Время на прочтение
8 мин
Количество просмотров 347K

Инструменты web scraping (парсинг) разработаны для извлечения, сбора любой открытой информации с веб-сайтов. Эти ресурсы нужны тогда, когда необходимо быстро получить и сохранить в структурированном виде любые данные из интернета. Парсинг сайтов – это новый метод ввода данных, который не требует повторного ввода или копипастинга.
Такого рода программное обеспечение ищет информацию под контролем пользователя или автоматически, выбирая новые или обновленные данные и сохраняя их в таком виде, чтобы у пользователя был к ним быстрый доступ. Например, используя парсинг можно собрать информацию о продуктах и их стоимости на сайте Amazon. Ниже рассмотрим варианты использования веб-инструментов извлечения данных и десятку лучших сервисов, которые помогут собрать информацию, без необходимости написания специальных программных кодов. Инструменты парсинга могут применяться с разными целями и в различных сценариях, рассмотрим наиболее распространенные случаи использования, которые могут вам пригодиться. И дадим правовую оценку парсинга в России.
1. Сбор данных для исследования рынка
Веб-сервисы извлечения данных помогут следить за ситуацией в том направлении, куда будет стремиться компания или отрасль в следующие шесть месяцев, обеспечивая мощный фундамент для исследования рынка. Программное обеспечение парсинга способно получать данные от множества провайдеров, специализирующихся на аналитике данных и у фирм по исследованию рынка, и затем сводить эту информацию в одно место для референции и анализа.
2. Извлечение контактной информации
Инструменты парсинга можно использовать, чтобы собирать и систематизировать такие данные, как почтовые адреса, контактную информацию с различных сайтов и социальных сетей. Это позволяет составлять удобные списки контактов и всей сопутствующей информации для бизнеса – данные о клиентах, поставщиках или производителях.
3. Решения по загрузке с StackOverflow
С инструментами парсинга сайтов можно создавать решения для оффлайнового использования и хранения, собрав данные с большого количества веб-ресурсов (включая StackOverflow). Таким образом можно избежать зависимости от активных интернет соединений, так как данные будут доступны независимо от того, есть ли возможность подключиться к интернету.
4. Поиск работы или сотрудников
Для работодателя, который активно ищет кандидатов для работы в своей компании, или для соискателя, который ищет определенную должность, инструменты парсинга тоже станут незаменимы: с их помощью можно настроить выборку данных на основе различных прилагаемых фильтров и эффективно получать информацию, без рутинного ручного поиска.
5. Отслеживание цен в разных магазинах
Такие сервисы будут полезны и для тех, кто активно пользуется услугами онлайн-шоппинга, отслеживает цены на продукты, ищет вещи в нескольких магазинах сразу.
В обзор ниже не попал Российский сервис парсинга сайтов и последующего мониторинга цен XMLDATAFEED (xmldatafeed.com), который разработан в Санкт-Петербурге и в основном ориентирован на сбор цен с последующим анализом. Основная задача — создать систему поддержки принятия решений по управлению ценообразованием на основе открытых данных конкурентов. Из любопытного стоит выделить публикация данные по парсингу в реальном времени 🙂

10 лучших веб-инструментов для сбора данных:
Попробуем рассмотреть 10 лучших доступных инструментов парсинга. Некоторые из них бесплатные, некоторые дают возможность бесплатного ознакомления в течение ограниченного времени, некоторые предлагают разные тарифные планы.
1. Import.io
Import.io предлагает разработчику легко формировать собственные пакеты данных: нужно только импортировать информацию с определенной веб-страницы и экспортировать ее в CSV. Можно извлекать тысячи веб-страниц за считанные минуты, не написав ни строчки кода, и создавать тысячи API согласно вашим требованиям.
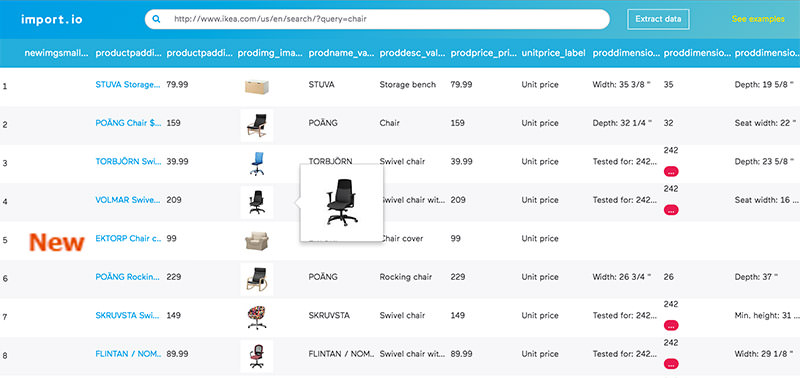
Для сбора огромных количеств нужной пользователю информации, сервис использует самые новые технологии, причем по низкой цене. Вместе с веб-инструментом доступны бесплатные приложения для Windows, Mac OS X и Linux для создания экстракторов данных и поисковых роботов, которые будут обеспечивать загрузку данных и синхронизацию с онлайновой учетной записью.
2. Webhose.io
Webhose.io обеспечивает прямой доступ в реальном времени к структурированным данным, полученным в результате парсинга тысяч онлайн источников. Этот парсер способен собирать веб-данные на более чем 240 языках и сохранять результаты в различных форматах, включая XML, JSON и RSS.

Webhose.io – это веб-приложение для браузера, использующее собственную технологию парсинга данных, которая позволяет обрабатывать огромные объемы информации из многочисленных источников с единственным API. Webhose предлагает бесплатный тарифный план за обработку 1000 запросов в месяц и 50 долларов за премиальный план, покрывающий 5000 запросов в месяц.
3. Dexi.io (ранее CloudScrape)
CloudScrape способен парсить информацию с любого веб-сайта и не требует загрузки дополнительных приложений, как и Webhose. Редактор самостоятельно устанавливает своих поисковых роботов и извлекает данные в режиме реального времени. Пользователь может сохранить собранные данные в облаке, например, Google Drive и Box.net, или экспортировать данные в форматах CSV или JSON.
CloudScrape также обеспечивает анонимный доступ к данным, предлагая ряд прокси-серверов, которые помогают скрыть идентификационные данные пользователя. CloudScrape хранит данные на своих серверах в течение 2 недель, затем их архивирует. Сервис предлагает 20 часов работы бесплатно, после чего он будет стоить 29 долларов в месяц.
4. Scrapinghub
Scrapinghub – это облачный инструмент парсинга данных, который помогает выбирать и собирать необходимые данные для любых целей. Scrapinghub использует Crawlera, умный прокси-ротатор, оснащенный механизмами, способными обходить защиты от ботов. Сервис способен справляться с огромными по объему информации и защищенными от роботов сайтами.

Scrapinghub преобразовывает веб-страницы в организованный контент. Команда специалистов обеспечивает индивидуальный подход к клиентам и обещает разработать решение для любого уникального случая. Базовый бесплатный пакет дает доступ к одному поисковому роботу (обработка до 1 Гб данных, далее — 9$ в месяц), премиальный пакет дает четырех параллельных поисковых ботов.
5. ParseHub
ParseHub может парсить один или много сайтов с поддержкой JavaScript, AJAX, сеансов, cookie и редиректов. Приложение использует технологию самообучения и способно распознать самые сложные документы в сети, затем генерирует выходной файл в том формате, который нужен пользователю.

ParseHub существует отдельно от веб-приложения в качестве программы рабочего стола для Windows, Mac OS X и Linux. Программа дает бесплатно пять пробных поисковых проектов. Тарифный план Премиум за 89 долларов предполагает 20 проектов и обработку 10 тысяч веб-страниц за проект.
6. VisualScraper
VisualScraper – это еще одно ПО для парсинга больших объемов информации из сети. VisualScraper извлекает данные с нескольких веб-страниц и синтезирует результаты в режиме реального времени. Кроме того, данные можно экспортировать в форматы CSV, XML, JSON и SQL.
Пользоваться и управлять веб-данными помогает простой интерфейс типа point and click. VisualScraper предлагает пакет с обработкой более 100 тысяч страниц с минимальной стоимостью 49 долларов в месяц. Есть бесплатное приложение, похожее на Parsehub, доступное для Windows с возможностью использования дополнительных платных функций.
7. Spinn3r
Spinn3r позволяет парсить данные из блогов, новостных лент, новостных каналов RSS и Atom, социальных сетей. Spinn3r имеет «обновляемый» API, который делает 95 процентов работы по индексации. Это предполагает усовершенствованную защиту от спама и повышенный уровень безопасности данных.
Spinn3r индексирует контент, как Google, и сохраняет извлеченные данные в файлах формата JSON. Инструмент постоянно сканирует сеть и находит обновления нужной информации из множества источников, пользователь всегда имеет обновляемую в реальном времени информацию. Консоль администрирования позволяет управлять процессом исследования; имеется полнотекстовый поиск.
8. 80legs
80legs – это мощный и гибкий веб-инструмент парсинга сайтов, который можно очень точно подстроить под потребности пользователя. Сервис справляется с поразительно огромными объемами данных и имеет функцию немедленного извлечения. Клиентами 80legs являются такие гиганты как MailChimp и PayPal.

Опция «Datafiniti» позволяет находить данные сверх-быстро. Благодаря ней, 80legs обеспечивает высокоэффективную поисковую сеть, которая выбирает необходимые данные за считанные секунды. Сервис предлагает бесплатный пакет – 10 тысяч ссылок за сессию, который можно обновить до пакета INTRO за 29 долларов в месяц – 100 тысяч URL за сессию.
9. Scraper
Scraper – это расширение для Chrome с ограниченными функциями парсинга данных, но оно полезно для онлайновых исследований и экспортирования данных в Google Spreadsheets. Этот инструмент предназначен и для новичков, и для экспертов, которые могут легко скопировать данные в буфер обмена или хранилище в виде электронных таблиц, используя OAuth.
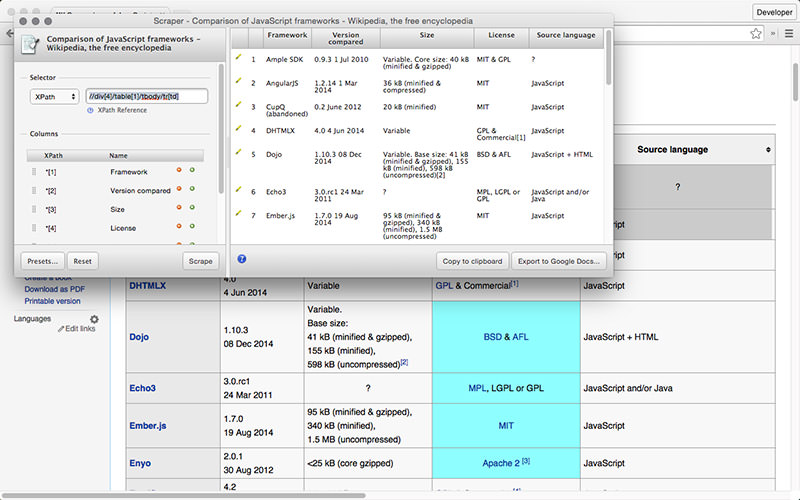
Scraper – бесплатный инструмент, который работает прямо в браузере и автоматически генерирует XPaths для определения URL, которые нужно проверить. Сервис достаточно прост, в нем нет полной автоматизации или поисковых ботов, как у Import или Webhose, но это можно рассматривать как преимущество для новичков, поскольку его не придется долго настраивать, чтобы получить нужный результат.
10. OutWit Hub
OutWit Hub – это дополнение Firefox с десятками функций извлечения данных. Этот инструмент может автоматически просматривать страницы и хранить извлеченную информацию в подходящем для пользователя формате. OutWit Hub предлагает простой интерфейс для извлечения малых или больших объемов данных по необходимости.
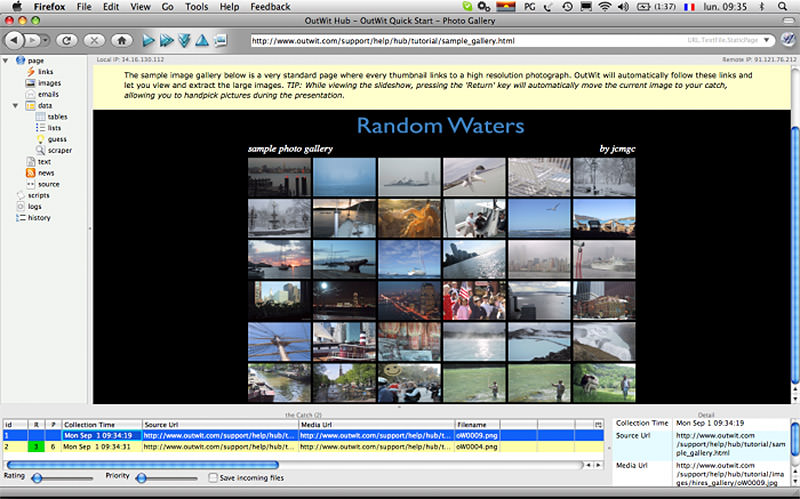
OutWit позволяет «вытягивать» любые веб-страницы прямо из браузера и даже создавать в панели настроек автоматические агенты для извлечения данных и сохранения их в нужном формате. Это один из самых простых бесплатных веб-инструментов по сбору данных, не требующих специальных знаний в написании кодов.
Самое главное — правомерность парсинга?!
Вправе ли организация осуществлять автоматизированный сбор информации, размещенной в открытом доступе на сайтах в сети интернете (парсинг)?
В соответствии с действующим в Российской Федерации законодательством разрешено всё, что не запрещено законодательством. Парсинг является законным, в том случае, если при его осуществлении не происходит нарушений установленных законодательством запретов. Таким образом, при автоматизированном сборе информации необходимо соблюдать действующее законодательство. Законодательством Российской Федерации установлены следующие ограничения, имеющие отношение к сети интернет:
1. Не допускается нарушение Авторских и смежных прав.
2. Не допускается неправомерный доступ к охраняемой законом компьютерной информации.
3. Не допускается сбор сведений, составляющих коммерческую тайну, незаконным способом.
4. Не допускается заведомо недобросовестное осуществление гражданских прав (злоупотребление правом).
5. Не допускается использование гражданских прав в целях ограничения конкуренции.
Из вышеуказанных запретов следует, что организация вправе осуществлять автоматизированный сбор информации, размещенной в открытом доступе на сайтах в сети интернет если соблюдаются следующие условия:
1. Информация находится в открытом доступе и не защищается законодательством об авторских и смежных правах.
2. Автоматизированный сбор осуществляется законными способами.
3. Автоматизированный сбор информации не приводит к нарушению в работе сайтов в сети интернет.
4. Автоматизированный сбор информации не приводит к ограничению конкуренции.
При соблюдении установленных ограничений Парсинг является законным.
p.s. по правовому вопросу мы подготовили отдельную статью, где рассматривается Российский и зарубежный опыт.
Какой инструмент для извлечения данных Вам нравится больше всего? Какого рода данные вы хотели бы собрать? Расскажите в комментариях о своем опыте парсинга и свое видение процесса…
Часто у вебмастера, маркетолога или SEO-специалиста возникает необходимость извлечь данные со страниц сайтов и отобразить их в удобном виде для дальнейшей обработки. Это может быть парсинг цен в интернет-магазине, получение числа лайков или извлечение содержимого отзывов с интересующих ресурсов.
По умолчанию большинство программ технического аудита сайтов собирают только содержимое заголовков H1 и H2, однако, если например, вы хотите собрать заголовки H5, то их уже нужно будет извлекать отдельно. И чтобы избежать рутинной ручной работы по парсингу и извлечению данных из HTML-кода страниц – обычно используют веб-скраперы.
Веб-скрейпинг – это автоматизированный процесс извлечения данных с интересующих страниц сайта по определенным правилам.
Возможные сферы применения веб-скрейпинга:
- Отслеживание цен на товары в интернет-магазинах.
- Извлечение описаний товаров и услуг, получение числа товаров и картинок в листинге.
- Извлечение контактной информации (адреса электронной почты, телефоны и т.д.).
- Сбор данных для маркетинговых исследований (лайки, шеры, оценки в рейтингах).
- Извлечение специфичных данных из кода HTML-страниц (поиск систем аналитики, проверка наличия микроразметки).
- Мониторинг объявлений.
Основными способами веб-скрейпинга являются методы разбора данных используя XPath, CSS-селекторы, XQuery, RegExp и HTML templates.
- XPath представляет собой специальный язык запросов к элементам документа формата XML / XHTML. Для доступа к элементам XPath использует навигацию по DOM путем описания пути до нужного элемента на странице. С его помощью можно получить значение элемента по его порядковому номеру в документе, извлечь его текстовое содержимое или внутренний код, проверить наличие определенного элемента на странице. Описание XPath >>
- CSS-селекторы используются для поиска элемента его части (атрибут). CSS синтаксически похож на XPath, при этом в некоторых случаях CSS-локаторы работают быстрее и описываются более наглядно и кратко. Минусом CSS является то, что он работает лишь в одном направлении – вглубь документа. XPath же работает в обе стороны (например, можно искать родительский элемент по дочернему). Таблица сравнения CSS и XPath >>
- XQuery имеет в качестве основы язык XPath. XQuery имитирует XML, что позволяет создавать вложенные выражения в таким способом, который невозможен в XSLT. Описание XQuery >>
- RegExp – формальный язык поиска для извлечения значений из множества текстовых строк, соответствующих требуемым условиям (регулярному выражению). Описание RegExp >>
- HTML templates – язык извлечения данных из HTML документов, который представляет собой комбинацию HTML-разметки для описания шаблона поиска нужного фрагмента плюс функции и операции для извлечения и преобразования данных. Описание HTML templates >>
Обычно при помощи парсинга решаются задачи, с которыми сложно справиться вручную. Это может быть веб скрейпинг описаний товаров при создании нового интернет-магазина, скрейпинг в маркетинговых исследованиях для мониторинга цен, либо для мониторинга объявлений (например, по продаже квартир). Для задач SEO-оптимизации обычно используются узко специализированные инструменты, в которых уже встроены парсеры со всеми необходимыми настройками извлечения основных SEO параметров.
BatchURLScraper
Существует множество инструментов, позволяющих осуществлять скрейпинг (извлекать данные из веб-сайтов), однако большинство из них платные и громоздкие, что несколько ограничивает их доступность для массового использования.
Поэтому нами был создан простой и бесплатный инструмент – BatchURLScraper, предназначенный для сбора данных из списка URL с возможностью экспорта полученных результатов в Excel.
Интерфейс программы достаточно прост и состоит всего из 3-х вкладок:
- Вкладка “Список URL” предназначена для добавления страниц парсинга и отображения результатов извлечения данных с возможностью их последующего экспорта.
- На вкладке “Правила” производится настройка правил скрейпинга при помощи XPath, CSS-локаторов, XQuery, RegExp или HTML templates.
- Вкладка “Настройки” содержит общие настройки программы (число потоков, User-Agent и т.п.).
Также нами был добавлен модуль для отладки правил.
При помощи встроенного отладчика правил можно быстро и просто получить HTML-содержимое любой страницы сайта и тестировать работу запросов, после чего использовать отлаженные правила для парсинга данных в BatchURLScraper.
Разберем более подробно примеры настроек парсинга для различных вариантов извлечения данных.
Извлечение данных со страниц сайтов в примерах
Так как BatchURLScraper позволяет извлекать данные из произвольного списка страниц, в котором могут встречаться URL от разных доменов и, соответственно, разных типов сайта, то для примеров тестирования извлечения данных мы будем использовать все пять вариантов скрейпинга: XPath, CSS, RegExp, XQuery и HTML templates. Список тестовых URL и настроек правил находятся в дистрибутиве программы, таким образом можно протестировать все это лично, используя пресеты (предустановленные настройки парсинга).
Механика извлечения данных
1. Пример скрейпинга через XPath.
Например, в интернет-магазине мобильных телефонов нам нужно извлечь цены со страниц карточек товаров, а также признак наличия товара на складе (есть в наличии или нет).
Для извлечения цен нам нужно:
- Перейти на карточку товара.
- Выделить цену.
- Кликнуть по ней правой кнопкой мыши и нажать «Показать код элемента» (или «Inspect», если вы используете англоязычный интерфейс).
- В открывшемся окне найти элемент, отвечающий за цену (он будет подсвечен).
- Кликнуть по нему правой кнопкой мыши и выбрать «Копировать» > «Копировать XPath».
Для извлечения признака наличия товара на сайте операция будет аналогичной.
Так как типовые страницы обычно имеют одинаковый шаблон, достаточно проделать операцию по получению XPath для одной такой типовой страницы товара, чтобы спарсить цены всего магазина.
Далее, в списке правил программы мы добавляем поочередно правила и вставляем в них ранее скопированные коды элементов XPath из браузера.
2. Определяем присутствие счетчика Google Analytics при помощи RegExp или XPath.
- XPath: Открываем исходный код любой страницы по Ctrl-U, затем ищем в нем текст “gtm.start”, ищем в коде идентификатор UA-…, и далее также используя отображение кода элемента копируем его XPath и вставляем в новое правило в BatchURLScraper.
- RegExp: Поиск счетчика через регулярные выражения еще проще: код правила извлечения данных вставляем [‘](UA-.*?)[‘].
3. Извлечь контактный Email используя CSS.
Тут совсем все просто. Если на страницах сайта встречаются гиперссылки вида “mailto:”, то из них можно извлечь все почтовые адреса.
Для этого мы добавляем новое правило, выбираем в нем CSSPath, и в код правила извлечения данных вставляем правило a[href^=”mailto:”].
4. Извлечь значения в списках или в таблице при помощи XQuery.
В отличии от других селекторов, XQuery позволяет использовать циклы и прочие возможности языков программирования.
Например, при помощи оператора FOR можно получить значения всех списков LI. Пример:
Либо узнать, есть ли почта на страницах сайта:
- if (count(//a[starts-with(@href, ‘mailto:’)])) then “Есть почта” else “Нет почты”
5. Использование HTML templates.
В данном языке извлечения данных в качестве функций можно использовать XPath/XQuery, CSSpath, JSONiq и обычные выражения.
Тестовая таблица:
Например, данный шаблон ищет таблицу с атрибутом id=”t2″ и извлекает текст из второго столбца таблицы:
- <table id=”t2″><template:loop><tr><td></td><td>{text()}</td></tr></template:loop></table>
Извлечение данных из второй строки:
- <table id=”t2″><tr></tr><tr><template:loop><td>{text()}</td></template:loop></tr></table>
А этот темплейт вычисляет сумму чисел в колонке таблицы:
- <table id=”t2″>{_tmp := 0}<template:loop><tr><td>{_tmp := $_tmp + .}</td></tr></template:loop>{result := $_tmp}</table>
Таким образом, мы получили возможность извлекать практически любые данные с интересующих страниц сайтов, используя произвольный список URL, включающий страницы с разных доменов.
Скачать BatchURLScraper и протестировать работу правил извлечения данных можно по этой ссылке
Сегодняшний проект послужит основой многих наших дальнейших программ. Мы научимся собирать с сайтов любые данные, которые нам нужны.
У нас есть рабочий проект на цепях Маркова. Цепи Маркова — это несложный алгоритм, который анализирует сочетаемость слов в заданном тексте и выдаёт новый текст на основе старого. Похоже на работу нейронок, но на самом деле это просто перебор слов и бессмысленное их сочетание.
Для работы наших первых проектов на цепях Маркова мы скачали книгу с рассказами Чехова. Программа анализирует сочетаемость чеховских слов и выдаёт текст в чеховском духе (хотя и бессмысленный).
Но что, если мы хотим сделать текст не в духе Чехова, а в духе журнала «Код»? Или в духе какого-нибудь издания-иноагента? Или сделать генератор статей в духе какого-нибудь блогера?
Решение — написать программу, которая посмотрит на сайте наши статьи и вытащит оттуда весь значимый текст. Единственное, что для этого понадобится, — список ссылок на статьи, но мы их уже собрали, когда делали проект с гаданием на статьях Кода.
Программа будет работать на Python на локальной машине. Алгоритм:
👉 Главное в таких проектах — знать структуру содержимого страницы и понимать, где именно и в каких тегах находятся нужные для вас данные.
Чтобы было проще, на старте сделаем программу, которая собирает названия страниц. Как освоимся — сделаем что посложнее.
Прежде чем заниматься парсингом (сбором) со страницы чего угодно, нужно выяснить, где это лежит и в какой кодировке. Мы знаем, что все статьи Кода созданы по одному и тому же шаблону, поэтому нам достаточно посмотреть, как устроена одна, чтобы понять их все.
Смотрим исходный код любой нашей статьи. Нас интересуют два момента — кодировка страницы и тег <title>. Нам нужно убедиться, что в этом теге прописано название.
Эта строчка означает, что страница работает с кодировкой UTF-8. Запомним это.
Теперь пролистываем исходный код ниже и находим тег <title> — именно он отвечает за заголовок страницы. Убеждаемся, что он есть и с ним всё в порядке:
В проекте нам понадобятся две библиотеки: urllib и BeautifulSoup.
Первая отвечает за доступ к страницам по их адресу, причём оттуда нам будет нужна только одна команда urlopen().read — она отправляется по указанному адресу и получает весь исходный код страницы.
Вторая библиотека входит в состав большой библиотеки bs4 — в ней уже собраны все команды для парсинга исходного HTML-кода и разбора тегов. Чтобы установить bs4, запускаем терминал и пишем:
Теперь объявим список страниц, которые нужно посетить и забрать оттуда заголовки. Мы уже составили такой список для проекта с гаданием на статьях Кода, поэтому просто возьмём его оттуда и адаптируем под Python:
url = [
“https://thecode.media/is-not-defined-jquery/”,
“https://thecode.media/arduino-projects-2/”,
“https://thecode.media/10-raspberry/”,
“https://thecode.media/easy-css/”,
“https://thecode.media/to-be-front/”,
“https://thecode.media/cryptex/”,
“https://thecode.media/ali-coders/”,
“https://thecode.media/po-glandy/”,
“https://thecode.media/megaexcel/”,
“https://thecode.media/chat-bot-generators/”,
“https://thecode.media/wifi/”,
“https://thecode.media/andri-oxa/”,
“https://thecode.media/free-hosting/”,
“https://thecode.media/hotwheels/”,
“https://thecode.media/do-not-disturb/”,
“https://thecode.media/dyno-ai/”,
“https://thecode.media/snake-ai/”,
“https://thecode.media/leet/”,
“https://thecode.media/ninja/”,
“https://thecode.media/supergirl/”,
“https://thecode.media/vpn/ “,
“https://thecode.media/what-is-wordpress/”,
“https://thecode.media/hardware/”,
“https://thecode.media/division/”,
“https://thecode.media/nuggets/”,
“https://thecode.media/binary-notation/”,
“https://thecode.media/bootstrap/”,
“https://thecode.media/chat-bot/”,
“https://thecode.media/myadblock3000/”,
“https://thecode.media/trello/”,
“https://thecode.media/python-time/”,
“https://thecode.media/editor/”,
“https://thecode.media/timer/”,
“https://thecode.media/intro-bootstrap/”,
“https://thecode.media/php-form/”,
“https://thecode.media/hr-quiz/”,
“https://thecode.media/c-sharp/”,
“https://thecode.media/showtime/”,
“https://thecode.media/uchtel-rasskazhi/”,
“https://thecode.media/sshhhh/”,
“https://thecode.media/marry-me-python/”,
“https://thecode.media/haters-gonna-code/”,
“https://thecode.media/speed-css/”,
“https://thecode.media/fired/”,
“https://thecode.media/zabuhal/”,
“https://thecode.media/est-tri-shkatulki/”,
“https://thecode.media/milk-that/”,
“https://thecode.media/binary-mouse/”,
“https://thecode.media/bowling/”,
“https://thecode.media/dealership/”,
“https://thecode.media/best-seller/”,
“https://thecode.media/hr/”,
“https://thecode.media/no-comments/”,
“https://thecode.media/drakoni-yajca/”,
“https://thecode.media/who-is-who/”,
“https://thecode.media/get-a-room/”,
“https://thecode.media/alps/”,
“https://thecode.media/handshake/”,
“https://thecode.media/choose-life/”,
“https://thecode.media/high-voltage/”,
“https://thecode.media/spy/”,
“https://thecode.media/squirrelrrel/”,
“https://thecode.media/so-agile/”,
“https://thecode.media/wedding/”,
“https://thecode.media/supper/”,
“https://thecode.media/le-tarakan/”,
“https://thecode.media/batareyki-besyat/”,
“https://thecode.media/dr_jekyll/”,
“https://thecode.media/everybody_lies/”,
“https://thecode.media/electrician/”,
“https://thecode.media/einstein/”,
“https://thecode.media/bugz/”,
“https://thecode.media/needforspeed/”,
“https://thecode.media/be-smart/”,
“https://thecode.media/bot-online/”,
“https://thecode.media/microb/”,
“https://thecode.media/jquery/”,
“https://thecode.media/split-screen/”,
“https://thecode.media/calculus/”,
“https://thecode.media/big-data-sales/”,
“https://thecode.media/ambient/”,
“https://thecode.media/fatality/”,
“https://thecode.media/biggest-loser/”,
“https://thecode.media/wifi/”,
“https://thecode.media/nosock/”,
“https://thecode.media/variables/”,
“https://thecode.media/start_python/”,
“https://thecode.media/i-gonna-code/”,
“https://thecode.media/sigi-est/”,
“https://thecode.media/nes-game/”,
“https://thecode.media/live-view/”,
“https://thecode.media/remote/”,
“https://thecode.media/arduino-code/”,
“https://thecode.media/horses/”,
“https://thecode.media/runinstein/”,
“https://thecode.media/wp-template/”,
“https://thecode.media/tilda/”,
“https://thecode.media/todo/”,
“https://thecode.media/telebot/”,
“https://thecode.media/summator-2/”,
“https://thecode.media/get-rich-coding/”,
“https://thecode.media/content-manager/”,
“https://thecode.media/vzrosly-stal/”,
“https://thecode.media/py-install/”,
“https://thecode.media/quantum/”,
“https://thecode.media/dns/”,
“https://thecode.media/practicum/”,
“https://thecode.media/react/”,
“https://thecode.media/1september/”,
“https://thecode.media/summator/”,
“https://thecode.media/vds/”,
“https://thecode.media/made-in-china/”,
“https://thecode.media/bar/”,
“https://thecode.media/zodiac/”,
“https://thecode.media/crc32/”,
“https://thecode.media/css-links/”,
“https://thecode.media/oop_battle/”,
“https://thecode.media/be-combo/”,
“https://thecode.media/unity/”,
“https://thecode.media/data-science/”,
“https://thecode.media/junior/”,
“https://thecode.media/qc/”,
“https://thecode.media/be-middle/”,
“https://thecode.media/senior/”,
“https://thecode.media/teamlead/”,
“https://thecode.media/frontend/”,
“https://thecode.media/lift/”,
“https://thecode.media/be-fuzzy/”,
“https://thecode.media/best-2020/”,
“https://thecode.media/git/”,
“https://thecode.media/stt-cloud/”,
“https://thecode.media/matrix-pills/”,
“https://thecode.media/na-stile/”,
“https://thecode.media/no-coffee/”,
“https://thecode.media/framelibs/”,
“https://thecode.media/children/”,
“https://thecode.media/balls-possibly/”,
“https://thecode.media/le-meduza/”,
“https://thecode.media/electricity/”,
“https://thecode.media/tailored-swift/”,
“https://thecode.media/objective/”,
“https://thecode.media/host/”,
“https://thecode.media/go-public/”,
“https://thecode.media/how-internet-works-1/”,
“https://thecode.media/domain/”,
“https://thecode.media/this-is-object/”,
“https://thecode.media/ole-ole-ole/”,
“https://thecode.media/thousand/”,
“https://thecode.media/average/”,
“https://thecode.media/stt-python/”,
“https://thecode.media/ping-pong/”,
“https://thecode.media/pygames/”,
“https://thecode.media/odobreno/”,
“https://thecode.media/qwerty123/”,
“https://thecode.media/neurocorrector/”,
“https://thecode.media/neuro-cam/”,
“https://thecode.media/10-jquery/”,
“https://thecode.media/repeat/”,
“https://thecode.media/assembler/”,
“https://thecode.media/sublime-one-love/”,
“https://thecode.media/zloy/”,
“https://thecode.media/mariya-ivanovna/”,
“https://thecode.media/ruby/”,
“https://thecode.media/electron-password/”,
“https://thecode.media/plane/”,
“https://thecode.media/glitch/”,
“https://thecode.media/security/”,
“https://thecode.media/stupid-2019/”,
“https://thecode.media/jquery-search/”,
“https://thecode.media/pimp-my-pass/”,
“https://thecode.media/text-ultimate/”,
“https://thecode.media/hurry/”,
“https://thecode.media/siri/”,
“https://thecode.media/zero-cool/”,
“https://thecode.media/small-talk/”,
“https://thecode.media/die-hard/”,
“https://thecode.media/le-piton/”,
“https://thecode.media/hr-code/”,
“https://thecode.media/nano-code/”,
“https://thecode.media/the_question/”,
“https://thecode.media/godlike/”,
“https://thecode.media/be-logic/”,
“https://thecode.media/snake-js/”,
“https://thecode.media/be-mobile/”,
“https://thecode.media/baboolya/”,
“https://thecode.media/timelag/”,
“https://thecode.media/doors/”,
“https://thecode.media/phone-code/”,
“https://thecode.media/snake-arduino/”,
“https://thecode.media/css-intro/”,
“https://thecode.media/le-timer/”,
“https://thecode.media/oop_battle/”,
“https://thecode.media/good-morning/”,
“https://thecode.media/study-bot/”,
“https://thecode.media/python-bot/”,
“https://thecode.media/robot-quiz/”,
“https://thecode.media/hacking-quiz/”,
“https://thecode.media/lulz-quiz/”,
“https://thecode.media/hard-quiz/”,
“https://thecode.media/torrent/”,
“https://thecode.media/travel/”,
“https://thecode.media/le-snob/”,
“https://thecode.media/no-spagetti/”,
“https://thecode.media/house/”,
“https://thecode.media/cryptorush/”,
“https://thecode.media/coronarelax/”,
“https://thecode.media/pure/”,
“https://thecode.media/c-cpp/”,
“https://thecode.media/machine-loving/”,
“https://thecode.media/orwell/”,
“https://thecode.media/darknet/”,
“https://thecode.media/ai/”,
“https://thecode.media/oop-class/”,
“https://thecode.media/cookie/”,
“https://thecode.media/malware/”,
“https://thecode.media/ftp/”,
“https://thecode.media/html/”,
“https://thecode.media/java/”,
“https://thecode.media/php-haters/”,
“https://thecode.media/tor/”,
“https://thecode.media/crack-safe/”,
“https://thecode.media/epidemic/”,
“https://thecode.media/hash-brown/”,
“https://thecode.media/java-js/”,
“https://thecode.media/js-types/”,
“https://thecode.media/losers/”,
“https://thecode.media/ssl/”,
“https://thecode.media/uncaughtsyntaxerror-unexpected-identifier/”,
“https://thecode.media/uncaughtsyntaxerror-unexpected-token/”,
“https://thecode.media/uncaughttyperrror-cannot-read-property/”,
“https://thecode.media/mobile-dev/”,
“https://thecode.media/verevka/”,
“https://thecode.media/speed/”,
“https://thecode.media/buckwheat/”,
“https://thecode.media/distance/”,
“https://thecode.media/node-js/”,
“https://thecode.media/pascal/”,
“https://thecode.media/ill-be-clean/”,
“https://thecode.media/to-be-back/”,
“https://thecode.media/replaceable/”,
“https://thecode.media/code-review/”,
“https://thecode.media/gasoline/”,
“https://thecode.media/to-be-test/”,
“https://thecode.media/scala/”,
“https://thecode.media/row-power/”,
“https://thecode.media/percent/”,
“https://thecode.media/с/”,
“https://thecode.media/things/”,
“https://thecode.media/prof-newsletter/”,
“https://thecode.media/backend/”,
“https://thecode.media/immortal-pong/”,
“https://thecode.media/blind/”,
“https://thecode.media/go-faster/”,
“https://thecode.media/cpp/”,
“https://thecode.media/uncaught-syntaxerror-unexpected-end-of-input/”,
“https://thecode.media/stress-quiz/”,
“https://thecode.media/secret-pong/”,
“https://thecode.media/override/”,
“https://thecode.media/whg/”,
“https://thecode.media/profit/”,
“https://thecode.media/memas/”,
“https://thecode.media/digital-sound/”,
“https://thecode.media/api/”,
“https://thecode.media/be-math-2/”,
“https://thecode.media/backup/”,
“https://thecode.media/backup-master/”,
“https://thecode.media/glvrd/”,
“https://thecode.media/id/”,
“https://thecode.media/uncaught-syntaxerror-missing-after-argument-list/”,
“https://thecode.media/ex-startup/”,
“https://thecode.media/doom-everywhere/”,
“https://thecode.media/template-one/”,
“https://thecode.media/david-roganov/”,
“https://thecode.media/spacex/”,
“https://thecode.media/webstorm/”,
“https://thecode.media/json/”,
“https://thecode.media/treger/”,
“https://thecode.media/ya-blitz/”,
“https://thecode.media/radius/”,
“https://thecode.media/xhr/”,
“https://thecode.media/treger2/”,
“https://thecode.media/raidemption/”,
“https://thecode.media/chief-technical-officer/”,
“https://thecode.media/summary/”,
“https://thecode.media/ex-wallpaper/”,
“https://thecode.media/soap/”,
“https://thecode.media/decompose/”,
“https://thecode.media/desc/”,
“https://thecode.media/sprint/”,
“https://thecode.media/bye-or-die/”,
“https://thecode.media/who-win/”,
“https://thecode.media/vladimir-olokhtonov/”,
“https://thecode.media/lossless/”,
“https://thecode.media/parse/”,
“https://thecode.media/typeerror-is-not-an-abject/”,
“https://thecode.media/backup-me/”,
“https://thecode.media/stress-test/”,
“https://thecode.media/syntaxerror-missing-formal-parameter/”,
“https://thecode.media/start-fast/”,
“https://thecode.media/halkechev/”,
“https://thecode.media/halkechev2/”,
“https://thecode.media/le-design/”,
“https://thecode.media/syntaxerror-missing-after-property-id/”,
“https://thecode.media/attrb-mthd/”,
“https://thecode.media/headphones/”,
“https://thecode.media/active-noise-cancelling/”,
“https://thecode.media/remote-work-quiz/”,
“https://thecode.media/garbage/”,
“https://thecode.media/ubuntu-linux/”,
“https://thecode.media/trie/”,
“https://thecode.media/func/”,
“https://thecode.media/laravel/”,
“https://thecode.media/save-json/”,
“https://thecode.media/syntaxerror-missing-after-formal-parameters/”,
“https://thecode.media/recursion/”,
“https://thecode.media/haskell/”,
“https://thecode.media/gen/”,
“https://thecode.media/db/”,
“https://thecode.media/boosting/”,
“https://thecode.media/pavel-sviridov/”,
“https://thecode.media/mnogo/”,
“https://thecode.media/sokr/”,
“https://thecode.media/dbsm/”,
“https://thecode.media/pik-balmera/”,
“https://thecode.media/kanban/”,
“https://thecode.media/check-list/”,
“https://thecode.media/text-quiz/”,
“https://thecode.media/mysql/”,
“https://thecode.media/mysql/”,
“https://thecode.media/rust/”,
“https://thecode.media/manage-this/”,
“https://thecode.media/altshuller/”,
“https://thecode.media/interview/”,
“https://thecode.media/fotorama/”,
“https://thecode.media/tetris/”,
“https://thecode.media/ai-tetris/”,
“https://thecode.media/scrum/”,
“https://thecode.media/speed-two/”,
“https://thecode.media/quick-share/”,
“https://thecode.media/stack/”,
“https://thecode.media/mobile-first/”,
“https://thecode.media/nosql/”,
“https://thecode.media/narazves/”,
“https://thecode.media/oop-class-2/”,
“https://thecode.media/design-first/”,
“https://thecode.media/arcanoid/”,
“https://thecode.media/donut/”,
“https://thecode.media/casino/”,
“https://thecode.media/heap/”,
“https://thecode.media/rust/”,
“https://thecode.media/float/”,
“https://thecode.media/markdown/”,
“https://thecode.media/books/”,
“https://thecode.media/daniil-popov/”,
“https://thecode.media/android-developer/”,
“https://thecode.media/symbols/”,
“https://thecode.media/oauth/”,
“https://thecode.media/kotlin/”,
“https://thecode.media/todo/”,
“https://thecode.media/plotly/”,
“https://thecode.media/no-digit-code/”,
“https://thecode.media/asymmetric/”,
“https://thecode.media/qi/”,
“https://thecode.media/vernam/”,
“https://thecode.media/vernam-js/”,
“https://thecode.media/shtykov/”,
“https://thecode.media/memory/”,
“https://thecode.media/ark/”,
“https://thecode.media/7-oshibok-na-sobesedovanii/”,
“https://thecode.media/dh/”,
“https://thecode.media/typescript/”,
“https://thecode.media/stark/”,
“https://thecode.media/crypto/”,
“https://thecode.media/zapusk-2/”,
“https://thecode.media/fingerprint/”,
“https://thecode.media/puzzle/”,
“https://thecode.media/python-time-2/”,
“https://thecode.media/no-chance/”,
“https://thecode.media/lossy/”,
“https://thecode.media/1wire/”,
“https://thecode.media/pasha-flipper/”,
“https://thecode.media/perl/”,
“https://thecode.media/alexey-vasilev/”,
“https://thecode.media/viasat/”,
“https://thecode.media/podcast/”,
“https://thecode.media/copy-ya-ru/”,
“https://thecode.media/mircrosd/”,
“https://thecode.media/bash/”,
“https://thecode.media/rotation/”,
“https://thecode.media/css-grid/”,
“https://thecode.media/train/”,
“https://thecode.media/grid-2/”,
“https://thecode.media/za-proezd/”,
“https://thecode.media/grid-3/”,
“https://thecode.media/david/”,
“https://thecode.media/alien-vs-predator/”,
“https://thecode.media/grid-portfolio/”,
“https://thecode.media/podcast-lavka/”,
“https://thecode.media/it-start-2/”,
“https://thecode.media/anastasiya-nikulina/”,
“https://thecode.media/linter/”,
“https://thecode.media/bomberman/”,
“https://thecode.media/5-linters/”,
“https://thecode.media/lineynaya-algebra-vektory/”,
“https://thecode.media/no-nda/”,
“https://thecode.media/code-swap/”,
“https://thecode.media/how-to-start/”,
“https://thecode.media/referenceerror-invalid-left-hand-side-in-assignment/”,
“https://thecode.media/vectors-operations/”,
“https://thecode.media/oop-abstract/”,
“https://thecode.media/leonov/”,
“https://thecode.media/lucky-strike/”,
“https://thecode.media/browser/”,
“https://thecode.media/2020/”,
“https://thecode.media/3d-stars/”,
“https://thecode.media/anna-leonova/”,
“https://thecode.media/cold-fusion/”,
“https://thecode.media/normalize/”,
“https://thecode.media/hotkey/”,
“https://thecode.media/oven/”,
“https://thecode.media/vim/”,
“https://thecode.media/draw/”,
“https://thecode.media/visual-studio-code/”,
“https://thecode.media/tetris-2/”,
“https://thecode.media/start-now/”,
“https://thecode.media/lapsha-1/”,
“https://thecode.media/cubism/”,
“https://thecode.media/lapsha-2/”,
“https://thecode.media/zerocode/”,
“https://thecode.media/cat/”,
“https://thecode.media/static/”,
“https://thecode.media/komm/”,
“https://thecode.media/path-js/”,
“https://thecode.media/cloudly/”,
“https://thecode.media/haters-gonna-code-2/”,
“https://thecode.media/csp/”,
“https://thecode.media/mitin-says-no/”,
“https://thecode.media/hire-js/”,
“https://thecode.media/tableau/”,
“https://thecode.media/impossible/”,
“https://thecode.media/csp-on/”,
“https://thecode.media/maze/”,
“https://thecode.media/mix/”,
“https://thecode.media/le-beton/”,
“https://thecode.media/3d-print/”,
“https://thecode.media/5-and-a-half/”,
“https://thecode.media/lineynaya-zavisimost-vektorov/”,
“https://thecode.media/fast-m1/”,
“https://thecode.media/ninja-run/”,
“https://thecode.media/matrix-101/”,
“https://thecode.media/arm-x86/”,
“https://thecode.media/piano-js/”,
“https://thecode.media/10-swift/”,
“https://thecode.media/travel-plane/”,
“https://thecode.media/extention/”,
“https://thecode.media/obratnaya-matritsa/”,
“https://thecode.media/svg/”,
“https://thecode.media/freelance/”,
“https://thecode.media/brat-2/”,
“https://thecode.media/angular/”,
“https://thecode.media/rgb/”,
“https://thecode.media/10-go/”,
“https://thecode.media/coffee/”,
]
Теперь перебираем все элементы этого массива в цикле, используя всю мощь библиотек. Обратите внимание на строчку, где мы получаем исходный код страницы — мы сразу конвертируем его в нужную кодировку, которую выяснили на предыдущем этапе:
# подключаем urlopen из модуля urllib
from urllib.request import urlopen
# подключаем библиотеку BeautifulSout
from bs4 import BeautifulSoup
url = [
"https://thecode.media/is-not-defined-jquery/",
"https://thecode.media/arduino-projects-2/",
"https://thecode.media/10-raspberry/",
"https://thecode.media/easy-css/",
"https://thecode.media/to-be-front/",
"https://thecode.media/cryptex/",
"https://thecode.media/ali-coders/",
"https://thecode.media/po-glandy/",
"https://thecode.media/megaexcel/",
"https://thecode.media/chat-bot-generators/",
"https://thecode.media/wifi/",
"https://thecode.media/andri-oxa/",
"https://thecode.media/free-hosting/",
"https://thecode.media/hotwheels/",
"https://thecode.media/do-not-disturb/",
"https://thecode.media/dyno-ai/",
"https://thecode.media/snake-ai/",
"https://thecode.media/leet/",
"https://thecode.media/ninja/",
"https://thecode.media/supergirl/",
"https://thecode.media/vpn/ ",
"https://thecode.media/what-is-wordpress/",
"https://thecode.media/hardware/",
"https://thecode.media/division/",
"https://thecode.media/nuggets/",
"https://thecode.media/binary-notation/",
"https://thecode.media/bootstrap/",
"https://thecode.media/chat-bot/",
"https://thecode.media/myadblock3000/",
"https://thecode.media/trello/",
"https://thecode.media/python-time/",
"https://thecode.media/editor/",
"https://thecode.media/timer/",
"https://thecode.media/intro-bootstrap/",
"https://thecode.media/php-form/",
"https://thecode.media/hr-quiz/",
"https://thecode.media/c-sharp/",
"https://thecode.media/showtime/",
"https://thecode.media/uchtel-rasskazhi/",
"https://thecode.media/sshhhh/",
"https://thecode.media/marry-me-python/",
"https://thecode.media/haters-gonna-code/",
"https://thecode.media/speed-css/",
"https://thecode.media/fired/",
"https://thecode.media/zabuhal/",
"https://thecode.media/est-tri-shkatulki/",
"https://thecode.media/milk-that/",
"https://thecode.media/binary-mouse/",
"https://thecode.media/bowling/",
"https://thecode.media/dealership/",
"https://thecode.media/best-seller/",
"https://thecode.media/hr/",
"https://thecode.media/no-comments/",
"https://thecode.media/drakoni-yajca/",
"https://thecode.media/who-is-who/",
"https://thecode.media/get-a-room/",
"https://thecode.media/alps/",
"https://thecode.media/handshake/",
"https://thecode.media/choose-life/",
"https://thecode.media/high-voltage/",
"https://thecode.media/spy/",
"https://thecode.media/squirrelrrel/",
"https://thecode.media/so-agile/",
"https://thecode.media/wedding/",
"https://thecode.media/supper/",
"https://thecode.media/le-tarakan/",
"https://thecode.media/batareyki-besyat/",
"https://thecode.media/dr_jekyll/",
"https://thecode.media/everybody_lies/",
"https://thecode.media/electrician/",
"https://thecode.media/einstein/",
"https://thecode.media/bugz/",
"https://thecode.media/needforspeed/",
"https://thecode.media/be-smart/",
"https://thecode.media/bot-online/",
"https://thecode.media/microb/",
"https://thecode.media/jquery/",
"https://thecode.media/split-screen/",
"https://thecode.media/calculus/",
"https://thecode.media/big-data-sales/",
"https://thecode.media/ambient/",
"https://thecode.media/fatality/",
"https://thecode.media/biggest-loser/",
"https://thecode.media/wifi/",
"https://thecode.media/nosock/",
"https://thecode.media/variables/",
"https://thecode.media/start_python/",
"https://thecode.media/i-gonna-code/",
"https://thecode.media/sigi-est/",
"https://thecode.media/nes-game/",
"https://thecode.media/live-view/",
"https://thecode.media/remote/",
"https://thecode.media/arduino-code/",
"https://thecode.media/horses/",
"https://thecode.media/runinstein/",
"https://thecode.media/wp-template/",
"https://thecode.media/tilda/",
"https://thecode.media/todo/",
"https://thecode.media/telebot/",
"https://thecode.media/summator-2/",
"https://thecode.media/get-rich-coding/",
"https://thecode.media/content-manager/",
"https://thecode.media/vzrosly-stal/",
"https://thecode.media/py-install/",
"https://thecode.media/quantum/",
"https://thecode.media/dns/",
"https://thecode.media/practicum/",
"https://thecode.media/react/",
"https://thecode.media/1september/",
"https://thecode.media/summator/",
"https://thecode.media/vds/",
"https://thecode.media/made-in-china/",
"https://thecode.media/bar/",
"https://thecode.media/zodiac/",
"https://thecode.media/crc32/",
"https://thecode.media/css-links/",
"https://thecode.media/oop_battle/",
"https://thecode.media/be-combo/",
"https://thecode.media/unity/",
"https://thecode.media/data-science/",
"https://thecode.media/junior/",
"https://thecode.media/qc/",
"https://thecode.media/be-middle/",
"https://thecode.media/senior/",
"https://thecode.media/teamlead/",
"https://thecode.media/frontend/",
"https://thecode.media/lift/",
"https://thecode.media/be-fuzzy/",
"https://thecode.media/best-2020/",
"https://thecode.media/git/",
"https://thecode.media/stt-cloud/",
"https://thecode.media/matrix-pills/",
"https://thecode.media/na-stile/",
"https://thecode.media/no-coffee/",
"https://thecode.media/framelibs/",
"https://thecode.media/children/",
"https://thecode.media/balls-possibly/",
"https://thecode.media/le-meduza/",
"https://thecode.media/electricity/",
"https://thecode.media/tailored-swift/",
"https://thecode.media/objective/",
"https://thecode.media/host/",
"https://thecode.media/go-public/",
"https://thecode.media/how-internet-works-1/",
"https://thecode.media/domain/",
"https://thecode.media/this-is-object/",
"https://thecode.media/ole-ole-ole/",
"https://thecode.media/thousand/",
"https://thecode.media/average/",
"https://thecode.media/stt-python/",
"https://thecode.media/ping-pong/",
"https://thecode.media/pygames/",
"https://thecode.media/odobreno/",
"https://thecode.media/qwerty123/",
"https://thecode.media/neurocorrector/",
"https://thecode.media/neuro-cam/",
"https://thecode.media/10-jquery/",
"https://thecode.media/repeat/",
"https://thecode.media/assembler/",
"https://thecode.media/sublime-one-love/",
"https://thecode.media/zloy/",
"https://thecode.media/mariya-ivanovna/",
"https://thecode.media/ruby/",
"https://thecode.media/electron-password/",
"https://thecode.media/plane/",
"https://thecode.media/glitch/",
"https://thecode.media/security/",
"https://thecode.media/stupid-2019/",
"https://thecode.media/jquery-search/",
"https://thecode.media/pimp-my-pass/",
"https://thecode.media/text-ultimate/",
"https://thecode.media/hurry/",
"https://thecode.media/siri/",
"https://thecode.media/zero-cool/",
"https://thecode.media/small-talk/",
"https://thecode.media/die-hard/",
"https://thecode.media/le-piton/",
"https://thecode.media/hr-code/",
"https://thecode.media/nano-code/",
"https://thecode.media/the_question/",
"https://thecode.media/godlike/",
"https://thecode.media/be-logic/",
"https://thecode.media/snake-js/",
"https://thecode.media/be-mobile/",
"https://thecode.media/baboolya/",
"https://thecode.media/timelag/",
"https://thecode.media/doors/",
"https://thecode.media/phone-code/",
"https://thecode.media/snake-arduino/",
"https://thecode.media/css-intro/",
"https://thecode.media/le-timer/",
"https://thecode.media/oop_battle/",
"https://thecode.media/good-morning/",
"https://thecode.media/study-bot/",
"https://thecode.media/python-bot/",
"https://thecode.media/robot-quiz/",
"https://thecode.media/hacking-quiz/",
"https://thecode.media/lulz-quiz/",
"https://thecode.media/hard-quiz/",
"https://thecode.media/torrent/",
"https://thecode.media/travel/",
"https://thecode.media/le-snob/",
"https://thecode.media/no-spagetti/",
"https://thecode.media/house/",
"https://thecode.media/cryptorush/",
"https://thecode.media/coronarelax/",
"https://thecode.media/pure/",
"https://thecode.media/c-cpp/",
"https://thecode.media/machine-loving/",
"https://thecode.media/orwell/",
"https://thecode.media/darknet/",
"https://thecode.media/ai/",
"https://thecode.media/oop-class/",
"https://thecode.media/cookie/",
"https://thecode.media/malware/",
"https://thecode.media/ftp/",
"https://thecode.media/html/",
"https://thecode.media/java/",
"https://thecode.media/php-haters/",
"https://thecode.media/tor/",
"https://thecode.media/crack-safe/",
"https://thecode.media/epidemic/",
"https://thecode.media/hash-brown/",
"https://thecode.media/java-js/",
"https://thecode.media/js-types/",
"https://thecode.media/losers/",
"https://thecode.media/ssl/",
"https://thecode.media/uncaughtsyntaxerror-unexpected-identifier/",
"https://thecode.media/uncaughtsyntaxerror-unexpected-token/",
"https://thecode.media/uncaughttyperrror-cannot-read-property/",
"https://thecode.media/mobile-dev/",
"https://thecode.media/verevka/",
"https://thecode.media/speed/",
"https://thecode.media/buckwheat/",
"https://thecode.media/distance/",
"https://thecode.media/node-js/",
"https://thecode.media/pascal/",
"https://thecode.media/ill-be-clean/",
"https://thecode.media/to-be-back/",
"https://thecode.media/replaceable/",
"https://thecode.media/code-review/",
"https://thecode.media/gasoline/",
"https://thecode.media/to-be-test/",
"https://thecode.media/scala/",
"https://thecode.media/row-power/",
"https://thecode.media/percent/",
"https://thecode.media/things/",
"https://thecode.media/prof-newsletter/",
"https://thecode.media/backend/",
"https://thecode.media/immortal-pong/",
"https://thecode.media/blind/",
"https://thecode.media/go-faster/",
"https://thecode.media/cpp/",
"https://thecode.media/uncaught-syntaxerror-unexpected-end-of-input/",
"https://thecode.media/stress-quiz/",
"https://thecode.media/secret-pong/",
"https://thecode.media/override/",
"https://thecode.media/whg/",
"https://thecode.media/profit/",
"https://thecode.media/memas/",
"https://thecode.media/digital-sound/",
"https://thecode.media/api/",
"https://thecode.media/be-math-2/",
"https://thecode.media/backup/",
"https://thecode.media/backup-master/",
"https://thecode.media/glvrd/",
"https://thecode.media/id/",
"https://thecode.media/uncaught-syntaxerror-missing-after-argument-list/",
"https://thecode.media/ex-startup/",
"https://thecode.media/doom-everywhere/",
"https://thecode.media/template-one/",
"https://thecode.media/david-roganov/",
"https://thecode.media/spacex/",
"https://thecode.media/webstorm/",
"https://thecode.media/json/",
"https://thecode.media/treger/",
"https://thecode.media/ya-blitz/",
"https://thecode.media/radius/",
"https://thecode.media/xhr/",
"https://thecode.media/treger2/",
"https://thecode.media/raidemption/",
"https://thecode.media/chief-technical-officer/",
"https://thecode.media/summary/",
"https://thecode.media/ex-wallpaper/",
"https://thecode.media/soap/",
"https://thecode.media/decompose/",
"https://thecode.media/desc/",
"https://thecode.media/sprint/",
"https://thecode.media/bye-or-die/",
"https://thecode.media/who-win/",
"https://thecode.media/vladimir-olokhtonov/",
"https://thecode.media/lossless/",
"https://thecode.media/parse/",
"https://thecode.media/typeerror-is-not-an-abject/",
"https://thecode.media/backup-me/",
"https://thecode.media/stress-test/",
"https://thecode.media/syntaxerror-missing-formal-parameter/",
"https://thecode.media/start-fast/",
"https://thecode.media/halkechev/",
"https://thecode.media/halkechev2/",
"https://thecode.media/le-design/",
"https://thecode.media/syntaxerror-missing-after-property-id/",
"https://thecode.media/attrb-mthd/",
"https://thecode.media/headphones/",
"https://thecode.media/active-noise-cancelling/",
"https://thecode.media/remote-work-quiz/",
"https://thecode.media/garbage/",
"https://thecode.media/ubuntu-linux/",
"https://thecode.media/trie/",
"https://thecode.media/func/",
"https://thecode.media/laravel/",
"https://thecode.media/save-json/",
"https://thecode.media/syntaxerror-missing-after-formal-parameters/",
"https://thecode.media/recursion/",
"https://thecode.media/haskell/",
"https://thecode.media/gen/",
"https://thecode.media/db/",
"https://thecode.media/boosting/",
"https://thecode.media/pavel-sviridov/",
"https://thecode.media/mnogo/",
"https://thecode.media/sokr/",
"https://thecode.media/dbsm/",
"https://thecode.media/pik-balmera/",
"https://thecode.media/kanban/",
"https://thecode.media/check-list/",
"https://thecode.media/text-quiz/",
"https://thecode.media/mysql/",
"https://thecode.media/mysql/",
"https://thecode.media/rust/",
"https://thecode.media/manage-this/",
"https://thecode.media/altshuller/",
"https://thecode.media/interview/",
"https://thecode.media/fotorama/",
"https://thecode.media/tetris/",
"https://thecode.media/ai-tetris/",
"https://thecode.media/scrum/",
"https://thecode.media/speed-two/",
"https://thecode.media/quick-share/",
"https://thecode.media/stack/",
"https://thecode.media/mobile-first/",
"https://thecode.media/nosql/",
"https://thecode.media/narazves/",
"https://thecode.media/oop-class-2/",
"https://thecode.media/design-first/",
"https://thecode.media/arcanoid/",
"https://thecode.media/donut/",
"https://thecode.media/casino/",
"https://thecode.media/heap/",
"https://thecode.media/rust/",
"https://thecode.media/float/",
"https://thecode.media/markdown/",
"https://thecode.media/books/",
"https://thecode.media/daniil-popov/",
"https://thecode.media/android-developer/",
"https://thecode.media/symbols/",
"https://thecode.media/oauth/",
"https://thecode.media/kotlin/",
"https://thecode.media/todo/",
"https://thecode.media/plotly/",
"https://thecode.media/no-digit-code/",
"https://thecode.media/asymmetric/",
"https://thecode.media/qi/",
"https://thecode.media/vernam/",
"https://thecode.media/vernam-js/",
"https://thecode.media/shtykov/",
"https://thecode.media/memory/",
"https://thecode.media/ark/",
"https://thecode.media/7-oshibok-na-sobesedovanii/",
"https://thecode.media/dh/",
"https://thecode.media/typescript/",
"https://thecode.media/stark/",
"https://thecode.media/crypto/",
"https://thecode.media/zapusk-2/",
"https://thecode.media/fingerprint/",
"https://thecode.media/puzzle/",
"https://thecode.media/python-time-2/",
"https://thecode.media/no-chance/",
"https://thecode.media/lossy/",
"https://thecode.media/1wire/",
"https://thecode.media/pasha-flipper/",
"https://thecode.media/perl/",
"https://thecode.media/alexey-vasilev/",
"https://thecode.media/viasat/",
"https://thecode.media/podcast/",
"https://thecode.media/copy-ya-ru/",
"https://thecode.media/mircrosd/",
"https://thecode.media/bash/",
"https://thecode.media/rotation/",
"https://thecode.media/css-grid/",
"https://thecode.media/train/",
"https://thecode.media/grid-2/",
"https://thecode.media/za-proezd/",
"https://thecode.media/grid-3/",
"https://thecode.media/david/",
"https://thecode.media/alien-vs-predator/",
"https://thecode.media/grid-portfolio/",
"https://thecode.media/podcast-lavka/",
"https://thecode.media/it-start-2/",
"https://thecode.media/anastasiya-nikulina/",
"https://thecode.media/linter/",
"https://thecode.media/bomberman/",
"https://thecode.media/5-linters/",
"https://thecode.media/lineynaya-algebra-vektory/",
"https://thecode.media/no-nda/",
"https://thecode.media/code-swap/",
"https://thecode.media/how-to-start/",
"https://thecode.media/referenceerror-invalid-left-hand-side-in-assignment/",
"https://thecode.media/vectors-operations/",
"https://thecode.media/oop-abstract/",
"https://thecode.media/leonov/",
"https://thecode.media/lucky-strike/",
"https://thecode.media/browser/",
"https://thecode.media/2020/",
"https://thecode.media/3d-stars/",
"https://thecode.media/anna-leonova/",
"https://thecode.media/cold-fusion/",
"https://thecode.media/normalize/",
"https://thecode.media/hotkey/",
"https://thecode.media/oven/",
"https://thecode.media/vim/",
"https://thecode.media/draw/",
"https://thecode.media/visual-studio-code/",
"https://thecode.media/tetris-2/",
"https://thecode.media/start-now/",
"https://thecode.media/lapsha-1/",
"https://thecode.media/cubism/",
"https://thecode.media/lapsha-2/",
"https://thecode.media/zerocode/",
"https://thecode.media/cat/",
"https://thecode.media/static/",
"https://thecode.media/komm/",
"https://thecode.media/path-js/",
"https://thecode.media/cloudly/",
"https://thecode.media/haters-gonna-code-2/",
"https://thecode.media/csp/",
"https://thecode.media/mitin-says-no/",
"https://thecode.media/hire-js/",
"https://thecode.media/tableau/",
"https://thecode.media/impossible/",
"https://thecode.media/csp-on/",
"https://thecode.media/maze/",
"https://thecode.media/mix/",
"https://thecode.media/le-beton/",
"https://thecode.media/3d-print/",
"https://thecode.media/5-and-a-half/",
"https://thecode.media/lineynaya-zavisimost-vektorov/",
"https://thecode.media/fast-m1/",
"https://thecode.media/ninja-run/",
"https://thecode.media/matrix-101/",
"https://thecode.media/arm-x86/",
"https://thecode.media/piano-js/",
"https://thecode.media/10-swift/",
"https://thecode.media/travel-plane/",
"https://thecode.media/extention/",
"https://thecode.media/obratnaya-matritsa/",
"https://thecode.media/svg/",
"https://thecode.media/freelance/",
"https://thecode.media/brat-2/",
"https://thecode.media/angular/",
"https://thecode.media/rgb/",
"https://thecode.media/10-go/",
"https://thecode.media/coffee/",
]
# открываем текстовый файл, куда будем добавлять заголовки
file = open("zag.txt", "a")
# перебираем все адреса из списка
for x in url:
# получаем исходный код очередной страницы из списка
html_code = str(urlopen(x).read(),'utf-8')
# отправляем исходный код страницы на обработку в библиотеку
soup = BeautifulSoup(html_code, "html.parser")
# находим название страницы с помощью метода find()
s = soup.find('title').text
# выводим его на экран
print(s)
# сохраняем заголовок в файле и переносим курсор на новую строку
file.write(s + '. ')
# закрываем файл
file.close()А дальше логичное продолжение — программа на цепях Маркова, которая будет генерировать заголовки для статей Кода на основе наших старых заголовков.
От посещаемости до секретов.
Сегодня мы продолжаем играть в детективов. Началось все с двух статей о сборе досье на человека с помощью общедоступных источников:
- 15 фишек для сбора информации о человеке в интернете
- Как снять девушку в сети
Теперь перед нами стоит задача собрать максимум информации о чужом сайте с минимальными усилиями.
Эта статья не для веб-разработчиков и специалистов по SEO или информационной безопасности. Она для простого человека, которому надо по-быстрому получить представление о ценности и качестве определенного интернет-ресурса.
Критерии отбора сервисов для статьи:
- Искомая информация предоставляется бесплатно;
- Чтобы посмотреть сведения о сайте, не нужно иметь к нему доступа;
- Желаемый результат можно получить немедленно, без регистрации или длительного ожидания.
Посещаемость сайта
Нам поможет старый добрый SimilarWeb. Набираем адрес сайта:
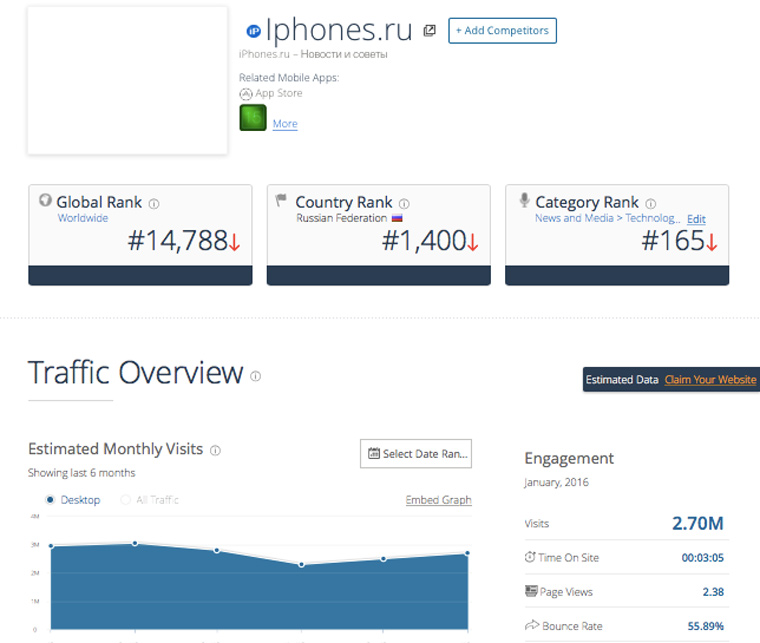
iPhones.ru находится на 165 месте в рейтинге самых посещаемых новостных сайтов мира, посвященных технологиям. Для сравнения, знаменитый на весь мир англоязычный macworld.com находится на 75-м.
У многих людей, когда они впервые сталкиваются с SimilarWeb, возникает вопрос: «Каким образом сервис узнает посещаемость сайта, не устанавливая на него счетчик?». Детальный ответ на него могут дать только работники компании.
Если говорить вкратце, то SimilarWeb собирает данные о трафике пользователей, у которых установлен тулбар от компании + с помощью поискового робота подсчитывает ссылки на сайты, анализирует каким запросам соответствует контент сайта и какую позицию в поисковиках ресурс по ним занимает. Доверять на 100% таким данным нельзя (они очень приблизительные).
Примерно тем же способом рассчитывается сайтов России. На 66 позиций выше, чем cosmo.ru.
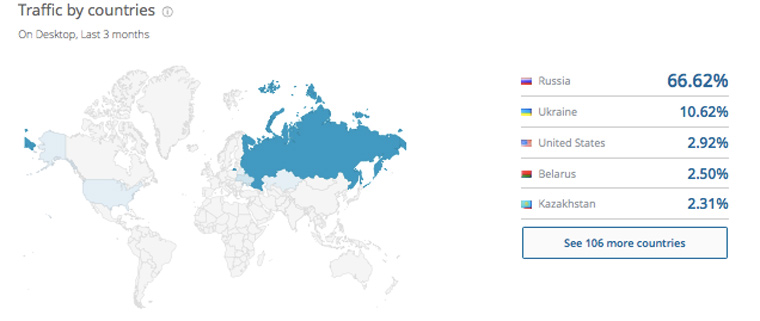
2. Распределение посетителей по странам
Ниже на странице с отчетом от SimilarWeb наглядно видим распределение посетителей на карте мира:
3. Основные источники трафика
Пролистаем страницу еще ниже и смотрим на диаграмму:
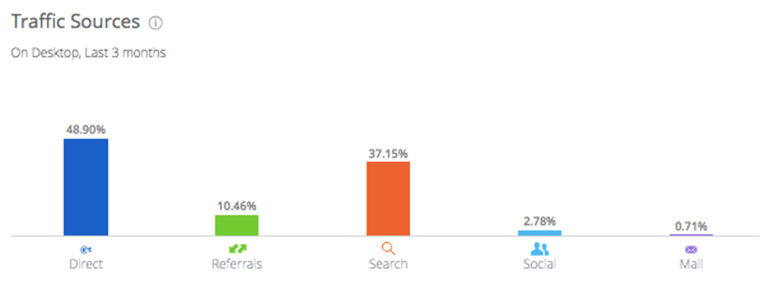
Не зря комментаторы пишут, что заходить на наш сайт, это такая же вредная привычка, как курить или грызть ногти. Доля прямого траффика (когда человек осознанно набирает в адресной строке iPhones.ru) очень велика.
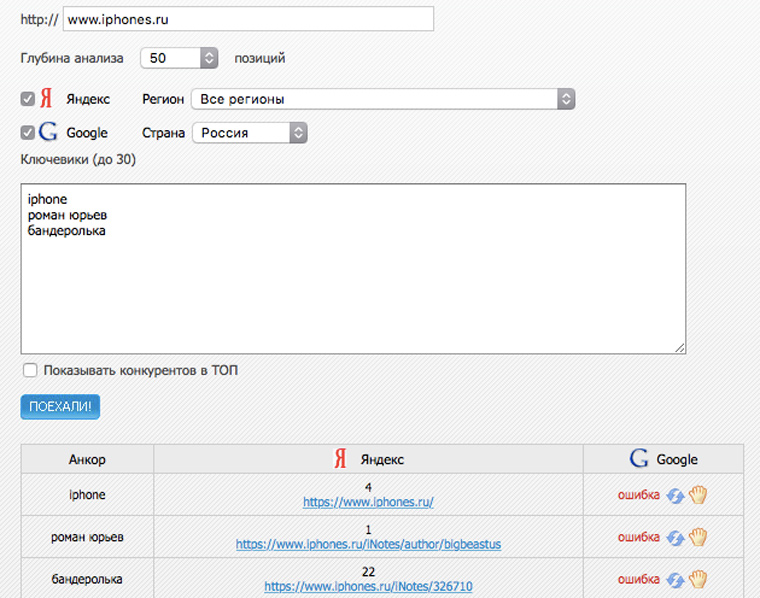
3. Статистика сайта в поисковиках по разным запросам?
На seogadget.ru можно бесплатно проверить позиции сайта по 25 запросам в поисковой выдачи «Яндекса»:
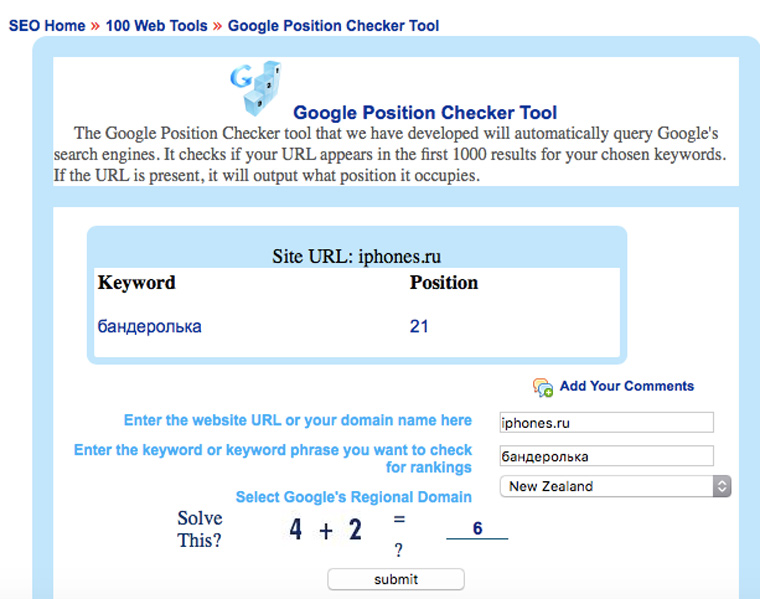
А позиции в Google можно посмотреть на searchengenie.com:
4. Как выглядит сайт в разных браузерах
Идем на Browserling, выбираем операционную систему, название браузера и номер версии:
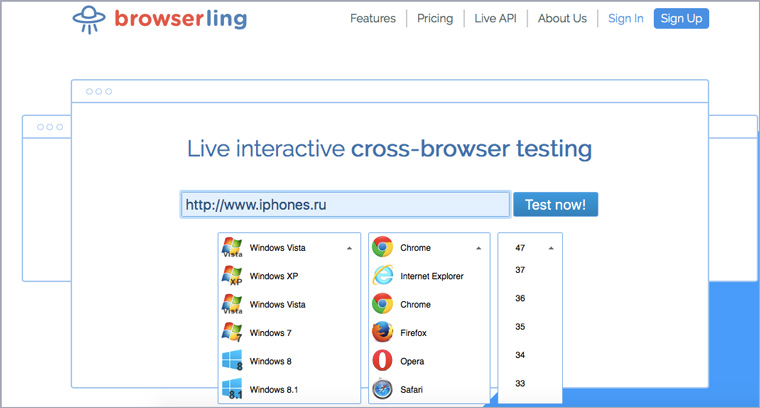
Любуемся и ищем косяки. Если что-то нашлось, то можно скопировать ссылку на комбинацию сайт-браузер и отправить разработчику:
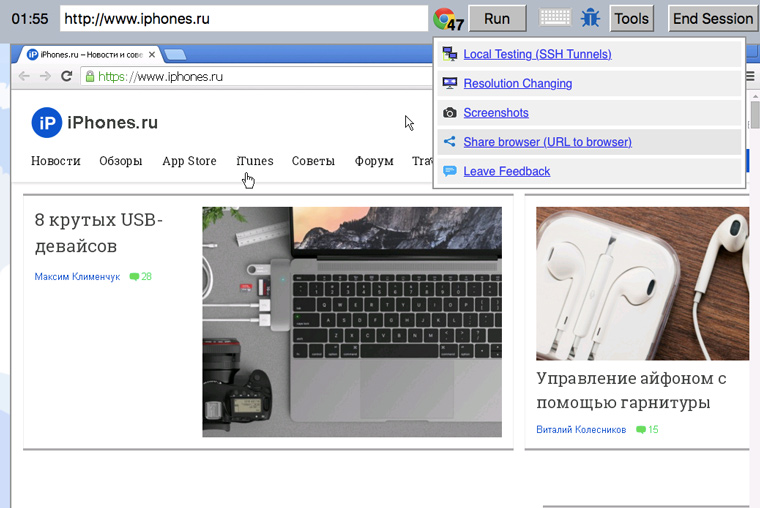
5. Как смотрится сайт на разных девайсах
Посмотреть, как будет выглядеть сайт на самых распространенных телефонах, планшетах и мониторах можно здесь. Либо выбирайте фиксированные размеры конкретных девайсов:
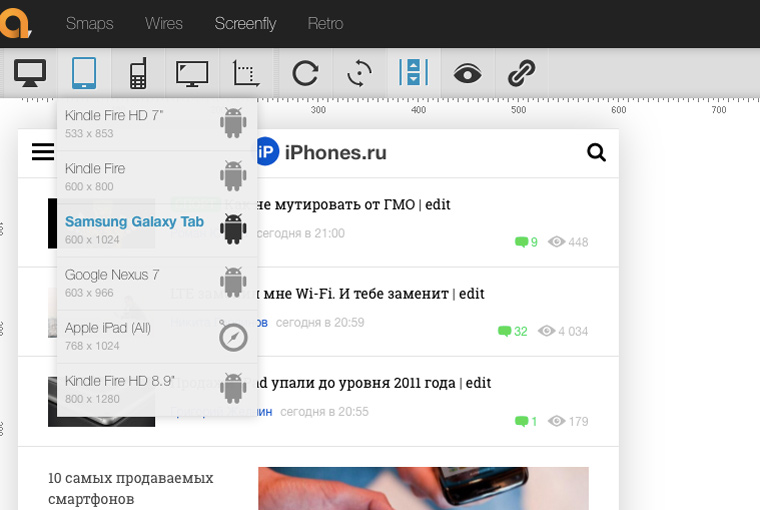
Либо вводите высоту и ширину вручную:
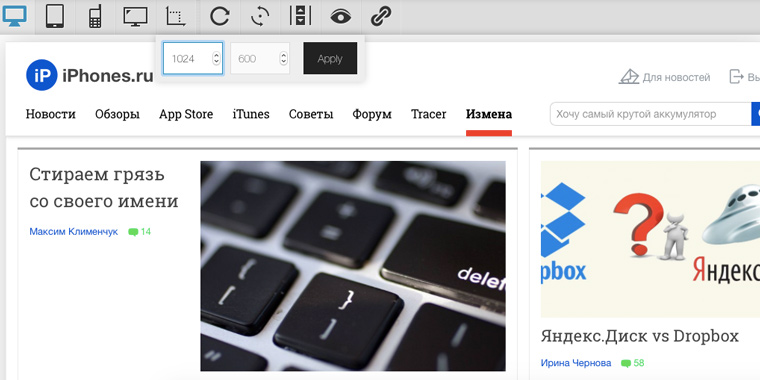
6. С какой скоростью загружается сайт из разных точек планеты
Идем на webpagetest.org и выбираем географическое положение сервера для тестирования:
На выходе получаем подробный отчет о загрузке страницы с указаниями над какими местами надо поработать (где отметки F и D, у нас все плохо):
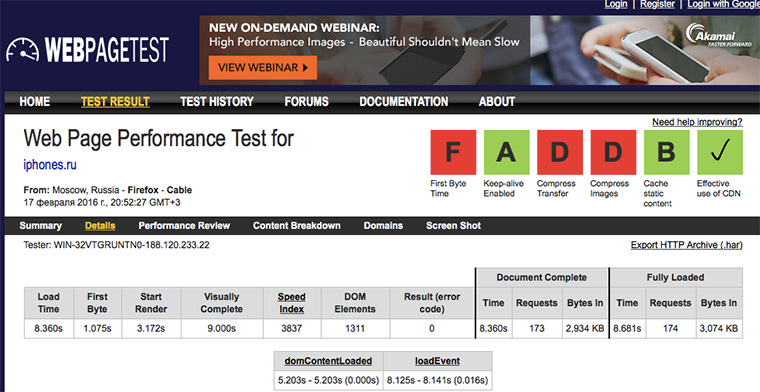
Иногда перед получением результата приходиться минуту другую подождать, но оно того стоит.
7. Что именно тормозит работу сайта
Когда вы открываете iphones.ru, то происходит почти две сотни http-запросов (это абсолютно нормальная цифра). Под общими сведениями в отчете из предыдущего пункта имеется диаграмма в виде водопада, на которой отображаются сведения о загрузке каждого элемента страницы:
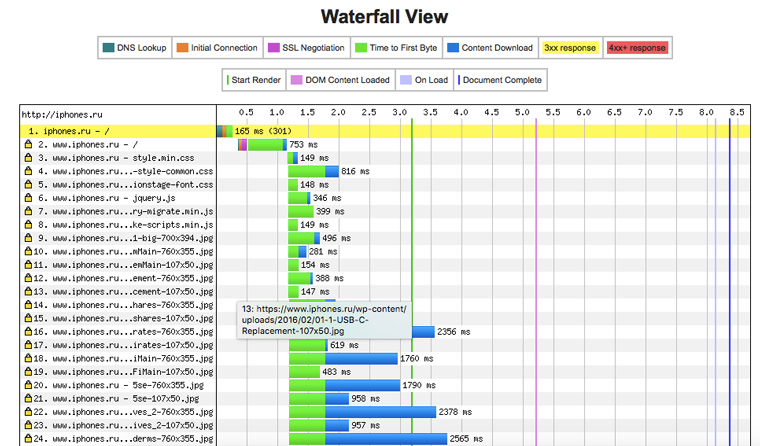
Ясно видно, какие картинки или файлы со скриптами больше всего тормозят сайт.
8. К каким доменам сайт посылает запросы при загрузке
Чуть ниже есть еще одна полезная диаграмма. По ней можно определить какими счетчиками посещаемости пользуется сайт и откуда подгружает баннеры. Плюс к этому видно влияние внешних доменов на скорость его работы:
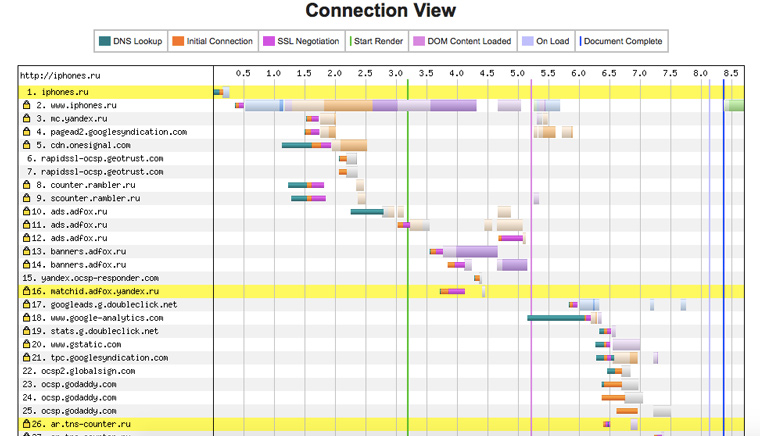
9. Когда зарегистрирован домен для сайта
А вот сервис для просмотра данных о домене: когда создан, какая фирма регистрировала и окончание срока регистрации:
10. Качество html-кода сайта
Чтобы сайт хорошо индексировался поисковыми системам и корректно отображался в разных браузерах, его код должен соответствовать стандартам консорциума W3C. Так написано в валидаторе от консорциума:

Там же проверяется на правильность синтаксис RSS-каналов.
А здесь можно найти ошибки в JS-скриптах.
11. Есть ли на сайте битые ссылки?
Отдельным пунктом стоит отметить проверку на наличие битых ссылок, которые поисковые системы очень не любят. Найти их все можно здесь:

Проверка может занять пару минут, но если вы взялись тестировать собственный сайт, то этот этап лучше не пропускать.
12. Наличие оптимизации под мобильные устройства
А вот сервис от Google, который определяет годен ли сайт для просмотра на мобильных устройствах:
13. Доступность для людей с ограниченными возможностями?
Для Google важно, чтобы сайтом могли пользоваться люди с ограниченными возможностями. Подробнее о том, зачем это нужно и как это осуществить технически можно прочитать на сайте консорциума W3C.
А проверить страницу на доступность для инвалидов можно здесь:
14. Как много людей ссылаются на сайт в соцсетях
На muckruck.com можно узнать, как много людей и в каких соцсетях поделились ссылкой на определенную страницу:
К сожалению, самую интересную и детальную информацию сервис предоставляет за деньги и российские соцсети не учитываются. Но общие масштабы народной любви к сайту с его помощью прикинуть можно.
15. Визуальное восприятие цветов сайта
На сайте у Темы Лебедева есть таблица «безопасных цветов», которые рекомендуется использовать в экранном дизайне. Эти 216 оттенков будут правильно отображаться на любом устройстве, независимо от технических характеристик его дисплея.
Проверить все цветные элементы своего сайта на корректность восприятия человеком на экране можно здесь:
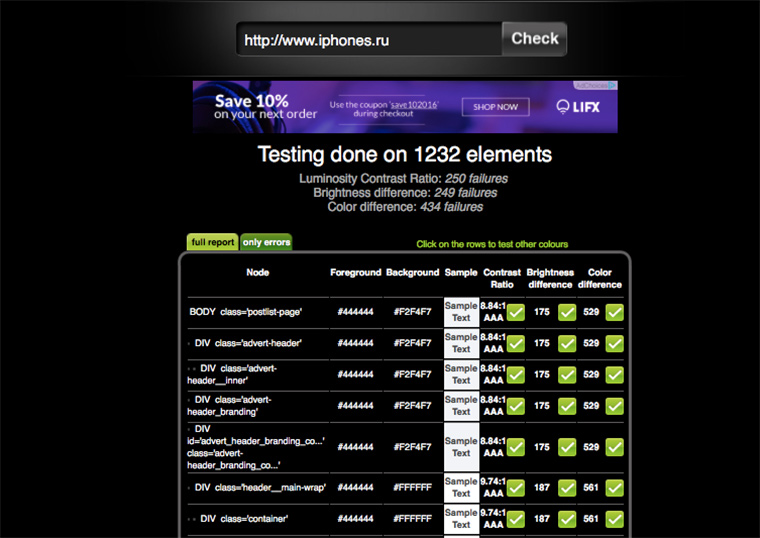
16. ТИЦ и PR сайта
ТИЦ (тематический индекс цитирования) – это показатель, который рассчитывается поисковой системой Яндекс для определения авторитетности ресурса (чем он больше, тем выше позиции сайта в поисковиках). PR (Page Rank) – аналогичный показатель у Google. Проверить их можно здесь:
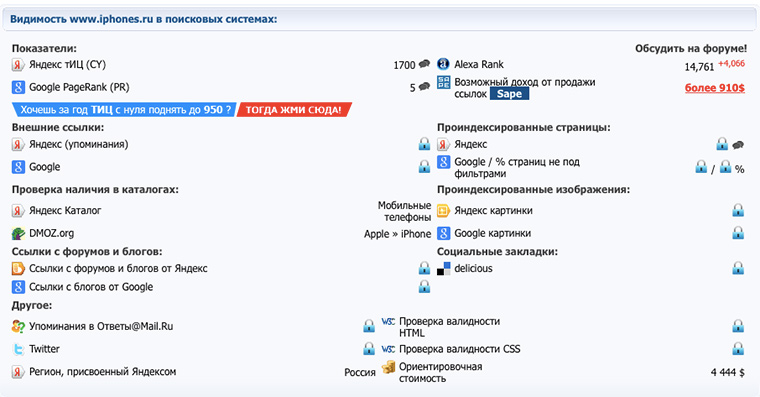
Значения индексов меняются каждые несколько месяцев. Их величина зависит от количества ссылок на сайт на других ресурсах.
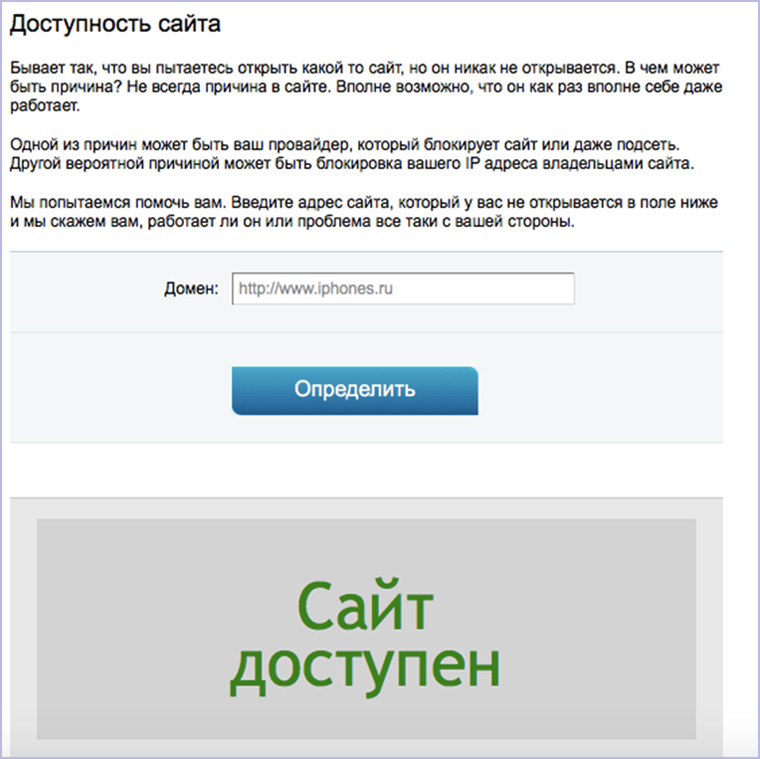
17. Работает ли сайт в данный момент
Конечно, веселее написать кому-нибудь посреди рабочего дня и спросить: «Эй, а у тебя контактик открывается или это только у меня так?». Но лучше зайти на сервис для проверки доступности сайта:
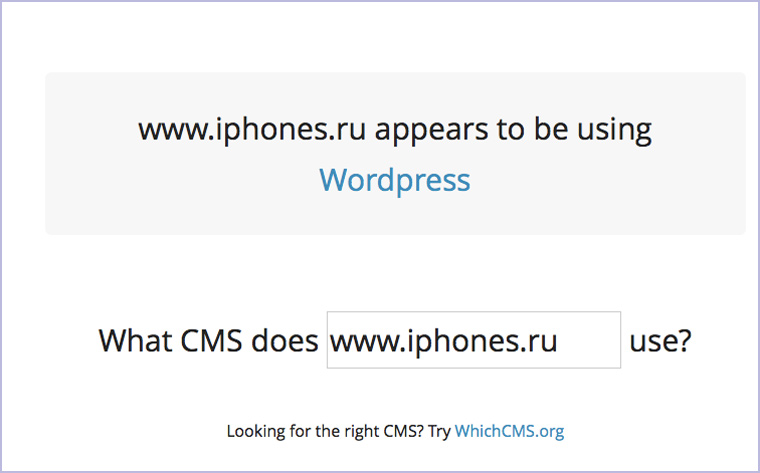
18. Какую CMS использует сайт
Предельно минималистичный сервис, где можно узнать на каком движке работает ресурс:
19. Как сайт выглядел в былые времена
Проследить изменение внешнего вида и контента сайта можно в Архиве Интернета. Вбиваем адрес на главной и смотрим доступные версии:
20. Сравнение с конкурентами
Идем на WolframAlpha и набираем через запятую адреса сайтов, которые мы хотим сравнить:

Можно ввести не два адреса, а три, четыре, пять и т.д.
Кстати, об экспертной системе WolframAlpha у нас вышла подробная статья на новогодних каникулах:
- 35 команд, которые наглядно покажут, в чем Wolfram Alpha круче Google
Все! Естественно, это очень малая часть из всех онлайн-сервисов для тестирования и сбора информации о сайтах, которые есть в интернете. Но большинство из них не выполняют заявленных функций, жестоко тормозят, требуют денег, не сказав «Здрасти» или предназначены для узких специалистов.
Рекомендую сохранить эту подборку, чтобы иметь ее всегда под рукой, когда вам или вашим близким нужно будет собрать максимум информации о сайте за 10-15 минут.
Качественный сбор информации о сайте подразумевает также исследование изображений на нем. Об этом можно почитать в статье:
- 10 веб-сервисов для анализа фотографий

 (8 голосов, общий рейтинг: 4.88 из 5)
(8 голосов, общий рейтинг: 4.88 из 5)
🤓 Хочешь больше? Подпишись на наш Telegram.
![]()
iPhones.ru
От посещаемости до секретов. Сегодня мы продолжаем играть в детективов. Началось все с двух статей о сборе досье на человека с помощью общедоступных источников: 15 фишек для сбора информации о человеке в интернете Как снять девушку в сети Теперь перед нами стоит задача собрать максимум информации о чужом сайте с минимальными усилиями. Эта статья не…
- полезный в быту софт,
- сеть,
- хаки
![]()

Идеи
15 парсеров для сбора данных с сайтов
Парсинг помогает быстро собрать, обработать и проанализировать большие объёмы информации на различных сайтах. Это полезно при изучении целевой аудитории, анализе конкурентов, исследовании рынка и не только. Однако важно выбрать подходящий инструмент с учётом конкретной задачи.
Сделали подборку парсеров для сбора данных с сайтов и разобрались, для каких целей они подходят.
Что такое парсеры и как они работают
Парсеры — это специальные программы, которые собирают различные данные с сайтов по заданным критериям. Общий принцип работы всех парсеров примерно одинаков:
- переход на нужный ресурс и копирование его кода;
- анализ кода и нахождение необходимой информации;
- структуризация и сохранение данных.
Работу парсера можно представить так, как будто человек ходит по разным сайтам и копирует нужные данные. В случае с парсингом по сайтам ходит робот, который выполняет нужные задачи в десятки раз быстрее.
Вид информации, которую собирает парсер, зависит от его исходной функции и настроек. Можно собирать самые разные данные: цены конкурентов, товарные позиции, характеристики и описания товаров, контактные данные, контент определённых тематики и формата.
После анализа и обработки парсер сохраняет все данные в определённом формате — например, в таблице Excel, документах PDF или TXT.
Насколько законно применение парсеров
О законности использования парсеров много спорят. Есть мнение, что автоматический сбор данных нарушает сразу несколько законов — о защите персональных данных, об охране конфиденциальной информации, об авторском праве и т.д. Это не совсем так.
Согласно Конституции РФ каждый человек может «свободно искать, получать, передавать, производить и распространять информацию любым законным способом». То есть теоретически ручной или автоматический сбор информации, выложенной в общий доступ, преступлением не является. Но есть нюансы.
Для законного использования парсеров важно соблюдать три основных условия:
- Все данные, которые собирает сервис, должны находиться в открытом доступе и не попадать под закон об авторском праве.
- Сбор информации не должен негативно влиять на анализируемый сайт и вызывать сбои в его работе.
- Собирать данные можно только законными способами, без взлома сайта.
Если кратко, то парсинг любых данных, которые можно найти в открытом доступе и скопировать вручную — это законная деятельность.
Программу для парсинга можно разработать с нуля специально под конкретную задачу. Но такое решение будет дороже в использовании. В большинстве случаев можно обойтись готовыми инструментами. Рассмотрим парсеры для разных задач.
Для сбора контента
Под сбором контента подразумевают парсинг новостей и заголовков, описаний к товарам, комментариев, любых публикаций по ключевым словам, видеоматериалов, картинок, постов в соцсетях.
При парсинге контента важно учитывать один важный нюанс , который касается последующего использования данных. Если вы собираете информацию, например, для отслеживания ситуации в нише или поиска актуальных идей, то вы не совершаете ничего противозаконного. Если же планируете публикацию собранных данных, то не забывайте об авторском праве. При размещении спарсенного материала в исходном виде обязательно указывайте источник и/или запрашивайте согласие автора на публикацию.
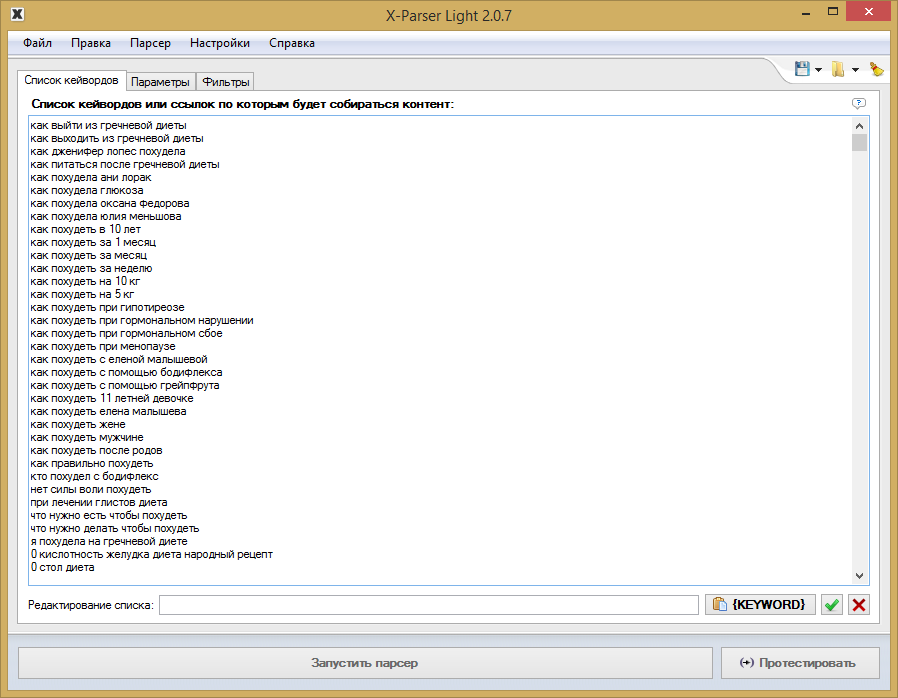
Пример настройки парсинга по ключевым словам
Примеры парсеров для сбора контента:
X-Parser Light. Собирает тематический контент по списку ключевых слов или ссылок. Кроме текстовых данных парсит видео и изображения. Поддерживает любые поисковые системы и практически любой язык. Работает в формате десктопного приложения. Стоимость — 4 100 ₽ единоразово (периодически бывают скидки).
Catalogloader. Умеет парсить информацию с сайтов интернет-магазинов — описания товаров, фото, характеристики, артикулы и пр. Можно самостоятельно настраивать критерии сбора. Весомый плюс — парсер работает в облаке, без скачивания на ПК. Есть бесплатная версия. Платные тарифы начинаются от 5 400 ₽/мес.
XMLDATAFEED. Сервис позиционирует себя как инструмент для парсинга любой информации, которую можно собрать законным способом. Например, можно искать товарные описания, тексты, фото и изображения, ассортимент и характеристики. Особенность сервиса — в отсутствии готовых решений. Под каждый запрос команда разработчиков создаёт уникальный парсер для нужной задачи. Стоимость — индивидуально.
Диггернаут. Облачный сервис, предлагающий платные и бесплатные парсеры. Стоимость платных решений — от 700 ₽/мес. С помощью специальных инструментов пользователь может создать собственный парсер (диггер) под нужный запрос. Можно заказать разработку сложных решений.
Поиск товаров конкурентов с помощью парсера
Примеры парсеров для мониторинга конкурентов:
Marketparser. Сервис мониторит цены в интернет-магазинах и на маркетплейсах. Достаточно загрузить список товаров, и в течение 3–20 минут по ним будет составлен актуальный отчёт. Можно использовать функцию автоматического ценообразования — на основе собранных данных сервис определит оптимальную стоимость товаров. Стоимость парсера зависит от количества проверок и начинается от 4 500 ₽/мес.
ALL RIVAL. Этот парсер собирает цены конкурентов по указанным ссылкам. Из преимуществ — есть бесплатное автосопоставление результатов. Сервис доступен на бесплатном тарифе с ограничением до двух сайтов. Стоимость платного тарифа начинается от 5 099 ₽/мес.
Priceva. С помощью этого сервиса можно собирать цены конкурентов. Есть функция автоматической переоценки товаров пользователя. Все собранные цены конвертируются в валюту аккаунта на любом тарифе. Стоимость от 7 000 ₽/мес. Есть бесплатный тариф с мониторингом до десяти сайтов.
uXprice. Это SaaS-решение. Программа собирает цены из рекламных объявлений, по ссылкам на конкретные товары и на указанных сайтах. Есть возможность сравнительного анализа цен конкурентов. Можно использовать функции конкурентного ценообразования для определения оптимальной стоимости своих товаров. Сервис умеет мониторить цены конкурентов в 36 странах. Стоимость парсера — от $99/мес. Есть бесплатная версия на 7 дней.
Для парсинга SEO-параметров
Сбор SEO-данных полезен при внутренней, технической и внешней оптимизации. Парсеры помогают быстро осуществить комплексный анализ ресурса. Некоторые инструменты имеют узкий функционал, другие умеют собирать самые разные параметры.
SEO-парсеры можно применять как для анализа собственного ресурса, так и для отслеживания конкурентов.
Пример отчёта парсинга SEO-данных
Примеры парсеров для сбора SEO-данных:
Screaming Frog SEO Spider. Многофункциональный парсер-сканер, который умеет собирать огромное количество разных данных — метатеги, XML-карты, битые ссылки, атрибуты Alt у картинок, дублированный контент, сведения о технической оптимизации и многое другое. Бесплатно можно проверить до 500 URL-адресов. Платная версия — $209/год. SEO Spider работает в формате приложения для ПК.
PR-CY. Сервис позволяет в режиме онлайн выполнить SEO-аудит сайта. Можно искать позиции ресурса в поиске, мета-теги, коды ответов сервера, заголовки, внешние исходящие ссылки, проблемные страницы. Стоимость — от 990 ₽/месяц. Есть бесплатный доступ на 7 дней.
Xenu’s Link Sleuth. Бесплатный парсер для поиска неработающих ссылок. Список собранных URL можно сортировать по любым критериям. Отчёт можно запросить в любое время. Работает как декстопное приложение.
A-Parser. Многофункциональный инструмент для профессионального использования. Умеет парсить любые данные в неограниченном объёме: ссылки, анкоры, сниппеты, позиции в поиске, рекламные блоки, ключевые слова и многое другое. Всего в сервисе доступно 90+ разных парсеров. Стоимость от $179 за пожизненную лицензию. При необходимости здесь можно заказать индивидуальную разработку парсеров по нужным параметрам.
Для сбора контактных данных
Больше всего сомнений в законности парсинга возникает при сборе контактных данных — телефонов, email-адресов, контактных лиц. Здесь важно понимать разницу между персональными и общедоступными данными. Кроме того, имеет значение способ использования собранной информации.
Например, собрать базу контактов потенциальных партнёров или поставщиков — это законно. А вот автоматический сбор email-адресов для рассылки нарушает закон о персональных данных. А за массовую рассылку по адресам, собранным из открытых источников, можно улететь в спам.
Настройка парсинга email-адресов
Примеры парсеров для сбора контактных данных:
ZoomInfo. Собирает контактные данные B2B — номера телефонов, email-адреса, ссылки на профили в соцсетях. Дополнительно можно парсить и другие важные данные о клиентах и партнёрах — веб-упоминания, должностные обязанности и иную информацию из публичного доступа. Стоимость сервиса — по запросу. Есть бесплатная пробная версия.
Hunter. Парсер для поиска людей, работающих в определённой компании, с их именем и адресом электронной почты. Дополнительное преимущество — бесплатный сервис для рассылки «холодных» писем. Стоимость парсера — от $49/мес. Есть бесплатный тариф с ограничениями.
Scrapebox Email Scraper. Собирает email-адреса в разных поисковых системах, на разных сайтах и из локальных файлов. При экспорте можно сохранять URL-адрес, с которого получен email. Стоимость приложения для парсинга — $97 за лицензию (цена без скидки $197).
Выбирая подходящий парсер, учитывайте ваши задачи и периодичность использования. Часто за один раз можно собрать определённый тип данных — для этого хватит бесплатного инструмента или триал-версии платного сервиса. Для регулярного сбора данных выбирайте парсер, который настроен на работу с нужным вам типом данных. Если планируете собирать большое количество разной информации и в приоритете гибкие настройки парсинга, то, вероятно, стоит заказать индивидуальное решение.
ЭКСКЛЮЗИВЫ ⚡️
Читайте только в блоге
Unisender
Поделиться
СВЕЖИЕ СТАТЬИ
Другие материалы из этой рубрики
![]()
![]()
Не пропускайте новые статьи
Подписывайтесь на соцсети
Делимся новостями и свежими статьями, рассказываем о новинках сервиса
«Честно» — авторская рассылка от редакции Unisender
Искренние письма о работе и жизни. Свежие статьи из блога. Эксклюзивные кейсы
и интервью с экспертами диджитала.
