Базы данных (БД) — набор упорядоченной информации, которая хранится в одном месте. Их создают, чтобы быстро находить, систематизировать и редактировать нужные данные, а при необходимости собирать их в отчёт или показывать в виде диаграммы.
Специализированных программ для формирования и ведения баз данных много. В том же MS Office для этого есть отдельное приложение — Microsoft Access. Но и в Excel достаточно возможностей для создания простых баз и удобного управления ими. Есть ограничение — количество строк базы данных в Excel не должно быть больше одного миллиона.
В статье разберёмся:
- как выглядит база данных в Excel;
- как её создать и настроить;
- как работать с готовой базой данных в Excel — фильтровать, сортировать и искать записи.
База данных в Excel — таблица с информацией. Она состоит из однотипных строк — записей базы данных. Записи распределены по столбцам — полям базы данных.
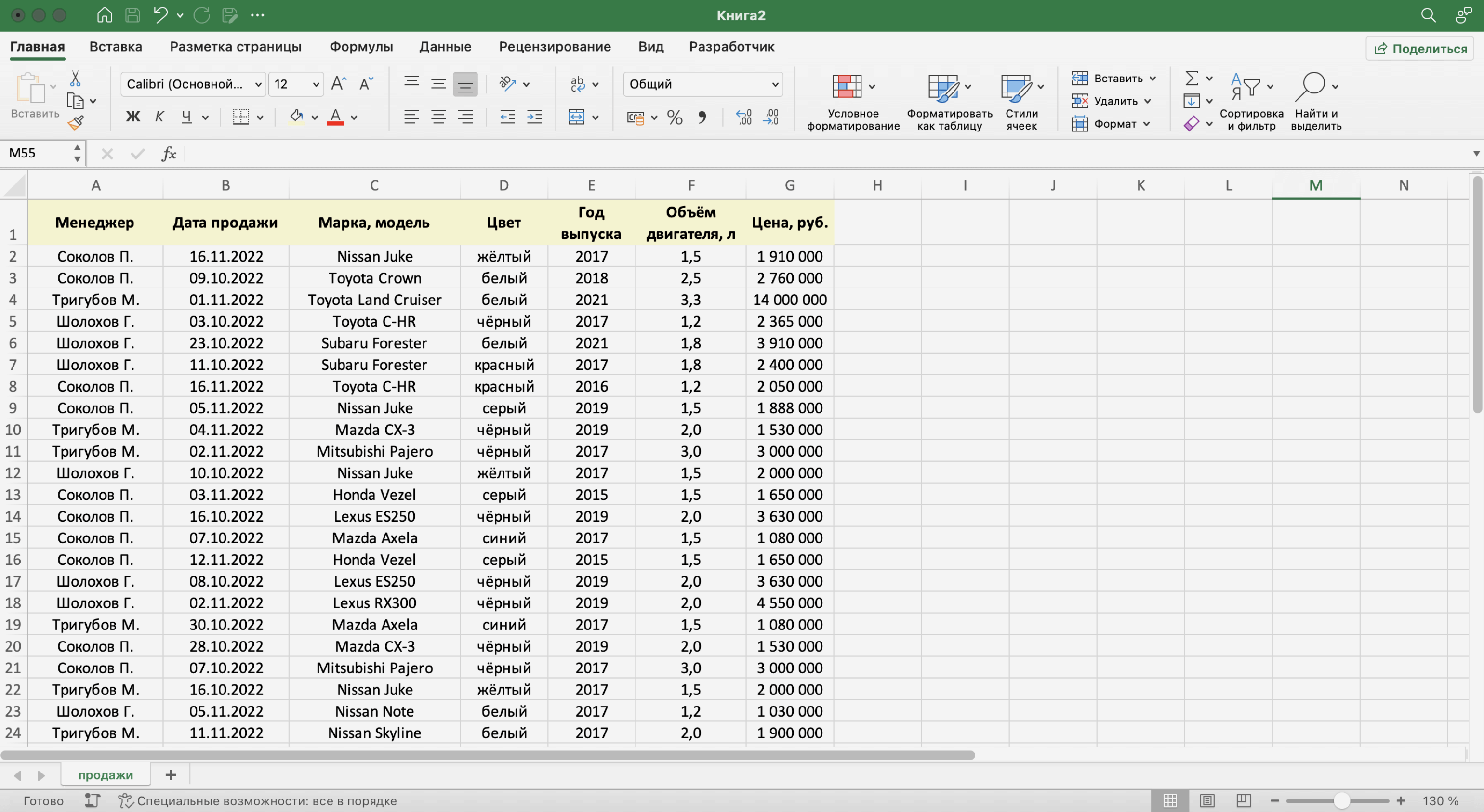
Скриншот: Excel / Skillbox Media
Названия полей — шапка таблицы — определяют структуру базы данных. Они показывают, какую информацию содержит база. В примере выше это имя менеджера автосалона, дата продажи, модель и характеристики автомобиля, который он продал.
Каждая запись — строка таблицы — относится к одному объекту базы данных и содержит информацию о нём. В нашем примере записи характеризуют продажи, совершённые менеджерами автосалона.
При создании базы данных нельзя оставлять промежуточные строки полностью пустыми, как на скриншоте ниже. Так база теряет свою целостность — в таком виде ей нельзя управлять как единым объектом.
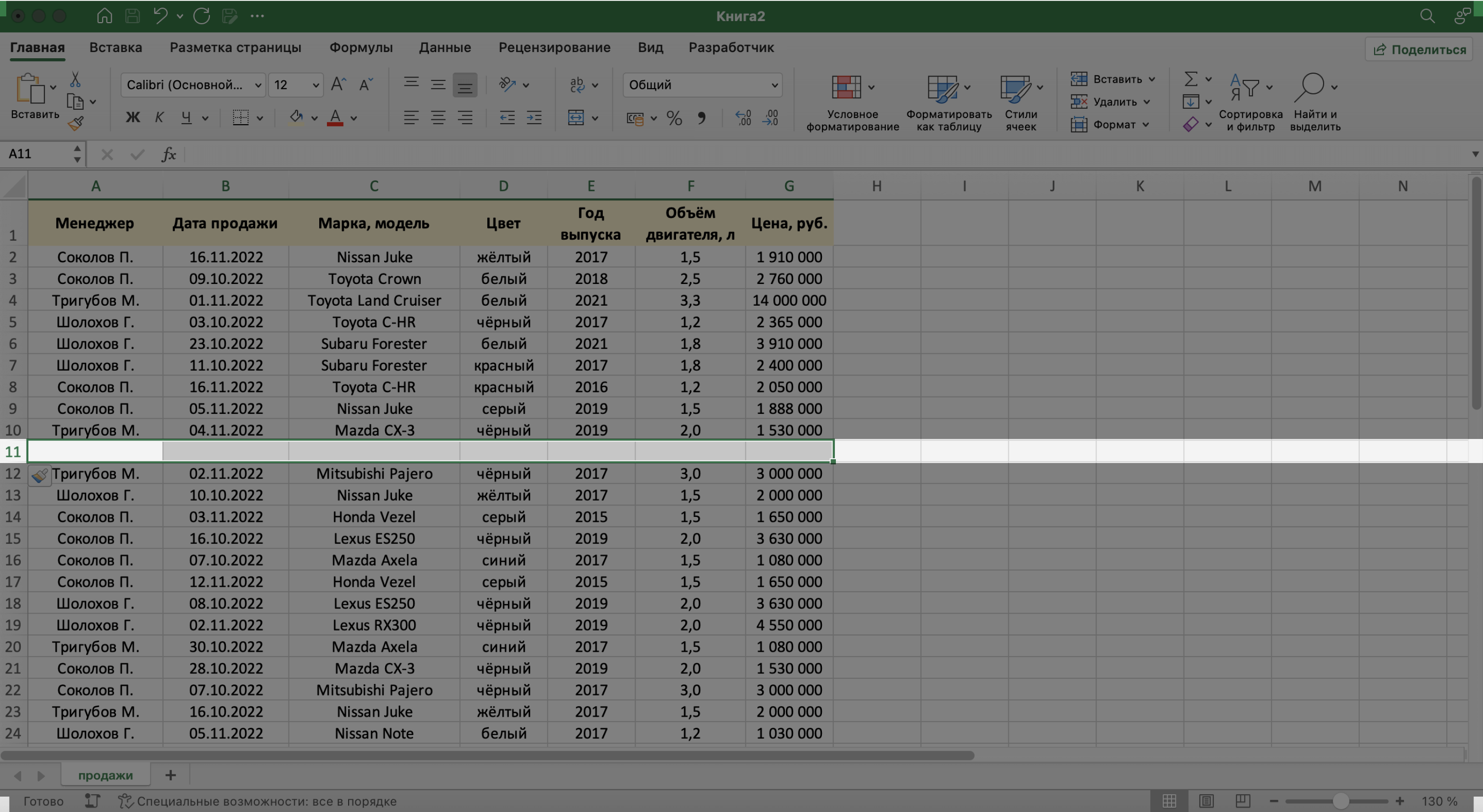
Скриншот: Excel / Skillbox Media
Разберём пошагово, как создать базу данных из примера выше и управлять ей.
Создаём структуру базы данных
Выше мы определили, что структуру базы данных определяют названия полей (шапка таблицы).
Задача для нашего примера — создать базу данных, в которой будут храниться все данные о продажах автомобилей менеджерами автосалона. Каждая запись базы — одна продажа, поэтому названия полей БД будут такими:
- «Менеджер»;
- «Дата продажи»;
- «Марка, модель»;
- «Цвет»;
- «Год выпуска»;
- «Объём двигателя, л»;
- «Цена, руб.».
Введём названия полей в качестве заголовков столбцов и отформатируем их так, чтобы они визуально отличались от дальнейших записей.
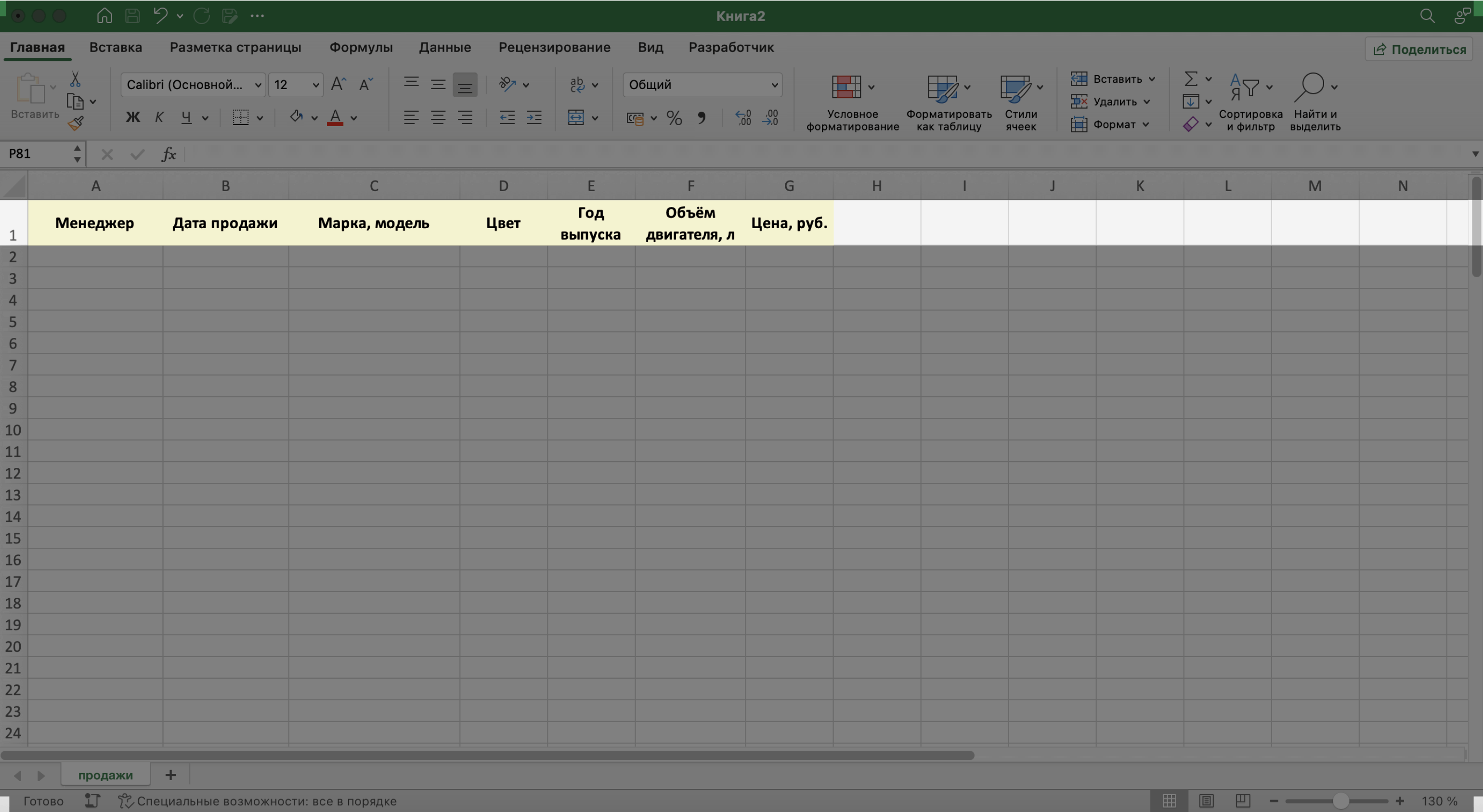
Скриншот: Excel / Skillbox Media
Создаём записи базы данных
В нашем примере запись базы данных — одна продажа. Перенесём в таблицу всю имеющуюся информацию о продажах.
При заполнении ячеек с записями важно придерживаться одного стиля написания. Например, Ф. И. О. менеджеров во всех строках вводить в виде «Иванов И. И.». Если где-то написать «Иван Иванов», то дальше в работе с БД будут возникать ошибки.
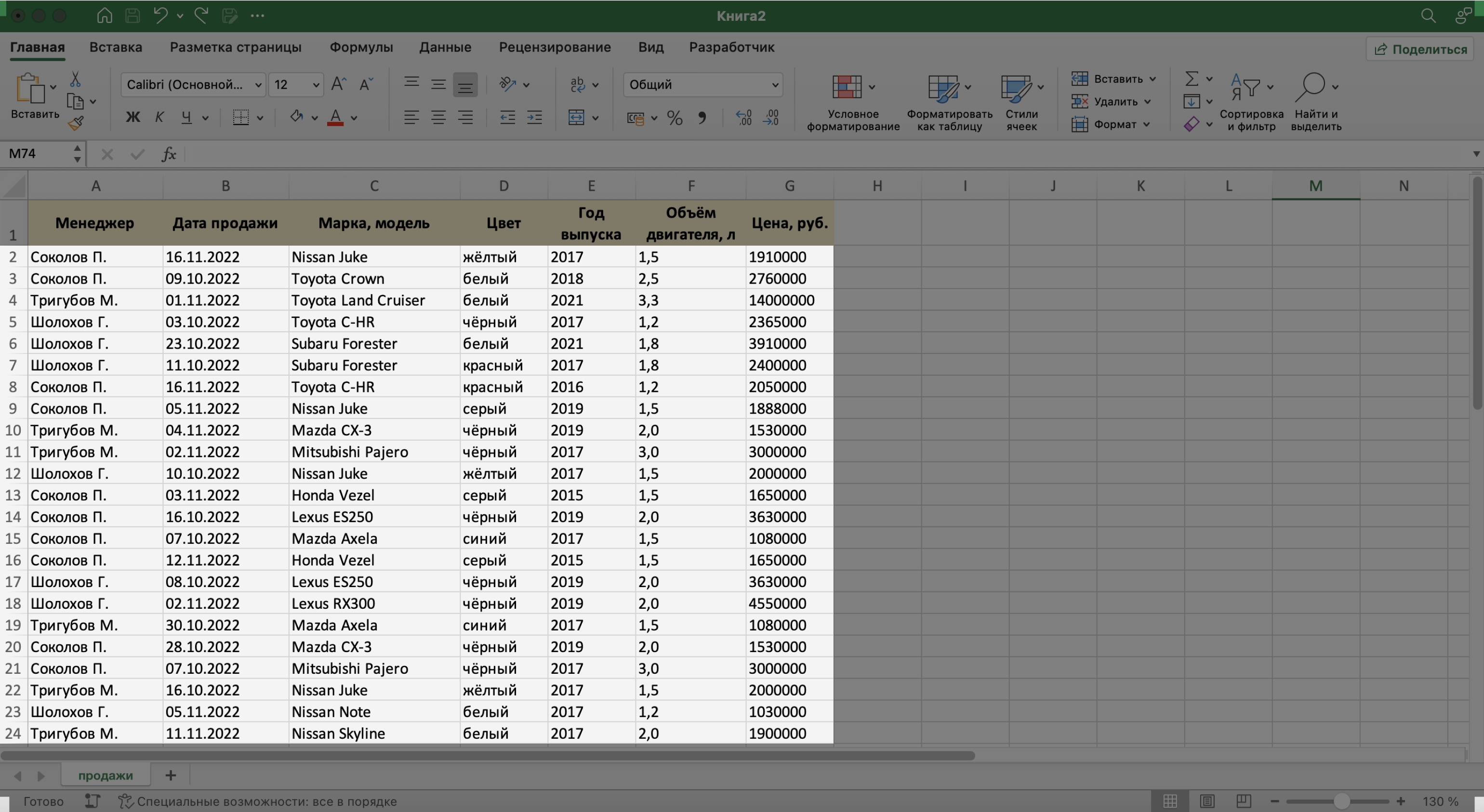
Скриншот: Excel / Skillbox Media
На этом же этапе важно проконтролировать, подходит ли формат ячеек данным в них. По умолчанию все ячейки получают общий формат. Чтобы в дальнейшем базой данных было удобнее пользоваться, можно изменить формат там, где это нужно.
В нашем примере данные в столбцах A, C и D должны быть в текстовом формате. Данные столбца B должны быть в формате даты — его Excel определил и присвоил автоматически. Данные столбцов E, F — в числовом формате, столбца G — в финансовом.
Чтобы изменить формат ячейки, выделим нужный столбец, кликнем правой кнопкой мыши и выберем «Формат ячеек».
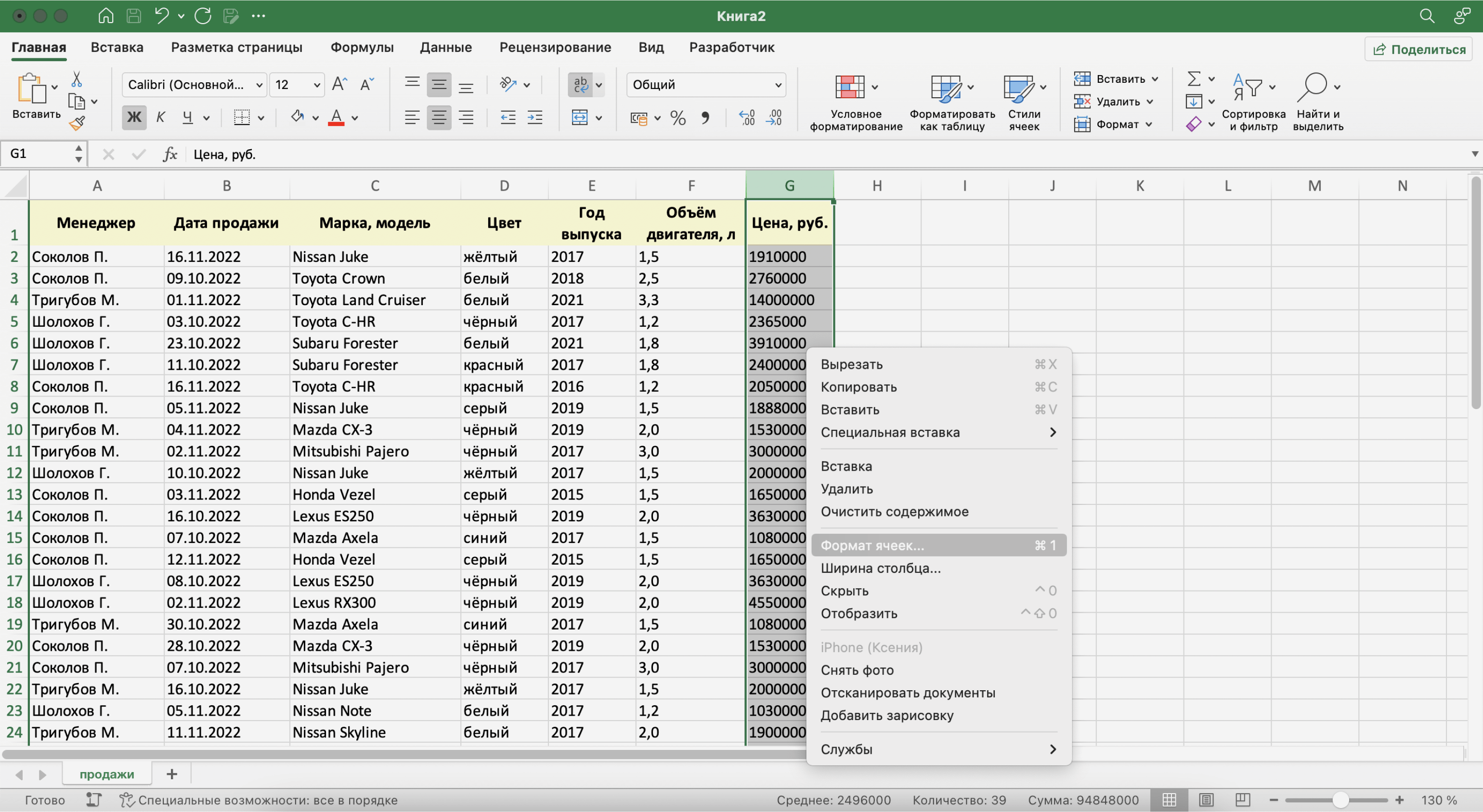
Скриншот: Excel / Skillbox Media
В появившемся меню выберем нужный формат и настроим его. В нашем примере для ячейки «Цена, руб.» выберем финансовый формат, уберём десятичные знаки (знаки после запятой) и выключим отображение символа ₽.
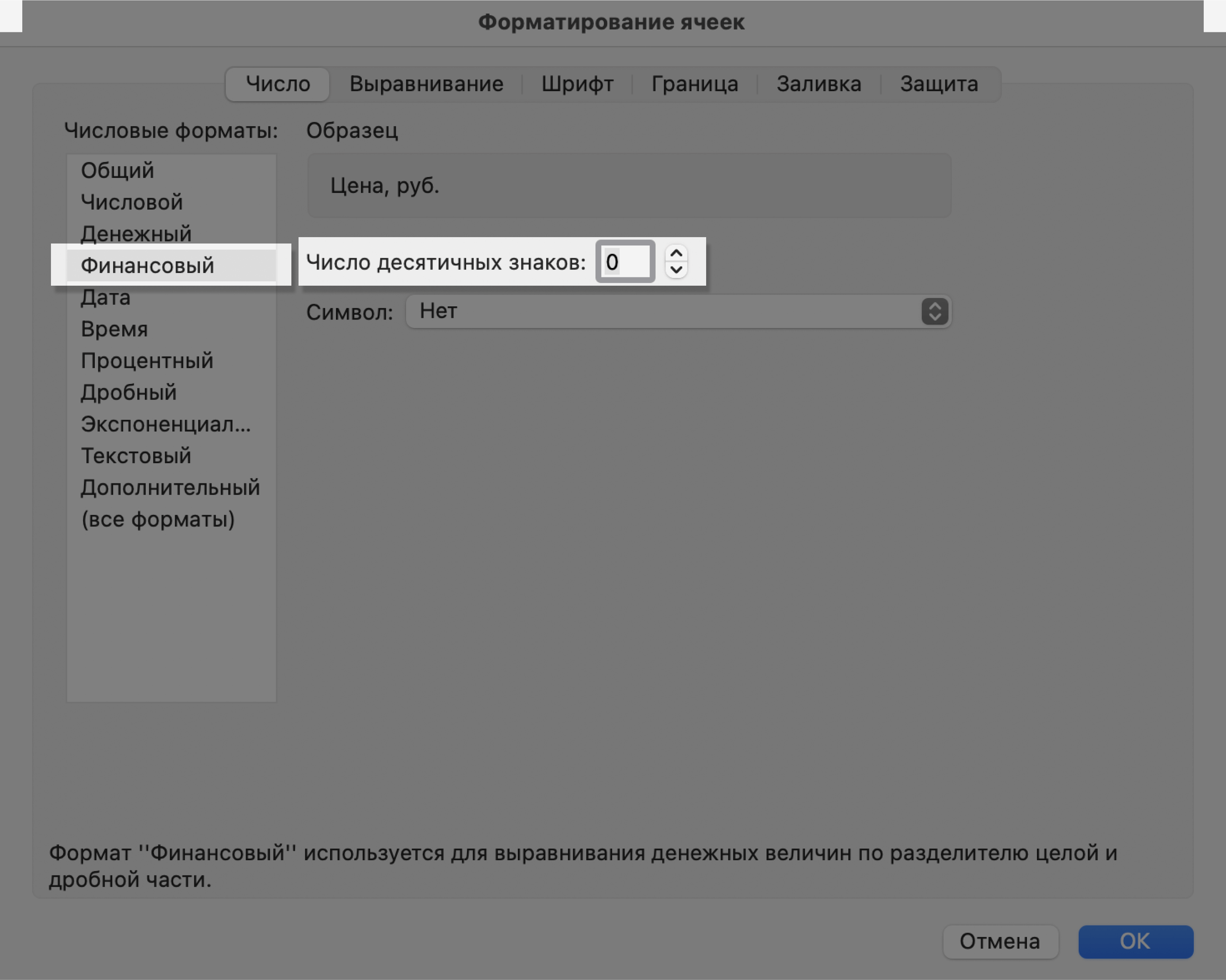
Скриншот: Excel / Skillbox Media
Также изменить формат можно на панели вкладки «Главная».
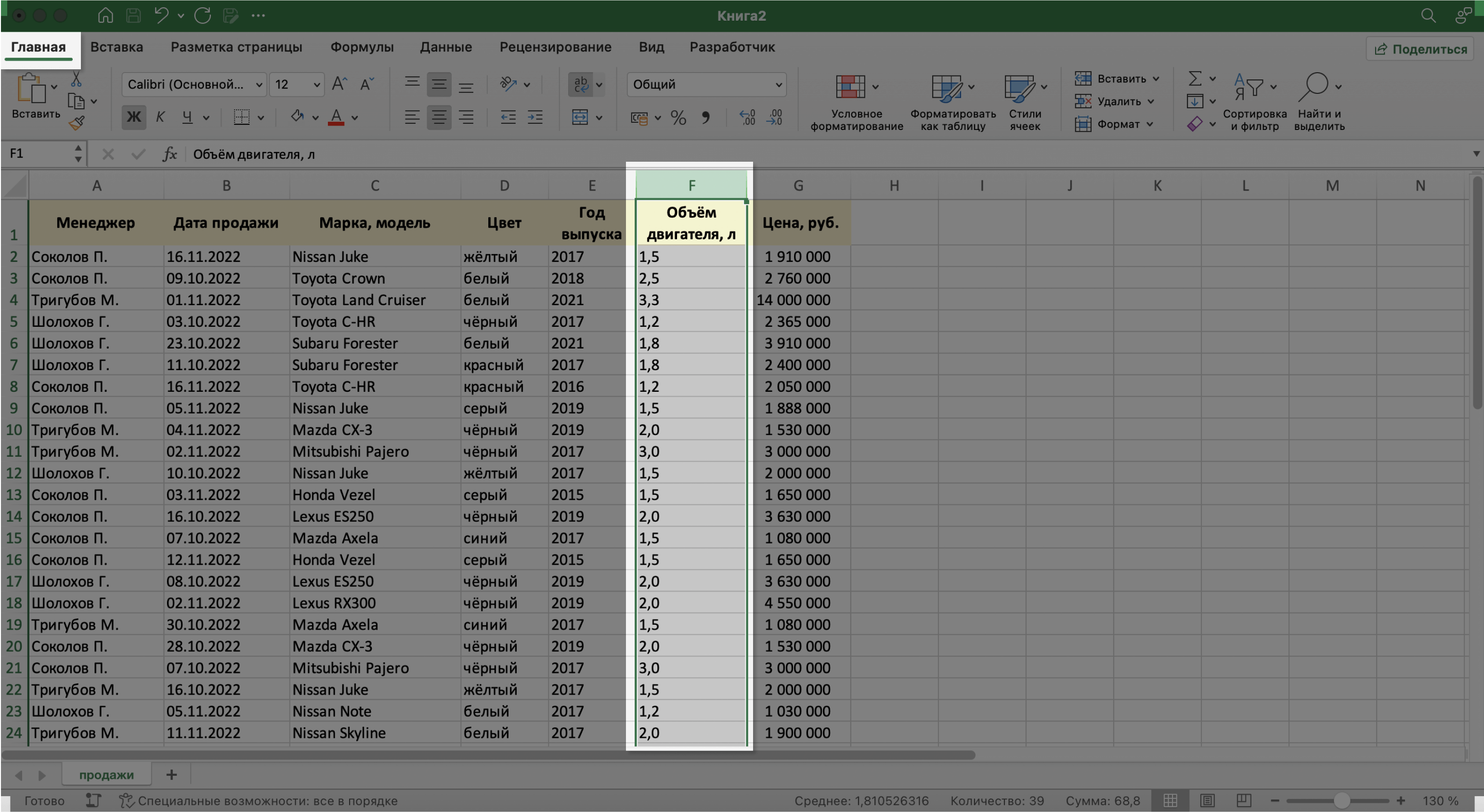
Скриншот: Excel / Skillbox Media
Присваиваем базе данных имя
Для этого выделим все поля и записи базы данных, включая шапку. Нажмём правой кнопкой мыши и выберем «Имя диапазона».
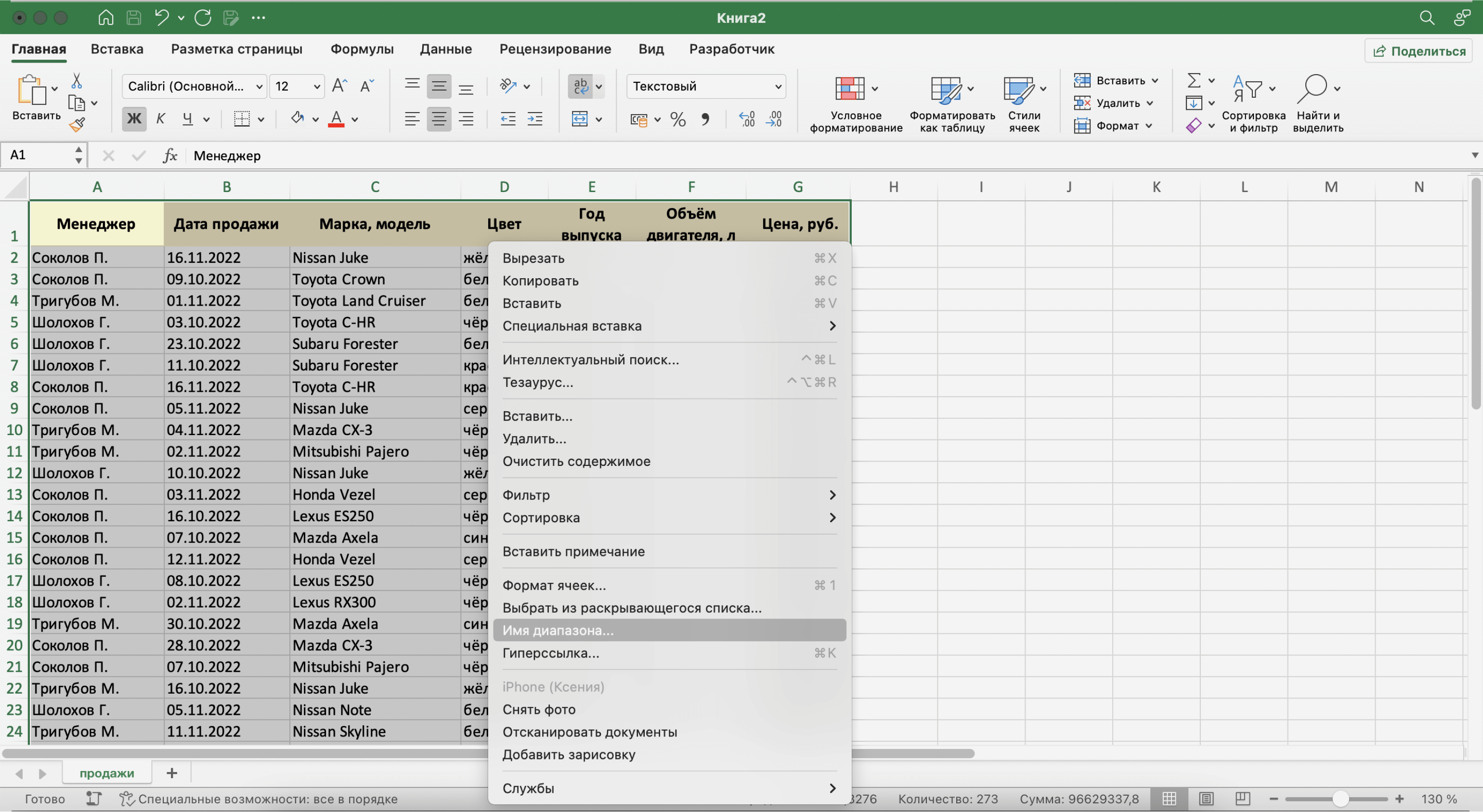
Скриншот: Excel / Skillbox Media
В появившемся окне вводим имя базы данных без пробелов.
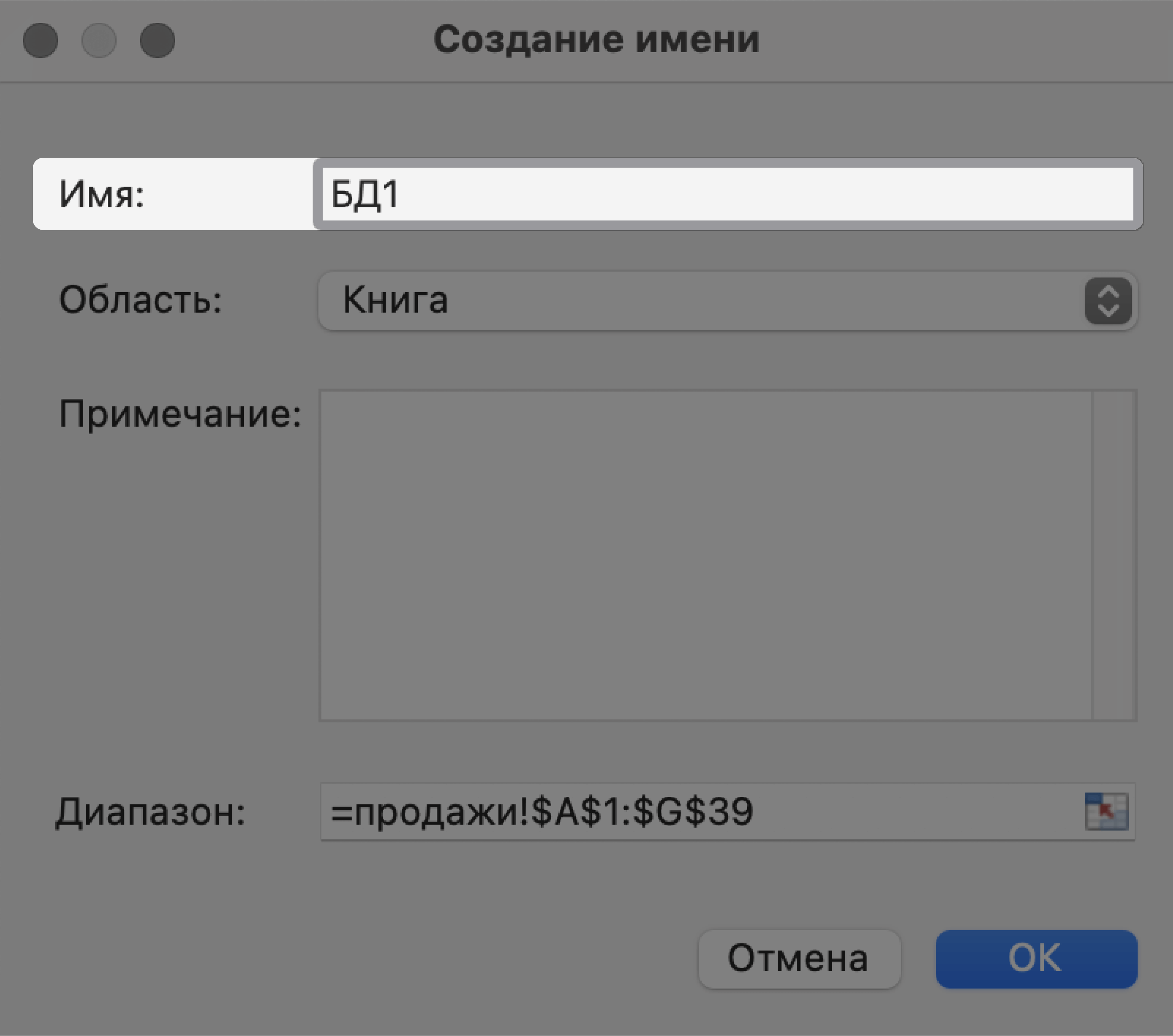
Скриншот: Excel / Skillbox Media
Готово — мы внесли в базу данных информацию о продажах и отформатировали её. В следующем разделе разберёмся, как с ней работать.
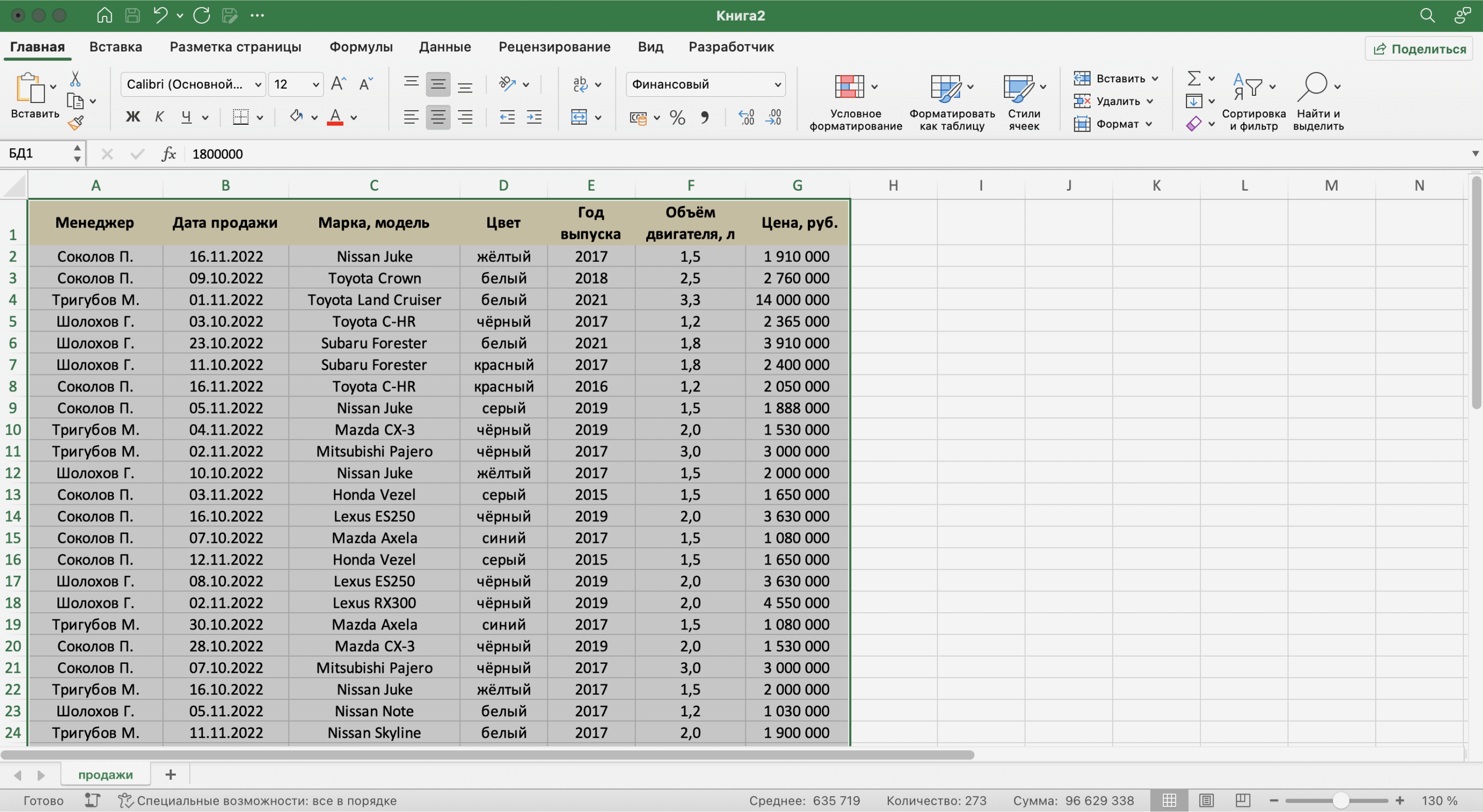
Скриншот: Excel / Skillbox Media
Сейчас в созданной базе данных все записи расположены хаотично — не упорядочены ни по датам, ни по фамилиям менеджеров. Разберёмся, как привести БД в более удобный для работы вид. Все необходимые для этого функции расположены на вкладке «Данные».
Скриншот: Excel / Skillbox Media
Для начала добавим фильтры. Это инструмент, с помощью которого из большого объёма информации выбирают и показывают только нужную в данный момент.
Подробнее о фильтрах в Excel говорили в этой статье Skillbox Media.
Выберем любую ячейку из базы данных и на вкладке «Данные» нажмём кнопку «Фильтры».
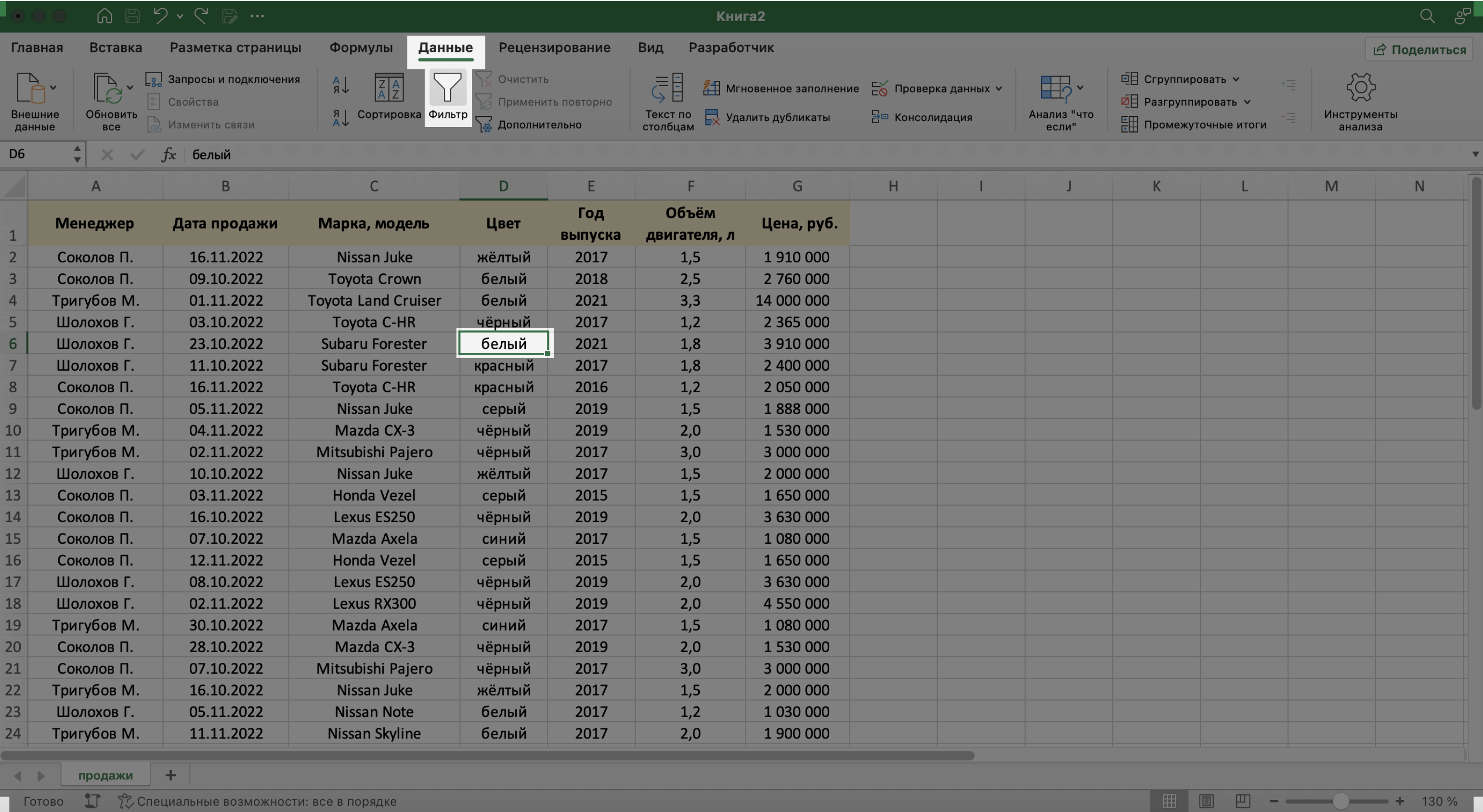
Скриншот: Excel / Skillbox Media
В каждой ячейке шапки таблицы появились кнопки со стрелками.
Предположим, нужно показать только сделки менеджера Тригубова М. — нажмём на стрелку поля «Менеджер» и оставим галочку только напротив него. Затем нажмём «Применить фильтр».
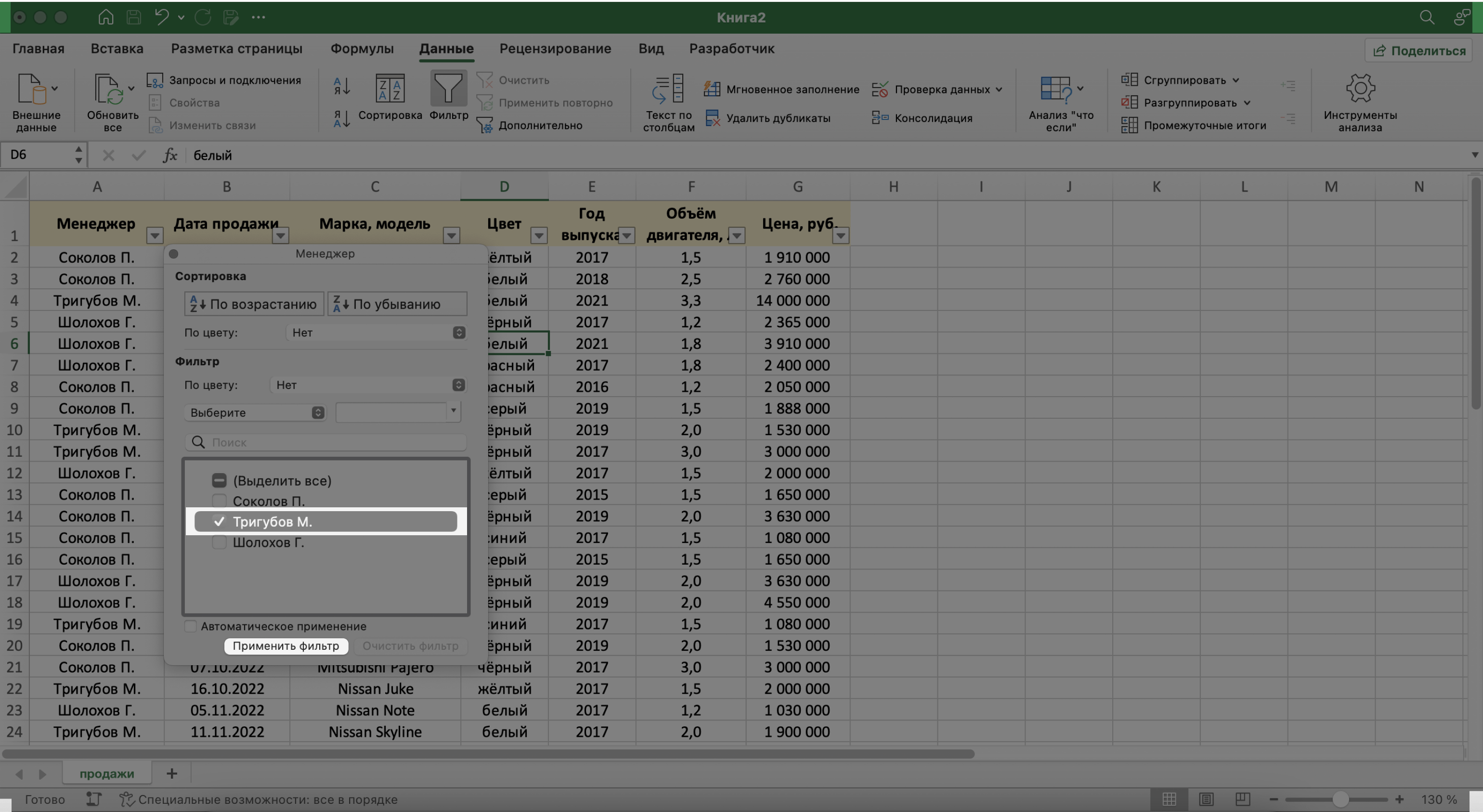
Скриншот: Excel / Skillbox Media
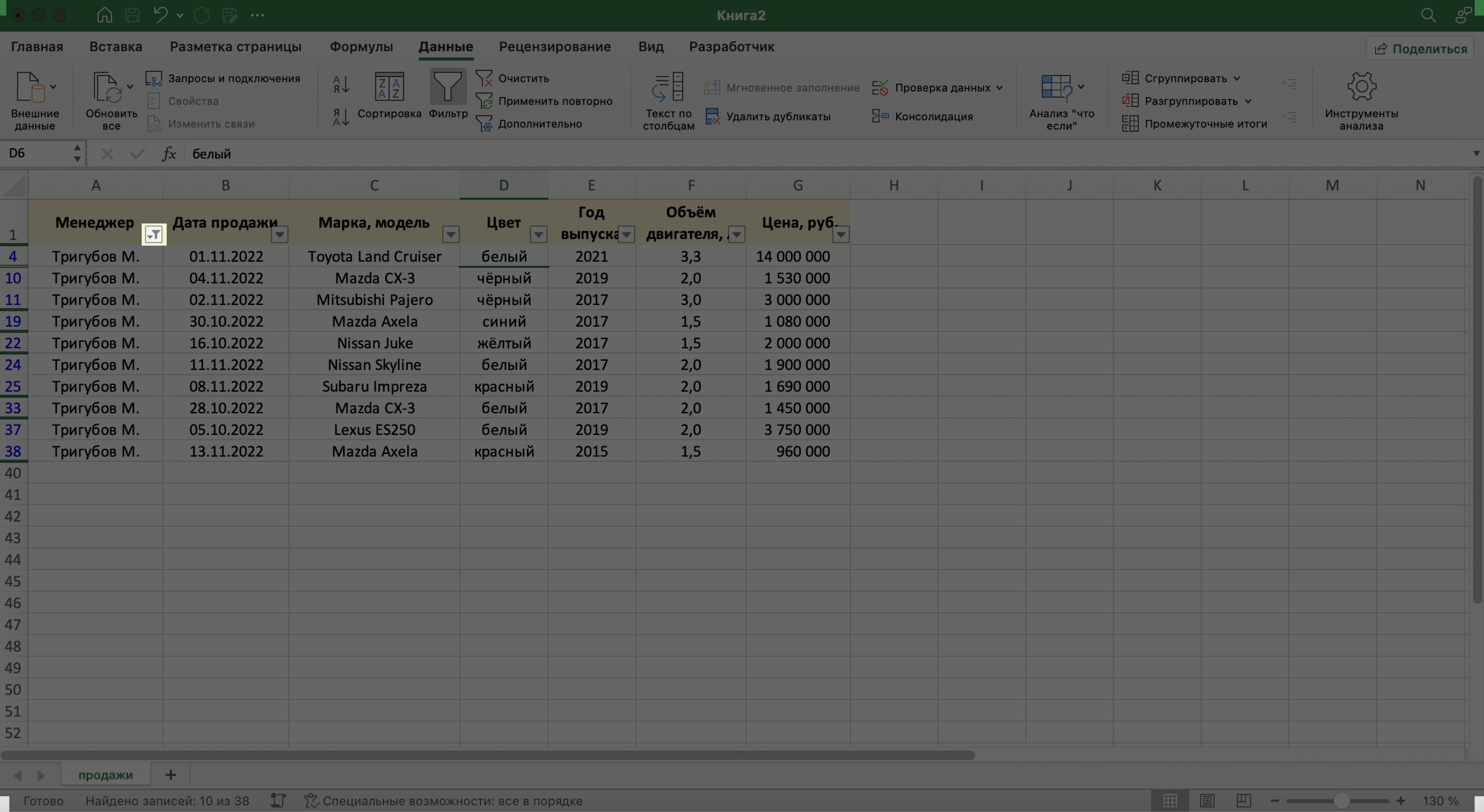
Готово — в базе отражены данные о продажах только одного менеджера. На кнопке со стрелкой появился дополнительный значок. Он означает, что в этом столбце настроена фильтрация. Чтобы её снять, нужно нажать на этот дополнительный значок и выбрать «Очистить фильтр».
Скриншот: Excel / Skillbox Media
Записи БД можно фильтровать по нескольким параметрам одновременно. Для примера покажем среди продаж Тригубова М. только автомобили дешевле 2 млн рублей.
Для этого в уже отфильтрованной таблице откроем меню фильтра для столбца «Цена, руб.» и нажмём на параметр «Выберите». В появившемся меню выберем параметр «Меньше».
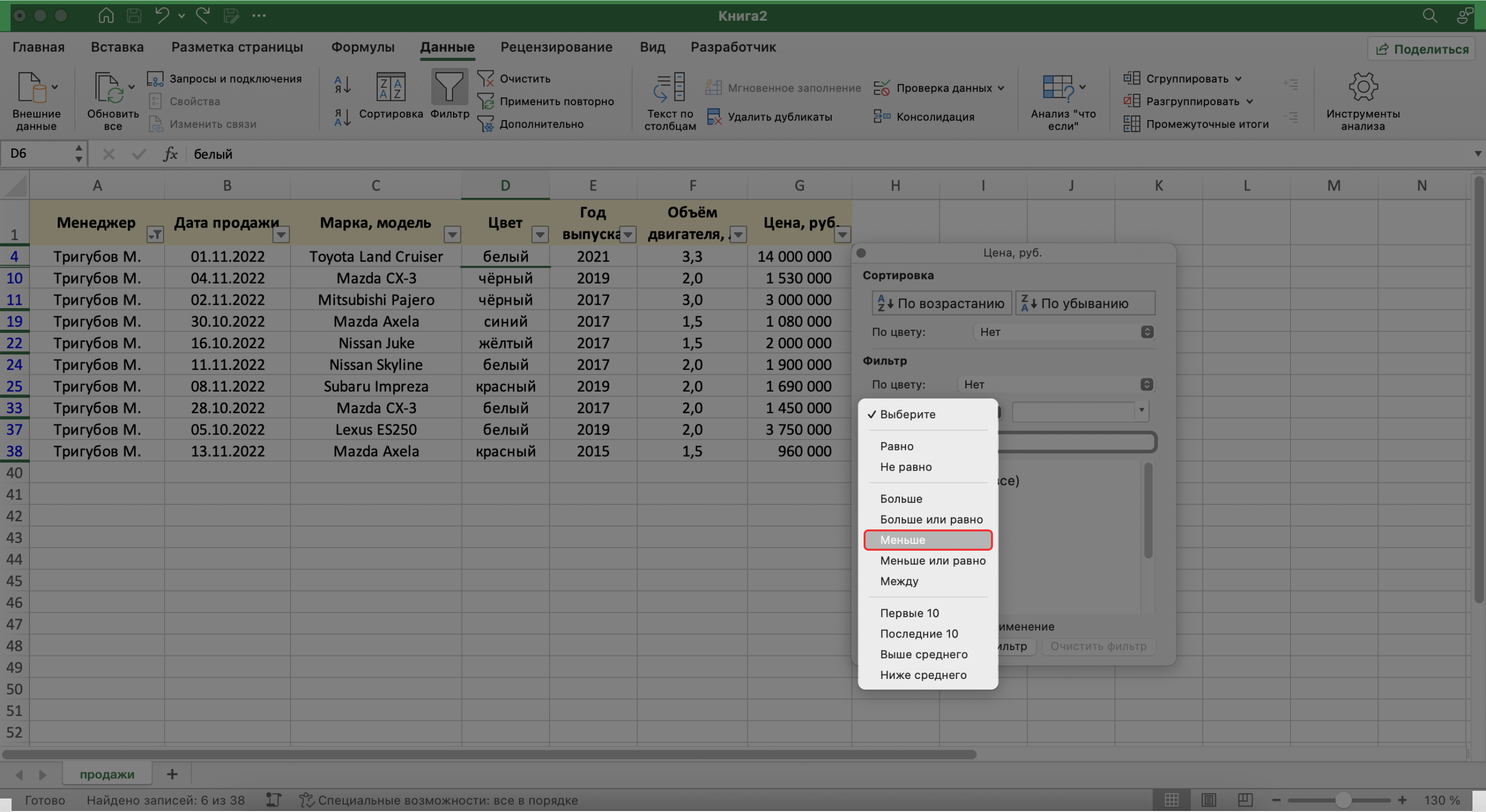
Скриншот: Excel / Skillbox Media
Затем в появившемся окне дополним условие фильтрации — в нашем случае «Меньше 2000000» — и нажмём «Применить фильтр».
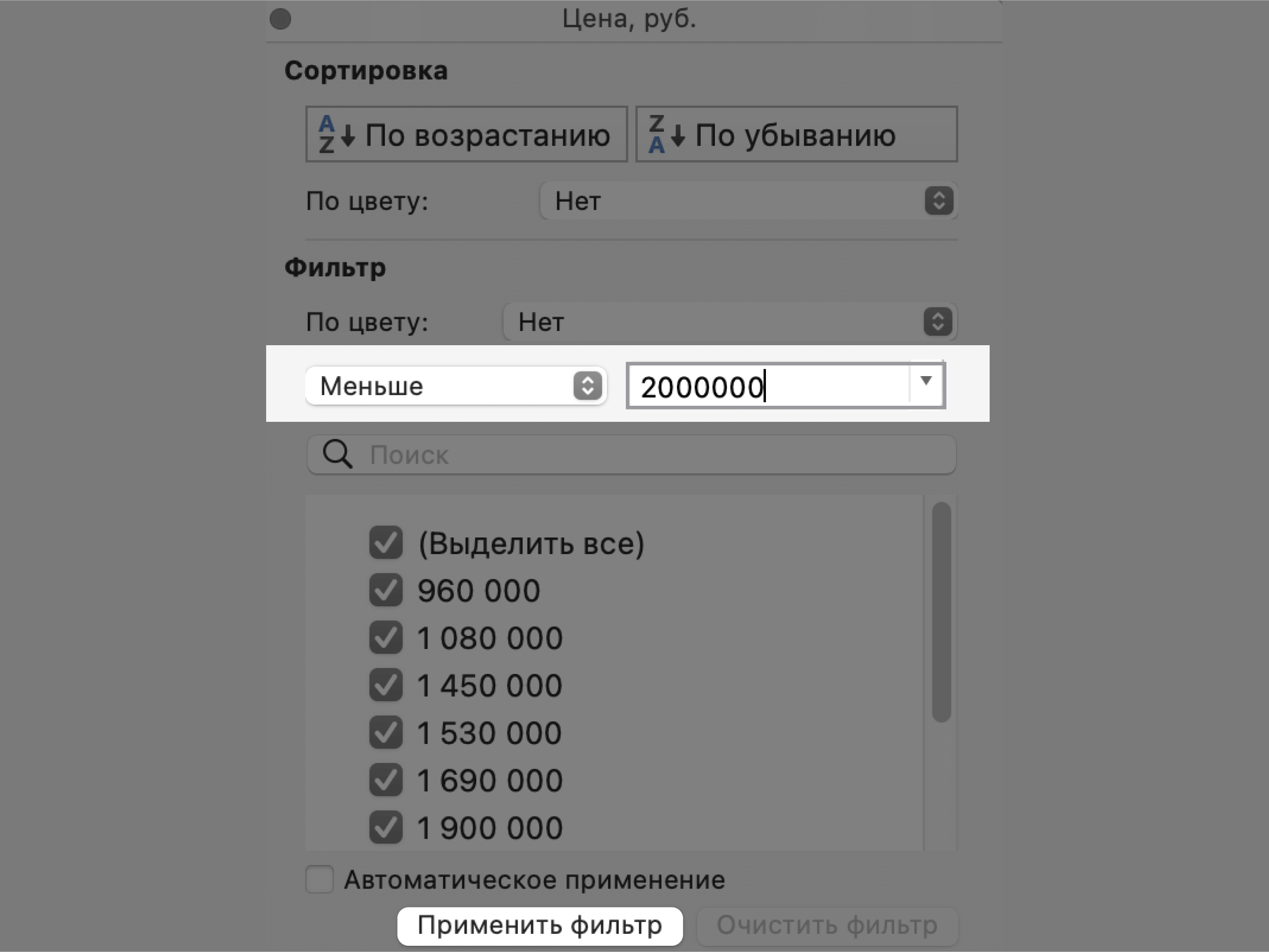
Скриншот: Excel / Skillbox Media
Готово — фильтрация сработала по двум параметрам. Теперь БД показывает только те проданные менеджером авто, цена которых ниже 2 млн рублей.
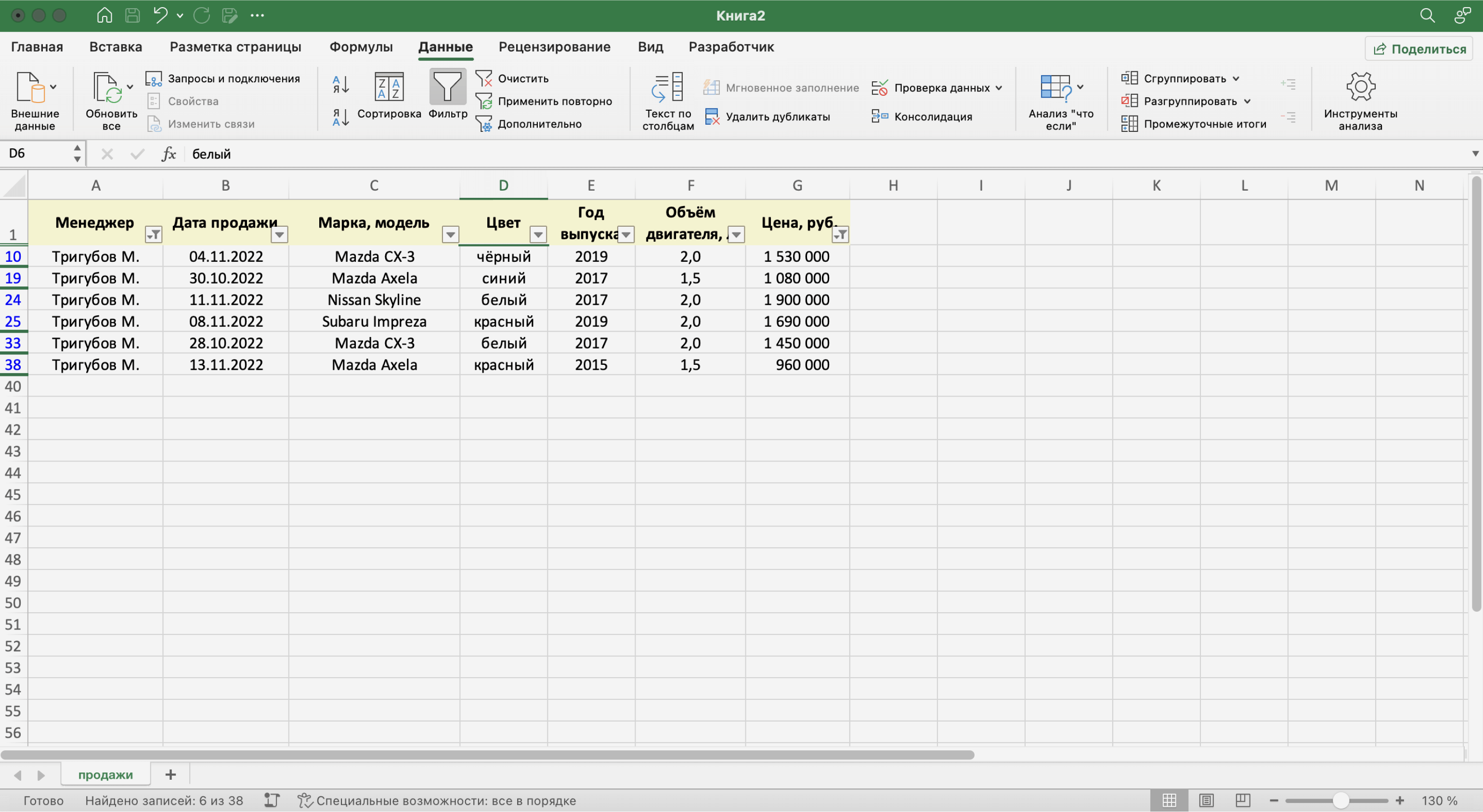
Скриншот: Excel / Skillbox Media
Кроме этого, в Excel можно установить расширенный фильтр. Он позволяет фильтровать БД по сложным критериям сразу в нескольких столбцах. Подробно о том, как настроить расширенный фильтр, говорили в статье.
Сортировка — инструмент, с помощью которого данные в БД организовывают в необходимом порядке. Их можно сортировать по алфавиту, по возрастанию и убыванию чисел, по дате.
Для примера отсортируем сделки выбранного менеджера в хронологическом порядке — по датам. Для этого выделим любую ячейку в поле «Дата продажи» и нажмём кнопку «Сортировка».
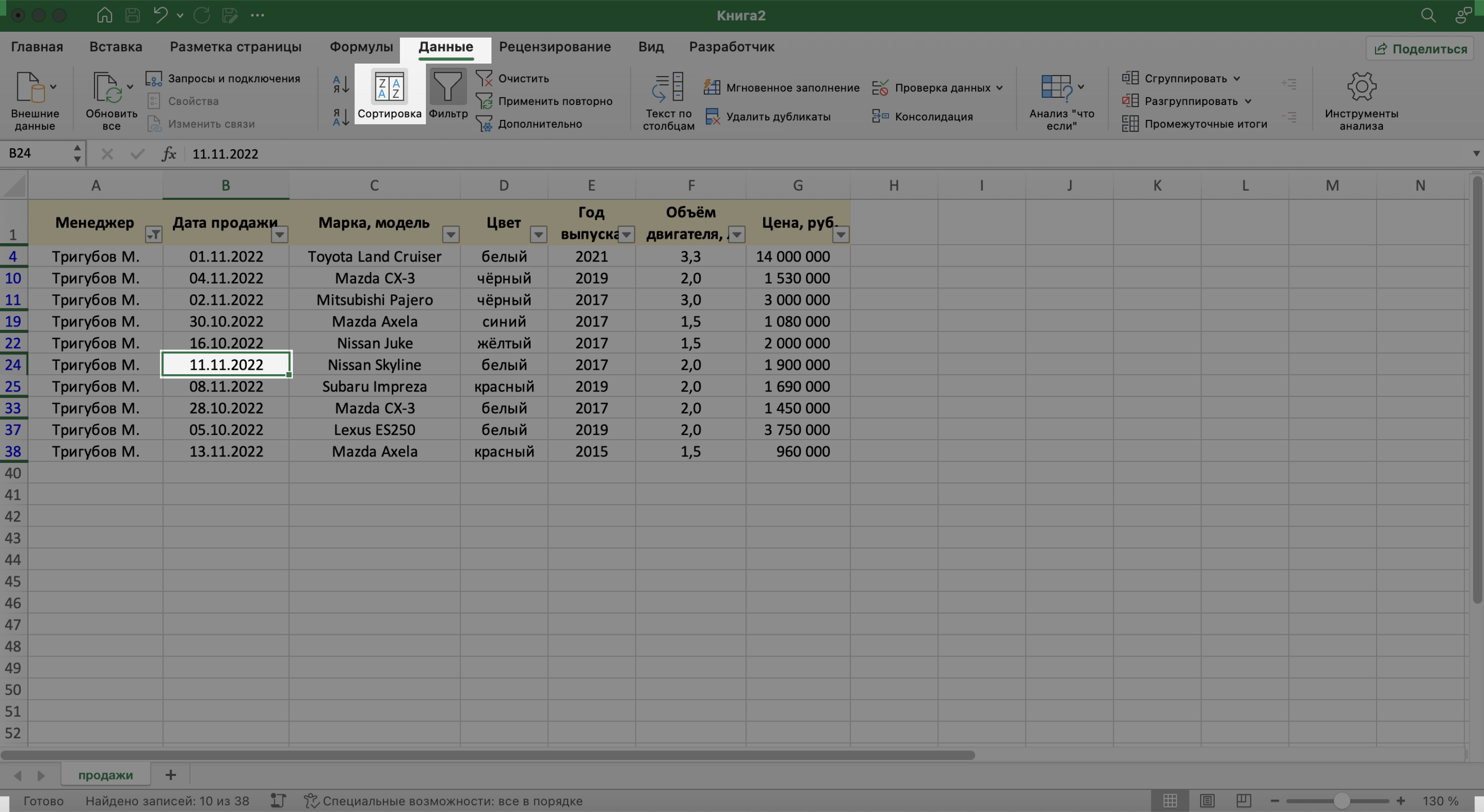
Скриншот: Excel / Skillbox Media
В появившемся окне выберем параметр сортировки «От старых к новым» и нажмём «ОК».
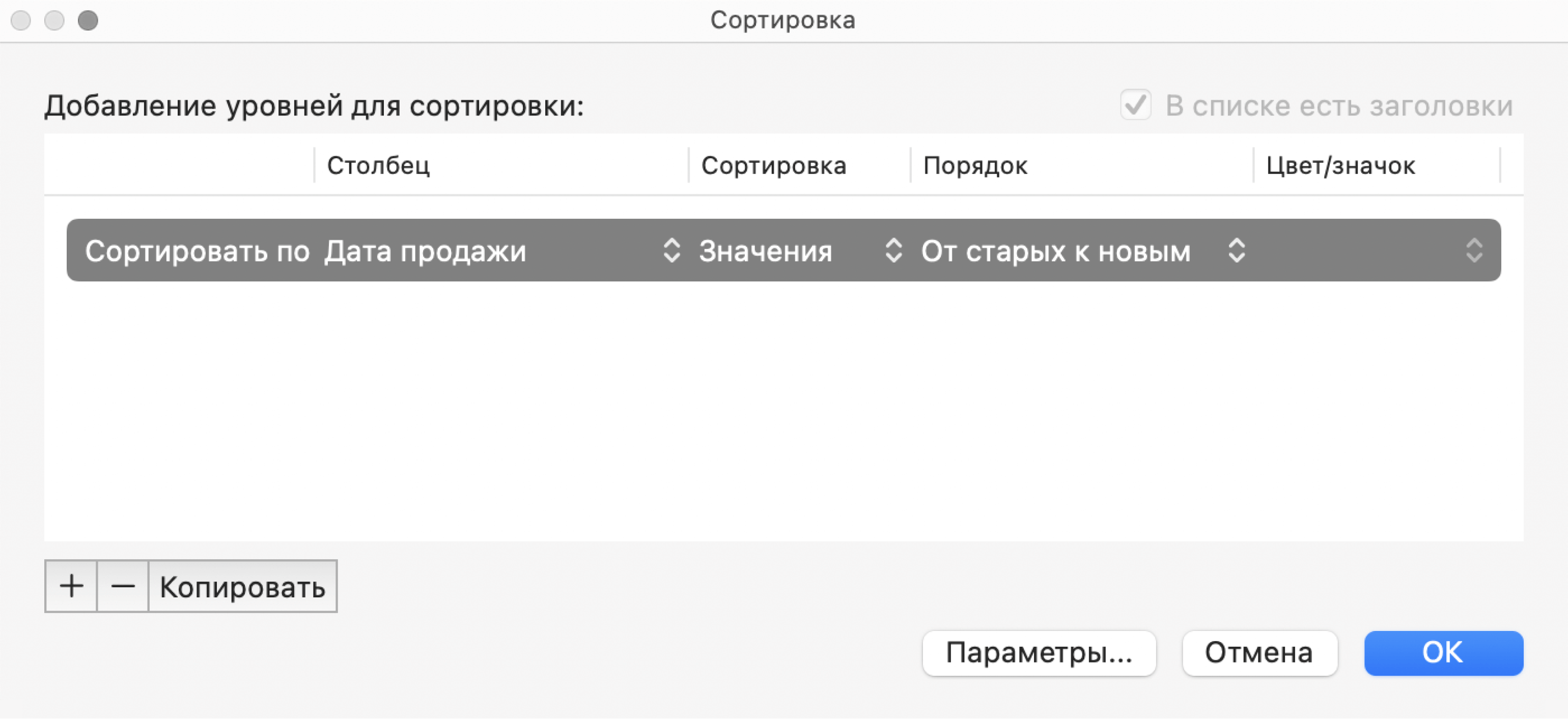
Скриншот: Excel / Skillbox Media
Готово — теперь все сделки менеджера даны в хронологическом порядке.
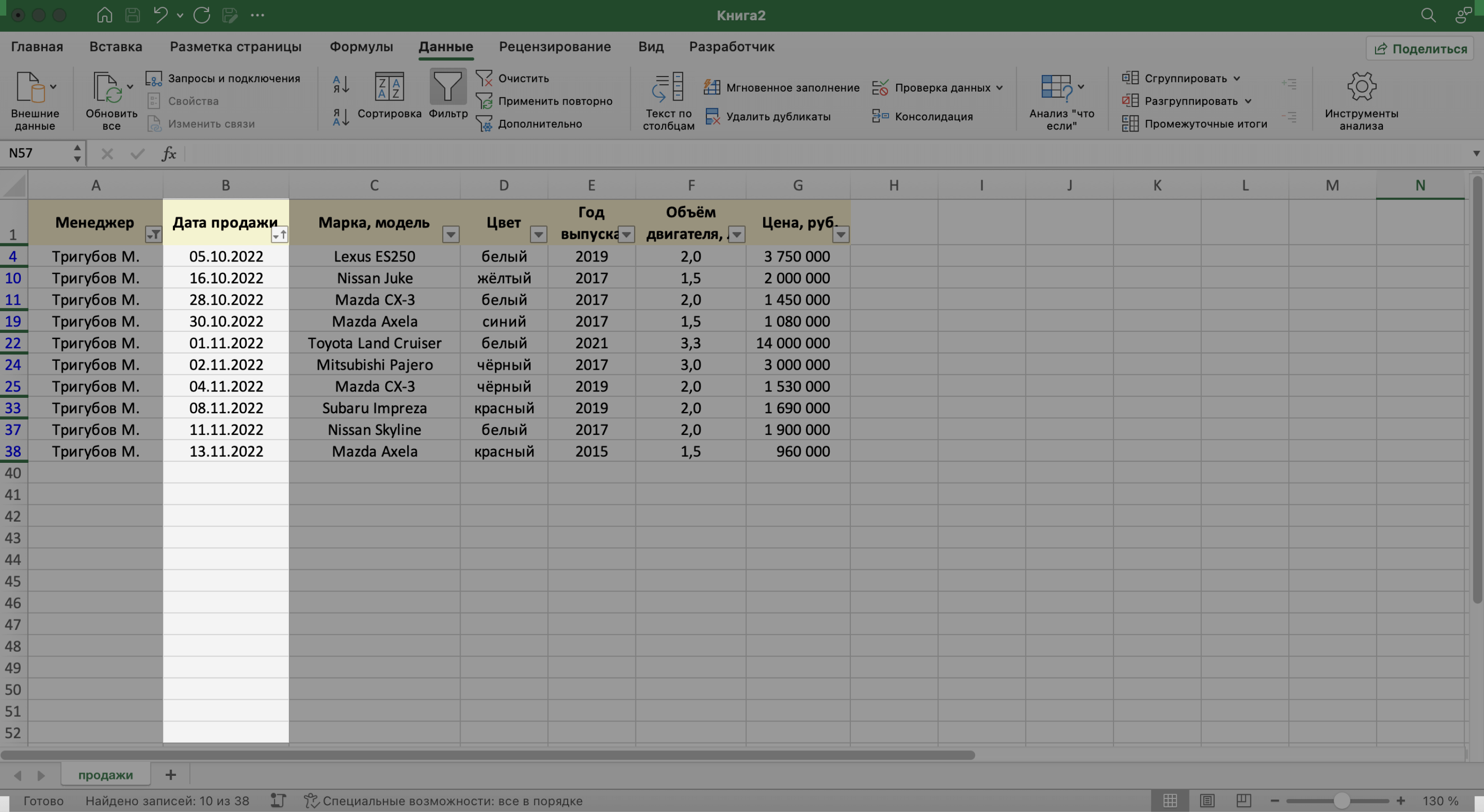
Скриншот: Excel / Skillbox Media
То же самое можно сделать другим способом — выбрать любую ячейку столбца, который нужно отсортировать, и нажать на одну из двух кнопок рядом с кнопкой «Сортировка»: «Сортировка от старых к новым» или «Сортировка от новых к старым». В этом случае данные отсортируются без вызова дополнительных окон.
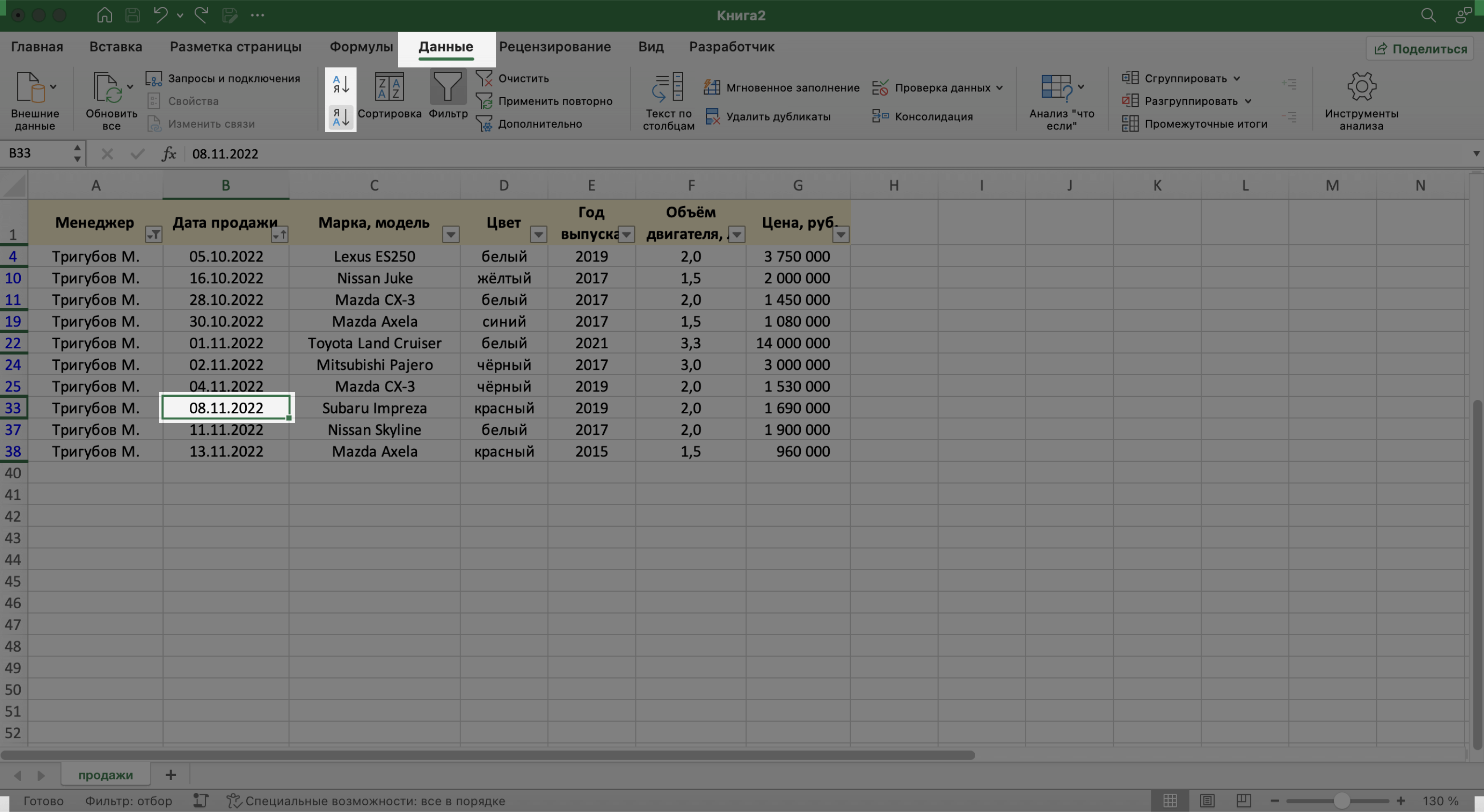
Скриншот: Excel / Skillbox Media
Кроме стандартной сортировки в Excel, можно настроить сортировку по критериям, выбранным пользователем. Эта функция полезна, когда нужные критерии не предусмотрены стандартными настройками. Например, если требуется отсортировать данные по должностям сотрудников или по названиям отделов.
Подробнее о пользовательской сортировке в Excel говорили в этой статье Skillbox Media.
В процессе работы базы данных могут разрастись до миллиона строк — найти нужную информацию станет сложнее. Фильтрация и сортировка не всегда упрощают задачу. В этом случае для быстрого поиска нужной ячейки — текста или цифры — можно воспользоваться функцией поиска.
Предположим, нужно найти в БД автомобиль стоимостью 14 млн рублей. Перейдём на вкладку «Главная» и нажмём на кнопку «Найти и выделить». Также быстрый поиск можно задавать с любой вкладки Excel — через значок лупы в правом верхнем углу экрана.
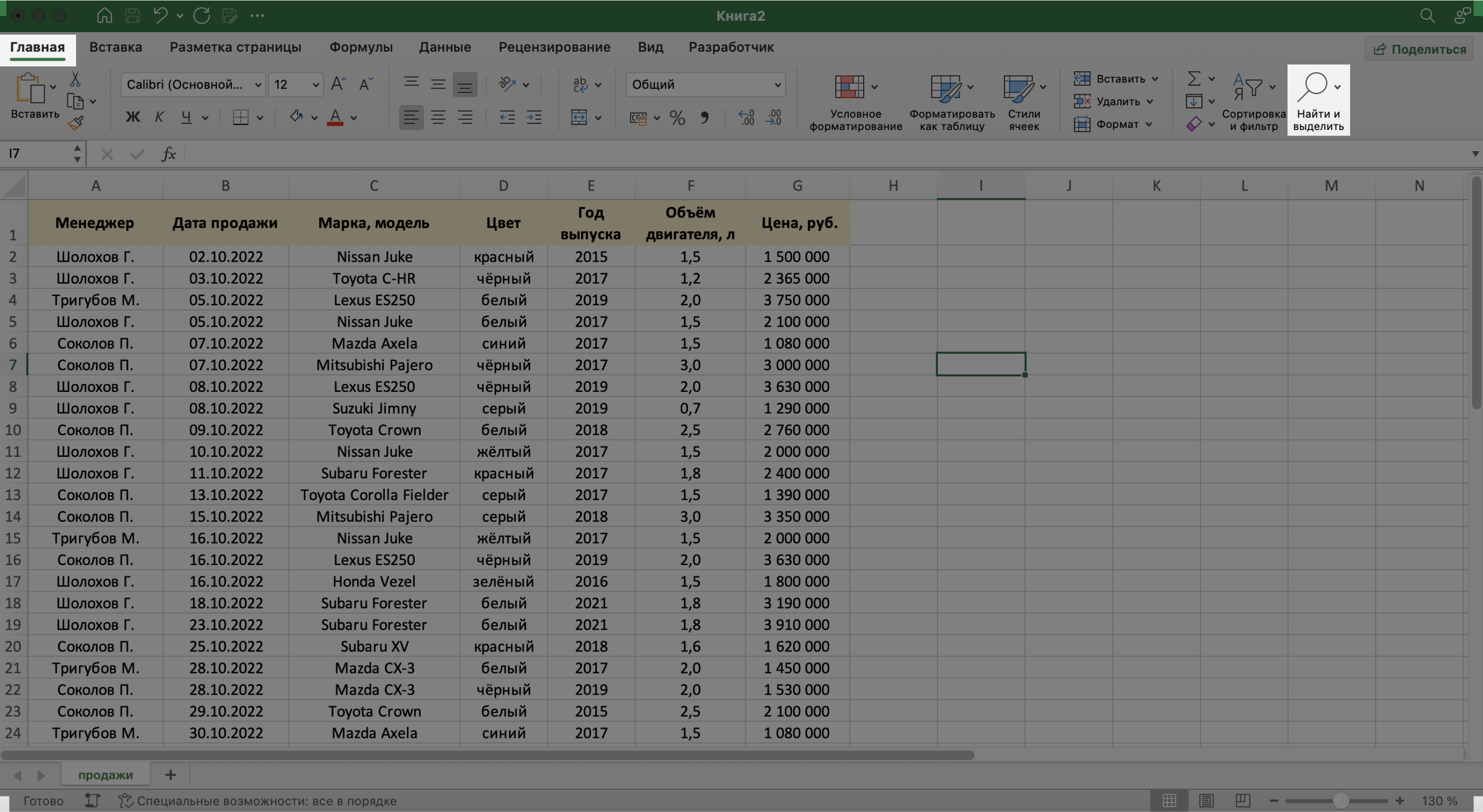
Скриншот: Excel / Skillbox Media
В появившемся окне введём значение, которое нужно найти, — 14000000 — и нажмём «Найти далее».
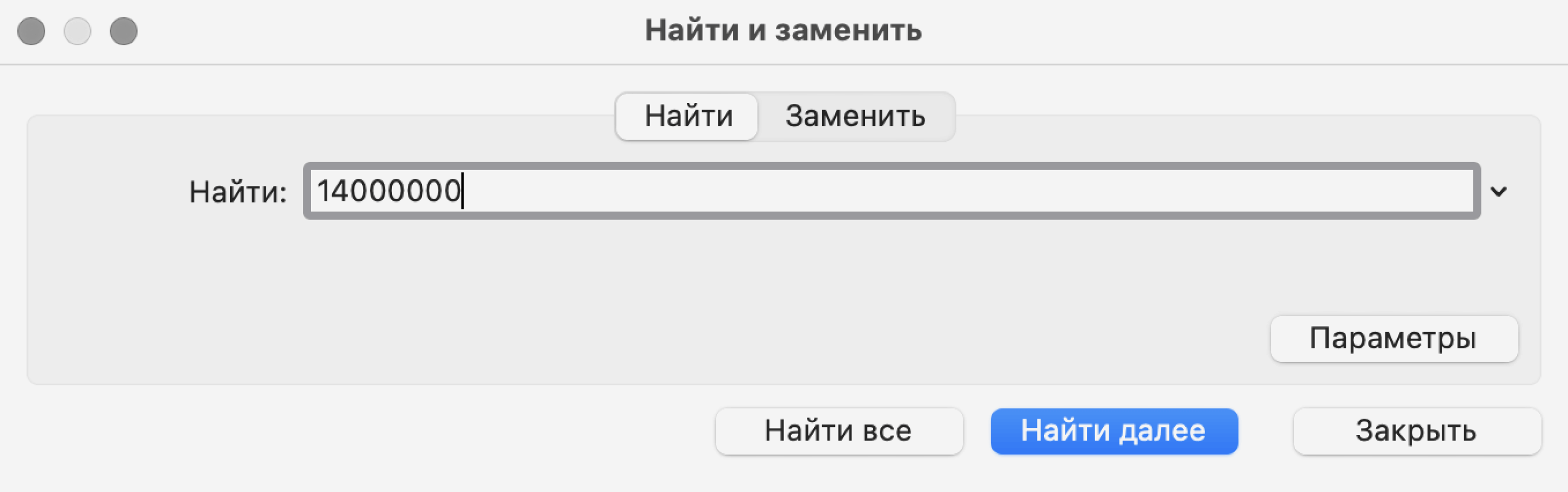
Скриншот: Excel / Skillbox Media
Готово — Excel нашёл ячейку с заданным значением и выделил её.
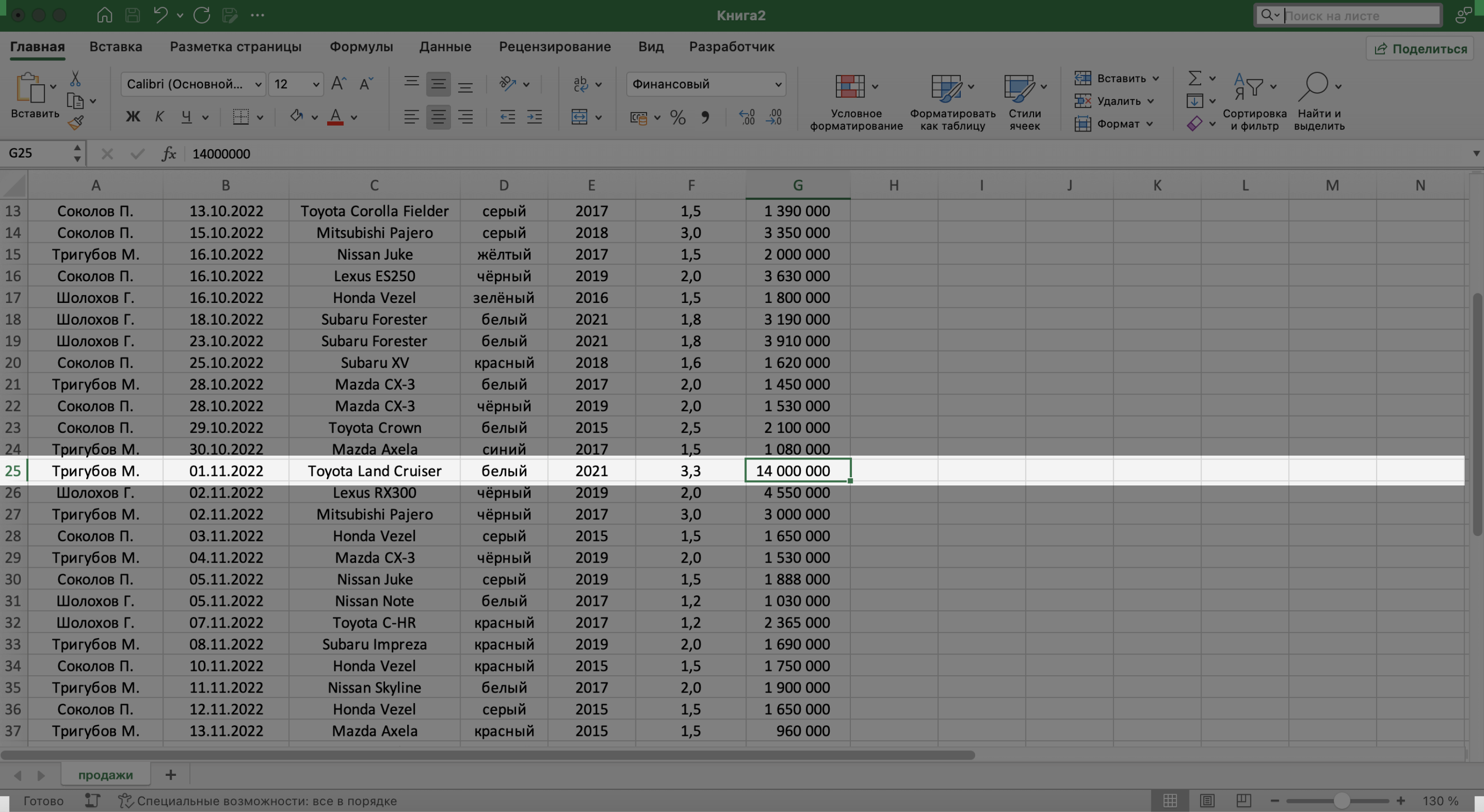
Скриншот: Excel / Skillbox Media
- В этой статье Skillbox Media собрали в одном месте 15 статей и видео об инструментах Excel, которые ускорят и упростят работу с электронными таблицами.
- Также в Skillbox есть курс «Excel + Google Таблицы с нуля до PRO». Он подойдёт как новичкам, которые хотят научиться работать в Excel с нуля, так и уверенным пользователям, которые хотят улучшить свои навыки. На курсе учат быстро делать сложные расчёты, визуализировать данные, строить прогнозы, работать с внешними источниками данных, создавать макросы и скрипты.
- Кроме того, Skillbox даёт бесплатный доступ к записи онлайн-интенсива «Экспресс-курс по Excel: осваиваем таблицы с нуля за 3 дня». Он подходит для начинающих пользователей. На нём можно научиться создавать и оформлять листы, вводить данные, использовать формулы и функции для базовых вычислений, настраивать пользовательские форматы и создавать формулы с абсолютными и относительными ссылками.
Другие материалы Skillbox Media по Excel
- Как сделать сортировку в Excel: детальная инструкция со скриншотами
- Как установить фильтр и расширенный фильтр в Excel: детальные инструкции со скриншотами
- Как сделать ВПР в Excel: пошаговая инструкция со скриншотами
- Основы Excel: работаем с выпадающим списком. Пошаговая инструкция со скриншотами
- Основы Excel: как использовать функцию ЕСЛИ
- Как сделать сводные таблицы в Excel: пошаговая инструкция со скриншотами
Основы правил проектирования базы данных
Время на прочтение
11 мин
Количество просмотров 172K
Введение
Как это часто бывает, архитектору БД нужно разработать базу данных под конкретное решение.
Однажды в пятницу вечером, возвращаясь на электричке домой с работы, я подумал о том, как бы я создал сервис по найму сотрудников в разные компании. Ведь ни один из существующих сервисов не позволяет быстро понять насколько подходит тебе кандидат. Нет возможности создать сложные фильтры, включающие или исключающие совокупность определенных навыков, проектов или позиций. Максимум, что обычно предлагают сервисы — фильтры по компаниям и частично по навыкам.
В данной статье я позволю себе немного разбавить строгое изложение материала, смешав техническую информацию с не техническими примерами из жизни.
Для начала, разберем создание базы данных в MS SQL Server для сервиса поиска соискателей на работу.
Этот материал можно перенести и на другую СУБД такую как MySQL или PostgreSQL.
Основы правил проектирования
Для проектирования схемы базы данных, нужно вспомнить 7 формальных правил и саму концепцию нормализации и денормализации. Они и лежат в основе всех правил проектирования.
Опишем более детально 7 формальных правил:
- отношение один к одному:
1.1) с обязательной связью:
примером может выступать гражданин и его паспорт: у любого гражданина должен быть паспорт; паспорт один для каждого гражданина
Реализовать данную связь можно двумя способами:
1.1.1) в одной сущности (таблице):

Рис.1. Сущность CitizenЗдесь таблица Citizen представляет собой сущность гражданина, а атрибут (поле) PassportData содержит все паспортные данные гражданина и не может быть пустым (NOT NULL).
1.1.2) в двух разных сущностях (таблицах):

Рис.2. Отношение сущностей Citizen и PassportDataЗдесь таблица Citizen представляет собой сущность гражданина, а таблица PassportData — сущность паспортных данных гражданина (самого паспорта). Сущность гражданина содержит атрибут (поле) PassportID, который ссылается на первичный ключ таблицы PassportData. В свою очередь сущность паспортных данных содержит атрибут (поле) CitizenID, которое ссылается на первичный ключ CitizenID таблицы Citizen. Поле PassportID таблицы Citizen не может быть пустым (NOT NULL). Также здесь важно поддерживать целостность поля CitizenID таблицы PassportData, чтобы обеспечить связь один к одному. Иными словами, поле PassportID таблицы Citizen и поле CitizenID таблицы PassportData должны ссылаться на одни и те же записи как если бы это была одна сущность (таблица), представленная в пункте 1.1.1.
1.2) с необязательной связью:
примером может выступать человек, имеющий или не имеющий паспорт конкретной страны. В первом случае он будет являться гражданином рассматриваемой страны, а во втором — нет.
Реализовать данную связь можно двумя способами:
1.2.1) в одной сущности (таблице):

Рис.3. Сущность PersonТаблица Person представляет собой сущность человека, а атрибут (поле) PassportData содержит все его паспортные данные и может быть пустым (NULL).
1.2.2) в двух сущностях (таблицах):
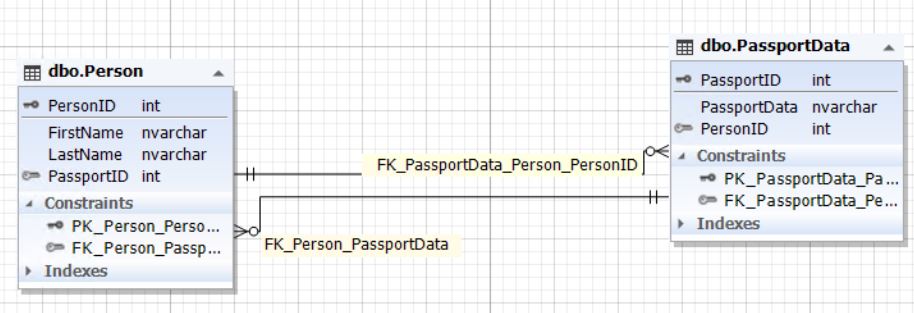
Рис.4. Отношение сущностей Person и PassportData
Таблица Person представляет собой сущность человека, а таблица PassportData — сущность паспортных данных человека (самого паспорта). Сущность человека содержит атрибут (поле) PassportID, который ссылается на первичный ключ таблицы PassportData. В свою очередь сущность паспортных данных содержит атрибут (поле) PersonID, которое ссылается на первичный ключ PersonID таблицы Person. Поле PassportID таблицы Person может быть пустым (NULL). Здесь также важно поддерживать целостность поля PersonID таблицы PassportData. Это нужно, чтобы обеспечить связь один к одному. Поле PassportID таблицы Person и поле PersonID таблицы PassportData должны ссылаться на одни и те же записи как если бы это была одна сущность (таблица), показанная в пункте 1.2.1. Или же данные поля должны быть неопределенными, то есть, содержать NULL. - отношение один ко многим:
2.1) с обязательной связью:
примером могут выступать родитель и его дети. У каждого родителя есть как минимум один ребенок.
Реализовать данную связь можно двумя способами:
2.1.1) в одной сущности (таблице):
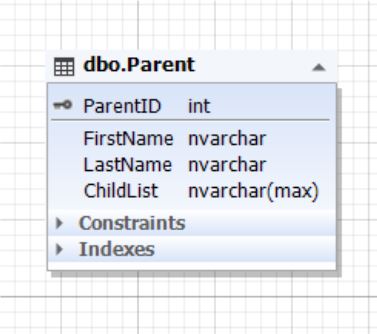
Рис.5. Сущность ParentТаблица Parent представляет сущность родителя, а атрибут (поле) ChildList содержит информацию о детях. Данное поле не может быть пустым (NOT NULL). Обычно типом поля ChildList выступают неполно структурированные данные (NoSQL) такие как XML, JSON и т д.
2.1.2) в двух сущностях (таблицах):
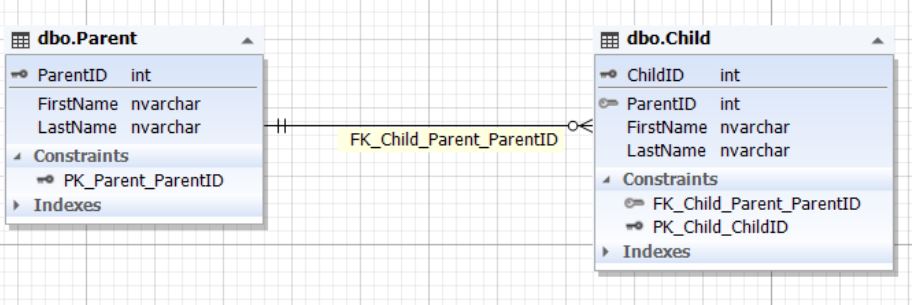
Рис.6. Отношение сущностей Parent и ChildТаблица Parent представляет сущность родителя, а таблица Child — сущность ребенка. У таблицы Child есть поле ParentID, ссылающееся на первичный ключ ParentID таблицы Parent. Поле ParentID таблицы Child не может быть пустым (NOT NULL).
2.2) с необязательной связью:
примером может выступать человек, у которого могут быть дети или их может не быть.
Реализовать данную связь можно двумя способами:
2.2.1) в одной сущности (таблице):
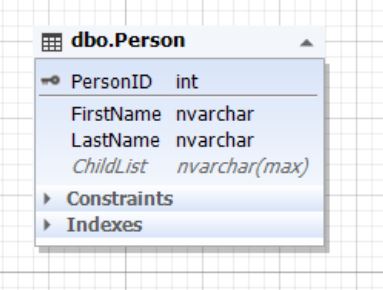
Рис.7. Сущность Person
Таблица Parent представляет сущность родителя, а атрибут (поле) ChildList содержит информацию о детях. Данное поле может быть пустым (NULL). Обычно типом поля ChildList выступают неполно структурированные данные (NoSQL) такие как XML, JSON и т д.2.2.2) в двух сущностях (таблицах):
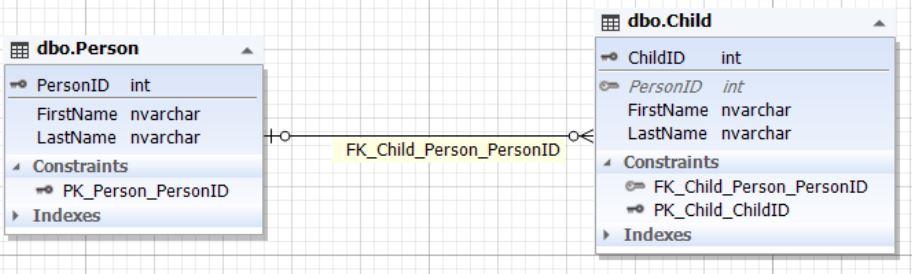
Рис.8. Отношение сущностей Person и ChildТаблица Parent представляет сущность родителя, а таблица Child — сущность ребенка. У таблицы Child есть поле ParentID, ссылающееся на первичный ключ ParentID таблицы Parent. Поле ParentID таблицы Child может быть пустым (NULL).
2.2.3) в одной сущности со ссылкой на саму себя при условии, что у сущностей (таблиц) родителя и ребенка будут одинаковые наборы атрибутов (полей) без учета ссылки на родителя:

Рис.9. Сущность Person со связью на саму себя
Сущность (таблица) Person содержит атрибут (поле) ParentID, который ссылается на первичный ключ PersonID этой же таблицы Person и может содержать пустое значение (NULL).Также данная реализация является примером реализации отношения «многие к одному» с необязательной связью.
- отношение многие к одному:
Эту связь можно рассмотреть зеркально к приведенной выше связи один ко многим. Иными словами, отношение сущности «дети» к сущности «родители», где обязательная связь будет при условии, что у ребенка есть хотя бы один родитель. Если же участвуют все дети, в том числе и находящиеся в детских домах, отношение будет с необязательной связью.
- отношение многие ко многим:
Примером может выступить недвижимость: она может быть в собственности как одного человека, так и нескольких. С другой стороны, один человек может владеть несколькими домами или долями нескольких домов.
Реализовать данное отношение, с привлечением NoSQL, можно так же, как в описанных выше отношениях. Однако, в рамках реляционной модели обычно такое отношение реализуют через 3 сущности (таблицы):
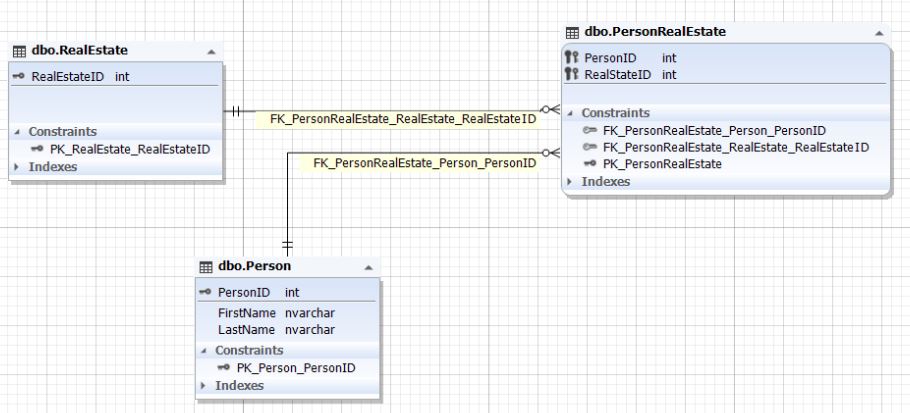
Рис.10. Отношение сущностей Person и RealEstate Таблицы Person и RealEstate представляют соответственно сущности человека и недвижимости. Связываются данные сущности (таблицы) через сущность (таблицы) PersonRealEstate. Атрибуты (поля) PersonID и RealEstateID ссылаются на первичные ключи PersonID таблицы Person и RealEstateID таблицы RealEstate соответственно. Обратите внимание, что для таблицы PersonRealEstate пара (PersonID; RealEstateID) всегда является уникальной и потому может выступать первичный ключем для самой связующей сущности PersonRealEstate.Также данное отношение можно реализовать через более чем три сущности. Для этого добавляются нужные атрибуты, которые ссылаются на первичные ключи необходимых соответствующих сущностей. Такая реализация схожа с примерами, описанными выше в пунктах 1.1.2 и 1.2.2.
Отношения один ко многим и многие к одному можно реализовать через более чем две сущности. Для этого добавляются нужные атрибуты, которые ссылаются на первичные ключи необходимых соответствующих сущностей. Такая реализация схожа с примерами, описанными выше в пунктах 1.1.2 и 1.2.2.
А где же семь формальных правил?
Вот они:
- п.1 (п.1.1 и п.1.2) — первое и второе формальные правила
- п.2 (п.2.1 и п.2.2) — третье и четвертое формальные правила
- п.3 (аналогично п.2) — пятое и шестое формальные правила
- п.4 — седьмое формальное правило
В тексте выше эти семь формальных правил объединены в четыре блока по функционалу.
Говоря о нормализации, нужно понимать ее суть. Нормализация ведет к уменьшению повторяемости хранения информации, а следовательно и к уменьшению возможности появления аномалий в данных. Однако, нормализация при дроблении сущностей приводит к более сложным построениям запросов для манипуляций с данными (вставки, модификации, выборки и удаления).
Обратным процессом нормализации называется денормализация. Это упрощение построения запросов доступа к данным за счет укрупнения и вложенности сущностей (например, как было показано выше в пунктах 2.1.1 и 2.2.1 с помощью неполно-структурированных данных (NoSQL)).
Вот и вся суть правил проектирования баз данных.
А вы уверены, что поняли отношения в семи формальных правилах? Именно поняли, а не узнали? Ведь знать и понимать — две совершенно разных концепции.
Объясню более детально. Спросите себя, можете ли вы за пару часов набросать пусть и укрупненную по сущностям, но модель базы данных для любой предметной области и для любой информационной системы? (тонкости и детали можно достроить, поспрашивав аналитиков и представителей заказчиков). Если вопрос вас удивил, и вы думаете, что это невозможно, значит вы знаете семь формальных правил, но не понимаете их.
Почему-то многие источники игнорируют тот факт, что эти отношения были не придуманы, а выявлены. Они изначально существуют в реальном мире как между субъектами, так и между субъектами и объектами.
Также, эти отношения могут меняться, переходя из один к одному к одному ко многим, многие к одному или многие ко многим. Обязательность связи может меняться или остаться неизменной.
Позволю себе рассказать об одном случае, когда от знания семи формальных правил я пришел именно к пониманию этих отношений.
В свое время меня смущало то, что в ВУЗе я знал эти семь формальных правил, но на производственной практике (ВУЗ отправляет студентов в различные компании для приобретения профессионального опыта) очень долго строил модели баз для разных предметных областей. Я задумался и понял, что не понимаю этих отношений.
Мне помогло наблюдение за людьми, а суть отношений раскрылась в сновидении. Этот сон я перескажу в упрощенной форме: только то, что позволяет лучше понять именно эти семь формальных правил — без детализации всего остального.
Сон был про семью, в которой есть отец, мать и дети. Отец погибает в автомобильной катастрофе, а мать начинает пить, и детей в итоге забирают в детский дом. Эти дети надолго остаются без родителей. Затем у некоторых детей появляются попечители, их тоже несколько.
Вы проследили, какие отношения были между субъектами, и как менялись эти отношения?
Давайте присмотримся внимательнее.
- Когда семья была полной, с несколькими детьми, отношение между родителями и детьми имело вид многие ко многим.
- Когда остались мать и дети, отношение между родителем и детьми стало один ко многим с обязательной связью. Однако, в любой семье, где может и не быть детей, это отношение будет таким же, но уже с необязательной связью.
- А вот со стороны детей отношение к родителю было как многие к одному с обязательной связью пока родителя не лишили родительских прав.
- Когда дети оказались в детском доме — отношение изменилось на многие к одному с необязательной связью.
- Когда у детей появились попечители, связь между ними стала многие ко многим: у каждого попечителя могут быть другие подопечные дети, а у каждого ребенка могут быть другие попечители (родители).
Отношение между мужем и женой один к одному с обязательной связью при официальной брака или один к одному с необязательной связью до регистрации. Жена может быть только одна, как и муж может быть только один. По крайней мере, в России. Но в другой стране возможно многоженство, и тогда связь между мужем и женами будет один ко многим, а между женами и мужем — многие к одному.
Надеюсь, теперь вы значительно приблизились к пониманию этих семи формальных правил.
Стоит постоянно практиковаться: наблюдать за людьми и выявлять существующие отношения как между субъектами, так и между субъектами и объектами. Выше описывался гражданин и его паспорт как отношение один к одному с обязательной связью. В тоже время, пример человека и его паспорта — это отношение один к одному с необязательной связью.
Поняв семь формальных правил, вы сможете без труда спроектировать модель базы данных любой сложности для любой информационной системы.
Также вы увидите, что реализовать отношение можно разными способами, а сами отношения могут меняться. Модель (схема) базы данных — это «снимок» отношений между сущностями в определенный момент времени. Именно поэтому важно определить как сами сущности — образы объектов из реального мира или предметной области, так и их отношения между собой с учетом изменений в будущем.
Хорошо спроектированную модель базы данных с учетом изменения отношений в реальности или в предметной области не понадобится менять годами или даже десятилетия. Это особенно важно для хранилищ данных, где изменения влекут пересохранение больших объемов данных (от нескольких гигабайт до многих терабайт).
Важно запомнить, что таблицы в реляционной модели — это отношения сущностей, а строки (кортежи) — это экземпляры этих отношений. Но чтобы было проще, под таблицами часто понимаются сущности, а под строками таблицы — экземпляры сущностей. Их отношения выражаются через связи в форме внешних ключей.
Проектирование схемы базы данных для поиска соискателей на работу
После того, как мы описали основы правил проектирования БД в первой части, давайте создадим схему базы данных для поиска соискателей на работу.
Для начала, определим, что важно для сотрудников из компании, которые ищут кандидатов:
- для HR:
1.1) компании, где работал соискатель
1.2) позиции, которые ранее занимал соискатель в данных компаниях
1.3) навыки и умения, которыми соискатель пользовался в работе;
а также продолжительность работы соискателя в каждой компании на каждой позиции и длительность использования каждого навыка и умения - для технического специалиста:
2.1) позиции, которые занимал соискатель в данных компаниях
2.2) навыки и умения, которыми соискатель пользовался в работе
2.3) проекты, в которых участвовал соискатель;
а также продолжительность работы соискателя на каждой позиции и в каждом проекте, длительность использования каждого навыка и умения
Для начала выявим нужные сущности:
- Сотрудник (Employee)
- Компания (Company)
- Позиция (должность) (Position)
- Проект (Project)
- Навык (Skill)
- Компании и сотрудники относятся как многие ко многим, так как сотрудник мог работать в нескольких компаниях, а в компании работают многие люди.
- Аналогично относятся позиции и сотрудники: несколько сотрудников могут занимать одну позицию как в рамках как одной, так и нескольких компаний.
- С другой стороны, сотрудник мог работать на разных позициях как в рамках одной, так разных компаний. Таким образом, отношение между позициями и компаниями — многие ко многим.
- Аналогично и по проектам: проекты относятся ко всем выше рассмотренным сущностям как многие ко многим.
- Для простоты будем считать, что в проекте сотрудник использует один набор навыков.
- Тогда проекты и навык относятся как многие ко многим.
Поскольку очень важно зафиксировать, как долго сотрудник работал на той или иной позиции в той или иной компании, а также на каждом проекте, схема нашей базы данных может быть следующей:
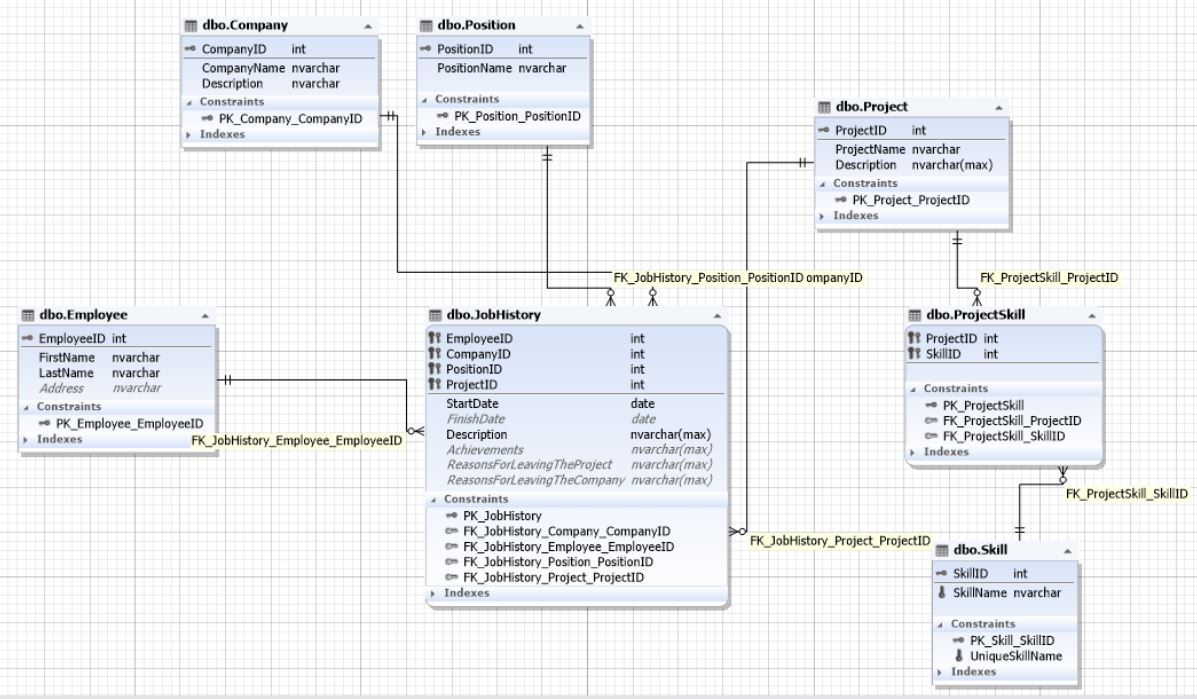
Рис.11. Схема базы данных для поиска соискателей на работу
Здесь таблица JobHistory выступает как сущность истории работы каждого соискателя. То есть, это резюме, которое педставляет отношения многие ко многим между сущностями сотрудник, компания, позиция и проект.
Проекты и навыки относятся друг другу как многие ко многим и потому связываются между собой через сущность (таблицу) ProjectSkill.
Когда вы понимаете отношения между субъектами и между субъектами и объектами — уже упомянутые семь формальных правил — эту или схожую схему можно реализовать «на коленке»: на листке бумаги, мене чем за час. И это еще с учетом усталости после плодотворного рабочего дня.
Здесь можно было упростить схему добавления данных, если «навыки» вложить в сущность «проекты» через неполно структурированные данные (NoSQL) в виде XML, JSON или просто перечислять названия навыков через точку с запятой. Но это бы усложнило выборку с группировкой по навыкам и фильтрацию по отдельным навыкам.
Подобная модель лежит в основе базы данных проекта Geecko.
Как видите, ничего сложного в проектировании информационных систем в части проектирования базы данных нет. Это всего лишь отражение объектов и субъектов из реальности, перенесенное в «сущности» схемы базы данных. Отношения между этими сущностями фиксируются на определенный момент времени, с учетом будущих изменений.
Что именно мы возьмем из реальности и вложим в сущность схемы, и какие отношения построим в модели, будет зависеть от того, что мы хотим от информационной системы в общем, здесь и в будущем. Иными словами — какие данные мы хотим получить в текущий момент времени и через определенное время в будущем.
Немного лирики
После того, как вы внедрите модель в работу, остановитесь на миг и подумайте: только что был создан новый маленький мир. В нем есть свои сущности из реального мира и свои отношения. Да, это цифровой мир, но он теперь будет развиваться своей дорогой. Он будет общаться (интегрироваться) с другими системами (мирами), тоже созданными по своим правилам. Данные будут течь в этих системах, как кровь в живом организме.
А перед сном подумайте о том, что семь формальных правил были всегда, и что они окружают нас всюду. Не больше и не меньше, всегда семь. Все отношения реальной жизни можно разложить на эти семь формальных правил. А когда вы думаете или видите сны, как там сущности относятся друг к другу — не по тем же семи формальным правилам?
Вообще, я уверен, что эти отношения (семь формальных правил) выявил очень хороший психотерапевт, возможно — женщина. Это было очень давно, задолго до появления самого понятия информационных технологий. И самое интересное, что эти отношения живут вне базы данных и ИТ — последние лишь используют их для моделирования информационных систем.
Но мы немного отошли от темы. Я лишь призываю в момент создания новой системы подойти к этому процессу с душой. И тогда поверьте, случится момент творения. Спроектированная таким образом система будет живее всех живых в цифровом мире.
Послесловие
Диаграммы для примеров были реализованы с помощью инструмента Database Diagram Tool for SQL Server. Однако, подобный функционал есть и в DBeaver.
Источники
- SQL Database Design Basics with Example
- Geecko
- Microsoft SQL documentation
- SSMS
- Database Diagram Tool for SQL Server
В современном мире нужны инструменты, которые бы позволяли хранить, систематизировать и обрабатывать большие объемы информации, с которыми сложно работать в Excel или Word.
Подобные хранилища используются для разработки информационных сайтов, интернет-магазинов и бухгалтерских дополнений. Основными средствами, реализующими данный подход, являются MS SQL и MySQL.
Продукт от Microsoft Office представляет собой упрощенную версию в функциональном плане и более понятную для неопытных пользователей. Давайте рассмотрим пошагово создание базы данных в Access 2007.

Microsoft Access 2007 – это система управления базами данных (СУБД), реализующая полноценный графический интерфейс пользователя, принцип создания сущностей и связей между ними, а также структурный язык запросов SQL. Единственный минус этой СУБД – невозможность работать в промышленных масштабах. Она не предназначена для хранения огромных объемов данных. Поэтому MS Access 2007 используется для небольших проектов и в личных некоммерческих целях.
Но прежде чем показывать пошагово создание БД, нужно ознакомиться с базовыми понятиями из теории баз данных.

Определения основных понятий
Без базовых знаний об элементах управления и объектах, использующихся при создании и конфигурации БД, нельзя успешно понять принцип и особенности настройки предметной области. Поэтому сейчас я постараюсь простым языком объяснить суть всех важных элементов. Итак, начнем:
- Предметная область – множество созданных таблиц в базе данных, которые связаны между собой с помощью первичных и вторичных ключей.
- Сущность – отдельная таблица базы данных.
- Атрибут – заголовок отдельного столбца в таблице.
- Кортеж – это строка, принимающая значение всех атрибутов.
- Первичный ключ – это уникальное значение (id), которое присваивается каждому кортежу.
- Вторичный ключ таблицы «Б» – это уникальное значение таблицы «А», использующееся в таблице «Б».
- SQL запрос – это специальное выражение, выполняющее определенное действие с базой данных: добавление, редактирование, удаление полей, создание выборок.
Теперь, когда в общих чертах есть представление о том, с чем мы будем работать, можно приступить к созданию БД.
Создание БД
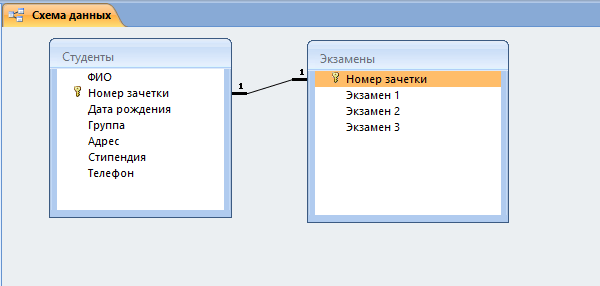
Для наглядности всей теории создадим тренировочную базу данных «Студенты-Экзамены», которая будет содержать 2 таблицы: «Студенты» и «Экзамены». Главным ключом будет поле «Номер зачетки», т.к. данный параметр является уникальным для каждого студента. Остальные поля предназначены для более полной информации об учащихся.
Итак, выполните следующее:
- Запустите MS Access 2007.
- Нажмите на кнопку «Новая база данных».
- В появившемся окне введите название БД и выберите «Создать».
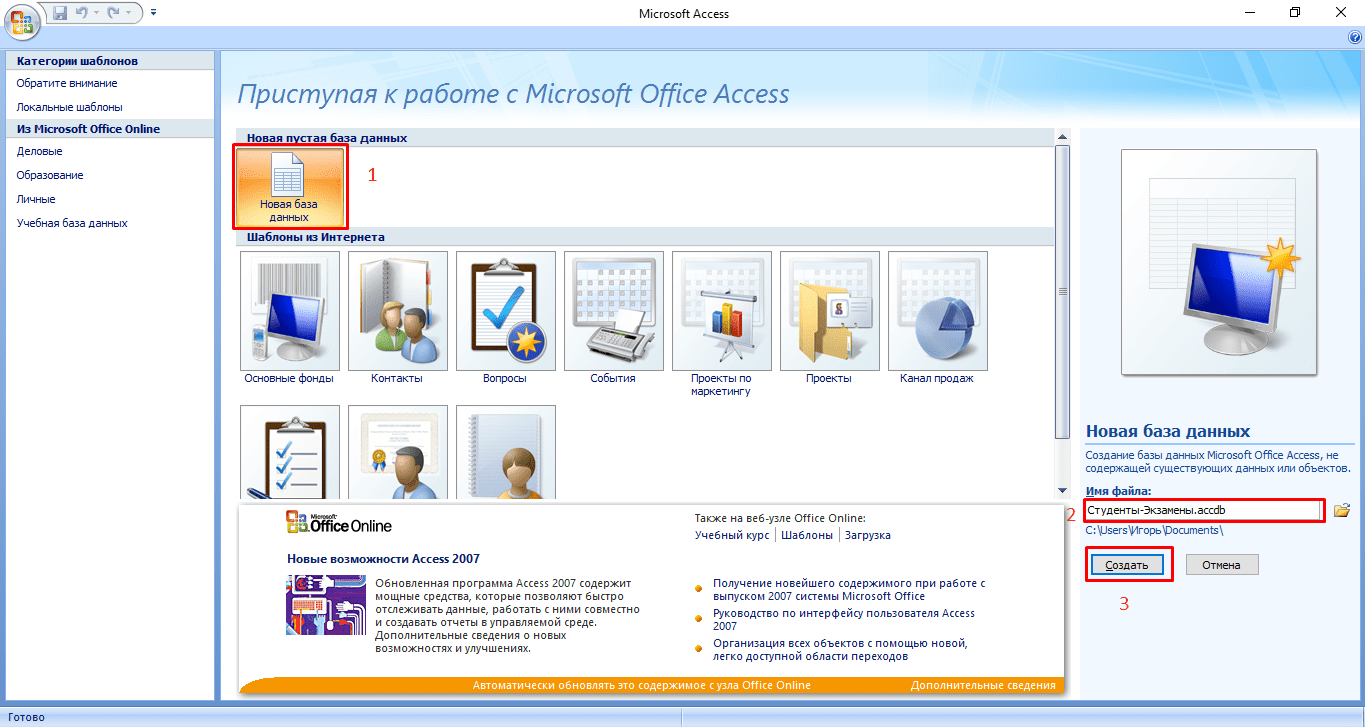
Все, теперь осталось только создать, заполнить и связать таблицы. Переходите к следующему пункту.
Создание и заполнение таблиц
После успешного создания БД на экране появится пустая таблица. Для формирования ее структуры и заполнения выполните следующее:
- Нажмите ПКМ по вкладке «Таблица1» и выберите «Конструктор».
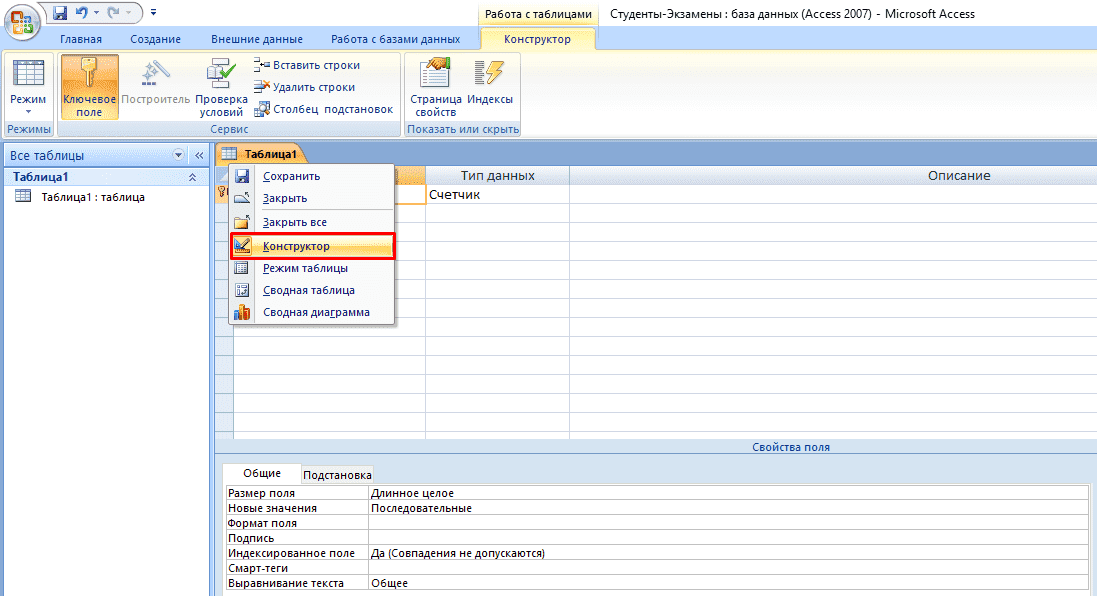
- Теперь начинайте заполнять названия полей и соответствующий им тип данных, который будет использоваться.
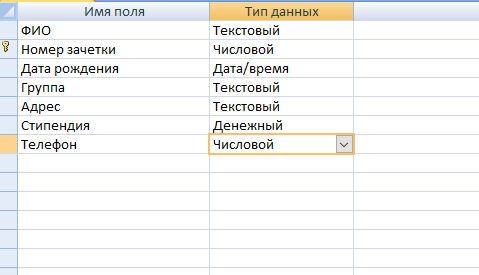
Внимание! Первым полем принято устанавливать уникальное значение (первичный ключ). Для него предпочтительно числовое значение.
- После создания необходимых атрибутов сохраните таблицу и введите ее название.
- Снова нажмите ПКМ по вкладке с уже новым название и выберите «Режим таблицы».
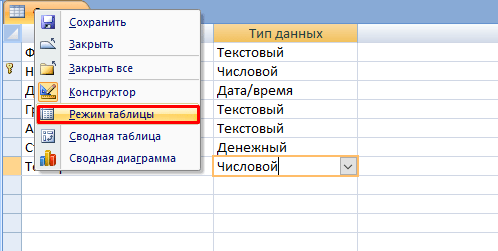
- Заполните таблицу необходимыми значениями.

Совет! Для тонкой настройки формата данных перейдите на ленте во вкладку «Режим таблицы» и обратите внимание на блок «Форматирование и тип данных». Там можно кастомизировать формат отображаемых данных.
Создание и редактирование схем данных
Перед тем, как приступить к связыванию двух сущностей, по аналогии с предыдущим пунктом нужно создать и заполнить таблицу «Экзамены». Она имеет следующие атрибуты: «Номер зачетки», «Экзамен1», «Экзамен2», «Экзамен3».
Для выполнения запросов нужно связать наши таблицы. Иными словами, это некая зависимость, которая реализуется с помощью ключевых полей. Для этого нужно:
- Перейти во вкладку «Работа с базами данных».
- Нажать на кнопку «Схема данных».
- Если схема не была создана автоматически, нужно нажать ПКМ на пустой области и выбрать «Добавить таблицы».
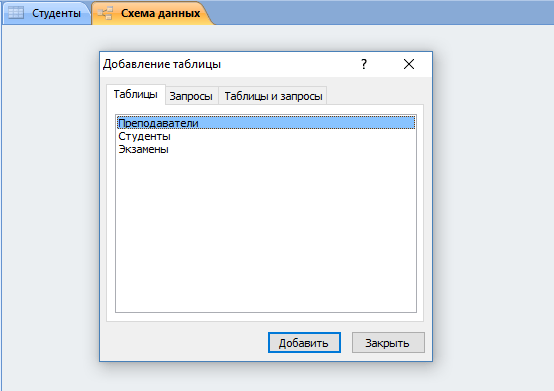
- Выберите каждую из сущностей, поочередно нажимая кнопку «Добавить».
- Нажмите кнопку «ОК».
Конструктор должен автоматически создать связь, в зависимости от контекста. Если же этого не случилось, то:
- Перетащите общее поле из одной таблицы в другую.
- В появившемся окне выберите необходимы параметры и нажмите «ОК».
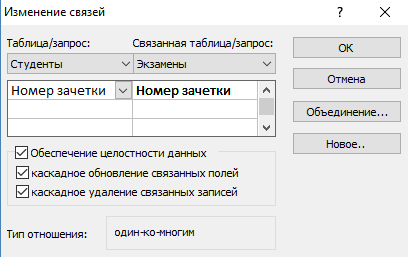
- Теперь в окне должны отобразиться миниатюры двух таблиц со связью (один к одному).
Выполнение запросов
Что же делать, если нам нужны студенты, которые учатся только в Москве? Да, в нашей БД только 6 человек, но что, если их будет 6000? Без дополнительных инструментов узнать это будет сложно.
Именно в этой ситуации к нам на помощь приходят SQL запросы, которые помогают изъять лишь необходимую информацию.
Виды запросов
SQL синтаксис реализует принцип CRUD (сокр. от англ. create, read, update, delete — «создать, прочесть, обновить, удалить»). Т.е. с помощью запросов вы сможете реализовать все эти функции.
На выборку
В этом случае в ход вступает принцип «прочесть». Например, нам нужно найти всех студентов, которые учатся в Харькове. Для этого нужно:
- Перейти во вкладку «Создание».
- Нажать кнопку «Конструктор запросов» в блоке «Другие».
- В новом окне нажмите на кнопку SQL.
- В текстовое поле введите команду: SELECT * FROM Студенты WHERE Адрес = “Харьков”; где «SELECT *» означает, что выбираются все студенты, «FROM Студенты» – из какой таблицы, «WHERE Адрес = “Харьков”» – условие, которое обязательно должно выполняться.
- Нажмите кнопку «Выполнить».
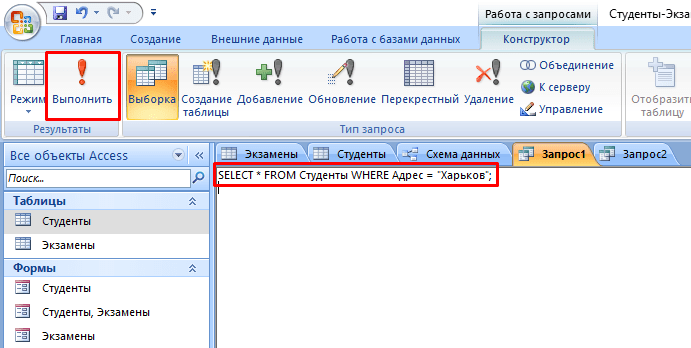
- На выходе мы получаем результирующую таблицу.
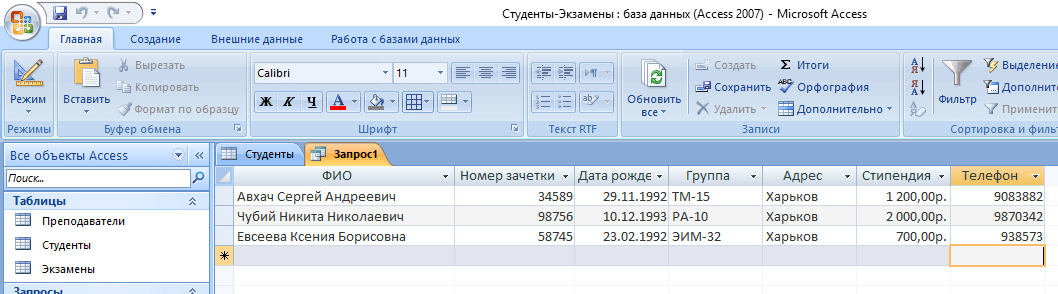
А что делать, если нас интересуют студенты из Харькова, стипендии у которых больше 1000? Тогда наш запрос будет выглядеть следующим образом:
SELECT * FROM Студенты WHERE Адрес = “Харьков” AND Стипендия > 1000;
а результирующая таблица примет следующий вид:

На создание сущности
Кроме добавления таблицы с помощью встроенного конструктора, иногда может потребоваться выполнение этой операции с помощью SQL запроса. В большинстве случаев это нужно во время выполнения лабораторных или курсовых работ в рамках университетского курса, ведь в реальной жизни необходимости в этом нет. Если вы, конечно, не занимаетесь профессиональной разработкой приложений. Итак, для создания запроса нужно:
- Перейти во вкладку «Создание».
- Нажать кнопку «Конструктор запросов» в блоке «Другие».
- В новом окне нажмите на кнопку SQL, после чего в текстовое поле введите команду:
CREATE TABLE Преподаватели
(КодПреподавателя INT PRIMARY KEY,
Фамилия CHAR(20),
Имя CHAR (15),
Отчество CHAR (15),
Пол CHAR (1),
Дата_рождения DATE,
Основной_предмет CHAR (200));
где «CREATE TABLE» означает создание таблицы «Преподаватели», а «CHAR», «DATE» и «INT» – типы данных для соответствующих значений.
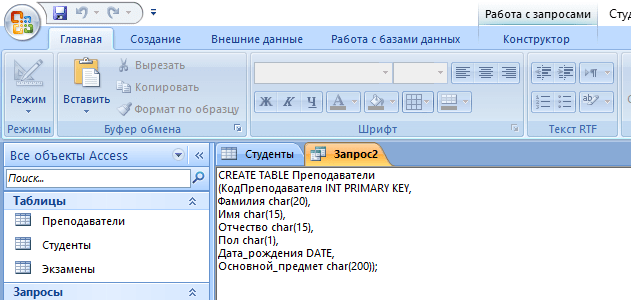
- Кликните по кнопке «Выполнить».
- Откройте созданную таблицу.
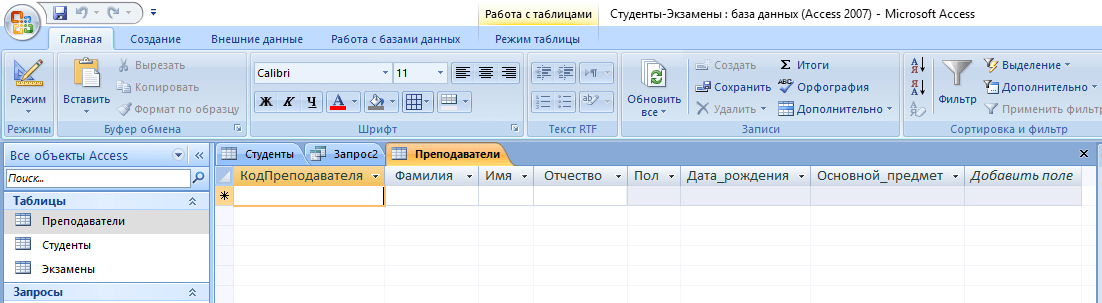
Внимание! В конце каждого запроса должен стоять символ «;». Без него выполнение скрипта приведет к ошибке.
На добавление, удаление, редактирование
Здесь все гораздо проще. Снова перейдите в поле для создания запроса и введите следующие команды:
Создание формы
При огромном количестве полей в таблице заполнять базу данных становится сложно. Можно случайно пропустить значение, ввести неверное или другого типа. В данной ситуации на помощь приходят формы, с помощью которых можно быстро заполнять сущности, а вероятность допустить ошибку минимизируется. Для этого потребуются следующие действия:
- Откройте интересующую таблицу.
- Перейдите во вкладку «Создание».
- Нажмите на необходимый формат формы из блока «Формы».
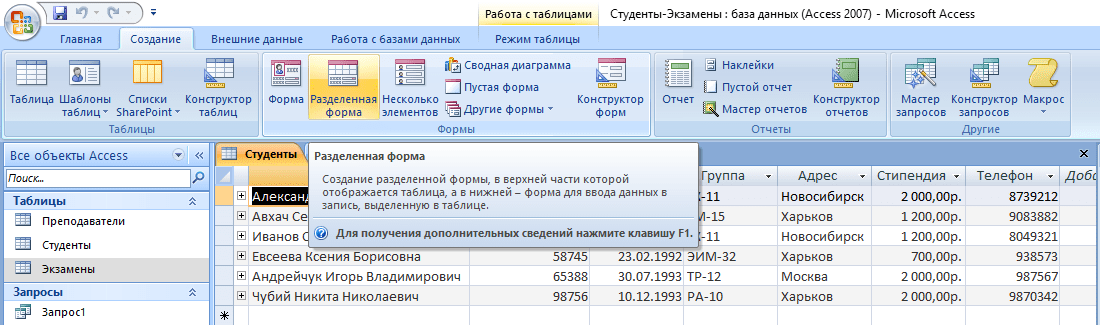
Совет! Рекомендуется использовать «Разделенную форму» – кроме самого шаблона, в нижней части будет отображаться миниатюра таблицы, которая сделает процесс редактирования еще более наглядным.
- С помощью навигационных кнопок переходите к следующей записи и вносите изменения.
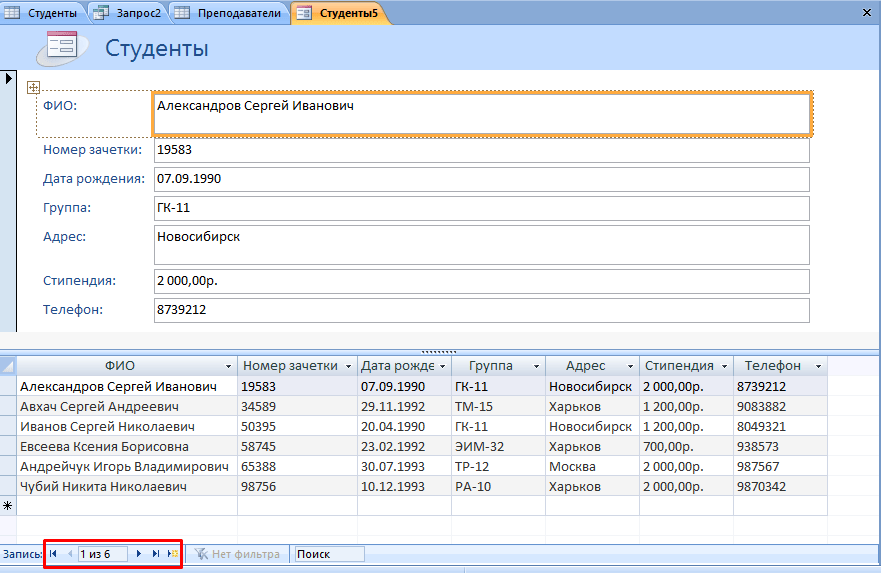
Все базовые функции MS Access 2007 мы уже рассмотрели. Остался последний важный компонент – формирование отчета.
Формирование отчета
Отчет – это специальная функция MS Access, позволяющая оформить и подготовить для печати данные из базы данных. В основном это используется для создания товарных накладных, бухгалтерских отчетов и прочей офисной документации.
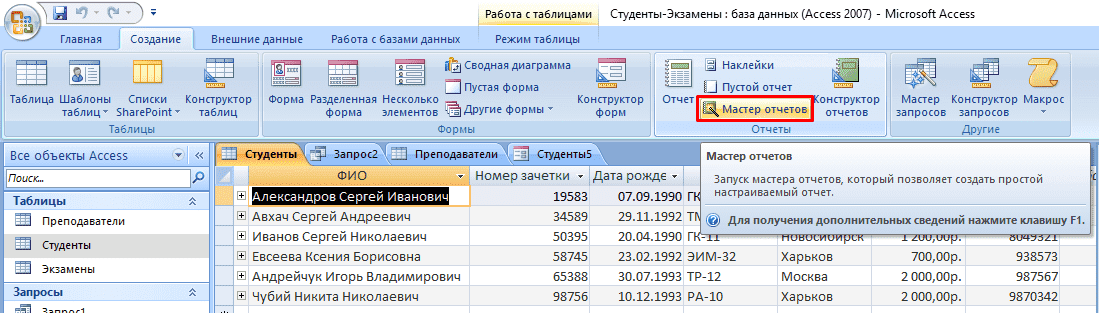
Если вы никогда не сталкивались с подобной функцией, рекомендуется воспользоваться встроенным «Мастером отчетов». Для этого сделайте следующее:
- Перейдите во вкладку «Создание».
- Нажмите на кнопку «Мастер отчетов» в блоке «Отчеты».
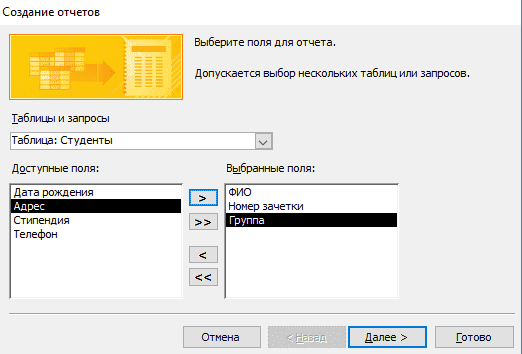
- Выберите интересующую таблицу и поля, нужные для печати.
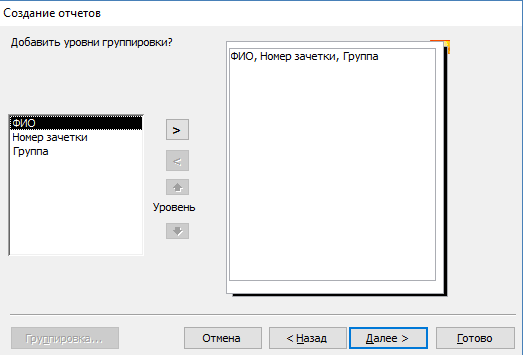
- Добавьте необходимый уровень группировки.
- Выберите тип сортировки каждого из полей.

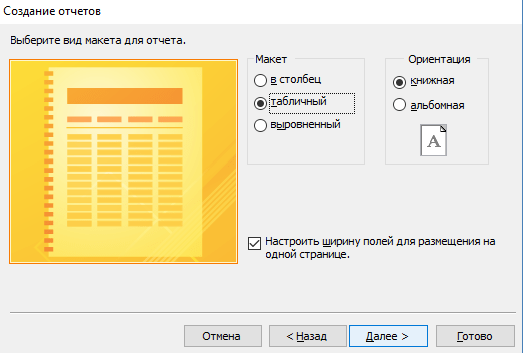
- Настройте вид макета для отчета.
- Выберите подходящий стиль оформления.
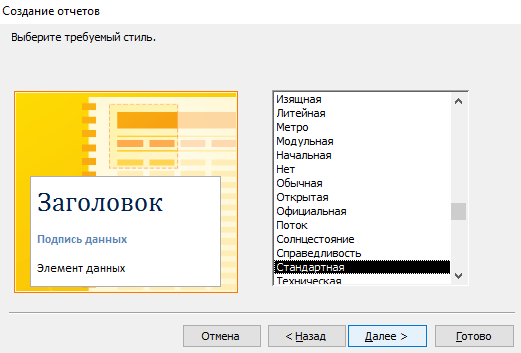
Внимание! В официальных документах допускается только стандартный стиль оформления.
- Просмотрите созданный отчет.
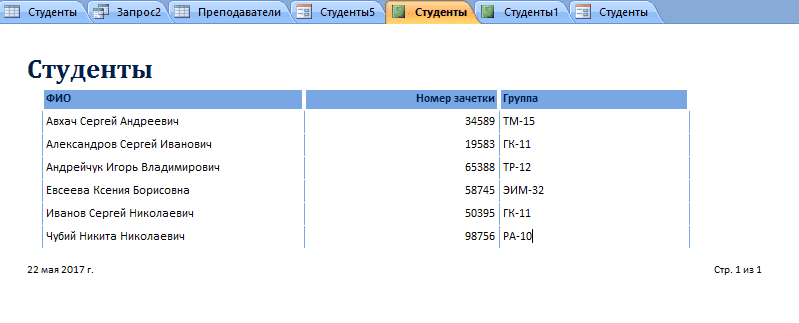
Если отображение вас не устраивает, его можно немного подкорректировать. Для этого:
- Нажмите ПКМ на вкладке отчета и выберите «Конструктор».
- Вручную расширьте интересующие столбцы.
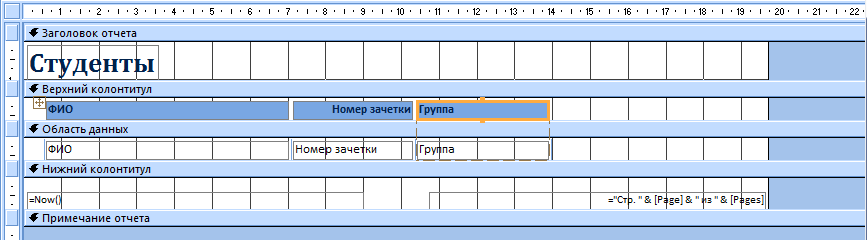
- Сохраните изменения.
Вывод
Итак, с уверенностью можно заявить, что создание базы данных в MS Access 2007 мы разобрали полностью. Теперь вам известны все основные функции СУБД: от создания и заполнения таблиц до написания запросов на выборку и создания отчетов. Этих знаний хватит для выполнения несложных лабораторных работ в рамках университетской программы или использования в небольших личных проектах.
Для проектирования более сложных БД необходимо разбираться в объектно-ориентированном программировании и изучать такие СУБД, как MS SQL и MySQL. А для тех, кому нужна практика составления запросов, рекомендую посетить сайт SQL-EX, где вы найдете множество практических занимательных задачек.
Удачи в освоении нового материала и если есть какие-либо вопросы – милости прошу в комментарии!
Многие пользователи активно применяют Excel для генерирования отчетов, их последующей редакции. Для удобного просмотра информации и получения полного контроля при управлении данными в процессе работы с программой.
Внешний вид рабочей области программы – таблица. А реляционная база данных структурирует информацию в строки и столбцы. Несмотря на то что стандартный пакет MS Office имеет отдельное приложение для создания и ведения баз данных – Microsoft Access, пользователи активно используют Microsoft Excel для этих же целей. Ведь возможности программы позволяют: сортировать; форматировать; фильтровать; редактировать; систематизировать и структурировать информацию.
То есть все то, что необходимо для работы с базами данных. Единственный нюанс: программа Excel – это универсальный аналитический инструмент, который больше подходит для сложных расчетов, вычислений, сортировки и даже для сохранения структурированных данных, но в небольших объемах (не более миллиона записей в одной таблице, у версии 2010-го года выпуска ).
Структура базы данных – таблица Excel
База данных – набор данных, распределенных по строкам и столбцам для удобного поиска, систематизации и редактирования. Как сделать базу данных в Excel?
Вся информация в базе данных содержится в записях и полях.
Запись – строка в базе данных (БД), включающая информацию об одном объекте.
Поле – столбец в БД, содержащий однотипные данные обо всех объектах.
Записи и поля БД соответствуют строкам и столбцам стандартной таблицы Microsoft Excel.
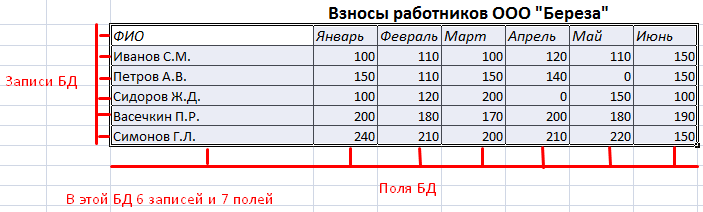
Если Вы умеете делать простые таблицы, то создать БД не составит труда.
Создание базы данных в Excel: пошаговая инструкция
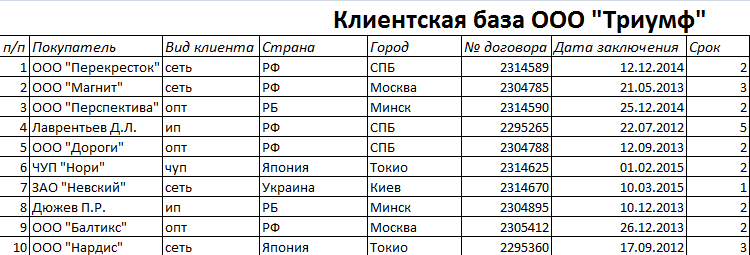
Пошаговое создание базы данных в Excel. Перед нами стоит задача – сформировать клиентскую БД. За несколько лет работы у компании появилось несколько десятков постоянных клиентов. Необходимо отслеживать сроки договоров, направления сотрудничества. Знать контактных лиц, данные для связи и т.п.
Как создать базу данных клиентов в Excel:
- Вводим названия полей БД (заголовки столбцов).
- Вводим данные в поля БД. Следим за форматом ячеек. Если числа – то числа во всем столбце. Данные вводятся так же, как и в обычной таблице. Если данные в какой-то ячейке – итог действий со значениями других ячеек, то заносим формулу.
- Чтобы пользоваться БД, обращаемся к инструментам вкладки «Данные».
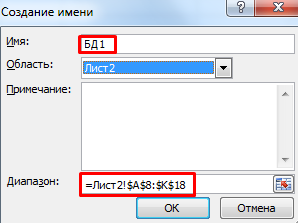
- Присвоим БД имя. Выделяем диапазон с данными – от первой ячейки до последней. Правая кнопка мыши – имя диапазона. Даем любое имя. В примере – БД1. Проверяем, чтобы диапазон был правильным.


Основная работа – внесение информации в БД – выполнена. Чтобы этой информацией было удобно пользоваться, необходимо выделить нужное, отфильтровать, отсортировать данные.
Как вести базу клиентов в Excel
Чтобы упростить поиск данных в базе, упорядочим их. Для этой цели подойдет инструмент «Сортировка».
- Выделяем тот диапазон, который нужно отсортировать. Для целей нашей выдуманной компании – столбец «Дата заключения договора». Вызываем инструмент «Сортировка».
- При нажатии система предлагает автоматически расширить выделенный диапазон. Соглашаемся. Если мы отсортируем данные только одного столбца, остальные оставим на месте, то информация станет неправильной. Открывается меню, где мы должны выбрать параметры и значения сортировки.
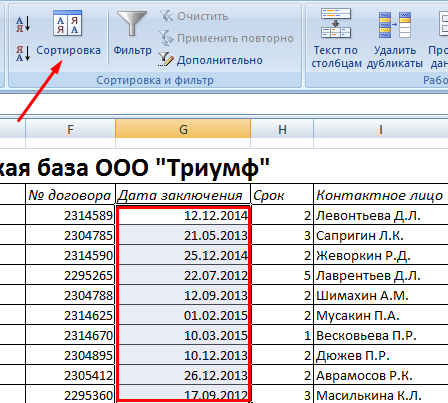
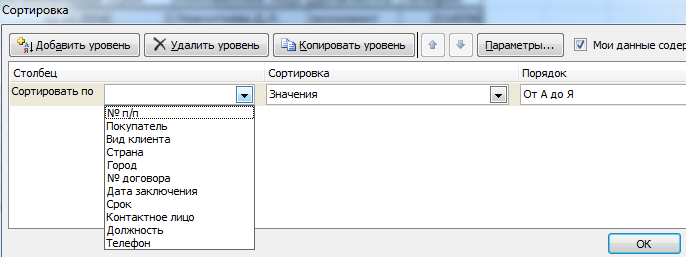
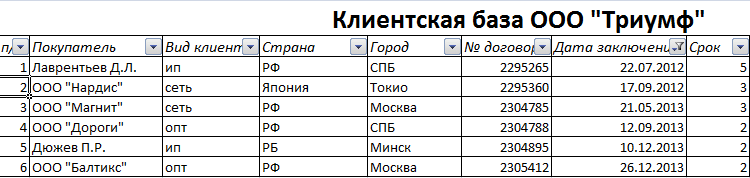
Данные в таблице распределились по сроку заключения договора.
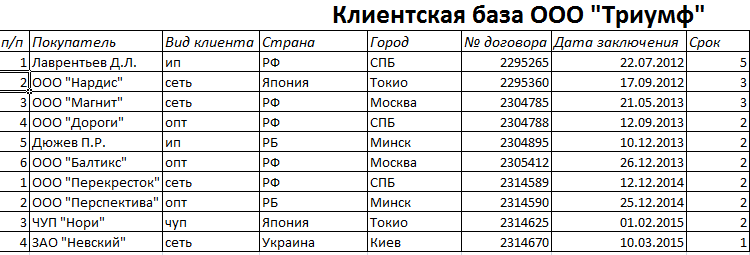
Теперь менеджер видит, с кем пора перезаключить договор. А с какими компаниями продолжаем сотрудничество.
БД в процессе деятельности фирмы разрастается до невероятных размеров. Найти нужную информацию становится все сложнее. Чтобы отыскать конкретный текст или цифры, можно воспользоваться одним из следующих способов:
- Одновременным нажатием кнопок Ctrl + F или Shift + F5. Появится окно поиска «Найти и заменить».
- Функцией «Найти и выделить» («биноклем») в главном меню.
Посредством фильтрации данных программа прячет всю не интересующую пользователя информацию. Данные остаются в таблице, но невидимы. В любой момент их можно восстановить.
В программе Excel чаще всего применяются 2 фильтра:
- Автофильтр;
- фильтр по выделенному диапазону.
Автофильтр предлагает пользователю выбрать параметр фильтрации из готового списка.
- На вкладке «Данные» нажимаем кнопку «Фильтр».
- После нажатия в шапке таблицы появляются стрелки вниз. Они сигнализируют о включении «Автофильтра».
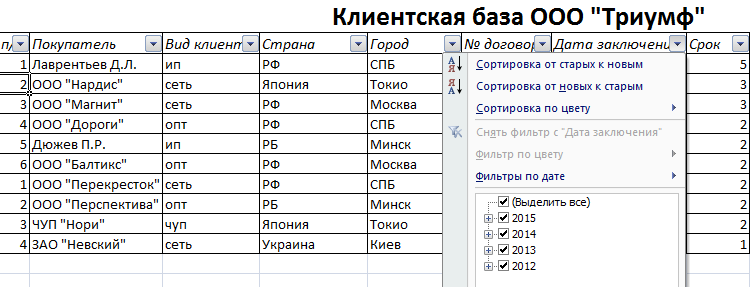
- Чтобы выбрать значение фильтра, щелкаем по стрелке нужного столбца. В раскрывающемся списке появляется все содержимое поля. Если хотим спрятать какие-то элементы, сбрасываем птички напротив их.
- Жмем «ОК». В примере мы скроем клиентов, с которыми заключали договоры в прошлом и текущем году.
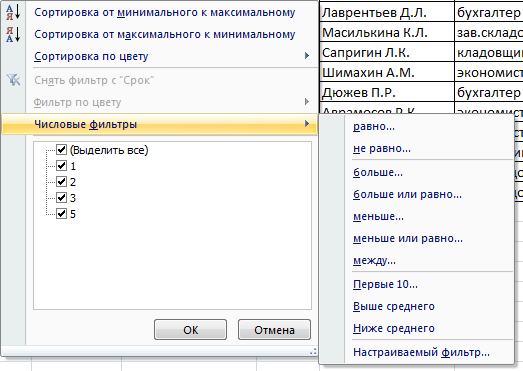
- Чтобы задать условие для фильтрации поля типа «больше», «меньше», «равно» и т.п. числа, в списке фильтра нужно выбрать команду «Числовые фильтры».
- Если мы хотим видеть в таблице клиентов, с которыми заключили договор на 3 и более лет, вводим соответствующие значения в меню пользовательского автофильтра.

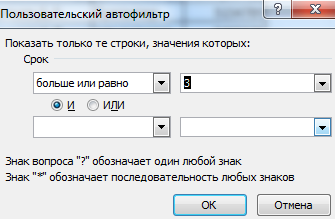
Готово!

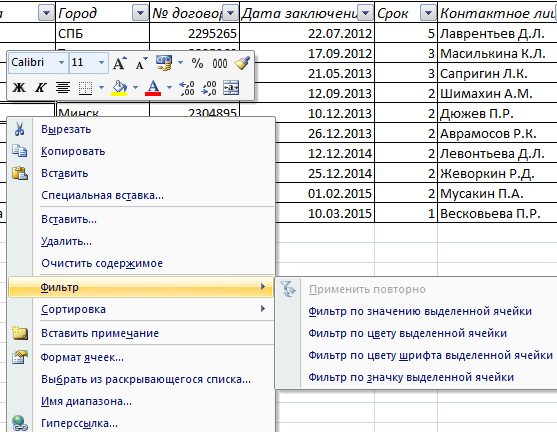
Поэкспериментируем с фильтрацией данных по выделенным ячейкам. Допустим, нам нужно оставить в таблице только те компании, которые работают в Беларуси.
- Выделяем те данные, информация о которых должна остаться в базе видной. В нашем случае находим в столбце страна – «РБ». Щелкаем по ячейке правой кнопкой мыши.
- Выполняем последовательно команду: «фильтр – фильтр по значению выделенной ячейки». Готово.

Если в БД содержится финансовая информация, можно найти сумму по разным параметрам:
- сумма (суммировать данные);
- счет (подсчитать число ячеек с числовыми данными);
- среднее значение (подсчитать среднее арифметическое);
- максимальные и минимальные значения в выделенном диапазоне;
- произведение (результат умножения данных);
- стандартное отклонение и дисперсия по выборке.
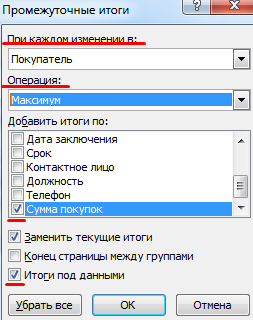
Порядок работы с финансовой информацией в БД:
- Выделить диапазон БД. Переходим на вкладку «Данные» – «Промежуточные итоги».
- В открывшемся диалоге выбираем параметры вычислений.

Инструменты на вкладке «Данные» позволяют сегментировать БД. Сгруппировать информацию с точки зрения актуальности для целей фирмы. Выделение групп покупателей услуг и товаров поможет маркетинговому продвижению продукта.
Готовые образцы шаблонов для ведения клиентской базы по сегментам.
- Шаблон для менеджера, позволяющий контролировать результат обзвона клиентов. Скачать шаблон для клиентской базы Excel. Образец:
- Простейший шаблон.Клиентская база в Excel скачать бесплатно. Образец:
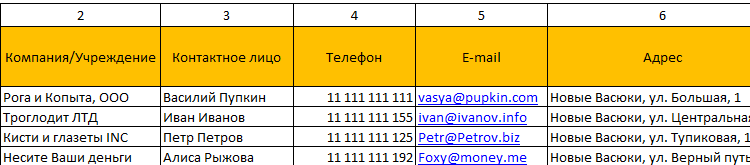
Шаблоны можно подстраивать «под себя», сокращать, расширять и редактировать.
В качестве примера спроектируем несложную базу данных информационной системы кинотеатра. При этом, решим следующие задачи:
- анализ предметной области для определения состава и содержания информации, обрабатываемой информационной системой, а также пользовательских потребностей;
- построение концептуальной модели предметной области, заключающееся в выявлении сущностей и связей между ними, а также отображение этой информации в виде ER-диаграммы;
- физическое проектирование базы данных и ее реализация в MS SQL Server.
1 Анализ предметной области
Зачастую, кинотеатр состоит из нескольких залов разной конфигурации, а посетителю предоставляется возможность выбора билета, для этого ему отображается текущее состояние зала. Выбранные места посетитель сообщает кассиру, который вводит их в систему и места помечаются как «проданные». Это «основной» сценарий использования информационной системы, однако надо учесть следующее:
- репертуар и расписание проката кинотеатра должен кто-то вносить в систему — соответствующую роль назовем «Менеджер»;
- посетитель и кассир должны иметь возможность просматривать расписание, при этом интересно расписание, начиная с некоторого момента времени (например, текущего времени). Составлять оно может по-разному:
- расписание показа всех фильмов, упорядоченное по времени;
- расписание прокатов в отдельных залах кинотеатра;
- расписание проката определенного фильма.
Из этого описания понятны основные функции системы, изображенные на рисунке с помощью нотации диаграммы прецедентов UML. На диаграмме не отображена роль администратора базы данных, так как администратор обычно взаимодействует с системой не через интерфейс, а через выполнение SQL-запросов.

Несмотря на то, что мы не будет разрабатывать интерфейс информационной системы и текстовые описания прецедентов, дальше нас будут интересовать данные, необходимые для выполнения того или иного прецедента, а для этого надо выделить и описать сущности. Иначе, невозможно определить «какие данные должен вводить менеджер при добавлении фильма». Основные сущности, данные которых потребуются во время работы, показаны на рисунке, при этом используется нотация диаграммы классов UML. Каждый прямоугольник соответствует одной сущности, внутри записаны поля и типы данных.

Каждая сущность, кроме hall_row содержит поле id, которое идентифицирует объект. У сущности hall_row поле id не нужно, так как в одном и том же зале кинотеатра (id_hall) не могут повторяться номера рядов (number).
Когда пользователь выберет зал и прокат — система должна отобразить заполненность зала, при этом надо отобразить конфигурацию зала с пометкой занятых и свободных мест. Под конфигурацией зала тут имеется ввиду, что разные залы имеют разный размер, а ряды зала могут иметь различное количество мест. Поэтому в базе данных зал (hall) составляется из рядов (hall_row), одним из параметров которых является вместимость (capacity).
2 Построение концептуальной модели
Выше были отображены основные сущности, но не отображены роли пользователей, хотя их тоже должна хранить система. Они показаны ниже на ER-диаграмме в нотации Чена [1].

На диаграмме выделены роли кассира и менеджера, а также основные отношения между сущностями. На диаграмме нет роли администратора, но его роль заключается в:
- создании всех таблиц базы;
- добавлении залов и рядов в них;
- добавлении кассиров и менеджеров.
На диаграмме не отражена роль посетителя, так как:
- билет не содержит информации о том, кто его купил (посетитель может подарить билет другу);
- система вообще не хранит информацию о посетителях;
- покупку билета он осуществляет через общение с кассиром вне системы;
- никакие данные в базе посетитель самостоятельно изменить не может.
На диаграмме проставлены кратности связей, например, видно, что один менеджер может добавить много (N) прокатов. В этой базе не оказалось связей типа N:M, сложных или рекурсивных связей — такие связи являются препятствиями в проектировании и решаются изменением ее структуры.
Для формирования схемы данных необходимо сначала дополнить ER-диаграмму реквизитами сущностей (уточнить ее) — результат приведен на рисунке.

В ходе анализа этой диаграммы были найдены несколько недочетов, допущенных при выделении сущностей системы:
- система не должна позволять продавать несколько билетов на одно и то же место при одном показе фильма. Это значит, что вторичным ключем для Билета должен быть кортеж (id_screening, row, seat). Однако, тогда нет необходимости в id билета — на билеты не ссылается ни одна таблица, это поле может быть удалено. Изначально id был добавлен потому, что обычно на билетах в кинотеатрах печатается номер;
- билет хранит поле id_hall, это было сделано для того, чтобы посетитель кинотеатра мог найти свой кинозал. Однако, билет, выдаваемый пользователю — это не тоже самое, что информация о билетах, хранимая в базе данных. Билет базы данных хранит также поле id_screening, а Показ уже ссылается на id_hall. Таким образом, в базе нет смысла хранить id_hall в таблице билетов.
Исправленная ER-диаграмма приведена ниже:

Таблица менеджеров и кассиров не объединены в таблицу Users так как вопросы разграничения прав доступа в различных СУБД решаются по-разному. Так, в MS SQL пользователи добавляются с помощью специальных запросов типа:
CREATE LOGIN Manager_Name WITH PASSWORD='Some Passwrd';
при этом вообще нет необходимости хранить информацию об их логинах и паролях в таблицах. Однако, вопросы разграничения доступа решаются позже — на этапе физического проектирования.
3 Физическое проектирование
ER-диаграмма отражает основные таблицы, связи и атрибуты, на ее основе можно построить модель БД. На ER-диаграммы нет стандарта, но есть ряд нотаций (Чена, IDEFIX, Мартина и т.п.) [2], но на модель предметной области не удалось найти ни стандарта, ни нотаций. Однако, в ходе построения такой диаграммы обязательно выделяются ключевые поля (внешние и внутренние), иногда — индексы и типы данных. Схема базы данных, приведенная на рисунке, выполнена с использованием открытого инструмента plantuml [3], при этом:
- для связей используется нотация Мартина («вороньи лапки»);
- таблицы изображены прямоугольниками, разделенными на 3 секции:
- имя таблицы;
- внутренние ключи (помечаются маркером);
- остальные поля, при этом обязательные поля помечаются маркером.

3.1 Составление и нормализация реляционных отношений
Схема отношения «Билеты» (tickets):
|
Наименование поля |
Тип поля |
Размер поля |
Значение по умолчанию |
Ограничения |
Ключ или индекс |
|
id_screening |
int |
4 |
|
обязательное поле |
первичный ключ (составной) |
|
row |
smallint |
2 |
— |
обязательное поле |
первичный ключ (составной) |
|
seat |
smallint |
2 |
— |
обязательное поле |
первичный ключ (составной) |
Схема отношения «Прокаты» (screening):
|
Наименование поля |
Тип поля |
Размер поля |
Значение по умолчанию |
Ограничения |
Ключ или индекс |
|
id |
int |
4 |
|
обязательное поле |
Первичный ключ, уникальный |
|
hall_id |
int |
4 |
— |
обязательное поле |
Внешний ключ к hall |
|
film_id |
int |
4 |
— |
обязательное поле |
Внешний ключ к film |
|
time |
datetime |
8 |
— |
обязательное поле |
— |
Схема отношения «Кинозалы» (hall):
|
Наименование поля |
Тип поля |
Размер поля |
Значение по умолчанию |
Ограничения |
Ключ или индекс |
|
id |
int |
4 |
|
обязательное поле |
первичный ключ |
|
name |
varchar |
100 |
— |
обязательное поле |
первичный ключ |
Схема отношения «Ряд кинозала» (hall_row):
|
Наименование поля |
Тип поля |
Размер поля |
Значение по умолчанию |
Ограничения |
Ключ или индекс |
|
id_hall |
int |
4 |
|
обязательное поле |
первичный ключ (составной) |
|
number |
smallint |
2 |
— |
обязательное поле |
первичный ключ (составной) |
|
capacity |
smallint |
2 |
— |
обязательное поле |
— |
Схема отношения «Фильмы» (film):
|
Наименование поля |
Тип поля |
Размер поля |
Значение по умолчанию |
Ограничения |
Ключ или индекс |
|
id |
int |
4 |
|
обязательное поле |
первичный ключ |
|
name |
varchar |
255 |
— |
обязательное поле |
— |
|
description |
varchar |
2000 |
NULL |
необязательное поле |
— |
При выборе типов данных и описании их размеров использовалась документация [4]. Для ряда полей, где известно что значениями будут целые числа в небольшом диапазоне используется тип smallint. Для строковых полей используется varchar, однако мог бы использоваться и тип char, критично это только для поля film.description. Дело в том, что описания фильмов бывают длинными, поэтому при создании таблицы надо указать заранее «достаточный» размер поля, например 2000 символов. Однако, согласно документации, при использовании типа char, под все описания фильмов будет выделено 2000 символов, а при использовании varchar более короткие описания будут потреблять меньше памяти — ровно столько, сколько необходимо.
Разработанная схема БД находится в:
- первой нормальной форме, так как в качестве доменов выступают только скалярные значения и информация в таблицах не дублируется. Почти во всех таблицах есть идентификатор (id), а в остальных — в качестве первичного ключа выступает кортеж (набор полей);
- во второй и третьей нормальных формах, так как каждый не ключевой атрибут неприводимо и нетранзитивно зависит от первичного ключа. Для всех таблиц нашей БД это очевидно — количество мест в ряду зависит только от пары (номер зала, номер ряда) и никаким другим образом вывести его из информации в базе нельзя.
Таким образом, схема базы данных находится в нормальной форме Бойса-Кодда [5].
3.2 Инсталляция MS SQL Server и создание пустой базы
Был скачан и проинсталлирован MS SQL Server 2014 [6], так как работа выполнялась на 32х-разрядном компьютере, а более новые версии программы не поддерживают такую архитектуру. При установке была выбрана «Установка нового изолированного экземпляра SQL Server» с параметрами по умолчанию. Как показано на рисунке, при установке задано имя экземпляра «my_project».

В результате, на компьютер была установлена программа SQL Server Management Studio, внутри которой выбирается имя сервера, как показано ниже:

После выбора сервера в обозревателе объектов отобразились компоненты сервера, в том числе вкладка «базы данных». В контекстом меню был выбран пункт добавления базы, в качестве имени указано «my_db», как показано на рисунке:

3.3 Формирование таблиц
После создания базы данных в обозревателе объектов появилась возможно добавить в базу данных таблицы. На рисунке ниже показан процесс добавления таблицы hall — видно, что указываются имена полей и их типы, а для ключевого поля указано «начальное значение» и «шаг приращения».

Ключевые поля добавляются в таблицы с помощью контекстоного меню, выпадающего после клика по полю правой кнопкой. Однако, для таблиц с составными и внешними ключами, например hall_row сделать это через графический интерфейс не получилось. В нем были созданы только заготовки таблиц, для них были сгенерированы скрипты T-SQL и дополнены соответствующими параметрами. Для генерации T-SQL скрипта для таблицы в меню выбирается «создать скрипт для таблицы -> используя DROP и CREATE». Сгенерированные скрипты были поправлены, в результате получено следующее:
USE [my_db]
GO
DROP TABLE [dbo].[hall_row]
GO
DROP TABLE [dbo].[tickets]
GO
DROP TABLE [dbo].[screening]
GO
DROP TABLE [dbo].[hall]
GO
DROP TABLE [dbo].[film]
GO
CREATE TABLE [dbo].[film](
id int IDENTITY(1,1) NOT NULL,
name varchar(255) NOT NULL,
description varchar(2000) NOT NULL,
CONSTRAINT [PK_film] PRIMARY KEY CLUSTERED
(
id ASC
)
)
GO
CREATE TABLE [dbo].[hall](
id int IDENTITY(1,1) NOT NULL,
name nvarchar(100) NOT NULL,
CONSTRAINT [PK_hall] PRIMARY KEY CLUSTERED
(
id ASC
)
)
GO
CREATE TABLE [dbo].[screening](
id int IDENTITY(1,1) NOT NULL,
hall_id int NOT NULL,
film_id int NOT NULL,
time datetime NOT NULL,
FOREIGN KEY (hall_id) REFERENCES hall (id),
FOREIGN KEY (film_id) REFERENCES film (id),
CONSTRAINT [PK_screening] PRIMARY KEY CLUSTERED
(
id ASC
)
)
GO
CREATE TABLE [dbo].[hall_row](
id_hall int NOT NULL,
number smallint NOT NULL,
capacity smallint NOT NULL,
FOREIGN KEY (id_hall) REFERENCES hall (id),
CONSTRAINT [PK_hall_row] PRIMARY KEY CLUSTERED
(
id_hall, number
)
)
GO
CREATE TABLE [dbo].[tickets](
id_screening int NOT NULL,
row smallint NOT NULL,
seat smallint NOT NULL,
cost int NOT NULL,
FOREIGN KEY (id_screening) REFERENCES screening (id),
CONSTRAINT [PK_ticket] PRIMARY KEY CLUSTERED
(
id_screening, row, seat
)
)
GO
Измененный скрипт был запущен в MS SQL Management Studio, в результате были обновлены таблицы. Затем, на их основе сгенерирована схема базы данных:

3.4 Наполнение базы
Для наполнения базы был создан такой запрос (приведен фрагмент):
INSERT INTO [dbo].[film] (name, description)
VALUES ('Багратион', '«Багратион» — советский двухсерийный историко-биографический фильм 1985 года о жизни прославленного российского полководца Петра Ивановича Багратиона — героя Отечественной войны 1812 года. Совместное производство «Грузия-фильм» и «Мосфильм». Режиссёры Гиули Чохонелидзе и Караман Мгеладзе. Премьера — декабрь 1985 года. ')
INSERT INTO [dbo].[hall] (name) VALUES ('красный зал')
INSERT INTO [dbo].[hall] (name) VALUES ('желтый зал')
INSERT INTO [dbo].[hall] (name) VALUES ('синий зал')
INSERT INTO [dbo].[hall_row] (id_hall ,number ,capacity) VALUES (1, 1, 10)
INSERT INTO [dbo].[hall_row] (id_hall ,number ,capacity) VALUES (1, 2, 15)
INSERT INTO [dbo].[hall_row] (id_hall ,number ,capacity) VALUES (1, 3, 20)
INSERT INTO [dbo].[screening] (hall_id ,film_id, time) VALUES (1, 1, '20210101 10:35:00 AM')
INSERT INTO [dbo].[screening] (hall_id ,film_id, time) VALUES (1, 1, '20210101 00:00:00 AM')
INSERT INTO [dbo].[screening] (hall_id ,film_id, time) VALUES (1, 2, '20210101 1:35:00 PM')
INSERT INTO [dbo].[tickets] (id_screening ,row ,seat ,cost) VALUES (1, 2, 3, 150)
INSERT INTO [dbo].[tickets] (id_screening ,row ,seat ,cost) VALUES (1, 3, 3, 200)
INSERT INTO [dbo].[tickets] (id_screening ,row ,seat ,cost) VALUES (1, 3, 5, 150)
% ...
Запрос выполняется успешно, а результаты его выполнения проверялись с помощью SELECT-запросов:

3.5 Проектирование наиболее востребованных запросов
Как отмечалось в разделе 1, при продаже билета посетитель кинотеатра устно передает кассиру номер и место. Кассир вводит эти данные в систему, которая не должна позволить продать билеты на несуществующие места. Для этого программа-клиент кассира должна получить вместимость ряда конкретного зала. Чтобы получить количество мест во втором ряду третьего зала надо выполнить запрос:
SELECT capacity FROM hall_row WHERE id_hall = 3 AND number = 2
программа клиент получит набор строк, соответствующих условию запросу. Если запрос выполнился успешно — в этом наборе всегда будет одна строка, иначе — пустое множество строк.
Затем, программа-клиент должна проверить не продано ли это место. Для этого можно выполнить отдельный SELECT, но можно попробовать выполнить INSERT INTO и если место было ранее продано — запрос завершится с ошибкой, ведь на таблицу билетов наложены соответствующие ограничения.
Чтобы сформировать расписание показов фильмов, прокатываемых с определенного момента (обычно в запрос будет поставляться текущее время) можно использовать такой запрос:
SELECT * FROM film, screening WHERE time > '20210101 11:00:00 AM' AND screening.film_id = film.id;
в данном случае в запросе используется две таблицы, которые связываются по идентификатору. Выбираются названия фильмов, показ которых начинается после 11 часов 01.01.2021. Результат выполнения запроса:

Для получения расписания проката в конкретном зале кинотеатра надо добавить в запрос связь с третьей таблицей и ограничения на эту таблицу:
SELECT film.name, hall.id, screening.time FROM film, screening, hall WHERE time > '20210101 11:00:00 AM' AND screening.film_id = film.id AND screening.hall_id = hall.id AND hall.id = 2;
При соединении нескольких таблиц в вывод попадают лишние столбцы, чтобы этого избежать в приведенном запросе явно указаны интересующие нас столбцы — название фильма, номер зала и время.
Для получения расписания проката конкретного фильма — можно вставить в запрос его идентификатор:
SELECT film.name, hall.name, screening.time FROM film, screening, hall WHERE time > '20210101 11:00:00 AM' AND screening.film_id = film.id AND screening.hall_id = hall.id AND film.id = 2;
Если вдруг нас интересуют фильмы, названия которых соответствует определенному шаблону — можно использовать оператор LIKE. Так, приведенный ниже запрос выбирает все фильмы, прокатываемые с определенного момента, названия которых начинаются с символа 'Б', шаблон '%' задает в T-SQL любое количество любых символов.
SELECT film.name, hall.name, screening.time FROM film, screening, hall WHERE time > '20210101 11:00:00 AM' AND screening.film_id = film.id AND screening.hall_id = hall.id AND film.name LIKE 'Б%';
Чтобы вывести расписание прокатов, упорядоченное по залу и дате нужно применить конструкцию ORDER BY:
SELECT film.name, hall.name, screening.time FROM film, screening, hall WHERE time > '20210101 11:00:00 AM' AND screening.film_id = film.id AND screening.hall_id = hall.id ORDER BY hall.name, screening.time;
Список полезной литературы
- Учимся проектированию Entity Relationship — диаграмм // Хабр URL: https://habr.com/ru/post/440556/ (дата обращения: 02.01.2021).
- Технологии баз данных. Лекция 3. Модель «Сущность-связь». URL: https://docplayer.ru/27886777-Model-sushchnost-svyaz-tehnologii-baz-dannyh-lekciya-3.html (дата обращения: 02.01.2021).
- Entity Relationship Diagram. URL: https://plantuml.com/ru/ie-diagram (дата обращения: 03.01.2021).
- Transact-SQL Reference (Database Engine) // Microsoft Docs URL: https://docs.microsoft.com/ru-ru/sql/t-sql/language-reference?view=sql-server-ver15 (дата обращения: 05.01.2021).
- Нормализация отношений. Шесть нормальных форм // Хабр URL: https://habr.com/ru/post/254773/ (дата обращения: 05.01.2021).
- Материалы для скачивания по SQL Server // Microsoft URL: https://www.microsoft.com/ru-ru/sql-server/sql-server-downloads (дата обращения: 05.01.2021).
- Другой пример проектирования базы данных (MySQL). URL: https://pro-prof.com/forums/topic/db_example
