Время на прочтение
11 мин
Количество просмотров 37K
В основу статьи легли мои собственные выработанные нелегким путем знания о принципах работы и правильном использовании целых чисел в C/C++. Помимо самих правил, я решил привести список распространенных заблуждений и сделать небольшое сравнение системы целочисленных типов в нескольких передовых языках. Все изложение строилось вокруг баланса между краткостью и полноценностью, чтобы не усложнять восприятие и при этом отчетливо передать важные детали.
Всякий раз, когда я читаю или пишу код на C/C++, мне приходится вспоминать и применять эти правила в тех или иных ситуациях, например при выборе подходящего типа для локальной переменной/элемента массива/поля структуры, при преобразовании типов, а также в любых арифметических операциях или сравнениях. Обратите внимание, что типы чисел с плавающей запятой мы затрагивать не будем, так как это большей частью относится к анализу и обработке ошибок аппроксимации, вызванных округлением. В противоположность этому, математика целых чисел лежит в основе как программирования, так и компьютерной науки в целом, и в теории вычисления здесь всегда точны (не считая проблем реализации вроде переполнения).
Типы данных
Базовые целочисленные типы
Целочисленные типы устанавливаются с помощью допустимой последовательности ключевых слов, взятых из набора {char, short, int, long, signed, unsigned}.
Несмотря на то, что битовая ширина каждого базового целочисленного типа определяется реализацией (т.е. зависит от компилятора и платформы), стандартом закреплены следующие их свойства:
char: минимум 8 бит в ширину;short: минимум 16 бит и при этом не меньшеchar;int: минимум 16 бит и при этом не меньшеshort;long: минимум 32 бит и при этом не меньшеint;long long: минимум 64 бит и при этом не меньшеlong.
Наличие знака
- Стандартный
сharможет иметь знак или быть беззнаковым, что зависит от реализации. - Стандартные
short,int,longиlong longидут со знаком. Беззнаковыми их можно сделать, добавив ключевое словоunsigned. - Числа со знаком можно кодировать в двоичном формате в виде дополнительного кода, обратного или как величину со знаком. Это определяется реализацией. Заметьте, что обратный код и величина со знаком имеют различные шаблоны битов для отрицательного нуля и положительного, в то время как дополнительный код имеет уникальный нуль.
- Символьные литералы (в одинарных кавычках) имеют тип (
signed)intв C, но (signedилиunsigned)charв C++.
Дополнительные правила
sizeof(char)всегда равен 1, независимо от битовой шириныchar.- Битовая ширина не обязательно должна отличаться. Например, допустимо использовать
char,shortиint, каждый шириной в 32 бита. - Битовая ширина должна быть кратна 2. Например,
intможет иметь ширину 36 бит. - Есть разные способы написания целочисленного типа. К примеру, в каждой следующей строке перечислен набор синонимов:
int,signed,signed int,int signed;short,short int,short signed,short signed int;unsigned long long,long unsigned int long,int long long unsigned.
Типы из стандартных библиотек
size_t(определен в stddef.h) является беззнаковым и содержит не менее 16 бит. При этом не гарантируется, что его ширина будет как минимум равнаint.ptrdiff_t(определен в stddef.h) является целочисленным типом со знаком. Вычитание двух указателей будет давать этот тип. При этом не стоит ожидать, что вычитание двух указателей дастint.- В stdint.h определена конкретная ширина типов:
uint8_t,int8_t,16,32и64. Будьте внимательны к операциям, подразумевающим продвижение типов. Например,uint8_t + uint8_tдастint(со знаком и шириной не менее 16 бит), а неuint8_t, как можно было предположить.
Преобразования
Представим, что значение исходного целочисленного типа нужно преобразовать в значение целевого целочисленного типа. Такая ситуация может возникнуть при явном приведении, неявном приведении в процессе присваивания или при продвижении типов.
Как происходит преобразование?
Главный принцип в том, что, если целевой тип может содержать значение исходного типа, то это значение семантически сохраняется.
Говоря конкретнее:
- Когда исходный тип расширяется до целевого типа с аналогичной знаковой характеристикой (например,
signed char -> intилиunsigned short -> unsigned long), каждое исходное значение после преобразования сохраняется. - Даже если исходный и целевой типы имеют разные диапазоны, все значения в их пересекающейся части будут сохранены. Например,
int, содержащий значение в диапазоне[0, 255], будет без потерь преобразован вunsigned char.
В более точной форме эти правила звучат так:
- При преобразовании в беззнаковый тип новое значение равняется старому значению по модулю 2целевая ширина в битах. Объяснение:
- Если исходный тип беззнаковый и шире целевого, тогда старшие биты отбрасываются.
- Если исходный тип имеет знак, тогда в процессе преобразования берется исходное значение, и из него/к нему вычитается/прибавляется 2целевая ширина в битах до тех пор, пока новое значение не впишется в диапазон целевого типа. Более того, если число со знаком представлено в дополнительном коде, то в процессе преобразования старшие биты отбрасываются, как и в случае с беззнаковыми числами.
- В случае преобразования в тип со знаком случаи могут быть такими:
- Если исходное значение вписывается в диапазон целевого типа, тогда процесс преобразования (например, расширение знака) производит целевое значение, семантически равное исходному.
- Если же оно не вписывается, тогда поведение будет определяться реализацией и может вызвать исключение (к примеру, прерывание из-за переполнения).
Арифметика
Продвижение/преобразование
- Унарный арифметический оператор применяется только к одному операнду. Примеры:
-,~. - Бинарный оператор применяется к двум операндам. Примеры:
+,*,&.<<. - Если операнд имеет тип
bool,charилиshort(какsigned, так иunsigned), тогда он продвигается доint(signed), еслиintможет содержать все значения исходного типа. В противном случае он продвигается доunsigned int. Процесс продвижения происходит без потерь. Примеры:- В реализации присутствуют 16-битный
shortи 24-битныйint. Если переменныеxиyимеют типunsigned short, то операцияx & yпродвигает оба операнда доsigned int. - В реализации присутствуют 32-битный
charи 32-битныйint. Если переменныеxиyимеют типunsigned char, то операцияx – yпродвигает оба операнда доunsigned int.
- В реализации присутствуют 16-битный
- В случае двоичных операторов оба операнда перед арифметической операцией неявно преобразуются в одинаковый общий тип. Ранги преобразования возрастают в следующем порядке:
int,long,long long. Рангом общего типа считается старший ранг среди типов двух операндов. Если оба операнда являютсяsigned/unsigned, то их общий тип будет иметь ту же характеристику. Если же операнд с беззнаковым типом имеет старший или равный ранг по отношению ко второму операнду, то их общий тип будет беззнаковым. В случае, когда тип операнда со знаком может представлять все значения другого типа операнда, общий тип будет иметь знак. В противном случае общий тип получается беззнаковым. Примеры:(long) + (long) → (long);(unsigned int) * (int) → (unsigned int);(unsigned long) / (int) → (unsigned long);- если
intявляется 32-битным, а long 64-битным:(unsigned int) % (long) → (long); - если
intиlongоба являются 32-битными:(unsigned int) % (long) → (unsigned long).
Неопределенное поведение
Знаковое переполнение:
- При выполнении арифметических операций над целочисленным типом переполнение считается неопределенным поведением (UB). Такое поведение может вызывать верные, несогласованные и/или неверные действия как сразу, так и в дальнейшем.
- При выполнении арифметики над беззнаковым целым (после продвижений и преобразований) любое переполнение гарантированно вызовет оборот значения. Например,
UINT_MAX + 1 == 0. - Выполнение арифметики над беззнаковыми целыми фиксированного размера может привести к едва уловимым ошибкам. Например:
- Пусть
uint16_t = unsigned short, иintравен 32-битам. Тогдаuint16_t x=0xFFFF,y=0xFFFF,z=x*y;xиyбудут продвинуты доint, иx * yприведет к переполнениюint, вызвав неопределенное поведение. - Пусть
uint32_t = unsigned char, иintравен 33-битам. Тогдаuint32_t x=0xFFFFFFFF,y=0xFFFFFFFF,z=x+y;xиyбудут продвинуты доint, иx + yприведет к переполнениюint, то есть неопределенному поведению. - Чтобы обеспечить безопасную арифметику с беззнаковыми целыми, нужно либо прибавить
0U, либо умножить на1Uв качестве пустой операции. Например:0U + x + yили1U * x * y. Это гарантирует, что операнды будут продвинуты как минимум до рангаintи при этом останутся без знаков.
- Пусть
Деление/остаток:
- Деление на нуль и остаток с делителем нуля также относятся к неопределенному поведению.
- Беззнаковое деление/остаток не имеют других особых случаев.
- Деление со знаком может вызывать переполнение, например
INT_MIN / -1. - Остаток со знаком при отрицательных операндах может вызывать сложности, так как некоторые части являются однообразными, в то время как другие определяются реализацией.
Битовые сдвиги:
- Неопределенным поведением считается битовый сдвиг (< < и >>) на размер, который либо отрицателен, либо равен или больше битовой ширины.
- Левый сдвиг беззнакового операнда (после продвижения/преобразования) считается определенным правильно и отклонений в поведении не вызывает.
- Левый сдвиг операнда со знаком, содержащего неотрицательное значение, вследствие которого 1 бит переходит в знаковый бит, является неопределенным поведением.
- Левый сдвиг отрицательного значения относится к неопределенному поведению.
- Правый сдвиг неотрицательного значения (в типе операнда без знака или со знаком) считается определенным правильно и отклонений в поведении не вызывает.
- Правый сдвиг отрицательного значения определяется реализацией.
Счетчик цикла
Выбор типа
Предположим, что у нас есть массив, в котором нужно обработать каждый элемент последовательно. Длина массива хранится в переменной len типа T0. Как нужно объявить переменную счетчика цикла i типа T1?
- Самым простым решением будет использовать тот же тип, что и у переменной длины. Например:
uint8_t len = (...);
for (uint8_t i = 0; i < len; i++) { ... }
- Говоря обобщенно, переменная счетчика типа
T1будет работать верно, если диапазонT1будет являться (не строго) надмножетсвом диапазонаT0. Например, еслиlenимеет типuint16_t, тогда отсчет с использованиемsigned long(не менее 32 бит) сработает. - Говоря же более конкретно, счетчик цикла должен просто покрывать всю фактическую длину. Например, если
lenтипаintгарантированно будет иметь значение в диапазоне[3,50](обусловленное логикой приложения), тогда допустимо отсчитывать цикл, используяcharбез знака или со знаком (в котором однозначно можно представить диапазон[0,127]). - Нежелательно использовать переменную длины и переменную счетчика с разной знаковостью. В этом случае сравнение вызовет неявное сложное преобразование, сопровождаемое характерными для платформы проблемами. К примеру, не стоит писать такой код:
size_t len = (...); // Unsigned
for (int i = 0; i < len; i++) { ... }Отсчет вниз
Для циклов, ведущих отсчет вниз, более естественным будет использовать счетчик со знаком, потому что тогда можно написать:
for (int i = len - 1; i >= 0; i--) {
process(array[i]);
}При этом для беззнакового счетчика код будет таким:
for (unsigned int i = len; i > 0; i--) {
process(array[i - 1]);
}Примечание: сравнение i >= 0 имеет смысл только, когда i является числом со знаком, но всегда будет давать true, если оно будет беззнаковым. Поэтому, когда это выражение встречается в беззнаковом контексте, значит, автор кода скорее всего допустил ошибку в логике.
Заблуждения
Все пункты приведенного ниже списка являются мифами. Не опирайтесь на эти ложные убеждения, если хотите писать корректный и портируемый код.
charвсегда равен 8 битам.intвсегда равен 32 битам.sizeof(T)представляет число из 8-битных байтов (октетов), необходимых для хранения переменной типаT. (Это утверждение ложно, потому что если, скажем,charравняется 32 битам, тогдаsizeof(T)измеряется в 32-битных словах).- Можно использовать
intв любой части программы и игнорировать более точные типы вродеsize_t,uint32_tи т.д. - Знаковое переполнение гарантированно вызовет оборот значения. (например,
INT_MAX + 1 == INT_MIN). - Символьные литералы равны их значениям в коде ASCII, например
‘A’ == 65. (Согласно EBCDIC это утверждение ложно). - Преобразование указателя в
intи обратно в указатель происходит без потерь. - Преобразование
{указателя на один целочисленный тип}в{указатель на другой целочисленный тип}безопасно. Например,int *p (…); long *q = (long*)p;. (см. каламбур типизации и строгий алиасинг). - Когда все операнд(ы) арифметического оператора (унарного или бинарного) имеют беззнаковые типы, арифметическая операция выполняется в беззнаковом режиме, никогда не вызывая неопределенного поведения, и в результате получается беззнаковый тип. Например: предположим, что
uint8_t x; uint8_t y; uint32_t z;, тогда операцияx + yдолжна дать тип вродеuint8_t, беззнаковыйint, или другой разумный вариант, а+zпо-прежнему будетuint32_t. (Это не так, потому что при продвижении типов предпочтение отдается типам со знаком).
Моя критика
- Если вкратце, то знание и постоянное использование всех этих правил сильно нагружает мышление. Допущение же ошибки в их применении приводит к риску написания неверного или непортируемого кода. При этом такие ошибки могут как всплыть сразу, так и таиться в течение дней или даже долгих лет.
- Сложности начинаются с битовой ширины базовых целочисленных типов, которая зависит от реализации. Например,
intможет иметь 16, 32, 64 бита или другое их количество. Всегда нужно выбирать тип с достаточным диапазоном. Но иногда использование слишком обширного типа (например, необычного 128-битногоint) может вызвать сложности или даже внести уязвимости. Усугубляется это тем, что такие типы из стандартных библиотек, какsize_t, не имеют связи с другими типами вроде беззнаковогоintилиuint32_t; стандарт позволяет им быть шире или уже. - Правила преобразования совершенно безумны. Что еще хуже, практически везде допускаются неявные преобразования, существенно затрудняющие аудит человеком. Беззнаковые типы достаточно просты, но знаковые имеют очень много допустимых реализаций (например, обратный код, создание исключений). Типы с меньшим рангом, чем
int, продвигаются автоматически, вызывая труднопонимаемое поведение с диапазонами и переполнение. Когда операнды отличаются знаковостью и рангами, они преобразуются в общий тип способом, который зависит от определяемой реализацией битовой ширины. Например, выполнение арифметики над двумя операндами, как минимум один из которых имеет беззнаковый тип, приведет к преобразованию их обоих либо в знаковый, либо в беззнаковый тип в зависимости от реализации. - Арифметические операции изобилуют неопределенным поведением: знаковое переполнение в
add/sub/mul/div, деление на нуль, битовые сдвиги. Несложно создать такие условия неопределенного поведения по случайности, но сложно вызвать их намеренно или обнаружить при выполнении, равно как выявить их причины. Необходима повышенная внимательность и усилия для проектирования и реализации арифметического кода, исключающего переполнение/UB. Стоит учитывать, что впоследствии становится сложно отследить и исправить код, при написании которого не соблюдались принципы защиты от переполнения/UB. - Присутствие
signedиunsignedверсии каждого целочисленного типа удваивает количество доступных вариантов. Это создает дополнительную умственную нагрузку, которая не особо оправдывается, так как типы со знаком способны выполнять практически все те же функции, что и беззнаковые. - Ни в одном другом передовом языке программирования нет такого числа правил и подводных камней касательно целочисленных типов, как в С и C++. Например:
- В Java целые числа ведут себя одинаково в любой среде. В этом языке определено конкретно 5 целочисленных типов (в отличие от C/C++, где их не менее 10). Они имеют фиксированную битовую ширину, практически все из них имеют знаки (кроме
char), числа со знаком должны находиться в дополнительном коде, неявные преобразования допускают только их варианты без потерь, а вся арифметика и преобразования определяются точно и не вызывают неоднозначного поведения. Целочисленные типы в Java поддерживают быстрое вычисление и эффективное упаковывание массивов в сравнении с языками вроде Python, где есть толькоbigintпеременного размера. - Java в значительной степени опирается на 32-битный тип
int, особенно для перебора массивов. Это означает, что этот язык не может эффективно работать на малопроизводительных 16-битных ЦПУ (часто используемых во встраиваемых микроконтроллерах), а также не может непосредственно работать с большими массивами в 64-битных системах. К сравнению, C/C++ позволяет писать код, эффективно работающий на 16, 32 и/или 64-битных ЦПУ, но при этом требует от программиста особой осторожности. - В Python есть всего один целочисленный тип, а именно
signed bigint. В сравнении с C/C++ это сводит на нет все рассуждения на тему битовой ширины, знаковости и преобразований, так как во всем коде правит один тип. Тем не менее за это приходится платить низкой скоростью выполнения и несогласованным потреблением памяти. - В JavaScript вообще нет целочисленного типа. Вместо этого в нем все выражается через математику
float64(doubleв C/C++). Из-за этого битовая ширина и числовой диапазон оказываются фиксированными, числа всегда имеют знаки, преобразования отсутствуют, а переполнение считается нормальным. - Язык ассемблера для любой конкретной машинной архитектуры (x86, MIPS и т.д.) определяет набор целочисленных типов фиксированной ширины, арифметические операции и преобразования – с редкими случаями неопределенного поведения или вообще без них.
- В Java целые числа ведут себя одинаково в любой среде. В этом языке определено конкретно 5 целочисленных типов (в отличие от C/C++, где их не менее 10). Они имеют фиксированную битовую ширину, практически все из них имеют знаки (кроме
Дополнительная информация (англ.)
- Wikipedia: C data types
- cppreference.com: C++ — Fundamental types
- cppreference.com: C — Implicit conversions — Integer conversions
- cppreference.com: C — Implicit conversions — Usual arithmetic conversions
- C in a Nutshell: Chapter 4. Type Conversions
- Stack Overflow: Implicit type promotion rules
- Stack Overflow: 32 bit unsigned multiply on 64 bit causing undefined behavior?
- Stack Overflow: What’s the best C++ way to multiply unsigned integers modularly safely?
- Stack Overflow: Is masking before unsigned left shift in C/C++ too paranoid?

Программирование, не могу разобратся
Спец-авто
Мыслитель
(5532),
на голосовании
13 лет назад
Как найти значение целочисленных переменных х и у после выполнения фрагмента программы ?
Например вот:
х :=336
у :=8;
х := х div y
y := mod y
и вот
х :=11
у :=5
т :=у
у := х mod y
х :=т
у :=у+2*т
Обьясните пжл принцип решения….
Голосование за лучший ответ
Николай
Просветленный
(35577)
13 лет назад
div – значение от деления без остатка
mod – остаток от деления,
в первом случае х присвоится значение после деления х на у без остатка
а и у присвоится все что после запятой от у
Глеб
Мастер
(1447)
13 лет назад
Возьмем
х :=336
у :=8;
х := х div y
y := mod y
Считаем:
#3
x=336 div 8=42
#4
y=x mod y = 336 mod 8 =0 (mod – остаток от деления)
Возьмем
х :=11
у :=5
т :=у
у := х mod y
х :=т
у :=у+2*т
Считаем
#3 t=y=5
#4 y=11 mod 5 = 1
#5 t=y=1
#6 y=y+2*t=1 + 2*1 = 2
Спец-автоМыслитель (5532)
13 лет назад
Все понятно , кроме этого
#3
x=336 div 3=42
Как получил , и откуда 3
Глеб
Мастер
(1447)
опс
опечатка
x=336 div 8=42

На этом уроке мы рассмотрим целочисленные типы данных в языке С++, их диапазоны значений, операцию деления, а также переполнение (что это такое и примеры).
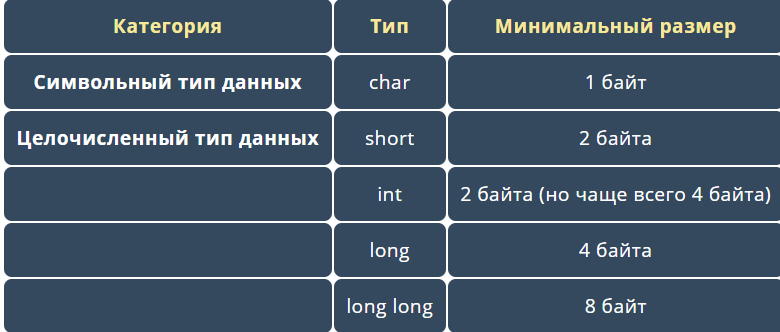
Целочисленные типы данных
Целочисленный тип данных — это тип, переменные которого могут содержать только целые числа (без дробной части, например: -2, -1, 0, 1, 2). В языке C++ есть 5 основных целочисленных типов, доступных для использования:
Примечание : Тип char — это особый случай: он является как целочисленным, так и символьным типом данных. Об этом детально мы поговорим на одном из следующих уроков.
Основным различием между целочисленными типами, перечисленными выше, является их размер , чем он больше, тем больше значений сможет хранить переменная этого типа.
Определение целочисленных переменных
Определение происходит следующим образом:
char c ;
short int si ; // допустимо
short s ; // предпочтительнее
int i ;
long int li ; // допустимо
long l ; // предпочтительнее
long long int lli ; // допустимо
long long ll ; // предпочтительнее
В то время как полные названия short int , long int и long long int могут использоваться, их сокращенные версии (без int ) более предпочтительны для использования. К тому же постоянное добавление int затрудняет чтение кода (легко перепутать с именем переменной).
Диапазоны значений и знак целочисленных типов данных
Как вы уже знаете из предыдущего урока, переменная с n-ным количеством бит может хранить 2n возможных значений. Но что это за значения? Это значения, которые находятся в диапазоне. Диапазон — это значения от и до, которые может хранить определенный тип данных. Диапазон целочисленной переменной определяется двумя факторами: её размером (измеряется в битах) и её знаком (который может быть signed или unsigned ).
Целочисленный тип signed (со знаком) означает, что переменная может содержать как положительные, так и отрицательные числа. Чтобы объявить переменную как signed, используйте ключевое слово signed :
signed char c ;
signed short s ;
signed int i ;
signed long l ;
signed long long ll ;
По умолчанию, ключевое слово signed пишется перед типом данных.
1-байтовая целочисленная переменная со знаком (signed) имеет диапазон значений от -128 до 127, т.е. любое значение от -128 до 127 (включительно) может храниться в ней безопасно.
В некоторых случаях мы можем заранее знать, что отрицательные числа в программе использоваться не будут. Это очень часто встречается при использовании переменных для хранения количества или размера чего-либо (например, ваш рост или вес не может быть отрицательным).
Целочисленный тип unsigned (без знака) может содержать только положительные числа. Чтобы объявить переменную как unsigned , используйте ключевое слово unsigned :
unsigned char c ;
unsigned short s ;
unsigned int i ;
unsigned long l ;
unsigned long long ll ;
1-байтовая целочисленная переменная без знака (unsigned) имеет диапазон значений от 0 до 255.
Обратите внимание, объявление переменной как unsigned означает, что она не сможет содержать отрицательные числа (только положительные).
Теперь, когда вы поняли разницу между signed и unsigned, давайте рассмотрим диапазоны значений разных типов данных:
Для математиков: Переменная signed с n-ным количеством бит имеет диапазон от -(2n-1 ) до 2n-1 -1. Переменная unsigned с n-ным количеством бит имеет диапазон от 0 до (2n )-1.
Для нематематиков: Используем таблицу
Начинающие программисты иногда путаются между signed и unsigned переменными. Но есть простой способ запомнить их различия. Чем отличается отрицательное число от положительного? Правильно! Минусом спереди. Если минуса нет, значит число — положительное. Следовательно, целочисленный тип со знаком (signed) означает, что минус может присутствовать, т.е. числа могут быть как положительными, так и отрицательными. Целочисленный тип без знака (unsigned) означает, что минус спереди отсутствует, т.е. числа могут быть только положительными.
Что используется по умолчанию: signed или unsigned?
Так что же произойдет, если мы объявим переменную без указания signed или unsigned?
Все целочисленные типы данных, кроме char, являются signed по умолчанию. Тип char может быть как signed, так и unsigned (но, обычно, signed).
В большинстве случаев ключевое слово signed не пишется (оно и так используется по умолчанию).
Программисты, как правило, избегают использования целочисленных типов unsigned, если в этом нет особой надобности, так как с переменными unsigned ошибок, по статистике, возникает больше, нежели с переменными signed.
Правило: Используйте целочисленные типы signed, вместо unsigned .
Переполнение
Вопрос: «Что произойдет, если мы попытаемся использовать значение, которое находится вне диапазона значений определенного типа данных?». Ответ: «Переполнение».
Переполнение (англ. «overflow» ) случается при потере бит из-за того, что переменной не было выделено достаточно памяти для их хранения.
На уроке №28 мы говорили о том, что данные хранятся в бинарном (двоичном) формате и каждый бит может иметь только 2 возможных значения (0 или 1 ). Вот как выглядит диапазон чисел от 0 до 15 в десятичной и двоичной системах:
Как вы можете видеть, чем больше число, тем больше ему требуется бит. Поскольку наши переменные имеют фиксированный размер, то на них накладываются ограничения на количество данных, которые они могут хранить.
Примеры переполнения
Рассмотрим переменную unsigned, которая состоит из 4-х бит. Любое из двоичных чисел, перечисленных в таблице выше, поместится внутри этой переменной.
«Но что произойдет, если мы попытаемся присвоить значение, которое занимает больше 4-х бит?». Правильно! Переполнение. Наша переменная будет хранить только 4 наименее значимых (те, что справа) бита, все остальные — потеряются.
Например, если мы попытаемся поместить число 21 в нашу 4-битную переменную:
Число 21 занимает 5 бит (10101). 4 бита справа (0101) поместятся в переменную, а крайний левый бит (1) просто потеряется. Т.е. наша переменная будет содержать 0101, что равно 101 (нуль спереди не считается), а это уже число 5, а не 21.
Примечание : О конвертации чисел из двоичной системы в десятичную и наоборот будет отдельный урок, где мы всё детально рассмотрим и обсудим.
Теперь рассмотрим пример в коде (тип short занимает 16 бит):
#include <iostream>
int main ( )
{
unsigned short x = 65535 ; // наибольшее значение, которое может хранить 16-битная unsigned переменная
std :: cout << “x was: ” << x << std :: endl ;
x = x + 1 ; // 65536 – это число больше максимально допустимого числа из диапазона допустимых значений. Следовательно, произойдет переполнение, так как переменнная x не может хранить 17 бит
std :: cout << “x is now: ” << x << std :: endl ;
return 0 ;
}
Результат выполнения программы:
x was: 65535
x is now: 0
Что случилось? Произошло переполнение, так как мы попытались присвоить переменной x значение больше, чем она способна в себе хранить.
Для тех, кто хочет знать больше: Число 65 535 в двоичной системе счисления представлено как 1111 1111 1111 1111. 65 535 — это наибольшее число, которое может хранить 2-байтовая (16 бит) целочисленная переменная без знака, так как это число использует все 16 бит. Когда мы добавляем 1, то получаем число 65 536. Число 65 536 представлено в двоичной системе как 1 0000 0000 0000 0000, и занимает 17 бит! Следовательно, самый главный бит (которым является 1) теряется, а все 16 бит справа — остаются. Комбинация 0000 0000 0000 0000 соответствует десятичному 0, что и является нашим результатом.
Аналогичным образом, мы получим переполнение, использовав число меньше минимального из диапазона допустимых значений:
#include <iostream>
int main ( )
{
unsigned short x = 0 ; // наименьшее значение, которое 2-байтовая unsigned переменная может хранить
std :: cout << “x was: ” << x << std :: endl ;
x = x – 1 ; // переполнение!
std :: cout << “x is now: ” << x << std :: endl ;
return 0 ;
}
Результат выполнения программы:
x was: 0
x is now: 65535
Переполнение приводит к потере информации, а это никогда не приветствуется. Если есть хоть малейшее подозрение или предположение, что значением переменной может быть число, которое находится вне диапазона допустимых значений используемого типа данных — используйте тип данных побольше!
Правило: Никогда не допускайте возникновения переполнения в ваших программах!
Деление целочисленных переменных
В языке C++ при делении двух целых чисел, где результатом является другое целое число, всё довольно предсказуемо:
#include <iostream>
int main ( )
{
std :: cout << 20 / 4 << std :: endl ;
return 0 ;
}
Результат:
5
Но что произойдет, если в результате деления двух целых чисел мы получим дробное число? Например:
#include <iostream>
int main ( )
{
std :: cout << 8 / 5 << std :: endl ;
return 0 ;
}
Результат:
1
В языке C++ при делении целых чисел результатом всегда будет другое целое число. А такие числа не могут иметь дробь (она просто отбрасывается, не округляется! ).
Рассмотрим детально вышеприведенный пример: 8 / 5 = 1.6 . Но как мы уже знаем, при делении целых чисел результатом является другое целое число. Таким образом, дробная часть (0.6 ) значения отбрасывается и остается 1 .
Правило: Будьте осторожны при делении целых чисел, так как любая дробная часть всегда отбрасывается.
|
0 / 0 / 0 Регистрация: 20.11.2010 Сообщений: 10 |
|
|
1 |
|
|
18.12.2010, 13:43. Показов 10726. Ответов 2
Определить значение целочисленной переменной S после выполнения фрагмента алгоритма: S:=128; задание из зачета.я посчитала,получилось значение S=108,мне выдали ошибку,что S=110. Можете объяснить,как правильно посчитать?
0 |

|
Фрилансер 452 / 433 / 117 Регистрация: 01.06.2010 Сообщений: 1,314 |
|
|
18.12.2010, 13:47 |
2 |
|
Правильно указали на ошибку… Тут “в уме” нечего считать!!! Возьми и напиши программку, или уж на калькуляторе…
0 |
|
0 / 0 / 0 Регистрация: 20.11.2010 Сообщений: 10 |
|
|
18.12.2010, 13:50 [ТС] |
3 |
|
блин,я же все правильно считала,как оказалось,вместо 6 вычла 8 в последнем случае..благодарю ))
0 |
#Руководства
- 2 июн 2020
-

14
Разбираемся, как работать с данными в программе на C++. Будет много теории и примеров, чтобы вы углубились в язык ещё больше.
vlada_maestro / shutterstock

Пишет о программировании, в свободное время создаёт игры. Мечтает открыть свою студию и выпускать ламповые RPG.
Это вторая часть из серии «Глубокое погружение в C++». В прошлый раз мы разобрались, что такое программа и из чего она состоит, а сейчас узнаем азы работы с данными.
Все программы работают с данными. Данные — это любые значения, которые используются в работе программы: строки, числа, ссылки и символы. Например: имя, возраст, количество денег на счету, здоровье персонажа в игре и так далее. Даже отсутствие данных — это данные.
Все эти и другие значения хранятся в оперативной памяти. Для каждого значения выделяется отдельная ячейка, и одновременно в ней может находиться только что-то одно.
Давайте рассмотрим это на примере коробок:
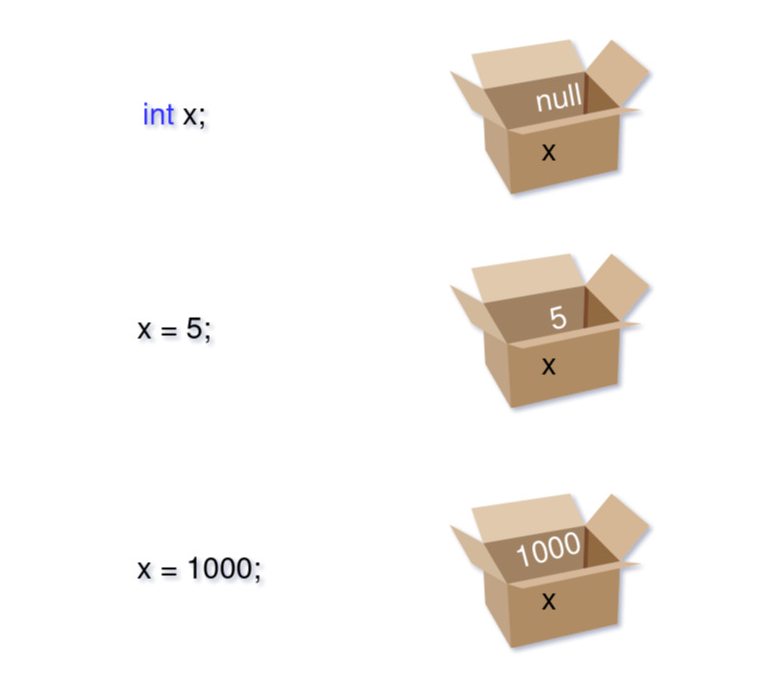
Мы говорим компьютеру, что нам нужна коробка x, которая будет хранить целые числа, но пока не помещаем в неё никакого значения. Компьютер создаёт такую коробку, подписывает её и помещает в неё null.
Далее мы пишем команду x = 5;, и компьютер меняет значение внутри коробки. Размер коробки при этом не меняется. Так получается, потому что для хранения каждого примитивного типа данных выделяется определённое количество памяти. Например, для целых чисел это четыре байта, что позволяет хранить значения в диапазоне от −2 147 483 648 до 2 147 483 647.
Коробки, описанные выше, в программировании называются переменными (англ. variable). Их значение можно менять во время работы программы. Также существуют коробки, которые менять нельзя, — их называют константами.
То, какие данные сейчас хранятся в памяти, называется состоянием. Состояние может быть у программы, системы, компьютера и так далее. В C++ очень важно иметь доступ к состоянию, чтобы писать полезные программы.
Теперь попробуем создать свои переменные.
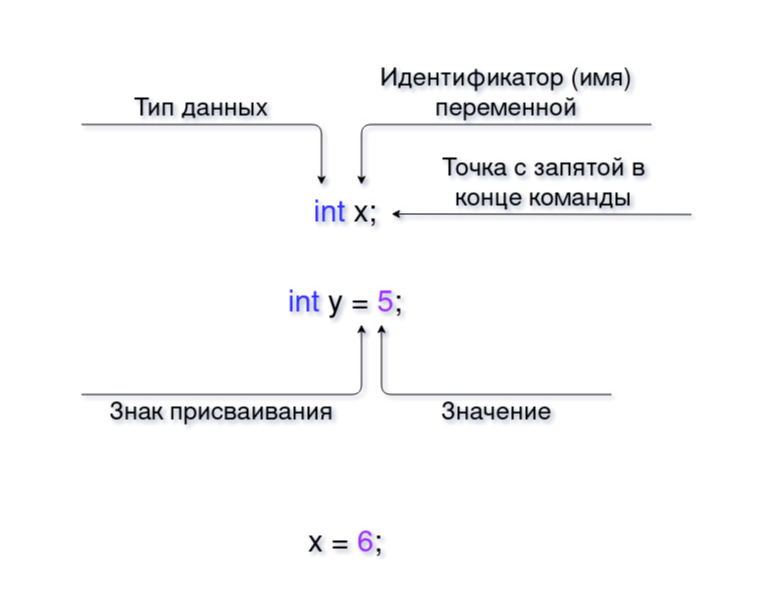
Для начала объявим переменную, то есть скажем компьютеру, что нам нужно занять место в памяти. Для этого укажем тип данных, а потом название переменной.
| Код | Как читается |
|---|---|
| int x; | Объявить целочисленную переменную x без значения. |
Так создаётся переменная без значения. Если вы хотите, чтобы в ней сразу было какое-то число, то нужно использовать знак присваивания (=):
| Код | Как читается |
|---|---|
| int y = 5; | Объявить целочисленную переменную y со значением 5. |
Теперь в любое время можно менять значения переменных:
| Код | Как читается |
|---|---|
| x = 6; | Присвоить переменной x значение 6. |
Математический знак равенства (=) в программировании называется знаком присваивания.
Важно! Указывать тип данных нужно только при объявлении переменной.
Давайте попробуем вывести значение какой-нибудь переменной на экран. Для этого напишем следующий код:
#include <iostream> int main() { int age = 21; std::cout << "Your age is "; std::cout << age; std::cout << "n"; }
Внимательно прочтите этот код, а потом скомпилируйте и запустите программу:
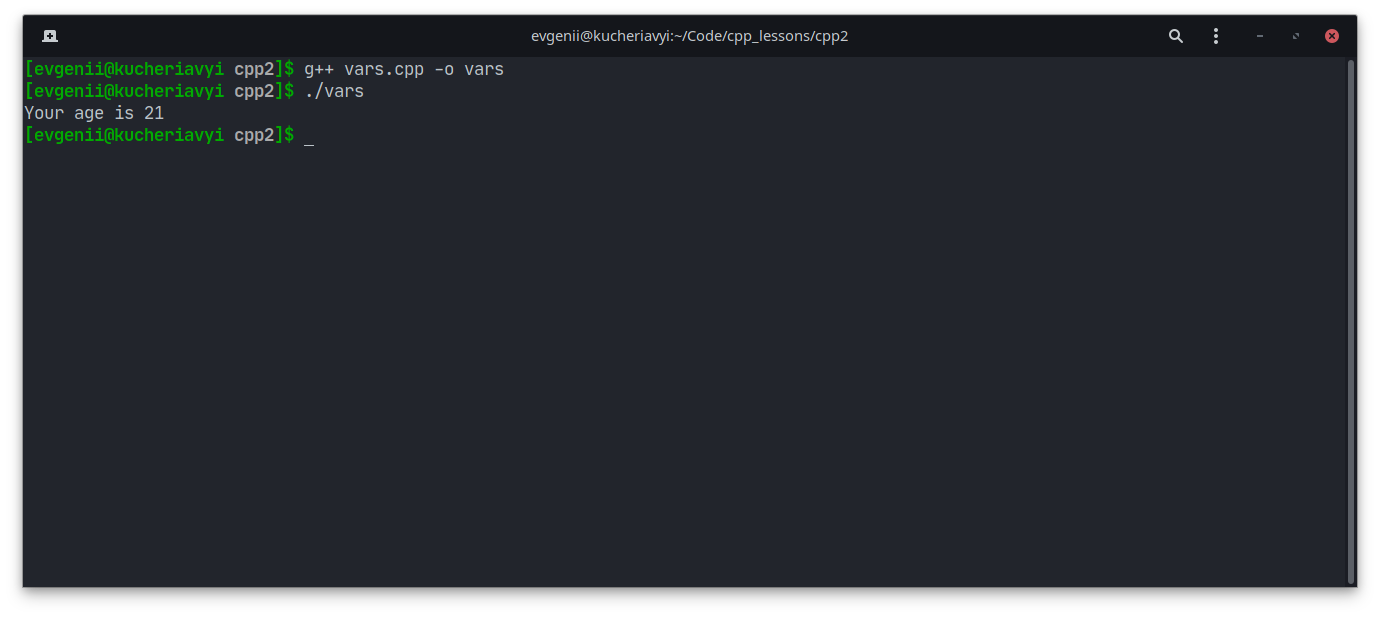
Попробуйте изменить значение переменной age на любое другое число и посмотрите, как изменится вывод.
Идентификаторы переменных могут содержать в себе:
- латинские буквы;
- цифры;
- знак нижнего подчёркивания.
При этом название не может начинаться с цифр. Примеры названий:
- age;
- name;
- _sum;
- first_name;
- a1;
- a2;
- a_5.
Все идентификаторы регистрозависимы. Это значит, что name и Name — разные переменные.
Рекомендуется давать именам простые названия на английском языке, чтобы код был понятен и вам, и другим людям. Например:
- price, а не stoimost;
- currentId, а не pupa;
- carsCount, а не lupa и так далее.
Если название должно состоять из нескольких слов, то рекомендуется использовать camelCase (с англ. «верблюжий регистр»): первое слово пишется со строчной буквы, а каждое последующее — с заглавной.

Чаще всего используются следующие типы данных:
- int — целое число;
- byte — число от 0 до 255;
- float — число с плавающей запятой;
- double — число с плавающей запятой повышенной точности;
- char — символ;
- bool — логический тип, который может содержать в себе значения true (истина) и false (ложь).
Эти типы данных называются примитивными (значимыми), потому что они базово встроены в язык.
Также существуют ссылочные типы — такие переменные хранят в себе не само значение, а ссылку на него в оперативной памяти. К ссылочным типам относятся массивы, объекты, строки (так называют любой текст) и многое другое. Для строк используется тип std: string.
Вот несколько примеров переменных разных типов:
//Строки записываются внутри двойных кавычек std::string name = "Evgenii Kucheriavyi"; int age = 21; //Символы записываются внутри одинарных кавычек //Тип char вмещает в себя только один символ char firstNameInitial = 'E'; char lastNameInitial = 'K'; //Дробная часть числа записывается после точки //После самого числа должна стоять буква F float x = 5.4F; float y = 7.3F; //Для типа double буква F не нужна double discount = 0.4; bool isHungry = true; //Истина bool hasFood = false; //Ложь
В коде выше русский текст после двойных слэшей (//) — это комментарии. Они позволяют разработчикам делать заметки, объяснять код так, чтобы все могли в нём ориентироваться. Компилятор игнорирует комментарии, поэтому они никак не влияют на работу программы.
Есть два типа комментариев:
- Однострочные — их вы видели в примере выше. Всё, что находится после двойных слэшей и до конца строки — комментарий.
- Многострочные — для них используются символы /* (начало комментария) и */ (конец комментария).
Попробуйте написать в коде и те, и другие комментарии, чтобы понять, как они работают.
Чтобы создать константу, используйте ключевое слово const:
const double Pi = 3.14; const double g = 9.8;
Константы обычно нужны, чтобы хранить какие-то постоянные величины из физики, математики или геометрии: число пи, ускорение свободного падения, скорость света и так далее. Однако вы можете хранить в них и другие значения, которые должны оставаться постоянными:
- частоту обновления экрана (например, 60 кадров в секунду);
- ваш год рождения;
- имя персонажа в игре и так далее.
В С++ есть пять базовых математических операций:
- Сложение (+).
- Вычитание (-).
- Умножение (*).
- Деление (/).
- Остаток от деления (%).
Используются они следующим образом:
int a = 2 + 2; //4 int b = 6 - 3; //3 //В вычислениях можно использовать переменные и константы int c = 11 - b; //8 int d = 12 / 6; //2 //Так как int может содержать в себе только целые числа, остаток от деления будет отброшен int e = 13 / 5; //2 int f = 13 % 5; //3 //Чтобы получить более точный результат деления, нужно использовать дробные числа double g = 13.0 / 5; //2.6 //При делении целых чисел даже в типах double или float результатом деления будет целое число, без остатка double j = 13 / 5; //2 int h = 5 * 5; //25 //Вы можете использовать скобки, чтобы определить порядок действий int k = 5 + 2 * 2; //9 int l = (5 + 2) * 2; //14 //Можно использовать отрицательные числа int m = 2 + -2; //0
Важно! Сначала выполняется правая часть выражения после знака =, а потом левая. То есть переменной не будет присвоено значения, пока не выполнены все вычисления. Поэтому можно записать в переменную результат вычислений, в которых использовалась эта же переменная:
int x = 2; x = x + 5; //7
Если вам нужно провести какую-то операцию с переменной, а потом записать значение в неё же, используйте следующие операторы:
x += 5; //x = x + 5; x -= 7; //x = x - 7; x *= 2; //x = x * 2; x /= 3; //x = x / 3; x %= 8; //x = x % 8;
Во время работы с С++ вы будете часто прибавлять или отнимать единицу от какой-нибудь переменной. Для этого тоже есть сокращённая запись:
//Инкремент (увеличение переменной) x++; //x = x + 1; //Декремент (уменьшение переменной) x--; //x = x - 1;
Инкремент и декремент могут быть префиксными (++x) и постфиксными (x++). Префиксный инкремент сначала прибавляет к переменной единицу, а потом использует эту переменную, а постфиксный — наоборот.
int x = 5; //Сначала к x будет прибавлена единица, и только потом он будет использован в выражении int y = ++x + 2; //8 //Сначала x будет использован в выражении, и только потом к нему будет прибавлена единица int z = x++ + 2; //7
Единственный способ разобраться, как это всё работает, — практиковаться. Придумайте программы, которые могли бы использовать переменные:
- калькулятор для уравнений;
- определитель размера скидки или комиссии;
- вывод суммы характеристик персонажа и так далее.
Напишите как можно больше программ, и тогда вы сможете лучше усвоить материал. В следующей статье мы поговорим о ветвлении и условных конструкциях.

Научитесь: Профессия Разработчик на C++
Узнать больше
