Скачать материал

Скачать материал


- Сейчас обучается 389 человек из 62 регионов


- Сейчас обучается 271 человек из 65 регионов




Описание презентации по отдельным слайдам:
-

1 слайд
-1-
Методика составления управленческого классификатора
1. Как составить классификаторы?
Имеющиеся классификаторы
Список хозяйственных операций
План счетов бухучета
Стандартный шаблон
Форматы бюджетов из книг по бюджетированию
Согласование с заинтересованными лицами -
2 слайд
-2-
2. Доходы в БДР -
3 слайд
-3-
3. Прямые расходы в БДР – по реализации!! -
4 слайд
-4-
4. Расходы периода в БДР -
5 слайд
-5-
5. Расходы из Фонда Генерального директора – не входят в расходы периода -
6 слайд
-6-
6. Поступления по операционной деятельности в БДДС -
7 слайд
-7-
7. Выплаты в БДДС по операционной деятельности -
8 слайд
-8-
8. Классификатор БДДС по финансовой деятельности -
9 слайд
-9-
9. Классификатор БДДС по финансовой деятельности -
10 слайд
-10-
10. Классификатор Бюджета инвестиций -
11 слайд
-11-
11. Классификатор БДДС по инвестиционной деятельности -
12 слайд
-12-
12. Различия в статьях БДР и БДДС -
13 слайд
-13-
13. Будут ли «биться» между собой классификаторы БДР и БДДС?
Удобно, когда статьи «бьются» между собой там, где это возможно. Коды и названия статей должны отражать связь между ними.Суммы по соответствующим статьям не будут одинаковыми!
-
14 слайд
-14-
14. Управленческая аналитика
По регионам (для доходов и поступлений);
По группам товаров (для доходов, поступлений и прямой себестоимости);
По подразделениям (для расходов периода, выплат и инвестиций);
По группам клиентов (для доходов, поступлений и коммерческих расходов);
По юридическим лицам (для движения денег, налогов, кредитов)
По местам хранения денежных средств (для движения денег)
Проекты или группы проектов (заказов) -
15 слайд
-15-
15. Аналитические справочники
Составить укрупненные аналитические справочники одновременно с классификатором
Для каждой статьи классификатора указать, какая аналитика по ней должна быть -
16 слайд
-16-
16. Группировка статей в классификаторах
Часто приходится принимать решение, разделить ли статьи классификатора или использовать аналитику.
Например, «Доходы от продаж»:
Доходы от оптовых продаж;
Доходы от мелкооптовых продаж;
Доходы от розницы.
Вместо разделения по статьям можно использовать аналитику по группам покупателей. -
17 слайд
-17-
17. Признак статьи БДДС: приоритет выплаты:
1 – налоги и кредиты;
2- заработная плата;
3- оплата сырья и материалов для основного производства;
4-оплата административных и общехозяйственных расходов;
5-выплаты, не влияющие на производственный процесс (ссуды, дивиденты и т.п.). -
18 слайд
-18-
18. Признак статьи в БДР – защищенная (не может быть секвестирована):
1 – налоги и кредиты;
2- статьи, относящиеся к прямым расходам (сырье, сдельная заработная плата)
3-другие статьи, согласно Положению о бюджетировании. -
19 слайд
-19-
19. Классификатор управленческого баланса -
20 слайд
-20-
20. Два способа планирования и учета хозяйственных операций
1 способ – через управленческий план счетов (УПС):
двойная запись по плану счетов в момент фиксации хозяйственной операции ;
статьи БДР, БДДС – становятся одним из разрезов аналитики для плана счетов, баланс агрегирует остатки по группам счетов – как в бухучете.
2 способ:
отражение доходов, расходов, выплат, поступлений в БДР, БДДС при учете хозяйственной операции;
фиксация остатков по статьям баланса и ввод по ним оборота по статьям БДР, БДДС за период.
Баланс
БДР, БДДС
Операция
Остатки
Баланс
Операция
БДР, БДДС
УПС -
21 слайд
-21-
21. Расходы и затраты
Под затратами понимаются закупка материалов, потребление услуг и т.д., осуществленные в текущем периоде, но не списанные в этом периоде на себестоимость продукции, т.е. обратившиеся в активы в виде запасов. Таким образом, затраты отразятся в Балансе и, если они были оплачены, в Бюджете Движения Денежных Средств.
Расходы по этим суммам возникнут тогда, когда эти запасы войдут в реализованную продукцию в качестве прямых расходов, либо закончится период, для которого эти запасы войдут в косвенные расходы. Тогда произойдет отражение в БДР. -
22 слайд
-22-
22. Статьи расходов агрегируют статьи затрат
Баланс
БДР
Остатки
Сумма, отнесенная на реализованную продукцию, в т.ч. амортизация -
23 слайд
-23-
23. Дополнительные статьи классификатора, не входящие в БДР, БДДС, Баланс
Эти статьи нужны для правильного составления баланса.
Поступления и перемещения должны «биться» с БДР и
БДДС. -
24 слайд
-24-
24. Что еще нужно для планирования:
целевые и контрольные показатели;
рецептуры, спецификации, нормативы;
численность персонала;
статистические коэффициенты для планирования.
В зависимости от способа автоматизации их можно ввести
в отдельную группу классификатора
или в самостоятельные справочники. -
25 слайд
-25-
25. Вывод: состав управленческого классификатора
управленческий план счетов, если он используется;
классификатор баланса;
классификатор БДР;
классификатор БДДС;
классификатор инвестиций;
целевые и контрольные показатели;
статьи для планирования в нат. ед.
Выделены статьи, за которые обязательно должны быть ответственные ЦФО.












;
По...")



: 1 –...")







Найдите материал к любому уроку, указав свой предмет (категорию), класс, учебник и тему:
6 257 204 материала в базе
- Выберите категорию:
- Выберите учебник и тему
- Выберите класс:
-
Тип материала:
-
Все материалы
-
Статьи
-
Научные работы
-
Видеоуроки
-
Презентации
-
Конспекты
-
Тесты
-
Рабочие программы
-
Другие методич. материалы
-
Найти материалы
Другие материалы
- 10.01.2021
- 956
- 2
- 10.01.2021
- 614
- 1
- 10.01.2021
- 647
- 0
- 10.01.2021
- 660
- 0
- 10.01.2021
- 761
- 0
- 10.01.2021
- 649
- 0
- 09.01.2021
- 511
- 0
- 09.01.2021
- 568
- 0
Вам будут интересны эти курсы:
-
Курс повышения квалификации «Правовое обеспечение деятельности коммерческой организации и индивидуальных предпринимателей»
-
Курс повышения квалификации «Основы управления проектами в условиях реализации ФГОС»
-
Курс повышения квалификации «История и философия науки в условиях реализации ФГОС ВО»
-
Курс повышения квалификации «Организация практики студентов в соответствии с требованиями ФГОС технических направлений подготовки»
-
Курс повышения квалификации «Этика делового общения»
-
Курс повышения квалификации «Маркетинг в организации как средство привлечения новых клиентов»
-
Курс повышения квалификации «Организация маркетинга в туризме»
-
Курс профессиональной переподготовки «Политология: взаимодействие с органами государственной власти и управления, негосударственными и международными организациями»
-
Курс повышения квалификации «Финансовые инструменты»
-
Курс профессиональной переподготовки «Метрология, стандартизация и сертификация»
Первое правило
классификации. Основание классификации
должно быть определено признаком,
существенным для решения задачи с
помощью данной классификации. Если не
указывать основания классификации, она
может быть подменена простым перечислением
множества объектов. Первое правило
классификации проиллюстрировано на
рис. 3.2. Пример 1 представляет существенную
для целей таможенного тарифа классификацию,
а пример 2 – несущественную.
Пример 1

Пример 2

Рис. 3.2. Первое
правило классификации
Второе правило
классификации – члены деления должны
исключать друг друга. На рис. 3.3 в примере
1 классификация выполнена неверно, так
как продукты в ней различаются по
фракционному составу, а газойль и
вакуумный газойль таких различий не
имеют.


рис. 3.3. Второе
правило классификации
Третье правило
классификации – деление на каждом его
этапе должно производиться только по
одному основанию (рис. 3.4).

В обоих примерах
на одном этапе классификации наблюдается
объединение нескольких оснований
(материал и наличие электрического
обогрева для одеял; место установки и
пол потребителя для часов). В первом
случае это просто затрудняет понимание
классификации, а во втором случае
приводит к потерям группировок,
отличающихся по месту установки
(настенные, настольные и т. п.).
Четвертое правило
классификации – деление должно быть
соразмерным – объем делимого понятия
должен быть равен объединению объемов
членов деления.
На рис. 3.5 сумма
понятий «тонкий волос» и «грубый волос»
равна объему делимого понятия. В случае
с часами объем делимого понятия шире,
чем сумма понятий, полученных в результате
деления. Во избежание этой ошибки
необходимо добавить еще один член
деления – «прочее». Этот метод позволяет
предсказывать существование ранее
неизвестных объектов или создавать
новые.

Пятое правило
классификации – каждое понятие,
полученное в результате деления, должно
быть определено.
Группировка
«прочие» в нижнем правом углу рис. 3.6
должна включать велосипеды двухколесные
и прочие велосипеды без двигателя с
шарикоподшипниками, отличные от просто
велосипедов. Данная группировка не
определена.

Классификация
выступает как метод познания некоторого
множества объектов, являясь, таким
образом, методом изучения товаров.
Глава 4 классификаторы продукции и товаров
4.1. Развитие единой системы классификации и кодирования технико-экономической и социальной информации
В современном мире
практически во всех сферах производственной
и социальной деятельности широко
используются методы классификации и
кодирования информации. Совокупность
общероссийских классификаторов образует
Единую систему классификации и кодирования
технико-экономической и социальной
информации (ЕСКК Объектом классификации
и кодирования в ЕСКК является информация
в различных областях хозяйственной
деятельности – это статистика финансовая
и правоохранительная деятельность,
банковское дело, бухгалтерский учет,
стандартизация, таможенное дело, торговля
и внешнеэкономическая деятельность.
Координацию работ в ЕСКК осуществляют
два федеральных органа: Госстандарт
России и Госкомстат России. В качестве
основных методов классификации приняты
иерархический и фасетный, а в качестве
методов кодирования – последовательный,
параллельный, порядковый и серийно-порядковый.
В наследство от
Советского Союза Россия получила
разветвленную систему классификаторов.
В последние годы многие действующие
классификаторы были существенно
изменены, а в ряде случаев разработаны
новые. В перечень общероссийских
классификаторов технико-экономической
и социальной информации, включающих и
формацию о продукции и товарах, входят:
• ОК стандартов
(ОКС);
• ОК продукции
(ОКП);
• ОК изделий и
конструкторских документов (ЕСКД);
• ОК единиц
измерения (ОКЕИ);
• ОК деталей,
изготавливаемых сваркой, пайкой,
склеиванием и термической резкой (ОКД);
• ОК видов
экономической деятельности, продукции
и услуг (ОКДП).
По состоянию на
2001 г. находятся в применении, например,
Общесоюзный классификатор грузов (ОКГ),
Общесоюзный классификатор видов грузов,
упаковки и упаковочных материалов
(ОКВГУМ), ведет которые МПС России.
Ряд российских
классификаторов полностью соответствует
международным классификациям или
стандартам – это ОКДП, ОКС, ОКЕИ.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
26.05.20153.57 Mб36ТМиСЗИ л.2-3 (20-14).doc
- #
- #
- #
- #
- #
- #
- #
ПОСТРОЕНИЕ КЛАССИФИКАТОРА Юнусова Л.Р.1, Магсумова А.Р.2
1Юнусова Лилия Рафиковна – магистрант;
2Магсумова Алия Рафиковна – магистрант, направление: информатика и вычислительная техника, магистерская программа: технология разработки программного обеспечения, кафедра информационных систем, отделение информационных технологий и энергетических систем, Высшая инженерная школа Набережночелнинский институт Казанский федеральный университет, г. Набережные Челны
Аннотация: в статье рассматривается и анализируется работа по построению и использование классификаторов, описываются методы классификаторов. Ключевые слова: классификация, нейросети, методы классификации.
Классификатор представляет собой иерархическую (древовидную) классификационную структуру, которая создает классификаторы, которые эффективны для поиска отдельных классификаторов и связей между ними (для этой цели используются различные методы кодирования и автоматизации). Вы можете искать и выбирать информацию и искать, и выбирать элементы. Например, если устройство может удалять компоненты из смеси, оно также называется классификатором, поскольку оно выполняет операцию классификации (группирование первоначально смешанных элементов).
С развитием информационных технологий число различных классификаторов неуклонно растет. В настоящее время классификаторы документов (например, нормативные), информация (например, технические, экономические, социальные), объекты (транспортные средства, товары, здания и сооружения, отходы), юридические отрасли, виды деятельности И формы, связанные с развитием (например, сектор, экономическая деятельность, услуги), события (например, чрезвычайная ситуация, болезнь), элементы пространства (например, административно-территориальная структура, местоположение, предмет события), профессиональная деятельность особенно.
Создание классификаторов
Самый простой вид классификации – это список. Пример неупорядоченного списка: яблоки, груши и сливы на столе. Упорядочением списка является код упорядоченного объекта или внешний код для них, такой как упорядочение кода, который указывает упорядоченный объект, то есть серийный номер (или номер дома или товар улицы, род занятий, страну, Используйте код, который указывает на почтовое отделение). Внутренние функции (классифицированные свойства или отношения элементов) включают списки, регистры, каталоги, часто каталоги, например, компании, каталоги товаров. Оптимальность метода кодирования при классификации сначала определяется характеристиками набора объектов, подлежащих классификации. При создании классификации, в которой код (структура) не изменяется при добавлении новых заголовков, код для каждого уровня классификации должен быть ограничен определенным количеством цифр.
Вот пример классификации, где количество членов подразделения не превышает 10 (то есть они пронумерованы от 0 до 9). В этом случае на каждом уровне классификации количество заголовков ограничивается одной цифрой, как в десятичной классификации Дьюи.
Методы классификации
Классификация – это разделение набора объектов на подмножества в соответствии с принятыми методами. Захват классификации и вспомогательных классов, связанных с природой.
Объект классификации – это обозначенный элемент, используемый в классификации.
Классификационный символ – символ, по которому данный набор делится на подмножества.
Классификация группировки-Подмножество, полученное путем разделения указанного набора.
Глубина классификации – количество шагов классификации.
Существует три способа классификации: базовый, иерархический и фасетный.
Следующие требования применяются к выбранной системе классификации:
– достаточная емкость и необходимая полнота для обеспечения охвата всех объектов классификации в указанных пределах;
– обоснованная глубина;
– предоставление возможности решать задачи управления объектами;
– возможность расширения набора классифицируемых объектов и внесения необходимых изменений в классификационную структуру;
– возможность сопряжения с другими классификациями подобных объектов;
– обеспечение простоты обслуживания классификатора.
– Каждая система классификации характеризуется следующими свойствами:
– гибкость системы;
– емкость системы;
– степень загруженности системы.
Гибкость системы заключается в возможности разрешать включение новых функций, объектов, не разрушая структуру классификатора. Необходимая гибкость определяется сроком службы системы.
Емкость системы – это наибольшее количество классификационных групп, разрешенных в данной системе классификации.
Степень загруженности системы определяется как коэффициент деления фактического количества группировок на величину емкости системы.
Элементарный метод
Метод предполагает упорядочение множества объектов по одному признаку классификации. Наиболее часто используется лексикография (в алфавитном порядке) и хронология.
Иерархический метод
Иерархическая классификация – это метод, в котором данный набор последовательно разделяется на подчиненные подмножества, и объекты классификации постепенно воплощаются.
Основным преимуществом иерархического метода является большая информационная емкость, значение которой зависит от глубины классификации (количества этапов разделения) и количества объектов классификации, которые могут быть размещены на каждом этапе. Количество объектов на каждом этапе классификации определяется на основе кода, количества символов в выбранном коде алфавита. Существенным недостатком иерархической классификации является жесткость схемы классификации. Это связано с предопределенным выбором функции классификации и порядка использования на этапе классификации. Это требует фундаментального пересмотра плана классификации при изменении структуры объекта классификации, его характеристик или характера проблемы, решаемой с помощью классификатора. Гибкость этой системы является структурой классификатора. Обеспечивается только за счет большого перекрытия ветвей, что
приводит к слабому заполнению. Поэтому при разработке классификатора метод иерархической классификации более предпочтителен для решения объектов с относительно стабильными характеристиками и рядом устойчивых задач.
Фасетный (многоаспектный) метод
Аспект – точка зрения объекта классификации, которая характеризуется одним или несколькими признаками.
Многомерная система – это система классификации, которая использует несколько независимых признаков (аспектов) параллельно в качестве основы для классификации. Существует два типа многомерных систем: ограненные и дескрипторные.
Фасет – это аспект классификации, который используется для формирования независимых классификационных группировок.
Дескриптор – ключевое слово, которое определяет концепцию, которая формирует описание объекта и дает принадлежность этого объекта классу, группе.
Фасетный (многоаспектный) Метод классификации включает в себя разделение набора объектов на независимые группы классификации. Он не предполагает строгой структуры классификации и предварительно собранной конечной группы. У организации классификации есть этот аспект от объединенного значения. Порядок граней в формировании таксона задается уравнением фасетов. Особенности комбинаций, которые можно определить по фасетным выражениям чисел.
К классификатору, построенному на основе метода классификации фасетов, применяются следующие требования:
1. Должен соблюдаться принцип непересекаемости фасета, т. Е. Состав признаков одного фасета не должен повторяться в других фасетах того же класса;
2. Структура классификатора должна включать только те грани и признаки, которые необходимы для решения конкретных задач.
Список литературы
1. Бенджио, Гудфеллоу, Курвилль: Глубокое обучение. Издательство: ДМК-Пресс,
2018 г. С.400-455.
2. Осовский С. Нейронные сети для обработки информации, 2002г, С.252-291.
3. Васильев А.Н. Принципы и техника нейросетевого моделирования, 2014г,
С. 126-198.

Таня Пучило
ментор курса Wargaming Forge: Game Data Analytics
В разработке ПО в целом и видеоигр в частности важно всегда иметь возможность проанализировать работу системы и поведение пользователей. Для того чтобы аналитики имели возможность собрать информацию и дать полезные рекомендации, а разработчики — воспользоваться этими рекомендациями для улучшения продукта, нужно заранее позаботиться не только о корректном логировании, но и о правильной разметке данных. Так как это не всегда возможно, часть данных не используется при анализе, или, что ещё хуже, на их основе делаются некорректные выводы.
Подход к работе с неверно размеченными данными, описанный в статье, пригодится любому аналитику или датасаентисту, который имеет дело с неверно размеченными данными, но очень хочет использовать их для построения решений, и не ищет лёгких путей.
Что такое неверная разметка и почему это происходит?
Неверно размеченные данные — это данные, метки которых не соответствуют действительности. К примеру, у вас есть набор картинок котиков и собачек, но часть котиков почему-то оказывается собачками согласно разметке. Такая проблема может возникнуть по нескольким причинам: субъективность человека, размечающего данные; ошибки при получении данных, и, в случае косвенной разметки, выбор неверного алгоритма. Очевидно, такие проблемы могут возникнуть в абсолютно любых областях: в медицине, развлечениях, обучении — где угодно.
Я работаю в Wargaming, наша область — это игры. А как известно, в играх проходит множество событий (таких, как акции на какой-либо контент, запуск нового режима), имеющих совершенно разные цели: начиная от привлечения новых игроков, заканчивая монетизацией или повышением их вовлеченности. Проведя очередное игровое событие, вы, как аналитик, получаете следующую задачу: реализовать алгоритм, с помощью которого можно будет прогнозировать участие игроков в подобном событии в будущем. Вы хотите получить инструмент вида:

Входные данные, которые вам доступны, включают:
- характеристики игроков (сколько они играют боев, в каких режимах, какую технику предпочитают и т. д.),
- факт участия игрока в событии (к примеру, совершили ли игроки покупку предлагаемого контента).
Кажется, что ничто не мешает вам обучить алгоритм на основе характеристик игроков для прогнозирования вероятности его участия в событии. Однако во время проведения события что-то идёт не так, и вы понимаете, что часть игроков, которые хотели в нём поучаствовать, не могут этого сделать. Если это покупка — они пытаются её совершить, но не могут, — количество предлагаемого контента ограничено; если это новый режим — они пытаются сыграть в него, но у них не получается зайти в бой по каким-то техническим проблемам. Эти игроки так и останутся в статусе «не поучаствовал, но хотел бы».

Вот незадача! Ведь вам, как аналитику, очень нужны точные данные об участниках события, чтобы использовать эту информацию для обучения алгоритма. А данные, которые у вас есть, выглядят следующим образом:

При этом третьего столбца на самом деле не существует. И нет никакого технического способа проверить, правильна метка или нет. Всё, что вы знаете, — это то, что часть игроков попала в ошибочный класс.
Что делать?
Вариант первый: ничего!
Ну не можем мы обучить модель и сделать прогноз, — бывает. Мы всегда можем посчитать описательные статистики по игрокам-участникам события (к примеру, среднее количество боёв в день) и выделить простые правила для отбора потенциальных участников в новом событии. В случае среднего количества боёв в день, может получиться так, что у группы участников значение метрики в среднем на 30% выше, чем у не участников. Вот мы и будем предполагать, что все игроки, с похожим значением метрики, как у участников события, станут потенциальными участниками следующего события.
Плюсы:
- Просто и быстро.
Минусы:
- Отсутствие масштабируемости или ограниченное количество метрик, которые вы можете охватить. Если речь идёт про 1–2 метрики, использовать правила для них не составит труда. Но в действительности метрик, которые вы захотите сравнить, окажется в разы больше. А если вам вдруг захочется посмотреть на взаимное влияние нескольких признаков, сделать это будет очень сложно и преимущество, связанное со скоростью, уже не будет актуальным.
- Точность/качество. Вы просто не сможете их адекватно оценить.
- Влияние ошибочных данных. Неверно размеченных игроков вы всё же никуда не денете, поэтому их характеристики будут искажать значения рассматриваемых метрик. К примеру, в «не участников» события попадут потенциальные участники, с количеством боёв в день гораздо более высоким, чем у не участников. В итоге среднее значение или другая статистика, будут иметь ошибочно завышенное значение.
Вариант второй: обучить алгоритм на той разметке, которая есть
В качестве вектора признаков для характеристики игроков берём всевозможные метрики, которые приходят нам на ум (включая среднее количество боёв в день), а в качестве целевой переменной — участие игрока в событии, предполагая, что ошибок в данных у нас нет. На этих данных обучаем алгоритм, используя магию машинного обучения, и с помощью полученного алгоритма прогнозируем участие игроков в следующем событии.
Плюсы:
- Масштабируемость. За счёт того, что это алгоритм машинного обучения, вы учитываете гораздо больше признаков и их взаимное влияние на целевую переменную.
- Точность/качество. Теперь-то вы можете оценить качество полученной модели (недаром было придумано такое огромное количество метрик качества методов машинного обучения), однако, скорее всего, то, что вы получите, вас не устроит.
Минусы:
- Влияние ошибочных данных. А качество алгоритма не устроит вас потому, что ошибочные данные всё так же присутствуют в обучающей выборке и оказывают существенное влияние на обучение.
Вариант третий – переразметить игроков и обучить модель на переразмеченных данных
Прежде чем обучать модель на характеристиках игроков и целевой переменной, попытаемся получить новые, более точные, значения целевой переменной. И только после этого, используя обновлённые значения, обучим финальный алгоритм.
Плюсы:
- Масштабируемость. Это всё та же модель машинного обучения, с помощью которой вы учтёте множество признаков и их взаимосвязи.
- Точность/качество. Смотри предыдущий пункт.
- Отсутствие влияния ошибочных данных. Если у вас получилось качественно (а как это понять — будет описано ниже) переразметить выборку, то влияние ошибочных данных на результат обучения будет сведено к минимуму.
Учитывая, что последний вариант имеет наибольшее количество преимуществ и мы не ищем лёгких путей, остановимся именно на нём.
Как найти в выборке неверно размеченные объекты?
Качество финальной модели зависит от двух вещей: от качества исходных данных (в частности — их разметки) и возможностей/настройки выбранной модели. В нашем случае основной упор делается на качество данных, поэтому заниматься оптимизацией характеристик моделей мы не будем. Однако это не повод этого не делать! Чтобы переразметить данные, нам понадобится:
- исходная выборка с «неверной» разметкой,
- несколько разных по архитектуре методов машинного обучения,
- время и высокие мощности вашего железа.
Допустим, исходные данные выглядят следующим образом. Здесь X={x1,x2,…, xn} — вектор признаков, описывающих каждого игрока, а y — целевая переменная, соответствующая тому, участвовал игрок в событии или нет (1 — участвовал, 0 — не участвовал соответственно).
import pandas as pd
import numpy as np
data = pd.read_csv('../data.csv')
data.head(n=10)
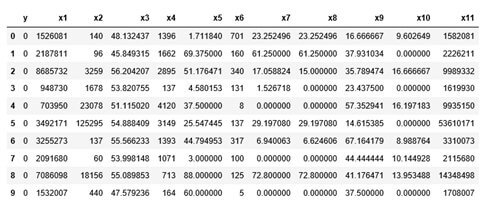
data.y.value_counts(normalize=True)![]()
Для начала обучим базовый классификатор для того, чтобы понимать качество модели на неверно размеченной выборке. В качестве классификатора выберем Random Forest и его реализацию в Sklearn.
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
X_data, y_data = data.drop(['y'], axis = 1), data['y']
X_train, X_test, y_train, y_test = train_test_split(X_data, y_data, test_size=.3, random_state=RS)
clf = RandomForestClassifier(n_estimators=250, random_state=42, n_jobs=15)
clf.fit(X_train, y_train)
y_pred = clf.predict(X_test)
Посмотрим на качество модели: выведем матрицу ошибок и основные метрики качества.
df_confusion = pd.crosstab(y_test, y_pred, rownames=['Actual'], colnames=['Predicted'], margins=True)
print(df_confusion)
from sklearn.metrics import classification_report
print(classification_report(y_test, y_pred))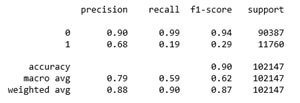
Видим, что качество классификации для 1-го класса, т. е. участников события, очень низкая: recall1= 0,19, а f1-score= 0,29. Средний для модели f1-score= 0,62.
Если бы вы не собирались делать переразметку данных, то вряд ли бы решились остаться на таких результатах, учитывая, что модель практически всех участников события отнесла к тем, кто не будет участвовать. В итоге вы бы вернулись к подсчётам базовых статистик.
Будем надеяться, что вы решили идти дальше. Схематично вся переразметка данных сведётся к следующему. Исходные данные разобьём на N частей с равным распределением объектов из 0-го и 1-го классов. На каждых (N-1) частях обучим 5 или более методов машинного обучения, желательно разных по архитектуре и предсказывающих вероятность. В нашем случае используем уже знакомый Random Forest, а также Logistic regression, Naive Bayes, XGBoost, CatBoost.
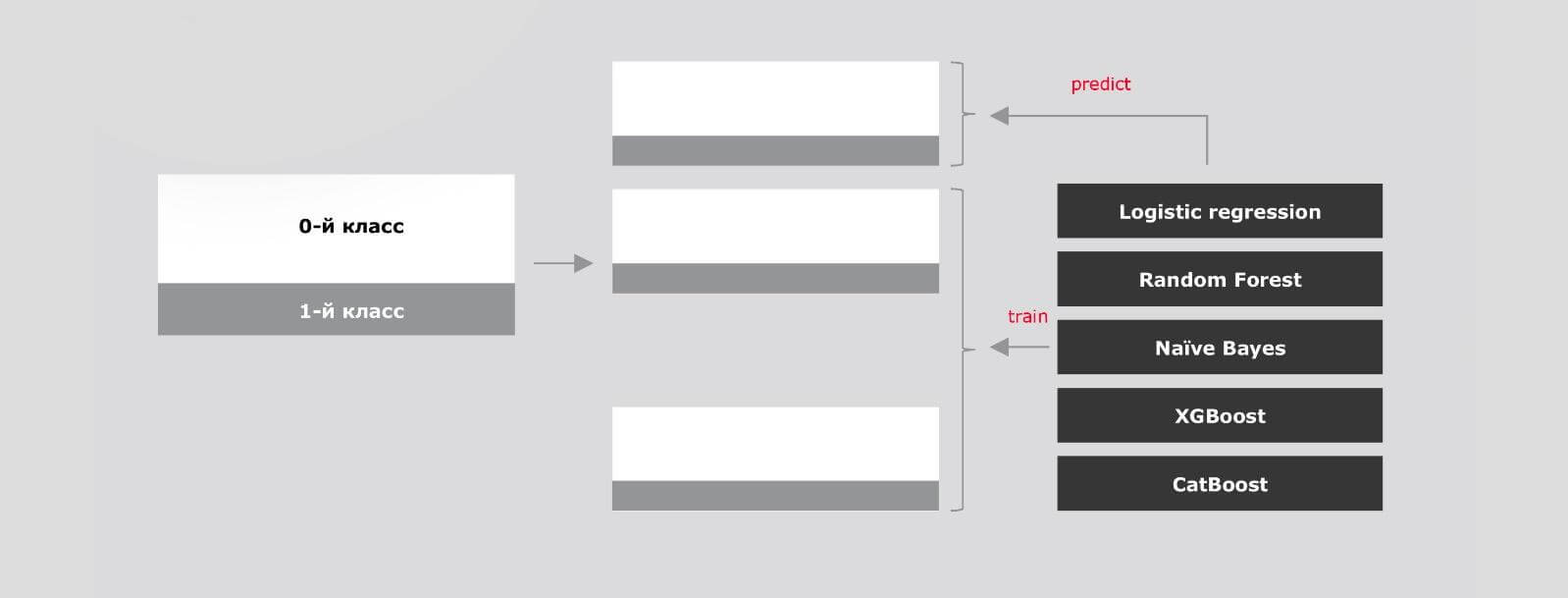
Для этого инициализируем модели с нужными параметрами. Параметры, к слову, уже на этом этапе лучше выбирать путем оптимизации гиперпараметров.
from catboost import CatBoostClassifier
from sklearn.naive_bayes import GaussianNB
from sklearn.linear_model import LogisticRegression
from xgboost import XGBClassifier
clfs = {}
logreg_model = LogisticRegression(C=100)
clfs['LogReg'] = {'clf': LogisticRegression(), 'name':'LogisticRegression', 'model': logreg_model}
rf_model = RandomForestClassifier(n_estimators=250, max_depth=18, n_jobs=15)
clfs['RandomForest'] = {'clf': RandomForestClassifier(), 'name':'RandomForest', 'model': rf_model}
xgb_model = XGBClassifier(n_estimators=500, max_depth=10, learning_rate=0.1, n_jobs=15)
clfs['XGB'] = {'clf': XGBClassifier(), 'name': 'XGBClassifier', 'model': xgb_model}
catb_model = CatBoostClassifier(learning_rate=0.2, iterations=500, depth=10, thread_count=15, verbose=False)
clfs['CatBoost'] = {'clf': CatBoostClassifier(), 'name': 'CatBoostClassifier', 'model': catb_model}
nb_model = GaussianNB()
clfs['NB'] = {'clf': GaussianNB(), 'name':'GaussianNB', 'model': nb_model}Далее исходные данные разбиваем на 5 частей с равномерным распределением примеров 0-го и 1-го классов.
data_0 = np.array_split(data[data['y'] == 0].sample(frac=1), 5)
data_1 = np.array_split(data[data['y'] == 1].sample(frac=1), 5)
dfs = {i: data_0[i].append(data_1[i]) for i in range(5)}И наконец, производим переразметку данных, итерируясь по каждой из 5-и частей выборки и используя для прогнозирования каждую из 5-и вышеобъявленных моделей.
from sklearn.preprocessing import StandardScaler
threshold = 0.5
relabeled_data = pd.DataFrame()
for i in range(5):
# test - i-й dataframe, train - все оставшиеся кроме i-го
df_test = dfs[i]
df_train = pd.concat([value for key, value in dfs.items() if key != i])
X_train, y_train = df_train.drop(['y'], axis=1), df_train['y']
X_test, y_test = df_test.drop(['y'], axis=1), df_test['y']
df_w_predicts = df_test.copy()
# обучение каждой модели на train и прогноз на test
for value in clfs.values():
model = value['model']
if value['name'] in ['LogisticRegression', 'GaussianNB']:
model.fit(StandardScaler().fit_transform(X_train), y_train)
predicts = (model.predict_proba(StandardScaler().fit_transform(X_test)
)[:, 1] >= threshold).astype(bool)
else:
model.fit(X_train, y_train)
predicts = (model.predict_proba(X_test)[:, 1] >= threshold).astype(bool)
df_w_predicts[value['name']] = predicts
relabeled_data = relabeled_data.append(df_w_predicts)
В результате переразметки каждая модель предскажет вероятность того, что игрок был участником события. Переразметка целевой переменной происходит в том случае, если все модели предсказали вероятность выше некоторого порога (threshold). В текущем примере threshold=0.5. Данные будут выглядеть следующим образом:

Возникает логичный вопрос: как проверить качество переразметки? Как вариант, построить распределения признаков, характеризующих игроков, в разрезе реальных участников события, потенциальных участников (т. е. тех, кого мы переразметили с 0-го класса в 1-й), и не участников события. В результате вы получите следующее:
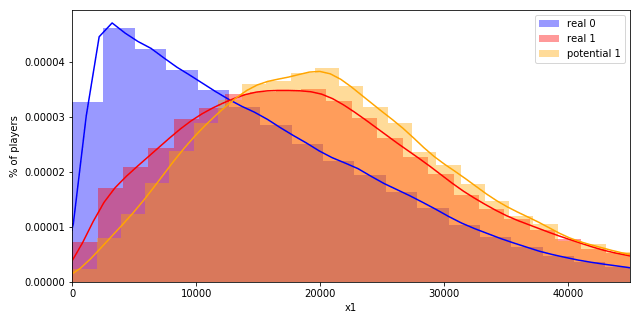

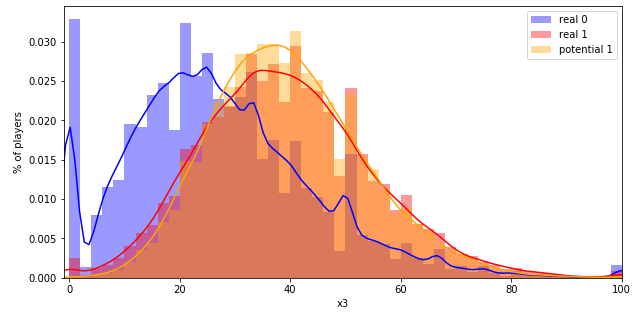

Отчётливо видно, что распределения основных метрик потенциальных участников (в прошлом «не участников») практически совпадают с распределениями реальных участников.
Снова обучаем Random Forest, чтобы сравнить качества моделей до и после переразметки. Также полученную модель уже можно использовать для прогнозирования участия новых игроков в следующем событии.
relabeled_data.drop(['y_old'], axis=1, inplace=True)
X_data, y_data = relabeled_data.drop(['y_new'], axis = 1), relabeled_data['y_new']
X_train, X_test, y_train, y_test = train_test_split(X_data, y_data, test_size=.3, random_state=42)
clf = RandomForestClassifier(n_estimators=250, random_state=42, n_jobs=15)
clf.fit(X_train, y_train)
y_pred = clf.predict(X_test)
df_confusion = pd.crosstab(y_test, y_pred, rownames=['Actual'], colnames=['Predicted'], margins=True)
print(df_confusion)
print(classification_report(y_test, y_pred))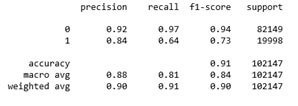
Видим, что качество классификации, f1-score, вырос до 0.84, т. е. на 35%! Также теперь recall1= 0,64, при этом мы не потеряли в recall0. А значит, мы начали гораздо правильнее классифицировать потенциальных участников события.
Что дальше?
Я рассказала об одном из вариантов повышения качества исходных данных. Чтобы улучшить финальный алгоритм классификации, можно ещё поэкспериментировать:
- Финальный метод классификации. Кроме Random Forest можно попробовать другие методы. Также нужно провести оптимизацию гиперпараметров алгоритма и порогового значения вероятности, при котором модель относит объект к 1-му классу.
- Пороговое значение вероятности для переразметки. В нашем примере это значение 0.5. Его можно «двигать» в обе стороны в зависимости от результата, который вы хотите получить: переразметить как можно больше или как можно меньше игроков. В целом,при выборке порогового значения нужно, в первую очередь, руководствоваться здравым смыслом, каким-либо референсом (если он, конечно, есть) и, как было продемонстрировано, используя сравнения распределений основных метрик в фактическом и переразмеченном классах.
- Попробовать другой подход к переразметке выборки. На просторах интернета можно найти реализации переразметки выборки основанные, к примеру, на сегментации. Изначально решается задача обучения без учителя, все данные делятся на сегменты. После этого, каждому сегменту присваивается метка класса, которая наиболее часто встречается среди объектов в данном сегменте. Таким образом, объекты с меткой, отличной от присвоенной, будут являться переразмеченными.
Надеюсь, в вашей работе такие ситуации будут встречаться очень редко, но если и будут, то данный материал окажется вам полезным!
Товарный классификатор
Правильно составленный и структурированный товарный классификатор является тем ресурсом, который позволит категорийному менеджеру и закупщику анализировать ассортимент и принимать решения о его обновлении или ротации. На основании классификатора затем можно будет определять роли товаров в категории, распределять торговое пространство, видеть общую структуру ассортимента.
Для описания ассортимента принят ряд основных терминов, которыми мы предлагаем воспользоваться, чтобы навести порядок в своем ассортименте.
Товарный классификатор – разделение всех товаров на уровни: классы, товарные группы и товарные категории. При этом товары на каждом уровне объединяются или в класс, или в категорию, или в позицию по общим признакам или свойствам.
Выделяют три основных уровня деления товарного классификатора.
1-й уровень – класс товаров: чем крупнее формат магазина, тем больше уровней деления. В ряде случаев первым (высшим) уровнем классификатора может являться класс товаров; например, «продовольственные товары» и «непродовольственные товары» или «одежда» и «обувь», то есть то, что в представлении покупателя объединено общим функциональным назначением. Например, «продовольственные товары» – это то, что едят, а «непродовольственные товары» – то, что никак не едят, «одежда» – то, что носят на теле, «обувь» – то, что носят на ногах. Но в магазинах более мелкого формата или там, где все товары однородны (например, магазин торгует только одеждой, причем для определенного покупателя, скажем для молодежи), выделение класса необязательно.
2-й уровень – товарная группа: это совокупность товаров, объединенных некими общими признаками – видом товара, способом производства и т. д. (например, «молочные продукты», «хлебобулочные изделия», «женская одежда», «мужская обувь», «мебель», «светильники», «аксессуары для дома»). Как правило, в магазине любого формата этот уровень присутствует и часто является высшим уровнем, ниже которого уже идет товарная категория.
В крупных компаниях с большим ассортиментом может выделяться еще подгруппа товаров — более детальное деление ассортимента по совокупным признакам (например, группа «Гигиена и красота» может делиться на подгруппы «Уход за волосами», «Ватно-бумажная продукция», «Гигиена полости рта», «Товары для уборки»).
3-й уровень – товарная категория: это совокупность товаров, которые покупатель воспринимает как сходные между собой, или товаров, объединенных совместным использованием. Проще говоря, товарная категория – это то, за каким товаром покупатель идет в магазин. (За молоком. За хлебом. За шампунем. За туфлями, за сапогами. За моющим пылесосом. За плазменным телевизором. За обоями для прихожей. За диваном в гостиную.) Здесь важно провести очень четкий, детальный анализ своего главного покупателя, чтобы понять, какими категориями он мыслит, за чем он пришел именно в ваш магазин? Если ваш магазин имеет глубокую специализацию по тем же компьютерам, то к вам будут заходить люди, желающие получить подробную консультацию и найти нечто особенное – например, компьютер для домашнего офиса с большим количеством специальных программ. В таком случае деление в вашем магазине на категории, возможно, будет «компьютеры для офиса», «компьютеры для дома», «компьютеры для школьников», «компьютеры для профессионалов», а затем уже пойдут подкатегории (или субкатегории) по брендам и производителям, по размеру, объему памяти и т. д.
Важно еще раз отметить, что мы объединяем товары по совокупности общих признаков в представлении нашего покупателя. Не так, как удобно категорийному менеджеру или поставщику, а именно так, как воспринимает товар целевой покупатель.
Категория далее будет делиться на подкатегории по различным признакам (по брендам или свойствам или размерам, цвету, объему и т. д. – в зависимости от самой категории). Таких уровней деления может быть до восьми (может быть и больше, но это уже нерационально, подобный «ветвистый» классификатор трудно поддается управлению).
После того как будет составлен классификатор – а именно выделены категории, сгруппированы и объединены в классы или направления (по нашему опыту, составление классификатора занимает от месяца до трех), можно будет проводить анализ сбалансированности всех категорий.
Примеры деления товаров на уровни
Важно: ассортимент подлежит структурированию в обязательном порядке. Есть товар, и он должен быть определенным образом разделен на классы, группы, категории. Если мы неверно структурируем классификатор, то в дальнейшем не сможем его правильно оценить и сбалансировать.

Рис. 3.3
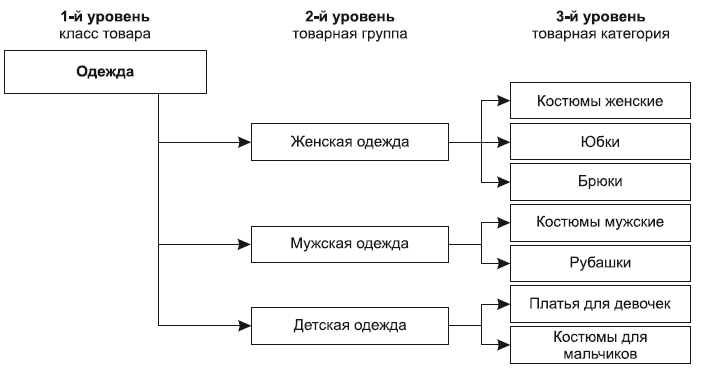
Рис. 3.4
Образцы товарных классификаторов
 Больше образцов товарных классификаторов можно найти в электронном приложении.
Больше образцов товарных классификаторов можно найти в электронном приложении.
1. Образец товарного классификатора для продуктового супермаркета (фрагмент)





2. Образец товарного классификатора для магазина бытовой техники и электроники (фрагмент)

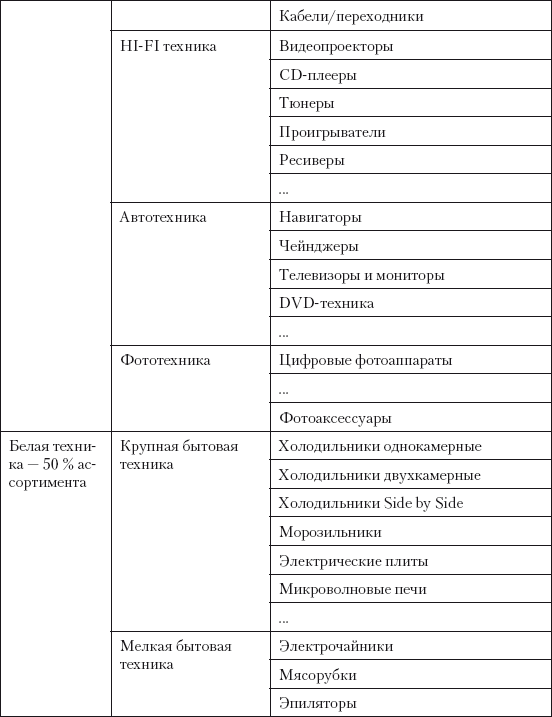

3. Образец товарного классификатора для магазина строительных и отделочных материалов



4. Образец товарного классификатора для магазина одежды (фрагмент) (повседневная одежда, магазин с позиционированием среднего уровня)


5. Образец товарного классификатора для магазина цветов (товары и услуги)


Важно: в зависимости от формата магазина один и тот же товар может быть группой, а может быть и категорией. Например, часы: в специализированном магазине часов это будет класс товаров, а в магазине, торгующем бизнес-сувенирами и подарками, – категория. А в гипермаркете это будет лишь одна из множества подкатегорий в составе категории «Товары для дома» (рис. 3.5, 3.6).
