
Калькулятор для расчета достаточного объема выборки
Калькулятор ошибки выборки для доли признака
Калькулятор ошибки выборки для среднего значения
Калькулятор значимости различий долей
Калькулятор значимости различий средних
1. Формула (даже две)
Бытует заблуждение, что чем больше объем генеральной совокупности, тем больше должен быть объем выборки маркетингового исследования. Это отчасти так, когда объем выборки сопоставим с размером генеральной совокупности. Например, при опросах организаций (B2B).
Если речь идет об исследовании жителей городов, то не важно, Москва это или Рязань – оптимальный объем выборки будет одинаков в обоих городах. Этот принцип следует из закона больших чисел и применим, только если выборка простая случайная.
На рис.1. пример выборки 15000 человек (!) при опросе в муниципальном районе. Возможно, от численности населения взяли 10%?
Размер выборки никогда не рассчитывается как процент от генеральной совокупности!

Рис.1. Размер выборки 15000 человек, как реальный пример некомпетентности (или хуже).
В таких случаях для расчета объема выборки используется следующая формула:

где
n – объем выборки,
Z – коэффициент, зависящий от выбранного исследователем доверительного уровня,
p – доля респондентов с наличием исследуемого признака,
q = 1 – p – доля респондентов, у которых исследуемый признак отсутствует,
∆ – предельная ошибка выборки.
Доверительный уровень – это вероятность того, что реальная доля лежит в границах полученного доверительного интервала: выборочная доля (p) ± ошибка выборки (Δ). Доверительный уровень устанавливает сам исследователь в соответствии со своими требованиями к надежности полученных результатов. Чаще всего применяются доверительные уровни, равные 0,95 или 0,99. В маркетинговых исследованиях, как правило, выбирается доверительный уровень, равный 0,95. При этом уровне коэффициент Z равен 1,96.
Значения p и q чаще всего неизвестны до проведения исследования и принимаются за 0,5. При этом значении размер ошибки выборки максимален.
Допустимая предельная ошибка выборки выбирается исследователем в зависимости от целей исследования. Считается, что для принятия бизнес-решений ошибка выборки должна быть не больше 4%. Этому значению соответствует объем выборки 500-600 респондентов. Для важных стратегических решений целесообразно минимизировать ошибку выборки.
Рассмотрим кривую зависимости ошибки выборки от ее объема (Рис.2).

Рис.2. Зависимость ошибки выборки от ее объема при 95% доверительном уровне
Как видно из диаграммы, с ростом объема выборки значение ошибки уменьшается все медленнее. Так, при объеме выборки 1500 человек предельная ошибка выборки составит ±2,5%, а при объеме 2000 человек – ±2,2%. То есть, при определенном объеме выборки дальнейшее его увеличение не дает значительного выигрыша в ее точности.
Подходы к решению проблемы:
Случай 1. Генеральная совокупность значительно больше выборки:

Случай 2. Генеральная совокупность сопоставима с объемом выборки: (см. раздел исследований B2B)

где
n – объем выборки,
N – объем генеральной совокупности,
Z – коэффициент, зависящий от выбранного исследователем доверительного уровня,
p – доля респондентов с наличием исследуемого признака,
q = 1 – p – доля респондентов, у которых исследуемый признак отсутствует, (значения p и q обычно принимаются за 0,5, поскольку точно неизвестны до проведения исследования)
∆ – предельная ошибка выборки.
Например,
рассчитаем ошибку выборки объемом 1000 человек при 95% доверительном уровне, если генеральная совокупность значительно больше объема выборки:
Ошибка выборки = 1,96 * КОРЕНЬ(0,5*0,5/1000) = 0,031 = ±3,1%
При расчете объема выборки следует также учитывать стоимость проведения исследования. Например, при цене за 1 анкету 200 рублей стоимость опроса 1000 человек составит 200 000 рублей, а опрос 1500 человек будет стоить 300 000 рублей. Увеличение затрат в полтора раза сократит ошибку выборки всего на 0,6%, что обычно неоправданно экономически.
2. Причины «раздувать» выборку
Анализ полученных данных обычно включает в себя и анализ подвыборок, объемы которых меньше основной выборки. Поэтому ошибка для выводов по подвыборкам больше, чем ошибка по выборке в целом. Если планируется анализ подгрупп / сегментов, объем выборки должен быть увеличен (в разумных пределах).
Рис.3 демонстрирует данную ситуацию. Если для исследования авиапассажиров используется выборка численностью 500 человек, то для выводов по выборке в целом ошибка составляет 4,4%, что вполне приемлемо для принятия бизнес-решений. Но при делении выборки на подгруппы в зависимости от цели поездки, выводы по каждой подгруппе уже недостаточно точны. Если мы захотим узнать какие-либо количественные характеристики группы пассажиров, совершающих бизнес-поездку и покупавших билет самостоятельно, ошибка полученных показателей будет достаточно велика. Даже увеличение выборки до 2000 человек не обеспечит приемлемой точности выводов по этой подвыборке.

Рис.3. Проектирование объема выборки с учетом необходимости анализа подвыборок
Другой пример – анализ подгрупп потребителей услуг торгово-развлекательного центра (Рис.4).

Рис.4. Потенциальный спрос на услуги торгово-развлекательного центра
При объеме выборки в 1000 человек выводы по каждой отдельной услуге (например, социально-демографический профиль, частота пользования, средний чек и др.) будут недостаточно точными для использования в бизнес планировании. Особенно это касается наименее популярных услуг (Таблица 1).
Таблица 1. Ошибка по подвыборкам потенциальных потребителей услуг торгово-развлекательного центра при выборке 1000 чел.

Чтобы ошибка в самой малочисленной подвыборке «Ночной клуб» составила меньше 5%, объем выборки исследования должен составлять около 4000 человек. Но это будет означать 4-кратное удорожание проекта. В таких случаях возможно компромиссное решение:
- увеличение выборки до 1800 человек, что даст достаточную точность для 6 самых популярных видов услуг (от кинотеатра до парка аттракционов);
- добор 200-300 пользователей менее популярных услуг с опросом по укороченной анкете (см. Таблицу 2).
Таблица 2. Разница в ошибке выборки по подвыборкам при разных объемах выборки.

При обсуждении с исследовательским агентством точности результатов планируемого исследования рекомендуется принимать во внимание бюджет, требования к точности результатов в целом по выборке и в разрезе подгрупп. Если бюджет не позволяет получить информацию с приемлемой ошибкой, лучше пока отложить проект (или поторговаться).
КАЛЬКУЛЯТОРЫ ДЛЯ РАСЧЕТА СТАТИСТИЧЕСКИХ ПОКАЗАТЕЛЕЙ И ОПРЕДЕЛЕНИЯ ЗНАЧИМОСТИ РАЗЛИЧИЙ:
КАЛЬКУЛЯТОР ДЛЯ РАСЧЕТА
ДОСТАТОЧНОГО ОБЪЁМА ВЫБОРКИ
Доверительный уровень:
Ошибка выборки (?):
%
Объём генеральной совокупности (N):
(можно пропустить, если больше 100 000)
РЕЗУЛЬТАТ
Один из важных вопросов, на которые нужно ответить при планировании исследования, — это оптимальный объем выборки. Слишком маленькая выборка не сможет обеспечить приемлемую точность результатов опроса, а слишком большая приведет к лишним расходам.
Онлайн-калькулятор объема выборки поможет рассчитать оптимальный размер выборки, исходя из максимально приемлемого для исследователя размера ошибки выборки.
Все дальнейшие формулы и расчеты относятся только к простой случайной выборке!
Формулы для других типов выборки отличаются.
Объем выборки рассчитывается по следующим формулам
1) если объем выборки значительно меньше генеральной совокупности:
(в данной формуле не используется показатель объема генеральной совокупности N)
2) если объем выборки сопоставим с объемом генеральной совокупности:

В приведенных формулах:
Z – коэффициент, зависящий от выбранного исследователем доверительного уровня. Доверительный уровень (или доверительная вероятность) – это вероятность того, что реальное значение измеряемого показателя (по всей генеральной совокупности) находится в пределах доверительного интервала, полученного в исследовании. Доверительный уровень выбирает сам исследователь, исходя из требований к надежности результатов исследования. В маркетинговых исследованиях обычно применяется 95%-й доверительный уровень. Ему соответствует значение Z = 1,96.
N – объем генеральной совокупности. Генеральная совокупность – это все люди, которые изучаются в исследовании (например, все покупатели соков и нектаров, постоянно проживающие в Москве и Московской области). Если генеральная совокупность значительно больше объема выборки (в сотни и более раз), ее размером можно пренебречь (формула 1).
p – доля респондентов с наличием исследуемого признака. Например, если 20% опрошенных заинтересованы в новом продукте, то p = 0,2.
q = 1 – p – доля респондентов, у которых исследуемый признак отсутствует. Значения p и q обычно принимаются за 0,5, поскольку точно неизвестны до проведения исследования. При этом значении размер ошибки выборки максимален. В данном калькуляторе значения p и q по умолчанию равны 0,5.
Δ– предельная ошибка выборки (для доли признака), приемлемая для исследователя. Считается, что для принятия бизнес-решений ошибка выборки не должна превышать 4%.
n – объем выборки. Объем выборки – это количество людей, которые опрашиваются в исследовании.
ПРИМЕР РАСЧЕТА ОБЪЕМА ВЫБОРКИ:
Допустим, мы хотим рассчитать объем выборки, предельная ошибка которой составит 4%. Мы принимаем доверительный уровень, равный 95%. Генеральная совокупность значительно больше выборки. Тогда объем выборки составит:
n = 1,96 * 1,96 * 0,5 * 0,5 / (0,04 * 0,04) = 600,25 ≈ 600 человек
Таким образом, если мы хотим получить результаты с предельной ошибкой 4%, нам нужно опросить 600 человек.
КАЛЬКУЛЯТОР ОШИБКИ ВЫБОРКИ ДЛЯ ДОЛИ ПРИЗНАКА
Доверительный уровень:
Объём выборки (n):
Объём генеральной совокупности (N):
(можно пропустить, если больше 100 000)
Доля признака (p):
%
РЕЗУЛЬТАТ
Зная объем выборки исследования, можно рассчитать значение ошибки выборки (или, другими словами, погрешность выборки).
Если бы в ходе исследования мы могли опросить абсолютно всех интересующих нас людей, мы могли бы быть на 100% уверены в полученном результате. Но ввиду экономической нецелесообразности сплошного опроса применяют выборочный подход, когда опрашивается только часть генеральной совокупности. Выборочный метод не гарантирует 100%-й точности измерения, но, тем не менее, вероятность ошибки может быть сведена к приемлемому минимуму.
Все дальнейшие формулы и расчеты относятся только к простой случайной выборке! Формулы для других типов выборки отличаются.
Ошибка выборки для доли признака рассчитывается по следующим формулам.
1) если объем выборки значительно меньше генеральной совокупности:
(в данной формуле не используется показатель объема генеральной совокупности N)
2) если объем выборки сопоставим с объемом генеральной совокупности:
В приведенных формулах:
Z – коэффициент, зависящий от выбранного исследователем доверительного уровня. Доверительный уровень (или доверительная вероятность) – это вероятность того, что реальное значение измеряемого показателя (по всей генеральной совокупности) находится в пределах доверительного интервала, полученного в исследовании. Доверительный уровень выбирает сам исследователь, исходя из требований к надежности результатов исследования. В маркетинговых исследованиях обычно применяется 95%-й доверительный уровень. Ему соответствует значение Z = 1,96.
N – объем генеральной совокупности. Генеральная совокупность – это все люди, которые изучаются в исследовании (например, все покупатели шоколада, постоянно проживающие в Москве). Если генеральная совокупность значительно больше объема выборки (в сотни и более раз), ее размером можно пренебречь (формула 1).
n – объем выборки. Объем выборки – это количество людей, которые опрашиваются в исследовании. Существует заблуждение, что чем больше объем генеральной совокупности, тем больше должен быть и объем выборки маркетингового исследования. Это отчасти так, когда объем выборки сопоставим с объемом генеральной совокупности. Например, при опросах организаций (B2B). Если же речь идет об исследовании жителей городов, то не важно, Москва это или Рязань – оптимальный объем выборки будет одинаков в обоих городах. Этот принцип следует из закона больших чисел и применим, только если выборка простая случайная. ВАЖНО: если предполагается сравнивать какие-то группы внутри города, например, жителей разных районов, то выборку следует рассчитывать для каждой такой группы.
p – доля респондентов с наличием исследуемого признака. Например, если 20% опрошенных заинтересованы в новом продукте, то p = 0,2.
q = 1 – p – доля респондентов, у которых исследуемый признак отсутствует. Значения p и q обычно принимаются за 0,5, поскольку точно неизвестны до проведения исследования. При этом значении размер ошибки выборки максимален.
Δ– предельная ошибка выборки.
Таким образом, зная объем выборки исследования, мы можем заранее оценить показатель ее ошибки.
А получив значение p, мы можем рассчитать доверительный интервал для доли признака: (p – ∆; p + ∆)
ПРИМЕР РАСЧЕТА ОШИБКИ ВЫБОРКИ ДЛЯ ДОЛИ ПРИЗНАКА:
Например, в ходе исследования были опрошены 1000 человек (n=1000). 20% из них заинтересовались новым продуктом (p=0,2). Рассчитаем показатель ошибки выборки по формуле 1 (выберем доверительный уровень, равный 95%):
∆ = 1,96 * КОРЕНЬ (0,2*0,8/1000) = 0,0248 = ±2,48%
Рассчитаем доверительный интервал:
(p – ∆; p + ∆) = (20% – 2,48%; 20% + 2,48%) = (17,52%; 22,48%)
Таким образом, с вероятностью 95% мы можем быть уверены, что реальная доля заинтересованных в новом продукте (среди всей генеральной совокупности) находится в пределах полученного диапазона (17,52%; 22,48%).
Если бы мы выбрали доверительный уровень, равный 99%, то для тех же значений p и n ошибка выборки была бы больше, а доверительный интервал – шире. Это логично, поскольку, если мы хотим быть более уверены в том, что наш доверительный интервал «накроет» реальное значение признака, то интервал должен быть более широким.
КАЛЬКУЛЯТОР ОШИБКИ ВЫБОРКИ ДЛЯ СРЕДНЕГО ЗНАЧЕНИЯ
Доверительный уровень:
Объём выборки (n):
Объём генеральной совокупности (N):
(можно пропустить, если больше 100 000)
Среднее значение (x̄):
Стандартное отклонение (s):
РЕЗУЛЬТАТ
Зная объем выборки исследования, можно рассчитать значение ошибки выборки (или, другими словами, погрешность выборки).
Если бы в ходе исследования мы могли опросить абсолютно всех интересующих нас людей, мы могли бы быть на 100% уверены в полученном результате. Но ввиду экономической нецелесообразности сплошного опроса применяют выборочный подход, когда опрашивается только часть генеральной совокупности. Выборочный метод не гарантирует 100%-й точности измерения, но, тем не менее, вероятность ошибки может быть сведена к приемлемому минимуму.
Все дальнейшие формулы и расчеты относятся только к простой случайной выборке! Формулы для других типов выборки отличаются.
Ошибка выборки для среднего значения рассчитывается по следующим формулам.
1) если объем выборки значительно меньше генеральной совокупности:

(в данной формуле не используется показатель объема генеральной совокупности N)
2) если объем выборки сопоставим с объемом генеральной совокупности:

В приведенных формулах:
Z – коэффициент, зависящий от выбранного исследователем доверительного уровня. Доверительный уровень (или доверительная вероятность) – это вероятность того, что реальное значение измеряемого показателя (по всей генеральной совокупности) находится в пределах доверительного интервала, полученного в исследовании. Доверительный уровень выбирает сам исследователь, исходя из требований к надежности результатов исследования. В маркетинговых исследованиях обычно применяется 95%-й доверительный уровень. Ему соответствует значение Z = 1,96
N – объем генеральной совокупности. Генеральная совокупность – это все люди, которые изучаются в исследовании (например, все покупатели мороженого, постоянно проживающие в Москве). Если генеральная совокупность значительно больше объема выборки (в сотни и более раз), ее размером можно пренебречь (формула 1).
n – объем выборки. Объем выборки – это количество людей, которые опрашиваются в исследовании. Существует заблуждение, что чем больше объем генеральной совокупности, тем больше должен быть и объем выборки маркетингового исследования. Это отчасти так, когда объем выборки сопоставим с объемом генеральной совокупности. Например, при опросах организаций (B2B). Если же речь идет об исследовании жителей городов, то не важно, Москва это или Рязань – оптимальный объем выборки будет одинаков в обоих городах. Этот принцип следует из закона больших чисел и применим, только если выборка простая случайная. ВАЖНО: если предполагается сравнивать какие-то группы внутри города, например, жителей разных районов, то выборку следует рассчитывать для каждой такой группы.
s – выборочное стандартное отклонение измеряемого показателя. В идеале на месте этого аргумента должно быть стандартное отклонение показателя в генеральной совокупности (σ), но так как обычно оно неизвестно, используется выборочное стандартное отклонение, рассчитываемое по следующей формуле:

где, x ̅ – среднее арифметическое показателя, xi– значение i-го показателя, n – объем выборки
Δ– предельная ошибка выборки.
Зная среднее значение показателя x ̅ и ошибку ∆, мы можем рассчитать доверительный интервал для среднего значения:(x ̅ – ∆; x ̅ + ∆)
ПРИМЕР РАСЧЕТА ОШИБКИ ВЫБОРКИ ДЛЯ СРЕДНЕГО ЗНАЧЕНИЯ:
Например, в ходе исследования были опрошены 1000 человек (n=1000). Каждого из них попросили указать их примерную среднюю сумму покупки (средний чек) в известной сети магазинов. Среднее арифметическое всех ответов составило 500 руб. (x ̅=500), а стандартное отклонение составило 120 руб. (s=120). Рассчитаем показатель ошибки выборки по формуле 1 (выберем доверительный уровень, равный 95%):
∆ = 1,96 * 120 / КОРЕНЬ (1000) = 7,44
Рассчитаем доверительный интервал:
(x ̅ – ∆; x ̅ + ∆) = (500 – 7,44; 500 + 7,44) = (492,56; 507,44)
Таким образом, с вероятностью 95% мы можем быть уверены, что значение среднего чека по всей генеральной совокупности находится в границах полученного диапазона: от 492,56 руб. до 507,44 руб.
КАЛЬКУЛЯТОР ЗНАЧИМОСТИ РАЗЛИЧИЙ ДОЛЕЙ
Доверительный уровень:
| Измерение 1 | Измерение 2 | |
| Доля признака (p): | % | % |
| Объём выборки (n): |
РЕЗУЛЬТАТ
Если в прошлогоднем исследовании вашу марку вспомнили 10% респондентов, а в исследовании текущего года – 15%, не спешите открывать шампанское, пока не воспользуетесь нашим онлайн-калькулятором для оценки статистической значимости различий.
Сравнивая два разных значения, полученные на двух независимых выборках, исследователь должен убедиться, что различия статистически значимы, прежде чем делать выводы.
Как известно, выборочные исследования не обеспечивают 100%-й точности измерения (для этого пришлось бы опрашивать всю целевую аудиторию поголовно, что слишком дорого). Тем не менее, благодаря методам математической статистики, мы можем оценить точность результатов любого количественного исследования и учесть ее в выводах.
В приведенном здесь калькуляторе используется двухвыборочный z-тест для долей. Для его применения должны соблюдаться следующие условия:
- Обе выборки – простые случайные
- Выборки независимы (между значениями двух выборок нет закономерной связи)
- Генеральные совокупности значительно больше выборок
- Произведения n*p и n*(1-p), где n=размер выборки а p=доля признака, – не меньше 5.
В калькуляторе используются следующие вводные данные:
Доверительный уровень (или доверительная вероятность) – это вероятность того, что реальное значение измеряемого показателя (по всей генеральной совокупности) находится в пределах доверительного интервала, полученного в исследовании. Доверительный уровень выбирает сам исследователь, исходя из требований к надежности результатов исследования. В маркетинговых исследованиях обычно применяется 95%-й доверительный уровень.
Доля признака (p) – доля респондентов с наличием исследуемого признака. Например, если 20% опрошенных заинтересованы в новом продукте, то p = 0,2.
Объем выборки (n) – это количество людей, которые опрашиваются в исследовании.
Результат расчетов – вывод о статистической значимости или незначимости различий двух измерений.
КАЛЬКУЛЯТОР ЗНАЧИМОСТИ РАЗЛИЧИЙ СРЕДНИХ
Доверительный уровень:
| Измерение 1 | Измерение 2 | |
| Среднее значение (x̄): | ||
| Стандартное отклонение (s): | ||
| Объём выборки (n): |
РЕЗУЛЬТАТ
Допустим, выборочный опрос посетителей двух разных ТРЦ показал, что средний чек в одном из них равен 1000 рублей, а в другом – 1200 рублей. Следует ли отсюда вывод, что суммы среднего чека в двух этих ТРЦ действительно отличаются?
Сравнивая два разных значения, полученные на двух независимых выборках, исследователь должен убедиться, что различия статистически значимы, прежде чем делать выводы.
Как известно, выборочные исследования не обеспечивают 100%-й точности измерения (для этого пришлось бы опрашивать всю целевую аудиторию поголовно, что слишком дорого). Тем не менее, благодаря методам математической статистики, мы можем оценить точность результатов любого количественного исследования и учесть ее в выводах.
В приведенном здесь калькуляторе используется двухвыборочный z-тест для средних значений. Для его применения должны соблюдаться следующие условия:
- Обе выборки – простые случайные
- Выборки независимы (между значениями двух выборок нет закономерной связи)
- Генеральные совокупности значительно больше выборок
- Распределения значений в выборках близки к нормальному распределению.
В калькуляторе используются следующие вводные данные:
Доверительный уровень (или доверительная вероятность) – это вероятность того, что реальное значение измеряемого показателя (по всей генеральной совокупности) находится в пределах доверительного интервала, полученного в исследовании. Доверительный уровень выбирает сам исследователь, исходя из требований к надежности результатов исследования. В маркетинговых исследованиях обычно применяется 95%-й доверительный уровень.
Среднее значение ( ̅x) – среднее арифметическое показателя.
Стандартное отклонение (s) – выборочное стандартное отклонение измеряемого показателя. В идеале на месте этого аргумента должно быть стандартное отклонение показателя в генеральной совокупности (σ), но так как обычно оно неизвестно, используется выборочное стандартное отклонение, рассчитываемое по следующей формуле:
где, x ̅ – среднее арифметическое показателя, xi– значение i-го показателя, n – объем выборки
Объем выборки (n) – это количество людей, которые опрашиваются в исследовании.
Результат расчетов – вывод о статистической значимости или незначимости различий двух измерений.
Вы можете подписаться на уведомления о новых материалах СканМаркет
 Приведенная ниже формула для расчета объема выборки используется в тех случаях, когда опрашиваемым (респондентам) задается только один вопрос, на который существует только два варианта ответа. Например: «Да» и «Нет», «Покупаю» и «Не покупаю», «Пользуюсь» и «Не пользуюсь». Конечно, данную формулу можно применять только при проведении простейших исследований. Если Вам нужно определить объем выборочной совокупности при проведении более масштабных исследований, например анкетирования, то следует использовать другие формулы.
Приведенная ниже формула для расчета объема выборки используется в тех случаях, когда опрашиваемым (респондентам) задается только один вопрос, на который существует только два варианта ответа. Например: «Да» и «Нет», «Покупаю» и «Не покупаю», «Пользуюсь» и «Не пользуюсь». Конечно, данную формулу можно применять только при проведении простейших исследований. Если Вам нужно определить объем выборочной совокупности при проведении более масштабных исследований, например анкетирования, то следует использовать другие формулы.
Содержание:
- формула с пояснениями;
- пример расчета объема выборки;
- нормированное отклонение (таблица);
- область применения;
- особенности формулы.
Простая формула для расчета объема выборки
Ниже приведена простая формула для расчета объема выборки для тех случаев когда на заданный вопрос возможны лишь два варианта ответа:

где: n – объем выборки;
z – нормированное отклонение, определяемое исходя из выбранного уровня доверительности (доверительного интервала, доверительной вероятности).
Этот показатель характеризует вероятность попадания ответов в специальный доверительный интервал — диапазон, границам которого соответствует определенный процент определенных ответов на некоторый вопрос.
Можно сказать, что уровень доверительности выражает вероятность того, что респонденты генеральной совокупности ответят так же, как и представители анализируемой выборки.
На практике доверительный интервал при проведении маркетинговых исследований часто принимают за 95% или 99%. Тогда значения z будут соответственно 1,96 и 2,58.
Также существует специальная таблица «Значение интеграла вероятностей», используя которую можно найти значение z для различных доверительных интервалов. Сокращенный вариант такой таблицы приведен ниже;
p – вариация для выборки, в долях.
Вариация характеризует величину схожести / несхожести ответов респондентов на вопрос. По сути, p — вероятность того, что респонденты выберут той или иной вариант ответа.
Допустим, если мы считаем, что четверть опрашиваемых выберут ответ «Да», то p будет равно 25%, то есть p = 0,25;
q = 1 – p.
Можно сказать, что q — это вероятность того, что респонденты не выберут анализируемый вариант ответа (в нашем примере ответят «Нет»). Например, если p = 0,25, то q = 1 – 0,25 = 0,75;
e – допустимая ошибка, в долях.
Значение допустимой ошибки заранее определяют исследователь и заказчик маркетингового исследования.
Пример расчета объема выборочной совокупности
Маркетинговая компания получила заказ на проведение социологического исследования с целью выявить долю курящих лиц в населении города. Для этого сотрудники компании будут задавать прохожим один вопрос: «Вы курите?». Возможных вариантов ответа, таким образом, только два: «Да» и «Нет».
Объем выборки в этом случае рассчитывается следующим образом. Уровень доверительности принимается за 95% (одно из стандартных значений для маркетинговых исследований), тогда нормированное отклонение z = 1,96. Проведя предварительный анализ населения города, вариацию принимаем за 50%, то есть условно считаем, что половина респондентов может ответить на вопрос о том, курят ли они — «Да». Тогда p = 0,5. Отсюда находим q = 1 – p = 1 – 0,5 = 0,5. исходя из требуемой заказчиком точности, допустимую ошибку выборки принимаем за 10%, то есть e = 0,1.
Подставляем эти данные в формулу и считаем:

Округлив расчетное значение, получаем объем выборки n = 96 человек.
Следовательно, для проведения исследования с заданными параметрами (уровень доверительности, допустимая ошибка) компании необходимо опросить 96 человек.
Значение нормированного отклонения для различных доверительных интервалов
В таблице приведены некоторые значения нормированного отклонения (z) для важнейших уровней доверительности, или, иначе, доверительной вероятности (α):
| α (%) | 60 | 70 | 80 | 85 | 90 | 95 | 97 | 99 | 99,7 |
|---|---|---|---|---|---|---|---|---|---|
| z | 0,84 | 1,03 | 1,29 | 1,44 | 1,65 | 1,96 | 2,18 | 2,58 | 3,0 |
Конечно, в таблице приведены значения z только для основных уровней доверительности. Полную версию таблицы можно найти в интернете.
Область применения простой формулы выборки
При проведении простых исследований, когда нужно получить ответ всего на один простой вопрос. При этом шкала ответов, как правило, дихотомического характера. То есть предлагаются (или подразумеваются) варианты ответов по типу «Да» — «Нет», «Черное» — «Белое», «Куплю» — «Не куплю», и т. д. Иными словами возможны лишь два варианта ответа на заданный вопрос.
Особенности формулы расчета размера выборки
Для рассмотренной нами простой формулы определения объема выборки можно выделить несколько характерных особенностей:
- перед тем, как рассчитывать объем выборки в данном случае желательно предварительно провести качественный анализ изучаемой генеральной совокупности. В частности установить степень схожести, близости изучаемых единиц совокупности в части их социальных, демографических, географических, иных характеристик. Также полезно провести пилотное (разведочное) исследование, чтобы установить приблизительную величину p;
- нужно иметь в виду, что максимальная изменчивость (вариация ответов) соответствует значению p = 50%, так как тогда q = 50% и p × q = 0,5 × 0,5 = 0,25. Это наихудший случай, все другие значения p дадут изменчивость меньшего размера (например, при p = 80%, p × q = 0,8 × 0,2 = 0,16; а при p = 10%, p × q = 0,1 × 0,9 = 0,09). Впрочем, данный показатель влияет на объем выборки не очень сильно.
Также стоит отметить, что существует ряд иных формул для определения объема выборки в случаях с дихотомической шкалой ответов на единственный вопрос. Для более сложных маркетинговых исследований применяются другие формулы.
Источники
- Голубков Е. П. Маркетинговые исследования: теория, методология и практика. – М.: Издательство «Финпресс», 1998.
Статья дополнена и доработана автором 10 дек 2020 г.
© Копирование любых материалов статьи допустимо только при указании прямой индексируемой ссылки на источник: Галяутдинов Р.Р.
Нашли опечатку? Помогите сделать статью лучше! Выделите орфографическую ошибку мышью и нажмите Ctrl + Enter.
Библиографическая запись для цитирования статьи по ГОСТ Р 7.0.5-2008:
Галяутдинов Р.Р. Формула выборки – простая // Сайт преподавателя экономики. [2020]. URL: https://galyautdinov.ru/post/formula-vyborki-prostaya (дата обращения: 18.05.2023).
Задача 1.
Для примера,
исследуем выборку из 20 предприятий по
величине производительности труда
(всех предприятий -100). Предприятий с
низким уровнем производительности
оказалось 2. С вероятностью 0,683 необходимо
найти пределы, в которых можно ожидать
долю предприятий со средним и высоким
уровнем производительности. Выборка
случайная, бесповторная. Имеются данные:
n=20
(шт.)
N=100
(шт.)
m=20-2=18
(шт.)
t=1
P(t)=0,683
w=18/20=0,9
Определим среднюю
ошибку выборки:
![]()
или 2,7%
Рассчитаем
предельную ошибку:
![]()
Определим пределы,
в которых можно ожидать долю предприятий
с высоким и средним уровнем
производительности:
![]()
С вероятностью
0,683, т.е. в 683 случаях из 1000, можно утверждать,
что средний процент предприятий с
высоким и средним уровнем производительности
будет находиться в пределах от 87 до 93%.
Рассчитаем
относительную ошибку:
![]()
=
3,63/21,51=0,169 или 16,9%,
![]()
=
0,03/0,9=0,033 или 3,3%
Следовательно,
как для оценки средних показателей, так
и для оценки доли, выборка репрезентативна.
Задача 2
Из
партии деталей взята 20%-ная случайная
бесповторная выборка для определения
среднего веса детали. Результаты выборки
следующие:
|
Вес (г), х |
76-80 |
80-84 |
84-88 |
88-92 |
|
Число деталей, f |
30 |
60 |
90 |
20 |
Определить
с вероятностью 0,954 доверительные пределы,
в которых лежит средний вес детали для
всей партии.
Решение.
Доверительные
интервалы для генеральной средней с
вероятностью Р:
![]()
,
где
![]()
—
средний уровень признака по выборке:
![]()
г.
Определим численность
генеральной совокупности:
![]()
.
Дисперсия выборки
равна:
![]()
Предельная ошибка
равна:
![]()
г.
При
вероятности Р
=
0,954 t
= 2. Доверительные интервалы для генеральной
средней с вероятностью Р
=
0,954 следующие:
![]()
;
![]()
;
На основе проведенной
выборки сделаем вывод: установлен
средний вес детали с возможным отклонением
в ту или иную сторону не более, чем на
0,66 г, или в пределах от 83,34
до
84,66
г, что можно
утверждать с вероятностью 0,954, т.е. в 954
случаях из 1000.
Задача 3
Рассмотрим 20 из
100 единиц совокупности. Таким образом,
мы имеем дело с выборкой. Исходя из
предыдущих расчетов для ряда
производительности труда, при условии,
что отбор случайный, бесповторный, а
вероятность равна 0,954, имеются следующие
данные:
![]()
ден.ед.
![]()
шт.
n=20
шт.
![]()
ден. ед.
t=2
Тогда средняя
ошибка выборки будет равна:
![]()
.
Отсюда получим
величину предельной ошибки:
![]()
.
Вычислим пределы
для генеральной средней:
![]()
.
На основе проведенной
выборки сделаем вывод: установлена
средняя производительность труда для
предприятий с возможным отклонением в
ту или иную сторону не более, чем на 3,63
ден.ед., или в пределах от 17,88 до 25,14
ден.ед., что можно утверждать с вероятностью
0,954, т.е. в 954 случаях из 1000.
Определим пределы,
в которых можно ожидать суммарную
производительность труда для всех
предприятий генеральной совокупности:
![]()
Таким образом,
суммарную производительность труда
для всех предприятий, составляющих
генеральную совокупность, можно ожидать
в пределах от 1788 до 2514 ден.ед.
Далее определим
пределы, в которых можно ожидать
количество предприятий с высоким и
средним уровнем производительности в
генеральной совокупности:
![]()
Таким
образом, среди ста предприятий генеральной
совокупности количество предприятий,
обладающих искомым признаком можно
ожидать в пределах от 87 до 93.
Задача 4
На
предприятии из партии продукции в
количестве 20000 шт. деталей взято на
выборку 2000 шт. (отбор случайный,
бесповторный), из которых 50 шт. оказались
бракованными.
Определить
с вероятностью 0,997 пределы, в которых
будет находиться процент брака для всей
партии продукции.
Решение
Определяется
доля бракованной продукции по выборке:
![]()
или
2,5%.
При
вероятности Р(t)=
0,997
t
= 3,0.
Размер предельной
ошибки:
![]()
,
или 1%.
Доверительные
интервалы для генеральной доли с
вероятностью Р(t)
=
0,997:
![]()
![]()
;
![]()
.
С вероятностью
0,997, т.е. в 997 случаях из 1000 можно утверждать,
что средний процент бракованных деталей
будет находиться в пределах от 1,5 до
3,5%.
Задача 5
По
городской телефонной сети в порядке
случайной выборки (механический отбор)
произвели 100 наблюдений и установили
среднюю продолжительность одного
телефонного разговора 7 минут при среднем
квадратическом отклонении 2 минуты.
Какова
вероятность того, что ошибка
репрезентативности при определении
средней продолжительности телефонного
разговора не превысит 15 секунд?
Решение
По условию задачи
известны:
объем
выборки п
= 100;
выборочная
средняя
![]()
=
7 мин;
выборочное
среднее квадратическое отклонение
![]()
=
2 мин;
предельная
ошибка выборки равна:
![]()
=
15 сек = 0,25 мин.
Рассчитаем среднюю
ошибку выборки:
![]()
мин.
Рассчитаем значение
t:
![]()
Затем
по таблице на основе значения t
определяется вероятность того, что
ошибка не превысит заданной величины.
При
t=1,25
вероятность Р(t)
= 0,789.
Задача 6
На
основе выборочного обследования в
отделении связи города предполагается
определить долю поздравительной
корреспонденции в общем объеме
отправляемой корреспонденции. Никаких
предварительных данных об удельном
весе этих писем в общей массе отравляемой
корреспонденции не имеется.
Определить
численность выборки, если результаты
выборки дать с точностью до 1 % и
гарантировать это с вероятностью 0,683.
Решение.
По условию задачи
известны:
размер
допустимой (предельной) ошибки
![]()
=
1%, или 0,01;
при
Р(t)
=
0,683
t=
1.
Так
как значение w
не
дано, то следует ориентироваться на
наибольшую дисперсию, которой соответствует
значение w
=
0,5.
Необходимая
численность выборки равна:
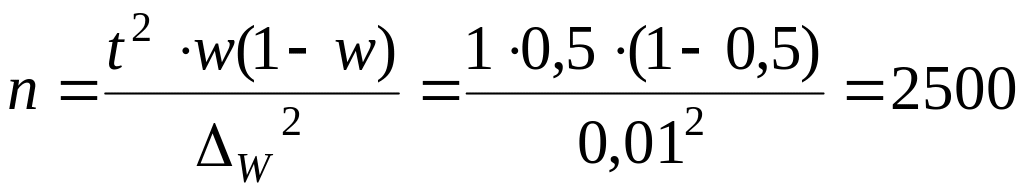
единиц.
Таким
образом, чтобы с заданной точностью
определить долю поздравительных писем
в общем объеме отправляемой корреспонденции,
необходимо в порядке случайной выборки
отобрать 2500 писем.
Задача 7
В
университете в порядке случайной
бесповторной выборки было опрошено 100
студентов из 1000 и получены следующие
данные о времени, потраченном на дорогу
из дома в университет:
|
Время на дорогу, ч |
0,6-0,8 |
0,8-1,0 |
1,0-1,2 |
1,2-1,4 |
|
Число студентов |
14 |
50 |
30 |
6 |
Определить:
1) среднее
время, потраченное на дорогу, для
студентов данного университета,
гарантируя результат с вероятностью
0,997;
2) долю
студентов, потративших дорогу 1,2 часа
и более, гарантируя результат с
вероятностью 0,954;
3)
необходимую численность выборки при
определении среднего времени, потраченного
на дорогу, чтобы с вероятностью 0,954
предельная ошибка выборки не превышала
0,02 часа;
4)
необходимую численность выборки при
определении доли
студентов, потративших
на дорогу 1,2 часа и больше, чтобы
с
вероятностью 0,954 предельная ошибка
не превышала 4%.
Решение.
-
Доверительный
интервал среднего размера времени на
дорогу:.
Средний
размер времени по выборке:
![]()
ч.
Дисперсия по
выборке:
![]()
При
вероятности Р
(t)
=
0,997 t
=
3,0.
Предельная ошибка
выборки равна:
![]()
Доверительные
интервалы для генеральной средней:
1-0,15![]()
1+0,15.
0,85
1,15
Таким образом,
среднее
время, потраченное на дорогу, для
студентов данного университета находится
в пределах от 0,85 до 1,15 часа, это можно
утверждать с вероятностью 0,997 или в 997
случаев из 1000.
2. Доля студентов,
затрачивающих на дорогу 1,2 часа и более,
по выборочным данным составляет:
![]()
.
При
вероятности Р
(t)
=
0,954 t
=
2,0.
Предельная ошибка
доли:
![]()
.
Доверительные
интервалы для генеральной доли:
![]()
;
![]()
.
Таким образом,
доля
студентов данного университета, тратящих
на дорогу 1,2 часа и более, находится в
интервале от 1,5% до 15%, что можно утверждать
с вероятностью 0,954 или в 954 случаев из
1000.
3.
Необходимая численность выборки для
определения среднего месячного
дохода определяется по формуле:
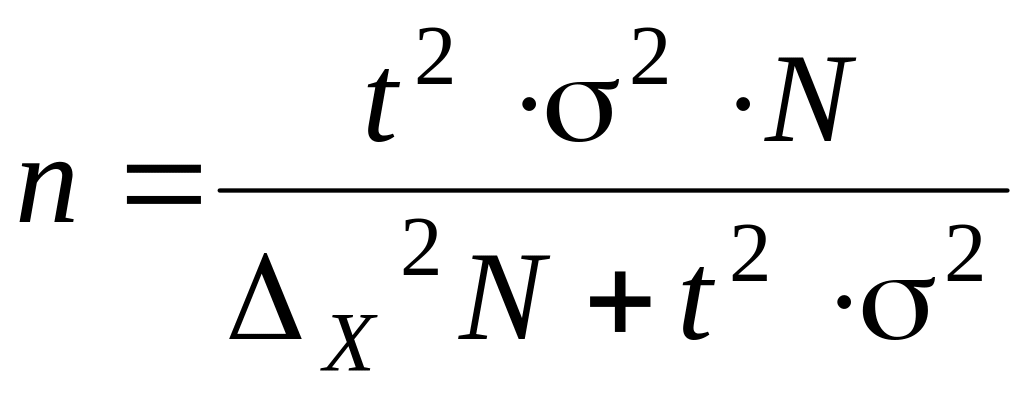
.
По условию задачи
известны:
при
вероятности Р
=
0,954 t
= 2
![]()
;
![]()
(по
данным предыдущей выборки).
![]()
чел.
Таким образом, в
выборку необходимо отобрать 206 человек,
что выполнялись указанные условия.
4.
Необходимая численность выборки для
определения доли студентов, тратящих
на дорогу 1,2 часа и выше, определяется
по формуле:
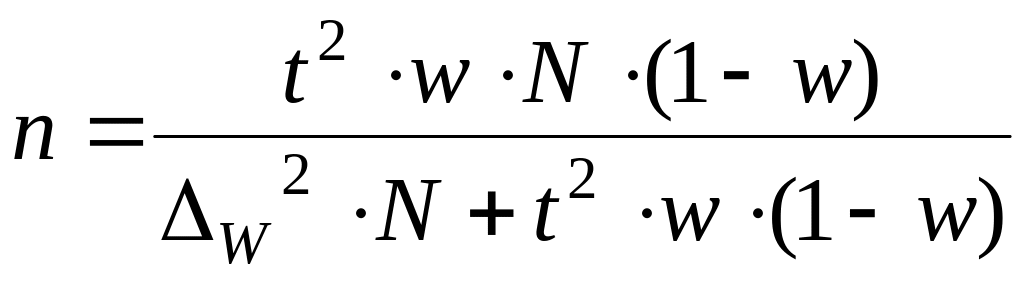
По условию задачи
известны:
![]()
=
4%, или 0,04; при вероятности Р
=
0,954 t
= 2;
w
= 0,06 (по данным предыдущей выборки).
![]()
человека.
Таким образом, в
выборку необходимо отобрать 124 человека,
что выполнялись указанные условия.
Задача 8
Операция
шлифования при обработке детали № 18
производится в цехе на трех станках.
Для определения процента брака для всей
партии продукции, выработанной за день,
проведена расслоенная (типическая)
10%-ная выборка. Отбор деталей из выработки
каждого станка – случайный бесповторный;
объем выборки пропорционален размеру
выпуска. На первом станке было обработано
1500 деталей, на втором – 1800, на третьем
– 1200 деталей. Число забракованных
деталей в выборке: по первому станку
–3, по второму – 4, по третьему – 2.
Определить:
1)
доверительные интервалы, в которых с
вероятностью 0,683 заключен процент брака
для всей партии продукции;
2)
вероятность того, что процент брака для
всей партии продукции отличается от
полученного по выборке не более чем на
0,5 %.
Решение.
1.
Рассчитаем общий объем генеральной
совокупности –
N =
N1
+ N2
+ N3
= 1500 + 1800 + 1200 = 4500 деталей.
Численность
выборки:
![]()
деталей,
в том
числе по станкам численность выборки
рассчитывается по формуле:
![]()
,
отсюда:
n1
=150
деталей,
n2
=180
деталей,
n3
=120 деталей.
Доверительные
интервалы процента брака для всей партии
продукции:
![]()
,
где W
– процент брака для всей выборочной
совокупности:
![]()
;
![]()
—
предельная ошибка
выборки.
По
условию задачи
![]()
Расчет
ошибки доли при типической выборке при
пропорциональном размещении единиц
определяется по формуле:
![]()
где
![]()
—
среднегрупповая выборочная дисперсия
доли рассчитывается по формуле:
![]()
,
где
![]()
—
доля брака для каждого станка.
![]()
;
![]()
;
![]()
.
![]()
.
При вероятности
P(t)=
0,683 t=1.
![]()
или
4%.
Доверительные
интервалы:
![]()
,
![]()
.
Таким образом,
доля
процент брака для всей партии продукции
находится в интервале от 1,6% до 2,4%, что
можно утверждать с вероятностью 0,683 или
в 683 случаев из 1000.
2. По
второму заданию известна допустимая
ошибка
=
0,5% или 0,005,
![]()
=0,004
(по первому заданию).
![]()
;
Отсюда
![]()
,
![]()
.
Величине t
= 1,25 соответствует вероятность 0,7887.
Задача 9
При
контрольной проверке качества яблок
проведена 10%-ная серийная выборка. Из
партии, содержащей 50 ящиков яблок (вес
ящиков одинаков), методом механического
отбора взято 5 ящиков. В результате
сплошного обследования находящихся в
ящике яблок получили данные об удельном
весе бракованных яблок. Результаты
представлены в таблице:
|
Номер ящика, попавшего в |
1 |
2 |
3 |
4 |
5 |
|
Удельный вес бракованной |
1,3 |
1,7 |
1,8 |
1,3 |
1,4 |
Требуется
с вероятностью 0,954 установить доверительные
интервалы удельного веса бракованной
продукции для всей партии яблок.
Для
установления доверительного интервала,
в котором для всей партии поставки
находится доля бракованной продукции,
используется формула:
![]()
.
![]()
,
где
![]()
– межсерийная (межгрупповая) выборочная
дисперсия доли;
m
– число ящиков, попавших в выборку;
М
– общее число ящиков.
При
вероятности Р
=
0,954 t
=
2
![]()
или 0,015
(при
расчете использована простая
арифметическая, так как вес ящиков
одинаков).
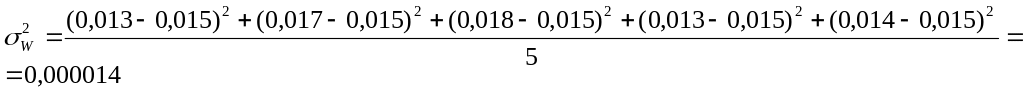
![]()
или 0,3%.
Доля находится в
пределах:
![]()
![]()
.
Доверительные
интервалы удельного веса бракованной
продукции для всей партии яблок
находятся в интервале от 1,2 до 1,8%, что
можно утверждать с вероятностью 0,954.
Задача 10
В цехе
проектируется проведение моментных
наблюдений для выявления текущих
простоев производственного оборудования.
Требуется
для организации моментных наблюдений
определить необходимое число наблюдений
и число обходов, если в цехе имеется 50
единиц предназначенного к работе
оборудования. Никаких предварительных
данных о доле простоев в сменном фонде
не имеется. Ошибка наблюдения не должна
превышать 5%
и
быть гарантирована с вероятностью
0,954.
Решение
Необходимая
численность моментов наблюдения
определяется по формуле:
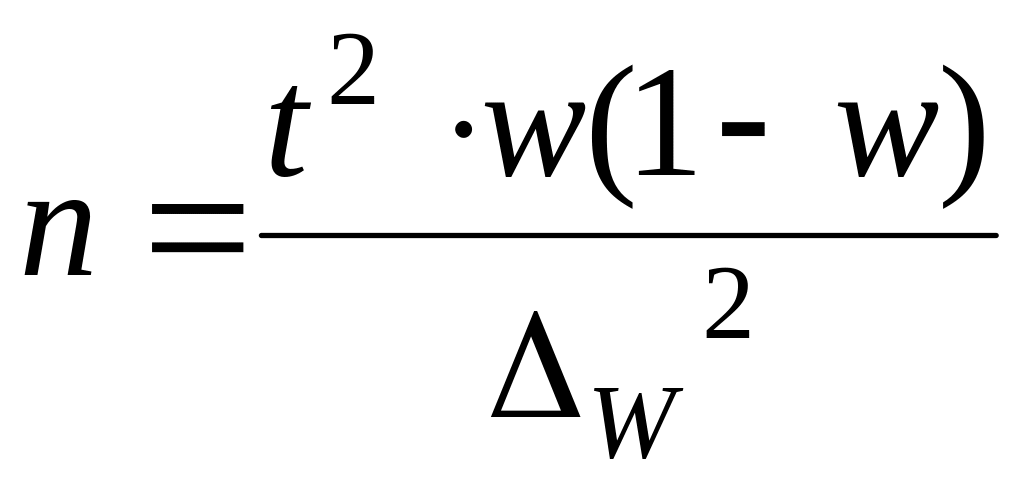
По условию задачи:
t
=
2 (так как вероятность Р
= 0,954);
w
–
доля
простоев по условию не дана, поэтому
принимается наибольшая дисперсия
альтернативного признака, когда w
= 0,5.
![]()
=
5%, или 0,05,
тогда необходимая
численность равна:
![]()
.
Число
обходов (т.е. число записей о каждой
единице оборудования) определяется
путем деления числа наблюдений на число
единиц оборудования:
![]()
.
Задача 11
Согласно условию
вышерассмотренного примера, из
совокупности отобрано 20 предприятий
из 100 или 20%. При этом предельная ошибка
равна 3,63. Если из генеральной совокупности
отобрать 5% предприятий (5 из 100), то какой
будет величина средней и предельной
ошибки?
Рассчитаем величину
средней и предельной ошибки:
![]()
.
![]()
Следовательно,
ошибка увеличилась более, чем в 2 раза
(8:3,63).
Выборка. Типы выборок
Суммарная численность объектов наблюдения (люди, домохозяйства, предприятия, населенные пункты и т.д.), обладающих определенным набором признаков (пол, возраст, доход, численность, оборот и т.д.), ограниченная в пространстве и времени. Примеры генеральных совокупностей
- Аналитика бизнеса
- Методы анализа данных Data Mining
- Выборка. Типы выборок
Оглавление
Генеральная совокупность
Суммарная численность объектов наблюдения (люди, домохозяйства, предприятия, населенные пункты и т.д.), обладающих определенным набором признаков (пол, возраст, доход, численность, оборот и т.д.), ограниченная в пространстве и времени. Примеры генеральных совокупностей
- Все жители Москвы (10,6 млн. человек по данным переписи 2002 года)
- Мужчины-Москвичи (4,9 млн. человек по данным переписи 2002 года)
- Юридические лица России (2,2 млн. на начало 2005 года)
- Розничные торговые точки, осуществляющие продажу продуктов питания (20 тысяч на начало 2008 года) и т.д.
Выборка (Выборочная совокупность)
Часть объектов из генеральной совокупности, отобранных для изучения, с тем чтобы сделать заключение обо всей генеральной совокупности. Для того чтобы заключение, полученное путем изучения выборки, можно было распространить на всю генеральную совокупность, выборка должна обладать свойством репрезентативности.
Репрезентативность выборки
Свойство выборки корректно отражать генеральную совокупность. Одна и та же выборка может быть репрезентативной и нерепрезентативной для разных генеральных совокупностей.
Пример:
- Выборка, целиком состоящая из москвичей, владеющих автомобилем, не репрезентирует все население Москвы.
- Выборка из российских предприятий численностью до 100 человек не репрезентирует все предприятия России.
- Выборка из москвичей, совершающих покупки на рынке, не репрезентирует покупательское поведение всех москвичей.
В то же время, указанные выборки (при соблюдении прочих условий) могут отлично репрезентировать москвичей-автовладельцев, небольшие и средние российские предприятия и покупателей, совершающих покупки на рынках соответственно.
Важно понимать, что репрезентативность выборки и ошибка выборки – разные явления. Репрезентативность, в отличие от ошибки никак не зависит от размера выборки.
Пример:
Как бы мы не увеличивали количество опрошенных москвичей-автовладельцев, мы не сможем репрезентировать этой выборкой всех москвичей.
Ошибка выборки (доверительный интервал)
Отклонение результатов, полученных с помощью выборочного наблюдения от истинных данных генеральной совокупности.
Ошибка выборки бывает двух видов – статистическая и систематическая. Статистическая ошибка зависит от размера выборки. Чем больше размер выборки, тем она ниже.
Пример:
Для простой случайной выборки размером 400 единиц максимальная статистическая ошибка (с 95% доверительной вероятностью) составляет 5%, для выборки в 600 единиц – 4%, для выборки в 1100 единиц – 3% Обычно, когда говорят об ошибке выборки, подразумевают именно статистическую ошибку.
Систематическая ошибка зависит от различных факторов, оказывающих постоянное воздействие на исследование и смещающих результаты исследования в определенную сторону.
Пример:
- Использование любых вероятностных выборок занижает долю людей с высоким доходом, ведущих активный образ жизни. Происходит это в силу того, что таких людей гораздо сложней застать в каком-либо определенном месте (например, дома).
- Проблема респондентов, отказывающихся отвечать на вопросы анкеты (доля «отказников» в Москве, для разных опросов, колеблется от 50% до 80%)
В некоторых случаях, когда известны истинные распределения, систематическую ошибку можно нивелировать введением квот или перевзвешиванием данных, но в большинстве реальных исследований даже оценить ее бывает достаточно проблематично.
Типы выборок
Выборки делятся на два типа:
- вероятностные
- невероятностные
Вероятностные выборки
1.1 Случайная выборка (простой случайный отбор)
Такая выборка предполагает однородность генеральной совокупности, одинаковую вероятность доступности всех элементов, наличие полного списка всех элементов. При отборе элементов, как правило, используется таблица случайных чисел.
1.2 Механическая (систематическая) выборка
Разновидность случайной выборки, упорядоченная по какому-либо признаку (алфавитный порядок, номер телефона, дата рождения и т.д.). Первый элемент отбирается случайно, затем, с шагом ‘n’ отбирается каждый ‘k’-ый элемент. Размер генеральной совокупности, при этом – N=n*k
1.3 Стратифицированная (районированная)
Применяется в случае неоднородности генеральной совокупности. Генеральная совокупность разбивается на группы (страты). В каждой страте отбор осуществляется случайным или механическим образом.
1.4 Серийная (гнездовая или кластерная) выборка
При серийной выборке единицами отбора выступают не сами объекты, а группы (кластеры или гнёзда). Группы отбираются случайным образом. Объекты внутри групп обследуются сплошняком.
2.Невероятностные выборки
Отбор в такой выборке осуществляется не по принципам случайности, а по субъективным критериям – доступности, типичности, равного представительства и т.д..
2.1. Квотная выборка
Изначально выделяется некоторое количество групп объектов (например, мужчины в возрасте 20-30 лет, 31-45 лет и 46-60 лет; лица с доходом до 30 тысяч рублей, с доходом от 30 до 60 тысяч рублей и с доходом свыше 60 тысяч рублей) Для каждой группы задается количество объектов, которые должны быть обследованы. Количество объектов, которые должны попасть в каждую из групп, задается, чаще всего, либо пропорционально заранее известной доле группы в генеральной совокупности, либо одинаковым для каждой группы. Внутри групп объекты отбираются произвольно. Квотные выборки используются в маркетинговых исследованиях достаточно часто.
2.2. Метод снежного кома
Выборка строится следующим образом. У каждого респондента, начиная с первого, просятся контакты его друзей, коллег, знакомых, которые подходили бы под условия отбора и могли бы принять участие в исследовании. Таким образом, за исключением первого шага, выборка формируется с участием самих объектов исследования. Метод часто применяется, когда необходимо найти и опросить труднодоступные группы респондентов (например, респондентов, имеющих высокий доход, респондентов, принадлежащих к одной профессиональной группе, респондентов, имеющих какие-либо схожие хобби/увлечения и т.д.)
2.3 Стихийная выборка
Опрашиваются наиболее доступные респонденты. Типичные примеры стихийных выборок – опросы в газетах/журналах, анкеты, отданные респондентам на самозаполнение, большинство интернет-опросов. Размер и состав стихийных выборок заранее не известен, и определяется только одним параметром – активностью респондентов.
2.4 Выборка типичных случаев
Отбираются единицы генеральной совокупности, обладающие средним (типичным) значением признака. При этом возникает проблема выбора признака и определения его типичного значения.
Почитать еще



Машинное обучение
Глубокое обучение – это продвинутая форма машинного обучения. Глубокое обучение относится к способности компьютерных систем, известных


Выборка. Типы выборок
Суммарная численность объектов наблюдения (люди, домохозяйства, предприятия, населенные пункты и т.д.), обладающих определенным набором признаков


Обзор основных видов сегментации
Загрузить программу ВІ Демонстрации решений Аналитика бизнеса Оглавление Сегментация бренда Сегментация помогает принимать более эффективные


Несколько видео о наших продуктах

Проиграть видео
Презентация аналитической платформы Tibco Spotfire

Проиграть видео
Отличительные особенности Tibco Spotfire 10X

Проиграть видео
Как аналитика данных помогает менеджерам компании
Методы выборки: Типы с примерами
Опубликовано 2023-02-11 19:53 пользователем

Выборка является важной частью любого исследовательского проекта. Правильный метод выборки может сделать или разрушить достоверность вашего исследования, и очень важно выбрать правильный метод для вашего конкретного вопроса. В этой статье мы подробно рассмотрим некоторые из наиболее популярных методов выборки и приведем реальные примеры того, как их можно использовать для сбора точных и надежных данных.
От простой случайной выборки до сложной стратифицированной выборки, мы рассмотрим плюсы, минусы и лучшие практики каждого метода. Итак, независимо от того, являетесь ли вы опытным исследователем или только начинаете свой путь, эта статья – обязательное чтение для всех, кто хочет освоить методы выборки. Давайте начнем!
Индекс содержания
- Что такое выборка?
- Типы выборки: методы выборки
- Типы вероятностной выборки с примерами:
- Использование вероятностной выборки
- Типы не вероятностной выборки с примерами
- Использование не вероятностной выборки
- Как вы решаете, какой тип выборки использовать?
- Разница между вероятностной и не вероятностной выборкой
- Вывод
Что такое выборка?
Выборка – это техника отбора отдельных членов или подмножества населения для того, чтобы сделать на их основе статистические выводы и оценить характеристики всего населения. Различные методы выборки широко используются исследователями в маркетинговых исследованиях, так что им не нужно изучать все население, чтобы получить действенные выводы.
Это также удобный и экономически эффективный метод, и поэтому он составляет основу любого плана исследования. Методы выборки могут быть использованы в программном обеспечении для проведения исследовательских опросов для получения оптимальных результатов.
Например, предположим, производитель лекарств хотел бы исследовать неблагоприятные побочные эффекты лекарства на население страны. В этом случае практически невозможно провести исследование, в котором участвовали бы все. В этом случае исследователь определяет выборку людей из каждой демографической группы и затем исследует их, получая ориентировочные данные о поведении препарата.
Узнайте больше об Аудитории
Типы выборки: Методы выборки
Выборка в исследованиях рыночных действий бывает двух типов – вероятностная и не вероятностная выборка. Давайте подробнее рассмотрим эти два метода выборки.
- Вероятностная выборка: Вероятностная выборка – это метод выборки, при котором исследователь выбирает несколько критериев и отбирает членов популяции случайным образом. При таком параметре отбора все члены имеют равную возможность участвовать в выборке.
- Невероятностная выборка: При невероятностной выборке исследователь случайным образом выбирает членов для исследования. Этот метод выборки не является фиксированным или заранее определенным процессом отбора. Это затрудняет для всех элементов населения равные возможности быть включенными в выборку.
В этом блоге обсуждаются различные вероятностные и не вероятностные методы выборки, которые вы можете применить в любом исследовании рынка.
Типы вероятностной выборки с примерами:
Вероятностная выборка – это метод, при котором исследователи выбирают образцы из большей совокупности на основе теории вероятности. Этот метод выборки учитывает каждого члена популяции и формирует выборки на основе фиксированного процесса.
Например, в популяции из 1000 человек каждый член имеет шанс 1/1000 быть отобранным для включения в выборку. Вероятностная выборка устраняет смещение выборки в популяции и позволяет включить в выборку всех членов.
Существует четыре типа методов вероятностной выборки:

- Простая случайная выборка: Одним из лучших методов вероятностной выборки, который помогает экономить время и ресурсы, является метод простой случайной выборки. Это надежный метод получения информации, при котором каждый отдельный член популяции выбирается случайно, чисто случайно. Например, в организации из 500 сотрудников, если команда HR решит провести мероприятия по сплочению коллектива, они, скорее всего, предпочтут выбирать фишки из миски. В этом случае каждый из 500 сотрудников имеет равную возможность быть отобранным.
- Кластерная выборка: Кластерная выборка – это метод, при котором исследователи делят всю совокупность на части или кластеры, представляющие совокупность. Кластеры определяются и включаются в выборку на основе таких демографических параметров, как возраст, пол, местоположение и т.д. Это позволяет создателю опроса сделать эффективные выводы из полученных данных.
Например, предположим, правительство Соединенных Штатов хочет оценить количество иммигрантов, проживающих на материковой части США. В этом случае они могут разделить его на кластеры, основанные на таких штатах, как Калифорния, Техас, Флорида, Массачусетс, Колорадо, Гавайи и т. д. Такой способ проведения опроса будет более эффективным, так как результаты будут распределены по штатам и предоставят глубокие данные об иммиграции. - Систематическая выборка: Исследователи используют метод систематической выборки для отбора членов выборки из популяции через регулярные промежутки времени. Он требует выбора начальной точки для выборки и размера выборки, который можно повторять через регулярные промежутки времени. Этот метод выборки имеет заранее определенный диапазон; следовательно, этот метод выборки наименее трудоемкий.
Например, исследователь намеревается собрать систематическую выборку из 500 человек в популяции численностью 5000 человек. Он/она пронумерует каждый элемент популяции от 1 до 5000 и выберет каждого 10-го человека для включения в выборку (Общая популяция/Размер выборки = 5000/500 = 10). - Стратифицированная случайная выборка: Стратифицированная случайная выборка – это метод, при котором исследователь делит популяцию на более мелкие группы, которые не пересекаются, но представляют всю популяцию. Например, исследователь, желающий проанализировать характеристики людей, принадлежащих к различным группам по годовому доходу, создает страты (группы) в соответствии с годовым доходом семьи. Например, менее $20 000, $21 000 – $30 000, $31 000 – $40 000, $41 000 – $50 000 и т. д. Таким образом, исследователь делает вывод о характеристиках людей, принадлежащих к различным группам доходов. Маркетологи могут проанализировать, на какие группы доходов ориентироваться, а какие исключить, чтобы создать дорожную карту, которая принесет плодотворные результаты.
Uses of probability sampling
Существует множество вариантов использования вероятностной выборки:
- Снижение погрешности выборки: При использовании метода вероятностной выборки погрешность выборки, полученной из совокупности, незначительна или вообще отсутствует. Выборка в основном отражает понимание и умозаключения исследователя. Вероятностная выборка приводит к более качественному сбору данных, поскольку выборка адекватно представляет население.
- Разнородное население: Когда население обширно и разнообразно, важно иметь адекватное представительство, чтобы данные не были перекошены в сторону одной демографической группы. Например, предположим, что компания Square хотела бы понять, какие люди могли бы использовать ее устройства в точках продаж. В этом случае поможет опрос, проведенный на выборке людей по всей территории США из разных отраслей промышленности и социально-экономического положения.
- Создание точной выборки: Выборка вероятностей помогает исследователям планировать и создавать точную выборку. Это помогает получить четко определенные данные.
Типы не вероятностной выборки с примерами
Не вероятностный метод – это метод выборки, который предполагает сбор обратной связи на основе возможностей исследователя или статистика по отбору выборки, а не на основе фиксированного процесса отбора. В большинстве ситуаций результаты опроса, проведенного с использованием не вероятностной выборки, приводят к искаженным результатам, которые могут не представлять желаемую целевую совокупность. Однако существуют ситуации, например, на предварительных этапах исследования или при ограничении затрат на проведение исследования, когда не вероятностная выборка будет гораздо полезнее, чем другой тип.
Четыре типа непроизводственной выборки лучше объясняют цель этого метода выборки:
- Выборка удобства: Этот метод зависит от легкости доступа к испытуемым, например, опрос покупателей в торговом центре или прохожих на оживленной улице. Обычно его называют выборкой удобства из-за того, что исследователю легко проводить его и вступать в контакт с испытуемыми. Исследователи практически не имеют полномочий для отбора элементов выборки, и он осуществляется исключительно на основе близости, а не репрезентативности. Этот метод не вероятностной выборки используется, когда существуют ограничения по времени и затратам на сбор обратной связи. В ситуациях с ограниченными ресурсами, например, на начальных этапах исследования, используется выборка по удобству.
Например, стартапы и НПО обычно проводят выборку по удобству в торговом центре для распространения листовок о предстоящих событиях или продвижения дела – они делают это, стоя у входа в торговый центр и раздавая брошюры случайным образом. - Суждение или целенаправленная выборка: Суждение или целенаправленная выборка формируется по усмотрению исследователя. Исследователи в обязательном порядке учитывают цель исследования, а также понимание целевой аудитории. Например, когда исследователи хотят понять ход мыслей людей, заинтересованных в получении степени магистра. Критерием отбора будет: “Заинтересованы ли вы в получении степени магистра в …?”, а те, кто ответит “нет”, будут исключены из выборки.
- Выборка снежного кома: Выборка снежного кома – это метод выборки, который исследователи применяют, когда субъектов трудно отследить. Например, опрос людей без жилья или нелегальных иммигрантов будет чрезвычайно сложным. В таких случаях, используя теорию снежного кома, исследователи могут отследить несколько категорий для опроса и получить результаты. Исследователи также применяют этот метод выборки, когда тема очень чувствительна и не обсуждается открыто – например, опросы для сбора информации о ВИЧ СПИДе. Не многие жертвы охотно ответят на вопросы. Тем не менее, исследователи могут связаться с людьми, которых они могут знать, или с волонтерами, связанными с этим делом, чтобы установить контакт с жертвами и собрать информацию.
- Квотная выборка: В квотной выборке при этом методе отбор участников происходит на основе заранее установленного стандарта. В этом случае, поскольку выборка формируется по определенным признакам, созданная выборка будет обладать теми же качествами, которые встречаются в генеральной совокупности. Это быстрый метод сбора выборки.
Uses of non-probability sampling
Невероятностная выборка используется для следующего:
- Создание гипотезы: Исследователи используют метод непропорциональной выборки для создания предположения, когда имеется ограниченная или вообще отсутствует предварительная информация. Этот метод помогает немедленно получить данные и создает базу для дальнейшего исследования.
- Исследовательские исследования: Исследователи широко используют этот метод выборки при проведении качественных исследований, пилотных исследований или исследовательских работ.
- Бюджет и временные ограничения: Невероятностный метод применяется, когда есть бюджетные и временные ограничения, и необходимо собрать некоторые предварительные данные. Поскольку схема опроса не является жесткой, проще выбрать респондентов случайным образом и попросить их пройти опрос или анкетирование.
Как вы решаете, какой тип выборки использовать?
Для любого исследования важно точно выбрать метод выборки, чтобы он соответствовал целям вашего исследования. Эффективность выборки зависит от различных факторов. Вот несколько шагов, которым следуют опытные исследователи, чтобы выбрать оптимальный метод выборки.
- Запишите цели исследования. Как правило, это должно быть сочетание стоимости, точности или аккуратности.
- Определите эффективные методы выборки, которые потенциально могут достичь целей исследования.
- Протестируйте каждый из этих методов и проверьте, помогают ли они достичь цели.
- Выберите метод, который лучше всего подходит для исследования.
Откройте силу точной выборки!
Разница между вероятностной и не вероятностной выборкой
Выше мы рассмотрели различные типы методов выборки и их подтипы. Однако, чтобы подытожить все обсуждение, ниже приведены существенные различия между вероятностными и не вероятностными методами выборки:
| Вероятностные методы выборки | Невероятностные методы выборки. | |
| Определение | Вероятностная выборка – это метод выборки, при котором выборки из большей совокупности отбираются с помощью метода, основанного на теории вероятности. | Невероятностная выборка – это метод выборки, при котором исследователь отбирает образцы на основе субъективного суждения исследователя, а не случайного отбора. |
| Альтернативно известный как | Случайный метод выборки. | Неслучайный метод выборки |
| Отбор популяции | Популяция отбирается случайным образом. | Население выбрано произвольно. |
| Натура | Исследование является окончательным. | Исследование является исследовательским. |
| Выборка | Поскольку существует метод определения выборки, демографические характеристики населения представлены убедительно. | Поскольку метод выборки произволен, демографические характеристики населения представлены почти всегда искаженно. |
| Время, затрачиваемое | На проведение исследования требуется больше времени, поскольку план исследования определяет параметры отбора до начала маркетингового исследования. | Этот тип выборочного метода является быстрым, поскольку ни выборка, ни критерии отбора выборки не определены. |
| Результаты | Данный тип выборки является полностью беспристрастным, следовательно, результаты также являются убедительными. | Данный тип выборки является полностью необъективным, следовательно, результаты также являются необъективными, что делает исследование спекулятивным. |
| Гипотеза | При вероятностной выборке существует основная гипотеза до начала исследования, и этот метод направлен на доказательство гипотезы. | При не вероятностной выборке гипотеза выводится после проведения исследования. |
Вывод
Теперь, когда мы узнали, как работают различные методы выборки, которые широко используются исследователями в маркетинговых исследованиях, чтобы им не нужно было исследовать все население для сбора действенных выводов, давайте рассмотрим инструмент, который может помочь вам управлять этими выводами.
понимает необходимость точного, своевременного и экономически эффективного метода отбора нужной выборки; именно поэтому мы предлагаем программное обеспечение Software – набор инструментов, позволяющих эффективно отбирать целевую аудиторию, управлять полученными данными в организованном, настраиваемом хранилище и управлять сообществом для обратной связи после проведения опроса.
Не упустите шанс повысить ценность исследований.
Попробуйте сегодня!
Рубрика:
- Бизнес
Ключевые слова:
- исследование рынка
Автор:
- Dan Fleetwood
Источник:
- questionpro
Перевод:
- Дмитрий Л
