Надежность результата многократных измерений. Коэффициент Стьюдента.
Доверительной
вероятностью или надежностью
P
серии измерений называется вероятность
попадания истинного значения измеряемой
величины в данный интервал (выражается
в долях единицы или в процентах).
Интервал
(<x>±-
∆x)
в который попадает истинное значение
искомой величины с заданной доверительной
вероятностью P(∆x)
, называют доверительным
интервалом или интервалом надежности
и для краткости обозначают как ∆x.
Чем
больше доверительный интервал, тем
больше доверительная вероятность того,
что результат измерения попадет в него.
Величина доверительного интервала,
рассчитывается методами теории
вероятностей и математической статистики
и определяется выбором вида функции
распределения случайных величин f(∆x).
Для
всех функций распределения, базовым
является распределение
Гаусса,
справедливое для большого количества
равноточных
измерений
![]() :
:
 [1.5]
[1.5]
где
величина
![]()
называется среднеквадратичным
или стандартным отклонением
![]()
от среднего
значения <x>
а,
![]() дисперсией
дисперсией
распределения.
Распределение
Гаусса показывает, что вероятность
появления малых случайных погрешностей
больше вероятности появления больших
погрешностей, при этом случайные
погрешности равные по абсолютной
величине, но противоположные по знаку
встречаются одинаково часто.
При
лабораторных измерениях (n
< 20) для расчета интервала надежности
используется распределение
Стьюдента (при
![]()
распределение Стьюдента переходит в
распределение Гаусса),
которое
позволяет по заданной величине надежности
P(∆x)
найти величину доверительного интервала
∆x,
с помощью поправочных коэффициентов
Стьюдента:
![]() [1.6]
[1.6]
где
![]()
– коэффициент
Стьюдента, зависящий от выбора
доверительной вероятности p
и числа измерений n,
S
– среднеквадратичное отклонение –
(СКО), вычисляемое по формуле:
 [1.7]
[1.7]
Величина
интервала ∆x,
рассчитанная при помощи формулы [1.6]
стремится к нулю при увеличении числа
опытов.
Коэффициенты Стьюдента
|
Число измерений n |
Доверительная |
|||
|
0,90 |
0,95 |
0,99 |
0,999 |
|
|
2 |
6,314 |
12,706 |
63,657 |
636,619 |
|
3 |
2,920 |
4,303 |
9,925 |
31,598 |
|
4 |
2,353 |
3,182 |
5,841 |
12,941 |
|
5 |
2,132 |
2,776 |
4,604 |
8,610 |
|
6 |
2,015 |
2,571 |
4,032 |
6,859 |
|
7 |
1,943 |
2,447 |
3,707 |
5,959 |
|
8 |
1,895 |
2,365 |
3,499 |
5,405 |
|
9 |
1,860 |
2,306 |
3,355 |
5,041 |
|
10 |
1,833 |
2,262 |
3,250 |
4,781 |
Очевидно, что число
опытов имеет смысл выбрать таким, чтобы
случайная погрешность среднего сравнялась
с погрешностью прибора либо стала меньше
ее. Дальнейшее увеличение числа измерений
теряет смысл, так как не увеличит точность
получаемого результата
Расчет погрешности прямых измерений
Прежде,
чем приступить к измерениям, необходимо
предварительно определить пределы
точности данных приборов (инструментальные
погрешности
![]() ).
).
Равноточные
измерения любой физической величины
делаются не менее трех раз и заносятся
в таблицу, с учетом инструментальной
погрешности. В зависимости от поведения
значений результатов измерения, возникают
две различные схемы:
Случайная
погрешность много меньше инструментальной
Если
оказывается, что все время получается
один и тот же результат (нет разброса),
то в качестве интервала надежности
берется стандартная (инструментальная)
погрешность прибора ∆и,
рассчитанная по его классу точности
(или погрешность градуировки прибора)
и результат записывается в виде:
![]()
При
этом доверительная вероятность
(надежность) равна
![]() и, как правило, не указывается.
и, как правило, не указывается.
Случайная
погрешность сравнима с инструментальной
Если
разброс значений физической величины
x
превышает погрешность градуировки, то
количество измерений n
увеличивают до тех пор, пока они не
окажутся величинами одного порядка.
Интервал надежности вычисляют в следующей
последовательности:
-
Находят
среднее значение:

-
Оценивают
среднеквадратичное отклонение – СКО:

-
По
заданному значению надежности p
и числу измерений n,
находят
случайную составляющую погрешности:

-
Полную
погрешность вычисляют как корень
квадратный из суммы квадратов случайной
∆хсл
и инструментальной ∆xи
составляющих:
![]()
-
Находят
относительную погрешность:

-
Результат
записывают в виде:
 ,
,
 ,
,
р
= …

Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
| Распределение Стьюдента | |
|---|---|
 Плотность вероятности Плотность вероятности |
|
 Функция распределения Функция распределения |
|
| Обозначение |
 |
| Параметры |
 — число степеней свободы — число степеней свободы |
| Носитель |
 |
| Плотность вероятности |
 |
| Функция распределения |
  где где  — гипергеометрическая функция — гипергеометрическая функция |
| Математическое ожидание |
 , если , если  |
| Медиана |
|
| Мода |
|
| Дисперсия |
 , если , если  |
| Коэффициент асимметрии |
, если  |
| Коэффициент эксцесса |
 , если , если  |
| Дифференциальная энтропия |
|
| Производящая функция моментов | не определена |
![{begin{matrix}{frac {n+1}{2}}left[psi ({frac {1+n}{2}})-psi ({frac {n}{2}})right]\[0.5em]+log {left[{sqrt {n}}B({frac {n}{2}},{frac {1}{2}})right]}end{matrix}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/1cd3fdc61973f68042141bd52ef3b36cd233e8a0)


Распределе́ние Стью́дента ( -распределение) в теории вероятностей — это однопараметрическое семейство абсолютно непрерывных распределений. Уильям Сили Госсет первым опубликовал работы, посвящённые этому распределению, под псевдонимом «Стьюдент».
-распределение) в теории вероятностей — это однопараметрическое семейство абсолютно непрерывных распределений. Уильям Сили Госсет первым опубликовал работы, посвящённые этому распределению, под псевдонимом «Стьюдент».
Распределение Стьюдента играет важную роль в статистическом анализе и используется, например, в t-критерии Стьюдента для оценки статистической значимости разности двух выборочных средних, при построении доверительного интервала для математического ожидания нормальной совокупности при неизвестной дисперсии, а также в линейном регрессионном анализе. Распределение Стьюдента также появляется в байесовском анализе данных, распределённых по нормальному закону.
График плотности распределения Стьюдента, как и нормального распределения, является симметричным и имеет вид колокола, но с более «тяжёлыми» хвостами, то есть реализациям случайной величины, имеющей распределение Стьюдента, более свойственно сильно отличаться от математического ожидания. Это делает его важным для понимания статистического поведения определённых типов отношений случайных величин, в которых отклонение в знаменателе увеличено и может производить отдалённые величины, когда знаменатель соотношения близок к нулю.
Распределение Стьюдента — частный случай обобщённого гиперболического распределения.
История и этимология[править | править код]
В статистике t-распределение было впервые получено как апостериорное распределение в 1876 году Фридрихом Гельмертом[1][2][3] и Якобом Люротом[en][4][5][6].
В англоязычной литературе распределение берёт название из статьи Уильяма Госсета в журнале Пирсона «Биометрика», опубликованной под псевдонимом «Стьюдент»[7][8].
Госсет работал в пивоварне Гиннесс в Дублине, Ирландия, и применял свои знания в области статистики как при варке пива, так и на полях — для выведения самого урожайного сорта ячменя. Исследования были обращены к нуждам пивоваренной компании и проводились на малом количестве наблюдений, что послужило толчком для развития методов, работающих на малых выборках.
Госсету пришлось скрывать свою личность при публикации из-за того, что ранее другой исследователь, работавший на Гиннесс, опубликовал в своих материалах сведения, составлявшие коммерческую тайну компании, после чего Гиннесс запретил своим работникам публикацию любых материалов, независимо от содержавшейся в них информации.
Статья Госсета описывает распределение как «Частотное распределение стандартных отклонений выборок, извлечённых из генеральной совокупности». Оно стало известным благодаря работе Роналда Фишера, который называл распределение «распределением Стьюдента», а величину — буквой t[9].
Определение[править | править код]
Пусть  — независимые стандартные нормальные случайные величины, такие что
— независимые стандартные нормальные случайные величины, такие что  . Тогда распределение случайной величины , где
. Тогда распределение случайной величины , где

называется распределением Стьюдента с  степенями свободы
степенями свободы  .
.
Это распределение абсолютно непрерывно с плотностью:
 ,
,

где  — гамма-функция Эйлера. Таким образом:
— гамма-функция Эйлера. Таким образом:
- для чётных

и соответственно
- для нечётных .

Также плотность распределения Стьюдента можно выразить воспользовавшись бета-функцией Эйлера  :
:
- .

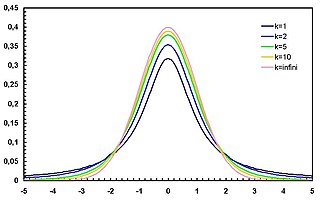
График функции плотности t-распределения симметричен, а его форма напоминает форму колокола, как у стандартного нормального распределения, но он ниже и шире.
Следующие графики отражают плотность t-распределения при увеличении числа степеней свободы. Можно наблюдать как по мере возрастания , кривая функции плотности все больше напоминает стандартное нормальное распределение.
|
1 степень свободы |
2 степени свободы |
3 степени свободы |
|
5 степеней свободы |
10 степеней свободы |
30 степеней свободы |





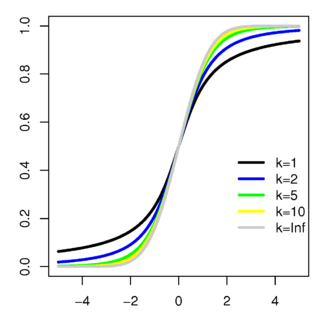
Функция распределения[править | править код]
Функция распределения может быть выражена через регуляризованную неполную бета-функцию  .
.
Для  ,
,
- где [10]


Для  значения можно получить в силу симметричности распределения.
значения можно получить в силу симметричности распределения.
Другая формула верна для  [10]:
[10]:
- ,

где 2F1 является частным случаем гипергеометрической функции.
Частные случаи[править | править код]
- Распределение Стьюдента с одной степенью свободы () это стандартное распределение Коши.

-
- Функция распределения:
- Плотность вероятности:
- Функция распределения:


- Распределение Стьюдента с двумя степенями свободы ():

-
- Функция распределения:
- Плотность вероятности: ;
- Функция распределения:


- Распределение Стьюдента с тремя степенями свободы ():

-
- Плотность вероятности:
- Плотность вероятности:

- Распределение Стьюдента с бесконечным числом степеней свободы ():

-
- Плотность вероятности
- Плотность вероятности

совпадает с плотностью вероятности стандартного нормального распределения.
Свойства распределения Стьюдента[править | править код]
-
- , если нечётно;
- , если чётно. В частности,
![{mathbb {E}}left[t^{k}right]=0](https://wikimedia.org/api/rest_v1/media/math/render/svg/03e22470d6afaa3397555bea76f3fecd20968fad)
![{displaystyle mathbb {E} left[t^{k}right]={frac {1}{{sqrt {pi }}Gamma left({frac {n}{2}}right)}}left[Gamma left({frac {k+1}{2}}right)Gamma left({frac {n-k}{2}}right)n^{frac {k}{2}}right]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/aecd6a751df7ace0449d2eddecbfbf244c13405b)
Характеристики[править | править код]
Распределение Стьюдента с  степенями свободы может быть определено как распределение случайной величины
степенями свободы может быть определено как распределение случайной величины  [10][11]
[10][11]
- ,

где
Пусть,  , независимые случайные величины, имеющие нормальное распределение
, независимые случайные величины, имеющие нормальное распределение  ,
,
 – выборочное среднее,
– выборочное среднее,
- – несмещённая оценка дисперсии.

Тогда случайная величина

имеет распределение хи-квадрат с  степенями свободы[12].
степенями свободы[12].
Случайная величина  имеет стандартное нормальное распределение,
имеет стандартное нормальное распределение,  , так как выборочное среднее
, так как выборочное среднее  имеет нормальное распределение
имеет нормальное распределение  . Более того, можно показать, что эти две случайные величины (нормальная
. Более того, можно показать, что эти две случайные величины (нормальная  и хи-квадрат
и хи-квадрат  ) независимы.
) независимы.
Подставим получившиеся величины в величину
- ,

которая имеет распределение Стьюдента и отличается от тем, что стандартное отклонение  заменено случайной величиной
заменено случайной величиной  , . Заметим, что неизвестная дисперсия
, . Заметим, что неизвестная дисперсия  не появляется в , так как она была и в числителе, и в знаменателе. Госсет интуитивно получил плотность вероятности, установленную выше, где соответствует
не появляется в , так как она была и в числителе, и в знаменателе. Госсет интуитивно получил плотность вероятности, установленную выше, где соответствует  ; Фишер доказал это в 1925 году [9].
; Фишер доказал это в 1925 году [9].
Распределение статистики критерия , зависит от , но не зависит от μ или σ2, что и делает распределение важным как в теории, так и на практике.
Как возникает t-распределение[править | править код]
Выборочная дисперсия[править | править код]
Распределение Стьюдента возникает в связи с распределением выборочной дисперсии.
Пусть независимые случайные величины, такие что  . Обозначим
. Обозначим  выборочное среднее этой выборки, а
выборочное среднее этой выборки, а  её выборочную дисперсию. Тогда
её выборочную дисперсию. Тогда
- .

С этим фактом связано использование распределения Стьюдента в статистике для точечного оценивания, построения доверительных интервалов и тестирования гипотез, касающихся неизвестного среднего выборки из нормального распределения.
Байесовская статистика[править | править код]
В байесовской статистике, нецентральное t-распределение встречается как маргинальное распределение коэффициента  нормального распределения
нормального распределения  .
.
Зависимость неизвестной дисперсии выражается через:

где  – это данные {xi}, а представляет собой любую другую информацию, которая могла быть использована для создания модели.
– это данные {xi}, а представляет собой любую другую информацию, которая могла быть использована для создания модели.
Когда данные неинформативны из теоремы Байеса следует


нормальное распределение и масштабированное обратное хи-квадрат распределение, где
- .

Маргинализованный интеграл в таком случае имеет вид

после замены  , где
, где  ,
,
получим 
и оценку 
 теперь стандартный Гамма интеграл, который оценивается константой
теперь стандартный Гамма интеграл, который оценивается константой

это нестандартизированное t-распределение.
С помощью замены  получаем стандартизированное t-распределение.
получаем стандартизированное t-распределение.
Дифференцирование выше было представлено для случая неинформативной априорной вероятности для  и
и  ; но очевидно, что любая априорная вероятность, ведет к смешению нормального распределения и масштабированного обратного хи-квадрат распределение, что нецентральному t-распределению с масштабированием и смещением на
; но очевидно, что любая априорная вероятность, ведет к смешению нормального распределения и масштабированного обратного хи-квадрат распределение, что нецентральному t-распределению с масштабированием и смещением на  , параметр масштабирования
, параметр масштабирования  будет в находиться под влиянием априорной информации и данных, а не только данных, как в примере выше.
будет в находиться под влиянием априорной информации и данных, а не только данных, как в примере выше.
Обобщения распределения Стьюдента[править | править код]
Нестандартизированное распределение Стьюдента[править | править код]
Распределение Стьюдента можно обобщить до семейства функций с тремя параметрами, включающими коэффициент сдвига  и коэффициент масштаба , через отношение
и коэффициент масштаба , через отношение

или
- ,

где  классическое распределение Стьюдента с степенями свободы.
классическое распределение Стьюдента с степенями свободы.
Плотность нестандартизированного распределения Стьюдента представляет собой репараметризованное распределение Пирсона типа VII и определяется следующим выражением[13]

Здесь не является стандартным отклонением, как в нормальном распределении, это, вообще говоря, другой параметр масштаба. Однако при  плотность распределения Пирсона типа VII стремится к плотности нормального распределения со стандартным отклонением .
плотность распределения Пирсона типа VII стремится к плотности нормального распределения со стандартным отклонением .
В байесовском выводе предельное распределение неизвестного среднего значения выше чем , и соответствует  , где
, где

 для ,
для ,
 для
для

Такое распределение является результатом комбинации распределения Гаусса (нормального распределения) со средним значением и неизвестной дисперсией, с обратным гамма-распределением, с дисперсией, имеющей параметры  и
и  . Другими словами, предполагается, что случайная величина X обладает нормальным распределением с неизвестной дисперсией, распределенной как обратная гамма, а затем дисперсия исключается. Такое свойство полезно из-за того, что обратное гамма-распределение – это сопряженное априорное распределение дисперсии распределения Гаусса, именно поэтому нестандартизированное распределение Стьюдента естественным образом возникает во многих байесовских задачах.
. Другими словами, предполагается, что случайная величина X обладает нормальным распределением с неизвестной дисперсией, распределенной как обратная гамма, а затем дисперсия исключается. Такое свойство полезно из-за того, что обратное гамма-распределение – это сопряженное априорное распределение дисперсии распределения Гаусса, именно поэтому нестандартизированное распределение Стьюдента естественным образом возникает во многих байесовских задачах.
Эквивалентно, это распределение является результатом комбинации распределения Гаусса с масштабированным обратным хи-квадрат распределением с параметрами and . Масштабированное обратное хи-квадрат распределение – точно то же самое распределение, что и обратное гамма-распределение, но с другой параметризацией, а именно  .
.
Альтернативная параметризация на основании обратного параметра масштабирования λ[14] (аналогично тому, как мера точности обратна дисперсии), определенная отношением  ,
,
тогда плотность определяется как

Свойства:
для ,
 для
для
Это распределение является результатом комбинации распределения Гаусса со средним и неизвестной мерой точности (обратной дисперсии), с гамма-распределением с параметрами and  . Другими словами, предполагается, что случайная величина X обладает нормальным распределением с неизвестной гамма-распределённой мерой точности.
. Другими словами, предполагается, что случайная величина X обладает нормальным распределением с неизвестной гамма-распределённой мерой точности.
Нецентральное распределение Стьюдента[править | править код]
Нецентральное распределение Стьюдента, это один способов обобщения стандартного распределения Стьюдента, включающий дополнительный коэффициент сдвига (параметр нецентральности) .

В нецентральном распределении Стьюдента медиана не совпадает с модой, т.е. оно не симметрично (в отличие от нестандартизированного).
Это распределение важно для изучения статистической мощности t-критерия Стьюдента.
Дискретное распределение Стьюдента[править | править код]
Дискретное распределение Стьюдента имеет следующую функцию распределения с r пропорциональным:[15]

Где a, b, и k – параметры. Такое распределение возникает при работе с системами из дискретных распределений, таких как распределение Пирсона.[16]
Связь с другими распределениями[править | править код]
Обобщение распределения Гаусса[править | править код]
Мы можем получить выборку с t-распределением, взяв отношение величин из нормального распределения и квадратный корень из распределения хи-квадрат.
где  — независимые стандартные нормальные случайные величины, такие что
— независимые стандартные нормальные случайные величины, такие что 

Если мы вместо нормального распределения, возьмём например, Ирвин-Холл, получится симметричное распределение с 4 параметрами, которое включает в себя нормальное, равномерное, треугольное, а также распределения Стьюдента и Коши; таким образом, это обобщение более гибкое, чем многие другие симметричные обобщения распределения Гаусса.
Применение распределения Стьюдента[править | править код]
Проверка гипотезы[править | править код]
Некоторые статистики могут иметь распределение Стьюдента на выборках небольшого размера, поэтому распределение Стьюдента формирует основу критериев значимости. Например, тест ранговой корреляции Спирмена ρ, в нулевом случае (нулевая корреляция) хорошо аппроксимируется распределением Стьюдента при размере выборки больше 20.
Построение доверительного интервала[править | править код]
Распределение Стьюдента может быть использовано для оценки того, насколько вероятно, что истинное среднее находится в каком-либо заданном диапазоне.
Предположим, что число A выбрано так, что
 .
.
Тогда T имеет t-распределение с n–1 степенями свободы. В силу симметрии распределения, это равноценно утверждению, что А удовлетворяет
 или
или  , тогда
, тогда

что эквивалентно

таким образом, интервал с доверительным пределом в точках  — это 90% доверительный интервал для μ. Следовательно, если мы находим среднее множества наблюдений (нормально распределённых), мы можем использовать распределение Стьюдента, чтобы определить, включают ли доверительные пределы по этому среднему какое-либо теоретически предсказанное значение, например, значение, предсказанное, исходя из нулевой гипотезы.
— это 90% доверительный интервал для μ. Следовательно, если мы находим среднее множества наблюдений (нормально распределённых), мы можем использовать распределение Стьюдента, чтобы определить, включают ли доверительные пределы по этому среднему какое-либо теоретически предсказанное значение, например, значение, предсказанное, исходя из нулевой гипотезы.
Такой подход применяется в t-критерии Стьюдента: если разность между средними значениями выборок из двух нормальных распределений сама может быть нормально распределена, распределение Стьюдента может быть использовано для исследования того, можно ли с большой долей вероятности полагать эту разность равной нулю.
Для нормально распределённых выборок односторонний (1−a) верхний доверительный предел (UCL) среднего значения равен
 .
.
Полученный в результате верхний доверительный предел будет наибольшим средним значением для данного доверительного интервала и размера выборки. Другими словами, если среднее значение множества наблюдений, вероятность того, что среднее значение распределения уступает  равна уровню значимости 1–a.
равна уровню значимости 1–a.
Построение интервала-предиктора[править | править код]
Распределение Стьюдента может быть использовано для получения интервала-предиктора для ненаблюдаемой выборки из нормального распределения с неизвестным средним и дисперсией.
В байесовской статистике[править | править код]
Распределение Стьюдента, особенно нецентральное, часто возникает в байесовской статистике как результат связи с нормальным распределением.
Действительно, если нам неизвестна дисперсия нормально распределенной случайной величины, но известно сопряженное априорное распределение, можно будет подобрать такое гамма-распределение, что полученные в результате величины будут обладать распределением Стьюдента.
Эквивалентные конструкции с теми же результатами включают сопряжённое масштабированное обратное хи-квадратное распределение. Если некорректное априорное распределение, пропорциональное , расположено над дисперсией, то также возникает распределение Стьюдента. Это происходит независимо от того, известно ли среднее нормально распределенной величины, распределённое с сопряжённым априорным распределением, или нет.
Параметрическое моделирование, устойчивое к нарушениям исходных предпосылок[править | править код]
Распределение Стьюдента часто используется в качестве альтернативы нормальному распределению для модели данных.[18] Это происходит из-за того, что довольно часто настоящие данные имеют более тяжелые хвосты, чем позволяет нормальное распределение. Классический подход заключается в определении выбросов и их исключении (или понижении их веса). Однако не всегда легко определить выброс (особенно в задачах с большой размерностью), и распределение Стьюдента является естественным выбором, обеспечивающим параметрический подход к робастной статистике.
Ланж и другие исследовали использование распределения Стьюдента для робастного (устойчивого к нарушениям исходных предпосылок) моделирования данных. Байесовский расчет обнаруживается у Гельмана и др.
Количество степеней свободы контролирует эксцесс распределения и коррелируется с параметром масштабирования.
Некоторые другие свойства распределения Стьюдента[править | править код]
Пусть,  – интеграл функции плотности вероятности Стьюдента,
– интеграл функции плотности вероятности Стьюдента,
 – вероятность того, что значение t, меньше, чем значение, рассчитанное по данным наблюдений.
– вероятность того, что значение t, меньше, чем значение, рассчитанное по данным наблюдений.
Функция может быть использована для тестировании того, является ли разница между средними значениями двух наборов данных взятых из одной совокупности, статистически значимой, это достигается путём вычисления соответствующего значения t и вероятности его возникновения.
Это используется например, в T-критерии Стьюдента. Для t-распределения с степенями свободы, – вероятность того, что t будет меньше наблюдаемого значения, если два средних значения были одинаковыми. Его можно легко вычислить из кумулятивной функции распределения  распределения Стьюдента:
распределения Стьюдента:

где Ix – регуляризированная неполная бета функция (a, b).
При статистической проверки гипотез эта функция используется для построения р-значения.
Выборка по методу Монте-Карло[править | править код]
Есть разные подходы к получению случайных величин из распределения Стьюдента. Всё зависит от того, требуются независимые выборки, или они могут быть построены путём применения обратной функции распределения над выборкой с однородным распределением.
В случае с независимой выборкой легко применить расширение метода Бокса-Мюллера в его полярной (тригонометрической) форме[19]. Преимущество этого метода в том, что он одинаково относится ко всем положительным степеням свободы , в то время как многие другие методы не будут работать, если близка к нулю.[19]
Плотность распределения Стьюдента через решение дифференциального уравнения[править | править код]
Плотность распределения Стьюдента можно получить, решив следующее дифференциальное уравнение:

Процентили[править | править код]
Таблицы значений[править | править код]
Многие учебники по статистике включают в себя таблицы распределения Стьюдента.
В наши дни лучший способ узнать полностью точное критическое значение t или кумулятивную вероятность — это использование статистической функции, встроенной в электронные таблицы (Office Excel, OpenOffice Calc и т.д.), или интерактивного веб-калькулятора. Нужные функции электронных таблиц — TDIST и TINV.
Таблица ниже включает в себя значения некоторых значений для распределений Стьюдента с v степенями свободы для ряда односторонних или двусторонних критических областей.
В качестве примера того, как читать эту таблицу, возьмём четвёртый ряд, который начинается с 4; это означает, что v, количество степеней свободы, равно 4 (и если мы работаем, как это показано выше, с n величин с фиксированной суммой, то n = 5). Возьмём пятое значение в колонке 95% для односторонних(90% для двусторонних). Значение это равно “2.132”. Значит, вероятность, что T меньше 2.132 равна 95% или Pr(−∞ <T< 2.132) = 0.95; это также означает, что Pr(−2.132 <T< 2.132) = 0.9.
Это может быть вычислено по симметрии распределения,
- Pr(T < −2.132) = 1 − Pr(T > −2.132) = 1 − 0.95 = 0.05,
получаем
- Pr(−2.132 < T < 2.132) = 1 − 2(0.05) = 0.9.
Обратите внимание, что последний ряд также даёт критические точки: распределение Стьюдента с бесконечным количеством степеней – это нормальное распределение.
Первая колонка отображает число степеней свободы.
| односторонний | 75% | 80% | 85% | 90% | 95% | 97.5% | 99% | 99.5% | 99.75% | 99.9% | 99.95% |
|---|---|---|---|---|---|---|---|---|---|---|---|
| двусторонний | 50% | 60% | 70% | 80% | 90% | 95% | 98% | 99% | 99.5% | 99.8% | 99.9% |
| 1 | 1.000 | 1.376 | 1.963 | 3.078 | 6.314 | 12.71 | 31.82 | 63.66 | 127.3 | 318.3 | 636.6 |
| 2 | 0.816 | 1.080 | 1.386 | 1.886 | 2.920 | 4.303 | 6.965 | 9.925 | 14.09 | 22.33 | 31.60 |
| 3 | 0.765 | 0.978 | 1.250 | 1.638 | 2.353 | 3.182 | 4.541 | 5.841 | 7.453 | 10.21 | 12.92 |
| 4 | 0.741 | 0.941 | 1.190 | 1.533 | 2.132 | 2.776 | 3.747 | 4.604 | 5.598 | 7.173 | 8.610 |
| 5 | 0.727 | 0.920 | 1.156 | 1.476 | 2.015 | 2.571 | 3.365 | 4.032 | 4.773 | 5.893 | 6.869 |
| 6 | 0.718 | 0.906 | 1.134 | 1.440 | 1.943 | 2.447 | 3.143 | 3.707 | 4.317 | 5.208 | 5.959 |
| 7 | 0.711 | 0.896 | 1.119 | 1.415 | 1.895 | 2.365 | 2.998 | 3.499 | 4.029 | 4.785 | 5.408 |
| 8 | 0.706 | 0.889 | 1.108 | 1.397 | 1.860 | 2.306 | 2.896 | 3.355 | 3.833 | 4.501 | 5.041 |
| 9 | 0.703 | 0.883 | 1.100 | 1.383 | 1.833 | 2.262 | 2.821 | 3.250 | 3.690 | 4.297 | 4.781 |
| 10 | 0.700 | 0.879 | 1.093 | 1.372 | 1.812 | 2.228 | 2.764 | 3.169 | 3.581 | 4.144 | 4.587 |
| 11 | 0.697 | 0.876 | 1.088 | 1.363 | 1.796 | 2.201 | 2.718 | 3.106 | 3.497 | 4.025 | 4.437 |
| 12 | 0.695 | 0.873 | 1.083 | 1.356 | 1.782 | 2.179 | 2.681 | 3.055 | 3.428 | 3.930 | 4.318 |
| 13 | 0.694 | 0.870 | 1.079 | 1.350 | 1.771 | 2.160 | 2.650 | 3.012 | 3.372 | 3.852 | 4.221 |
| 14 | 0.692 | 0.868 | 1.076 | 1.345 | 1.761 | 2.145 | 2.624 | 2.977 | 3.326 | 3.787 | 4.140 |
| 15 | 0.691 | 0.866 | 1.074 | 1.341 | 1.753 | 2.131 | 2.602 | 2.947 | 3.286 | 3.733 | 4.073 |
| 16 | 0.690 | 0.865 | 1.071 | 1.337 | 1.746 | 2.120 | 2.583 | 2.921 | 3.252 | 3.686 | 4.015 |
| 17 | 0.689 | 0.863 | 1.069 | 1.333 | 1.740 | 2.110 | 2.567 | 2.898 | 3.222 | 3.646 | 3.965 |
| 18 | 0.688 | 0.862 | 1.067 | 1.330 | 1.734 | 2.101 | 2.552 | 2.878 | 3.197 | 3.610 | 3.922 |
| 19 | 0.688 | 0.861 | 1.066 | 1.328 | 1.729 | 2.093 | 2.539 | 2.861 | 3.174 | 3.579 | 3.883 |
| 20 | 0.687 | 0.860 | 1.064 | 1.325 | 1.725 | 2.086 | 2.528 | 2.845 | 3.153 | 3.552 | 3.850 |
| 21 | 0.686 | 0.859 | 1.063 | 1.323 | 1.721 | 2.080 | 2.518 | 2.831 | 3.135 | 3.527 | 3.819 |
| 22 | 0.686 | 0.858 | 1.061 | 1.321 | 1.717 | 2.074 | 2.508 | 2.819 | 3.119 | 3.505 | 3.792 |
| 23 | 0.685 | 0.858 | 1.060 | 1.319 | 1.714 | 2.069 | 2.500 | 2.807 | 3.104 | 3.485 | 3.767 |
| 24 | 0.685 | 0.857 | 1.059 | 1.318 | 1.711 | 2.064 | 2.492 | 2.797 | 3.091 | 3.467 | 3.745 |
| 25 | 0.684 | 0.856 | 1.058 | 1.316 | 1.708 | 2.060 | 2.485 | 2.787 | 3.078 | 3.450 | 3.725 |
| 26 | 0.684 | 0.856 | 1.058 | 1.315 | 1.706 | 2.056 | 2.479 | 2.779 | 3.067 | 3.435 | 3.707 |
| 27 | 0.684 | 0.855 | 1.057 | 1.314 | 1.703 | 2.052 | 2.473 | 2.771 | 3.057 | 3.421 | 3.690 |
| 28 | 0.683 | 0.855 | 1.056 | 1.313 | 1.701 | 2.048 | 2.467 | 2.763 | 3.047 | 3.408 | 3.674 |
| 29 | 0.683 | 0.854 | 1.055 | 1.311 | 1.699 | 2.045 | 2.462 | 2.756 | 3.038 | 3.396 | 3.659 |
| 30 | 0.683 | 0.854 | 1.055 | 1.310 | 1.697 | 2.042 | 2.457 | 2.750 | 3.030 | 3.385 | 3.646 |
| 40 | 0.681 | 0.851 | 1.050 | 1.303 | 1.684 | 2.021 | 2.423 | 2.704 | 2.971 | 3.307 | 3.551 |
| 50 | 0.679 | 0.849 | 1.047 | 1.299 | 1.676 | 2.009 | 2.403 | 2.678 | 2.937 | 3.261 | 3.496 |
| 60 | 0.679 | 0.848 | 1.045 | 1.296 | 1.671 | 2.000 | 2.390 | 2.660 | 2.915 | 3.232 | 3.460 |
| 80 | 0.678 | 0.846 | 1.043 | 1.292 | 1.664 | 1.990 | 2.374 | 2.639 | 2.887 | 3.195 | 3.416 |
| 100 | 0.677 | 0.845 | 1.042 | 1.290 | 1.660 | 1.984 | 2.364 | 2.626 | 2.871 | 3.174 | 3.390 |
| 120 | 0.677 | 0.845 | 1.041 | 1.289 | 1.658 | 1.980 | 2.358 | 2.617 | 2.860 | 3.160 | 3.373 |
| ∞ | 0.674 | 0.842 | 1.036 | 1.282 | 1.645 | 1.960 | 2.326 | 2.576 | 2.807 | 3.090 | 3.291 |
Например, если нам дана выборка с выборочной дисперсией 2 и выборочным средним 10, взятая из выборочного набора 11 (10 степеней свободы), используя формулу

Мы можем определить с 90% уровнем доверия, что истинное среднее таково:

(то есть, в среднем, в 90% случаев верхний предел превышает истинное среднее)
и, всё также с 90% уверенностью, мы находим истинное среднее значение, превышающее

(В среднем, в 90% случаев нижний предел меньше истинного среднего)
Так что с 80% уверенностью (1-2*(1-90%) = 80%), мы находим истинное значение, лежащее в интервале

Другими словами, в 80% случаев истинное среднее ниже верхнего предела и выше нижнего предела.
Это не эквивалентно утверждению, что с 80% вероятностью истинное среднее лежит между определенной парой верхних и нижних пределов.
Обобщение[править | править код]
Обобщением распределения Стьюдента является обобщённое гиперболическое распределение.
Примечания[править | править код]
- ↑ Helmert, F. R. (1875). “Über die Bestimmung des wahrscheinlichen Fehlers aus einer endlichen Anzahl wahrer Beobachtungsfehler”. Z. Math. Phys., 20, 300–3.
- ↑ Helmert, F. R. (1876a). “Über die Wahrscheinlichkeit der Potenzsummen der Beobachtungsfehler und uber einige damit in Zusammenhang stehende Fragen”. Z. Math. Phys., 21, 192–218.
- ↑ Helmert, F. R. (1876b). “Die Genauigkeit der Formel von Peters zur Berechnung des wahrscheinlichen Beobachtungsfehlers directer Beobachtungen gleicher Genauigkeit”, Astron. Nachr., 88, 113–32.
- ↑ Lüroth, J. Vergleichung von zwei Werten des wahrscheinlichen Fehlers (нем.) // Astron. Nachr. : magazin. — 1876. — Bd. 87, Nr. 14. — S. 209—220. — doi:10.1002/asna.18760871402. — Bibcode: 1876AN…..87..209L.
- ↑ Pfanzagl, J.; Sheynin, O. A forerunner of the t-distribution (Studies in the history of probability and statistics XLIV) (англ.) // Biometrika : journal. — 1996. — Vol. 83, no. 4. — P. 891—898. — doi:10.1093/biomet/83.4.891.
- ↑ Sheynin, O. Helmert’s work in the theory of errors (англ.) // Arch. Hist. Exact Sci. : journal. — 1995. — Vol. 49. — P. 73—104. — doi:10.1007/BF00374700.
- ↑ “Student” [William Sealy Gosset]. The probable error of a mean (англ.) // Biometrika : journal. — 1908. — March (vol. 6, no. 1). — P. 1—25. — doi:10.1093/biomet/6.1.1.
- ↑ “Student” (William Sealy Gosset), original Biometrika paper as a scan Архивная копия от 5 марта 2016 на Wayback Machine
- ↑ 1 2 Рональд Фишер. Applications of “Student’s” distribution (англ.) // metron. — 1925. — Vol. 5. — P. 90—104. Архивировано 5 марта 2016 года.
- ↑ 1 2 3 Johnson, N.L., Kotz, S., Balakrishnan, N. глава 28 // Continuous Univariate Distributions, Volume 2, 2nd Edition.. — 1995. — ISBN 0-471-58494-0.
- ↑ Hogg & Craig (1978, Sections 4.4 and 4.8.)
- ↑ W. G. Cochran. The distribution of quadratic forms in a normal system, with applications to the analysis of covariance // Mathematical Proceedings of the Cambridge Philosophical Society. — 1934-04-01. — Т. 30, вып. 02. — С. 178—191. — ISSN 1469-8064. — doi:10.1017/S0305004100016595.
- ↑ Simon Jackman. Bayesian Analysis for the Social Sciences. — Wiley. — 2009. — С. 507.
- ↑ Bishop C.M. Pattern recognition and machine learning. — Springer. — 2006.
- ↑ Ord, J.K. (1972) Families of Frequency Distributions, Griffin. ISBN 0-85264-137-0 (Table 5.1)
- ↑ Ord, J.K. (1972) Families of Frequency Distributions, Griffin. ISBN 0-85264-137-0 (Chapter 5)
- ↑ Королюк, 1985, с. 134.
- ↑ Kenneth L. Lange, Roderick J. A. Little, Jeremy M. G. Taylor. Robust Statistical Modeling Using the t Distribution // Journal of the American Statistical Association. — 1989-12-01. — Т. 84, вып. 408. — С. 881—896. — ISSN 0162-1459. — doi:10.1080/01621459.1989.10478852.
- ↑ 1 2 Ralph W. Bailey. Polar Generation of Random Variates with the t-Distribution // Mathematics of Computation. — 1994-01-01. — Т. 62, вып. 206. — С. 779—781. — doi:10.2307/2153537. Архивировано 3 апреля 2016 года.
Литература[править | править код]
- Королюк В. С., Портенко Н. И., Скороход А. В., Турбин А. Ф. Справочник по теории вероятностей и математической статистике. — М.: Наука, 1985. — 640 с.
Предположим, что надо сравнить между собой результаты выполнения тестов на внимание в двух группах. Чтобы узнать различаются ли группы между собой необходимо вычислить t-критерий Стьюдента для независимых выборок.
1. Внесем данные по группам в таблицу:
| № | Результаты группы №1 (сек.) | Результаты группы №2 (сек.) |
| 1 | 30 | 46 |
| 2 | 45 | 49 |
| 3 | 41 | 52 |
| 4 | 38 | 55 |
| 5 | 34 | 56 |
| 6 | 36 | 40 |
| 7 | 31 | 47 |
| 8 | 30 | 51 |
| 9 | 49 | 58 |
| 10 | 50 | 46 |
| 11 | 51 | 46 |
| 12 | 46 | 56 |
| 13 | 41 | 53 |
| 14 | 37 | 57 |
| 15 | 36 | 44 |
| 16 | 34 | 42 |
| 17 | 33 | 40 |
| 18 | 49 | 58 |
| 19 | 32 | 54 |
| 20 | 46 | 53 |
| 21 | 41 | 51 |
| 22 | 44 | 57 |
| 23 | 38 | 56 |
| 24 | 50 | 44 |
| 25 | 37 | 42 |
| 26 | 39 | 49 |
| 27 | 40 | 50 |
| 28 | 46 | 55 |
| 29 | 42 | 43 |
Шаг 2. Проверить распределения на нормальность.
Шаг 3. Рассчитать среднее арифметическое, стандартное отклонение и количество человек в каждой группе.
| Результаты группы №1 (сек.) | Результаты группы №2 (сек.) |
Шаг 4. Вычисляем эмпирическое значения по формуле t-критерия Стьюдента для независимых выборок
Шаг 5. Вычисляем степени свободы.
Шаг 6. Определяем по таблице критических значений t-Стьюдента уровень значимости.
Значение 6,09 больше чем значение 3,473 следовательно уровень значимости меньше 0,001
Шаг 7. Если уровень значимости меньше 0,05 делается вывод о наличи различий между группами. Таким образом между двумя группами есть различия в скорости выполнения тестов на внимание.
| Расчет критерия Т-Стьюдента для независимых выборок | |
| Расчет критерия Т-Стьюдента для независимых выборок в SPSS | Пример критерия Т-Стьюдента для независимых выборок в SPSS |
| Расчет критерия Т-Стьюдента для независимых выборок в Excell | Пример критерия Т-Стьюдента для независимых выборок в Excell |
| Критерий Т-Стьюдента для независимых выборок |
Пример расчета t-критерия Стьюдента для независимых выборок
Предположим, что надо сравнить между собой результаты выполнения тестов на внимание в двух группах. Чтобы узнать различаются ли группы между собой необходимо вычислить t-критерий Стьюдента для независимых выборок.
Чтобы узнать различаются ли группы между собой необходимо вычислить t-критерий Стьюдента для независимых выборок.
1. Внесем данные по группам в таблицу:
| № | Результаты группы №1 (сек.) | Результаты группы №2 (сек.) |
| 1 | 30 | 46 |
| 2 | 45 | 49 |
| 3 | 41 | 52 |
| 4 | 38 | 55 |
| 5 | 34 | 56 |
| 6 | 36 | 40 |
| 7 | 31 | 47 |
| 8 | 30 | 51 |
| 9 | 49 | 58 |
| 10 | 50 | 46 |
| 11 | 51 | 46 |
| 12 | 46 | 56 |
| 13 | 41 | 53 |
| 14 | 37 | 57 |
| 15 | 36 | 44 |
| 16 | 34 | 42 |
| 17 | 33 | 40 |
| 18 | 49 | 58 |
| 19 | 32 | 54 |
| 20 | 46 | 53 |
| 21 | 41 | 51 |
| 22 | 44 | 57 |
| 23 | 38 | 56 |
| 24 | 50 | 44 |
| 25 | 37 | 42 |
| 26 | 39 | 49 |
| 27 | 40 | 50 |
| 28 | 46 | 55 |
| 29 | 42 | 43 |
Шаг 2. Проверить распределения на нормальность.
Проверить распределения на нормальность.
Шаг 3. Рассчитать среднее арифметическое, стандартное отклонение и количество человек в каждой группе.
| Результаты группы №1 (сек.) | Результаты группы №2 (сек.) |
Шаг 4. Вычисляем эмпирическое значения по формуле t-критерия Стьюдента для независимых выборок
Шаг 5. Вычисляем степени свободы.
Шаг 6. Определяем по таблице критических значений t-Стьюдента уровень значимости.
Значение 6,09 больше чем значение 3,473 следовательно уровень значимости меньше 0,001
Шаг 7. Если уровень значимости меньше 0,05 делается вывод о наличи различий между группами. Таким образом между двумя группами есть различия в скорости выполнения тестов на внимание.
| Расчет критерия Т-Стьюдента для независимых выборок | |
| Расчет критерия Т-Стьюдента для независимых выборок в SPSS | Пример критерия Т-Стьюдента для независимых выборок в SPSS |
| Расчет критерия Т-Стьюдента для независимых выборок в Excell | Пример критерия Т-Стьюдента для независимых выборок в Excell |
| Критерий Т-Стьюдента для независимых выборок |
T Формула распределения | Вычислить распределение T студентов
Формула для расчета распределения T (которое также широко известно как распределение T Стьюдента) показана как вычитание среднего значения генеральной совокупности (среднее значение второй выборки) из среднего значения выборки (среднего значения первой выборки), которое составляет [ x̄ – μ ], которое затем делится на стандартное отклонение средних значений, которое изначально делится на квадратный корень из n, который представляет собой количество единиц в этой выборке [s ÷ √(n)].

Т-распределение — это вид распределения, который выглядит почти как кривая нормального распределения или кривая нормального распределения, но с немного более толстым и коротким хвостом. Если размер выборки мал, то это распределение будет использоваться вместо нормального распределения.
t = (x̄ – μ) / (s/√n)
Т-критерий Стьюдента (t-тест) простым языком
Сегодня мы говорим о t-критерии. Т-критерий наиболее популярный статистический тест в биомедицинских исследованиях. Также его называют парный Т-критерий Стьюдента, t-test, two-sample unpaired t-test. Однако, при использовании этого статистического инструмента допускается достаточно много ошибок. Сегодня в этой статье мы постараемся разобраться, как избежать ошибок применения t-критерия Стьюдента, как интерпретировать его результаты и как рассчитывать t-критерий самостоятельно. Об этом обо всем читайте далее.
При описании любого статистического критерия, будь то t-критерий Стьюдента, либо какой-либо еще, нужно вспомнить о том, как же вообще используются статистические критерии. Для того, чтобы понять, как используется любой критерий, нужно перейти к нескольким достаточно логичным для понимания этапам:
Этапы статистического вывода (statistic inference)
- Первый из них – это вопрос, который мы хотим изучить с помощью статистических методов. То есть первый этап: что изучаем? И какие у нас есть предположения относительно результата? Этот этап называется этап статистических гипотез.
- Второй этап – нужно определиться с тем, какие у нас есть в реальности данные для того, чтобы ответить на первый вопрос. Этот этап – тип данных.
- Третий этап состоит в том, чтобы выбрать корректный для применения в данной ситуации статистический критерий.
- Четвертый этап это логичный этап применения интерпретации любой формулы, какие результаты мы получили.
- Пятый этап это создание, синтез выводов относительно первого, второго, третьего, четвертого, пятого этапа, то есть что же получили и что же это в реальности значит.
Предлагаю долго не ходить вокруг да около и посмотреть применение t-критерия Стьюдента на реальном примере.
Видео-версия статьи
Пример использования т-критерия Стьюдента
А пример будет достаточно простой: мне интересно, стали ли люди выше за последние 100 лет. Для этого нужно подобрать некоторые данные. Я обнаружил интересную информацию в достаточно известной статье The Guardian (Tall story’s men and women have grown taller over last century, Study Shows (The Guardian, July 2016), которая сравнивает средний возраст человека в разных странах в 1914 году и в аналогичных странах в 2014 году.
Там приведены данные практически по всем государствам. Однако, я взял лишь 5 стран для простоты вычислений: это Россия, Германия, Китай, США и ЮАР, соответственно 1914 год и 2014 год.
Общее количество наблюдений – 5 в 1914 году в группе 1914 года и общее значение также 5 в 2014 году. Будем думать опять же для простоты, что эти данные сопоставимы, и с ними можно работать.
Дальше нужно выбрать критерии – критерии, по которым мы будем давать ответ. Равны ли средние по росту в 1914 году x̅1914 и в 2014 году x̅2014. Я считаю, что нет. Поэтому моя гипотеза это то, что они не равны (x̅1914≠x̅2014). Соответственно альтернативная гипотеза моему предположению, так называемая нулевая гипотеза (нулевая гипотеза консервативна, обратная вашей, часто говорит об отсутствии статистически значимых связей/зависимостей) будет говорить о том, что они между собой на самом деле равны (x̅1914=x̅2014), то есть о том, что все эти находки случайны, и я, по сути, не прав.
Теперь нужно дать какой-то аргументированный ответ. Даем его с помощью статистического критерия. Соответственно теперь наступает самое важное: как выбрать статистический критерий? Я думаю, это будет темой отдельной статьи. Для корректности использования t-критерия Стьюдента лишь скажу, что нужно, чтобы:
Условия применения статистического критерия т-теста (критерия Стьюдента)
— данные распределялись по закону нормального распределения;
— данные были количественными;
— и это две независимые между собой выборки (независимые это значит, что в этих группах разные люди, а никак, например, до и после применения препарата у одной группы, люди должны быть разными, тогда группы являются несвязанными, либо независимыми), этот аспект стоит учитывать для выбора вида т-критерия Стьюдента, так как для парных выборок существует свой парный т-критерий (paired t-test).
В итоге Мы определились с тем, что это будет t-критерий Стьюдента.
Формула t-критерия Стьюдента достаточно простая. Она гласит о том, что в числителе у нас разница средних, в знаменателе у нас корень квадратный суммы ошибок репрезентативности по этим группам:
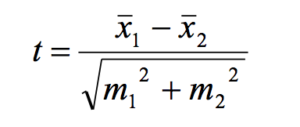
Ошибки репрезентативности были подробно объяснены мною в статье по доверительным интервалам. Поэтому я рекомендую вам ознакомиться с ней, чтобы лучше разобраться, что такое ошибки репрезентативности, что такое выборка, как она соотносится с генеральной совокупностью.
Для того, чтобы не тратить время, я в принципе все уже рассчитал по каждой из групп: средняя (x̅) ,стандартное отклонение (SD) и ошибка репрезентативности (mr).
Давайте остановимся на том, что же значат эти значения:
— средняя (x̅) это среднеарифметическое по 5 наблюдениям в каждой группе;
— если совсем упрощать значение стандартного отклонения (SD), то можно сказать, что оно представляет собой обобщенную среднюю отклонения каждого значения от среднего (стандартное отклонение показывает, насколько широко значения рассеяны (разбросаны) относительно средней). И дальше мы находим нечто среднее отклонений каждого варианта в группе от среднего;
— и ошибка репрезентативности она тоже находится достаточно просто: это как раз наше отклонение от средней некоторое стандартизованное, поэтому стандартное отклонение на размер выборки (mr=).
Итак, продолжаем. В ходе подстановки каждого значения в нашу формулу, мы находим, что t-критерий Стьюдента равен 3,78. Однако, я думаю, пока тем, кто не знаком со статистическими критериями, это мало о чем говорит.
Итак, теперь настает четвертый этап вопрос интерпретации. Ранее мы получили значение t-критерия в 3,78. Однако, что же это значит? Стоит отметить, что результаты статистических критериев и вообще их интерпретация не говорит о точном «да», либо «нет» в выводе, то есть рост отличается, либо рост не отличается. Всегда это вопрос определенной доли вероятности – доли вероятности ошибиться при констатации положительного результата (речь об ошибке первого рода (I type error, Alpha)). То есть, например, если мы скажем, что средний рост в начале ХХ и в начале XXI века отличаются с долей ошибкой меньше 5 %. Как раз эта величина в 5 % и фиксируется как достаточная для большинства биомедицинских исследований, помните, р больше, либо меньше 0,05.
Итак, как нам перейти от нашей t к р вероятности? Это сделать достаточно просто, стоит лишь воспользоваться табличными значениями t для определенных степеней свободы. Теперь вопрос: как найти эти степени свободы? Но это сделать достаточно просто. Для того, чтобы обнаружить степени свободы для наших групп, нужно лишь сложить количество наблюдений 5 и 5 в нашем случае и вычесть 2. В нашем случае степень свободы равна 8.
Итак, t=3,78, степень свободы равна 8. Переходим в табличное значение и получаем р вероятность – вероятность равна 0,005. То есть вероятность того, что мы ошибаемся при констатации факта различия роста ранее и сейчас, крайне мала – это 0,005 %, не 5 %, а 0,005 %. То есть мы можем говорить с высокой долей достоверности того, что наш рост сейчас в XXI веке и 100 лет назад отличаются.
Вот то, что касается расчета t-критерия Стьюдента и его интерпретации.
На этом наш разговор о t-критерии Стьюдента закончен. Спасибо, что ознакомились с этой статьей. Я очень надеюсь на вашу обратную связь. Пожалуйста, подписывайтесь на наш сайте, ставьте лайки, предлагайте свои темы для следующих выпусков. Спасибо большое за поддержку. С вами был Кирилл Мильчаков. Пока, до новых встреч!

Если Вам понравилась статья и оказалась полезной, Вы можете поделиться ею с коллегами и друзьями в социальных сетях:
Критерий Фишера и критерий Стьюдента в эконометрике
С помощью критерия Фишера оценивают качество регрессионной модели в целом и по параметрам.
Для этого выполняется сравнение полученного значения F и табличного F значения. F-критерия Фишера. F фактический определяется из отношения значений факторной и остаточной дисперсий, рассчитанных на одну степень свободы:

где n — число наблюдений;
m — число параметров при факторе х.
F табличный — это максимальное значение критерия под влиянием случайных факторов при текущих степенях свободы и уровне значимости а.
Уровень значимости а — вероятность не принять гипотезу при условии, что она верна. Как правило а принимается равной 0,05 или 0,01.
Если Fтабл > Fфакт то признается статистическая незначимость модели, ненадежность уравнения регрессии.
Таблицы по нахождению критерия Фишера и Стьюдента
Таблицы значений F-критерия Фишера и t-критерия Стьюдента Вы можете посмотреть здесь.
Табличное значение критерия Фишера вычисляют следующим образом:
- Определяют k1, которое равно количеству факторов (Х). Например, в однофакторной модели (модели парной регрессии) k1=1, в двухфакторной k=2.
- Определяют k2, которое определяется по формуле n — m — 1, где n — число наблюдений, m — количество факторов. Например, в однофакторной модели k2 = n — 2.
- На пересечении столбца k1 и строки k2 находят значение критерия Фишера
Для нахождения табличного значения критерия Стьюдента определяют число степеней свободы, которое определяется по формуле n — m — 1 и находят его значение при определенном уровне значимости (0,10, 0,05, 0,01).
Критерии Стьюдента
Для оценки статистической значимости модели по параметрам рассчитывают t-критерии Стьюдента.
Оценка значимости модели с помощью критерия Стьюдента проводится путем сравнения их значений с величиной случайной ошибки:

Случайные ошибки коэффициентов линейной регрессии и коэффициента корреляции определяются по формулам:

Сравнивая фактическое и табличное значения t-статистики и принимается или отвергается гипотеза о значимости модели по параметрам.
Зависимость между критерием Фишера и значением t-статистики Стьюдента определяется так

Как и в случае с оценкой значимости уравнения модели в целом, модель считается ненадежной если tтабл > tфакт
Видео лекциий по расчету критериев Фишера и Стьюдента
Для более подробного изучения расчетов критериев Фишера и Стьюдента советуем посмотреть это видео
Лекция 1. Критерии и Гипотезы
Лекция 2. Критерии и Гипотезы
Лекция 3. Критерии и Гипотезы
Определение доверительных интервалов
Для построения доверительного интервала определяется предельная ошибка А для обоих показателей:

Формулы для нахождения доверительных интервалов выглядят так

Прогнозное значение у определяется с помощью подстановки в
уравнение регрессии прогнозного значения х. Вычисляется средняя стандартная ошибка прогноза

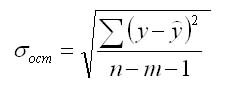
и находится доверительный интервал
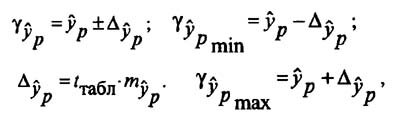
Задача регрессионного анализа в предмете эконометрика состоит в анализе дисперсии изучаемого показателя y:

 общая сумма квадратов отклонений (TSS)
общая сумма квадратов отклонений (TSS)
 сумма квадратов отклонений, обусловленная регрессией (RSS)
сумма квадратов отклонений, обусловленная регрессией (RSS)
 остаточная сумма квадратов отклонений (ESS)
остаточная сумма квадратов отклонений (ESS)
Долю дисперсии, обусловленную регрессией, в общей дисперсии показателя у характеризует коэффициент детерминации R, который должен превышать 50% (R2 > 0,5). В контрольных по эконометрике в ВУЗах этот показатель рассчитывается всегда.

