Урок № 9.
Этапы создания информационных моделей в базах данных
Цели урока:
- Рассмотреть особенности
проведения моделирования в среде электронных таблиц по каждому этапу..
Ход урока:
- Организационный
момент; - Лекция;
- Домашнее задание.
Моделирование
в СУБД проводится по общей схеме, которая содержит четыре основных этапа:
постановка задачи, разработка модели, компьютерный эксперимент и анализ
результатов. Рассмотрим поэтапно особенности моделирования в подобных средах.
1 этап. Постановка задачи
ОПИСАНИЕ ЗАДАЧИ
При
помощи картотек и справочников обычно решаются следующие задачи:
•
формирование упорядоченных данных;
•
быстрый поиск интересующих потребителя данных;
•
представление данных в удобной для потребителя форме.
ЦЕЛИ МОДЕЛИРОВАНИЯ
Как
и любая картотека, компьютерная информационная модель должна отвечать интересам
пользователя. Поэтому постановка задачи создания информационной модели тесно
увязана с целями моделирования. В самом общем случае можно выделить следующие
цели:
•
хранение информации и своевременное ее редактирование;
•
упорядочение данных по некоторым признакам;
•
создание различных критериев выбора данных;
•
удобное представление отобранной информации.
формализация задачи
При
формализации задачи следует четко выделить основные свойства описываемых
объектов. Их количество следует ограничить в соответствии с поставленной целью.
Этот ограниченный набор параметров ляжет в основу структуры электронной
карточки. Выбор наиболее значимых характеристик описываемых объектов осуществляется
либо на основе опыта создателя базы данных с учетом пожеланий будущих
пользователей, либо на основе сложившихся традиций описания подобных объектов.
На
этапе формализации выделяются исходные данные, которые должны быть известны
заранее, и определяется предполагаемый перечень данных, которые могут
понадобиться потребителю. Часть параметров можно не задавать, получив их из
исходных.
2 этап. Разработка модели
ИИФОРМАЦИОЧНАЯ
МОДЕЛЬ
В
качестве первого шага на основе исходных данных формируется структура будущей
базы данных.
Обсудим
особенности этапа разработки информационной модели данных. Шаги построения
информационной модели данных представлены на схеме (см. рис. 4.1).
Рассмотрим
это на примере описания книг в домашней библиотеке. Книги могут характеризоваться
множеством параметров: тематика, жанр, автор, издательство, год издания,
оформление, бумага, обложка, формат и т. п. Для систематизации домашней
библиотеки достаточно следующих характеристик: тематика, название, автор,
объем, цена. Результаты отбора описываемых характеристик и определения их типов
можно представить в виде таблицы:
|
Название поля |
Тип поля |
|
Тематика |
текст |
|
Название книги |
текст |
|
Автор |
текст |
|
Объем (стр.) |
число |
|
Цена (руб.) |
число |
КОМПЬЮТЕРНАЯ МОДЕЛЬ
Создание
компьютерной модели данных начинается с выбора среды. В качестве таковой мы
будем использовать MS Access.
Затем
формируется структура данных и после предлагается перейти в режим заполнения.
Заполнив даже одну запись, можно выявить ошибки и неточности в задании типов
полей, формата вводимых данных.
III этап.
Компьютерный эксперимент
Применительно
к базе данных компьютерный эксперимент означает манипулирование данными в соответствии
с поставленной целью при помощи инструментов СУБД. Цель эксперимента может
быть сформирована на основании общей цели моделирования и с учетом требований
конкретного пользователя. Например, имеется школьная база данных. Общая цель создания
этой модели — управление школой. В школу обратился представитель военкомата с
просьбой выдать список юношей, достигших 16-летнего возраста. Он не имеет
никакого отношения к школе, но на основании его запроса можно осуществить
эксперимент для выборки нужной информации.
Инструментарий среды
позволяет выполнять следующие операции над данными:
• сортировка —
упорядочение данных по какому-то признаку;
• поиск (фильтрация) —
выбор данных, удовлетворяющих некоторому условию;
• создание расчетных
полей — преобразование исходных данных в другой вид на основании формул.
ПЛАН ЭКСПЕРИМЕНТА
Компьютерный эксперимент включает две
стадии:
• тестирование —
проверка правильности выполнения операций;
• проведение
экспериментов с реальными данными.
Простейшая
форма тестирования проводится еще на этапе наполнения информационной структуры
данными. Это тестирование частично осуществляется средой. Например, при попытке
ввода в поле Цена, с заданным типом число, стоимости книги 27 руб. 55 коп.
будет выдано сообщение об ошибке ввода. Правильный ввод: 27,55.
После
составления формул для расчетных полей и фильтров необходимо убедиться в
правильности их работы. Для этого можно ввести тестовые записи, для которых
заранее известен результат операции. Подбор исходных данных для тестирования —
это очень важное умение, которое приходит с опытом.
ПРОВЕДЕНИЕ
ЭКСПЕРИМЕНТОВ
Суть
компьютерных экспериментов состоит в манипулировании данными. В результате
операций фильтрации и сортировки появляется видоизмененная, преобразованная
информация об объектах. Она должна быть представлена в удобном для анализа и
принятия решения
виде. Одним из преимуществ компьютерных информационных моделей является
возможность создания различных форм представления выходной информации,
называемых отчетами. Каждый отчет содержит информацию, отвечающую цели
конкретного эксперимента. Удобство компьютерных отчетов заключается в том, что
они позволяют группировать информацию по заданным признакам, в любом порядке, с
введением итоговых полей подсчета записей по группам и в целом по всей базе.
Среда
позволяет создавать и хранить несколько типовых, часто используемых форм
отчетов. По результатам некоторых экспериментов можно создать временный отчет,
который удаляется после копирования его в текстовый документ или распечатки.
Некоторые эксперименты вообще не требуют составления отчета. Например,
требуется выбрать самого высокого юношу в школе. Для этого достаточно провести
сортировку по признаку пола (отделить мальчиков от девочек), потом по росту (в
порядке убывания). Искомую информацию будет содержать первая запись в списке
мальчиков.
4 этап. Анализ результатов моделирования
Конечным
пунктом всякого моделирования является анализ результатов и принятие решения.
Полученные в результате компьютерных экспериментов данные позволяют сделать
выводы.
Если полученные
результаты не соответствуют планируемым, то принимается решение о проведении
новых экспериментов с измененными условиями сортировки и поиска данных.
Если
в процессе работы появляется необходимость дополнить базу новыми расчетными
полями, то производится возврат на этап формирования структуры данных.
Иногда
после анализа результатов становится ясно, что полученная информационная модель
недостаточно полно описывает объекты. Тогда принимается решение о корректировке
информационной модели, добавлении исходных данных для более точной
характеристики объектов. Для этого производится возврат на первый этап
моделирования. Любая СУБД позволяют сделать это. В результате получается новая
уточненная модель.
Любое
решение о возврате на более ранние этапы моделирования сопровождается новыми
компьютерными экспериментами, пока результаты не будут удовлетворять
потребителя информации.
Моделирование и компьютерный эксперимент
Общая структура деятельности по созданию компьютерных моделей
Объект (лат. objectum — предмет) — это некоторая часть окружающего мира, рассматриваемая как единое целое. Все, что человек изучает, использует, производит, является объектом. Каждый объект имеет имя, что позволяет отличить один объект от другого (например, стол, атом, город Москва, ураган Катрин и т. п.). Конкретизировать объект можно с помощью параметров. Параметры — это признаки, которые характеризуют какое-либо свойство объекта. Они могут быть количественные (рост, вес, возраст, размер и т. п.) и качественные (форма, материал, цвет, запах, вкус и т. п.). Очень часто можно наблюдать смену состояний объекта в течение времени и, как результат, изменение параметров объекта. Говорят, что происходит некоторый процесс. Переход объекта из одного состояния в другое происходит при воздействии на него других объектов.
Модель (лат. modulus — мера; франц. modele — образец) — искусственно созданный объект в виде схем, чертежей, логико-математических знаковых формул, компьютерной программы, физической конструкции, который, будучи аналогичен (подобен, сходен) исследуемому объекту (явлению, процессу, устройству, сооружению, механизму, конструкции), отображает и воспроизводит в более простом, уменьшенном виде структуру, свойства, взаимосвязи и отношения между элементами исследуемого объекта, непосредственное изучение которого связано с какими-либо трудностями, большими затратами средств и энергии или просто недоступно, и тем самым облегчает процесс изучения информации об интересующем нас предмете.
Исследуемый объект по отношению к модели является оригиналом (образцом, прототипом). Модели могут создаваться как из однородного с оригиналом материала (например, макет деревянного сооружения можно сделать тоже из дерева), так и из материала, совершенно отличного от материала оригинала (например, бумажная модель самолета). Кроме того, модели могут быть нематериальными, или абстрактными (например, математическая модель самолета, компьютерная модель электрической сети).
Моделирование — это исследование каких-либо объектов (конкретных или абстрактных) на моделях. Объектом моделирования может быть объект, явление или процесс.
При создании модели стараются отразить наиболее существенные свойства объекта, а несущественные свойства отбрасываются. Например, на глобус наносятся океаны и моря, материки и крупные острова, а маленькие озера и островки на него не попадают: в масштабе глобуса они будут просто не видны.
Человек постоянно занимается моделированием, поскольку модели, упрощая объекты и явления, помогают человеку понять реальный мир. Более того, любая наука начинается с разработки простых и адекватных моделей.
Кроме материальных (предметных) моделей (игрушки, глобуса, макета дома…), существуют нематериальные — абстрактные модели: описания, формулы, изображения, схемы, чертежи, графики и т. д. С помощью математических формул описываются, например, арифметические операции, соотношения геометрии, законы движения и взаимодействия тел (S = Vt, F = mа) и многое другое. Химические формулы помогают представить молекулярный состав химических веществ и реакции, в которые они вступают. Пользуясь таблицами, графиками, диаграммами можно отображать различные закономерности и зависимости реального мира.
Все абстрактные модели не имеют физического воплощения. Абстрактные модели, которые можно представить с помощью набора знаков (геометрических фигур, символов, фрагментов текста), — это знаковые модели. Любую знаковую модель можно изобразить на бумаге. Чтобы построить знаковую модель, нужно представлять значение знаков и знать правила их преобразования. Абстрактная модель, прежде чем оформиться в виде знаковой модели, сначала рождается в голове человека. Она может передаваться человека к человеку в устной форме. В таких случаях модель еще не является знаковым образом, поскольку не имеет вида чертежа, формулы, текста. Модель в голове человека существует в форме мысленных представлений (мысленная модель). Модели, полученные в результате умозаключений, называются вербальными (лат. verbalis — устный). Вербальными называются также модели, изложенные в разговорной форме. Таким образом, все абстрактные модели можно разделить на знаковые и вербальные.
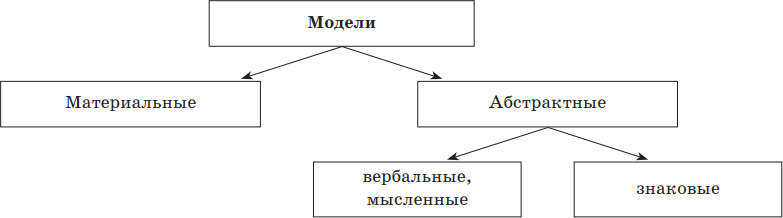
Представленная классификация моделей самая простая. Она основана на делении моделей по способу представления. Возможны и другие классификации, — например, по предметному признаку: физические, химические модели, модели строительных конструкций, различных механизмов и т. д.
Если модель формулируется таким образом, что ее можно обработать на компьютере, то она называется компьютерной. Компьютерная модель — это модель, реализуемая с помощью программных средств.
Компьютерные модели обычно различают по программному обеспечению, которое применяется при создании и работе с моделью. Для обработки компьютерных моделей используются существующие программные приложения (математические пакеты, электронные таблицы, графические редакторы и т. д.) либо разрабатываются оригинальные программы с помощью языков программирования (Ваsic, Раsсаl, Dеlpi, С++ и др.).
Моделирование с использованием компьютера предоставляет неизмеримо больше возможностей, чем простое моделирование с помощью реальных предметов или материалов. Например, применение компьютера для раскроя (листового металла, ткани и пр.) позволяет снизить до минимума потери материала. Поиск оптимального решения этой задачи с помощью шаблонов потребует значительно больше времени и средств.
Этапы создания модели
Моделирование — творческий процесс, и разложить его на какие-либо этапы и шаги очень сложно. Многие модели и теории рождаются как соединение опыта и интуиции ученого или специалиста. Однако решение большинства конкретных задач все же можно представить поэтапно.
Моделирование, в том числе компьютерное, начинается с постановки задачи. На этом этапе формулируется задача и требования, которые предъявляются к решению. Постановка задачи заключается, прежде всего, в ее описании. Задача может быть описана на обыденном языке — например, в форме вопроса «что будет, если… ?» или «как сделать, чтобы… ?». Математическую задачу описывают с помощью формул и знаков, а инженерная, экономическая задача может быть описана с помощью различных схем, графиков.
При постановке задачи нужно отразить (или хотя бы понять) цель или мотив создания модели. Одни модели создаются, чтобы разобраться в устройстве или составе того или иного объекта. Другие модели направлены на изучение возможностей управления объектом. Третьи модели ставят целью предсказать поведение объекта (задачи прогнозирования). На этапе постановки задачи полезным оказывается предварительный анализ объекта. Разложение объекта на составляющие, выяснение связей между ними позволяет уточнить постановку задачи.
За постановкой задачи следует этап разработки модели. На этом этапе необходимо выделить существенные факторы, т. е. выяснить основные свойства описываемого объекта, правильно определить связи между ними и с другими объектами окружающего мира. Анализ информации, по возможности, должен быть разносторонним и полным. Те факторы, которые оказались несущественными, могут быть отброшены.
После того как сформулированы основные свойства разрабатываемой модели, определены исходные данные и желаемый результат, наступает очень важный момент — составление алгоритма решения задачи.
При разработке компьютерной модели весьма существенным будет выбор программного обеспечения, с помощью которого выполняется моделирование. Программное обеспечение должно позволять эффективно решать задачи, подобные той, которая рассматривается. Например, для создания рисунка на компьютере нужно выбрать тот или иной графический редактор (какой именно — зависит от требуемого формата файла и приемов, которые необходимо применять при рисовании). Чтобы решить систему уравнений, нужно воспользоваться языками программирования Basic, Pascal или каким-либо другим или же использовать для решения математические пакеты. Программная среда должна соответствовать поставленной задаче — только в этом случае задача может быть успешно решена. Выбор программного обеспечения и составление алгоритма — это взаимосвязанные действия. Возможно, что для решения поставленной задачи придется разработать собственную компьютерную программу.
Когда модель разработана, можно приступать к наиболее интересному этапу — компьютерным экспериментам. В ходе этих экспериментов проверяется работа модели, а также выполняются необходимые расчеты или преобразования, ради которых и создавалась модель.
Проверка модели осуществляется обычно с помощью ее тестирования. При тестировании проверяется разработанный алгоритм функционирования модели. В качестве теста задаются исходные данные, для которых заранее известен ответ. Если ответ, полученный при тестировании, совпадает с известным ответом, а тест составлен правильно, то считается, что модель работает корректно. В противном случае нужно искать и устранять причины расхождений. Все эти действия называются отладкой модели.
После выполнения тестирования и отладки можно приступать непосредственно к моделированию. Технология моделирования может заключаться в расчете модели при различных наборах входных данных, различных параметрах.
Завершается компьютерное моделирование анализом результатов. Материалом для анализа являются результаты компьютерных экспериментов. Поэтому эксперименты должны быть проведены таким образом, чтобы получить достоверный результат. Анализ результатов может привести к необходимости уточнения модели, т. е. к повторному выполнению второго этапа и всех последующих этапов.
Этапы компьютерного моделирования можно представить в виде таблицы.
| 1. ПОСТАНОВКА ЗАДАЧИ | Описание |
| Мотивация | |
| Предварительный анализ |
| 2. РАЗРАБОТКА МОДЕЛИ | Выделение существенных факторов |
| Составление алгоритма | |
| Выбор программного обеспечения | |
| Программирование |
| 3. КОМПЬЮТЕРНЫЙ ЭКСПЕРИМЕНТ | Тестирование модели |
| Отладка модели | |
| Расчет модели при различных входных данных |
Представление и считывание данных в разных типах информационных моделей
(схемы, карты, таблицы, графики и формулы)
Многообразие объектов предполагает использование огромного количества инструментов для реализации и описания этих моделей. Для исследования большинства объектов не обязательно создавать материальные модели. Если ясно представлять цель исследования, то часто достаточно иметь нужную информацию и представить ее в оптимальной форме. В этом случае речь идет о создании информационной модели. Информационные модели — это абстрактные модели, поскольку, как известно, информация — это нематериальная категория.
Информационная модель — это целенаправленно отобранная информация об объекте, представленная в некоторой форме.
Простейшими примерами информационных моделей являются различные загадки, в которых описываются свойства, по которым нужно угадать название объекта («Летом серый, зимой белый»; «Зимой и летом одним цветом»). К информационным моделям можно отнести тексты справочных изданий, энциклопедий.
Формы представления информационных моделей могут быть различными. Наиболее известны следующие формы:
- в виде сигналов;
- устная, словесная;
- символьная (числа, текст, символы);
- табличная;
- схемы, карты;
- графики.
Один и тот же объект, в зависимости от поставленной цели, можно представить несколькими информационными моделями, отличающимися набором параметров и способом их представления. Рассмотрим примеры анализа информации для модели, представленной в табличной форме.
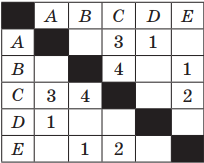
Пример 1. Таблица стоимости перевозок между станциями A, B, C, D, E построена следующим образом: числа, стоящие в ячейках на пересечении строк и столбцов, означают стоимость проезда между соответствующими соседними станциями. Стоимость проезда по маршруту складывается из стоимостей проезда между соответствующими соседними станциями. Если на пересечении строки и столбца пусто, то станции не являются соседними. Выбрать таблицу, для которой выполняется условие: «Минимальная стоимость проезда из А в B не больше 6».
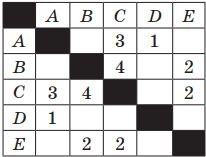
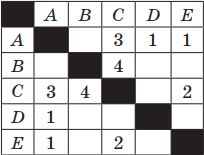
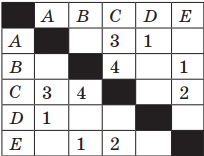
Решение. Прежде всего, нужно отметить, что данные в таблицах симметричны относительно главной диагонали, т. е. проезд из А в В стоит столько же, сколько и из В в А.
Рассмотрим первую таблицу. Выберем все возможные варианты проезда из А в В и соответственно подсчитаем стоимости: AC(3) + CB(4); AC(3) + CE(2) + EB(2)
Примечание. В скобках указана стоимость проезда.
Стоимость, как первого, так и второго варианта маршрута равна 7.
Аналогично поступим для второй таблицы: AC(3) + CB(4); AE(1) + EC(2) + CB(4).
Как и в случае с предыдущей таблицей, стоимость как первого, так и второго варианта маршрута равна 7.
Выписываем все варианты для третьей таблицы: AC(3) + CB(4); AC(3) + CE(2) + EB(1).
Стоимость последнего варианта маршрута равна 6.
Ответ: таблица номер 3 содержит маршрут из А в В, стоимость которого не превышает 6.
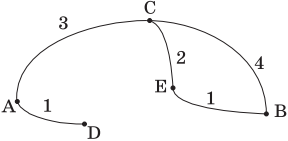
Пример 2. Для заданной информационной модели, записанной в форме таблицы, построить модель в виде схемы. В ячейках на пересечении строк и столбцов таблицы указана стоимость проезда между соседними станциями. Пустые ячейки означают, что станции не являются соседними.
Решение. Отметим точку A, она должна быть соединена с C и D. Отмечаем точки C и D и соединяем их с точкой А дугами; над каждой дугой указываем стоимость проезда. Точка С должна быть соединена, кроме А, с точками В и Е. Точка D является соседней только с А. Точка В должна быть соединена, кроме С, с точкой Е. В результате можно получить следующую схему:
Математические модели (графики, исследование функций)
Знаковые модели принято делить на математические и информационные.
Математическая модель — это знаковая модель, сформулированная на языке математики и логики. Это система математических соотношений — формул, уравнений, неравенств, графиков и т. д., отображающих связи различных параметров объекта, системы объектов, процесса или явления.
Над элементами математической модели можно выполнять определенные математические преобразования. Например, в модели нахождения наименьшего числа выполняются операции сравнения, а в модели вычисления корня уравнения — различные арифметические операции. С помощью математических моделей описываются решения различных инженерных задач, многие физические процессы (движение планет, автомобиля и т. п.); технологические процессы (сварка, плавление металла и т. п.). Графики, таблицы, диаграммы позволяют отображать различные закономерности и зависимости реального мира. Например, модель развития эпидемии можно описать как с помощью формул, так и с помощью графика. Полет снаряда, выпущенного из орудия, можно математически смоделировать с помощью известных формул движения, затем построить график движения снаряда — баллистическую кривую, которая отображает реальный полет снаряда. Математически изменяя параметры снаряда или характеристики движения, можно изучать, например, вопросы увеличения дальности или высоты полета и т. п.
Как известно, не все математические задачи можно решить аналитически, т. е. получить решение в виде формул. Значительно больше задач, которые решаются приближенно, с заданной точностью, т. е. с использованием численных методов. Реализация приближенных расчетов на компьютерах позволяет повысить точность и скорость расчетов.
В настоящее время расчеты для большинства математических моделей проводят на компьютерах, используя специальные прикладные программные комплексы, которые позволяют:
- в несколько раз сократить время проведения исследований;
- уменьшить количество участников эксперимента;
- повысить точность и достоверность эксперимента, а следовательно, увеличить контроль;
- за счет средств графической визуализации, например анимации, получить реальную «картинку»;
- повысить качество и информативность эксперимента за счет увеличения числа контролируемых параметров и более точной обработки данных. На экране компьютера возможно, например, формирование целой системы приборов, которые будут отслеживать изменение параметров объекта.
Построение и использование информационных моделей реальных процессов (физических, химических, биологических, экономических)
Моделирование занимает центральное место в исследовании объекта. Компьютеры дают широкие возможности для постановки компьютерных экспериментов. Компьютерное моделирование позволяет воссоздать явления, которые в реальных условиях воспроизвести невозможно. Это, например, движение материков, эффекты землетрясений и наводнений, рождение сверхновых звезд, изменение направлений морских подводных течений и т. д. При изучении этих явлений на помощь приходят компьютеры и компьютерные программы, причем последние составляются квалифицированными программистами совместно с различными специалистами: физиками, географами, биологами, медиками и др.
Компьютерное моделирование используется также при описании и расчете экспериментов, которые выполнять в реальности не следует. Это, например, модели ядерного взрыва, пожара на предприятии, столкновения на железной дороге, военных действий и т. д. С помощью компьютерных моделей можно с достаточной точностью описать детали этих катастроф и спрогнозировать последствия.
Построение моделей позволяет осознанно принимать решения по усовершенствованию имеющихся объектов и созданию новых, изменению процессов управления ими. И, как следствие, наблюдается изменение окружающего нас мира.
Примеры информационных компьютерных моделей для различных отраслей знаний приведены в таблице.
| Физика | Моделирование движения на плоскости и в пространстве, моделирование различного вида колебаний, процесса расщепления атомного ядра; моделирование работы двигателя, турбины и т. п.; моделирование магнитных, электрических явлений и т. д. |
| Химия | Моделирование строения молекул; моделирование процесса взаимодействия веществ; моделирование отдельных этапов химического производства; моделирование процессов нагревания или остывания различных тел и т. п. |
| Биология | Моделирование развития биологического объекта в зависимости от условий (например, климатических); моделирование побочных действий лекарственных препаратов; моделирование процесса распространения эпидемий; моделирование при решении задач генетики; различные модели изменения численности популяций и т. д. |
| Экономика | Моделирование работы предприятия, банка, отрасли экономики или экономики в целом; моделирование процесса миграции трудовых ресурсов, кризисных явлений в экономике и т. д. |
Объектом моделирования может быть
информационная система (ИС).
Например, информационная система учета
книгооборота библиотеки. Рассмотрим
такой аспект этой системы: в библиотеке
фиксируются данные обо всех поступающих
книгах (договоримся, что поставщик не
важен, а важен только факт поступления
книги); также заносятся данные обо всех
записывающихся читателях; по запросу
читателя может быть выдана книга, которую
он должен вернуть.
Рассмотрим следующую ситуацию. Приобретен
персональный компьютер для оснащения
библиотеки, в которой до этого не
использовалась компьютерная техника.
Требуется автоматизировать систему
учета книгооборота в библиотеке.
Построим информационную модель в
соответствии с описанными ранее этапами.
:
|
Этапы построения
|
1 этап. Определение задачи:
автоматизация учета книгооборота в
библиотеке.
2 этап. Цель построения информационной
модели: описать объекты ИС учета
книгооборота библиотеки, их взаимодействие
в процессе книгооборота.
3 Этап. Анализ объекта моделирования и выделение его существенных свойств
Предметной областью исследуемой ИС
является библиотека. Объектом моделирования
является ИС учета книгооборота в
библиотеке.
Отобразим объекты предметной области,
которые важны с точки зрения ИС:

Обратите внимание, что библиотекарь
может быть в роли и средства работы с
информацией в ИС, и пользователя ИС.
Когда библиотекарь осуществляет запись
читателей в библиотеку, регистрацию
поступающих книг, поиск и выдачу книг
– он выступает в качестве средства ИС,
когда библиотекарь получает информацию
о должниках, о наиболее популярных
книгах (например, для того, чтобы сделать
дополнительный заказ на поставку книг)
и т.п. – он выступает в качестве
пользователя ИС.
Главное назначение ИС – осуществление
информационных процессов, поэтому при
анализе ИС придерживаются следующей
последовательности действий.
-
Выделение основных информационных
процессов в ИС. -
Выделение объектов предметной области
ИС, участвующих в этих процессах
– эти объекты в дальнейшем будут
представлены, как объекты информационной
модели.
Объектом предметной области ИС может
быть человек, предмет, организационная
структура и т.д. Например, в различных
предметных областях объектом может
быть читатель библиотеки, парикмахер,
водитель – люди; автобус, здание, станок
– предметы; школьный класс, кружок,
отдел в организации – организационные
структуры.
При построении информационной модели
ИС рассматриваются не конкретные
объекты, а классы однотипных объектов.
Например, в информационной модели ИС
библиотеки будет рассматриваться не
конкретный читатель (допустим, Иванов
Сергей), а читатель вообще, т.е. любой
читатель, записанный и в библиотеку.
-
Выделение существенных свойств
объектов.
При выделении существенных свойств
объектов необходимо учитывать, что
объекты реального мира, информация о
которых отражается в ИС, всегда отличны
друг от друга. Даже, например, две
одинаковые книги, только что выпущенные
издательством, – это два различных
объекта. В ИС информацию об однотипных
объектах необходимо различать, поэтому
в свойствах объектов должен присутствовать
некий идентификатор, чаще всего
уникальный номер (код), который
закреплен за конкретным объектом.
Например, табельный номер сотрудника
в организации, регистрационный номер
книги в библиотеке, номер свидетельства
о рождении.
-
Анализ каждого процесса на предмет
появления новых существенных свойств,
отличных от свойств объектов,
участвующих в этом процессе – эти
процессы также будут представлены как
самостоятельные объекты информационной
модели. Например, прием пациента у
врача – процесс, в котором участвуют
пациент и врач, новое существенное
свойство этого процесса – время приема,
которое не является свойством ни врача,
ни пациента в отдельности. -
Определение взаимосвязей объектов
информационной модели, отражающих
объекты и процессы предметной области
ИС. Например, ученик учится в классе
(связь объектов «Ученик» и «Класс»),
библиотекарь регистрирует новую книгу
(связь объектов «Библиотекарь» и
«Книга»); врач и пациент участвуют в
процессе приема, т.е. связаны через
объект информационной модели «Прием».
Результаты выполнения перечисленных
первых четырех действий приведены
в таблице (уникальные коды объектов
выделены подчеркиванием):
|
Процессы |
Объекты, |
Существенные |
Существенные |
|
Запись читателя в |
Читатель |
№ читательского билета ФИО читателя Адрес читателя Место |
Не обнаружено |
|
Библиотекарь |
Табельный номер ФИО |
||
|
Получение новых книг |
Книга |
Регистрационный номер книги Автор книги Название книги Издательство Год |
Не обнаружено |
|
Библиотекарь |
Табельный номер ФИО |
||
|
Выдача/возврат книги |
Читатель |
№ читательского билета ФИО читателя Адрес читателя Место |
Дата выдачи книги Дата возврата книги |
|
Книга |
Регистрационный номер книги Автор книги Название книги Издательство Год издания |
||
|
Библиотекарь |
Табельный номер ФИО |
Таким образом, в информационной модели
необходимо отразить следующие объекты:
-
Читатель
-
Книга
-
Библиотекарь
-
Выдача/возврат книги. Этот объект
соответствует процессу, в котором
участвуют Читатель, Книга, Библиотекарь,
однако для этого процесса выявлены и
самостоятельные существенные свойства
– Дата выдачи книги, Дата возврата
книги. В информационной модели ИС для
данного объекта (Выдача/возврат книги)
существенными свойствами будут
уникальные коды объектов-участников
процесса и его самостоятельные
существенные свойства.
Определим взаимосвязи объектов
информационной модели, отражающих
объекты и процессы предметной области
ИС.
Для выделения взаимосвязей необходимо
проверить возможность взаимодействия
каждого объекта с каждым. Если это
взаимодействие существенно для целей
моделирования, его учитываем в
информационной модели, если не существенно
– не учитываем.
Обозначим связи стрелкой с пояснением
над ними.
-
Читатель – Выдача/Возврат книги.
Имеется прямое взаимодействие –
Читатель участвует в Выдаче/Возврате
книги. -
К

нига
– Выдача/Возврат книги. Имеется
прямое взаимодействие – Книга
участвует в Выдаче/Возврате книги. -
Б

иблиотекарь
– Выдача/Возврат книги. Имеется
прямое взаимодействие – Библиотекарь
осуществляет Выдачу/Возврат книги.

-
Книга – Библиотекарь. Взаимодействуют
в двух вариантах – Библиотекарь
регистрирует Книгу при получении
новой Книги. Библиотекарь ищет
Книгу (по запросу читателя). -
Ч


итатель
– Библиотекарь. Взаимодействуют в
двух вариантах: Библиотекарь
записывает Читателя в библиотеку,
Читатель делает запрос на книгу
Библиотекарю. -
Читатель
Книга. Напрямую они не взаимодействуют
в рамках нашей предметной области –
только через объект Выдачу/Возврат
книги.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
Моделирование данных: зачем нужно и как реализовать
Время на прочтение
8 мин
Количество просмотров 29K
Моделирование данных ощутимо упрощает взаимодействие между разработчиками, аналитиками и маркетологами, как и сам процесс создания отчетов. Поэтому я перевела статью IBM Cloud Education о ценности моделирования и от себя добавила инфо о способах трансформации данных для моделирования.
Моделирование данных
Узнайте, как моделирование данных использует абстракцию для представления и лучшего понимания природы данных в информационной системе предприятия.
Что такое моделирование данных
Моделирование данных — это создание визуального представления о всей информационной системе либо ее части. Цель в том, чтобы проиллюстрировать типы данных, которые используются и хранятся в системе, отношения между этими типами данных, способы группировки и организации данных, их форматы и атрибуты.
Модели данных строятся на основе бизнес-потребностей. Правила и требования к модели данных определяются заранее на основе обратной связи с бизнесом, поэтому их можно включить в разработку новой системы или адаптировать к существующей.
Данные можно моделировать на различных уровнях абстракции. Процесс начинается со сбора бизнес-требований от заинтересованных сторон и конечных пользователей. Эти бизнес-правила затем преобразуются в структуры данных. Модель данных можно сравнить с дорожной картой, планом архитектора или любой формальной схемой, которая способствует более глубокому пониманию того, что разрабатывается.
Моделирование данных использует стандартизированные схемы и формальные методы. Это обеспечивает последовательный и предсказуемый способ управления данными в организации или за ее пределами.
В идеале модели данных — это живые документы, которые развиваются вместе с потребностями бизнеса. Они играют важную роль в поддержке бизнес-процессов и планировании ИТ-архитектуры и стратегии. Моделями данных можно делиться с поставщиками, партнерами и коллегами.
Преимущества моделирования данных
Моделирование упрощает просмотр и понимание взаимосвязей между данными для разработчиков, архитекторов данных, бизнес-аналитиков и других заинтересованных лиц. Кроме того, моделирование данных помогает:
-
Уменьшить количество ошибок при разработке программного обеспечения и баз данных.
-
Унифицировать документацию на предприятии.
-
Повысить производительность приложений и баз данных.
-
Упростить отображение данных по всей организации.
-
Улучшить взаимодействие между разработчиками и командами бизнес-аналитики.
-
Упростить и ускорить процесс проектирования базы данных на концептуальном, логическом и физическом уровнях.
Типы моделей данных
Разработка баз данных и информационных систем начинается с высокого уровня абстракции и с каждым шагом становится все точнее и конкретнее. В зависимости от степени абстракции модели данных можно разделить на три категории. Процесс начинается с концептуальной модели, переходит к логической модели и завершается физической моделью.
-
Концептуальные модели данных. Также они называются моделями предметной области и описывают общую картину: что будет содержать система, как она будет организована и какие бизнес-правила будут задействованы. Концептуальные модели обычно создаются в процессе сбора исходных требований к проекту. Как правило, они включают классы сущностей (вещи, которые бизнесу важно представить в модели данных), их характеристики и ограничения, отношения между сущностями, требования к безопасности и целостности данных. Любые обозначения обычно просты.

-
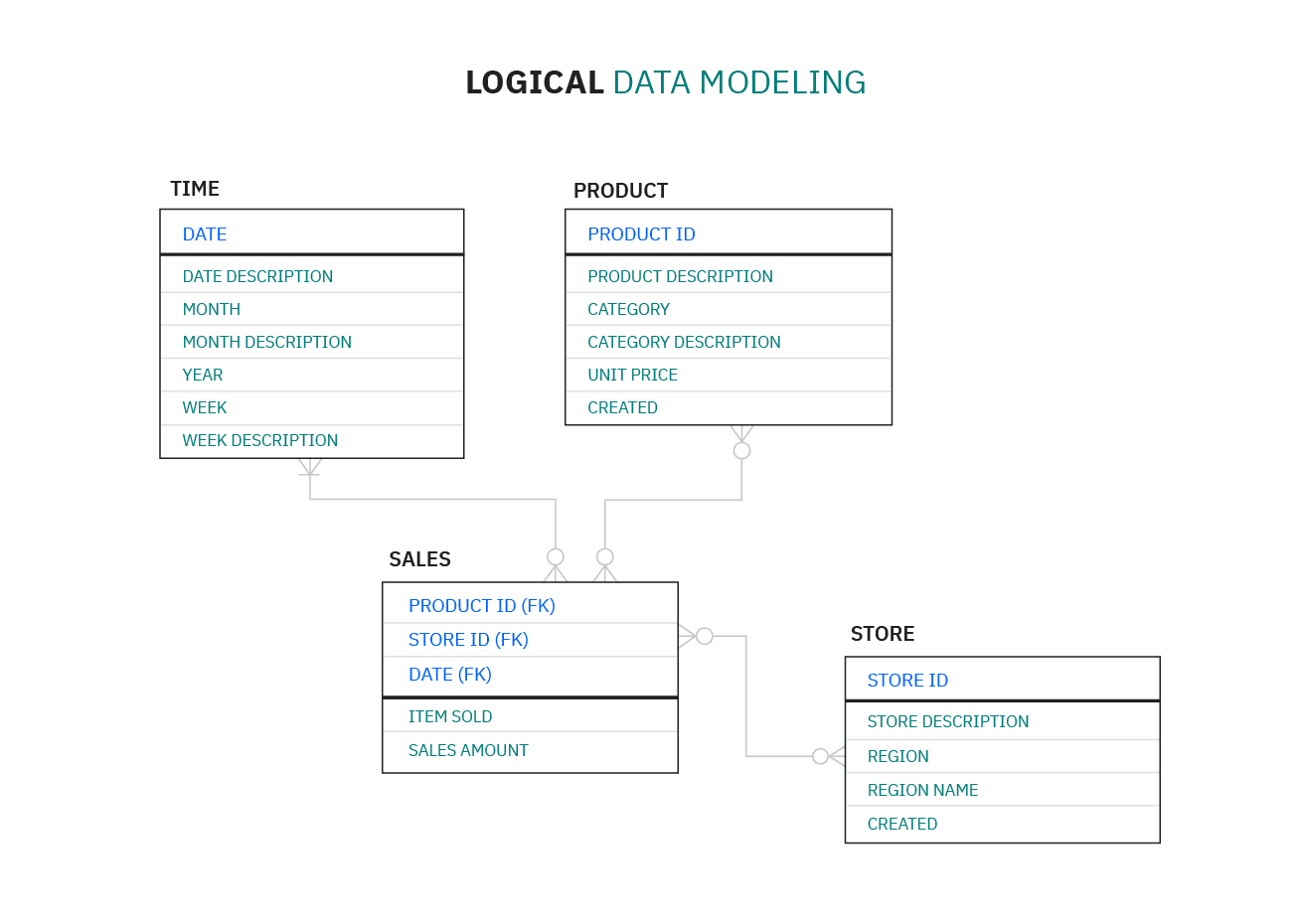
Логические модели данных уже не так абстрактны и предоставляют более подробную информацию о концепциях и взаимосвязях в рассматриваемой области. Они содержат атрибуты данных и показывают отношения между сущностями. Логические модели данных не определяют никаких технических требований к системе. Этот этап часто пропускается в agile или DevOps-практиках. Логические модели данных могут быть полезны для проектов, ориентированных на данные по своей природе. Например, для проектирования хранилища данных или разработки системы отчетности.
-
Физические модели данных представляют схему того, как данные будут храниться в базе. По сути, это наименее абстрактные из всех моделей. Они предлагают окончательный дизайн, который может быть реализован как реляционная база данных, включающая ассоциативные таблицы, которые иллюстрируют отношения между сущностями, а также первичные и внешние ключи для связи данных.

Процесс моделирования данных
Моделирование данных начинается с договоренности о том, какие символы используются для представления данных, как размещаются модели и как передаются бизнес-требования. Это формализованный рабочий процесс, включающий ряд задач, которые должны выполняться итеративно. Сам процесс обычно выглядят так:
-
Определите сущности. На этом этапе идентифицируем объекты, события или концепции, представленные в наборе данных, который необходимо смоделировать. Каждая сущность должна быть целостной и логически отделенной от всех остальных.
-
Определите ключевые свойства каждой сущности. Каждый тип сущности можно отличить от всех остальных, поскольку он имеет одно или несколько уникальных свойств, называемых атрибутами. Например, сущность «клиент» может обладать такими атрибутами, как имя, фамилия, номер телефона и т.д. Сущность «адрес» может включать название и номер улицы, город, страну и почтовый индекс.
-
Определите связи между сущностями. Самый ранний черновик модели данных будет определять характер отношений, которые каждая сущность имеет с другими. В приведенном выше примере каждый клиент «живет по» адресу. Если бы эта модель была расширена за счет включения сущности «заказы», каждый заказ также был бы отправлен на адрес. Эти отношения обычно документируются с помощью унифицированного языка моделирования (UML).
-
Полностью сопоставьте атрибуты с сущностями. Это гарантирует, что модель отражает то, как бизнес будет использовать данные. Широко используются несколько формальных шаблонов (паттернов) моделирования данных. Объектно-ориентированные разработчики часто применяют шаблоны для анализа или шаблоны проектирования, в то время как заинтересованные стороны из других областей бизнеса могут обратиться к другим паттернам.
-
Назначьте ключи по мере необходимости и определите степень нормализации. Нормализация — это метод организации моделей данных, в которых числовые идентификаторы (ключи) назначаются группам данных для установления связей между ними без повторения данных. Например, если каждому клиенту назначен ключ, этот ключ можно связать как с его адресом, так и с историей заказов, без необходимости повторять эту информацию в таблице с именами клиентов. Нормализация помогает уменьшить объем дискового пространства, необходимого для базы данных, но может сказываться на производительности запросов.
-
Завершите и проверьте модель данных. Моделирование данных — это итеративный процесс, который следует повторять и совершенствовать под потребности бизнеса.
Типы моделирования данных
Моделирование данных развивалось вместе с системами управления базами данных (СУБД), при этом типы моделей усложнялись по мере роста потребностей предприятий в хранении данных.
Иерархические модели данных представляют отношения «один ко многим» в древовидном формате. В модели этого типа каждая запись имеет единственный корень или родительский элемент, который сопоставляется с одной или несколькими дочерними таблицами. Эта модель была реализована в IBM Information Management System (IMS) в 1966 году и быстро нашла широкое применение, особенно в банковской сфере. Хотя этот подход менее эффективен, чем недавно разработанные модели баз данных, он все еще используется в системах расширяемого языка разметки (XML) и географических информационных системах (ГИС).
Реляционные модели данных были предложены исследователем IBM Э. Ф. Коддом в 1970 году. Они до сих пор встречаются во многих реляционных базах данных, обычно используемых в корпоративных вычислениях. Реляционное моделирование не требует детального понимания физических свойств используемого хранилища данных. В нем сегменты данных объединяются с помощью таблиц, что упрощает базу данных.
Реляционные базы данных часто используют язык структурированных запросов (SQL) для управления данными. Эти базы подходят для поддержания целостности данных и минимизации избыточности. Они часто используются в кассовых системах, а также для других типов обработки транзакций.
В ER-моделях данных используют диаграммы для представления взаимосвязей между сущностями в базе данных. ER-модель представляет собой формальную конструкцию, которая не предписывает никаких графических средств её визуализации. В качестве стандартной графической нотации, с помощью которой можно визуализировать ER-модель, была предложена диаграмма «сущность-связь» (Entity-Relationship diagram). Однако для визуализации ER-моделей могут использоваться и другие графические нотации, либо визуализация может вообще не применяться (например, только текстовое описание).
Объектно-ориентированные модели данных получили распространение как объектно-ориентированное программирование и стали популярными в середине 1990-х годов. Вовлеченные «объекты» — это абстракции сущностей реального мира. Объекты сгруппированы в иерархии классов и имеют связанные черты. Объектно-ориентированные базы данных могут включать таблицы, но могут также поддерживать более сложные связи. Этот подход часто используется в мультимедийных и гипертекстовых базах данных.
Размерные модели данных разработал Ральф Кимбалл для быстрого поиска данных в хранилище. Реляционные и ER-модели делают упор на эффективное хранение и уменьшают избыточность данных, а размерные модели упорядочивает данные таким образом, чтобы легче было извлекать информацию и создавать отчеты. Это моделирование обычно используется в системах OLAP.
Две популярные размерные модели данных — это схемы «звезда» и «снежинка». В схеме «звезда» данные организованы в факты (измеримые элементы) и измерения (справочная информация), где каждый факт окружен связанными с ним измерениями в виде звездочки. Схема «снежинка» напоминает схему «звезда», но включает дополнительные слои связанных измерений, что усложняет схему ветвления.
Инструменты для моделирования данных
Сегодня широко используются многочисленные коммерческие и CASE-решения с открытым исходным кодом, в том числе различные инструменты моделирования данных, построения диаграмм и визуализации. Вот несколько примеров:
-
erwin Data Modeler — это инструмент моделирования данных, основанный на языке IDEF1X, который теперь поддерживает и другие нотации, включая нотацию для размерного моделирования.
-
Enterprise Architect — это инструмент визуального моделирования и проектирования, который поддерживает моделирование корпоративных информационных систем и архитектур, программных приложений и баз данных. Он основан на объектно-ориентированных языках и стандартах.
-
ER/Studio — это программа для проектирования баз данных, совместимая с некоторыми из самых популярных СУБД. Она поддерживает как реляционное, так и размерное моделирование данных.
-
Бесплатные инструменты моделирования данных включают решения с открытым исходным кодом, такие как Open ModelSphere.
Для того, чтобы преобразовать данные в структуру, которая соответствует требованиям модели, можно использовать встроенный механизм регулярных запросов, которые выполняются в Google BigQuery, Scheduled Queries и AppScript. Их легко можно освоить, потому что это привычный SQL, но проводить отладку в Scheduled Queries практически нереально. Особенно, если это какой-то сложный запрос или каскад запросов.
Есть специализированные инструменты для управления SQL-запросами, например, dbt и Dataform.
dbt (data build tool) — это фреймворк с открытым исходным кодом для выполнения, тестирования и документирования SQL-запросов, который позволяет привнести элемент программной инженерии в процесс анализа данных. Он помогает оптимизировать работу с SQL-запросами: использовать макросы и шаблоны JINJA, чтобы не повторять в сотый раз одни и те же фрагменты кода.
Главная проблема, которую решают специализированные инструменты — это уменьшение времени, необходимого на поддержку и обновление. Это достигается за счет удобства отладки.
