Edit me
| Шаг 1. Описание ресурса | > | Шаг 2. Конечные точки и методы | > | Шаг 3. Параметры | > | Шаг 4. Пример запроса | > | Шаг 5. Пример и схема ответа |
Пример запроса включает в себя запрос с использованием конечной точки, показывающий некоторые настроенные параметры. Пример запроса обычно не показывает все возможные конфигурации параметров, но он должен быть максимально насыщенным параметрами.
Примеры запросов может содержать фрагменты кода, которые показывают один и тот же запрос на разных языках (помимо curl). Запросы, показанные на других языках программирования, являются необязательными (но при их наличии, пользователи приветствуют их).
Примеры запросов
Пример ниже показывает пример запроса Callfire API
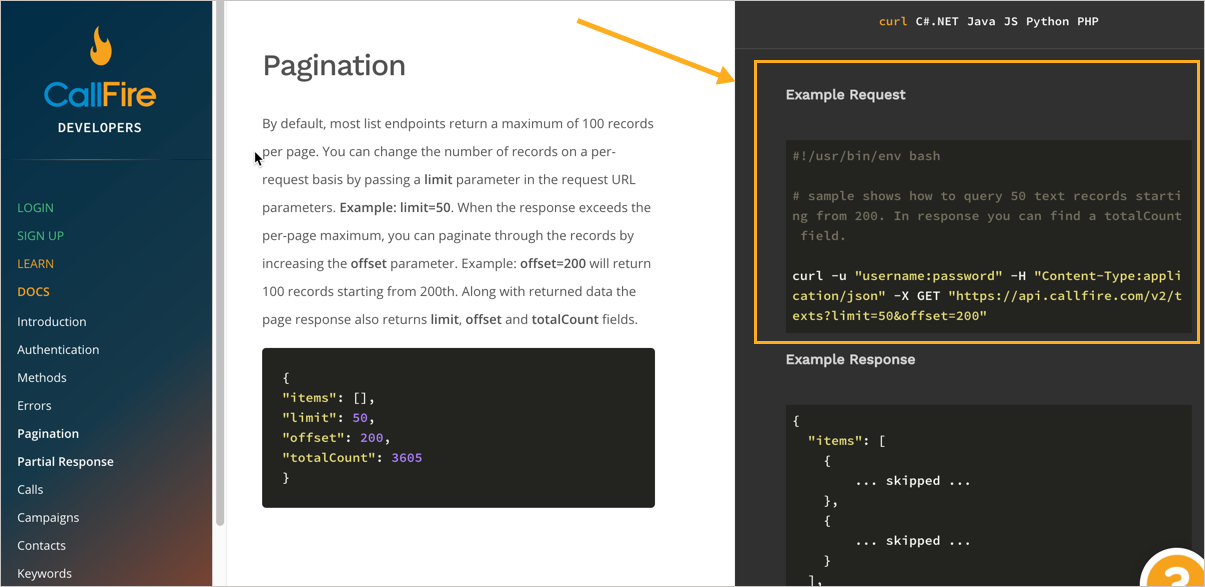
Дизайн этого сайта API задуман таким образом, что примеры запросов и ответов размещаются в правом столбце страницы. Запрос отформатирован в curl, который мы рассмотрели ранее в разделе Создание curl запроса.
curl -u "username:password" -H "Content-Type:application/json" -X GET "https://api.callfire.com/v2/texts?limit=50&offset=200"
curl – это обычный формат для отображения запросов по нескольким причинам:
- curl не зависит от языка, поэтому он не относится к какому-либо конкретному языку программирования;
- curl показывает информацию заголовка, необходимую в запросе;
- curl показывает метод, используемый в запросе.
В общем, чтобы показать пример запроса, используйте curl. Вот еще один пример запроса curl в Parse API:

Можно добавить обратную косую черту в curl, чтобы разделить каждый параметр на отдельной строке (хотя, как оговаривалось раньше, в Windows возникают проблемы с обратной косой чертой ).
Бывает и так, что сайты документации API могут использовать полный URL-адрес ресурса, например, этот простой пример из Twitter:
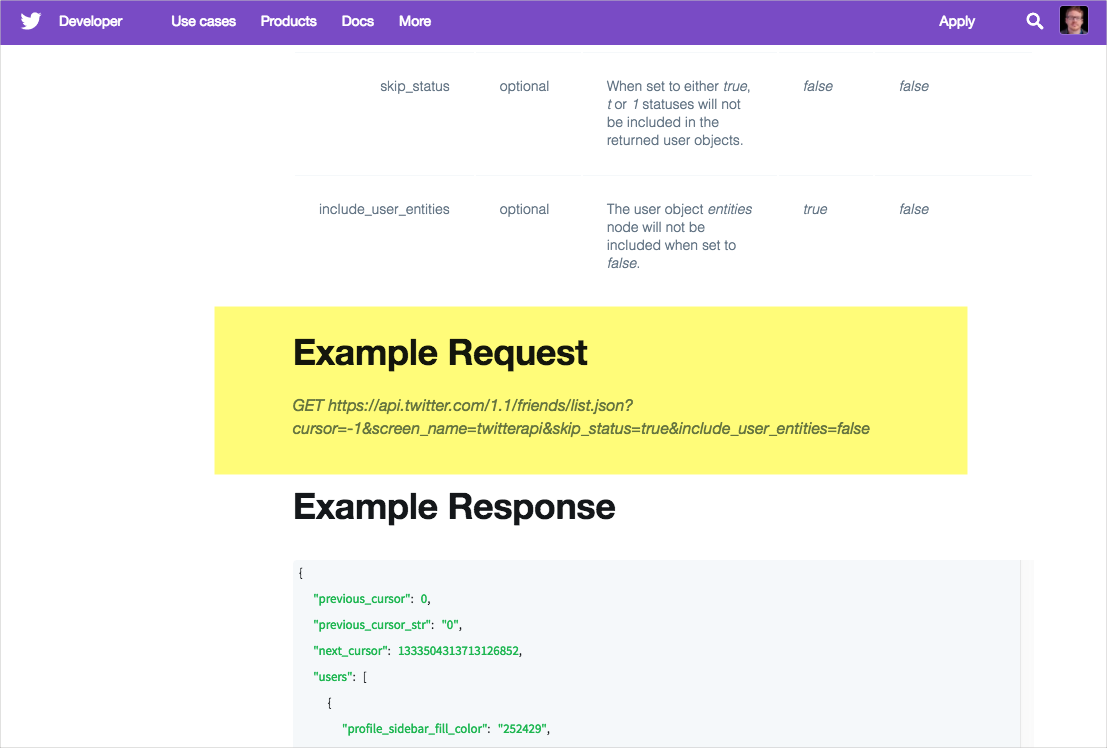
URL ресурса включает в себя как базовый путь, так и конечную точку. Проблема с отображением полного URL ресурса состоит в том, что он не указывает, нужно ли передавать какую-либо информацию заголовка для авторизации запроса. (Если ваш API состоит только из запросов GET и не требует авторизации, отлично, но только немногие API настроены таким образом.) Запросы curl могут легко отображать любые параметры заголовка.
Множественные примеры запросов
Если имеется много параметров, можно попробовать включить несколько примеров запросов. В API CityGrid Places конечная точка where выглядит следующим образом:
https://api.citygridmedia.com/content/places/v2/search/where
Однако есть буквально 17 возможных параметров строки запроса, которые можно использовать с этой конечной точкой. В результате документация включает несколько примеров запросов, которые показывают различные комбинации параметров:

Добавление множественных примеров запросов имеет смысл, когда параметры обычно не используются вместе. Например, есть несколько случаев, когда можно фактически включить все 17 параметров в один и тот же запрос, поэтому любой пример будет ограничен в том, что он может показать.
В этом примере показано, как «Найти отели в Бостоне, просматривая результаты с 1 по 5 страницы в алфавитном порядке»:
https://api.citygridmedia.com/content/places/v2/search/where?what=hotels&where=boston,ma&page=1&rpp=5&sort=alpha&publisher=test&format=json
Если кликнуть по ссылке, то увидим ответ. В следующем разделе есть описание динамического отображении ответа, когда пользователь нажимает на запрос.
Сколько разных запросов и ответов нужно показать? Вероятно, это не простой ответ, но, не более, чем несколько. Нам решать, что нужно для нашего API. Пользователи обычно вникнут в шаблон после нескольких примеров.
Запросы на разных языках
Как было сказано ранее в разделе Что такое REST API? REST API не зависит от языка. Универсальный протокол помогает облегчить широкое распространение для разных языков программирования. Разработчики могут кодировать свои приложения на любом языке, от Java до Ruby, JavaScript, Python, C #, Node JS или каком-либо еще. Пока разработчики могут отправлять HTTP-запросы на своем языке, они могут использовать API. Ответ от веб-запроса будет содержать данные в формате JSON или XML.
Поскольку невозможно знать, на каком языке будут писать конечные пользователи, попытка предоставить примеры кода на каждом языке бесполезна. Многие API просто показывают формат для отправки запросов и пример ответа, и авторы предполагают, что разработчики будут знать, как отправлять HTTP-запросы на своем конкретном языке программирования.
Однако некоторые API отображают простые запросы на разных языках. Вот пример из Twilio:
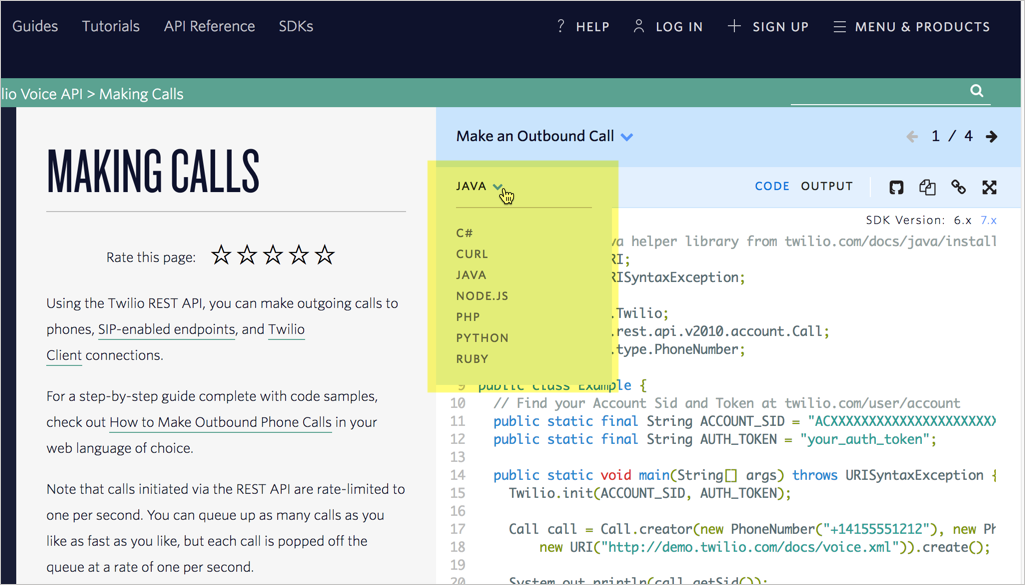
в выпадающем списке можно выбрать, какой язык использовать для примера запроса: C #, curl, Java, Node.js, PHP, Python или Ruby.
Вот еще пример API от Clearbit:
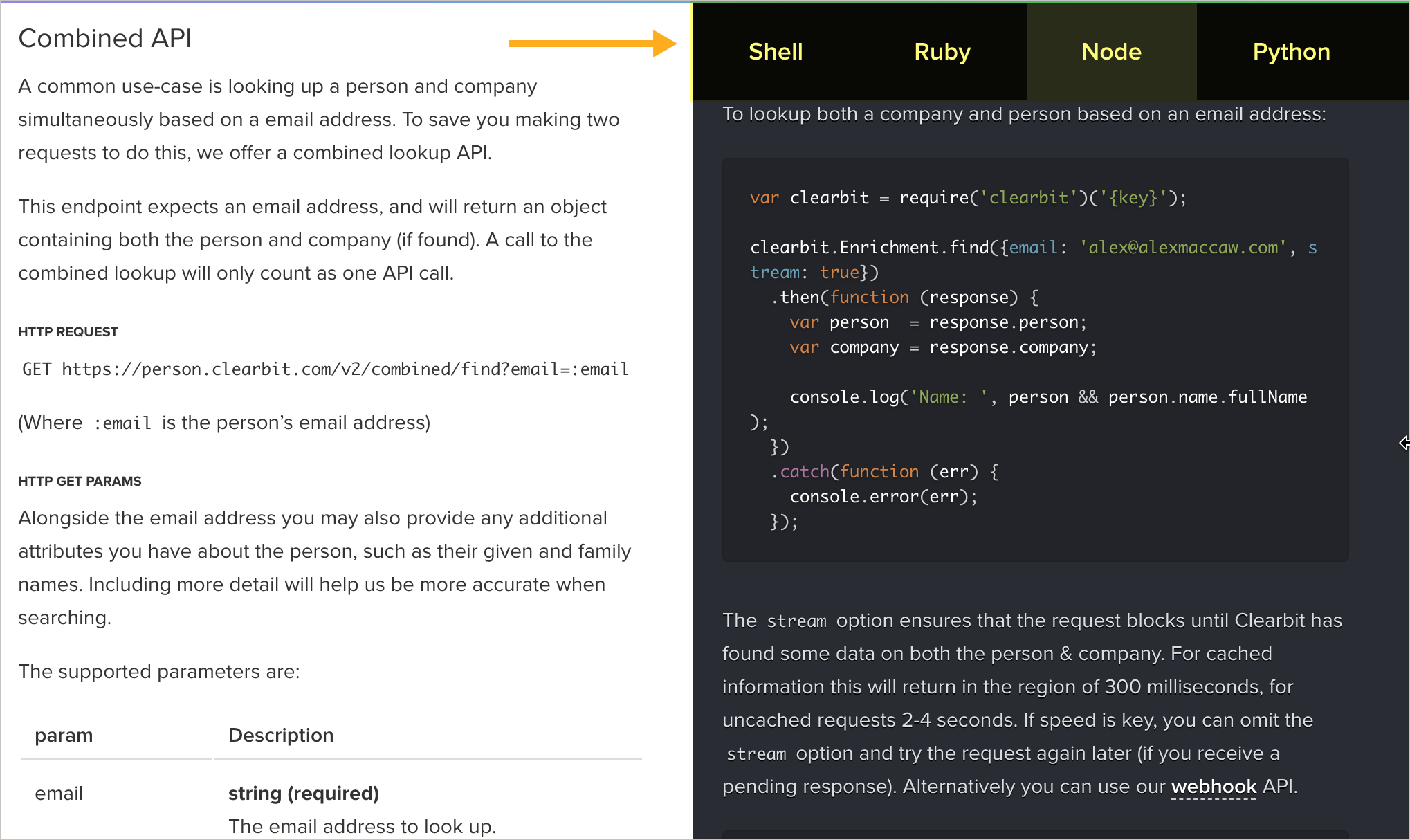
Можно увидеть запрос в Shell (curl), Ruby, Node или Python. Разработчики могут легко скопировать необходимый код в свои приложения, вместо того чтобы выяснить, как заставить запрос curl перевести на определенный язык программирования.
Предоставление различных запросов, подобных этому, часто отображаемых на вкладках, помогает упростить реализацию API. Еще лучше, если есть возможность автоматически заполнять ключи API фактическими пользовательскими ключами API на основе их авторизованного профиля.
Но нас не испугает этот шведский стол с примерами кода. Некоторые инструментальные средства API (такие как Readme.io или SwaggerHub) могут автоматически генерировать эти примеры кода, поскольку паттерны выполнения запросов REST на разных языках программирования следуют общему шаблону.
Авто генерация примеров кода
Если технический писатель не пользуется инструментом с функцией автоматической генерации примера кода, но предоставить эти фрагменты кода необходимо, то можно автоматически генерировать примеры кода из Postman и Paw.
Paw (на MacOS) позволяет экспортировать запрос практически на все мыслимые языки:
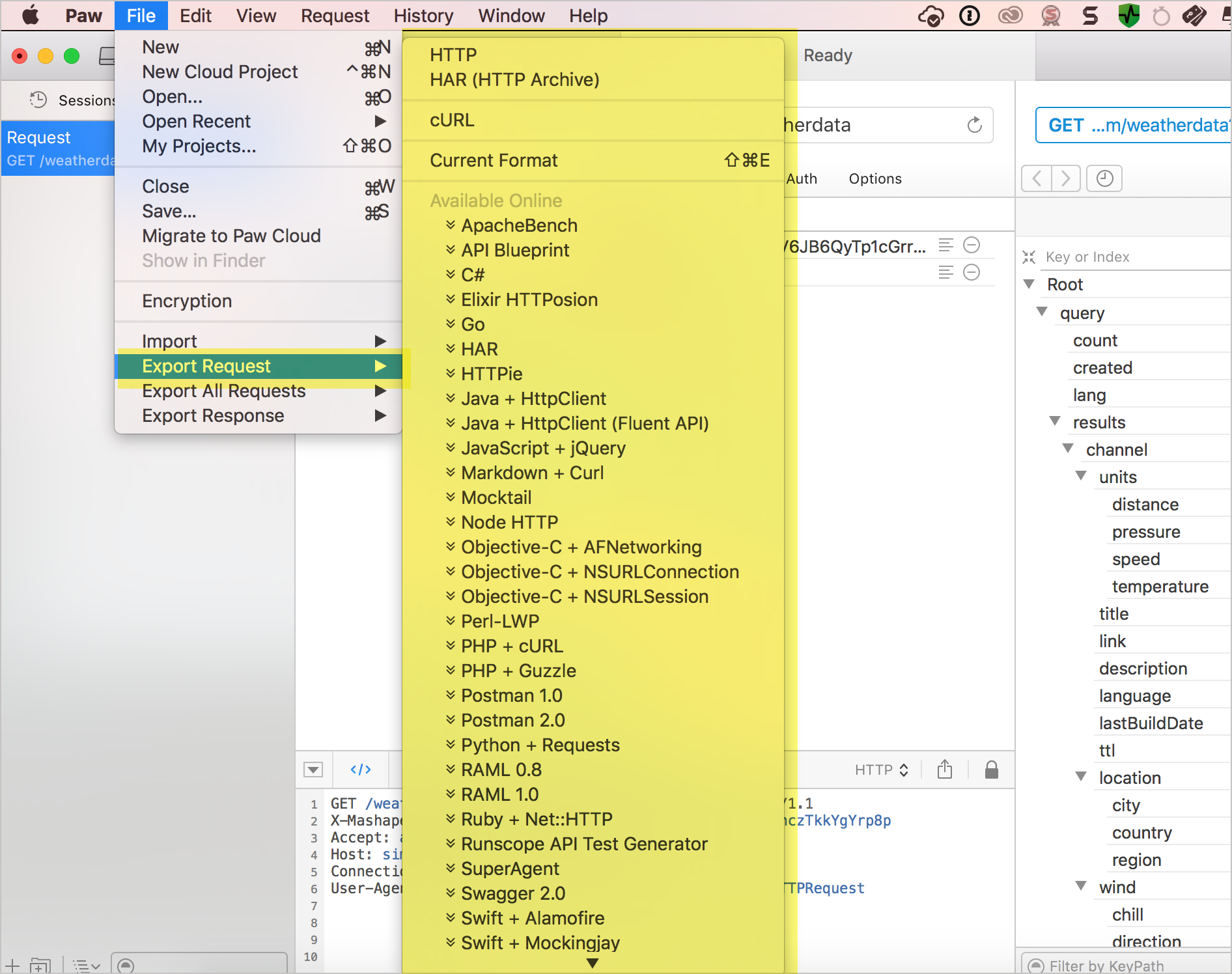
После того, как мы сконфигурировали запрос (процесс похож на Postman), можно сгенерировать фрагмент кода, выбрав Файл> Экспорт запроса.
Приложение Postman также может генерировать фрагменты кода аналогичным образом. Мы рассмотрели этот процесс раннее в разделе Изучение полезных данных JSON ответа. В Postman после конфигурации запроса, кликаем ссылку Code (которая появляется под кнопкой «Сохранить» в правом верхнем углу).
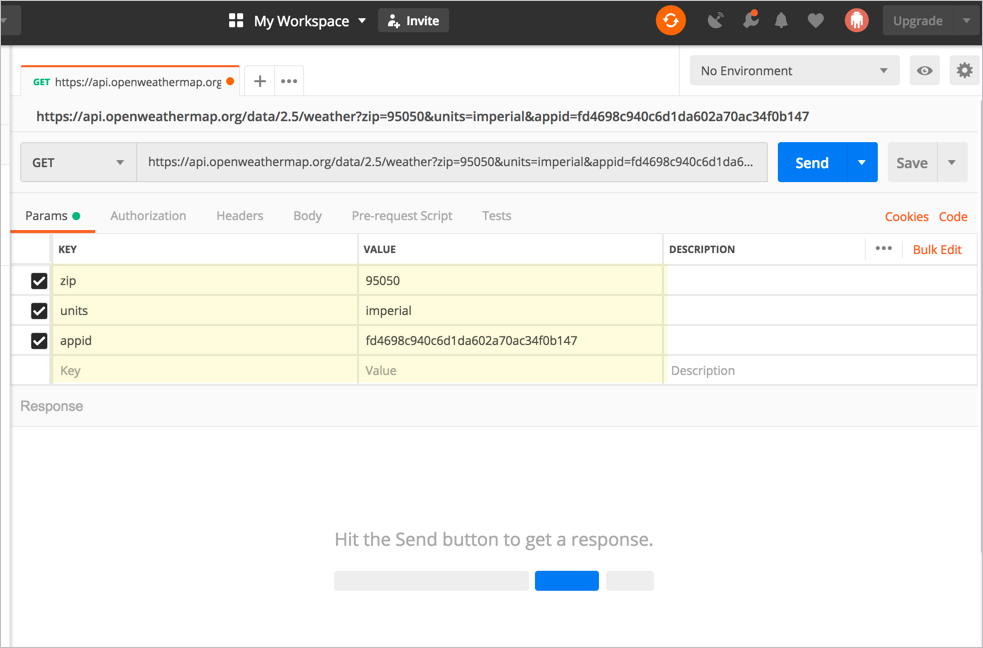
Затем выбираем нужный язык, например JavaScript> Jquery AJAX:
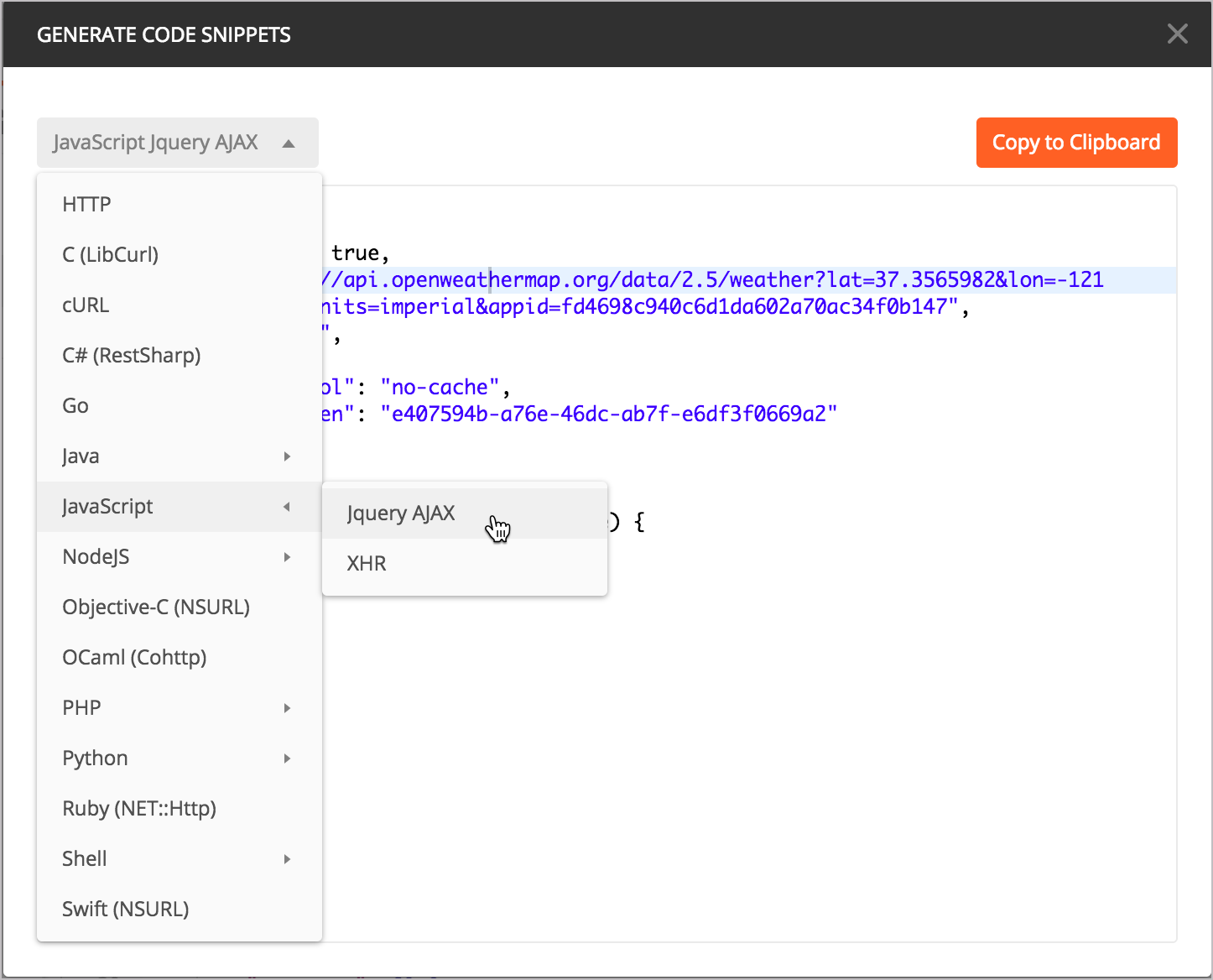
(Для практики, включающей использование сгенерированного кода jQuery из Postman, открываем разделы Изучение полезных данных JSON ответа и Доступ и вывод на страницу определенного значения JSON.)
SDK представляют инструменты для API
Часто разработчики создают SDK (комплект разработки программного обеспечения), который сопровождает REST API. SDK помогает разработчикам реализовать API с помощью специальных инструментов. API не зависят от языка, SDK зависит от языка.
Например, в одной компании был и REST API, и JavaScript SDK. Поскольку JavaScript был целевым языком, над которым работали разработчики, компания разработала SDK JavaScript, чтобы упростить работу с REST с использованием JavaScript. Стало возможным отправлять вызовы REST через JavaScript SDK, передавая ряд параметров, относящихся к веб-дизайнерам.
SDK по сути, это любой инструмент, облегчающий работу с API. Обычно компании предоставляют независимый от языка REST API, а затем разрабатывают SDK, который облегчает реализацию API на том основном языке, на котором они ожидают, что пользователи будут реализовывать API. Таким образом, добавлять в свои примеры запросов небольшие фрагменты запросов на других языках не так страшно, так как SDK обеспечивает более простую реализацию. Если у вас есть SDK, вы захотите сделать более подробные примеры кода, показывающие, как использовать SDK.
API explorer обеспечивает интерактивность с нашими собственными данными
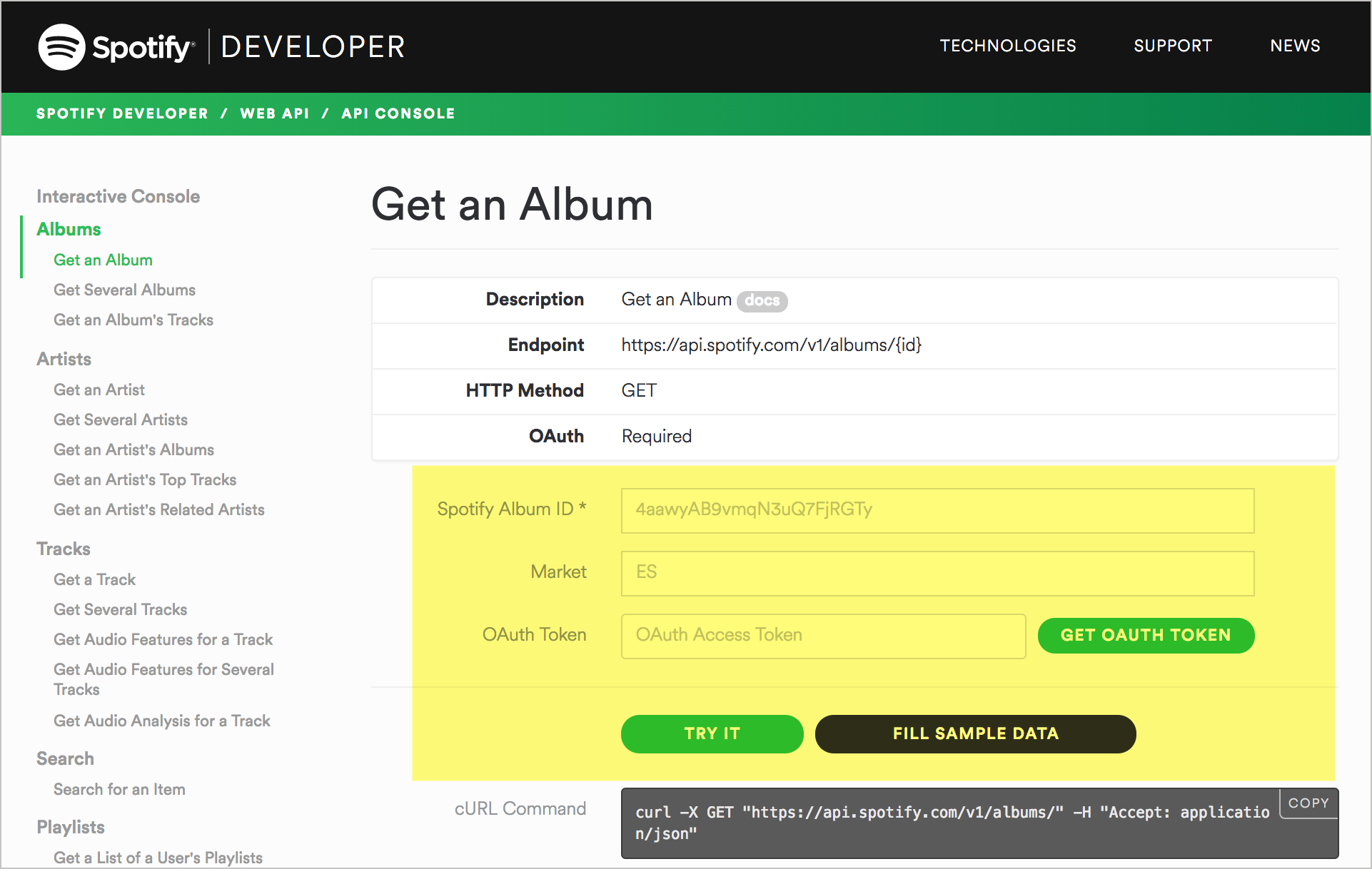
Многие API имеют функцию API Explorer, которая позволяет пользователям делать реальные запросы непосредственно из документации. Например, вот типичная справочная страница для документов API Spotify:
API Flickr также имеют встроенный API Explorer:
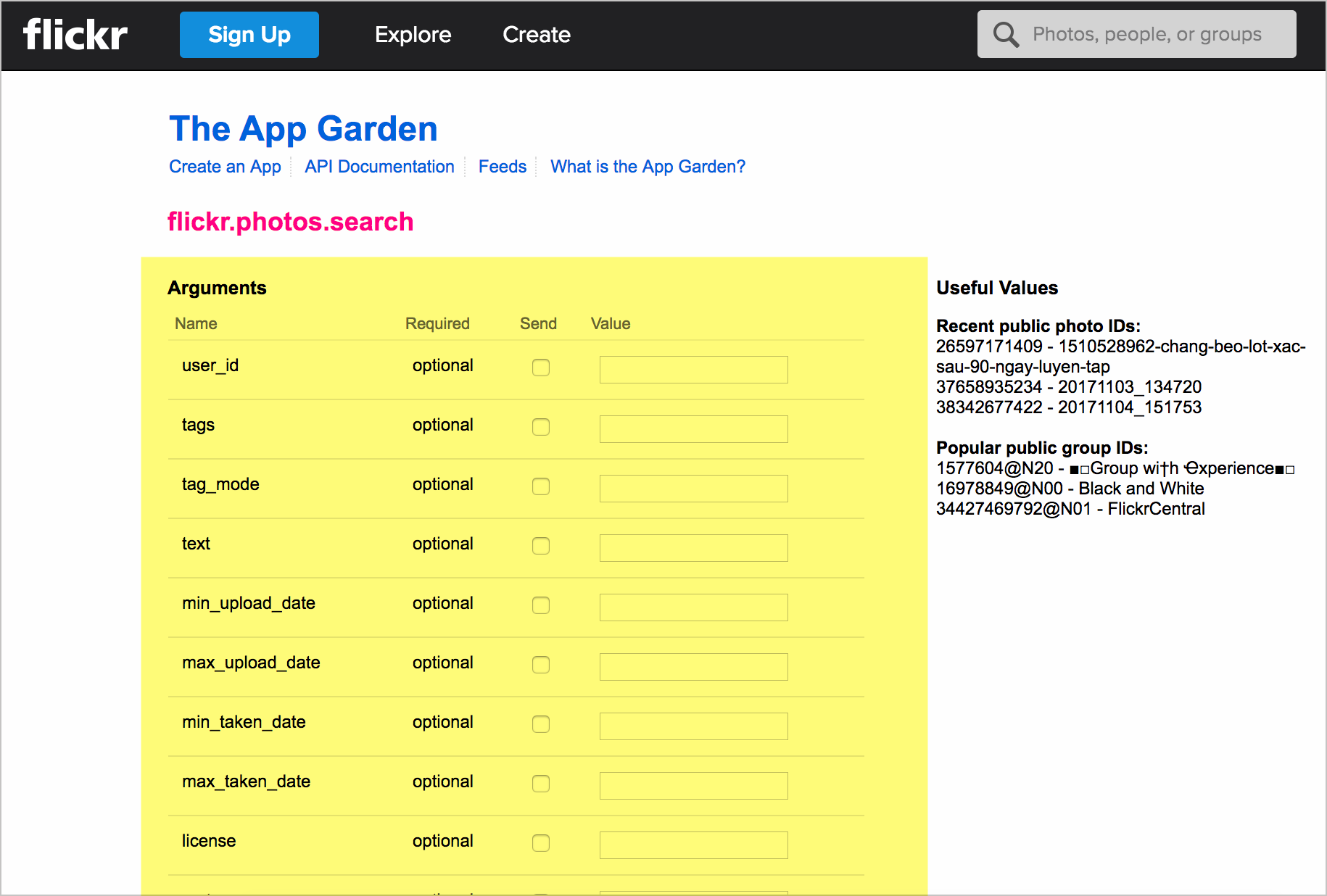
Как и API New York Times:
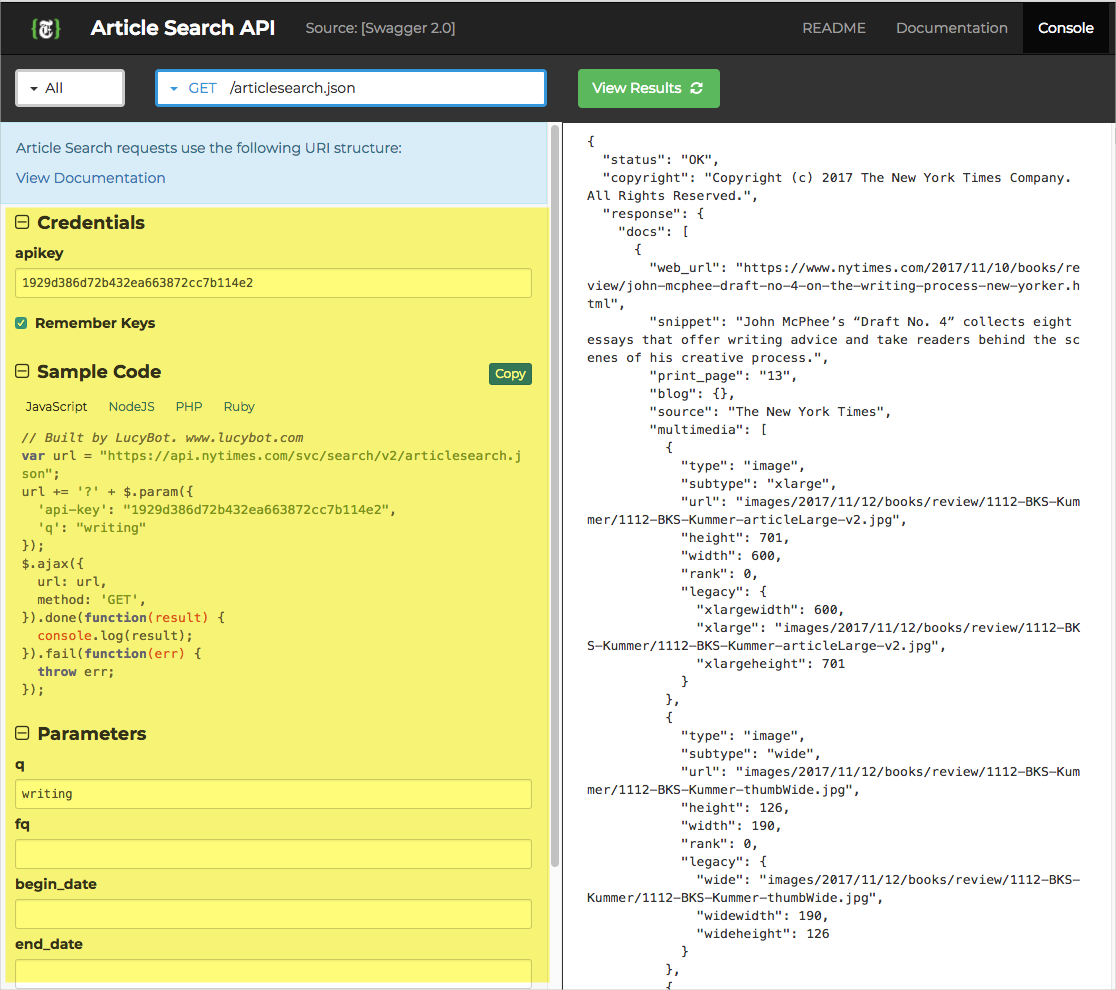
API Explorer позволяет вставлять свои собственные значения, свой собственный ключ API и другие параметры в запрос, чтобы увидеть ответы непосредственно в API Explorer. Возможность видеть свои собственные данные делает ответ более реальным.
Однако, если у вас нет нужных данных в вашей системе, использование собственного ключа API может не показать вам полный возможный ответ. Это работает лучше всего, когда ресурсы включают публичную информацию, а запросами являются запросы GET.
API Explorer может быть опасным в руках пользователя
Хотя интерактивность является мощным средством, API Explorer может быть опасным дополнением к вашему сайту. Что, если начинающий пользователь, который пробует метод DELETE, случайно удалит данные? Как мы позже удалим тестовые данные, добавленные методами POST или PUT?
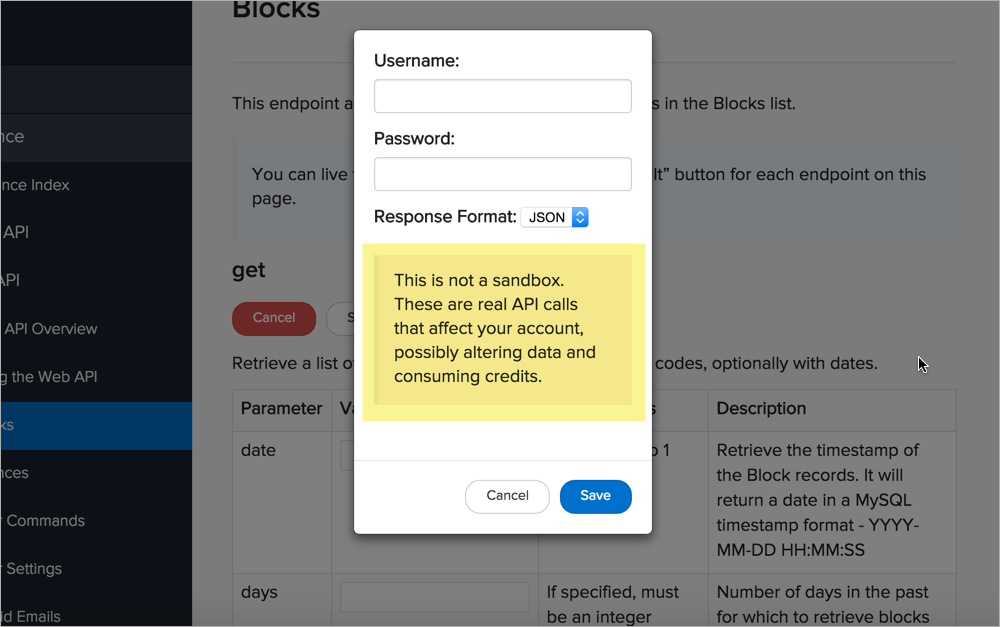
Одно дело разрешить методы GET, но если включить другие методы, пользователи могут случайно повредить свои данные. В API Sendgrid появляется предупреждающее сообщение для пользователей перед проверкой вызовов с помощью их API Explorer:
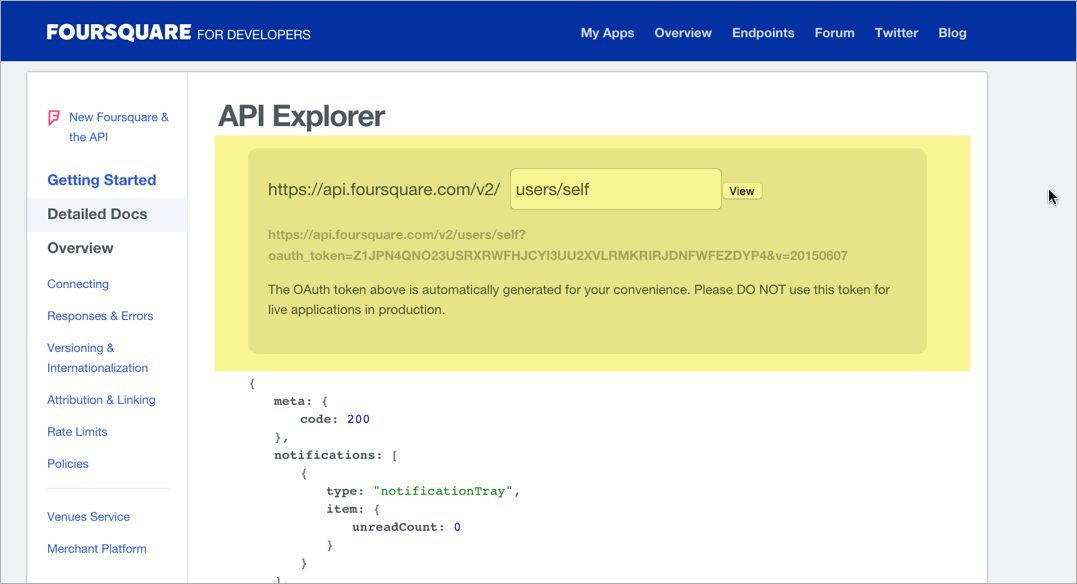
Документация API Foursquare раньше имела встроенный API Explorer в предыдущей версии своих документов (см. Ниже), но позже его удалили. Возможно, они столкнулись с некоторыми из этих проблем.
Что касается интеграции пользовательских инструментов API Explorer, эта задача должна быть относительно простой для разработчиков. Все, что делает API Explorer, это отображает значения из поля в вызов API и возвращает ответ в тот же интерфейс. Другими словами, API-интерфейс – это все, что нужно, плюс немного понимания JavaScript и навыков фронтенда, для успешной работы.
Не обязательно создавать свои собственные инструменты. Существующие инструменты, такие как Swagger UI (который анализирует спецификацию OpenAPI) и Readme.io (который позволяет вводить детали вручную или из спецификации OpenAPI), могут интегрировать функционал API Explorer непосредственно в документацию.
Пример запроса для SurfReport
Вернемся к нашей конечной точке surfreport/{beachId} и создадим пример запроса для нее:
Sample Request
curl -I -X GET "https://api.openweathermap.org/data/2.5/surfreport?zip=95050&appid=fd4698c940c6d1da602a70ac34f0b147&units=imperial&days=2"
Следующие шаги
Теперь, когда мы создали образец запроса, естественно, следующий шаг – включить пример ответа, который соответствует этому запросу. Также мы задокументируем модель или схему ответа. Переходим в Шаг 5: Пример и схема ответа
🔙
Go next ➡
Время на прочтение
8 мин
Количество просмотров 300K
 Эта памятка писалась для внутренних нужд (открыть глаза менее опытным в вебе коллегам). Но, т.к. я насмотрелся велосипедов от довольно уважаемых, казалось бы, контор, — выкладываю на хабр. Мне кажется, многим будет полезно.
Эта памятка писалась для внутренних нужд (открыть глаза менее опытным в вебе коллегам). Но, т.к. я насмотрелся велосипедов от довольно уважаемых, казалось бы, контор, — выкладываю на хабр. Мне кажется, многим будет полезно.
Зачем
Надеюсь, читающий уже понимает, зачем ему вообще нужен именно REST api, а не какой-нибудь монстр типа SOAP. Вопрос в том, зачем соблюдать какие-то стандарты и практики, если браузеры вроде бы позволяют делать что хочешь.
- Стандарт HTTP это стандарт. Его несоблюдение вредно для кармы и ведёт к постоянным проблемам с безопасностью, кэшированием и прочими “закидонами” браузеров, которые совсем не закидоны, а просто следование стандарту.
- Велосипеды со всякими
{error: "message","result":...}невозможно нормально тестировать и отлаживать - Поддержка большим количеством готовых клиентских библиотек на все случаи жизни. Те, кто будет вашим api пользоваться, скажут большое человеческое спасибо.
- Поддержка автоматизированного интеграционного тестирования. Когда сервер на любые запросы отдаёт
200 ОК— ну, это такое себе развлечение.
Структура запросов и ответов
Любой http-запрос начинается со строки
METHOD URI
где METHOD — это метод доступа (GET, PUT и т.д.), а URI — адрес запрашиваемого ресурса.
В начале запроса идут заголовки — просто текстовые строки вида key: value
Затем передаётся пустая строка, означающая конец секции заголовков, и затем — тело запроса, если оно есть.
В ответе сначала передаётся строка с версией http, кодом и строковым статусом ответа (например HTTP/1.1 200 OK), далее текстовые заголовки ответа, потом пустая строка, потом тело ответа.
Тут вроде всё просто.
Кодирование запросов и ответов
Кодировка для всех и запросов, и ответов — UTF-8 и только UTF-8, т.к. некоторые, кхм, “браузеры” имеют привычку игнорировать содержимое заголовка charset.
Использование кодов символов и html-сущностей не допускается, т.е. режим JSON_UNESCAPED_UNICODE обязателен. Не все клиенты знают всю таблицу html сущностей (типа каких-нибудь ù ), да и при чём тут html. Не все клиенты готовы/хотят заниматься перекодированием uXXXX; и &#XX;. Плюс возможны “весёлые” ситуации с избыточным экранированием или пропаданием слэшей и амперсандов.
Все данные, кроме URI и двоичных файлов, передаются в формате JSON. Обратите внимание, что далеко не всякий валидный javascript код является валидным JSON.
В частности, для строк используются только двойные кавычки. Одинарные кавычки в json-данных, хотя и допустимы в “обычном” javascript, могут вызвать непредсказуемые плохо отлавливаемые баги.
В запросах обязательно указывается заголовок
Accept: application/json, */*; q=0.01Вызовы к API отличаются от прочих вызовов (например, обычной загрузки html страницы по данному URI) именно по наличию application/json в Accept.
Сама строка Accept формируется браузером/клиентом и может немного отличаться от браузера к браузеру, например, наличием и других форматов типа text/javascript, поэтому нужно проверять не равенство, а именно вхождение “application/json”.
В ответах 2хх с непустым телом обязательно наличие заголовка ответа
Content-Type: application/json; charset=UTF-8При наличии тела запроса также обязателен заголовок запроса
Content-Type: application/json; charset=UTF-8либо, при загрузке файлов,
Content-Type: multipart/form-dataи далее, в первой части
-----------------
Content-Type: application/json; charset=UTF-8
Content-Disposition: form-data; name="data"после чего для каждого файла
-----------------
Content-Type: image/jpeg
Content-Disposition: form-data; name="avatar"; filename="user.jpg"Если вы используете защиту от CSRF (а лучше бы вам её использовать), то удобнее передавать CSRF-токен в отдельном заголовке (типа X-CSRF-Token) для всех запросов, а не внедрять вручную в каждый запрос. Хранить CSRF токен в куках плохо по той причине, что куки можно украсть, в чём собственно и состоит суть CSRF атаки.
Структура URI
Нагородить можно всякое, но лучшая практика — чтобы все URI имели вид
/:entity[/:id][/?:params]
ну, или если у вас api лежит в какой-то папке,
/api/:entity[/:id][/?:params]
Здесь:
- entity — название сущности, например, класса или таблицы/представления в БД. Примеры:
users,dictionary - id opt. — первичный ключ объекта. Если первичный ключ составной, то части указываются через слэш. Примеры:
/users/10,/dictionary/ru/apptitle - params opt. — дополнительные параметры выборки для списочных запросов (фильтрация, сортировка, паджинация и пр.). Форматируются по правилам HTTP GET параметров (функции encodeURIComponent и пр.)
Для разбора части URI до знака вопроса можно использовать регулярку
#^/(<entity>([a-z]-_)+)/?(<id>([a-z][A-Z][0-9]-_/)*)?$#Ведущий слэш обязателен, т.к. неизвестно, с какого URL будет осуществлён запрос.
Методы HTTP
GET /:entity/:id — getById
В случае успеха сервер возвращает 200 OK с полями объекта в формате JSON в теле ответа (без дополнительного оборачивания в какой-либо объект)
В случае, если объект с такими id не существует, сервер возвращает 404 Not Found
В ответе обязательно должны быть заголовки, касающиеся политики кэширования, т.к. браузеры активно кешируют GET и HEAD запросы. При остутствии какой-либо политики управления кэшем должно быть:
Cache-Control: no-store, no-cache, must-revalidate
Pragma: no-cacheGET /:entity[?param1=...¶m2=...] — списочный get
Простой случай: в случае успеха сервер возвращает 200 OK с массивом объектов в формате JSON в теле ответа (т.е. ответ начинается с [ и заканчивается ]).
Если массив получился пустой, всё равно вовзращается 200 OK с пустым масивом [] в теле ответа.
Более сложный вариант: возвращается объект, в одном из полей которого — искомый массив. В остальных полях — данные о пагинации, фильтры, счётчики и пр. Только держите это консистентным по всем api.
HEAD /:entity[/:id] — запрос заголовков
Полный аналог GET с таким же URI, но не возвращает тело ответа, а только HTTP-заголовки.
Реализация поддержки HEAD запросов веб-сервером обязательна.
Активно используется браузерами в качестве автоматических pre-flight запросов перед выполнением потенциально опасных, по их мнению, операций. Например, браузер Chrome активно кидается head-запросами для получения политик CORS при кросс-доменных операциях (виджеты и пр). При этом ошибка обработки такого head-запроса приведёт к тому, что основной запрос вообще не будет выполнен браузером.
Может использоваться для проверки существования объекта без его передачи (например, для больших объектов типа мультимедиа-файлов).
POST /:entity — создаёт новый объект типа :entity
В теле запроса должны быть перечислены поля объекта в формате JSON без дополнительного заворачивания, т.е. {"field1":"value","field2":10}
В случае успеха сервер должен возвращать 201 Created с пустым телом, но с дополнительным заголовком
Location: /:entity/:new_id
указывающим на месторасположение созданного объекта.
Возвращать тело ответа чаще всего не требуется, так как у клиента есть все необходимые данные, а id созданного объекта он может получить из Location.
Также метод POST используется для удалённого вызова процедур (RPC), в этом случае ответ будет иметь статус 200 OK и результаты в теле. Вообще смешивать REST и RPC в одном api — идея сомнительная, но всякое бывает.
Единственный неидемпотентный некешируемый метод, т.е. повтор двух одинаковых POST запросов создаст два одинаковых объекта.
PUT /:entity/:id — изменяет объект целиком
В запросе должны содержаться все поля изменяемого объекта в формате JSON.
В случае успеха должен возвращать 204 No Data с пустым телом, т.к. у клиента есть все необходимые данные.
Идемпотентный запрос, т.е. повторный PUT с таким же телом не приводит к каким-либо изменениям в БД.
PATCH /:entity/:id — изменяет отдельные поля объекта
В запросе должны быть перечислены только поля, подлежащие изменению.
В случае успеха возвращает 200 OK с телом, аналогичным запросу getById, со всеми полями изменённого объекта.
Используется с осторожностью, т.к. два параллельных PATCH от двух разных клиентов могут привести объект в невалидное состояние.
Идемпотентный запрос.
DELETE /:entity/:id — удаляет объект, если он существует.
В случае успеха возвращает 204 No Data с пустым телом, т.к. возвращать уже нечего.
Идемпотентный запрос, т.е. повторный DELETE с таким же адресом не приводит к ошибке 404.
OPTIONS /:entity[/:id]
Получает список методов, доступных по данному URI.
Сервер должен ответить 200 OK с дополнительным заголовком
Allow: GET, POST, ...Некешиуремый необязательный метод.
Обработка ошибок
Возвращаемые ошибки передаются с сервера на клиент как ответы со статусами 4хх (ошибка клиента) или 5хх (ошибка сервера). При этом описание ошибки, если оно есть, приводится в теле ответа в формате text/plain (без всякого JSON). Соответственно, передаётся заголовок ответа
Content-Type: text/plain; charset=UTF-8Использовать html для оформления сообщений об ошибках в api — так себе идея, будут проблемы журналированием и т.д. Предполагается, что клиент способен сам красиво оформить сообщение об ошибке для пользователя.
При выборе конкретных кодов ошибок не следует слишком увлекаться и пытаться применить существующие коды только потому, что название кажется подходящим. У многих кодов есть дополнительные требования к наличию определённых заголовков и специальная обработка браузерами. Например, код 401 запускает HTTP-аутентификацию, которая будет странно смотреться в каком-нибудь приложении на react или electron.
UPD по мотивам комментариев. Клиенты у вас будут разные: не только веб и мобильные приложения, но и такие штуки, как запускалка интеграционных тестов (CI), балансировщик нагрузки или система мониторинга у админов. Использование или неиспользование того или иного статуса ошибки определяется тем, будет ли он полезен хоть какому-то клиенту (т.е. этот клиент сможет предпринять какие-то действия конкретно по этому коду) и, наоборот, не будет ли проблем у какого-то из клиентов из-за неиспользования вами этого кода. Придумать реальный use-case, когда реакция клиента будет различаться в зависимости от 404 или 410, довольно сложно. При этом отличий 404 от 200 или 500 — вагон и телега.
400 Bad Request
Универсальный код ошибки, если серверу непонятен запрос от клиента.
403 Forbidden
Возвращается, если операция запрещена для текущего пользователя. Если у оператора есть учётка с более высокими правами, он должен перелогиниться самостоятельно. См. также 419
404 Not Found
Возвращается, если в запросе был указан неизвестный entity или id несуществующего объекта.
Списочные методы get не должны возвращать этот код при верном entity (см. выше).
Если запрос вообще не удалось разобрать, следует возвращать 418.
415 Unsupported Media Type
Возвращается при загрузке файлов на сервер, если фактический формат переданного файла не поддерживается. Также может возвращаться, если не удалось распарсить JSON запроса, или сам запрос пришёл не в формате JSON.
418 I'm a Teapot
Возвращается для неизвестных серверу запросов, которые не удалось даже разобрать. Обычно это указывает на ошибку в клиенте, типа ошибки при формировании URI, либо что версии протокола клиента и сервера не совпадают.
Этот ответ удобно использовать, чтобы отличать запросы на неизвестные URI (т.е. явные баги клиента) от ответов 404, у которых просто нет данных (элемент не найден). В отличие от 404, код 418 не бросается никаким промежуточным софтом. Альтернатива — использовать для обозначения ситуаций “элемент не найден” 410 Gone, но это не совсем корректно, т.к. предполагает, что ресурс когда-то существовал. Да и выделить баги клиента из потока 404 будет сложнее.
419 Authentication Timeout
Отправляется, если клиенту нужно пройти повторную авторизацию (например, протухли куки или CSRF токены). При этом на клиенте могут быть несохранённые данные, которые будут потеряны, если просто выкинуть клиента на страницу авторизации.
422 Unprocessable Entity
Запрос корректно разобран, но содержание запроса не прошло серверную валидацию.
Например, в теле запроса были указаны неизвестные серверу поля, или не были указаны обязательные, или с содержимым полей что-то не так.
Обычно это означает ошибку в введённых пользователем данных, но может также быть вызвано ошибкой на клиенте или несовпадением версий.
500 Internal Server Error
Возвращается, если на сервере вылетело необработанное исключение или произошла другая необработанная ошибка времени исполнения.
Всё, что может сделать клиент в этом случае — это уведомить пользователя и сделать console.error(err) для более продвинутых товарищей (админов, разработчиков и тестировщиков).
501 Not Implemented
Возвращается, если текущий метод неприменим (не реализован) к объекту запроса.
Ну вот, в общем-то, и всё. Спасибо за внимание!
В этом уроке вы узнаете:
- Что нужно для выполнения запроса
- Какие есть форматы взаимодействия с API Директа
- Куда отправлять запросы
- Какие HTTP-заголовки используются
- Чем выполнять запросы
- Выполняем первый запрос
- Что дальше
- Полезные ссылки
- Вопросы
В этом уроке мы расскажем о форматах взаимодействия с API Директа и покажем, как выполнить первый запрос.
Пройдя предыдущие уроки, вы уже выполнили все условия, необходимые для успешного выполнения запросов:
-
У вас есть аккаунт в Директе, и вы приняли пользовательское соглашение в разделе API веб-интерфейса Директа.
-
Вы зарегистрировали приложение на Яндекс.OAuth.
-
Вы подали заявку на доступ к API и получили одобрение заявки.
-
Вы получили OAuth-токен.
-
Вы включили Песочницу.
Внимание. Поскольку вы подавали заявку на тестовый доступ, то работать сможете только с Песочницей и тестовыми данными.
Приложение обращается к серверу API Директа по сетевому протоколу HTTPS, выполняя POST-запросы. Каждый POST-запрос должен быть сформирован в определенном формате. В этом же формате сервер API вернет ответ.
API Директа поддерживает два формата:
-
JSON (англ. JavaScript Object Notation) — текстовый формат обмена данными;
-
SOAP (англ. Simple Object Access Protocol) — протокол обмена структурированными сообщениями в формате XML.
Адрес для отправки запросов в Песочницу зависит от выбранного формата:
-
Для JSON-запросов —
https://api-sandbox.direct.yandex.com/json/v5/{сервис} -
Для SOAP-запросов —
https://api-sandbox.direct.yandex.com/v5/{сервис} -
WSDL-описание находится по адресу
https://api-sandbox.direct.yandex.com/v5/{сервис}?wsdl
Здесь {сервис} — имя сервиса, с которым вы хотите работать. Каждый сервис предназначен для работы с определенным классом объектов. Например, для управления рекламными кампаниями используется сервис Campaigns, и запросы к этому сервису нужно отправлять на следующие адреса:
-
https://api-sandbox.direct.yandex.com/json/v5/campaigns — JSON-запросы;
-
https://api-sandbox.direct.yandex.com/v5/campaigns — SOAP-запросы.
Адрес для запросов является регистрозависимым — необходимо указывать все символы в нижнем регистре, в том числе и название сервиса, иначе возникнет ошибка.
Внимание. Адреса для работы с реальными рекламными материалами отличаются от адресов Песочницы: они начинаются с https://api.direct.yandex.com.
Для выполнения запросов к API вы можете разработать свое приложение на любом языке программирования. Пока вы учитесь, запросы можно выполнять любой программой для отправки POST-запросов — например, с помощью плагина для браузера или из командной строки с помощью утилиты cURL.
Приведенные здесь и далее примеры пригодны для использования с помощью утилиты cURL. Вы можете скорректировать предложенный код под ваше приложение на любом языке программирования.
Формат примеров для ОС Windows отличается: JSON-код заключен в двойные кавычки, а в самом коде экранированы все двойные кавычки. Например:
-d "{"method":"get","params"...Внимание. Не забудьте изменить токен и идентификаторы объектов в примерах на ваши данные.
Посмотрим, какие тестовые кампании создались в Песочнице. Обратите внимание на ключевые параметры запроса:
-
Запрос отправляется к сервису Campaigns на адрес Песочницы:
https://api-sandbox.direct.yandex.com/json/v5/campaigns -
В заголовке Authorization передан OAuth-токен.
-
Вызван метод get для получения кампаний.
- cURL
-
curl -k -H "Authorization: Bearer ТОКЕН" -d '{"method":"get","params":{"SelectionCriteria":{},"FieldNames":["Id","Name"]}}' https://api-sandbox.direct.yandex.com/json/v5/campaigns - cURL для Windows
-
curl -k -H "Authorization: Bearer ТОКЕН" -d "{"method":"get","params":{"SelectionCriteria":{},"FieldNames":["Id","Name"]}}" https://api-sandbox.direct.yandex.com/json/v5/campaigns - Запрос
-
POST /json/v5/campaigns/ HTTP/1.1 Host: api-sandbox.direct.yandex.com Authorization: Bearer ТОКЕН Accept-Language: ru Client-Login: ЛОГИН_КЛИЕНТА Content-Type: application/json; charset=utf-8 { "method": "get", "params": { "SelectionCriteria": {}, "FieldNames": ["Id", "Name"] } } - Ответ
-
HTTP/1.1 200 OK Connection:close Content-Type:application/json Date:Fri, 28 Jun 2016 17:07:02 GMT RequestId: 1111111111111111112 Units: 10/20828/64000 Server:nginx Transfer-Encoding:chunked { "result": { "Campaigns": [{ "Name": "Test API Sandbox campaign 1", "Id": 1234567 }, { "Name": "Test API Sandbox campaign 2", "Id": 1234578 }, { "Name": "Test API Sandbox campaign 3", "Id": 1234589 }] } }
Итак, вы выполнили первый запрос к API Директа. В следующих уроках мы подробно расскажем о принципах работы с данными в API и рассмотрим более сложные примеры.
-
Как приложение может взаимодействовать с API Директа?
По сетевому протоколу HTTPS путем выполнения POST-запросов.С помощью передачи XLS/XLSX-файлов.Через обмен пакетами посредством FTP и SFTP.
 Верно!
Верно! Неверно. Неверно.
Неверно. Неверно. -
Какой HTTP-заголовок обязательно должен быть указан в запросе к серверу API Директа?
Client-Login.Client-IDBearer.Authorization.
Неверно. Неверно. Неверно. Верно! -
Как сервер API Директа отличает запросы к тестовым данным от запросов к реальным данным?
По адресу, на который отправлен запрос.Сервер API автоматически определяет тип данных по типу заявки на доступ приложения к API Директа.Тип данных определяется сервером API по наличию в запросе HTTP-заголовков X-Data-Production и X-Data-Sandbox.
Верно! Неверно. Неверно.
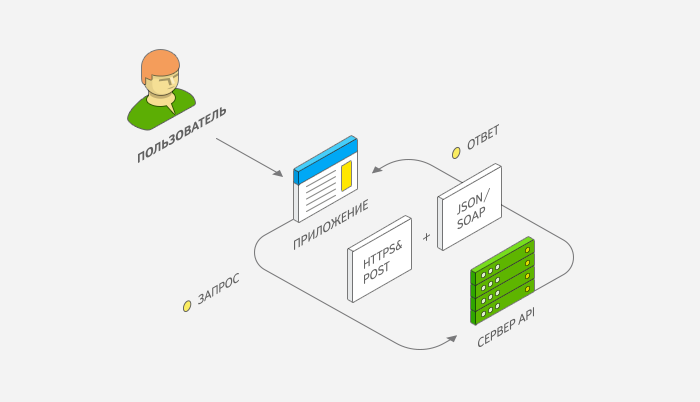
API InSales позволяет работать с бэк-офисом магазина, используя HTTP-запросы. При помощи API можно получать, добавлять, изменять и удалять информацию о различных объектах (например, товарах, категориях, дополнительных полях и т.д.)
Предполагается, что работа с API организована на внешнем сервере (НЕ на сервере платформы), который отправляет к серверу платформы запросы определенного типа. Для удобства в этой статье будет рассмотрена отправка запросов при помощи приложения Postman. В качестве альтернативы можно использовать Advanced REST Client.
Все доступные запросы в форматах XML и JSON описаны на api.insales.ru. Типовые запросы в формате XML с более подробным описанием можно найти на api.insales.ru.
- Ограничения
- Авторизация
- Общие принципы
- Примеры XML-запросов
- Примеры JSON-запросов
- Возможные коды ответов сервера
Ограничения
На платформе присутствует ограничение в 500 запросов к API в течение 5 минут. Время рассчитывается с момента первого запроса в серии. Количество выполненных запросов в текущем промежутке времени передается в HTTP-заголовке API-Usage-Limit (например, API-Usage-Limit: 1/500).
При достижении лимита доступ к API ограничивается до окончания текущих 5 минут. При этом в HTTP-заголовке Retry-After передается время в секундах до восстановления доступа.
Авторизация
Для отправки запросов к API необходимо создать ключ доступа.
Внимание! Не используйте логин-пароль от бэк-офиса для работы с API, иначе ваш аккаунт может быть заблокирован.
Для создания ключа доступа нужно в бэк-офисе перейти в раздел “Приложения” → “Разработчикам” и нажать кнопку “Создать новый ключ доступа”. При необходимости можно указать его название.
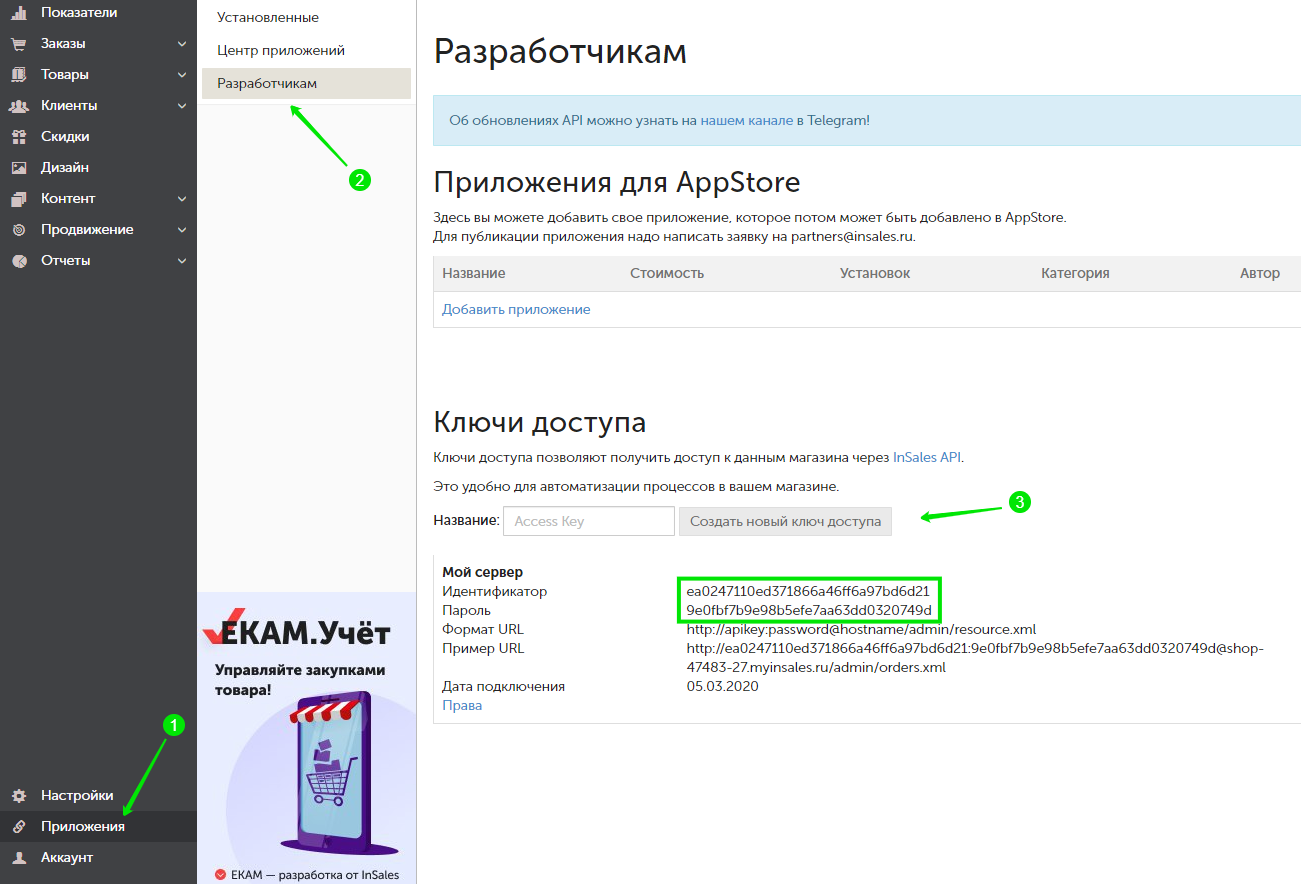
Далее в статье мы будем использовать созданные логин (идентификатор) и пароль. Их можно указывать как в адресе запроса:
https://логин:пароль@shop-47483-27.myinsales.ru/admin/orders.xml
Так и в виде HTTP-заголовка Authorization:
Authorization: Basic ZGlnaXRhbC1nb29kczpjNTFjOTA3MDdhMTNjZTNmZmYyMTNhZmJiNWNkMTI3MA==
Вместо shop-47483-27.myinsales.ru необходимо использовать технический или обычный домен вашего магазина. Его можно взять, например, из строки “Пример URL” около выданного ключа доступа.
Общие принципы
API InSales принимает POST, GET, PUT и DELETE-запросы в зависимости от выполняемого действия. Тип и адрес запроса для требуемого действия можно найти на api.insales.ru.
Текст самого запроса должен соответствовать формату XML или JSON. В зависимости от формата меняется адрес запроса и значение HTTP-заголовка Content-Type.
Для XML необходим Content-Type: application/xml
А для JSON – Content-Type: application/json
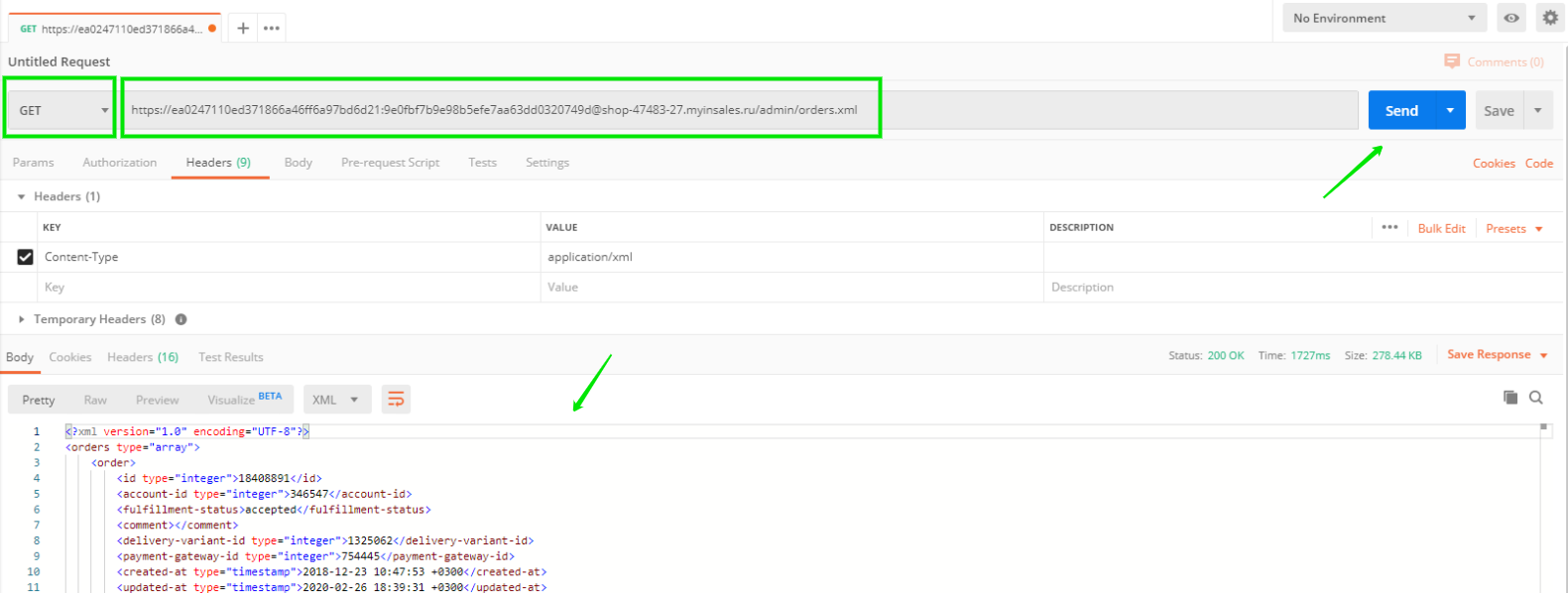
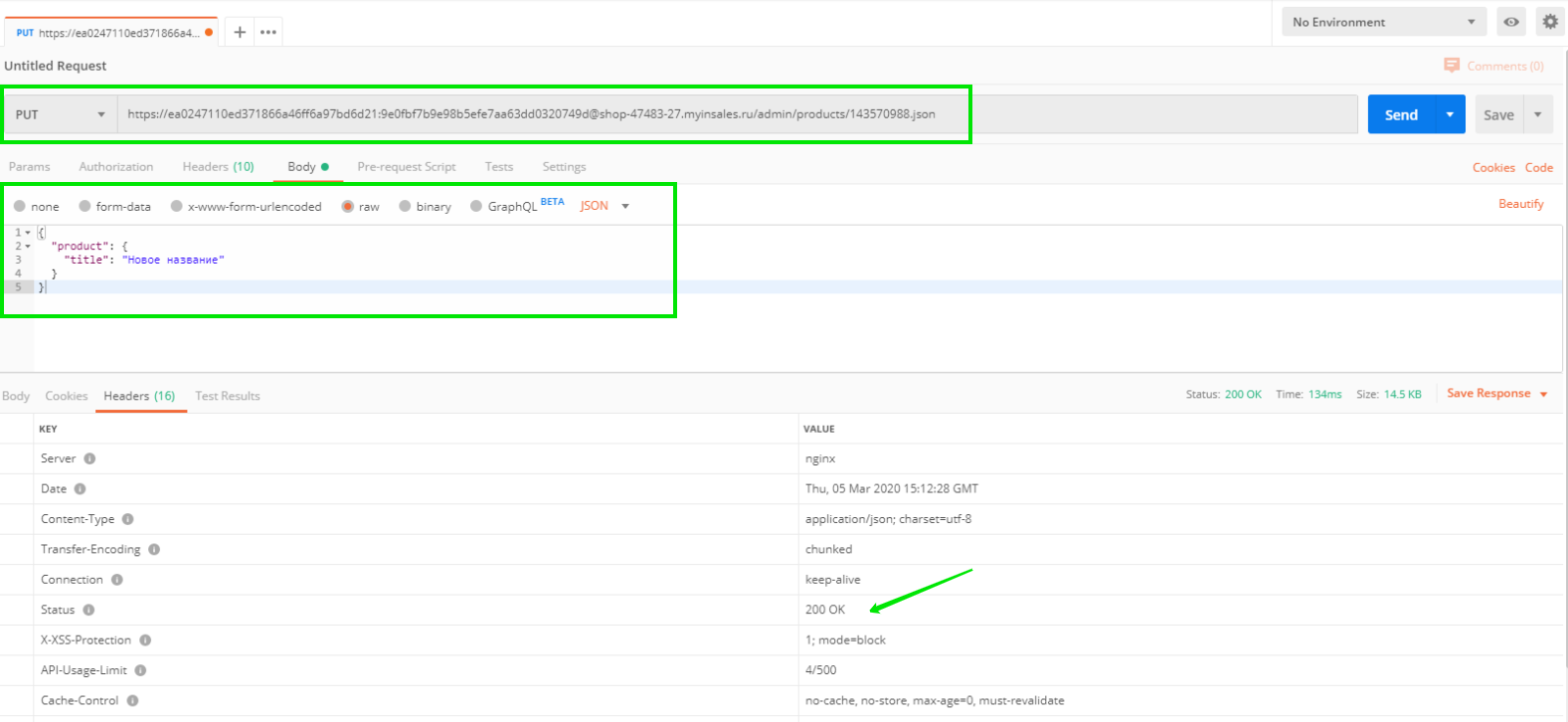
На скриншоте программы Postman показан выбранный тип запроса, адрес и заголовки. После нажатия кнопки Send появится ответ сервера InSales.
Примеры XML-запросов
Рассмотрим GET-запрос к товару с id 143570988. Такой запрос не требует передачи серверу каких-либо параметров. В качестве адреса необходимо указать https://логин:пароль@shop-47483-27.myinsales.ru/admin/products/143570988.xml
В ответ сервер пришлёт всю доступную информацию об этом товаре.
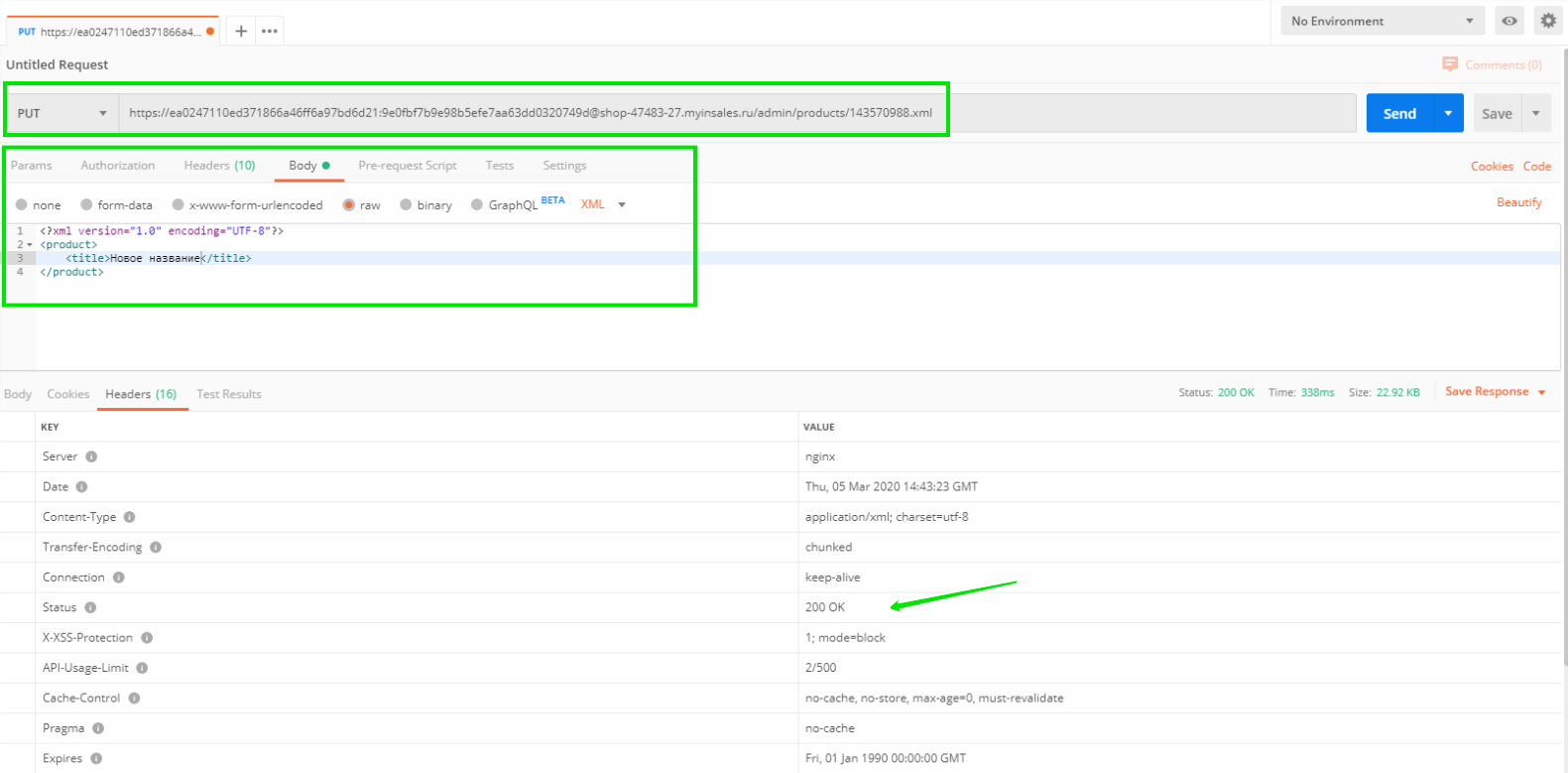
PUT-запрос служит для обновления данных выбранного объекта. Для обновления названия того же товара с id 143570988 потребуется отправить запрос с телом
<?xml version=”1.0″ encoding=”UTF-8″?>
<product>
<title>Новое название</title>
</product>
В ответ сервер пришлёт обновлённую информацию о товаре (в том числе новое название). Соответственно, в бэк-офисе также будет отображаться новое название товара. В ответе виден код 200, что означает успешное выполнение операции.
Примеры JSON-запросов
Запросы в формате JSON отличаются адресом и заголовком Content-Type.
GET-запрос отправляется на адрес https://логин:пароль@shop-47483-27.myinsales.ru/admin/products/143570988.json . Ответ, соответственно, также будет этом формате.
Тело PUT-запроса на обновление названия товара выглядит следующим образом:
{
“product”: {
“title”: “Новое название”
}
}
Возможные коды ответов сервера
- 200 – штатный ответ на операцию; означает, что никаких ошибок не возникло
- 201 – в некоторых случаях при создании объектов может вернуться этот код; по смыслу не отличается от кода 200
- 400 – некорректный HTTP-запрос, сервер не смог его обработать
- 401 – не удалось авторизоваться (необходимо проверить логин и пароль)
- 403 – нет прав для данной операции (необходимо проверить настройки прав для приложения)
- 404 – запрашиваемый объект не найден (возможно, его уже удалили или указан неверный id объекта)
- 500 – внутренняя ошибка сервера (возможно, вы некорректно сформировали запрос или что-то сломалось на нашей стороне; необходимо обратиться в тех поддержку)
- 503 – превышен лимит запросов к API
- 504 – сервер не смог обработать ваш запрос за 50 секунд и прервал его выполнение (возможно, вы пытаетесь получить слишком много данных за один запрос)
Продолжая разбирать актуальные для начинающих системных и бизнес-аналитиков темы по основам работы распределенных систем и межсистемной интеграции, сегодня рассмотрим, как система с REST API отвечает на запросы клиента. Рассмотрим наиболее частые коды HTTP-ответов на GET, POST, PUT, PATCH и DELETE-запросы на примере интернет-магазина.
GET-и POST-запросы и ответы на них
В качестве примера распределенной системы возьмем интернет-магазин. Предположим, менеджер интернет-магазина хочет просмотреть ТОП-10 самых дорогих игрушечных машин белого цвета и добавить новую туда новую игрушку, если там нет аналогичной. В системе с REST API это будет выглядеть следующим образом: сперва менеджер отправляет с клиентского компьютера HTTP-запрос GET к конечной точке по URL-адресу http://site-domain-name/products/toys?category=car&color=white&count=10&view=list&sort=pricedown. В этом запросе http://site-domain-name/products/toys – это URL-адрес ресурса, т.е. конечная точка (endpoint), который является пунктом доступа к системе извне. Параметры фильтрации и сортировки данных идут в заголовке запроса после вопросительного знака (?). В частности, выражение category=car задает, что нужны только машины, т.е. те товары, которые относятся к этой категории. Следующие параметры, разделенные знаком амперсанда (&), уточняют цвет (color=white), количество возвращаемых результатов (count =10), вариант их представления (view=list) и сортировку вывода (sort=pricedown).
В ответ система возвращает клиенту список товаров, отвечающих заданным условием, включив в ответное сообщение статус выполнения посланного HTTP-запроса со статусом 200 (OK), который означает успешное выполнение запроса: данные в системе есть и у пользователя есть право их чтения. В отличие от SOAP, REST может возвращать данные в любом формате (HTML, XML, JSON), но чаще всего это человеко-читаемый текстовый формат JSON (JavaScript Object Notation) на основе JavaScript. Подробнее о сходствах и различиях SOAP и REST, а также их сравнении с другими стилями межсистемной интеграции по API я писала здесь.
Вообще протокол HTTP поддерживает следующие группы кодов ответа, которые показывают состояние выполнения запроса, был ли он выполнен успешно, или возникла какая-либо ошибка:
- информационные коды имеют номера от 100 до 199;
- коды успешного выполнения запросов имеют номера от 200 до 299;
- перенаправления кодируются номерами от 300 до 399;
- клиентские ошибки имеют коды от 400 до 499;
- ошибки сервера кодируются номерами от 500 до 599.
Примечательно, что некоторые коды могут не поддерживаться старыми версиями HTTP-протокола.
Просмотрев возвращенный список товаров, менеджер решает добавить новый товар, послав HTTTP-запрос POST к конечной точке http://site-domain-name/products/toys. Здесь параметры нового добавляемого товара передаются не в заголовке, а в теле HTTP-запроса. Если у пользователя с ролью «Менеджер» есть право добавлять новые товары, т.е. создавать ресурсы, в ответ система возвратит данные с идентификатором вновь созданного ресурса и HTTP-кодом успешного ответа со статусом 201 (Created), т.к. изначально целевой ресурс не имел отправляемой сущности и POST-запрос создал её. Новый ресурс возвращается в теле сообщения, его местоположение представляет собой URL-адрес запроса или содержимое заголовка Location. Например, http://site-domain-name/products/toys/4689, где 4689 – это идентификатор только что добавленного товара. Иначе система вернет ответ с кодом 401 (Unauthorized), который означает статус ошибки и указывает, что запрос не был выполнен из-за отсутствия у клиента прав, т.е. действующих учётных данных для манипуляций с целевым ресурсом.
Основы архитектуры и интеграции информационных систем
Код курса
OAIS
Ближайшая дата курса
29 июня, 2023
Длительность обучения
8 ак.часов
Стоимость обучения
15 000 руб.
Запросы PUT, POST и DELETE
Когда менеджер захочет изменить характеристики ранее созданного товара, он отправит PUT-запрос к конечной точке http://site-domain-name/products/toys/4689 с данными для полного обновления этого ресурса в теле запроса. Можно использовать и PATCH-запрос для частичного обновления данных, однако, здесь нужно вспомнить про различия между этими методами в плане идемпотентности. PATCH может как идемпотентным или не быть, в отличие от PUT-запроса, который всегда идемпотентен. Напомним, операция считается идемпотентной, если её повторное выполнение приводит к тому же результату, что и первичное. PUT-запрос перезапишет автоинкрементируемое поле при обращении к ресурсу, а PATCH может и не перезаписать. Разумеется, чтобы выполнить операцию изменения, менеджер должен иметь права на выполнение этой операции. Если целевой ресурс содержит отправляемую сущность (в нашем случае игрушку с идентификатором 4689) и ее характеристики были успешно обновлены согласно данным в теле запроса, в HTTP-коде ответа будет статус 200 (OK) или 204 (No Content), который указывает, что запрос успешно выполнено, но клиенту не нужно уходить со своей текущей страницы. Иначе, если у менеджера нет прав на изменение характеристик товара, система вернет ответ с кодом 401 (Unauthorized).
Наконец, предположим, что менеджер решил удалить из каталога игрушку с идентификатором 4689. Для этого надо отправить HTTP-запрос DELETE на конечную точку http://site-domain-name/products/toys/4689. Если у менеджера есть права на удаление ресурсов, метод DELETE может вернуть следующие коды состояния ответа:
- 200 (OK) – удаление успешно выполнено;
- 202 (Accepted) – запрос получен, но еще не обработан, но он будет успешно выполнен;
- 204 (No Content) – удаление успешно выполнено, клиенту не нужно уходить со своей текущей страницы, тело ответа отсутствует.
При отсутствии у менеджера прав на операцию удаления указанного товара, система вернет ответ с кодом 401 (Unauthorized). Подробнее про процедуры аутентификации и авторизации в веб-приложениях читайте в моей новой статье.
Покажем некоторые операции этого взаимодействие пользователя с REST API системой в виде BPMN-диаграммы.
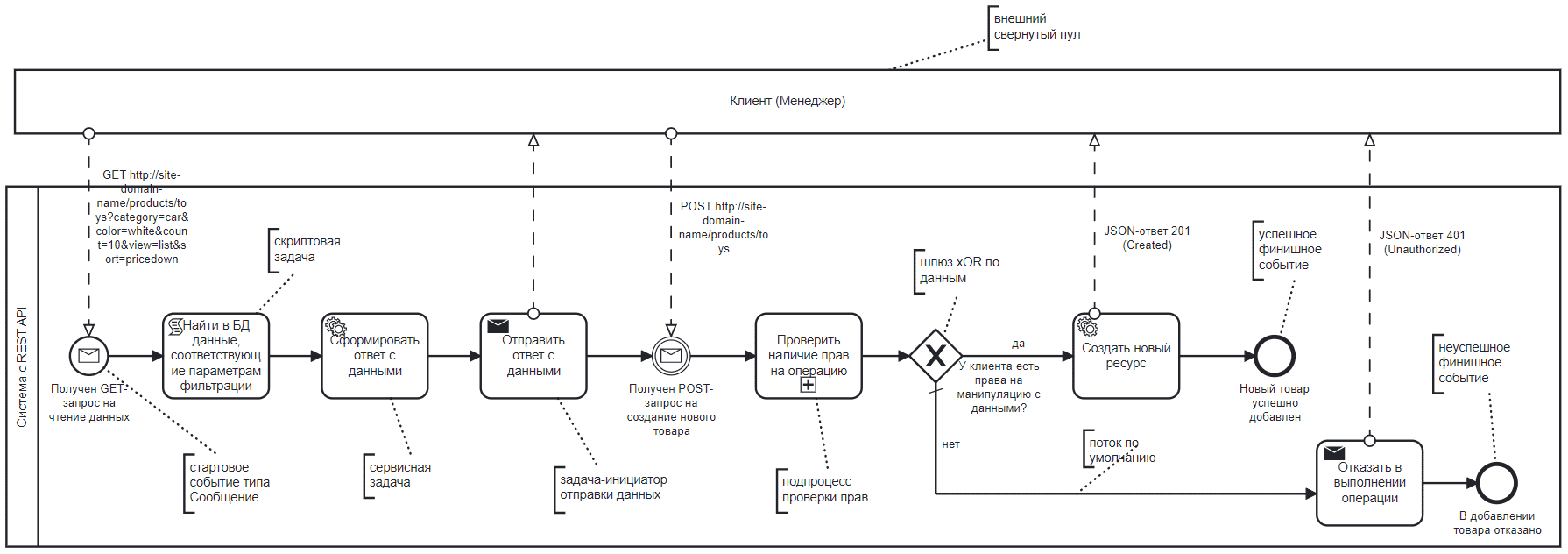
Однако, на самом деле в веб-приложениях все описанные операции выполняются чуть сложнее. Как это работает, рассмотрим в следующий раз. А пока предлагаем вам проверить, как вы усвоили материалы по REST API в открытом интерактивном тесте.
API межсистемной интеграции: тест для аналитика
А подробнее познакомиться с основами архитектуры и интеграции информационных систем вам помогут курсы Школы прикладного бизнес-анализа в нашем лицензированном учебном центре обучения и повышения квалификации системных и бизнес-аналитиков в Москве:
- Основы архитектуры и интеграции информационных систем
- Разработка ТЗ на информационную систему по ГОСТ и SRS
Источники
- https://developer.mozilla.org/ru/docs/Web/HTTP/Methods
- https://developer.mozilla.org/ru/docs/Web/HTTP/Status
