Взявшись за написание небольшого, но реального и растущего проекта, мы «на собственной шкуре» убедились, насколько важно то, чтобы программа не только хорошо работала, но и была хорошо организована. Не верьте, что продуманная архитектура нужна только большим проектам (просто для больших проектов «смертельность» отсутствия архитектуры очевидна). Сложность, как правило, растет гораздо быстрее размеров программы. И если не позаботиться об этом заранее, то довольно быстро наступает момент, когда ты перестаешь ее контролировать. Правильная архитектура экономит очень много сил, времени и денег. А нередко вообще определяет то, выживет ваш проект или нет. И даже если речь идет всего лишь о «построении табуретки» все равно вначале очень полезно ее спроектировать.
К моему удивлению оказалось, что на вроде бы актуальный вопрос: «Как построить хорошую/красивую архитектуру ПО?» — не так легко найти ответ. Не смотря на то, что есть много книг и статей, посвященных и шаблонам проектирования и принципам проектирования, например, принципам SOLID (кратко описаны тут, подробно и с примерами можно посмотреть тут, тут и тут) и тому, как правильно оформлять код, все равно оставалось чувство, что чего-то важного не хватает. Это было похоже на то, как если бы вам дали множество замечательных и полезных инструментов, но забыли главное — объяснить, а как же «проектировать табуретку».
Хотелось разобраться, что вообще в себя включает процесс создания архитектуры программы, какие задачи при этом решаются, какие критерии используются (чтобы правила и принципы перестали быть всего лишь догмами, а стали бы понятны их логика и назначение). Тогда будет понятнее и какие инструменты лучше использовать в том или ином случае.
Данная статья является попыткой ответить на эти вопросы хотя бы в первом приближении. Материал собирался для себя, но, может, он окажется полезен кому-то еще. Мне данная работа позволила не только узнать много нового, но и в ином контексте взглянуть на кажущиеся уже почти банальными основные принципы ООП и по настоящему оценить их важность.
Информации оказалось довольно много, поэтому приведены лишь общая идея и краткие описания, дающие начальное представление о теме и понимание, где искать дальше.
Критерии хорошей архитектуры
Вообще говоря, не существует общепринятого термина «архитектура программного обеспечения». Тем не менее, когда дело касается практики, то для большинства разработчиков и так понятно какой код является хорошим, а какой плохим. Хорошая архитектура это прежде всего выгодная архитектура, делающая процесс разработки и сопровождения программы более простым и эффективным. Программу с хорошей архитектурой легче расширять и изменять, а также тестировать, отлаживать и понимать. То есть, на самом деле можно сформулировать список вполне разумных и универсальных критериев:
Эффективность системы. В первую очередь программа, конечно же, должна решать поставленные задачи и хорошо выполнять свои функции, причем в различных условиях. Сюда можно отнести такие характеристики, как надежность, безопасность, производительность, способность справляться с увеличением нагрузки (масштабируемость) и т.п.
Гибкость системы. Любое приложение приходится менять со временем — изменяются требования, добавляются новые. Чем быстрее и удобнее можно внести изменения в существующий функционал, чем меньше проблем и ошибок это вызовет — тем гибче и конкурентоспособнее система. Поэтому в процессе разработки старайтесь оценивать то, что получается, на предмет того, как вам это потом, возможно, придется менять. Спросите у себя: «А что будет, если текущее архитектурное решение окажется неверным?», «Какое количество кода подвергнется при этом изменениям?». Изменение одного фрагмента системы не должно влиять на ее другие фрагменты. По возможности, архитектурные решения не должны «вырубаться в камне», и последствия архитектурных ошибок должны быть в разумной степени ограничены. “Хорошая архитектура позволяет ОТКЛАДЫВАТЬ принятие ключевых решений” (Боб Мартин) и минимизирует «цену» ошибок.
Расширяемость системы. Возможность добавлять в систему новые сущности и функции, не нарушая ее основной структуры. На начальном этапе в систему имеет смысл закладывать лишь основной и самый необходимый функционал (принцип YAGNI — you ain’t gonna need it, «Вам это не понадобится») Но при этом архитектура должна позволять легко наращивать дополнительный функционал по мере необходимости. Причем так, чтобы внесение наиболее вероятных изменений требовало наименьших усилии.
Требование, чтобы архитектура системы обладала гибкостью и расширяемостью (то есть была способна к изменениям и эволюции) является настолько важным, что оно даже сформулировано в виде отдельного принципа — «Принципа открытости/закрытости» (Open-Closed Principle — второй из пяти принципов SOLID): Программные сущности (классы, модули, функции и т.п.) должны быть открытыми для расширения, но закрытыми для модификации.
Иными словами: Должна быть возможность расширить/изменить поведение системы без изменения/переписывания уже существующих частей системы.
Это означает, что приложение следует проектировать так, чтобы изменение его поведения и добавление новой функциональности достигалось бы за счет написания нового кода (расширения), и при этом не приходилось бы менять уже существующий код. В таком случае появление новых требований не повлечет за собой модификацию существующей логики, а сможет быть реализовано прежде всего за счет ее расширения. Именно этот принцип является основой «плагинной архитектуры» (Plugin Architecture). О том, за счет каких техник это может быть достигнуто, будет рассказано дальше.
Масштабируемость процесса разработки. Возможность сократить срок разработки за счёт добавления к проекту новых людей. Архитектура должна позволять распараллелить процесс разработки, так чтобы множество людей могли работать над программой одновременно.
Тестируемость. Код, который легче тестировать, будет содержать меньше ошибок и надежнее работать. Но тесты не только улучшают качество кода. Многие разработчики приходят к выводу, что требование «хорошей тестируемости» является также направляющей силой, автоматически ведущей к хорошему дизайну, и одновременно одним из важнейших критериев, позволяющих оценить его качество: “Используйте принцип «тестируемости» класса в качестве «лакмусовой бумажки» хорошего дизайна класса. Даже если вы не напишите ни строчки тестового кода, ответ на этот вопрос в 90% случаев поможет понять, насколько все «хорошо» или «плохо» с его дизайном” (Идеальная архитектура).
Существует целая методология разработки программ на основе тестов, которая так и называется — Разработка через тестирование (Test-Driven Development, TDD).
Возможность повторного использования. Систему желательно проектировать так, чтобы ее фрагменты можно было повторно использовать в других системах.
Хорошо структурированный, читаемый и понятный код. Сопровождаемость. Над программой, как правило, работает множество людей — одни уходят, приходят новые. После написания сопровождать программу тоже, как правило, приходится людям, не участвовавшем в ее разработке. Поэтому хорошая архитектура должна давать возможность относительно легко и быстро разобраться в системе новым людям. Проект должен быть хорошо структурирован, не содержать дублирования, иметь хорошо оформленный код и желательно документацию. И по возможности в системе лучше применять стандартные, общепринятые решения привычные для программистов. Чем экзотичнее система, тем сложнее ее понять другим (Принцип наименьшего удивления — Principle of least astonishment. Обычно, он используется в отношении пользовательского интерфейса, но применим и к написанию кода).
Ну и для полноты критерии плохого дизайна:
- Его тяжело изменить, поскольку любое изменение влияет на слишком большое количество других частей системы. (Жесткость, Rigidity).
- При внесении изменений неожиданно ломаются другие части системы. (Хрупкость, Fragility).
- Код тяжело использовать повторно в другом приложении, поскольку его слишком тяжело «выпутать» из текущего приложения. (Неподвижность, Immobility).
Модульная архитектура. Декомпозиция как основа
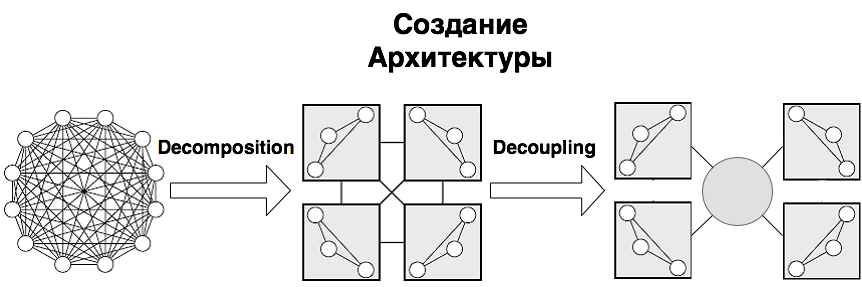
Не смотря на разнообразие критериев, все же главной при разработке больших систем считается задача снижения сложности. А для снижения сложности ничего, кроме деления на части, пока не придумано. Иногда это называют принципом «разделяй и властвуй» (divide et impera), но по сути речь идет об иерархической декомпозиции. Сложная система должна строится из небольшого количества более простых подсистем, каждая из которых, в свою очередь, строится из частей меньшего размера, и т.д., до тех пор, пока самые небольшие части не будут достаточно просты для непосредственного понимания и создания.
Удача заключается в том, что данное решение является не только единственно известным, но и универсальным. Помимо снижения сложности, оно одновременно обеспечивает гибкость системы, дает хорошие возможности для масштабирования, а также позволяет повышать устойчивость за счет дублирования критически важных частей.
Соответственно, когда речь идет о построении архитектуры программы, создании ее структуры, под этим, главным образом, подразумевается декомпозиция программы на подсистемы (функциональные модули, сервисы, слои, подпрограммы) и организация их взаимодействия друг с другом и внешним миром. Причем, чем более независимы подсистемы, тем безопаснее сосредоточиться на разработке каждой из них в отдельности в конкретный момент времени и при этом не заботиться обо всех остальных частях.
В этом случае программа из «спагетти-кода» превращается в конструктор, состоящий из набора модулей/подпрограмм, взаимодействующих друг с другом по хорошо определенным и простым правилам, что собственно и позволяет контролировать ее сложность, а также дает возможность получить все те преимущества, которые обычно соотносятся с понятием хорошая архитектура:
- Масштабируемость (Scalability)
возможность расширять систему и увеличивать ее производительность, за счет добавления новых модулей. - Ремонтопригодность (Maintainability)
изменение одного модуля не требует изменения других модулей - Заменимость модулей (Swappability)
модуль легко заменить на другой - Возможность тестирования (Unit Testing)
модуль можно отсоединить от всех остальных и протестировать / починить - Переиспользование (Reusability)
модуль может быть переиспользован в других программах и другом окружении - Сопровождаемость (Maintenance)
разбитую на модули программу легче понимать и сопровождать
Можно сказать, что в разбиении сложной проблемы на простые фрагменты и заключается цель всех методик проектирования. А термином «архитектура», в большинстве случаев, просто обозначают результат такого деления, плюс “некие конструктивные решения, которые после их принятия с трудом поддаются изменению” (Мартин Фаулер «Архитектура корпоративных программных приложений»). Поэтому большинство определений в той или иной форме сводятся к следующему:
“Архитектура идентифицирует главные компоненты системы и способы их взаимодействия. Также это выбор таких решений, которые интерпретируются как основополагающие и не подлежащие изменению в будущем.“
“Архитектура — это организация системы, воплощенная в ее компонентах, их отношениях между собой и с окружением.
Система — это набор компонентов, объединенных для выполнения определенной функции.“
Таким образом, хорошая архитектура это, прежде всего, модульная/блочная архитектура. Чтобы получить хорошую архитектуру надо знать, как правильно делать декомпозицию системы. А значит, необходимо понимать — какая декомпозиция считается «правильной» и каким образом ее лучше проводить?
«Правильная» декомпозиция
1. Иерархическая
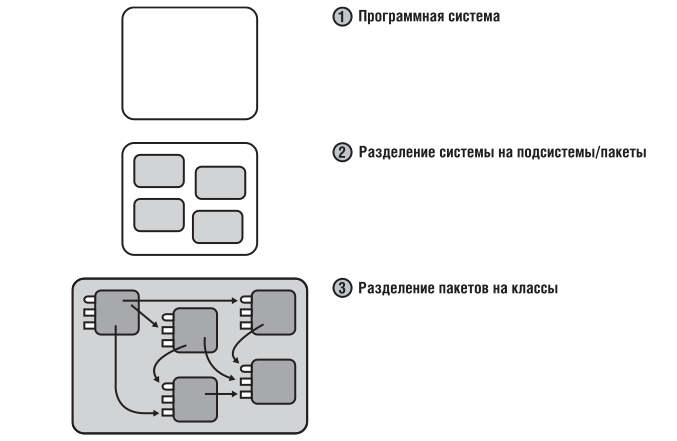
Не стоит сходу рубить приложение на сотни классов. Как уже говорилось, декомпозицию надо проводить иерархически — сначала систему разбивают на крупные функциональные модули/подсистемы, описывающие ее работу в самом общем виде. Затем, полученные модули, анализируются более детально и, в свою очередь, делятся на под-модули либо на объекты.
Перед тем как выделять объекты разделите систему на основные смысловые блоки хотя бы мысленно. Для небольших приложений двух уровней иерархии часто оказывается вполне достаточно — система вначале делится на подсистемы/пакеты, а пакеты делятся на классы.
Эта мысль, при всей своей очевидности, не так банальна как кажется. Например, в чем заключается суть такого распространенного «архитектурного шаблона» как Модель-Вид-Контроллер (MVC)? Всего навсего в отделении представления от бизнес-логики, то есть в том, что любое пользовательское приложение вначале делится на два модуля — один из которых отвечает за реализацию собственно самой бизнес логики (Модель), а второй — за взаимодействие с пользователем (Пользовательский Интерфейс или Представление). Затем, для того чтобы эти модули могли разрабатываться независимо, связь между ними ослабляется с помощью паттерна «Наблюдатель» (подробно о способах ослабления связей будет рассказано дальше) и мы фактически получаем один из самых мощных и востребованных «шаблонов», которые используются в настоящее время.
Типичными модулями первого уровня (полученными в результате первого деления системы на наиболее крупные составные части) как раз и являются — «бизнес-логика», «пользовательский интерфейс», «доступ к БД», «связь с конкретным оборудованием или ОС».
Для обозримости на каждом иерархическом уровне рекомендуют выделять от 2 до 7 модулей.
2. Функциональная
Деление на модули/подсистемы лучше всего производить исходя из тех задач, которые решает система. Основная задача разбивается на составляющие ее подзадачи, которые могут решаться/выполняться независимо друг от друга. Каждый модуль должен отвечать за решение какой-то подзадачи и выполнять соответствующую ей функцию. Помимо функционального назначения модуль характеризуется также набором данных, необходимых ему для выполнения его функции, то есть:
Модуль = Функция + Данные, необходимые для ее выполнения.
Причем желательно, чтобы свою функцию модуль мог выполнить самостоятельно, без помощи остальных модулей, лишь на основе своих входящих данных.
Модуль — это не произвольный кусок кода, а отдельная функционально осмысленная и законченная программная единица (подпрограмма), которая обеспечивает решение некоторой задачи и в идеале может работать самостоятельно или в другом окружении и быть переиспользуемой. Модуль должен быть некой “целостностью, способной к относительной самостоятельности в поведении и развитии” (Кристофер Александер).
Таким образом, грамотная декомпозиция основывается, прежде всего, на анализе функций системы и необходимых для выполнения этих функций данных.
3. High Cohesion + Low Coupling
Самым же главным критерием качества декомпозиции является то, насколько модули сфокусированы на решение своих задач и независимы. Обычно это формулируют следующим образом: “Модули, полученные в результате декомпозиции, должны быть максимально сопряженны внутри (high internal cohesion) и минимально связанны друг с другом (low external coupling).“
- High Cohesion, высокая сопряженность или «сплоченность» внутри модуля, говорит о том, модуль сфокусирован на решении одной узкой проблемы, а не занимается выполнением разнородных функций или несвязанных между собой обязанностей. (Сопряженность — cohesion, характеризует степень, в которой задачи, выполняемые модулем, связаны друг с другом )
Следствием High Cohesion является принцип единственной ответственности (Single Responsibility Principle — первый из пяти принципов SOLID), согласно которому любой объект/модуль должен иметь лишь одну обязанность и соответственно не должно быть больше одной причины для его изменения.
- Low Coupling, слабая связанность, означает что модули, на которые разбивается система, должны быть, по возможности, независимы или слабо связанны друг с другом. Они должны иметь возможность взаимодействовать, но при этом как можно меньше знать друг о друге (принцип минимального знания).
Это значит, что при правильном проектировании, при изменении одного модуля, не придется править другие или эти изменения будут минимальными. Чем слабее связанность, тем легче писать/понимать/расширять/чинить программу.
Считается, что хорошо спроектированные модули должны обладать следующими свойствами:
- функциональная целостность и завершенность — каждый модуль реализует одну функцию, но реализует хорошо и полностью; модуль самостоятельно (без помощи дополнительных средств) выполняет полный набор операций для реализации своей функции.
- один вход и один выход — на входе программный модуль получает определенный набор исходных данных, выполняет содержательную обработку и возвращает один набор результатных данных, т.е. реализуется стандартный принцип IPO — вход–процесс–выход;
- логическая независимость — результат работы программного модуля зависит только от исходных данных, но не зависит от работы других модулей;
- слабые информационные связи с другими модулями — обмен информацией между модулями должен быть по возможности минимизирован.
Грамотная декомпозиция — это своего рода искусство и гигантская проблема для многих программистов. Простота тут очень обманчива, а ошибки обходятся очень дорого. Если выделенные модули оказываются сильно сцеплены друг с другом, если их не удается разрабатывать независимо или не ясно за какую конкретно функцию каждый из них отвечает, то стоит задуматься а правильно ли вообще производится деление. Должно быть понятно, какую роль выполняет каждый модуль. Самый же надежный критерий того, что декомпозиция делается правильно, это если модули получаются самостоятельными и ценными сами по себе подпрограммами, которые могут быть использованы в отрыве от всего остального приложения (а значит, могут быть переиспользуемы).
Делая декомпозицию системы желательно проверять ее качество задавая себе вопросы: “Какую функцию выполняет каждый модуль?“, “Насколько модули легко тестировать?”, “Возможно ли использовать модули самостоятельно или в другом окружении?”, “Как сильно изменения в одном модуле отразятся на остальных?”
В первую очередь следует, конечно же, стремиться к тому, чтобы модули были предельно автономны. Как и было сказано, это является ключевым параметром правильной декомпозиции. Поэтому проводить ее нужно таким образом, чтобы модули изначально слабо зависели друг от друга. Но кроме того, имеется ряд специальных техник и шаблонов, позволяющих затем дополнительно минимизировать и ослабить связи между подсистемами. Например, в случае MVC для этой цели использовался шаблон «Наблюдатель», но возможны и другие решения. Можно сказать, что техники для уменьшения связанности, как раз и составляют основной «инструментарий архитектора». Только необходимо понимать, что речь идет о всех подсистемах и ослаблять связанность нужно на всех уровнях иерархии, то есть не только между классам, но также и между модулями на каждом иерархическом уровне.
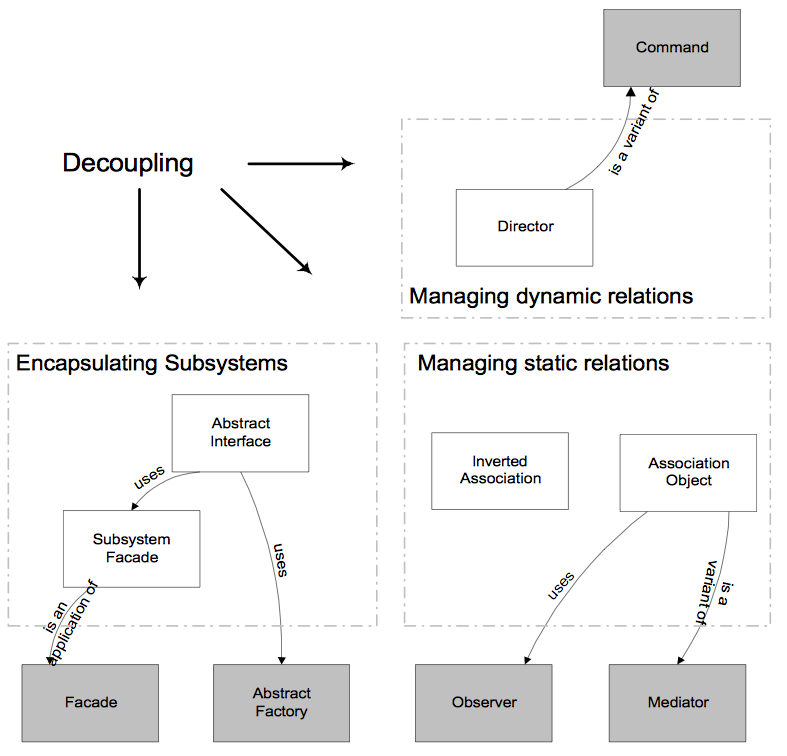
Как ослаблять связанность между модулями
Для наглядности, картинка из неплохой статьи “Decoupling of Object-Oriented Systems”, иллюстрирующая основные моменты, о которых будет идти речь.
1. Интерфейсы. Фасад
Главным, что позволяет уменьшать связанность системы, являются конечно же Интерфейсы (и стоящий за ними принцип Инкапсуляция + Абстракция + Полиморфизм):
- Модули должны быть друг для друга “черными ящиками” (инкапсуляция). Это означает, что один модуль не должен «лезть» внутрь другого модуля и что либо знать о его внутренней структуре. Объекты одной подсистемы не должны обращаться напрямую к объектам другой подсистемы
- Модули/подсистемы должны взаимодействовать друг с другом лишь посредством интерфейсов (то есть, абстракций, не зависящих от деталей реализации) Соответственно каждый модуль должен иметь четко определенный интерфейс или интерфейсы для взаимодействия с другими модулями.
Принцип «черного ящика» (инкапсуляция) позволяет рассматривать структуру каждой подсистемы независимо от других подсистем. Модуль, представляющий собой черный ящик, можно относительно свободно менять. Проблемы могут возникнуть лишь на стыке разных модулей (или модуля и окружения). И вот это взаимодействие нужно описывать в максимально общей (абстрактной) форме — в форме интерфейса. В этом случае код будет работать одинаково с любой реализацией, соответствующей контракту интерфейса. Собственно именно эта возможность работать с различными реализациями (модулями или объектами) через унифицированный интерфейс и называется полиморфизмом. Полиморфизм это вовсе не переопределение методов, как иногда ошибочно полагают, а прежде всего — взаимозаменяемость модулей/объектов с одинаковым интерфейсом, или «один интерфейс, множество реализаций» (подробнее тут). Для реализации полиморфизма механизм наследования совсем не нужен. Это важно понимать, поскольку наследования вообще, по возможности, следует избегать.
Благодаря интерфейсам и полиморфизму, как раз и достигается возможность модифицировать и расширять код, без изменения того, что уже написано (Open-Closed Principle). До тех пор, пока взаимодействие модулей описано исключительно в виде интерфейсов, и не завязано на конкретные реализации, мы имеем возможность абсолютно «безболезненно» для системы заменить один модуль на любой другой, реализующий тот же самый интерфейс, а также добавить новый и тем самым расширить функциональность. Это как в конструкторе или «плагинной архитектуре» (plugin architecture) — интерфейс служит своего рода коннектором, куда может быть подключен любой модуль с подходящим разъемом. Гибкость конструктора обеспечивается тем, что мы можем просто заменить одни модули/«детали» на другие, с такими же разъемами (с тем же интерфейсом), а также добавить сколько угодно новых деталей (при этом уже существующие детали никак не изменяются и не переделываются). Подробнее про Open-Closed Principle и про то, как он может быть реализован можно почитать тут + хорошая статья на английском.
Интерфейсы позволяют строить систему более высокого уровня, рассматривая каждую подсистему как единое целое и игнорируя ее внутреннее устройство. Они дают возможность модулям взаимодействовать и при этом ничего не знать о внутренней структуре друг друга, тем самым в полной мере реализуя принцип минимального знания, являющейся основой слабой связанности. Причем, чем в более общей/абстрактной форме определены интерфейсы и чем меньше ограничений они накладывают на взаимодействие, тем гибче система. Отсюда фактически следует еще один из принципов SOLID — Принцип разделения интерфейса (Interface Segregation Principle), который выступает против «толстых интерфейсов» и говорит, что большие, объемные интерфейсы надо разбивать на более маленькие и специфические, чтобы клиенты маленьких интерфейсов (зависящие модули) знали только о методах, которые необходимы им в работе. Формулируется он следующим образом: “Клиенты не должны зависеть от методов (знать о методах), которые они не используют” или “Много специализированных интерфейсов лучше, чем один универсальный”.
Итак, когда взаимодействие и зависимости модулей описываются лишь с помощью интерфейсов, те есть абстракций, без использования знаний об их внутреннем устройстве и структуре, то фактически тем самым реализуется инкапсуляция, плюс мы имеем возможность расширять/изменять поведения системы за счет добавления и использования различных реализаций, то есть за счет полиморфизма. Из этого следует, что концепция интерфейсов включает в себя и в некотором смысле обобщает почти все основные принципы ООП — Инкапсуляцию, Абстракцию, Полиморфизм. Но тут возникает один вопрос. Когда проектирование идет не на уровне объектов, которые сами же и реализуют соответствующие интерфейсы, а на уровне модулей, то что является реализацией интерфейса модуля? Ответ: если говорить языком шаблонов, то как вариант, за реализацию интерфейса модуля может отвечать специальный объект — Фасад.
Фасад — это объект-интерфейс, аккумулирующий в себе высокоуровневый набор операций для работы с некоторой подсистемой, скрывающий за собой ее внутреннюю структуру и истинную сложность. Обеспечивает защиту от изменений в реализации подсистемы. Служит единой точкой входа — “вы пинаете фасад, а он знает, кого там надо пнуть в этой подсистеме, чтобы получить нужное”.
Таким образом, мы получаем первый, самый важный паттерн, позволяющий использовать концепцию интерфейсов при проектировании модулей и тем самым ослаблять их связанность — «Фасад». Помимо этого «Фасад» вообще дает возможность работать с модулями точно также как с обычными объектами и применять при проектировании модулей все те полезные принципы и техники, которые используются при проектирования классов.
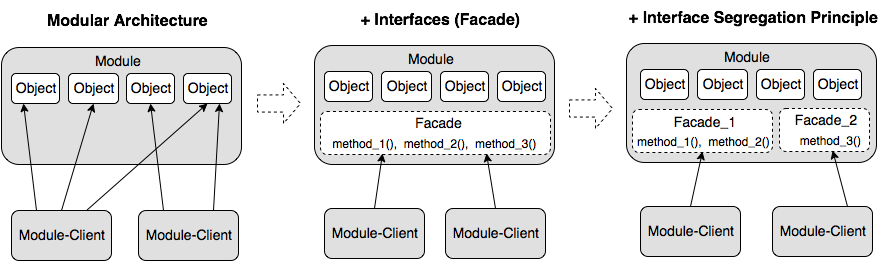
Замечание: Хотя большинство программистов понимают важность интерфейсов при проектировании классов (объектов), складывается впечатление, что идея необходимости использовать интерфейсы также и на уровне модулей только зарождается. Мне встретилось очень мало статей и проектов, где интерфейсы бы применялись для ослабления связанности между модулями/слоями и соответственно использовался бы паттерн «Фасад». Кто, например, видел «Фасад» на схемах уже упоминавшегося «архитектурного шаблона» Модель-Вид-Контроллер, или хотя бы слышал его упоминание среди паттернов, входящих в состав MVC (наряду с Observer и Composite)? А ведь он там должен быть, поскольку Модель это не класс, это модуль, причем центральный. И у создателя MVC Трюгве Реенскауга он, конечно же, был (смотрим «The Model-View-Controller (MVC ). Its Past and Present», только учитываем, что это писалось в 1973 году и то, что мы сейчас называем Представлением — Presentaition/UI тогда называлось Editior). Странным образом «Фасад» потерялся на многие годы и вновь обнаружить его мне удалось лишь недавно, в основном, в обобщенном варианте MVC от Microsoft («Microsoft Application Architecture Guide»). Вот соответствующие слайды:
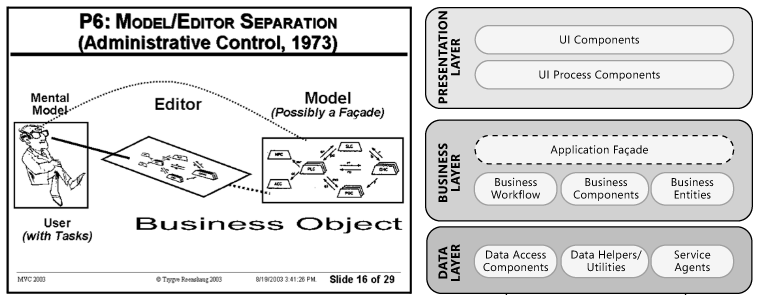
А разработчикам, к сожалению, приходится заново «переоткрывать» идею, что к объектам Модели, отвечающей за бизнес-логику приложения, нужно обращаться не напрямую а через интерфейс, то есть «Фасад», как например, в этой статье, откуда для полноты картины взят еще один слайд:
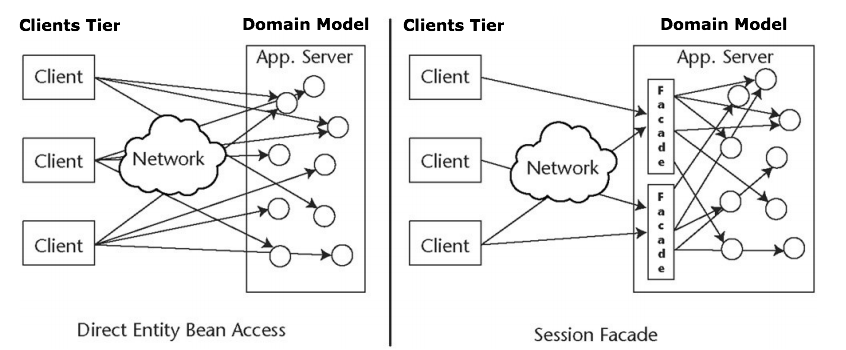
2. Dependency Inversion. Корректное создание и получение зависимостей
Формально, требование, чтобы модули не содержали ссылок на конкретные реализации, а все зависимости и взаимодействие между ними строились исключительно на основе абстракций, то есть интерфейсов, выражается принципом Инвертирования зависимостей (Dependency Inversion — последний из пяти принципов SOLID):
- Модули верхнего уровня не должны зависеть от модулей нижнего уровня. И те, и другие должны зависеть от абстракций.
- Абстракции не должны зависеть от деталей. Реализация должна зависеть от абстракции.
У этого принципа не самая очевидная формулировка, но суть его, как и было сказано, выражается правилом: «Все зависимости должны быть в виде интерфейсов». Подробно и очень хорошо принцип инвертирования зависимостей разбирается в статье Модульный дизайн или «что такое DIP, SRP, IoC, DI и т.п.». Статья из разряда must-read, лучшее, что доводилось читать по архитектуре ПО.
Не смотря на свою фундаментальность и кажущуюся простоту это правило нарушается, пожалуй, чаще всего. А именно, каждый раз, когда в коде программы/модуля мы используем оператор new и создаем новый объект конкретного типа, то тем самым вместо зависимости от интерфейса образуется зависимость от реализации.
Понятно, что этого нельзя избежать и объекты где-то должны создаваться. Но, по крайней мере, нужно свести к минимуму количество мест, где это делается и в которых явно указываются классы, а также локализовать и изолировать такие места, чтобы они не были разбросаны по всему коду программы. Решение заключается в том, чтобы сконцентрировать создание новых объектов в рамках специализированных объектов и модулей — фабрик, сервис локаторов, IoC-контейнеров.
В каком-то смысле такое решение следует Принципу единственного выбора (Single Choice Principle), который говорит: “всякий раз, когда система программного обеспечения должна поддерживать множество альтернатив, их полный список должен быть известен только одному модулю системы“. В этом случае, если в будущем придется добавить новые варианты (или новые реализации, как в рассматриваемом нами случае создания новых объектов), то достаточно будет произвести обновление только того модуля, в котором содержится эта информация, а все остальные модули останутся незатронутыми и смогут продолжать свою работу как обычно.
Ну а теперь разберем подробнее, как это делается на практике и каким образом модули могут корректно создавать и получать свои «зависимости», не нарушая принципа Dependency Inversion.
Итак, при проектировании модуля должны быть определены следующие ключевые вещи:
- что модуль делает, какую функцию выполняет
- что модулю нужно от его окружения, то есть с какими объектами/модулями ему придется иметь дело и
- как он это будет получать
Крайне важно то, как модуль получает ссылки на объекты, которые он использует в своей работе. И тут возможны следующие варианты:
- Модуль сам создает объекты необходимые ему для работы.
Но, как и было сказано, модуль не может это сделать напрямую — для создания необходимо вызвать конструктор конкретного типа, и в результате модуль будет зависеть не от интерфейса, а от конкретной реализации. Решить проблему в данном случае позволяет шаблон Фабричный Метод (Factory Method).
“Суть заключается в том, что вместо непосредственного инстанцирования объекта через new, мы предоставляем классу-клиенту некоторый интерфейс для создания объектов. Поскольку такой интерфейс при правильном дизайне всегда может быть переопределён, мы получаем определённую гибкость при использовании низкоуровневых модулей в модулях высокого уровня”.
В случаях, когда нужно создавать группы или семейства взаимосвязанных объектов, вместо Фабричного Метода используется Абстрактная Фабрика (Abstract factory).
- Модуль берет необходимые объекты у того, у кого они уже есть (обычно это некоторый, известный всем репозиторий, в котором уже лежит все, что только может понадобиться для работы программы).
Этот подход реализуется шаблоном Локатор Сервисов (Service Locator), основная идея которого заключается в том, что в программе имеется объект, знающий, как получить все зависимости (сервисы), которые могут потребоваться.
Главное отличие от фабрик в том, что Service Locator не создаёт объекты, а фактически уже содержит в себе инстанцированные объекты (или знает где/как их получить, а если и создает, то только один раз при первом обращении). Фабрика при каждом обращении создает новый объект, который вы получаете в полную собственность и можете делать с ним что хотите. Локатор же сервисов выдает ссылки на одни и те же, уже существующие объекты. Поэтому с объектами, выданными Service Locator, нужно быть очень осторожным, так как одновременно с вами ими может пользоваться кто-то еще.
Объекты в Service Locator могут быть добавлены напрямую, через конфигурационный файл, да и вообще любым удобным программисту способом. Сам Service Locator может быть статическим классом с набором статических методов, синглетоном или интерфейсом и передаваться требуемым классам через конструктор или метод.
Вообще говоря, Service Locator иногда называют антипаттерном и не рекомендуют использовать (главным образом потому, что он создает неявные связности и дает лишь видимость хорошего дизайна). Подробно можно почитать у Марка Симана:
Service Locator is an Anti-Pattern
Abstract Factory or Service Locator? - Модуль вообще не заботиться о «добывании» зависимостей. Он лишь определяет, что ему нужно для работы, а все необходимые зависимости ему поставляются («впрыскиваются») из вне кем-то другим.
Это так и называется — Внедрение Зависимостей (Dependency Injection). Обычно требуемые зависимости передаются либо в качестве параметров конструктора (Constructor Injection), либо через методы класса (Setter injection).
Такой подход инвертирует процесс создания зависимости — вместо самого модуля создание зависимостей контролирует кто-то извне. Модуль из активного элемента, становится пассивным — не он делает, а для него делают. Такое изменение направления действия называется Инверсия Контроля (Inversion of Control), или Принцип Голливуда — «Не звоните нам, мы сами вам позвоним».
Это самое гибкое решение, дающее модулям наибольшую автономность. Можно сказать, что только оно в полной мере реализует «Принцип единственной ответственности» — модуль должен быть полностью сфокусирован на том, чтобы хорошо выполнять свою функцию и не заботиться ни о чем другом. Обеспечение его всем необходимым для работы это отдельная задача, которой должен заниматься соответствующий «специалист» (обычно управлением зависимостями и их внедрениями занимается некий контейнер — IoC-контейнер).
По сути, здесь все как в жизни: в хорошо организованной компании программисты программируют, а столы, компьютеры и все необходимое им для работы покупает и обеспечивает кладовщик. Или, если использовать метафору программы как конструктора — модуль не должен думать о проводах, сборкой конструктора занимается кто-то другой, а не сами детали.
Более подробно и с примерами о способах создания и получения зависимостей можно почитать, например, в этой статье (только надо иметь ввиду, что хотя автор пишет о Dependency Inversion, он использует термин Inversion of Control; возможно потому, что в русской википедии содержится ошибка и этим терминам даны одинаковые определения). А принцип Inversion of Control (вместе с Dependency Injection и Service Locator) детально разбирается Мартином Фаулером и есть переводы обеих его статей: “Inversion of Control Containers and the Dependency Injection pattern” и “Inversion of Control”.
Не будет преувеличением сказать, что использование интерфейсов для описания зависимостей между модулями (Dependency Inversion) + корректное создание и внедрение этих зависимостей (прежде всего Dependency Injection) являются центральными/базовыми техниками для снижения связанности. Они служат тем фундаментом, на котором вообще держится слабая связанность кода, его гибкость, устойчивость к изменениям, переиспользование, и без которого все остальные техники имеют мало смысла. Но, если с фундаментом все в порядке, то знание дополнительных приемов может быть очень даже полезным. Поэтому продолжим.
3. Замена прямых зависимостей на обмен сообщениями
Иногда модулю нужно всего лишь известить других о том, что в нем произошли какие-то события/изменения и ему не важно, что с этой информацией будет происходить потом. В этом случае модулям вовсе нет необходимости «знать друг о друге», то есть содержать прямые ссылки и взаимодействовать непосредственно, а достаточно всего лишь обмениваться сообщениями (messages) или событиями (events).
Связь модулей через обмен сообщениями является гораздо более слабой, чем прямая зависимость и реализуется она чаще всего с помощью следующих шаблонов:
- Наблюдатель (Observer). Применяется в случае зависимости «один-ко-многим», когда множество модулей зависят от состояния одного — основного. Использует механизм рассылки, который заключается в том, что основной модуль просто осуществляет рассылку одинаковых сообщений всем своим подписчикам, а модули, заинтересованные в этой информации, реализуют интерфейс «подписчика» и подписываются на рассылку. Находит широкое применение в системах с пользовательским интерфейсом, позволяя ядру приложения (модели) оставаться независимым и при этом информировать связанные с ним интерфейсы о том что произошли какие-то изменения и нужно обновиться.
Организация взаимодействия посредством рассылки сообщений имеет дополнительный «бонус» — необязательность существования «подписчиков» на «опубликованные» (т.е. рассылаемые) сообщения. Качественно спроектированная подобная система допускает добавление/удаление модулей в любое время.
- Посредник (Mediator). Применяется, когда между модулями имеется зависимость «многие ко многим. Медиатор выступает в качестве посредника в общении между модулями, действуя как центр связи и избавляет модули от необходимости явно ссылаться друг на друга. В результате взаимодействие модулей друг с другом («все со всеми») заменяется взаимодействием модулей лишь с посредником («один со всеми»). Говорят, что посредник инкапсулирует взаимодействие между множеством модулей.

Типичный пример — контроль трафика в аэропорту. Все сообщения, исходящие от самолетов, поступают в башню управления диспетчеру, вместо того, чтобы пересылаться между самолетами напрямую. А диспетчер уже принимает решения о том, какие самолеты могут взлетать или садиться, и в свою очередь отправляет самолетам соответствующие сообщения. Подробнее, например, тут.
Дополнение: Модули могут пересылать друг другу не только «простые сообщения, но и объекты-команды. Такое взаимодействие описывается шаблоном Команда (Command). Суть заключается в инкапсулировании запроса на выполнение определенного действия в виде отдельного объекта (фактически этот объект содержит один единственный метод execute()), что позволяет затем передавать это действие другим модулям на выполнение в качестве параметра, и вообще производить с объектом-командой любые операции, какие могут быть произведены над обычными объектами. Кратко рассмотрен тут, соответствующая глава из книги банды четырех тут, есть также статья на хабре.
4. Замена прямых зависимостей на синхронизацию через общее ядро
Данный подход обобщает и развивает идею заложенную в шаблоне «Посредник». Когда в системе присутствует большое количество модулей, их прямое взаимодействие друг с другом становится слишком сложным. Поэтому имеет смысл взаимодействие «все со всеми» заменить на взаимодействие «один со всеми». Для этого вводится некий обобщенный посредник, это может быть общее ядро приложения, хранилище или шина данных, а все остальные модули становятся независимыми друг от друга клиентами, использующими сервисы этого ядра или выполняющими обработку содержащейся там информации. Реализация этой идеи позволяет модулям-клиентам общаться друг с другом через посредника и при этом ничего друг о друге не знать.
Ядро-посредник может как знать о модулях-клиентах и управлять ими (пример — архитектура apache ), так и может быть полностью, или почти полностью, независимым и ничего о клиентах не знать. В сущности именно этот подход реализован в «шаблоне» Модель-Вид-Контроллер (MVC), где с одной Моделью (являющейся ядром приложение и общим хранилищем данных) могут взаимодействовать множество Пользовательских Интерфейсов, которые работают синхронно и при этом не знают друг о друге, а Модель не знает о них. Ничто не мешает подключить к общей модели и синхронизировать таким образом не только интерфейсы, но и другие вспомогательные модули.
Очень активно эта идея также используется при разработке игр, где независимые модули, отвечающие за графику, звук, физику, управление программой синхронизируются друг с другом через игровое ядро (модель), где хранятся все данные о состоянии игры и ее персонажах. В отличие от MVC, в играх согласование модулей с ядром (моделью) происходит не за счет шаблона «Наблюдатель», а по таймеру, что само по себе является интересным архитектурным решением весьма полезным для программ с анимацией и «бегущей» графикой.
5. Закон Деметры (law of Demeter)
Закон Деметры запрещает использование неявных зависимостей: “Объект A не должен иметь возможность получить непосредственный доступ к объекту C, если у объекта A есть доступ к объекту B и у объекта B есть доступ к объекту C“. Java-пример.
Это означает, что все зависимости в коде должны быть «явными» — классы/модули могут использовать в работе только «свои зависимости» и не должны лезть через них к другим. Кратко этот принцип формулируют еще таким образом: “Взаимодействуй только с непосредственными друзьями, а не с друзьями друзей“. Тем самым достигается меньшая связанность кода, а также большая наглядность и прозрачность его дизайна.
Закон Деметры реализует уже упоминавшийся «принцип минимального знания», являющейся основой слабой связанности и заключающийся в том, что объект/модуль должен знать как можно меньше деталей о структуре и свойствах других объектов/модулей и вообще чего угодно, включая собственные подкомпоненты. Аналогия из жизни: Если Вы хотите, чтобы собака побежала, глупо командовать ее лапами, лучше отдать команду собаке, а она уже разберётся со своими лапами сама.
6. Композиция вместо наследования
Одну из самых сильных связей между объектами дает наследование, поэтому, по возможности, его следует избегать и заменять композицией. Эта тема хорошо раскрыта в статье Герба Саттера — «Предпочитайте композицию наследованию».
Могу только посоветовать в данном контексте обратить внимание на шаблон Делегат (Delegation/Delegate) и пришедший из игр шаблон Компонет (Component), который подробно описан в книге «Game Programming Patterns» (соответствующая глава из этой книги на английском и ее перевод).
Что почитать
Статьи в интернете:
- Design patterns for decoupling (небольшая полезная глава из UML Tutorial);
- Немного про архитектуру;
- Patterns For Large-Scale JavaScript Application Architecture;
- Слабое связывание компонентов в JavaScript;
- Как писать тестируемый код — статья из которой хорошо видно что критерии тестируемости кода и хорошего дизайна совпадают;
- сайт Мартина Фаулера.
Замечательный ресурс — Архитектура приложений с открытым исходным кодом, где “авторы четырех дюжин приложений с открытым исходным кодом рассказывают о структуре созданных ими программ и о том, как эти программы создавались. Каковы их основные компоненты? Как они взаимодействуют? И что открыли для себя их создатели в процессе разработки? В ответах на эти вопросы авторы статей, собранных в данных книгах, дают вам уникальную возможность проникнуть в то, как они творят“. Одна из статей полностью была опубликована на хабре — «Масштабируемая веб-архитектура и распределенные системы».
Интересные решения и идеи можно найти в материалах, посвященных разработке игр. Game Programming Patterns — большой сайт с подробным описанием многих шаблонов и примерами их применения к задаче создания игр (оказывается, есть уже его перевод — «Шаблоны игрового программирования», спасибо strannik_k за ссылку). Возможно будет полезна также статья «Гибкая и масштабируемая архитектура для компьютерных игр» (и ее оригинал. Нужно только иметь ввиду что автор почему-то композицию называет шаблоном “Наблюдатель”).
По поводу паттернов проектирования:
- Интересная «Мысль про паттерны проектирования»;
- Удобный сайт с краткими описаниями и схемами всех шаблонов проектирования — «Обзор паттернов проектирования»;
- сайт на базе книги банды четырех, где все шаблоны описаны очень подробно — «Шаблоны [Patterns] проектирования».
Есть еще принципы/паттерны GRASP, описанные Крэгом Лэрманом в книге «Применение UML 2.0 и шаблонов проектирования», но они больше запутывают чем проясняют. Краткий обзор и обсуждение на хабре (самое ценное в комментариях).
Ну и конечно же книги:
- Мартин Фаулер «Архитектура корпоративных программных приложений»;
- Стив Макконнелл «Совершенный код»;
- Шаблоны проектирования от банды четырех (Gang of Four, GoF) — «Приемы объектно-ориентированного проектирования. Паттерны проектирования».
Сегодня, несмотря на то, что поставщики IT-решений для бизнеса становятся все более централизованными, сам же бизнес становится более атомарным. Становится все больше и больше маленьких компаний, которые также нуждаются в технологических решениях, и эти потребности могут быть удовлетворены в том числе и частными разработчиками.
Неважно, ведется ли разработка в одиночку либо небольшой командой, сроки всегда сжаты, что увеличивает стоимость ошибок, совершенных на этапе проектирования, так как это может привести к необходимости возврата за «чертежи» в ходе реализации проекта.
Проблемой маленьких команд или проектов является то, что не все методологии написанные и публикуемые в сети к ним применимы. И команды зачастую не состоят из “ветеранов проектирования” — потому что те просто “не по карману” стартапам и частным командам.
Поэтому в этой статье приводится план построения архитектуры проекта, основанный на многолетнем опыте разработки Enterprise решений, адаптированный под небольшие системы, который поможет избежать критических проблем в ходе реализации самой системы.
Шаг 1: Основной процесс
Любое решение строится вокруг какого-то процесса — например совершение покупки, или подача заявки, даже публикация поста. Здесь речь идет не только о последовательности действий пользователей — участников будущей системы, но и про внутренние процессы: проверки одной системой, регистрация другой, подготовка публикации и так далее.
Описание процесса лучше делать “сверху вниз” то есть начинать с более высокого уровня детализации, а потом “спускаться” из абстракций в детали. Например:
… а затем:
Здесь можно не бояться добавлять детали не только на текущем уровне детализации, но и возвращаться на “верхний уровень” — добавлять большие блоки и детализировать их. Например:
В конце должна получиться картина, которая полностью закрывает ожидания от будущего решения для всех участников проекта.
Ввиду того, что на данном этапе отсутствует структура как таковая, я предлагаю использовать простой текстовый редактор например https://docs.google.com/, потому что любой другой инструмент, требующий более структурированного подхода, на текущем этапе будет только ограничивать свободу мысли. Например, если, для того чтобы добавить простую функцию, надо переработать структуру документа, мозг подсознательно начнет оценивать целесообразность затрат и многие мысли не будут зафиксированы. А в IT фраза «Дьявол кроется в деталях» может запомниться как очень дорогой урок.
После того, как описан основной процесс, таким же образом формализуются остальные — служебные процессы, которые зависят от основного.
Шаг 2: Участники процесса
После того, как список действий определен, становится возможным понять кто и какое действие выполняет. То есть для каждого шага мы определяем исполнителей, кто должен или может делать какое-то действие в рамках процессов.
Для простоты исполнителей можно просто указать в скобках напротив каждого действия:
Таким образом мы не только понимаем кто будет выполнять действия, но и начинаем формировать список интерфейсов и устройств, с которых будут поддерживаться эти действия.
Шаг 3: Диаграмма процесса
В современном мире, текст не является самым быстрым способом донести структурную информацию, поэтому необходима визуализация работы, проведенной на предыдущих этапах.
Для этого, корпоративный мир использует диаграммы процессов, и для них существует множество стандартов и нотаций. Для нашего контекста я бы посоветовал BPMN.
Несмотря на определенные неудобства, я рекомендую использовать https://app.diagrams.net/, ввиду того, что этот инструмент бесплатный и предоставляет очень много шаблонов, которые окажутся очень полезными для новичков.
BPMN как язык диаграмм, предоставляет очень богатый инструментарий, который… нам с вами не нужен. В рамках объявленного в заголовке масштаба задачи, нам достаточно использования:
- Действия
- Связ
- Условий
Остальное – оставим корпоративщикам.
В итоге получается диаграмма, которую можно согласовать с клиентом.
Шаг 4: Наборы данных
Диаграмма помогает понять “кто?”, “что?” и “когда?”, однако не отвечает на вопрос “с чем?”.
Для этого нам необходимо построить модель данных – совокупность объектов, их атрибутов и связей между ними. На основании именно этой модели, впоследствии, будет строиться архитектура Базы данных, разбиваться система на сервисы и формироваться форматы вызовов сервисов и многое другое.
Здесь есть следующие понятия:
- Бизнес атрибуты – в которые, например, входят Табельный номер сотрудника и его Адрес
- Служебные атрибуты – здесь речь идет о таких, как дата регистрации или логин
Для каждого блока “Действие” в нашей диаграмме, необхродимо описать какие именно данные нужны этому участнику процесса для выполнения этого действия. Например:
Этот шаг, выполненный для всех действий позволит сформировать общее понимание всей модели данных с Бизнес-перспективы.
Дальше на основании собственного опыта и подходов самих разработчиков, сюда же добавляются и служебные атрибуты. В скором времени я планирую написать отдельную статью о том, какие из них спасают время при дебаге и разбирательствах (напишите в комментариях, интересно ли это).
Шаг 5: Модель данных
На текущем шаге, мы уже имеем на руках процесс, его визуализацию, данные, которые нужны участникам и нам самим, самое время строить модель данных.
В качестве инструментов можно использовать все тот же https://app.diagrams.net/, однако для случае, когда связей много а модели простые, я бы предложил использование https://start.jhipster.tech/jdl-studio/ который является окном в мир кодогенераторов и hgjfrnbdyjuj прототипирования и точно заслуживает отдельной статьи. Здесь мы только поскребем по поверхности и используем бесплатный инструмент JDL-studio.
Синтаксис достаточно простой, разобраться может любой новичок минут за 5, тем более что все изменения применяются сразу и диаграмма моделей перестраивается.
Шаг 6: Интерфейсные модули
Теперь мы должны вернуться к самому первому документу и извлечь из него данные в следующем формате:
Либо, как делается в корпоративных проектах, ввиду сложной иерархии:
Где, для каждого раздела необходимо расписать набор из:
- Данных для отображения: Какие данные и из какой модели отображаются
- Органов управления: Какие кнопки / фильтры / виджеты должны присутствовать и какие функции они выполняют
Эта структура позволяет дать более-менее структурированное понимание функций системы “from user perspective”, что очень удобно дизайнерам.
Шаг 7: Прототипирование
На текущем этапе у нас есть достаточно данных для того, чтобы приступить к шагу, который легче всего оценить клиенту – прототипирование.
Здесь есть множество решений платных и бесплатных, сложный и простых, интерактивных и нет.
На собственном опыте, принимая во внимание распространенность, бесплатность и интерактивность я бы порекомендовал https://www.figma.com/. Единственное, что он не умеет (хотя бы из коробки) – это давать возможность заполнять текстовые поля в режиме Презентации.
Важно упомянуть – что работа с Figma станет гораздо удобнее при использовании готовых шаблонов и наборов компонентов, доступных в сети.
Мобильные прототипы можно “скачать” и посмотреть как они выглядят на устройстве (обязательно делайте эту проверку)
Прототип можно продемонстрировать клиенту, получить обратную связь, и внести какие-либо исправления назад в документы (вплоть до описания процессов). Это на первый взгляд кажется растратой времени и ресурсов, но по опыту, это инвестиции в более предсказуемую разработку самого решения.
Шаг 8: Проектирование API
Этот этап вынесен в самый конец неспроста – в ходе демонстрации прототипа, зачастую всплывают изменения в том, кто и в каком устройстве должен что-то делать, что накладывает достаточно драматические изменения в архитектуру API систем и сервисов.
Более того, проектирование API критично еще и потому, что структура API – это контракт между разработчиками разных компонентов, например Front-end и Back-end систем. И управляемость совместной разработки напрямую зависит от того, насколько детально прописаны API-calls, и насколько полно они удовлетворяют вызывающую и принимающую сторону.
На этом этапе, имея на руках формализованный процесс, диаграмма которого показывает точки “соприкосновения” систем, структурированную модель данных, интерфейсы и их функции, разработка архитектуры завершается тем, что команда (или все альтер-эго одного разработчика) совместно прописывает API-calls, расходится и приступает к планомерной разработке итогового решения, имея на руках все, необходимые для этого документы, данные и диаграммы.
Заключение
Весь этот процесс, в зависимости от сложности проекта, “размера” клиента и количества вовлеченных человек, занимает от одной до двух недель. Но эти затраты ничто по сравнению с теми, которые придется нести в случае, если это процесс не выполнять в каждом проекте. И, по опыту, они окупаются со 100% вероятностью.

Что это такое? Архитектура системы – это описание продукта программирования (ОС, приложений, программ) с точки зрения пользователя, заказчика и специалиста по проектированию. В ней объясняется, из чего состоит система, как элементы взаимодействуют между собой.

Какие различают? Существует несколько основных типов архитектуры: многослойные, многоуровневые, сервис-ориентированные, микросервисные.
В статье рассказывается:
- Суть архитектуры системы
- Многослойная архитектура системы программ
- Многоуровневая архитектура системы ПО
- Сервис-ориентированная архитектура системы ПО (SOA)
- Mикросервисная архитектура
-

Пройди тест и узнай, какая сфера тебе подходит:
айти, дизайн или маркетинг.Бесплатно от Geekbrains
Суть архитектуры системы
Определение архитектуры системы обозначает её как фундаментальную организацию целевой системы. Простыми словами, это описание основных компонентов и модулей с принципами их работы и взаимосвязи друг с другом. Также архитектура отображает различные вариации развития и эволюции системы.
Существует минимум три тематических определения архитектуры системы (наборов рабочих моделей).

То, как видит систему пользователь, называется операционным (практическим) описанием, или Operation View. Описание содержит в себе этапы применения системы оператором, сценарии и потоки работ:
- графический и числовой вид операций;
- организационную структуру схемы (organization charts);
- различные вариации использования (use cases) и сценарии;
- диаграммы потоков задач (task flow diagrams);
- диаграммы потоков информации (information flow diagrams).
Скачать
файл
Логическое описание (Logical View) это видение системы со стороны руководителя или заказчика. Logical View включает в себя продукты, определяющие границы между самой системой и ее окружением, между функциональными интерфейсами и внешними системами. Кроме того, логическое описание включает в себя артефакты видов поведения и функций системы, потоков данных, внешних и внутренних наборов данных, внешних и внутренних пользователей и внутренних функциональных интерфейсов:
- принципиальные схемы;
- функциональная декомпозиция (data flow chart);
- диаграммы IDEF0;
- схемы или диаграммы функциональных потоков (FFBD).
Физическое описание (Physical View) определяет видение системы с точки зрения экспертов по проектированию. Здесь определяется физическая граница системы и её компонентов, информационно-технологическая структура, взаимодействие модулей и их интерфейсов, структура данных и её внутренняя база, а также применяемые в разработке системы правил. Вот некоторые примеры физических описаний архитектуры системы:
- физические блок-схемы с подробной детализацией;
- классификация базы данных;
- контроль интерфейса документов и их управления (interface control document, ICD);
- стандарты.
Архитектура операционной системы должна логически связывать между собой все три вида описаний, которые на выходе образуют конечный продукт со всеми основными функциями. Существует термин «архитектурные требования». Он определяет запросы, имеющие максимальное влияние на проектирование архитектуры системы, и указывает на её неразрывную связь с требованиями.
Разработкой архитектуры системы занимаются системные архитекторы. Это является одним из преобладающих видов специализации для этой профессии. Архитектура системы содержит большое количество структур, которые напрямую зависят от потребностей и требований заказчика и разработчика. Это требует определенного системного подхода. Отсюда вытекает ещё одно определение для архитектурного проектирования – системное проектирование.
Первые разработки компьютерных систем происходили без архитектуры. У такого подхода, как тогда казалось, было много плюсов. Разработчики не несли издержек по планированию и быстро реализовывали проект.
Однако со временем, по мере нагрузки и усложнения ПО, оно теряло управляемость. Приходилось добавлять новые изменения, которые с каждым разом становились дороже. Изначальные планы развивать проект за границей рушились. Системы без архитектуры того времени получили название «Большой комок грязи» (Big Ball of Mud).


Читайте также
На сегодняшний день разработчики придумали способы устранения недостатков проектирования программного обеспечения без архитектуры.
Многослойная архитектура системы программ
Многослойная архитектура системы приложений и программ работает по методу разделения ответственностей. Программное обеспечение состоит из слоёв, которые накладываются один на другой. У каждого слоя ПО есть своя обязанность.
Архитектура вычислительных систем разделяет ПО на следующие слои:
- Слой представления (Presentation Layer). Это интерфейс пользователя, который несет ответственность за удовлетворение использования программы юзером.
- Слой бизнес-логики (Business Logic Layer). Он разделяет UI/UX от вычислений, относящихся к бизнесу. Бизнес-требования постоянно меняются, а слой Business Logic Layer позволяет легко менять логику и подстраиваться под нововведения, никак не касаясь других слоев.
- Слой передачи данных (Data Link Layer). Система постоянно коммуницирует с постоянными хранилищами и производит большое количество операций по обработке информации, не связанной с бизнесом. Именно за это взаимодействие и отвечает слой Data Link Layer.
Каждый слой в дизайне содержит элементы управления и данные, которые переходят от одного к другому. Благодаря этой системе увеличивается уровень абстракции и отчасти стабильность программного обеспечения.
Плюсы многослойного построения архитектуры системы:
- в сравнении с другими подходами имеет более простое исполнение;
- разделение ответственности между уровнями увеличивает абстракцию;
- каждый слой защищен от изменений других благодаря изолированию;
- управление программным обеспечением находится на высоком уровне из-за незначительной связанности слоев.

Топ-30 самых востребованных и высокооплачиваемых профессий 2023
Поможет разобраться в актуальной ситуации на рынке труда

Подборка 50+ ресурсов об IT-сфере
Только лучшие телеграм-каналы, каналы Youtube, подкасты, форумы и многое другое для того, чтобы узнавать новое про IT
ТОП 50+ сервисов и приложений от Geekbrains
Безопасные и надежные программы для работы в наши дни
Уже скачали 20825 ![]()
Несмотря на множество плюсов такой подход имеет свои минусы:
- небольшие масштабы построения;
- монолитная структура с усложненным процессом внесения нововведений;
- прохождение данных по каждому слою вне зависимости от необходимости их передачи.
Многоуровневая архитектура системы ПО
Многоуровневая архитектура информационных систем делит программное обеспечение на уровни по принципу взаимоотношения «клиент-сервис». Уровни разграничивают ответственность поставщика данных и конечного потребителя.
Рассмотрим подробно возможные уровни архитектуры системы:
Одноуровневая система
В этом методе единая система работает одновременно на стороне сервера и на стороне пользователя. Она подходит для несложных программ, рассчитанных на одного клиента. Упрощенный вариант архитектуры исключает межсистемное взаимодействие и обеспечивает простоту развертывания и хорошую скорость связи.
Двухуровневая система
Работа двухуровневой системы строится на разделение работы физических машин сервера и пользователя. Такой подход обеспечивает обособленность операций по управлению данными, операций представления и обработки данных. Клиент включает в себя слои презентации, передачу данных и бизнес-логики. Сервер — базу данных и хранилище.
Трехуровневая и n-уровневая системы
Такие архитектуры вычислительных систем наделены высоким уровнем масштабируемости как по вертикали, так и по горизонтали. Кроме того, n-уровневая система позволяет создать программу высокой производительности.
Бюджет на создание такой системы будет гораздо выше. Высокая стоимость подразумевает использование метода в крупных программных разработках с комплексным решением (например, сложные ПО, требующие определенных параметров производительности и масштабируемости). В тандеме с современной сервис-ориентированной архитектурой это подход способен создавать самые сложные модели.
Масштабируемость метода может быть горизонтальной и вертикально. Высокопроизводительные узлы используются в горизонтальной, улучшение производительности отдельных узлов – в вертикальной.
Сервис-ориентированная архитектура системы ПО (SOA)
Такой тип архитектуры систем содержит в себе связанные друг с другом компоненты и приложения. Связь устанавливается с помощью строго определенных сервисов.
Основы и элементы архитектуры системы такого типа:
- сервисы (Services);
- связующее программное обеспечение или сервисная шина (Service Bus);
- хранилище данных сервиса или сервисный репозиторий (ServiceRepository catalogue of services);
- безопасность набора архитектурных принципов —SOA (SOA Security);
- управление SOA (SOA Governance).
Пользователь направляет запрос со стандартным протоколом и форматом данных по сети. Сервисная шина предприятия (ESB — enterprise service bus) обрабатывает запрос. Она считается центром сервис-ориентированной архитектуры компьютерных систем, так как несет ответственность за маршрутизацию и оркестровку.
Далее ESB с помощью сервисного репозитория направляет запрос в специальный сервис, и уже он взаимодействует с другими сервисами и базами данных. На основании этого формируется ответ, содержащий данные о полезной нагрузке.
Для проведения безопасной и отвечающей требованиям транзакции полный вызов ответа согласуется с установленными правилами управления и безопасности набора архитектурных принципов.
Существует два вида сервисов:
- Атомарные сервисы (Atomic services). Предоставляют функции, не подлежащие последующему разделению.
- Композиционные сервисы (Composite services). Это несколько атомарных сервисов, которые обеспечивают сложную составную функциональность.
Только до 18.05
Скачай подборку тестов, чтобы определить свои самые конкурентные скиллы
Список документов:
 Тест на определение компетенций
Тест на определение компетенций
Чек-лист «Как избежать обмана при трудоустройстве»
Инструкция по выходу из выгорания
Чтобы получить файл, укажите e-mail:
Подтвердите, что вы не робот,
указав номер телефона:

Уже скачали 7503
Типы сервисов:
- организационные (Entity service);
- доменные (Domain Service);
- вспомогательные (Utility Service);
- интегрированные (Integrated Service);
- сервис безопасности (Security Service);
- сервис приложений (Application Service).
Mикросервисная архитектура
Микросервисная архитектура систем программирования основывается на разработке приложений как набора сервисов. Каждый из небольших сервисов обособлен в собственном процессе и связывается с несложными легковесными механизмами. Зачастую это API для HTTP-ресурса.
Основа таких сервисов – бизнес-возможности. Они имеют отдельный автоматизированный механизм и работают отдельно друг от друга.
Административное управление между сервисами сводится к минимуму. Они могут использовать разные технологии хранения данных и иметь отличные друг от друга языки написания.
Создание микросервисной архитектуры систем основывается на компонентизации сервисов, которая делит программное обеспечение на различные компоненты (сервисы) изолированные друг от друга. Каждый из таких сервисов несёт свою ответственность. Изменение одних компонентов не должны влиять на другие.
Архитектура работает по принципу компонентизации сервисов. Она разделяет программное обеспечение на различные изолированные компоненты (сервисы) каждый из которых несет единую ответственность. Изменения в одной сервисе не должны затрагивать другие.

Архитектура включает в себя отдельные компактные микросервисы. Они способны расширяться обособленно и не зависят друг от друга. Вот 5 основных компонентов такой архитектуры:
- сервисы (Services);
- сервисная шина (Service Bus);
- внешняя конфигурация (External configuration);
- шлюз API (API Gateway);
- контейнеры (Containers).
Основными характеристиками микросервисной архитектуры являются:
- сервисная компонентизация;
- организация отталкивается от бизнес-возможностей;
- ориентация на продукты, а не на проекты;
- умные конечные точки и глупые каналы (Smart endpoints and dumb pipes);
- децентрализованное управление;
- децентрализованное управление данными;
- автоматизированная инфраструктура;
- защита от сбоев;
- эволюционное проектирование.
Отдельное развитие каждого микросервиса под управлением различных команд наиболее оптимально в таком подходе. Передача данных осуществляется по стандартному протоколу и формату данных, поэтому структура одного сервиса не повлияет на функциональность смежных.
Плюсы:
- Высокий уровень изоляции со слабой связанностью.
- Повышенная модульность.
- Изолированные системы предотвращают влияние сбоя в одном сервисе на другой.
- Гибкость и масштабируемость на высоком уровне.
- Ускоренные итерации, благодаря простой модификации.
- Улучшенная система обработки ошибок.
- В отличие от многослойной архитектуры, решает проблемы с потоками данных.

Читайте также
Недостатки:
- При обмене данных между сервисами есть повышенный риск сбоя.
- Затрудненное управление из-за большого количества сервисов.
- Распределительная архитектура обязывает искать пути решения ряда проблем: задержка в сети, удержание гармоничного баланса нагрузки.
- Требует обязательного тестирования в распределительной среде.
- Долгое время реализации.
Мы рассмотрели все виды архитектуры систем. Отражение взаимодействия бизнеса и ИТ является основной задачей при создании архитектуры. С одной стороны, это документирование и стандартизация бизнес-процессов. С другой – описание составляющих архитектуры веб-систем на логическом уровне с учетом связей с бизнес-процессами.

- ITSM Frameworks
- Обо мне
- Библиотека (new)
- Блог
- Контакты

Мы собираем метаданные (cookie, данные об IP-адресе и местоположении) для функционирования сайта, если вы не согласны, чтобы эти данные обрабатывались, то должны покинуть сайт.
Я согласен, не показывать снова
Close
Шаблон описания архитектуры программного обеспечения
Для кого полезен шаблон
Разработчикам, корпоративным архитекторам, системным архитекторам, архитекторам решений.
Определение архитектуры программного обеспечения
Архитектура системы — это набор фундаментальных понятий или свойств системы в ее окружении, воплощенных в элементах, отношениях и принципах проектирования и эволюции. Определение взято из стандарта ISO/IEC 42 010 «Systems and Software Engineering-Architecture Description».
При проектировании архитектуры системы определяют требования к программному обеспечению, данным, с которыми оно взаимодействует и аппаратной платформе.
Идея создания шаблона описания архитектуры программного обеспечения
Интерес к архитектуре компьютерных систем появился благодаря работе в подразделении корпоративной архитектуры, где пришлось погрузиться в подходы к управлению архитектурой.
Углубляясь в тему проектирования архитектуры познакомилась с книгой «Архитектура программных систем» и шаблоном описания архитектуры ПО Эоина Вудса и Ника Розански. Чтобы уложить по полочкам материалы книги и сохранить полезный артефакт перевела шаблон, дополнила примерами из книги, личного опыта и материалами TOGAF.
Благодаря обратной связи шаблон ожил и на ближайшие месяцы запланированы задачи по развитию.
Польза шаблона описания архитектуры ПО
Шаблон поможет:
- собрать и систематизировать информацию об архитектуре, основных функциях и качественных характеристиках информационной системы;
- спроектировать решение с учетом требований заинтересованных лиц и обеспечить функциональную полноту и надежность системы;
- снизить вероятность сбоев, нарушений безопасности и рисков незапланированных затрат при развитии и эволюции системы.
Источники:
Шаблон составлен на основе шаблона архитектурного описания и книги «Архитектура программных систем» Эоина Вудса и Ника Розански, материалов The TOGAF® Standard, Version 9.2. и дополнен примерами представлений в форматах *.fm, *.archimate и *.vsd.
Скачать:
Получать первым новые публикации:
- Обо мне
- Библиотека (new)
- Блог
- Онлайн-курсы
- Контакты
- Политика обработки ПД
#Мнения
- 15 окт 2021
-

0
Как проектируют приложения: разбираемся в архитектуре
Старший iOS-разработчик из «ВКонтакте» рассказывает, почему архитектура не главное в проекте и как сделать продукт поддерживаемым и масштабируемым.

Старший iOS-разработчик во «ВКонтакте». Раньше был фулстеком, бэкендером и DevOps, руководил отделом мобильной разработки, три года преподавал iOS-разработку в GeekBrains, был деканом факультета. Состоит в программном комитете конференции Podlodka iOS Crew, ведёт YouTube-канал с видеоуроками по Flutter. В Twitter пишет под ником @tygeddar.

об авторе
Старший iOS-разработчик во «ВКонтакте». Раньше был фулстеком, бэкендером и DevOps, руководил отделом мобильной разработки, три года преподавал iOS-разработку в GeekBrains, был деканом факультета. Состоит в программном комитете конференции Podlodka iOS Crew, ведёт YouTube-канал с видеоуроками по Flutter. В Twitter пишет под ником @tygeddar.
Я люблю спорить о том, какая архитектура лучше. Может, из-за своего внутреннего перфекциониста или диплома архитектора информационных систем, а может, потому, что мне лень копаться в плохих проектах.
Спойлер: больше всего я люблю архитектуру MVC. Дальше расскажу, как она работает и почему мне не нравятся всякие MVVM, MVP и VIPER. Кстати, недавно я разобрался во Flux и её имплементации Redux и понял, что их я тоже недолюбливаю.
В основе статьи — тред автора в Twitter.
Впервые с архитектурой Model-View-Controller (MVC) я столкнулся в 2009 году, когда изучал веб-фреймворк Zend. В его документации было написано, что Model — это база данных, View — HTML-шаблон, а Controller — логика, которая берёт данные из БД, обрабатывает их, кладёт в шаблон и отдаёт страницу.
Я тогда был студентом, делал курсовые и пет-проекты. У них была сложная вёрстка и непростая структура БД, но максимально простая логика. Код получался простым, но в целом меня такой подход устраивал.
Мне не приходило в голову, что можно делать не так, как написано в документации к инструментам и в примерах на форумах. Я был счастлив и не забивал голову чепухой.
Сомневаться в своём подходе я начал из-за статей на «Хабре», где говорили, что логику нужно закладывать в модель, чтобы контроллер оставался максимально простым. Так я узнал о двух версиях MVC — с тонким и толстым контроллером.
Я пробовал поменять логику в своём проекте — перенёс её из одного файла в другой, но разницы не заметил. По факту ничего и не изменилось, только код теперь лежал в другом файле.
Изучая дискуссии в интернете и рассуждая самостоятельно, я понял, что «толстая» модель мне не нравится. Пусть лучше модель остаётся базой данных, а контроллер и дальше управляет логикой.
Со временем мои проекты становились всё сложнее, а контроллеры пухлее (правда, не как UIViewController в iOS). Я пробовал с этим бороться, выносил логику в сторонние файлы, которые включал в контроллеры, но это мало что меняло: архитектура сохранялась, просто код переносился из одного файла в другой.

В 2013 году я пересел на Laravel, разобрался с автозагрузкой классов в PHP, начал разбираться с ООП и прочитал «Совершенный код» Стива Макконнелла.
Стало ясно, что не стоит складывать всё в один файл — код и классы должны организовывать структуру, а некоторые фрагменты кода лучше убрать из MVC и выделить в самостоятельные части, которые можно переиспользовать.
С этого момента я начал писать проекты по-другому. В них появились иерархии классов, которые хранили логику, а контроллер сильно похудел — он получал данные от базы, передавал их в разные пакеты, получал от них результат и отправлял на HTML-страницу.
Архитектура проектов не была идеальной, потому что не подошла бы ни для одной сложной системы. Но для моих целей она была крутой и удобной: код получался читабельный, а все элементы проекта оставались довольно независимы.
Следующий качественный скачок случился, когда я отошёл от веб-разработки и углубился в бэкенд. Мне пришлось проектировать и разрабатывать сложную систему управления VDS-сервером. Там были API, плагины, менеджер зависимостей для плагинов, асинхронный код, много режимов работы, связь с операционной системой и разным софтом. Основная задача проекта — чтобы у системы было ядро и самостоятельные плагины, которые бы умели работать вместе.
В сложной системе нельзя передавать все данные через один контроллер, поэтому каждый плагин отдельно реализовывал веб- и API-интерфейсы, доступ к данным и бизнес-логику, вынесенную в пакеты для переиспользования.
Получилось так: HTML ⟷ JavaScript (модели, общение с API) ⟷ API ⟷ переиспользуемые пакеты ⟷ бизнес-логика и доступ к данным. Всё это не было похоже на MVC.
Потом я ушёл в iOS-разработку и временно перестал думать про архитектуру. Изучал UIKit, а компоненты располагал по наитию. HTML и CSS превратились в разные UIView, тонкий контроллер — в UIViewController, бизнес-логика — в сервисы.
C MVC всё работало хорошо, но я читал и про другие архитектуры. Люди рассказывали, как MVVM, MVP или VIPER упростили им жизнь, поэтому я тоже решил их попробовать.
Когда я увидел, как это реализуют в других компаниях, то осознал несколько важных нюансов.
Архитектура не даёт преимуществ. Ни одна продвинутая архитектура не была лучше того, что я делал в самом начале. За всё время я перепробовал разные подходы и поэтому мог оценить их пользу для проекта. Но между MVC и MVP не было разницы — кроме названий классов и правил вроде тех, когда элементы вызывают друг друга.
Компании понимают архитектуру по-разному. Одни говорят, что используют MVVM, у других то же самое называется MVC. Я видел пять MVVM-систем, и все были разными. Исключение — VIPER, у которой благодаря Егору Толстому есть подробная документация и много примеров. Но даже там были отличия.
Популярная архитектура не значит лучшая. Выбирать архитектуру из-за мейнстримности бесполезно. Кто-то решает использовать MVVM, но одни и те же компоненты кладёт в разные части проекта.
Архитектура не спасёт проект. Сама по себе она не решает проблемы и не гарантирует успеха.
Я постоянно изучал архитектуры, читал книги и спорил с коллегами, несколько раз пересматривал идею MVC в языке Smalltalk и несколько раз менял к ней отношение.
В итоге я понял, что MVC — это не три файла, и даже не несколько классов для каждого элемента. Модель — не про данные и не про бизнес-логику, а контроллер давно не нужен, и пора использовать MV.
Приложения с бизнес-логикой и доступом к данным были и до MVC, им не хватало только пользовательского интерфейса. Главная задача MVC — связать UI со всем остальным. Единственная рекомендация от создателя — при надобности создавать для каждой View свой фасад для Model и слушать его через паттерн-наблюдатель.
View — это и есть пользовательский интерфейс, Model — остальное приложение. Задача Controller — не быть прослойкой между V и M, а всего лишь принимать информацию от пользователя.
Принцип MVC — не мешать UI с бизнес-логикой, базой данных и другими частями приложения. А как это реализовать, уже пускай думает архитектор. Это не космическая инженерия.
Важно понимать, что MVP, MVVM или VIPER не заменяют MVC, а только дополняют её. Контроллер уже не нужен, потому что за ввод данных отвечает View, это стало его неотъемлемой частью.
Получается, что MVC в Apple, MVVM и другие варианты — это MV, где контроллер убрали за ненадобностью. Из всех современных MV(x) именно MVVM больше всего похожа на каноническую MVC.
Все эти термины усложняют общение. Иногда сложно понять, о чём тебе говорят, хотя задача архитектуры в том, чтобы всё было проще и понятнее.

Может показаться, что все архитектуры одинаковые, и им вообще не стоит уделять внимания. Но это не так. У меня есть несколько правил.
Главное — реализация. Глобальная архитектура не так важна, как её воплощение. Всё зависит от того, как вы называете классы, где храните элементы и как классы общаются между собой. Все из команды должны соблюдать ваш стандарт, и тогда проект будет проще поддерживать.
Model — ваша ответственность. Архитектура MVC не даёт инструкций, как правильно написать основную часть приложения. Ваша ответственность в том, чтобы не устраивать в Model кашу, где половина классов — Service, а вторая половина — Helper.
Нужно разбираться в основах. Не стоит изучать конкретную архитектуру, лучше понять, из чего она логически следует. Тут поможет история, объектно-ориентированное и функциональное программирование, паттерны, SOLID и всё остальное. Обязательно надо прочитать «Совершенный код» Стива Макконнелла.
Когда вы разобрались с основами, можно подходить к архитектуре Flux и библиотеке Redux. Я выделил их, потому что Facebook* сформулировал подробный гайд по Flux, а также выпустил под неё библиотеку. Неожиданно, но это тоже MVC — M и V разделены, и V слушает изменения в M. Правда, тут появились дополнительные ограничения, которые все тоже трактуют по-своему.
Redux — хорошая штука, но и у неё есть проблемы. Я использовал эту библиотеку в проекте, который писал и поддерживал сам. Всем компонентам старался давать правильные названия, завязывал на Store не все View, а только начальную сцену, группировал middleware и редюсеры, даже связывал их со стейтом.
С какого-то момента я начал теряться в проекте. У меня появилась куча сущностей с похожими названиями и похожими данными, я создал миллиард экшенов. В итоге сам запутался, что, как и с чем взаимодействует.
Код был расширяемый и поддерживаемый, но, если я хотел что-то изменить, приходилось править гору файлов. Это очень больно. А если учесть, что проект работал на бойлерплейтном Flutter, то боль усиливалась на порядок.
Redux хороша для больших проектов, ориентированных на офлайн, где одновременно происходит куча асинхронных неблокируемых событий. Там этот бойлерплейт стоит терпеть, потому что он спасёт вам жизнь. Но в обычном тонком клиенте лучше использовать стандартную MV и не париться.
Настоящая архитектура — та, которая описывает ваши подходы, она должна быть понятна всей команде. Если я буду делать приложение на SwiftUI, то выберу классическую MV — ту, где View следит за Model (многие называют это MVVM). И вам рекомендую поступать так же.
* Решением суда запрещена «деятельность компании Meta Platforms Inc. по реализации продуктов — социальных сетей Facebook* и Instagram* на территории Российской Федерации по основаниям осуществления экстремистской деятельности».

Научитесь: Архитектор ПО
Узнать больше
