Geometry of Flowers by Mookiezoolook
Для приложений, которые будут масштабироваться по трафику и сложности, крайне важно изначально спроектировать грамотную схему базы данных. Если сделать плохой выбор, придется потратить много усилий, чтобы этот плохой шаблон не распространился на службы и контроллеры бэкендов и, наконец, на фронтенд.
Но как оценить, какая схема лучше? И что вообще значит «лучше», когда мы говорим об архитектуре БД? Команда Mail.ru Cloud Solutions предлагает познакомиться с рекомендациями Майка Алча, консультанта по разработке программного обеспечения. Нам кажется, что он довольно лаконично резюмировал некоторые принципы грамотной архитектуры.

Директор: «Думаю, мы должны построить базу данных SQL».
Разработчик (он вообще понимает, о чем говорит, или просто увидел какую-то рекламу в бизнес-журнале?..): «Какого цвета хотите базу данных?».
Директор: «Пожалуй, у сиреневого больше всего памяти».
Несколько базовых советов
Итак, важно стремиться к двум основным вещам:
- При разбиении информации по таблицам сохраняется вся информация.
- Избыточность хранения минимальна.
Что касается второго момента: хотим ли мы уменьшить избыточность только из-за проблемы с размером хранилища? Нет, мы делаем это главным образом потому, что наличие избыточных данных приводит к проблемам несогласованности, если во время обновления вы не обновляете все поля, представляющие одну и ту же информацию.
Вот некоторые рекомендации, которые помогут приблизиться к хорошей архитектуре:
- Используйте как минимум третью нормальную форму (в которой каждый неключевой атрибут «должен предоставлять информацию о ключе, полном ключе и ни о чем, кроме ключа», согласно формулировке Билла Кента).
- Создайте последнюю линию обороны в виде ограничений.
- Никогда не храните в одном поле целые адреса.
- Никогда не храните в одном поле имя и фамилию.
- Установите соглашения для имен таблиц и полей и придерживайтесь их.

— Над чем работаешь?
— Оптимизирую этот SQL-запрос. Он тормозит, и пользователи начинают жаловаться.
— А нецензурная лексика в комментариях обязательна для оптимизации?
— Если бы ты видел оригинальный код, то не спрашивал бы.
Рассмотрим эти рекомендации подробнее.
1. Используйте как минимум третью нормальную форму
Архитектуру баз данных можно разделить на следующие категории:
- Первая нормальная форма.
- Вторая нормальная форма.
- Третья нормальная форма.
- Нормальная форма Бойса-Кодда.
Эти категории представляют классификацию по качеству. Вкратце рассмотрим все категории и разберем, почему нужна хотя бы третья нормальная форма.
Первая нормальная форма
Для первой нормальной формы каждое значение каждого столбца каждой таблицы в БД должно быть атомарным. Что значит атомарным? Если вкратце, атомарное значение представляет собой «единичную вещь».
Например, у нас есть такая таблица:
Здесь столбец areas («Области») содержит значения, которые не являются атомарными. Например, в строке Джона Доу поле хранит две сущности: «Дизайн веб-сайтов» и «Исследование клиентуры».
Таким образом, эта таблица не находится в первой нормальной форме.
Чтобы привести ее к такой форме, в каждом поле должно храниться только одно значение.
Вторая нормальная форма
Во второй нормальной форме ни один столбец, который не является частью первичного ключа (или который может действовать как часть другого первичного ключа), не может быть выведен из меньшей части первичного ключа.
Что это значит?
Допустим, у вас такая архитектура базы (я подчеркнул поля, соответствующие первичному ключу в этой таблице):
В этом проекте имя сотрудника может быть непосредственно выведено из employeee_id, поскольку идея заключается в том, что имя сотрудника однозначно определяется его идентификатором.
Аналогично, имя проекта однозначно определяется идентификатором project_id.
Таким образом, у нас два столбца можно вывести из части первичного ключа.
Каждого из этих примеров было бы достаточно, чтобы выбросить эту таблицу из второй нормальной формы.
Еще один вывод заключается в том, что если таблица была в первой нормальной форме и все первичные ключи являются одиночными столбцами, то таблица уже находится во второй нормальной форме.
Третья нормальная форма
Чтобы таблица соответствовала третьей нормальной форме, она должна быть во второй нормальной форме, при этом в ней не должно быть атрибутов (столбцов), кроме первичного, которые транзитивно зависят от первичного ключа.
Что это значит?
Допустим, у вас следующая архитектура (которая далека от идеала):
В этой таблице department_number можно вывести из employee_id, а department_name можно вывести из department_number. Таким образом, department_name транзитивно зависит от employee_id!
Если существует такая транзитивная зависимость: employee_id → department_number → department_name, то данная таблица не находится в третьей нормальной форме.
Какие проблемы возникают из-за этого?
Если название отдела можно вывести из его номера, то хранение этого поля для каждого сотрудника вводит лишнюю избыточность.
Представьте, что отдел маркетинга меняет название на «Маркетинг и продажи». Чтобы сохранить согласованность, придется обновить ячейку в каждой строке таблицы для каждого сотрудника этого отдела! В третьей нормальной форме такого бы не произошло.
Кроме того, вот, что произойдет, если Мэри решит покинуть компанию: мы должны удалить ее строку из таблицы, но если она была единственным сотрудником оперативного отдела, то отдел тоже придется удалить.
Всех этих проблем можно полностью избежать в третьей нормальной форме.

Мамины эксплойты. Ее дочь зовут Помогите! Меня заставляют подделывать паспорта
2. Создайте последнюю линию обороны в виде ограничений
База данных, с которой вы работаете, — это больше, чем просто группа таблиц. В нее встроена определенная функциональность. Многие из этих функций помогают обеспечить качество и корректность данных.
Ограничения устанавливают правила, какие значения можно вносить в поля БД.
Когда определяете отношения в базе данных, обязательно установите ограничения внешних ключей.
Обязательно укажите, что должно произойти при удалении и обновлении строки, связанной с другими строками в других таблицах (правила ON DELETE и ON UPDATE).
Обязательно используйте NOT NULL для всех полей, которые никогда не должны обнуляться. Возможно, есть смысл установить проверку на бэкенде, но помните, что сбои случаются всегда, поэтому не помешает добавить и такое ограничение.
Установите проверочные ограничения CHECK, чтобы убедиться — значения таблицы находятся в допустимом диапазоне, например, цена на товар всегда имеет положительное значение.
Интересный факт: в апреле 2020 года именно такое ограничение в программном обеспечении помешало торгам на московской бирже ММВБ, потому что цена на нефтяные фьючерсы WTI опустилась ниже нуля. В отличие от московской биржи, Нью-Йоркская товарная биржа NYMEX обновила софт за неделю до инцидента, поэтому сумела успешно провести сделки по отрицательной цене, то есть с доплатой покупателю от продавца — прим. пер.
Обо всех ограничениях PostgreSQL можно почитать здесь.
3. Никогда не храните в одном поле целые адреса
Если в вашем приложении или на веб-сайте есть форма с одним полем, где пользователь вводит свой адрес, то это уже плохо пахнет. Очень вероятно, что в этом случае у вас будет также одно поле в базе данных для хранения адреса в виде простой строки.
Но что делать, если нужно объединить покупки клиентов по городам, чтобы посмотреть, в каком городе какой продукт более популярен? Вы сможете это сделать?
Это будет очень тяжело!
Поскольку полный адрес хранится как строка в поле БД, в первую очередь придется разбираться, какая часть этой строки является городом! И это почти невыполнимая задача, учитывая все возможные форматы адресов в этом поле.
Поэтому обязательно разбивайте универсальное поле «Адрес» на конкретные поля: улица, номер дома, город, область, почтовый индекс и так далее.
Еще одна проблема адресов — «анонимные» поля
Вот иллюстрация из книги Майклза Блаха «Медная пуля для улучшения качества программного обеспечения»:

Какие тут видны возможные проблемы? Сможете ли вы легко отличить город Чикаго от улицы Чикаго? Наверное, нет.
Поэтому не забывайте всегда давать четкие имена столбцов каждой единице информации.

Как составлять резюме
— У тебя есть опыт в SQL?
— Нет (No).
— Так и пиши: эксперт по NoSQL.
4. Никогда не храните в одном поле имя и фамилию
Аналогично ситуации с адресами: количество вариаций имени и фамилии слишком велико, чтобы их четко различать.
Конечно, можно отделить имя от фамилии, если между ними пробел.
Например, «Майк Альче» → имя «Майк» и фамилия «Альче».
Но что делать, если пользователь ввел второе имя? Или у него двойная фамилия? А что, если есть и второе имя, и двойная фамилия?
Как определить, где имя, а где фамилия, чтобы разделить строку? Ошибки неизбежны.
Способ избежать многих проблем — создать отдельные поля (в формах) для имен пользователей first_name и last_name. Таким образом, вы позволите пользователям разделить свои собственные имена и сможете хранить данные согласованным образом.
Примечание: я не говорю, что в полях БД запрещены пробелы. Например, для таких имен, как «Хуан Мартин Дель Потро», первая часть «Хуан Мартин» входит в поле first_name, а «Дель Потро» — в поле last_name. Конечно, это не идеально. Можно дополнительно завести столбцы middle_name и second_last_name. Посмотрите подробнее о возможных вариациях имен и фамилий в списке «Заблуждения программистов об именах» и статье «Заблуждения программистов об именах — с примерами». Придется согласиться на какой-то компромисс между точностью и практичностью.
5. Установите соглашения для имен таблиц и полей и придерживайтесь их
Довольно неприятно работать с данными, которые выглядят как user.firstName, user.lst_name, user.birthDate и так далее.
Я бы посоветовал установить правила именования с подчеркиванием, потому что не все SQL-движки одинаково обрабатывают заглавные буквы, а заключать всё в кавычки весьма утомительно.
Выберите так же, как называть таблицы — во множественном или единственном числе (например, users во множественном числе или user в единственном). Мне больше нравится единственное число, но все фреймворки для бэкенда, кажется, по умолчанию настроены на множественное. Приходится следовать шаблону и использовать множественное число.
Что еще почитать:
- Какую базу данных выбрать для проекта, чтобы не пришлось выбирать снова.
- Базы данных в IIoT-платформе: как Mail.ru Cloud Solutions работают с петабайтами данных от множества устройств.
- Наш канал в Телеграме о цифровой трансформации.
Прим. перев. Предполагается, что вы уже имеете начальные знания по SQL. Если вы плохо понимаете, что такое таблицы, строки, индексы, первичные ключи и ссылочная целостность, то лучше сначала изучить их, например по этим видео:
А если вы знакомы с SQL и вас не остановили предыдущие термины, на всякий случай напомним, что:
- атомарность предполагает, что значение нельзя разделить на несколько атрибутов;
- под кортежем понимается запись (строка) в таблице базы данных;
- атрибут — это колонка таблицы;
- неключевой атрибут — это атрибут, не входящий в состав никакого потенциального ключа.
***
Есть минимум два требования, которые должны быть соблюдены при проектировании структуры БД:
- Сохранить всю информацию после разделения её на таблицы.
- Минимизировать избыточность того, как эта информация хранится.
Примечание Второй пункт важен не только из-за того, что избыточность влияет на размер БД. Чаще всего при обновлении данных нужно обработать много строк. В таком случае вы рискуете просто забыть обновить некоторые из них, что приведёт к коллизиям внутри БД.
Ниже перечислены некоторые рекомендации, которые помогут добиться эффективной структуры:
- используйте хотя бы третью нормальную форму;
- создавайте ограничения для входных данных;
- не храните ФИО в одном поле, также как и полный адрес;
- установите для себя правила именования таблиц и полей.
Используйте хотя бы третью нормальную форму
Нормальные формы — это требования, которые должны соблюдаться при правильной проектировке базы данных.
Нормальных форм существует целых 6 штук, однако обычно соблюдают всего лишь 3 и для начала этого более чем достаточно.
Первая нормальная форма
Для примера будем использовать отношение сотрудники_отделы_проекты. В нём есть информация о номере сотрудника, его фамилии, номере отдела, в котором он работает, номере телефона отдела и так далее.

Это отношение, как и любое другое, автоматически находится в первой нормальной форме:
- в отношении нет одинаковых кортежей;
- кортежи не упорядочены;
- атрибуты не упорядочены и различаются по наименованию;
- все значения атрибутов атомарны.
Вторая нормальная форма
В нашем случае у таблицы выше имеется сложный (составной) ключ {Н_СОТР, Н_ПРО}. От части ключа Н_СОТР зависят неключевые атрибуты ФАМ, Н_ОТД, ТЕЛ. От части ключа Н_ПРО зависит неключевой атрибут ПРОЕКТ. А вот атрибут Н_ЗАДАН зависит от всего составного ключа, так как сотрудник может выполнять одно задание в одном проекте.
Поэтому для приведения отношения ко второй нормальной форме из отношения сотрудники_отделы_проекты нужно выделить два отношения сотрудники_отделы и проекты, а исходное отношение оставим отношением задания.
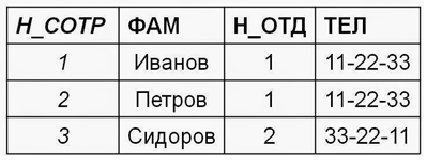
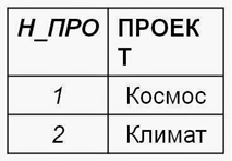

Наконец, третья нормальная форма
Отношение находится в третьей нормальной форме, когда отношение находится во второй нормальной форме и все неключевые атрибуты взаимно независимы.
Для того, чтобы устранить зависимость неключевых атрибутов, нужно произвести декомпозицию отношения ещё на несколько отношений. При этом те неключевые атрибуты, которые являются зависимыми, выносятся в отдельное отношение.
Отношение сотрудники_отделы не находится в третьей нормальной форме, так как имеется зависимость неключевых атрибутов, таких как зависимость номера телефона от номера отдела. Поэтому декомпозируем отношение сотрудники_отделы на два отношения — сотрудники и отделы:
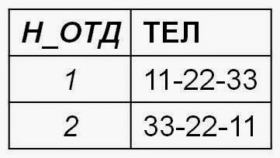
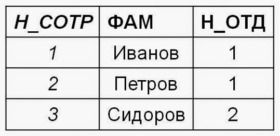
Используйте проверочные ограничения
База данных — это не просто набор таблиц. В неё встроено много инструментов, которые помогут с сохранностью и качеством данных.
В первую очередь БД поможет с ограничением значений, которые принимают поля.
Внешние ключи регламентируют отношения между таблицами. Благодаря им сильно упрощается контроль за структурой базы, уменьшается и упрощается код приложения. Правильно настроенные внешние ключи — это гарант того, что увеличится целостность данных за счёт уменьшения избыточности. Поэтому обязательно применяйте ограничение внешнего ключа при определении связей между таблицами.
Выражения ON DELETE и ON UPDATE внешних ключей используются для указания действий, которые будут выполняться при удалении строк родительской таблицы (ON DELETE) или изменении родительского ключа (ON UPDATE). Не пренебрегайте ими.
Стоит убедиться, что обязательность заполнения (NOT NULL) проверяется для полей, которые строго не должны оставаться пустыми.
Используйте CHECK, чтобы убедиться, что значения входят в диапазон (например чтобы цена не была отрицательной).
Не храните ФИО в одном поле, также как и полный адрес
Представим ситуацию, когда вам понадобится узнать, в каком городе продукт более популярен. В таком случае, если полный адрес хранится в виде цельной строки, сделать это будет очень тяжело, ведь вам нужно будет каким-то образом выделить из этой строки город. Учитывая все возможные форматы и варианты адресов, эта задача становится практически невыполнимой. Похожая ситуация и с ФИО. Даже если кажется, что это ни к чему, храните эти данные в разных полях, и в будущем вы поблагодарите себя.
Установите для себя правила именования таблиц и полей
Сложно работать с данными, которые выглядят как-то так: user.firstName, user.last_name, user.birthDate. Конечно, каждый программист в праве сам выбирать для себя стиль наименования, но для SQL рекомендуется выбрать наименование с подчёркиванием. Потому что не все SQL-движки одинаково работают с заглавными буквами, а помещать всё в кавычки бывает утомительно.
Ещё нужно определиться как будут называться таблицы — во множественном числе (users) или в единственном (user). Каждая базовая структура в БД обычно настроена на множественное число, поэтому и именовать таблицы стоит соответственно.
Не упускайте возможность сложить побольше обязанностей на базу данных, чтобы облегчить себе работу над приложением и думать о его структуре, а не о контроле табличных связей.
Всё приходит с опытом. Спроектируйте две-три схемы, и картинка сама сложится у вас в голове. Отталкивайтесь от задачи —некоторыми рекомендациями иногда можно пренебречь.
Перевод статьи «A humble guide to database schema design»
Время от времени я заглядываю на Toster.ru и иногда даже отвечаю там на вопросы. Чаще всего люди спрашивают две вещи — как стать программистом и как правильно спроектировать схему базы данных. Мне лично кажется очень странным, что так много людей задают последний вопрос. Мне почему-то всегда казалось, что это такая простая вещь, которую умеют вообще все. Но, раз так много людей интересуются, здесь я постараюсь дать достаточно развернутый и в то же время краткий ответ.
Дополнение: Также вас могут заинтересовать заметки Начало работы с PostgreSQL, Потоковая репликация в PostgreSQL и пример фейловера, Некоторые интересные отличия PostgreSQL от MySQL и Обратная совместимость и изменение схемы базы данных.
Я предполагаю, что SQL вы знаете. То есть, объяснять, что такое таблицы, строки, индексы, первичные ключи и ссылочная целостность, не требуется. Если это не так, боюсь, я вынужден отправить вас к соответствующей литературе. Благо, ее сейчас очень много.
Рисуем диаграмму
Допустим, требуется спроектировать схему базы данных, в которой хранится информация о музыкальных исполнителях, альбомах и песнях. На начальном этапе, когда у нас еще совсем ничего нет, удобно начать с рисования диаграммы будущей схемы. Можно начать с наброска ручкой на листе бумаги, можно сразу взять специализированный редактор. Их сейчас очень много, все они устроены довольно похожим образом. При подготовке этой заметки я воспользовался DbSchema. Это платная программа, но мне кажется, что она стоит своих денег. К тому же, в нормальных компаниях обычно оплачивают стоимость софта, необходимого для работы. Триал у DbSchema, если что, составляет две недели.
Нарисовать следюущую диаграмму заняло у меня порядко десяти минут:
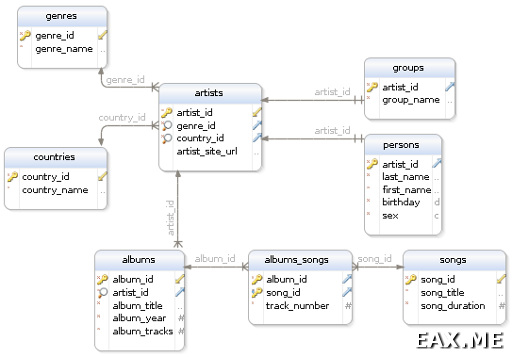
Если раньше вам не доводилось работать с такими диаграммами, не пугайтесь, тут все просто. Прямоугольнички — это таблицы, строки в прямоугольничках — имена столбцов, стрелочками обозначаются внешние ключи, а ключиками — первичные ключи. При желании тут можно разглядеть даже индексы, типы столбцов и обязательность их заполнения (null / not null), но для нас сейчас это не так важно.
Дополнение: Аналогичную диаграмму можно построить при помощи открытого инструмента PlantUML.
Генерируем SQL и скармливаем его СУБД
Нетрудно заметить, что данная диаграмма легко отображается в код для создания схемы базы данных на языке SQL. В DbSchema сгенерировать SQL можно, сказав Schema → Generate Schema and Data Script. Затем полученный скрипт можно скормить используемой вами СУБД:
cat music.sql | psql -hlocalhost test_database test_user
Я использовал PostgreSQL. Информацию о том, как установить эту СУБД, вы найдете в этой заметке.
Итак, чем же я руководствовался при проектировании схемы?
Нормальные формы
Процесс устранения избыточности и ликвидации противоречивости базы данных называется нормализацией. Выделяют так называемые нормальные формы, из которых на практике редко кто помнит больше первых трех.
Грубо говоря, таблица находится в первой нормальной форме (1НФ), если на пересечении любой строки и любого столбца в таблице находится ровно одно значение. В современных РСУБД это условие всегда выполняется. Даже если СУБД поддерживает множества или массивы, на пересечении строки и столбца хранится ровно одно значение типа множество или массив. Но в таблице (user varchar(100), phone integer) не может быть строки alex - 1234, 5678. В 1НФ может быть только две сроки — alex - 1234 и alex - 5678.
Вторая нормальная форма (2НФ) означает, что таблица находится в первой нормальной форме, и каждый неключевой атрибут неприводимо зависит от значения первичного ключа. Неприводимость означает следующее. Если первичный ключ состоит из одного атрибута, то любая функциональная зависимость от него неприводима. Если первичный ключ является составным, то в таблице не может быть атрибута, значение которого однозначно определяется значением подмножества атрибутов первичного ключа.
Таблица находится в третьей нормальной форме, если она находится в 2НФ и ни один неключевой атрибут не находится в транзитивной функциональной зависимости от первичного ключа. Например, рассмотрим таблицу (employee varchar(100) primary key, department varchar(100), department_phone integer). Очевидно, что она находится в 2НФ. Но телефон отдела находится в транзитивной функциональной зависимости от имени сотрудника, так как сотрудник однозначно задает отдел, а отдел однозначно задает телефон отдела. Для приведения таблицы в 3НФ нужно разбить ее на две таблицы — employee - department и departmnet - phone.
Легко видеть, что нормализация уменьшает избыточность базы данных и препятствует внесению случайных ошибок. Например, если оставить таблицу из последнего примера в 2НФ, то можно по ошибке прописать одному и тому же отделу разные телефоны. Или рассмотрим компанию с пятью отделами и 1000 сотрудниками. Если у отдела поменялся номер телефона, то для его обновления в базе данных в случае 2НФ потребуется просканировать 1000 строк, а в случае с 3НФ только пять.
Как я уже отмечал, есть и более строгие нормальные формы, но на практике обычно используются только первые три.
Отношение один ко многим
На приведенной диаграмме можно заметить, что каждый исполнитель относится к какой-то стране, и каждый альбом принадлежит какому-то исполнителю. Это и есть отношение один ко многим. Например, к одной стране относится множество исполнителей, и каждый исполнитель может иметь множество альбомов. Но приведенная схема, например, запрещает одному альбому принадлежать множеству исполнителей. Хотя в реальной жизни, конечно, это возможно, например, в случае со сборниками.
Для моделирования такого типа отношения в каждом альбоме указывается id исполнителя, и в каждом исполнителе указывается id страны. Понятное дело, мы не просто пишем туда какую-то циферку, а возлагаем ответственность по контролю ссылочной целостности на нашу СУБД:
ALTER TABLE albums ADD CONSTRAINT fk_albums_artists FOREIGN KEY ( artist_id ) REFERENCES artists( artist_id );
Это часто оказывается большим сюрпризом для тех, кто всю жизнь работал с MySQL и его бэкендом MyISAM, который так не умеет. Я не вижу причин не проверять ссылочную целостность, если только вы не пишите супер-пупер высоконагруженный проект, у которого исполнители хранятся на одном сервере, а альбомы — на другом. В противном случае вас ждет много часов увлекательной отладки вашего приложения в ночь с субботы на воскресенье, потому что как-то так получилось, что кто-то создал альбом с несуществующим исполнителем.
Жанры и страны в приведенной схеме иногда еще называют «словарями». Это сравнительно небольшие таблицы, состоящие из двух столбцов — id и названия. Если, например, мы захотим переименовать страну Russia в Russian Federation, нам придется поменять всего лишь одну строчку в таблице countries, а не править кучу строк в таблице artists, что может привести к очень большому количеству дисковых операций. Кроме того, если требуется отобразить в диалоге создания нового исполнителя выпадающий список с выбором страны, нам не придется делать дорогих группировок по таблице artists, достаточно сделать простую выборку из countries.
Отношение многие ко многим
Один альбом, как правило, содержит множество песен. Кроме того, нет веских причин, почему одна песня не может находится сразу в нескольких альбомах. Здесь мы имеем место с типичным отношением многие ко многим.
Оно моделируется путем введения дополнительной таблицы. В нашем примере эта таблица называется albums_songs. Первичный ключ в этой таблицы состоит из двух внешних ключей — album_id и song_id. Теперь нетрудно с помощью пары join’ов получить все песни, входящие в данный альбом или все альбомы, в которые входит заданная песня. Кроме того, ничто не мешает завести в связующей таблице дополнительные столбцы. Например, столбец, хранящий номер трека, под которым песня входит в заданный альбом.
На практике связаны могут быть не две, а три и более таблиц. Например, некий пользователь сделал некий заказ, выбрав указанный способ оплаты, адрес и способ доставки — пожалуйста, пять таблиц как с куста.
Отношение родитель-потомок (или общее-частное)
Исполнители могут быть разных типов. Это может быть отдельно взятый(ая) певец/певица, или же группа. У всех исполнителей, независимо от конкретного типа, есть что-то общее. Например, страна, адрес официального сайта и так далее. Но кроме того, есть некоторые свойства, характерные только для данного типа. У певицы явно нет никакого названия группы, а у группы нет имени, фамилии и пола. Аналогичная ситуация возникает, скажем, если у вас есть сотрудники, занимающие различные должности и свойства сотрудников зависят от занимаемых должностей.
Один из способов моделирования такой ситуации заключается в введении по отдельной таблице на каждый из возможных подтипов. В приведенном примере это таблицы groups и persons. В качестве первичного ключа в каждой из этих таблиц используется artist_id, первичный ключ родительской таблицы artists. Кто-то при использовании такой схемы предпочитает добавить в родительскую таблицу столбец type, но, строго говоря, он является избыточным. Недостаток этого метода заключается в том, что можно создать исполнителя, являющегося как группой, так и человеком одновременно.
Есть и другие подходы. В PostgreSQL, например, есть наследование таблиц, предназначенное для решения как раз такой вот проблемы. Если вы работаете с PostgreSQL, нет причин не использовать этот механизм. Кто-то предпочитает ввести одну таблицу для всех типов с дополнительным столбцом type. Если некий столбец не имеет смысла для заданного типа, в него пишется null. Но это, как вы можете подозревать, не очень-то удобно, если у вас 10 типов, каждый из которых имеет по дюжине столбцов, характерных только для этого типа, а также парочку собственных подтипов. Кроме того, можно опрометчиво реализовать смену типа, как простое обновление столбца type, и получить массу интереснейших эффектов.
Что еще нужно принять во внимание
Принцип при моделировании других отношений тот же. Например, один человек имеет двух родителей и при этом один человек может иметь сколько угодно детей. Казалось бы, связь 2:N, этого мы не проходили. На самом деле, это просто две связи 1:N. Вводим столбцы mother_id, father_id и вперед. Да, связь в рамках одной таблицы, ну и что?
Иногда на практике можно столкнутся с древовидными структурами. На самом деле, это то же самое отношение один ко многим, один родитель имеет много потомков. В общем, вводится столбец parent_id, куда пишется «внешний» первичный ключ из этой же таблицы. В корневом элементе устанавливается parent_id равный null. Главное при работе с этим хозяйством — не наплодить случайно циклов.
В общем, все, что нужно, это немного здравого смысла.
Также при проектировании схемы базы данных нужно уделять внимание индексам. Тут все сильно зависит от конкретной СУБД, поддерживает ли она составные индексы, частичные индексы, функциональные индексы, bitmap scans и так далее. Кое-что по этой теме я писал здесь, а вообще — курите мануалы по вашей СУБД. Также за кадром остались вьюхи, триггеры и многое другое.
В высоконагруженных проектах в целях оптимизации иногда прибегают к денормализации, то есть, процессу, обратному нормализации. Действительно, в некоторых случаях намного эффективнее держать все в одной таблице, чем делать несколько десятков джоинов. Иногда данные распределяют между несколькими серверами. Понятно, что в этом случае ссылочная целостность никем не проверяется и может быть случайно нарушена. Сплошь и рядом базы данных содержат в себе некоторую избыточность. Например, стоимость заказа можно однозначно определить, сложив стоимость товаров в корзине. Но иногда эффективнее хранить уже посчитанную стоимость, особенно если речь идет не об одной корзине, а о месячном отчете по всей системе. Иногда избыточность добавляется, чтобы данные можно было починить в случае программных ошибок. Например, все критичные операции сопровождаются записью в таблицу-журнал.
Ну и нельзя не отметить, что приведенный здесь пример с исполнителями и альбомами довольно игрушечный. В реальных условиях база данных может запросто содержать сотню таблиц, каждая из которых имеет многие десятки столбцов и миллионы строк. Или, например, одну таблицу, имеющую пару сотен столбцов. Примите также во внимание, что схема базы данных имеет свойство довольно часто меняться, что, разумеется, приводит к необходимости мигрировать данные, и вы получите более-менее правдоподобную картину того, с чем на самом деле вам предстоит столкнуться.
Заключение
Все приходит с опытом. Самостоятельно спроектируйте две-три схемы, и картинка сама сложится у вас в голове. В качестве ДЗ можете спроектировать базу данных блога, интернет-магазина или базу с сотрудниками компании, их должностями и контактами. Отталкивайтесь от задачи. Учитывайте, кто и какие действия будет совершать с базой данных. Например, с базой интернет-магазина работают не только клиенты, но и, например, отдел доставки.
Проект для DbSchema, а также сгенерированный из него SQL, вы можете скачать здесь. Как всегда, если у вас есть вопросы или дополнения, не стесняйтесь писать их в комментариях.
Метки: Разработка, СУБД.
Реляционная база данных, созданная в соответствии с проектом канонической модели данных предметной области, состоит из нормализованных таблиц, связанных одно-многозначными отношениями. В такой базе данных обеспечивается отсутствие дублирования описательных данных, их однократный ввод, поддержание целостности данных средствами системы. Связи между таблицами позволяют выполнить объединение данных различных таблиц, необходимое для решения большинства задач ввода, просмотра и корректировки данных, получения информации по запросам и вывода отчетов.
Связи между таблицами устанавливаются в соответствии с проектом логической структуры базы данных и запоминаются в схеме данных Access. Схема данных в Access является не только средством графического отображения логической структуры базы данных, она активно используется системой в процессе обработки данных. Создание схемы данных позволяет упростить конструирование многотабличных форм, запросов, отчетов, а также обеспечить поддержание целостности взаимосвязанных данных при вводе и корректировке данных в таблицах.
Создание схемы данных
Создание схемы данных начинается с выполнения команды Схема данных (Relationships) в группе Отношения (Relationships) на вкладке ленты Работа с базами данных (Database Tools). В результате выполнения этой команды открывается окно схемы данных и диалоговое окно Добавление таблицы (Show Table), в котором осуществляется выбор таблиц, включаемых в схему (см. рис. 3.48). Диалоговое окно Добавление таблицы откроется автоматически, если в базе данных еще не определена ни одна связь. Если окно не открылось, на ленте Работа со связями | Конструктор (Relationship Tools | Design) в группе Связи (Relationships) нажмите кнопку Отобразить таблицу (Show Table).
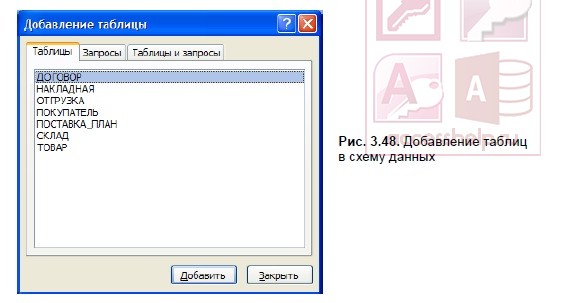
Включение таблиц в схему данных
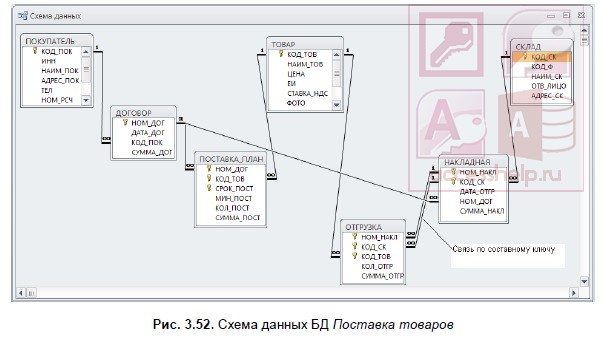
В окне Добавление таблицы (Show Table) (рис. 3.48) отображены все таблицы и запросы, содержащиеся в базе данных. Выберем вкладку Таблицы (Tables) и с помощью кнопки Добавить (Add) разместим в окне Схема данных (Relationships) все ранее созданные таблицы базы данных Поставка товаров, отображенные в окне Добавление таблицы (Show Table). Затем нажмем кнопку Закрыть (Close). В результате в окне Схема данных (Relationships) таблицы базы будут представлены окнами со списками своих полей и выделенными жирным шрифтом ключами (см. рис. 3.52).
Создание связей между таблицами схемы данных
При создании связей в схеме данных используется проект логической структуры реляционной базы данных, в котором показаны все одно-многозначные связи таблиц. Реализуются связи с помощью добавления в связанные таблицы общих полей, называемых ключом связи. При одно-многозначных отношениях между таблицами ключом связи является ключ главной таблицы (простой или составной). В подчиненной таблице он может быть частью уникального ключа или вовсе не входить в состав ключа таблицы. Одно-многозначные связи являются основными в реляционных базах данных. Одно-однозначные связи используются, как правило, при необходимости распределять большое количество полей, определяемых одним и тем же ключом, по разным таблицам, имеющим разный регламент обслуживания.
Создание связей по простому ключу
Установим связь между таблицами ПОКУПАТЕЛЬ и ДОГОВОР, которые находятся в отношении «один-ко-многим». Устанавливая связи между парой таблиц, находящихся в отношении типа 1 : M, выделим в главной таблице ПОКУПАТЕЛЬ ключевое поле КОД_ПОК, по которому устанавливается связь. Далее при нажатой кнопке мыши перетащим его в соответствующее поле подчиненной таблицы ДОГОВОР.
Поскольку поле связи является уникальным ключом в главной таблице связи, а в подчиненной таблице связи не является ключевым, схема данных в Access выявляет отношение «один-ко-многим» между записями этих таблиц. Значение «один-ко-многим» (One-To-Many) отобразится в окне Изменение связей (Edit Relationships) в строке Тип отношения (Relationship Type) (рис. 3.49).
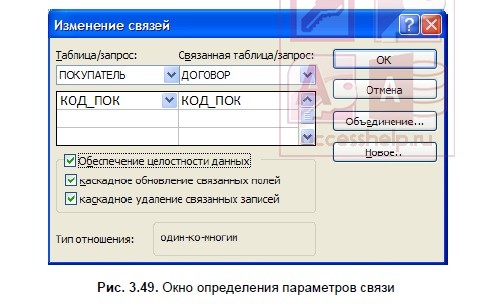
ЗАМЕЧАНИЕ
Если поле связи является уникальным ключом в обеих связываемых таблицах, схема данных в Access выявляет отношение «один-к-одному«. Если для связи таблиц вместо ключевого поля главной таблицы используется некоторый уникальный индекс, система также констатирует отношение таблиц как 1 : М или 1 : 1.
Определение связей по составному ключу
Определим связи между таблицами НАКЛАДНАЯ ОТГРУЗКА, которые связаны по составному ключу НОМ_НАКЛ + КОД_СК. Для этого в главной таблице НАКЛАДНАЯ выделим оба этих поля, нажав клавишу <Ctrl>, и перетащим их в подчиненную таблицу ОТГРУЗКА.
В окне Изменение связей (Edit Relationships) (рис. 3.50) для каждого поля составного ключа главной таблицы НАКЛАДНАЯ, названной Таблица/запрос (Table/Query), выберем соответствующее поле подчиненной таблицы ОТГРУЗКА, названной Связанная таблица/запрос (Related Table/Query).
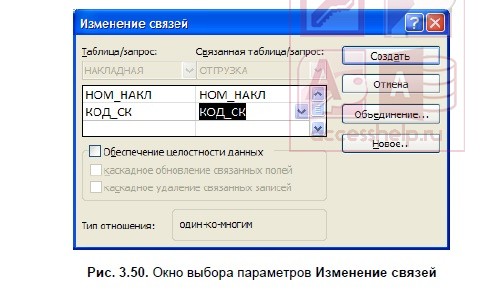
Каскадное обновление и удаление связанных записей
Если для выбранной связи обеспечивается поддержание целостности, можно задать режим каскадного удаления связанных записей и режим каскадного обновления связанных полей. Такие параметры делают возможным в главной таблице, соответственно, удаление записей и изменение значения в ключевом поле, т. к. при этих параметрах система автоматически выполнит необходимые изменения в подчиненных таблицах, обеспечив сохранение свойств целостности базы данных.
В режиме каскадного удаления связанных записей при удалении записи из главной таблицы будут автоматически удаляться все связанные записи в подчиненных таблицах. При удалении записи из главной таблицы выполняется каскадное удаление подчиненных записей на всех уровнях, если этот режим задан на каждом уровне.
В режиме каскадного обновления связанных полей при изменении значения ключевого поля в записи главной таблицы Access автоматически изменит значения в соответствующем поле в подчиненных записях.
Установить в окне Изменение связей (Edit Relationships) (см. рис. 3.49) флажки каскадное обновление связанных полей (Cascade Update Related Fields) и каскадное удаление связанных записей (Cascade Delete Related Records) можно только после задания параметра обеспечения целостности данных.
После создания связей изображения таблиц могут перемещаться в пределах рабочего пространства окна схемы данных. Перемещения и изменения размеров окон со списками полей таблиц в окне схемы данных осуществляются принятыми в Windows способами.
Заметим, если каскадное удаление не разрешено, невозможно удалить запись в главной таблице, если имеются связанные с ней записи в подчиненной.
Смотрим видео:
Вот основное, что мы хотели рассказать на тему «Схема данных в Access».
Дальше будем изучать запросы в Access.
На чтение 10 мин Просмотров 7.6к. Опубликовано 19.05.2021
При создании серверной части приложения необходимо учитывать, как интерфейс будет взаимодействовать с серверной частью. Однако более важным является построение и дизайн вашей базы данных. Отношения между вашими формами данных приведут к построению вашей схемы базы данных.
Схема базы данных является абстрактным дизайн, который представляет собой хранение ваших данных в базе данных. Он описывает как организацию данных, так и отношения между таблицами в данной базе данных. Разработчики заранее планируют схему базы данных, чтобы знать, какие компоненты необходимы и как они будут соединяться друг с другом.
В этом руководстве мы узнаем, что такое схема базы данных и почему они используются. Мы рассмотрим несколько распространенных примеров, чтобы вы могли узнать, как настроить схему базы данных самостоятельно.

Содержание
- Что такое схемы базы данных?
- Типы схемы базы данных
- Логический
- Физический
- Пример NoSQL
- Пример SQL-сервера
- Пример PostgreSQL
- Что изучать дальше
Что такое схемы базы данных?
Когда дело доходит до выбора базы данных, одна из вещей, о которой вы должны подумать, — это форма ваших данных, модель, которой они будут следовать, и то, как сформированные отношения помогут нам при разработке схемы.
Схема базы данных — это план или архитектура того, как будут выглядеть наши данные. Он не содержит самих данных, а вместо этого описывает форму данных и то, как они могут быть связаны с другими таблицами или моделями. Запись в нашей базе данных будет экземпляром схемы базы данных. Он будет содержать все свойства, описанные в схеме.
Думайте о схеме базы данных как о типе структуры данных. Он представляет собой структуру и структуру содержимого данных организации.
Схема базы данных будет включать:
- Все важные или важные данные
- Единое форматирование для всех записей данных
- Уникальные ключи для всех записей и объектов базы данных
- Каждый столбец в таблице имеет имя и тип данных.
Размер и сложность схемы вашей базы данных зависит от размера вашего проекта. Визуальный стиль схемы базы данных позволяет программистам правильно структурировать базу данных и ее взаимосвязи, прежде чем переходить к коду. Процесс планирования дизайна базы данных называется моделированием данных.
Схемы важны для проектирования систем управления базами данных (СУБД) или систем управления реляционными базами данных (СУБД). СУБД — это программное обеспечение, которое хранит и извлекает пользовательские данные безопасным способом в соответствии с концепцией ACID.
Во многих компаниях ответственность за проектирование базы данных и СУБД обычно ложится на роль администратора базы данных (DBA). Администраторы баз данных несут ответственность за обеспечение беспрепятственного доступа к информации аналитикам данных и пользователям баз данных. Они работают вместе с командами менеджеров для планирования и безопасного управления базой данных организации.
Примечание. Некоторыми популярными СУБД являются MySQL, Oracle, PostgreSQL, Microsoft Access, MariaBB и dBASE, а также другие.
Типы схемы базы данных
Существует два основных типа схемы базы данных, которые определяют разные части схемы: логическую и физическую.

Логический
Схема логической базы данных представляет, как данные организованы в виде таблиц. Он также объясняет, как атрибуты из таблиц связаны друг с другом. В разных схемах используется разный синтаксис для определения логической архитектуры и ограничений.
Примечание. Ограничения целостности — это набор правил для СУБД, которые поддерживают качество вставки и обновления данных.
Чтобы создать логическую схему базы данных, мы используем инструменты для иллюстрации отношений между компонентами ваших данных. Это называется моделированием сущности-отношения (моделирование ER). Он определяет отношения между типами сущностей.
Схема ниже представляет собой очень простую модель ER, которая показывает логический поток в базовом коммерческом приложении. Он объясняет продукт покупателю, который его покупает.

Идентификаторы в каждом из трех верхних кружков указывают первичный ключ объекта. Это идентификатор, который однозначно определяет запись в документе или таблице. FK на схеме — это внешний ключ. Это то, что связывает отношения от одной таблицы к другой.
- Первичный ключ: идентифицировать запись в таблице
- Внешний ключ: первичный ключ для другой таблицы
Модели сущностей-отношений могут быть созданы всевозможными способами, и существуют онлайн-инструменты, которые помогают в построении диаграмм, таблиц и даже SQL для создания вашей базы данных из существующей модели ER. Это поможет создать физическое представление схемы вашей базы данных.
Физический
Схема физической базы данных представляет, как данные хранятся на диске. Другими словами, это реальный код, который будет использоваться для создания структуры вашей базы данных. Например, в MongoDB с мангустом это примет форму модели мангуста. В MySQL вы будете использовать SQL для создания базы данных с таблицами.
По сравнению с логической схемой она включает имена таблиц базы данных, имена столбцов и типы данных.
Теперь, когда мы знакомы с основами схемы базы данных, давайте рассмотрим несколько примеров. Мы рассмотрим наиболее распространенные примеры, с которыми вы можете столкнуться.
Пример NoSQL
Базы данных NoSQL в первую очередь называются нереляционными или распределенными базами данных. Разработка схемы для NoSQL является предметом некоторых дискуссий, поскольку они имеют динамическую схему. Некоторые утверждают, что привлекательность NoSQL заключается в том, что вам не нужно создавать схему, но другие говорят, что дизайн очень важен для этого типа базы данных, поскольку он не предоставляет одно решение.
Этот фрагмент является примером того, как будет выглядеть физическая схема базы данных при использовании Mongoose (MongoDB) для создания базы данных, представляющей приведенную выше диаграмму отношения сущность. Просматривайте вкладки кода, чтобы увидеть различные части.
CustomerSchema.js
const mongoose = require(‘mongoose’);
const Customer = new mongoose.Schema({
name: {
type: String,
required: true
},
zipcode: {
type: Number,
}
})
module.exports = mongoose.model(«Customer», Customer);
ProductSchema.js
const mongoose = require(‘mongoose’);
const Product = new mongoose.Schema({
name: {
type: String,
required: true
},
price: {
type: String,
required: true
}
})
module.exports = mongoose.model(«Product», Product);
TransactionSchema.js
const mongoose = require(‘mongoose’);
const Transaction = new mongoose.Schema({
date: {
type: String,
required: true
},
cust_id: {
type: mongoose.Schema.Types.ObjectId, // signifies relationship to Customer Schema
ref: ‘Customer’
},
products: [{
type: mongoose.Schema.Types.ObjectId, // signifies relationship to Product Schema
ref: ‘Product’
}]
})
module.exports = mongoose.model(«Transaction», Transaction);
Здесь важно помнить, что в базах данных NoSQL, таких как MongoDB, нет внешних ключей. Другими словами, между схемами нет отношений. ObjectIdПросто представляет собой _id(идентификатор, который Монго автоматически присваивает при создании) документа в другой коллекции. На самом деле это не создает соединение.
Пример SQL-сервера
База данных SQL содержит такие объекты, как представления, таблицы, функции, индексы и представления. Нет никаких ограничений на количество объектов, которые мы можем использовать. Схемы SQL определяются на логическом уровне, и пользователь, владеющий этой схемой, называется владельцем схемы.
SQL используется для доступа, обновления и управления данными. MySQL — это СУБД для хранения и организации.
Мы можем использовать SQL Server CREATE SCHEMAдля создания новой схемы в базе данных. В MySQL схема является синонимом базы данных. Вы можете заменить ключевое слово SCHEMAдля DATABASEсинтаксиса MySQL SQL.
Некоторые другие продукты баз данных различаются. Например, в продукте Oracle Database схема представляет только часть базы данных: таблицы и другие объекты принадлежат одному пользователю.
Примечание. В SQL представление — это виртуальная таблица, основанная на наборе результатов оператора. Представление содержит как строки, так и столбцы.
Первичные ключи и внешние ключи оказываются здесь полезными, поскольку они представляют отношения от одной таблицы к другой.
CREATE DATABASE example;
USE example;
DROP TABLE IF EXISTS customer;
CREATE TABLE customer (
id INT AUTO_INCREMENT PRIMARY KEY,
postalCode VARCHAR(15) default NULL,
)
DROP TABLE IF EXISTS product;
CREATE TABLE product (
id INT AUTO_INCREMENT PRIMARY KEY,
product_name VARCHAR(50) NOT NULL,
price VARCHAR(7) NOT NULL,
qty VARCHAR(4) NOT NULL
)
DROP TABLE IF EXISTS transactions;
CREATE TABLE transactions (
id INT AUTO_INCREMENT PRIMARY KEY,
cust_id INT,
timedate TIMESTAMP,
FOREIGN KEY(cust_id)
REFERENCES customer(id),
)
CREATE TABLE product_transaction (
prod_id INT,
trans_id INT,
PRIMARY KEY(prod_id, trans_id),
FOREIGN KEY(prod_id)
REFERENCES product(id),
FOREIGN KEY(trans_id)
REFERENCES transactions(id)
Пример PostgreSQL
PostgreSQL — это бесплатная система управления реляционными базами данных с открытым исходным кодом, которая отличается высокой расширяемостью и соответствует требованиям SQL. В PostgreSQL схема базы данных — это пространство имен с именованными объектами базы данных.
Сюда входят таблицы, представления, индексы, типы данных, функции и операторы. В этой системе схемы являются синонимами каталогов, но они не могут быть вложены в иерархию.
Примечание. В программировании пространство имен — это набор знаков (называемых именами), которые мы используем для идентификации объектов. Пространство имен гарантирует, что всем объектам присваиваются уникальные имена, чтобы их было легко идентифицировать.
Итак, хотя база данных Postgres может содержать несколько схем, уровень будет только один. Посмотрим на визуальное представление:

В PostgreSQL кластер баз данных содержит одну или несколько баз данных. Пользователи совместно используются в кластере, но данные не передаются. Вы можете использовать одно и то же имя объекта в нескольких схемах.
Мы используем это выражение CREATE SCHEMAдля начала. Обратите внимание, что PostgreSQL автоматически создаст общедоступную схему. Здесь будет размещаться каждый новый объект.
CREATE SCHEMA name;
Чтобы создать объекты в схеме базы данных, мы пишем полное имя, которое включает имя схемы и имя таблицы:
schema.table
В следующем примере из документации Postgres вызывается CREATE SCHEMAновая схема scm, вызывается таблица deliveriesи вызывается представление delivery_due_list.
CREATE SCHEMA scm
CREATE TABLE deliveries(
id SERIAL NOT NULL,
customer_id INT NOT NULL,
ship_date DATE NOT NULL
)
CREATE VIEW delivery_due_list AS
SELECT ID, ship_date
FROM deliveries
WHERE ship_date <= CURRENT_DATE;
Что изучать дальше
Поздравляю! Теперь вы знаете основы схем баз данных и готовы вывести свои навыки проектирования баз данных на новый уровень. Схемы баз данных жизненно важны для создания баз данных. Независимо от того, используете ли вы базу данных на основе NoSQL или SQL, схемы баз данных составляют основу ваших приложений.
Чтобы продолжить обучение, вам необходимо рассмотреть следующие темы:
- Архитектура с тремя схемами
- Модели сущности-отношения
- Понятия реляционной модели
- Функциональные зависимости
- Нормализация
