Как найти страницы сайта в поиске Яндекса
Опубликовано: 13.09.2019г.
Летом 2019 года Яндекс модифицировал фильтр по результатам поиска, который отображается кнопкой справа от поисковой строки. В итоге функция “Поиск по сайту” стала недоступна. Яндекс убрал ее из фильтра, но сам оператор поиска по сайту site был сохранен.
Любой пользователь может получить список страниц сайта используя простые действия.
Метод 1. Модификация GET запроса с использованием параметра site
Используем несложную модификацию стандартного запроса к результатам поиска Яндекса
https://yandex.ru/search/?lr=54&text=[запрос]

добавив оператор site через амперсанд & в конец строки
https://yandex.ru/search/?lr=54&text=[запрос]&site=[домен сайта]

Метод 2. Добавление оператора site в поисковую строку
Этот метод более удобен рядовым пользователям. Он не требует вносить изменения в строку запроса, а достаточно просто в поисковой строке к основному запросу добавить через пробел site:[домен сайта].

Полученнный результат ничем не будет отличаться от результата, полученного при использованиии первого метода.
Получение списка всех страниц в поиске
Если есть задача получить список всех страниц сайта, то достаточно в поисковой строке ввести оператор site без запроса.

Получение списка страниц с нескольких сайтов
Для того, чтобы получить результаты поиска с нескольких сайтов, можно воспользоваться дополнительным оператором ИЛИ (|) и круглыми скобками для группировки.
[запрос] ( site:domen1.ru | site:domen2.ru )
В этом случае, поисковый запрос будет выглядеть следующим образом:

Данный метод отлично позволяет оценить уровень ранжирования сайта по запросу в сравнении с другими сайтами.
Как правило, оператор указывается после текста поискового запроса и отделяется от него пробелом. В одном запросе одновременно можно использовать несколько фильтров и операторов, так же разделяя их пробелом — [поиск site:www.yandex.ru mime:pdf]. Если пробел стоит внутри оператора, его нужно заменить символами %20.
При использовании операторов, где в качестве параметра задается имя хоста (url, host и rhost), следует указывать главное зеркало сайта. Например, [host:lib.ru], а не [host:www.lib.ru]. Узнать, является ли сайт главным зеркалом, можно, добавив хост в базу Яндекса.
Чтобы найти все документы, адреса которых начинаются с заданного значения, поставьте в конце URL символ *. URL в запросе следует заключить в кавычки, если он содержит один из следующих символов:' " ( ) _.
Примечание. Регистр букв в адресе не учитывается.
| Оператор | Синтаксис | Пример запроса |
site: |
|
[яндекс site:narod.ru] Будут найдены документы, содержащие слово «яндекс» и размещенные на поддоменах и страницах сайта narod.ru. |
| Оператор | Синтаксис | Пример запроса |
host: |
|
[поиск host:www.yandex.ru] Будут найдены документы, содержащие слово «поиск» и размещенные на хосте www.yandex.ru. |
Идентичен оператору url: с заданным именем хоста.
| Оператор | Синтаксис | Пример запроса |
rhost: |
|
[новости rhost:com.livejournal.www] Будут найдены документы, содержащие слово «новости» и размещенные на домене livejournal.com. [новости rhost:com.livejournal.*] Будут найдены документы, содержащие слово «новости» и размещенные на всех поддоменах домена livejournal.com. |
Идентичен оператору host:, но имя хоста записывается в обратном порядке: сначала домен верхнего уровня, затем домен второго уровня и т. д.
Для поиска по всем поддоменам заданного домена в конце URL поставьте символ *.
| Оператор | Синтаксис | Пример запроса |
domain: |
|
[яндекс domain:ua] Будут найдены документы, содержащие слово «яндекс» и размещенные на домене ua. |
Как найти все страницы сайта в яндексе?
Никто не подскажет, как найти все страницы сайта в Яндексе. Помню надо сделать запрос вида или что-то похожее на // http://www.yandex.ru/ или : http://www.yandex.ru/ , в общем какие то символы и имя домена, но как точно не помню.
В поиск:
[title:(доменное имя вашего сайта)] Яндекс
intitle:доменное имя вашего сайта Гугл
Иногда оптимизатору нужно получить список всех страниц сайта, в том числе технических и не проиндексированных. Чтобы собрать их вручную, придется потратить не один час, особенно если сайт большой. Существуют сервисы, которые упрощают задачу. Чтобы при аудите ни один документ не потерялся, можно воспользоваться не одним, а сразу несколькими инструментами.
Расскажем, как найти все страницы сайта и какие сервисы для этого нужны.
Зачем нужна такая информация
Список страниц полезен для того, чтобы:
- Найти все страницы, которые не проиндексированы или выпали из индекса поисковой системы. Их нужно проанализировать. Возможно, причина в технических настройках (например, URL закрыт от роботов ПС) или в низком качестве документов. При необходимости их нужно доработать.
- Такой список — хорошая помощь, когда нужно найти причину проблем. Например, при резком падении трафика.
- Настроить перелинковку — проставить внутренние ссылки, правильно распределить ссылочный вес.
- Избавиться от «мусорных» документов, ошибок, дублей.
- Найти все страницы сайта с кодом ответа, отличным от 200 OK.
Почему для сбора данных одного инструмента мало
Выбор инструмента зависит от задачи. Если встал вопрос, как найти все проиндексированные документы или только те, на которые идет трафик, Вебмастера и Метрики будет достаточно. Если проводится технический аудит, подходит Screaming frog SEO spider.
Если нужен полный список страниц, удобнее воспользоваться сразу несколькими инструментами и объединить получившиеся списки. Если ограничиться только одним способом, перечень будет неполным. Например, если использовать только xml-карту, в списке не окажется «мусорных» файлов, сгенерированных из-за неправильных технических настроек. Яндекс.Вебмастер показывает только те документы, которые попали в поиск или выпали из него.
Пиксель Тулс
С помощью онлайн-инструмента «Анализ структуры проекта» можно узнать все страницы, проиндексированные поисковой системой Яндекс. Для анализа не нужен доступ к файлам сайта и Метрике. Можно получить список URL любого проекта, например, конкурента.
Введите домен в верхнюю строку и кликните на кнопку «Найти». Если выбрать опцию «Анализировать число документов только для разделов второго уровня», сервис подсчитает количество страниц в категориях и не будет определять объем подкатегорий.
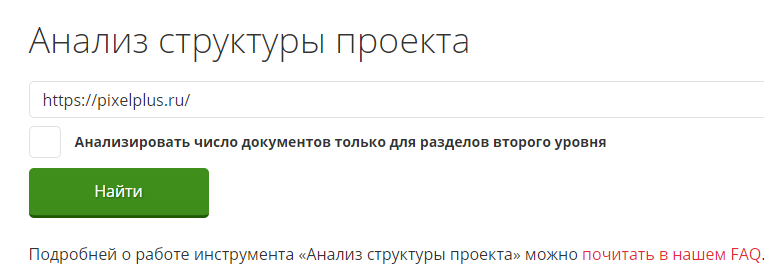
Инструмент строит подробную наглядную структуру (иерархию), подсчитывает количество документов в разделах и процент от общего объема проекта.
Яндекс.Вебмастер
Откройте подраздел «Страницы в поиске» в разделе «Индексирование».
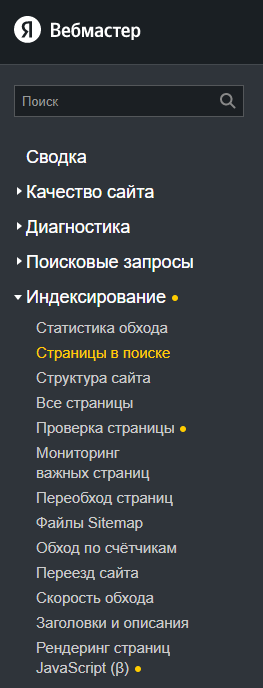
Откройте вкладку «Все страницы» и скачайте таблицу в формате CSV или XLS.
Чтобы получить перечень не попавших в индекс документов, нужно скачать таблицу в разделе «Исключенные страницы».
Яндекс.Метрика
Полный список страниц, на которые заходят пользователи, можно найти в Яндекс.Метрике. Для этого нужно выбрать большой период, например, год, и зайти в раздел «Адрес страницы».
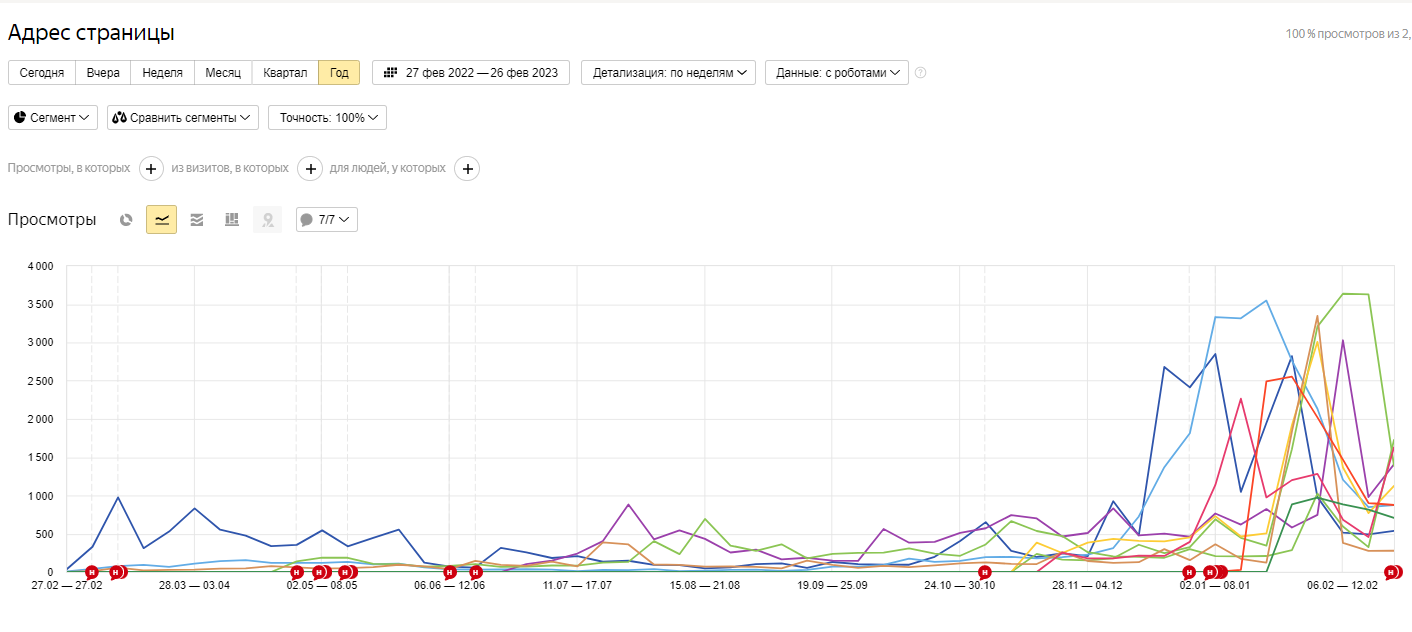
По умолчанию документы ранжируются по количеству просмотров.

В список попадают не только проиндексированные, но и неканонические документы: пагинационные, с результатами поиска и другие.
Xml-карта сайта
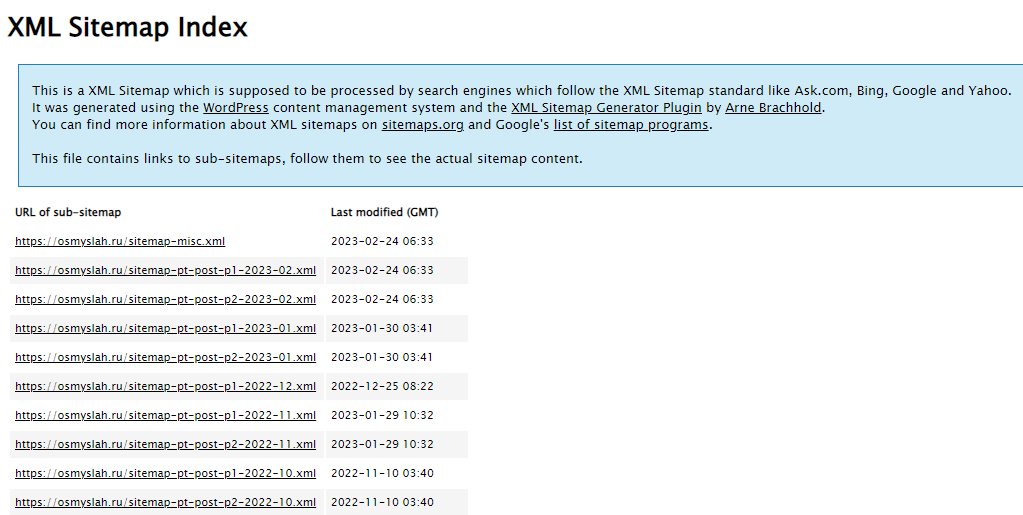
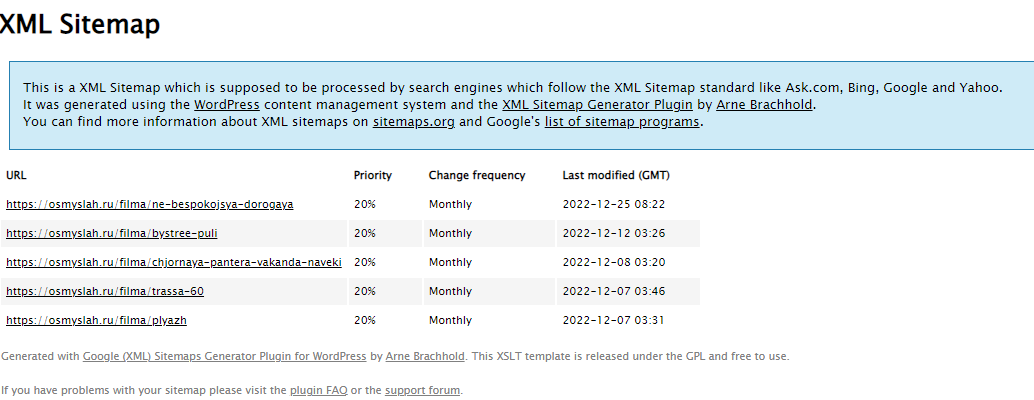
Обычно Xml-карта располагается по стандартному адресу site.ru/sitemap.xml, но может находиться и на другом URL. Иногда карта строится как список всех адресов, расположенных по датам индексации.
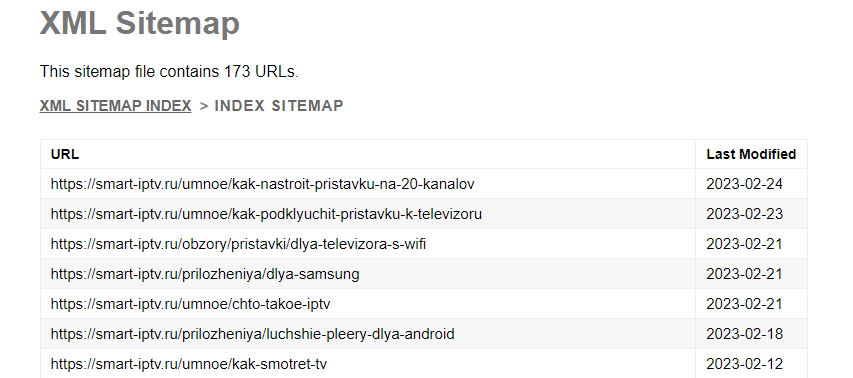
Карта может представлять собой набор файлов со ссылками. Чтобы получить полный список страниц, нужно открыть каждый файл и скопировать ссылки.
Google Analytics
В счетчике Google Analytics, так же, как и в метрике, можно посмотреть все адреса, на которые есть заходы.
Откройте отчет «Страницы и экраны». Кликните на «Путь к странице и класс экрана».
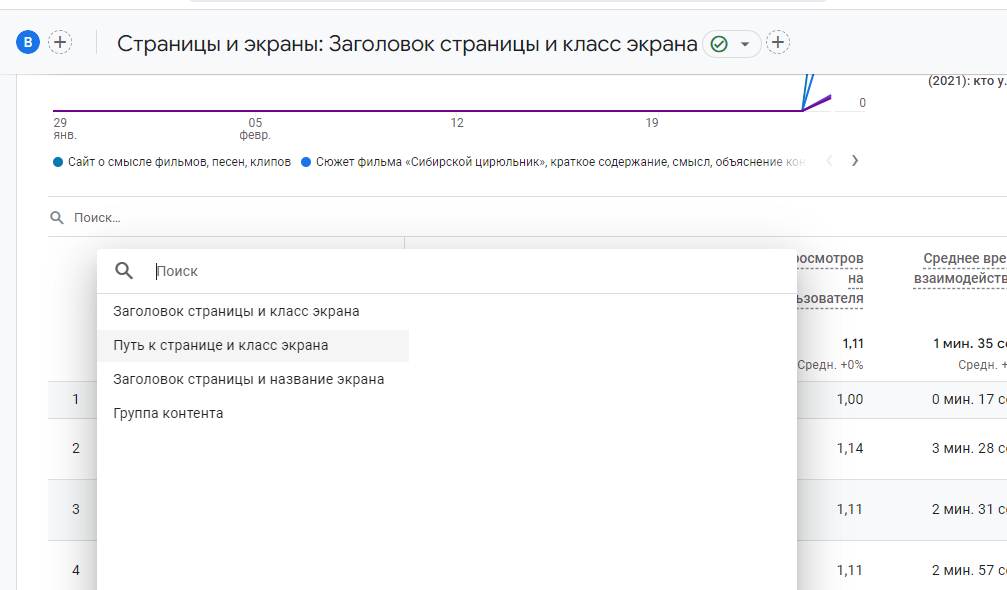
Чтобы скачать результат, выберите опцию «Поделиться отчетом»-«Загрузить файл».
Google Search Console
Еще один способ получить нужные данные — скачать их через консоль Google. В разделе «Индексирование» сформированы два перечня — проиндексированных и не проиндексированных документов. Здесь же показаны причины, почему документы не индексируются. Например, ошибка 404, переадресация, блокировка в файле robots.txt.
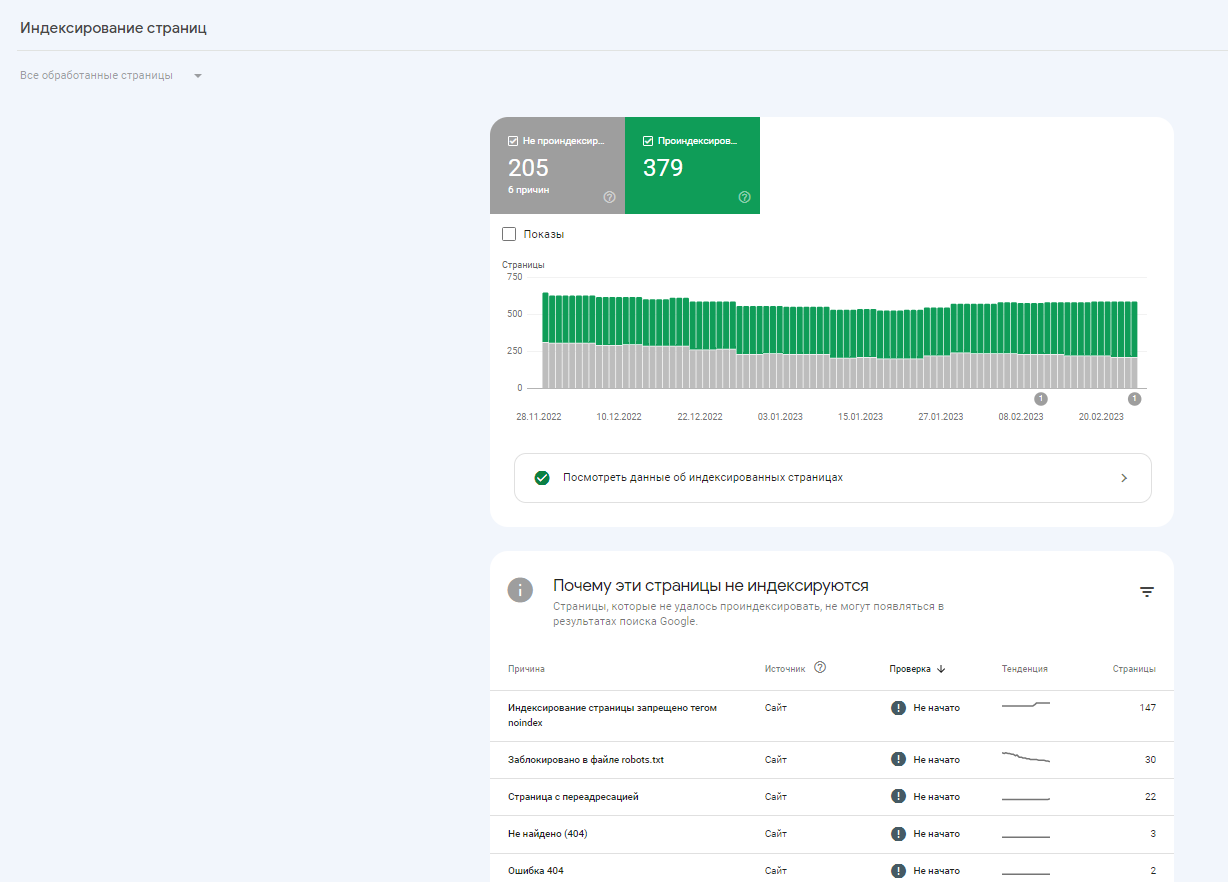
Чтобы скачать отчет, кликните «Экспортировать» в правом верхнем углу и выберите удобный формат.
Сканирование через Screaming frog SEO spider
Screaming Frog SEO Spider («Паук», «Лягушка») – десктопная платная программа, один из самых популярных и продвинутых парсеров. Умеет без доступа к файлам и админпанели сканировать любые сайты.
- Проверяет весь сайт или указанный раздел, файлы только основного домена или всех поддоменов.
- Находит все страницы сайта, проверяет коды ответа сервера.
- Составляет список битых ссылок.
- Находит все страницы с очень длинными заголовками, тегами или URL-адресами.
- Ищет изображения без тега alt.
- Вычисляет дубли SEO-тегов или URL.
- Проверяет орфографию.
- Находит документы с директивами nofollow, noindex, canonical.
- Проверяет файл robots.txt, микроразметку Schema.
- Выявляет все страницы без контента или с минимумом контента.
Иногда лучше ограничить парсинг только некоторыми разделами или типами документов. Чтобы уменьшить время сканирования и объем работы, можно снять галочки с Изображений, CSS, JavaScript и SWF ресурсов.
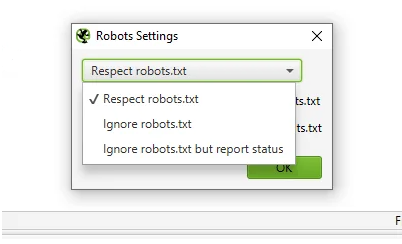
Во вкладке Settings можно настроить парсинг относительно правил robots.txt.
Respect robots.txt — сканируются только те файлы, которые открыты в файле robots.txt.
Ignore robots.txt — парятся все файлы домена, независимо от того, открыты ли они для индексирования.
Ignore robots.txt but report status — сканируются все файлы, но отдельно выводится информация, проиндексирован документ или нет.
Чтобы запустить сканирование, введите адрес сайта, выберите функцию Spider, кликните на кнопку Start.
Итоговый список страниц можно скачать на компьютер в удобном формате.
Заключение
Существуют сервисы, которые формируют списки документов сайта. Выбор инструмента зависит от задачи. Если нужно просканировать свой проект, возможно, будет достаточно Google Analytics, Яндекс.Метрики и Яндекс.Вебмастера. Если планируется глубокий технический аудит, с задачей справится Screaming frog SEO spider. Он же подходит для парсинга конкурентов. Также для анализа чужого сайта можно воспользоваться Xml-картой и инструментом «Анализ структуры проекта» от Пиксель Тулс.

Существует много различных способов, чтобы узнать о страницах сайта в поиске и существуют ли эти страницы вообще. В этой статье мы разберём, как быстро и качественно это сделать, владея лишь базовыми навыками в Яндексе.
Интересным фактом является то, что на данном этапе развития поисковых систем, в базе индексирующего робота есть огромное количество адресов различных сайтов, и каждый день их количество возрастает и робот скачивает ещё больше файлов. Самое главное во всём этом огромном циклическом процессе – это то, как индексирующий робот «прочитает» конкретно Ваш сайт, и как он внесет его в результаты поиска.
Страницы сайта в поиске: как узнать
Начнём с того, как узнать о странице сайта в поиске. После создания сайта, Вы размещаете его на сервисе, добавляете какую-то информацию и делаете сайт доступным для читателей и самого робота. Робот должен узнать о существовании сайта, чтобы он начал индексироваться.
Как только в Интернете появляется информация о том, что появился новый сайт, робот посещает Ваш сайт, посылает некоторые запросы к сервису, получает информацию, которую после вносит в базу поиска и соответственно его результаты.

Например, робот может узнавать о страницах с сайта Яндекс.Вебмастера. Ранее мы уже говорили, зачем нужен Яндекс Вебмастер и в чём его преимущества, так что мы не будем повторяться. Просто советуем прочесть её самостоятельно, в ней действительно много интересного.
Как узнать на какой странице поиска находится мой сайт в Яндексе
Для того чтобы узнать, на какой странице поиска находится Ваш сайт в Яндексе, необходимо зарегистрироваться в Яндекс Вебмастере, где будет Ваш личный кабинет, в котором можно добавить ссылку на сайт и отслеживать его показатели по разным позициям и критериям.

Понятно, что сразу сайт не будет появляться на первых страницах в поисковой системы и уж тем более в топе, но с помощью продвижения сайта в Яндексе по позициям, Ваш сайт будет более популярным и более посещаемым, соответственно иметь большее количество заявок и потенциальных клиентов.
Как узнать количество страниц в поиске Яндекса
Простой способ узнать количество страниц в поиске Яндекса: наберите в поиске Ваш запрос, и Вы увидите количество найденных страниц так, как это представлено на рисунке.

Страницы, которые нужно выводить в поиске, должны быть в индексе поисковых систем. Давайте разберемся, что это из себя представляет. Индексом поисковой системы называется некая база данных, которая хранится в поисковом сервисе, и соответственно по ней происходит поиск нужной информации для читателя.
Некоторые страницы не входят в индекс. Например, если робот поисковой системы сочтет страницу Вашего сайта некачественной, то она может и не войти в индекс и не принять участия в поиске. Поэтому, если у Вас не получается разобраться с этой проблемой самостоятельно, лучше сразу же обратиться в агентство, где занимаются качественным SEO продвижением и корректировкой сайтов, где Вам не только окажут все необходимые услуги, но и будут заниматься сопровождением и технической поддержкой сайта.
