Поиск подстрок
При
необходимости поиска в одной строке
последовательности символов, заданной
в другом символьном массиве (подстроке,
лексеме), стандартная библиотека string,
h предлагает воспользоваться одной из
следующих функций.
Функция
strstr () описана следующим образом:
char*
strstr{const char* str,
const
char* substr)
Данная
функция осуществляет сканирование
строки str и находит место первого
вхождения подстроки substr в строку str. В
случае успешного поиска функция strstr
возвращает указатель на первый символ
строки str, начиная с которого следует
точное совпадение части str обязательно
со всей лексемой substr. Если подстрока
substr не найдена в str, возвращается NULL.
Следующий
пример показывает использование функции
strstr ().
char
strl[]=”Производится поиск элемента.”
;
char
str2[] = “поиск”;
char*
ptr;
ptr=strstr(strl,
str2);
cout
« ptr « ‘n’;
На
экран будет выведено “поиск элемента”,
так как подстрока, содержащаяся в str2,
находится внутри строки strl и функция
strstr {) установит указатель ptr на
соответствующий элемент символьного
массива strl.
Чтобы
найти место последнего вхождения
подстроки в строку, можно воспользоваться
следующим приемом: обе строки реверсируются
с помощью функции strrev(), а затем полученный
результат анализируется в функции
strstr ().
Функция
strtok () имеет синтаксис:
char*
strtok(char* str, const char* delim)
Эта
функция выполняет поиск в строке str
подстроки, обрамленной с обеих сторон
любым символом-разделителем из строки
delim. В случае успешного поиска данная
функция обрезает строку str. помещая
символ ” в месте, где заканчивается
найденная лексема. Таким образом, при
повторном поиске лексемы в указанной
строке str первым параметром следует
указывать null. Так как strtok () модифицирует
строку-оригинал, рекомендуется
предварительно сохранять копию последней.
Приведенный ниже пример иллюстрирует
вышесказанное.
Предположим,
необходимо разбить имеющееся в строковом
массиве предложение по словам и вывести
каждое из них на экран.
#include
<string.h>
#include
<iostream.h>
int
main()
{
char
str[]-”Язык программирования C++”;
char
*Delimiters = “.!?,;:”/0123456789> @#$%^&*()<>{}[]~+
-=”;
char
*ptr;
ptr
= strtok(str. Delimiters);
if
(ptr)
cout
« ptr « ‘n’;
while
(ptr)
{
ptr
= strtok(NULL, Delimiters);
if(ptr)
cout
« ptr « ‘n’;
}
return
0;
}
В
данной программе объявляется подлежащая
анализу строка str, подстрока, содержащая
набор разделителей Delimiters и указатель
на символьный тип данных ptr. Вызов функции
strtok (str, Delimiters) сканирует строку str и как
только в ней встретится любой символ,
входящий в подстроку Delimiters (в данном
случае это символ пробела), указатель
ptr станет ссылаться на начало исходной
строки до найденного символа. То есть
ptr будет содержать:
*ptr
– “Язык” .
Благодаря
тому, что функция strtok () помешает в
найденном месте нуль-терминатор (‘ ‘).
исходная строка модифицируется. Таким
образом, массив символов str примет
значение:
“программирования
C++”
Осуществив
проверку указателя ptr на существование
в операторе if (ptr), найденное слово
выводится на экран. Далее в цикле с
помощью функции strtok () находится последний
нуль-терминатор строки str:
ptr
= strtok(NULL, Delimiters);
что,
фактически, соответствует локализации
следующего слова предложения, и найденная
последовательность символов выводится
на экран.
Соседние файлы в папке ЯзыкС++Глушаков
- #
- #
- #
- #
- #
- #
- #
- #
Поиск подстроки и смежные вопросы
Время на прочтение
13 мин
Количество просмотров 111K
Здравствуйте, уважаемое сообщество! Недавно на Хабре проскакивала неплохая обзорная статья о разных алгоритмах поиска подстроки в строке. К сожалению, там отсутствовали подробные описания каких либо из упомянутых алгоритмов. Я решил восполнить данный пробел и описать хотя бы парочку тех, которые потенциально можно запомнить. Те, кто еще помнит курс алгоритмов из института, не найдут, видимо, ничего нового для себя.
Сначала хотел бы предотвратить вопрос «на кой это надо? все уже и так написано». Да, написано. Но во-первых, полезно знать как работает используемые тобой иструменты на более низком уровне чтобы лучше понимать их ограничения, а во-вторых, есть достаточно большие смежные области, где работающей из коробочки функции strstr() окажется недостаточно. Ну и в-третьих, вам может неповезти и придется разрабатывать под мобильную платформу с неполноценным runtime, а тогда лучше знать на что подписываетесь, если решитесь самостоятельно его дополнять (чтобы убедиться, что это не сферическая проблема в вакууме, достаточно попробовать wcslen() и wcsstr() из Android NDK).
А разве просто поискать нельзя?
Дело в том, что очевидный способ, который все формулирует как «взять и поискать», является отнюдь не самым эффективным, а для такой низкоуровневой и сравнительно частовызываемой функции это немаловажно. Итак, план такой:
- Постановка задачи: здесь перечислены определения и условные обозначения.
- Решение «в лоб»: здесь будет описано, как делать не надо и почему.
- Z-функция: простейший вариант правильной реализации поиска подстроки.
- Алгоритм Кнута-Морриса-Пратта: еще один вариант правильного поиска.
- Другие задачи поиска: вкратце пробегусь по ним без подробного описания.
Постановка задачи
Канонический вариант задачи выглядит так: есть у нас строка A (текст). Необходимо проверить, есть ли в ней подстрока X (образец), и если есть, то где она начинается. То есть именно то, что делает функция strstr() в C. Дополнительно к этому можно еще попросить найти все вхождения образца. Очевидно, что задача имеет смысл только если X не длинее A.
Для простоты дальнейшего объяснения введу сразу пару понятий. Что такое строка все, наверное, понимают — это последовательность символов, возможно пустая. Символы, или буквы, принадлежат некоторому множеству, которое называют алфавитом (данный алфавит, вообще говоря, может не иметь ничего общего с алфавитом в бытовом понимании). Длина строки |A| — это, очевидно, количество символов в ней. Префикс строки A[..i] — это строка из i первых символов строки A. Суффикс строки A[j..] — это строка из |A|-j+1 последних символов. Подстроку из A будем обозначать как A[i..j], а A[i] — i-ый символ строки. Вопрос про пустые суффиксы и префиксы и т.д. не трогаем — с ними разобраться не сложно по месту. Еще есть такое понятие как сентинел — некий уникальный символ, не встречающийся в алфавите. Его обозначают значком $ и дополняют допустимый алфавит таким символом (это в теории, на практике проще применить дополнительные проверки, чем придумать такой символ, которого не могло бы оказаться во входных строках).
В выкладках будем считать символы в строке с первой позиции. Код писать традиционно проще отсчитывая от нуля. Переход от одного к другому не составляет трудностей.
Решение «в лоб»
Прямой поиск, или, как еще часто говорят, «просто взять и поискать»- это Первое решение, которое приходит в голову неискушенному программисту. Суть проста: идти по проверяемой строке A и искать в ней вхождение первого символа искомой строки X. Когда находим, делаем гипотезу, что это и есть то самое искомое вхождение. Затем остается проверять по очереди все последующие символы шаблона на совпадение с соответствующими символами строки A. Если они все совпали — значит вот оно, прямо перед нами. Но вот если какой-то из символов не совпал, то ничего не остается, как признать нашу гипотезу неверной, что возвращает нас к символу, следующему за вхождением первого символа из X.
Многие люди ошибаются в этом пункте, считая, что не надо возвращаться назад, а можно продолжать обработку строки A с текущей позиции. Почему это не так легко продемонстрировать на примере поиска X=«AAAB» в A=«AAAAB». Первая гипотеза нас приведет к четвертому символу A: “AAAAB”, где мы обнаружим несоответствие. Если не откатиться назад, то вхождение мы так и не обнаружим, хотя оно есть.
Неправильные гипотезы неизбежны, а из-за таких откатываний назад при плохом стечении обстоятельств может оказаться, что мы каждый символ в A проверили около |X| раз. То есть вычислительная сложность сложность алгоритма O(|X||A|). Так поиск фразы в параграфе может и затянуться…
Справедливости ради следует отметить, что если строки невелики, то такой алгоритм может работать быстрее «правильных» алгоритмов за счет более предсказуемого с точки зрения процессора поведения.
Z-функция
Одна из категорий правильных способов поиска строки сводится к вычислению в каком-то смысле корреляции двух строк. Сначала отметим, что задача сравнения начал двух строк проста и понятна: сравниваем соответствующие буквы, пока не найдем несоответствие либо какая-нибудь из строк закончится. Рассмотрим множество всех суффиксов строки A: A[|A|..] A[|A|-1..],… A[1..]. Будем сравнивать начало самой строки с каждым из ее суффиксов. Сравнение может дойти до конца суффикса, либо оборваться на каком-то символе ввиду несовпадения. Длину совпавшей части и назовем компонентой Z-функции для данного суффикса.
То есть Z-функция — это вектор длин наибольшего общего префикса строки с ее суффиксом. Ух! Отличная фраза, когда надо кого-то запутать или самоутвердиться, а чтобы понять что же это такое, лучше рассмотреть пример.
Исходная строка «ababcaba». Сравнивая каждый суффикс с самой строкой получим табличку для Z-функции:
| суффикс | строка | Z | |
|---|---|---|---|
| ababcaba | ababcaba | -> | 8 |
| babcaba | ababcaba | -> | 0 |
| abcaba | ababcaba | -> | 2 |
| bcaba | ababcaba | -> | 0 |
| caba | ababcaba | -> | 0 |
| aba | ababcaba | -> | 3 |
| ba | ababcaba | -> | 0 |
| a | ababcaba | -> | 1 |
Префикс суффикса это ничто иное, как подстрока, а Z-функция — длины подстрок, которые встречаются одновременно в начале и в середине. Рассматривая все значения компонент Z-функции, можно заметить некоторые закономерности. Во-первых, очевидно, что значение Z-функции не превышает длины строки и совпадает с ней только для «полного» суффикса A[1..] (и поэтому это значение нас не интересует — мы его будем опускать в своих рассуждениях). Во-вторых, если в строке есть некий символ в единственном экземпляре, то совпасть он может только с самим собой, и значит он делит строку на две части, а значение Z-функции нигде не может превысить длины более короткой части.
Использовать эти наблюдения предлагается следующим образом. Допустим в строке «ababcabсacab» мы хотим поискать «abca». Берем эти строчки и конкатенируем, вставляя между ними сентинел: «abca$ababcabсacab». Вектор Z-функции выглядит для такой строки так:
| a b c a $ a b a b c a b с a c a b |
| 17 0 0 1 0 2 0 4 0 0 4 0 0 1 0 2 0 |
Если отбросить значение для полного суффикса, то наличие сентинела ограничивает Zi длиной искомого фрагмента (он является меньшей половиной строки по смыслу задачи). Но вот если этот максимум и достигается, то только в позициях вхождения подстроки. В нашем примере четверками отмечены
все
позиции вхождения искомой строки (отметьте, что найденные участки расположены внахлест друг с другом, но все-равно наши рассуждения остаются верны).
Ну, значит если мы сможем быстро строить вектор Z-функции, то поиск с его помощью всех вхождений строки сводится к поиску в нем значения ее длины. Вот только если вычислять Z-функцию для каждого суффикса, то будет это явно не быстрее, чем решение «в лоб». Выручает нас то, что значение очередного элемента вектора можно узнать опираясь на предыдущие элементы.
Допустим, мы каким-то образом посчитали значения Z-функции вплоть до соответствующего i-1-ому символу. Рассмотрм некую позицию r<i, где мы уже знаем Zr.
Значит Zr символов начиная с этой позиции точно такие же, как и в начале строки. Они образуют так называемый Z-блок. Нас будет интересовать самый правый Z-блок, то-есть тот, кто заканчивается дальше всех (самый первый не в счет). В некоторых случаях самый правый блок может быть нулевой длины (когда никакой из непустых блоков не покрывает i-1, то самым правым будет i-1-ый, даже если Zi-1= 0).
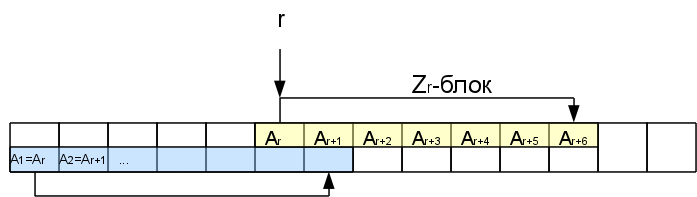
Когда мы будем рассматривать последующие символы внутри этого Z-блока, сравнивать очередной суффикс с самого начала не имеет смысла, так как часть этого суфикса уже встречалась в начале строки, а значит уже была обработана. Можно будет сразу пропускать символы аж до конца Z-блока.
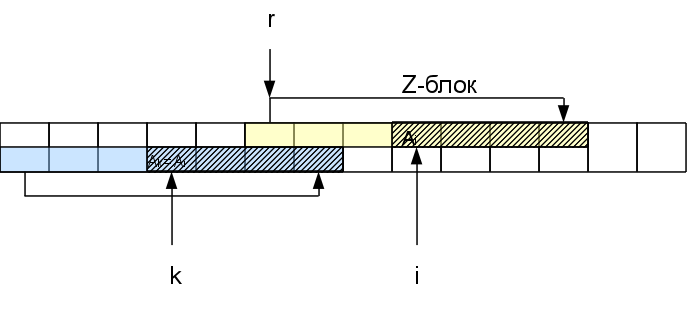
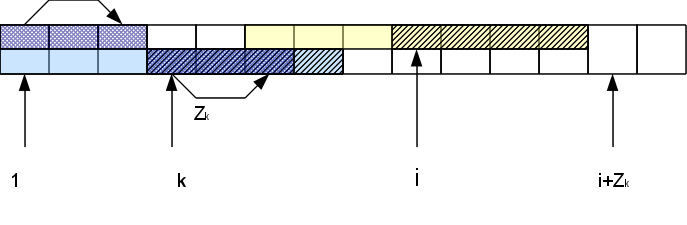
А именно, если мы рассматриваем i-й символ, находящийся в Zr-блоке, то есть соответствующий символ в начале строки на позиции k=i-r+1. Функция Zk нам уже известна. Если она меньше, чем оставшееся до конца Z-блока расстояние Zr-(i-r), то сразу можем быть уверены, что вся область совпадения для этого символа лежит внутри r-того Z-блока и значит результат будет тот же, что и в начале строки: Zi=Zk. Если же Zk >= Zr-(i-r), то Zi тоже больше или равна Zr-(i-r). Чтобы узнать насколько именно она больше, нам надо будет проверять следующие за Z-блоком символы. При этом в случае совпадения h этих символов с соответствующими им в начале строки, Zi увеличивается на h: Zi=Zk + h. В результате у нас может появиться новый самый правый Z-блок (если h>0).
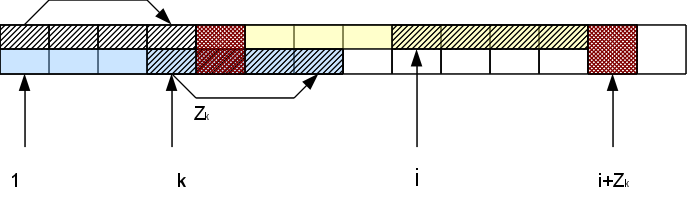
Таким образом, сравнивать символы нам приходится только правее самого правого Z-блока, причем за счет успешных сравнений блок «продвигается» правее, а неуспешные сообщают, что вычисление для данной позиции окончено. Это обеспечивает нам построение всего вектора Z-функции за линейное по длине строки время.
Применив этот алгоритм для поиска подстроки получим сложность по времени O(|A|+|X|), что значительно лучше, чем произведение, которое было в первом варианте. Правда, нам пришлось хранить вектор для Z-функции, на что уйдет дополнительной памяти порядка O(|A|+|X|). На самом деле, если не нужно находить все вхождения, а достаточно только одного, то можно обойтись и O(|X|) памяти, так как длина Z-блока все-равно не может быть больше чем |X|, кроме этого можно не продолжать обработку строки после обнаружения первого вхождения.
Напоследок, пример функции, вычисляющей Z-функцию. Просто модельный вариант без каких либо хитростей.
void z_preprocess(vector<int> & Z, const string & str)
{
const size_t len = str.size();
Z.clear();
Z.resize(len);
if (0 == len)
return;
Z[0] = len;
for (size_t curr = 1, left = 0, right = 1; curr < len; ++curr)
{
if (curr >= right)
{
size_t off = 0;
while ( curr + off < len && str[curr + off] == str[off] )
++off;
Z[curr] = off;
right = curr + Z[curr];
left = curr;
}
else
{
const size_t equiv = curr - left;
if (Z[equiv] < right - curr)
Z[curr] = Z[equiv];
else
{
size_t off = 0;
while ( right + off < len && str[right - curr + off] == str[right + off] )
++off;
Z[curr] = right - curr + off;
right += off;
left = curr;
}
}
}
}
Алгоритм Кнута-Морриса-Пратта (КМП)
Не смотря на логическую простоту предыдущего метода, более популярным является другой алгоритм, который в некотором смысле обратный Z-функции — алгоритм Кнута-Морриса-Пратта (КМП). Введем понятие префикс-функции. Префикс-функция для i-ой позиции — это длина максимального префикса строки, который короче i и который совпадает с суффиксом префикса длины i. Если определение Z-функции не сразило оппонента наповал, то уж этим комбо вам точно удастся поставить его на место 🙂 А на человеческом языке это выглядит так: берем каждый возможный префикс строки и смотрим самое длинное совпадение начала с концом префикса (не учитывая тривиальное совпадение самого с собой). Вот пример для «ababcaba»:
| префикс | префикс | p |
|---|---|---|
| a | a | 0 |
| ab | ab | 0 |
| aba | aba | 1 |
| abab | abab | 2 |
| ababc | ababc | 0 |
| ababca | ababca | 1 |
| ababcab | ababcab | 2 |
| ababcaba | ababcaba | 3 |
Опять же наблюдаем ряд свойств префикс-функции. Во-первых, значения ограничены сверху своим номером, что следует прямо из определения — длина префикса должна быть больше префикс-функции. Во-вторых, уникальный символ точно так же делит строку на две части и ограничивает максимальное значение префикс-функции длиной меньшей из частей — потому что все, что длиннее, будет содержать уникальный, ничему другому не равный символ.
Отсюда получается интересующий нас вывод. Допустим, мы таки достигли в каком-то элементе этого теоретического потолка. Это значит, что здесь закончился такой префикс, что начальная часть совпадает с конечной и одна из них представляет «полную» половинку. Понятно, что в префиксе полная половинка обязана быть спереди, а значит при таком допущении это должна быть более короткая половинка, максимума же мы достигаем на более длинной половинке.
Таким образом, если мы, как и в предыдущей части, конкатенируем искомую строчку с той, в которой ищем, через сентинел, то точка вхождения длины искомой подстроки в компоненту префикс-функции будет соответствовать месту окончания вхождения. Возьмем наш пример: в строке «ababcabсacab» мы ищем «abca». Конкатенированный вариант «abca$ababcabсacab». Префикс-функция выглядит так:
| a b c a $ a b a b c a b с a c a b |
| 0 0 0 1 0 1 2 1 2 3 4 2 3 4 0 1 2 |
Снова мы нашли все вхождения подстроки одним махом — они оканчиваются на позициях четверок. Осталось понять как же эффективно посчитать эту префикс-функцию. Идея алгоритма незначительно отличается от идеи построения Z-функции.

Самое первое значение префикс-функции, очевидно, 0. Пусть мы посчитали префикс-функцию до i-ой позиции включительно. Рассмотрим i+1-ый символ. Если значение префикс-функции в i-й позиции Pi, то значит префикс A[..Pi] совпадает с подстрокой A[i-Pi+1..i]. Если символ A[Pi+1] совпадет с A[i+1], то можем спокойно записать, что Pi+1=Pi+1. Но вот если нет, то значение может быть либо меньше, либо такое же. Конечно, при Pi=0 сильно некуда уменьшаться, так что в этом случае Pi+1=0. Допустим, что Pi>0. Тогда есть в строке префикс A[..Pi], который эквивалентен подстроке A[i-Pi+1..i]. Искомая префикс-функция формируется в пределах этих эквивалентных участков плюс обрабатываемый символ, а значит нам можно забыть о всей строке после префикса и оставить только данный префикс и i+1-ый символ — ситуация будет идентичной.
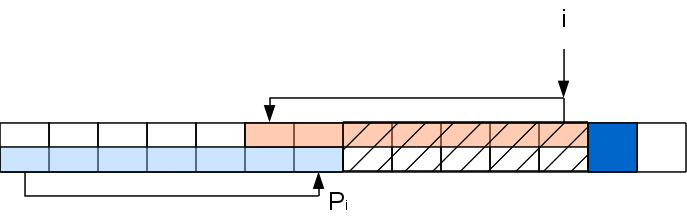
Задача на данном шаге свелась к задаче для строки с вырезанной серединкой: A[..Pi]A[i+1], которую можно решать рекурсивно таким же способом (хотя хвостовая рекурсия и не рекурсия вовсе, а цикл). То есть если A[PPi+1] совпадет с A[i+1], то Pi+1=PPi+1, а иначе снова выкидываем из рассмотрения часть строки и т.д. Повторяем процедуру пока не найдем совпадение либо не дойдем до 0.
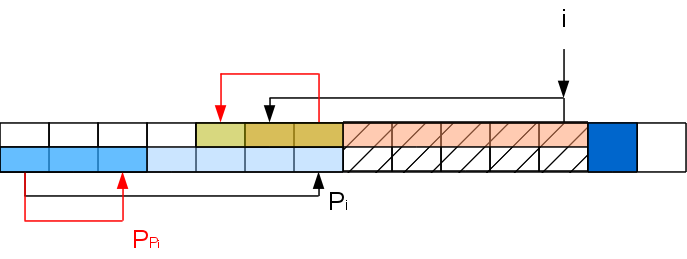
Повторение этих операций должно насторожить — казалось бы получается два вложенных цикла. Но это не так. Дело в том, что вложенный цикл длиной в k итераций уменьшает префикс-функцию в i+1-й позиции хотя бы на k-1, а для того, чтобы нарастить префикс-функцию до такого значения, нужно хотя бы k-1 раз успешно сопоставить буквы, обработав k-1 символов. То есть длина цикла соответствует промежутку между выполнением таких циклов и поэтому сложность алгоритма по прежнему линейна по длине обрабатываемой строки. С памятью тут такая-же ситуация, как и с Z-функцией — линейная по длине строки, но есть способ сэкономить. Кроме этого есть удобный факт, что символы обрабатываются последовательно, то есть мы не обязаны обрабатывать всю строку, если первое вхождение мы уже получили.
Ну и для примера фрагмент кода:
void calc_prefix_function(vector<int> & prefix_func, const string & str)
{
const size_t str_length = str.size();
prefix_func.clear();
prefix_func.resize(str_length);
if (0 == str_length)
return;
prefix_func[0] = 0;
for (size_t current = 1; current < str_length; ++current)
{
size_t matched_prefix = current - 1;
size_t candidate = prefix_func[matched_prefix];
while (candidate != 0 && str[current] != str[candidate])
{
matched_prefix = prefix_func[matched_prefix] - 1;
candidate = prefix_func[matched_prefix];
}
if (candidate == 0)
prefix_func[current] = str[current] == str[0] ? 1 : 0;
else
prefix_func[current] = candidate + 1;
}
}
Не смотря на то, что алгоритм более замысловат, реализация его даже проще, чем для Z-функции.
Другие задачи поиска
Дальше пойдет просто много букв о том, что этим задачи поиска строк не ограничиваются и что есть другие задачи и другие способы решения, так что если кому не интересно, то дальше можно не читать. Эта информация просто для ознакомления, чтобы в случае необходимости хотя бы осознавать, что «все уже украдено до нас» и не переизобретать велосипед.
Хоть вышеописанные алгоритмы и гарантируют линейное время выполнения, звание «алгоритма по умолчанию» получил алгоритм Бойера-Мура. В среднем он тоже дает линейное время, но еще и имеет лучше константу при этой линейной функции, но это в среднем. Бывают «плохие» данные, на которых он оказываются не лучше простейшего сравнения «в лоб» (ну прямо как с qsort). Он на редкость запутан и рассматривать его не будем — все-равно не упомнить. Есть еще ряд экзотических алгоритмов, которые ориентированы на обработку текстов на естественном языке и опираются в своих оптимизациях на статистические свойства слов языка.
Ну ладно, есть у нас алгоритм, который так или иначе за O(|X|+|A|) ищет подстроку в строке. А теперь представим, что мы пишем движок для гостевой книги. Есть у нас список запрещенных матерных слов (понятно, что так не поможет, но задача просто для примера). Мы собираемся фильтровать сообщения. Будем каждое из запрещенных слов искать в сообщении и… на это у нас уйдет O(|X1|+|X2|+…+|Xn|+n|A|). Как-то так себе, особенно если словарь «могучих выражений» «великого и могучего» очень «могуч». Для этого случая есть способ так предобработать словарь искомых строк, что поиск будет занимать только O(|X1|+|X2|+…+|Xn|+|A|), а это может быть существенно меньше, особенно если сообщения длинные.
Такая предобработка сводится к построению бора (trie) из словаря: дерево начинается в некотором фиктивном корне, узлы соответствует буквам слов в словаре, глубина узла дерева соответствует номеру буквы в слове. Узлы, в которых заканчивается слово из словаря называются терминальными и помечены неким образом (красным цветом на рисунке).
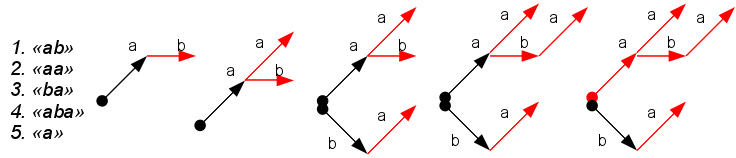
Полученное дерево является аналогом префикс-функции алгоритма КМП. С его помощью можно найти все вхождения всех слов словаря в фразе. Надо идти по дереву, проверяя наличие очередного символа в виде узла дерева, попутно отмечая встречающиеся терминальные вершины — это вхождения слов. Если соответствующего узла в дереве нет, то как и в КМП, происходит откат выше по дереву по специальным ссылкам. Данный алгоритм носит название алгоритма Ахо-Корасика. Такую же схему можно применять для поиска во время ввода и предсказания следующего символа в электронных словарях.
В данном примере построение бора несложно: просто добавляем в бор слова по очереди (нюансы только с дополнительными ссылками для «откатов»). Есть ряд оптимизаций, направленный на сокращение использования памяти этим деревом (т.н. сжатие бора — пропуск участков без ветвлений). На практике эти оптимизации чуть ли не обязательны. Недостатком данного алгоритма является его алфавитозависимость: время на обработку узла и занимаемая память зависят от количества потенциально возможных детей, которое равно размеру алфавита. Для больших алфавитов это серьезная проблема (представляете себе набор символов юникода?). Подробнее про это все можно почитать в этом хабратопике или воспользовавшись гуглояндексом — благо инфы по этомоу вопросу много.
Теперь посмотрим на другую задачу. Если в предыдущей мы знали заранее, что мы должны будем найти в поступающих потом данных, то здесь с точностью до наоборот: нам заранее выдали строчку, в которой будут искать, но что будут искать — неизвестно, а искать будут много. Типичный пример — поисковик. Документ, в котором ищется слово, известен заранее, а вот слова, которые там ищут, сыпятся на ходу. Вопрос, опять же, как вместо O(|X1|+|X2|+…+|Xn|+n|A|) получить O(|X1|+|X2|+…+|Xn|+|A|)?
Предлагается построить бор, в котором будут все возможные суффиксы имеющейся строки. Тогда поиск шаблона сведется к проверки наличия пути в дереве, соответствующего искомому шаблону. Если строить такой бор перебором всех суффиксов, то эта процедура может занять O(|A|2) времени, да и по памяти много. Но, к счастью, существуют алгоритмы, которые позволяют построить такое дерево сразу в сжатом виде — суффиксное дерево, причем сделать это за O(|A|). Недавно на Хабре была по этому поводу статья, так что интересующиеся могут прочитать про алгоритм Укконена там.
Плохо в суффиксном дереве, как обычно, две вещи: то, что это дерево, и то, что узлы дерева алфавитозависимы. От этих недостатков избавлен суффиксный массив. Суть суффиксного массива заключается в том, что если все суффиксы строки отсортировать, то поиск подстроки сведется к поиску группы расположенных рядом суффиксов по первой букве искомого образца и дальнейшего уточнения диапазона по последующим. При этом сами суффиксы в отсортированном виде хранить незачем, достаточно хранить позиции, в которых они начинаются в исходных данных. Правда, временные зависимости у данной структуры несколько хуже: единичный поиск будет обходиться O(|X| + log|A|) если подумать и сделать все аккуратно, и O(|X|log|A|) если не заморачиваться. Для сравнения в дереве для фиксированного алфавита O(|X|). Но зато то, что это массив, а не дерево, может улучшить ситуацию с кэшированием памяти и облегчить задачу предсказателю переходов процессора. Строится суффиксный массив за линейное время с помощью алгоритма Kärkkäinen-Sanders (уж извините, но плохо представляю как это должно звучать на русском). Нынче это один из самых популярных методов индексирования строк.
Вопросов приближенного поиска строк и анализа степени похожести мы тут касаться не будем совсем — слишком большая область для того, чтобы запихнуть в эту статью. Просто упомяну, что там люди зря хлеб не ели и придумали много всяких подходов, поэтому если столкнетесь с подобной задачей — найдите и почитайте. Весьма возможно такая задача уже решена.
Спасибо тем, кто читал! А тем, кто дочитал досюда, спасибо особенное!
UPD: Добавил ссылку на содержательную статью про бор (он же луч, он же префиксное дерево, он же нагруженное дерево, он же trie).
Мини-задача на разогрев: являются ли две строки анаграммами?
Как проверить, содержит ли строка Python другую строку?
Проверка, содержит ли строка какую-нибудь другую строку, это одна из самых распространенных операций, осуществляемых разработчиками.
Если вы раньше (до перехода на Python) писали код, скажем, на Java, для подобной проверки вы могли использовать метод contains.
В Python есть два способа достичь той же
цели.
1. Использование оператора
in
Самый простой способ проверить, содержится ли в строке другая строка, это использовать оператор Python in.
Давайте рассмотрим пример.
>>> str = "Messi is the best soccer player" >>> "soccer" in str True >>> "football" in str False
Как видите, оператор in возвращает True, если указанная подстрока является частью строки. В противном случае он возвращает False.
Этот метод очень простой, понятный,
читаемый и идиоматичный.
2. Использование метода find
Также для проверки вхождения одной строки в другую можно использовать строковый метод find.
В отличие от оператора, возвращающего булево значение, метод find возвращает целое число.
Это число является по сути индексом начала подстроки, если она есть в указанной строке. Если этой подстроки в строке не содержится, метод возвращает -1.
Давайте посмотрим, как работает метод find.
>>> str = "Messi is the best soccer player"
>>> str.find("soccer")
18
>>> str.find("Ronaldo")
-1
>>> str.find("Messi")
0
Что особенно хорошо в применении этого
метода — вы можете при желании ограничить
пределы поиска, указав начальный и
конечный индекс.
Например:
>>> str = "Messi is the best soccer player"
>>> str.find("soccer", 5, 25)
18
>>> str.find("Messi", 5, 25)
-1
Обратите внимание, что для подстроки «Messi» метод вернул -1. Это произошло потому, что мы ограничили поиск в строке промежутком символов с индексами от 5-го до 25-го.
Более сложные способы
Представьте на минутку, что в Python нет
никаких встроенных функций или методов,
позволяющих проверить, входит ли одна
строка в другую. Как бы вы написали
функцию для этой цели?
Можно использовать брутфорс-подход
и на каждой возможной позиции в строке
проверять, начинается ли там искомая
подстрока. Но для длинных строк этот
процесс будет очень медленным.
Есть лучшие алгоритмы поиска строк. Если вы хотите углубиться в эту тему, можем порекомендовать статью «Rabin-Karp and Knuth-Morris-Pratt Algorithms». Также вам может пригодиться статья «Поиск подстроки» в Википедии.
Если вы прочитаете указанные статьи,
у вас может родиться закономерный
вопрос: так какой же алгоритм используется
в Python?
Для поиска ответов на подобные вопросы практически всегда нужно углубиться в исходный код. В этом плане вам повезло: Python это технология с открытым кодом. Давайте же в него заглянем.
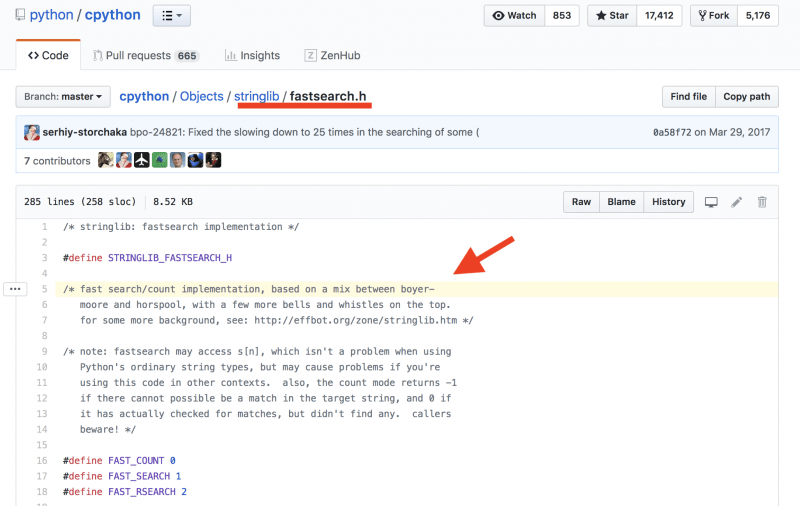
Как удачно, что разработчики прокомментировали свой код! Теперь нам совершенно ясно, что метод find использует смесь алгоритмов Бойера-Мура и Бойера-Мура-Хорспула.
Заключение
Для проверки, содержится ли указанная строка в другой строке, в Python можно использовать оператор in или метод find.
Оператор in возвращает True, если указанная подстрока является частью другой строки. В противном случае он возвращает False.
Метод find возвращает индекс начала подстроки в строке, если эта подстрока там есть, или -1 — если подстрока не найдена.

В этой статье поговорим про строки в Python, особенности поиска, а также о том, как искать подстроку или символ в строке.

Но сначала давайте вспомним основные методы для обработки строк в Python:
• isalpha(str): если строка в Python включает в себя лишь алфавитные символы, возвращается True;
• islower(str): True возвращается, если строка включает лишь символы в нижнем регистре;
• isupper(str): True, если символы строки в Python находятся в верхнем регистре;
• startswith(str): True, когда строка начинается с подстроки str;
• isdigit(str): True, когда каждый символ строки — цифра;
• endswith(str): True, когда строка в Python заканчивается на подстроку str;
• upper(): строка переводится в верхний регистр;
• lower(): строка переводится в нижний регистр;
• title(): для перевода начальных символов всех слов в строке в верхний регистр;
• capitalize(): для перевода первой буквы самого первого слова строки в верхний регистр;
• lstrip(): из строки в Python удаляются начальные пробелы;
• rstrip(): из строки в Python удаляются конечные пробелы;
• strip(): из строки в Python удаляются и начальные, и конечные пробелы;
• rjust(width): когда длина строки меньше, чем параметр width, слева добавляются пробелы, строка выравнивается по правому краю;
• ljust(width): когда длина строки в Python меньше, чем параметр width, справа от неё добавляются пробелы для дополнения значения width, при этом происходит выравнивание строки по левому краю;
• find(str[, start [, end]): происходит возвращение индекса подстроки в строку в Python. В том случае, если подстрока не найдена, выполняется возвращение числа -1;
• center(width): когда длина строки в Python меньше, чем параметр width, слева и справа добавляются пробелы (равномерно) для дополнения значения width, причём происходит выравнивание строки по центру;
• split([delimeter[, num]]): строку в Python разбиваем на подстроки в зависимости от разделителя;
• replace(old, new[, num]): в строке одна подстрока меняется на другую;
• join(strs): строки объединяются в одну строку, между ними вставляется определённый разделитель.
Обрабатываем строку в Python
Представим, что ожидается ввод числа с клавиатуры. Перед преобразованием введенной нами строки в число можно легко проверить, введено ли действительно число. Если это так, выполнится операция преобразования. Для обработки строки используем такой метод в Python, как isnumeric():
string = input("Введите какое-нибудь число: ") if string.isnumeric(): number = int(string) print(number)Следующий пример позволяет удалять пробелы в конце и начале строки:
string = " привет мир! " string = string.strip() print(string) # привет мир!Так можно дополнить строку пробелами и выполнить выравнивание:
print("iPhone 7:", "52000".rjust(10)) print("Huawei P10:", "36000".rjust(10))В консоли Python будет выведено следующее:
iPhone 7: 52000 Huawei P10: 36000Поиск подстроки в строке
Чтобы в Python выполнить поиск в строке, используют метод find(). Он имеет три формы и возвращает индекс 1-го вхождения подстроки в строку:
• find(str): поиск подстроки str производится с начала строки и до её конца;
• find(str, start): с помощью параметра start задаётся начальный индекс, и именно с него и выполняется поиск;
• find(str, start, end): посредством параметра end задаётся конечный индекс, поиск выполняется до него.
Когда подстрока не найдена, метод возвращает -1:
welcome = "Hello world! Goodbye world!" index = welcome.find("wor") print(index) # 6 # ищем с десятого индекса index = welcome.find("wor",10) print(index) # 21 # ищем с 10-го по 15-й индекс index = welcome.find("wor",10,15) print(index) # -1Замена в строке
Чтобы в Python заменить в строке одну подстроку на другую, применяют метод replace():
• replace(old, new): подстрока old заменяется на new;
• replace(old, new, num): параметр num показывает, сколько вхождений подстроки old требуется заменить на new.Пример замены в строке в Python:
phone = "+1-234-567-89-10" # дефисы меняются на пробелы edited_phone = phone.replace("-", " ") print(edited_phone) # +1 234 567 89 10 # дефисы удаляются edited_phone = phone.replace("-", "") print(edited_phone) # +12345678910 # меняется только первый дефис edited_phone = phone.replace("-", "", 1) print(edited_phone) # +1234-567-89-10Разделение на подстроки в Python
Для разделения в Python используется метод split(). В зависимости от разделителя он разбивает строку на перечень подстрок. В роли разделителя в данном случае может быть любой символ либо последовательность символов. Этот метод имеет следующие формы:
• split(): в роли разделителя применяется такой символ, как пробел;
• split(delimeter): в роли разделителя применяется delimeter;
• split(delimeter, num): параметром num указывается, какое количество вхождений delimeter применяется для разделения. При этом оставшаяся часть строки добавляется в перечень без разделения на подстроки.Соединение строк в Python
Рассматривая простейшие операции со строками, мы увидели, как объединяются строки через операцию сложения. Однако есть и другая возможность для соединения строк — метод join():, объединяющий списки строк. В качестве разделителя используется текущая строка, у которой вызывается этот метод:
words = ["Let", "me", "speak", "from", "my", "heart", "in", "English"] # символ разделителя - пробел sentence = " ".join(words) print(sentence) # Let me speak from my heart in English # символ разделителя - вертикальная черта sentence = " | ".join(words) print(sentence) # Let | me | speak | from | my | heart | in | EnglishА если вместо списка в метод join передать простую строку, разделитель будет вставляться уже между символами:
word = "hello" joined_word = "|".join(word) print(joined_word) # h|e|l|l|o

Поиск подстроки
Последнее обновление: 02.03.2023
Функция find() возвращает индекс первого вхождения подстроки или отдельного символа в строке в виде значние я типа size_t:
#include <iostream>
#include <string>
int main()
{
std::string text {"A friend in need is a friend indeed."};
std::cout << text.find("ed") << std::endl; // 14
std::cout << text.find("friend") << std::endl; // 2
std::cout << text.find('d') << std::endl; // 7
std::cout << text.find("apple") << std::endl; // 18446744073709551615
}
Если строка или символ не найдены (как в примере выше в последнем случае), то возвращается специальная константа std::string::npos,
которая представляет очень большое число (как видно из примера, число 18446744073709551615). И при поиске мы можем проверять результат функции find() на равенство этой константе:
if (text.find("banana") == std::string::npos)
{
std::cout << "Not found" << std::endl;
}
Функция find имеет ряд дополнительных версий. Так, с помощью второго параметра мы можем указать индекс, с которого надо вести поиск:
#include <iostream>
#include <string>
int main()
{
std::string text {"A friend in need is a friend indeed."};
// поиск с 10-го индекса
std::cout << text.find("friend", 10) << std::endl; // 22
}
Используя эту версию, мы можем написать программу для поиска количества вхождений строки в тексте, то есть выяснить, сколько раз строка встречается в тексте:
#include <iostream>
#include <string>
int main()
{
std::string text {"A friend in need is a friend indeed."};
std::string word {"friend"};
unsigned count{}; // количество вхождений
for (unsigned i {}; i <= text.length() - word.length(); )
{
// получаем индекс
size_t position = text.find(word, i);
// если не найдено ни одного вхождения с индекса i, выходим из цикла
if (position == std::string::npos) break;
// если же вхождение найдено, увеличиваем счетчик вхождений
++count;
// переходим к следующему индексу после position
i = position + 1;
}
std::cout << "The word is found " << count << " times." << std::endl; // The word is found 2 times.
}
Здесь в цикле пробегаемся по тексту, в котором надо найти строку, пока счетчик i не будет равен text.length() - word.length().
С помощью функции find() получаем индекс первого вхождения слова в тексте, начиная с индекса i. Если таких вхождений не найдено, то выходим из цикла.
Если же найден индекс, то счетчик i получает индекс, следующий за индексом найденного вхождения.
В итоге, поскольку искомое слово “friend” встречается в тексте два раза, то программа выведет
The word is found 2 times.
В качестве альтернативы мы могли бы использовать цикл while:
#include <iostream>
#include <string>
int main()
{
std::string text {"A friend in need is a friend indeed."};
std::string word {"friend"};
unsigned count{}; // количество вхождений
size_t index{}; // начальный индекс
while ((index = text.find(word, index)) != std::string::npos)
{
++count;
index += word.length(); // перемещаем индекс на позицию после завершения слова в тексте
}
std::cout << "The word is found " << count << " times." << std::endl;
}
Еще одна версия позволяет искать в тексте не всю строку, а только ее часть. Для этого в качестве третьего параметра передается количество символов из искомой строки, которые программа будет искать в тексте:
#include <iostream>
#include <string>
int main()
{
std::string text {"A friend in need is a friend indeed."};
std::string word {"endless"};
// поиск с 10-го индекса 3 первых символов слова "endless", то есть "end"
std::cout << text.find("endless", 10, 3) << std::endl; // 25
}
Стоит отметить, что в этом случае искомая строка должна представлять строковый литерал или строку в С-стиле (например, символьный массив с концевым нулевым байтом).
Функция rfind. Поиск в обратном порядке
Функция rfind() работает аналогично функции find(), принимает те же самые параметры, только ищет подстроку в обратном порядке – с конца строки:
#include <iostream>
#include <string>
int main()
{
std::string text {"A friend in need is a friend indeed."};
std::cout << text.rfind("ed") << std::endl; // 33
std::cout << text.rfind("friend") << std::endl; // 22
std::cout << text.rfind('d') << std::endl; // 34
std::cout << text.rfind("apple") << std::endl; // 18446744073709551615
}
Поиск любого из набора символов
Пара функций – find_first_of() и find_last_of() позволяют найти соответственно первый и последний индекс любого из набора символов:
#include <iostream>
#include <string>
int main()
{
std::string text {"Phone number: +23415678901"};
std::string letters{"0123456789"}; // искомые символы
std::cout << text.find_first_of(letters) << std::endl; // 15
std::cout << text.find_last_of(letters) << std::endl; // 25
}
В данном случае ищем в строке “Phone number: +23415678901” первую и последнюю позицию любого из символов из строки “0123456789”. То есть таким образом мы найдем начальный и конечный индекс
номера телефона.
Если нам, наоборот, надо найти позиции символов, которые НЕ представляют любой символ из набора, то мы можем использовать функции find_first_not_of() (первая позиция)
и find_last_not_of() (последняя позиция):
#include <iostream>
#include <string>
int main()
{
std::string text {"Phone number: +23415678901"};
std::string letters{"0123456789"}; // искомые символы
std::cout << text.find_first_not_of(letters) << std::endl; // 0
std::cout << text.find_last_not_of(letters) << std::endl; // 14
}
Мы можем комбинировать функции. Например, найдем количество слов в строке:
#include <iostream>
#include <string>
int main()
{
std::string text {"When in Rome, do as the Romans do."}; // исходный текст
const std::string separators{ " ,;:."!?'*n" }; // разделители слов
unsigned count{}; // счетчик слов
size_t start { text.find_first_not_of(separators) }; // начальный индекс первого слова
while (start != std::string::npos) // если нашли слово
{
// увеличиваем счетчик слов
count++;
size_t end = text.find_first_of(separators, start + 1); // находим, где кончается слово
if (end == std::string::npos)
{
end = text.length();
}
start = text.find_first_not_of(separators, end + 1); // находим начальный индекс следующего слова и переустанавливаем start
}
// выводим количество слов
std::cout << "Text contains " << count << " words" << std::endl; // Text contains 8 words
}
Вкратце рассмотрим данный код. В качестве текста, где будем подсчитывать слова, определям переменную text. И также определяем строку разделителей, такие как знаки пунктуации, пробелы, символ перевода строки, которые не являются словами:
const std::string separators{ " ,;:."!?'*n" }; // разделители слов
Перед обработкой введенного текста фиксируем индекс первого символа первого слова в тексте. Для этого применяется функция find_first_not_of(), которая возвращает
первый индекс любого символа, который не входит в строку separators:
size_t start { text.find_first_not_of(separators) };
Далее в цикле while смотрим, является ли полученный индекс действительным индексом:
while (start != std::string::npos)
Например, если в строке одни только символы из набора separators, тогда функция find_first_not_of() возвратит значение std::string::npos,
что будет означать, что в тексте больше нет непунктационных знаков.
И если start указывает на действительный индекс начала слова, то увеличиваем счетчик слово. Далее находим индекс первого символа из separators, который идет сразу после слова. То есть фактически это индекс после
последнего символа слова, который помещаем в переменную end:
size_t end = text.find_first_of(separators, start + 1); // находим, где закончилось слово
Для нахождения позиции окончания слова используем функцию find_first_of(), которая возвращает первую позицию любого символа из separators, начиная с индекса start+1
Причем может быть, что функция find_first_of() не найдет ни одного символа из separators (например, слово является поседним в тексте, и после него нет никаких знаков пунктуации или пробелов),
в этом случае конечный индекс равен длине текста.
if (end == std::string::npos) // если НЕ найден ни один из символов-разделителей
end = text.length(); // устанавливаем переменную end на конец текста
После того, как мы нашли начальный индексы слова и его конец, переустанавливаем start на начальный индекс следующего слова и повторяем действия цикла:
start = text.find_first_not_of(separators, end + 1); // находим начальный индекс следующего слова и переустанавливаем start
В конце выводим количество найденных слов.
