Одним словом: список всех уровней
![]()
Одним словом – все ответы на игру
ЧТО ОБЩЕГО?
Часть 1
Часть 2
Часть 3
Часть 4
Часть 5
Часть 6
Часть 7
Часть 8
Часть 9
Часть 10
Часть 11
Часть 12
Часть 13
Часть 14
Часть 15
Часть 16
Часть 17
Часть 18
Часть 19
Часть 20
Часть 21
Часть 22
Часть 23
Часть 24
Часть 25
Часть 26
Часть 27
Часть 28
Часть 29
Часть 30
Часть 31
Часть 32
Часть 33
Часть 34
Часть 35
Часть 36
Часть 37
Часть 38
Часть 39
Часть 40
Часть 41
Часть 42
Часть 43
Часть 44
Часть 45
Часть 46
Часть 47
Часть 48
Часть 49
Часть 50
Часть 51
Часть 52
Часть 53
Часть 54
Часть 55
Часть 56
Часть 57
Часть 58
Часть 59
Часть 60
АССОЦИАЦИИ
Часть 01
Часть 02
Часть 03
Часть 04
Часть 05
Часть 06
Часть 07
Часть 08
Часть 09
Часть 10
Часть 11
Часть 12
Часть 13
Часть 14
Часть 15
Часть 16
Часть 17
Часть 18
Часть 19
Часть 20
Часть 21
ЧТО СПРЯТАНО
Часть 01
Часть 02
Часть 03
Часть 04
Часть 05
Часть 06
Часть 07
Часть 08
Часть 09
Часть 10
Часть 11
Часть 12
Часть 13
Часть 14
Часть 15
Часть 16
Часть 17
Часть 18
Часть 19
Часть 20
Часть 21
Часть 22
Часть 23
РЕБУСЫ
Часть 1
Часть 2
Часть 3
Часть 4
Часть 5
Часть 6
Часть 7
Часть 8
Часть 9
Часть 10
Часть 11
Часть 12
Часть 13
Часть 14
Часть 15
Часть 16
Часть 17
Часть 18
Часть 19
АНТОНИМЫ
Часть 1
Часть 2
Часть 3
Часть 4
Часть 5
Часть 6
Часть 7
Часть 8
СЛОВОСОЧЕТАНИЯ
Часть 1-А (1)
Часть 1-Б (2)
Часть 1-В (3)
Часть 1-Г (4)
Часть 1-Д (5)
Часть 2-А (6)
Часть 2-Б (7)
Часть 2-В (8)
Часть 2-Г (9)
Часть 2-Д (10)
Часть 3-А (11)
Часть 3-Б (12)
Часть 3-В (13)
Часть 3-Г (14)
Часть 3-Д (15)
Часть 4-А (16)
Часть 4-Б (17)
Часть 4-В (18)
Часть 4-Г (19)
Часть 4-Д (20)
Часть 5-А (21)
Часть 5-Б (22)
Часть 5-В (23)
Часть 5-Г (24)
Часть 5-Д (25)
Часть 6-А (26)
Часть 6-Б (27)
Часть 6-В (28)
Часть 6-Г (29)
Часть 6-Д (30)
Часть 7 (31)
Часть 8 (32)
Часть 9 (33)
Похожие игры
Что такое поисковые подсказки
Подсказки – варианты поисковых запросов, которые предлагает Google и «Яндекс» при вводе основного запроса. Поисковые подсказки формируются на основе реальных запросов пользователей. Например, для фразы «купить кроссовки» подсказкой будет «купить кроссовки спб женские».
Продвинем ваш бизнес
В Google и «Яндексе», соцсетях, рассылках, на видеоплатформах, у блогеров
Подробнее

Что такое LSI фразы, и чем они отличаются от подсказок
LSI-фразы – похожие по смыслу и околотематические словосочетания. Эти фразы и слова помогают поисковым роботам правильно понимать тематическое содержание текста. К примеру, для того же поискового запроса «купить кроссовки» примером LSI-фразы будет «улучшенная амортизация». Как видите, ни о каких синонимах речи вообще не идет.
Поисковые подсказки для одного и того же запроса имеют разный интент (намерение, которое пользователь вкладывает в поисковую фразу). Но их можно распределить по кластерам (смысловым группам). У LSI-фраз интент и кластеры отсутствуют.
Пример LSI-фраз и поисковых подсказок
LSI-семантика – это все семантически близкие главному ключу фразы и слова. Сюда относятся: околотематические, релевантные, синонимичные слова. Это и те слова, которые пользователи поиска указывают вместе с главным ключом.
LSI-семантика может включать в себя поисковые подсказки. Вот как такая семантика будет выглядеть для запроса «построить дачу»:

В правой колонке «Яндекс.Вордстат» обычно выводятся околотематические, похожие, переформулированные поисковые подсказки, синонимичные фразы
В качестве LSI-фраз могут выступать даже абсолютно не схожие с главной фразой слова, потому что часто к ним относятся вообще любые слова, если они достаточно часто указывались с основным запросом.
Поисковые подсказки представляют собой вариации первоначальной поисковой фразы.

Не все варианты в левом столбике являются поисковыми подсказками
Как определяется вес LSI-слов и поисковых подсказок
LSI с точки зрения математического метода – это сингулярное разложение терм документной матрицы, проще говоря: документов по конкретному запросу. Далее – определяется вес каждого термина/фразы в зависимости от их популярности в документах. По факту, полученная матрица имеет мало общего с фразами из «Вордстата» или поисковыми подсказками. Ведь эта семантика (подсказки, синонимы, околотематические слова) может иметь разный интент и полностью несовпадающие кластеры.
Поисковые подсказки указываются самими пользователями поиска и не вычисляются искусственными алгоритмами. Чем больше пользователи указывают определенную фразу с другой, тем вероятнее, что этот вариант появится в подсказках.
Зачем собирать поисковые подсказки и LSI-фразы
Главное назначение поисковых подсказок заключается в максимальном расширении семантики. Благодаря им вы можете сформировать точное представление о том, что именно пользователи ищут здесь и сейчас, а затем использовать эти данные при создании нового контента.
Поисковые подсказки можно добавлять в заголовки, подзаголовки, названия разделов. Так они будут улучшать видимость страницы по низкочастотным запросам. Правильно будет собрать подсказки в отдельный список – еще на этапе формирования семантического ядра.
LSI – словосочетания, которые нужно использовать для написания контента страницы, чтобы увеличить тематическую близость и соответствие документам из топа. Если говорить упрощенно: мы наполняем текст специальными околотематическими словами и поисковыми подсказками, чтобы поисковые системы считали нашу страницу более релевантной.
Для наглядности рассмотрим пример некачественного SEO-текста (без LSI):

Ключевое слово зачем-то выделено подчеркиванием и даже взято в кавычки. Доменное имя сайта вынесено прямо в текст. Обратите внимание на искусственность подачи материала в угоду ключевым фразам
А вот так выглядит текст, который можно построить из нескольких поисковых подсказок, околотематических фраз (всё это можно назвать LSI-семантикой):

Продающих ключей нет, а полное раскрытие темы достигается благодаря второстепенным словам, задающим тематику главной фразы – «тонировочные пленки»
Обратите внимание на текст выше: в нем присутствует большое количество дополнительной информации. Хотя и этот вариант нельзя назвать экспертным, он гораздо лучше, чем простой SEO-текст.
Не следует злоупотреблять слишком частым повторением ключей на одной странице: не нужно использовать не более 2-3 ключевых фраз на 2000 символов.
Лучше не гнаться за идеальными параметрами тошноты, водности, вхождений, а просто сделать текст по-настоящему полезным и экспертным. Наличие узкоспециализированных LSI-фраз на странице – один из индикаторов экспертности контента для поисковика
Если текст пишет эксперт, то вы автоматически получите множество LSI-фраз. Эксперт, если он знает, о чем пишет, полноценно раскроет тему и употребит все специализированные слова по теме, которые должны быть в тексте. Не нужно вписывать их специально, как в классическом SEO.
Сбор поисковых подсказок при помощи Google и «Яндекс»
Чтобы найти подсказки для единичных поисковых фраз, достаточно воспользоваться возможностями Google и «Яндекс».
Попробуем найти поисковые подсказки при помощи Google. Вводим интересующий ключ в поисковую строку и наблюдаем, какие подсказки нам предлагает поисковая система:

Поисковые подсказки Google по запросу «купить дачу». Регион – Москва
А это поисковые подсказки «Яндекса»:

Поисковые подсказки «Яндекс» по запросу «купить дачу». Регион – Москва
LSI-фразы могут встречаться и в поисковых подсказках. Здесь важную роль играет региональная привязка запроса.
При сборе околотематических фраз при помощи поисковых подсказок совсем необязательно зацикливаться только на одной поисковой системе. Попробуйте изучать подсказки сразу в обоих: такой подход позволит получить наиболее полный лист дополнительных слов.
«Вордстат» (он же «Подбор слов»)
Сервис «Яндекса» незаменим для ручного сбора поисковых подсказок. Просто введите ключ в поисковой строке:

Запросы, похожие на «купить дачу» – это разная семантика, часть из нее и есть поисковые подсказки
Таким образом, мы получили 9 околотематических фраз для выбранной поисковой фразы. При необходимости можно выделить сегменты по интересующему типу устройств:

Доступны данные по показам только для десктопов / мобильных устройств / только телефонов / только планшетов
Можно ознакомиться с историей популярности каждой подобранной подсказки:

История запросов показывает волнообразную популярность фразы
Полезными будут и данные по регионам:

Самая большая популярность – в Москве и Московской области
Сервис полностью бесплатный.
Сбор поисковых подсказок и LSI-фраз при помощи сервисов
Чтобы собрать поисковые подсказки для десятков, сотен и тысяч ключевых фраз, разумнее задействовать автоматические сервисы. Рассмотрим самые удобные из них.
Rush Analytics
Достоинство сервиса в том, что он умеет собирать поисковые подсказки не только из Google и «Яндекса», но и из YouTube. В его составе есть инструмент «Сбор подсказок», позволяющий за пару минут собрать поисковые подсказки для любого ключа:

Найти поисковые подсказки поможет инструмент «Сбор подсказок» Rush Analytics
Регистрируемся в сервисе и создаем новую задачу:

Для сбора поисковых подсказок нужно создать новую задачу
Указываем название задачи (любое) и выбираем источник поисковых подсказок – Google или Yandex:

Выбираем поисковую систему для сбора подсказок + ГЕО запроса
По желанию добавляем перебор символов алфавита. Это влияет на суммарное число собранных фраз:
")
3 единицы – наиболее глубокий вариант парсинга (настраивается в пункте меню «Глубина парсинга»)
Вот подробное объяснение всех пяти вариантов перебора:
- «ключевое слово» – подсказки по указанному ключу;
- «ключевое слово » – то же самое, но с пробелом после ключа;
- «ключевое слово [a-z]» – после пробела будут подставлены все буквы выбранного алфавита;
- «ключевое слово [a-я]» – после пробела будут подставлены все буквы русского алфавита;
- «ключевое слово [0-9]» – после пробела будут подставлены все цифры.
На следующем шаге указываем ключи – эту семантику вы ищете сами, на основе «Вордстат», например. При необходимости – вносим стоп-слова:

Ключи можно добавить вручную или загрузить файлом
Отправляем задачу в работу и ждем. Парсинг может занять различное время: от пары секунд до десятков минут, если ключей очень много.

Поисковые подсказки по фразе «купить дачу». Источник: Google и «Яндекс». Регион – Москва
Стартовый тариф обойдется в 500 рублей за месяц использования.
Serpstat
В Serpstat есть целый отчет – «Поисковые подсказки»:

Отчет по поисковым подсказкам находится в разделе «SEO-анализ»

На бесплатном тарифе доступны только 10 случайных подсказок
Удобно, что перед списком отображается топ самых популярных фраз, которые можно добавить к первоначальному ключу для расширения семантики.
В этом сервисе вы найдете одну из самых больших баз по региональным подсказкам в Рунете.
Сервис ищет поисковые подсказки как из Google, так и из «Яндекса».
Стартовый тариф обойдется в 69 $ за месяц.
Arsenkin Tools
Сервисы Александра Арсёнкина известны многим оптимизаторам. Для сбора поисковых подсказок и тематических слов там есть 2 инструмента. Сперва рассмотрим «Парсинг подсветок Yandex»:

Парсинг подсветок Yandex в Arsenkin Tools
Парсинг подсветок Yandex
Парсинг подсветок Yandex позволяет копировать весь топ-50 поисковой выдачи «Яндекса». Подсветки – слова из сниппетов, выделенные болдом (жирным), а также – дополнительные слова (их еще называют словами, задающими тематику). Таким образом, «подсветки» – это не совсем LSI, но LSI-слова могут встречаться в «подсветках».
Вернемся к сервису. При необходимости можно установить глубину проверки и топ-10 или топ-20. За один раз можно указать максимум 50 поисковых фраз. Доступен выбор региона и поисковой системы.
Переходим к подсказкам. Для их добычи Арсёнкин приготовил «Сбор поисковых подсказок в Яндексе, Google и YouTube».
Сбор поисковых подсказок в Яндексе, Google и YouTube
У инструмента есть дополнительные возможности:
- Перебор символов (по аналогии с Rush Analytics),
- Возможность расширенного парсинга по типам подсказок (местные подсказки, подсказки-отзывы, вопросительные подсказки, запросы со словом «купить»).
- Можно указать глубину (тщательность) парсинга. 1 – только базовые ключи, 2 – более широкий сбор, за счет включения средне- и низкочастотной семантики, 3 – самый полный метод сбора.

Парсер поисковых подсказок Arsenkin выделяется наличием дополнительных настроек
Благодаря инструменту Арсёнкина можно за считанные секунды собрать подсказки не только из «Яндекса», но и из Google, а также YouTube:

Поисковые подсказки для фразы «построить дачу». Регион – Москва
Стартовый тариф сервиса обойдется в 549 рублей за месяц использования.
JustMagic
«Акварель-генератор» – инструмент, позволяющий находить LSI-фразы и поисковые подсказки в два клика. Выбираем поисковую систему (поддерживается Google и «Яндекс):

Указываем поисковую систему, язык запроса и вставляем проверяемые фразы
Преимущество «Акварель-генератора» в том, что сервис позволяет проверить до 500 фраз за один раз.
Фразы даже для одного ключа «Акварель-генератор» искал довольно долго – более минуты. Зато здесь мы бесплатно получили самый большой список околотематических слов по сравнению со всеми сервисами, которые мы разбирали сегодня:

Результат задачи для фразы «построить дачу»
Для каждой фразы «Акварель-генератор» показывает индекс релевантности, который выводится с учетом всех слов присутствующих в поисковой фразе. Чем выше индекс релевантности, тем фраза ближе главному ключу.
Сервис платный, и проверять большое количество фраз без подписки невыгодно. Стартовая подписка обойдется в 1000 рублей за месяц использования.
Key Collector
Мощный инструмент для составления семантического ядра и дальнейшей оптимизации. Понять масштаб Key Collector можно просто взглянув на его интерфейс:

Интерфейс Key Collector
Вот основные возможности инструмента:
- выявляет сложность ключа (она же конкурентность);
- дает рекомендации по созданию перелинковки;
- помогает определять конкурирующие домены;
- выявляет сезонный фактор;
- кластеризует любые запросы;
- собирает подсказки.
Key Collector имеет один из лучших парсеров, который я видел в таких сервисах. Есть поддержка прокси. А еще можно определять ориентировочную цену ключей, анализировать их популярность, делать массовый съем позиций существующих страниц.
Удобно работать с группами фраз – в Key Collector для этого есть специальный раздел и несколько инструментов.
Но сейчас нас интересуют только поисковые подсказки.
- Открываем вкладку «Парсинг»:

- Для быстрого сбора подсказок нужно кликнуть по этой иконке:

- Теперь указываем, откуда именно собираем подсказки: Yandex, Google, Mail.ru. Подтверждаем выбор.
- Откроется новое окно. Здесь нужно добавить поисковые фразы в активную группу:

- Нажимаем «Далее» и запускаем парсер. Ждать можно от нескольких секунд до нескольких минут (смотря сколько у вас фраз):

Когда задача парсинга будет завершена, вы получите длинный лист поисковых подсказок для выбранной вами поисковой системы:

Лицензия обойдется в 2200 рублей (навсегда).
Заключение
Что делать с поисковыми подсказками? Во-первых, можете начать мониторинг популярности самых разночастотных запросов. Изучайте динамику их актуальности, а самые перспективные (по частотности) добавляйте в семантическое ядро. Во-вторых, можно оптимизировать непопулярные страницы с учетом релевантных подсказок и попытаться привлечь трафик таким методом. В-третьих – создавать абсолютно новые страницы за счет расширения уже существующей семантики.
Как часто обновлять и проверять подсказки? Чем чаще, тем лучше. Хотя бы 2 раза в месяц делать это точно не помешает. Так вы сможете вовремя заметить тренды и отразить их в своем контенте.

Игра “Одним словом – Словосочетания” в Одноклассниках, ВКонтакте.
Где найти ответы, подсказки и прохождение игры “Одним словом – Словосочетания”.

Многие ответы для игры “одним словом можно посмотреть здесь: Ответы на игру “одним словом”
Но ответы надо искать глядя на картинку, так как уровни в игре не постоянны и перемешиваются в хаотичном порядке. например у меня это был первый уровень ответ на который “Газ”

система выбрала этот ответ лучшим
N I K o l a
[76.6K]
9 лет назад

Все ответы к игре “Одним словом – Словосочетания” вы найдете на этом игровом портале. Только вот есть одна загвоздка, задания в игре “Одним словом” перемешаны, и поэтому искать ответы с подсказками придется не по уровням, а по картинкам. В разделах “Одним словом: Что общего, Ребусы, Ассоциации, Что спрятано, Антонимы” обновлений пока не было.

Ниннелль
[35.6K]
9 лет назад
Ответы ко многим играм есть в интернете, можно поискать ответы к игре “Одним словом” на сайте Большой вопрос – в строку поиска списывайте номер уровня, а еще лучше словами то, что видите на картинках, тогда ответ вам выдаст автоматически поисковик. А можно еще на портал зайти и там найти нужный ответ.
Но на мой взгляд пользоваться подсказками надо в самом крайнем случае, а то играть неинтересно будет.

Нэпэйшни
[18.2K]
9 лет назад
Честно говоря ища ответы на загадки,теряется смысл таких игр.Которые доставляют удовольствие только после собственной разгадки.Но иногда это необходимо если например попадается оч. сложный вопрос на котором застреваешь.Очень много ответов на подобные можно найти на этом же форуме или тут

Leona-100
[110K]
9 лет назад
Думаю самым оптимальным способом искать ответы на популярную игру “Одним словом – Словосочетания” в социальной сети “Одноклассники” будет на нашем любимой сайте Большой вопрос. Ведь именно здесь регулярно появляются и обновляются вопросы и ответы посвященные этой игре.

-Ежик-
[20.8K]
9 лет назад
К игре “Одним словом-сочетания” в Одноклассниках все,Вас интересующие, ответы на вопросы можно найти вот на этом портале.Но сначала попробуйте найти решение сами.Это очень интересно и познавательно.Позволит испытать удовольствие от игры,не банально все списать.

Асюшка
[101K]
9 лет назад
http://branto.ru/
Вот по этой ссылочке можно пройти и найти все ответы на интересующие уровни игры: ОДНИМ СЛОВОМ – СЛОВОСОЧЕТАНИЯ.
Однако помните, играть без подглядываний в готовые ответы, куда интереснее, чем списывание ответов. Удачи в игре!

Tvoy NLO
[22.3K]
9 лет назад
Игра “Одним словом – Словосочетания” в Одноклассниках, ВКонтакте.
Ответы и прохождение к этой игре можно найти, например, на этом сайте.
Также ответы можно поискать и на сайте “Большой вопрос”, указав в тегах название игры.
Знаете ответ?
Здравствуйте!
Поисковые подсказки – ценный источник ключевых слов при работе с семантическим ядром. И дополнительный ресурс для привлечения целевого трафика. Очевидно, что сбор поисковых подсказок делать нужно и не один раз. А вот про то, как это можно сделать, и как их потом использовать, расскажем в статье.
топ сервисов
Поисковые подсказки можно собирать вручную, но такой способ оправдан, если требуются сбор по 1–2 фразам. В остальных случаях лучше упростить себе жизнь и автоматизировать процесс при помощи разных сео инструментов.
Для этого есть не только специальные онлайн сервисы с помесячной оплатой, но и программы с лицензией. Мы собрали их в таблицах ниже.


![]()
Как собирать подсказки
Прежде чем перейду к руководству, напомню, как формируются подсказки. Поисковые системы либо генерируют подсказки в зависимости от вида запроса, либо выбирают готовые из своей базы данных, она существует отдельно от ключевых запросов.
 По одним и тем же ключевым фразам могут показываться разные подсказки. На их формирование влияет множество факторов, самые значимые это:
По одним и тем же ключевым фразам могут показываться разные подсказки. На их формирование влияет множество факторов, самые значимые это:
- Частотность. Самые популярные хвосты запросов отображаются чаще;
- Актуальность. Особенно важно для новостей. Свежие и актуальные запросы выводятся первыми;
- Местоположение. Поисковики стараются не показывать подсказки из других регионов;
- Персонализация. Учитывается история поиска и интересы пользователя;
- Разнообразие. Могут подмешиваться варианты из разных тематик, чтобы максимально попасть в запрос пользователя.
Все они могут быть Вам полезны при работе с собственным ядром. Поэтому, еще раз, собирать подсказки важно и нужно. В сервисах это делается по одинаковому алгоритму. Чтобы рассмотреть его подробнее, разберу сбор поисковых подсказок на примере топового сервиса ПиксельТулс.
Шаг 1. Добавление ключевых слов
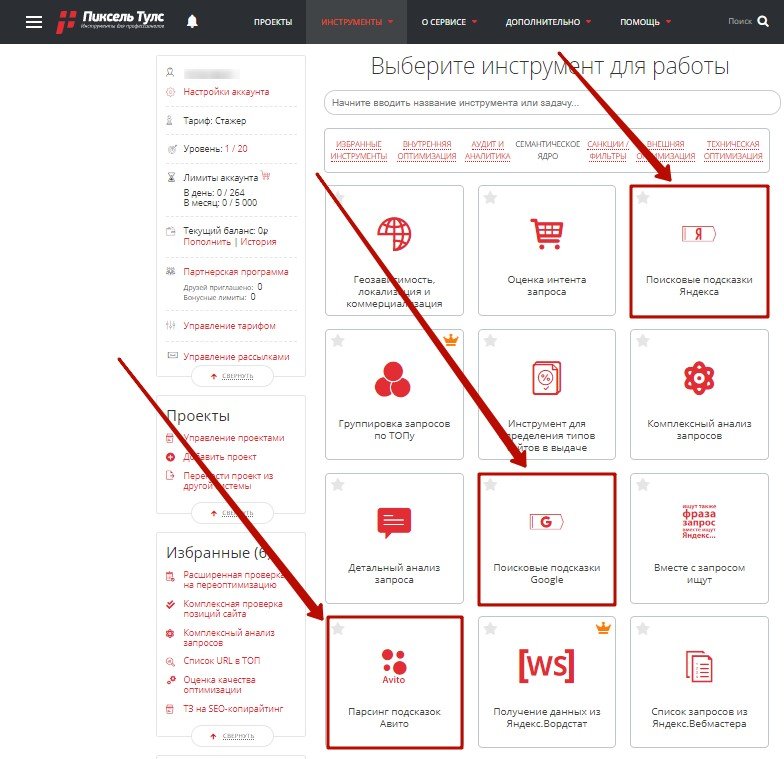 Чтобы начать работать, перейдите во вкладку “Инструменты”. В сервисе предусмотрены отдельные инструменты для работы с подсказками в поисковых системах Яндекс, Google, а также для сайта Авито.
Чтобы начать работать, перейдите во вкладку “Инструменты”. В сервисе предусмотрены отдельные инструменты для работы с подсказками в поисковых системах Яндекс, Google, а также для сайта Авито.
Выбор поисковой системы
После выбора поисковой системы или сайта, добавьте исходные запросы. За 1 операцию сервис может обрабатывать до 25 фраз, только обязательно пишите каждую с новой строки.
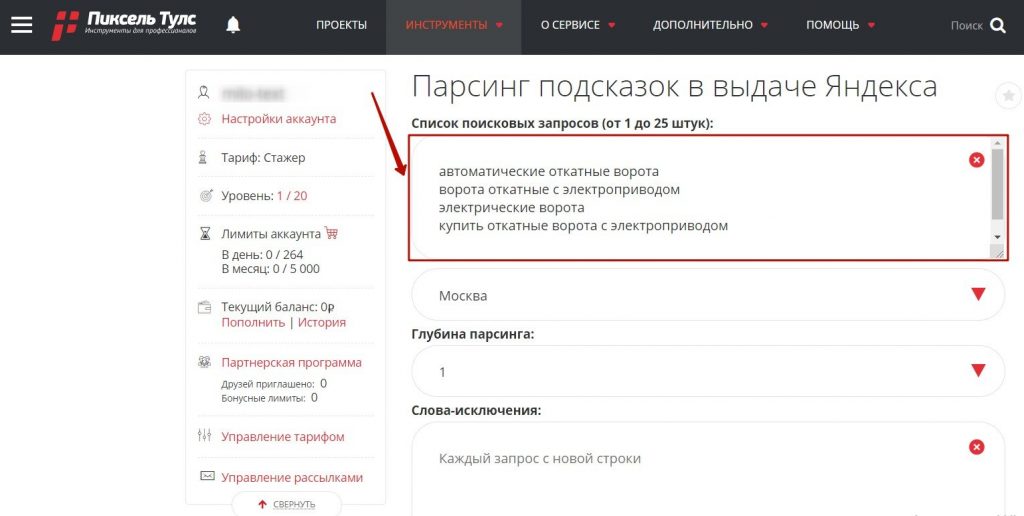
Поисковые запросы
Шаг 2. Настройка региона парсинга
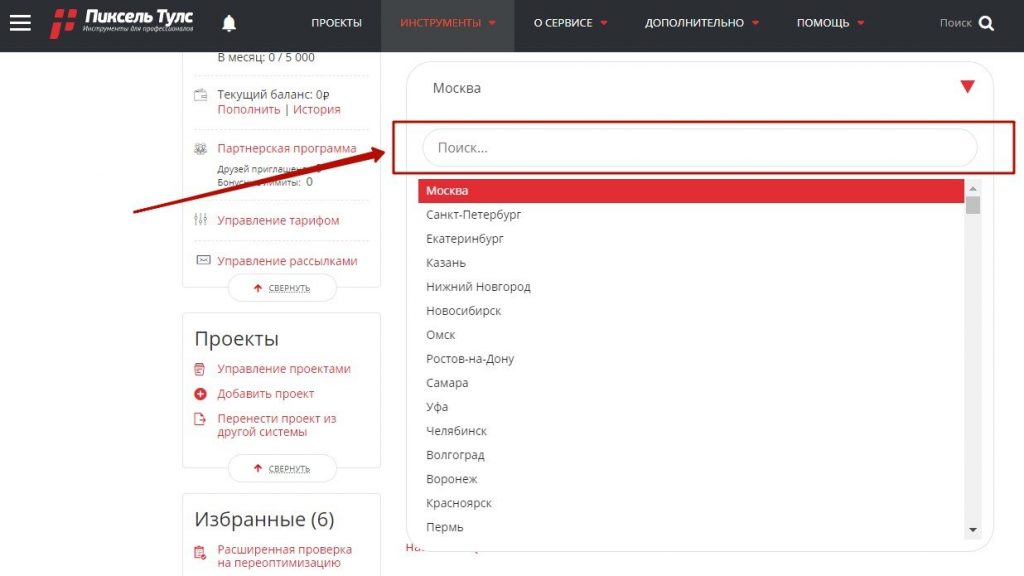 В инструменте для Яндекса можно настроить региональность, доступны все регионы России и соседних стран.
В инструменте для Яндекса можно настроить региональность, доступны все регионы России и соседних стран.
Выбор региона
Для Google настраиваются только страны, можно выбрать нужную локальную версию поисковика в пункте “Поисковая система”.
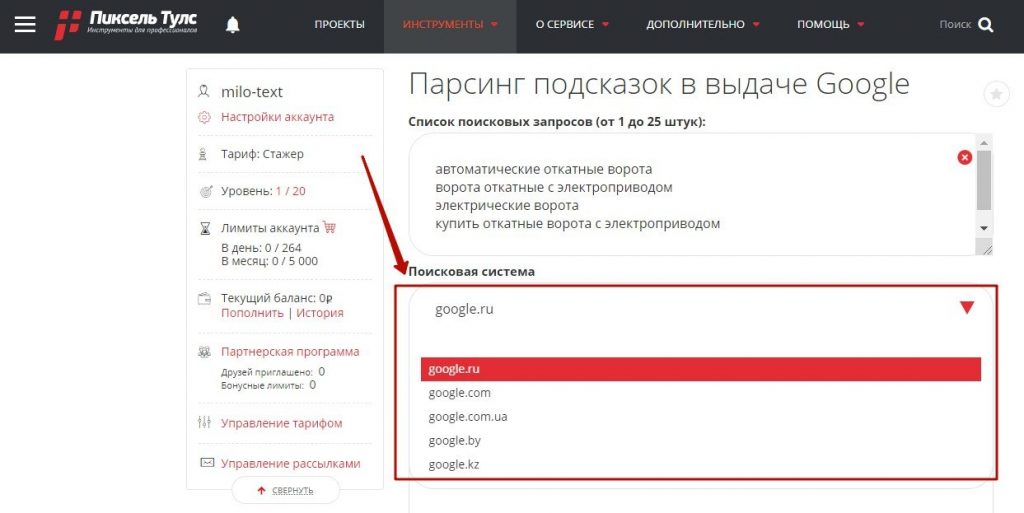
Выбор поисковой системы
Шаг 3. Настройка глубины сбора
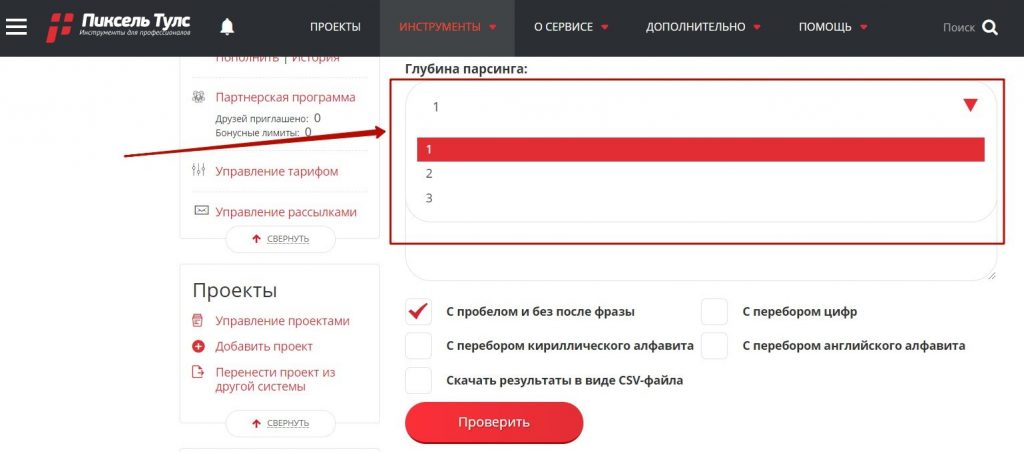 Далее задайте глубину парсинга, в сервисе она от 1 до 3. При глубине 1 – подсказки будут собираться только по исходным фразам, при 2 – сначала соберутся подсказки по имеющимся ключевым фразам, а после – дополнительно подсказки к уже полученным, а при 3 – Вы получите подсказки по исходному списку, плюс фразы после парсинга первого уровня и дополнительные подсказки уже к ним.
Далее задайте глубину парсинга, в сервисе она от 1 до 3. При глубине 1 – подсказки будут собираться только по исходным фразам, при 2 – сначала соберутся подсказки по имеющимся ключевым фразам, а после – дополнительно подсказки к уже полученным, а при 3 – Вы получите подсказки по исходному списку, плюс фразы после парсинга первого уровня и дополнительные подсказки уже к ним.
Настройка глубины
– При глубине 1. Найдено 40 подсказок Яндекс.
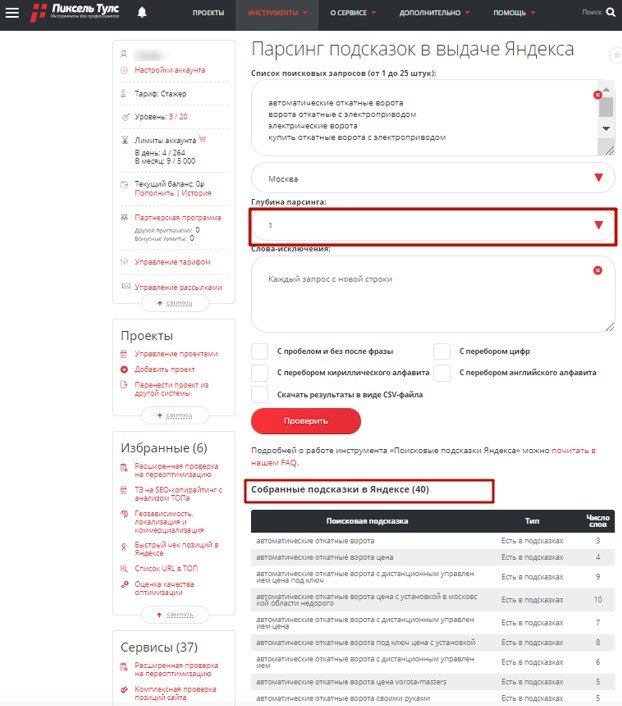
Глубина 1
– При глубине 2. Найдено 163 подсказки Яндекс.
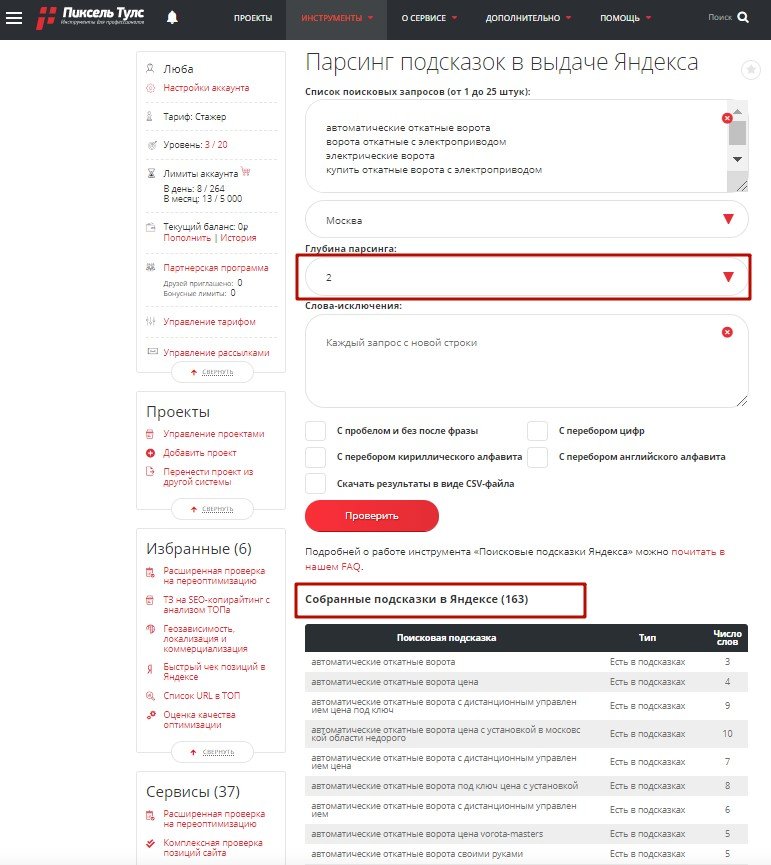
Глубина 2
– При глубине 3. Найдено 245 подсказок Яндекс.
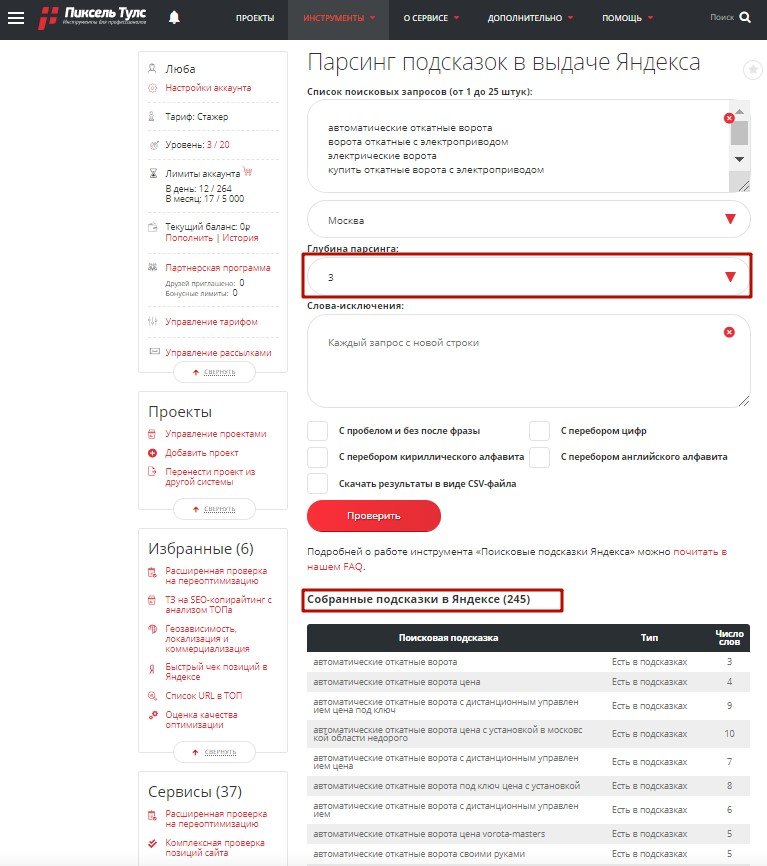 Глубина 3
Глубина 3
В большинстве случаев достаточно глубины 1. Уровень 2 позволяет сильно расширить семантику, ну а 3 – самый продвинутый вариант, для максимального охвата семантики. Подходит для крупных сайтов и сложных узких тематик, поскольку в результате получатся тысячи фраз, которые потом придется проверять и чистить от нерелевантных.
Шаг 4. Слова-исключения
В специальном поле задайте стоп-слова, по которым не будут собираться подсказки.
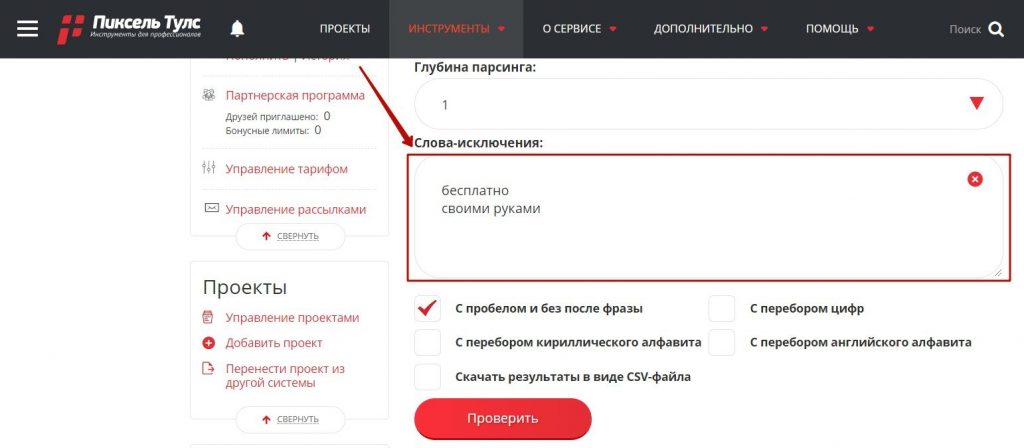
Стоп-слова
Шаг 5. Выбор способов сбора
 По умолчанию система собирает подсказки только по заданным фразам. Но Вы можете активировать другие опции (ниже). Например, до активации дополнительных способов сбора фраз в Яндексе нашлось 40 подсказок. Но если использовать некоторые опции, выходит аж 669.
По умолчанию система собирает подсказки только по заданным фразам. Но Вы можете активировать другие опции (ниже). Например, до активации дополнительных способов сбора фраз в Яндексе нашлось 40 подсказок. Но если использовать некоторые опции, выходит аж 669.
- C пробелом и без после фразы. Пользователи вводят запросы не всегда прибегая к пробелам;
- С перебором цифр. Тогда к каждой фразе будет добавлен пробел и поочередно цифры от 0 до 9;
- С перебором кириллицы. К каждой фразе будет добавлен пробел и поочередно 29 букв русского алфавита без “ь, ъ, ё, ы”;
- С перебором английского алфавита. Будет добавлен пробел и по очереди 26 букв латинского алфавита.
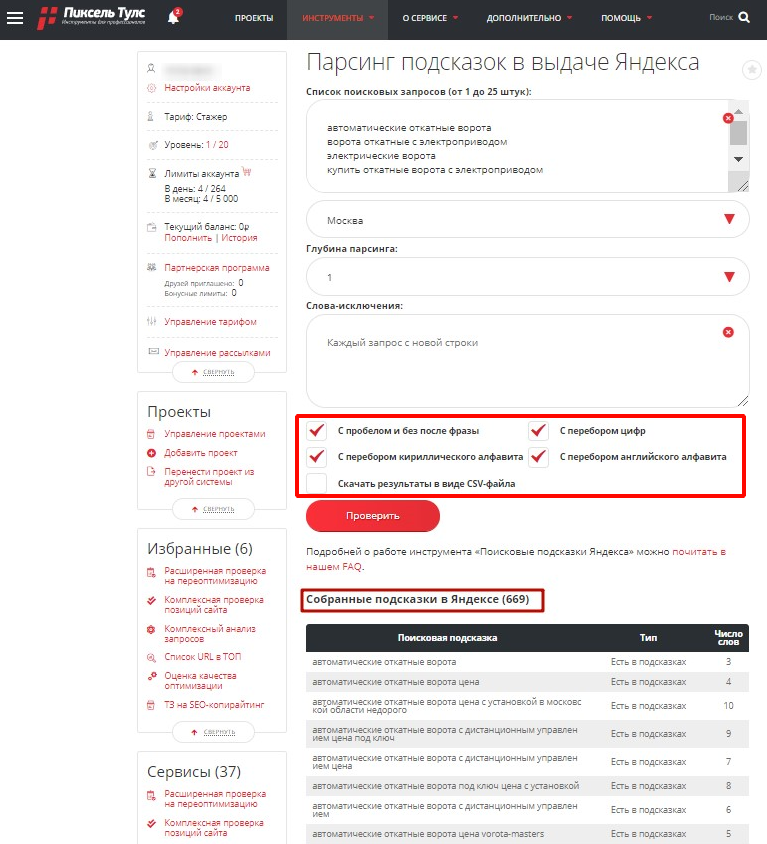 Способ сбора
Способ сбора
Проверка занимает всего несколько минут. Она позволяет быстро перебрать все возможные варианты ключевых запросов и ничего не упустить.
Шаг 6. Получение результата
Данные обрабатываются в фоновом режиме. Результат доступен прямо в личном кабинете, а для дальнейшей работы Вы можете скачать его в виде scv-файла.
Результаты
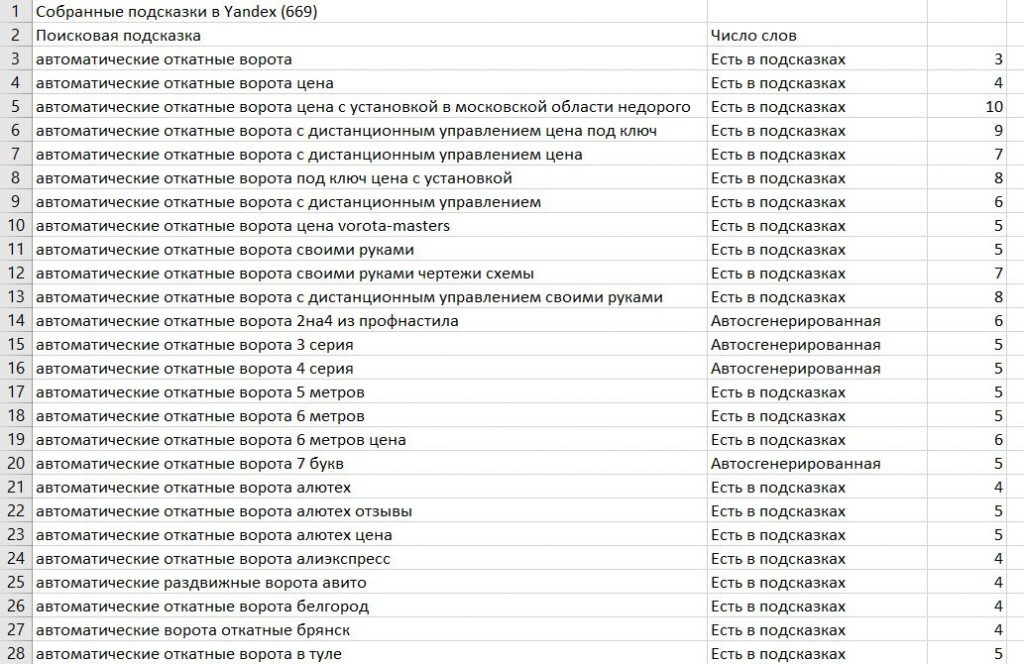 Когда файл с поисковыми подсказками готов, пройдитесь по списку и удалите нерелевантные запросы. Далее объедините оставшиеся ключевые фразы с исходными на одном листе, кластеризуйте их, и у Вас получится семантическое ядро, с которым уже можно работать.
Когда файл с поисковыми подсказками готов, пройдитесь по списку и удалите нерелевантные запросы. Далее объедините оставшиеся ключевые фразы с исходными на одном листе, кластеризуйте их, и у Вас получится семантическое ядро, с которым уже можно работать.
Шаг 7. Использование результатов
Далее Вы можете использовать популярные подсказки при составлении контент-плана и написании статей. В частности оптимизировать структуру, добавляя прямые вхождения в мета-теги и тексты.
Кроме того, сможете создать максимально полное семантическое ядро и привлечь дополнительных целевых посетителей из поисковых систем и поймать максимально актуальный, сезонный трафик.
Главная ценность подсказок в том, что можно найти ключи, которых еще нет в Wordstat. В том числе трафиковые запросы, по которым нет конкуренции вообще, либо она низкая. Удачное использование подсказок может повысить популярность сайта и поднять его в выдаче.
 Важно. Будьте внимательны с частотностями. Обычно при чистке семантики проверяются частотности запросов и нулевые убираются. С подсказками это может не сработать – они обновляются чаще, чем статистика Wordstat. Соответственно хорошие, популярные запросы с низкой конкуренцией могут иметь 0 просто потому, что еще не успели попасть в базу Wordstat.
Важно. Будьте внимательны с частотностями. Обычно при чистке семантики проверяются частотности запросов и нулевые убираются. С подсказками это может не сработать – они обновляются чаще, чем статистика Wordstat. Соответственно хорошие, популярные запросы с низкой конкуренцией могут иметь 0 просто потому, что еще не успели попасть в базу Wordstat.
Лайфхаки
 Чтобы Ваша работа по сбору поисковых подсказок проходила эффективнее, мы оставим здесь простые советы, как выжать максимальное количество подсказок из Вашей семантики.
Чтобы Ваша работа по сбору поисковых подсказок проходила эффективнее, мы оставим здесь простые советы, как выжать максимальное количество подсказок из Вашей семантики.
- Подсказки для разных словоформ одного и того же запроса отличаются. Используйте разные падежи, числа, лица и т.д. Например, “торт” – будут названия, “торты” – где заказать;
- Для брендов лучше указывайте и латинское, и кириллическое написание – так соберется больше подсказок. Например, “Ин скейл” и “In-scale”;
- Добавьте синонимы и схожие по смыслу слова. К примеру, “монтаж” и “установка”, “продвижение” и “раскрутка” и т.д. Словарный запас пользователей разный;
- При сборе подсказок для информационных сайтов, используйте маркеры типа “как”, “что”, “почему”, “лучший” и т.д., чтобы отсечь коммерческие ключи уже на начальном этапе;
- Соответственно, в подсказках для коммерческих сайтов, информационные маркеры добавьте в список слов-исключений. А заменить их можно “купить”, “заказать”, “продать” и т.п.;
- Чем яснее интент, тем меньше чистить подсказки от нерелевантных. Например, “Samsung” хуже, чем “телевизоры Samsung”, поскольку бренд выпускает и другие товары;
- Подсказки обновляются часто, как и меняются запросы пользователей, поэтому регулярно проверяйте их и актуализируйте.
коротко о главном
Поисковые подсказки отражают реальные, свежие и популярные запросы пользователей. Это полезный дополнительный ресурс для сбора или расширения семантики, так как используя их, Вы создаете на сайте материал, который действительно интересует людей.
 Соответственно, растет полезность для пользователя и релевантность ресурса для поисковиков. Отдельный плюс в том, что с помощью инструментов это можно сделать очень быстро. Напоследок оставлю топ самых:
Соответственно, растет полезность для пользователя и релевантность ресурса для поисковиков. Отдельный плюс в том, что с помощью инструментов это можно сделать очень быстро. Напоследок оставлю топ самых:
- ПиксельТулс;
- Keys.so;
- Rush Analytics.
Поисковые подсказки изнутри
Время на прочтение
11 мин
Количество просмотров 26K
Ночная зала. Тысячи таинственных ликов в темноте, подсвеченных голубоватым свечением мониторов. Оглушительный треск миллиона клавиш. Подобные выстрелам автомата удары по клавишам «Enter». Зловещее стрекотание сотен тысяч мышек… Так, наверняка, играло воображение каждого разработчика высоконагруженной системы. И если его вовремя не остановить, то может выйти целый триллер или фильм ужасов. Но в данной статье мы будем гораздо ближе к земле. Мы кратко рассмотрим известные подходы к решению задачи поисковых подсказок, как мы научились делать их полнотекстовыми, а также расскажем о парочке уловок, на которые мы пошли, чтобы придать им скорости, но при этом не научить жадности к ресурсам. В конце статьи вас ждёт бонус — небольшой рабочий пример.
Что должно быть «под капотом»?
- Поиск по подсказкам должен быть полнотекстовым, то есть должен уметь искать по текстам подсказок все слова из пользовательского запроса в любой их последовательности. Например, если пользователь ввёл запрос «смотреть», а в базе мы располагаем следующими подсказками:

то пользователь должен увидеть все три, несмотря на то, что слово «смотреть» находится в разных местах этих подсказок.
- Запрос пользователя может быть неполным, пока набирает его на клавиатуре. Поэтому искать нужно не по словам, а по их префиксам. Для предыдущего примера мы должны увидеть все три подсказки не только по целому слову «смотреть», но и для любой его префиксной части. Например, «смотр».
- Поиск Mail.Ru — поисковик общего назначения, а значит разнообразие возможных запросов велико, и система должна уметь искать среди десятков миллионов подсказок.
- Скорость реакции крайне важна, поэтому мы хотим выдавать ответ за считанные миллисекунды.
- Наконец, сервис должен быть надёжной системой, работающей в режиме 24/7/365. Со всей России и стран СНГ наши подсказки ежесекундно обрабатывают тысячи запросов. Для отказоустойчивости, а, следовательно, ради простоты реализации и отладки, нам крайне желательно иметь в основе сервиса некую идею, которая была бы крайне проста и элегантна.
Известные подходы
1. Префиксное автодополнение
a. Подсказки с весами (вес == популярность) сортируются в лексикографическом порядке по текстам подсказок.
b. Когда пользователь вводит запрос (префикс), бинарным поиском находится подмножество подсказок, начало которых удовлетворяет этому префиксу.
c. Найденное подмножество сортируется по убыванию веса, а ТОП самых «тяжёлых» подсказок отдаётся пользователю в качестве результата.
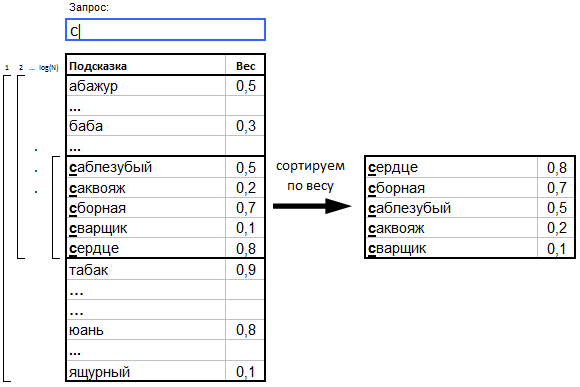
Очевидной оптимизацией такого подхода является Patricia Tree с весами в узлах дерева. При выборе самых «тяжёлых» запросов, как правило, используется очередь с приоритетами, либо segment tree, что даёт логарифмическое время поиска. При желании можно потратить память сервера, использовав алгоритм LCA via RMQ, и тогда мы получим очень быстрые префиксные подсказки. Плюсов у этого подхода целых три: скорость, компактность и простота реализации. Однако очевидным и самым неприятным недостатком является невозможность искать перестановки слов по текстам подсказок. Иными словами, такие подсказки будут лишь префиксными, а не полнотекстовыми.
2. Полнотекстовое автодополнение
a. Тексты подсказок и запрос пользователя рассматривается как последовательность слов.
b. Когда пользователь вводит запрос, в базе ищется подмножество подсказок, которые содержат все слова пользователя (а точнее, префиксы) вне зависимости от их позиции в подсказке.
c. Найденное подмножество сортируется по убыванию соответствия слов подсказки к словам запроса, затем по убыванию веса, и пользователю возвращается ТОП самых «тяжёлых».

Собственно, это и есть полнотекстовый подход, о котором будем говорить далее. По этой теме в интернете доступно обширное количество публикаций отечественных и зарубежных авторов. Например:
- Реализация нечёткого поиска — автор реализовал поисковые подсказки по названиям баров, ресторанов и прочих заведений, совмещённые с исправлением опечаток. Так как подсказок было всего ~2.5 тысячи, то достаточно оказалось искать перебором по всем подсказкам алгоритмом Вагнера-Фишера, модифицированного под поиск по префиксам слов. Метод качественный, но не подходит нам по причине низкой скорости.
- TASTIER approach — live-поиск по статьям, находит не только точное соответствие, но и связанные по теме публикации. Хранит контекст пользователя в оперативной памяти, чтобы адаптировать его по мере ввода пользовательского запроса, что довольно затратно по памяти и пагубно для скорости.
- Sphinx Simple autocomplete and correction suggestions — автодополнение на базе известного открытого поискового движка Sphinx. Основная идея автодополнения — использование wildcard’а в языке запросов MySQL: «the wor*». Исправление опечаток — на основе n-gram’ного подхода. Разумеется, такой поиск не совсем то, что нам нужно: ведь пользователь не обязательно набирает последнее слово; а как показывает практика, пользователь может вводить слова запроса как угодно, в любой последовательности. Кроме того, n-gram’ный подход потребует много ресурсов, чтобы применить его в real-time подсказках.
Приведённые выше и прочие не рассмотренные здесь подходы не удовлетворили нас по сочетанию: экономичность + скорость + простота. Поэтому мы разработали свой алгоритм, который соответствует нашим потребностям.
Формальная постановка задачи
Перед описанием алгоритма сформулируем нашу задачу более формально. Итак, дано:
- Множество текстов подсказок S = {s1, s2, …, sN}, каждый из которых состоит из слов W(si) = {wi1, wi2, …, wiK}. Тексты подсказок мы получаем из логов запросов, которые пользователи задают нашей поисковой системе.
- Множество весов популярности подсказок F = {f1, f2, …, fN}. Под популярностью здесь мы будем понимать частоту употребления конкретного запроса, то есть как часто пользователи ищут что-то в нашей поисковой системе по данному запросу.
- Неполный пользовательский запрос, состоящий из упорядоченной последовательности префиксов Q = {p1, p2, …, pM}. Как мы уже сказали выше, запрос пользователя мы рассматриваем именно как последовательность префиксов, так как запрос может быть неполным.
Требуется:
- Найти множество R всех подсказок si из S, таких, что каждому префиксу pj из Q соответствует одно уникальное слово wk из W(si).
- Упорядочить найденное множество подсказок R по двум критериям:
- по убыванию соответствия порядка слов wk из W(si) порядку префиксов pi из пользовательского запроса Q;
- по убыванию веса популярности fl из F подсказок si из R.
Индекс
Так как нам нужен полнотекстовый поиск по подсказкам, то и в основу нашего индекса лёг классический подход к реализации полнотекстового поиска общего назначения, на котором базируется любой современный веб-поисковик. Полнотекстовый поиск в общем случае ведётся среди так называемых документов, то есть текстов, внутри которых мы хотим искать слова из запроса пользователя. Суть же алгоритма сводится к двум простым структурам данных, прямому и обратному индексам:
- прямой индекс — список документов, в котором можно найти этот документ по его id. Иными словами, прямой индекс — это массив строк (вектор документов), где id документа — это его индекс.

- обратный индекс — список слов, которые мы «выпотрошили» из всех документов. За каждым словом закреплён список отсортированных id документов (posting list), в которых это слово встретилось.
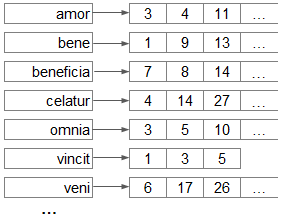
По этим двум структурам данных достаточно легко найти все документы, удовлетворяющие пользовательскому запросу. Для этого нужно:
- В обратном индексе: по словам из запроса найти списки id тех документов, где эти слова встречались. Получить пересечение этих списков — результирующий список id документов, где встречаются все слова из запроса.
- В прямом индексе: по полученным id найти исходные документы и «отдать» их пользователю.
Описанного вполне достаточно для данной статьи, поэтому за подробностями о поиске мы отправляем вас к книге Стэнфордского университета «An Introduction to Information Retrieval».
Классический алгоритм прост и хорош, но в чистом виде он неприменим к подсказкам, ведь слова в запросе в общем случае являются «незаконченными». Или, как мы сказали выше, запрос состоит не из слов, а скорее из префиксов. Для решения этой проблемы мы доработали обратный индекс, и вот что у нас получилось:
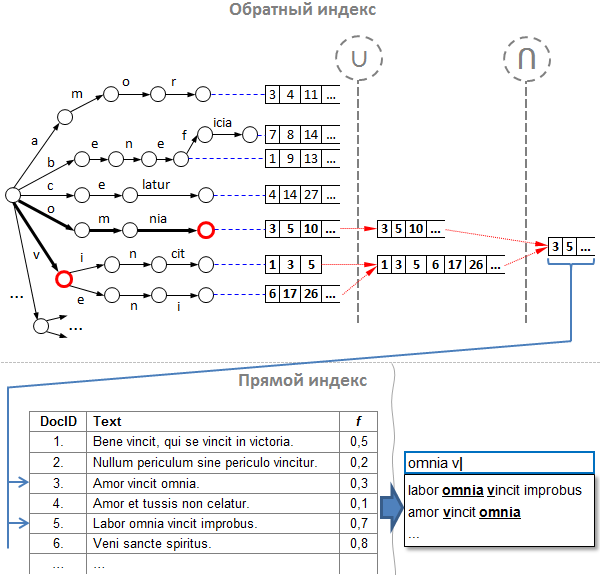
Прим: на рисунке здесь и далее для краткости некоторые узлы дерева «слиты» в один переход из нескольких символов.
Разберём поиск по индексу на примере:
- Предположим, что в нашем распоряжении есть указанный выше индекс, и пользователь уже ввёл часть запроса. Следующая введённая буква на клавиатуре, и вот мы получили неполный запрос «omnia v».
- Разбиваем запрос на слова-префиксы: получаем «omnia» и «v».
- По аналогии с поисковой системой, сначала по заданным словам-префиксам находим списки id подсказок в обратном индексе. Обратим внимание, что наш обратный индекс состоит из двух частей:
a. префиксное дерево (оно же «trie», оно же «бор»), содержащее слова, которые мы «выпотрошили» из текстов подсказок;
b. списки id подсказок — индексы текстов подсказок в прямом индексе, о котором речь пойдёт ниже. Списки отсортированы по возрастанию значения id и находятся в тех вершинах, где заканчиваются слова.
Надо сказать, что trie хорош для нас по двум причинам:- по нему можно найти любой префикс слова за время O(log(n)), где n — длина префикса;
- для заданного префикса легко определить все варианты его продолжений.
Итак, для каждого префикса углубляемся вниз по дереву и оказываемся в промежуточных узлах. Теперь нужно получить правильные списки id подсказок.
- Объединяем списки всех дочерних узлов. Для чего? По аналогии с обычным поисковиком, мы должны бы пересечь списки id для каждого префикса, однако есть два «НО»:
a. во-первых, не всякий узел содержит список id подсказок, а только те узлы, в которых закачивается целое слово;
b. а во-вторых, каждый узел дерева имеет некое продолжение, за исключением листовых узлов. Это значит, что продолжений у одного префикса может быть целое множество, и эти продолжения нужно учесть.
Поэтому, прежде чем найти пресечение, нужно «просуммировать» списки id подсказок для каждого отдельно взятого префикса. Таким образом, для каждого префикса обходим дерево рекурсивно в глубину, начиная с того узла, где мы остановились в дереве по данному префиксу, и конструируем объединение всех списков его дочерних узлов алгоритмом слияния. На рисунке узлы, в которых мы остановились по префиксу, помечены красным кружком, а операция объединения помечена значком «U». - Теперь пересекаем синтетические списки-объединения каждого из префиксов. Надо сказать, что различных алгоритмов пересечения сортированных списков просто море, и каждый подходит больше для различных типов последовательностей. Один из самых эффективных — алгоритм Рикардо Баеза-Ятеса и Алехандро Салингера. В боевых подсказках мы используем свой алгоритм, который наиболее подходит для решения конкретной задачи, однако алгоритм Баеза-Ятеса-Салингера был для нас в своё время вдохновляющим.
- Теперь по найденным id ищем тексты подсказок. Прямой индекс в нашем случае ничем не отличается от прямого индекса любой поисковой системы, то есть представляет собой простой массив (вектор) строк. Кроме текстов подсказок здесь может быть любая дополнительная информация. В частности, здесь мы храним веса популярности.
Итак, к концу шестого этапа мы уже имеем все подсказки, в которых есть все префиксы из пользовательского запроса. Очевидно, что на деле количество подсказок, которые мы получаем к этому этапу, может быть очень много — тысячи или даже сотни тысяч, а «подсказать» пользователю нам нужно только лучшие. Такую задачу решает другой алгоритм — алгоритм ранжирования.
Далее мы рассмотрим один маленький приём, который позволит нам «наполовину» отранжировать подсказки, ровным счётом ничего не делая. И об этом мы поговорим ниже, по ходу рассмотрения двух проблем.
Ускоряемся
«Преждевременная оптимизация — корень всех зол» — твердит народная программистская мудрость, сформулированная Дональдом Кнутом. Но если мы реализуем приведённый выше алгоритм в чистом виде, то отхватим две проблемы с производительностью. Поэтому для нас отсутствие борьбы за скорость будет тем ещё злом.
Проблема первая — медленное объединение списков. Рассмотрим эту проблему подробнее:
- Предположим, в нашем дереве (трае) уже лежит 1000 слов, начинающихся на букву «а» (в реальной ситуации таких слов ещё больше).
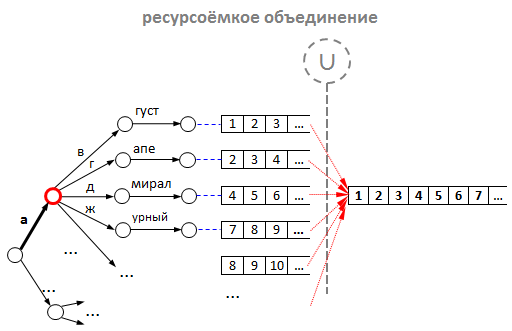
- Очевидно, что для 1000 слов минимальное среднее количество id подсказок будет также около 1000. То есть в среднем будет минимум 1000 подсказок, в которых есть слова, начинающиеся на букву «а».
- Теперь представим, что пользователь решил поискать что-нибудь на эту букву «а». По нашему алгоритму, для префикса «а» начинается операция объединения списков для всех дочерних узлов, которые лежат ниже узла «а». Очевидно, эта операция потребует приличных ресурсов: во-первых, на выделение памяти под новый список, а во-вторых, на копирование id в этот новый список.
Объединение можно оптимизировать использованием двух приёмов:
- зарезервировать память для итогового списка, дабы не выделять её при каждом новом запросе;
- производить объединение «ленивым» образом, то есть по мере необходимости.
Однако наши эксперименты показали, что любые ухищрения с объединением не идут ни в какое сравнение с оптимизацией за счёт кэширования. Да-да, мы просто стали складывать id подсказок в каждый узел дерева, а не только в листовые вершины. Итого: нет необходимости в объединении — готовые списки для каждого возможного префикса лежат прямо в узлах дерева. А наш обратный индекс приобрёл следующий вид:
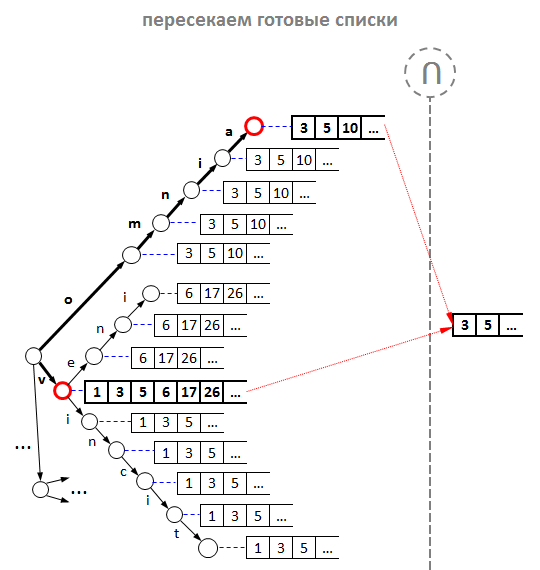
Но стойте! В каждый узел дерева класть id подсказки?! Выглядит крайне расточительно, не правда ли? Но так ли это расточительно? Рассуждаем:
- Для каждой новой подсказки, нам придётся добавить её id столько раз, сколько символов содержится в её тексте. Это в худшем случае, так как для пробелов id добавлять не нужно, а для повторяющихся слов («винни пух и все
все все») повторно добавлять id тоже нет необходимости. - Например, при средней длине подсказки в 25 символов 1 миллион поисковых подсказок содержит 25 млн. символов. А если id подсказки — это 4-байтовое целое (стандартный int), то в худшем случае все списки id подсказок в обратном индексе займут в памяти: 4 байт * 25 000 000 = 100 Мбайт. А такой объём, очевидно, не так уж и расточителен, даже для обычной персоналки. Пропорционально, для 50 миллионов подсказок индекс займёт 5 Гбайт, что для полномасштабного сервиса поисковых подсказок вполне уместно.
Итак, проблему объединения списков мы решили путём кэширования всех списков для каждого возможного префикса.
Проблема вторая — медленное пересечение списков и ранжирование (сортировка) подсказок по весу. По нашему алгоритму после объединения следует два важных этапа, и каждый имеет проблемы с производительностью:
- Пересечение объединённых списков. В большой базе реальные списки слишком длинные, особенно для коротких префиксов. Поэтому пересечение списков для коротких запросов, как «а б», будет слишком долгим.
- Ранжирование подсказок, прежде всего, по убыванию веса. Итоговый список после пересечения может быть также довольно большим, поэтому сортировать тысячи id, как для запроса «а б», тоже оказывается накладно.
Помня, что для результата нам нужно всего-то 7-10 «самых хороших» подсказок, мы обнаружили очень простое решение, которое состоит из двух моментов:
- Правильный порядок id подсказок. Списки id составляем таким образом, чтобы подсказка с наибольшим весом имела наименьший id. Иными словами, подсказки нужно добавлять в индекс в порядке убывания их веса. Таким образом, результирующий список после пересечения уже будет отсортирован одновременно по убыванию веса и значению id. Такой подход мы называем «пре-ранжированием».
- Нам не нужно полное пересечение. Опытным путём было установлено: при пересечении можно брать не всё, а достаточно взять первых K подсказок (где K > N и пропорционально целевому количеству подсказок N), и среди них уже найдутся такие, из которых можно выбрать что-нибудь подходящее как по весу, так и по порядку слов. Например, если нам нужны ТОП N = 10 самых хороших подсказок, то нам достаточно выбрать из результирующего пересечения примерно первых K = 100. Для этого, при пересечении мы можем считать, сколько id в результирующем списке, и как только мы набрали первые 100, останавливаем пересечение.
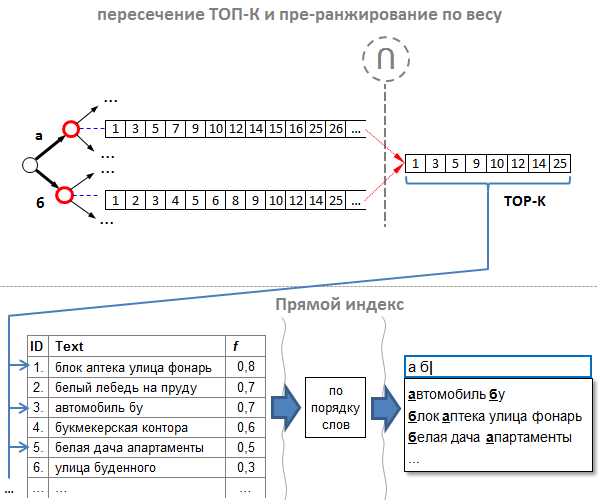
Таким образом, мы оптимизировали как ранжирование по весу, так и пересечение до «ленивых» K первых подсказок.
Реализация
Как и было обещано в начале, мы выкладываем рабочий пример на C++, реализующий описанный в статье алгоритм. В качестве исходной базы можно использовать любой текстовый файл, где каждая строка — это подсказка. Наполнить его можно, например, пословицами и крылатыми выражениями на латыни (первоисточник), чтобы иметь возможность быстро получать их перевод на русский и наоборот.
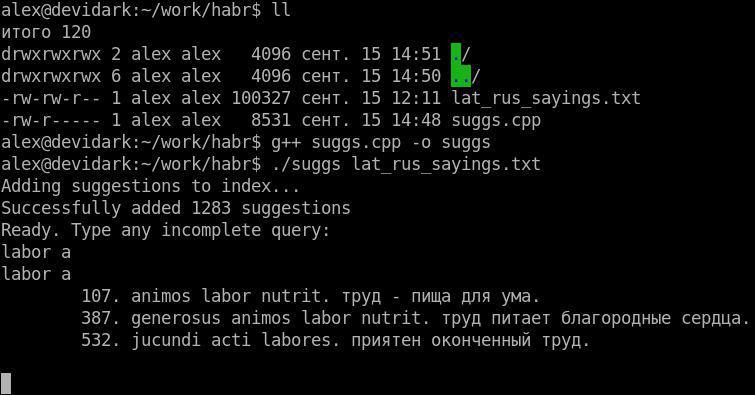
Не будем останавливаться на особенностях реализации, предоставив это читателю: благо пример довольно простой.
Вместо заключения: что осталось «за бортом»
Конечно, представленный здесь алгоритм описан в самом общем виде, и многие вопросы остались за рамками рассмотрения статьи. Над чем ещё было бы полезно подумать разработчику подсказок:
- алгоритм ранжирования подсказок с учётом позиций слов;
- инвертирование языковой раскладки клавиатуры: «ghbdtn» -> «привет»;
- исправление опечаток в пользовательском запросе; здесь мы отправим вас к хорошей статье разработчиков из Microsoft: S. Chaudhuri, R. Kaushik, Extending Autocompletion To Tolerate Errors;
- конструирование концовки запроса пользователя для случая, когда нам нечего подсказать из базы заготовленных подсказок: «что пела в середине 80х алла пу» -> «что пела в середине 80х алла пугачева»;
- учёт географии пользователя: «кинотеатр» -> для пользователя из Саратова не стоит подсказывать московские и питерские кинотеатры, которые ищут часто из-за большой аудитории пользователей;
- масштабирование алгоритма на 2, 3 и более серверов, когда мы захотим добавить 100-200-500 миллионов подсказок и упрёмся в ресурсы памяти и процессора;
- и прочее, и прочее, что только можно ориентировать на нашего любимого пользователя и на наши потребности.
На этом всё. Спасибо за внимание.
Алексей Медвещек,
разработчик поисковых подсказок.
