Определение.
Арифметическое
значение квадратного
корня из выборочной дисперсии называется
выборочным
средним квадратическим отклонением:
![]() (10)
(10)
Исправленное
выборочное среднее квадратическое
отклонение
![]() (11)
(11)
4. Мода.
Определение.
Модой М0
называют значение
признака, которое имеет наибольшую
частоту
(ni
= max).
Например, для
распределения, данного табл. 5, мода
равна 5.
5. Медиана.
Медианой
те
называют значение признака, которое
делит статистическое распределение на
две равные части:
me
=
xk+1,
если
n
=
2k+1,
me
=
![]() ,
,
если n=2k
6. Коэффициент
вариации.
Для сравнивания меры рассеяния значений
признаков около выборочной средней в
разных выборках служит коэффициент
вариации.
Определение.
Коэффициентом
вариации V
называется
отношение выборочного среднего
квадратического
отклонения к выборочной средней,
выраженное в процентах:
![]() (12)
(12)
Пусть изучается
случайная величина X.
Из генеральной
совокупности сделана выборка объема п
со значениями
признака х1
х2,…,
хn.
Предположим,
что х1,
х2,…,хn
различны.
Их можно рассматривать как случайные
величины Х1,
Х2,
…, Хn,
имеющие то
же распределение, что и случайная
величина X,
и, следовательно,
одинаковые значения М(Х)
и
D(Х).
Тогда
![]()
Воспользовавшись
свойствами дисперсии находим
![]()
Пусть σ![]() – средняя
– средняя
квадратическая ошибка выборочной
средней. Тогда
![]()
Вывод. Средняя
квадратическая ошибка выборочной
средней σ(![]() B)
B)
в
![]() раз меньше среднего квадратического
раз меньше среднего квадратического
отклонения случайной величиныX,
возможные
значения которой попали в выборочную
совокупность.
1.6. Статистические оценки параметров распределения
Оценки
математического ожидания и дисперсии.
С понятием параметров
распределения мы познакомились в теории
вероятностей. Например, в нормальном
законе распределения, задаваемом
функцией плотности вероятности

параметрами служат
а –
математическое ожидание и а
– среднее
квадратическое отклонение. В распределении
Пуассона параметром является число а
= пр.
Определение.
Статистической
оценкой неизвестного параметра
теоретического распределения называют
его приближенное значение, зависящее
от данных выборки (х1,
х2,
х3,
…, хk;
п1,
п2,
п3,…,
пk),
т. е. некоторую функцию этих величин.
Здесь х1,
х2,
х3,
…, хk
– значения признака, п1,
п2,
п3,…,
пk
–соответствующие частоты. Статистическая
оценка является случайной величиной.
Обозначим через
θ
– оцениваемый параметр, а через
θ*
– его статистическую оценку. Величину
|θ*–θ|
называют
точностью
оценки. Чем
меньше |θ*–θ|,
тем лучше, точнее определен неизвестный
параметр.
Чтобы оценка θ*
имела практическое значение, она не
должна содержать систематической ошибки
и вместе с тем иметь возможно меньшую
дисперсию. Кроме того, при увеличении
объема выборки вероятность сколь угодно
малых отклонений |θ*–θ|
должна быть близка к 1.
Сформулируем
следующие определения.
-
Оценка параметра
называется несмещенной, если ее
математическое ожидание М(θ*)
равно
оцениваемому параметру θ,
т. е.
М(θ*)
= θ, (1)
и смещенной, если
М(θ*)
≠ θ, (2)
-
Оценка θ*
называется состоятельной, если при
любом δ > 0
![]() (3)
(3)
Равенство (3)
читается так: оценка θ*
сходится по вероятности к θ.
3. Оценка θ*
называется эффективной, если при заданном
п она имеет наименьшую дисперсию.
Теорема
1. Выборочная
средняя ХВ
является несмещенной и состоятельной
оценкой математического ожидания.
Доказательство.
Пусть выборка репрезентативна, т. е..
все элементы генеральной совокупности
имеют одинаковую возможность попасть
в выборку. Значения признака х1,
х2,
х3,…,хn
можно принять
за независимые случайные величины Х1,
Х2,
Х3, …,Хn
с одинаковыми
распределениями и числовыми
характеристиками, в том числе с равными
математическими ожиданиями, равными
а,
![]()
Так
как каждая из величин Х1,
Х2,
Х3,
…,
Хп
имеет
распределение,
совпадающее с распределением генеральной
совокупности, то М(Х)
= а. Поэтому
![]()
Далее, на основании
закона больших чисел имеем
![]()
откуда следует,
что
![]()
–
состоятельная оценка М(Х).
Используя правило
исследования на экстремум, можно
доказать, что
![]() является и эффективной оценкойМ(Х).
является и эффективной оценкойМ(Х).
В качестве оценки
дисперсии изучаемого признака в
генеральной совокупности D(Х)
принимается
исправленная дисперсия.
Теорема
2. Исправленная
выборочная дисперсия
![]()
является
несмещенной и состоятельной
оценкой
дисперсии D(Х).
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
Интервальный вариационный ряд и его характеристики
- Построение интервального вариационного ряда по данным эксперимента
- Гистограмма и полигон относительных частот, кумулята и эмпирическая функция распределения
- Выборочная средняя, мода и медиана. Симметрия ряда
- Выборочная дисперсия и СКО
- Исправленная выборочная дисперсия, стандартное отклонение выборки и коэффициент вариации
- Алгоритм исследования интервального вариационного ряда
- Примеры
п.1. Построение интервального вариационного ряда по данным эксперимента
Интервальный вариационный ряд – это ряд распределения, в котором однородные группы составлены по признаку, меняющемуся непрерывно или принимающему слишком много значений.
Общий вид интервального вариационного ряда
| Интервалы, (left.left[a_{i-1},a_iright.right)) | (left.left[a_{0},a_1right.right)) | (left.left[a_{1},a_2right.right)) | … | (left.left[a_{k-1},a_kright.right)) |
| Частоты, (f_i) | (f_1) | (f_2) | … | (f_k) |
Здесь k – число интервалов, на которые разбивается ряд.
Размах вариации – это длина интервала, в пределах которой изменяется исследуемый признак: $$ F=x_{max}-x_{min} $$
Правило Стерджеса
Эмпирическое правило определения оптимального количества интервалов k, на которые следует разбить ряд из N чисел: $$ k=1+lfloorlog_2 Nrfloor $$ или, через десятичный логарифм: $$ k=1+lfloor 3,322cdotlg Nrfloor $$
Скобка (lfloor rfloor) означает целую часть (округление вниз до целого числа).
Шаг интервального ряда – это отношение размаха вариации к количеству интервалов, округленное вверх до определенной точности: $$ h=leftlceilfrac Rkrightrceil $$
Скобка (lceil rceil) означает округление вверх, в данном случае не обязательно до целого числа.
Алгоритм построения интервального ряда
На входе: все значения признака (left{x_jright}, j=overline{1,N})
Шаг 1. Найти размах вариации (R=x_{max}-x_{min})
Шаг 2. Найти оптимальное количество интервалов (k=1+lfloorlog_2 Nrfloor)
Шаг 3. Найти шаг интервального ряда (h=leftlceilfrac{R}{k}rightrceil)
Шаг 4. Найти узлы ряда: $$ a_0=x_{min}, a_i=1_0+ih, i=overline{1,k} $$ Шаг 5. Найти частоты (f_i) – число попаданий значений признака в каждый из интервалов (left.left[a_{i-1},a_iright.right)).
На выходе: интервальный ряд с интервалами (left.left[a_{i-1},a_iright.right)) и частотами (f_i, i=overline{1,k})
Заметим, что поскольку шаг h находится с округлением вверх, последний узел (a_kgeq x_{max}).
Например:
Проведено 100 измерений роста учеников старших классов.
Минимальный рост составляет 142 см, максимальный – 197 см.
Найдем узлы для построения соответствующего интервального ряда.
По условию: (N=100, x_{min}=142 см, x_{max}=197 см).
Размах вариации: (R=197-142=55) (см)
Оптимальное число интервалов: (k=1+lfloor 3,322cdotlg 100rfloor=1+lfloor 6,644rfloor=1+6=7)
Шаг интервального ряда: (h=lceilfrac{55}{5}rceil=lceil 7,85rceil=8) (см)
Получаем узлы ряда: $$ a_0=x_{min}=142, a_i=142+icdot 8, i=overline{1,7} $$
| (left.left[a_{i-1},a_iright.right)) cм | (left.left[142;150right.right)) | (left.left[150;158right.right)) | (left.left[158;166right.right)) | (left.left[166;174right.right)) | (left.left[174;182right.right)) | (left.left[182;190right.right)) | (left[190;198right]) |
п.2. Гистограмма и полигон относительных частот, кумулята и эмпирическая функция распределения
Относительная частота интервала (left.left[a_{i-1},a_iright.right)) – это отношение частоты (f_i) к общему количеству исходов: $$ w_i=frac{f_i}{N}, i=overline{1,k} $$
Гистограмма относительных частот интервального ряда – это фигура, состоящая из прямоугольников, ширина которых равна шагу ряда, а высота – относительным частотам каждого из интервалов.
Площадь гистограммы равна 1 (с точностью до округлений), и она является эмпирическим законом распределения исследуемого признака.
Полигон относительных частот интервального ряда – это ломаная, соединяющая точки ((x_i,w_i)), где (x_i) – середины интервалов: (x_i=frac{a_{i-1}+a_i}{2}, i=overline{1,k}).
Накопленные относительные частоты – это суммы: $$ S_1=w_1, S_i=S_{i-1}+w_i, i=overline{2,k} $$ Ступенчатая кривая (F(x)), состоящая из прямоугольников, ширина которых равна шагу ряда, а высота – накопленным относительным частотам, является эмпирической функцией распределения исследуемого признака.
Кумулята – это ломаная, которая соединяет точки ((x_i,S_i)), где (x_i) – середины интервалов.
Например:
Продолжим анализ распределения учеников по росту.
Выше мы уже нашли узлы интервалов. Пусть, после распределения всех 100 измерений по этим интервалам, мы получили следующий интервальный ряд:
| i | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| (left.left[a_{i-1},a_iright.right)) cм | (left.left[142;150right.right)) | (left.left[150;158right.right)) | (left.left[158;166right.right)) | (left.left[166;174right.right)) | (left.left[174;182right.right)) | (left.left[182;190right.right)) | (left[190;198right]) |
| (f_i) | 4 | 7 | 11 | 34 | 33 | 8 | 3 |
Найдем середины интервалов, относительные частоты и накопленные относительные частоты:
| (x_i) | 146 | 154 | 162 | 170 | 178 | 186 | 194 |
| (w_i) | 0,04 | 0,07 | 0,11 | 0,34 | 0,33 | 0,08 | 0,03 |
| (S_i) | 0,04 | 0,11 | 0,22 | 0,56 | 0,89 | 0,97 | 1 |
Построим гистограмму и полигон:

Построим кумуляту и эмпирическую функцию распределения: 

Эмпирическая функция распределения (относительно середин интервалов): $$ F(x)= begin{cases} 0, xleq 146\ 0,04, 146lt xleq 154\ 0,11, 154lt xleq 162\ 0,22, 162lt xleq 170\ 0,56, 170lt xleq 178\ 0,89, 178lt xleq 186\ 0,97, 186lt xleq 194\ 1, xgt 194 end{cases} $$
п.3. Выборочная средняя, мода и медиана. Симметрия ряда
Выборочная средняя интервального вариационного ряда определяется как средняя взвешенная по частотам: $$ X_{cp}=frac{x_1f_1+x_2f_2+…+x_kf_k}{N}=frac1Nsum_{i=1}^k x_if_i $$ где (x_i) – середины интервалов: (x_i=frac{a_{i-1}+a_i}{2}, i=overline{1,k}).
Или, через относительные частоты: $$ X_{cp}=sum_{i=1}^k x_iw_i $$
Модальным интервалом называют интервал с максимальной частотой: $$ f_m=max f_i $$ Мода интервального вариационного ряда определяется по формуле: $$ M_o=x_o+frac{f_m-f_{m-1}}{(f_m-f_{m-1})+(f_m+f_{m+1})}h $$ где
(h) – шаг интервального ряда;
(x_o) – нижняя граница модального интервала;
(f_m,f_{m-1},f_{m+1}) – соответственно, частоты модального интервала, интервала слева от модального и интервала справа.
Медианным интервалом называют первый интервал слева, на котором кумулята превысила значение 0,5. Медиана интервального вариационного ряда определяется по формуле: $$ M_e=x_o+frac{0,5-S_{me-1}}{w_{me}}h $$ где
(h) – шаг интервального ряда;
(x_o) – нижняя граница медианного интервала;
(S_{me-1}) накопленная относительная частота для интервала слева от медианного;
(w_{me}) относительная частота медианного интервала.
Расположение выборочной средней, моды и медианы в зависимости от симметрии ряда аналогично их расположению в дискретном ряду (см. §65 данного справочника).
Например:
Для распределения учеников по росту получаем:
| (x_i) | 146 | 154 | 162 | 170 | 178 | 186 | 194 | ∑ |
| (w_i) | 0,04 | 0,07 | 0,11 | 0,34 | 0,33 | 0,08 | 0,03 | 1 |
| (x_iw_i) | 5,84 | 10,78 | 17,82 | 57,80 | 58,74 | 14,88 | 5,82 | 171,68 |
$$ X_{cp}=sum_{i=1}^k x_iw_i=171,68approx 171,7 text{(см)} $$ На гистограмме (или полигоне) относительных частот максимальная частота приходится на 4й интервал [166;174). Это модальный интервал.
Данные для расчета моды: begin{gather*} x_o=166, f_m=34, f_{m-1}=11, f_{m+1}=33, h=8\ M_o=x_o+frac{f_m-f_{m-1}}{(f_m-f_{m-1})+(f_m+f_{m+1})}h=\ =166+frac{34-11}{(34-11)+(34-33)}cdot 8approx 173,7 text{(см)} end{gather*} На кумуляте значение 0,5 пересекается на 4м интервале. Это – медианный интервал.
Данные для расчета медианы: begin{gather*} x_o=166, w_m=0,34, S_{me-1}=0,22, h=8\ \ M_e=x_o+frac{0,5-S_{me-1}}{w_me}h=166+frac{0,5-0,22}{0,34}cdot 8approx 172,6 text{(см)} end{gather*} begin{gather*} \ X_{cp}=171,7; M_o=173,7; M_e=172,6\ X_{cp}lt M_elt M_o end{gather*} Ряд асимметричный с левосторонней асимметрией.
При этом (frac{|M_o-X_{cp}|}{|M_e-X_{cp}|}=frac{2,0}{0,9}approx 2,2lt 3), т.е. распределение умеренно асимметрично.
п.4. Выборочная дисперсия и СКО
Выборочная дисперсия интервального вариационного ряда определяется как средняя взвешенная для квадрата отклонения от средней: begin{gather*} D=frac1Nsum_{i=1}^k(x_i-X_{cp})^2 f_i=frac1Nsum_{i=1}^k x_i^2 f_i-X_{cp}^2 end{gather*} где (x_i) – середины интервалов: (x_i=frac{a_{i-1}+a_i}{2}, i=overline{1,k}).
Или, через относительные частоты: $$ D=sum_{i=1}^k(x_i-X_{cp})^2 w_i=sum_{i=1}^k x_i^2 w_i-X_{cp}^2 $$
Выборочное среднее квадратичное отклонение (СКО) определяется как корень квадратный из выборочной дисперсии: $$ sigma=sqrt{D} $$
Например:
Для распределения учеников по росту получаем:
| $x_i$ | 146 | 154 | 162 | 170 | 178 | 186 | 194 | ∑ |
| (w_i) | 0,04 | 0,07 | 0,11 | 0,34 | 0,33 | 0,08 | 0,03 | 1 |
| (x_iw_i) | 5,84 | 10,78 | 17,82 | 57,80 | 58,74 | 14,88 | 5,82 | 171,68 |
| (x_i^2w_i) – результат | 852,64 | 1660,12 | 2886,84 | 9826 | 10455,72 | 2767,68 | 1129,08 | 29578,08 |
$$ D=sum_{i=1}^k x_i^2 w_i-X_{cp}^2=29578,08-171,7^2approx 104,1 $$ $$ sigma=sqrt{D}approx 10,2 $$
п.5. Исправленная выборочная дисперсия, стандартное отклонение выборки и коэффициент вариации
Исправленная выборочная дисперсия интервального вариационного ряда определяется как: begin{gather*} S^2=frac{N}{N-1}D end{gather*}
Стандартное отклонение выборки определяется как корень квадратный из исправленной выборочной дисперсии: $$ s=sqrt{S^2} $$
Коэффициент вариации это отношение стандартного отклонения выборки к выборочной средней, выраженное в процентах: $$ V=frac{s}{X_{cp}}cdot 100text{%} $$
Подробней о том, почему и когда нужно «исправлять» дисперсию, и для чего использовать коэффициент вариации – см. §65 данного справочника.
Например:
Для распределения учеников по росту получаем: begin{gather*} S^2=frac{100}{99}cdot 104,1approx 105,1\ sapprox 10,3 end{gather*} Коэффициент вариации: $$ V=frac{10,3}{171,7}cdot 100text{%}approx 6,0text{%}lt 33text{%} $$ Выборка однородна. Найденное значение среднего роста (X_{cp})=171,7 см можно распространить на всю генеральную совокупность (старшеклассников из других школ).
п.6. Алгоритм исследования интервального вариационного ряда
На входе: все значения признака (left{x_jright}, j=overline{1,N})
Шаг 1. Построить интервальный ряд с интервалами (left.right[a_{i-1}, a_ileft.right)) и частотами (f_i, i=overline{1,k}) (см. алгоритм выше).
Шаг 2. Составить расчетную таблицу. Найти (x_i,w_i,S_i,x_iw_i,x_i^2w_i)
Шаг 3. Построить гистограмму (и/или полигон) относительных частот, эмпирическую функцию распределения (и/или кумуляту). Записать эмпирическую функцию распределения.
Шаг 4. Найти выборочную среднюю, моду и медиану. Проанализировать симметрию распределения.
Шаг 5. Найти выборочную дисперсию и СКО.
Шаг 6. Найти исправленную выборочную дисперсию, стандартное отклонение и коэффициент вариации. Сделать вывод об однородности выборки.
п.7. Примеры
Пример 1. При изучении возраста пользователей коворкинга выбрали 30 человек.
Получили следующий набор данных:
18,38,28,29,26,38,34,22,28,30,22,23,35,33,27,24,30,32,28,25,29,26,31,24,29,27,32,24,29,29
Постройте интервальный ряд и исследуйте его.
1) Построим интервальный ряд. В наборе данных: $$ x_{min}=18, x_{max}=38, N=30 $$ Размах вариации: (R=38-18=20)
Оптимальное число интервалов: (k=1+lfloorlog_2 30rfloor=1+4=5)
Шаг интервального ряда: (h=lceilfrac{20}{5}rceil=4)
Получаем узлы ряда: $$ a_0=x_{min}=18, a_i=18+icdot 4, i=overline{1,5} $$
| (left.left[a_{i-1},a_iright.right)) лет | (left.left[18;22right.right)) | (left.left[22;26right.right)) | (left.left[26;30right.right)) | (left.left[30;34right.right)) | (left.left[34;38right.right)) |
Считаем частоты для каждого интервала. Получаем интервальный ряд:
| (left.left[a_{i-1},a_iright.right)) лет | (left.left[18;22right.right)) | (left.left[22;26right.right)) | (left.left[26;30right.right)) | (left.left[30;34right.right)) | (left.left[34;38right.right)) |
| (f_i) | 1 | 7 | 12 | 6 | 4 |
2) Составляем расчетную таблицу:
| (x_i) | 20 | 24 | 28 | 32 | 36 | ∑ |
| (f_i) | 1 | 7 | 12 | 6 | 4 | 30 |
| (w_i) | 0,033 | 0,233 | 0,4 | 0,2 | 0,133 | 1 |
| (S_i) | 0,033 | 0,267 | 0,667 | 0,867 | 1 | – |
| (x_iw_i) | 0,667 | 5,6 | 11,2 | 6,4 | 4,8 | 28,67 |
| (x_i^2w_i) | 13,333 | 134,4 | 313,6 | 204,8 | 172,8 | 838,93 |
3) Строим полигон и кумуляту

Эмпирическая функция распределения: $$ F(x)= begin{cases} 0, xleq 20\ 0,033, 20lt xleq 24\ 0,267, 24lt xleq 28\ 0,667, 28lt xleq 32\ 0,867, 32lt xleq 36\ 1, xgt 36 end{cases} $$ 4) Находим выборочную среднюю, моду и медиану $$ X_{cp}=sum_{i=1}^k x_iw_iapprox 28,7 text{(лет)} $$ На полигоне модальным является 3й интервал (самая высокая точка).
Данные для расчета моды: begin{gather*} x_0=26, f_m=12, f_{m-1}=7, f_{m+1}=6, h=4\ M_o=x_o+frac{f_m-f_{m-1}}{(f_m-f_{m-1})+(f_m+f_{m+1})}h=\ =26+frac{12-7}{(12-7)+(12-6)}cdot 4approx 27,8 text{(лет)} end{gather*}
На кумуляте медианным является 3й интервал (преодолевает уровень 0,5).
Данные для расчета медианы: begin{gather*} x_0=26, w_m=0,4, S_{me-1}=0,267, h=4\ M_e=x_o+frac{0,5-S_{me-1}}{w_{me}}h=26+frac{0,5-0,4}{0,267}cdot 4approx 28,3 text{(лет)} end{gather*} Получаем: begin{gather*} X_{cp}=28,7; M_o=27,8; M_e=28,6\ X_{cp}gt M_egt M_0 end{gather*} Ряд асимметричный с правосторонней асимметрией.
При этом (frac{|M_o-X_{cp}|}{|M_e-X_{cp}|} =frac{0,9}{0,1}=9gt 3), т.е. распределение сильно асимметрично.
5) Находим выборочную дисперсию и СКО: begin{gather*} D=sum_{i=1}^k x_i^2w_i-X_{cp}^2=838,93-28,7^2approx 17,2\ sigma=sqrt{D}approx 4,1 end{gather*}
6) Исправленная выборочная дисперсия: $$ S^2=frac{N}{N-1}D=frac{30}{29}cdot 17,2approx 17,7 $$ Стандартное отклонение (s=sqrt{S^2}approx 4,2)
Коэффициент вариации: (V=frac{4,2}{28,7}cdot 100text{%}approx 14,7text{%}lt 33text{%})
Выборка однородна. Найденное значение среднего возраста (X_{cp}=28,7) лет можно распространить на всю генеральную совокупность (пользователей коворкинга).

Евгений Николаевич Беляев
Эксперт по предмету «Математика»
Задать вопрос автору статьи
Генеральная дисперсия
Пусть нам дана генеральная совокупность относительно случайной величины $X$. Для начала напомним следующее определение:
Определение 1
Генеральная совокупность — совокупность случайно отобранных объектов данного вида, над которыми проводят наблюдения с целью получения конкретных значений случайной величины, проводимых в неизменных условиях при изучении одной случайной величины данного вида.
Определение 2
Генеральная дисперсия — среднее арифметическое квадратов отклонений значений вариант генеральной совокупности от их среднего значения.
Пусть значения вариант $x_1, x_2,dots ,x_k$ имеют, соответственно, частоты $n_1, n_2,dots ,n_k$. Тогда генеральная дисперсия вычисляется по формуле:
Рассмотрим частный случай. Пусть все варианты $x_1, x_2,dots ,x_k$ различны. В этом случае $n_1, n_2,dots ,n_k=1$. Получаем, что в этом случае генеральная дисперсия вычисляется по формуле:
С этим понятием также связано понятие генерального среднего квадратического отклонения.
Определение 3
Генеральное среднее квадратическое отклонение — квадратный корень из генеральной дисперсии:
[{sigma }_г=sqrt{D_г}]
Выборочная дисперсия
Пусть нам дана выборочная совокупность относительно случайной величины $X$. Для начала напомним следующее определение:
Определение 4
Выборочная совокупность — часть отобранных объектов из генеральной совокупности.
Определение 5
Выборочная дисперсия — среднее арифметическое значений вариант выборочной совокупности.
«Дисперсия: генеральная, выборочная, исправленная» 👇
Пусть значения вариант $x_1, x_2,dots ,x_k$ имеют, соответственно, частоты $n_1, n_2,dots ,n_k$. Тогда выборочная дисперсия вычисляется по формуле:
Рассмотрим частный случай. Пусть все варианты $x_1, x_2,dots ,x_k$ различны. В этом случае $n_1, n_2,dots ,n_k=1$. Получаем, что в этом случае выборочная дисперсия вычисляется по формуле:
С этим понятием также связано понятие выборочного среднего квадратического отклонения.
Определение 6
Выборочное среднее квадратическое отклонение — квадратный корень из генеральной дисперсии:
[{sigma }_в=sqrt{D_в}]
Исправленная дисперсия
Для нахождения исправленной дисперсии $S^2$ необходимо умножить выборочную дисперсию на дробь $frac{n}{n-1}$, то есть
С этим понятием также связано понятие исправленного среднего квадратического отклонения, которое находится по формуле:
!!! В случае, когда значение вариант не являются дискретными, а представляют из себя интервалы, то в формулах для вычисления генеральной или выборочной дисперсий за значение $x_i$ принимается значение середины интервала, которому принадлежит $x_i.$
Пример задачи на нахождение дисперсии и среднего квадратического отклонения
Пример 1
Выборочная совокупность задана следующей таблицей распределения:

Рисунок 1.
Найдем для нее выборочную дисперсию, выборочное среднее квадратическое отклонение, исправленную дисперсию и исправленное среднее квадратическое отклонение.
Решение:
Для решения этой задачи для начала сделаем расчетную таблицу:

Рисунок 2.
Величина $overline{x_в}$ (среднее выборочное) в таблице находится по формуле:
[overline{x_в}=frac{sumlimits^k_{i=1}{x_in_i}}{n}]
То есть
[overline{x_в}=frac{sumlimits^k_{i=1}{x_in_i}}{n}=frac{305}{20}=15,25]
Найдем выборочную дисперсию по формуле:
[D_в=frac{sumlimits^k_{i=1}{{{(x}_i-overline{x_в})}^2n_i}}{n}=frac{523,75}{20}=26,1875]
Выборочное среднее квадратическое отклонение:
[{sigma }_в=sqrt{D_в}approx 5,12]
Исправленная дисперсия:
[{S^2=frac{n}{n-1}D}_в=frac{20}{19}cdot 26,1875approx 27,57]
Исправленное среднее квадратическое отклонение:
[S=sqrt{S^2}approx 5,25]
Находи статьи и создавай свой список литературы по ГОСТу
Поиск по теме
Из предыдущей статьи мы узнали о таких показателях, как размах вариации, межквартильный размах и среднее линейное отклонение. В этой статье изучим дисперсию, среднеквадратичное отклонение и коэффициент вариации.
Дисперсия
Дисперсия случайной величины – это один из основных показателей в статистике. Он отражает меру разброса данных вокруг средней арифметической.
Сейчас небольшой экскурс в теорию вероятностей, которая лежит в основе математической статистики. Как и матожидание, дисперсия является важной характеристикой случайной величины. Если матожидание отражает центр случайной величины, то дисперсия дает характеристику разброса данных вокруг центра.
Формула дисперсии в теории вероятностей имеет вид:
![]()
То есть дисперсия — это математическое ожидание отклонений от математического ожидания.
На практике при анализе выборок математическое ожидание, как правило, не известно. Поэтому вместо него используют оценку – среднее арифметическое. Расчет дисперсии производят по формуле:
![]()
где
s2 – выборочная дисперсия, рассчитанная по данным наблюдений,
X – отдельные значения,
X̅– среднее арифметическое по выборке.
Стоит отметить, что у такого расчета дисперсии есть недостаток – она получается смещенной, т.е. ее математическое ожидание не равно истинному значению дисперсии. Подробней об этом здесь. Однако при увеличении объема выборки она все-таки приближается к своему теоретическому аналогу, т.е. является асимптотически не смещенной.
Простыми словами дисперсия – это средний квадрат отклонений. То есть вначале рассчитывается среднее значение, затем берется разница между каждым исходным и средним значением, возводится в квадрат, складывается и затем делится на количество значений в данной совокупности. Разница между отдельным значением и средней отражает меру отклонения. В квадрат возводится для того, чтобы все отклонения стали исключительно положительными числами и чтобы избежать взаимоуничтожения положительных и отрицательных отклонений при их суммировании. Затем, имея квадраты отклонений, просто рассчитываем среднюю арифметическую. Средний – квадрат – отклонений. Отклонения возводятся в квадрат, и считается средняя. Теперь вы знаете, как найти дисперсию.
Генеральную и выборочную дисперсии легко рассчитать в Excel. Есть специальные функции: ДИСП.Г и ДИСП.В соответственно.

В чистом виде дисперсия не используется. Это вспомогательный показатель, который нужен в других расчетах. Например, в проверке статистических гипотез или расчете коэффициентов корреляции. Отсюда неплохо бы знать математические свойства дисперсии.
Свойства дисперсии
Свойство 1. Дисперсия постоянной величины A равна 0 (нулю).
D(A) = 0
Свойство 2. Если случайную величину умножить на постоянную А, то дисперсия этой случайной величины увеличится в А2 раз. Другими словами, постоянный множитель можно вынести за знак дисперсии, возведя его в квадрат.
D(AX) = А2 D(X)
Свойство 3. Если к случайной величине добавить (или отнять) постоянную А, то дисперсия останется неизменной.
D(A + X) = D(X)
Свойство 4. Если случайные величины X и Y независимы, то дисперсия их суммы равна сумме их дисперсий.
D(X+Y) = D(X) + D(Y)
Свойство 5. Если случайные величины X и Y независимы, то дисперсия их разницы также равна сумме дисперсий.
D(X-Y) = D(X) + D(Y)
Среднеквадратичное (стандартное) отклонение
Если из дисперсии извлечь квадратный корень, получится среднеквадратичное (стандартное) отклонение (сокращенно СКО). Встречается название среднее квадратичное отклонение и сигма (от названия греческой буквы). Общая формула стандартного отклонения в математике следующая:
![]()
На практике формула стандартного отклонения следующая:
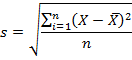
Как и с дисперсией, есть и немного другой вариант расчета. Но с ростом выборки разница исчезает.
Расчет cреднеквадратичного (стандартного) отклонения в Excel
Для расчета стандартного отклонения достаточно из дисперсии извлечь квадратный корень. Но в Excel есть и готовые функции: СТАНДОТКЛОН.Г и СТАНДОТКЛОН.В (по генеральной и выборочной совокупности соответственно).
 отклонение в Excel")
Среднеквадратичное отклонение имеет те же единицы измерения, что и анализируемый показатель, поэтому является сопоставимым с исходными данными.
Коэффициент вариации
Значение стандартного отклонения зависит от масштаба самих данных, что не позволяет сравнивать вариабельность разных выборках. Чтобы устранить влияние масштаба, необходимо рассчитать коэффициент вариации по формуле:
![]()
По нему можно сравнивать однородность явлений даже с разным масштабом данных. В статистике принято, что, если значение коэффициента вариации менее 33%, то совокупность считается однородной, если больше 33%, то – неоднородной. В реальности, если коэффициент вариации превышает 33%, то специально ничего делать по этому поводу не нужно. Это информация для общего представления. В общем коэффициент вариации используют для оценки относительного разброса данных в выборке.
Расчет коэффициента вариации в Excel
Расчет коэффициента вариации в Excel также производится делением стандартного отклонения на среднее арифметическое:
=СТАНДОТКЛОН.В()/СРЗНАЧ()
Коэффициент вариации обычно выражается в процентах, поэтому ячейке с формулой можно присвоить процентный формат:

Коэффициент осцилляции
Еще один показатель разброса данных на сегодня – коэффициент осцилляции. Это соотношение размаха вариации (разницы между максимальным и минимальным значением) к средней. Готовой формулы Excel нет, поэтому придется скомпоновать три функции: МАКС, МИН, СРЗНАЧ.

Коэффициент осцилляции показывает степень размаха вариации относительно средней, что также можно использовать для сравнения различных наборов данных.
Таким образом, в статистическом анализе существует система показателей, отражающих разброс или однородность данных.
Ниже видео о том, как посчитать коэффициент вариации, дисперсию, стандартное (среднеквадратичное) отклонение и другие показатели вариации в Excel.
Поделиться в социальных сетях:
Среднеквадрати́ческое отклонение (среднеквадрати́чное отклонение, стандартное отклонение[1]) — наиболее распространённый показатель рассеивания значений случайной величины относительно её математического ожидания (аналога среднего арифметического с бесконечным числом исходов). Обычно означает квадратный корень из дисперсии случайной величины, но иногда может означать тот или иной вариант оценки этого значения.
В литературе обычно обозначают греческой буквой  (сигма). В статистике принято два обозначения: — для генеральной совокупности и
(сигма). В статистике принято два обозначения: — для генеральной совокупности и  (с англ. standard deviation — стандартное отклонение) — для выборки.
(с англ. standard deviation — стандартное отклонение) — для выборки.
Варианты определения[править | править код]
Обычно определяется как квадратный корень из дисперсии случайной величины: ![{displaystyle sigma ={sqrt {D[X]}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/8c535aeb360aec0139028ee203973550bb364cbb) . Измеряется в единицах измерения самой случайной величины и используется при расчёте стандартной ошибки среднего арифметического, при построении доверительных интервалов, при статистической проверке гипотез, при измерении линейной взаимосвязи между случайными величинами.
. Измеряется в единицах измерения самой случайной величины и используется при расчёте стандартной ошибки среднего арифметического, при построении доверительных интервалов, при статистической проверке гипотез, при измерении линейной взаимосвязи между случайными величинами.
На практике, когда вместо точного распределения случайной величины в распоряжении имеется лишь выборка, стандартное отклонение, как и математическое ожидание, оценивают (выборочная дисперсия), и делать это можно разными способами. Термины «стандартное отклонение» и «среднеквадратическое отклонение» обычно применяют к квадратному корню из дисперсии случайной величины (определённому через её истинное распределение), но иногда и к различным вариантам оценки этой величины на основании выборки.
В частности, если  —
—  -й элемент выборки,
-й элемент выборки,  — объём выборки,
— объём выборки,  — среднее арифметическое выборки (выборочное среднее — оценка математического ожидания величины):
— среднее арифметическое выборки (выборочное среднее — оценка математического ожидания величины):
 ,
,

то два основных способа оценки стандартного отклонения записываются нижеследующим образом.
Оценка стандартного отклонения на основании смещённой оценки дисперсии (иногда называемой просто выборочной дисперсией[2]):
- .

Это в буквальном смысле среднее квадратическое разностей измеренных значений и среднего.
Оценка стандартного отклонения на основании несмещённой оценки дисперсии (подправленной выборочной дисперсии[2], в ГОСТ Р 8.736-2011 — «среднее квадратическое отклонение»):

Само по себе, однако,  не является несмещённой оценкой квадратного корня из дисперсии, то есть извлечение квадратного корня «портит» несмещённость.
не является несмещённой оценкой квадратного корня из дисперсии, то есть извлечение квадратного корня «портит» несмещённость.
Обе оценки являются состоятельными[2].
Кроме того, среднеквадратическим отклонением называют математическое ожидание квадрата разности истинного значения случайной величины и её оценки для некоторого метода оценки[3]. Если оценка несмещённая (выборочное среднее — как раз несмещённая оценка для случайной величины), то эта величина равна дисперсии этой оценки.
Среднее значение выборки также является случайной величиной с оценкой среднеквадратичного отклонения[3][нет в источнике]:

Правило трёх сигм[править | править код]

Правило трёх сигм ( ) гласит: вероятность того, что любая случайная величина отклонится от своего среднего значения менее чем на :
) гласит: вероятность того, что любая случайная величина отклонится от своего среднего значения менее чем на :
- .

Практически все значения нормально распределённой случайной величины лежат в интервале  , где
, где  — математическое ожидание случайной величины. Более строго — приблизительно с вероятностью 0,9973 значение нормально распределённой случайной величины лежит в указанном интервале.
— математическое ожидание случайной величины. Более строго — приблизительно с вероятностью 0,9973 значение нормально распределённой случайной величины лежит в указанном интервале.
Интерпретация[править | править код]
Большее значение среднеквадратического отклонения показывает больший разброс значений в представленном множестве со средней величиной множества; меньшее значение, соответственно, показывает, что значения в множестве сгруппированы вокруг среднего значения.
Например, для у всех трёх числовых множеств: {0, 0, 14, 14}, {0, 6, 8, 14} и {6, 6, 8, 8} средние значения равны 7, а среднеквадратические отклонения, соответственно, равны 7, 5 и 1. У последнего множества среднеквадратическое отклонение маленькое, так как значения в множестве сгруппированы вокруг среднего значения; у первого множества самое большое значение среднеквадратического отклонения — значения внутри множества сильно расходятся со средним значением.
В общем смысле среднеквадратическое отклонение можно считать мерой неопределённости. К примеру, в физике среднеквадратическое отклонение используется для определения погрешности серии последовательных измерений какой-либо величины. Это значение очень важно для определения правдоподобности изучаемого явления в сравнении с предсказанным теорией значением: если среднее значение измерений сильно отличается от предсказанных теорией значений (большое значение среднеквадратического отклонения), то полученные значения или метод их получения следует перепроверить.
Практическое применение[править | править код]
На практике среднеквадратическое отклонение позволяет оценить, насколько значения из множества могут отличаться от среднего значения.
Экономика и финансы[править | править код]
Среднее квадратическое отклонение доходности портфеля отождествляется с риском портфеля.
В техническом анализе среднеквадратическое отклонение используется для построения линий Боллинджера, расчёта волатильности.
Оценка рисков и критика[править | править код]
Среднеквадратическое отклонение широко распространено в финансовой сфере в качестве критерия оценки инвестиционного риска. По мнению американского экономиста Нассима Талеба, этого делать не следует. Так, по теории около двух третей изменений должны укладываться в определённые рамки (среднеквадратические отклонения −1 и +1) и что колебания свыше семи стандартных отклонений практически невозможны. Однако в реальной жизни, по мнению Талеба, всё иначе — скачки отдельных показателей могут превышать 10, 20, а иногда и 30 стандартных отклонений. Талеб считает, что риск-менеджерам следует избегать использования средств и методов, связанных со стандартными отклонениями, таких как регрессионные модели, коэффициент детерминации (R-квадрат) и бета-факторы. Кроме того, по мнению Талеба, среднеквадратическое отклонение — слишком сложный для понимания метод. Он считает, что тот, кто пытается оценить риск с помощью единственного показателя, обречён на неудачу[4].
Климат[править | править код]
Предположим, существуют два города с одинаковой средней максимальной дневной температурой, но один расположен на побережье, а другой внутри континента. Известно, что в городах, расположенных на побережье, множество различных максимальных дневных температур меньше, чем у городов, расположенных внутри континента. Поэтому среднеквадратическое отклонение максимальных дневных температур у прибрежного города будет меньше, чем у второго города, несмотря на то, что среднее значение этой величины у них одинаковое, что на практике означает, что вероятность того, что максимальная температура воздуха каждого конкретного дня в году будет сильнее отличаться от среднего значения, выше у города, расположенного внутри континента.
Спорт[править | править код]
Предположим, что есть несколько футбольных команд, которые оцениваются по некоторому набору параметров, например, количеству забитых и пропущенных голов, голевых моментов и т. п. Наиболее вероятно, что лучшая в этой группе команда будет иметь лучшие значения по большему количеству параметров. Чем меньше у команды среднеквадратическое отклонение по каждому из представленных параметров, тем предсказуемее является результат команды, такие команды являются сбалансированными. С другой стороны, у команды с большим значением среднеквадратического отклонения сложно предсказать результат, что в свою очередь объясняется дисбалансом, например, сильной защитой, но слабым нападением.
Использование среднеквадратического отклонения параметров команды позволяет в той или иной мере предсказать результат матча двух команд, оценивая сильные и слабые стороны команд, а значит, и выбираемых способов борьбы.
Пример[править | править код]
Предположим, что интересующая нас группа (генеральная совокупность) это класс из восьми учеников, которым выставляются оценки по 10-бальной системе. Так как мы оцениваем всю группу, а не её выборку, можно использовать стандартное отклонение на основании смещённой оценки дисперсии. Для этого берём квадратный корень из среднего арифметического квадратов отклонений величин от их среднего значения.
Пусть оценки учеников класса следующие:
- .

Тогда средняя оценка равна:
- .

Вычислим квадраты отклонений оценок учеников от их средней оценки:

Среднее арифметическое этих значений называется дисперсией:

Стандартное отклонение равно квадратному корню дисперсии:

Эта формула справедлива только если эти восемь значений и являются генеральной совокупностью. Если бы эти данные были случайной выборкой из какой-то большой совокупности (например, оценки восьми случайно выбранных учеников большого города), то в знаменателе формулы для вычисления дисперсии вместо n = 8 нужно было бы поставить n − 1 = 7:

и стандартное отклонение равнялось бы:

Этот результат называется стандартным отклонением на основании несмещённой оценки дисперсии. Деление на n − 1 вместо n даёт неискажённую оценку дисперсии для больших генеральных совокупностей.
Примечания[править | править код]
- ↑ Встречаются также различные синонимы: среднее квадратическое отклонение, стандартный разброс, стандартная неопределённость; термин «среднее квадратическое» означает «среднее степени 2»
- ↑ 1 2 3 Ивченко Г. И., Медведев Ю. И. Введение в математическую статистику. — М. : Издательство ЛКИ, 2010. — §2.2. Выборочные моменты: точная и асимптотическая теория. — ISBN 978-5-382-01013-7.
- ↑ 1 2 C. Patrignani et al. (Particle Data Group). 39. STATISTICS. — В: Review of Particle Physics // Chin. Phys. C. — 2016. — Vol. 40. — P. 100001. — doi:10.1088/1674-1137/40/10/100001.
- ↑ Талеб, Гольдштейн, Шпицнагель, 2022, с. 46.
Литература[править | править код]
- Боровиков В. STATISTICA. Искусство анализа данных на компьютере: Для профессионалов / В. Боровиков. — СПб.: Питер, 2003. — 688 с. — ISBN 5-272-00078-1..
- Нассим Талеб, Дениэл Гольдштейн, Марк Шпицнагель. Шесть ошибок руководителей компаний при управлении рисками // Управление рисками (Серия «Harvard Business Review: 10 лучших статей») = On Managing Risk / Коллектив авторов. — М.: Альпина Паблишер, 2022. — С. 41—50. — 206 с. — ISBN 978-5-9614-8186-0.
