![]()
Загрузить PDF
![]()
Загрузить PDF
Дисперсия случайной величины является мерой разброса значений этой величины. Малая дисперсия означает, что значения сгруппированы близко друг к другу. Большая дисперсия свидетельствует о сильном разбросе значений. Понятие дисперсии случайной величины применяется в статистике. Например, если сравнить дисперсию значений двух величин (таких как результаты наблюдений за пациентами мужского и женского пола), можно проверить значимость некоторой переменной.[1]
Также дисперсия используется при построении статистических моделей, так как малая дисперсия может быть признаком того, что вы чрезмерно подгоняете значения.[2]
-

1
Запишите значения выборки. В большинстве случаев статистикам доступны только выборки определенных генеральных совокупностей. Например, как правило, статистики не анализируют расходы на содержание совокупности всех автомобилей в России – они анализируют случайную выборку из нескольких тысяч автомобилей. Такая выборка поможет определить средние расходы на автомобиль, но, скорее всего, полученное значение будет далеко от реального.
- Например, проанализируем количество булочек, проданных в кафе за 6 дней, взятых в случайном порядке. Выборка имеет следующий вид: 17, 15, 23, 7, 9, 13. Это выборка, а не совокупность, потому что у нас нет данных о проданных булочках за каждый день работы кафе.
- Если вам дана совокупность, а не выборка значений, перейдите к следующему разделу.
-
2
Запишите формулу для вычисления дисперсии выборки. Дисперсия является мерой разброса значений некоторой величины. Чем ближе значение дисперсии к нулю, тем ближе значения сгруппированы друг к другу. Работая с выборкой значений, используйте следующую формулу для вычисления дисперсии:[3]
-
3
Вычислите среднее значение выборки. Оно обозначается как x̅.[4]
Среднее значение выборки вычисляется как обычное среднее арифметическое: сложите все значения в выборке, а затем полученный результат разделите на количество значений в выборке.- В нашем примере сложите значения в выборке: 15 + 17 + 23 + 7 + 9 + 13 = 84
Теперь результат разделите на количество значений в выборке (в нашем примере их 6): 84 ÷ 6 = 14.
Выборочное среднее x̅ = 14. - Выборочное среднее – это центральное значение, вокруг которого распределены значения в выборке. Если значения в выборке группируются вокруг выборочного среднего, то дисперсия мала; в противном случае дисперсия велика.
- В нашем примере сложите значения в выборке: 15 + 17 + 23 + 7 + 9 + 13 = 84
-
4
Вычтите выборочное среднее из каждого значения в выборке. Теперь вычислите разность
– x̅, где – каждое значение в выборке. Каждый полученный результат свидетельствует о мере отклонения конкретного значения от выборочного среднего, то есть как далеко это значение находится от среднего значения выборки.[5]
-
5
Возведите в квадрат каждый полученный результат. Как отмечалось выше, сумма разностей
– x̅ должна быть равна нулю. Это означает, что средняя дисперсия всегда равна нулю, что не дает никакого представления о разбросе значений некоторой величины. Для решения этой проблемы возведите в квадрат каждую разность – x̅. Это приведет к тому, что вы получите только положительные числа, которые при сложении никогда не дадут 0.[6]
-
6
-
7
Полученный результат разделите на n – 1, где n – количество значений в выборке. Некоторое время назад для вычисления дисперсии выборки статистики делили результат просто на n; в этом случае вы получите среднее значение квадрата дисперсии, которое идеально подходит для описания дисперсии данной выборки. Но помните, что любая выборка – это лишь небольшая часть генеральной совокупности значений. Если взять другую выборку и выполнить такие же вычисления, вы получите другой результат. Как выяснилось, деление на n – 1 (а не просто на n) дает более точную оценку дисперсии генеральной совокупности, в чем вы и заинтересованы. Деление на n – 1 стало общепринятым, поэтому оно включено в формулу для вычисления дисперсии выборки.[7]
- В нашем примере выборка включает 6 значений, то есть n = 6.
Дисперсия выборки = 33,2
- В нашем примере выборка включает 6 значений, то есть n = 6.
-
8
Отличие дисперсии от стандартного отклонения. Заметьте, что в формуле присутствует показатель степени, поэтому дисперсия измеряется в квадратных единицах измерения анализируемой величины. Иногда такой величиной довольно сложно оперировать; в таких случаях пользуются стандартным отклонением, которое равно квадратному корню из дисперсии. Именно поэтому дисперсия выборки обозначается как
, а стандартное отклонение выборки – как .
- В нашем примере стандартное отклонение выборки: s = √33,2 = 5,76.
Реклама












-
1
Проанализируйте некоторую совокупность значений. Совокупность включает в себя все значения рассматриваемой величины. Например, если вы изучаете возраст жителей Ленинградской области, то совокупность включает возраст всех жителей этой области. В случае работы с совокупностью рекомендуется создать таблицу и внести в нее значения совокупности. Рассмотрим следующий пример:
-
2
Запишите формулу для вычисления дисперсии генеральной совокупности. Так как в совокупность входят все значения некоторой величины, то приведенная ниже формула позволяет получить точное значение дисперсии совокупности. Для того чтобы отличить дисперсию совокупности от дисперсии выборки (значение которой является лишь оценочным), статистики используют различные переменные: [8]
-
3
Вычислите среднее значение совокупности. При работе с генеральной совокупностью ее среднее значение обозначается как μ (мю). Среднее значение совокупности вычисляется как обычное среднее арифметическое: сложите все значения в генеральной совокупности, а затем полученный результат разделите на количество значений в генеральной совокупности.
- Имейте в виду, что средние величины не всегда вычисляются как среднее арифметическое.
- В нашем примере среднее значение совокупности: μ = = 10,5
-
4
Вычтите среднее значение совокупности из каждого значения в генеральной совокупности. Чем ближе значение разности к нулю, тем ближе конкретное значение к среднему значению совокупности. Найдите разность между каждым значением в совокупности и ее средним значением, и вы получите первое представление о распределении значений.
- В нашем примере: – μ = 5 – 10,5 = -5,5 – μ = 5 – 10,5 = -5,5 – μ = 8 – 10,5 = -2,5 – μ = 12 – 10,5 = 1,5 – μ = 15 – 10,5 = 4,5 – μ = 18 – 10,5 = 7,5
- В нашем примере:
-
5
Возведите в квадрат каждый полученный результат. Значения разностей будут как положительными, так и отрицательными; если нанести эти значения на числовую прямую, то они будут лежать справа и слева от среднего значения совокупности. Это не годится для вычисления дисперсии, так как положительные и отрицательные числа компенсируют друг друга. Поэтому возведите в квадрат каждую разность, чтобы получить исключительно положительные числа.
- В нашем примере:
( – μ) для каждого значения совокупности (от i = 1 до i = 6):
(-5,5) = 30,25
(-5,5) = 30,25
(-2,5) = 6,25
(1,5) = 2,25
(4,5) = 20,25
(7,5) = 56,25
- В нашем примере:
-
6
Найдите среднее значение полученных результатов. Вы нашли, как далеко каждое значение совокупности расположено от ее среднего значения. Найдите среднее значение суммы квадратов разностей, поделив ее на количество значений в генеральной совокупности.
- В нашем примере:
Дисперсия совокупности = 24,25
- В нашем примере:
-
7
Соотнесите это решение с формулой. Если вы не поняли, как приведенное выше решение соотносится с формулой, ниже представлено объяснение решения:
Реклама
















Советы
- Дисперсию довольно сложно интерпретировать, поэтому в большинстве случаев она вычисляется как промежуточная величина, которая необходима для нахождения стандартного отклонения.
- При вычислении дисперсии выборки деление на n-1, а не просто на n, называется коррекцией Бесселя. Дисперсия выборки представляет собой только оценочное значение дисперсии генеральной совокупности, при этом выборочное среднее смещено, чтобы соответствовать этому оценочному значению. Коррекция Бесселя устраняет такое смещение.[9]
Это связано с тем, что при анализе n – 1 значения использование n-го значения уже ограничено, так как только определенные значения приводят к выборочному среднему (x̅), которое используется в формуле для вычисления дисперсии.[10]
Реклама
Об этой статье
Эту страницу просматривали 122 174 раза.
Была ли эта статья полезной?
Как найти дисперсию?
Понравилось? Добавьте в закладки
Дисперсия – это мера разброса значений случайной величины $X$ относительно ее математического ожидания $M(X)$ (см. как найти математическое ожидание случайной величины). Дисперсия показывает, насколько в среднем значения сосредоточены, сгруппированы около $M(X)$: если дисперсия маленькая – значения сравнительно близки друг к другу, если большая – далеки друг от друга (см. примеры нахождения дисперсии ниже).
Если случайная величина описывает физические объекты с некоторой размерностью (метры, секунды, килограммы и т.п.), то дисперсия будет выражаться в квадратных единицах (метры в квадрате, секунды в квадрате и т.п.). Ясно, что это не совсем удобно для анализа, поэтому часто вычисляют также корень из дисперсии – среднеквадратическое отклонение $sigma(X)=sqrt{D(X)}$, которое имеет ту же размерность, что и исходная величина и также описывает разброс.
Еще одно формальное определение дисперсии звучит так: “Дисперсия – это второй центральный момент случайной величины” (напомним, что первый начальный момент – это как раз математическое ожидание).
Нужна помощь? Решаем теорию вероятностей на отлично
Формула дисперсии случайной величины
Дисперсия случайной величины Х вычисляется по следующей формуле:
$$
D(X)=M(X-M(X))^2,
$$
которую также часто записывают в более удобном для расчетов виде:
$$
D(X)=M(X^2)-(M(X))^2.
$$
Эта универсальная формула для дисперсии может быть расписана более подробно для двух случаев.
Если мы имеем дело с дискретной случайной величиной (которая задана перечнем значений $x_i$ и соответствующих вероятностей $p_i$), то формула принимает вид:
$$
D(X)=sum_{i=1}^{n}{x_i^2 cdot p_i}-left(sum_{i=1}^{n}{x_i cdot p_i} right)^2.
$$
Если же речь идет о непрерывной случайной величине (заданной плотностью вероятностей $f(x)$ в общем случае), формула дисперсии Х выглядит следующим образом:
$$
D(X)=int_{-infty}^{+infty} f(x) cdot x^2 dx – left( int_{-infty}^{+infty} f(x) cdot x dx right)^2.
$$
Пример нахождения дисперсии
Рассмотрим простые примеры, показывающие как найти дисперсию по формулам, введеным выше.
Пример 1. Вычислить и сравнить дисперсию двух законов распределения:
$$
x_i quad 1 quad 2 \
p_i quad 0.5 quad 0.5
$$
и
$$
y_i quad -10 quad 10 \
p_i quad 0.5 quad 0.5
$$
Для убедительности и наглядности расчетов мы взяли простые распределения с двумя значениями и одинаковыми вероятностями. Но в первом случае значения случайной величины расположены рядом (1 и 2), а во втором – дальше друг от друга (-10 и 10). А теперь посмотрим, насколько различаются дисперсии:
$$
D(X)=sum_{i=1}^{n}{x_i^2 cdot p_i}-left(sum_{i=1}^{n}{x_i cdot p_i} right)^2 =\
= 1^2cdot 0.5 + 2^2 cdot 0.5 – (1cdot 0.5 + 2cdot 0.5)^2=2.5-1.5^2=0.25.
$$
$$
D(Y)=sum_{i=1}^{n}{y_i^2 cdot p_i}-left(sum_{i=1}^{n}{y_i cdot p_i} right)^2 =\
= (-10)^2cdot 0.5 + 10^2 cdot 0.5 – (-10cdot 0.5 + 10cdot 0.5)^2=100-0^2=100.
$$
Итак, значения случайных величин различались на 1 и 20 единиц, тогда как дисперсия показывает меру разброса в 0.25 и 100. Если перейти к среднеквадратическому отклонению, получим $sigma(X)=0.5$, $sigma(Y)=10$, то есть вполне ожидаемые величины: в первом случае значения отстоят в обе стороны на 0.5 от среднего 1.5, а во втором – на 10 единиц от среднего 0.
Ясно, что для более сложных распределений, где число значений больше и вероятности не одинаковы, картина будет более сложной, прямой зависимости от значений уже не будет (но будет как раз оценка разброса).
Пример 2. Найти дисперсию случайной величины Х, заданной дискретным рядом распределения:
$$
x_i quad -1 quad 2 quad 5 quad 10 quad 20 \
p_i quad 0.1 quad 0.2 quad 0.3 quad 0.3 quad 0.1
$$
Снова используем формулу для дисперсии дискретной случайной величины:
$$
D(X)=M(X^2)-(M(X))^2.
$$
В случае, когда значений много, удобно разбить вычисления по шагам. Сначала найдем математическое ожидание:
$$
M(X)=sum_{i=1}^{n}{x_i cdot p_i} =-1cdot 0.1 + 2 cdot 0.2 +5cdot 0.3 +10cdot 0.3+20cdot 0.1=6.8.
$$
Потом математическое ожидание квадрата случайной величины:
$$
M(X^2)=sum_{i=1}^{n}{x_i^2 cdot p_i}
= (-1)^2cdot 0.1 + 2^2 cdot 0.2 +5^2cdot 0.3 +10^2cdot 0.3+20^2cdot 0.1=78.4.
$$
А потом подставим все в формулу для дисперсии:
$$
D(X)=M(X^2)-(M(X))^2=78.4-6.8^2=32.16.
$$
Дисперсия равна 32.16 квадратных единиц.
Пример 3. Найти дисперсию по заданному непрерывному закону распределения случайной величины Х, заданному плотностью $f(x)=x/18$ при $x in(0,6)$ и $f(x)=0$ в остальных точках.
Используем для расчета формулу дисперсии непрерывной случайной величины:
$$
D(X)=int_{-infty}^{+infty} f(x) cdot x^2 dx – left( int_{-infty}^{+infty} f(x) cdot x dx right)^2.
$$
Вычислим сначала математическое ожидание:
$$
M(X)=int_{-infty}^{+infty} f(x) cdot x dx = int_{0}^{6} frac{x}{18} cdot x dx = int_{0}^{6} frac{x^2}{18} dx =
left.frac{x^3}{54} right|_0^6=frac{6^3}{54} = 4.
$$
Теперь вычислим
$$
M(X^2)=int_{-infty}^{+infty} f(x) cdot x^2 dx = int_{0}^{6} frac{x}{18} cdot x^2 dx = int_{0}^{6} frac{x^3}{18} dx = left.frac{x^4}{72} right|_0^6=frac{6^4}{72} = 18.
$$
Подставляем:
$$
D(X)=M(X^2)-(M(X))^2=18-4^2=2.
$$
Дисперсия равна 2.
Другие задачи с решениями по ТВ
Подробно решим ваши задачи на вычисление дисперсии
Вычисление дисперсии онлайн
Как найти дисперсию онлайн для дискретной случайной величины? Используйте калькулятор ниже.
- Введите число значений случайной величины К.
- Появится форма ввода для значений $x_i$ и соответствующих вероятностей $p_i$ (десятичные дроби вводятся с разделителем точкой, например: -10.3 или 0.5). Введите нужные значения (проверьте, что сумма вероятностей равна 1, то есть закон распределения корректный).
- Нажмите на кнопку “Вычислить”.
- Калькулятор покажет вычисленное математическое ожидание $M(X)$ и затем искомое значение дисперсии $D(X)$.
Видео. Полезные ссылки
Видеоролики: что такое дисперсия и как найти дисперсию
Если вам нужно более подробное объяснение того, что такое дисперсия, как она вычисляется и какими свойствами обладает, рекомендую два видео (для дискретной и непрерывной случайной величины соответственно).
Лучшее спасибо – порекомендовать эту страницу
Полезные ссылки
Не забывайте сначала прочитать том, как найти математическое ожидание. А тут можно вычислить также СКО: Калькулятор математического ожидания, дисперсии и среднего квадратического отклонения.
Что еще может пригодиться? Например, для изучения основ теории вероятностей – онлайн учебник по ТВ. Для закрепления материала – еще примеры решений задач по теории вероятностей.
А если у вас есть задачи, которые надо срочно сделать, а времени нет? Можете поискать готовые решения в решебнике или заказать в МатБюро:
Дисперсия, виды и свойства дисперсии
Понятие дисперсии
Дисперсия в статистике находится как среднее квадратическое отклонение индивидуальных значений признака в квадрате от средней арифметической. В зависимости от исходных данных она определяется по формулам простой и взвешенной дисперсий:
1. Простая дисперсия (для несгруппированных данных) вычисляется по формуле:

2. Взвешенная дисперсия (для вариационного ряда):

где n — частота (повторяемость фактора Х)
Пример нахождения дисперсии
На данной странице описан стандартный пример нахождения дисперсии, также Вы можете посмотреть другие задачи на её нахождение
Пример 1. Имеются следующие данные по группе из 20 студентов заочного отделения. Нужно построить интервальный ряд распределения признака, рассчитать среднее значение признака и изучить его дисперсию
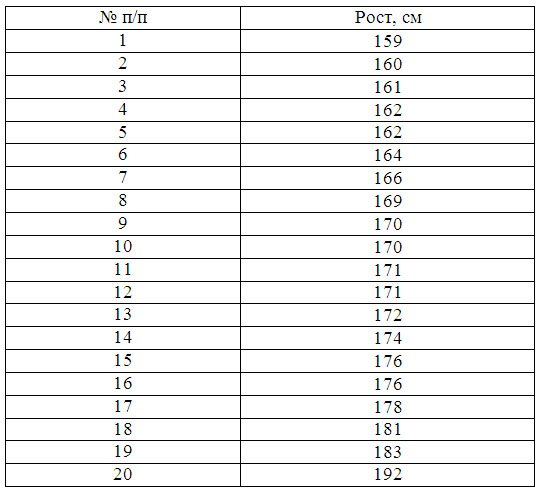
Построим интервальную группировку. Определим размах интервала по формуле:

где X max– максимальное значение группировочного признака;
X min–минимальное значение группировочного признака;
n – количество интервалов:

Принимаем n=5. Шаг равен: h = (192 — 159)/ 5 = 6,6
Составим интервальную группировку

Для дальнейших расчетов построим вспомогательную таблицу:
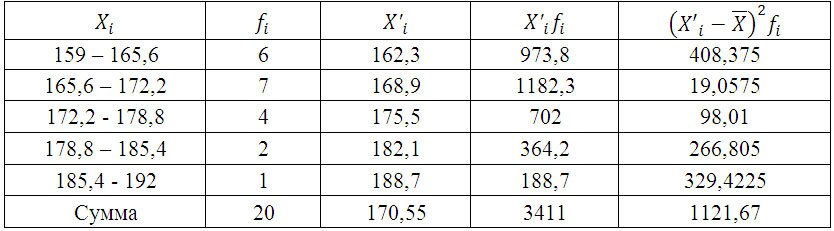
X’i– середина интервала. (например середина интервала 159 – 165,6 = 162,3)
Среднюю величину роста студентов определим по формуле средней арифметической взвешенной:
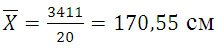
Определим дисперсию по формуле:
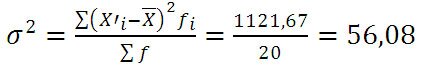
Пример 2. Определение групповой, средней из групповой, межгрупповой и общей дисперсии
Пример 3. Нахождение дисперсии и коэффициента вариации в группировочной таблице
Пример 4. Нахождение дисперсии в дискретном ряду
Формулу дисперсии можно преобразовать так:

Из этой формулы следует, что дисперсия равна разности средней из квадратов вариантов и квадрата и средней.
Дисперсия в вариационных рядах с равными интервалами по способу моментов может быть рассчитана следующим способом при использовании второго свойства дисперсии (разделив все варианты на величину интервала). Определении дисперсии, вычисленной по способу моментов, по следующей формуле менее трудоемок:

где i — величина интервала;
А — условный ноль, в качестве которого удобно использовать середину интервала, обладающего наибольшей частотой;
m1 — квадрат момента первого порядка;
m2 — момент второго порядка
Дисперсия альтернативного признака (если в статистической совокупности признак изменяется так, что имеются только два взаимно исключающих друг друга варианта, то такая изменчивость называется альтернативной) может быть вычислена по формуле:

Подставляя в данную формулу дисперсии q =1- р, получаем:

Виды дисперсии
Общая дисперсия измеряет вариацию признака по всей совокупности в целом под влиянием всех факторов, обуславливающих эту вариацию. Она равняется среднему квадрату отклонений отдельных значений признака х от общего среднего значения х и может быть определена как простая дисперсия или взвешенная дисперсия.
Внутригрупповая дисперсия характеризует случайную вариацию, т.е. часть вариации, которая обусловлена влиянием неучтенных факторов и не зависящую от признака-фактора, положенного в основание группировки. Такая дисперсия равна среднему квадрату отклонений отдельных значений признака внутри группы X от средней арифметической группы и может быть вычислена как простая дисперсия или как взвешенная дисперсия.
Таким образом, внутригрупповая дисперсия измеряет вариацию признака внутри группы и определяется по формуле:

где хi — групповая средняя;
ni — число единиц в группе.
Например, внутригрупповые дисперсии, которые надо определить в задаче изучения влияния квалификации рабочих на уровень производительности труда в цехе показывают вариации выработки в каждой группе, вызванные всеми возможными факторами (техническое состояние оборудования, обеспеченность инструментами и материалами, возраст рабочих, интенсивность труда и т.д.), кроме отличий в квалификационном разряде (внутри группы все рабочие имеют одну и ту же квалификацию).
Средняя из внутри групповых дисперсий отражает случайную вариацию, т. е. ту часть вариации, которая происходила под влиянием всех прочих факторов, за исключением фактора группировки. Она рассчитывается по формуле:

Межгрупповая дисперсия характеризует систематическую вариацию результативного признака, которая обусловлена влиянием признака-фактора, положенного в основание группировки. Она равняется среднему квадрату отклонений групповых средних от общей средней. Межгрупповая дисперсия рассчитывается по формуле:

Правило сложения дисперсии в статистике
Согласно правилу сложения дисперсий общая дисперсия равна сумме средней из внутригрупповых и межгрупповых дисперсий:

Смысл этого правила заключается в том, что общая дисперсия, которая возникает под влиянием всех факторов, равняется сумме дисперсий, которые возникают под влиянием всех прочих факторов, и дисперсии, возникающей за счет фактора группировки.
Пользуясь формулой сложения дисперсий, можно определить по двум известным дисперсиям третью неизвестную, а также судить о силе влияния группировочного признака.
Свойства дисперсии
1. Если все значения признака уменьшить (увеличить) на одну и ту же постоянную величину, то дисперсия от этого не изменится.
2. Если все значения признака уменьшить (увеличить) в одно и то же число раз n, то дисперсия соответственно уменьшится (увеличить) в n^2 раз.
Источник: Балинова B.C. Статистика в вопросах и ответах: Учеб. пособие. — М.: ТК. Велби, Изд-во Проспект, 2004. — 344 с.
Основными
обобщающими показателями вариации в
статистике являются дисперсии и среднее
квадратическое отклонение.
Дисперсия
это средняя
арифметическая
квадратов отклонений каждого значения
признака от общей средней. Дисперсия
обычно называется средним квадратом
отклонений и обозначается 2.
В зависимости от исходных данных
дисперсия может вычисляться по средней
арифметической простой или взвешенной:
![]()
дисперсия
невзвешенная (простая);

дисперсия
взвешенная.
Среднее
квадратическое отклонение
это обобщающая характеристика абсолютных
размеров вариации
признака в совокупности. Выражается
оно в тех же единицах измерения, что и
признак (в метрах, тоннах, процентах,
гектарах и т. д.).
Среднее
квадратическое отклонение представляет
собой корень квадратный из дисперсии
и обозначается :

среднее
квадратическое отклонение невзвешенное;

среднее
квадратическое отклонение взвешенное.
Среднее
квадратическое отклонение является
мерилом надежности средней. Чем меньше
среднее квадратическое отклонение, тем
лучше средняя арифметическая отражает
всю представляемую совокупность.
Вычислению
среднего квадратического отклонения
предшествует расчет дисперсии.
Порядок
расчета дисперсии взвешенной следующий:
1)
определяют среднюю арифметическую
взвешенную:

2)
рассчитывают отклонения вариантов от
средней:
![]()
3)
возводят в квадрат отклонение каждого
варианта от средней:
![]()
4)
умножают квадраты отклонений на веса
(частоты):
![]()
5)
суммируют полученные произведения:
![]()
6)
полученную сумму делят на сумму весов:

Пример 2.1
Имеются
следующие данные о производительности
труда рабочих:

Исчислим
среднюю арифметическую взвешенную:

Значения
отклонений от средней и их квадратов
представлены в таблице. Определим
дисперсию:

Среднее
квадратическое отклонение будет равно:

Если
исходные данные представлены в виде
интервального ряда
распределения,
то сначала нужно определить дискретное
значение признака, а затем применить
изложенный метод.
Пример 2.2
Покажем
расчет дисперсии для интервального
ряда на данных о распределении посевной
площади колхоза по урожайности пшеницы.

Средняя
арифметическая равна:
![]()
Исчислим
дисперсию:
![]()
6.3. Расчет дисперсии по формуле по индивидуальным данным
Техника
вычисления дисперсии
сложна, а при больших значениях вариантов
и частот может быть громоздкой. Расчеты
можно упростить, используя свойства
дисперсии.
Дисперсия
имеет следующие свойства.
1.
Уменьшение или увеличение весов (частот)
варьирующего признака в определенное
число раз дисперсию не изменяет.
2.
Уменьшение или увеличение каждого
значения признака на одну и ту же
постоянную величину А
дисперсию не изменяет.
3.
Уменьшение или увеличение каждого
значения признака в какое-то число раз
k
соответственно уменьшает или увеличивает
дисперсию в k2
раз, а среднее
квадратическое отклонение
в k
раз.
4.
Дисперсия признака относительно
произвольной величины
![]()
всегда больше дисперсии относительно
средней арифметической на квадрат
разности между средней и произвольной
величинами:
![]()
Если
А
0, то приходим к следующему равенству:
![]()
т.
е. дисперсия признака равна разности
между средним квадратом значений
признака и квадратом средней.
Каждое
свойство при расчете дисперсии может
быть применено самостоятельно или в
сочетании с другими.
Порядок
расчета дисперсии простой:
1)
определяют среднюю
арифметическую:
![]()
2)
возводят в квадрат среднюю арифметическую:

3)
возводят в квадрат отклонение каждого
варианта ряда:
хi2.
4)
находят сумму квадратов вариантов:
![]()
5)
делят сумму квадратов вариантов на их
число, т. е. определяют средний квадрат:
![]()
6)
определяют разность между средним
квадратом признака и квадратом средней:
![]()
Пример 3.1
Имеются
следующие данные о производительности
труда рабочих:

Произведем
следующие расчеты:
![]()

Рассмотрим
расчет дисперсии в интервальном ряду
распределения.
Порядок
расчета дисперсии взвешенной (по формуле
![]() )
)
следующий:
1)
определяют среднюю арифметическую:

2)
возводят в квадрат полученную среднюю:
![]()
3)
возводят в квадрат каждый вариант ряда:
![]()
4)
умножают квадраты вариантов на частоты:
![]()
5)
суммируют полученные произведения:
![]()
6)
делят полученную сумму на сумму весов
и получают средний квадрат признака:

7)
определяют разность между средним
значением квадратов и квадратом средней
арифметической, т. е. дисперсию:
![]()
Пример 3.2
Имеются
следующие данные о распределении
посевной площади колхоза по урожайности
пшеницы:

В
подобных случаях прежде всего определяется
дискретное значение признака в каждом
интервале, а затем применяется
рассмотренный метод расчета:

Средняя
величина
отражает тенденцию развития, т. е.
действие главных причин. Среднее
квадратическое отклонение измеряет
силу воздействия прочих факторов.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
18.12.2018130.46 Кб297.docx
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
Мишель Мэтьюз, MBA, CPCC
6 октября 2021 г.
Основатель RBG Royalty Enterprises Мишель Мэтьюз — сертифицированный профессиональный карьерный коуч и специалист по работе с кредиторской задолженностью, которая помогает людям вырабатывать стратегические подходы на рабочем месте, используя свою фирменную структуру Boss Up & Hustle.
Что такое дисперсия?
Дисперсия — это статистическое измерение, позволяющее увидеть, насколько далеко каждое число в наборе данных от среднего. Дисперсия часто обозначается этим символом: σ². Этот расчет может быть индикатором для аналитиков и трейдеров того, как часто меняется число, также называемое волатильностью, что также может быть сигналом дальнейших изменений и риска, который они представляют для людей, на которых они влияют. Квадратный корень из дисперсии представляет собой стандартное отклонение (σ), которое помогает определить постоянство доходности инвестиций в течение определенного периода времени.
Прочитайте больше: Меры вариации: определения, примеры и карьера
Понимание дисперсии
Чем выше дисперсия числа, тем больше оно отделено от среднего, рассчитанного на основе чисел набора данных. С другой стороны, небольшая дисперсия оказывает противоположное влияние, делая ее ближе к среднему значению, тогда как нулевая дисперсия показывает, что числа имеют одинаковое значение в наборе данных. Дисперсия не может быть отрицательным значением, так как квадрат числа никогда не может стать отрицательным значением.
Говоря об инвестициях, дисперсия является важным показателем. Волатильность — это показатель риска, который позволяет инвесторам оценить риск, связанный с покупкой конкретного актива, а также его потенциальную прибыльность. Инвесторы могут анализировать дисперсию доходности различных активов в портфеле, чтобы определить наилучшее распределение активов. В финансах дисперсия используется для сравнения эффективности элементов портфеля друг с другом и со средним значением.
Прочитайте больше: Как выполнить анализ рисков
Как рассчитать дисперсию
В статистике дисперсия рассчитывается путем взятия различий между каждым числом в наборе данных и средним значением, затем возведения в квадрат различий, чтобы сделать их положительными, и, наконец, деления суммы квадратов на количество значений в наборе данных.
Дисперсия рассчитывается по следующей формуле:
Стоимость акций, которые вы инвестируете на открытом рынке, может меняться ежедневно, но вы все равно можете просматривать финансовые отчеты, чтобы отслеживать эффективность ваших инвестиций за определенный период. Мы начнем с определения дисперсии доходности акций, которую можно использовать для помощи в постановке целей в отношении финансового будущего вашей компании. Вот пример и список шагов для расчета дисперсии:
1. Определите доходность акций за определенный период
Для этого примера мы скажем, что вы отслеживаете свои инвестиции в течение трех лет, и они принесли 13% прибыли в первый год, 24% во второй год и -10% в течение третьего года.
2. Рассчитайте среднее значение доходности
Сложите 13, 24 и -10 вместе, и вы получите в общей сложности 27. Вы делите 27 на 3, так как вы вычисляете сумму по числам в наборе данных, и вы получаете 9% как среднюю доходность акций за три года. срок год.
3. Найдите разницу между каждым доходом и средним значением за каждый год.
Затем вам нужно сравнить доход, который вы получали от акций каждый год, и среднее значение, которое вы рассчитали ранее. Для этого вычтите процент доходности акций от среднего, чтобы найти разницу.
Первый год: 13% — 9% = 4%
Второй год: 24% — 9% = 15%
Третий год: -10% — 9% = -19%
4. Возведите в квадрат разницы (отклонения) и сложите их за каждый год.
4² = 16%
15² = 225%
-19²= 361%
16% + 225% + 361% = 602%
5. Разделите сумму отклонений на количество возвратов в вашем наборе данных, чтобы получить дисперсию.
602% / 3 = 206,67%
Это означает, что доходность акций отличается от среднего значения, что означает, что в вашем портфеле находятся акции с высоким риском.
Важно: Волатильность может быть отмечена как стандартное отклонение, а не как дисперсия, потому что ее часто легче интерпретировать.
Чтобы получить стандартное отклонение, вычислите квадратный корень из дисперсии. Используя данный пример, это будет 14,37% для возврата.
Прочитайте больше: Узнайте о том, как стать финансовым консультантом
Дисперсия населения
Далее мы рассмотрим дисперсию с точки зрения населения.
См. шаги и расчет в примере ниже:
1. Определите население по числам в наборе данных.
Вместо использования процентов числа в наборе данных представляют собой целые числа для каждого человека.
Для этого примера мы скажем, что общее количество каждой совокупности включает 4, 22, 99, 204, 18 и 20.
2. Сложите все числа в наборе данных
4 + 22 + 99 + 204 + 18 + 20 = 367
3. Возведите в квадрат сумму всех чисел
367² = 134 689
4. Разделите сумму на количество чисел, включенных в набор данных.
134 689/6 = 22 448,1667 или 22 448,2
5. Возведите в квадрат числа из исходного набора данных и сложите их.
16 + 484 + 9 801 + 204 + 41 616 + 400 = 52 521
6. Вычтите сумму ваших ответов на пятом шаге из суммы на четвертом шаге.
52 521 — 22 448,2 = 30 072,8
7. Вычтите единицу из количества чисел, включенных в ваш набор данных.
6 — 1 = 5
8. Разделите сумму шестого шага на результат седьмого шага, чтобы получить общую дисперсию населения.
30 072,8 / 5 = 6 014,56
Дисперсия населения составляет 6 014,56 человек.
