляется после каждого поступления l информационных символов, где l = 1, 2,…, причем l кратно N, т.е. N/ l= n.
Для задания сверточного кода достаточно указать длину
регистра, и какие его ячейки связаны с каждом из сумматоров по модулю 2. Число
сумматоров в схеме на рисунке 15 (б) m=3, так как для упрощения на рисунке не
показан сумматор, включенный между ячейкой и контактом 1 коммутатора. Связи i-сумматора описываются i-порождающей последовательностью
gi = gi1, gi2,….., gin,
где gij =![]() 1
1
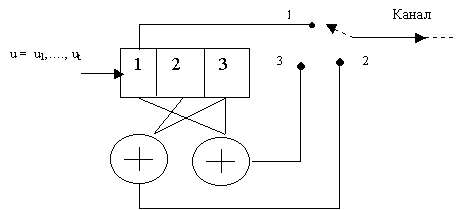 |
а)
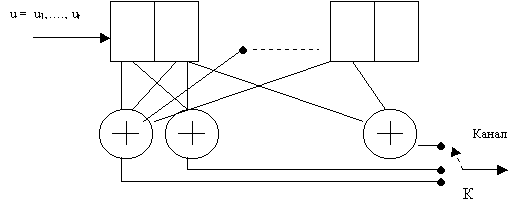 |
б)
Рисунок 15 – Пример структуры схемы
сверточного кодера
Матрица ![]() , i=
, i=
1, 2,….., N
называется порождающей матрицей. Например, для кодера рисунка 15 (а) N=3, m=3 gi1=101, gi2= 010, gi3 = 011,
следовательно, gi = 101010011. Выходной сигнал i-го символа ut равен
![]()
где ut=0 при ![]() .
.
Важным параметром сверточного кода является кодовое
ограничение ![]() . Длина кодового ограничения в теории сверточных кодов играет
. Длина кодового ограничения в теории сверточных кодов играет
роль, аналогичную длине блока в теории блочных кодов. В случае l=1, т.е. N=n, ![]() . Кодовое ограничение представляет число кодовых символов,
. Кодовое ограничение представляет число кодовых символов,
порождаемых кодером в промежутке времени между поступлением в него данного
информационного символа и выводом его в канал. В примере
(рисунок
15 а) ![]() .
.
Удобным аппаратом для рассмотрения кодирования и
декодирования сверточных кодов является кодовое дерево. На рисунке 16 изображен
пример кодового дерева для сверточного кодера (рисунок 15 (а)).
 |
Рисунок 16 – Кодовое дерево
Точками обозначены узлы кодового дерева, соответствующие
определенной информационной последовательности на входе кодера. Начальный
(крайний слева) узел соответствует моменту до начала поступления информации.
Отрезки между двумя соседними узлами называются ребрами. Совокупность нескольких
последовательных ребер называется ветвью. Для определения узла,
соответствующего некоторой определенной информационной последовательности,
двигаются из начального узла по кодовому дереву, делая шаг вниз при поступлении
информационного символа 0 и шаг вверх при поступлении информационного символа
1. Вдоль ребер написаны кодовые символы на выходе кодера, генерируемые при
переходе от данного узла к соседнему, справа. Пунктиром показана ветвь,
соответствующая входящей информационной последовательности 101.
Рассмотрим в качестве примера работу кодера (рисунок 15
(а)) при поступлении на его вход информационной последовательности 101.
Предположим, что к моменту поступления кодовой последовательности все ячейки
регистра находились в состоянии 0. Тогда после записи единицы в первую ячейку
на выходе кодера будет считана кодовая комбинация 101
(вторую
строку в таблице 15). Затем в первую ячейку регистра записывается второй символ
информационной последовательности (нуль), а ее первый символ переписывается во
вторую ячейку, в результате чего в канал будет передана кодовая комбинация 010.
После записи в первую ячейку регистра третьего информационного символа
(единицы) в канал будет передана кодовая комбинация 110. После поступления на
вход кодера информационного символа подаются N нулей (в рассматриваемом примере N=3), в результате чего в канал передаются
еще три группы символов: 010, 011, 000, а регистр возвращается в первоначальное
положение.
Таким образом, информационная последовательность 101,
состоящая из L=3 символов, в результате сверточного
кодирования превращается в кодовую комбинацию 101010110010011000, состоящую из ![]() . Обычно информационная последовательность состоит из
. Обычно информационная последовательность состоит из
большого числа символов, так что L>>N, поэтому число символов в выходной последовательности превышает
их число во входной в m раз. Несмотря на большую избыточность, сверточные коды находят
распространение благодаря хорошим корректирующим свойствам.
Таблица 15
|
Номер пункта |
Содержимое |
Содержимое |
Примечания |
||||
|
1 |
2 |
3 |
1 |
2 |
3 |
||
|
1 |
0 |
0 |
0 |
0 |
0 |
0 |
Исходное |
|
2 3 4 |
1 0 1 |
0 1 0 |
0 0 1 |
1 0 1 |
0 1 1 |
0 0 |
Ввод в |
|
5 6 7 |
0 0 0 |
1 0 0 |
0 1 0 |
0 0 0 |
1 1 0 |
1 0 |
Ввод в |
Процедура декодирования сверточных кодов аналогична
процедуре кодирования,
и ее удобно рассматривать с помощью кодового дерева, рисунок 16. Поступающая на
вход декодера последовательность анализируется по группам из m=3 элемента. Сначала m первых элементов подаются на два входных
дешифратора, первый из которых выделяет комбинацию 101, а второй – комбинацию
000. В зависимости от того, какая из комбинаций поступила в m первых элементов, открывается путь А
одной из пар дешифраторов, выделяющих m вторых элементов, значения которых определяются кодовым
деревом до тех пор, пока сигнал не появится на одном из 2N=8 выходов декодера. Такая процедура
декодирования получила название последовательного декодирования.
Описанный процесс происходит таким образом, когда в
принимаемой последовательности отсутствуют ошибки. Например, при передаче информационной
последовательности 101 в дискретный канал, как выше было показано, поступает
последовательность 101010110, которая при отсутствии ошибок в соответствии с
кодовым деревом (рисунок 16 (пунктир)) правильно декодируется в 101. При
наличии ошибок декодирование окажется
неэффективным так как
отдельные группы принятой кодовой последовательности не будут совпадать
с ребрами кодового дерева.
Возенкрафтом предложена вероятностная процедура
декодирования, заключающаяся в выборе при декодировании такой кодовой
комбинации, которая отличается от принятой последовательности в наименьшем числе разрядов. В таком случае если принятая
последовательность (вернее, ее отдельная группа из m элементов) не совпадает ни с одним
ребром, выходящим из данного узла, то декодер следует сначала по ребру у
каждого числа совпадающих символов больше. Очевидно, что при числе ошибок в
группе из m
элементов, большем, чем m/2, такой декодер сначала проследует к неправильному А узлу.
Однако маловероятно, чтобы, сделав такую ошибку, декодер нашел в этом
неправильном узле ребро, хорошо согласующееся со следующей группой m принятых символов.
Рассмотрим, например, кодовое дерево (рисунок 17),
соответствующее декодеру N=4, m=5,
изображенному на рисунке 18.
При передаче информационной последовательности х=1010 на
выходе кодера получим у = 11111, 01010, 11000, 01001.Предположим, что вектор
ошибки в канале е = 00010, 01101, 00000, 00000, тогда на вход декодера поступит
последовательность γ = 11101, 00111, 11000, 01001. В этом случае,
как
показано на рисунке 17 сплошной линией, декодер из начального А узла следует сначала по правильному пути к узлу
В, а из него – по неправильному пути к узлу С (пунктир), так как 00111
отличается от 10101 в двух разрядах, а от 01010 – в трех. Но из ребер,
выходящих из узла С, не совпадает с 11000 столько же разрядов (два или три),
сколько у правильного пути (в узел Д), что дает основание декодеру обнаружить
ошибочный поворот и вернуться в узел В для исправления ошибки.
Алгоритм Возенкрафта аналогичен последовательности действий
водителя автомобиля, который, сделав
неправильный поворот на развилке дорог, быстро обнаруживает ошибку,
возвращается на развилку и требует новую дорогу.
 |
Рисунок 17 – Кодовое дерево для декодера

Рисунок 18 – Схемы
сверхточных кодера и декодера
Рассмотрим в качестве примера работу декодера (рисунок
18) при поступлении на его вход последовательности Г, которая записывается в
буфер входа, откуда группами по пять элементов переписывается в регистр 1,
одновременно в Х-регистр от генератора Г подается случайная последовательность
нулей и единиц, и в регистр 2 записывается гипотетическая последовательность
у*. Затем производится вычисление расстояния
Хемминга между принятой и гипотетической последовательностями d(l)=γ![]() y*. Пусть в первый разряд регистра
y*. Пусть в первый разряд регистра
Х от Г записана единица, тогда на первом ребре d(l)=11101![]() 1111=1.
1111=1.
Так как декодер выбирает путь по принципу d<m/2-путь
правильный, d>m/2-путь неправильный , то в рассматриваемом примере (m=5, d=1) в узле а
путь выбран правильно, в первом разряде Х-регистра фиксируется единица. После
этого в регистр 1 записывается группа символов 00111, а в регистр 2 поступает
вторая гипотетическая комбинация. Предположим, что при этом в первый разряд
Х-регистра от Г поступила единица, тогда d(2)=00111![]() 10101=2. Если же в первый разряд Х-регистра был записан нуль,
10101=2. Если же в первый разряд Х-регистра был записан нуль,
то d/ (2)=
00111![]() 01010=3
01010=3
Поскольку 2<5/2<3, то декодер в узле принимает неправильное решение и идет в узел
С. Для обнаружения факта принятие
неправильного решения декодер по мере движения вдоль кодового дерева вычисляет
текущее значение d(l) и в каждом узле сравнивает d(l) с исключающей функцией критерия k(l). Если d(l) превышает
k(l), то пробный путь отбрасывается как маловероятный и
декодер возвращается на ближайшее неисследованное ребро, для которого d(l) < k(l), и снова
движется вперед, пока удовлетворяется это условие. Для простоты реализации
декодера в качестве k(l) выбирают прямую линию. При больших l доля
искаженных сигналов в дискретном симметричном канале приблизительно равна переходной вероятности канала p, поэтому если y*l соответствует правильному пути, то, естественно, ожидать, что d(l) будет колебаться около прямой, коэффициент наклона
которой равен рm (I на рисунке 19). Если те y*l соответствует неправильному пути из начального узла (l=0), то d(l) будет колебаться около прямой с наклоном m/2 (II на рисунке 19). Исходя из вышеизложенного, Возенкрафт предлагает в качестве d(l) принять прямую с коэффициентом наклона p’m, где p<p’<0.5, не
проходящую через путь при l=0, т.к. начальные символы могут быть тоже искажены (III на рисунке 19). На этом рисунке показаны примеры личные графики значений d(l) для
правильного (IV на рисунке 19) и неправильного
(V на рисунке 19) путей.
Алгоритм последовательного декодирования Возенкрафт
был усовершенствован Фано, который ввел вместо d(l) так называемое переношенное расстояние t(l) =d(l)-p’ml, где l– количество ребер, на которое декодер углубился в
кодовом дереве, и назвал соответствующие критерии порогами. Эти пороги
принимают вид горизонтальных прямых, отстоящих друг от друга на расстоянии D (на рисунке 20).
Если y*(l) соответствует правильному пути, то t(l) обычно близко к отрицательной величине (p–p’)ml и уменьшается с ростом l. Если y*(l) соответствует правильному пути, то t(l), как правило, близко к (1/2-p’)ml
и увеличивается с ростом l (I на рисунке 20) при безошибочном декодировании
поведение t(l) будет характеризовываться с неуклонным следованием вниз от исходного нулевого порога (II на рисунке 20). Если же в начале возникли ошибки, то их действие на каком-либо участке
вызывает увеличение t(l) и принятый на данном этапе текущий порог iD, где i=1,2,…, в
следующем узле нарушается (III на рисунке 20).
Если y*(l)
соответствует правильному пути, то t(l) обычно
близко к отрицательной величине (р-p’)ml
и уменьшается с ростом l. Если y*(l)
соответствует неправильному пути, то t(l), как
правило, близко к (1/2- p’)ml и увеличивается с ростом l (I на рисунке
20). При бесконечном декодировании поведение t(l) будет характеризовываться неуклонным следованием
вниз от исходного нулевого порога (II на
рисунке 20). Если же в канале возникли ошибки, то их действие на каком – либо
участке вызывает увеличение t(l), и
принятый на данном этапе текущий порог i∆, где i=1,2,….,
в следующем узле нарушается (III на рисунке
20).Это свидетельствует о том, что декодер может находиться на неверном пути и
следуя заложенным в алгоритме указаниям, “возвращаться” на один узел назад.
Проверяем возможные варианты путей из
этого узла.
Если этот путь отыскивается, декодер следует по тому пути, но в случае, если варианты пути
требуют увеличения порога, декодер возвращается к первоначальному варианту, считая его правильным, и начинает
дальнейшее движение- поиск по кодовому дереву. Рассмотрим пример (рисунок 21):
первая кодовая комбинация или первый исследуемый узел обозначаются единицей.
Для этого узла текущий порог равен D. Вторая поступившая комбинация ошибочна в трех
элементах. Из первого узла возможны два пути – узел 2-2’. Так как узел 2’ не
превышает текущего порога. Декодер направляется в узел 2’. Но следующие
поступившие комбинации превышают сразу два порога, поэтому декодер, согласно
алгоритму, возвращается в узел 1.
Исследуем узел 2. Из узла 2 возникает благоприятный путь в узел 3 и т.п. Таким
образом, декодер благополучно исправляет вторую искаженную кодовую
комбинацию.
 |
Рисунок 19 – К выбору критерия исключения
 |
|||
 |
|||
Рисунок 21 – Пример поиска по
алгоритму Фано
Рисунок
20 – К пояснению
Алгоритма Фано
1.19 Программная реализация «Сверточного кодера»
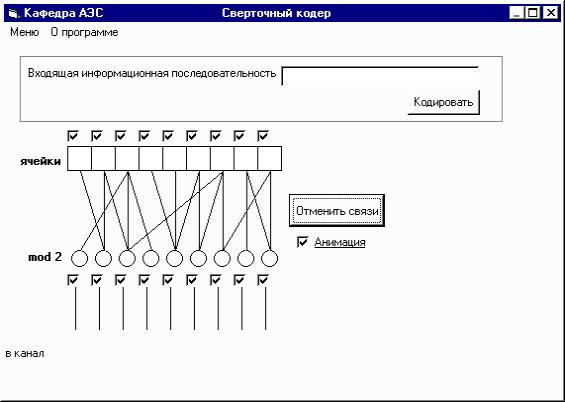
При создании программы была использована программа Visual Basic 6.0
В программе использованы следующие объекты
Таблица 16
|
Объект |
Описание |
|
|
Данный объект предназначен для ввода бинарной (двоичной |
|
|
Кнопка кодировать, при нажатии выполняется функция |
|
|
Объекты Check1 |
|
|
Объекты Check2 |
|
|
Данная кнопка предназначена для отмены связей между |
|
|
Объект Animation(Check) используется для |
|
|
Объект Kanal(Label) используется для |




В программе содержатся
следующие функции и процедуры:
Таблица
17
|
Процедуры |
Описание |
|
Sub |
Выбор ячеек |
|
Sub Check2_Click(Index |
Выбор сумматоров mod 2 кодера |
|
Sub |
Отменить связи между кодерами и сумматорами |
|
Sub |
Непосредственное кодирование входного сигнала, действие кнопки кодировать |
|
Sub |
Создает связь между ячейкой и сумматором |
|
Sub |
Создает связь между сумматором и ячейкой |
|
Sub |
Загрузка начальных параметров |
|
Sub |
Меню выход |
|
Sub |
Меню кодировать |
|
Sub mnuName_Click() |
Меню о программе |
|
Sub |
Включение таймера анимации |
|
Sub |
Непосредственная анимация |
Ниже приводится листинг
программы
Public i As
Integer
Public j As Integer
Dim YachSumm As Integer
Dim numYachSumm As Integer
Dim logYachSumm As Boolean
Dim G(9, 9) As Integer
Public kolYach As Integer
Public kolSumm As Integer
Public Slovo As String
Dim kMig As Integer
Dim k2Mig As Integer
Private Sub Check1_Click(Index As Integer)
Dim iK As Integer
If Check1(Index).Value = 1 Then
If Index < 8 Then
Check1(Index + 1).Visible
= True
End If
Shape1(Index).Visible =
True
kolYach = kolYach + 1
Else
kolYach = kolYach – 1
For iK = Index To 8
If iK < 8 Then
If Check1(iK).Value = 1
Then
kolYach = kolYach – 1
End If
Check1(iK + 1).Visible =
False
Check1(iK + 1).Value = 0
End If
Shape1(iK).Visible = False
Next iK
End If
‘ Print Str(kolYach)
End Sub
Private Sub Check2_Click(Index As Integer)
Dim iK As Integer
If Check2(Index).Value = 1 Then
If Index < 8 Then
Check2(Index + 1).Visible
= True
End If
Shape2(Index).Visible =
True
Line1(Index).Visible = True
kolSumm = kolSumm + 1
Else
kolSumm = kolSumm – 1
For iK = Index To 8
If iK < 8 Then
If Check2(iK).Value = 1
Then
kolSumm = kolSumm – 1
End If
Check2(iK + 1).Visible
= False
Check2(iK + 1).Value =
0
End If
Shape2(iK).Visible =
False
Line1(iK).Visible = False
Next iK
End If
End Sub
Private Sub Command1_Click()
Dim clrFore As Variant
clrFore = frmMain.ForeColor
frmMain.ForeColor =
frmMain.BackColor
For i = 0 To 8
For j = 0 To 8
frmMain.Line (Shape1(i).Left
+ Round(Shape1(i).Width / 2), _
Shape1(i).Top +
Round(Shape1(i).Height))- _
(Shape2(j).Left +
Round(Shape2(j).Width / 2), _
Shape2(j).Top)
G(i, j) = 0
Next j
Next i
frmMain.ForeColor = clrFore
End Sub
Private Sub Command2_Click()
kanal.Caption = “”
‘ïðîâåðêà
ïðàâèëüíîñòè
ââîäà
äàííûõ
Dim Msg, Style, Title, Help, Ctxt, Response, MyString
Msg = “Do you want to continue ?” ‘ Define message.
Style = vbYes ‘ Define buttons.
Title = “MsgBox Demonstration” ‘ Define title.
If Len(Trim(Signal.Text)) <> kolYach Or Len(Trim(Signal.Text)) = 0
Then
Response =
MsgBox(“Êîëè÷åñòâî
ñèìâîëîâ
äîëæíî ðàâíÿòüñÿ
êîëè÷åñòâó
ÿ÷ååê è
íåðàâíÿòüñÿ íóëþ
!”, Style, “Îøèáêà â
ïðîãðàììå”)
Exit Sub
End If
For i = 1 To kolYach
If Not (Mid(Signal.Text, i,
1) = “0” Or Mid(Signal.Text, i, 1) = “1”) Then
Response =
MsgBox(“Ââåäåííûé
êîä äîëæåí
áûòü äâîè÷íûì
0 èëè 1 !”, Style,
“Îøèáêà â
ïðîãðàììå”)
Exit Sub
End If
Next i
If kolSumm = 0 Then
Response =
MsgBox(“Íåâåðíîå
çàäàíèå
ïàðàìåòðîâ êîäåðà.
Âû çàáûëè
âêëþ÷èòü
ñóììàòîðû mod 2
!”, Style, “Îøèáêà â
ïðîãðàììå”)
Exit Sub
End If
‘ Var
S:array[1..kolYach,1..kolSumm] of integer;
‘ U,Sm:array[1..kolYach] of
integer;
‘ U0,k,j,Code,i:integer;
‘ Sl:string;
ReDim S(kolYach, kolSumm) As Integer
ReDim U(kolYach) As Integer
ReDim Sm(kolYach) As Integer
Dim U0 As Integer
Dim k As Integer
Dim Sl As String
Slovo = “”
For i = 1 To kolYach
U0 = Val(Mid(Signal.Text, i,
1))
If i > 1 Then
For j = kolYach – 1 To 1
Step -1
U(j + 1) = U(j)
Next j
End If
U(1) = U0
For j = 1 To i
For k = 1 To kolSumm
S(j, k) = G(j, k) * U(j)
Next k
Next j
For j = 1 To i – 1
For k = 1 To kolSumm
If S(j, k) = S(j + 1, k) Then
S(j + 1, k) = 0
Else
S(j + 1, k) = 1
End If
Next k
Next j
For k = 1 To kolSumm
Sl = Str(S(i, k))
Slovo = Slovo + Sl
Next k
Next i
‘label5.Caption:=’Â
êàíàë ‘+label5.Caption;
If Animation.Value = 1 Then
Timer1.Enabled = True
Else
kanal.Caption = Slovo
End If
End Sub
Private Sub Image1_Click(Index As Integer)
If logYachSumm Then
If (YachSumm = 1) Then
If YachSumm = 0 Then
G(numYachSumm + 1,
Index + 1) = 1
frmMain.Line
(Shape1(numYachSumm).Left + Round(Shape1(numYachSumm).Width / 2), _
Shape1(numYachSumm).Top +
Round(Shape1(numYachSumm).Height))- _
(Shape2(Index).Left +
Round(Shape2(Index).Width / 2), _
Shape2(Index).Top)
Else
G(Index + 1,
numYachSumm + 1) = 1
frmMain.Line
(Shape1(Index).Left + Round(Shape1(Index).Width / 2), _
Shape1(Index).Top +
Round(Shape1(Index).Height))- _
(Shape2(numYachSumm).Left +
Round(Shape2(numYachSumm).Width / 2), _
Shape2(numYachSumm).Top)
End If
End If
logYachSumm = False
Else
logYachSumm = True
YachSumm = 0
numYachSumm = Index
End If
‘Print logYachSumm, Str(YachSum), Str(numYachSumm)
End Sub
Private Sub Form_Load()
kolYach = 0
kolSumm = 0
Command1_Click
logYachSumm = False
Shape1(0).Visible = False
Shape2(0).Visible = False
For i = 1 To 8
Shape1(i).Visible = False
Check1(i).Visible = False
Shape2(i).Visible = False
Check2(i).Visible = False
Next i
End Sub
Private Sub Image2_Click(Index As Integer)
If logYachSumm Then
If (YachSumm = 0) Then
If YachSumm = 0 Then
G(numYachSumm + 1,
Index + 1) = 1
frmMain.Line (Shape1(numYachSumm).Left
+ Round(Shape1(numYachSumm).Width / 2), _
Shape1(numYachSumm).Top +
Round(Shape1(numYachSumm).Height))- _
(Shape2(Index).Left +
Round(Shape2(Index).Width / 2), _
Shape2(Index).Top)
Else
G(Index + 1, numYachSumm
+ 1) = 1
frmMain.Line
(Shape1(Index).Left + Round(Shape1(Index).Width / 2), _
Shape1(Index).Top +
Round(Shape1(Index).Height))- _
(Shape2(numYachSumm).Left +
Round(Shape2(numYachSumm).Width / 2), _
Shape2(numYachSumm).Top)
End If
End If
logYachSumm = False
Else
logYachSumm = True
YachSumm = 1
numYachSumm = Index
End If
‘Print logYachSumm, Str(YachSum), Str(numYachSumm)
End Sub
Private Sub mnuExit_Click()
End
End Sub
Private Sub mnuKoder_Click()
Command2_Click
End Sub
Private Sub mnuName_Click()
frmAbout.Show
End Sub
Private Sub Timer1_Timer()
If kMig > 8 Then
kMig = 0
End If
Migalka (kMig)
kMig = kMig + 1
End Sub
Sub Migalka(k As Integer)
k2Mig = k2Mig + 1
Line1(k).BorderColor =
vbGreen
Line1(k).BorderWidth = 4
kanal.Caption =
kanal.Caption + Mid(Slovo, k2Mig, 1)
If k > 0 Then
Line1(k – 1).BorderColor =
vbBlack
Line1(k – 1).BorderWidth =
1
Else
Line1(kolSumm –
1).BorderColor = vbBlack
Line1(kolSumm –
1).BorderWidth = 1
End If
If k2Mig = Len(Slovo) Then
Line1(k).BorderColor =
vbBlack
Line1(k).BorderWidth = 1
Timer1.Enabled = False
kMig = 0
k2Mig = 0
End If
End Sub
Список литературы
1 Скляр Б. Цифровая связь. Теоретические
основы и практическое применение: 2-е изд. /Пер. с англ.– М.: Издательский дом «Вильямс», 2003. – 1104 с.
2 Прокис Дж. Цифровая связь. Радио и связь, 2000: –
797с.
3 М. Вернер. Мир программирования. «Основы кодирования»:
Учебник для вузов.-М.: Техносфера, 2004.-286с.
1 Никитин Г.И., Антипова И.Б., Красновидов А.В.
Корректирующие коды: Методические указания./ ЛИАП.Л., 1989.- 32 с.
2 Блейхут Р. Теория
и практика кодов, контролирующих ошибки: Пер. с англ.-М.:Мир, 1986. -576 с.
3 Питерсон У., Уэлдон Э., Коды, исправляющие ошибки: Пер. с
англ.- М.: Мир, 1976.- 600 с.
Замрий А.С. Помехоустойчивые коды: Учебное
пособие/ЛВВИУС.Л., 1990.-58 с.
4 Колесников В.Д., Мирончиков Е.Т. Декодирование
циклических кодов. – М.: Связь, 1968.
5 Дмитриев В.И. Прикладная теория информации: Учебник. – М:
Высш.шк., 1989.
6 Скляр Б. Цифровая связь: Теоретические основы и
практическое применение. – М.: Вильямс,2003.
7 Тутевич В.Н. Телемеханика: Учебное пособие.- М.: Высш.
Шк., 1985. -423 с.
8 Передача дискретных сообщений: Учебник/Под ред. В.П.
Шувалова.- М.: Радио и связь, 1990.
Содержание
|
Введение …………………………………………………………………… |
3 |
|
1 Классификация корректирующих |
3 |
|
с ними ………………………………………………………………… |
4 |
|
|
6 |
|
кодовых комбинаций циклических кодов………………………… |
11 |
|
|
21 |
|
|
23 |
|
|
24 |
|
|
26 |
|
1.8 |
30 |
|
1.9 |
33 |
|
1.10 Циклические коды Боуза -Чоудхури |
37 |
|
1.11 Декодирование и исправлением нескольких |
43 |
|
1.12 Код Хэмминга……………………………………………………… |
49 |
|
1.13 Применение кода Рида – Соломона……………………………… |
50 |
|
1.14 Общая характеристика кодов Рида – Соломона………………… |
57 |
|
1.15 Выбор числа символов и образующего многочлена……………. |
58 |
|
1.16 Кодирование кодов Рида – Соломона……………………………. |
59 |
|
1.17 Декодирование кодов Рида – Соломона…………………………. |
61 |
|
1.18 Понятие о сверточном кодировании……………………………… |
62 |
|
1.19 Программная реализация сверточного кодера………………….. |
71 |
|
Список |
76 |
Адильжан Джакипбекович Джангозин
Катипа Сламбаевна Чежимбаева
ПОМЕХОУСТОЙЧИВЫЕ
ЦИКЛИЧЕСКИЕ КОДЫ
Учебное пособие
Редактор Сыздыкова Ж.М.
Доп.план 2006г., поз.7
Сдано в набор 2006
Формат 60х84 1/16
Бумага типографская №2
Объем
4,8 уч.-изд.л Тираж
100 экз. Цена
195 тг.
Подписано в печать
Копировально-множительное бюро
Алматинского института энергетики и
связи
050013, г.Алматы,
ул.Байтурсынова, 126
