Эффективный анализ данных имеет важное значение для всех сотрудников, независимо от департамента и занимаемой должности. Умение выявлять и изучать скрытые тенденции — необходимый навык как для маркетолога, анализирующего окупаемость рекламных кампаний, так и для продакт-менеджера, просматривающего данные об использовании продукта.
К сожалению, многие компании испытывают затруднения со сбором, обработкой и анализом данных. Глобальный опрос Splunk показал, что 55% всех данных, собираемых компаниями, остаются необработанными и не используются. Иногда в компании даже не знают о сборе информации, в других случаях сотрудники просто не умеют анализировать данные.
76% руководителей считают, что обучение сотрудников анализу и обработке различных типов данных поможет решить проблему и компания сможет эффективно использовать информацию.
К счастью, анализ данных — навык, которому можно научиться. Чтобы понять, как анализировать данные, вам не нужно иметь ученую степень в области статистики или часами изучать учебные модули. Вместо этого мы составили данное руководство, чтобы помочь вам понять, как анализировать данные — очистка данных, выбор правильных инструментов анализа, анализ закономерностей и тенденций. Вы сможете получить ценные практические сведения и на их основании сделать точные выводы.
Определите цели
Поставьте перед собой конкретные цели еще до начала анализа данных. Если вы не имеете четкого представления, что ищете, то будете часами, ожидая момента озарения, просто смотреть в электронную таблицу или просматривать бесчисленные запросы в службу поддержки.
Цели зависят от того, в какой команде вы состоите, какие данные собираете и какую должность занимаете:
- Команда финансового департамента анализирует расходы и ищет возможности экономии средств.
- Команда маркетинга наблюдает за активностью потенциальных клиентов и ищет способы повысить конверсию за счет бесплатной пробной версии продукта.
- Команда инженеров должна понимать, сколько клиентов пострадало в результате недавнего сбоя в системе, поэтому просматривает данные об использовании продукта.
- Команда разработчиков продукта должна установить очерёдность разработки новых функций и исправлений ошибок, поэтому анализирует последние запросы в службу поддержки и выделяет среди них наиболее важные.
Цели будут влиять на то, какие именно данные вы собираете, какие инструменты анализа используете и какую полезную информацию в результате получите.
Очистите данные и удалите все ненужное
Ваш анализ данных будет настолько хорош, насколько хороши исходные данные. Если полученная информация фрагментарна, неточна или непоследовательна, то выводы в результате будут неполными или вводящими в заблуждение. Поэтому после сбора данных обязательно очистите их и убедитесь, что они непротиворечивы и не содержат повторяющуюся информацию.
Если вы работаете с небольшим объемом данных, вам может быть проще вручную очистить его в электронной таблице. Вот несколько простых вещей, которые вы можете сделать, чтобы очистить данные:
- Добавьте в электронную таблицу строки заголовков, это упростит понимание информации.
- Удалите повторяющиеся строки или столбцы, если у вас оказалось несколько копий одной и той же записи.
- Если вы экспортировали данные, удалите строки или столбцы, которые не собираетесь использовать. Например, многие инструменты добавляют столбец «ID» или временные отметки, которые вам не нужны.
- Стандартизируйте данные, чтобы числовые значения, такие как числа, даты или валюта, выражались в едином формате.
Если вы работаете с обширным массивом данных, намного сложнее очищать их вручную. Чтобы ускорить процесс, используйте инструменты для очистки данных, такие как OpenRefine или Talend. Они быстро убирают запутанную, противоречивую информацию и данные после их обработки готовы к следующему этапу анализа.
Внедрите стратегию управления данными, чтобы установить четкие принципы организации данных и сократить количество времени на процесс очистки в будущем. Вот несколько передовых методов управления данными:
- Разработайте стандартную процедуру, когда и как собирать данные.
- Утвердите стандартизированное соглашение по присвоению имён, чтобы уменьшить несоответствия.
- Если у вас автоматизирован процесс сбора данных, внимательно относитесь к любым некорректным данным. В случае сообщения об ошибке, изучите свои настройки, чтобы определить причину.
- Редактируйте и обновляйте данные, собранные в прошлом, чтобы они соответствовали вашим новым стандартам качества.
Очистка и стандартизация данных — важный подготовительный шаг к анализу. Этот этап снижает вероятность неправильных выводов, полученных на основе противоречивых данных, и повышает вероятность получить ценную и полезную информацию.
Создайте свой набор инструментов для анализа данных
Многие компании для хранения и анализа данных полагаются на Excel или другие инструменты для работы с электронными таблицами. Но существует множество других сервисов, которые помогут вам анализировать данные. Выбор инструмента зависит от двух вещей:
- Тип данных. Количественные данные часто переданы в числовой форме, что идеально подходит для их представления в электронных таблицах и инструментах визуализации. Но качественные данные, такие как ответы на анкеты, ответы на опросы, запросы в службу поддержки или сообщения в социальных сетях, неструктурированны, что затрудняет извлечение полезной информации в файл электронной таблицы. Для эффективного анализа качественных данных вам нужно их структурировать.
- Объем данных. Если вы анализируете небольшое количество данных один раз в неделю или в месяц, можно это делать вручную. Но чем больше данных вы обрабатываете, тем больше вероятность того, что придется инвестировать в инструменты для автоматизации процесса. Специализированные сервисы снизят вероятность человеческой ошибки и ускорят процесс анализа.
Вот несколько инструментов для анализа данных, которые будут полезным дополнением к вашему набору. Конечно, вы не будет использовать их все одновременно, так как каждый из них подходит для определенного типа данных.
- Электронные таблицы, такие как Excel или Google Sheets — традиционные инструменты для изучения данных. Они отлично подходят для анализа небольших и средних объемов данных и не требуют глубоких технических знаний.
- Инструменты бизнес-аналитики (BI) используют компании, которые собирают и анализируют большие объемы данных.
- Инструменты прогнозного анализа используют алгоритмы машинного обучения и данные компании за прошедшие периоды. Они просчитывают, как изменения в рабочих процессах повлияют на результаты в будущем.
- Инструменты моделирования данных показывают структуру и характер информационных потоков и их связь с различными бизнес-системами. Компании используют этот тип инструментов, чтобы увидеть, какие отделы хранят какие данные и как эти данные взаимодействуют.
- Инструменты аналитики для конкретных департаментов используются командами для анализа данных с учетом специфики их функциональных обязанностей. Например, отдел кадров отслеживает множество данных о людях, такие как заработная плата, производительность и данные о назначениях, поэтому для HR-аналитики подходит сервис ChartHop. Он будет проще в использовании, чем электронная таблица.
- Инструменты визуализации данных представляют информацию в виде диаграмм, графиков и других графических изображений, что упрощает выявление тенденций.
Выберите те инструменты, которые помогут быстро проанализировать данные и извлечь труднодоступную информацию.
Ищите закономерности и тенденции
Ваши данные очищены, и у вас в распоряжении множество инструментов — начинайте процесс анализа данных.
Сначала необходимо определить тенденции. Если большая часть данных в числовом формате, относительно легко отобразить закономерности на диаграммах или других средствах визуализации. Но если присутствуют неструктурированные данные, такие как электронные письма или заявки в службу поддержки, вам может понадобиться другой подход. Вот несколько методов анализа данных, которые можно попробовать в таком случае:
- Анализ текста использует машинное обучение для извлечения информации из неструктурированных текстовых данных, таких как электронные письма, сообщения в социальных сетях, запросы в службу поддержки и обзоры продуктов. Этот метод обнаруживает и интерпретирует закономерности в неструктурированных данных. Примеры инструментов для анализа текста: Thematic, Re:infer
- Анализ тональности текста использует машинное обучение и обработку естественного языка для обнаружения положительных или отрицательных эмоций в неструктурированных текстовых данных. Компании часто используют этот анализ, чтобы оценить восприятие бренда в сообщениях социальных сетей, в отзывах о продуктах и в запросах службы поддержки. Примеры инструментов анализа тональности текста: IBM Watson, MonkeyLearn.
- Тематический анализ использует обработку естественного языка для присвоения текстовым данным предварительно заданных тегов. Это полезно для организации и структурирования текстовых данных. Например, можно использовать тематический анализ для классификации отзывов службы поддержки, чтобы понять, какие направления вызывают у клиентов наибольшие проблемы. Примеры инструментов тематического анализа: Datumbox, MonkeyLearn.
- Групповой анализ включает в себя изучение данных в группах похожих клиентов в определенные временные рамки. Вы можете отследить изменения в использовании продукта клиентами, которые подписались на извещения в один и тот же период времени. Примеры инструментов группового анализа: электронные таблицы, Looker
Выявляя закономерности, не думайте, что связь между двумя вещами всегда является причинно-следственной. Например, если вы наблюдаете значительное увеличение количества подписчиков в социальных сетях и параллельно рост числа подписок на извещения, то можете предположить, что все новые клиенты приходят из социальных сетей. Но если вы отследите данные в Google Analytics, то увидите, что очень мало людей посещают ваш сайт из социальных сетей, не говоря уже о подписке.
Предположение, что при связи между двумя вещами одна из них является причиной, называется ложной причинно-следственной связью, и это одна из самых распространенных ошибок при анализе данных. Часто есть еще один фактор, который и вызвал обнаруженную тенденцию. Поэтому найдите время, чтобы собрать достаточно информации и убедиться, что ваши выводы точны.
Сопоставьте текущие данные с прошлым периодом
Если вам сложно определить тенденции и закономерности, это может быть связано с тем, что вы обособленно рассматриваете данные. Вы не можете отследить тенденции, потому что все, что вы видите — это лишь часть чего-то большего. Вам не хватает связи с данными предыдущего периода.
Чтобы найти эту связь, сравните текущие данные с показателями прошлых периодов. Если это невозможно — например, вы просматриваете данные об использовании совершенно новой функции продукта или это ваш первый анализ — тогда взгляните на эталонные показатели вашей отрасли.
Поиск в Google по запросу «статистика работы [отдела]» или «статистика [отрасли] [отдела]» предоставит полезные контрольные показатели для различных компаний, отделов и отраслей. Тематические издания, а также исследования, представленные на конференциях, также являются хорошими источниками контрольных данных.
Например, Zendesk Benchmark позволяет компаниям сравнивать данные о работе службы поддержки клиентов со средними показателями по отрасли:
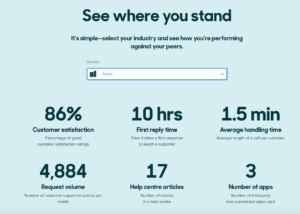
Zendesk Benchmark — это возможность сравнить свои данные с контрольными, что поможет оценить эффективность вашей службы поддержки внутри отрасли.
Совет: если вы используете контрольные данные, может быть сложно найти компании такого же размера или уровня развития. Поэтому используйте цифры как ориентир, но не проводите прямое сравнение результатов.
Ищите данные, которые идут в разрез с вашими ожиданиями
Когда вы анализируете данные, то устанавливаете четкие цели и ожидания в отношении того, что хотите узнать и какую информацию ожидаете найти. Но это может привести к необъективности восприятия, когда вы с большей вероятностью заметите тенденции, которые подтверждают ваши существующие предположения или гипотезы.
Сохраняйте объективность, ищите тенденции или результаты, которые идут вразрез с вашими ожиданиями. Также ищите в необработанных данных выбросы. Эта практика поможет избежать избирательных выводов, которые подтверждают уже укоренившиеся убеждения.
Если вы обнаружите отклонения от нормы, изучите их глубже — здесь может быть простое объяснение. Например, ваша маркетинговая команда разослала информационное письмо, но вы не видите никакого трафика на веб-сайт. Возможно, они отправили его во внутренний тестовый список или забыли добавить UTM-параметры к ссылкам.
Также отслеживайте, насколько значительные выбросы влияют на конечные результаты. Они могут легко исказить средние значения — тогда вместо них необходимо отслеживать медиану. Она использует среднее значение числовых данных, поэтому выбросы искажают ее меньше. Возможно, понадобится полностью исключить выбросы из анализа.
Визуализируйте данные и интерпретируйте результаты
Часто легче понять и интерпретировать данные, когда они представлены визуально, а не в электронной таблице. Используйте Google Data Studio или Tableau для представления данных в виде диаграмм, графиков или других графических изображений, чтобы вы могли четко изложить результаты работы другим членам команды.
Если вы работаете с большими объемами данных, не пытайтесь одномоментно представлять слишком много информации. Зрители намного лучше воспринимают результаты анализа данных, если они будут показаны в простых диаграммах.
Следующие шаги: что делать после анализа данных
Нет смысла собирать и анализировать все эти данные, если вы ничего не делаете с полученной информацией. Используя результаты, вы можете:
- Установить реальные цели и ключевые показатели эффективности (KPI) на основе текущих данных.
- Улучшить качество обслуживания клиентов, так как анализ поможет понять потребности и поведение клиентов.
- Расставить приоритеты в плане-графике развития вашего продукта на основе анализа использования продукта и запросов в службу поддержки.
- Принимать более обдуманные и уверенные деловые решения, поскольку у вас будет четкое понимание того, что работает, а что нет.
Хотя анализ данных часто занимает много времени, важно помнить, что это не конечная цель. Вы анализируете данные, чтобы иметь возможность принимать обоснованные решения в будущем.
Учимся анализировать — полный цикл
Время на прочтение
24 мин
Количество просмотров 12K
Всем привет! Долго собирался выложить данный пост и вот настал момент = )
Контент будет ориентирован на новичков в анализе данных, ниже мы с Вами рассмотрим статистику работающих и безработных людей, поставим цели и проверим гипотезы.
Язык программирования: Python
Весь код указан с пояснениями, но если у Вас возникли вопросы – отвечу в комментариях.
Начнем!!!
Тема: “Демографическая ситуация по субъектам РФ”
Описание проекта:
Перед нами представлен набор данных, который несет в себе информацию о численности экономически активного населения, безработных, уровне безработицы и сопоставляет все эти показатели между различными возрастными группами по субьектам РФ за период 2001-2019 гг.
Цель проекта:
1.
Определить на какой территории минимальный и максимальный процент безработных за весь период времени.
2. Проверить гипотезу: в каждой из возрастных категорий среднее значение занятых идентично средниму значению безработных
3. Проверить гипотезу: среднее значение безработных (в возрасте от 40 до 49 лет) в Брянской области одинаково со средним значением безработных возрасте до 20 лет
4. Проверить гипотеза: средний показатель безработицы в 2009 и 2019 году одинаков
План анализа данных:
1.
Изучение общей информации
2. Предобработка данных
2.1. Проверка корректности наименований колонок;
2.2. Проверка и обработка пропущенных значений;
2.3. Проверка и обработка дубликатов;
2.4. Проверка и обработка типов данных;
3. Исследовательский анализ данных
3.1. Построение гистограммы с количеством безработных и занятых (общему количеству и по конкретной территории);
3.2. Определение на какой территории минимальный и максимальный процент безработных;
3.3. Вычислить среднее число безработных и занятых (по каждой территории)
3.4. Выделить ТОП-5 территорий по безработным и занятым
3.5. Построение столбчатой диаграммы с количеством занятых (по возрастным категориям)
3.6. Построение столбчатой диаграммы с количеством безработных (по возрастным категориям)
4. Проверка гипотез
4.1. Гипотеза: в каждой из возрастных категорий среднее значение занятых идентично среднему значению безработных
4.3. Гипотеза: среднее значение безработных (в возрасте от 40 до 49 лет) в Брянской области одинаково со средним значением безработных возрасте до 20 лет
4.4. Гипотеза: средний показатель безработицы в 2009 и 2019 одинаков
5. Дополнительная информация
5.1. Подготовка документации по библиотекам
6. Общий вывод
Описание данных:
territory – наименование территории по ОКАТО
num_economactivepopulation_all – численность экономически активного населения – всего
employed_num_all – занятые в экономике
unemployed_num_all – безработные
eactivity_lvl – уровень экономической активности
employment_lvl – уровень занятости
unemployment_lvl – уровень безработицы
dis_unagegroup_to20 – распределение безработных в возрасте до 20 лет по регионам РФ
dis_unagegroup_20-29 – распределение безработных в возрасте от 20 до 29 лет по регионам РФ
dis_unagegroup_30-39 – распределение безработных в возрасте от 30 до 39 лет по регионам РФ
dis_unagegroup_40-49 – распределение безработных в возрасте от 40 до 49 лет по регионам РФ
dis_unagegroup_50-59 – распределение безработных в возрасте от 50 до 59 лет по регионам РФ
dis_unagegroup_60older – распределение безработных в возрасте 60 и более лет по регионам РФ
dis_emagegroup_to20 – распределение занятых в экономике в возрасте до 20 лет по регионам РФ
dis_emagegroup_20-29 – распределение занятых в экономике в возрасте от 20 до 29 лет по регионам РФ
dis_emagegroup_30-39 – распределение занятых в экономике в возрасте от 30 до 39 лет по регионам РФ
dis_emagegroup_40-49 – распределение занятых в экономике в возрасте от 40 до 49 лет по регионам РФ
dis_emagegroup_50-59 – распределение занятых в экономике в возрасте от 50 до 59 лет по регионам РФ
dis_emagegroup_60older – распределение занятых в экономике в возрасте 60 и более лет по регионам РФ
num_unagegroup_to20 – численность безработных в возрасте до 20 лет по регионам РФ
num_unagegroup_20-29 – численность безработных в возрасте от 20 до 29 лет по регионам РФ
num_unagegroup_30-39 – численность безработных в возрасте от 30 до 39 лет по регионам РФ
num_unagegroup_40-49 – численность безработных в возрасте от 40 до 49 лет по регионам РФ
num_unagegroup_50-59 – численность безработных в возрасте от 50 до 59 лет по регионам РФ
num_unagegroup_60older – численность безработных в возрасте 60 и более лет по регионам РФ
num_emagegroup_to20 – численность занятых в экономике регионов РФ в возрасте до 20 лет
num_emagegroup_20-29 – численность занятых в экономике регионов РФ в возрасте от 20 до 29 лет
num_emagegroup_30-39 – численность занятых в экономике регионов РФ в возрасте от 30 до 39 лет
num_emagegroup_40-49 – численность занятых в экономике регионов РФ в возрасте от 40 до 49 лет
num_emagegroup_50-59 – численность занятых в экономике регионов РФ в возрасте от 50 до 59 лет
num_emagegroup_60older – численность занятых в экономике регионов РФ в возрасте 60 и более лет
year – отчетный год
Изучение общей информации
Откроем файл с данными и изучим общую информацию
# импортируем необходимые библиотеки
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import numpy as np
from scipy import stats as st
import warnings
warnings.filterwarnings('ignore')
# для полноценной работы со строками мы уберем ограничение строк и столбцов в отображении
pd.set_option('display.max_rows', None)
pd.set_option('display.max_columns', None)# присвоим переменной data нашу таблицу
data = pd.read_csv('Desktop/Датасеты/Статистические данные о занятости и безработице среди населения/data.csv')
# выведем первые пять строки нашей таблицы
data.head()
Посмотрим на информацию по нашим столбцам.
С помощью метода info() мы можем увидеть типы каждого из столбцов.
# проверяем типы столбцов
data.info()
Мы ознакомились с данными, с которыми в дальнейшем будем работать. Теперь перейдем к самой обработке.
Предобработка данных
Проверка корректности наименований колонок
# отобразим названия колонок
list(data.columns)
Теперь мы переименуем наши колонки, чтобы они стали более понятными.
data.rename(columns = {
'territory' : 'Территория',
'num_economactivepopulation_all' : 'Численность населения',
'employed_num_all' : 'Занятые в экономике',
'unemployed_num_all' : 'Безработные',
'eactivity_lvl' : 'Уровень экономической активности',
'employment_lvl' : 'Уровень занятости',
'unemployment_lvl' : 'Уровень безработицы',
'dis_unagegroup_to20' : 'Распределение безработных (до 20 лет)',
'dis_unagegroup_20-29' : 'Распределение безработных (от 20 до 29 лет)',
'dis_unagegroup_30-39' : 'Распределение безработных (от 30 до 39 лет)',
'dis_unagegroup_40-49' : 'Распределение безработных (от 40 до 49 лет)',
'dis_unagegroup_50-59' : 'Распределение безработных (от 50 до 59 лет)',
'dis_unagegroup_60older' : 'Распределение безработных (60 и более лет)',
'dis_emagegroup_to20' : 'Распределение занятых (до 20 лет)',
'dis_emagegroup_20-29' : 'Распределение занятых (от 20 до 29 лет)',
'dis_emagegroup_30-39' : 'Распределение занятых (от 30 до 39 лет)',
'dis_emagegroup_40-49' : 'Распределение занятых (от 40 до 49 лет)',
'dis_emagegroup_50-59' : 'Распределение занятых (от 50 до 59 лет)',
'dis_emagegroup_60older' : 'Распределение занятых (60 и более лет)',
'num_unagegroup_to20' : 'Численность безработных (до 20 лет)',
'num_unagegroup_20-29' : 'Численность безработных (от 20 до 29 лет)',
'num_unagegroup_30-39' : 'Численность безработных (от 30 до 39 лет)',
'num_unagegroup_40-49' : 'Численность безработных (от 40 до 49 лет)',
'num_unagegroup_50-59' : 'Численность безработных (от 50 до 59 лет)',
'num_unagegroup_60older' : 'Численность безработных (60 и более лет)',
'num_emagegroup_to20' : 'Численность занятых (до 20 лет)',
'num_emagegroup_20-29' : 'Численность занятых (от 20 до 29 лет)',
'num_emagegroup_30-39' : 'Численность занятых (от 30 до 39 лет)',
'num_emagegroup_40-49' : 'Численность занятых (от 40 до 49 лет)',
'num_emagegroup_50-59' : 'Численность занятых (от 50 до 59 лет)',
'num_emagegroup_60older' : 'Численность занятых (60 и более лет)',
'year' : 'Год',
}, inplace = True)Далее проверим как изменились наши столбцы.
list(data.columns)
Теперь колонки имеют более читабельный вид. Перейдем к обработке пропусков.
Проверка и обработка пропущенных значений
Перед тем, как мы будем делать обработку – нам необходимо проверить количество пропусков в каждом столбце.
# проверим количество пропусков (метод isnull()) и посчитаем сумму (метод sum())
data.isnull().sum()
Мы видим в каждой ячейке пропущенные значения, кроме “Территории” и “Год”. В большинстве столбцов пропущенных значений (2) и мы можем предположить, что две строки полностью пустые. Но для того, чтобы точно определиться мы это проверим.
# проверяем пропуска, во всех ли столбцах они есть? и предпримем необходимые действия
data[pd.isnull(data).any(axis=1)]
Действительно строка 40 и строка 131 с пустыми значениями. Предположительно по этим территориям не фиксировались данные, поэтому мы исключим строки.
# удаляем строки, в которых отсутствуют данные по всем ячейкам. Это строки 40 и 131
data.drop(labels = [40,131],axis = 0, inplace = True)# проверяем, как удалились строки 40 и 131
data[pd.isnull(data).any(axis=1)]
Проверим сколько пропусков у нас осталось сейчас.
data.isnull().sum()
Осталось еще несколько столбцов с пропусками – поработаем и с ними.
Значения в этих ячейках указаны в процентах. Посчитаем сколько процентов сейчас, учитывая, что у нас есть незаполненные ячейки. В указанных столбцах распределение безработных и занятых.
# выведем индексы, они нам понадобятся в дальнейшей работе
data_index = data[pd.isnull(data).any(axis=1)]
print(data_index.index)
# создадим функцию для расчета значений по нескольким столбцам
def data_dis_unage_emage (index):
data_dis_unage = data.loc[index, ['Распределение безработных (до 20 лет)', 'Распределение безработных (от 20 до 29 лет)',
'Распределение безработных (от 30 до 39 лет)', 'Распределение безработных (от 40 до 49 лет)',
'Распределение безработных (от 50 до 59 лет)', 'Распределение безработных (60 и более лет)']].sum()
data_dis_emage = data.loc[index, ['Распределение занятых (до 20 лет)', 'Распределение занятых (от 20 до 29 лет)',
'Распределение занятых (от 30 до 39 лет)', 'Распределение занятых (от 40 до 49 лет)',
'Распределение занятых (от 50 до 59 лет)', 'Распределение занятых (60 и более лет)']].sum()
# выведем значение столбца с наименованием территорий
name = data.loc[index, 'Территория']
print(name)
print('Распределение безработных -', data_dis_unage.round(), '%')
print('Распределение занятых -', data_dis_emage.round(), '%')
print()
# пройдемся циклом по всем нашим строкам со значением NaN в рассматриваемых столбцах
for i in data_index.index:
data_dis_unage_emage(i)Калининградская область
Распределение безработных – 100.0 %
Распределение занятых – 100.0 %
Псковская область
Распределение безработных – 100.0 %
Распределение занятых – 100.0 %
Республика Ингушетия
Распределение безработных – 100.0 %
Распределение занятых – 100.0 %
Карачаево-Черкесская Республика
Распределение безработных – 100.0 %
Распределение занятых – 100.0 %
Республика Мордовия
Распределение безработных – 100.0 %
Распределение занятых – 100.0 %
Республика Ингушетия
Распределение безработных – 100.0 %
Распределение занятых – 100.0 %
Республика Алтай
Распределение безработных – 100.0 %
Распределение занятых – 100.0 %
Орловская область
Распределение безработных – 100.0 %
Распределение занятых – 100.0 %
Тамбовская область
Распределение безработных – 100.0 %
Распределение занятых – 100.0 %
Ямало-Ненецкий автономный округ
Распределение безработных – 100.0 %
Распределение занятых – 100.0 %
Республика Тыва
Распределение безработных – 100.0 %
Распределение занятых – 100.0 %
Чукотский автономный округ
Распределение безработных – 100.0 %
Распределение занятых – 100.0 %
Орловская область
Распределение безработных – 100.0 %
Распределение занятых – 100.0 %
Республика Адыгея
Распределение безработных – 100.0 %
Распределение занятых – 100.0 %
г. Севастополь
Распределение безработных – 100.0 %
Распределение занятых – 100.0 %
Кабардино-Балкарская Республика
Распределение безработных – 100.0 %
Распределение занятых – 100.0 %
Тамбовская область
Распределение безработных – 100.0 %
Распределение занятых – 100.0 %
Ямало-Ненецкий автономный округ
Распределение безработных – 100.0 %
Распределение занятых – 100.0 %
Амурская область
Распределение безработных – 100.0 %
Распределение занятых – 100.0 %
Чукотский автономный округ
Распределение безработных – 100.0 %
Распределение занятых – 100.0 %
Мы проверили распределение занятых и безработных людей, и учитывая что некоторые ячейки у нас имели значение NaN, то все равно общий процент 100%. Тем самым мы можем заменить NaN на значение 0 в этих ячейках.
# заменяем с помощью метода fillna()
data[['Распределение безработных (до 20 лет)', 'Распределение безработных (от 20 до 29 лет)', 'Распределение безработных (от 30 до 39 лет)', 'Распределение безработных (от 40 до 49 лет)', 'Распределение безработных (от 50 до 59 лет)', 'Распределение безработных (60 и более лет)']] = data[['Распределение безработных (до 20 лет)', 'Распределение безработных (от 20 до 29 лет)', 'Распределение безработных (от 30 до 39 лет)', 'Распределение безработных (от 40 до 49 лет)', 'Распределение безработных (от 50 до 59 лет)', 'Распределение безработных (60 и более лет)']].fillna(0)
data[['Распределение занятых (до 20 лет)', 'Распределение занятых (от 20 до 29 лет)', 'Распределение занятых (от 30 до 39 лет)', 'Распределение занятых (от 40 до 49 лет)', 'Распределение занятых (от 50 до 59 лет)', 'Распределение занятых (60 и более лет)']] = data[['Распределение занятых (до 20 лет)', 'Распределение занятых (от 20 до 29 лет)','Распределение занятых (от 30 до 39 лет)', 'Распределение занятых (от 40 до 49 лет)', 'Распределение занятых (от 50 до 59 лет)', 'Распределение занятых (60 и более лет)']].fillna(0)
# делаем проверку по индексу 26
data.loc[26]
В столбце “Распределение безработных (60 и более лет)” значение с “NaN” поменялось на 0.0, значения изменились. Продолжим работать с остальными пропусками.
# проверяем какие пропуска остались
data[pd.isnull(data).any(axis=1)]
# выведем индексы, они нам понадобятся в дальнейшей работе
data_index_1 = data[pd.isnull(data).any(axis=1)]# заменяем с помощью метода fillna()
data[['Численность безработных (до 20 лет)',
'Численность безработных (от 20 до 29 лет)',
'Численность безработных (от 30 до 39 лет)',
'Численность безработных (от 40 до 49 лет)',
'Численность безработных (от 50 до 59 лет)',
'Численность безработных (60 и более лет)']] = data[['Численность безработных (до 20 лет)',
'Численность безработных (от 20 до 29 лет)',
'Численность безработных (от 30 до 39 лет)',
'Численность безработных (от 40 до 49 лет)',
'Численность безработных (от 50 до 59 лет)',
'Численность безработных (60 и более лет)']].fillna(0)
data[['Численность занятых (до 20 лет)',
'Распределение занятых (от 20 до 29 лет)',
'Распределение занятых (от 30 до 39 лет)',
'Распределение занятых (от 40 до 49 лет)',
'Распределение занятых (от 50 до 59 лет)',
'Распределение занятых (60 и более лет)']] = data[['Распределение занятых (до 20 лет)',
'Распределение занятых (от 20 до 29 лет)',
'Распределение занятых (от 30 до 39 лет)',
'Распределение занятых (от 40 до 49 лет)',
'Распределение занятых (от 50 до 59 лет)',
'Распределение занятых (60 и более лет)']].fillna(0)# делаем проверку по индексу 26
data.loc[683]
Пропуска заполнили, но чтобы быть точно уверенными, что все в порядке – давайте проверим сколько пропусков осталось.
# проверим сколько пропусков сейчас осталось
data.isnull().sum()
Все пропуска обработаны. Теперь проверим дубликаты.
Проверка и обработка дубликатов
# проверим количество дубликатов (метод duplicated())
sum_duplicated = data.duplicated().sum()
print('Количество дубликатов: ', sum_duplicated)Количество дубликатов: 0
Проверка и обработка типов данных
Перед тем, как приступить к обработке типов данных столбцов – рассмотрим какиетипы данных в данный момент.
data.info()
# изменением типы на int
data['Численность населения'] = data['Численность населения'].astype(int)
data['Занятые в экономике'] = data['Занятые в экономике'].astype(int)
data['Безработные'] = data['Безработные'].astype(int)Посмотрим прошли ли изменения типов
data.dtypes
Мы изменили только “Численность населения”, “Занятые в экономике”, “Безработные” на целочисленное значение. По остальным столбцам оставили дробное, т.к. указаны значения в процентном соотношении.
Вывод
В предыдущих разделах мы изучили и подготовили наши данные для того, чтобы в дальнейшем можно было без трудностей проанализировать их.
В следующем разделе мы будем исследовать данные и при необходимости построим различные гистограммы.
Исследовательский анализ данных
# изучаем зависимость занятых и безработных от года
#sns.pairplot(data, x_vars=['Занятые в экономике', 'Безработные'], y_vars=['Год'], size=6)
#plt.show()Построение гистограммы с количеством безработных и занятых (общему количеству и по конкретной территории)
Посчитаем общее количество безработных по территориям сначала в табличном варианте и выведем первые 10 строк.
sum_unemployed = data.groupby('Территория')['Безработные'].sum().sort_values(ascending=False)
print(sum_unemployed.head(10))
Теперь построим гистограмму на основе полученной таблицы.
# Количество безработных на разных территориях
# построим гистограмму
sum_unemployed.plot(x = 'Территория', y = 'Безработные', kind = 'bar', figsize=(20,8), grid=True, title = 'Количество безработных на разных территориях')
# меняем наименование горизонтальной линии ('X')
plt.xlabel('Территория')
# меняем наименование вертикальной линии ('Y')
plt.ylabel('Безработные')
plt.show()
sum_unemployed.head(2)
Большая часть безработных, а именно на территориях Республики Северной Осетии – Алания и Российская Федерация.
Предположительно Республики Северной Осетии – Алания нехватка рабочих мест, а в РФ это может быть обусловлено большим количеством субьектов.
Так же давайте не забывать, что у нас подсчет по всем безработным по всем возрастам. И может быть такое, что некоторые люди не подходят к той или иной работе в силу возраста, а та работа, которая им необходима уже переполнена персоналом.
sum_unemployed.tail(2)
Минимальное количество может говорить о том, что большиству жителей этих регионов находится свое место в трудовых резервах.
Посчитаем общее количество занятых по территориям.
sum_employed = data.groupby('Территория')['Занятые в экономике'].sum().sort_values(ascending=False)
print(sum_employed.head(10))
# Количество занятых на разных территориях
# построим гистограмму
sum_employed.plot(x = 'Территория', y = 'Занятые в экономике', kind = 'bar', figsize=(20,8), grid=True, title = 'Количество безработных на разных территориях')
# меняем наименование горизонтальной линии ('X')
plt.xlabel('Территория')
# меняем наименование вертикальной линии ('Y')
plt.ylabel('Занятые в экономике')
plt.show()
sum_employed.head(2)
sum_employed.tail(2)
По данной таблице РФ опять показывает значительные результаты, но давайте не будем забыть о ее площади. Если мы посмотрим внимательнее, то можем обратить внимание, что количество занятых в РФ значительно больше чем совокупность регионов РФ, которые указаны в нашей выборке, это может быть обусловлено тем, что не по всем субьектам указаны данные.
Определение на какой территории минимальный и максимальный процент безработных
# считаем долю безработицы по сравнению с общий количеством на территории
data_ter_count_full = data.groupby('Территория')['Численность населения'].sum()
# вычисляем процентное соотношение
percent_data_count_ter_unemployed = sum_unemployed / data_ter_count_full * 100
percent_data_count_ter_unemployed = percent_data_count_ter_unemployed.round(2)
percent_data_count_ter_unemployed = percent_data_count_ter_unemployed.sort_values(ascending=False)
percent_data_count_ter_filter_unemployed = percent_data_count_ter_unemployed.sort_values().head(10)
print('Доля безработицы:')
display(percent_data_count_ter_unemployed)
Большое соотношение безработных приходится на Республику Северная Осетия – Алания, возможно это связано с переодическими военными действиями, которые там проходят.
Прошу обратить внимание на РФ, у которой были значительно высокие показатели как безработных. По соотношению безработных по всем территориям у РФ 6.38%.
percent_data_count_ter_unemployed.plot(x = 'Территория', y = 'Безработные', kind = 'bar', figsize=(20,8), grid=True, title = 'Процентное соотношение безработных на разных территориях')
plt.show()
Теперь сделаем такой же график, только без Руспублики Северная Осетия.
percent_data_count_ter_unemployed_new = percent_data_count_ter_unemployed[1:]
percent_data_count_ter_unemployed_new.plot(x = 'Территория', y = 'Безработные', kind = 'bar', figsize=(20,8), grid=True, title = 'Процентное соотшошение безработных на разных территориях')
plt.show()
print(percent_data_count_ter_unemployed.sort_values(ascending=False).head())
Обратим внимание на Республика Северная Осетия – Алания. Доля безработных составляет 2590,43%
Давайте проверим почему такая большая доля.
# выведем суммарное количество за все года по Республика Северная Осетия - Алания
data_alaniya = data[data['Территория'] == 'Республика Северная Осетия - Алания']
data_alaniya_1 = data_alaniya.groupby('Территория').sum()
data_alaniya_1
Количество безработных по годам в Республика Северная Осетия – Алания
data_alaniya
Мы видим, что общее количество безработных составляет 44141, хотя общее количество составляет 1704. Давайте посмотрим данные за каждый год.
В строке 221 мы видим, что за 2007 год у нас значение безработных “огромное” и в связи с этим у нас некорректно формируется доля безработных. Предлагаю удалить строку с этими показателями.
data = data.drop(index = [221])data_alaniya = data[data['Территория'] == 'Республика Северная Осетия - Алания']
data_alaniya_1 = data_alaniya.groupby('Территория').sum()
data_alaniya_1
Еще рассчитаем доли безработных
# считаем долю безработицы по сравнению с общий количеством на этой территории (после корректировки количества)
data_count_ter_1 = data.groupby('Территория')['Безработные'].sum()
data_ter_count_full_1 = data.groupby('Территория')['Численность населения'].sum()
# вычисляем процентное соотношение
percent_data_count_ter_1 = data_count_ter_1 / data_ter_count_full_1 * 100
percent_data_count_ter_2 = percent_data_count_ter_1.sort_values(ascending=False).round(2)
print('Доля безработицы:')
display(percent_data_count_ter_2.head())
print('Максимальная доля безработицы')
print(percent_data_count_ter_2.index[0], '-', percent_data_count_ter_2.max(), '%')
print()
print('Минимальная доля безработицы')
print(percent_data_count_ter_2.index[-1], '-', percent_data_count_ter_2.min(), '%')
Небольшой вывод: после чистки некорректных данных в записях мы рассчитали максимальную и минимальную долю безработицы.
Максимальная доля безработицы в Республике Ингушетия – 38.64 %
Минимальная доля безработицы в г.Москве – 1.55 %
Вычислить среднее число безработных и занятых (по каждой территории)
Создадим отдельную таблицу,в которой отобразим среднее число по регионам по занятым и безработным.
data_mean_people = pd.DataFrame()
data_mean_people['Среднее значение занятых'] = data.groupby('Территория')['Занятые в экономике'].mean().round(2)
data_mean_people['Среднее значение безработных'] = data.groupby('Территория')['Безработные'].mean().round(2)
display(data_mean_people.head())
axs = data_mean_people.plot.area(figsize=(24, 10), subplots=True)
plt.xticks(rotation=90)
plt.xticks(np.arange(len(data_mean_people)))
plt.show()

Давайте отдельно выясним резкий и единственный рост в графиках занятых и безработных.
people_1 = data.groupby('Территория')['Занятые в экономике'].mean().round(2).sort_values(ascending=False)
people_2 = data.groupby('Территория')['Безработные'].mean().round(2).sort_values(ascending=False)
print('Среднее число занятые')
print(data.loc[0, 'Территория'], '-', people_1[0])
print('Среднее число безработные')
print(data.loc[0, 'Территория'], '-', people_2[0])
Мы видим, что у РФ большое количество как занятых, так и безработных, и как писалось ранее это можно аргументировать тем, что достаточно много субъектов входит в ее состав. Поэтому и на графике мы видим значительный рост показателей в отличии от других.
Посчитаем среднее количество безработных по каждому году, хоть это и не прописано в нашем влане, но давайте взглянем на эти данные.
data_mean_people_years = pd.DataFrame()
data_mean_people_years['Среднее значение занятых'] = data.groupby('Год')['Занятые в экономике'].mean().round(2)
data_mean_people_years['Среднее значение безработных'] = data.groupby('Год')['Безработные'].mean().round(2)
display(data_mean_people_years)
axs = data_mean_people_years.plot.area(figsize=(24, 10), subplots=True)
plt.xticks(rotation=90)
plt.show()

Среднее значение занятых людей в стабольном состоянии из года в год. А вот безработица из года в год уменьшается с небольшими скачками.
Выделить ТОП-5 территорий по безработным и занятым
# выведем ТОП 5 территорий с занятыми
top_5_data_mean_people_employed = data.groupby('Территория')['Занятые в экономике'].mean().sort_values(ascending=False).head(5).round(2)
print(top_5_data_mean_people_employed)
# выведем ТОП 5 территорий с безработными
top_5_data_mean_people_unemployed = data.groupby('Территория')['Безработные'].mean().sort_values(ascending=False).head(5).round(2)
print(top_5_data_mean_people_unemployed)
Построение столбчатой диаграммы с количеством занятых (по возрастным категориям)
data_2 = data[['Численность занятых (до 20 лет)', 'Численность занятых (от 20 до 29 лет)',
'Численность занятых (от 30 до 39 лет)', 'Численность занятых (от 40 до 49 лет)',
'Численность занятых (от 50 до 59 лет)', 'Численность занятых (60 и более лет)']].sum()
display(data_2)
data_2 = data_2.plot()
plt.xticks(rotation=90)
plt.show()
Построение столбчатой диаграммы с количеством безработных (по возрастным категориям)
data_3 = data[['Численность безработных (до 20 лет)', 'Численность безработных (от 20 до 29 лет)',
'Численность безработных (от 30 до 39 лет)', 'Численность безработных (от 40 до 49 лет)',
'Численность безработных (от 50 до 59 лет)', 'Численность безработных (60 и более лет)']].sum()
display(data_3)
data_3 = data_3.plot()
plt.xticks(rotation=90)
plt.show()
В нашей ТОП-5 выборке привалирует количество занятых людей во всех возрастных категориях, кроме людей до 20 лет и людей старше 60 лет. Объяснить это можно тем, что не все молодое поколение хочет работать, а более приклонный возраст или не может работать в связи с ограниченными возможностями или могут просто не доживать до этого возраста.
Проверка гипотез
В финальной части нам необходимо проверить три гипотезы:
-
в каждой из возрастных категорий среднее значение занятых идентично со средним значением безработных
-
среднее значение безработных (в возрасте от 40 до 49 лет) в Брянской области одинаково со средним значением безработных возрасте до 20 лет
-
средний показатель безработицы в 2009 и 2019 году одинаков
Гипотеза: в каждой из возрастных категорий среднее значение занятых идентично среднему значению безработных
Подготовим выгрузку для проверки гипотезы
# сумма занятых до 20
employed_aged_20 = data['Численность занятых (до 20 лет)'].sum().round()
#print("Сумма занятых до 20 лет -", employed_aged_20)
# сумма занятых от 20 до 29 лет
employed_aged_20_to_29 = data['Численность занятых (от 20 до 29 лет)'].sum().round()
#print("Сумма занятых от 20 до 29 лет -", employed_aged_20_to_29)
# сумма занятых от 30 до 39 лет
employed_aged_30_to_39 = data['Численность занятых (от 30 до 39 лет)'].sum().round()
#print("Сумма занятых от 30 до 39 лет -", employed_aged_30_to_39)
# сумма занятых от 40 до 49 лет
employed_aged_40_to_49 = data['Численность занятых (от 40 до 49 лет)'].sum().round()
#print("Сумма занятых от 40 до 49 лет -", employed_aged_40_to_49)
# сумма занятых от 50 до 59 лет
employed_aged_50_to_59 = data['Численность занятых (от 50 до 59 лет)'].sum().round()
#print("Сумма занятых от 50 до 59 лет -", employed_aged_50_to_59)
# сумма занятых с возрастом 60 и более лет
employed_aged_60_or_more = data['Численность занятых (60 и более лет)'].sum().round()
#print("Сумма занятых в возрасте от 60 и более лет -", employed_aged_60_or_more)
#print()
# сумма безработных до 20
unemployed_aged_20 = data['Численность безработных (до 20 лет)'].sum().round()
#print("Сумма безработных до 20 лет -", unemployed_aged_20)
# сумма безработных от 20 до 29 лет
unemployed_aged_20_to_29 = data['Численность безработных (от 20 до 29 лет)'].sum().round()
#print("Сумма безработных от 20 до 29 лет -", unemployed_aged_20_to_29)
# сумма безработных от 30 до 39 лет
unemployed_aged_30_to_39 = data['Численность безработных (от 30 до 39 лет)'].sum().round()
#print("Сумма безработных от 30 до 39 лет -", unemployed_aged_30_to_39)
# сумма безработных от 40 до 49 лет
unemployed_aged_40_to_49 = data['Численность безработных (от 40 до 49 лет)'].sum().round()
#print("Сумма безработных от 40 до 49 лет -", unemployed_aged_40_to_49)
# сумма безработных от 50 до 59 лет
unemployed_aged_50_to_59 = data['Численность безработных (от 50 до 59 лет)'].sum().round()
#print("Сумма безработных от 50 до 59 лет -", unemployed_aged_50_to_59)
# сумма безработных с возрастом 60 и более лет
unemployed_aged_60_or_more = data['Численность безработных (60 и более лет)'].sum().round()
#print("Сумма безработных в возрасте от 60 и более лет -", unemployed_aged_60_or_more)Для проверки гипотезы “в каждой из возрастных категорий безработных больше, чем занятых” в качестве нулевой и альтернативной гипотезы мы взяли следующее: H0: количество занятых и безработных одинаковые H1: количество занятых и безработных различно.
employed_under_20 = data['Численность занятых (до 20 лет)']
unemployed_under_20 = data['Численность безработных (до 20 лет)']
print('Среднее количество занятых (до 20 лет) -', data['Численность занятых (до 20 лет)'].mean())
print('Среднее количество безработных (до 20 лет) -', data['Численность безработных (до 20 лет)'].mean())
print()
alpha = .05 # критический уровень статистической значимости
# если p-value окажется меньше него - отвегнем гипотезу
results = st.ttest_ind(
employed_under_20,
unemployed_under_20)
print('p-значение: ', results.pvalue)
if results.pvalue < alpha:
print("Отвергаем нулевую гипотезу")
else:
print("Не получилось отвергнуть нулевую гипотезу") 
Результат говорит о том, что нулевая гипотеза не отвергается.
employed_aged_20_to_29 = data['Численность занятых (от 20 до 29 лет)']
unemployed_aged_20_to_29 = data['Численность безработных (от 20 до 29 лет)']
print('Среднее количество занятых (от 20 до 29 лет) -', data['Численность занятых (от 20 до 29 лет)'].mean())
print('Среднее количество безработных (от 20 до 29 лет) -', data['Численность безработных (от 20 до 29 лет)'].mean())
print()
alpha = .05 # критический уровень статистической значимости
# если p-value окажется меньше него - отвегнем гипотезу
results = st.ttest_ind(
employed_aged_20_to_29,
unemployed_aged_20_to_29)
print('p-значение: ', results.pvalue)
if results.pvalue < alpha:
print("Отвергаем нулевую гипотезу")
else:
print("Не получилось отвергнуть нулевую гипотезу") 
employed_aged_30_to_39 = data['Численность занятых (от 30 до 39 лет)']
unemployed_aged_30_to_39 = data['Численность безработных (от 30 до 39 лет)']
print('Среднее количество занятых (от 30 до 39 лет) -', data['Численность занятых (от 30 до 39 лет)'].mean())
print('Среднее количество безработных (от 30 до 39 лет) -', data['Численность безработных (от 30 до 39 лет)'].mean())
print()
alpha = .05 # критический уровень статистической значимости
# если p-value окажется меньше него - отвегнем гипотезу
results = st.ttest_ind(
employed_aged_30_to_39,
unemployed_aged_30_to_39)
print('p-значение: ', results.pvalue)
if results.pvalue < alpha:
print("Отвергаем нулевую гипотезу")
else:
print("Не получилось отвергнуть нулевую гипотезу") 
employed_aged_40_to_49 = data['Численность занятых (от 40 до 49 лет)']
unemployed_aged_40_to_49 = data['Численность безработных (от 40 до 49 лет)']
print('Среднее количество занятых (от 40 до 49 лет) -', data['Численность занятых (от 40 до 49 лет)'].mean())
print('Среднее количество безработных (от 40 до 49 лет) -', data['Численность безработных (от 40 до 49 лет)'].mean())
print()
alpha = .05 # критический уровень статистической значимости
# если p-value окажется меньше него - отвегнем гипотезу
results = st.ttest_ind(
employed_aged_40_to_49,
unemployed_aged_40_to_49)
print('p-значение: ', results.pvalue)
if results.pvalue < alpha:
print("Отвергаем нулевую гипотезу")
else:
print("Не получилось отвергнуть нулевую гипотезу") 
employed_aged_50_to_59 = data['Численность занятых (от 50 до 59 лет)']
unemployed_aged_50_to_59 = data['Численность безработных (от 50 до 59 лет)']
print('Среднее количество занятых (от 50 до 59 лет) -', data['Численность занятых (от 50 до 59 лет)'].mean())
print('Среднее количество безработных (от 50 до 59 лет) -', data['Численность безработных (от 50 до 59 лет)'].mean())
print()
alpha = .05 # критический уровень статистической значимости
# если p-value окажется меньше него - отвегнем гипотезу
results = st.ttest_ind(
employed_aged_50_to_59,
unemployed_aged_50_to_59)
print('p-значение: ', results.pvalue)
if results.pvalue < alpha:
print("Отвергаем нулевую гипотезу")
else:
print("Не получилось отвергнуть нулевую гипотезу") 
employed_aged_60_or_more = data['Численность занятых (60 и более лет)']
unemployed_aged_60_or_more = data['Численность безработных (от 50 до 59 лет)']
print('Среднее количество занятых (60 и более лет) -', data['Численность занятых (60 и более лет)'].mean())
print('Среднее количество безработных (от 50 до 59 лет) -', data['Численность безработных (от 50 до 59 лет)'].mean())
print()
alpha = .05 # критический уровень статистической значимости
# если p-value окажется меньше него - отвегнем гипотезу
results = st.ttest_ind(
employed_aged_60_or_more,
unemployed_aged_60_or_more)
print('p-значение: ', results.pvalue)
if results.pvalue < alpha:
print("Отвергаем нулевую гипотезу")
else:
print("Не получилось отвергнуть нулевую гипотезу") 
После проверки гипотезы по всем возрастным категория мы можем сделать единый вывод – среднее количество занятых длюдей не одинаково со средним количество безработных.
Гипотеза: среднее значение безработных (в возрасте от 40 до 49 лет) в Брянской области одинаково со средним значением безработных возрасте до 20 лет
data_bryansk = data.query('Территория == "Брянская область"')
#display(data_bryansk.head())# сумма безработных Брянская область от 40 до 49 лет
unemployed_aged_40_to_49_bryansk = data_bryansk['Численность безработных (от 40 до 49 лет)'].sum().round(2)
#display(unemployed_aged_40_to_49_bryansk)
#print()
# сумма безработных до 20 лет
unemployed_aged_20_bryansk = data_bryansk['Численность безработных (до 20 лет)'].sum().round(2)
#display(unemployed_aged_20_bryansk)unemployed_under_40_bryansk = data['Численность безработных (от 40 до 49 лет)']
unemployed_under_20_bryansk = data['Численность безработных (до 20 лет)']
print('Среднее количество безработных (от 40 до 49 лет) -', data['Численность безработных (от 40 до 49 лет)'].mean())
print('Среднее количество безработных (до 20 лет) -', data['Численность безработных (до 20 лет)'].mean())
print()
alpha = .05 # критический уровень статистической значимости
# если p-value окажется меньше него - отвегнем гипотезу
results = st.ttest_ind(
employed_aged_60_or_more,
unemployed_aged_60_or_more)
print('p-значение: ', results.pvalue)
if results.pvalue < alpha:
print("Отвергаем нулевую гипотезу")
else:
print("Не получилось отвергнуть нулевую гипотезу") 
Количество занятых в разы больше безработных – гипотеза отвергнута.
Гипотеза: средний показатель безработицы в 2009 и 2019 году одинаков
data_unemployed_2009 = data.query('Год == 2009')
#display(data_unemployed_2009.head())
#print()
data_unemployed_2019 = data.query('Год == 2019')
#display(data_unemployed_2019.head())# сумма безработных 2009
unemployed_year_2009 = data_unemployed_2009['Безработные'].count()
#display(unemployed_year_2009)
#print()
# сумма безработных 2019
unemployed_year_2019 = data_unemployed_2019['Безработные'].count()
#display(unemployed_year_2019)Средний показатель безработицы за 2009 и 2019 года примерно одинаковый.
unemployed_2009 = unemployed_year_2009
unemployed_2019 = unemployed_year_2019
print('Среднее количество безработных в 2009 -', unemployed_2009)
print('Среднее количество безработных в 2019 -', unemployed_2019)
print()
alpha = .05 # критический уровень статистической значимости
# если p-value окажется меньше него - отвегнем гипотезу
results = st.ttest_ind(
unemployed_2009,
unemployed_2019)
print('p-значение: ', results.pvalue)
if results.pvalue < alpha:
print("Отвергаем нулевую гипотезу")
else:
print("Не получилось отвергнуть нулевую гипотезу") 
Средний показатель безработицы за 2019 года преобладает.
Дополнительная информация
Подготовка документации по библиотекам
pandas – это библиотека Python для обработки и анализа структурированных данных, её название происходит от «panel data» («панельные данные»). Панельными данными называют информацию, полученную в результате исследований и структурированную в виде таблиц. Для работы с такими массивами данных и создан Pandas.
matplotlib – это библиотека на языке Python для визуализации данных. В ней можно построить двумерные (плоские) и трехмерные графики.
matplotlib.pyplot – самый высокоуровневый интерфейс с набором команд и функций. В высокоуровневом интерфейсе все автоматизировано, поэтому его проще всего осваивать новичкам.
seaborn – библиотека для создания статистических графиков на Python. Она построена на основе matplotlib и тесно интегрируется со структурами данных pandas. Seaborn помогает вам изучить и понять данные. Его функции построения графиков работают с датасетами и выполняют все необходимы преобразования для создания информативных графиков.
numpy – библиотека с открытым исходным кодом для языка программирования Python. Возможности: поддержка многомерных массивов (включая матрицы); поддержка высокоуровневых математических функций, предназначенных для работы с многомерными массивами.
scipy – это еще одна научная библиотека, на базе которой реализована SciPy. Ее особенность — использование специальных структур данных — многомерных массивов, в которых хранится информация. С этим типом данных также работает SciPy. NumPy содержит данные массивов и такие операции, как индексация, сортировка и т. д., а SciPy состоит из числового кода.
warnings – полезен, когда необходимо предупредить пользователя о каком-либо условии в программе и это условие не требует создания исключения и завершения программы. Например, может возникнуть необходимость выдать предупреждение, когда программа использует устаревший модуль.
Общий вывод
Сделаем вывод по проделанной работе. После тщательной подготовки файла с данными мы провели диагностику.
В финальной части нам необходимо проверить три гипотезы:
• в каждой из возрастных категорий среднее значение занятых идентично со средним значением безработных
При проверке данной гипотезы мы выяснили, что не по одной возрастной категории нет совпадений в средних значениях между занятыми и безработными.
• среднее значение безработных (в возрасте от 40 до 49 лет) в Брянской области одинаково со средним значением безработных возрасте до 20 лет
Так же нулевая гипотеза опровергнута:
Среднее количество безработных (от 40 до 49 лет) – 598.7747584541063
Среднее количество безработных (до 20 лет) – 10.09806763285024
• средний показатель безработицы в 2009 и 2019 году одинаков
Данная гипотеза была доказана, значения равны с допустимой погрешностью.
Анализ данных можно описать как процесс, состоящий из нескольких шагов, в которых сырые данные превращаются и обрабатываются с целью создать визуализации и сделать предсказания на основе математической модели.
Анализ данных — это всего лишь последовательность шагов, каждый из которых играет ключевую роль для последующих. Этот процесс похож на цепь последовательных, связанных между собой этапов:
- Определение проблемы;
- Извлечение данных;
- Подготовка данных — очистка данных;
- Подготовка данных — преобразование данных;
- Исследование и визуализация данных;
- Предсказательная модель;
- Проверка модели, тестирование;
- Развертывание — визуализация и интерпретация результатов;
- Развертывание — развертывание решения.

Определение проблемы
Процесс анализа данных начинается задолго до сбора сырых данных. Он начинается с проблемы, которую необходимо сперва определить, а затем и решить.
Определить ее можно только сосредоточившись на изучаемой системе: механизме, приложении или процессе в целом. Исследование может быть предназначено для лучшего понимания функционирования системы, но его лучше спроектировать так, чтобы понять принципы поведения и впоследствии делать предсказания или выбор (осознанный).
Процессы определения и документации результатов научной проблемы или бизнеса нужны для того, чтобы сосредоточить анализ на получении результатов.
На самом деле, всеобъемлющее и исчерпывающее исследование системы — это сложный процесс, и почти всегда нет достаточного количества информации, с которой можно начать. Поэтому определение проблемы и особенно планирование приводят к появлению руководящих принципов, которым необходимо следовать в течение всего проекта.
Когда проблема определена и задокументирована, можно двигаться к этапу планирования проекта анализа данных. Планирование необходимо для понимания того, какие профессионалы и ресурсы понадобятся для выполнения требований проекта максимально эффективно. Таким образом задача — рассмотреть те вопросы в области, которые касаются решения этой проблемы Необходимо найти специалистов с разными интересами и установить ПО, нужное для анализа данных.
Построение хорошей команды — один из ключевых факторов успешного анализа данных.
Также во время фазы планировки выбирается эффективная команда. Такие команды должны быть междисциплинарными, чтобы у них была возможность решать проблемы, рассматривая данные с разных точек зрения.
Извлечение данных
Когда проблема определена, первый шаг для проведения анализа — получение данных. Они должны быть выбраны с одной базовой целью — построение предсказательной модели. Поэтому выбор данных — также важный момент для успешного анализа.
Данные должны максимально отражать реальный мир — то, как система реагирует на него. Например, использовании больших наборов сырых данных, которые были собраны неграмотно, это привести либо к неудаче, либо к неопределенности.
Поэтому недостаточное внимание, уделенное выбору данных или выбор таких, которые не представляют систему, приведет к тому, что модели не будут соответствовать изучаемым системам.
Поиск и извлечение данных часто требует интуиции, границы которой лежат за пределами технических исследований и извлечения данных. Этот процесс также требует понимания природы и формы данных, предоставить которое может только опыт и знания практической области проблемы.
Вне зависимости от количества и качества необходимых данных важный вопрос — использование лучших источников данных.
Если средой изучения выступает лаборатория (техническая или научная), а сгенерированные данные экспериментальные, то источник данных легко определить. В этом случае речь идет исключительно о самих экспериментах.
Но при анализе данных невозможно воспроизводить системы, в которых данные собираются исключительно экспериментальным путем, во всех областях применения. Многие области требуют поиска данных в окружающем мире, часто полагаясь на внешние экспериментальные данные или даже на сбор их с помощью интервью и опросов.
В таких случаях поиск хорошего источника данных, способного предоставить все необходимые данные, — задача не из легких. Часто необходимо получать данные из нескольких источников данных для устранения недостатков, выявления расхождений и с целью сделать данные максимально общими.
Интернет — хорошее место для начала поиска данных. Но большую часть из них не так просто взять. Не все данные хранятся в виде файла или базы данных. Они могут содержаться в файле HTML или другом формате. Тут на помощь приходит техника парсинга. Он позволяет собирать данные с помощью поиска определенных HTML-тегов на страницах. При появлении таких совпадений специальный софт извлекает нужные данные. Когда поиск завершен, у вас есть список данных, которые необходимо проанализировать.
Подготовка данных
Из всех этапов анализа подготовка данных кажется наименее проблемным шагом, но на самом деле требует наибольшего количества ресурсов и времени для завершения. Данные часто собираются из разных источников, каждый из которых может предлагать их в собственном виде или формате. Их нужно подготовить для процесса анализа.
Подготовка данных включает такие процессы:
- получение,
- очистка,
- нормализация,
- превращение в оптимизированный набор данных.
Обычно это табличная форма, которая идеально подходит для этих методов, что были запланированы на этапе проектировки.
Многие проблемы могут возникнуть при появлении недействительных, двусмысленных или недостающих значений, повторении полей или данных, несоответствующих допустимому интервалу.
Изучение данных/визуализация
Изучение данных — это их анализ в графической или статистической репрезентации с целью поиска моделей или взаимосвязей. Визуализация — лучший инструмент для выделения подобных моделей.
За последние годы визуализация данных развилась так сильно, что стала независимой дисциплиной. Многочисленные технологии используются исключительно для отображения данных, а многие типы отображения работают так, чтобы получать только лучшую информацию из набора данных.
Исследование данных состоит из предварительного изучения, которое необходимо для понимания типа и значения собранной информации. Вместе с информацией, собранной при определении проблемы, такая категоризация определяет, какой метод анализа данных лучше всего подойдет для определения модели.
Эта фаза, в дополнение к изучению графиков, состоит из следующих шагов:
- Обобщение данных;
- Группировка данных;
- Исследование отношений между разными атрибутами;
- Определение моделей и тенденций;
- Построение моделей регрессионного анализа;
- Построение моделей классификации.
Как правило, анализ данных требует обобщения заявлений касательно изучаемых данных.
Обобщение — процесс, при котором количество данных для интерпретации уменьшается без потери важной информации.
Кластерный анализ — метод анализа данных, используемый для поиска групп, объединенных общими атрибутами (также называется группировкой).
Еще один важный этап анализа — идентификация отношений, тенденций и аномалий в данных. Для поиска такой информации часто нужно использовать инструменты и проводить дополнительные этапы анализа, но уже на визуализациях.
Другие методы поиска данных, такие как деревья решений и ассоциативные правила, автоматически извлекают важные факты или правила из данных. Эти подходы используются параллельно с визуализацией для поиска взаимоотношений данных.
Предсказательная (предиктивная) модель
Предсказательная аналитика — это процесс в анализе данных, который нужен для создания или поиска подходящей статистической модели для предсказания вероятности результата.
После изучения данных у вас есть вся необходимая информация для развития математической модели, которая кодирует отношения между данными. Эти модели полезны для понимания изучаемой системы и используются в двух направлениях.
Первое — предсказания о значениях данных, которые создает система. В этом случае речь идет о регрессионных моделях.
Второе — классификация новых продуктов. Это уже модели классификации или модели кластерного анализа. На самом деле, можно разделить модели в соответствии с типом результатов, к которым те приводят:
- Модели классификации: если полученный результат — качественная переменная.
- Регрессионные модели: если полученный результат числовой.
- Кластерные модели: если полученный результат описательный.
Простые методы генерации этих моделей включают такие техники:
- линейная регрессия,
- логистическая регрессия,
- классификация,
- дерево решений,
- метод k-ближайших соседей.
Но таких методов много, и у каждого есть свои характеристики, которые делают их подходящими для определенных типов данных и анализа. Каждый из них приводит к появлению определенной модели, а их выбор соответствует природе модели продукта.
Некоторые из методов будут предоставлять значения, относящиеся к реальной системе и их структурам. Они смогут объяснить некоторые характеристики изучаемой системы простым способом. Другие будут делать хорошие предсказания, но их структура будет оставаться «черным ящиком» с ограниченной способностью объяснить характеристики системы.
Проверка модели
Проверка (валидация) модели, то есть фаза тестирования, — это важный этап. Он позволяет проверить модель, построенную на основе начальных данных. Он важен, потому что позволяет узнать достоверность данных, созданных моделью, сравнив их с реальной системой. Но в этот раз вы берете за основу начальные данные, которые использовались для анализа.
Как правило, при использовании данных для построения модели вы будете воспринимать их как тренировочный набор данных (датасет), а для проверки — как валидационный набор данных.
Таким образом сравнивая данные, созданные моделью и созданные системой, вы сможете оценивать ошибки. С помощью разных наборов данных оценивать пределы достоверности созданной модели. Правильно предсказанные значения могут быть достоверны только в определенном диапазоне или иметь разные уровни соответствия в зависимости от диапазона учитываемых значений.
Этот процесс позволяет не только в числовом виде оценивать эффективность модели, но также сравнивать ее с другими. Есть несколько подобных техник; самая известная — перекрестная проверка (кросс-валидация). Она основана на разделении учебного набора на разные части. Каждая из них, в свою очередь, будет использоваться в качестве валидационного набора. Все остальные — как тренировочного. Так вы получите модель, которая постепенно совершенствуется.
Развертывание (деплой)
Это финальный шаг процесса анализа, задача которого — предоставить результаты, то есть выводы анализа. В процессе развертывания бизнес-среды анализ является выгодой, которую получит клиент, заказавший анализ. В технической или научной средах результат выдает конструкционные решения или научные публикации.
Развертывание — это процесс использования на практике результатов анализа данных.
Есть несколько способов развертывания результатов анализа данных или майнинга данных. Обычно развертывание состоит из написания отчета для руководства или клиента. Этот документ концептуально описывает полученные результаты. Он должен быть направлен руководству, которое будет принимать решения. Затем оно использует выводы на практике.
В документации от аналитика должны быть подробно рассмотрены следующие темы:
- Результаты анализа;
- Развертывание решения;
- Анализ рисков;
- Измерения влияния на бизнес.
Когда результаты проекта включают генерацию предсказательных моделей, они могут быть использованы в качестве отдельных приложений или встроены в ПО.
Подготовка данных к статистической обработке, описательные статистики
«Если достаточно долго мучить данные, они признаются [в чем угодно]»,
– Рональд Х. Коуз
Введение
Если вы хотите превратить большой объем цифровых данных в форму удобную для восприятия и обсуждения, то Вам необходим описательный анализ данных. Мы подготовили для Вас серию статей, посвященных процессу анализа данных. В них мы расскажем о базовых принципах построения практического проекта по анализу данных.
Анализ данных в современном мире
Данные собирают все — от студента, который пишет диссертацию до компаний-монополистов с миллионной клиентской базой. Мы помогаем сделать так, чтобы собранная информация работала на Вас – приносила пользу и прибыль.
Анализ данных полезно использовать в любой сфере деятельности, однако, за время нашей работы, нам удалось отметить области с наиболее высоким спросом на аналитику данных:
- Медицина и психология (научные работы)
- Маркетинг
- E-commerce
- Страхование
- Производство
- Сфера оказания услуг
- Ритейл
Развитие идет полным ходом, количество накопленной информации продолжает расти. Исследования требуют сложной обработки большого количества данных. Мало просто собрать данные – их обязательно нужно использовать, например, чтобы проверить гипотезы, выявить связи или построить прогнозы.
Анализ данных — это междисциплинарная область знаний, находящаяся на стыке математики и информационных технологий. Анализ позволяет преобразовать данные в выводы, полезные для принятия решений и построения дальнейших планов.
Виды анализа данных
Существуют разные варианты типов/видов анализа данных. Мы выделяем 3 вида анализа данных, за которыми к нам чаще всего обращаются клиенты:
- Описательный анализ
- Диагностический анализ
- Предиктивный анализ
Каждый из этих анализов начинается с подготовки данных для дальнейшей обработки и завершается обзором результатов. Все три типа анализа отличаются уровнем сложности работы с информацией и степенью человеческого участия.
В этой статье мы поговорим об описательном анализе данных.
Подготовка исходных данных к обработке
Прежде чем мы перейдем к описательным статистикам, поговорим о важном этапе подготовки статистических данных – обеспечение качества. Прежде, чем приступать к любому виду анализа, необходимо убедиться, что в данных нет ошибок или пропусков, что данные полные, без дубликатов, корректно организованы и годятся для дальнейшего анализа.
Чаще всего, мы получаем данные в строках и столбцах в форме таблицы, но не всегда эти данные корректно организованы для дальнейших манипуляций. Ошибки в данных влекут за собой недостоверные результаты, неправильная структура данных – увеличивает срок выполнения задачи. Поэтому, на первом этапе любого анализа, мы проверяем исходные данные на корректность, при необходимости исправляем ошибки, структурируем данные.
Описательные статистики
Как мы писали выше, первым, наиболее простым типом анализа данных является описательный анализ (= он же описательные статистики).
Описательные статистики — это краткая и информативная характеристика данных в виде графиков, таблиц и числовых выражений. Важно отметить, что выбор статистических методов для анализа данных определяет тип переменных.

Для количественных данных выполняется проверка на нормальность, а в качестве описательных статистик рассчитываются средние ± средние квадратические отклонения; медиана и квартили; минимальные и максимальные значения в выборке.
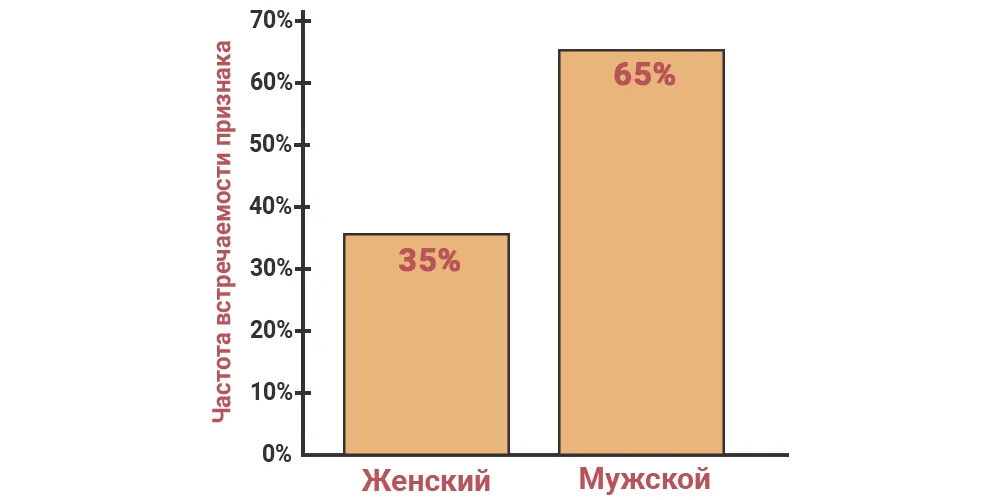
Для качественных показателей рассчитываются частоты встречаемости.
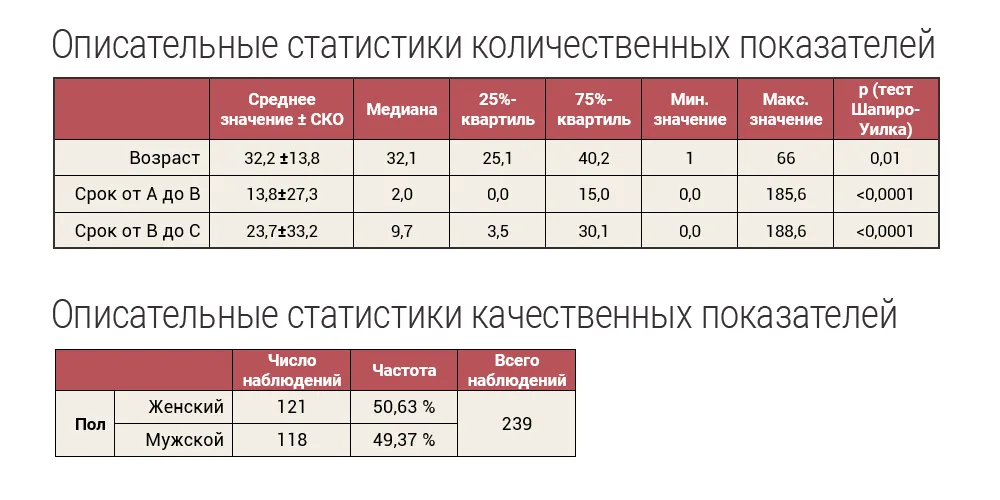
Описательный анализ отвечает на вопрос “Что произошло?” Это может быть:
- характеристика пациентов
в выборке 34% здоровых и 66% больных человек
- портрет клиентов
13% женщин и 87% мужчин, средний возраст которых – 35 лет
- сводка по клиентам
всего за год – 92 клиента, из них: 25 (27%) обратились повторно, а 67 (73%) – не вернулись.
Описательные статистики данных включают в себя:
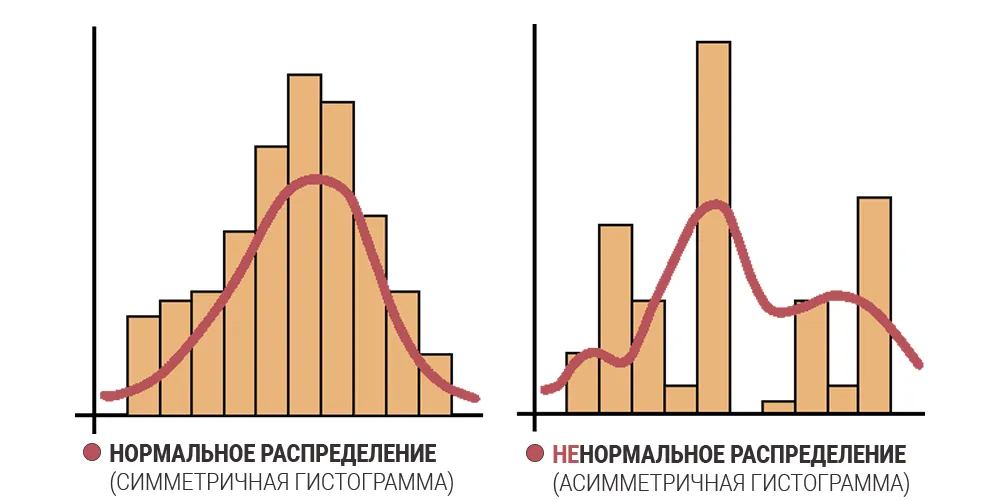
- Тест на нормальность распределения
Первым делом при обработке данных необходимо их проверить на нормальность распределения, это позволит правильно выбрать дальнейшие методы обработки данных для получения достоверных результатов. Для нормального распределения применяются параметрические методы, для ненормального распределения – непараметрические методы.
Существует множество тестов для проверки нормальности распределения. Среди часто используемых можно отметить:
- Критерий Шапиро-Уилка
- Критерий хи-квадрат
- Критерий Колмогорова-Смирнова
Если вероятность случайного отличия мала (Р – значение меньше 0,05), то отличие признается достоверным (не случайным) – распределение признака не является нормальным.
- Анализ показателей центра распределения
Определение среднего или наиболее типичного значения для совокупности данных.
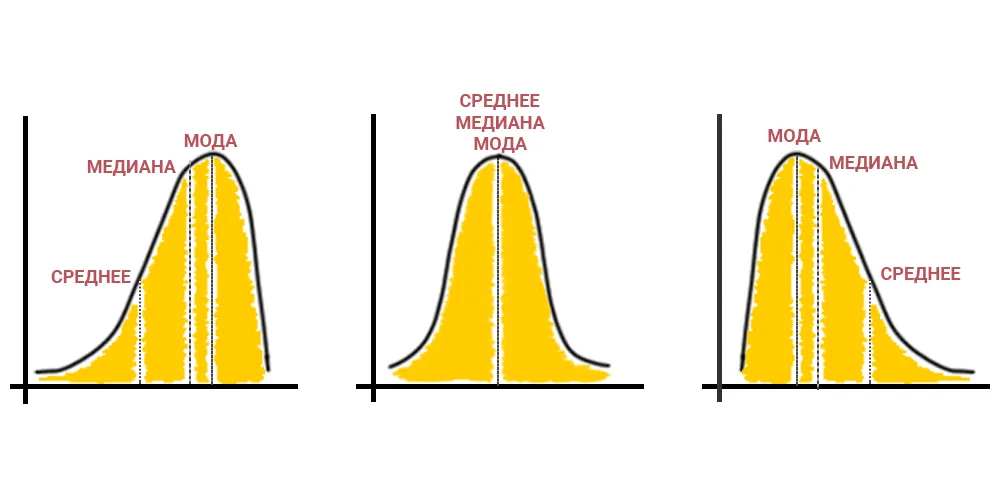
- Оценка разброса данных в совокупности
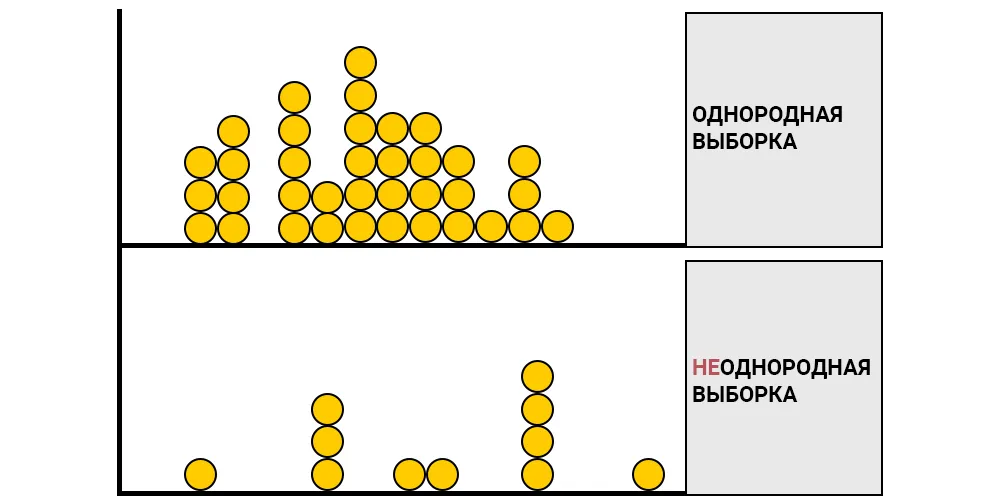
Степень индивидуальных отклонений от центральной тенденции, изменчивость данных (среднее квадратическое отклонение, квартильный размах).
- Частотный анализ
Оценка частоты встречаемости признака.
- Визуализация данных
Гистограммы распределения, диаграммы частот.
Таким образом, описательные статистики позволяют представить данные более осмысленно, что упрощает их интерпретацию.
О том как выявить различия признаков между группами, проверить наличие связи между показателями, выявить однородные группы и построить статистическую модель, мы расскажем в следующих статьях.
О проекте BIRDYX
Мы оказываем помощь в статистических расчетах. Чтобы заказать качественный анализ данных свяжитесь с нами одним из удобных способов, чтобы обсудить детали:
WhatsApp: +7 (919) 882-93-67
Telegram: birdyx_ru
E-mail: mail@birdyx.ru
Мы растем, развиваемся, постоянно работаем над автоматизацией аналитических процессов, чтобы предоставлять Вам качественную аналитику оперативно и по доступной цене.
Практическое руководство по анализу данных: с чего начать?
Перевод
Ссылка на автора
Многие новички не понимают, как научиться анализировать данные. Сегодня я представлю весь процесс анализ данных ответить на ваши сомнения и открыть новые идеи.
Я полагаю, вы уже знаете важность анализа данных в современном обществе. Овладение данными означает овладение законом. Когда вы понимаете рыночные данные и анализируете их, вы можете получить рыночные правила. Когда вы осваиваете данные самого продукта, анализируете их, вы можете понять источник пользователя продукта, его портреты и так далее. Анализ данных настолько важен, что это не только «структура данных + алгоритм» новой эры, но и высокая основа для борьбы предприятий за таланты.

1. Что такое процесс анализа данных?
Анализ данных в основном делится на три этапа.
- Сбор информации
То есть брать сырье, мы не можем анализировать без данных.
- Сбор данных
Интеллектуальный анализ данных – это ценность всего бизнеса. Ядром интеллектуального анализа данных является добыча коммерческой ценности данных, которую мы называем бизнес-аналитикой.
- Визуализация данных
Проще говоря, давайте интуитивно поймем результаты анализа данных.

Говорить, как это может быть слишком просто, позвольте мне представить вам эти три шага подробно.
1.1 Сбор данных
В разделе сбора данных вы обычно работаете с различными источниками данных, а затем используете инструменты для их сбора.
В Интернете вы можете собирать самые разные наборы данных. Есть также много инструментов, которые могут помочь вам автоматически очистить данные. Конечно, если вы напишете сканер Python, это будет еще эффективнее. Веселье в освоении Python crawlers бесконечно. Он не только позволяет вам получать горячие отзывы в социальных сетях, автоматически загружает плакаты с ключевыми словами, но также автоматически добавляет поклонников в вашу учетную запись, давая вам острые ощущения от автоматизации.

1.2 Интеллектуальный анализ данных
Вторая часть – это анализ данных, который можно сравнить с «алгоритмической» частью всего процесса анализа данных. Во-первых, вам нужно знать его основной поток, десять лучших алгоритмов и математическое обоснование этого. В этой части мы познакомимся с некоторыми понятиями, такими как анализ ассоциаций, алгоритм Adaboost и т. Д.
Освоение интеллектуального анализа данных похоже на удержание хрустального шара. Он использует исторические данные, чтобы сказать вам, что произойдет в будущем. Конечно, это также покажет вам высокую надежность.

1.3 Визуализация данных
Третий визуализация данных Это очень важный шаг, который нас особенно интересует. Данные часто неявны, особенно когда данные большие, а визуализация – хороший способ понять структуру данных и представление результатов. Как мы можем визуализировать данные? Есть два пути.
Во-первых, использовать Python. В процессе очистки и добычи данных в Python для рендеринга мы можем использовать сторонние библиотеки, такие как Matplotlib и Seaborn.
Второе – использовать сторонние инструменты. Если вы уже создали файл формата CSV и хотите использовать WYSIWYG для его рендеринга, вы можете использовать сторонние инструменты, такие как Data GIF Maker, живописная картина, FineReport и т. д., которые могут легко обработать данные и помочь вам сделать презентацию. Дополнительную информацию об инструментах визуализации данных вы можете прочитать в этой статье. 9 инструментов визуализации данных, которые нельзя пропустить в 2019 году,

Конечно, эти теории относительно абстрактны, поэтому я думаю, что лучший способ научиться анализу данных – это использовать их в инструментах и углубить понимание в проектах.
2. Практическое руководство
Только что мы поговорили о панораме анализа данных, в том числе о сборе, извлечении и визуализации данных. Вам может показаться, что есть много вещей, которые вы не можете запустить, или вам кажется, что анализ данных включает в себя множество алгоритмов, а некоторые трудно освоить. На самом деле, это ненужные проблемы.
Здесь мы представляемMAS (многомерный, Ask, Share) метод обучения, С этим методом, анализ данных обучения является процессомот «мышления» к «инструменту» к «практике»,
Сегодня я поделюсь с вами своим опытом обучения под другими углами. Мы можем
Назовите сегодняшнее содержание «практическим руководством». Мы превращаем знания в наш собственный язык, и это действительно становится нашим собственным делом. Процесс этой трансформации является процессом познания.
Так как же улучшить свои способности к обучению? Проще говоря, это «знать и делать».
Если познание – это мозг, инструменты подобны нашим рукам, и инженеры данных и ученые-алгоритмы работают с инструментами каждый день. Если вы начинаете заниматься проектами анализа данных и уже подумали об алгоритмической модели интеллектуального анализа данных, имейте в виду следующие два принципа.
2.1 Не повторять изготовление колес
Я видел много компаний, которые нуждаются в сборе данных. Они думали, что некоторые инструменты не могут удовлетворить их индивидуальные потребности, поэтому они решили нанять людей для этой работы. Что произошло? После более чем года практики они вложили много денег, нашли много ошибок и, наконец, выбрали сторонние инструменты. В настоящее время, по сути, при своевременной оценке потребностей вы сможете своевременно сэкономить на потерях. Например, представление данных инструменты, такие как FineReport может предоставить решения для различных отраслей. Это также поможет вам в оценке ваших потребностей.
2.2 Инструменты определения эффективности
«Не повторяйте производство колес» означает, что вам сначала нужно найти колесо, которое можно использовать, которое является инструментом. Итак, как мы выбираем?
Это зависит от работы, которую вы собираетесь делать. Инструменты не хорошие или плохие, только подходящие или нет. В дополнение к исследовательской работе, в большинстве случаев инженеры выбирают наиболее удобные инструменты. Например, в Python есть много сторонних библиотек для обработки данных. Эти библиотеки имеют большое количество пользователей и файлов справки, которые помогут вам начать работу.
Если вы ищете подходящий инструмент для анализа данных, вы можете обратиться к этой статье Топ 6 инструментов аналитики данных в 2019 году,
После выбора хорошего инструмента все, что вам нужно сделать, это накопить «активы». Трудно запомнить много моментов знания, и мы не можем следовать инструкциям инструментов, но обычно мы можем помнить истории, проекты, которые мы сделали, и проблемы, которые мы сделали. Эти темы и проекты – ваши первые «активы».
Как мы быстро накапливаем эти «активы»? Ответ – мастерство. Решение проблем – это только первый шаг. Ключ в том, чтобы обучить «мастерству», используемому нашими инструментами. По мере того, как мастерство возрастает, ваша когнитивная модель мышления постепенно улучшается, и эффективность естественным образом возрастает.
Вывод
Когнитивная трилогия, от познания до орудий боя, – вот совет, которым я больше всего хочу поделиться с вами. И я надеюсь, что эта статья будет вам полезна!
Вы также можете быть заинтересованы в …
Как новички могут создать отличную панель инструментов?
Какие инструменты анализа данных я должен изучить, чтобы начать карьеру в качестве аналитика данных?
Сравнение инструментов анализа данных: Excel, R, Python и BI Tools
6 шагов для принятия успешных маркетинговых решений с анализом данных
6 ключевых навыков, которые аналитики данных должны освоить
Как мы можем захватывать динамические данные и визуализировать их?
Четыре основных способа автоматизации извлечения данных
