Время на прочтение
3 мин
Количество просмотров 44K
Сегодня мы рассмотрим пример базы данных и различные команды агрегации, группировки, сортировки, соединения таблиц и другое на примере MySQL. Сами данные представляют собой набор таблиц с произвольными названиями и значениями. Структура таблиц и их связи представлены ниже.
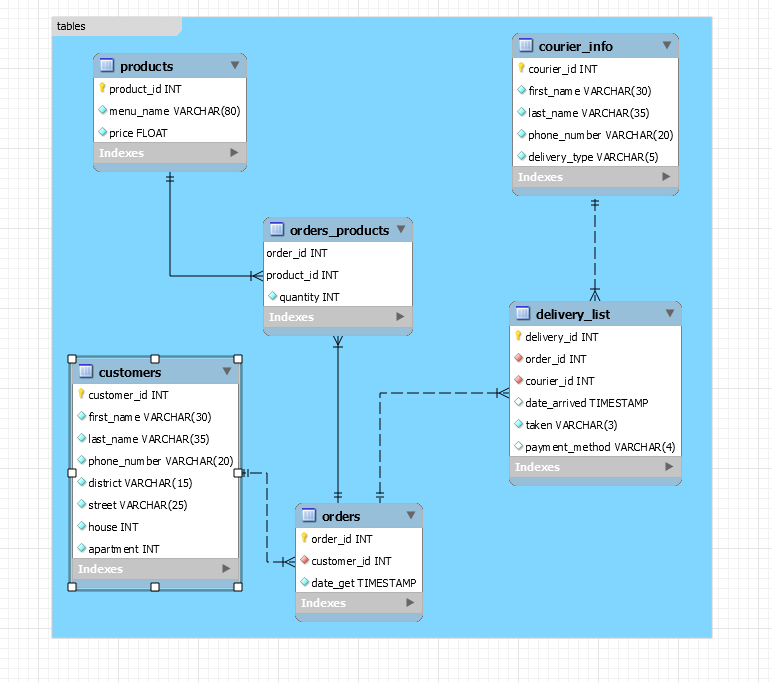
Для понимания дальнейшего Вам будут желательно начальные знания SQL и баз данных. Данное пособие поможет структурировать информацию, обновить память и может выступать в роли шпаргалки, которую вы можете использовать при надобности. Запросы на создание всех таблиц находятся тут.
С содержанием таблиц удобно ознакомиться в формате excel:






Как ни странно, но начнем мы анализ с таблицы, которая не упоминалась выше и не имеет связей с другими. Она представляет собой статистику за год по некоторым ключевым показателям.
Примечание: дабы не загружать статью всеми видами таблиц из запросов, визуально представлены будут только некоторые, а с остальными Вы без проблем можете поэкспериментировать сами.

Агрегация, группировка, сортировка
Сумма заказов за весь год:
SELECT SUM(amount_of_orders) AS orders_per_year FROM year_statistics;
Убывающая сортировка заказов по месяцам:
SELECT month_name, amount_of_orders
FROM year_statistics
ORDER BY amount_of_orders DESC;
Вывести месяц, где больше всего заказов:
SELECT month_name, amount_of_orders FROM year_statistics WHERE amount_of_orders = (SELECT MAX(amount_of_orders)
FROM year_statistics);
Популярность районов по количествам клиентов:
SELECT district
FROM customers
GROUP BY district
ORDER BY COUNT(district) DESC;
Сколько каждый курьер доставил заказов:
SELECT courier_id, COUNT(order_id)
From delivery_list
WHERE date_arrived IS NOT NULL
GROUP BY courier_id;
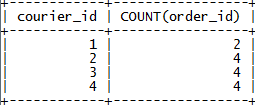
Общие запросы и использование операторов IN, EXISTS, UNION и др.
Выборка клиентов, которые живут в районе “South”:
SELECT * FROM Customers
WHERE district IN ('South');
Информация о заказах, которые не были доставлены клиентам:
SELECT * FROM delivery_list
WHERE taken NOT IN ('Yes');
Запрос продуктов из меню, которые были заказаны:
SELECT menu_name FROM products
WHERE EXISTS
(SELECT * FROM orders_products
WHERE orders_products.product_id = products.product_id);
Запрос тех продуктов, которые не заказывали:
SELECT menu_name FROM products WHERE NOT EXISTS
(SELECT * FROM orders_products
WHERE orders_products.product_id = products.product_id);
Получаем общую таблицу с информацией о клиентах и курьеров:
SELECT 'Customer' AS category, first_name, last_name, phone_number
FROM customers
UNION
SELECT 'Employee' AS category, first_name, last_name, phone_number
FROM courier_info;
INNER, NATURAL, CROSS, LEFT JOIN
Наиболее интересный запрос, который позволяет видеть детали заказа(номер, название блюда, количество и цена). К тому же здесь использован метод ROUND, позволяющий округлять дробные числа:
SELECT orders_products.order_id, products.menu_name, quantity,
ROUND(price*quantity, 2) AS total_price
FROM orders_products
INNER JOIN products ON orders_products.product_id = products.product_id
ORDER BY order_id, quantity;

Еще один довольно любопытный запрос, показывающий детальную информацию по заказам, а также время их доставки:
SELECT *, SEC_TO_TIME(TIMESTAMPDIFF(second, date_get, date_arrived))
AS time_of_delivery
FROM orders
NATURAL JOIN delivery_list;
Не совсем тривиальный запрос на выборку о том, что каждому курьеру на машине доступен любой район из таблицы клиентов:
SELECT DISTINCT courier_info.courier_id, customers.district
FROM courier_info
CROSS JOIN customers WHERE courier_info.delivery_type = 'car'
ORDER BY courier_id;

И напоследок запрос на информацию об имени клиента, его мобильном телефоне и номере заказа:
SELECT customers.first_name, customers.last_name,
customers.phone_number, orders.order_id
FROM customers
LEFT JOIN orders ON customers.customer_id = orders.customer_id;

Заключение
По итогу мы с вами разобрали множество полезных запросов на выборку SQL. Были показаны основные и более редкие операции. В сущности не важно, сколько данных в Вашей таблице – десять или тысяча, от этого запросы не поменяются, а всегда будут оставаться такими же. Главное, чтобы был понятен смысл, количество данных играет намного меньшую роль. Бояться и расстраиваться от того, что у Вас пока не получается получить желаемый запрос, совершенно глупо. Абсолютно нормально, если Вы гуглите, читаете книгу на интересующую тему, а результата так и нет. На это может уходить от десятка минут до целых дней. Мы все люди и одному человеку не под силу знать все. Наберитесь терпения, спросите у товарищей, на форумах и просто продолжайте искать сами, у Вас все получится! Удачи.
В качестве примера спроектируем несложную базу данных информационной системы кинотеатра. При этом, решим следующие задачи:
- анализ предметной области для определения состава и содержания информации, обрабатываемой информационной системой, а также пользовательских потребностей;
- построение концептуальной модели предметной области, заключающееся в выявлении сущностей и связей между ними, а также отображение этой информации в виде ER-диаграммы;
- физическое проектирование базы данных и ее реализация в MS SQL Server.
1 Анализ предметной области
Зачастую, кинотеатр состоит из нескольких залов разной конфигурации, а посетителю предоставляется возможность выбора билета, для этого ему отображается текущее состояние зала. Выбранные места посетитель сообщает кассиру, который вводит их в систему и места помечаются как «проданные». Это «основной» сценарий использования информационной системы, однако надо учесть следующее:
- репертуар и расписание проката кинотеатра должен кто-то вносить в систему — соответствующую роль назовем «Менеджер»;
- посетитель и кассир должны иметь возможность просматривать расписание, при этом интересно расписание, начиная с некоторого момента времени (например, текущего времени). Составлять оно может по-разному:
- расписание показа всех фильмов, упорядоченное по времени;
- расписание прокатов в отдельных залах кинотеатра;
- расписание проката определенного фильма.
Из этого описания понятны основные функции системы, изображенные на рисунке с помощью нотации диаграммы прецедентов UML. На диаграмме не отображена роль администратора базы данных, так как администратор обычно взаимодействует с системой не через интерфейс, а через выполнение SQL-запросов.

Несмотря на то, что мы не будет разрабатывать интерфейс информационной системы и текстовые описания прецедентов, дальше нас будут интересовать данные, необходимые для выполнения того или иного прецедента, а для этого надо выделить и описать сущности. Иначе, невозможно определить «какие данные должен вводить менеджер при добавлении фильма». Основные сущности, данные которых потребуются во время работы, показаны на рисунке, при этом используется нотация диаграммы классов UML. Каждый прямоугольник соответствует одной сущности, внутри записаны поля и типы данных.

Каждая сущность, кроме hall_row содержит поле id, которое идентифицирует объект. У сущности hall_row поле id не нужно, так как в одном и том же зале кинотеатра (id_hall) не могут повторяться номера рядов (number).
Когда пользователь выберет зал и прокат — система должна отобразить заполненность зала, при этом надо отобразить конфигурацию зала с пометкой занятых и свободных мест. Под конфигурацией зала тут имеется ввиду, что разные залы имеют разный размер, а ряды зала могут иметь различное количество мест. Поэтому в базе данных зал (hall) составляется из рядов (hall_row), одним из параметров которых является вместимость (capacity).
2 Построение концептуальной модели
Выше были отображены основные сущности, но не отображены роли пользователей, хотя их тоже должна хранить система. Они показаны ниже на ER-диаграмме в нотации Чена [1].

На диаграмме выделены роли кассира и менеджера, а также основные отношения между сущностями. На диаграмме нет роли администратора, но его роль заключается в:
- создании всех таблиц базы;
- добавлении залов и рядов в них;
- добавлении кассиров и менеджеров.
На диаграмме не отражена роль посетителя, так как:
- билет не содержит информации о том, кто его купил (посетитель может подарить билет другу);
- система вообще не хранит информацию о посетителях;
- покупку билета он осуществляет через общение с кассиром вне системы;
- никакие данные в базе посетитель самостоятельно изменить не может.
На диаграмме проставлены кратности связей, например, видно, что один менеджер может добавить много (N) прокатов. В этой базе не оказалось связей типа N:M, сложных или рекурсивных связей — такие связи являются препятствиями в проектировании и решаются изменением ее структуры.
Для формирования схемы данных необходимо сначала дополнить ER-диаграмму реквизитами сущностей (уточнить ее) — результат приведен на рисунке.

В ходе анализа этой диаграммы были найдены несколько недочетов, допущенных при выделении сущностей системы:
- система не должна позволять продавать несколько билетов на одно и то же место при одном показе фильма. Это значит, что вторичным ключем для Билета должен быть кортеж (id_screening, row, seat). Однако, тогда нет необходимости в id билета — на билеты не ссылается ни одна таблица, это поле может быть удалено. Изначально id был добавлен потому, что обычно на билетах в кинотеатрах печатается номер;
- билет хранит поле id_hall, это было сделано для того, чтобы посетитель кинотеатра мог найти свой кинозал. Однако, билет, выдаваемый пользователю — это не тоже самое, что информация о билетах, хранимая в базе данных. Билет базы данных хранит также поле id_screening, а Показ уже ссылается на id_hall. Таким образом, в базе нет смысла хранить id_hall в таблице билетов.
Исправленная ER-диаграмма приведена ниже:

Таблица менеджеров и кассиров не объединены в таблицу Users так как вопросы разграничения прав доступа в различных СУБД решаются по-разному. Так, в MS SQL пользователи добавляются с помощью специальных запросов типа:
CREATE LOGIN Manager_Name WITH PASSWORD='Some Passwrd';
при этом вообще нет необходимости хранить информацию об их логинах и паролях в таблицах. Однако, вопросы разграничения доступа решаются позже — на этапе физического проектирования.
3 Физическое проектирование
ER-диаграмма отражает основные таблицы, связи и атрибуты, на ее основе можно построить модель БД. На ER-диаграммы нет стандарта, но есть ряд нотаций (Чена, IDEFIX, Мартина и т.п.) [2], но на модель предметной области не удалось найти ни стандарта, ни нотаций. Однако, в ходе построения такой диаграммы обязательно выделяются ключевые поля (внешние и внутренние), иногда — индексы и типы данных. Схема базы данных, приведенная на рисунке, выполнена с использованием открытого инструмента plantuml [3], при этом:
- для связей используется нотация Мартина («вороньи лапки»);
- таблицы изображены прямоугольниками, разделенными на 3 секции:
- имя таблицы;
- внутренние ключи (помечаются маркером);
- остальные поля, при этом обязательные поля помечаются маркером.

3.1 Составление и нормализация реляционных отношений
Схема отношения «Билеты» (tickets):
|
Наименование поля |
Тип поля |
Размер поля |
Значение по умолчанию |
Ограничения |
Ключ или индекс |
|
id_screening |
int |
4 |
|
обязательное поле |
первичный ключ (составной) |
|
row |
smallint |
2 |
— |
обязательное поле |
первичный ключ (составной) |
|
seat |
smallint |
2 |
— |
обязательное поле |
первичный ключ (составной) |
Схема отношения «Прокаты» (screening):
|
Наименование поля |
Тип поля |
Размер поля |
Значение по умолчанию |
Ограничения |
Ключ или индекс |
|
id |
int |
4 |
|
обязательное поле |
Первичный ключ, уникальный |
|
hall_id |
int |
4 |
— |
обязательное поле |
Внешний ключ к hall |
|
film_id |
int |
4 |
— |
обязательное поле |
Внешний ключ к film |
|
time |
datetime |
8 |
— |
обязательное поле |
— |
Схема отношения «Кинозалы» (hall):
|
Наименование поля |
Тип поля |
Размер поля |
Значение по умолчанию |
Ограничения |
Ключ или индекс |
|
id |
int |
4 |
|
обязательное поле |
первичный ключ |
|
name |
varchar |
100 |
— |
обязательное поле |
первичный ключ |
Схема отношения «Ряд кинозала» (hall_row):
|
Наименование поля |
Тип поля |
Размер поля |
Значение по умолчанию |
Ограничения |
Ключ или индекс |
|
id_hall |
int |
4 |
|
обязательное поле |
первичный ключ (составной) |
|
number |
smallint |
2 |
— |
обязательное поле |
первичный ключ (составной) |
|
capacity |
smallint |
2 |
— |
обязательное поле |
— |
Схема отношения «Фильмы» (film):
|
Наименование поля |
Тип поля |
Размер поля |
Значение по умолчанию |
Ограничения |
Ключ или индекс |
|
id |
int |
4 |
|
обязательное поле |
первичный ключ |
|
name |
varchar |
255 |
— |
обязательное поле |
— |
|
description |
varchar |
2000 |
NULL |
необязательное поле |
— |
При выборе типов данных и описании их размеров использовалась документация [4]. Для ряда полей, где известно что значениями будут целые числа в небольшом диапазоне используется тип smallint. Для строковых полей используется varchar, однако мог бы использоваться и тип char, критично это только для поля film.description. Дело в том, что описания фильмов бывают длинными, поэтому при создании таблицы надо указать заранее «достаточный» размер поля, например 2000 символов. Однако, согласно документации, при использовании типа char, под все описания фильмов будет выделено 2000 символов, а при использовании varchar более короткие описания будут потреблять меньше памяти — ровно столько, сколько необходимо.
Разработанная схема БД находится в:
- первой нормальной форме, так как в качестве доменов выступают только скалярные значения и информация в таблицах не дублируется. Почти во всех таблицах есть идентификатор (id), а в остальных — в качестве первичного ключа выступает кортеж (набор полей);
- во второй и третьей нормальных формах, так как каждый не ключевой атрибут неприводимо и нетранзитивно зависит от первичного ключа. Для всех таблиц нашей БД это очевидно — количество мест в ряду зависит только от пары (номер зала, номер ряда) и никаким другим образом вывести его из информации в базе нельзя.
Таким образом, схема базы данных находится в нормальной форме Бойса-Кодда [5].
3.2 Инсталляция MS SQL Server и создание пустой базы
Был скачан и проинсталлирован MS SQL Server 2014 [6], так как работа выполнялась на 32х-разрядном компьютере, а более новые версии программы не поддерживают такую архитектуру. При установке была выбрана «Установка нового изолированного экземпляра SQL Server» с параметрами по умолчанию. Как показано на рисунке, при установке задано имя экземпляра «my_project».

В результате, на компьютер была установлена программа SQL Server Management Studio, внутри которой выбирается имя сервера, как показано ниже:

После выбора сервера в обозревателе объектов отобразились компоненты сервера, в том числе вкладка «базы данных». В контекстом меню был выбран пункт добавления базы, в качестве имени указано «my_db», как показано на рисунке:

3.3 Формирование таблиц
После создания базы данных в обозревателе объектов появилась возможно добавить в базу данных таблицы. На рисунке ниже показан процесс добавления таблицы hall — видно, что указываются имена полей и их типы, а для ключевого поля указано «начальное значение» и «шаг приращения».

Ключевые поля добавляются в таблицы с помощью контекстоного меню, выпадающего после клика по полю правой кнопкой. Однако, для таблиц с составными и внешними ключами, например hall_row сделать это через графический интерфейс не получилось. В нем были созданы только заготовки таблиц, для них были сгенерированы скрипты T-SQL и дополнены соответствующими параметрами. Для генерации T-SQL скрипта для таблицы в меню выбирается «создать скрипт для таблицы -> используя DROP и CREATE». Сгенерированные скрипты были поправлены, в результате получено следующее:
USE [my_db]
GO
DROP TABLE [dbo].[hall_row]
GO
DROP TABLE [dbo].[tickets]
GO
DROP TABLE [dbo].[screening]
GO
DROP TABLE [dbo].[hall]
GO
DROP TABLE [dbo].[film]
GO
CREATE TABLE [dbo].[film](
id int IDENTITY(1,1) NOT NULL,
name varchar(255) NOT NULL,
description varchar(2000) NOT NULL,
CONSTRAINT [PK_film] PRIMARY KEY CLUSTERED
(
id ASC
)
)
GO
CREATE TABLE [dbo].[hall](
id int IDENTITY(1,1) NOT NULL,
name nvarchar(100) NOT NULL,
CONSTRAINT [PK_hall] PRIMARY KEY CLUSTERED
(
id ASC
)
)
GO
CREATE TABLE [dbo].[screening](
id int IDENTITY(1,1) NOT NULL,
hall_id int NOT NULL,
film_id int NOT NULL,
time datetime NOT NULL,
FOREIGN KEY (hall_id) REFERENCES hall (id),
FOREIGN KEY (film_id) REFERENCES film (id),
CONSTRAINT [PK_screening] PRIMARY KEY CLUSTERED
(
id ASC
)
)
GO
CREATE TABLE [dbo].[hall_row](
id_hall int NOT NULL,
number smallint NOT NULL,
capacity smallint NOT NULL,
FOREIGN KEY (id_hall) REFERENCES hall (id),
CONSTRAINT [PK_hall_row] PRIMARY KEY CLUSTERED
(
id_hall, number
)
)
GO
CREATE TABLE [dbo].[tickets](
id_screening int NOT NULL,
row smallint NOT NULL,
seat smallint NOT NULL,
cost int NOT NULL,
FOREIGN KEY (id_screening) REFERENCES screening (id),
CONSTRAINT [PK_ticket] PRIMARY KEY CLUSTERED
(
id_screening, row, seat
)
)
GO
Измененный скрипт был запущен в MS SQL Management Studio, в результате были обновлены таблицы. Затем, на их основе сгенерирована схема базы данных:

3.4 Наполнение базы
Для наполнения базы был создан такой запрос (приведен фрагмент):
INSERT INTO [dbo].[film] (name, description)
VALUES ('Багратион', '«Багратион» — советский двухсерийный историко-биографический фильм 1985 года о жизни прославленного российского полководца Петра Ивановича Багратиона — героя Отечественной войны 1812 года. Совместное производство «Грузия-фильм» и «Мосфильм». Режиссёры Гиули Чохонелидзе и Караман Мгеладзе. Премьера — декабрь 1985 года. ')
INSERT INTO [dbo].[hall] (name) VALUES ('красный зал')
INSERT INTO [dbo].[hall] (name) VALUES ('желтый зал')
INSERT INTO [dbo].[hall] (name) VALUES ('синий зал')
INSERT INTO [dbo].[hall_row] (id_hall ,number ,capacity) VALUES (1, 1, 10)
INSERT INTO [dbo].[hall_row] (id_hall ,number ,capacity) VALUES (1, 2, 15)
INSERT INTO [dbo].[hall_row] (id_hall ,number ,capacity) VALUES (1, 3, 20)
INSERT INTO [dbo].[screening] (hall_id ,film_id, time) VALUES (1, 1, '20210101 10:35:00 AM')
INSERT INTO [dbo].[screening] (hall_id ,film_id, time) VALUES (1, 1, '20210101 00:00:00 AM')
INSERT INTO [dbo].[screening] (hall_id ,film_id, time) VALUES (1, 2, '20210101 1:35:00 PM')
INSERT INTO [dbo].[tickets] (id_screening ,row ,seat ,cost) VALUES (1, 2, 3, 150)
INSERT INTO [dbo].[tickets] (id_screening ,row ,seat ,cost) VALUES (1, 3, 3, 200)
INSERT INTO [dbo].[tickets] (id_screening ,row ,seat ,cost) VALUES (1, 3, 5, 150)
% ...
Запрос выполняется успешно, а результаты его выполнения проверялись с помощью SELECT-запросов:

3.5 Проектирование наиболее востребованных запросов
Как отмечалось в разделе 1, при продаже билета посетитель кинотеатра устно передает кассиру номер и место. Кассир вводит эти данные в систему, которая не должна позволить продать билеты на несуществующие места. Для этого программа-клиент кассира должна получить вместимость ряда конкретного зала. Чтобы получить количество мест во втором ряду третьего зала надо выполнить запрос:
SELECT capacity FROM hall_row WHERE id_hall = 3 AND number = 2
программа клиент получит набор строк, соответствующих условию запросу. Если запрос выполнился успешно — в этом наборе всегда будет одна строка, иначе — пустое множество строк.
Затем, программа-клиент должна проверить не продано ли это место. Для этого можно выполнить отдельный SELECT, но можно попробовать выполнить INSERT INTO и если место было ранее продано — запрос завершится с ошибкой, ведь на таблицу билетов наложены соответствующие ограничения.
Чтобы сформировать расписание показов фильмов, прокатываемых с определенного момента (обычно в запрос будет поставляться текущее время) можно использовать такой запрос:
SELECT * FROM film, screening WHERE time > '20210101 11:00:00 AM' AND screening.film_id = film.id;
в данном случае в запросе используется две таблицы, которые связываются по идентификатору. Выбираются названия фильмов, показ которых начинается после 11 часов 01.01.2021. Результат выполнения запроса:

Для получения расписания проката в конкретном зале кинотеатра надо добавить в запрос связь с третьей таблицей и ограничения на эту таблицу:
SELECT film.name, hall.id, screening.time FROM film, screening, hall WHERE time > '20210101 11:00:00 AM' AND screening.film_id = film.id AND screening.hall_id = hall.id AND hall.id = 2;
При соединении нескольких таблиц в вывод попадают лишние столбцы, чтобы этого избежать в приведенном запросе явно указаны интересующие нас столбцы — название фильма, номер зала и время.
Для получения расписания проката конкретного фильма — можно вставить в запрос его идентификатор:
SELECT film.name, hall.name, screening.time FROM film, screening, hall WHERE time > '20210101 11:00:00 AM' AND screening.film_id = film.id AND screening.hall_id = hall.id AND film.id = 2;
Если вдруг нас интересуют фильмы, названия которых соответствует определенному шаблону — можно использовать оператор LIKE. Так, приведенный ниже запрос выбирает все фильмы, прокатываемые с определенного момента, названия которых начинаются с символа 'Б', шаблон '%' задает в T-SQL любое количество любых символов.
SELECT film.name, hall.name, screening.time FROM film, screening, hall WHERE time > '20210101 11:00:00 AM' AND screening.film_id = film.id AND screening.hall_id = hall.id AND film.name LIKE 'Б%';
Чтобы вывести расписание прокатов, упорядоченное по залу и дате нужно применить конструкцию ORDER BY:
SELECT film.name, hall.name, screening.time FROM film, screening, hall WHERE time > '20210101 11:00:00 AM' AND screening.film_id = film.id AND screening.hall_id = hall.id ORDER BY hall.name, screening.time;
Список полезной литературы
- Учимся проектированию Entity Relationship — диаграмм // Хабр URL: https://habr.com/ru/post/440556/ (дата обращения: 02.01.2021).
- Технологии баз данных. Лекция 3. Модель «Сущность-связь». URL: https://docplayer.ru/27886777-Model-sushchnost-svyaz-tehnologii-baz-dannyh-lekciya-3.html (дата обращения: 02.01.2021).
- Entity Relationship Diagram. URL: https://plantuml.com/ru/ie-diagram (дата обращения: 03.01.2021).
- Transact-SQL Reference (Database Engine) // Microsoft Docs URL: https://docs.microsoft.com/ru-ru/sql/t-sql/language-reference?view=sql-server-ver15 (дата обращения: 05.01.2021).
- Нормализация отношений. Шесть нормальных форм // Хабр URL: https://habr.com/ru/post/254773/ (дата обращения: 05.01.2021).
- Материалы для скачивания по SQL Server // Microsoft URL: https://www.microsoft.com/ru-ru/sql-server/sql-server-downloads (дата обращения: 05.01.2021).
- Другой пример проектирования базы данных (MySQL). URL: https://pro-prof.com/forums/topic/db_example
Чтобы помочь начинающим аналитикам разобраться с основами SQL и реляционных баз данных, сегодня рассмотрим практический пример построения модели данных, заполнения таблиц значениями и генерации запросов к полученной базе. DDL-запросы для создания таблиц и примеры DML-запросов для наполнения их данными, а также выборки с условиями WHERE, GROUP BY, HAVING, операторы работы с датами и временем.
Проектирование реляционной модели (схемы базы данных)
Как я уже рассказывала здесь, системные и бизнес-аналитики часто сталкиваются с моделированием данных в рамках задачи разработки требований к ИС. Однако, зачастую простого концептуального моделирования, которое переводит ключевые сущности домена (предметной области) в плоскость программной системы, бывает недостаточно для разработки или более детального проектирования базы данных на физическом уровне. Основным фактором, определяющим ценность концептуальной модели, является возможность ее использования для дальнейшей работы. И чтобы повысить эту ценность, аналитику полезно понимать, какие именно потребности бизнеса позволит обеспечить разработанная им модель. Применительно к моделированию данных это примеры SQL-запросов.
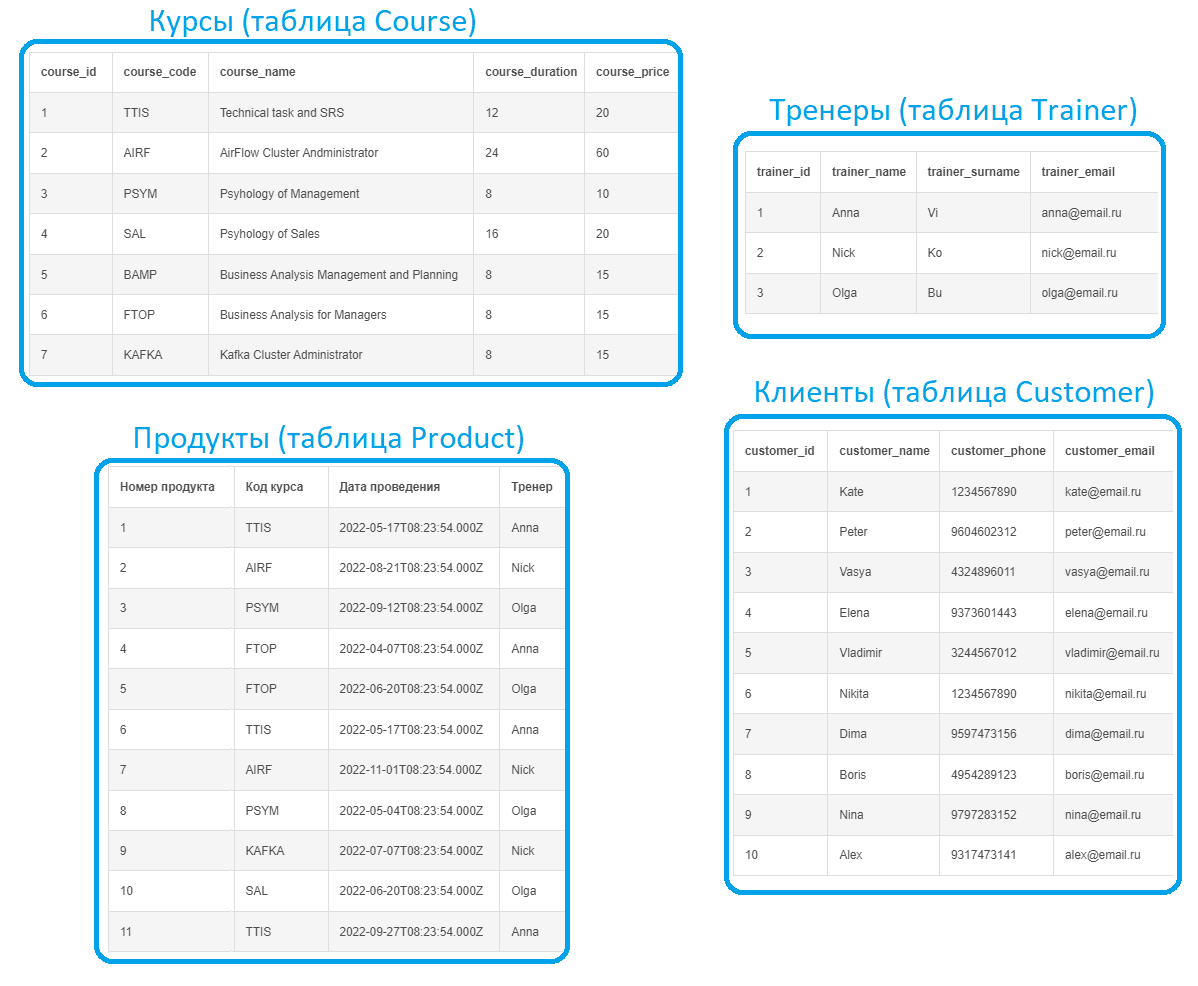
Предположим, учебный центр, который предлагает курсы по 3-м направлениям: системный и бизнес-анализ, технологии Big Data, а также менеджмент, имеет данные о заявках слушателей на разные курсы.
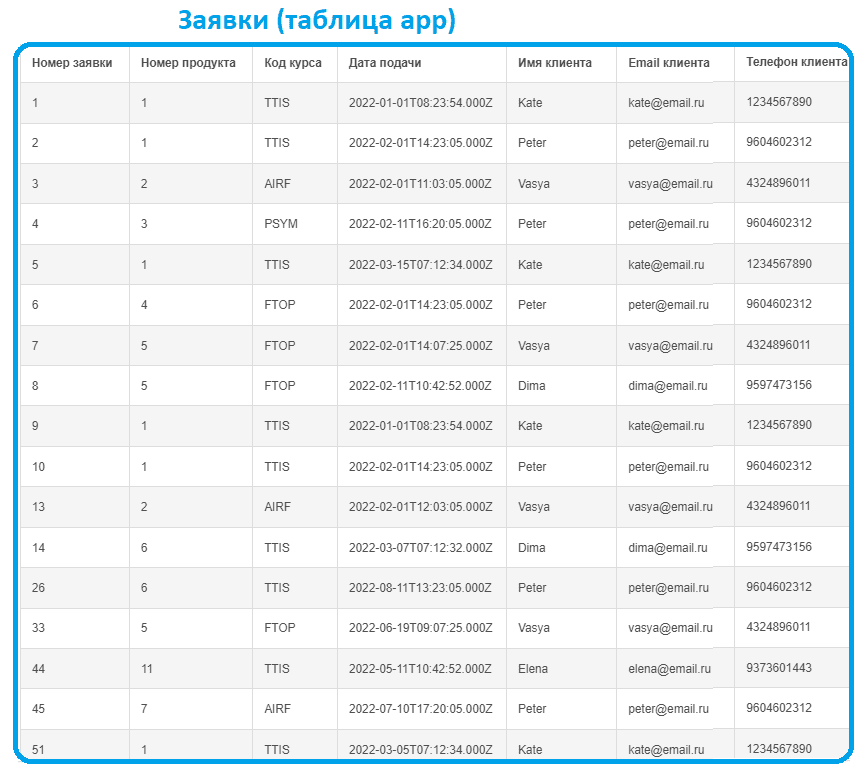
Имеется каталог курсов и расписание их проведение, а также данные по потенциальным клиентам, подавшим заявки и тренерам, которые проводят курсы.
Реляционная модель данных, спроектированная для рассматриваемого случая, будет выглядеть следующим образом:
Выделено 5 сущностей, которые связаны между собой разными типами отношений. Каждая сущность в итоге представляет собой таблицу реляционной базы данных с набором столбцов, т.е. атрибутов или полей, каждое из которых содержит данные определенного типа. Поскольку база данных является реляционной, таблицы связаны между собой по ключам. Например, один тренер может вести несколько курсов. Таблица Course представляет собой каталог курсов, каждый из которых может проводиться несколько раз в разное время разными тренерами, что хранится в таблице Product. Один клиент (Customer) может подать много заявок, но каждая заявка может быть только по одному продукту.
Чтобы сократить избыточность данных в разных таблицах, проведена нормализация, т.е. приведение структуры данных к нормальной форме. В частности, данные клиентов хранятся не в таблице заявки, а выделены в отдельную таблицу Customer. Аналогичным образом данные о курсах и тренерах, которые их проводят содержатся не в таблице с расписанием (Product), а в отдельных таблицах. Это исключает транзитивную зависимость полей друг от друга. Чаще всего ER-модель приводят к 3-ей нормальной форме, когда каждая таблица атомарна и любой не ключевой атрибут в ней зависит только от первичного ключа.
В каждой таблице определен первичный ключ (Primary Key, PK),– столбец, каждое значение которого уникально и однозначно идентифицирует запись (строку) этой таблицы. Для ускорения работы базы данных в качестве первичного ключа обычно принимается целочисленный идентификатор, который реализуется автоматической генерацией поля ID с автоинкрементом, т.е. увеличением на 1 при создании новой записи. Большинство современных СУБД сами следят за этим, т.е. на уровне концептуального проектирования при описании модели предметной области, этот атрибут не обязательно добавлять в словарь данных.
Связи между таблицами реализованы с помощью внешних ключей (Foreign Key, FK). Внешний (ссылочный) ключ показывает, что поведение записи в одной таблице (зависимой сущности) меняется при изменении или удалении записей из другой связанной таблицы (независимой сущности). Внешний ключ также нужен для объединения двух таблиц. Можно сказать, FK в одной таблице – это один или несколько столбцов, значения которых соответствуют PK в другой таблице. Связь между двумя таблицами задается через соответствие PK в одной таблице FK во второй. Например, в таблице App внешними ключами будут поля product и customer, соответствующие первичным ключам (id) в таблицах Product и Customer соответственно.
После проектирования схемы модели данных в редакторе StarUML, который я часто использую для разработки UML-диаграмм, с помощью расширения Postgresql DDL Extension for StarUML 2 для создания DDL-запросов к СУБД PostgreSQL, я получила набор SQL-команд по созданию таблиц:
CREATE TABLE public.course (
course_id integer NOT NULL,
course_code char(8) NOT NULL,
course_name text NOT NULL,
course_duration integer NOT NULL,
course_price integer NOT NULL,
PRIMARY KEY (course_id)
);
ALTER TABLE public.course
ADD UNIQUE (course_code);
CREATE TABLE public.customer (
customer_id integer NOT NULL,
customer_name text NOT NULL,
customer_phone char(10) NOT NULL,
customer_email char(20) NOT NULL,
PRIMARY KEY (customer_id)
);
ALTER TABLE public.customer
ADD UNIQUE (customer_email);
CREATE TABLE public.app (
app_id integer NOT NULL,
app_datetime timestamp with time zone NOT NULL,
product integer NOT NULL,
customer integer NOT NULL,
PRIMARY KEY (app_id)
);
CREATE INDEX ON public.app
(product);
CREATE INDEX ON public.app
(customer);
CREATE TABLE public.trainer (
trainer_id integer NOT NULL,
trainer_name text NOT NULL,
trainer_surname text NOT NULL,
trainer_email char(20) NOT NULL,
PRIMARY KEY (trainer_id)
);
ALTER TABLE public.trainer
ADD UNIQUE (trainer_email);
CREATE TABLE public.product (
product_id integer NOT NULL,
product_course integer NOT NULL,
product_trainer integer NOT NULL,
product_date timestamp with time zone NOT NULL,
PRIMARY KEY (product_id)
);
CREATE INDEX ON public.product
(product_course);
CREATE INDEX ON public.product
(product_trainer);
Автоматическая генерация DDL-запросов по спроектированной схеме сэкономила мне время на прописывание SQL-команд вручную, чтобы создать нужные таблицы, определить их атрибуты и связи между таблицами. Полученный код я внесла в бесплатный веб-движок тестирования SQL-запросов https://www.db-fiddle.com/, определив схему SQL. Там же внесла данные в мои таблицы с помощью следующих DML-запросов:
INSERT INTO app VALUES (1, '2022-01-01 10:23:54', 1, 1); INSERT INTO app VALUES (2, '2022-02-01 16:23:05', 1, 2); INSERT INTO app VALUES (3, '2022-02-01 13:03:05', 2, 3); INSERT INTO app VALUES (4, '2022-02-11 18:20:05', 3, 2); INSERT INTO app VALUES (5, '2022-03-15 09:12:34', 1, 1); INSERT INTO app VALUES (6, '2022-02-01 16:23:05', 4, 2); INSERT INTO app VALUES (7, '2022-02-01 16:07:25', 5, 3); INSERT INTO app VALUES (8, '2022-02-11 12:42:52', 5, 7); INSERT INTO app VALUES (9, '2022-01-01 10:23:54', 1, 1); INSERT INTO app VALUES (10, '2022-02-01 16:23:05', 1, 2); INSERT INTO app VALUES (13, '2022-02-01 14:03:05', 2, 3); INSERT INTO app VALUES (45, '2022-07-10 19:20:05', 7, 2); INSERT INTO app VALUES (51, '2022-03-05 09:12:34', 1, 1); INSERT INTO app VALUES (26, '2022-08-11 15:23:05', 6, 2); INSERT INTO app VALUES (33, '2022-06-19 11:07:25', 5, 3); INSERT INTO app VALUES (44, '2022-05-11 12:42:52', 11, 4); INSERT INTO app VALUES (14, '2022-03-07 09:12:32', 6, 7); INSERT INTO customer VALUES (1, 'Kate', 1234567890, 'kate@email.ru'); INSERT INTO customer VALUES (2, 'Peter', 9604602312, 'peter@email.ru'); INSERT INTO customer VALUES (3, 'Vasya', 4324896011, 'vasya@email.ru'); INSERT INTO customer VALUES (4, 'Elena', 9373601443, 'elena@email.ru'); INSERT INTO customer VALUES (5, 'Vladimir', 3244567012, 'vladimir@email.ru'); INSERT INTO customer VALUES (6, 'Nikita', 1234567890, 'nikita@email.ru'); INSERT INTO customer VALUES (7, 'Dima', 9597473156, 'dima@email.ru'); INSERT INTO customer VALUES (8, 'Boris', 4954289123, 'boris@email.ru'); INSERT INTO customer VALUES (9, 'Nina', 9797283152, 'nina@email.ru'); INSERT INTO customer VALUES (10, 'Alex', 9317473141, 'alex@email.ru'); INSERT INTO trainer VALUES (1, 'Anna', 'Vi', 'anna@email.ru'); INSERT INTO trainer VALUES (2, 'Nick', 'Ko', 'nick@email.ru'); INSERT INTO trainer VALUES (3, 'Olga', 'Bu', 'olga@email.ru'); INSERT INTO course VALUES (1, 'TTIS', 'Technical task and SRS', 12, 20); INSERT INTO course VALUES (2, 'AIRF', 'AirFlow Cluster Andministrator', 24, 60); INSERT INTO course VALUES (3, 'PSYM', 'Psyhology of Management', 8, 10); INSERT INTO course VALUES (4, 'SAL', 'Psyhology of Sales', 16, 20); INSERT INTO course VALUES (5, 'BAMP', 'Business Analysis Management and Planning', 8, 15); INSERT INTO course VALUES (6, 'FTOP', 'Business Analysis for Managers', 8, 15); INSERT INTO course VALUES (7, 'KAFKA', 'Kafka Cluster Administrator', 8, 15); INSERT INTO product VALUES (1, 1, 1, '2022-05-17 10:23:54'); INSERT INTO product VALUES (2, 2, 2, '2022-08-21 10:23:54'); INSERT INTO product VALUES (3, 3, 3, '2022-09-12 10:23:54'); INSERT INTO product VALUES (4, 6, 1, '2022-04-07 10:23:54'); INSERT INTO product VALUES (5, 6, 3, '2022-06-20 10:23:54'); INSERT INTO product VALUES (6, 1, 1, '2022-05-17 10:23:54'); INSERT INTO product VALUES (7, 2, 2, '2022-11-01 10:23:54'); INSERT INTO product VALUES (8, 3, 3, '2022-05-04 10:23:54'); INSERT INTO product VALUES (9, 7, 2, '2022-07-07 10:23:54'); INSERT INTO product VALUES (10, 4, 3, '2022-06-20 10:23:54'); INSERT INTO product VALUES (11, 1, 1, '2022-09-27 10:23:54');
Когда схема данных создана и таблицы наполнены, можно приступить к самому интересному: SQL-запросам на выборку нужных данных.
Разработка ТЗ на информационную систему по ГОСТ и SRS
Код курса
TTIS
Ближайшая дата курса
24 июля, 2023
Длительность обучения
12 ак.часов
Стоимость обучения
20 000 руб.
SQL-запросы для анализа данных
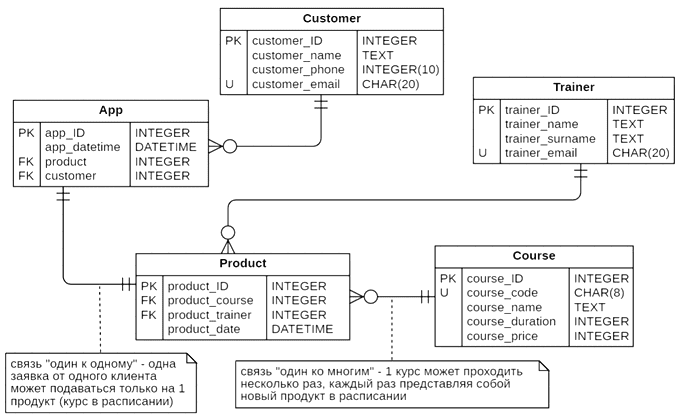
Напомню, для доступа к данным в реляционных СУБД используется язык структурированных запросов SQL (Structured Query Language) – декларативный язык программирования. Он содержит операторы определения данных (DDL), манипулирования данными (DML), определения доступа к данным (DCL) и управления транзакциями (TCL). Все эти операторы реализуют не только базовые CRUDL-операции, но и обеспечивают целостность и непротиворечивость информации. В рамках этой статьи мы рассматриваем только самые распространенные DDL- и DML-запросы. Например, следующий запрос покажет, сколько заявок подано на каждый курс:
SELECT course.course_code AS "Код курса",
course.course_name AS "Название курса",
count(*) AS aps_number
FROM app
JOIN product ON product.product_id=app.product
JOIN course ON course.course_id=product.product_course
GROUP BY app.product,
course.course_code,
course.course_name
ORDER BY aps_number DESC;
В этом запросе выполнено несколько соединений таблиц через оператор JOIN. Например, чтобы получить код и название курса, таблицу с заявками app нужно было соединить с таблицей продуктов, где указаны внешние ключи курсов, а не сами курсы. А чтобы получить название и код курса, пришлось выполнять соединение с таблицей курсов по внешним ключам, что указывается после ключевого слова ON. Для группировки заявок, поданных по одному и тому же курсу, в конце запроса добавлено выражение GROUP BY, в котором указаны поля группировки. В нашем случае некоторые из них совпадают с теми, что указаны в выборке после ключевого слова SELECT. Оператор COUNT(*) считает все строки таблицы с заявками. За сортировку по убыванию отвечает оператор ORDER BY с уточнением DESC.
Рассмотрим другой бизнес-запрос. Например, нужно определить, сколько денег на каком курсе заработает каждый тренер. На это ответит следующий SQL-запрос:
SELECT course.course_code AS "Код курса",
trainer.trainer_name AS "Тренер",
count(*)*(course.course_price) AS income
FROM product
JOIN app ON app.product=product.product_id
JOIN course ON course.course_id=product.product_course
JOIN trainer ON trainer.trainer_id=product.product_trainer
GROUP BY course.course_code,
trainer.trainer_name,
course.course_price
ORDER BY income DESC;

В этом SQL-запросе тоже появилась группировка, поскольку здесь выполняется агрегация строк по курсу. Поэтому встречается оператор GROUP BY с указанием полей, по которым выполняется группировка. Агрегатные функции, такие как расчет суммы, среднего или количества строк, выполняют вычисление на наборе ненулевых значений и возвращают одиночное значение. Исключением из этого правила является функция подсчета количества значений COUNT().
Также в запрос добавлен оператор сортировки по убыванию дохода от проведения курса, который вычисляется как произведение стоимости курса на количество поданных заявок. В свою очередь, количество заявок по определенному продукту, с которым связан курс, определяется через соединение с таблицей заявок.
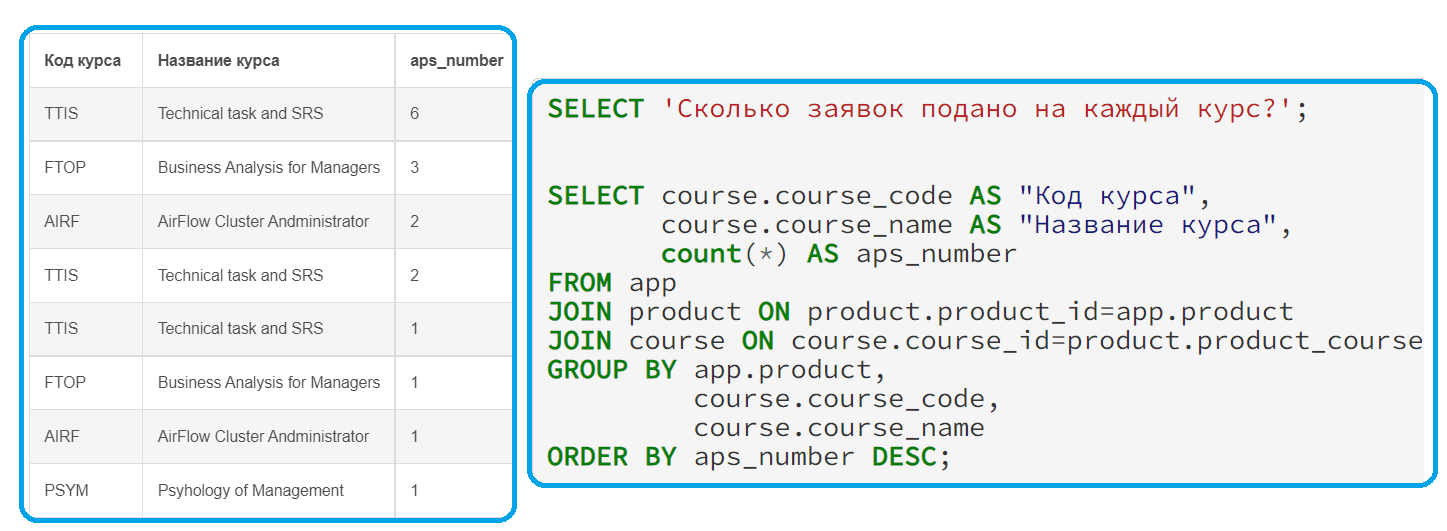
В заключение рассмотрим еще один пример с использованием группировки и фильтрации значений по агрегатным функциям через добавление HAVING после GROUP BY. Например, на каком курсе тренер Anna заработает больше 10 в ближайший месяц от текущей даты? Для этого используем следующий SQL-запрос:
SELECT 'На каком курсе тренер Анна заработает больше 10 у.е. в ближайший месяц?';
SELECT course.course_code AS "Код курса",
product.product_date AS "Дата",
trainer.trainer_name AS "Тренер",
count(*)*(course.course_price) AS income
FROM product
JOIN app ON app.product=product.product_id
JOIN course ON course.course_id=product.product_course
JOIN trainer ON trainer.trainer_id=product.product_trainer
WHERE trainer.trainer_name='Anna'
GROUP BY course.course_code,
product.product_date,
trainer.trainer_name,
course.course_price
HAVING count(*)*(course.course_price)> 10
AND product.product_date>(CURRENT_DATE-30);
Основы архитектуры и интеграции информационных систем
Код курса
OAIS
Ближайшая дата курса
29 июня, 2023
Длительность обучения
8 ак.часов
Стоимость обучения
15 000 руб.
Разумеется, в рамках это статьи не рассматривались все типы SQL-запросов и возможности этого языка. Наиболее эффективным способом освоить их будет самостоятельная работа с выполнением упражнений. Для этого есть множество открытых ресурсов, платных и бесплатных курсов, а также свободных и проприетарных инструментов. В частности, очень советую следующие онлайн-учебники и тренажеры:
- https://sql-academy.org/ru/guide
- https://learndb.ru/articles
- https://www.sql-ex.ru/
- https://stepik.org/course/63054/promo?search=882582677
Чтобы освоить все нюансы проектирования реляционных моделей и написания SQL-запросов к ним, также необходимо читать документацию и выполнять упражнения в соответствующей среде, развернув ее на своем компьютере. Например, для MySQL отлично подходит платформа MySQL Workbench (>https://www.mysql.com/products/workbench/), а для PostgreSQL можно использовать pgAdmin (>https://www.pgadmin.org/). Эти инструменты поддерживают как визуальное проектирование ER-модели, так и выполнение SQL-запросов. Они способны заменить целый набор инструментов, которые использовались при подготовке этой статьи:
- StarUML – среда разработки UML и ER-диаграмм;
- расширение Postgresql DDL Extension for StarUML 2 для создания DDL-запросов к СУБД PostgreSQL по спроектированной диаграмме;
- https://www.db-fiddle.com/ – онлайн-движок реляционных баз данных для тестирования, отладки и обмена фрагментами SQL-запросов;
- https://sqlformat.org/ – онлайн-форматер для операторов SQL, который делает код более читаемым;
- https://postgrespro.ru/docs/postgrespro/14/index – документация по Postgres Pro Standard, популярной объектно-реляционной СУБД.
В заключение отмечу, что проверить, как вы усвоили материал этой статьи можно бесплатно прямо на нашем сайте, выполнив интерактивный тест по основам баз данных и языку запросов SQL.
10 вопросов по основам теории баз данных и SQL: тест для начинающих
А подробнее познакомиться с основами реляционных СУБД и моделированием данных вам помогут курсы Школы прикладного бизнес-анализа в нашем лицензированном учебном центре обучения и повышения квалификации системных и бизнес-аналитиков в Москве:
- Основы архитектуры и интеграции информационных систем
- Разработка ТЗ на информационную систему по ГОСТ и SRS
База данных автозагрузки
В следующем примере – База данных для бизнеса автомагазина, у нас есть список отделов, сотрудников, клиентов и автомобилей клиентов. Мы используем внешние ключи для создания связей между различными таблицами.
Пример Live: скрипт SQL
Отношения между таблицами
- У каждого Департамента может быть 0 или более сотрудников
- У каждого сотрудника может быть 0 или 1 менеджер
- У каждого Клиента может быть 0 или более автомобилей
ведомства
| Я бы | название |
|---|---|
| 1 | HR |
| 2 | Продажи |
| 3 | Технология |
Операторы SQL для создания таблицы:
CREATE TABLE Departments (
Id INT NOT NULL AUTO_INCREMENT,
Name VARCHAR(25) NOT NULL,
PRIMARY KEY(Id)
);
INSERT INTO Departments
([Id], [Name])
VALUES
(1, 'HR'),
(2, 'Sales'),
(3, 'Tech')
;
Сотрудники
| Я бы | FName | LName | Номер телефона | ManagerID | DepartmentID | Оплата труда | Дата приема на работу |
|---|---|---|---|---|---|---|---|
| 1 | Джеймс | кузнец | 1234567890 | НОЛЬ | 1 | 1000 | 01-01-2002 |
| 2 | Джон | Джонсон | 2468101214 | 1 | 1 | 400 | 23-03-2005 |
| 3 | Майкл | Williams | 1357911131 | 1 | 2 | 600 | 12-05-2009 |
| 4 | Джонатон | кузнец | 1212121212 | 2 | 1 | 500 | 24-07-2016 |
Операторы SQL для создания таблицы:
CREATE TABLE Employees (
Id INT NOT NULL AUTO_INCREMENT,
FName VARCHAR(35) NOT NULL,
LName VARCHAR(35) NOT NULL,
PhoneNumber VARCHAR(11),
ManagerId INT,
DepartmentId INT NOT NULL,
Salary INT NOT NULL,
HireDate DATETIME NOT NULL,
PRIMARY KEY(Id),
FOREIGN KEY (ManagerId) REFERENCES Employees(Id),
FOREIGN KEY (DepartmentId) REFERENCES Departments(Id)
);
INSERT INTO Employees
([Id], [FName], [LName], [PhoneNumber], [ManagerId], [DepartmentId], [Salary], [HireDate])
VALUES
(1, 'James', 'Smith', 1234567890, NULL, 1, 1000, '01-01-2002'),
(2, 'John', 'Johnson', 2468101214, '1', 1, 400, '23-03-2005'),
(3, 'Michael', 'Williams', 1357911131, '1', 2, 600, '12-05-2009'),
(4, 'Johnathon', 'Smith', 1212121212, '2', 1, 500, '24-07-2016')
;
Клиенты
| Я бы | FName | LName | Эл. адрес | Номер телефона | PreferredContact |
|---|---|---|---|---|---|
| 1 | Уильям | Джонс | [email protected] | 3347927472 | ТЕЛЕФОН |
| 2 | Дэвид | мельник | [email protected] | 2137921892 | ЭЛ. АДРЕС |
| 3 | Ричард | Дэвис | [email protected] | НОЛЬ | ЭЛ. АДРЕС |
Операторы SQL для создания таблицы:
CREATE TABLE Customers (
Id INT NOT NULL AUTO_INCREMENT,
FName VARCHAR(35) NOT NULL,
LName VARCHAR(35) NOT NULL,
Email varchar(100) NOT NULL,
PhoneNumber VARCHAR(11),
PreferredContact VARCHAR(5) NOT NULL,
PRIMARY KEY(Id)
);
INSERT INTO Customers
([Id], [FName], [LName], [Email], [PhoneNumber], [PreferredContact])
VALUES
(1, 'William', 'Jones', '[email protected]', '3347927472', 'PHONE'),
(2, 'David', 'Miller', '[email protected]', '2137921892', 'EMAIL'),
(3, 'Richard', 'Davis', '[email protected]', NULL, 'EMAIL')
;
Машины
| Я бы | Пользовательский ИД | EmployeeID | модель | Статус | Общая стоимость |
|---|---|---|---|---|---|
| 1 | 1 | 2 | Ford F-150 | ГОТОВЫ | 230 |
| 2 | 1 | 2 | Ford F-150 | ГОТОВЫ | 200 |
| 3 | 2 | 1 | Ford Mustang | ОЖИДАНИЯ | 100 |
| 4 | 3 | 3 | Toyota Prius | ЗА РАБОТОЙ | 1254 |
Операторы SQL для создания таблицы:
CREATE TABLE Cars (
Id INT NOT NULL AUTO_INCREMENT,
CustomerId INT NOT NULL,
EmployeeId INT NOT NULL,
Model varchar(50) NOT NULL,
Status varchar(25) NOT NULL,
TotalCost INT NOT NULL,
PRIMARY KEY(Id),
FOREIGN KEY (CustomerId) REFERENCES Customers(Id),
FOREIGN KEY (EmployeeId) REFERENCES Employees(Id)
);
INSERT INTO Cars
([Id], [CustomerId], [EmployeeId], [Model], [Status], [TotalCost])
VALUES
('1', '1', '2', 'Ford F-150', 'READY', '230'),
('2', '1', '2', 'Ford F-150', 'READY', '200'),
('3', '2', '1', 'Ford Mustang', 'WAITING', '100'),
('4', '3', '3', 'Toyota Prius', 'WORKING', '1254')
;
База данных библиотек
В этой базе данных для библиотеки есть таблицы авторов , книг и книг .
Пример Live: скрипт SQL
Авторы и книги известны как базовые таблицы , поскольку они содержат определение столбцов и данные для реальных объектов в реляционной модели. BooksAuthors известна как таблица отношений , так как эта таблица определяет взаимосвязь между таблицей « Книги и авторы» .
Отношения между таблицами
- У каждого автора может быть 1 или более книг
- В каждой книге может быть 1 или более авторов
Авторы
( таблица просмотра )
| Я бы | название | Страна |
|---|---|---|
| 1 | Дж. Д. Сэлинджер | Соединенные Штаты Америки |
| 2 | Ф. Скотт. Fitzgerald | Соединенные Штаты Америки |
| 3 | Джейн Остин | Соединенное Королевство |
| 4 | Скотт Гензельман | Соединенные Штаты Америки |
| 5 | Джейсон Н. Гейлорд | Соединенные Штаты Америки |
| 6 | Пранав Растоги | Индия |
| 7 | Тодд Миранда | Соединенные Штаты Америки |
| 8 | Кристиан Венц | Соединенные Штаты Америки |
SQL для создания таблицы:
CREATE TABLE Authors (
Id INT NOT NULL AUTO_INCREMENT,
Name VARCHAR(70) NOT NULL,
Country VARCHAR(100) NOT NULL,
PRIMARY KEY(Id)
);
INSERT INTO Authors
(Name, Country)
VALUES
('J.D. Salinger', 'USA'),
('F. Scott. Fitzgerald', 'USA'),
('Jane Austen', 'UK'),
('Scott Hanselman', 'USA'),
('Jason N. Gaylord', 'USA'),
('Pranav Rastogi', 'India'),
('Todd Miranda', 'USA'),
('Christian Wenz', 'USA')
;
книги
( таблица просмотра )
| Я бы | заглавие |
|---|---|
| 1 | Ловец во ржи |
| 2 | Девять историй |
| 3 | Фрэнни и Зои |
| 4 | Великий Гэтсби |
| 5 | Тендерный идентификатор Ночь |
| 6 | Гордость и предубеждение |
| 7 | Профессиональный ASP.NET 4.5 в C # и VB |
SQL для создания таблицы:
CREATE TABLE Books (
Id INT NOT NULL AUTO_INCREMENT,
Title VARCHAR(50) NOT NULL,
PRIMARY KEY(Id)
);
INSERT INTO Books
(Id, Title)
VALUES
(1, 'The Catcher in the Rye'),
(2, 'Nine Stories'),
(3, 'Franny and Zooey'),
(4, 'The Great Gatsby'),
(5, 'Tender id the Night'),
(6, 'Pride and Prejudice'),
(7, 'Professional ASP.NET 4.5 in C# and VB')
;
( таблица просмотра )
| BookID | AuthorID |
|---|---|
| 1 | 1 |
| 2 | 1 |
| 3 | 1 |
| 4 | 2 |
| 5 | 2 |
| 6 | 3 |
| 7 | 4 |
| 7 | 5 |
| 7 | 6 |
| 7 | 7 |
| 7 | 8 |
SQL для создания таблицы:
CREATE TABLE BooksAuthors (
AuthorId INT NOT NULL,
BookId INT NOT NULL,
FOREIGN KEY (AuthorId) REFERENCES Authors(Id),
FOREIGN KEY (BookId) REFERENCES Books(Id)
);
INSERT INTO BooksAuthors
(BookId, AuthorId)
VALUES
(1, 1),
(2, 1),
(3, 1),
(4, 2),
(5, 2),
(6, 3),
(7, 4),
(7, 5),
(7, 6),
(7, 7),
(7, 8)
;
Примеры
Просмотреть всех авторов ( просмотреть живой пример ):
SELECT * FROM Authors;
Просмотр всех названий книг ( просмотр живого примера ):
SELECT * FROM Books;
Просмотреть все книги и их авторов ( посмотреть живой пример ):
SELECT
ba.AuthorId,
a.Name AuthorName,
ba.BookId,
b.Title BookTitle
FROM BooksAuthors ba
INNER JOIN Authors a ON a.id = ba.authorid
INNER JOIN Books b ON b.id = ba.bookid
;
Таблица стран
В этом примере у нас есть таблица стран . Таблица для стран имеет много применений, особенно в финансовых приложениях, связанных с валютами и обменными курсами.
Пример Live: скрипт SQL
Некоторые программные приложения для данных рынка, такие как Bloomberg и Reuters, требуют, чтобы вы предоставили свой API код страны или 2 символа страны вместе с кодом валюты. Следовательно, эта таблица примеров содержит как 2- ISO3 столбец ISO кода, так и 3 символьных ISO3 кода ISO3 .
страны
( таблица просмотра )
| Я бы | ISO | ISO3 | ISONumeric | Название страны | Капитал | ContinentCode | Код валюты |
|---|---|---|---|---|---|---|---|
| 1 | AU | AUS | 36 | Австралия | Канберра | OC | AUD |
| 2 | Делавэр | DEU | 276 | Германия | Берлин | Евросоюз | евро |
| 2 | В | IND | 356 | Индия | Нью-Дели | КАК | INR |
| 3 | Луизиана | ЛАО | 418 | Лаос | Вьентьян | КАК | LAK |
| 4 | НАС | Соединенные Штаты Америки | 840 | Соединенные Штаты | Вашингтон | Не Доступно | доллар США |
| 5 | ZW | ZWE | 716 | Зимбабве | Хараре | AF | ZWL |
SQL для создания таблицы:
CREATE TABLE Countries (
Id INT NOT NULL AUTO_INCREMENT,
ISO VARCHAR(2) NOT NULL,
ISO3 VARCHAR(3) NOT NULL,
ISONumeric INT NOT NULL,
CountryName VARCHAR(64) NOT NULL,
Capital VARCHAR(64) NOT NULL,
ContinentCode VARCHAR(2) NOT NULL,
CurrencyCode VARCHAR(3) NOT NULL,
PRIMARY KEY(Id)
)
;
INSERT INTO Countries
(ISO, ISO3, ISONumeric, CountryName, Capital, ContinentCode, CurrencyCode)
VALUES
('AU', 'AUS', 36, 'Australia', 'Canberra', 'OC', 'AUD'),
('DE', 'DEU', 276, 'Germany', 'Berlin', 'EU', 'EUR'),
('IN', 'IND', 356, 'India', 'New Delhi', 'AS', 'INR'),
('LA', 'LAO', 418, 'Laos', 'Vientiane', 'AS', 'LAK'),
('US', 'USA', 840, 'United States', 'Washington', 'NA', 'USD'),
('ZW', 'ZWE', 716, 'Zimbabwe', 'Harare', 'AF', 'ZWL')
;
Введение
В этой статье разберем пример создания структуры базы данных для социальной сети.
У нас нет задачи создать полноценную структуру для всех объектов базы, основная идея – показать как выделять объекты и как их связывать, а также показать некоторые тактические моменты по созданию структуры БД.
Описание таблицы БД будет в следующем формате:
Название таблицы – перечень столбцов через запятую.
Во всех таблицах первичный ключ это id int identity(1,1).
Внешние ключи обозначаются как elementID int (суффикс ID подсказывает нам что это внешний ключ на другую таблицу). Это просто наше соглашение для изменования полей.
Шаг 1. Выделение объектов базы данных
Откройте свою страницу в ВК и самостоятельно посмотрите какие объекты можно выделять.

Что есть объект – это некая независимая сущность, информацию о которой мы можем хранить в базе данных.
Я вижу следующие объекты, я сразу их разделю на подгруппы:
Общие
- Пользователь (users)
- Сообщение на стене (posts)
Группы
- Группа (groups)
- Участник группы (groupMembers)
- Сообщение в группе (posts)
Галерея
- Альбом (albums)
- Элемент альбома (albumItems)
Чаты
- Сообщение (messages)
- Комната в чате (rooms)
Этим пока ограничимся (не берем видео, аудио, рекламу и т.д.).
Сразу пишем название будущей таблицы (мы используем практически всегда название во множественном числе).
Шаг 2. Определяем более детально объекты
Давайте теперь более детально изучим что будет внутри объектов, т.к. из каких атрибутов они состоят и какие связи между ними будут.
Особую важность имеют именно связи, т.к. их потом гораздо сложнее менять – важно сразу правильно определить тип связи (один ко одному, один ко многим, много ко многим).
Один ко одному
Случай когда одна строка таблицы однозначно соотносится со строкой в другой таблице. Например, храним мы статьи – в отдельной таблице все мета данные по статье. В другой – только тело самой статьи (для производительности – чтобы основная таблица была относительно небольших размеров). В этом случае 1 строка в первой таблице однозначно соответствует 1 строке во второй таблице.
Один ко многим
Есть у нас сотрудники, у каждого есть определенная должность. Какая связь между должностями и сотрудниками. Можно мыслить следующим образом: Сотрудник может иметь 1 должность. Конкретную должность может занимать несколько сотрудников – значит связь 1 ко многим.
Как она реализуется? С помощью внешнего ключа в таблице humans:
- posts(id, name) – должности
- humans (id, fio, postID) – сотрудники.
Много ко многим
Допустим есть у нас студенты и предметы. Один студент изучает множество предметов. Один предмет изучают множество студентов. Это связь много ко многим.
В этом случае необходимо добавление дополнительной таблицы связи, где будут указаны внешние ключи на 2 таблицы:
- students (id, fio)
- subjects (id, name)
- studentSubjects (id, studentID, subjectID) – мы называем таблицу Предметы студента (т.к. это соответствует реальному миру), но бывают и другие названия, например, studentsSubjects (на мой взгляд, более кривое название).
Детализация структуры БД
Теперь вернемся к структуре БД социальной сети:
- users (id, fio, sex … ) Пользователь – это центральная сущность, у нее может быть куча полей (исходя из профиля и настроек). Здесь мы указываем только самые базовые.
- messages (id, text, created, userID FK, roomID) Сообщения содержат ссылку на автора сообщения и комнату, где написано это сообщение.
- roomTypes (id, code, name) – типы комнат. Комнаты могут быть привязаны к каким-то объектам (группа, переписка личная и т.д.)
- rooms (id, typeID, itemID, created, [some settings for room]) – определяется к чему привязана комната через связку (typeID, itemID), когда создана.
- roomUsers (id, userID, roomID, created) – кто в комнате (чате) находится. Это связь много ко многим между Пользователями и Комнатами.
Если мы хотим фиксировать кто когда был добавлен и удален в комнате, то делаем дополнительную таблицу
- roomUsersLog (id, roomID, userID, created, operation), где operation – это либо add либо delete к примеру.
Разберемся с группами
- groups (id, name, ownerID, desc) – у группы есть владелец (это ссылка на users – один ко многим, у группы может быть только один владелец, а у юзера может быть несколько групп, где он владелец).
- groupMembers (id, groupID, userID, created, roleID) – какой юзер в какой группе с какой ролью (можно было бы кстати задать владение группой через это поле, тогда можно было бы сделать что у группы может быть несколько владельцев).
- groupMemberRoles (id, name, code) – роль пользователя в группе (админ, редактор, пользователь). Зачем поле code – для возможного обращения по нему к конкретной роли. Обращение по id из кода – это не очень хороший ход, т.к. при переносе данных из одной базы в другую id могут быть другие и это может сломать работу компонента.
Давайте разбираться с постами
Можно прикрепить посты прямо к группе, но у нас же есть еще личные страницы + в будущем могут еще появиться другие объекты, которым нужна стена.
Поэтому вводим такое понятие как Стена и уже его цепляем к нужному нам объекту. Делается это с целью не плодить кучу однотипных таблиц (посты, комментарии для группы ничем не отличаются от постов и комментариев для личной стены).
- wallTypes (id, name, code) – тип стены (личная или группы)
- walls (id, typeID, itemID) – стена задается типом и идентификатором стены (по сути это ссылка на id либо группы, либо юзера. Да, это не чистый внешний ключ (как было бы в случае отдельных таблиц), но зато достигается универсальность в плане хранения данных). Другой вариант мог бы быть хранение groupID и userID (т.е. если groupID не null – тогда это привязка к группе), но в этом случае нам придется менять структуру таблицы при появлении нового типа и что самое плохое – учитывать это изменение где-то в коде.
- posts (id, userID, created, wallID, text, repostID, likeCount) – это стена группа, ее посты. Автор userID. Связка с группой один ко многим (после принадлежит только одной группе). repostID – это случай, когда наш пост является репостом другого поста. likeCount – количество лайков.
- postComments (id, userID, created, postID, parentCommentID, likeCount) – указываем кто оставил коммент, когда, на какой пост. Если это комментарий к комментарию, то будет указан родительский комментарий. Также собираем агрегированное количество лайков в отдельном поле.
- likeTypes (id, name, code) – к чему мы ставим лайк (коммент, пост или что-то еще).
- likeLog(id, typeID, itemID, value, created, userID) – лог лайков, кто когда поставил лайк на какой объект.
Зачем хранить поле likeCount, если эта информация хранится в таблице likeLog? Все дело в производительности. Представьте, нам нужно вывести список постов, а для вывода количества лайков нам необходимо проводить обработку гигантской таблицы likeLog (вообще любую логовую таблицу лучше считать гигантской и обрабатывать очень осторожно в плане выборок).
Когда проектируете связи таблиц, обязательно думайте как это будет использоваться на практике. Например, можно в postComments хранить только для корневых комментов поле postID, а вложенные же можно достать по parentCommentID. На практике это очень плохо будет работать, т.к. вместо того, чтобы просто быстро по postID извлечь все комменты одним махом, вам придется пробегать по всему дереву комментариев в каждом посте. Это большие и ненужные затраты мощностей сервера. Поле postID необходимо ставить в каждом комментарии для быстрого извлечения комментариев на пост.
Разберем галерею фото
Можно рассматривать фото как пост и применить всю структуру данных к картинкам. По сути в этом есть смысл – у фото тоже есть комментарии, тоже есть лайки, есть автор.
Делать фото как посты? Все зависит от того, как будут в дальнейшем развиваться эти 2 подсистемы. Может в будущем получиться так, что Картинки надо будет развивать совсем в другом ключе, например, добавить такие возможности, которые не нужны постам. В этом случае надо будет придумывать как это обработать для картинок отдельно (вероятно создание дополнительных таблиц, специфичных именно для постов-фото).
В нашем случае есть альбомы – это сильно выбивается из концепции Посты. Поэтому давайте сделаем отдельную структуру.
- albums (id, name, desc, created, userID, ord, coverImageID) – альбомы с названием, когда создан, кто владелец. ord задает порядок вывода. coverImageID задает ссылку на обложку.
- albumImages (id, name, img, thumb, desc, albumID, created, likeCount, ord) – картинки в альбоме
Для хранения лайков мы можем задействовать таблицу likeLog (в эти моменты как раз и начинаешь ценить универсальный подход с typeID, itemID).
Заметим, что в данной структуре не получится хранить фото без альбома (т.е. albumID задает связь с владельцем фото).
Сами картинки хранятся как пути к файлам на сервере (малое и большое фото – thumb, img). В реальном приложении это может быть отдельная таблица ресурсов, и тогда это будут уже внешние ключи на эту таблицу.
Поле ord типа int задает порядок размещения фото в альбоме.
Кого-то может смутить такая зацикленная связь: albums ссылается на albumImages через coverImageID, а картинки ссылаются на альбомы через albumID. Тут лучше просто рассматривать ключи полностью отдельно.
coverImageID указывает нам на обложку альбома (она могла бы быть потенциально и в другой таблице), а albumID задает к чему цепляется наше фото (образно говоря в какой папке находится).
Нет ли здесь проблемы курицы и яйца? Нет. Мы создаем сначала альбом с coverImageID = NULL. Когда создаем первое фото в альбоме, то идет проверка: если не было еще фото, то у альбома тогда проставим coverImageID.
Либо другая может быть логика – создаем просто фото. Если альбом не был выбран из существующих, то создаем альбом Альбом 1 с coverImageID = NULL, затем создаем фото с новым albumID и после этого устанавливаем coverImageID, равным id новой картинки.
Шаг 3. Самостоятельное дополнение полей и объектов.
Мы, конечно, много чего не учли в этой структуре БД:
- музыка, видео.
- у фото могут быть комментарии
- вывод рекламы
- фиксация входа/выхода
- статусы человека, обложка и т.д.
- прикрепление к постам разных объектов (голосование, видео, фото и т.д.).
И это мы говорим только о внешней части. А есть еще и внутренняя:
- модерация пользователей
- контроль постов.
- обработка жалоб и вопросов в техподдержке.
- аналитика по разным разрезам (это может быть гигантский раздел).
- множество ролей в закрытой части (модератор, финансист, директор, техподдержка и т.д.).
- работа с внешними интеграциями
- платформа разработки
- документация, внутренняя база знаний, форум
Попробуйте сделать следующее: самостоятельно изначально постройте свою структуру БД с учетом всех объектов, которые обозначили в этой статье.
Детализируйте их настолько, сколько позволяет вам внешний интерфейс социальной сети.
Заключение
Основная цель статьи – дать понимание как выделять объекты, а также правильно определять тип связи. Это в итоге дает возможность правильно определить структуру базы данных.
Ошибки на уровне структуры базы данных довольно сложно исправлять на поздних стадиях (особенно когда система уже работает), поэтому этот шаг требует максимально возможной точности.
