Как обозначается алфавит в информатике
Содержание
- Ответ
- Проверено экспертом
- Описание термина
- Отображение символов в двоичном коде
- Вычисление мощности алфавита
- Определение информационного объёма в тексте
- Примеры расчёта мощности
Ответ
Проверено экспертом

1.алфавит — это множество символов, используемых при записи текста
2.Полное количество символов в алфавите называется мощностью (размером) алфавита.
3.Информационный объем текста равен произведению количества символов в тексте на вес одного символа I=K*i
запишем условие N=64, K=100, I-?
решение: из формулы мощности алфавита найдем вес одного символа
N=2^i, 64=2^i, 2^6=2^i, i=6 бит
вычислим информационный объем: I=100*6=600 бит
5.байт,килобайт,мегабайт и гигабайт — это единицы измерения информации
запишем условие: N=256, I=3.5 Кб, K=?
решение: вычислим вес одного символа
выразим информационный объем в битах
посчитаем количество символов К=I/i=28672/8=3584 символа
запишем условие: К1=К2, N1=32, N2=64, I1/I2=?
решение: вычислим вес одного символа первого алфавита
вычислим вес одного символа второго алфавита
запишем формулу для нахождения информационного объема первого алфавита I1=K1*i1
запишем формулу для нахождения информационного объема второго алфавита I2=K2*i2
поскольку количество символов в текстах одинаковое, то можно записать отношение

Описание термина
Понятие мощности алфавита находится в основании изучения информатики. Алфавитом принято называть набор многочисленных символов. Сумма всех их в определённом языке и есть алфавитная мощность. Иными словами, это количество всех символов, входящих в конкретно взятый язык. Сюда входят не только буквы, но и прочие обозначения, в частности:

- числа;
- спецсимволы;
- двоеточия;
- пробел;
- скобки;
- запятые;
- точки;
- многоточия и прочее.
Это определение считается обобщённым и не принимает во внимание вычисления информационной составляющей сообщения. Она может содержать в себе числа, знаки препинания и прочее. В этом случае прибегают к использованию другого способа. Его суть основывается на том, что любая буква, цифра или знак обладают собственным информационным объемом данных. Компьютер работает с этим информационным кодом и распознает то, что было написано.
Основным постулатом в информатике является тот факт, что устройство разбирает введённую информацию исключительно в двоичном коде в форме нуля и единицы. В итоге получается, что абсолютно любой символ алфавита может быть успешно закодирован при помощи соответствующего подбора этих двух цифровых символов. Самая маленькая последовательность, применяемая при обозначении какой-либо цифры, буквы или другого знака, состоит из двух элементов.
Информационная масса отдельно взятого символа обычно изображается в форме информационной стандартной измерительной единицы, которая называется «бит». Восемь битов становятся равны одному байту.
Отображение символов в двоичном коде
Алфавитная мощность может быть использована на практике только при наличии двоичного кода. В качестве примера можно использовать упрощённый алфавит, состоящий всего из четырёх символов. В этом случае разрядность их и информационное представление описываются следующим образом:
Из этого списка можно сделать вывод о том, что если алфавитная мощность равняется 4, то масса отдельного единичного символа будет составлять 2 бита. Если же есть алфавит, состоящий из 8 символов, то при подборе двоичного трёхзначного кода для него комбинационное количество будет следующим:
Иными словами, если алфавитная мощность равна 8, то вес отдельно взятого символа для двоичного трёхзначного кода составит 3 бита.
Вычисление мощности алфавита
Численность знаков в коде и мощность алфавита всегда выражают определённую зависимость. Для того чтобы определить информационный объём, который заключается в сообщении, прибегают к специальному способу измерения, которое выражается в формуле мощности алфавита: N = 2 в n -ной степени.

Эта формула была изобретена американским инженером Ральфом Хартли более сотни лет тому назад. Она применяется для работы с равновероятными событиями и используется для определения мощности конкретного буквенного набора, которая обозначается буквой N (информационная масса или объём). n означает численность бит в словесной единице, иными словами, количество знаков внутри двоичного кода. Так, если n равен 1, то N тоже равен 1, при n = 2 N = 4, при n = 3 N = 8, при n = 4 N = 16.
Чтобы сформулировать теорию о численности информации в набранном словосочетании, пользуются формулой I=K*i. В этом случае К обозначает численность всех символов в предложении, а i — это информационная масса символа.
При ответе на вопрос, как найти мощность алфавита, нужно сказать, что в русском языке 33 буквы, поэтому это можно выразить как N = 33. Для сравнения, аналогичный показатель в английском, немецком и французском языках равняется 26, в испанском — 27. Венгерский язык, например, является 40-символьным.
Существует также и клавиатурный язык, куда входят не только буквы, но и дополнительные знаки. Так, в русском языке есть ещё 10 цифр и 11 символов, а также пробел и пара скобок. Их мощность прибавляется к аналогичному буквенному показателю, и на выходе получается N = 33+10+11+1+2=57. В некоторых случаях букву «ё» не выделяют в качестве отдельного самостоятельного символа, и в таком случае полная мощность русского алфавита становится равна 56.
Определение информационного объёма в тексте
Почти всегда при наборе текста на компьютерах и других электронных устройствах приходится сталкиваться с написанием различных символов. К ним следует отнести:
- заглавные и жирные буквы;
- курсив;
- скобки;
- знаки препинания;
- вычислительные операции и прочее.
По всем расчётам получается, что мощность компьютерного алфавита составляет 256 различных символов и вариантов. В соответствии с формулой Хартли, N = 256, а i — масса любого из значков в клавиатурном алфавите соответствует одному байту, или восьми битам.

Размер любой напечатанной фразы может быть вычислен по формуле V=K ⋅ log2N. В этом случае N обозначает количество всех символов в алфавите, а K — это численность знаков непосредственно в напечатанной фразе. Так, например, имеется произвольный текст объёмом в 25 листов. На каждом из них расположено по 45 строчек текста, содержащих по 58 символов.
Исходя из этого, на любой отдельной странице будет 45*58 = 2610 байт информации. В целом же по всему тексту этот объём будет равен 2610*25 = 65250 байт. Для обозначения мощности алфавита в информатике общепринятым вариантом является буква N из формулы Хартли. Именно ее чаще всего указывают в большинстве учебников и профессиональной литературе.
В кодовой таблице ASCII используют восьмибитную кодировку текстовых сообщений. Она позволяет полностью вместить основной набор символов кириллического и латинского алфавитов как в строчном, так и в прописном вариантах. Также с её помощью можно отобразить знаки препинания, цифры и прочие базовые знаки. Часто пользователям приходится иметь дело с более крупными объёмами, состоящими из триллионов байтов.
Для удобства их всегда переводят в увеличенные величины — кило-, мега-, гигабайты и прочее. Для их упрощённого обозначения используются специальные сокращения: Кб, Мб, Гб и так далее. 1 Кб равняется 1024 байтам (2 байта в десятой степени), 1 Мб составляет 1024 Кб (2 Кб в десятой степени) и так далее. Исходя из этого, 65250 байт будут составлять 63,72 килобайта.
Поскольку один отдельный символ состоит из 8 битов, то устанавливать их кодировку целиком не представляется возможным. Вместо этого предпочтительнее образовать кодировку трёхбитовых комбинаций. Расчёт этого действия проводится по формуле Хартли, где n-ная степень будет равняться трём. В результате получается N, равная 8.
При определении мощности чаще всего используют алфавитный подход. Он говорит о том, что объём информации, заложенной в тексте, зависит исключительно от мощности самого алфавита и размера сообщения (то есть количества символов, содержащихся в нём). Этот показатель не имеет никакой связи со смысловым наполнением для человека.
Примеры расчёта мощности

От пользователей или обучающихся в задачах часто требуют научиться определять информационный объём какого-либо сообщения, приняв информационный вес символа за один байт. Так, в отрывке из поэмы Н. Н. Некрасова «Крестьянские дети»:
Я из лесу вышел; был сильный мороз»
будет 67 символов вместе с пробелами, то есть, в соответствии с условиями задания, 67 байт. Их количество умножают на 8 (количество битов в байте), и на выходе получается 536 битов.
Таким образом, зная в теории суть мощности, можно без проблем определять информационный объем различных сообщений.
Цель урока:
- Иметь представление об алфавитном подходе к определению количества информации;
- Знать формулу для определения количества информационных сообщений,количества информации в сообщений;
- Уметь решать задачи на определение количества информационных сообщений и количества информации, которое несет полученное сообщение.
Ход урока
1. Актуализация знаний:
— Ребята давайте понаблюдаем за тем , что мы видим за окном. Что вы можете сказать о природе? (Наступила зима.)
— Но почему вы решили, что наступила зима? (Холодно , идет снег.)
— Но ведь нигде не написано, что это признаки зимы. (Но мы знаем, что все это означает: наступила зима.)
Поэтому и получается, что , то знание, которое мы извлекаем из окружающей действительности и есть информация. (слайд 1)
Заполнить таблицу и стрелочками показать соответствия.
| Носители информации | Их использование |
| Дискета | Написать письмо |
| Бумага | Записать компьютерную игру |
| Аудиокассета | Сделать фотоизображение |
| Фотопленка | Записать исполнение песни |
| Видеокассета | Записать ноты песни |
— Можно ли измерить количество информации и как это сделать? (Да)
Оказывается, информацию также можно измерять и находить ее количество.
Существуют два подхода к измерению информации. С одним из них мы сегодня познакомимся. (Смотри приложение слайд 2)
2. Изучение нового материала.
Каким образом можно найти количество информации?
У нас есть небольшой текст, написанный на русском языке. Он состоит из букв русского алфавита, цифр, знаков препинания. Для простоты будем считать, что символы в тексте присутствуют с одинаковой вероятностью.
Множество используемых в тексте символов называется алфавитом.
В информатике под алфавитом понимают не только буквы, но и цифры, и знаки препинания, и другие специальные знаки.
У алфавита есть размер (полное количество символов), который называется мощностью алфавита. При алфавитном подходе считается, что каждый символ текста имеет определенный “информационный вес”. С увеличением мощности алфавита увеличивается информационный вес символов этого алфавита.
Обозначим мощность алфавита через N.
Найдем зависимость между информационным весом символа (i) и мощностью алфавита (N). Самый наименьший алфавит содержит 2 символа, которые обозначаются “0” и “1”. Информационный вес символа двоичного алфавита принят за единицу информации и называется 1 бит. (Cмотри приложение слайд 3)
| N | 2 | 4 | 8 | 16 | 32 | 64 | 128 | 256 |
| i | 1бит | 2бит | 3бит | 4бит | 5бит | 6бит | 7бит | 8бит |
N= 2 i
В компьютере также используется свой алфавит, который можно назвать компьютерным. Количество символов, которое в него входит, равно 256 символов. Это мощность компьютерного алфавита.
Также мы выяснили, что закодировать 256 разных символов можно показать с помощью 8 битов.
8 бит является настолько характерной величиной, что ей присвоили свое название – байт.
Используя этот факт: можно быстро подсчитать количество информации, содержащееся в компьютерном тексте, т.е.в тексте набранном с помощью компьютера, учитывая, что большинство статей, книг, публикаций и т.д. написаны с помощью текстовых редакторов, то таким способом можно найти информационный объем любого сообщения, созданного подобным образом.
Правило для измерения информации с точки зрения алфавитного подхода посмотрим на слайде. (Cмотри приложение слайд 4)
Пример:
Найти информационный объем страницы компьютерного текста.
1. Найдем мощность: N=256
2. Найдем информационный объем одного символа : N= 2 i i = 8 бит = 1 байт.
3. Найдем количество символов на странице. Примерно.
(Найти количество символов в строке и умножить на количество строк)
Пусть дети выберут произвольную строку и подсчитают количество символов в ней, учитывая все знаки препинания и пробелы.
40 символов * 50 строк = 2000символов.
4. Найдем информационный объем всей страницы: 2000 * 1 = 2000 байтам
Согласитесь, что байт – маленькая единица измерения информации. Для измерения больших объемов информации используют следующие единицы (Cмотри приложение слайд5)
3. Закрепление изученного материала.
Заполнить пропуски числами и проверить правильность.
1 Кбайт = ___ байт = ______бит,
2 Кбайт = _____ байт =______бит,
24576 бит =_____байт =_____Кбайт,
512 Кбайт = ___ байт =_____бит.
Предлагается ученикам задачи:
1) Сообщение записано с помощью алфавита, содержащего 8 символов. Какое количество информации несет одна буква этого алфавита?
Решение: N=8 , то i= 3 битам
2) Сообщение , записанное буквами из 128-символьного алфавита, содержит 30 символов. Какой объем информации оно несет?
1. N= 128 , K=30
2. N= 2 i i= 7 битам (объем одного символа)
3. I = 30*7 = 210бит (объем всего сообщения)
4. Творческая работа.
Наберите на компьютере текст, информационный объем которого равен 240 байт.
5. Итоги урока.
— Что нового сегодня мы узнали на уроке?
— Как определяется количество информации с алфавитной точки зрения?
— Как найти мощность алфавита?
— Чему равен 1байт?
6. Домашнее задание (Cмотри приложение слайд 6).
Выучить правило для измерения информации с точки зрения алфавитного подхода.
Выучить единицы измерения информации.
1) Мощность некоторого алфавита равна 64 символам. Каким будет объем информации в тексте, состоящем из 100символов.
2) Информационный объем сообщения равен 4096 бит. Оно содержит 1024 символа. Какова мощность алфавита, с помощью которого составлено это сообщение?
Алфавит языка Паскаль
Ключевые слова: Алфавит языка Паскаль,
Изучение алфавита языка лучше всего начинать на примере стандартной программы, используемой при изучении любого языка программирования:

Первое, что мы узнаем — какие же буквы, символы, значки можно использовать в программе на Паскале. Ведь алфавит — конечный набор знаков, из которых строятся все конструкции, — является основой любого языка.
Далее перечислены составляющие алфавита языка Паскаль:
- цифры (обычные десятичные арабские);
- латинские буквы, прописные и заглавные (будем их в дальнейшем называть маленькими и большими). К буквам еще относится символ «_» (подстрочник или нижнее подчеркивание), так как он используется именно в качестве буквы. Во многих конструкциях языка маленькие и большие буквы не различаются;
- специальные символы.
К специальным символам относятся разделители (пробел, разные скобки, знаки препинания, апострофы), знаки арифметических операций, операций сравнения, например:![]()
Есть среди специальных символов и такие, которые при печати на клавиатуре обозначаются двумя значками (парные символы):![]()
В языке они интерпретируются как один символ (писать символы, входящие в пару, надо обязательно подряд, в одной строке без пробела).
Особое место среди специальных символов занимают служебные (зарезервированные) слова. В языке имеется фиксированный небольшой набор (несколько десятков) слов, зарезервированных для определенных целей (для любых других целей их использовать запрещается). Для того чтобы отличить служебные слова от других наборов символов, в учебниках их принято выделять жирным шрифтом или курсивом, писать с большой буквы, на письме — подчеркивать. Служебные слова состоят из букв — символов алфавита, однако мы их выделяем как особые неделимые единицы алфавита языка.
Мы здесь не задаемся целью привести полностью весь набор символов, допустимых в языке, не предъявляем список служебных слов для заучивания — со всеми этими объектами мы познакомимся в процессе изучения материала.
Перечисленные символы входят в стандарт языка и используются для написания его конструкций. Однако для написания подсказок пользователю или некоторых конструкций в процессе работы программы этих символов бывает недостаточно. Для адаптации программы под пользователей разных стран в язык ввели четвертую группу символов, не входящую в стандарт языка. Это символы национального алфавита, они имеют особый статус, их использование ограничено.
В естественном языке из символов алфавита составляются слова, фразы. Так и в Паскале из символов алфавита строятся сложные конструкции: имена, константы, операторы и, в конце концов, целая программа.
Вернемся к нашей программе, посмотрим, какие элементы алфавита мы в ней использовали.
Слова Program, Begin, End относятся к служебным. Как видим, служебные слова «заимствованы» из английского языка, так что выучить их будет несложно. Большие и маленькие буквы в служебных словах Паскаль не различает.
В нашей программе использовано много разделителей, а вот никаких знаков операций нет. Во второй строке мы видим текст на русском языке. Это — комментарий, пояснение к программе. Комментарий представляет собой один из особых случаев, где можно использовать символы национального алфавита.
Также в нашей программе использованы имена и константы.
Константы. С точки зрения языка константы определяют изображения значений, запись которых подчиняется определенным правилам. Константы могут быть числовые, логические, символьные и строковые (об этом мы, естественно, поговорим подробнее позже).
В нашей программе присутствует одна константа-строка:
'Здравствуй, мир!'
Текст, составляющий содержимое константы-строки, заключен в символы-апострофы. В строковой константе (внутри апострофов) также можно использовать символы национального алфавита (и вообще любые символы, которые есть на клавиатуре). При этом большие и маленькие буквы различаются. Так, константы ‘TIGR’, ‘tigr’ и ‘Tigr’ — различные.
Имена. Объекты программы (переменные, функции, процедуры) должны иметь имена (идентификаторы). Иногда эти имена определены заранее, они называются стандартными (например, существует функция sin). В отличие от служебных слов назначение стандартного идентификатора может быть переопределено программистом (но делать это без особых причин во избежание путаницы не следует). Большинство же имен в своей программе придумывает программист.
В нашей программе именем является слово FIRST, мы его придумали, оно не определено языком. Writeln — тоже имя, но оно стандартное.
Имена (часто их называют идентификаторы) могут состоять из букв и цифр, начинаться должны с буквы, причем под буквами мы здесь подразумеваем только латинские буквы и значок «_». Большие и маленькие буквы в именах язык не различает. Длина имени, вообще говоря, не ограничивается (хотя понятно, что превышать длину строки она никак не может), но различаются идентификаторы по некоторому количеству первых символов (в большинстве версий — 63). Например, имена
A, A234, X45G, Dlina, Summa_Otr, Cos3 — правильные;
234A, СТОЛ, Summa-otr, cos(3) — неправильные;
KROKODIL, krokodil, Krokodil, KrokoDil — одинаковые.
Конспект урока по информатике «Алфавит языка Паскаль».
Вернуться к Списку конспектов по информатике.

Люба Снежкова
Эксперт по предмету «Информатика»
Задать вопрос автору статьи
Общее понятие кодирования информации
Познание окружающего мира начинается с восприятия его человеком с помощью органов чувств. Зрение, вкус, слух, обоняние, осязание доводят до нашего сознания информацию о самых разнообразных свойствах предметов, а также явлениях и процессах, происходящих вокруг нас.
Эта информация поступает к нам в виде набора символов или сигналов. Однако если эти символы или сигналы никому не ясны, то информация будет бесполезной. Поэтому требуется язык общения, который будет понятен всем.
Естественные и формальные языки представления информации
Определение 1
Язык — это знаковая система для представления и передачи информации.
Различают языки:
- естественные (например, мимика и жесты, музыка, живопись, речь человека);
- формальные (например, математическая символика, чертежи и схемы, нотная грамота, языки программирования).
![]()
Сдай на права пока
учишься в ВУЗе
Вся теория в удобном приложении. Выбери инструктора и начни заниматься!
Получить скидку 3 000 ₽
Естественный язык можно формализовать. Так для формализации музыки изобрели нотную грамоту, для формализации речи создали национальные алфавиты (например, латинский ($26$ символов), русский ($33$ символа)), кроме этого арабские цифры, азбуку Морзе и т.д.
Естественные языки развивались веками и служили для общения людей между собой. Формальные языки разрабатываются для специальных применений.
Коммуникативный язык несет в себе логическую информацию, именно с помощью него человек преобразует получаемую информацию в знания и передает эти знания другим людям.
Алфавиты представления информации
Первобытные люди для обозначения каждого нового предмета придумывали новые имена. Для получения необходимого разнообразия имен, названий они стали комбинировать звуки таким образом, чтобы получить в результате слова. Так в ходе эволюции человека появилась идея создания конечного алфавита, т.е. некоторого фиксированного набора знаков, из которого можно составить как угодно много слов. Комбинация знаков алфавита называется словом. Из слов можно составлять фразы, которые будут нести определенную смысловую нагрузку.
«Язык и алфавит представления информации» 👇
Таким образом, алфавит – это упорядоченный набор символов или сигналов, который составляет основу языка.
Мощность алфавита – это количество составляющих его символов.
Человек в своей практике общения использует самые разнообразные языки (например, дорожная грамота, включающая в себя знаки дорожного движения и разметки). Прежде всего, это, конечно же, языки устной и письменной речи, в том числе и иностранные.
Кроме того, человек использует ряд языков профессионального назначения. К ним относятся языки математических и химических формул, обозначений электроники (например, схема электрической цепи), языки программирования. При этом каждый язык имеет свой алфавит.
Замечание 1
С развитием технических средств передачи информации появилась необходимость использования помимо речевых алфавитов многих других. Одним из примеров первых алфавитов, используемых в технике, является азбука Морзе, в которой каждому знаку обычного алфавита соответствует набор точек и тире.
Общее понятие кодирования информации
Воспринимая информацию, человек стал стремиться зафиксировать ее таким образом, чтобы она стала понятной для других, представляя ее в той или иной форме.
Музыкальную тему композитор может наиграть на пианино, а затем записать с помощью нот. Образы, навеянные все той же мелодией, поэт может воплотить в виде стихотворения, хореограф выразить танцем, а художник — в картине.
Люди сохраняют свои знания, записывая их на различных носителях. Благодаря чему эти знания передаются не только в пространстве, но и во времени — от одного поколения к другому.
До наших дней дошли послания предков, которые с помощью различных символов пытались изобразить себя и свои поступки в памятниках и надписях. Примером могут служить наскальные рисунки (петроглифы), которые по сей день представляют загадку для ученых. Вероятнее всего, таким образом древние люди пытались вступить в контакт с будущими поколениями и сообщить о событиях их жизни.
Каждый народ имеет свой язык, состоящий из набора символов (букв): русский, английский, японский и многие другие. Об этом уже упоминалось ранее.
Определение 2
Представление информации с помощью какого-либо языка часто называют кодированием.
Определение 3
Код — это набор символов либо условных обозначений, используемый для представления информации.
Алфавит кодирования содержит полный набор кодов.
Определение 4
Кодирование — это процесс представления информации с помощью кода.
Пример 1
Так водитель пытается передать сигнал с помощью гудка или мигания фар. В данном случае гудок (его наличие или отсутствие) – это код, а в случае световой сигнализации кодом будет являться мигание фар или его отсутствие.
Пешеход встречается с кодированием информации при переходе дороги по сигналу светофора. Код определяет цвет светофора — красный, желтый, зеленый.
Естественный язык, на котором мы общаемся, тоже представляет собой код, называемый алфавитом. Во время устной речи этот код передается звуками, при письменной — буквами. Причем одну и ту же информацию можно представить различными способами. К примеру, запись разговора можно закодировать на бумажном носителе двумя способами: с помощью букв или специальных стенографических знаков.
В более узком смысле под кодированием часто понимают переход от одной формы представления информации к другой, которая более удобна при хранении, передаче или обработке.
В процессе развития технических средств появлялись новые способы кодирования информации. Так во второй половине XIX века американский изобретатель Сэмюэль Морзе придумал удивительно простой код, который применяется до сих пор. Используя этот код, информацию можно представить в виде: длинного сигнала (тире), короткого сигнала (точки) и отсутствия сигнала (паузы) для разделения букв. Таким образом, принцип кодирования сводился к использованию набора символов, расположенных в строго определенном порядке.
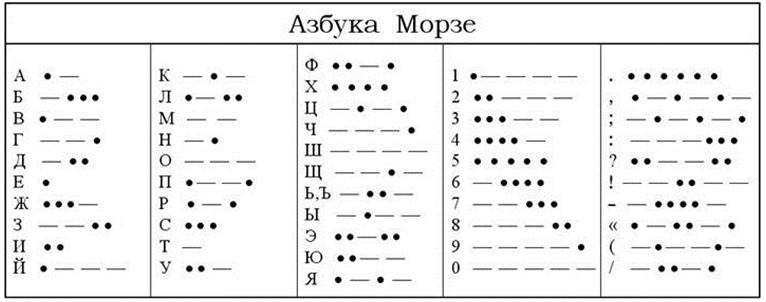
Рисунок 1.
Люди во все времена пытались найти способы быстрого обмена сообщениями. Для этого существовали гонцы, использовались почтовые голуби. Разные народы использовали различные способы оповещения о надвигающейся опасности: это и барабанный бой, и дым костров, и набат колокола, и флаги определенных цветов и пр. Однако при передаче таким способом информации требовалась предварительная договоренность, чтобы принимаемые сообщения были поняты.
Знаменитый немецкий ученый Готфрид Вильгельм Лейбниц предложил еще в XVII веке уникальную по своей простоте систему представления чисел, основанную на использовании вычислений с помощью двоек.
В настоящее время этот способ представления информации с помощью языка, в состав которого входит всего два символа: $0$ и $1$, называется двоичным кодированием информации и широко используется в технических устройствах, в том числе и в компьютере. Эти два символа $0$ и $1$ принято называть двоичными цифрами или битами (от англ. bit — Binary Digit – двоичный знак).
Инженеров такой способ кодирования информации привлек простотой технической реализации, поскольку при помощи $0$ и $1$ ($0$ – сигнала нет, $1$ – сигнал есть) можно закодировать любое сообщение.
Каждому человеку ежедневно в бытовых условиях приходится сталкиваться с устройствами, которые могут находиться только в двух устойчивых состояниях: включено или выключено. И это хорошо известные всем выключатели. Однако изобрести выключатель, который был бы способен устойчиво и быстро переключаться в любое из $10$ состояний, оказалось невозможно. В итоге после ряда неудачных попыток разработчики сделали вывод о невозможности создания компьютера на основе десятичной системы счисления. Поэтому представление чисел в компьютере осуществляется с помощью двоичной системы счисления.
Замечание 2
Способ кодирования информации зависит от цели, которая при этом должна быть достигнута. Целью может являться сокращение записи, засекречивание (шифровка) информации, или, напротив, достижение взаимопонимания. Например, система дорожных знаков, флажковая азбука на флоте, специальные научные языки и символы ― химические, математические, медицинские и др., предназначены для того, чтобы люди могли общаться и понимать друг друга. От того, как представлена информация, зависит способ ее обработки, хранения, передачи и т.д.
Находи статьи и создавай свой список литературы по ГОСТу
Поиск по теме
Алфавит языка Паскаль
Ключевые слова: Алфавит языка Паскаль,
Изучение алфавита языка лучше всего начинать на примере стандартной программы, используемой при изучении любого языка программирования:

Первое, что мы узнаем — какие же буквы, символы, значки можно использовать в программе на Паскале. Ведь алфавит — конечный набор знаков, из которых строятся все конструкции, — является основой любого языка.
Далее перечислены составляющие алфавита языка Паскаль:
- цифры (обычные десятичные арабские);
- латинские буквы, прописные и заглавные (будем их в дальнейшем называть маленькими и большими). К буквам еще относится символ «_» (подстрочник или нижнее подчеркивание), так как он используется именно в качестве буквы. Во многих конструкциях языка маленькие и большие буквы не различаются;
- специальные символы.
К специальным символам относятся разделители (пробел, разные скобки, знаки препинания, апострофы), знаки арифметических операций, операций сравнения, например:![]()
Есть среди специальных символов и такие, которые при печати на клавиатуре обозначаются двумя значками (парные символы):![]()
В языке они интерпретируются как один символ (писать символы, входящие в пару, надо обязательно подряд, в одной строке без пробела).
Особое место среди специальных символов занимают служебные (зарезервированные) слова. В языке имеется фиксированный небольшой набор (несколько десятков) слов, зарезервированных для определенных целей (для любых других целей их использовать запрещается). Для того чтобы отличить служебные слова от других наборов символов, в учебниках их принято выделять жирным шрифтом или курсивом, писать с большой буквы, на письме — подчеркивать. Служебные слова состоят из букв — символов алфавита, однако мы их выделяем как особые неделимые единицы алфавита языка.
Мы здесь не задаемся целью привести полностью весь набор символов, допустимых в языке, не предъявляем список служебных слов для заучивания — со всеми этими объектами мы познакомимся в процессе изучения материала.
Перечисленные символы входят в стандарт языка и используются для написания его конструкций. Однако для написания подсказок пользователю или некоторых конструкций в процессе работы программы этих символов бывает недостаточно. Для адаптации программы под пользователей разных стран в язык ввели четвертую группу символов, не входящую в стандарт языка. Это символы национального алфавита, они имеют особый статус, их использование ограничено.
В естественном языке из символов алфавита составляются слова, фразы. Так и в Паскале из символов алфавита строятся сложные конструкции: имена, константы, операторы и, в конце концов, целая программа.
Вернемся к нашей программе, посмотрим, какие элементы алфавита мы в ней использовали.
Слова Program, Begin, End относятся к служебным. Как видим, служебные слова «заимствованы» из английского языка, так что выучить их будет несложно. Большие и маленькие буквы в служебных словах Паскаль не различает.
В нашей программе использовано много разделителей, а вот никаких знаков операций нет. Во второй строке мы видим текст на русском языке. Это — комментарий, пояснение к программе. Комментарий представляет собой один из особых случаев, где можно использовать символы национального алфавита.
Также в нашей программе использованы имена и константы.
Константы. С точки зрения языка константы определяют изображения значений, запись которых подчиняется определенным правилам. Константы могут быть числовые, логические, символьные и строковые (об этом мы, естественно, поговорим подробнее позже).
В нашей программе присутствует одна константа-строка:
'Здравствуй, мир!'
Текст, составляющий содержимое константы-строки, заключен в символы-апострофы. В строковой константе (внутри апострофов) также можно использовать символы национального алфавита (и вообще любые символы, которые есть на клавиатуре). При этом большие и маленькие буквы различаются. Так, константы ‘TIGR’, ‘tigr’ и ‘Tigr’ — различные.
Имена. Объекты программы (переменные, функции, процедуры) должны иметь имена (идентификаторы). Иногда эти имена определены заранее, они называются стандартными (например, существует функция sin). В отличие от служебных слов назначение стандартного идентификатора может быть переопределено программистом (но делать это без особых причин во избежание путаницы не следует). Большинство же имен в своей программе придумывает программист.
В нашей программе именем является слово FIRST, мы его придумали, оно не определено языком. Writeln — тоже имя, но оно стандартное.
Имена (часто их называют идентификаторы) могут состоять из букв и цифр, начинаться должны с буквы, причем под буквами мы здесь подразумеваем только латинские буквы и значок «_». Большие и маленькие буквы в именах язык не различает. Длина имени, вообще говоря, не ограничивается (хотя понятно, что превышать длину строки она никак не может), но различаются идентификаторы по некоторому количеству первых символов (в большинстве версий — 63). Например, имена
A, A234, X45G, Dlina, Summa_Otr, Cos3 — правильные;
234A, СТОЛ, Summa-otr, cos(3) — неправильные;
KROKODIL, krokodil, Krokodil, KrokoDil — одинаковые.
Конспект урока по информатике «Алфавит языка Паскаль».
Вернуться к Списку конспектов по информатике.
Записать в тетради число и тему урока. Записать определения понятия: двоичный алфавит; двоичное кодирование.
Кодирование информации
Для решения своих задач человеку часто приходится преобразовывать имеющуюся информацию из одной формы представления в другую. Например, при чтении вслух происходит преобразование информации из дискретной (текстовой) формы в непрерывную (звук). Во время диктанта на уроке русского языка, наоборот, происходит преобразование информации из непрерывной формы (голос учителя) в дискретную (записи учеников).
Информация, представленная в дискретной форме, значительно проще для передачи, хранения или автоматической обработки. Поэтому в компьютерной технике большое внимание уделяется методам преобразования информации из непрерывной формы в дискретную.
Двоичное кодирование
В общем случае, чтобы представить информацию в дискретной форме, её следует выразить с помощью символов какого-нибудь естественного или формального языка. Таких языков тысячи. Каждый язык имеет свой алфавит.
Алфавит – конечный набор отличных друг от друга символов (знаков), используемых для представления информации. Мощность алфавита – это количество входящих в него символов (знаков).
Алфавит, содержащий два символа, называется двоичным алфавитом. Представление информации с помощью двоичного алфавита называют двоичным кодированием. Закодировав таким способом информацию, мы получим её двоичный код.


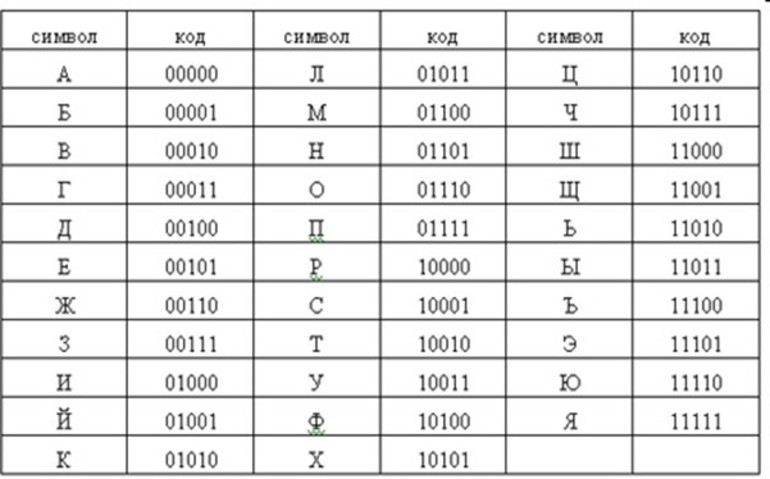
Рассмотрим в качестве символов двоичного алфавита цифры 0 и 1. Покажем, что любой алфавит можно заменить двоичным алфавитом. Прежде всего, присвоим каждому символу рассматриваемого алфавита порядковый номер. Номер представим с помощью двоичного алфавита. Полученный двоичный код будем считать кодом исходного символа.


Пример выполнения задания: Записать в виде двоичного кода имя Светлана:
Смотрим таблицу русского языка и составляем двоичный код имени:
С — это код 10010001;
В — это код 10000010;
Е — это код 10000101;
Т — это код 10010010;
Л — это код 10001011;
А — это код 10000000;
Н — это код 10001101;
А — это код 10000000;
Запишем только в двоичном коде: 1001000110000010100001011001001010001011100000001000110110000000.
Громоздко, не правда ли? 🙂
