![]()
Загрузить PDF
![]()
Загрузить PDF
В статистике выбросы — это значения, резко отличающиеся от других значений в собранном наборе данных. Выброс может указывать на аномалии в распределении данных или на ошибки при измерениях, поэтому зачастую выбросы исключаются из набора данных. Исключив выбросы из набора данных, вы можете прийти к неожиданным или более точным выводам.[1]
Поэтому необходимо уметь вычислять и оценивать выбросы, чтобы обеспечить надлежащее понимание статистических данных.
Шаги
-

1
Научитесь распознавать потенциальный выброс. Перед тем, как исключать выделяющиеся значения из набора данных, следует определить потенциальные выбросы. Выбросы являются значениями, которые сильно отличаются от большинства значений в наборе данных; другими словами, выбросы лежат вне тренда большинства значений. Это легко обнаружить в таблицах значений или (особенно) на графиках.[2]
Если значения в наборе данных нанести на график, то выбросы будут лежать далеко от большинства других значений. Если, например, большинство значений ложатся на прямую, то выбросы лежат по обе стороны от такой прямой.- Например, рассмотрим набор данных, представляющий температуры 12 различных объектов в комнате. Если 11 объектов имеют температуру примерно 70 градусов, но двенадцатый объект (возможно, печь) имеет температуру 300 градусов, то быстрый просмотр значений может показать, что печь является вероятным выбросом.
-
2
Упорядочите данные по возрастанию. Первый шаг при определении выбросов — это вычисление медианы набора данных. Эта задача значительно упрощается, если значения в наборе данных расположены по возрастанию (от меньшего к большему).
- Продолжая приведенный выше пример, рассмотрим следующий набор данных, представляющий температуры нескольких объектов: {71, 70, 73, 70, 70, 69, 70, 72, 71, 300, 71, 69}. Этот набор должен быть упорядочен следующим образом: {69, 69, 70, 70, 70, 70, 71, 71, 71, 72, 73, 300}.
-
3
Вычислите медиану набора данных. Медиана набора данных — это величина, находящаяся в середине набора данных.[3]
Если набор данных содержит нечетное количество значений, то медиана — это значение, до которого и после которого расположено одинаковое количество значений в наборе данных. Но если набор данных содержит четное число значений, то нужно найти среднее арифметическое двух средних значений. Обратите внимание, что при вычислении выбросов медиана, как правило, обозначается как Q2, так как она лежит между Q1 и Q3 — нижним и верхним квартилями, которые мы определим позже.- Не бойтесь работать с наборами данных, количество значений в которых четное. Средним арифметическим двух средних значений будет число, которого нет в наборе данных; это нормально. Но если два средних значения — это одно и то же число, то среднее арифметическое равно этому числу; это тоже в порядке вещей.
- В приведенном выше примере средние 2 значения — это 70 и 71, так что медиана равна ((70+71)/2) = 70,5.
-
4
Вычислите нижний квартиль. Эта величина, обозначаемая как Q1, ниже которой лежит 25% значений из набора данных. Другими словами, это половина значений, расположенных до медианы. Если до медианы лежит четное количество значений из набора данных, нужно найти среднее арифметическое двух средних значений, чтобы вычислить Q1 (это аналогично вычислению медианы).
- В нашем примере 6 значений расположены после медианы и 6 значений — до нее. Это означает, что для вычисления нижнего квартиля нам нужно найти среднее арифметическое двух средних значений из шести значений, лежащих до медианы. Здесь средние значения равны 70 и 70. Таким образом, Q1 = ((70 + 70)/2) = 70.
-
5
Вычислите верхний квартиль. Эта величина, обозначаемая как Q3, выше которой лежит 25% значений из набора данных. Процесс вычисления Q3 аналогичен процессу вычисления Q1, но здесь рассматриваются значения, расположенные после медианы.
- В приведенном выше примере два средних значения из шести значений, лежащих после медианы, равны 71 и 72. Таким образом, Q3 = ((71 + 72)/2) = 71,5.
-
6
Вычислите межквартильный диапазон. Вычислив Q1 и Q3, необходимо найти расстояние между этими величинами. Для этого вычтите Q1 из Q3. Значение межквартильного диапазона крайне важно для определения границ значений, которые не являются выбросами.
- В нашем примере Q1 = 70, а Q3 = 71,5. Межквартильный диапазон равен 71,5 – 70 = 1,5.
- Обратите внимание, что это применимо и к отрицательным значениям Q1 и Q3. Например, если Q1 = -70, то межквартильный диапазон равен 71,5 – (-70) = 141,5.
-
7
Найдите «внутренние границы» значений в наборе данных. Выбросы определяются через анализ значений — попадают ли они или нет в пределы так называемых «внутренних границ» и «внешних границ».[4]
Значение, лежащее вне «внутренних границ», классифицируется как «незначительный выброс», в то время как значение, находящееся за «внешними границами», классифицируется как «значительный выброс». Чтобы найти внутренние границы, необходимо умножить межквартильный диапазон на 1,5; результат нужно прибавить к Q3 и вычесть из Q1. Два найденных числа являются внутренними границами набора данных.- В нашем примере межквартильный диапазон равен (71,5 – 70) = 1,5. Далее: 1,5 * 1,5 = 2,25. Это число нужно прибавить к Q3 и вычесть его из Q1, чтобы найти внутренние границы:
- 71,5 + 2,25 = 73,75
- 70 – 2,25 = 67,75
- Таким образом, внутренние границы равны 67,75 и 73,75.
- В нашем примере только температура печи — 300 градусов — лежит вне этих границ и может считаться незначительным выбросом. Но не спешите с выводами —нам предстоит определить, является ли эта температура значительным выбросом.
- В нашем примере межквартильный диапазон равен (71,5 – 70) = 1,5. Далее: 1,5 * 1,5 = 2,25. Это число нужно прибавить к Q3 и вычесть его из Q1, чтобы найти внутренние границы:
-
8
Найдите «внешние границы» набора данных. Это делается таким же образом, как для внутренних границ, за исключением того, что межквартильный диапазон умножается на 3, а не на 1,5. Результат нужно прибавить к Q3 и вычесть из Q1. Два найденных числа являются внешними границами набора данных.
- В нашем примере умножьте межквартильный диапазон на 3: 1,5 * 3 = 4,5. Вычислите внешние границы:
- 71,5 + 4,5 = 76
- 70 – 4,5 = 65,5
- Таким образом, внешние границы равны 65,5 и 76.
- Любые значения, которые лежат за пределами внешних границ, считаются значительными выбросами. В нашем примере температура печи — 300 градусов — считается значительным выбросом.
- В нашем примере умножьте межквартильный диапазон на 3: 1,5 * 3 = 4,5. Вычислите внешние границы:
-
9
Воспользуйтесь качественной оценкой для определения того, нужно ли исключать выбросы из набора данных. Метод, описанный выше, позволяет определить, являются ли некоторые значения выбросами (незначительными или значительными). Тем не менее, не ошибитесь — значение, классифицируемое в качестве выброса, является только «кандидатом» на исключение, то есть вы не обязаны его исключать. Причина возникновения выброса — это основной фактор, влияющий на решение об исключении выброса. Как правило, выбросы, которые возникают из-за ошибки (в измерениях, записях и так далее), исключаются.[5]
С другой стороны, выбросы, связанные не с ошибками, а с новой информацией или тенденцией, как правило, оставляют в наборе данных.- Не менее важно оценить влияние выбросов на среднее арифметическое значение набора данных (искажают ли они его или нет). Это особенно важно в том случае, когда вы делаете выводы на основе среднего значения набора данных.
- В нашем примере крайне маловероятно, что печь нагреется до температуры 300 градусов (если только не учитывать природные аномалии). Поэтому можно заключить (с высокой долей уверенности), что такая температура — это ошибка измерений, которую нужно исключить из набора данных. Более того, если вы не исключите выброс, среднее значение набора данных будет равно (69 + 69 + 70 + 70 + 70 + 70 + 71 + 71 + 71 + 72 + 73 + 300)/12 = 89,67 градусов, но если вы исключите выброс, среднее значение составит (69 + 69 + 70 + 70 + 70 + 70 + 71 + 71 + 71 + 72 + 73)/11 = 70,55 градусов.
- Выбросы — это, как правило, результат человеческих ошибок, поэтому выбросы необходимо исключать из наборов данных.
-
10
Уясните важность (иногда) выбросов, оставляемых в наборе данных. Некоторые выбросы должны быть исключены из набора данных, так как их причинами являются ошибки и технические неполадки; другие выбросы необходимо оставить в наборе данных. Если, например, выброс не является результатом ошибки и/или дает новое понимание тестируемого явления, то его нужно оставить в наборе данных. Научные эксперименты особенно чувствительны к выбросам — исключив выброс по ошибке, вы можете пропустить некоторую новую тенденцию или открытие.
- Например, мы разрабатываем новый препарат для увеличения размера рыб в рыбном хозяйстве. Мы будем использовать старый набор данных ({71, 70, 73, 70, 70, 69, 70, 72, 71, 300, 71, 69}), но на этот раз каждое значение будет представлять массу рыбы (в граммах) после приема экспериментального препарата. Другими словами, первый препарат приводит к увеличению массы рыбы до 71 г, второй препарат — до 70 г и так далее. В этой ситуации 300 — это значительный выброс, но мы не должны исключать его; если предположить, что не было ошибок измерения, то такой выброс — это значительный успех в эксперименте. Препарат, который увеличил вес рыбы до 300 граммов, действует значительно лучше других препаратов; таким образом, 300 — это самое важное значение в наборе данных.
Реклама












Советы
- Когда выбросы найдены, попытайтесь объяснить их наличие до того, как исключить их из набора данных. Они могут указывать на ошибки измерения или аномалии в распределении.
Реклама
Что вам понадобится
- Калькулятор
Об этой статье
Эту страницу просматривали 59 263 раза.
Была ли эта статья полезной?
Отдельным вопросом работы с количественными данными являются выбросы (outliers), которые существенно влияют на многие статистические показатели, мешают масштабировать данные и ухудшают качество моделей машинного обучения.
Для визуализации некоторых результатов потребуется обновить sklearn и перезапустить среду выполнения.
Выбросы — это данные, которые сильно отличаются от общего распределения. При этом можно выделить:
Примечание. В последнем случае, хотя с точки зрения модели такой выброс будет считаться нежелательным, имеет смысл проверить, с чем связана такая цена.
Статистические показатели. На занятии по статистическому выводу мы провели тест Стьюдента, для того, чтобы определить на основе выборки вероятность того, что средний рост составляет 182 см.
|
[185.0, 179.0, 186.0, 195.0, 178.0, 178.0, 196.0, 188.0, 175.0, 185.0, 175.0, 175.0, 182.0, 161.0, 163.0, 174.0, 170.0, 183.0, 171.0, 166.0, 195.0, 178.0, 181.0, 166.0, 175.0, 181.0, 168.0, 184.0, 174.0, 177.0, 174.0, 199.0, 180.0, 169.0, 188.0, 168.0, 182.0, 160.0, 167.0, 182.0, 187.0, 182.0, 179.0, 177.0, 165.0, 173.0, 175.0, 191.0, 183.0, 162.0, 183.0, 176.0, 173.0, 186.0, 190.0, 189.0, 172.0, 177.0, 183.0, 190.0, 175.0, 178.0, 169.0, 168.0, 188.0, 194.0, 179.0, 190.0, 184.0, 174.0, 184.0, 195.0, 180.0, 196.0, 154.0, 188.0, 181.0, 177.0, 181.0, 160.0, 178.0, 184.0, 195.0, 175.0, 172.0, 175.0, 189.0, 183.0, 175.0, 185.0, 181.0, 190.0, 173.0, 177.0, 176.0, 165.0, 183.0, 183.0, 180.0, 178.0, 166.0, 176.0, 177.0, 172.0, 178.0, 184.0, 199.0, 182.0, 183.0, 179.0, 161.0, 180.0, 181.0, 205.0, 178.0, 183.0, 180.0, 168.0, 191.0, 188.0, 188.0, 171.0, 194.0, 166.0, 186.0, 202.0, 170.0, 174.0, 181.0, 175.0, 164.0, 181.0, 169.0, 185.0, 171.0, 195.0, 172.0, 177.0, 188.0, 168.0, 182.0, 193.0, 164.0, 182.0, 183.0, 188.0, 168.0, 167.0, 185.0, 183.0, 183.0, 183.0, 173.0, 182.0, 183.0, 173.0, 199.0, 185.0, 168.0, 187.0, 170.0, 188.0, 192.0, 172.0, 190.0, 184.0, 188.0, 199.0, 178.0, 172.0, 171.0, 172.0, 179.0, 183.0, 183.0, 188.0, 180.0, 195.0, 177.0, 207.0, 186.0, 171.0, 169.0, 185.0, 178.0, 187.0, 185.0, 179.0, 172.0, 165.0, 176.0, 189.0, 182.0, 168.0, 182.0, 184.0, 171.0, 182.0, 181.0, 169.0, 184.0, 186.0, 191.0, 191.0, 166.0, 171.0, 185.0, 185.0, 185.0, 219.0, 186.0, 191.0, 190.0, 187.0, 177.0, 188.0, 172.0, 178.0, 175.0, 181.0, 203.0, 161.0, 187.0, 164.0, 175.0, 191.0, 181.0, 169.0, 173.0, 187.0, 173.0, 182.0, 180.0, 173.0, 201.0, 186.0, 160.0, 182.0, 173.0, 189.0, 172.0, 179.0, 185.0, 189.0, 168.0, 177.0, 175.0, 173.0, 198.0, 184.0, 167.0, 189.0, 201.0, 190.0, 165.0, 175.0, 193.0, 173.0, 184.0, 188.0, 171.0, 179.0, 148.0, 170.0, 177.0, 168.0, 196.0, 166.0, 176.0, 181.0, 194.0, 166.0, 192.0, 180.0, 170.0, 185.0, 182.0, 174.0, 181.0, 176.0, 181.0, 187.0, 196.0, 168.0, 201.0, 160.0, 178.0, 186.0, 183.0, 174.0, 178.0, 175.0, 174.0, 188.0, 184.0, 173.0, 189.0, 183.0, 188.0, 186.0, 172.0, 174.0, 187.0, 186.0, 180.0, 181.0, 193.0, 174.0, 185.0, 178.0, 178.0, 191.0, 188.0, 188.0, 193.0, 180.0, 187.0, 177.0, 183.0, 179.0, 181.0, 186.0, 172.0, 201.0, 170.0, 168.0, 192.0, 188.0, 186.0, 186.0, 180.0, 171.0, 181.0, 173.0, 190.0, 179.0, 172.0, 177.0, 184.0, 174.0, 172.0, 182.0, 182.0, 175.0, 175.0, 182.0, 166.0, 166.0, 173.0, 178.0, 183.0, 195.0, 189.0, 178.0, 180.0, 170.0, 180.0, 177.0, 183.0, 172.0, 185.0, 195.0, 179.0, 184.0, 187.0, 176.0, 182.0, 180.0, 181.0, 172.0, 180.0, 185.0, 195.0, 190.0, 202.0, 172.0, 189.0, 182.0, 202.0, 172.0, 172.0, 174.0, 159.0, 175.0, 172.0, 182.0, 183.0, 199.0, 190.0, 174.0, 171.0, 185.0, 167.0, 198.0, 192.0, 175.0, 163.0, 194.0, 179.0, 192.0, 164.0, 174.0, 180.0, 180.0, 175.0, 186.0, 169.0, 179.0, 181.0, 185.0, 187.0, 169.0, 165.0, 193.0, 183.0, 173.0, 196.0, 181.0, 192.0, 181.0, 201.0, 198.0, 178.0, 190.0, 186.0, 194.0, 170.0, 187.0, 191.0, 162.0, 168.0, 160.0, 177.0, 187.0, 195.0, 181.0, 196.0, 166.0, 163.0, 179.0, 184.0, 180.0, 159.0, 179.0, 167.0, 187.0, 184.0, 171.0, 175.0, 169.0, 179.0, 190.0, 170.0, 185.0, 175.0, 172.0, 179.0, 170.0, 174.0, 168.0, 200.0, 180.0, 173.0, 182.0, 179.0, 178.0, 186.0, 188.0, 175.0, 174.0, 177.0, 157.0, 165.0, 194.0, 196.0, 178.0, 186.0, 183.0, 211.0, 191.0, 179.0, 170.0, 164.0, 182.0, 172.0, 166.0, 174.0, 169.0, 197.0, 189.0, 180.0, 195.0, 181.0, 171.0, 195.0, 185.0, 170.0, 178.0, 171.0, 166.0, 189.0, 199.0, 166.0, 186.0, 173.0, 175.0, 174.0, 171.0, 180.0, 172.0, 183.0, 179.0, 178.0, 171.0, 174.0, 188.0, 185.0, 170.0, 181.0, 188.0, 163.0, 185.0, 173.0, 186.0, 172.0, 162.0, 164.0, 180.0, 183.0, 171.0, 186.0, 163.0, 179.0, 168.0, 173.0, 180.0, 171.0, 176.0, 190.0, 174.0, 188.0, 169.0, 185.0, 194.0, 155.0, 172.0, 186.0, 178.0, 184.0, 174.0, 181.0, 178.0, 192.0, 183.0, 183.0, 176.0, 175.0, 176.0, 184.0, 176.0, 183.0, 201.0, 189.0, 177.0, 192.0, 176.0, 160.0, 170.0, 161.0, 176.0, 180.0, 197.0, 183.0, 178.0, 188.0, 158.0, 182.0, 188.0, 165.0, 191.0, 183.0, 176.0, 186.0, 203.0, 182.0, 182.0, 175.0, 172.0, 188.0, 171.0, 181.0, 175.0, 185.0, 183.0, 190.0, 175.0, 177.0, 170.0, 176.0, 184.0, 188.0, 171.0, 189.0, 194.0, 184.0, 199.0, 172.0, 168.0, 162.0, 195.0, 187.0, 179.0, 183.0, 169.0, 204.0, 181.0, 181.0, 187.0, 185.0, 182.0, 172.0, 185.0, 199.0, 193.0, 196.0, 175.0, 170.0, 179.0, 181.0, 191.0, 163.0, 195.0, 178.0, 176.0, 170.0, 163.0, 188.0, 181.0, 167.0, 167.0, 177.0, 197.0, 177.0, 165.0, 178.0, 177.0, 153.0, 179.0, 178.0, 187.0, 198.0, 191.0, 177.0, 169.0, 206.0, 181.0, 180.0, 180.0, 182.0, 179.0, 174.0, 175.0, 180.0, 175.0, 173.0, 181.0, 177.0, 195.0, 153.0, 191.0, 192.0, 159.0, 177.0, 176.0, 166.0, 172.0, 169.0, 198.0, 189.0, 193.0, 187.0, 169.0, 175.0, 185.0, 168.0, 187.0, 178.0, 176.0, 187.0, 184.0, 176.0, 192.0, 169.0, 186.0, 186.0, 177.0, 183.0, 167.0, 189.0, 178.0, 175.0, 190.0, 173.0, 166.0, 164.0, 186.0, 167.0, 198.0, 159.0, 197.0, 182.0, 179.0, 175.0, 184.0, 180.0, 191.0, 181.0, 182.0, 176.0, 179.0, 183.0, 163.0, 167.0, 187.0, 182.0, 178.0, 180.0, 183.0, 175.0, 172.0, 182.0, 170.0, 184.0, 163.0, 190.0, 185.0, 183.0, 190.0, 197.0, 190.0, 162.0, 167.0, 174.0, 180.0, 185.0, 173.0, 182.0, 172.0, 174.0, 166.0, 171.0, 166.0, 170.0, 191.0, 171.0, 206.0, 185.0, 182.0, 171.0, 187.0, 174.0, 181.0, 206.0, 179.0, 191.0, 173.0, 180.0, 198.0, 174.0, 198.0, 187.0, 174.0, 186.0, 190.0, 186.0, 164.0, 173.0, 178.0, 179.0, 186.0, 182.0, 167.0, 184.0, 186.0, 186.0, 191.0, 188.0, 185.0, 179.0, 163.0, 184.0, 182.0, 183.0, 167.0, 169.0, 191.0, 180.0, 187.0, 180.0, 180.0, 189.0, 175.0, 181.0, 175.0, 176.0, 177.0, 182.0, 175.0, 193.0, 171.0, 178.0, 176.0, 194.0, 182.0, 190.0, 165.0, 183.0, 189.0, 181.0, 191.0, 175.0, 194.0, 203.0, 176.0, 176.0, 195.0, 196.0, 175.0, 176.0, 177.0, 167.0, 171.0, 170.0, 172.0, 180.0, 182.0, 196.0, 170.0, 190.0, 178.0, 180.0, 187.0, 169.0, 184.0, 182.0, 185.0, 183.0, 205.0, 174.0, 175.0, 174.0, 174.0, 174.0, 192.0, 194.0, 174.0, 172.0, 185.0, 174.0, 186.0, 182.0, 165.0, 195.0, 198.0, 174.0, 176.0, 183.0, 183.0, 187.0, 200.0, 178.0, 172.0, 166.0, 173.0, 180.0, 198.0, 175.0, 182.0, 180.0, 192.0, 205.0, 175.0, 175.0, 190.0, 187.0, 198.0, 186.0, 176.0, 186.0, 191.0, 188.0, 185.0, 191.0, 192.0, 194.0, 186.0, 178.0, 181.0, 192.0, 172.0, 184.0, 176.0, 180.0, 193.0, 182.0, 180.0, 166.0, 187.0, 186.0, 202.0, 177.0, 182.0, 182.0, 196.0, 179.0, 183.0, 186.0, 182.0, 176.0, 182.0, 191.0, 170.0, 181.0, 173.0, 192.0, 165.0, 174.0, 184.0, 196.0, 179.0, 174.0, 199.0, 166.0, 158.0, 184.0, 175.0, 170.0, 187.0, 182.0, 174.0, 167.0, 189.0, 187.0, 179.0, 198.0, 169.0, 165.0, 173.0, 180.0, 182.0, 178.0, 184.0, 167.0, 194.0, 179.0, 191.0, 183.0, 185.0, 186.0, 184.0, 186.0, 193.0, 182.0, 187.0, 179.0, 194.0, 173.0, 198.0, 180.0, 166.0, 181.0, 173.0, 188.0, 173.0, 176.0, 161.0, 175.0, 156.0, 164.0, 188.0, 188.0, 184.0, 170.0, 180.0, 180.0, 168.0, 195.0, 189.0, 178.0, 180.0, 182.0, 160.0, 178.0, 173.0, 170.0, 177.0, 198.0, 186.0, 174.0, 186.0] |
Напомню, что исходя из данных мы смогли отвергнуть нулевую гипотезу, которая утверждала, что рост дейсвительно составляет 182 см.
Добавим выброс и повторно проверим гипотезу.
Как мы видим, одно сильно отличающееся наблюдение изменило результаты теста.
Масштабирование данных. Как мы только что видели, сильно отличающиеся от остальных значения мешают качественному масштабированию данных.
Модели ML. Выбросы влияют на качество модели линейной регрессии. Возьмем третий набор данных из квартета Энскомба (Anscombe’s quartet).
Посмотрим на коэффициент корреляции.
Удалим выброс.
Вновь посмотрим на график и коэффициент корреляции.
Выбросы особенно сильны, когда мы располагаем небольшим количеством данных.
Отличающееся наблюдение можно разделить на выбросы (outlier) и новые отличающиеся наблюдения (novelty). Выброс уже присутствует в данных. То есть мы смотрим на данные и понимаем, что часть содержащихся в них наблюдений существенно отличаются от общей массы. Во втором случае, у нас уже есть набор данных, нас просят определить, является ли новое наблюдение выбросом или нет.
Так как для выявления уже присутствующих выбросов у нас нет никакой разметки, это обучение без учителя. Во втором случае, это частичное обучение с учителем (semi-supervised). На практике это означает, что при использовании продвинутых алгоритмов для выявления выбросов, если речь идет о новых отличающихся наблюдениях (novelty), мы должны использовать .fit() на обучающей выборке, а .predict(), .decision_function() и .score_samples() на тестовой (про алгоритмы и эти методы поговорим дальше). Подробнее здесь⧉.
Начнем с более простых методов. Скачаем и подгрузим данные.
Выбросы можно увидеть на boxplot. По умолчанию, длина «усов» рассчитывается как $ 1,5 times IQR $. Данные, которые выходят за их пределы — выбросы.
Кроме того, выбросы можно попытаться выявить на точечной диаграмме.
Количественно выбросы можно найти через стандартизированную оценку (z-оценку, z-score). Эта оценка показывает на сколько средних квадратических отклонений значение отличается от среднего.
Так как мы знаем, что 99,7 процентов наблюдений лежат в пределах трех СКО от среднего, то можем предположить, что выбросами будут оставшиеся 0,3 процента.
Выведем эти значения.
Посмотрим, как удалить выбросы в отдельном столбце.
Теперь удалим выбросы во всем датафрейме.
Выведем корреляцию до и после удаления выбросов.
В данном случае корреляция увеличилась.
Важно понимать, что z-score, который мы используем для идентификации выбросов сам по себе зависит от сильно отличающихся значений, поскольку для расчета используется среднее арифметическое и СКО.
Вместо z-оценки можно использовать изменнную z-оценку (modified z-score), которая использует метрики робастной статистики.
где MAD представляет собой среднее абсолютное отклонение (median absolute deviation) и рассчитывается по формуле $MAD = median(|x-Q2|). Заметим⧉, что $MAD=0,6745sigma$.
Iglewicz и Hoaglin рекомендуют считать выбросами те значения, для которых $|z_{mod} > 3,5|$. Применим этот метод.
Обратите внимание, что в данном случае мы очень агрессивно удаляли значения. Посмотрим на корреляцию.
Еще одним распространенным способом выявления и удаления выбросов является правило $ 1,5 times IQR $. Рассмотрим, почему именно 1,5? В стандартном нормальном распределении Q1 и Q3 соответствуют $-0.6745sigma$ и $0.6745sigma$.
Зная эти показатели, мы можем рассчитать верхнюю и нижнюю границу.
Замечу, что для того, чтобы этот метод нахождения выбросов был аналогичен z-score, было бы точнее использовать показатель $ 1,75 times IQR $. При таком решении выбросами будет считаться большее количество наблюдений.
Найдем и удалим выбросы в столбце.
Найдем и удалим выбросы во всем датафрейме.
Как мы видим, несмотря на более активное удаление значений, коэффициент корреляции стал даже меньше, чем в изначальных данных.
Теперь посмотрим на методы выявления выбросов, основанные на модели (model-based approaches)
Изолирующий лес (Isolation Forest или iForest) использует принципы решающего дерева (Decision Tree) и построенного на его основе ансамблевого метода случайного леса (Random Forest).
Принцип построения изолирующиего дерева (Isolation Tree или iTree) довольно прост. Алгоритм случайным образом выбирает признак, затем в пределах диапазона этого признака случайно выбирает разделяющую границу (split). Та часть наблюдений, которая меньше либо равна этой границые. оказывается в левом потомке (left child node), та которая больше — в правом (right child node). Затем процесс рекурсивно повторяется.
Что интересно, в получившейся древовидной структуре путь (то есть количество сплитов) от корневого узла (root node) до выброса будет существенно короче, чем до обычного наблюдения. Это логично, например, в задаче классификации с помощью решающего дерева в первую очередь удается отделить тот класс, который наиболее удален от остальных.
Приведем классификацию с помощью решающего дерева на примере датасета цветов ириса.
Как вы видите, нулевой, наиболее удаленный класс (синие точки) удалось отделить уже на первом шаге. По этому же принципу отделяются выбросы.
Лес изолирующих деревьев соответственно дает усредненное расстояние до каждой из точек.
Рассмотрим как количественно выразить среднее расстояние до каждой из точек или показатель аномальности (anomaly score). Приведем формулу.
где x — это конкретное наблюдение из общего числа n наблюдений. При этом c(n) — это средний путь до листа в аналогичном по структуре двоичном дереве поиска (binary search tree, BST) с n наблюдений, а $ E(h(x)) $ — усредненное по всем деревьям расстояние до конкретного наблюдения x. Нормализуя показатель $ E(h(x)) $ по c(n) мы получаем, что:
При этом расстояние $h(x)$ находится в диапазоне $(0, n-1]$, а s в диапазоне $(0, 1]$. Таким образом,
Разберем пример⧉, приведенный на сайте sklearn. Вначале создадим синтетические данные с выбросами.
Разделим выборку.
Обучим класс изолирующего леса. Так как наблюдений мало, для каждого дерева будем брать все объекты обучающей выборки.
Сделаем прогноз на тесте и посмотрим на результат.
Выведем решающую границу.
Продемонстрируем особенности параметра contamination на простом примере. Возьмем небольшой набор данных и поочередно применим параметры contamination = ‘auto’, 0.1, 0.2. Несколько пояснений:
Применим алгоритм изолирующего леса к датасету boston.
Посмотрим на взаимосвязь признака RM с целевой переменной после удаления выбросов.
Для того чтобы увидеть недостаток алгоритма, рассмотрим тепловую карту, на которой цветом будут выводиться области с одинаковым anomaly score.
Как вы видите, в верхнем левом и нижнем правом углу также находятся области (их называют ghost areas), в которых объекты могли бы быть классифицированы как обычные наблюдения, хотя это неправильно (ложноположительный результат). Это связано с тем, что границы, проводимые алгоритмом параллельны осям координат.
Приведем иллюстрацию из статьи⧉ исследователей, усовершенствовавших этот алгоритм.
Для решения этой проблемы был предложен расширенный алгоритм изолирующего леса.
Расширенный алгоритм изолирующего леса (Extended Isolation Forest) делит пространство с помощью случайных, не обязательно параллельных осям координат, гиперплоскостей. Авторами этого алгоритма являются Sahand Hariri, Matias Carrasco Kind и Rober J. Brunner⧉. Для данных на предыдущей иллюстрации разделение с помощью расширенного алгоритма могло бы выглядеть вот так.
Рассмотрим работу этого алгоритма на практике. Приведу две библиотеки, в которых реализован Extended Isolation Forest.
Используем второй вариант.
Установим h2o в Google Colab.
Запустим сервер h2o.
Импортируем класс алгоритма⧉, создадим объекты этого класса для модели обычного изолирующего леса (без наклона гиперплоскостей) и для модели с максимальным наклоном гиперплоскостей.
Максимальный наклон задается параметром extension_level и находится в диапазоне $[0, P-1]$, где P — это количество признаков. В нашем случае признаков два, поэтому для расширенного алгоритма используем extension_level = 1.
Так как Extended Isolation Forest — это алгоритм без учителя (метод .predict() выдает anomaly_score), мы не можем напрямую посчитать точность прогноза. С другой стороны, так как в созданных нами данных есть разметка, мы можем провести косвенное сравнение.
Например, мы можем отсортировать данные по anomaly_score в убывающем порядке (то есть в начале будут наблюдения, которые наиболее вероятно являются выбросами) и посмотреть, какое количество единиц (то есть не выбросов), оказалось в результатах сортировки каждого из алгоритмов.
Начнем с алгоритма обычного изолирующего леса. Сделаем прогноз.
Создадим датафрейм из исходных признаков и целевой переменной.
Определимся с долей наблюдений, в которых будем считать количество выбросов и не выбросов.
Соединим датафрейм с признаками и целевой переменной с показателями аномальности. Затем отсортируем по этой метрике в убывающем порядке и рассчитаем количество выбросов и не выбросов в имеющихся данных.
Итак, в 60-ти наблюдениях с наибольшим anomaly score обычный алгоритм поместил 39 выбросов и 21 не выброс.
Сделаем то же самое с расширенным алгоритмом.
Расширенный алгоритм сделал чуть менее качественный прогноз.
Сравним тепловые карты обоих алгоритмов.
В данном случае, как мы видим, расширенному алгоритму не удалось сформировать два обособленных кластера.
На сегодняшнем занятии мы разобрали статистические методы выявления выбросов (boxplot, scatter plot, z-score и 1,5 IQR), а также два метода, основанные на модели (алгоритмы обычного и расширенного изолирующего леса).
Как найти выбросы, используя межквартильный диапазон
17 авг. 2022 г.
читать 2 мин
Выброс — это наблюдение , которое лежит аномально далеко от других значений в наборе данных. Выбросы могут быть проблематичными, поскольку они могут повлиять на результаты анализа.
Один из распространенных способов найти выбросы в наборе данных — использовать межквартильный диапазон .
Межквартильный диапазон, часто сокращенно IQR, представляет собой разницу между 25-м процентилем (Q1) и 75-м процентилем (Q3) в наборе данных. Он измеряет разброс средних 50% значений.
Один из популярных методов состоит в том, чтобы объявить наблюдение выбросом, если его значение в 1,5 раза больше, чем IQR, или в 1,5 раза меньше, чем IQR.
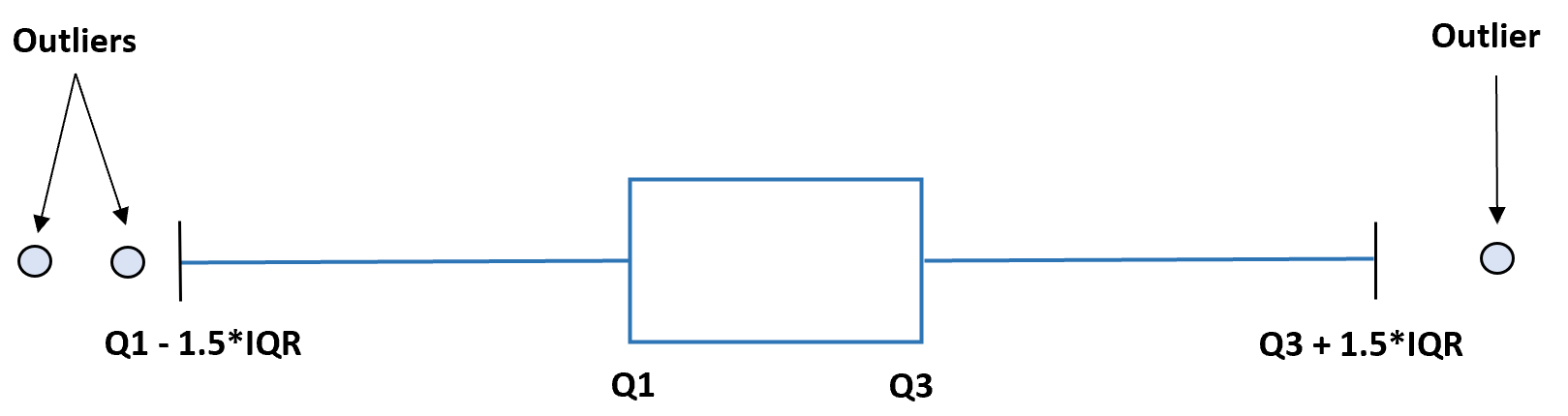
В этом руководстве представлен пошаговый пример того, как найти выбросы в наборе данных с помощью этого метода.
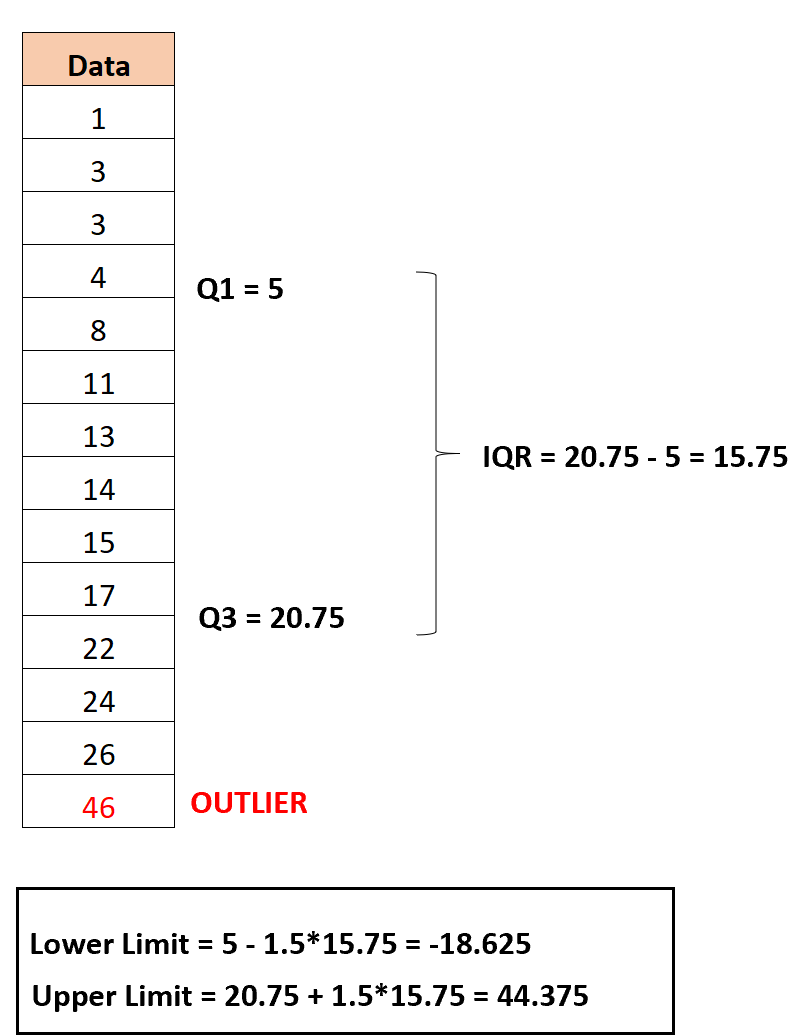
Шаг 1: Создайте данные
Предположим, у нас есть следующий набор данных:
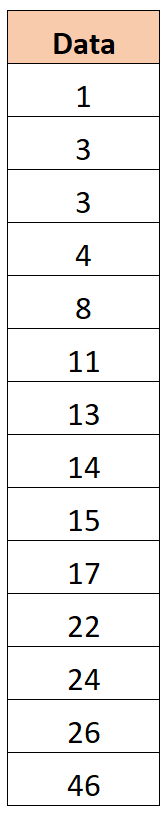
Шаг 2: Определите первый и третий квартиль
Первая квартиль оказывается равной 5 , а третья квартиль оказывается равной 20,75 .
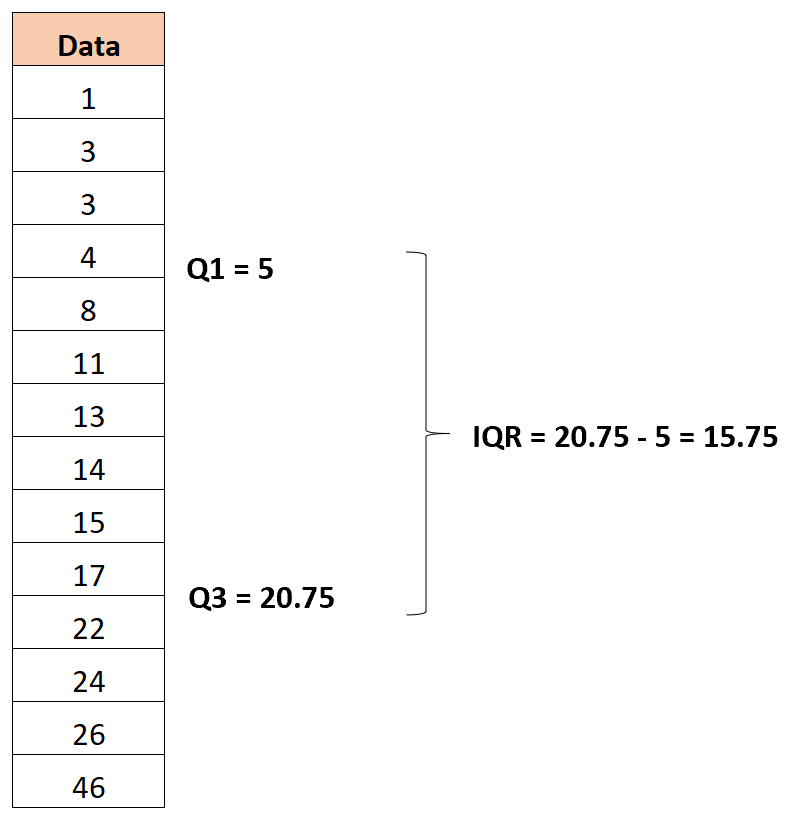
Таким образом, межквартильный размах оказывается равным 20,75 -5 = 15,75 .
Шаг 3: Найдите нижний и верхний пределы
Нижний предел рассчитывается как:
Нижний предел = Q1 – 1,5*IQR = 5 – 1,5*15,75 = -18,625
И верхний предел рассчитывается как:
Верхний предел = Q3 + 1,5 * IQR = 20,75 + 1,5 * 15,75 = 44,375
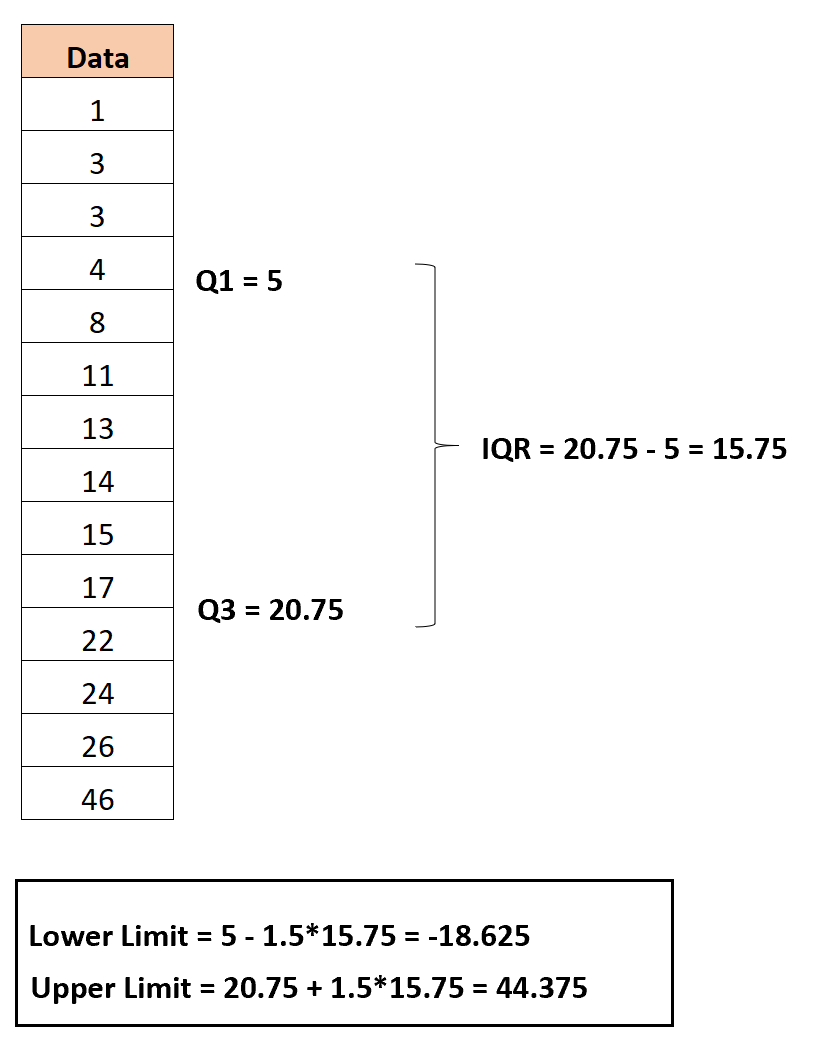
Шаг 4: Определите выбросы
Единственное наблюдение в наборе данных со значением меньше нижнего предела или больше верхнего предела — 46.Таким образом, это единственный выброс в этом наборе данных.
Примечание. Вы можете использовать этот калькулятор границ выбросов, чтобы автоматически находить верхнюю и нижнюю границы выбросов в заданном наборе данных.
Как найти выбросы на практике
В следующих руководствах объясняется, как найти выбросы, используя межквартильный диапазон в различных статистических программах:
Как найти выбросы в Excel
Как найти выбросы в R
Как найти выбросы в Python
Как найти выбросы в SPSS

Источник: Nuances of Programming
В начале реализации проекта по исследованию данных важно обнаружить и обработать выбросы. В этом заключается одна из задач эксплораторного анализа данных.
Мы рассмотрим три метода обнаружения выбросов. Но прежде выясним, что такое выброс, заглянув в Википедию:
Выброс (в статистике) — это измерительная точка данных, которая значительно выделяется из общей выборки. Выбросы могут быть вызваны вариативностью измерений или указывать на экспериментальную ошибку; в последнем случае они иногда исключаются из набора данных. Выброс может вызвать серьезные проблемы при статистическом анализе.
Итак, выброс — это данные, которые имеют слишком высокое или слишком низкое значение по отношению к другим исследуемым данным. Конечно, в наборе данных может быть несколько выбросов, поэтому приходится неоднократно исключать их из набора данных. В противном случае выбросы способны вызывать статистические проблемы в анализе данных.
Но каковы критерии исключения выбросов? Чтобы ответить на этот вопрос, рассмотрим три метода обнаружения выбросов.
1. Графический подход
Этот подход дает исследователю возможность самому принимать решение. Как уже отмечалось, зачастую приходится неоднократно удалять выбросы из набора данных, а поскольку этот подход является графическим, то визуализация данных позволяет специалисту решить, какие выбросы удалять. Более того, он сам решает, какие данные считать выбросами, просто наблюдая за графом.
Рассмотрим пару примеров, взятых из моих проектов.
Допустим, у нас есть датафрейм под названием cons. Создадим диаграмму рассеяния с помощью Seaborn:
import seaborn as sns построение диаграммы рассеяния
sns.relplot(data=food, x=’mean’, y=’latitude’)определение размера фигуры
sns.set(rc={‘figure.figsize’:(30,15)})разметка
plt.title(f’MEAN PRODUCTION PER LATITUDE’, fontsize=16) #название графика
plt.xlabel(‘Mean production [1000 tons]’, fontsize=14) #метка x-оси
plt.ylabel(‘Latitude’, fontsize=14) #метка y-оси
показ сетки для лучшей визуализации
sns.set_style(“ticks”,{‘axes.grid’ : True})
Не вдаваясь в значения параметров latitude (“интервал”) и mean production (“средняя производительность”), просто посмотрите на данные: какие точки считаете выбросами? Здесь ясно видно, что выбросы — “более высокие” числа. Исходя из этого, можно решить, что выбросы — это точки, чьи значения больше 75 000 или даже 50 000. Решайте сами, но принимайте решение на основе целостного анализа (одного этого графа недостаточно).
Это был один из графических методов обнаружения выбросов. Есть и другой — построение диаграммы размаха. Рассмотрим его на примере из одного из моих проектов.
Допустим, у нас есть датафрейм под названием phase. Нам нужно построить диаграмму размаха:
import seaborn as sns
диаграмма размаха
sns.boxplot(data=phase, x=’month’, y=’time’)
разметка
plt.title(f”BOXPLOT”, fontsize=16) #название графика
plt.xlabel(“MONTH”, fontsize=14) #метка x-оси
plt.ylabel(“CYCLE TIME[m]”, fontsize=14) #метка y-оси
добавление горизонтальной линии к среднему времени цикла
plt.axhline(mean, color=”red”)
red_line = mpatches.Patch(color=”red”,
label=f”mean value: {mean:.1f} [m]”)
обработка легенды
plt.legend(handles=[red_line],prop={“size”:12})
Снова рассмотрим график, не обращая внимания на то, что означают x и y. Здесь выбросами также являются только те данные, у которых значения “выше” (маленькие участки). Диаграмма размаха оставляет исследователю меньше возможностей контроля — выбросы здесь определяются на основе статистики. В данном случае это те точки, у которых значения больше максимального.
В диаграмме размаха максимальное значение рассчитывается как Q3+1.5*IQR, где IQR — это межквартильный размах. Он определяется по формуле IQR=Q3-Q1, где Q1 — первый квартиль, а Q3 — третий квартиль.
Как видите, использование этого графического метода не позволяет исследователю самому решать, какие точки считать выбросами. На помощь ему приходит статистическая (графическая) методика определения того, какие значения можно принимать за выбросы.
У обоих приведенных здесь графических методов есть один большой недостаток: их можно использовать только с двумерными данными. Это означает, что они подходят для случаев, когда у исследователя имеется только один столбец, представляющий вход, и другой, представляющий выход.
Если же будет 20 столбцов, представляющих входные данные, и один — выходные, то при использовании графического метода придется построить 20 графов. А если будет 100 столбцов, представляющих входные данные? Нужно понимать, что при всей эффективности графических методов, они могут использоваться не во всех ситуациях.
2. Метод Z-оценки
Z-оценка, или “стандартная оценка”, — это статистическая мера, которая показывает, на сколько стандартных отклонений наблюдаемая точка удалена от среднего значения.
Например, Z-оценка 1,2 означает, что точка данных находится на расстоянии 1,2 стандартного отклонения от среднего значения.
При использовании этого метода необходимо определить порог: если точка данных имеет значение, превышающее пороговое, то она является выбросом.
Вычисляем Z следующим образом:
В этой формуле:
- X — значение точки данных;
- μ — среднее значение;
- σ — стандартное отклонение.
Приведем пример. Предположим, что у нас есть такие числа:
import numpy as np
случайные данные
data = [1, 2, 2, 2, 3, 1, 1, 15, 2, 2, 2, 3, 1, 1, 2]
вычисление среднего значения
mean = np.mean(data)
вычисление стандартного отклонения
std = np.std(data)
вывод значений
print(f’the mean is: {mean: .2f}’)
print(f’the standard deviation ins:{std: .2f}’)
—————–
>>>
the mean is: 2.67
the standard deviation ins: 3.36
Установим порог для определения выбросов следующим образом:
порог
threshold = 3
список выбросов
outlier = []
обнаружение выбросов
for i in data:
z = (i-mean)/std
if z > threshold:
outlier.append(i)
print(f’the outliers are: {outlier}’)
—————–
>>>
the outliers are: [15]
Можно использовать stats.zscore из библиотеки Scipy, которая применяется к массиву Numpy и датафреймам. Рассмотрим пример с датафреймом:
import pandas as pd
import scipy.stats as stats
создание датафрейма
data = pd.DataFrame(np.random.randint(0, 10, size=(5, 3)), columns=[‘A’, ‘B’, ‘C’])
z-оценка
data.apply(stats.zscore)
—————-
>>>
A B C
0 -0.392232 -0.707107 0.500000
1 -0.392232 -0.353553 -1.166667
2 1.568929 1.767767 1.333333
3 -1.372813 -1.060660 -1.166667
4 0.588348 0.353553 0.500000
В этом случае также нужно определить порог и решить, какие значения удалить.
Метод Z-оценки имеет несколько недостатков.
- Его можно использовать только с одномерными данными (один столбец датафреймов, массивов, списков и т. д.).
- Он должен использоваться только с нормально распределенными данными.
- Исследователю придется определить порог, зависящий от данных.
3. Изолирующий лес
Чтобы разобраться с понятием “изолирующий лес”, снова обратимся к Википедии:
Изолирующий лес — это алгоритм обнаружения аномалий. Он обнаруживает аномалии, используя изолированность (насколько далеко точка данных находится от остальных данных), а не моделируя нормальные точки.
Углубляясь в это понятие, можно отметить, что алгоритм “изолирующий лес” построен на основе древовидной структуры данных, аналогично алгоритму “случайный лес”, и не является моделью супервизорного управления, поскольку в нем нет заранее заданных меток. Это не что иное, как ансамбль бинарных деревьев решений, где каждое дерево называется “изолирующим деревом”.
Это означает, что алгоритм “изолирующий лес” работает со случайной выборкой данных, которые обрабатываются в древовидной структуре на основе случайно выбранных признаков. Образцы, которые проникают глубже в дерево, с меньшей вероятностью являются аномалиями, поскольку для их изолированности требуется больше срезов.
Возьмем для примера известный набор данных diabetes, предоставленный scikit-learn:
from sklearn.datasets import load_diabetes #импортирование данных
from sklearn.ensemble import IsolationForest #импортирование алгоритма “изолирующий лес”
импортирование набора данных
diab = load_diabetes()
определение признака и метки
X = diab[‘data’]
y = diab[‘target’]
creating dataframe
df = pd.DataFrame(X, columns=[“age”,”sex”,”bmi”,”bp”, “tc”, “ldl”, “hdl”,”tch”, “ltg”, “glu”])
проверка формы
df.shape
——————
>>>
(442, 10)
Итак, этот датафрейм имеет 442 строки и 10 столбцов. Теперь воспользуемся алгоритмом “изолирующий лес”:
идентифицирование выбросов
iso = IsolationForest()
y_outliers = iso.fit_predict(df)
отбрасывание строк с выбросами
for i in range(len(y_outliers)):
if y_outliers[i] == -1:
df.drop(i, inplace = True)
проверка новой формы датафрейма
df.shape
———————
>>>
(388, 10)
Как видите, количество строк уменьшилось, потому что были отброшены строки с выбросами.
Обратите внимание, что в этом примере был использован ансамбль, а не модель супервизорного управления. Это означает, что если снова запустить весь код, то конечная форма (форма датафрейма после отбрасывания строк с выбросами) может отличаться от полученной выше с 388 строками (попробуйте сами в качестве упражнения).
Алгоритм “изолирующий лес” не оставляет исследователю никакой возможности контролировать данные (это не модель супервизорного управления). Однако он является единственным из трех методов, рассмотренных в этой статье, позволяющим обрабатывать (и отбрасывать) выбросы в многомерных датафреймах. Он предоставляет возможность работать со всем набором данных, не уменьшая его.
Заключение
Рассмотрев три метода обнаружения выбросов, мы убедились в том, что лишь изолирующий лес позволяет работать с многомерными данными. Поэтому его и следует использовать в большинстве случаев. Если же вам придется исследовать совсем простой набор данных, можете прибегнуть к графическому методу или воспользоваться Z-оценкой.
Читайте также:
Читайте нас в Telegram, VK
Перевод статьи Federico Trotta: How To Detect Outliers in a Data Science Project
Этот материал — перевод статьи «Outliers detection in R». А ещё у нас есть материал про обнаружение выбросов в Python.

Выбросы — значения или наблюдения, отклоняющиеся от других данных. Всегда нужно сравнивать наблюдение с другими значениями, полученными тем же способом, прежде чем называть их выбросами. Действительно, человек с ростом 200 см, скорее всего, будет считаться отклонением по сравнению с остальным населением, но этот же человек не будет считаться статистическим выбросом, если мы измерим рост баскетболистов.
Выбросы могут быть вызваны изменчивостью, присущей наблюдаемому явлению. Например, при сборе данных о заработной плате часто возникают выбросы, поскольку некоторые люди зарабатывают гораздо больше остальных. Выбросы также могут возникать из-за экспериментальной ошибки, ошибки измерения или кодирования. Например, вес человека 786 кг явно является ошибкой при кодировании веса объекта. Её или его вес, скорее всего, составляет 78,6 кг или 7,86 кг в зависимости от того, был измерен вес взрослого человека или ребёнка.
По этой причине иногда имеет смысл формально выделять два класса выбросов: экстремальные значения и ошибки. Экстремальные значения интереснее, потому что они возможны, но маловероятны.
В этой статье я представлю несколько подходов к обнаружению выбросов в R от простых методов, таких как описательная статистика (включая минимальные, максимальные значения, гистограмму, прямоугольную диаграмму и процентили), до более формальных методов, таких как фильтр Хэмпеля, тесты Граббса, Диксона и Рознера.
Не существует строгого и однозначного правила насчет того, следует ли удалять выбросы из набора данных перед проведением статистического анализа. Довольно часто переменные значения, вызванные экспериментальной ошибкой или ошибкой измерения удаляются или заменяются на новые значения. Некоторые статистические тесты требуют их отсутствия, чтобы сделать обоснованные выводы, но удаление выбросов рекомендуется не во всех случаях и должно выполняться с осторожностью.
Эта статья поможет обнаружить и проверить выбросы, но вы не узнаете, следует ли удалять, изменять или оставлять такие значения. После проверки вы можете исключить их или включить в свой анализ (а это обычно требует вдумчивого размышления со стороны исследователя). Удаление или сохранение выбросов, в основном, зависит от трех факторов:
- Область / контекст вашего анализа и вопрос исследования. В некоторых областях обычно удаляют посторонние значения, поскольку они часто возникают из-за сбоев в процессе. В других областях отклонения сохраняются, потому что они содержат ценную информацию. Также бывает, что анализ выполняется дважды, один раз с посторонними значениями и один раз без них, чтобы оценить их влияние на результаты. Если результаты резко изменятся из-за некоторых определяющих значений, это должно предостеречь исследователя от чрезмерно амбициозных утверждений.
- Устойчивость тестов. Например, наклон простой линейной регрессии может значительно варьироваться даже с одним выбросом, тогда как непараметрические тесты, такие как тест Уилкоксона, обычно устойчивы к ним.
- Дальность выбросов от других наблюдений. Некоторые наблюдения, рассматриваемые как выбросы, на самом деле не являются экстремальными значениями по сравнению со всеми другими наблюдениями, в то время как другие потенциальные выбросы могут быть действительно отстающими от остальных наблюдений.
Мы будем использовать набор данных mpg из библиотеки ggplot2, чтобы проиллюстрировать различные подходы к обнаружению выбросов в R, и в частности, мы сосредоточимся на работе с переменной hwy (пробег в милях на галлон израсходованного топлива).
Минимальные и максимальные значения
Первое, что необходимо для обнаружения выбросов в R — начать с описательной статистики, и, в частности, с минимальных и максимальных значений.
В R это легко сделать с помощью функции summary():
dat <- ggplot2::mpg
summary(dat$hwy)
## Min. 1st Qu. Median Mean 3rd Qu. Max.
## 12.00 18.00 24.00 23.44 27.00 44.00Минимум и максимум — первое и последнее значения в выходных данных выше. В качестве альтернативы, их также можно вычислить с помощью функций min() и max():
min(dat$hwy)
## [1] 12
max(dat$hwy)
## [1] 44Явная ошибка кодирования, такая как, например, человеческий вес в 786 кг уже будет легко обнаружена с помощью этой простой техники.
Гистограмма
Другой базовый способ обнаружения выбросов — построение гистограммы данных.
При помощи внутренних инструментов R:
hist(dat$hwy,
xlab = "hwy",
main = "Histogram of hwy",
breaks = sqrt(nrow(dat))
) # set number of bins
При помощи ggplot2:
library(ggplot2)
ggplot(dat) +
aes(x = hwy) +
geom_histogram(bins = 30L, fill = "#0c4c8a") +
theme_minimal()
Пара полосок справа в отрыве от основного графика — значения, которые больше остальных.
#Box plot
Помимо гистограмм, box plot (ящик с усами) также полезен для обнаружения потенциальных выбросов.
Используя R:
boxplot(dat$hwy,
ylab = "hwy"
)
или используя ggplot2:
ggplot(dat) +
aes(x = "", y = hwy) +
geom_boxplot(fill = "#0c4c8a") +
theme_minimal()Box plot помогает визуализировать количественную переменную, отображая пять общих сводных данных (минимальное значение, среднее значение, первый и третий квартили и максимальное значение) и любое значение, которое было классифицировано как предполагаемый выброс с использованием критерия межквартильного размаха (IQR). Критерий межквартильного размаха означает, что все единицы значения больше q₀,₇₅+ 1.5 ⋅ IQR или меньше q₀,₂₅ — 1,5⋅ IQR рассматриваются R, как потенциальные выбросы. Другими словами, все наблюдения за пределами следующего интервала будут рассматриваться как потенциальные выбросы:
I = [q₀,₂₅ — 1.5 * IQR; q₀,₇₅ + 1.5 * IQR]
Выбросы отображаются в виде точек на прямоугольной диаграмме. Исходя из этого критерия, есть 2 потенциальных выброса (смотрите на 2 точки над вертикальной линией в верхней части диаграммы размаха).
Даже если наблюдение рассматривается как потенциальный выброс по критерию IQR, это не означает, что его следует удалять. Удаление или сохранение выброса зависит от контекста вашего анализа, от того, являются ли тесты, которые вы собираетесь проводить с наборами данных, устойчивыми к выбросам или нет, и насколько далеки выбросы от других наблюдений.
Также возможно извлечь потенциальные выбросы на основе критерия IQR благодаря функции boxplot.stats()$out:
boxplot.stats(dat$hwy)$out
## [1] 44 44 41Как видите, на самом деле есть 3 точки, которые считаются потенциальными выбросами: две со значением 44 и одна со значением 41.
Благодаря функции which() можно извлечь номер строки, соответствующий этим посторонним значениям:
out <- boxplot.stats(dat$hwy)$out
out_ind <- which(dat$hwy %in% c(out))
out_ind
## [1] 213 222 223Имея эту информацию, вы теперь можете легко вернуться к определенным строкам в наборе данных, чтобы проверить их, или напечатать все переменные для этих выбросов:
dat[out_ind, ]
## # A tibble: 3 x 11
## manufacturer model displ year cyl trans drv cty hwy fl class
## <chr> <chr> <dbl> <int> <int> <chr> <chr> <int> <int> <chr> <chr>
## 1 volkswagen jetta 1.9 1999 4 manual… f 33 44 d compact
## 2 volkswagen new be… 1.9 1999 4 manual… f 35 44 d subcom…
## 3 volkswagen new be… 1.9 1999 4 auto(l… f 29 41 d subcom…Ещё можно напечатать выбросы прямо на диаграмме размаха с помощью функции mtext():
boxplot(dat$hwy,
ylab = "hwy",
main = "Boxplot of highway miles per gallon"
)
mtext(paste("Outliers: ", paste(out, collapse = ", ")))
Процентили
Этот метод обнаружения посторонних значений основан на процентилях. При использовании метода процентилей все наблюдения, выходящие за пределы интервала, образованного 2,5 и 97,5 процентилями будут рассматриваться как потенциальные выбросы. Другие процентили, такие как 1 и 99 или 5 и 95 процентили, тоже могут быть рассмотрены для построения интервала.
Значения нижнего и верхнего процентилей можно вычислить с помощью функции quantile():
lower_bound <- quantile(dat$hwy, 0.025)
lower_bound
## 2.5%
## 14
upper_bound <- quantile(dat$hwy, 0.975)
upper_bound
## 97.5%
## 35.175В соответствии с этим методом, все наблюдения ниже 14 и выше 35,175 будут рассматриваться как потенциальные выбросы. Номера рядов наблюдений за пределами интервала затем могут быть извлечены с помощью функции which():
outlier_ind <- which(dat$hwy < lower_bound | dat$hwy > upper_bound)
outlier_ind
## [1] 55 60 66 70 106 107 127 197 213 222 223Можно вывести значение пробега в милях на галлон израсходованного топлива для таких значений:
dat[outlier_ind, "hwy"]
## # A tibble: 11 x 1
## hwy
## <int>
## 1 12
## 2 12
## 3 12
## 4 12
## 5 36
## 6 36
## 7 12
## 8 37
## 9 44
## 10 44
## 11 41В качестве альтернативы можно вывести все переменные для этих выбросов:
dat[outlier_ind, ]
## # A tibble: 11 x 11
## manufacturer model displ year cyl trans drv cty hwy fl class
## <chr> <chr> <dbl> <int> <int> <chr> <chr> <int> <int> <chr> <chr>
## 1 dodge dakota … 4.7 2008 8 auto(… 4 9 12 e pickup
## 2 dodge durango… 4.7 2008 8 auto(… 4 9 12 e suv
## 3 dodge ram 150… 4.7 2008 8 auto(… 4 9 12 e pickup
## 4 dodge ram 150… 4.7 2008 8 manua… 4 9 12 e pickup
## 5 honda civic 1.8 2008 4 auto(… f 25 36 r subco…
## 6 honda civic 1.8 2008 4 auto(… f 24 36 c subco…
## 7 jeep grand c… 4.7 2008 8 auto(… 4 9 12 e suv
## 8 toyota corolla 1.8 2008 4 manua… f 28 37 r compa…
## 9 volkswagen jetta 1.9 1999 4 manua… f 33 44 d compa…
## 10 volkswagen new bee… 1.9 1999 4 manua… f 35 44 d subco…
## 11 volkswagen new bee… 1.9 1999 4 auto(… f 29 41 d subco…Согласно методу процентилей, существует 11 потенциальных выбросов. Чтобы уменьшить это число, вы можете установить процентили от 1 до 99:
lower_bound <- quantile(dat$hwy, 0.01)
upper_bound <- quantile(dat$hwy, 0.99)
outlier_ind <- which(dat$hwy < lower_bound | dat$hwy > upper_bound)
dat[outlier_ind, ]
## # A tibble: 3 x 11
## manufacturer model displ year cyl trans drv cty hwy fl class
## <chr> <chr> <dbl> <int> <int> <chr> <chr> <int> <int> <chr> <chr>
## 1 volkswagen jetta 1.9 1999 4 manual… f 33 44 d compact
## 2 volkswagen new be… 1.9 1999 4 manual… f 35 44 d subcom…
## 3 volkswagen new be… 1.9 1999 4 auto(l… f 29 41 d subcom…Установка процентилей на 1 и 99 дает те же потенциальные выбросы, что и для критерия IQR.
Фильтр Хэмпеля
Другой метод, известный как фильтр Хэмпеля, заключается в том, чтобы рассматривать как выбросы значения вне интервала, которые формируются медианным значением плюс-минус 3 медианы абсолютных отклонений (MAD):
I = [median - 3 * MAD; median + 3 * MAD]в которых MAD — это медианное абсолютное отклонение и определяется как медиана абсолютных отклонений от медианы данных:

Для этого метода мы сначала устанавливаем пределы интервала с помощью функций median() и mad():
lower_bound <- median(dat$hwy) - 3 * mad(dat$hwy, constant=1)
lower_bound
## [1] 9
upper_bound <- median(dat$hwy) + 3 * mad(dat$hwy, constant=1)
upper_bound
## [1] 39Все наблюдения меньше 9 и больше 39 будут рассматриваться как потенциальные выбросы. Номера строк наблюдений за пределами интервала затем могут быть извлечены с помощью функции which():
outlier_ind <- which(dat$hwy < lower_bound | dat$hwy > upper_bound)
outlier_ind
## 213 222 223Согласно фильтру Хэмпеля, для переменной hwy есть 3 потенциальных выброса.
Статистические тесты
В этом разделе мы представим еще 3 формальных метода обнаружения отклонений:
- Тест Граббса (Grubbs’s test)
- Тест Диксона (Dixon’s test)
- Тест Рознера (Rosner’s test)
Эти статистические тесты являются частью формальных методов обнаружения выбросов, поскольку все они включают вычисление с помощью тестовой статистики, которая сравнивается с табличными критическими значениями.
Обратите внимание, что эти тесты подходят только тогда, когда данные распределены нормально. Таким образом, предположение о соответствии нормальности должно быть проверено перед применением этих тестов для выбросов (Как проверить предположение о соответствии нормальному распределению в R).
Тест Граббса (Grubbs’s test)
Тест Граббса позволяет определить, является ли наибольшее или наименьшее значение в наборе данных выбросом. Он обнаруживает по одному выбросу за раз (максимальное или минимальное значение), поэтому нулевая и альтернативная гипотезы проверки максимального значения выглядит так:
- H₀: Наивысшее значение не является выбросом
- H₁: Наивысшее значение является выбросом
А минимального — так:
- H₀: Наименьшее значение не является выбросом
- H₁: Наименьшее значение является выбросом
Как и в любом статистическом тесте, если значение P меньше порогового уровня статистической значимости (обычно α = 0.05), то нулевая гипотеза отвергается, и мы приходим к выводу, что наименьшее/наибольшее значение является отклонением. Напротив, если значение P больше или равно пороговому уровню значимости, нулевая гипотеза не отвергается, и мы делаем вывод, что на основе данных о том, что наименьшее / наибольшее значение не является выбросом. Обратите внимание на то, что тест Граббса не подходит для выборки объемом 6 или меньше (n <= 6).
Чтобы выполнить тест Граббса в R, используем функцию grubbs.test() из пакетов outliers:
# install.packages("outliers")
library(outliers)
test <- grubbs.test(dat$hwy)
test
##
## Grubbs test for one outlier
##
## data: dat$hwy
## G = 3.45274, U = 0.94862, p-value = 0.05555
## alternative hypothesis: highest value 44 is an outlierЗначение P равняется 0,056. На уровне значимости 5% мы не отвергаем гипотезу о том, что наибольшее значение 44 не является выбросом.
По умолчанию тест выполняется на наибольшем значении (как показано в выходных данных R: alternative hypothesis: highest value). Если вы хотите провести тест для наименьшего значения, просто добавьте аргумент opposite = TRUE в функцию grubbs.test():
test <- grubbs.test(dat$hwy, opposite = TRUE)
test
##
## Grubbs test for one outlier
##
## data: dat$hwy
## G = 1.92122, U = 0.98409, p-value = 1
## alternative hypothesis: lowest value 12 is an outlierВывод указывает на то, что тест теперь выполняется при наименьшем значении
Значение P равно 1. На уровне значимости 5% мы не отвергаем гипотезу о том, что наименьшее значение 12 не является выбросом.
Для иллюстрации этого заменим наблюдения более экстремальным значением и выполним тест Граббса для нового набора данных. Давайте заменим 34-ую строку со значением 212:
dat[34, "hwy"] <- 212Применяем тест Граббса, чтобы проверить, является ли наибольшее значение выбросом:
test <- grubbs.test(dat$hwy)
test
##
## Grubbs test for one outlier
##
## data: dat$hwy
## G = 13.72240, U = 0.18836, p-value < 2.2e-16
## alternative hypothesis: highest value 212 is an outlierЗначение p < 0,001. На уровне значимости 5% мы делаем вывод, что наивысшее значение 212 является выбросом.
Тест Диксона (Dixon’s test)
Подобно тесту Граббса, тест Диксона используется для того, чтобы проверить, является ли самое высокое или самое низкое значение выбросом. Таким образом, если под сомнением находятся более одного выброса, тест необходимо проводить индивидуально для этих предполагаемых значений.
Обратите внимание на то, что тест Диксона наиболее полезен для выборки небольшого объема (обычно когда n <= 25).
Чтобы выполнить тест Диксона в R, мы используем функцию dixon.test() из пакета outliers. Однако мы ограничиваем наш набор данных 20 первыми наблюдениями, поскольку тест Диксона может быть выполнен только на небольшом размере выборки:
subdat <- dat[1:20, ]
test <- dixon.test(subdat$hwy)
test
##
## Dixon test for outliers
##
## data: subdat$hwy
## Q = 0.57143, p-value = 0.006508
## alternative hypothesis: lowest value 15 is an outlierРезультаты показывают, что самое наименьшее значение 15 является выбросом (p-значение = 0,007).
Чтобы проверить максимальное значение, просто добавьте аргумент opposite = TRUE к функции dixon.test():
test <- dixon.test(subdat$hwy,
opposite = TRUE
)
test
##
## Dixon test for outliers
##
## data: subdat$hwy
## Q = 0.25, p-value = 0.8582
## alternative hypothesis: highest value 31 is an outlierРезультаты показывают, что максимальное значение 31 не является выбросом (p-значение = 0,858).
Рекомендуется всегда сверять результаты статистического теста на выбросы с диаграммой, чтобы убедиться, что мы проверили все потенциальные выбросы:
out <- boxplot.stats(subdat$hwy)$out
boxplot(subdat$hwy,
ylab = "hwy"
)
mtext(paste("Outliers: ", paste(out, collapse = ", ")))
По box plot заметно, что мы можем применить тест Диксона к значению 20 в дополнение к значению 15, выполненному ранее. Это можно сделать, найдя номер строки минимального значения, исключив этот номер строки из набора данных, а затем применив тест Диксона к этому новому набору данных:
# find and exclude lowest value
remove_ind <- which.min(subdat$hwy)
subsubdat <- subdat[-remove_ind, ]
# Dixon test on dataset without the minimum
test <- dixon.test(subsubdat$hwy)
test
##
## Dixon test for outliers
##
## data: subsubdat$hwy
## Q = 0.44444, p-value = 0.1297
## alternative hypothesis: lowest value 20 is an outlierРезультаты показывают, что второе наименьшее значение 20 не является выбросом (p-значение = 0,13).
Тест Рознера (Rosner’s test)
- Тест Рознера на выбросы имеет следующие преимущества:
- Он используется для одновременного обнаружения нескольких выбросов (в отличие от теста Граббса и Диксона, которые должны выполняться итеративно для выявления нескольких выбросов)
- Он разработан чтобы избежать проблемы, когда выброс, близкий по значению к другому выбросу, может остаться незамеченным.
Обратите внимание, что в отличие от теста Диксона, тест Рознера подходит к большому объему выборки (n≥20). Поэтому мы снова используем исходный набор данных dat, который включает 234 наблюдения.
Для выполнения теста Рознера мы используем функцию rosnerTest() из пакета EnvStats. Для этой функции требуется как минимум 2 аргумента: данные и количество предполагаемых выбросов k.
library(EnvStats)
test <- rosnerTest(dat$hwy,
k = 3
)
test
## $distribution
## [1] "Normal"
##
## $statistic
## R.1 R.2 R.3
## 13.722399 3.459098 3.559936
##
## $sample.size
## [1] 234
##
## $parameters
## k
## 3
##
## $alpha
## [1] 0.05
##
## $crit.value
## lambda.1 lambda.2 lambda.3
## 3.652091 3.650836 3.649575
##
## $n.outliers
## [1] 1
##
## $alternative
## [1] "Up to 3 observations are notn from the same Distribution."
##
## $method
## [1] "Rosner's Test for Outliers"
##
## $data
## [1] 29 29 31 30 26 26 27 26 25 28 27 25 25 25 25 24 25 23
## [19] 20 15 20 17 17 26 23 26 25 24 19 14 15 17 27 212 26 29
## [37] 26 24 24 22 22 24 24 17 22 21 23 23 19 18 17 17 19 19
## [55] 12 17 15 17 17 12 17 16 18 15 16 12 17 17 16 12 15 16
## [73] 17 15 17 17 18 17 19 17 19 19 17 17 17 16 16 17 15 17
## [91] 26 25 26 24 21 22 23 22 20 33 32 32 29 32 34 36 36 29
## [109] 26 27 30 31 26 26 28 26 29 28 27 24 24 24 22 19 20 17
## [127] 12 19 18 14 15 18 18 15 17 16 18 17 19 19 17 29 27 31
## [145] 32 27 26 26 25 25 17 17 20 18 26 26 27 28 25 25 24 27
## [163] 25 26 23 26 26 26 26 25 27 25 27 20 20 19 17 20 17 29
## [181] 27 31 31 26 26 28 27 29 31 31 26 26 27 30 33 35 37 35
## [199] 15 18 20 20 22 17 19 18 20 29 26 29 29 24 44 29 26 29
## [217] 29 29 29 23 24 44 41 29 26 28 29 29 29 28 29 26 26 26
##
## $data.name
## [1] "dat$hwy"
##
## $bad.obs
## [1] 0
##
## $all.stats
## i Mean.i SD.i Value Obs.Num R.i+1 lambda.i+1 Outlier
## 1 0 24.21795 13.684345 212 34 13.722399 3.652091 TRUE
## 2 1 23.41202 5.951835 44 213 3.459098 3.650836 FALSE
## 3 2 23.32328 5.808172 44 222 3.559936 3.649575 FALSE
##
## attr(,"class")
## [1] "gofOutlier"Результаты представлены в таблице $all.stats:
test$all.stats
## i Mean.i SD.i Value Obs.Num R.i+1 lambda.i+1 Outlier
## 1 0 24.21795 13.684345 212 34 13.722399 3.652091 TRUE
## 2 1 23.41202 5.951835 44 213 3.459098 3.650836 FALSE
## 3 2 23.32328 5.808172 44 222 3.559936 3.649575 FALSEОсновываясь на тесте Рознера, мы видим, что существует только один выброс (см. Столбец Outlier), и что это наблюдение 34 (см. Obs.Num) со значением 212 (см. Value).
Итоги
Обратите внимание, что некоторые преобразования могут «естественным образом» устранить выбросы. Например, если взять натуральный логарифм или квадратный корень из значения, отклонение станет меньше. Я надеюсь, статья помогла вам обнаружить выбросы в R с помощью нескольких методов описательной статистики (включая минимум, максимум, гистограмму, диаграмму размаха и процентили) или благодаря более формальным методам обнаружения выбросов (включая фильтр Хампеля, тест Граббса, Диксона и Рознера). Следующим этапом проверьте эти значения, и если они действительно являются выбросами — решите, как с ними поступить (сохранить, удалить или изменить), прежде чем проводить анализ.
