Часть 1. Общий алгоритм поиска
Введение
Поиск пути — это одна из тех тем, которые обычно представляют самые большие сложности для разработчиков игр. Особенно плохо люди понимают алгоритм A*, и многим кажется, что это какая-то непостижимая магия.
Цель данной статьи — объяснить поиск пути в целом и A* в частности очень понятным и доступным образом, положив таким образом конец распространённому заблуждению о том, что эта тема сложна. При правильном объяснении всё достаточно просто.
Учтите, что в статье мы будем рассматривать поиск пути для игр; в отличие от более академических статей, мы опустим такие алгоритмы поиска, как поиск в глубину (Depth-First) или поиск в ширину (Breadth-First). Вместо этого мы постараемся как можно быстрее дойти от нуля до A*.
В первой части мы объясним простейшие концепции поиска пути. Разобравшись с этими базовыми концепциями, вы поймёте, что A* на удивление очевиден.
Простая схема
Хотя вы сможете применять эти концепции и к произвольным сложным 3D-средам, давайте всё-таки начнём с чрезвычайно простой схемы: квадратной сетки размером 5 x 5. Для удобства я пометил каждую ячейку заглавной буквой.

Простая сетка.
Самое первое, что мы сделаем — это представим эту среду в виде графа. Я не буду подробно объяснять, что такое граф; если говорить просто, то это набор кружков, соединённых стрелками. Кружки называются «узлами», а стрелки — «рёбрами».
Каждый узел представляет собой «состояние», в котором может находиться персонаж. В нашем случае состояние персонажа — это его позиция, поэтому мы создаём по одному узлу для каждой ячейки сетки:

Узлы, обозначающие ячейки сетки.
Теперь добавим рёбра. Они обозначают состояния, которых можно «достичь» из каждого заданного состояния; в нашем случае мы можем пройти из любой ячейки в соседнюю, за исключением заблокированных:

Дуги обозначают допустимые перемещения между ячейками сетки.
Если мы можем добраться из A в B, то говорим, что B является «соседним» с A узлом.
Стоит заметить, что рёбра имеют направление; нам нужны рёбра и из A в B, и из B в A. Это может показаться излишним, но не тогда, когда могут возникать более сложные «состояния». Например, персонаж может упасть с крыши на пол, но не способен допрыгнуть с пола на крышу. Можно перейти из состояния «жив» в состояние «мёртв», но не наоборот. И так далее.
Пример
Допустим, мы хотим переместиться из A в T. Мы начинаем с A. Можно сделать ровно два действия: пройти в B или пройти в F.
Допустим, мы переместились в B. Теперь мы можем сделать два действия: вернуться в A или перейти в C. Мы помним, что уже были в A и рассматривали варианты выбора там, так что нет смысла делать это снова (иначе мы можем потратить весь день на перемещения A → B → A → B…). Поэтому мы пойдём в C.
Находясь в C, двигаться нам некуда. Возвращаться в B бессмысленно, то есть это тупик. Выбор перехода в B, когда мы находились в A, был плохой идеей; возможно, стоит попробовать вместо него F?
Мы просто продолжаем повторять этот процесс, пока не окажемся в T. В этот момент мы просто воссоздадим путь из A, вернувшись по своим шагам. Мы находимся в T; как мы туда добрались? Из O? То есть конец пути имеет вид O → T. Как мы добрались в O? И так далее.
Учтите, что на самом деле мы не движемся; всё это было лишь мысленным процессом. Мы продолжаем стоять в A, и не сдвинемся из неё, пока не найдём путь целиком. Когда я говорю «переместились в B», то имею в виду «представьте, что мы переместились в B».
Общий алгоритм
Этот раздел — самая важная часть всей статьи. Вам абсолютно необходимо понять его, чтобы уметь реализовывать поиск пути; остальное (в том числе и A*) — это просто детали. В этом разделе вы будете разбираться, пока не поймёте смысл.
К тому же этот раздел невероятно прост.
Давайте попробуем формализовать наш пример, превратив его в псевдокод.
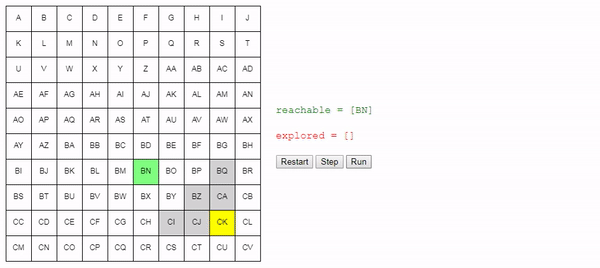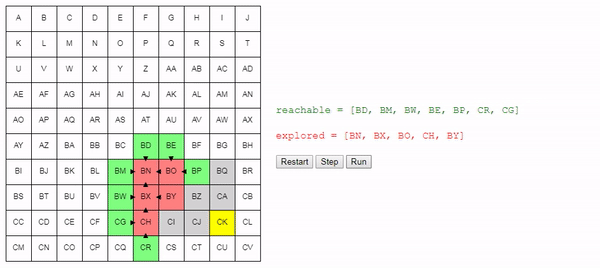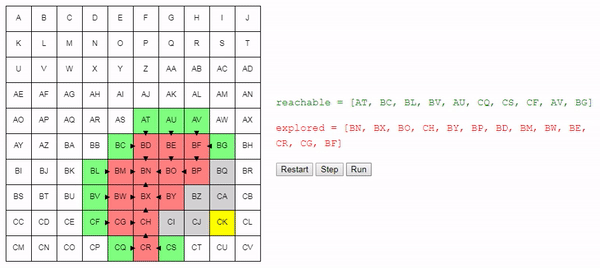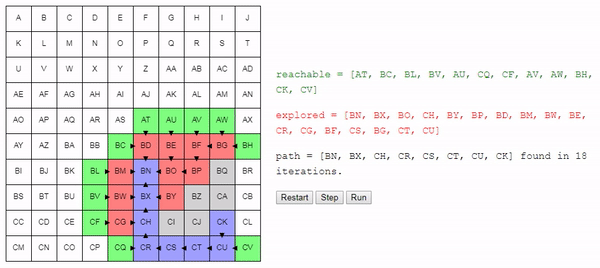
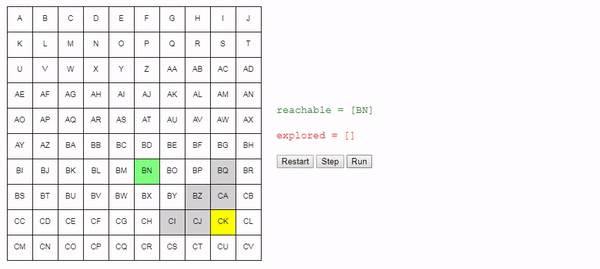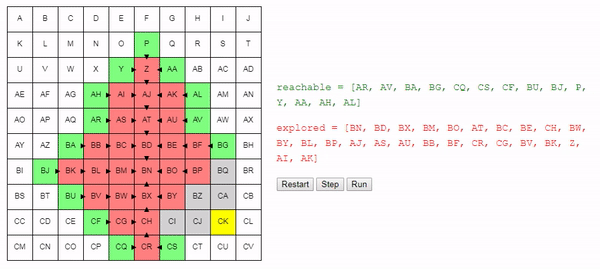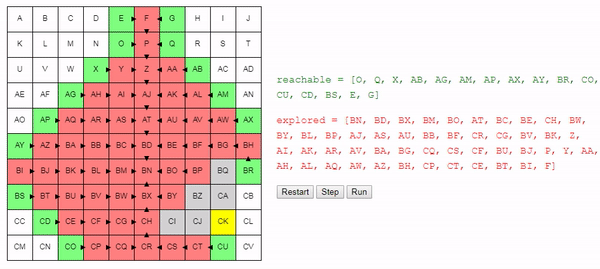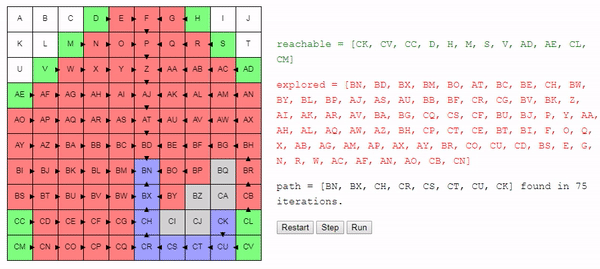
Нам нужно отслеживать узлы, которых мы знаем как достичь из начального узла. В начале это только начальный узел, но в процессе «исследования» сетки мы будем узнавать, как добираться до других узлов. Давайте назовём этот список узлов reachable:
reachable = [start_node]
Также нам нужно отслеживать уже рассмотренные узлы, чтобы не рассматривать их снова. Назовём их explored:
explored = []Дальше я изложу ядро алгоритма: на каждом шаге поиска мы выбираем один из узлов, который мы знаем, как достичь, и смотрим, до каких новых узлов можем добраться из него. Если мы определим, как достичь конечного (целевого) узла, то задача решена! В противном случае мы продолжаем поиск.
Так просто, что даже разочаровывает? И это верно. Но из этого и состоит весь алгоритм. Давайте запишем его пошагово псевдокодом.
Мы продолжаем искать, пока или не доберёмся до конечного узла (в этом случае мы нашли путь из начального в конечный узел), или пока у нас не закончатся узлы, в которых можно выполнять поиск (в таком случае между начальным и конечным узлами пути нет).
while reachable is not empty:Мы выбираем один из узлов, до которого знаем, как добраться, и который пока не исследован:
node = choose_node(reachable)
Если мы только что узнали, как добраться до конечного узла, то задача выполнена! Нам просто нужно построить путь, следуя по ссылкам previous обратно к начальному узлу:
if node == goal_node:
path = []
while node != None:
path.add(node)
node = node.previous
return pathНет смысла рассматривать узел больше одного раза, поэтому мы будем это отслеживать:
reachable.remove(node)
explored.add(node)Мы определяем узлы, до которых не можем добраться отсюда. Начинаем со списка узлов, соседних с текущим, и удаляем те, которые мы уже исследовали:
new_reachable = get_adjacent_nodes(node) - exploredМы берём каждый из них:
for adjacent in new_reachable:
Если мы уже знаем, как достичь узла, то игнорируем его. В противном случае добавляем его в список reachable, отслеживая, как в него попали:
if adjacent not in reachable:
adjacent.previous = node # Remember how we got there.
reachable.add(adjacent)
Нахождение конечного узла — это один из способов выхода из цикла. Второй — это когда reachable становится пустым: у нас закончились узлы, которые можно исследовать, и мы не достигли конечного узла, то есть из начального в конечный узел пути нет:
return NoneИ… на этом всё. Это весь алгоритм, а код построения пути выделен в отдельный метод:
function find_path (start_node, end_node):
reachable = [start_node]
explored = []
while reachable is not empty:
# Choose some node we know how to reach.
node = choose_node(reachable)
# If we just got to the goal node, build and return the path.
if node == goal_node:
return build_path(goal_node)
# Don't repeat ourselves.
reachable.remove(node)
explored.add(node)
# Where can we get from here?
new_reachable = get_adjacent_nodes(node) - explored
for adjacent in new_reachable:
if adjacent not in reachable
adjacent.previous = node # Remember how we got there.
reachable.add(adjacent)
# If we get here, no path was found :(
return None
Вот функция, которая строит путь, следуя по ссылкам previous обратно к начальному узлу:
function build_path (to_node):
path = []
while to_node != None:
path.add(to_node)
to_node = to_node.previous
return pathВот и всё. Это псевдокод каждого алгоритма поиска пути, в том числе и A*.
Перечитывайте этот раздел, пока не поймёте, как всё работает, и, что более важно, почему всё работает. Идеально будет нарисовать пример вручную на бумаге, но можете и посмотреть интерактивное демо:
Интерактивное демо
Вот демо и пример реализации показанного выше алгоритма (запустить его можно на странице оригинала статьи). choose_node просто выбирает случайный узел. Можете запустить алгоритм пошагово и посмотреть на список узлов reachable и explored, а также на то, куда указывают ссылки previous.
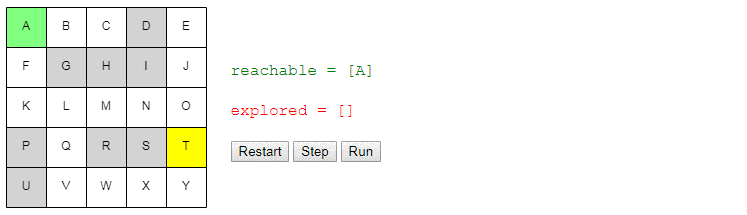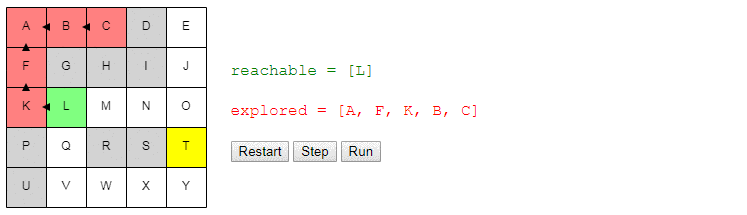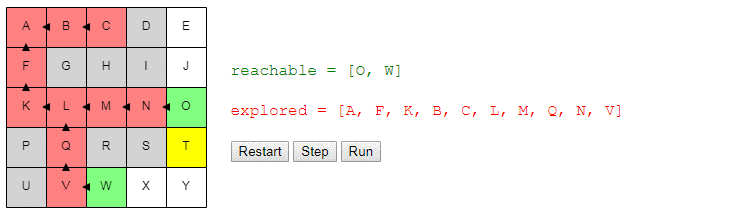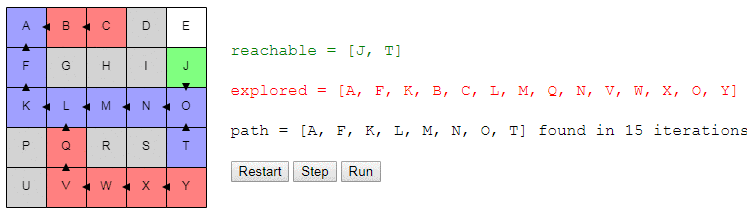
Заметьте, что поиск завершается, как только обнаруживается путь; может случиться так, что некоторые узлы даже не будут рассмотрены.
Заключение
Представленный здесь алгоритм — это общий алгоритм для любого алгоритма поиска пути.
Но что же отличает каждый алгоритм от другого, почему A* — это A*?
Вот подсказка: если запустить поиск в демо несколько раз, то вы увидите, что алгоритм на самом деле не всегда находит один и тот же путь. Он находит какой-то путь, и этот путь необязательно является кратчайшим. Почему?
Часть 2. Стратегии поиска
Если вы не полностью поняли описанный в предыдущем разделе алгоритм, то вернитесь к нему и прочтите заново, потому что он необходим для понимания дальнейшей информации. Когда вы в нём разберётесь, A* покажется вам совершенно естественным и логичным.
Секретный ингредиент
В конце предыдущей части я оставил открытыми два вопроса: если каждый алгоритм поиска использует один и тот же код, почему A* ведёт себя как A*? И почему демо иногда находит разные пути?
Ответы на оба вопроса связаны друг с другом. Хоть алгоритм и хорошо задан, я оставил нераскрытым один аспект, и как оказывается, он является ключевым для объяснения поведения алгоритмов поиска:
node = choose_node(reachable)
Именно эта невинно выглядящая строка отличает все алгоритмы поиска друг от друга. От способа реализации choose_node зависит всё.
Так почему же демо находит разные пути? Потому что его метод choose_node выбирает узел случайным образом.
Длина имеет значение
Прежде чем погружаться в различия поведений функции choose_node, нам нужно исправить в описанном выше алгоритме небольшой недосмотр.
Когда мы рассматривали узлы, соседние с текущим, то игнорировали те, которые уже знаем, как достичь:
if adjacent not in reachable:
adjacent.previous = node # Remember how we got there.
reachable.add(adjacent)
Это ошибка: что если мы только что обнаружили лучший способ добраться до него? В таком случае необходимо изменить ссылку previous узла, чтобы отразить этот более короткий путь.
Чтобы это сделать, нам нужно знать длину пути от начального узла до любого достижимого узла. Мы назовём это стоимостью (cost) пути. Пока примем, что перемещение из узла в один из соседних узлов имеет постоянную стоимость, равную 1.
Прежде чем начинать поиск, мы присвоим значению cost каждого узла значение infinity; благодаря этому любой путь будет короче этого. Также мы присвоим cost узла start_node значение 0.
Тогда вот как будет выглядеть код:
if adjacent not in reachable:
reachable.add(adjacent)
# If this is a new path, or a shorter path than what we have, keep it.
if node.cost + 1 < adjacent.cost:
adjacent.previous = node
adjacent.cost = node.cost + 1Одинаковая стоимость поиска
Давайте теперь рассмотрим метод choose_node. Если мы стремимся найти кратчайший возможный путь, то выбирать узел случайным образом — не самая лучшая идея.
Лучше выбирать узел, которого мы можем достичь из начального узла по кратчайшему пути; благодаря этому мы в общем случае будем предпочитать длинным путям более короткие. Это не значит, что более длинные пути не будут рассматриваться вовсе, это значит, что более короткие пути будут рассматриваться первыми. Так как алгоритм завершает работу сразу после нахождения подходящего пути, это должно позволить нам находить короткие пути.
Вот возможный пример функции choose_node:
function choose_node (reachable):
best_node = None
for node in reachable:
if best_node == None or best_node.cost > node.cost:
best_node = node
return best_nodeИнтуитивно понятно, что поиск этого алгоритма расширяется «радиально» от начального узла, пока не достигнет конечного. Вот интерактивное демо такого поведения:
Заключение
Простое изменение в способе выбора рассматриваемого следующим узла позволило нам получить достаточно хороший алгоритм: он находит кратчайший путь от начального до конечного узла.
Но этот алгоритм всё равно в какой-то степени остаётся «глупым». Он продолжает искать повсюду, пока не наткнётся на конечный узел. Например, какой смысл в показанном выше примере выполнять поиск в направлении A, если очевидно, что мы отдаляемся от конечного узла?
Можно ли сделать choose_node умнее? Можем ли мы сделать так, чтобы он направлял поиск в сторону конечного узла, даже не зная заранее правильного пути?
Оказывается, что можем — в следующей части мы наконец-то дойдём до choose_node, позволяющей превратить общий алгоритм поиска пути в A*.
Часть 3. Снимаем завесу тайны с A*
Полученный в предыдущей части алгоритм достаточно хорош: он находит кратчайший путь от начального узла до конечного. Однако, он тратит силы впустую: рассматривает пути, которые человек очевидно назовёт ошибочными — они обычно удаляются от цели. Как же этого можно избежать?
Волшебный алгоритм
Представьте, что мы запускаем алгоритм поиска на особом компьютере с чипом, который может творить магию. Благодаря этому потрясающему чипу мы можем выразить choose_node очень простым способом, который гарантированно создаст кратчайший путь, не теряя времени на исследование частичных путей, которые никуда не ведут:
function choose_node (reachable):
return magic(reachable, "любой узел, являющийся следующим на кратчайшем пути")Звучит соблазнительно, но магическим чипам всё равно требуется какой-то низкоуровневый код. Вот какой может быть хорошая аппроксимация:
function choose_node (reachable):
min_cost = infinity
best_node = None
for node in reachable:
cost_start_to_node = node.cost
cost_node_to_goal = magic(node, "кратчайший путь к цели")
total_cost = cost_start_to_node + cost_node_to_goal
if min_cost > total_cost:
min_cost = total_cost
best_node = node
return best_nodeЭто отличный способ выбора следующего узла: вы выбираем узел, дающий нам кратчайший путь от начального до конечного узла, что нам и нужно.
Также мы минимизировали количество используемой магии: мы точно знаем, какова стоимость перемещения от начального узла к каждому узлу (это node.cost), и используем магию только для предсказания стоимости перемещения от узла к конечному узлу.
Не магический, но довольно потрясающий A*
К сожалению, магические чипы — это новинка, а нам нужна поддержка и устаревшего оборудования. БОльшая часть кода нас устраивает, за исключением этой строки:
# Throws MuggleProcessorException
cost_node_to_goal = magic(node, "кратчайший путь к цели")То есть мы не можем использовать магию, чтобы узнать стоимость ещё не исследованного пути. Ну ладно, тогда давайте сделаем прогноз. Будем оптимистичными и предположим, что между текущим и конечным узлами нет ничего, и мы можем просто двигаться напрямик:
cost_node_to_goal = distance(node, goal_node)Заметьте, что кратчайший путь и минимальное расстояние разные: минимальное расстояние подразумевает, что между текущим и конечным узлами нет совершенно никаких препятствий.
Эту оценку получить достаточно просто. В наших примерах с сетками это расстояние городских кварталов между двумя узлами (то есть abs(Ax - Bx) + abs(Ay - By)). Если бы мы могли двигаться по диагонали, то значение было бы равно sqrt( (Ax - Bx)^2 + (Ay - By)^2 ), и так далее. Самое важное то, что мы никогда не получаем слишком высокую оценку стоимости.
Итак, вот немагическая версия choose_node:
function choose_node (reachable):
min_cost = infinity
best_node = None
for node in reachable:
cost_start_to_node = node.cost
cost_node_to_goal = estimate_distance(node, goal_node)
total_cost = cost_start_to_node + cost_node_to_goal
if min_cost > total_cost:
min_cost = total_cost
best_node = node
return best_nodeФункция, оценивающая расстояние от текущего до конечного узла, называется эвристикой, и этот алгоритм поиска, леди и джентльмены, называется … A*.
Интерактивное демо
Пока вы оправляетесь от шока, вызванного осознанием того, что загадочный A* на самом деле настолько прост, можете посмотреть на демо (или запустить его в оригинале статьи). Вы заметите, что в отличие от предыдущего примера, поиск тратит очень мало времени на движение в неверном направлении.
Заключение
Наконец-то мы дошли до алгоритма A*, который является не чем иным, как описанным в первой части статьи общим алгоритмом поиска с некоторыми усовершенствованиями, описанными во второй части, и использующим функцию choose_node, которая выбирает узел, который по нашей оценке приближает нас к конечному узлу. Вот и всё.
Вот вам для справки полный псевдокод основного метода:
function find_path (start_node, end_node):
reachable = [start_node]
explored = []
while reachable is not empty:
# Choose some node we know how to reach.
node = choose_node(reachable)
# If we just got to the goal node, build and return the path.
if node == goal_node:
return build_path(goal_node)
# Don't repeat ourselves.
reachable.remove(node)
explored.add(node)
# Where can we get from here that we haven't explored before?
new_reachable = get_adjacent_nodes(node) - explored
for adjacent in new_reachable:
# First time we see this node?
if adjacent not in reachable:
reachable.add(adjacent)
# If this is a new path, or a shorter path than what we have, keep it.
if node.cost + 1 < adjacent.cost:
adjacent.previous = node
adjacent.cost = node.cost + 1
# If we get here, no path was found :(
return None
Метод build_path:
function build_path (to_node):
path = []
while to_node != None:
path.add(to_node)
to_node = to_node.previous
return path
А вот метод choose_node, который превращает его в A*:
function choose_node (reachable):
min_cost = infinity
best_node = None
for node in reachable:
cost_start_to_node = node.cost
cost_node_to_goal = estimate_distance(node, goal_node)
total_cost = cost_start_to_node + cost_node_to_goal
if min_cost > total_cost:
min_cost = total_cost
best_node = node
return best_nodeВот и всё.
А зачем же нужна часть 4?
Теперь, когда вы поняли, как работает A*, я хочу рассказать о некоторых потрясающих областях его применения, которые далеко не ограничиваются поиском путей в сетке ячеек.
Часть 4. A* на практике
Первые три части статьи начинаются с самых основ алгоритмов поиска путей и заканчиваются чётким описанием алгоритма A*. Всё это здорово в теории, но понимание того, как это применимо на практике — совершенно другая тема.
Например, что будет, если наш мир не является сеткой?
Что если персонаж не может мгновенно поворачиваться на 90 градусов?
Как построить граф, если мир бесконечен?
Что если нас не волнует длина пути, но мы зависим от солнечной энергии и нам как можно больше нужно находиться под солнечным светом?
Как найти кратчайший путь к любому из двух конечных узлов?
Функция стоимости
В первых примерах мы искали кратчайший путь между начальным и конечным узлами. Однако вместо того, чтобы хранить частичные длины путей в переменной length, мы назвали её cost. Почему?
Мы можем заставить A* искать не только кратчайший, но и лучший путь, причём определение «лучшего» можно выбирать, исходя из наших целей. Когда нам нужен кратчайший путь, стоимостью является длина пути, но если мы хотим минимизировать, например, потребление топлива, то нужно использовать в качестве стоимости именно его. Если мы хотим по максимуму увеличить «время, проводимое под солнцем», то затраты — это время, проведённое без солнца. И так далее.
В общем случае это означает, что с каждым ребром графа связаны соответствующие затраты. В показанных выше примерах стоимость задавалась неявно и считалась всегда равной 1, потому что мы считали шаги на пути. Но мы можем изменить стоимость ребра в соответствии с тем, что мы хотим минимизировать.
Функция критерия
Допустим, наш объект — это автомобиль, и ему нужно добраться до заправки. Нас устроит любая заправка. Требуется кратчайший путь до ближайшей АЗС.
Наивный подход будет заключаться в вычислении кратчайшего пути до каждой заправки по очереди и выборе самого короткого. Это сработает, но будет довольно затратным процессом.
Что если бы мы могли заменить один goal_node на метод, который по заданному узлу может сообщить, является ли тот конечным или нет. Благодаря этому мы сможем искать несколько целей одновременно. Также нам нужно изменить эвристику, чтобы она возвращала минимальную оцениваемую стоимость всех возможных конечных узлов.
В зависимости от специфики ситуации мы можем и не иметь возможности достичь цели идеально, или это будет слишком много стоить (если мы отправляем персонажа через половину огромной карты, так ли важна разница в один дюйм?), поэтому метод is_goal_node может возвращать true, когда мы находимся «достаточно близко».
Полная определённость не обязательна
Представление мира в виде дискретной сетки может быть недостаточным для многих игр. Возьмём, например, шутер от первого лица или гоночную игру. Мир дискретен, но его нельзя представить в виде сетки.
Но есть проблема и посерьёзней: что если мир бесконечен? В таком случае, даже если мы сможем представить его в виде сетки, то у нас просто не будет возможности построить соответствующий сетке граф, потому что он должен быть бесконечным.
Однако не всё потеряно. Разумеется, для алгоритма поиска по графам нам определённо нужен граф. Но никто не говорил, что граф должен быть исчерпывающим!
Если внимательно посмотреть на алгоритм, то можно заметить, что мы ничего не делаем с графом, как целым; мы исследуем граф локально, получая узлы, которых можем достичь из рассматриваемого узла. Как видно из демо A*, некоторые узлы графа вообще не исследуются.
Так почему бы нам просто не строить граф в процессе исследования?
Мы делаем текущую позицию персонажа начальным узлом. При вызове get_adjacent_nodes она может определять возможные способы, которыми персонаж способен переместиться из данного узла, и создавать соседние узлы на лету.
За пределами трёх измерений
Даже если ваш мир действительно является 2D-сеткой, нужно учитывать и другие аспекты. Например, что если персонаж не может мгновенно поворачиваться на 90 или 180 градусов, как это обычно и бывает?
Состояние, представляемое каждым узлом поиска, не обязательно должно быть только позицией; напротив, оно может включать в себя произвольно сложное множество значений. Например, если повороты на 90 градусов занимают столько же времени, сколько переход из одной ячейки в другую, то состояние персонажа может задаваться как [position, heading]. Каждый узел может представлять не только позицию персонажа, но и направление его взгляда; и новые рёбра графа (явные или косвенные) отражают это.
Если вернуться к исходной сетке 5×5, то начальной позицией поиска теперь может быть [A, East]. Соседними узлами теперь являются [B, East] и [A, South] — если мы хотим достичь F, то сначала нужно скорректировать направление, чтобы путь обрёл вид [A, East], [A, South], [F, South].
Шутер от первого лица? Как минимум четыре измерения: [X, Y, Z, Heading]. Возможно, даже [X, Y, Z, Heading, Health, Ammo].
Учтите, что чем сложнее состояние, тем более сложной должна быть эвристическая функция. Сам по себе A* прост; искусство часто возникает благодаря хорошей эвристике.
Заключение
Цель этой статьи — раз и навсегда развеять миф о том, что A* — это некий мистический, не поддающийся расшифровке алгоритм. Напротив, я показал, что в нём нет ничего загадочного, и на самом деле его можно довольно просто вывести, начав с самого нуля.
Дальнейшее чтение
У Амита Патела есть превосходное «Введение в алгоритм A*» [перевод на Хабре] (и другие его статьи на разные темы тоже великолепны!).
%saved0% Граф — это (упрощенно) множество точек, называемых вершинами, соединенных какими-то линиями, называемыми рёбрами (необязательно все вершины соединены). Можно представлять себе как города, соединенные дорогами.
Любое клетчатое поле можно представить в виде графа. Вершинами будут являться клетки, а ребрами — смежные стороны клеток.
Наглядное представление о работе перечисленных далее алгоритмов можно получить благодаря визуализатору PathFinding.js.
Поиск в ширину (BFS, Breadth-First Search)
Алгоритм был разработан независимо Муром и Ли для разных приложений (поиск пути в лабиринте и разводка проводников соответственно) в 1959 и 1961 годах. Этот алгоритм можно сравнить с поджиганием соседних вершин графа: сначала мы зажигаем одну вершину (ту, из которой начинаем путь), а затем огонь за один элементарный промежуток времени перекидывается на все соседние с ней не горящие вершины. В последствие то же происходит со всеми подожженными вершинами. Таким образом, огонь распространяется «в ширину». В результате его работы будет найден кратчайший путь до нужной клетки.
Алгоритм Дейкстры (Dijkstra)
Этот алгоритм назван по имени создателя и был разработан в 1959 году. В процессе выполнения алгоритм проверит каждую из вершин графа, и найдет кратчайший путь до исходной вершины. Стандартная реализация работает на взвешенном графе — графе, у которого каждый путь имеет вес, т.е. «стоимость», которую надо будет «заплатить», чтобы перейти по этому ребру. При этом в стандартной реализации веса неотрицательны. На клетчатом поле вес каждого ребра графа принимается одинаковым (например, единицей).
А* (А «со звездочкой»)
Впервые описан в 1968 году Питером Хартом, Нильсом Нильсоном и Бертрамом Рафаэлем. Данный алгоритм является расширением алгоритма Дейкстры, ускорение работы достигается за счет эвристики — при рассмотрении каждой отдельной вершины переход делается в ту соседнюю вершину, предположительный путь из которой до искомой вершины самый короткий. При этом существует множество различных методов подсчета длины предполагаемого пути из вершины. Результатом работы также будет кратчайший путь. О реализации алгоритма читайте в здесь.
Поиск по первому наилучшему совпадению (Best-First Search)
Усовершенствованная версия алгоритма поиска в ширину, отличающаяся от оригинала тем, что в первую очередь развертываются узлы, путь из которых до конечной вершины предположительно короче. Т.е. за счет эвристики делает для BFS то же, что A* делает для алгоритма Дейкстры.
IDA* (A* с итеративным углублением)
Расшифровывается как Iterative Deeping A*. Является измененной версией A*, использующей меньше памяти за счет меньшего количества развертываемых узлов. Работает быстрее A* в случае удачного выбора эвристики. Результат работы — кратчайший путь.
Jump Point Search
Самый молодой из перечисленных алгоритмов был представлен в 2011 году. Представляет собой усовершенствованный A*. JPS ускоряет поиск пути, «перепрыгивая» многие места, которые должны быть просмотрены. В отличие от подобных алгоритмов JPS не требует предварительной обработки и дополнительных затрат памяти.
Материалы по более интересным алгоритмам мы обозревали в подборке материалов по продвинутым алгоритмам и структурам данных.
Когда вы пользуетесь навигатором, вы указываете точку А и точку Б, и дальше навигатор как-то сам строит маршрут. Сегодня посмотрим, что лежит в основе алгоритма, который это делает. Просто ради интереса.
Графы и «задача коммивояжёра»
Ещё до появления навигаторов у людей была такая же проблема: как найти кратчайший путь из одного места в другое, если есть ограниченное количество промежуточных точек? Или как объехать ограниченное количество точек, затратив минимальные усилия. В общем виде это называется «задачей коммивояжёра», и мы уже рассказывали, в чём там идея:
- есть несколько городов, и мы знаем расстояния между двумя любыми городами;
- в классической задаче нельзя дважды заезжать в один и тот же город, но в жизни — можно;
- если городов мало, то компьютер справится с задачей простым перебором, а если их больше 66 — то уже нет;
- кроме расстояния, иногда важно учесть время, комфорт и общую длительность поездки;
- есть много приблизительных алгоритмов, которые дают более-менее точный результат.
Если взять просто города и расстояния между ними, то с точки зрения математики это называется графом: города будут вершинами графа, а дороги между ними — рёбрами графа. Если мы знаем длину каждой дороги, то это будет значением (весом) рёбер графа. Этой теории нам уже хватит, чтобы понять, как работает навигатор в машине.

Алгоритм Дейкстры — ищем самый быстрый путь
Как только появилось решение полным перебором, математики стали искать другой подход, который работал бы гораздо быстрее и не требовал бы вычисления такого огромного объёма данных. В 1959 году Эдсгер Дейкстра придумал свой алгоритм, которым пользуются до сих пор. Идея его в том, чтобы не перебирать все варианты, а находить самый короткий путь только между соседними графами — и так, шаг за шагом, продвигаться к конечной точке.
Допустим, у нас есть улицы, перекрёстки и мы знаем время пути между ними. Нарисуем это в виде графа, а чтобы было проще ориентироваться — сделаем визуально всё одинаковой длины:

Чтобы найти самый быстрый путь из А в Б, мы смотрим сначала, какие пути у нас выходят из точки А. Видно, что поехать вниз будет быстрее, чем поехать направо:

Значит, выбираем путь вниз. Теперь делаем то же самое для этой точки — смотрим, где быстрее: справа или внизу. Вниз быстрее (1 меньше, чем 4), поэтому едем по ней:

При этом мы не отбрасываем уже сделанные вычисления (всё равно уже посчитали), а запоминаем их на всякий случай. Из нижней точки есть только одна дорога — направо, поэтому едем по ней:

А теперь у нас получилась интересная ситуация: в центральную точку мы можем попасть как сверху, так и снизу, при этом и там, и там у нас одинаковое время — 3 минуты. Значит, посчитаем оба варианта — вдруг сверху будет быстрее и нам нужно будет перестроить маршрут заново:

Оказывается, снизу ехать до центра быстрее, чем сверху — 4 минуты вместо 6, поэтому оставляем нижний маршрут. Наконец, из центральной точки до точки Б всего один путь — направо, поэтому выбираем его:

Как видите, нам не пришлось считать все варианты со всеми точками, а до некоторых мы просто не добрались. Это сильно сэкономило время и потребовало меньше ресурсов для вычисления.Такой алгоритм и лежит в основе автомобильных навигаторов — с вычислениями справится даже бюджетный смартфон.

Что ещё учитывает навигатор
Чтобы алгоритм оставался простым и работал только со временем, все остальные параметры дорог тоже привязывают ко времени. Покажем, как это работает, на паре примеров.
Комфорт. Если нам нужно построить не самый быстрый, а самый комфортный маршрут, то мы можем отдать предпочтение автомагистралям и дорогам с несколькими полосами — на них обычно и асфальт получше, и резких поворотов поменьше. Чтобы навигатор выбирал именно такие дороги, им можно присвоить коэффициент 0,8 — это виртуально сократит время на дорогу по ним на 20%, а навигатор всегда выберет то, что быстрее.
С просёлочными и грунтовыми дорогами ситуация обратная. Они редко бывают комфортными, а значит, им можно дать коэффициент 1,3, чтобы они казались алгоритму более долгими и он старался их избегать. А лесным дорогам можно поставить коэффициент 5 — навигатор их выберет, только если это единственная дорога то точки назначения.
Сложность маршрута и реальное время. Маршрут из А в Б почти никогда не бывает прямым — на нём всегда есть повороты, развороты и съезды, которые отнимают время. Чтобы навигатор это учитывал, в графы добавляют время прохождения поворота — либо коэффициентом, либо отдельным параметром. Из-за этого алгоритм будет искать действительно быстрый маршрут с учётом геометрии дорог.
Пробки. Если есть интернет, то всё просто: навигатор получает данные о состоянии дорог и добавляет разные коэффициенты в зависимости от загруженности. Иногда навигатор ведёт дворами, когда трасса свободна — это не ошибка навигатора, а его прогноз на время поездки: если через 10 минут в этом месте обычно собираются пробки, то там лучше не ехать, а заранее поехать в объезд.
Если интернета нет, то алгоритм просто использует усреднённую модель пробок на этом участке. Эта модель скачивается заранее и постоянно обновляется в фоновом режиме.
Как построить маршрут по всей России
Если нам нужно построить маршрут из Брянска в Тулу, то с точки зрения компьютера это безумно сложная задача: ему нужно перебрать десятки тысяч улиц и миллионы перекрёстков, чтобы понять, какой путь выбрать. С этим плохо справляется даже обычный компьютер, не говоря уже о телефоне.
Если мы в Яндекс Картах построим такой маршрут, то навигатор нам предложит сразу 4 варианта:

Но мы не ждали полчаса, пока сервер на той стороне посчитает все перекрёстки, а получили результат через пару секунд. Хитрость в том, что алгоритм использует уже заранее просчитанные варианты маршрутов и подставляет их для ускорения.
Например, если мы поедем в Тулу не из Брянска, а из Синезёрок, то поменяется только начальный маршрут по трассе М3, а всё остальное останется прежним:

Получается, что навигатору не нужно всё пересчитывать — он находит только ключевые точки пути, а маршрут между ними уже просчитан до этого. Этот приём работает и при перестроении маршрута во время движения: навигатор смотрит, как нужно поменять путь, чтобы вернуть вас на уже известную дорогу.
Что дальше
Следующий этап — напишем алгоритм Дейкстры сами и посмотрим, как он работает по шагам.
Вёрстка:
Кирилл Климентьев
Алгоритм поиска пути является основным кирпичиком, необходимым для создания A.I. (искусственный интеллект). и, с помощью различных заплаток, методом проб и ошибок, вы сможете сделать ваших персошажей чуточку умнее. Чтобы добраться до своей цели им, возможно, придется прогуляться через препятствия, найти свой путь в подземных лабиринтах или на улицах города. Но этого не достаточно и, в конечном итоге, они прибудут в пункт назначения каким-нибудь удручающе кружным путем, хотя маршрут должен быть максимально коротким.
Решение этой проблемы не является тривиальной задачей, но это стоит усилий. Пользователи, играющие в вашу игру, поймут, что юниты действуют разумно и смогут сосредоточиться на стратегии и тактике не няньчась с тупым AI.
Стандартный метод, который используется в большинстве игр называется A*, или “A-Star“.
Происхождение алгоритма поиска пути
В пятидесятые годы математик Эдсгер Дейкстра разработал метод для расчета оптимальных маршрутов, которые могут быть применены к любой гипотетической ситуации, требующей автоматизированный выбор между многими возможными шагами.
Он часто используется в примере грузовиков, идущих из одного места до другого. Выбор наиболее короткого маршрута приведет к большей прибыли.

Приведенная выше анимация является типичным примером работы этого алгоритма. Обратите внимание, что каждый узел установлен на игровом поле хаотично. Это идеальный пример того, что мы хотим сделать: мы складываем «издержки» каждого маршрута чтобы найти самый невыгодный маршрут.
Если вы смотрите на приведенный выше анимированный рисунок, вы увидите, что каждый раз, когда мы приходим к новому узлу, мы складываем расходы и, таким образом, находим наиболее затратный.
Проблема с алгоритмом Дейкстра
Алгоритм Дейкстра прекрасно работает, но имеет недостаток – он не использует никаких эвристических методов для выбора наиболее вероятных кандидатов, поэтому решение известно только после того, как будет проверены все варианты.

В приведенном выше анимированном изображении вы можете увидеть, что каждая “клетка” или “узел” проходит проверку. В конечном итоге, мы получаем требуемый результат, но программист, живущий в вас, наверняка, думает, “нужна оптимизация!”
Алгоритм A-star спешит на помощь!
A-star является более быстрым и эффективным вариантом алгоритма Дейкстра. Он находит наилучший путь от одного узла к другому узлу.
Иными словами, A-star пересекает узел графа (набор точек в пространстве, соединенных между собой) и находит путь, который менее затратен (самый короткий) не исследуя при этом все узлы графа. В случае с видеоигрой узлом графа является игровой мир, та карта, по которой перемещаются наши юниты.

В приведенном выше анимированном изображении показан тот же игровой мир, что бы рассмотрен для алгоритма Дейкстра, но на этот раз мы видим, что проверяется меньшее количество узлов. В результате наша функция поиска оптимального маршрута работает быстрее, а это очень важно в играх!
Всегда есть место для оптимизации
Чем более оптимизирован этот алгоритм, тем чаще мы можем наверняка угадать с оптимальным направлением, не вдаваясь в подробные расчеты. Приписывая значение узлам, пройденным на нашем пути, мы можем предсказать, в каком направлении двигаться дальше.
Под этим я подразумеваю, что с помощью более тонкого анализа мы можем предсказать в каком направлении лучше всего двигаться и попробовать его в первую очередь.

В приведенном выше анимированном изображении мы видим очень эффективный пример звездочного алгоритма, который пытается угадать оптимальный маршрут вместо начинать с нуля каждый раз, когда движение заблокировано. Более сложная геометрия все только запутает, но в общей сложности вам должно быть понятно, что выгодно придерживаться этого способа.
Это именно то, что требуется враждебному AI в большинстве игр: найти кратчайший маршрут из точки А в точку Б и как можно быстрее!
Не пугайтесь всей этой математики!
Прежде чем с головой нырнуть в захватывающий мир алгоритмов или (что еще хуже) разбить компьютер в приступе бешенства, вызванном безграничностью его математических возможностей, успокойте себя мыслью о том, что совсем скоро вы узнаете о функциях, которые сделают всю работу за вас.
Они пересекут граф (список древовидной структуры данных, являющийся картой вашего игрового мира) и добавят затратности (в форме пройденного расстояния) многим возможным маршрутам. Наименее затратный маршрут будет кратчайшим путем из точки А в точку В.
Функция, о которой я собираюсь рассказать, просто поможет нам определить массив координат x и y, являющийся кратчайшим путем к месту назначения. Звучит просто, не так ли?
Наглядная демонстрация
Перед тем, как написать алгоритм поиска пути, мы должны получить наглядное представление о нашем игровом мире. Ваш мир может быть гораздо сложнее представленного здесь, но, если вы используете HTML5 Canvas для создания своей игры, вам будет легко его модифицировать.
Мы постараемся сделать все как можно проще и создадим самый примитивный случайный мир, применив список спрайтов к холсту HTML5.
Спрайты
По этой упрощенной демонстрации работы игрового алгоритма, нам нужно всего несколько изображений. Вместо нескольких крошечных файлов, все они объединены в один, для ускорения загрузки. Нам нужна плитка со свободными участками (трава), плитка с заблокированными областями (валуны) и плитки, обозначающие начало, конец пути и траекторию движения.
Вот пример спрайта, с помощью которого будет нарисован наш игровой мир:
![]()
HTML файл
Начнем с кодирования! Для начала мы создадим базовую страницу HTML5, которое не содержит ничего, кроме этикетки, холста, и кнопку, которая будет генерировать новый случайный мир. Проще некуда.
<!doctype html>
<html>
<title>A-STAR алгоритм поиска пути для HTML5 Canvas</title>
<style>
body { padding:0; margin:0; height:100%; width:100%; }
div { font-family:arial; font-size:16px; font-weight:bold; text-align:center; }
</style>
<script type='text/javascript' src='astar-pathfinding-canvas.js'></script>
</head>
<body onload='onload()'>
<section>
<header>
Генератор игрового мира
</header>
<input type='button' onClick='createWorld()' value='New World'>
<canvas id="gameCanvas"></canvas>
</section>
</body>
</html>
Файл Javascript
Вот и все, что нам нужно в HTML файле. Остальная часть этого урока проходит в написании JavaScript. В файле, который мы назовем astar-pathfinding-canvas.js, напишем следующее:
// элемент игры - холст
var canvas = null;
// определяет тип контекста - 2d
var ctx = null;
// изображение со спрайтами
var spritesheet = null;
// true когда спрайт загрузится
var spritesheetLoaded = false;
// массив для игрового мира
var world = ;
// размер игрового мира (16 плиток)
var worldWidth = 16;
var worldHeight = 16;
// Размер плитки в пикселях
var tileWidth = 32;
var tileHeight = 32;
// начало и конец пути
var pathStart = [worldWidth,worldHeight];
var pathEnd = [0,0];
var currentPath = [];
// проверяем есть ли ошибки
if (typeof console == "undefined") var console = { log: function() {} };
В приведенном выше коде мы определяем переменные, необходимые для хранения данных для нашего игрового мира и ссылки на наш холст. Переменная world – двумерный массив (массив заполняется с массивами).
Таким образом, вы можете хранить данные в виде world[x][y]=значение;, где значение – индекс плитки используемой в данном месте.
Мы также определяем размер нашего мира и данные маршрута, которые будут меняться в ходе демонстрации A-star.
Наконец, мы добавляем чуть-чуть кода для проверки поддерживает ли данный браузер консоль для отладки. В случае успешной проверки, мы сможем добавлять отладочные записи журнала, которые выводятся во время выполнения программы.
Следующий шаг состоит в обработке содержимого функции onload() как только страница будет загружена.
Запуск
// Когда html страница загружена
function onload()
{
console.log('Страница загружена.');
canvas = document.getElementById('gameCanvas');
canvas.width = worldWidth * tileWidth;
canvas.height = worldHeight * tileHeight;
canvas.addEventListener("click", canvasClick, false);
ctx = canvas.getContext("2d");
spritesheet = new Image();
spritesheet.src = 'spritesheet.png';
spritesheet.onload = loaded;
}
Функция onload() подхватает ссылку на холст в нашем HTML файле, делает его равным нашему игровому миру, и начинает отлавливать щелчки мыши на холсте. Мы также загрузили наш файл со спрайтами spritesheet.png. Следующим шагом является создание навигации в нашем сказочном мире.
// файл с картинками загружен
function loaded()
{
console.log('Спрайты загружены.');
spritesheetLoaded = true;
createWorld();
}
// генерация ландшафта
function createWorld()
{
console.log('Создание мира...');
// создать пустоши
for (var x=0; x < worldWidth; x++)
{
world[x] = [];
for (var y=0; y < worldHeight; y++)
{
world[x][y] = 0;
}
}
// расставляем скалы случайным образом
for (var x=0; x < worldWidth; x++)
{
for (var y=0; y < worldHeight; y++)
{
if (Math.random() > 0.75)
world[x][y] = 1;
}
}
// рассчитать первоначальный возможный путь
// зы: маловероятно, но возможно, мы его не найдем))...
currentPath = [];
while (currentPath.length == 0)
{
pathStart = [Math.floor(Math.random()*worldWidth),Math.floor(Math.random()*worldHeight)];
pathEnd = [Math.floor(Math.random()*worldWidth),Math.floor(Math.random()*worldHeight)];
if (world[pathStart[0]][pathStart[1]] == 0)
currentPath = findPath(world,pathStart,pathEnd,'Manhattan');
}
redraw();
}
В приведенном выше коде запускалась функция обратного вызова в функции onload() когда spritesheet.png был загружен и готов к использованию. После этого мы сразу же приступали к созданию нашего игрового мира, запустив функцию createWorld.
Первоначально для каждой системы координат х и у координат мы установили значение массива world равным нулю (нулевому значению соответствует трава).
После того, как мы создаем бескрайние равнины, мы расставляем несколько валунов случайным образом, чтобы создать препятствия для нашего бесстрашного искателя приключений.
Наконец, выберем две случайные места на карте, соответствующие начальной и конечной точки маршрута, и рассчитаем алгоритм A-star, который очень скоро увидим в действии. Если маршрут недоступен, мы будем пробовать другие, пока не получим хорошую начальную конфигурацию.
Усовершенствованный генератор ландшафта
Естественно, вы можете разработать гораздо более интересный генератор ландшафта, чем этот. Вы можете использовать шум Перлина или Генератор псевдослучайных чисел для детерминировонного ландшафта с использованием случайных значений.
Вместо того, чтобы случайно расставлять предметы вокруг, вы могли бы использовать клеточные автоматы (cellular automata) для создания ячеек одинаковой местности, чтобы деревья складывались в лес, а скалы и просеки – в горы и долины.
Это невероятно увлекательно и, если вы хотите поупражняться в искусстве создания случайных ландшафтов, изучение таких аспектов, как генератор подземелий roguelike, процедурный ландшафт и создание случайных карт откроет перед вами поистине неограниченные возможности.
Отображение игрового мира
Следующим шагом, после того как мы заполнили массив world, нужно вывести его содержание на экран.
function redraw()
{
if (!spritesheetLoaded) return;
console.log('redrawing...');
var spriteNum = 0;
// очистить экран
ctx.fillStyle = '#000000';
ctx.fillRect(0, 0, canvas.width, canvas.height);
for (var x=0; x < worldWidth; x++)
{
for (var y=0; y < worldHeight; y++)
{
// выбираем область спрайта для рисования
switch(world[x][y])
{
case 1:
spriteNum = 1;
break;
default:
spriteNum = 0;
break;
}
// рисуем с помощью:
// ctx.drawImage(img,sx,sy,swidth,sheight,x,y,width,height);
ctx.drawImage(spritesheet,
spriteNum*tileWidth, 0,
tileWidth, tileHeight,
x*tileWidth, y*tileHeight,
tileWidth, tileHeight);
}
}
// рисуем маршрут
console.log('Длима текущего маршрута: '+currentPath.length);
for (rp=0; rp<currentPath.length; rp++)
{
switch(rp)
{
case 0:
spriteNum = 2; // начало пути
break;
case currentPath.length-1:
spriteNum = 3; // конец пути
break;
default:
spriteNum = 4; // маршрут
break;
}
ctx.drawImage(spritesheet,
spriteNum*tileWidth, 0,
tileWidth, tileHeight,
currentPath[rp][0]*tileWidth,
currentPath[rp][1]*tileHeight,
tileWidth, tileHeight);
}
}
В приведенном выше коде мы просто перебираем массив world и используем 2d функцию DrawImage для рисования на холсте путем копирования пикселей из нашего спрайта.
Следующий шаг – создать маршрут, нарисовав дополнительные спрайты для каждой координаты x и y, хранящихся в массиве currentPath, который мы вычислили перед этим.
Наш мир на данном этапе
Вот то, что мы с вами сделали – упрощенный генератор местности. Трава, по которой ваши персонажи могут ходить, и большие валуны, которые встретятся им на пути. Это хороший пример для демонстрации работы поиска оптимального пути.
Нажмите кнопку New World несколько раз, чтобы увидеть наш генератор местности в действии. Заметьте, что в примере выше прокомментирован код, использованный для A-star, поэтому здесь не может быть никаких ошибок, касающихся отсутствия нижеперечисленных функций.
Взаимодействие с пользователем
Теперь, когда у нас есть игровой мир, мы должны добавить некоторую интерактивность. Нам нужно отслеживать событие щелчка мыши по плитке на холсте. Для этого мы должы сначала определить, где в HTML-холст находится, а затем какая плитка на этом холсте находится под курсором мыши. Для простоты, каждый клик будет обозначать следующую точку нашего маршрута для нашего алгоритма поиска пути. Предыдущая конечная точка, следовательно, будет новой точкой отсчета.
// обработка события щелчка мыши на холсте
function canvasClick(e)
{
var x;
var y;
// определяем координаты курсора относительно
//левого верхнего угла браузера
if (e.pageX != undefined && e.pageY != undefined)
{
x = e.pageX;
y = e.pageY;
}
else
{
x = e.clientX + document.body.scrollLeft +
document.documentElement.scrollLeft;
y = e.clientY + document.body.scrollTop +
document.documentElement.scrollTop;
}
// определяем координаты курсора относительно холста
x -= canvas.offsetLeft;
y -= canvas.offsetTop;
// return tile x,y that we clicked
var cell =
[
Math.floor(x/tileWidth),
Math.floor(y/tileHeight)
];
// теперь мы знаем на какую плитку мы нажали
console.log('we clicked tile '+cell[0]+','+cell[1]);
pathStart = pathEnd;
pathEnd = cell;
// рассчитать путь
currentPath = findPath(world,pathStart,pathEnd);
redraw();
}
Процедура выше определяет координаты курсора мыши относительно верхнего левого угла браузера и переводит их в координаты относительно холста, так как холст может располагаться где угодно на странице. Как только мы получим координаты точки, на которую нажали кнопкой мыши, мы разделим ее на размер плитки и таким образом узнаем на какую плитку в массиве world мы нажали.
Теперь, когда конечное положение предыдущего хода стало начальным положением следующего, запустим алгоритм A-star еще раз. Таким образом, в результате каждого клика маршрут пролегает из одной точки в другую – это похоже на передвижение юнитов в стратегиях, которое происходит не поступательно, а последовательно.
Теперь, когда у нас есть генератор игрового мира, функции рендеринга и взаимодействия с пользователем, пришел черед сделать последний шаг и написать функцию поиска пути.
A-star алгоритм
Мы собираемся создать одну большую функцию под названием FindPath (). Чтобы не захламлять код игры и позволить вам легко редактировать алгоритм из этого учебника и использовать его в своей игре, все функции, которые потребует этот алгоритм будут вложены в него. Просто, но эффективно.
В альтернативных методах функции могут находиться в разных областях, а также могут использоваться фабрика класса или одинарный объект, но нет ничего проще, чем копипаст.
Если вам нужен алгоритм поиска пути A-star, который не зависит от другого кода и существует в виде единого блока кода, не затрагивающего глобальное пространство имен какими-либо временными переменными, вам понравится этот метод. Просто копируйте и вставляйте
Поскольку мы используем этот способ, все фрагменты кода действуют внутри одной функции. Мы просто разобьем весь код на логические части – весь алгоритм состоит из 250 строк. Начнем с того, определим функцию и параметры, которые должны ей передаваться, а именно:
// world - 2d массив целых чисел (eg world[10][15] = 0)
// pathStart и pathEnd массивы, например [5,10]
function findPath(world, pathStart, pathEnd)
{
// упростим запись
var abs = Math.abs;
var max = Math.max;
var pow = Math.pow;
var sqrt = Math.sqrt;
// Данные мира представляют собой целочисленные переменные:
// Все значения, превышающие эту цифру, блокируются.
// Это удобно, если вы используете пронумерованные спрайты.
// Ходить можно по дороге, траве, грязи и т.д.
var maxWalkableTileNum = 0;
// Отслеживаем размер массива world
// Обратите внимание, что A* предполагает, что наш мир квадратный,
// то есть имеет равную высоту и ширину. Если ваш игровой мир
// прямоугольный, просто заполните массив world фиктивными значениями,
// чтобы дополнить пустое пространство.
var worldWidth = world[0].length;
var worldHeight = world.length;
var worldSize = worldWidth * worldHeight;
// Какой эвристический анализ мы используем?
// по умолчанию: не ходим по диагонали (Манхэттен)
var distanceFunction = ManhattanDistance;
var findNeighbours = function(){}; // пока пусто
/*
// альтернативные эвристические методы в зависимости от вашей игры:
// можно ходить по диагонали, но не через трещины в скалах:
var distanceFunction = DiagonalDistance;
var findNeighbours = DiagonalNeighbours;
// ходьба по диагонали и через трещины в скалах допускаются:
var distanceFunction = DiagonalDistance;
var findNeighbours = DiagonalNeighboursFree;
// Евклидово расстояние, проход через трещины не возможен:
var distanceFunction = EuclideanDistance;
var findNeighbours = DiagonalNeighbours;
// Евклидово расстояние, проход через трещины возможен:
var distanceFunction = EuclideanDistance;
var findNeighbours = DiagonalNeighboursFree;
*/
В приведенном выше коде, вы можете увидеть, что мы опрашиваем двумерный массив чисел, которые является ссылкой на вашу карту в игре. Он использует тот же формат, что и массив карты мира в генераторе местности (см. код выше), поэтому мы можем просто обратиться к нему без изменений. Остальные два параметра, – начальный и конечный пункт назначения в нашем мире, формируются в виде массива из координат х и у.
Первые несколько строк ускорят наши вычисления, сохраняя ссылки на часто используемые Math – функции. Это достаточно простая оптимизация, которая делает код немного меньше.
Теперь мы определим номер плитки самого большого массива игрового мира, по которому смогут перемещаться ваши персонажи. В нашем примере – это только трава (плитка номер ноль), но в реальной игре можно разнообразить число плиток, например: земля или улица, стена или мост…
Наконец, мы добавим пару ссылок на функции, о которых поговорим ниже, когда будем рассчитывать расстояния. Какие из них мы будем использовать, зависит от того, как алгоритм поиска пути будет вести себя по отношению к диагоналям и углам заблокированных плиток. Просто поменяйте функции distanceFunction и findNeighbours на те, которые вам нужны, как показано в прокомментированных примерах.
Расчет расстояния – Какой эвристический алгоритм использовать?
Прежде чем начать сравнивать плитки карты, необходимо решить, какую эвристику использовать. В нашем уроке, мы особо не заморачивались и позволили персонажу двигаться только вдоль четырех сторон света (север, юг, восток и запад).
Вычисление расстояний этим способом называется манхэттеновское расстояние – в честь решетчатой структуры некоторых районов Нью-Йорка. Есть несколько способов вычислить расстояния на основе диагоналей.
Первый – просто назвать перемещение по диагонали 1 space, с той же затратностью, что и движение NSEW, которое в коде фигурирует как DiagonalDistance. Еще один, более правильный способ измерения диагональных расстояний между плитками называется EuclideanDistance. Он основан на использовании теоремы Пифагора для измерения настоящего расстояния, которое примерно в 1,4 раза больше, чем между соседями NSEW.
Однако, если вашы юниты не могут двигаться по диагонали, вы определенно должны измерять расстояние с помощью метода Манхэттен. В любом случае, выбор за вами.

Изображение выше показывает разницу между этими двумя метожами. Зеленая линия – Евклидово расстояние (примерно 8,5 единиц), а все остальные – расстояния, полученные с помощью метода Манхэттен (всего 12 единиц).
Функция расстояния
Продолжая разговор о коде findPath, давайте рассмотрим все возможные функции расстояния, которые могут вам понадобиться. Для вашей игры вам нужна только одна.
// функции distanceFunction
// возвращают расстояние между точками
function ManhattanDistance(Point, Goal) {
// линейное перемещение – никаких диагоналей,
// просто ориентация по сторонам света (NSEW)
return abs(Point.x - Goal.x) + abs(Point.y - Goal.y);
}
function DiagonalDistance(Point, Goal) {
// движение по диагонали – диагональное расстояние
// приравнивается к 1, как и стороны света
return max(abs(Point.x - Goal.x), abs(Point.y - Goal.y));
}
function EuclideanDistance(Point, Goal) {
// диагональное расстояние немного увеличивается по сравнению со сторонами света
// движение по диагонали вычисляя Евклидово расстояние (AC = sqrt(AB^2 + BC^2))
// когда AB = x2 - x1 и BC = y2 - y1 и AC будет [x3, y3]
return sqrt(pow(Point.x - Goal.x, 2) + pow(Point.y - Goal.y, 2));
}
Свободно перемещение по диагонали или нет?
Дополнительные функции также включены в код для перемещения по диагонали независимо от того, считаете ли вы приемлемым перемещение сквозь щели между двумя прилегающими плитками, расположенными по диагонали друг к другу
Для каждого типа эвристики перемещений существует два варианта кода: FREE и стандартный (без суффикса).
Как правило, если два блока прилегают друг к другу по диагонали, точка, в которой соприкасаются два угла, недостаточно широка, чтобы через нее можно было пройти. Использование FREE вариации кода позволит вашим юнитам протиснуться через крошечные щели между двумя стенами.

На этой картинке зеленые стрелочки показывают, что мы имеем в виду под FREE диагоналями. Если вы МОЖЕТЕ пройти в щель между двумя красными блоками, эвристика, используемая вами для перемещения по диагонали, должна соответствовать одной из FREE вариаций. Если нет, используйте один из стандартных способов
Что в соседней плитке?
Теперь создадим функции, определяющие, какие соседи у каждого узла.
Это зависит от того, как настроены перемещения по диагонали: если вы не собираетесь использовать FREE передвижение, вам не надо включать в код приставку FREE.
Продолжим код внутри функции FindPath. Добавьте следующие строки:
// Функции поиска соседних клеток, используются функцией
// findNeighbours для определения прилегающих незаблокированных клеток.
// Возвращает все доступные на севере, юге, востоке или западе ячейки.
// Диагонали отсутствуют, если функция distanceFunction
// не является манхэттоновским расстоянием
function Neighbours(x, y)
{
var N = y - 1,
S = y + 1,
E = x + 1,
W = x - 1,
myN = N > -1 && canWalkHere(x, N),
myS = S < worldHeight && canWalkHere(x, S),
myE = E < worldWidth && canWalkHere(E, y),
myW = W > -1 && canWalkHere(W, y),
result = [];
if(myN)
result.push({x:x, y:N});
if(myE)
result.push({x:E, y:y});
if(myS)
result.push({x:x, y:S});
if(myW)
result.push({x:W, y:y});
findNeighbours(myN, myS, myE, myW, N, S, E, W, result);
return result;
}
// Возвращает все доступные на северо-востоке, юго-востоке
// северо-западе и юго-западе ячейки – отсутствие свободного
// перемещения по диагонали
function DiagonalNeighbours(myN, myS, myE, myW, N, S, E, W, result)
{
if(myN)
{
if(myE && canWalkHere(E, N))
result.push({x:E, y:N});
if(myW && canWalkHere(W, N))
result.push({x:W, y:N});
}
if(myS)
{
if(myE && canWalkHere(E, S))
result.push({x:E, y:S});
if(myW && canWalkHere(W, S))
result.push({x:W, y:S});
}
}
// Возвращает все доступные на северо-востоке, юго-востоке
// северо-западе и юго-западе ячейки – включая перемещение по диагонали
// между углами прилегающих квадратов
function DiagonalNeighboursFree(myN, myS, myE, myW, N, S, E, W, result)
{
myN = N > -1;
myS = S < worldHeight;
myE = E < worldWidth;
myW = W > -1;
if(myE)
{
if(myN && canWalkHere(E, N))
result.push({x:E, y:N});
if(myS && canWalkHere(E, S))
result.push({x:E, y:S});
}
if(myW)
{
if(myN && canWalkHere(W, N))
result.push({x:W, y:N});
if(myS && canWalkHere(W, S))
result.push({x:W, y:S});
}
}
Можно ли ходить по данной плитке?
Теперь мы готовы создать вспомогательные функцию для окончательного алгоритма A-star. Для начала – простая функция, определяющая проходимость того или иного узла.
// возвращает логическое значение
// (клетка мира открыта для перемещения)
function canWalkHere(x, y)
{
return ((world[x] != null) &&
(world[x][y] != null) &&
(world[x][y] <= maxWalkableTileNum));
};
В приведенном выше коде, мы создали простое условие, проверяющее существование индекса массива world. Если индекс существует, мы проверяем, чтобы число, которое хранится там, было меньше или равно максимальному индексу плитки, по которой можно ходить (мы определили его в самом начале).
Сохранение расходов на движение во время поиска пути
Далее, нам необходимо создать временные объекты, которые используются для хранения затрат на передвижение и сокращают индексы массива во время обработки.
Описанный ниже алгоритм A-star создаст списки этих узлов, которые составляются путем пересечения всех маршрутов, проверенных нами по пути.
// Функция узла, возвращает новый объект
// со свойствами узла. Используется функцией calculatePath
// для хранения затрат на маршруты и т.д.
function Node(Parent, Point) {
var newNode = {
// указывает на другой объект узла
Parent:Parent,
// индекс массива узла в линейном массиве мира
value:Point.x + (Point.y * worldWidth),
// координаты расположения узла
x:Point.x,
y:Point.y,
// затратность distanceFunction при перемещении
// к этому узлу от НАЧАЛА
f:0,
// затратность distanceFunction при перемещении
// от этого узла к МЕСТУ НАЗНАЧЕНИЯ
g:0
};
return newNode;
}
Объекты узлов формируют список с указателями , поскольку каждый ссылается на родительский узел. Здесь также содержатся координаты x и y, расстояния между начальной и конечной точками и индексы массивов, которые используются для ускорения вычислений.
Рождение A-Star
И наконец, сам алгоритм A-star. Это последний блок в нашей функции findPath().
// функция маршрута, выполняет операции AStar
function calculatePath() {
// создает узлы на основе начальных и конечных координат x и y
var mypathStart = Node(null, {x:pathStart[0], y:pathStart[1]});
var mypathEnd = Node(null, {x:pathEnd[0], y:pathEnd[1]});
// создать массив, который будет содержать все клетки игрового мира
var AStar = new Array(worldSize);
// список открытых узлов
var Open = [mypathStart];
// список закрытых узлов
var Closed = [];
// список конечного массива для вывода
var result = [];
// ссылка на узел (находящийся поблизости)
var myNeighbours;
// ссылка на узел (который мы рассматриваем в данное время)
var myNode;
// ссылка на узел (лежащий в начале текущего маршрута)
var myPath;
// изменяем целочисленные переменные, используемые при расчете
var length, max, min, i, j;
// прокладываем маршруты через открытый список, пока не задействуем все узлы
while(length = Open.length) {
max = worldSize;
min = -1;
for(i = 0; i < length; i++) {
if(Open[i].f < max) {
max = Open[i].f;
min = i;
}
}
// берем следующий узел и удаляем его из открытого массива
myNode = Open.splice(min, 1)[0];
// это узел назначения?
if(myNode.value === mypathEnd.value) {
myPath = Closed[Closed.push(myNode) - 1];
do {
result.push([myPath.x, myPath.y]);
}
while (myPath = myPath.Parent);
// очистить рабочие массивы
AStar = Closed = Open = [];
// мы хотим сделать конечную точку началом маршрута
result.reverse();
}
else // не пункт назначения
{
// определите, какие узлы, находящиеся поблизости, являются проходимыми
myNeighbours = Neighbours(myNode.x, myNode.y);
// протестируйте каждый узел, который вы еще не пробовали
for(i = 0, j = myNeighbours.length; i < j; i++) {
myPath = Node(myNode, myNeighbours[i]);
if (!AStar[myPath.value]) {
// приблизительная затратность маршрута на данном этапе
myPath.g = myNode.g + distanceFunction(myNeighbours[i], myNode);
// приблизительная затратность всего
// предполагаемого маршрута до точки назначения
myPath.f = myPath.g + distanceFunction(myNeighbours[i], mypathEnd);
// запомним этот новый маршрут, чтобы протестировать его, как описано выше
Open.push(myPath);
// отметим этот узел в графе мира как посещенный
AStar[myPath.value] = true;
}
}
// запомним этот маршрут как полностью протестированный
Closed.push(myNode);
}
} // продолжаем прокладывать маршруты, пока не исчерпаем весь открытый список
return result;
}
Вы можете следовать этому алгоритму вместе со всеми комментариями. По сути, мы наполняем несколько списков с указателями объектами узлов, содержащих данные карты мира и место для хранения расстояний по ходу маршрута.
Заметьте, что в данном примере A-star используется квадратный мир с одинаковой шириной и длиной. Если вы хотите создать прямоугольный мир, просто заполните массив фиктивными значениями, чтобы заполнить пустое пространство.
Как написано в главе, посвященной оптимизации, сначала мы ищем маршруты, которые кажутся кратчайшими путями к цели. Мы продолжаем помещать узлы в каждый из массивов в зависимости от длины маршрута, по которому мы можем туда попасть. Исчерпав открытый список, мы получаем наименее затратный путь, который сохраняется в конечном массиве и готов к конечному выводу.
Начиная с первого узла, который является начальной точкой, предписанной функцией findPath, мы используем список узлов, которые нужно проверить.
Это открытый массив. Закрытый список (содержащий проверенные узлы) используется для повышения эффективности поиска.
Мы также учитываем пройденное расстояние; свойство узла g соответствует затратности пути от начальной точки, а свойство f – это значение g плюс эвристические затраты от данной точки до точки назначения.
Чем ниже свойство f, тем выше приоритет узла. На каждом этапе узел с наименьшим значением f удаляется из списка, значения f и g соседних узлов обновляются, и эти соседи добавляются в список и могут быть включены в маршрут.
Так продолжается, пока узел назначения не станет узлом с наименьшим значением f в очереди (или пока очередь не опустеет).
Этот алгоритм мог бы украсить любую магистерскую работу по программированию. Не расстраивайтесь, если это кажется немного запутанным и сложным. Зато теперь вы можете использовать эту функцию в вашей собственной игре и пожинать плоды высшей математики. Стоя на плечах гиганта, так сказать.
Теперь, когда мы создали несколько встроенных функций в алгоритме findPath(), we мы можем запустить A-star и применить результаты к нашей игре.
// рассчитывает маршрут a-star
// возвращает массив координат
// остается пустым, если нет возможного маршрута
return calculatePath();
} // конец функции findPath()
Теперь, когда мы хотим, чтобы персонаж в нашей в игре перемещался по местности, мы просто вызываем FindPath () и передаем в массив world координаты начальной и конечной точки маршрута.
Пример того, как эта функция должна быть вызвана находится в функции canvasClick выше. В принципе, вы просто сделать так currentPath = findPath(world,pathStart,pathEnd) и получите массив c координатами ([х, у]).
В реальном сценарии игры, вы можете ограничить расстояние, пройденное каждый ход. Например, в тактической игре вы можете позволить игроку переместиться только на шесть клеток за ход. Это можно сделать просто останавливая движение на полпути, используя только первые несколько значений массива.
Окончательный результат
Посмотрим на наш код в действии. Нажмите по карте и обратите внимание как рассчитывается кратчайший путь (если его возможно рассчитать). Представьте себе возможности для вашей будующей стратегической, тактической игры, или головоломки!
Вот и все! Вы можете не тратить время на копипастинг всего кода от каждого отдельного раздела этого учебника, а скачать полный код.
Практический пример
В качестве примера, вы можете увидеть как работает наш код в реальных играх. Уверен, это будет интересно тем, кто захочет применить A-star алгоритм в своих играх, поэтому хочу вам представить логическую игру, в которой как раз используется код из этого учебника. Она называется “Пафос” и я приглашаю вас поиграть в нее.
Наш урок закончен. Простые AI движения добавят в вашу игру элемент стратегического мышления, юниты, способные найти путь к цели, и другие интересные возможности для стратегий, тактических игр и головоломок.
Удачи вам в ваших будущих игровых проектах. Вам все по-плечу!
From Wikipedia, the free encyclopedia
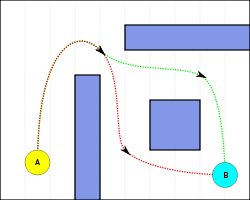
Equivalent paths between A and B in a 2D environment
Pathfinding or pathing is the plotting, by a computer application, of the shortest route between two points. It is a more practical variant on solving mazes. This field of research is based heavily on Dijkstra’s algorithm for finding the shortest path on a weighted graph.
Pathfinding is closely related to the shortest path problem, within graph theory, which examines how to identify the path that best meets some criteria (shortest, cheapest, fastest, etc) between two points in a large network.
Algorithms[edit]
At its core, a pathfinding method searches a graph by starting at one vertex and exploring adjacent nodes until the destination node is reached, generally with the intent of finding the cheapest route. Although graph searching methods such as a breadth-first search would find a route if given enough time, other methods, which “explore” the graph, would tend to reach the destination sooner. An analogy would be a person walking across a room; rather than examining every possible route in advance, the person would generally walk in the direction of the destination and only deviate from the path to avoid an obstruction, and make deviations as minor as possible.
Two primary problems of pathfinding are (1) to find a path between two nodes in a graph; and (2) the shortest path problem—to find the optimal shortest path. Basic algorithms such as breadth-first and depth-first search address the first problem by exhausting all possibilities; starting from the given node, they iterate over all potential paths until they reach the destination node. These algorithms run in 
The more complicated problem is finding the optimal path. The exhaustive approach in this case is known as the Bellman–Ford algorithm, which yields a time complexity of 

The above algorithms are among the best general algorithms which operate on a graph without preprocessing. However, in practical travel-routing systems, even better time complexities can be attained by algorithms which can pre-process the graph to attain better performance.[2] One such algorithm is contraction hierarchies.
Dijkstra’s algorithm[edit]
A common example of a graph-based pathfinding algorithm is Dijkstra’s algorithm. This algorithm begins with a start node and an “open set” of candidate nodes. At each step, the node in the open set with the lowest distance from the start is examined. The node is marked “closed”, and all nodes adjacent to it are added to the open set if they have not already been examined. This process repeats until a path to the destination has been found. Since the lowest distance nodes are examined first, the first time the destination is found, the path to it will be the shortest path.[3]
Dijkstra’s algorithm fails if there is a negative edge weight. In the hypothetical situation where Nodes A, B, and C form a connected undirected graph with edges AB = 3, AC = 4, and BC = −2, the optimal path from A to C costs 1, and the optimal path from A to B costs 2. Dijkstra’s Algorithm starting from A will first examine B, as that is the closest. It will assign a cost of 3 to it, and mark it closed, meaning that its cost will never be reevaluated. Therefore, Dijkstra’s cannot evaluate negative edge weights. However, since for many practical purposes there will never be a negative edgeweight, Dijkstra’s algorithm is largely suitable for the purpose of pathfinding.
A* algorithm[edit]
A* is a variant of Dijkstra’s algorithm commonly used in games. A* assigns a weight to each open node equal to the weight of the edge to that node plus the approximate distance between that node and the finish. This approximate distance is found by the heuristic, and represents a minimum possible distance between that node and the end. This allows it to eliminate longer paths once an initial path is found. If there is a path of length x between the start and finish, and the minimum distance between a node and the finish is greater than x, that node need not be examined.[4]
A* uses this heuristic to improve on the behavior relative to Dijkstra’s algorithm. When the heuristic evaluates to zero, A* is equivalent to Dijkstra’s algorithm. As the heuristic estimate increases and gets closer to the true distance, A* continues to find optimal paths, but runs faster (by virtue of examining fewer nodes). When the value of the heuristic is exactly the true distance, A* examines the fewest nodes. (However, it is generally impractical to write a heuristic function that always computes the true distance, as the same comparison result can often be reached using simpler calculations – for example, using Chebyshev distance over Euclidean distance in two-dimensional space.) As the value of the heuristic increases, A* examines fewer nodes but no longer guarantees an optimal path. In many applications (such as video games) this is acceptable and even desirable, in order to keep the algorithm running quickly.
RIPA algorithm[edit]
This is claimed to be the simplest and fastest of all pathfinding methods using nodes that branch out from central corridor ‘A’ to other connected Paths.
It can still calculate the optimal path without using any distance checks at all.
How it does this is by having pre-configured Paths from A to Z as it spreads out away from central corridor ‘A’.
If a final path cannot be reached mid way then will find its last connecting path at ‘A’.
At each step is checked from the start to the end as well as from the end to the start until a final connection can be made.
Its like driving from your street to a closer main road that gets to the highway until you exit the highway to the next main road and then the final street.
Paths can be from B to Z (after the central A) with 1,000 path nodes for each Path although can be expanded as necessary.
Each path node should be coded numerically in order for each path (ie B1, B2,B3 etc descending or ascending).
Written by Robert Codell in JavaScript but can be easily converted into other languages.
Open paths must be inserted into 2 arrays – one for fast check path points (ie AB or BD) and the other to record the actual node names to output later.
Runs very fast as very simply logic yet very functional.
Sample algorithm[edit]
This is a fairly simple and easy-to-understand pathfinding algorithm for tile-based maps. To start off, you have a map, a start coordinate and a destination coordinate. The map will look like this, X being walls, S being the start, O being the finish and _ being open spaces, the numbers along the top and right edges are the column and row numbers:
1 2 3 4 5 6 7 8 X X X X X X X X X X X _ _ _ X X _ X _ X 1 X _ X _ _ X _ _ _ X 2 X S X X _ _ _ X _ X 3 X _ X _ _ X _ _ _ X 4 X _ _ _ X X _ X _ X 5 X _ X _ _ X _ X _ X 6 X _ X X _ _ _ X _ X 7 X _ _ O _ X _ _ _ X 8 X X X X X X X X X X
First, create a list of coordinates, which we will use as a queue. The queue will be initialized with one coordinate, the end coordinate. Each coordinate will also have a counter variable attached (the purpose of this will soon become evident). Thus, the queue starts off as ((3,8,0)).
Then, go through every element in the queue, including new elements added to the end over the course of the algorithm, and for each element, do the following:
- Create a list of the four adjacent cells, with a counter variable of the current element’s counter variable + 1 (in our example, the four cells are ((2,8,1),(3,7,1),(4,8,1),(3,9,1)))
- Check all cells in each list for the following two conditions:
- If the cell is a wall, remove it from the list
- If there is an element in the main list with the same coordinate, remove it from the cells list
- Add all remaining cells in the list to the end of the main list
- Go to the next item in the list
Thus, after turn 1, the list of elements is this: ((3,8,0),(2,8,1),(4,8,1))
- After 2 turns: ((3,8,0),(2,8,1),(4,8,1),(1,8,2),(4,7,2))
- After 3 turns: (…(1,7,3),(4,6,3),(5,7,3))
- After 4 turns: (…(1,6,4),(3,6,4),(6,7,4))
- After 5 turns: (…(1,5,5),(3,5,5),(6,6,5),(6,8,5))
- After 6 turns: (…(1,4,6),(2,5,6),(3,4,6),(6,5,6),(7,8,6))
- After 7 turns: (…(1,3,7)) – problem solved, end this stage of the algorithm – note that if you have multiple units chasing the same target (as in many games – the finish to start approach of the algorithm is intended to make this easier), you can continue until the entire map is taken up, all units are reached or a set counter limit is reached
Now, map the counters onto the map, getting this:
1 2 3 4 5 6 7 8 X X X X X X X X X X X _ _ _ X X _ X _ X 1 X _ X _ _ X _ _ _ X 2 X S X X _ _ _ X _ X 3 X 6 X 6 _ X _ _ _ X 4 X 5 6 5 X X 6 X _ X 5 X 4 X 4 3 X 5 X _ X 6 X 3 X X 2 3 4 X _ X 7 X 2 1 0 1 X 5 6 _ X 8 X X X X X X X X X X
Now, start at S (7) and go to the nearby cell with the lowest number (unchecked cells cannot be moved to). The path traced is (1,3,7) -> (1,4,6) -> (1,5,5) -> (1,6,4) -> (1,7,3) -> (1,8,2) -> (2,8,1) -> (3,8,0). In the event that two numbers are equally low (for example, if S was at (2,5)), pick a random direction – the lengths are the same. The algorithm is now complete.
In video games[edit]
|
This section needs expansion. You can help by adding to it. (January 2017) |
Chris Crawford in 1982 described how he “expended a great deal of time” trying to solve a problem with pathfinding in Tanktics, in which computer tanks became trapped on land within U-shaped lakes. “After much wasted effort I discovered a better solution: delete U-shaped lakes from the map”, he said.[5]
Hierarchical path finding[edit]

Quadtrees can be used for hierarchical path finding
The idea was first described by the video game industry, which had a need for planning in large maps with a low amount of CPU time. The concept of using abstraction and heuristics is older and was first mentioned under the name ABSTRIPS (Abstraction-Based STRIPS)[6] which was used to efficiently search the state spaces of logic games.[7] A similar technique are navigation meshes (navmesh), which are used for geometrical planning in games and multimodal transportation planning which is utilized in travelling salesman problems with more than one transport vehicle.
A map is separated into clusters. On the high-level layer, the path between the clusters is planned. After the plan was found, a second path is planned within a cluster on the lower level.[8] That means, the planning is done in two steps which is a guided local search in the original space. The advantage is, that the number of nodes is smaller and the algorithm performs very well. The disadvantage is, that a hierarchical pathplanner is difficult to implement.[9]
Example[edit]
A map has a size of 3000×2000 nodes. Planning a path on a node base would take very long. Even an efficient algorithm will need to compute many possible graphs. The reason is, that such a map would contain 6 million nodes overall and the possibilities to explore the geometrical space are exceedingly large. The first step for a hierarchical path planner is to divide the map into smaller sub-maps. Each cluster has a size of 300×200 nodes. The number of clusters overall is 10×10=100. In the newly created graph the amount of nodes is small, it is possible to navigate between the 100 clusters, but not within the detailed map. If a valid path was found in the high-level-graph the next step is to plan the path within each cluster. The submap has 300×200 nodes which can be handled by a normal A* pathplanner easily.
Algorithms used in pathfinding[edit]
- Dijkstra’s algorithm
- A* search algorithm, a special case of the Dijkstra’s algorithm
- D* a family of incremental heuristic search algorithms for problems in which constraints vary over time or are not completely known when the agent first plans its path
- Any-angle path planning algorithms, a family of algorithms for planning paths that are not restricted to move along the edges in the search graph, designed to be able to take on any angle and thus find shorter and straighter paths
Multi-agent pathfinding[edit]
Multi-agent pathfinding is to find the paths for multiple agents from their current locations to their target locations without colliding with each other, while at the same time optimizing a cost function, such as the sum of the path lengths of all agents. It is a generalization of pathfinding. Many multi-agent pathfinding algorithms are generalized from A*, or based on reduction to other well studied problems such as integer linear programming.[10] However, such algorithms are typically incomplete; in other words, not proven to produce a solution within polynomial time. A different category of algorithms sacrifice optimality for performance by either making use of known navigation patterns (such as traffic flow) or the topology of the problem space.[11]
See also[edit]
- Motion planning
- Any-angle path planning
References[edit]
- ^ “7.2.1 Single Source Shortest Paths Problem: Dijkstra’s Algorithm”. Archived from the original on 2016-03-04. Retrieved 2012-05-18.
- ^ Delling, D.; Sanders, P.; Schultes, D.; Wagner, D. (2009). “Engineering route planning algorithms”. Algorithmics of Large and Complex Networks: Design, Analysis, and Simulation. Lecture Notes in Computer Science. Vol. 5515. Springer. pp. 117–139. CiteSeerX 10.1.1.164.8916. doi:10.1007/978-3-642-02094-0_7. ISBN 978-3-642-02093-3.
- ^ “5.7.1 Dijkstra Algorithm”.
- ^ “Introduction to A* Pathfinding”.
- ^ Crawford, Chris (December 1982). “Design Techniques and Ideas for Computer Games”. BYTE. p. 96. Retrieved 19 October 2013.
- ^ Sacerdoti, Earl D (1974). “Planning in a hierarchy of abstraction spaces” (PDF). Artificial Intelligence. 5 (2): 115–135. doi:10.1016/0004-3702(74)90026-5.
- ^ Holte, Robert C and Perez, MB and Zimmer, RM and MacDonald, AJ (1995). Hierarchical a*. Symposium on Abstraction, Reformulation, and Approximation.
{{cite conference}}: CS1 maint: multiple names: authors list (link) - ^ Pelechano, Nuria and Fuentes, Carlos (2016). “Hierarchical path-finding for Navigation Meshes (HNA⁎)” (PDF). Computers & Graphics. 59: 68–78. doi:10.1016/j.cag.2016.05.023. hdl:2117/98738.
{{cite journal}}: CS1 maint: multiple names: authors list (link) - ^ Botea, Adi and Muller, Martin and Schaeffer, Jonathan (2004). “Near optimal hierarchical path-finding”. Journal of Game Development. 1: 7–28. CiteSeerX 10.1.1.479.4675.
{{cite journal}}: CS1 maint: multiple names: authors list (link) - ^ Hang Ma, Sven Koenig, Nora Ayanian, Liron Cohen, Wolfgang Hoenig, T. K. Satish Kumar, Tansel Uras, Hong Xu, Craig Tovey, and Guni Sharon. Overview: generalizations of multi-agent path finding to real-world scenarios. In the 25th International Joint Conference on Artificial Intelligence (IJCAI) Workshop on Multi-Agent Path Finding. 2016.
- ^ Khorshid, Mokhtar (2011). “A Polynomial-Time Algorithm for Non-Optimal Multi-Agent Pathfinding”. SOCS.
External links[edit]
- https://melikpehlivanov.github.io/AlgorithmVisualizer
- http://sourceforge.net/projects/argorha
- StraightEdge Open Source Java 2D path finding (using A*) and lighting project. Includes applet demos.
- python-pathfinding Open Source Python 2D path finding (using Dijkstra’s Algorithm) and lighting project.
- Daedalus Lib Open Source. Daedalus Lib manages fully dynamic triangulated 2D environment modeling and pathfinding through A* and funnel algorithms.
