Сервисы и трюки, с которыми найдётся ВСЁ.
Зачем это нужно: с утра мельком прочитали статью, решили вечером ознакомиться внимательнее, а ее на сайте нет? Несколько лет назад ходили на полезный сайт, сегодня вспомнили, а на этом же домене ничего не осталось? Это бывало с каждым из нас. Но есть выход.
Всё, что попадает в интернет, сохраняется там навсегда. Если какая-то информация размещена в интернете хотя бы пару дней, велика вероятность, что она перешла в собственность коллективного разума. И вы сможете до неё достучаться.
Поговорим о простых и общедоступных способах найти сайты и страницы, которые по каким-то причинам были удалены.
1. Кэш Google, который всё помнит
Google специально сохраняет тексты всех веб-страниц, чтобы люди могли их просмотреть в случае недоступности сайта. Для просмотра версии страницы из кэша Google надо в адресной строке набрать:
http://webcache.googleusercontent.com/search?q=cache:https://www.iphones.ru/
Где https://www.iphones.ru/ надо заменить на адрес искомого сайта.
2. Web-archive, в котором вся история интернета

Во Всемирном архиве интернета хранятся старые версии очень многих сайтов за разные даты (с начала 90-ых по настоящее время). На данный момент в России этот сайт заблокирован.
3. Кэш Яндекса, почему бы и нет

К сожалению, нет способа добрать до кэша Яндекса по прямой ссылке. Поэтому приходиться набирать адрес страницы в поисковой строке и из контекстного меню ссылки на результат выбирать пункт Сохраненная копия. Если результат поиска в кэше Google вас не устроил, то этот вариант обязательно стоит попробовать, так как версии страниц в кэше Яндекса могут отличаться.
4. Кэш Baidu, пробуем азиатское
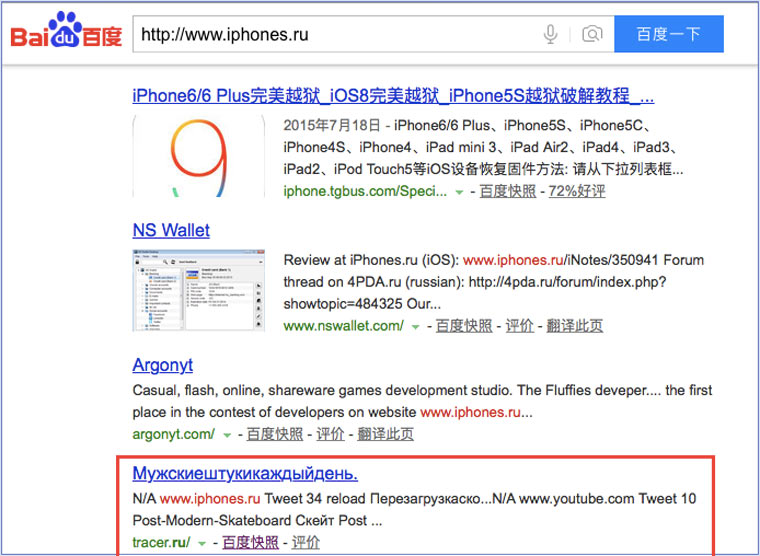
Когда ищешь в кэше Google статьи удаленные с habrahabr.ru, то часто бывает, что в сохраненную копию попадает версия с надписью «Доступ к публикации закрыт». Ведь Google ходит на этот сайт очень часто! А китайский поисковик Baidu значительно реже (раз в несколько дней), и в его кэше может быть сохранена другая версия.
Иногда срабатывает, иногда нет. P.S.: ссылка на кэш находится сразу справа от основной ссылки.
5. CachedView.com, специализированный поисковик
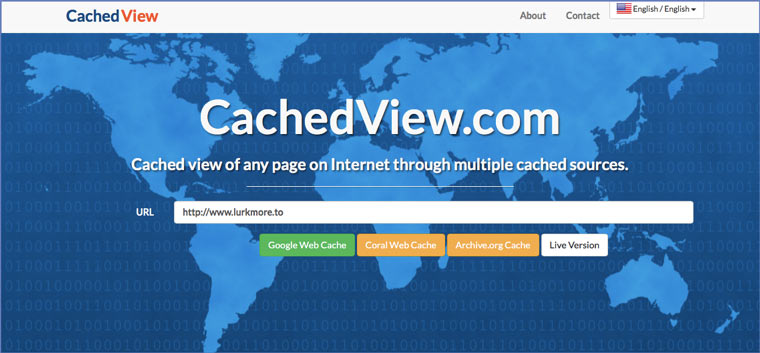
На этом сервисе можно сразу искать страницы в кэше Google, Coral Cache и Всемирном архиве интернета. У него также еcть аналог cachedpages.com.
6. Archive.is, для собственного кэша
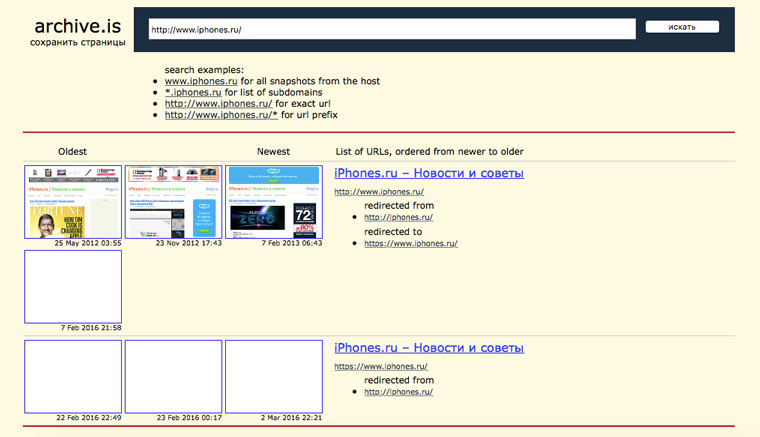
Если вам нужно сохранить какую-то веб-страницу, то это можно сделать на archive.is без регистрации и смс. Еще там есть глобальный поиск по всем версиям страниц, когда-либо сохраненных пользователями сервиса. Там есть даже несколько сохраненных копий iPhones.ru.
7. Кэши других поисковиков, мало ли
Если Google, Baidu и Yandeх не успели сохранить ничего толкового, но копия страницы очень нужна, то идем на seacrhenginelist.com, перебираем поисковики и надеемся на лучшее (чтобы какой-нибудь бот посетил сайт в нужное время).
8. Кэш браузера, когда ничего не помогает
Страницу целиком таким образом не посмотришь, но картинки и скрипты с некоторых сайтов определенное время хранятся на вашем компьютере. Их можно использовать для поиска информации. К примеру, по картинке из инструкции можно найти аналогичную на другом сайте. Кратко о подходе к просмотру файлов кэша в разных браузерах:
Safari
Ищем файлы в папке ~/Library/Caches/Safari.
Google Chrome
В адресной строке набираем chrome://cache
Opera
В адресной строке набираем opera://cache
Mozilla Firefox
Набираем в адресной строке about:cache и находим на ней путь к каталогу с файлами кеша.
9. Пробуем скачать файл страницы напрямую с сервера
Идем на whoishostingthis.com и узнаем адрес сервера, на котором располагается или располагался сайт:
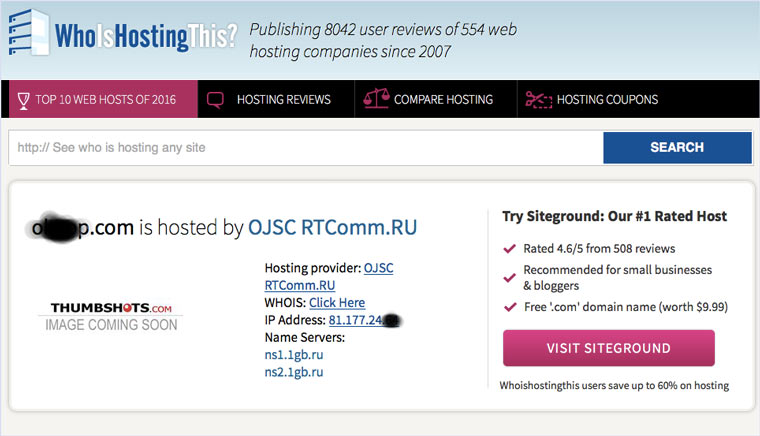
После этого открываем терминал и с помощью команды curl пытаемся скачать нужную страницу:

Что делать, если вообще ничего не помогло
Если ни один из способов не дал результатов, а найти удаленную страницу вам позарез как надо, то остается только выйти на владельца сайта и вытрясти из него заветную инфу. Для начала можно пробить контакты, связанные с сайтом на emailhunter.com:
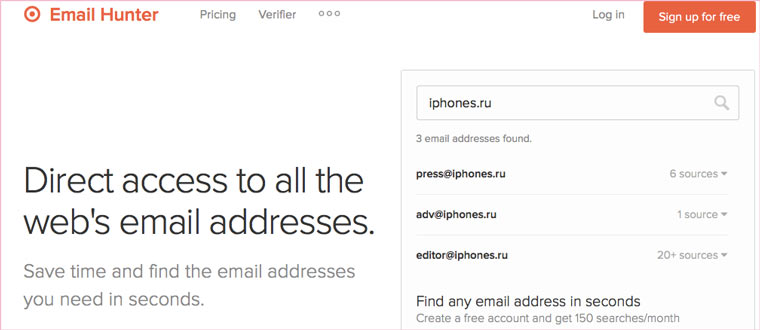
О других методах поиска читайте в статье 12 способов найти владельца сайта и узнать про него все.
А о сборе информации про людей читайте в статьях 9 сервисов для поиска информации в соцсетях и 15 фишек для сбора информации о человеке в интернете.

 (30 голосов, общий рейтинг: 4.80 из 5)
(30 голосов, общий рейтинг: 4.80 из 5)
🤓 Хочешь больше? Подпишись на наш Telegram.
![]()
iPhones.ru
Сервисы и трюки, с которыми найдётся ВСЁ. Зачем это нужно: с утра мельком прочитали статью, решили вечером ознакомиться внимательнее, а ее на сайте нет? Несколько лет назад ходили на полезный сайт, сегодня вспомнили, а на этом же домене ничего не осталось? Это бывало с каждым из нас. Но есть выход. Всё, что попадает в интернет,…
- Google,
- полезный в быту софт,
- хаки
![]()
Как найти информацию в Интернете, которую не отображают такие продвинутые поисковые системы как Google или Яндекс? Можно ли найти сайты, которые когда-то существовали в сети, но уже не работают, удалены или же заменены новыми? На эти вопросы мы постараемся дать ответ в этой статье.
Всемирный Веб архив сайтов интернета
Хранилище интернет-архив конечно не содержит всех страниц, которые когда-либо были созданы. Но шанс найти интересующий вас сайт и его архивную копию достаточно велик.
Самый мощный архив веб-сайтов доступен на Archive.org по адресу www.archive.org. Он индексирует веб, виде-, аудио и текстовые материалы, которые доступны в интернете.
Запустите ваш любимый веб-браузер и введите www.archive.org в адресной строке . Через некоторое время вы увидите главную страницу сайта интернет-архива. Она разделена на несколько частей. Каждая часть позволяет искать различный тип контента.
Раздел видео, содержит на момент написания статьи более 830 тысяч фильмов.
Раздел аудио, включает в себя более 2 миллионов записей, при это доступен еще раздел живой музыки, который насчитывает около 200 тысяч прямых трансляций с концертов в Интернет.
Однако наиболее интересным и значимым разделом сайта Archive.org является раздел web-страницы. На сегодняшний день он позволяет получить доступ к более чем 349 миллиардам архивных веб-сайтов. Для данного раздела даже выделен отдельный поддомен web.

Главная страница сайта Archive.org
Как пользоваться веб архивом
Если вы хотите выполнить поиск в архиве веб-страниц, введите в адресную строку вашего браузера адрес web.archive.org.ru, после чего в поле поиска укажите адрес интересуемого сайта. Например, введите адрес домашней страницы Яндекса http://yandex.ru и нажмите клавишу «Enter».

Сохраненные копии главной страницы Яндекс на сайте web.archive.org
Зелеными кружочками обозначены даты когда была проиндексирована страница, нажав на него вы перейдете на архивную копию сайта. Для того чтобы выбрать архивную дату, достаточно кликнуть по временной диаграмме по разделу с годом и выбрать доступные в этом году месяц и число. Так же если вы нажмете на ссылку «Summary of yandex.ru» то увидите, какой контент был проиндексирован и сохранен в архиве для конкретного сайта с 1 января 1996 года ( это дата начала работы веб архива).

Какой контент сохраняет веб-архив интернета
Нажав на выбранную дату, вам откроется архивная копия страницы, такая как она выглядела на веб-сайте в прошлом. Давайте посмотрим на Яндекс в молодости, ниже приведен снимок главной страницы Яндекса на 8 февраля 1999 года.

Веб архив копия сайта Яндекс на 08.02.1999
Вполне возможно, что в архивном варианте страниц, хранящемся на веб-сайте Archive.org, будут отсутствовать некоторые иллюстрации, и возможны ошибки форматирования текста. Это результатом того, что механизм архивирования веб-сайтов, пытается, прежде всего, сохранить текстовый контент web-сайтов. Помните об еще одном ограничении онлайн-архива. При поиске конкретного контента, размещенного на определенной архивной странице, лучше всего вводить ее точный адрес, а не главный адрес данного веб-сайта.
Возвращаясь к нашему примеру: вы получили доступ к архивному контенту, размещенному на главной странице Яндекса, при нажатии на ссылки в архивной версии могут как загружаться так и не загружаться другие страницы сайта. Так в нашем варианте страница «последние 20 запросов» была найдена, а вот страница «Реклама на yandex.ru» не нашлась.
Подводя итоги можно сказать, что web.archive.org поистине уникальный и грандиозный проект. Он действительно является машиной времени для интернета, позволяя найти удаленные сайты и их архивные версии . Как использовать предоставляемые возможности решать только вам, но использовать их можно и нужно обязательно !
Как скачать сайт из веб архива
Если вы желаете восстановить сайт из веб-архива, то вам в этом поможет программа Web Archive Downloader 6.0
Если страница (файл) уже удалена[править]
Если нужная вам веб-страница была по какой-либо причине удалена, попробуйте найти в Интернете зеркало сайта, на котором она была расположена.
Зеркало веб-сайта — это точная копия этого сайта, которая находится на другом сервере в Интернете. Если вы ищете удалённый файл, попробуйте найти зеркало страницы, на которой находилась ссылка на него. Может быть, на странице-зеркале ссылка будет изменена и файл, в отличие от оригинального, не будет удалён.
Найти зеркало веб-сайта очень просто: надо ввести известную часть текста одной из его страниц в качестве запроса поисковой системе. Если текст на страницах сайта вам совершенно незнаком, укажите имя страницы или файла, путь к которым вы знаете. Например, если вы не нашли страницу http://www.example.com/biology/human_body.html, зайдите на сайт одной из поисковых машин и введите запрос human_body.html. Если сама страница-зеркало и не будет найдена, возможно, отыщется веб-страница со ссылкой на неё.
Один из способ получить доступ к содержимому уже удалённой веб-страницы — воспользоваться функцией Восстановить текст «Рамблера» или схожей функцией Сохранено в кэше поисковой системы Google. Если в этих поисковых системах нужная вам страница не была сохранена, придётся обратиться к так называемому архиву Интернета.
Архив Интернета ( http://www.archive.org/ ) — глобальная программа. Была основанная в 1996 году в американском городе Сан-Франциско. Один из её подпроектов, The Wayback Machine (в переводе с англ. — «Машина времени»), предназначен для хранения «снимков» Интернета различных временных промежутков. Сервер «Машины времени» с определённой периодичностью просматривает все страницы Сети, которые может найти, и сохраняет содержимое каждой из них. И даже если какие-нибудь страницы когда-нибудь будут удалены, мы сможетем ознакомиться с их прежним содержанием. То же происходит и с файлами: если тот или иной файл был удалён, остаётся вероятность, что нам удастся отыскать его резервную копию в архиве Интернета.
Для того,чтобы воспользоваться услугами «Машины времени», надо:
зайти на сайт http://web.archive.org/ ;
в поле, где уже заданы первые символы адреса удалённой страницы или файла, http://, введите адрес, нажмите клавишу Enter. Перед вами появится список дат, когда были сделаны «снимки» веб-страницы, которую вы ищите;
щелкнуть на определённой дате — откроется нужная вам страница с прежним содержанием.
«Машина времени» сохраняет далеко не все страницы и файлы, выложенные во Всемирную паутину, но шанс найти удалённую из Интернета информацию достаточно велик.
Find the Wayback Machine useful?
DONATE

deviantart.com
Oct 15, 2013 21:28:20

cl.cam.ac.uk
Feb 29, 2000 18:34:39

foodnetwork.com
Oct 20, 2013 22:40:56

yahoo.com
Dec 20, 1996 15:45:10

spiegel.com
Oct 01, 2013 15:26:30

imdb.com
Oct 21, 2013 16:53:47

stackoverflow.com
Oct 14, 2013 21:22:10

ubl.com
Dec 27, 1996 20:38:47

bloomberg.com
Oct 01, 2013 23:10:45

reference.com
Oct 18, 2013 07:12:58

feedmag.com
Dec 23, 1996 10:53:17

wikihow.com
Oct 21, 2013 20:56:46

nbcnews.com
Oct 21, 2013 17:24:52

goodreads.com
Oct 21, 2013 00:42:42

obamaforillinois.com
Nov 09, 2004 04:28:06

geocities.com
Feb 22, 1997 17:47:51

amazon.com
Feb 04, 2005 00:47:33

nytimes.com
Oct 01, 2013 01:42:36

bbc.co.uk
Oct 01, 2013 00:13:32

huffingtonpost.com
Oct 21, 2013 17:11:12

reddit.com
Oct 01, 2013 03:15:39

cnet.com
Oct 21, 2013 02:07:03

whitehouse.gov
Dec 27, 1996 06:25:41

aol.com
Oct 01, 2013 05:01:31

yelp.com
Oct 19, 2013 02:44:53

etsy.com
Jun 01, 2013 01:38:52

foxnews.com
Oct 01, 2013 01:08:27

well.com
Jan 08, 1997 06:53:37

w3schools.com
Oct 19, 2013 00:55:10

buzzfeed.com
Oct 21, 2013 17:32:21

nasa.gov
Dec 31, 1996 23:58:47

mashable.com
Oct 21, 2013 02:16:14

nfl.com
Oct 21, 2013 07:39:25
![]()
Tools
Banish broken links from your blog.
Help users get where they were going.
![]()
Save Page Now
Capture a web page as it appears now for use as a trusted citation in the future.
Only available for sites that allow crawlers.
Иногда, зайдя на одну из ранее посещаемых страниц в сети Интернет, мы получаем 404 ошибку – страница не найдена. Возможно, что эта страница была удалена, возможно, что сайт на данный момент не доступен и т.д., но нам от этого не тепло и не холодно. Возникает закономерный вопрос: как просмотреть удалённую страницу? В данной статье я попробую дать ответ на этот вопрос и предложить Вам четыре готовых варианта решения данной задачи. Приступим?
Вариант 1: автономный режим браузера
Для экономии трафика и увеличения скорости загрузки страниц, многие современные браузеры используют, так называемый, кэш. Что это такое? Кэш (от англ. cache) – это дисковое пространство на Вашем компьютере, выделенное специально под временные файлы, к которым относятся и веб-страницы.
Так что если страница удалена или Интернет Вам не доступен, Вы можете воспользоваться данными из кэша браузера. Для этого Вам нужно перейти в, так называемый, автономный режим работы браузера. Как это сделать?
Примечание: для просмотра удалённой страницы в автономном режиме, она должна присутствовать в кэше браузера. Это происходит только в том случае, если Вы ранее уже посещали эту страницу. Но нужно помнить, что кэш периодически подчищается самим браузером. Многое здесь зависит от выделенного под кэш дискового пространства в настройках браузера.
Как включить автономный режим работы браузера?
Для браузером на движке Chromium, а это Google Chrome, Яндекс.Браузер, браузерИнтернет от Mail.ru, Рамблер Браузер и др., автономного режима не существует. Точнее он есть, но только в качестве эксперимента. Для его активизации перейдите на системную страницу: chrome://flags/ – и найдите там «Автономный режим кеша», а потом кликните в нём ссылку «Включить».
Включение и выключение автономного режима в браузере Google Chrome
В браузере Firefox (версия 29 и старше) нужно открыть меню (кликнув по кнопке с тремя полосками, она обычно находится в верхнем правом углу окна браузера) и кликнуть в нём пункт «Разработка» (в виде гаечного ключа), а потом пункт «Работать автономно».
Включение и выключение автономного режима в браузере Firefox
В браузере Opera кликните кнопку «Opera», найдите в меню пункт «Настройки», а потом кликните пункт «Работать автономно».
Как включить или отключить автономный режим в Opera?
В Internet Explorer нужно нажать кнопку Alt, выбрать пункт «Файл» (в появившемся меню) и кликнуть пункт меню «Автономный режим».
Как выключить или выключить автономный режим в Internet Explorer?
Как отключить автономный режим в Internet Explorer 11?
Стоит уточнить, что в IE 11 разработчики удалили возможность включения и отключения автономного режима. Здесь возникает другая проблема: как отключить автономный режим в Internet Explorer 11? Тут проделать обратные действия не получится, нужно сбрасывать настройки браузера.
Для этого закройте все приложения, в том числе и браузер. Дальше нажмите комбинацию клавиш Win+R и введите: inetcpl.cpl – в открывшемся окне «Выполнить», нажмите кнопку Enter. В открывшемся окне «Свойства: Интернет» перейдите на вкладку «Дополнительно». На открывшейся вкладке найдите и кликните кнопку «Восстановить дополнительные параметры», а потом и появившуюся кнопку «Сброс…». В окне подтверждения установите галочку «Удалить личные настройки» и нажмите кнопку «Сброс».
Вариант 2: копии страниц в поисковых системах
Я уже как-то отмечал, что пользователям поисковых систем нет смысла заходить на сайты, ведь можно просматривать копии их страниц в самой поисковой системе. Так или иначе, но это хороший способ просмотреть удалённую страницу.
В случае с поисковой системой Google, Вы можете использовать оператор поискового запроса info:, с указанием нужного URL-адреса, например:
Просмотр копии страницы в кэше поисковой системы Google
Здесь нам нужно кликнуть ссылку «сохраненную в Google версию» и мы получим последнюю сохранённую в Google версию удалённой страницы.
В случае с поисковой системой Яндекс, Вы можете использовать оператор поискового запроса url:, с указанием нужного URL-адреса, например:
Просмотр копии удаленной веб-страницы в индексе поисковой системы Яндекс
Здесь нам нужно навести курсор мыши на (зелёный) URL-адресс в сниппете, а потом кликнуть появившуюся ссылку «копия» и мы получим последнюю сохранённую в Яндекс версию удалённой страницы.
Проблема в том, что поисковые системы хранят только последние проиндексированные копии страниц. В том случае если страница была удалена, со временем она может стать недоступной и в кэше поисковых систем.
Вариант 3: WayBack Machine
Есть в сети Интернет и такой замечательный сервис, как WayBack Machine, рекомендую взять его на заметку. Фактически, это целый Интернет архив, который содержит историю существования многих сайтов.
Просмотр истории сайта на WayBack Machine
Суть его проста. Вы вводите нужный вам URL-адрес, а сервис пытается найти его копии в своей базе с привязкой к дате. К сожалению, сервис индексирует далеко не все сайты и тем более их страницы, но тем не менее. Это реальный способ восстановить ранее удалённую страницу.
Вариант 4: Archive.today
Достаточно простым и (к сожалению) пассивным сервис для создания копий веб-страниц сайтов является сервис Archive.today. Другими словами, для того, чтобы получить доступ к удалённой странице, нужно чтобы ранее она была кем-то скопирована в сервис. Для этого нужно ввести URL-адрес в первую (красную) форму и нажать кнопку «submit url».
Добавление и поиск копий веб-страниц на сайте Archive.today
После этого вы можете попробовать найти нужную страницу, используя вторую (синюю) форму. В результате Вы увидите имеющиеся в архиве копии страниц.
Просмотр копий страни на сайте Archive.today
Возможно, что существуют и другие варианты решения поставленной задачи с просмотром удаленных страниц, но думаю и того, что было сказано будет вполне достаточно. На этом у меня всё. Спасибо за внимание. Удачи!
Короткая ссылка: http://goo.gl/M0atyn
