Уследить за всеми страницами сайта сложно, особенно если сайт большой. Но иногда без полного списка страниц не обойтись. Например, если вы хотите создать xml карту сайта, удалить лишние страницы или настроить внутреннюю перелинковку.
С полным списком страниц вы сможете очистить сайт от мусора, исправить технические ошибки на страницах и улучшить ранжирование. Возникает логичный вопрос: как собрать такой список максимально быстро и просто.
Легче всего выгрузить все страницы из одного инструмента, но тогда ваш список может оказаться неполным. Чтобы собрать абсолютно все страницы, в том числе закрытые от поисковых роботов и страницы с техническими ошибками, придется потрудиться.
Почему для сбора данных одного инструмента мало
Собирать данные мы будем из трех инструментов:
- Из модуля «Аудит сайта» в SE Ranking выгрузим все страницы, открытые для поисковых роботов;
- В Google Analytics найдем все страницы, у которых есть просмотры;
- Из Google Search Console достанем оставшиеся закрытые от поисковых роботов страницы, у которых нет просмотров.
Сравнив все данные мы получим полный список страниц вашего сайта.
Проиндексированные URL-ы мы найдем еще на первом этапе. Но нам нужны не только они. У многих сайтов найдутся страницы, на которые не ведет ни одна внутренняя ссылка. Их называют страницами-сиротами.
Почему страницы оказываются «в изоляции»? Причины могут быть разные, к примеру:
- посадочные страницы создавались под конкретную кампанию;
- тестовые страницы создавались для сплит-тестирования;
- страницы убрали из системы внутренней перелинковки, но не удалили;
- страницы потерялись во время переноса сайта;
- была удалена страница категории товаров, а страницы товаров остались.
Такие страницы отрезаны от остального сайта, а значит поисковой робот не может их просканировать. Также кроулер не увидит страницы, закрытые от него через файл .htaccess. Ну, и наконец, часть страниц не индексируется из-за технических проблем.
С помощью разных инструментов мы найдем абсолютно все страницы. Но давайте по порядку. Для начала выгрузим список всех проиндексированных и корректно работающих страниц.
Ищем открытые для краулеров страницы в SE Ranking
Экспортировать страницы, открытые пользователям и краулерам, будем с помощью инструмента «Аудит сайта» SE Ranking.

Чтобы поисковый робот просканировал все необходимые страницы, выберем нужные параметры в настройках.
Заходим в Настройки → Источник страниц для анализа сайта и разрешаем системе сканировать Страницы сайта, Поддомены сайта и XML карту сайта. Так инструмент отследит все страницы сайта, включая поддомены.

Дальше переходим в раздел Правила сканирования страниц и разрешаем учитывать директивы robots.txt.

Осталось нажать кнопку Сохранить.
Затем переходим во вкладку Обзор и запускаем анализ — нажимаем кнопку Перезапустить аудит.

Когда анализ завершится, на главном дашборде нажимаем на зеленую линию в разделе Индексация страниц.

Вы увидите полный список страниц, открытых для поисковых роботов. Теперь можно выгрузить данные — нажимаем на кнопку Экспорт.

На следующем этапе мы будем сравнивать большие массивы данных. Если вам удобно это делать в Excel — оставляйте все как есть. Если вы предпочитаете Google таблицы, скопируйте оставшиеся строки и вставьте их в новую таблицу.
Через Google Analytics ищем все страницы с просмотрами
Поисковые роботы находят страницы переходя по внутренним ссылкам сайта. Поэтому если на страницу не ведет ни одна ссылка на сайте, кроулер ее не найдет.
Обнаружить их можно с помощью данных из Google Analytics — система хранит инфу о посещениях всех страниц. Одно плохо — GA не знает о тех просмотрах, которые были до того, как вы подключили аналитику к вашему сайту.
Просмотров у таких страниц будет немного, потому что с сайта на них перейти не получится. Находим их следующим образом.
Заходим в Поведение → Контент сайта → Все страницы. Если ваш сайт не молодой, стоит указать данные за какой период вы хотите получить. Это важно, так как Google Analytics применяет выборку данных — то есть анализирует не всю информацию, а только ее часть.

Дальше, кликаем на колонку Просмотры страниц, чтобы отсортировать список от меньшего к большему значению . В результате, вверху окажутся самые редко просматриваемые страницы — среди них-то и будут страницы-сироты.

Двигайтесь вниз по списку, пока не увидите страницы, у которых просмотров существенно больше. Это уже страницы с настроенной перелинковкой.
Собранные данные экспортируем в .csv файл.
Выделяем страницы-сироты
Наш следующий шаг — сравнить данные из SE Ranking и Google Analytics, чтобы понять, к каким страницам у поисковых роботов нет доступа.
Копируем данные из .csv файла, выгруженного из Google Analytics, и вставляем их в таблицу рядом с данными из SE Ranking.
Из Google Analytics мы выгрузили только окончания URL, а нам нужно, чтобы все данные были в одном формате. Поэтому в колонку B вставляем адрес главной страницы сайта как показано на скриншоте.

Далее, с помощью функции сцепить (concatenate) объединяем значения из колонок B и C в колонке D и протягиваем формулу вниз до конца списка.

А теперь самое интересное: будем сравнивать колонку «SE Ranking» и колонку «GA URLs», чтобы найти страницы-сироты.
На практике страниц будет намного больше, чем на скриншоте, поэтому анализировать их вручную пришлось бы бесконечно долго. К счастью, существует функция поискпоз (match), которая позволяет определить, какие значения из колонки «GA URLs» есть в колонке «SE Ranking». Вводим функцию в колонке E и протягиваем ее вниз до конца списка.
Результат должен выглядеть так:

В колонке E увидим, каких страниц из GA нет в колонке SE Ranking, там таблица выдаст ошибку (#N/A). В примере видно, что в ячейке E9 нет значения, потому что ячейка A11 — пустая.
Ваш список будет намного больше. Чтобы собрать все ошибки, отсортируйте данные в колонке E по алфавиту:

Теперь у вас есть полный список страниц, не связанных ссылками с сайтом. Перед тем, как двигаться дальше, изучите каждую одинокую страницу. Ваша цель — понять, что это за страница, какова ее роль, и почему на нее не ведет ни одна ссылка.
Дальше есть три варианта развития событий:
- Поставить на страницу внутреннюю ссылку. Для этого нужно определить ее место в структуре вашего сайта.
- Удалить страницу, настроив с нее 301 редирект, если это лишняя страница.
- Оставить все как есть, но присвоить странице тег <noindex>, если, например, страница создавалась под рекламную кампанию.
Поработав с изолированными страницами, можно еще раз выгрузить и сравнить списки из SE Ranking и GA. Так вы убедитесь, что ничего не упустили.
Ищем оставшиеся страницы через Google Search Console
Как найти страницы, не связанные ссылками с сайтом, разобрались. Приступим к остальным страницам, о которых знает Google, — будем анализировать данные Google Search Console.
Для начала откройте свой аккаунт и зайдите в раздел Покрытие. Убедитесь, что выбран режим отображения данных «Все обработанные страницы» и откройте вкладку «Страницы без ошибок».

Таким образом в список попадут Проиндексированные страницы, которых нет в карте сайта, а также Отправленные и проиндексированные страницы.

Кликните на список, чтобы развернуть его. Внимательно изучите данные: возможно в списке есть страницы, которые вы не видели в выгрузках из SE Ranking и GA. В таком случае убедитесь, что они должным образом выполняют свою роль в рамках вашего сайта.
Теперь перейдем во вкладку Исключено, чтобы отобразились только непроиндексированные страницы.

Чаще всего страницы из этой вкладки были намеренно заблокированы владельцами сайта — это страницы с переадресациями, закрытые тегом «noindex», заблокированные в файле robots.txt, и так далее. Также в этой вкладке можно выявить технические ошибки, которые нужно исправить.

Если обнаружите страницы, которые вам не встречались на предыдущих этапах, добавьте их в общий список. Таким образом, вы наконец получите список всех без исключения страниц вашего сайта.
В заключение
Если у вас есть доступ к необходимым инструментам, собрать все страницы сайта не сложно. Да, сделать все в два клика не получится, но в процессе сбора данных вы найдете страницы, о существовании которых могли и не догадываться.
Страницы, которые не видят ни поисковые роботы, ни пользователи, не приносят сайту никакой пользы. Так же как и страницы, которые не индексируются из-за технических ошибок. Если таких страниц на сайте много, это может негативно сказаться на результатах SEO.
Хотя бы один раз собрать все страницы сайта нужно обязательно, чтобы адекватно его оценивать и знать, откуда ждать проблем 🙂
Светлана — контент-маркетолог и редактор в SE Ranking. Светлана убеждена, что о сложных вещах можно писать просто и делится своими знаниями в области SEO и диджитал-маркетинга в блоге SE Ranking и других тематических медиа.
Вечера Светлана проводит, изучая новые языки, планируя увлекательные путешествия и играя с кошкой.
Иногда оптимизатору нужно получить список всех страниц сайта, в том числе технических и не проиндексированных. Чтобы собрать их вручную, придется потратить не один час, особенно если сайт большой. Существуют сервисы, которые упрощают задачу. Чтобы при аудите ни один документ не потерялся, можно воспользоваться не одним, а сразу несколькими инструментами.
Расскажем, как найти все страницы сайта и какие сервисы для этого нужны.
Зачем нужна такая информация
Список страниц полезен для того, чтобы:
- Найти все страницы, которые не проиндексированы или выпали из индекса поисковой системы. Их нужно проанализировать. Возможно, причина в технических настройках (например, URL закрыт от роботов ПС) или в низком качестве документов. При необходимости их нужно доработать.
- Такой список — хорошая помощь, когда нужно найти причину проблем. Например, при резком падении трафика.
- Настроить перелинковку — проставить внутренние ссылки, правильно распределить ссылочный вес.
- Избавиться от «мусорных» документов, ошибок, дублей.
- Найти все страницы сайта с кодом ответа, отличным от 200 OK.
Почему для сбора данных одного инструмента мало
Выбор инструмента зависит от задачи. Если встал вопрос, как найти все проиндексированные документы или только те, на которые идет трафик, Вебмастера и Метрики будет достаточно. Если проводится технический аудит, подходит Screaming frog SEO spider.
Если нужен полный список страниц, удобнее воспользоваться сразу несколькими инструментами и объединить получившиеся списки. Если ограничиться только одним способом, перечень будет неполным. Например, если использовать только xml-карту, в списке не окажется «мусорных» файлов, сгенерированных из-за неправильных технических настроек. Яндекс.Вебмастер показывает только те документы, которые попали в поиск или выпали из него.
Пиксель Тулс
С помощью онлайн-инструмента «Анализ структуры проекта» можно узнать все страницы, проиндексированные поисковой системой Яндекс. Для анализа не нужен доступ к файлам сайта и Метрике. Можно получить список URL любого проекта, например, конкурента.
Введите домен в верхнюю строку и кликните на кнопку «Найти». Если выбрать опцию «Анализировать число документов только для разделов второго уровня», сервис подсчитает количество страниц в категориях и не будет определять объем подкатегорий.
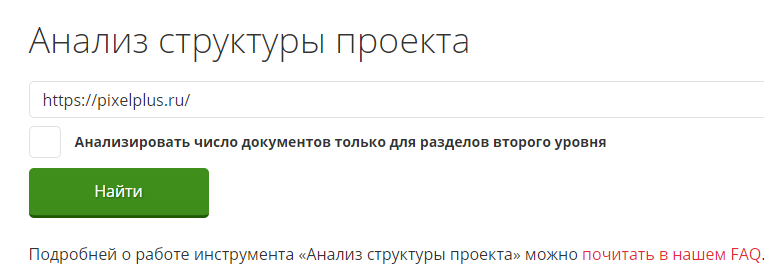
Инструмент строит подробную наглядную структуру (иерархию), подсчитывает количество документов в разделах и процент от общего объема проекта.
Яндекс.Вебмастер
Откройте подраздел «Страницы в поиске» в разделе «Индексирование».
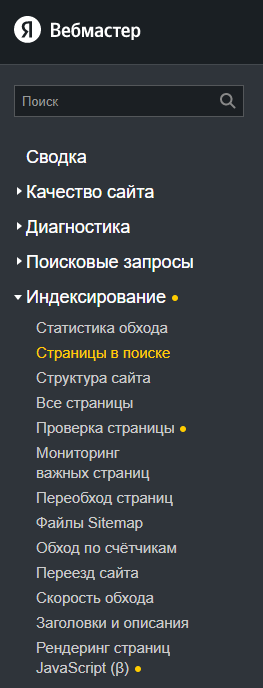
Откройте вкладку «Все страницы» и скачайте таблицу в формате CSV или XLS.
Чтобы получить перечень не попавших в индекс документов, нужно скачать таблицу в разделе «Исключенные страницы».
Яндекс.Метрика
Полный список страниц, на которые заходят пользователи, можно найти в Яндекс.Метрике. Для этого нужно выбрать большой период, например, год, и зайти в раздел «Адрес страницы».
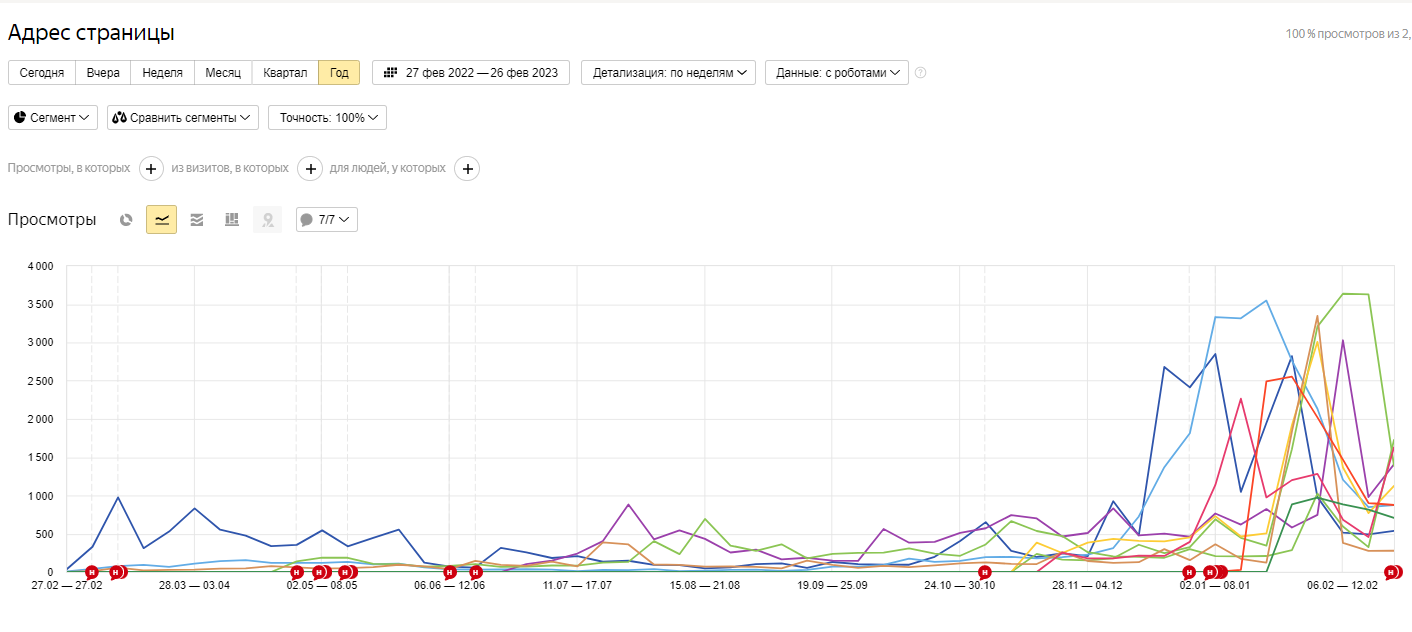
По умолчанию документы ранжируются по количеству просмотров.

В список попадают не только проиндексированные, но и неканонические документы: пагинационные, с результатами поиска и другие.
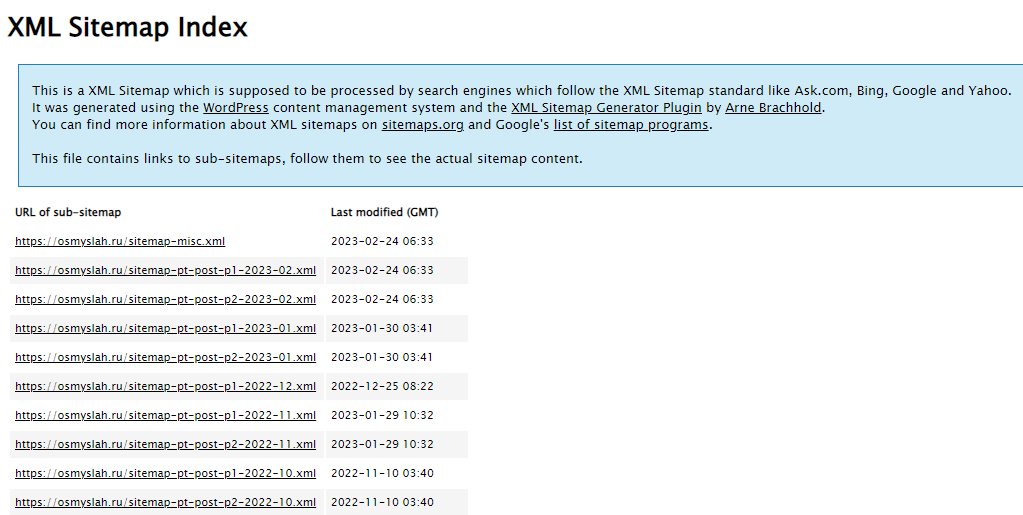
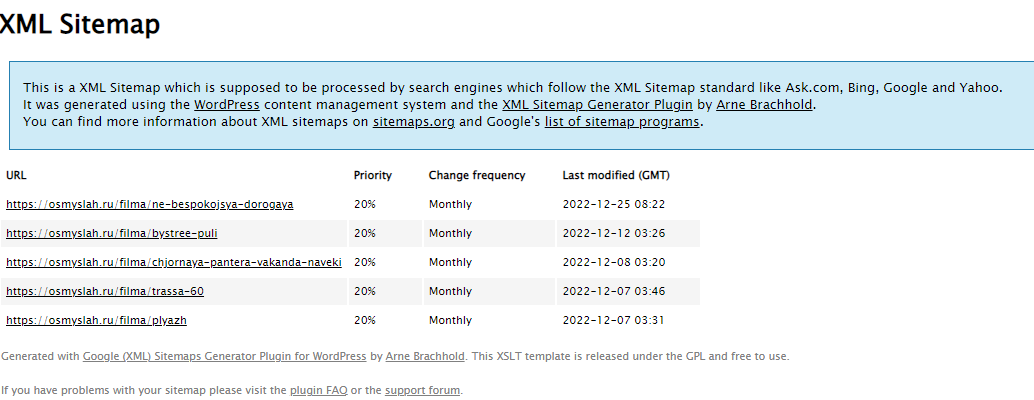
Xml-карта сайта
Обычно Xml-карта располагается по стандартному адресу site.ru/sitemap.xml, но может находиться и на другом URL. Иногда карта строится как список всех адресов, расположенных по датам индексации.
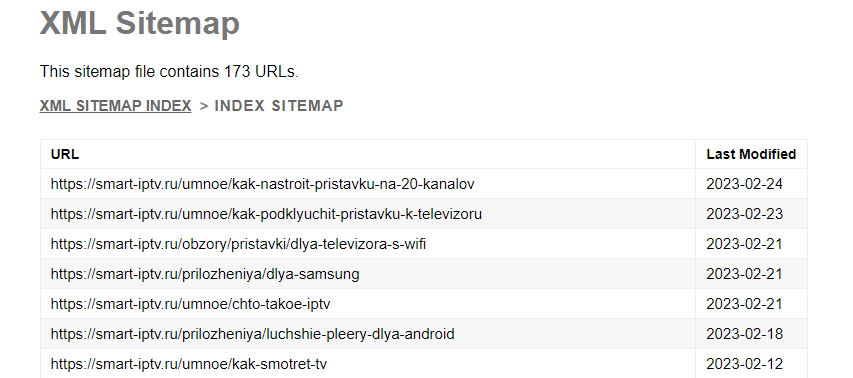
Карта может представлять собой набор файлов со ссылками. Чтобы получить полный список страниц, нужно открыть каждый файл и скопировать ссылки.
Google Analytics
В счетчике Google Analytics, так же, как и в метрике, можно посмотреть все адреса, на которые есть заходы.
Откройте отчет «Страницы и экраны». Кликните на «Путь к странице и класс экрана».
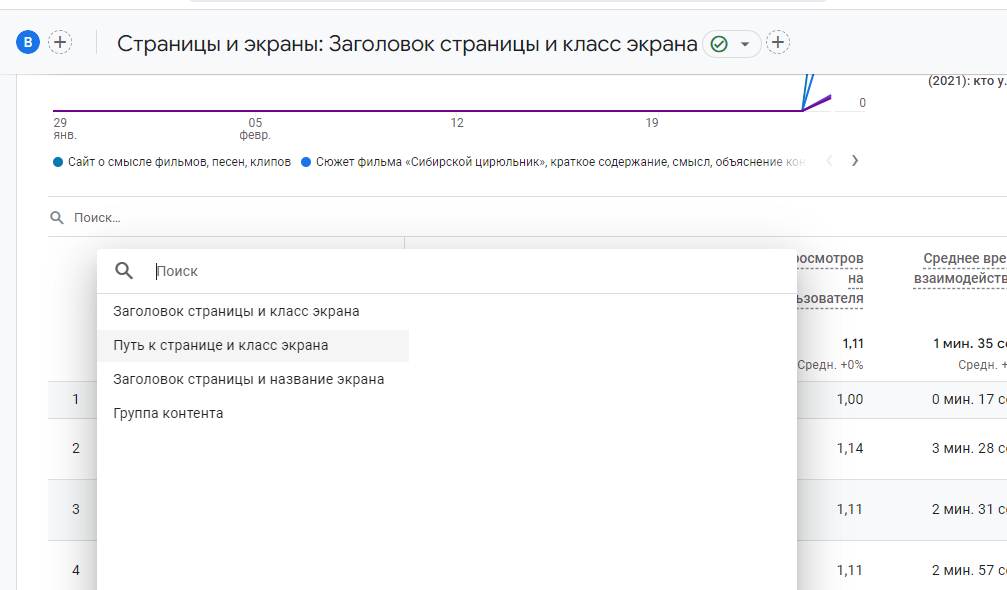
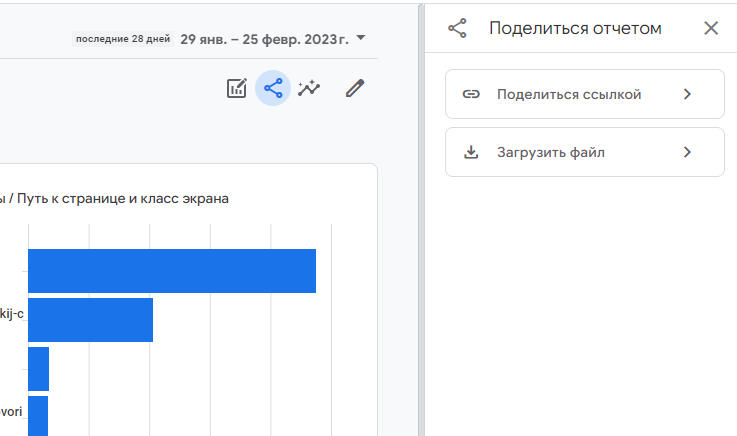
Чтобы скачать результат, выберите опцию «Поделиться отчетом»-«Загрузить файл».
Google Search Console
Еще один способ получить нужные данные — скачать их через консоль Google. В разделе «Индексирование» сформированы два перечня — проиндексированных и не проиндексированных документов. Здесь же показаны причины, почему документы не индексируются. Например, ошибка 404, переадресация, блокировка в файле robots.txt.
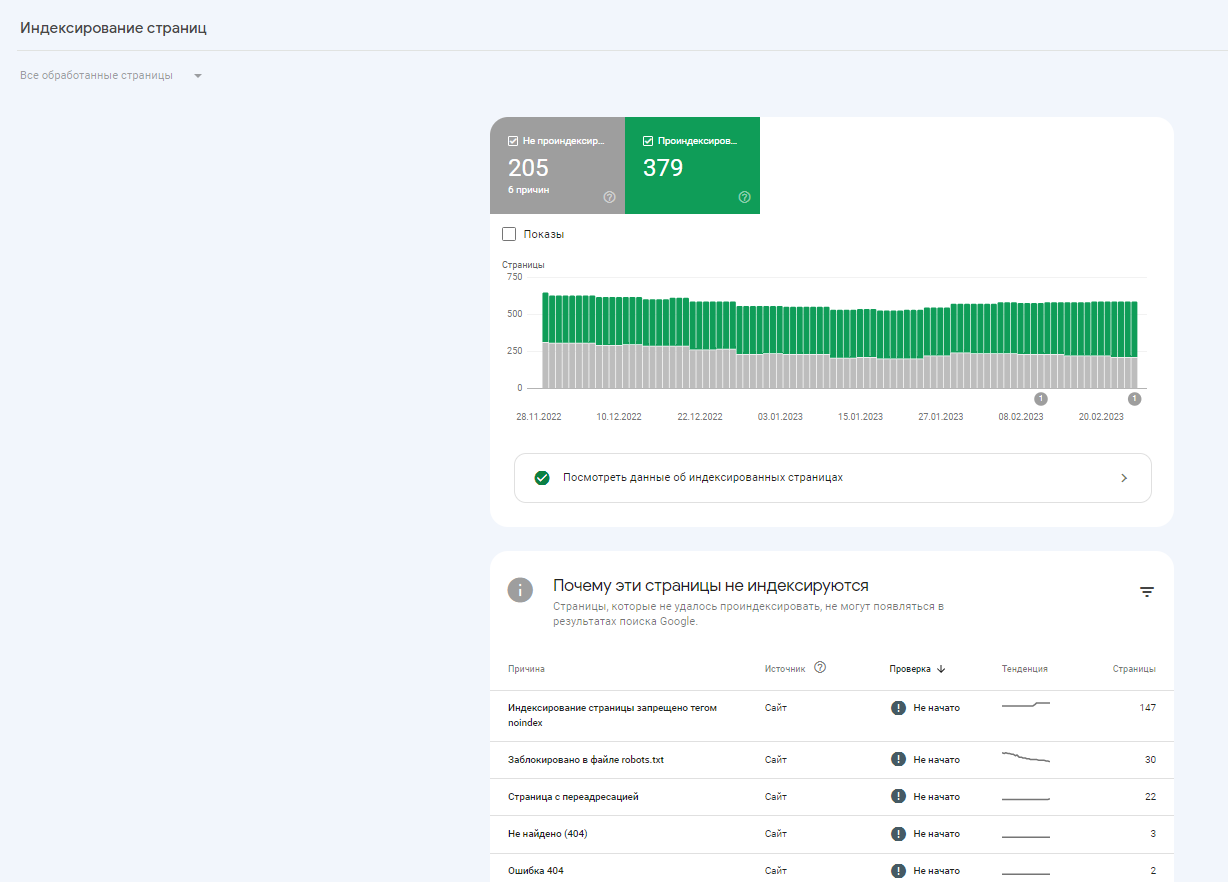
Чтобы скачать отчет, кликните «Экспортировать» в правом верхнем углу и выберите удобный формат.
Сканирование через Screaming frog SEO spider
Screaming Frog SEO Spider («Паук», «Лягушка») – десктопная платная программа, один из самых популярных и продвинутых парсеров. Умеет без доступа к файлам и админпанели сканировать любые сайты.
- Проверяет весь сайт или указанный раздел, файлы только основного домена или всех поддоменов.
- Находит все страницы сайта, проверяет коды ответа сервера.
- Составляет список битых ссылок.
- Находит все страницы с очень длинными заголовками, тегами или URL-адресами.
- Ищет изображения без тега alt.
- Вычисляет дубли SEO-тегов или URL.
- Проверяет орфографию.
- Находит документы с директивами nofollow, noindex, canonical.
- Проверяет файл robots.txt, микроразметку Schema.
- Выявляет все страницы без контента или с минимумом контента.
Иногда лучше ограничить парсинг только некоторыми разделами или типами документов. Чтобы уменьшить время сканирования и объем работы, можно снять галочки с Изображений, CSS, JavaScript и SWF ресурсов.
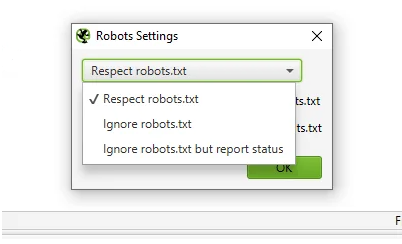
Во вкладке Settings можно настроить парсинг относительно правил robots.txt.
Respect robots.txt — сканируются только те файлы, которые открыты в файле robots.txt.
Ignore robots.txt — парятся все файлы домена, независимо от того, открыты ли они для индексирования.
Ignore robots.txt but report status — сканируются все файлы, но отдельно выводится информация, проиндексирован документ или нет.
Чтобы запустить сканирование, введите адрес сайта, выберите функцию Spider, кликните на кнопку Start.
Итоговый список страниц можно скачать на компьютер в удобном формате.
Заключение
Существуют сервисы, которые формируют списки документов сайта. Выбор инструмента зависит от задачи. Если нужно просканировать свой проект, возможно, будет достаточно Google Analytics, Яндекс.Метрики и Яндекс.Вебмастера. Если планируется глубокий технический аудит, с задачей справится Screaming frog SEO spider. Он же подходит для парсинга конкурентов. Также для анализа чужого сайта можно воспользоваться Xml-картой и инструментом «Анализ структуры проекта» от Пиксель Тулс.
Регулярный технический анализ сайта – это единственный путь к прибыли и постоянному росту. Для его проведения можно использовать самые разные инструменты от краулинг-сервисов до стандартизованных операторов типа site. Иногда для дополнительной проверки, контроля результатов аудита или других целей в рамках технического анализа веб-мастеру требуется полный список страниц ресурса. Как получить список страниц сайт? Получить их можно разными способами, но в каждом случае есть свои оговорки.
Так, варианты «формирования» перечня URL для конкретного сайта:
- Sitemap.xml. С этого инструмента начинают все оптимизаторы, что правильно. Поскольку карты, настроенные с ошибками, приводят к потере позиций в рейтинге поискового сервиса. С ними надо уметь работать всем.
- Яндекс.Вебмастер – еще один помощник, который надо знать.
- Поверхностное сканирование. Иногда используется для экспресс-анализа и аудита.
- Загрузка вручную из заранее сформированного при создании и доработках сайта перечня.
Работа с XML-картами
При проверке маленьких сайтов (до 100 тысяч страниц) это самый удобный способ получить список адресов, в том числе для написания кода на поиск уязвимостей. Но при аудите крупных ресурсов в выборке отразятся далеко не все страницы. Причин расхождений может быть много – неправильная настройка индексации, программные ошибки (баги), когда сайт сам формирует десятки дополнительных URL, так называемые мусорные страницы, которые не закрыты через robots.txt.
Практика показывает, что в полученном перечне может недоставать до 80% страниц. Если использовать выборку с таким дефицитом информации как основу для внесения исправлений на сайт, можно потерять массу полезной информации и получить совершенно неверные приоритетные ошибки: хвататься за скорость загрузки, тогда как основной проблемой является индексация, или наоборот. У технического анализа части страниц погрешность может оказаться очень большой.
Консоль Яндекса
Выборка из поисковой консоли дает более высокую вероятность полноты итогового списка адресов страниц. Это при условии, что сайт технически выполнен без откровенных ошибок. Если ошибки есть, и портал большой, то риск получить неполный список растет.
Правда, не так сильно, как в других случаях. Потому при необходимости провести анализ быстро (или получить список URL для других целей в режиме здесь и сейчас) этот вариант можно рассматривать как оптимальный.
Поверхностное сканирование
При поверхностном сканировании каждый URL анализируется на предмет присутствия на нем других адресов. Такой вариант дает самые высокие шансы получить полный перечень адресов. Но и по трудозатратам он первый. Рутинной работы с ним много. Надо:
- загрузить HTML;
- проверить загрузку (парсинг);
- выделить ссылки;
- переходить от одной страницы к другой по мере сканирования, чтобы не дублировать операции;
- отсеивать метатеги и т. д.
Если ни на одном из этапов не допустить ошибок, результат будет точным. Но когда он будет?
Ручная загрузка списка страниц сайта
Если ресурс создан меньше месяца назад (и ему де-факто не нужен список страниц, потому что такие молодые сайты можно проверять и без него), ручная загрузка подходит. В остальных случаях (особенно после года активного развития) веб-мастер уже не может быть на 100% уверенным, что у него полный список страниц.
Чтобы проверить себя, можно посмотреть файлы (логи) роботов, сформированные по запросу. С большой вероятностью там уже будут десятки URL неизвестной природы.
Окунись в чувственную атмосферу
Открой
Твоя скидка 10% по промокоду: VIVAZZI
Usage
Usually, to get of all site pages, simple enter any of its page in “Site” field and click on “Get site pages” button.
Read the next section, if you can not get the site pages for some reason.
How service works
In most cases, each site has a file, that consists of all inner links and called Sitemap. As a rule, it is located at [site]/sitemap.xml (ex.: vivazzi.pro/sitemap.xml). Using this file this service extract all inner page links.
Also, the service takes into account sites with a large number of pages that have multiple sitemap in one main sitemap. Sometimes the child sitemap files in the main Sitemap file have an extension other than .xml (for example, .zip to archive files). In this case, the service will ignore these files and will issue a corresponding message.
In normally, path to file is specified in [site]/robots.txt in Sitemap section, for example vivazzi.pro/robots.txt:
User-agent: * Host: https://vivazzi.pro Sitemap: https://vivazzi.pro/sitemap.xml
In rare cases, site developers can use another location for the Sitemap. In this case, the service will try to find the file specified in the robots.txt. If robots.txt is not available or sitemap file specified in robots.txt does not exists, the service can not display site pages, since service does not automatically crawl pages from site’s links, as search engines (Google, Yandex and so on) or spider programs (majento, xenu and so on).
If you did not get the site page, try using different spiders, but it’s probably hard for an ordinary user to understand.
There is also a way to get all the links of the site through the Google or Yandex search engine by typing in the address bar a query:
site:[site_name]
For example, site:vivazzi.pro (see more details about site: command on page: Исключить поддомены командой site: в google)
But this method has a disadvantage: displays only those pages that are included in the search , and the remaining pages will be ignored if they did not enter the search (not indexed) for some reason.
Also you can find all the links on the page using different services. For example: pr-cy.ru/link_extractor – will show internal and external links on the page. This service will be of little use if you want to get all the links of the site, because link_extractor does not crawl through all the links on the site.
Developed Services
Rate this article
4.8 from 5 (total 5 ratings)
You can send feedback, suggestions or comments on this article using this form:
Thank you for yor feedback!
After clicking the “Send” button, your message will be delivered to me on the mail.

Artem Maltsev
Rationalist-optimizer, developer of services; lover of applications aimed at improving human life.
The right to use content on this page https://vivazzi.pro/dev/site-urls/:
Permission is granted to copy an content with its author and reference to the original without using the parameter rel="nofollow" in tag <a>. Usage:
Author of Service: Artem Maltsev
Link to service: <a href="https://vivazzi.pro/dev/site-urls/">https://vivazzi.pro/dev/site-urls/</a>
More: Terms of site usage
Is it possible to find all the pages and links on ANY given website? I’d like to enter a URL and produce a directory tree of all links from that site?
I’ve looked at HTTrack but that downloads the whole site and I simply need the directory tree.
Davidmh
3,76718 silver badges35 bronze badges
asked Sep 17, 2009 at 14:43
Jonathan LyonJonathan Lyon
3,8027 gold badges39 silver badges52 bronze badges
1
Check out linkchecker—it will crawl the site (while obeying robots.txt) and generate a report. From there, you can script up a solution for creating the directory tree.
answered Sep 17, 2009 at 14:51
10
If you have the developer console (JavaScript) in your browser, you can type this code in:
urls = document.querySelectorAll('a'); for (url in urls) console.log(urls[url].href);
Shortened:
n=$$('a');for(u in n)console.log(n[u].href)
answered Jan 5, 2015 at 22:03
![]()
ElectroBitElectroBit
1,14211 silver badges16 bronze badges
7
Another alternative might be
Array.from(document.querySelectorAll("a")).map(x => x.href)
With your $$( its even shorter
Array.from($$("a")).map(x => x.href)
answered Mar 1, 2020 at 19:00
SebSeb
87812 silver badges20 bronze badges
1
If this is a programming question, then I would suggest you write your own regular expression to parse all the retrieved contents. Target tags are IMG and A for standard HTML. For JAVA,
final String openingTags = "(<a [^>]*href=['"]?|<img[^> ]* src=['"]?)";
this along with Pattern and Matcher classes should detect the beginning of the tags. Add LINK tag if you also want CSS.
However, it is not as easy as you may have intially thought. Many web pages are not well-formed. Extracting all the links programmatically that human being can “recognize” is really difficult if you need to take into account all the irregular expressions.
Good luck!
answered Sep 17, 2009 at 15:17
mizubashomizubasho
911 silver badge7 bronze badges
1
function getalllinks($url) {
$links = array();
if ($fp = fopen($url, 'r')) {
$content = '';
while ($line = fread($fp, 1024)) {
$content. = $line;
}
}
$textLen = strlen($content);
if ($textLen > 10) {
$startPos = 0;
$valid = true;
while ($valid) {
$spos = strpos($content, '<a ', $startPos);
if ($spos < $startPos) $valid = false;
$spos = strpos($content, 'href', $spos);
$spos = strpos($content, '"', $spos) + 1;
$epos = strpos($content, '"', $spos);
$startPos = $epos;
$link = substr($content, $spos, $epos - $spos);
if (strpos($link, 'http://') !== false) $links[] = $link;
}
}
return $links;
}
try this code….
![]()
Morgoth
4,8358 gold badges39 silver badges65 bronze badges
answered Dec 3, 2014 at 7:42
3
