I want to go through all the elements on a page using Javascript and see if they have a property set. Is there an easy way to do this, or do I have to use a recursive solution?
![]()
Deduplicator
44.4k7 gold badges65 silver badges115 bronze badges
asked May 10, 2009 at 7:28
![]()
You can use:
var divs = document.getElementsByTagName("div");
for(var i = 0; i < divs.length; i++){
//do something to each div like
divs[i].innerHTML = "something new...";
}
answered May 10, 2009 at 7:30
![]()
Jose BasilioJose Basilio
50.5k13 gold badges120 silver badges117 bronze badges
4
To find a property in one or more of all divs on a page:
var divs = document.getElementsByTagName("div"), i=divs.length;
while (i--) {
if (divs[i].getAttribute([yourProperty]) === 'yourValue'){
//do something
}
}
[edit october 2022] Very old answer. Today I would advise to use a css selector. For example:
const withStyle = document.querySelectorAll('[style]');
console.log(`Found ${withStyle.length} elements with style:n${
[...withStyle]
.map(el =>`<${el.tagName}>: ${el.getAttribute('style')}`)
.join(`; `) }` );<div style="color:#777">
<div style="color:red;background:#EEE">red</div>
<div>no color</div>
<div data-something>data-attribute</div>
<div style="color:green">green</div>
<span>Hello</span>
<h3 style="font-family:monospace">That's all folks</h3>
</div>answered May 10, 2009 at 7:36
![]()
KooiIncKooiInc
118k31 gold badges140 silver badges177 bronze badges
0
Using JS ES6 For ... of
for (elem of document.getElementsByTagName('div')){
elem.style.marginTop='20px'
}
answered Jan 9, 2022 at 14:48
![]()
TimoTimo
2,8563 gold badges29 silver badges27 bronze badges
You might also be able to use a selector engine such as Sizzle.
Steve
answered May 10, 2009 at 7:37
![]()
Steve HarrisonSteve Harrison
120k15 gold badges86 silver badges72 bronze badges
2
В этой статье мы изучим методы JavaScript для поиска элементов в HTML-документе: querySelector, querySelectorAll, getElementById и другие. Кроме них рассмотрим ещё следующие: matches, contains и closest. Первые два из них могут быть полезны для выполнения различных проверок, а третий использоваться, когда нужно получить родительский элемент по CSS-селектору.
Методы для выбора HTML-элементов
Работа с веб-страницей так или иначе связана с манипулированием HTML-элементами. Но перед тем, как над ними выполнить некоторые действия (например, добавить стили), их сначала нужно получить.
Выбор элементов в основном выполняется с помощью этих методов:
querySelector;querySelectorAll.
Они позволяют выполнить поиск HTML-элементов по CSS-селектору. При этом querySelector выбирает один элемент, а querySelectorAll – все.
Кроме них имеются ещё:
getElementById;getElementsByClassName;getElementsByTagName;getElementsByName.
Но они сейчас применяются довольно редко. В основном используется либо querySelector, либо querySelectorAll.
querySelectorAll
Метод querySelectorAll применяется для выбора всех HTML-элементов, подходящих под указанный CSS-селектор. Он позволяет искать элементы как по всей странице, так и внутри определённого элемента:
// выберем элементы по классу item во всем документе
const items = document.querySelectorAll('.item');
// выберем .btn внутри #slider
const buttons = document.querySelector('#slider').querySelectorAll('.btn');Здесь на первой строчке мы нашли все элементы с классом item. На следующей строчке мы сначала выбрали элемент с id="slider", а затем в нём все HTML-элементы с классом btn.
Метод querySelectorAll как вы уже догадались принимает в качестве аргумента CSS-селектор в формате строки, который соответственно и определяет искомые элементы. В качестве результата querySelectorAll возвращает объект класса NodeList. Он содержит все найденные элементы:

Полученный набор представляет собой статическую коллекцию HTML-элементов. Статической она называется потому, что она не изменяется. Например, вы удалили элемент из HTML-документа, а в ней как был этот элемент, так он и остался. Чтобы обновить набор, querySelectorAll нужно вызвать заново:
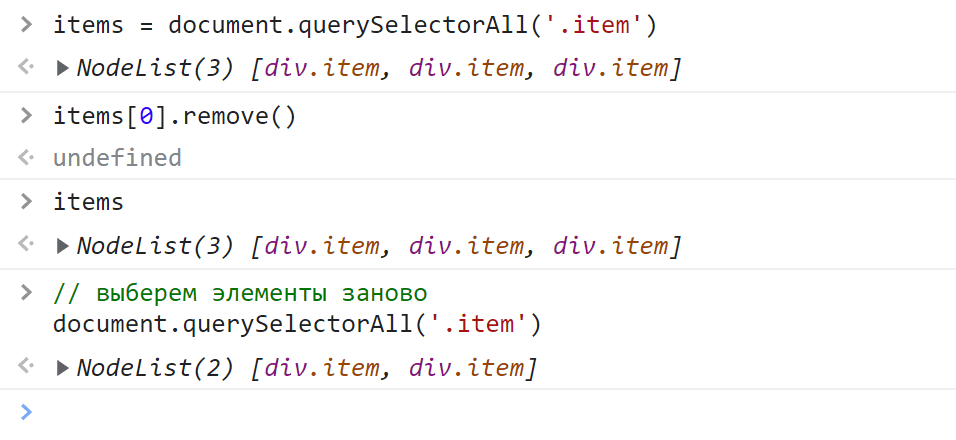
Узнать количество найденных элементов можно с помощью свойства length:
// выберем элементы с атрибутом type="submit"
const submits = document.querySelectorAll('[type="submit"]');
// получим количество найденных элементов
const countSubmits = submits.length;Обращение к определённому HTML-элементу коллекции выполняется также как к элементу массива, то есть по индексу. Индексы начинаются с 0:
// получим первый элемент
const elFirst = submits[0];
// получим второй элемент
const elSecond = submits[1];Здесь в качестве результата мы получаем HTML-элемент или undefined, если элемента с таким индексом в наборе NodeList нет.
Перебор коллекции HTML-элементов
Перебор NodeList обычно осуществляется с помощью forEach:
// получим все <p> на странице
const elsP = document.querySelectorAll('p');
// переберём выбранные элементы
elsP.forEach((el) => {
// установим каждому элементу background-color="yellow"
el.style.backgroundColor = 'yellow';
});Также перебрать набор выбранных элементов можно с помощью цикла for или for...of:
// получим все элементы p на странице
const elsP = document.querySelectorAll('p');
// for
for (let i = 0, length = elsP.length; i < length; i++) {
elsP[i].style.backgroundColor = 'yellow';
}
// for...of
for (let el of elsP) {
el.style.backgroundColor = 'yellow';
}querySelector
Метод querySelector также как и querySelectorAll выполняет поиск по CSS-селектору. Но в отличие от него, он ищет только один HTML-элемент:
// ищем #title во всём документе
const elTitle = document.querySelector('#title');
// ищем footer в <body>
const elFooter = document.body.querySelector('footer');На первой строчке мы выбираем HTML-элемент, имеющий в качестве id значение title. На второй мы ищем в <body> HTML-элемент по тегу footer.
В качестве результата этот метод возвращает найденный HTML-элемент или null, если он не был найден.
querySelector всегда возвращает один HTML-элемент, даже если под указанный CSS-селектор подходят несколько:
<ul id="list">
<li>First</li>
<li>Second</li>
<li>Third</li>
</ul>
<script>
// выберем <li>, расположенный в #list
const elFirst = document.querySelector('#list > li');
elFirst.style.backgroundColor = 'yellow';
</script>Задачу, которую решает querySelector можно выполнить через querySelectorAll:
const elFirst = document.querySelectorAll('#list > li')[0];Но querySelector в отличие от querySelectorAll делает это намного быстрее, да и писать так проще. То есть querySelectorAll не возвращает как querySelector сразу же первый найденный элемент. Он сначала ищет все элементы, и только после того, как он это сделает, мы можем уже обратиться к первому HTML-элементу в этой коллекции.
Обычно перед тем, как выполнить какие-то действия с найденным HTML-элементом необходимо сначала проверить, а действительно ли он был найден:
const elModal = document.querySelector('.modal');
// если элемент .modal найден, то ...
if (elModal) {
// переключим у elModal класс show
elModal.classList.toggle('show');
}Здесь мы сначала проверили существования HTML-элемента, и только потом выполнили над ним некоторые действия.
Методы getElement(s)By* для выбора HTML-элементов
Здесь мы рассмотрим методы, которые сейчас применяются довольно редко для поиска HTML-элементов. Но в некоторых случаях они могут быть очень полезны. Это:
getElementById– получает один элемент поid;getElementsByClassName– позволяет найти все элементы с указанным классом или классами;getElementsByTagName– выбирает элементы по тегу;getElementsByName– получает все элементы с указанным значением атрибутаname.
1. Метод getElementById позволяет найти HTML-элемент на странице по значению id:
<div id="comments">...</div>
...
<script>
// получим HTMLElement и сохраним его в переменную elComments
const elComments = document.getElementById('comments');
</script>В качестве результата getElementById возвращает объект класса HTMLElement или значение null, если элемент не был найден. Этот метод имеется только у объекта document.
Указывать значение id необходимо с учётом регистра. Так например, document.getElementById('aside') и document.getElementById('ASIDE') ищут элементы с разным id.
Обратите внимание, что в соответствии со стандартом в документе не может быть несколько тегов с одинаковым id, так как значение идентификатора на странице должно быть уникальным.
Тем не менее, если вы допустили ошибку и в документе существуют несколько элементов с одинаковым id, то метод getElementById более вероятно вернёт первый элемент, который он встретит в DOM. Но на это полагаться нельзя, так как такое поведение не прописано в стандарте.
То, что делает getElementById можно очень просто решить посредством querySelector:
// получим элемент #title
const elTitle = document.getElementById('title');
// получим элемента #title, используя querySelector
const elTitleSame = document.querySelector('#nav');Кстати, оба этих метода возвращают в качестве результата один и тот же результат. Это либо HTML-элемент (экземпляр класса HTMLElement) или null, если элемент не найден.
2. Метод getElementsByClassName позволяет найти все элементы с заданным классом или классами. Его можно применить для поиска элементов как во всём документе, так и внутри указанного. В первом случае его нужно будет вызывать как метод объекта document, а во втором – как метод соответствующего HTML-элемента:
// найдем элементы с классом control в документе
const elsControl = document.getElementsByClassName('control');
// выберем элементы внутри другого элемента, в данном случае внутри формы с id="myform"
const elsFormControl = document.forms.myform.getElementsByClassName('form-control');В качестве результата он возвращает живую HTML-коллекцию найденных элементов. Чем живая коллекция отличается от статической мы рассмотрим ниже.
Здесь мы сохранили найденные элементы в переменные elsControl и elsFormControl. В первой переменной будет находиться HTMLCollection, содержащая элементы с классом control. Во второй – набор элементов с классом form-control, находящиеся в форме с id="myform". Для получения этой формы мы использовали document.forms.myform.
Метод getElementsByClassName позволяет искать элементы не только по одному классу, но и сразу по нескольким, которые должны присутствовать у элемента:
// выберем элементы .btn.btn-danger
const elsBtn = document.getElementsByClassName('btn btn-danger');На querySelectorAll этот пример решается так:
const elsBtn = document.querySelectorAll('.btn.btn-danger');3. Метод getElementsByTagName предназначен для получения коллекции элементов по имени тега:
// найдем все <a> в документе
const anchors = document.getElementsByTagName('a');
// найдем все >li> внутри #list
const elsLi = document.getElementById('list').getElementsByTagName('li');На первой строчке мы выбрали все <a> в документе и присвоили полученную HTMLCollection переменной anchors. На второй – мы сначала получили #list, а затем в нём нашли все <li>.
Задачу по выбору элементов внутри другого элемента с помощью querySelectorAll выполняется намного проще:
const elsLi = document.querySelectorAll('#list li');Для выбора всех элементов можно использовать символ *:
// выберем все элементы в <body>
const els = document.body.getElementsByTagName('*');4. В JavaScript getElementsByName можно использовать для выбора элементов, имеющих определенное значение атрибута name:
// получим все элементы с name="phone"
const elsPhone = document.getElementsByName('phone');Через querySelectorAll это выполняется так:
const elsPhone = document.querySelectorAll('[name="phone"]');getElementsBy* и живые HTML-коллекции
В JavaScript getElementsByTagName, getElementsByClassName и getElementsByName в отличие от других методов (например, querySelectorAll) возвращают живую коллекцию HTML-элементов (на английском live HTMLCollection). То есть коллекцию содержимое которой автоматически обновляется при изменении DOM. Для наглядности рассмотрим следующий пример.
Например, на странице изначально имеется два <li>. Выберем их с помощью getElementsByTagName и сохраним полученную HTMLCollection в переменную els. Теперь с помощью els мы можем получить эту коллекцию. Сейчас в ней два <li>. Затем через 5 секунд, используя setTimeout добавим ещё один <li>. Если сейчас мы обратимся к переменной els, то увидим, что в ней уже находятся три <li>:
<ul>
<li>One</li>
<li>Two</li>
</ul>
<script>
// получим живую коллекцию <li>
const els = document.getElementsByTagName('li');
// выведем количество <li> в консоль
console.log(`Количество <li>: ${els.length}`); // 2
// через 5 секунд добавим ещё один <li>
setTimeout(() => {
// вставим на страницу новый <li>
document.querySelector('ul').insertAdjacentHTML('beforeend', '<li>Three</li>');
// выведем количество <li> в консоль
console.log(`Количество <li>: ${els.length}`); // 3
}, 5000);
</script>
Как вы видите, здесь полученная коллекция является живой, то есть она может автоматически измениться. В ней сначала было два <li>. Но после того, как мы на страницу добавили ещё один подходящий элемент, в ней их стало уже три.
Если в коде приведённом выше заменить выбор элементов на querySelectorAll, то мы увидим, что в ней находится статическая (не живая) коллекция элементов:
// получим статическую коллекцию
const els = document.querySelectorAll('li'); <li>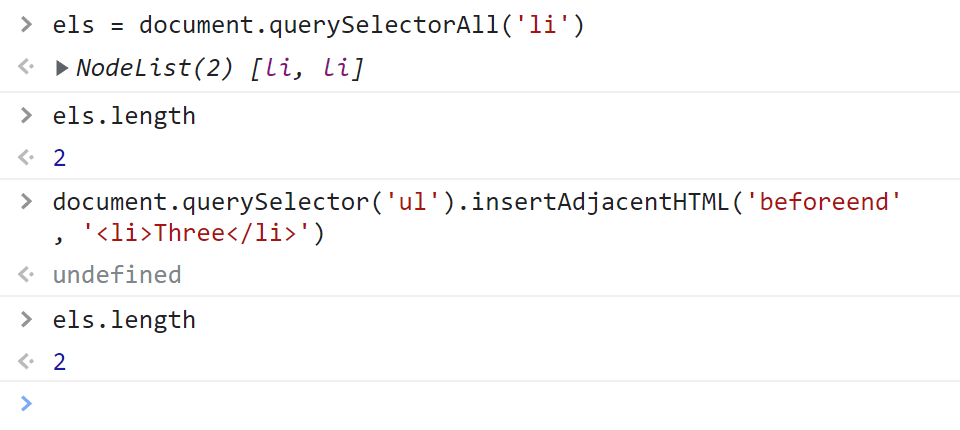
Как вы видите количество элементов в коллекции не изменилось. Чтобы после изменения DOM получить актуальную коллекцию элементов, их нужно просто выбрать заново посредством querySelectorAll:
<ul>
<li>One</li>
<li>Two</li>
</ul>
<script>
// получим статическую коллекцию <li>
let els = document.querySelectorAll('li');
// выведем количество <li> в консоль
console.log(`Количество <li>: ${els.length}`); // 2
// через 5 секунд добавим ещё один <li>
setTimeout(() => {
// вставим на страницу новый <li>
document.querySelector('ul').insertAdjacentHTML('beforeend', '<li>Three</li>');
// получим заново статическую коллекцию <li>
els = document.querySelectorAll('li');
// выведем количество <li> в консоль
console.log(`Количество <li>: ${els.length}`); // 3
}, 5000);
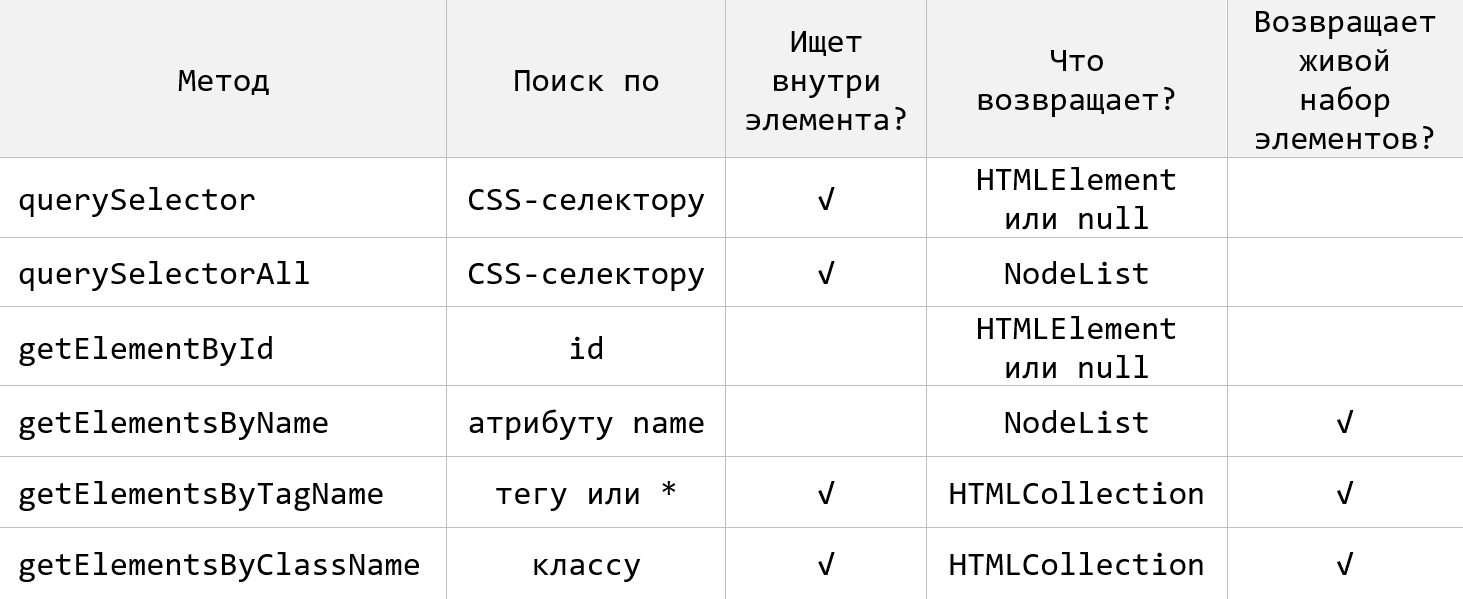
</script>Таким образом в JavaScript насчитывается 6 основных методов для выбора HTML-элементов на странице. По чему они ищут и что они возвращают приведено на следующем рисунке:
Экземпляры класса HTMLCollection не имеют в прототипе метод forEach. Поэтому если вы хотите использовать этот метод для перебора такой коллекции, её необходимо преобразовать в массив:
const items = document.getElementsByClassName('item');
[...items].forEach((el) => {
console.log(el);
});matches, closest и contains
В JavaScript имеются очень полезные методы:
matches– позволяет проверить соответствует ли HTML-элемент указанному CSS-селектору;closest– позволяет найти для HTML-элемента его ближайшего предка, подходящего под указанный CSS-селектор (поиск начинается с самого элемента);contains– позволяет проверить содержит ли данный узел другой в качестве потомка (проверка начинается с самого этого узла).
1. Метод matches ничего не выбирает, но он является очень полезным, так как позволяет проверить HTML-элемент на соответствие CSS-селектору. Он возвращает true, если элемент ему соответствует, иначе false.
// выберем HTML элемент, имеющий атрибут data-target="slider"
const elSlider = document.querySelector('[data-target="slider"]');
// проверим соответствует ли он CSS селектору 'div'
const result = element.matches('div');Пример, в котором выберем все <li>, расположенные внутри #questions, а затем удалим те из них, которые соответствуют селектору .answered:
// выберем все <li> в #questions
const els = document.querySelectorAll('#questions > li');
// переберём выбранные элементы
els.forEach((el) => {
// если элемент соответствует селектору .answered, то ...
if (el.matches('.answered')) {
// удалим элемент
el.remove();
}
});В этом примере проверим каждый <li> на соответствие селектору active. Выведем в консоль каждый такой элемент:
<ul>
<li>One</li>
<li class="active">Two</li>
<li>Three</li>
</ul>
<script>
document.querySelectorAll('li').forEach((el) => {
if (el.matches('.active')) {
console.log(el);
}
});
// li.active
</script>Ранее, в «старых» браузерах данный метод имел название matchesSelector, а также поддерживался с использованием префиксов. Если вам нужна поддержка таких браузеров, то можно использовать следующий полифилл:
if (!Element.prototype.matches) {
Element.prototype.matches = Element.prototype.matchesSelector || Element.prototype.webkitMatchesSelector || Element.prototype.mozMatchesSelector || Element.prototype.msMatchesSelector;
}2. Метод closest очень часто используется в коде. Он позволяет найти ближайшего предка, подходящего под указанный CSS-селектор. При этом поиск начинается с самого элемента, для которого данный метод вызывается. Если этот элемент будет ему соответствовать, то closest вернёт его.
<div class="level-1">
<div class="level-2">
<div class="level-3"></div>
</div>
</div>
<script>
const el = document.querySelector('.level-3');
const elAncestor = el.closest('.level-1');
console.log(elAncestor);
</script>Здесь мы сначала выбираем HTML-элемент .level-3 и присваиваем его переменной el. Далее мы пытаемся среди предков этого элемента включая его сам найти такой, который отвечает заданному CSS-селектору, в данном случае .level-1.
Начинается поиск всегда с самого этого элемента. В данном случае он не подходит под указанный селектор. Следовательно, этот метод переходит к его родителю. Он тоже не отвечает этому CSS-селектору. Значит, closest переходит дальше, то есть уже к его родителю. Этот элемент подходит под указанный селектор. Поэтому поиск прекращается и этот метод возвращает его в качестве результата.
Метод closest возвращает null, когда он дошёл бы конца иерархии и не нашёл элемент отвечающий указанному селектору. То есть, если такого элемента нет среди предков.
В этом примере найдем с помощью closest для .active его ближайшего родителя, отвечающего CSS-селектору #list > li:
<ul id="list">
<li>One</li>
<li>
Two
<ul>
<li>Four</li>
<li class="active">Five</li>
</ul>
</li>
<li>Three</li>
</ul>
<script>
const elActive = document.querySelector('.active');
const elClosest = elActive.closest('#list > li');
elClosest.style.backgroundColor = 'yellow';
</script>В JavaScript closest очень часто используется в обработчиках событий. Это связано с тем, чтобы события всплывают и нам нужно, например, узнать кликнул ли пользователь в рамках какого-то элемента:
document.addEventListener('click', (e) => {
if (e.closest.matches('.btn__action')) {
// пользователь кликнул внутри .btn__action
}
});3. Метод contains позволяет проверить содержит ли некоторый узел другой в качестве потомка. При этом проверка начинается с самого этого узла, для которого этот метод вызывается. Если узел соответствует тому для которого мы вызываем данный метод или является его потомком, то contains в качестве результата возвращает логическое значение true. В противном случае false:
<div id="div-1">
<div id="div-2">
<div id="div-3">...</div>
</div>
</div>
<div id="div-4">...</div>
<script>
const elDiv1 = document.querySelector('#div-1');
elDiv1.contains(elDiv1); // true
const elDiv3 = document.querySelector('#div-3');
elDiv1.contains(elDiv3); // true
const elDiv4 = document.querySelector('#div-4');
elDiv1.contains(elDiv4); // false
</script>Здесь выражение elDiv1.contains(elDiv1) возвращает true, так как проверка начинается с самого элемента. Это выражение elDiv1.contains(elDiv3) тоже возвращает true, так как elDiv3 находится внутри elDiv1. А вот elDiv1.contains(elDiv4) в качестве результата возвращает false, так как elDiv4 не находится внутри elDiv1.
В этом примере проверим с помощью contains содержит ли <p> другие узлы в качестве потомка:
<h1>Tag b</h1>
<p>This is <b>tag b</b>.</p>
<script>
const elP = document.querySelector('p');
const elB = document.querySelector('b');
const textNode = elB.firstChild;
const elH1 = document.querySelector('h1');
elP.contains(elP); // true
elP.contains(elB); // true
elP.contains(elH1); // false
elP.contains(textNode); // true
</script>Метод contains позволяет проверить является ли потомком не только узел-элемент, но и любой другой узел. Например, узнаем является ли потомком elDiv1 указанный текстовый узел:
const elDiv1 = document.querySelector('#div-1');
const textNode = document.querySelector('#div-3').firstChild;
elDiv1.contains(textNode); // trueЗадачи
1. Узнать количество элементов с атрибутом data-toggle="modal" на странице:
const count = document.querySelectorAll('[data-toggle="modal"]').length;
console.log(count);2. Найти все элементы <a> с классом nav внутри элемента <ul> :
const anchors = document.querySelectorAll('ul.nav a');3. Получить элемент по id, значение которого равно pagetitle:
var pagetitle = document.querySelector('#pagetitle');4. Выполнить поиск элемента по классу nav:
var el = document.querySelector('.nav');5. Найти элемент <h3>, находящийся в теге <div> с классом comments, который в свою очередь расположен в <main>:
var header = document.querySelector('main div.comments h3');6. Имеется страница. В ней следует выбрать:
- последний элемент с классом
article, расположенный в<main>(решение); - все элементы
.section, находящиеся в.asideкроме 2 второго (решение); - элемент
<nav>расположенный после<header>(решение).
- Поиск по id
- Поиск по тегу
- Получить всех потомков
-
Поиск по
name: getElementsByName - Другие способы
Стандарт DOM предусматривает несколько средств поиска элемента. Это методы getElementById, getElementsByTagName и getElementsByName.
Более мощные способы поиска предлагают javascript-библиотеки.
Поиск по id
Самый удобный способ найти элемент в DOM – это получить его по id. Для этого используется вызов document.getElementById(id)
Например, следующий код изменит цвет текста на голубой в div‘е c id="dataKeeper":
document.getElementById('dataKeeper').style.color = 'blue'
Поиск по тегу
Следующий способ – это получить все элементы с определенным тегом, и среди них искать нужный. Для этого служит document.getElementsByTagName(tag). Она возвращает массив из элементов, имеющих такой тег.
Например, можно получить второй элемент(нумерация в массиве идет с нуля) с тэгом li:
document.getElementsByTagName('LI')[1]
Что интересно, getElementsByTagName можно вызывать не только для document, но и вообще для любого элемента, у которого есть тег (не текстового).
При этом будут найдены только те объекты, которые находятся под этим элементом.
Например, следующий вызов получает список элементов LI, находящихся внутри первого тега div:
document.getElementsByTagName('DIV')[0].getElementsByTagName('LI')
Получить всех потомков
Вызов elem.getElementsByTagName('*') вернет список из всех детей узла elem в порядке их обхода.
Например, на таком DOM:
<div id="d1">
<ol id="ol1">
<li id="li1">1</li>
<li id="li2">2</li>
</ol>
</div>
Такой код:
var div = document.getElementById('d1')
var elems = div.getElementsByTagName('*')
for(var i=0; i<elems.length; i++) alert(elems[i].id)
Выведет последовательность: ol1, li1, li2.
Поиск по name: getElementsByName
Метод document.getElementsByName(name) возвращает все элементы, у которых имя (атрибут name) равно данному.
Он работает только с теми элементами, для которых в спецификации явно предусмотрен атрибут name: это form, input, a, select, textarea и ряд других, более редких.
Метод document.getElementsByName не будет работать с остальными элементами типа div,p и т.п.
Другие способы
Существуют и другие способы поиска по DOM: XPath, cssQuery и т.п. Как правило, они реализуются javascript-библиотеками для расширения стандартных возможностей браузеров.
Также есть метод getElementsByClassName для поиска элементов по классу, но он совсем не работает в IE, поэтому в чистом виде им никто не пользуется.
Частая опечатка связана с отсутствием буквы s в названии метода getElementById, в то время как в других методах эта буква есть: getElementsByName.
Правило здесь простое: один элемент – Element, много – Elements. Все методы *Elements* возвращают список узлов.
Как можно через консоль браузера, найти все элементы со значением 24 и удалить их со страницы.
<div id="shows" class="shows">
<div class="show">
<span class="label label-dark ec">24</span>
<a href="/show/xxx">
</div>
<div class="show">
<span class="label label-dark ec">24</span>
<a href="/show/xxx">
</div>
<div class="show">
<span class="label label-dark ec">21</span>
<a href="/show/xxx">
</div>
<div class="show">
<span class="label label-dark ec">13</span>
<a href="/show/xxx">
</div>
</div>
То есть удалить 2 блока
<div class="show">
<span class="label label-dark ec">24</span>
<a href="/show/xxx">
</div>
<div class="show">
<span class="label label-dark ec">24</span>
<a href="/show/xxx">
</div>
![]()
Vasily
11.5k4 золотых знака21 серебряный знак38 бронзовых знаков
задан 7 авг 2020 в 18:35
![]()
Для этого можно воспользоваться методом each():
$(".show").each(function() {
if ($(this).find("span").html() === "24") {
$(this).remove()
}
})<script src="https://cdnjs.cloudflare.com/ajax/libs/jquery/3.3.1/jquery.min.js"></script>
<div id="shows" class="shows">
<div class="show">
<span class="label label-dark ec">24</span>
<a href="/show/xxx">
</div>
<div class="show">
<span class="label label-dark ec">24</span>
<a href="/show/xxx">
</div>
<div class="show">
<span class="label label-dark ec">21</span>
<a href="/show/xxx">
</div>
<div class="show">
<span class="label label-dark ec">13</span>
<a href="/show/xxx">
</div>
</div>Имейте ввиду что проверка содержимого каждой ноды крайне ресурсозатратное мероприятие, поэтому такой вариант стоит использовать только в крайних случаях.
Тоже самое на JS:
document.querySelectorAll(".show").forEach(item => {
if (item.querySelector("span").innerHTML === "24") {
item.remove()
}
})
здесь метод для перебора называется forEach().
ответ дан 7 авг 2020 в 18:43
![]()
VasilyVasily
11.5k4 золотых знака21 серебряный знак38 бронзовых знаков
0
Данная статья написана, чтобы помочь быстро разобраться с тем, как парсить данные при помощи расширения от iDatica. Статья рассчитана на людей не знакомых с Xpath и CSS. Рассмотрим совсем немного теории и базовый (для парсинга данных) синтаксис которые позволят понять как собирать данные с подавляющего большинства сайтов.
Применение Xpath для парсинга
Прежде всего, нужно разобраться, что такое Xpath (XML Path Language) — это язык запросов к элементам хml-разметки. Это означает, что отправляя определенным образом составленный запрос, вы получаете в ответ нужные данные. Простая аналогия — адрес в строке браузера или путь в эксплорере до нужной папки, набирая правильный путь вы попадаете на нужный сайт или в нужную папку. С Xpath так же — пишем путь и попадаем к нужным данным, только в отличии от строки браузера Xpath применяем для поиска. И в нашем случаем для поиска по xml документам в формате html, другими словами по коду на котором построен сайт.
Если вы нажмете на пустом месте сайта правой клавишей мыши и выберете в контекстном меню «исходный код сайта» или «посмотреть код страницы», в разных браузерах по разному, вы как раз попадете на страницу с кодом из которого парсер извлекает данные.
Например, код может выглядеть так:
<html>
<body>
<div>Заголовок
<H1>Название</H1>
</div>
<div>Описание</div>
<div>Характеристики
<span class="text">Высота</span>
<span class="text">Ширина</span>
<span>Цена</span>
</div>
<a href="https://site.com/pic.png">Фотография товара</a>
</body>
</html>Как видно код представляет собой древовидную структуру, в которой каждый элемент определенным образом размечен, наша задача заключается в том, чтобы указать парсеру путь к нужному нам элементу.
Дальнейшие действия будем рассматривать на примере нашего каталога баз данных по этому адресу.
Для дальнейшей работы нам понадобится инструмент разработчика встроенный в браузер, в Chrome — контекстное меню — посмотреть код, в Firefox — контекстное меню — исследовать.
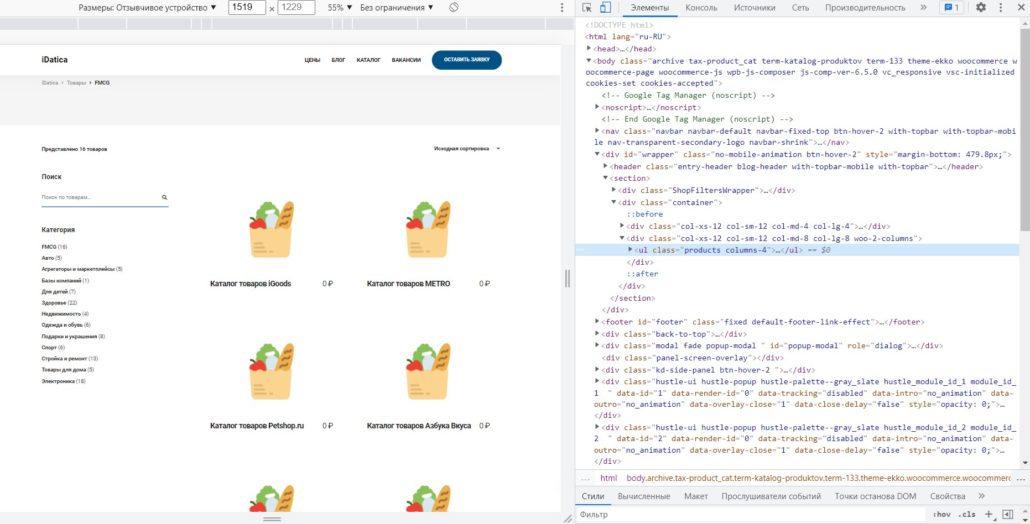
Итак, давайте найдем путь до названия карточки товара:

Кликаем на название товара правой клавишей мыши — откроется контекстное меню, выбераем — «посмотреть код» — нашли нужный элемент в коде. Как можно определить путь до него? Как и в случае с проводником опускаемся из верхней категории до «нужной папки». Верхняя директория «html», далее «body» , далее несколько блоков «div», «ul», если на каком-то уровне несколько блоков с одинаковым названием, то в квадратных скобках пишем какой элемент по счету нам нужен:
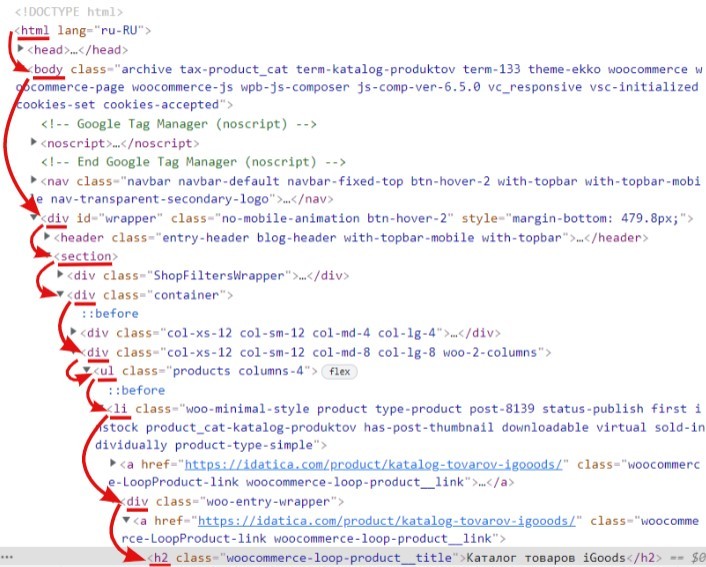
Если записать, этот путь то получится:
/html/body/div/section/div[2]/div[2]/ul/li/div/a/h2Этот путь можно проверить в том же инструменте разработчика, нажав Ctrl+F и записать путь:
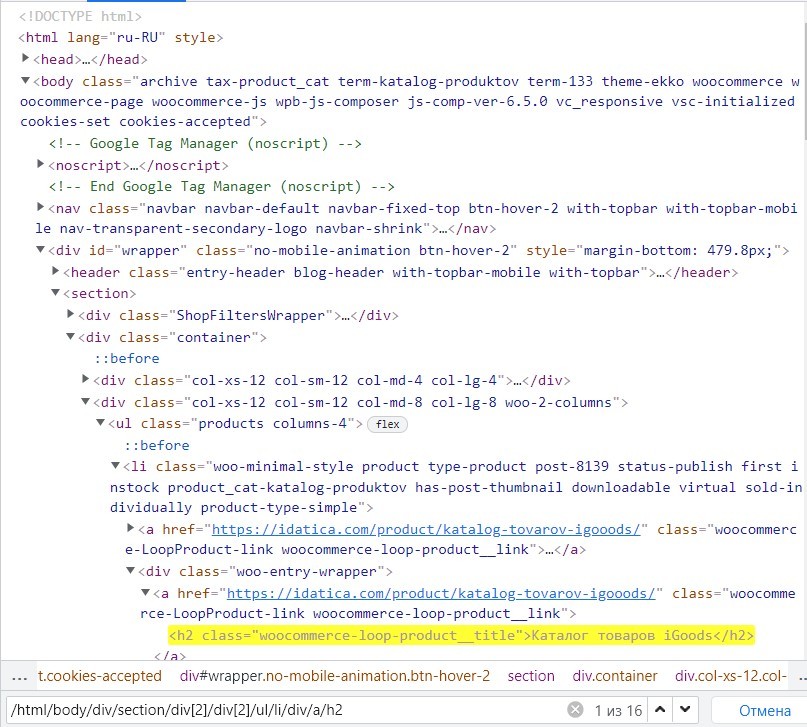
Можно проверить путь в расширении iDatica, нажав на пиктограмму поиска:
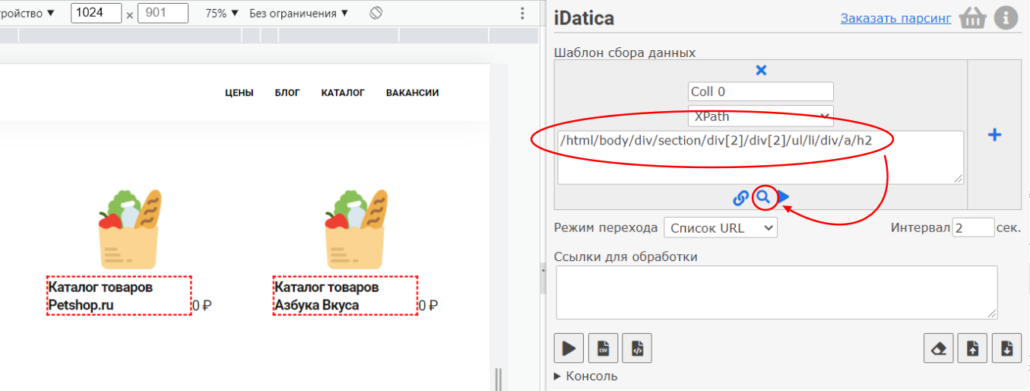
Если в расширении нажать на пиктограмму play, то программа покажет все элементы которые нашла на странице по этому пути — в нашем случае это все названия. Если нажать на кнопку парсинга и сохранить результат — то вы спарсите все названия, поздравляю — вы собрали первые данные!
Как быть с остальными элементами на странице? Так же — пишем путь и получаем данные. Можно получить этот путь сразу в инструменте разработчика — кликнуть правой клавишей мыши на нужном элементе в коде, выбрать — копировать и выбрать xpath:
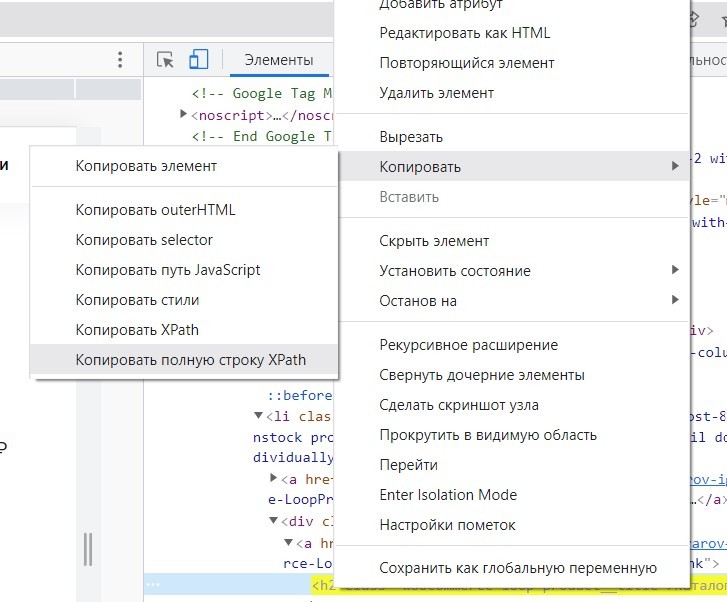
Можно получить этот путь сразу в расширении, нажав на пиктограмму ссылки и кликнув на нужный элемент на странице.
Работать с такими длинными путями не удобно и не на всех сайтах можно получить путь сразу ко всем элементам, в некоторых случаях его придется дорабатывать изучая особенности структуры сайта. Но составить путь к данным на много проще и быстрее. Тут нам нужно познакомится с синтаксисом Xpath.
Синтаксис Xpath
Относительный путь
Двойной слеш // — означает относительный путь и позволяет найти все варианты того, что вы ищете на странице. Таким образом — тк мы искали конечный элемент h2, то запись «//h2», даст тот же результат, что и длинный путь который мы написали в начале:
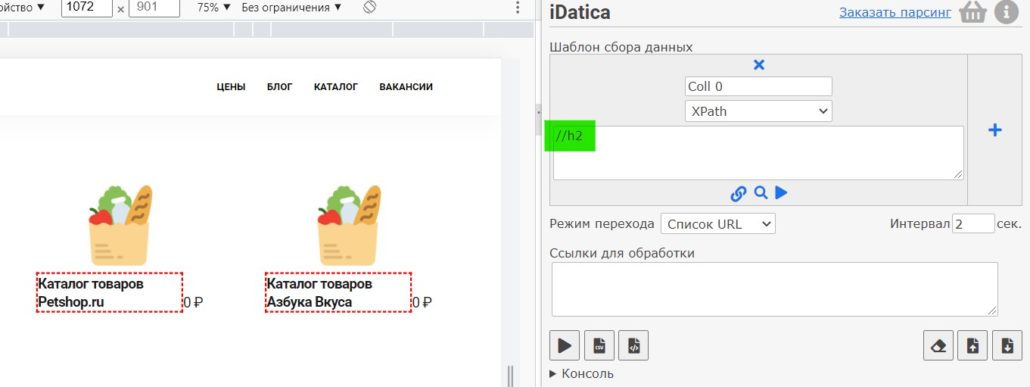
Таким образом можно обращаться к любым элементам на странице.
Условия поиска
Хорошо, идем дальше, скачаем цену. В коде она не обозначена одним элементом, как заголовок h2, цена находится в строковом элементе span, но их много на странице и они отвечают за разные данные, как нам обратиться к нужному?
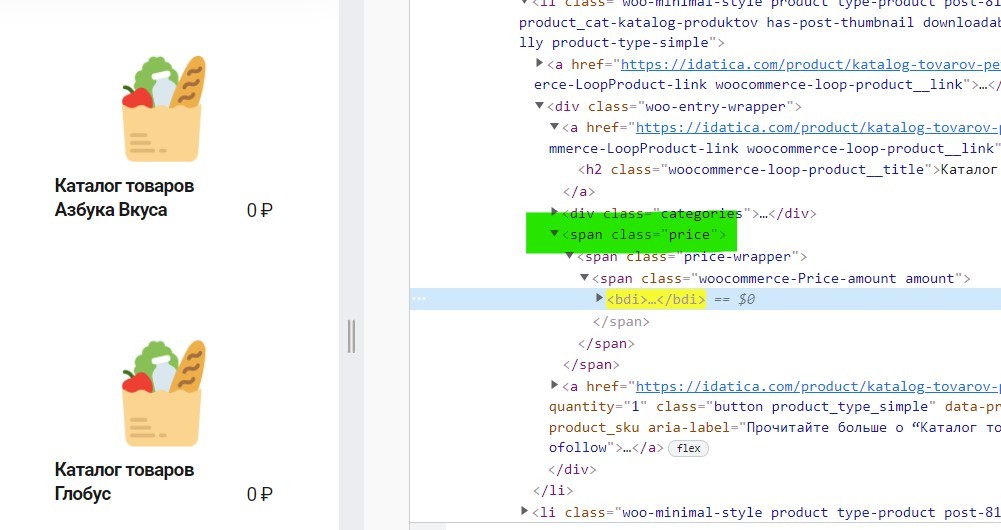
Если посмотреть на код то можно увидеть, что многие элементы на странице содержат атрибуты и названия, например, элемент цены — «span» имеет атрибут «class» с названием «price» — вот к этому названию мы и сможем обратиться. Для этого в квадратных скобках, после указания элемента который мы ищем, нужно прописать условия поиска этого элемента:
//span[@class="price"]Такая конструкция найдет все вложенные в этот элемент данные.
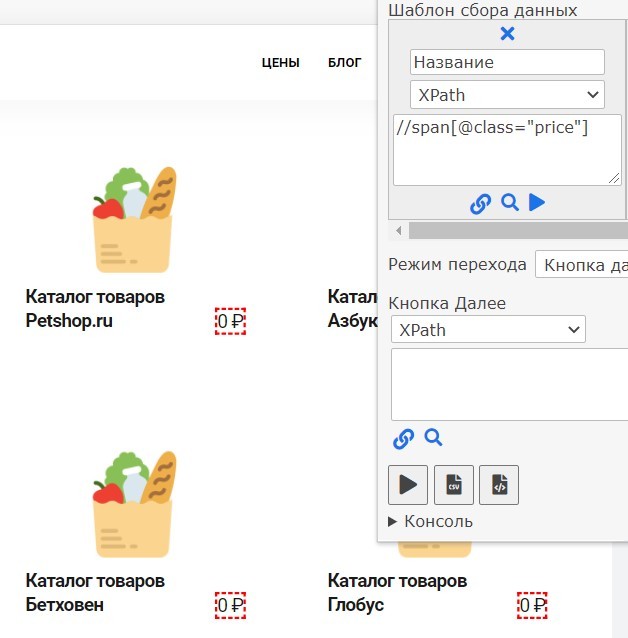
Таким образом можно обращаться ко всем элементам на странице, //div — будет искать во всех элементах «div», //a — во всех элементах «a» итд.
//* — будет искать во всех элементах
Поиск по части вхождения
Бывают ситуации, когда название атрибута не уникально, как например в списке категорий:
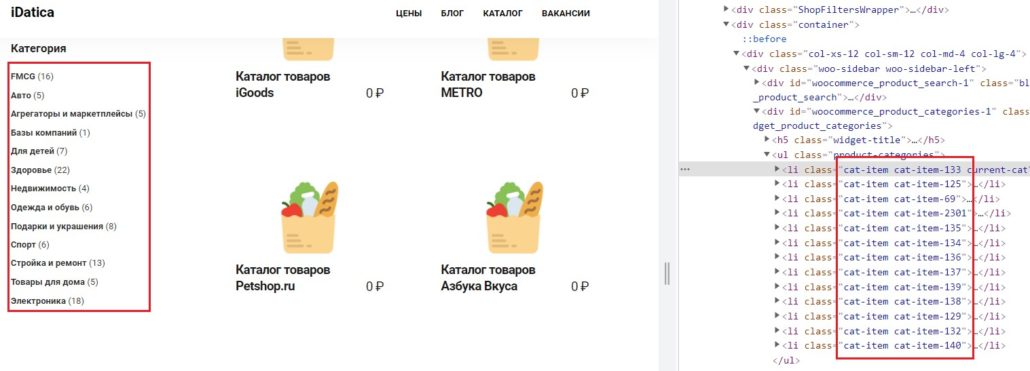
В таком случае можно искать нужные элементы по части вхождения, в данной ситуации — «cat-item», такие элементы найдет команда — «contains», обратите внимание в случае с «contains» элемент пишется в скобках и через «,» вместо «=».
//*[contains(@class,"cat-item")]При этом парсер захватит весь текст внутри элемента, т.е. и название и количество, чтобы получить только название нужно сузить поиск, указать, что внутри нужно взять только значения элемента «а»:

Необходимо через слеш указать дальнейший путь, вложенность может быть такой, какая вам необходима, в нашем случае:
//li[contains(@class,"cat-item")]/aСоответственно, если нужно получить только количество — обращаемся к элементу span:
//li[contains(@class,"cat-item")]/spanЕсли нужно получить данные из определенного элемента по счету, указываем номер элемента в квадратных скобках:
//*[contains(@class,"cat-item")][5]Чтобы получить первый элемент используем индекс — [1]
Получить только последний элемент — last():
/*[contains(@class,"cat-item")][last()]Поиск по тексту
Бывают ситуации, когда можно привязаться только к тексту на странце, в таком случае используем «text» позволяющий находить элементы с нужным текстовым вхождением. Например такая конструкция найдет все элементы в которых есть слово «Каталог»:
//*[contains(text(),'Каталог')]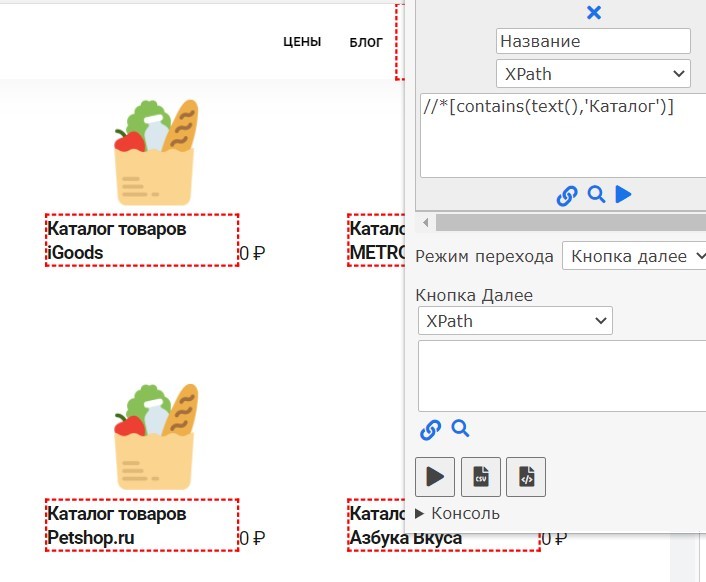
Родственные связи xpath
Можно сказать, что это уже продвинутые команды, они не часто требуются, но бывают ситуации когда они не заменимы. Html код представляет из себя древовидную структуру в которой одни элементы вложены в другие и xpath позволяет использовать вложенность элементов, чтобы поднимать или опускаться по такому дереву, для поиска нужного элемента. В терминах языка xpath элементы, которые содержат другие — являются предками (ancestor) по отношению к во всем вложенным в него. Вложенные в свою очередь — являются его потомками (descendant). Синтаксис использования будет такой — //начальный элемент/команда родственной связи::тег(фильтр) искомого элемента.
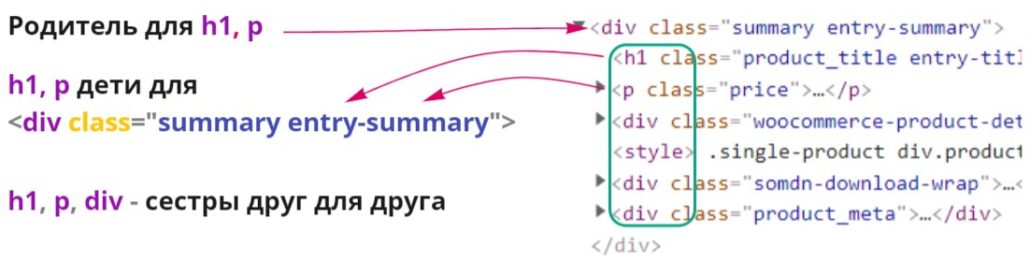
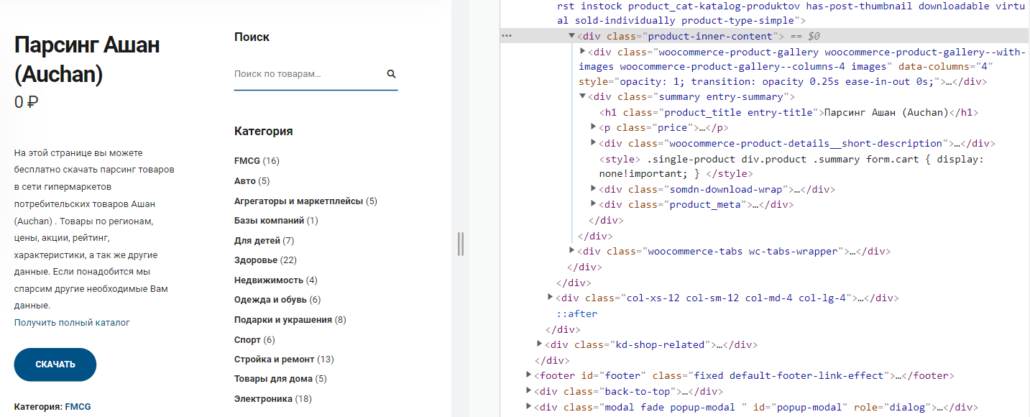
Родственные связи удобно использовать тогда, когда нет возможности привязаться к элементу, например класс не уникален, но рядом есть элемент за который можно «зацепиться». В приведенном примере можно найти нужные элементы проще, указывая вложенность последовательно перечисляя элементы, рассмотрим код в качестве примера работы команд. На примере этой страницы.
Sibling — cестринский элемент
Sibling перемещается к соседним элементам, расположенным на одном уровне. Бывают двух типов — preceding-sibling — сестринский элемент расположенный выше указанного и following-sibling – сестринский элемент, расположенный ниже указанного.
Например, получим цену отталкиваясь от заголовка:
//h1/following-sibling::pИ наоборот, получим заголовок отталкиваясь от цены:
//p[@class="price"]/preceding-sibling::h1Parent и child — родитель и ребенок
Команды позволяющие опускаться или подниматься на уровень. Уровней вложенности может быть несколько, если вам нужно спуститься или подняться на несколько уровней, используйте / в качестве разделителя.
Child — дети, элемент который является вложенным на один уровень вниз от родителя. Например, найдем цену от родительского элемента div:
//div[contains(@class,"entry-summary")]/child::pParent — родительский элемент позволяющий подниматься на уровень выше, находиться от вложенного элемента. Например, получим название категории с количеством товаров, отталкиваясь от названия категории:
//*[contains(text(),'Электроника')]/parent::liParent так же можно заменить на /.. те код выше будет выглядеть так:
//*[contains(text(),'Электроника')]/..Синтаксис и применение CSS для парсинга
CSS локаторы или стили, еще один вариант для получения данных с сайта. CSS удобно использовать тем, что можно указать класс элемента (если он уникален). Вернемся для примеров на эту страницу. Например, чтобы получить все названия достаточно написать стиль с точкой перед ним. Стиль можно посмотреть в инструменте разработчика на вкладке стили (не забудьте в расширении в типе селектора выбрать CSS):
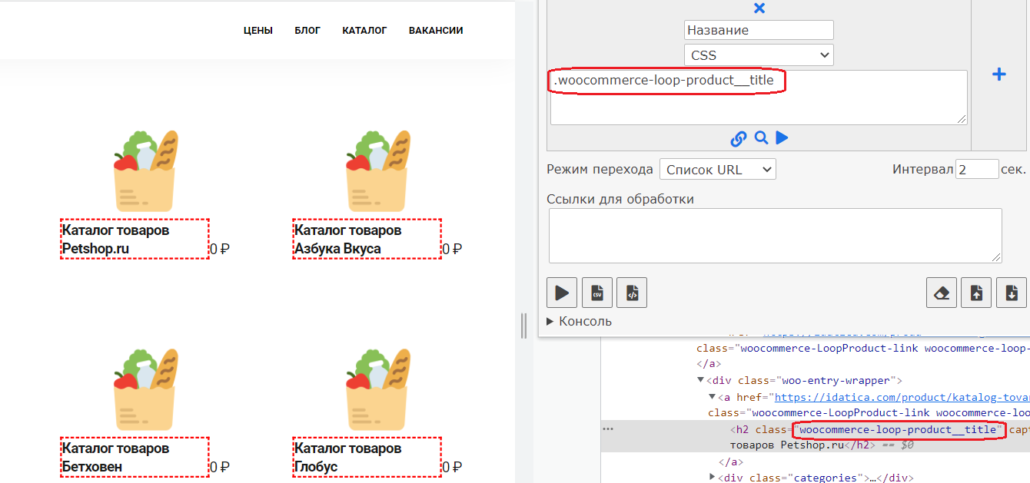
.woocommerce-loop-product__titleЧтобы получить цену, достаточно указать ее стиль: .price попробуйте, это просто.
id для поиска нужных данных
Далее перейдем на страницу поисковой выдачи, тк она содержит нужные нам элементы. Если в коде элементы размечены id, то достаточно указать символ # и значение id:
#hdtbMenus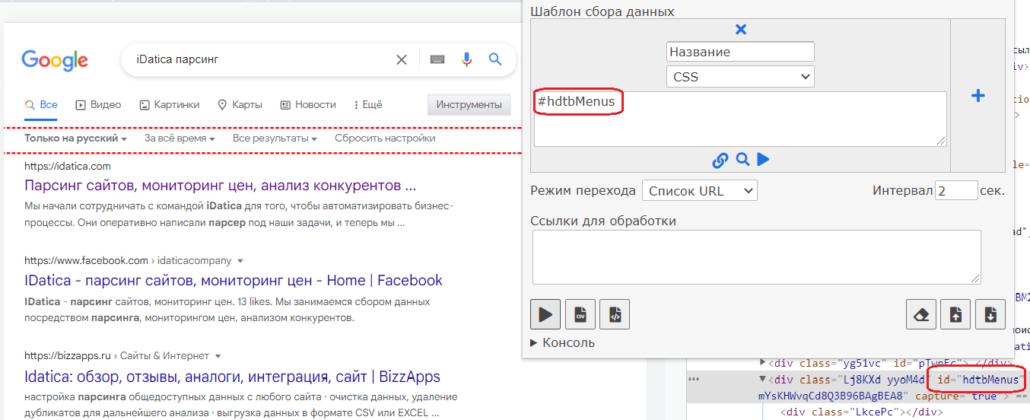
Поиск по значению атрибутов
Поиск по значению атрибутов применяется тогда, когда нет уникального класса или id является сгенерированным. Синтаксис: элемент[атрибут=»значение атрибута»]. Например:
div[class="KTBKoe"]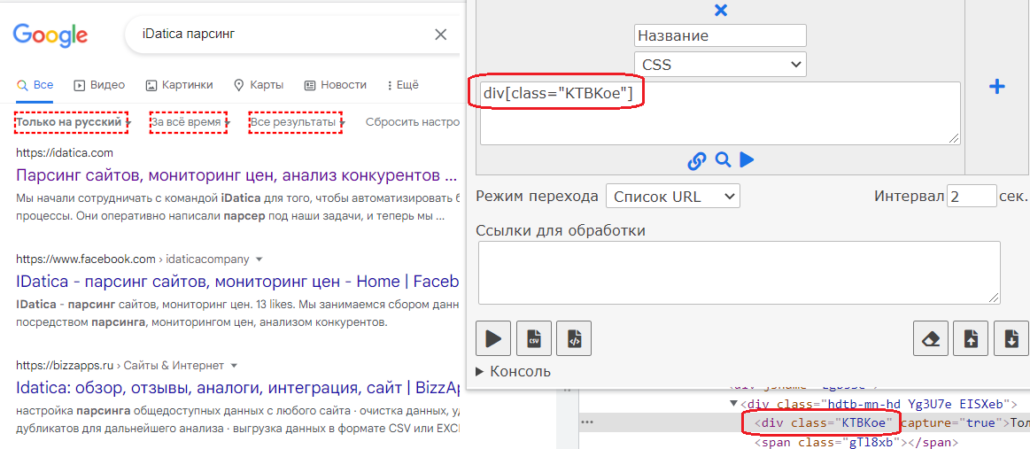
Поиск по частичному вхождению
Бывают случаи когда нужно использовать значение атрибута не циликом, а частично, например в случае когда множество элементов содержит общую часть. Рассмотрим на примере кода написаного выше, все предложенные варианты дадут тоже результат.
Если известна часть значения распологающаяся в любой его части, используется *
div[class*="TBKo"]Если нужно искать по начальной части значения, испоьзуется ^
div[class^="KTB"]Если нужно искать по конечной части значения, испоьзуется $
div[class$="Koe"]Если в значении слова разделены пробелом одно из которых точно известно, используется ~
div[class~="KTBKoe"]Родственные связи CSS
Принцип тот же, что и в xpath. Если нужно получить значение вложеного элемента, на уровень ниже используем >
div[class="Lj8KXd yyoM4d"]>spanЕсли нужно получить значение вложеного элемента, на уровень ниже используем пробел
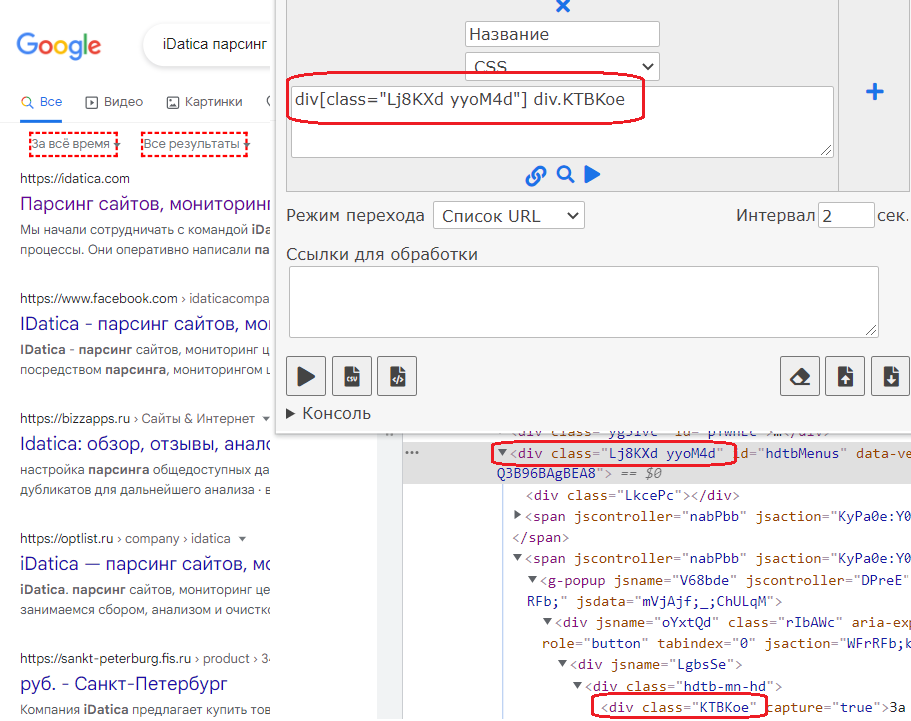
div[class="Lj8KXd yyoM4d"] div.KTBKoeCSS не позволяет найти родителя, тк поиск идет сверху вниз.
Возможности Xpath и CSS гораздо шире, но рассмотренные примеры хорошая база, каторая позволит решать большинство задач. Вы всегда можете поискать готовый пресет в нашем каталоге или если ваши задачи более масштабны, то обратиться за парсингом данных к нашим специалистам.
