Introduction
Who loves datasets?! At Kili Technology, we do love datasets –it won’t be a shocker. But guess what none of us like it? Spending too much time creating datasets (or searching for datasets). Although this step is essential to the machine learning process, we must admit it: this task gets daunting quickly. Do not worry, though: we’ve got you covered!
This article will go through the 6 common strategies to think of when building a dataset.
Although these strategies may not be suitable for every use case, they’re common approaches to consider when building a dataset and should give you a hand in building your ML dataset. Without further due, let’s create your dataset!
Strategy #1 to Create your Dataset: ask your IT
When it comes to building and fine-tuning your machine-learning models, one strategy should be at the top of your list: using your data. Not only is this data naturally tailored to your specific needs, but it’s also the best way to ensure that your model is optimized for the types of data it will encounter in the real world. So if you want to achieve maximum performance and accuracy, prioritize your internal data first.
Here are additional techniques to gather more data from your users:
User in the loop

Are you looking to get more data from your users? One effective way to do so is by designing your product to make it easy for users to share their data with you. Take inspiration from companies like Meta (formerly Facebook) and its fault-tolerant UX. Users might not see it, but its UX leads them to correct machine errors or improve ML algorithms.
Side business
Let’s focus on data gathered through the “freemium” model –which is particularly popular in the Computer Vision field. By offering a free-to-use app with valuable features, you can attract a large user base and gather valuable data in the process. A great example of this technique can be seen in popular photo-editing apps, which offer users powerful editing tools while collecting data (such as face images) for the company’s core business. It’s a win-win for everyone involved!”
Caveats
To make the most of your internal data, you should ensure it meets these three crucial criteria:
-
Compliance: Ensure your data is fully compliant with all relevant legislation and regulations, such as the GDPR and CCPA.
-
Security: Have the necessary credentials and safeguards to protect your data and ensure that only authorized personnel can access it.
-
Timeliness: Keep your data fresh and up-to-date to ensure it’s as valuable and relevant as possible.
Strategy #2 to Create your Dataset: Look for Research Dataset platforms

You can find several web pages or websites that gather ready-to-use datasets for machine learning. Among the most famous:
-
Kaggle dataset: https://www.kaggle.com/datasets
-
Hugging Face datasets: https://huggingface.co/docs/datasets/index
-
Amazon Datasets: https://registry.opendata.aws/
-
UCI Machine Learning Repository: https://archive.ics.uci.edu/ml/index.php
-
Google’s Datasets Search Engine: https://datasetsearch.research.google.com/
-
Paper with code datasets: https://paperswithcode.com/datasets
-
Subreddit datasets: r/datasets
-
US government’s datasets: Data.gov or Europe data platform: data.europa.eu
Strategy #3 to Create your Dataset: Look for GitHub Awesome pages

GitHub Awesome pages are lists that gather resources for a specific domain –isn’t it cool?! There are fantastic pages for many things, and lucky us: datasets as well.
Awesome pages can be on more or less specific topics:
– You can find datasets on awesome pages that gather resources with a broad scope, ranging from agriculture to economy and more:
https://github.com/awesomedata/awesome-public-datasets or https://github.com/NajiElKotob/Awesome-Datasets
– But you can also find awesome pages on more narrow and specific topics. For example, datasets focusing on tiny objects detection https://github.com/kuanhungchen/awesome-tiny-object-detection or few shot learning https://github.com/Bryce1010/Awesome-Few-shot.
Strategy #4 to Create your Dataset: Crawl and Scrape the Web

Crawling is browsing a vast number of web pages that might interest you. Scrapping is about gathering data from given web pages.
Both tasks can be more or less complex. Crawling will be easier if you narrow the pages to a specific domain (for example, all Wikipedia pages).
Both these techniques enable the collection of different types of datasets:
-
Available raw text, which can be used to train large language models.
-
A specific introductory text that is used to train models specialized in tasks: product reviews and stars.
-
Text with metadata that enables to train of classification models.
-
Multilingual text that instructs translation models.
-
Images with legends that enables training image classification or image-to-text models…
Pro tip: you can build your crawler and scrapper with the following python packages:
-
https://github.com/scrapy/scrapy
-
https://pypi.org/project/beautifulsoup4/
-
https://selenium-python.readthedocs.io/
You can also find more specific but ready-to-use repositories on Github, including:
Google Image scrapper: https://github.com/jqueguiner/googleImagesWebScraping
News scrapper: https://github.com/fhamborg/news-please
Strategy #5 to Create your Dataset: Use products API
Some big service providers or media give an API in their product that you can use to get data when it is open source. You can, for example, think of:
-
Twitter API to retrieve tweets: https://developer.twitter.com/en/docs/twitter-api and the lovely python library: https://github.com/tweepy/tweepy
-
Sentinelhub API to fetch satellite data from sentinels or Landsat satellites https://www.sentinel-hub.com/develop/api/
-
Bloomberg API for business news https://www.bloomberg.com/professional/support/api-library/
-
Spotify API to get metadata about songs: https://developer.spotify.com/documentation/web-api/
Strategy #6 to Create your Dataset: Look for datasets used in research papers

You may be scratching your head and wondering how on earth you’ll raise the suitable dataset to visualize and solve your problem – no need to pull your hair over it!
Odds are some chances that some researchers were already interested in your use case and faced the same problem as you. If this is the case, you can find the datasets they used and sometimes built themselves. If they publish this dataset on an open-source platform, you can retrieve it. If not, you can contact them to see if they accept sharing their dataset – polite requests wouldn’t hurt, wouldn’t they?
How to Create a Dataset of Amazon Reviews with Python and BeautifulSoup: A Step-by-Step Guide
Now that we’ve shared all our strategies to find or to build your own datasets, let’s practice our dataset-building skills with a real-life example.
Here’s your step-by-step tutorial on extracting valuable insights from Amazon reviews using Python and BeautifulSoup.
By the end of it, you’ll have a fully functional Python script that effectively scrapes Amazon reviews and compiles them into a clean, structured dataset ready for analysis.
Let’s jump right in!
Step 1: Install Required Libraries
Make sure you have Python and the required libraries installed on your system, and let’s examine the code. Before diving into the code, make sure you have the following libraries installed:
-
requests
-
BeautifulSoup4
-
pandas
You can install them using pip:
pip install requests beautifulsoup4 pandasStep 2: Import Libraries and Set Up the Base URL
Begin by importing the necessary libraries and establishing the base URL for Amazon’s product page:
import requests
from bs4 import BeautifulSoup
import pandas as pd
base_url = 'https://www.amazon.com/product-reviews/{}?pageNumber={}'
product_id = 'YOUR_PRODUCT_ID_HERE'This sets the groundwork for our script by importing the libraries and defining the base URL to access the Amazon product review pages.
Step 3: Define a Function to Scrape Reviews.
Now, create a function to scrape reviews from a single page:
def scrape_reviews(product_id, page_number):
url = base_url.format(product_id, page_number)
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3'}
response = requests.get(url, headers=headers)
soup = BeautifulSoup(response.content, 'html.parser')
reviews = []
for review in soup.find_all('div', class_='review'):
title = review.find('a', class_='review-title').text.strip()
content = review.find('span', class_='review-text-content').text.strip()
rating = float(review.find('i', class_='review-rating').text.strip().split()[0])
reviews.append({'title': title, 'content': content, 'rating': rating})
return reviewsThis function takes a product ID and a page number as input, constructs the URL, and sends an HTTP request to fetch the review page. It then parses the HTML content using BeautifulSoup and extracts the review title, content, and rating for each review on the page.
Step 4: Scrape Multiple Pages and Save the Dataset
Finally, create a function to scrape reviews from multiple pages and save them to a CSV file:
def scrape_all_reviews(product_id, num_pages):
all_reviews = []
for i in range(1, num_pages + 1):
print(f"Scraping page {i}...")
reviews = scrape_reviews(product_id, i)
all_reviews.extend(reviews)
return all_reviews
# Replace 'num_pages' with the number of pages you want to scrape
num_pages = 10
dataset = scrape_all_reviews(product_id, num_pages)
df = pd.DataFrame(dataset)
df.to_csv('amazon_reviews.csv', index=False)This function, scrape_all_reviews, takes the product ID and the number of pages you want to scrape. It calls the scrape_reviews function for each page and collects the reviews in a list. After all the pages have been scraped, it converts the list of reviews into a pandas DataFrame and saves it as a CSV file.
Conclusion
Congratulations! You’ve successfully created a dataset of Amazon reviews using Python and BeautifulSoup. You can now utilize this dataset for your machine learning or data science projects. This tutorial has provided you with a foundation for web scraping techniques and the ability to collect valuable data. Feel free to modify the script to suit your specific needs or to target other websites. We hope you found this tutorial beneficial in your journey towards data science mastery. Enjoy!
Key Takeaways

So there you have it! With these six strategies and this comprehensive tutorial, you should be well on building your dreams’ dataset.
But wait a minute: since your dataset is likely to be ready by now, wouldn’t it be time for you to annotate it? To help you keep on this dynamic, feel free to try the Kili Technology platform by signing up for a free trial.
Sometimes, to test models or perform simulations, you may need to create a dataset with python. We will not import this simulated or fake dataset from real-world data, but we will generate it from scratch using a couple of lines of code. In this article, I will be showing how to create a dataset for regression, classification, and clustering problems using python.
How to create a dataset for a classification problem with python?
To create a dataset for a classification problem with python, we use the make_classification method available in the sci-kit learn library. Let’s import the library.
from sklearn.datasets import make_regression, make_classification, make_blobs
import pandas as pd
import matplotlib.pyplot as pltThe make_classification method returns by default, ndarrays which corresponds to the variable/feature and the target/output. To generate a classification dataset, the method will require the following parameters:
- n_samples: the number of samples/rows.
- n_features: the number of features/columns.
- n_informative: the number of features that have a role in the prediction of the output.
- n_redundant: the number of features that are not related to the output class.
- n_classes: the number of classes/labels for the classification problem.
- weights: the proportion of samples for each output/class. Inserting None means balanced classes.
Let’s go ahead and generate the classification dataset using the above parameters.
# How to create a dataset for a classification problem
variables, target = make_classification(
n_samples = 1000,
n_features = 12,
n_informative = 7,
n_redundant = 3,
n_repeated = 2,
n_classes = 4,
# Distribution of classes 20% Output1
# 20%> output 2, 30% output 3 and 4
weights = [.2,.2, .3, .3],
random_state = 8)Let’s visualize the variable dataframe.
# View the some sample rows classification dataset
pd.DataFrame(variables,
columns=["col_name "+ str(i) for i in range(variables.shape[1])])
col_name 0 col_name 1 col_name 2 col_name 3 col_name 4 col_name 5 col_name 6 col_name 7 col_name 8 col_name 9 col_name 10 col_name 11
0 0.331723 0.509881 -0.175577 1.075973 -0.831905 -6.934965 1.075973 2.287544 -0.963859 -5.114866 -0.831905 -1.146492
1 0.195848 1.620299 1.106739 1.367136 -1.896274 -0.183035 1.367136 -2.046089 -0.047922 -0.678143 -1.896274 0.624624
2 -1.110011 -0.556873 1.688196 -1.093200 -0.784965 -3.192678 -1.093200 0.687897 -1.036923 -1.843979 -0.784965 -1.493613
3 -2.201790 -1.327092 -0.612005 4.771862 1.333772 -4.806040 4.771862 -0.140957 -3.054470 -0.449136 1.333772 -2.776526
4 -0.309355 -1.481214 -0.348062 -0.323696 1.007431 0.398226 -0.323696 0.890199 0.330016 1.649357 1.007431 -0.162269
... ... ... ... ... ... ... ... ... ... ... ... ...
995 2.667335 -0.417175 2.833952 0.914925 0.527134 -3.312023 0.914925 3.440490 1.359939 2.461748 0.527134 2.621739
996 -1.580031 -0.866029 0.304893 4.219823 -2.325976 -8.120002 4.219823 1.534977 4.459700 0.684456 -2.325976 3.559462
997 -4.297403 -0.778561 -1.248011 -2.836641 1.092944 3.943337 -2.836641 -1.993144 0.334962 1.419927 1.092944 -0.862761
998 0.996732 0.883047 5.827281 0.396347 -2.989223 -2.003943 0.396347 -1.810176 -2.486957 -0.346523 -2.989223 -1.164679
999 -0.362272 -1.051120 -1.444873 -0.235483 1.939468 -1.478216 -0.235483 2.507234 0.776497 0.359553 1.939468 0.404604Let’s visualize the output dataframe.
# View the target column
pd.DataFrame(target).head()0
0 2
1 0
2 2
3 0
4 1In the last word, if you have a multilabel classification problem, you can use the make_multilable_classification method to generate your data. The procedure for it is similar to the one we have above.
How to create a dataset for regression problems with python?
Similarly to make_classification, the make_regression method returns by default, ndarrays which corresponds to the variable/feature and the target/output. To generate a regression dataset, the method will require the following parameters:
- n_samples: the number of samples/rows
- n_features: the number of features/columns
- n_informative: the number of informative variables
- n_target: the number of regression targets/output. So a value of 2 means each sample will have 2 outputs.
- Noise: the standard deviation of the gaussian noise on the output
- shuffle: mix the samples and the features.
- coef: Return or not the coefficients of the underlying linear model.
- random state: state the seed for the random number generator, to reproduce the same dataset in case of reuse
Let’s go ahead and generate the regression dataset using the above parameters.
# How to create a dataset for a regression problem
variables, target = make_regression(n_samples = 1000,
n_features = 10,
n_informative = 8,
n_targets = 1,
noise = .5,
random_state = 8
)Let’s visualize the variable dataframe.
# View the some sample rows classification dataset
pd.DataFrame(variables,
columns=["col_name "+ str(i) for i in range(variables.shape[1])]).head() col_name 0 col_name 1 col_name 2 col_name 3 col_name 4 col_name 5 col_name 6 col_name 7 col_name 8 col_name 9
0 -1.840549 1.242176 -1.390003 -0.722689 1.632301 -0.577799 -0.222739 0.405041 -0.571550 -0.553471
1 -0.537855 1.669537 0.903670 0.420327 1.219688 2.431992 1.267145 -0.345046 0.020319 -0.540176
2 -1.142355 -1.221051 0.107340 -1.336418 0.876019 0.055713 0.306274 1.181244 0.479989 0.429356
3 0.178291 0.150575 -0.693476 -0.789158 0.307253 -0.693905 -0.280938 1.329255 0.949204 -1.348216
4 0.669372 1.204146 0.123464 -0.288869 0.012149 0.923918 -0.332575 -0.403318 0.728422 -0.046430Let’s visualize the output dataframe.
# Vizualize the target dataframe
pd.DataFrame(target, columns=['Bills']).head() Bills
0 37.230636
1 238.246502
2 84.744504
3 14.400635
4 70.771206How to create a dataset for a clustering problem with python?
The make_blob method returns by default, ndarrays which corresponds to the variable/feature/columns containing the data, and the target/output containing the labels for the cluster’s numbers. To generate a clustering dataset, the method will require the following parameters:
- n_samples: the number of samples/rows. Passed as an integer, it divides the various points equally among clusters. And Passed as an array, each element shows the number of samples per cluster.
- n_features: the number of features/columns
- centers: the number of centers (fixed center locations) to generate your clusters.
- clusters_std: the standard deviation of each cluster
- shuffle: mixes the various rows/samples
- random state: defines the random number used for the generation of the dataset
Let’s go ahead and generate the clustering dataset using the above parameters.
# How to create a dataset for a clustering problem
X, y = make_blobs(
n_samples = 1000,
n_features = 2,
centers = 5,
cluster_std = 0.5,
shuffle = True
random_state = 9)Let’s visualize the various clusters.
plt.scatter(X[:,0],
X[:,1],
c = ["red"])
plt.figure(figsize=(16,10)).show()
Bonus on creating your own dataset with python
The above were the main ways to create a handmade dataset for your data science testings. There are even more default architectures ways to generate datasets and even real-world data for free. Those datasets and functions are all available in the Scikit learn library, under sklearn.datasets. Feel free to check it out.
If you made this far in the article, I would like to thank you so much.
I hope it was of use to you.
Feel free to use any information from this page. I’d appreciate it if you can simply link to this article as the source. If you have any additional questions, you can reach out to [email protected] or message me on Twitter. If you want more content like this, join my email list to receive the latest articles. I promise I do not spam.
Importing Data
The tf.data API enables you to build complex input pipelines from
simple, reusable pieces. For example, the pipeline for an image model might
aggregate data from files in a distributed file system, apply random
perturbations to each image, and merge randomly selected images into a batch
for training. The pipeline for a text model might involve extracting symbols
from raw text data, converting them to embedding identifiers with a lookup
table, and batching together sequences of different lengths. The tf.data API
makes it easy to deal with large amounts of data, different data formats, and
complicated transformations.
The tf.data API introduces two new abstractions to TensorFlow:
-
A
tf.data.Datasetrepresents a sequence of elements, in which
each element contains one or moreTensorobjects. For example, in an image
pipeline, an element might be a single training example, with a pair of
tensors representing the image data and a label. There are two distinct
ways to create a dataset:-
Creating a source (e.g.
Dataset.from_tensor_slices()) constructs a
dataset from
one or moretf.Tensorobjects. -
Applying a transformation (e.g.
Dataset.batch()) constructs a dataset
from one or moretf.data.Datasetobjects.
-
-
A
tf.data.Iteratorprovides the main way to extract elements from a
dataset. The operation returned byIterator.get_next()yields the next
element of aDatasetwhen executed, and typically acts as the interface
between input pipeline code and your model. The simplest iterator is a
“one-shot iterator”, which is associated with a particularDatasetand
iterates through it once. For more sophisticated uses, the
Iterator.initializeroperation enables you to reinitialize and parameterize
an iterator with different datasets, so that you can, for example, iterate
over training and validation data multiple times in the same program.
Basic mechanics
This section of the guide describes the fundamentals of creating different kinds
of Dataset and Iterator objects, and how to extract data from them.
To start an input pipeline, you must define a source. For example, to
construct a Dataset from some tensors in memory, you can use
tf.data.Dataset.from_tensors() or
tf.data.Dataset.from_tensor_slices(). Alternatively, if your input
data are on disk in the recommended TFRecord format, you can construct a
tf.data.TFRecordDataset.
Once you have a Dataset object, you can transform it into a new Dataset by
chaining method calls on the tf.data.Dataset object. For example, you
can apply per-element transformations such as Dataset.map() (to apply a
function to each element), and multi-element transformations such as
Dataset.batch(). See the documentation for tf.data.Dataset
for a complete list of transformations.
The most common way to consume values from a Dataset is to make an
iterator object that provides access to one element of the dataset at a time
(for example, by calling Dataset.make_one_shot_iterator()). A
tf.data.Iterator provides two operations: Iterator.initializer,
which enables you to (re)initialize the iterator’s state; and
Iterator.get_next(), which returns tf.Tensor objects that correspond to the
symbolic next element. Depending on your use case, you might choose a different
type of iterator, and the options are outlined below.
Dataset structure
A dataset comprises elements that each have the same structure. An element
contains one or more tf.Tensor objects, called components. Each component
has a tf.DType representing the type of elements in the tensor, and a
tf.TensorShape representing the (possibly partially specified) static shape of
each element. The Dataset.output_types and Dataset.output_shapes properties
allow you to inspect the inferred types and shapes of each component of a
dataset element. The nested structure of these properties map to the structure
of an element, which may be a single tensor, a tuple of tensors, or a nested
tuple of tensors. For example:
dataset1 = tf.data.Dataset.from_tensor_slices(tf.random_uniform([4, 10])) print(dataset1.output_types) # ==> "tf.float32" print(dataset1.output_shapes) # ==> "(10,)" dataset2 = tf.data.Dataset.from_tensor_slices( (tf.random_uniform([4]), tf.random_uniform([4, 100], maxval=100, dtype=tf.int32))) print(dataset2.output_types) # ==> "(tf.float32, tf.int32)" print(dataset2.output_shapes) # ==> "((), (100,))" dataset3 = tf.data.Dataset.zip((dataset1, dataset2)) print(dataset3.output_types) # ==> (tf.float32, (tf.float32, tf.int32)) print(dataset3.output_shapes) # ==> "(10, ((), (100,)))"
It is often convenient to give names to each component of an element, for
example if they represent different features of a training example. In addition
to tuples, you can use collections.namedtuple or a dictionary mapping strings
to tensors to represent a single element of a Dataset.
dataset = tf.data.Dataset.from_tensor_slices( {"a": tf.random_uniform([4]), "b": tf.random_uniform([4, 100], maxval=100, dtype=tf.int32)}) print(dataset.output_types) # ==> "{'a': tf.float32, 'b': tf.int32}" print(dataset.output_shapes) # ==> "{'a': (), 'b': (100,)}"
The Dataset transformations support datasets of any structure. When using the
Dataset.map(), Dataset.flat_map(), and Dataset.filter() transformations,
which apply a function to each element, the element structure determines the
arguments of the function:
dataset1 = dataset1.map(lambda x: ...) dataset2 = dataset2.flat_map(lambda x, y: ...) # Note: Argument destructuring is not available in Python 3. dataset3 = dataset3.filter(lambda x, (y, z): ...)
Creating an iterator
Once you have built a Dataset to represent your input data, the next step is to
create an Iterator to access elements from that dataset. The tf.data API
currently supports the following iterators, in increasing level of
sophistication:
- one-shot,
- initializable,
- reinitializable, and
- feedable.
A one-shot iterator is the simplest form of iterator, which only supports
iterating once through a dataset, with no need for explicit initialization.
One-shot iterators handle almost all of the cases that the existing queue-based
input pipelines support, but they do not support parameterization. Using the
example of Dataset.range():
dataset = tf.data.Dataset.range(100) iterator = dataset.make_one_shot_iterator() next_element = iterator.get_next() for i in range(100): value = sess.run(next_element) assert i == value
Note: Currently, one-shot iterators are the only type that is easily usable
with an Estimator.
An initializable iterator requires you to run an explicit
iterator.initializer operation before using it. In exchange for this
inconvenience, it enables you to parameterize the definition of the dataset,
using one or more tf.placeholder() tensors that can be fed when you
initialize the iterator. Continuing the Dataset.range() example:
max_value = tf.placeholder(tf.int64, shape=[]) dataset = tf.data.Dataset.range(max_value) iterator = dataset.make_initializable_iterator() next_element = iterator.get_next() # Initialize an iterator over a dataset with 10 elements. sess.run(iterator.initializer, feed_dict={max_value: 10}) for i in range(10): value = sess.run(next_element) assert i == value # Initialize the same iterator over a dataset with 100 elements. sess.run(iterator.initializer, feed_dict={max_value: 100}) for i in range(100): value = sess.run(next_element) assert i == value
A reinitializable iterator can be initialized from multiple different
Dataset objects. For example, you might have a training input pipeline that
uses random perturbations to the input images to improve generalization, and
a validation input pipeline that evaluates predictions on unmodified data. These
pipelines will typically use different Dataset objects that have the same
structure (i.e. the same types and compatible shapes for each component).
# Define training and validation datasets with the same structure. training_dataset = tf.data.Dataset.range(100).map( lambda x: x + tf.random_uniform([], -10, 10, tf.int64)) validation_dataset = tf.data.Dataset.range(50) # A reinitializable iterator is defined by its structure. We could use the # `output_types` and `output_shapes` properties of either `training_dataset` # or `validation_dataset` here, because they are compatible. iterator = tf.data.Iterator.from_structure(training_dataset.output_types, training_dataset.output_shapes) next_element = iterator.get_next() training_init_op = iterator.make_initializer(training_dataset) validation_init_op = iterator.make_initializer(validation_dataset) # Run 20 epochs in which the training dataset is traversed, followed by the # validation dataset. for _ in range(20): # Initialize an iterator over the training dataset. sess.run(training_init_op) for _ in range(100): sess.run(next_element) # Initialize an iterator over the validation dataset. sess.run(validation_init_op) for _ in range(50): sess.run(next_element)
A feedable iterator can be used together with tf.placeholder to select
what Iterator to use in each call to tf.Session.run, via the familiar
feed_dict mechanism. It offers the same functionality as a reinitializable
iterator, but it does not require you to initialize the iterator from the start
of a dataset when you switch between iterators. For example, using the same
training and validation example from above, you can use
tf.data.Iterator.from_string_handle to define a feedable iterator
that allows you to switch between the two datasets:
# Define training and validation datasets with the same structure. training_dataset = tf.data.Dataset.range(100).map( lambda x: x + tf.random_uniform([], -10, 10, tf.int64)).repeat() validation_dataset = tf.data.Dataset.range(50) # A feedable iterator is defined by a handle placeholder and its structure. We # could use the `output_types` and `output_shapes` properties of either # `training_dataset` or `validation_dataset` here, because they have # identical structure. handle = tf.placeholder(tf.string, shape=[]) iterator = tf.data.Iterator.from_string_handle( handle, training_dataset.output_types, training_dataset.output_shapes) next_element = iterator.get_next() # You can use feedable iterators with a variety of different kinds of iterator # (such as one-shot and initializable iterators). training_iterator = training_dataset.make_one_shot_iterator() validation_iterator = validation_dataset.make_initializable_iterator() # The `Iterator.string_handle()` method returns a tensor that can be evaluated # and used to feed the `handle` placeholder. training_handle = sess.run(training_iterator.string_handle()) validation_handle = sess.run(validation_iterator.string_handle()) # Loop forever, alternating between training and validation. while True: # Run 200 steps using the training dataset. Note that the training dataset is # infinite, and we resume from where we left off in the previous `while` loop # iteration. for _ in range(200): sess.run(next_element, feed_dict={handle: training_handle}) # Run one pass over the validation dataset. sess.run(validation_iterator.initializer) for _ in range(50): sess.run(next_element, feed_dict={handle: validation_handle})
Consuming values from an iterator
The Iterator.get_next() method returns one or more tf.Tensor objects that
correspond to the symbolic next element of an iterator. Each time these tensors
are evaluated, they take the value of the next element in the underlying
dataset. (Note that, like other stateful objects in TensorFlow, calling
Iterator.get_next() does not immediately advance the iterator. Instead you
must use the returned tf.Tensor objects in a TensorFlow expression, and pass
the result of that expression to tf.Session.run() to get the next elements and
advance the iterator.)
If the iterator reaches the end of the dataset, executing
the Iterator.get_next() operation will raise a tf.errors.OutOfRangeError.
After this point the iterator will be in an unusable state, and you must
initialize it again if you want to use it further.
dataset = tf.data.Dataset.range(5) iterator = dataset.make_initializable_iterator() next_element = iterator.get_next() # Typically `result` will be the output of a model, or an optimizer's # training operation. result = tf.add(next_element, next_element) sess.run(iterator.initializer) print(sess.run(result)) # ==> "0" print(sess.run(result)) # ==> "2" print(sess.run(result)) # ==> "4" print(sess.run(result)) # ==> "6" print(sess.run(result)) # ==> "8" try: sess.run(result) except tf.errors.OutOfRangeError: print("End of dataset") # ==> "End of dataset"
A common pattern is to wrap the “training loop” in a try–except block:
sess.run(iterator.initializer) while True: try: sess.run(result) except tf.errors.OutOfRangeError: break
If each element of the dataset has a nested structure, the return value of
Iterator.get_next() will be one or more tf.Tensor objects in the same
nested structure:
dataset1 = tf.data.Dataset.from_tensor_slices(tf.random_uniform([4, 10])) dataset2 = tf.data.Dataset.from_tensor_slices((tf.random_uniform([4]), tf.random_uniform([4, 100]))) dataset3 = tf.data.Dataset.zip((dataset1, dataset2)) iterator = dataset3.make_initializable_iterator() sess.run(iterator.initializer) next1, (next2, next3) = iterator.get_next()
Note that next1, next2, and next3 are tensors produced by the
same op/node (created by Iterator.get_next()). Therefore, evaluating any of
these tensors will advance the iterator for all components. A typical consumer
of an iterator will include all components in a single expression.
Saving iterator state
The tf.contrib.data.make_saveable_from_iterator function creates a
SaveableObject from an iterator, which can be used to save and
restore the current state of the iterator (and, effectively, the whole input
pipeline). A saveable object thus created can be added to tf.train.Saver
variables list or the tf.GraphKeys.SAVEABLE_OBJECTS collection for saving and
restoring in the same manner as a tf.Variable. Refer to
Saving and Restoring for details on how to save and restore
variables.
# Create saveable object from iterator. saveable = tf.contrib.data.make_saveable_from_iterator(iterator) # Save the iterator state by adding it to the saveable objects collection. tf.add_to_collection(tf.GraphKeys.SAVEABLE_OBJECTS, saveable) saver = tf.train.Saver() with tf.Session() as sess: if should_checkpoint: saver.save(path_to_checkpoint) # Restore the iterator state. with tf.Session() as sess: saver.restore(sess, path_to_checkpoint)
Reading input data
Consuming NumPy arrays
If all of your input data fit in memory, the simplest way to create a Dataset
from them is to convert them to tf.Tensor objects and use
Dataset.from_tensor_slices().
# Load the training data into two NumPy arrays, for example using `np.load()`. with np.load("/var/data/training_data.npy") as data: features = data["features"] labels = data["labels"] # Assume that each row of `features` corresponds to the same row as `labels`. assert features.shape[0] == labels.shape[0] dataset = tf.data.Dataset.from_tensor_slices((features, labels))
Note that the above code snippet will embed the features and labels arrays
in your TensorFlow graph as tf.constant() operations. This works well for a
small dataset, but wastes memory—because the contents of the array will be
copied multiple times—and can run into the 2GB limit for the tf.GraphDef
protocol buffer.
As an alternative, you can define the Dataset in terms of tf.placeholder()
tensors, and feed the NumPy arrays when you initialize an Iterator over the
dataset.
# Load the training data into two NumPy arrays, for example using `np.load()`. with np.load("/var/data/training_data.npy") as data: features = data["features"] labels = data["labels"] # Assume that each row of `features` corresponds to the same row as `labels`. assert features.shape[0] == labels.shape[0] features_placeholder = tf.placeholder(features.dtype, features.shape) labels_placeholder = tf.placeholder(labels.dtype, labels.shape) dataset = tf.data.Dataset.from_tensor_slices((features_placeholder, labels_placeholder)) # [Other transformations on `dataset`...] dataset = ... iterator = dataset.make_initializable_iterator() sess.run(iterator.initializer, feed_dict={features_placeholder: features, labels_placeholder: labels})
Consuming TFRecord data
The tf.data API supports a variety of file formats so that you can process
large datasets that do not fit in memory. For example, the TFRecord file format
is a simple record-oriented binary format that many TensorFlow applications use
for training data. The tf.data.TFRecordDataset class enables you to
stream over the contents of one or more TFRecord files as part of an input
pipeline.
# Creates a dataset that reads all of the examples from two files. filenames = ["/var/data/file1.tfrecord", "/var/data/file2.tfrecord"] dataset = tf.data.TFRecordDataset(filenames)
The filenames argument to the TFRecordDataset initializer can either be a
string, a list of strings, or a tf.Tensor of strings. Therefore if you have
two sets of files for training and validation purposes, you can use a
tf.placeholder(tf.string) to represent the filenames, and initialize an
iterator from the appropriate filenames:
filenames = tf.placeholder(tf.string, shape=[None]) dataset = tf.data.TFRecordDataset(filenames) dataset = dataset.map(...) # Parse the record into tensors. dataset = dataset.repeat() # Repeat the input indefinitely. dataset = dataset.batch(32) iterator = dataset.make_initializable_iterator() # You can feed the initializer with the appropriate filenames for the current # phase of execution, e.g. training vs. validation. # Initialize `iterator` with training data. training_filenames = ["/var/data/file1.tfrecord", "/var/data/file2.tfrecord"] sess.run(iterator.initializer, feed_dict={filenames: training_filenames}) # Initialize `iterator` with validation data. validation_filenames = ["/var/data/validation1.tfrecord", ...] sess.run(iterator.initializer, feed_dict={filenames: validation_filenames})
Consuming text data
Many datasets are distributed as one or more text files. The
tf.data.TextLineDataset provides an easy way to extract lines from
one or more text files. Given one or more filenames, a TextLineDataset will
produce one string-valued element per line of those files. Like a
TFRecordDataset, TextLineDataset accepts filenames as a tf.Tensor, so
you can parameterize it by passing a tf.placeholder(tf.string).
filenames = ["/var/data/file1.txt", "/var/data/file2.txt"] dataset = tf.data.TextLineDataset(filenames)
By default, a TextLineDataset yields every line of each file, which may
not be desirable, for example if the file starts with a header line, or contains
comments. These lines can be removed using the Dataset.skip() and
Dataset.filter() transformations. To apply these transformations to each
file separately, we use Dataset.flat_map() to create a nested Dataset for
each file.
filenames = ["/var/data/file1.txt", "/var/data/file2.txt"] dataset = tf.data.Dataset.from_tensor_slices(filenames) # Use `Dataset.flat_map()` to transform each file as a separate nested dataset, # and then concatenate their contents sequentially into a single "flat" dataset. # * Skip the first line (header row). # * Filter out lines beginning with "#" (comments). dataset = dataset.flat_map( lambda filename: ( tf.data.TextLineDataset(filename) .skip(1) .filter(lambda line: tf.not_equal(tf.substr(line, 0, 1), "#"))))
Consuming CSV data
The CSV file format is a popular format for storing tabular data in plain text.
The tf.data.experimental.CsvDataset class provides a way to extract records from
one or more CSV files that comply with RFC 4180.
Given one or more filenames and a list of defaults, a CsvDataset will produce
a tuple of elements whose types correspond to the types of the defaults
provided, per CSV record. Like TFRecordDataset and TextLineDataset,
CsvDataset accepts filenames as a tf.Tensor, so you can parameterize it
by passing a tf.placeholder(tf.string).
# Creates a dataset that reads all of the records from two CSV files, each with
# eight float columns
filenames = ["/var/data/file1.csv", "/var/data/file2.csv"]
record_defaults = [tf.float32] * 8 # Eight required float columns
dataset = tf.data.experimental.CsvDataset(filenames, record_defaults)
If some columns are empty, you can provide defaults instead of types.
# Creates a dataset that reads all of the records from two CSV files, each with
# four float columns which may have missing values
record_defaults = [[0.0]] * 8
dataset = tf.data.experimental.CsvDataset(filenames, record_defaults)
By default, a CsvDataset yields every column of every line of the file,
which may not be desirable, for example if the file starts with a header line
that should be ignored, or if some columns are not required in the input.
These lines and fields can be removed with the header and select_cols
arguments respectively.
# Creates a dataset that reads all of the records from two CSV files with
# headers, extracting float data from columns 2 and 4.
record_defaults = [[0.0]] * 2 # Only provide defaults for the selected columns
dataset = tf.data.experimental.CsvDataset(filenames, record_defaults, header=True, select_cols=[2,4])
Preprocessing data with Dataset.map()
The Dataset.map(f) transformation produces a new dataset by applying a given
function f to each element of the input dataset. It is based on
the
map() function
that is commonly applied to lists (and other structures) in functional
programming languages. The function f takes the tf.Tensor objects that
represent a single element in the input, and returns the tf.Tensor objects
that will represent a single element in the new dataset. Its implementation uses
standard TensorFlow operations to transform one element into another.
This section covers common examples of how to use Dataset.map().
Parsing tf.Example protocol buffer messages
Many input pipelines extract tf.train.Example protocol buffer messages from a
TFRecord-format file (written, for example, using
tf.python_io.TFRecordWriter). Each tf.train.Example record contains one or
more “features”, and the input pipeline typically converts these features into
tensors.
# Transforms a scalar string `example_proto` into a pair of a scalar string and # a scalar integer, representing an image and its label, respectively. def _parse_function(example_proto): features = {"image": tf.FixedLenFeature((), tf.string, default_value=""), "label": tf.FixedLenFeature((), tf.int64, default_value=0)} parsed_features = tf.parse_single_example(example_proto, features) return parsed_features["image"], parsed_features["label"] # Creates a dataset that reads all of the examples from two files, and extracts # the image and label features. filenames = ["/var/data/file1.tfrecord", "/var/data/file2.tfrecord"] dataset = tf.data.TFRecordDataset(filenames) dataset = dataset.map(_parse_function)
Decoding image data and resizing it
When training a neural network on real-world image data, it is often necessary
to convert images of different sizes to a common size, so that they may be
batched into a fixed size.
# Reads an image from a file, decodes it into a dense tensor, and resizes it # to a fixed shape. def _parse_function(filename, label): image_string = tf.read_file(filename) image_decoded = tf.image.decode_jpeg(image_string) image_resized = tf.image.resize_images(image_decoded, [28, 28]) return image_resized, label # A vector of filenames. filenames = tf.constant(["/var/data/image1.jpg", "/var/data/image2.jpg", ...]) # `labels[i]` is the label for the image in `filenames[i]. labels = tf.constant([0, 37, ...]) dataset = tf.data.Dataset.from_tensor_slices((filenames, labels)) dataset = dataset.map(_parse_function)
Applying arbitrary Python logic with tf.py_func()
For performance reasons, we encourage you to use TensorFlow operations for
preprocessing your data whenever possible. However, it is sometimes useful to
call upon external Python libraries when parsing your input data. To do so,
invoke, the tf.py_func() operation in a Dataset.map() transformation.
import cv2 # Use a custom OpenCV function to read the image, instead of the standard # TensorFlow `tf.read_file()` operation. def _read_py_function(filename, label): image_decoded = cv2.imread(filename.decode(), cv2.IMREAD_GRAYSCALE) return image_decoded, label # Use standard TensorFlow operations to resize the image to a fixed shape. def _resize_function(image_decoded, label): image_decoded.set_shape([None, None, None]) image_resized = tf.image.resize_images(image_decoded, [28, 28]) return image_resized, label filenames = ["/var/data/image1.jpg", "/var/data/image2.jpg", ...] labels = [0, 37, 29, 1, ...] dataset = tf.data.Dataset.from_tensor_slices((filenames, labels)) dataset = dataset.map( lambda filename, label: tuple(tf.py_func( _read_py_function, [filename, label], [tf.uint8, label.dtype]))) dataset = dataset.map(_resize_function)
Batching dataset elements
Simple batching
The simplest form of batching stacks n consecutive elements of a dataset into
a single element. The Dataset.batch() transformation does exactly this, with
the same constraints as the tf.stack() operator, applied to each component
of the elements: i.e. for each component i, all elements must have a tensor
of the exact same shape.
inc_dataset = tf.data.Dataset.range(100) dec_dataset = tf.data.Dataset.range(0, -100, -1) dataset = tf.data.Dataset.zip((inc_dataset, dec_dataset)) batched_dataset = dataset.batch(4) iterator = batched_dataset.make_one_shot_iterator() next_element = iterator.get_next() print(sess.run(next_element)) # ==> ([0, 1, 2, 3], [ 0, -1, -2, -3]) print(sess.run(next_element)) # ==> ([4, 5, 6, 7], [-4, -5, -6, -7]) print(sess.run(next_element)) # ==> ([8, 9, 10, 11], [-8, -9, -10, -11])
Batching tensors with padding
The above recipe works for tensors that all have the same size. However, many
models (e.g. sequence models) work with input data that can have varying size
(e.g. sequences of different lengths). To handle this case, the
Dataset.padded_batch() transformation enables you to batch tensors of
different shape by specifying one or more dimensions in which they may be
padded.
dataset = tf.data.Dataset.range(100) dataset = dataset.map(lambda x: tf.fill([tf.cast(x, tf.int32)], x)) dataset = dataset.padded_batch(4, padded_shapes=(None,)) iterator = dataset.make_one_shot_iterator() next_element = iterator.get_next() print(sess.run(next_element)) # ==> [[0, 0, 0], [1, 0, 0], [2, 2, 0], [3, 3, 3]] print(sess.run(next_element)) # ==> [[4, 4, 4, 4, 0, 0, 0], # [5, 5, 5, 5, 5, 0, 0], # [6, 6, 6, 6, 6, 6, 0], # [7, 7, 7, 7, 7, 7, 7]]
The Dataset.padded_batch() transformation allows you to set different padding
for each dimension of each component, and it may be variable-length (signified
by None in the example above) or constant-length. It is also possible to
override the padding value, which defaults to 0.
Training workflows
Processing multiple epochs
The tf.data API offers two main ways to process multiple epochs of the same
data.
The simplest way to iterate over a dataset in multiple epochs is to use the
Dataset.repeat() transformation. For example, to create a dataset that repeats
its input for 10 epochs:
filenames = ["/var/data/file1.tfrecord", "/var/data/file2.tfrecord"] dataset = tf.data.TFRecordDataset(filenames) dataset = dataset.map(...) dataset = dataset.repeat(10) dataset = dataset.batch(32)
Applying the Dataset.repeat() transformation with no arguments will repeat
the input indefinitely. The Dataset.repeat() transformation concatenates its
arguments without signaling the end of one epoch and the beginning of the next
epoch.
If you want to receive a signal at the end of each epoch, you can write a
training loop that catches the tf.errors.OutOfRangeError at the end of a
dataset. At that point you might collect some statistics (e.g. the validation
error) for the epoch.
filenames = ["/var/data/file1.tfrecord", "/var/data/file2.tfrecord"] dataset = tf.data.TFRecordDataset(filenames) dataset = dataset.map(...) dataset = dataset.batch(32) iterator = dataset.make_initializable_iterator() next_element = iterator.get_next() # Compute for 100 epochs. for _ in range(100): sess.run(iterator.initializer) while True: try: sess.run(next_element) except tf.errors.OutOfRangeError: break # [Perform end-of-epoch calculations here.]
Randomly shuffling input data
The Dataset.shuffle() transformation randomly shuffles the input dataset
using a similar algorithm to tf.RandomShuffleQueue: it maintains a fixed-size
buffer and chooses the next element uniformly at random from that buffer.
filenames = ["/var/data/file1.tfrecord", "/var/data/file2.tfrecord"] dataset = tf.data.TFRecordDataset(filenames) dataset = dataset.map(...) dataset = dataset.shuffle(buffer_size=10000) dataset = dataset.batch(32) dataset = dataset.repeat()
Using high-level APIs
The tf.train.MonitoredTrainingSession API simplifies many aspects of running
TensorFlow in a distributed setting. MonitoredTrainingSession uses the
tf.errors.OutOfRangeError to signal that training has completed, so to use it
with the tf.data API, we recommend using
Dataset.make_one_shot_iterator(). For example:
filenames = ["/var/data/file1.tfrecord", "/var/data/file2.tfrecord"] dataset = tf.data.TFRecordDataset(filenames) dataset = dataset.map(...) dataset = dataset.shuffle(buffer_size=10000) dataset = dataset.batch(32) dataset = dataset.repeat(num_epochs) iterator = dataset.make_one_shot_iterator() next_example, next_label = iterator.get_next() loss = model_function(next_example, next_label) training_op = tf.train.AdagradOptimizer(...).minimize(loss) with tf.train.MonitoredTrainingSession(...) as sess: while not sess.should_stop(): sess.run(training_op)
To use a Dataset in the input_fn of a tf.estimator.Estimator, simply
return the Dataset and the framework will take care of creating an iterator
and initializing it for you. For example:
def dataset_input_fn(): filenames = ["/var/data/file1.tfrecord", "/var/data/file2.tfrecord"] dataset = tf.data.TFRecordDataset(filenames) # Use `tf.parse_single_example()` to extract data from a `tf.Example` # protocol buffer, and perform any additional per-record preprocessing. def parser(record): keys_to_features = { "image_data": tf.FixedLenFeature((), tf.string, default_value=""), "date_time": tf.FixedLenFeature((), tf.int64, default_value=""), "label": tf.FixedLenFeature((), tf.int64, default_value=tf.zeros([], dtype=tf.int64)), } parsed = tf.parse_single_example(record, keys_to_features) # Perform additional preprocessing on the parsed data. image = tf.image.decode_jpeg(parsed["image_data"]) image = tf.reshape(image, [299, 299, 1]) label = tf.cast(parsed["label"], tf.int32) return {"image_data": image, "date_time": parsed["date_time"]}, label # Use `Dataset.map()` to build a pair of a feature dictionary and a label # tensor for each example. dataset = dataset.map(parser) dataset = dataset.shuffle(buffer_size=10000) dataset = dataset.batch(32) dataset = dataset.repeat(num_epochs) # Each element of `dataset` is tuple containing a dictionary of features # (in which each value is a batch of values for that feature), and a batch of # labels. return dataset

Обнаружение объектов — одна из подзадач компьютерного зрения для идентификации определенных объектов. Например, люди, здания, растений, дорожных знаков или транспортные средства на изображениях и видео.
Для создания таких моделей существует множество различных типов алгоритмов, таких, как Scale-invariant feature transform (SIFT), Detectron, RefineDet или You Only Look Once (YOLO). Их часто используют в самых разных отраслях, начиная с автономного вождения и охранных систем, заканчивая автоматизацией на производстве и распознаванием лиц.
Как и с любой моделью машинного обучения, всё начинается с создания обучающего набора данных. Сделать это можно разными способами: можно заказать разметку данных, а можно всё сделать самому.
Конечно, второй вариант займет намного больше времени и сил, но с помощью правильно подобранного ПО можно неплохо упростить задачу. Сейчас я подробно расскажут, как быстро создать обучающий датасет для задач детекции объектов YOLO с помощью Label Studio.
Шаг 1: сбор данных
В зависимости от вашей сферы применения, вы можете столкнуться с проблемой специфичности данных. На данный момент в открытом доступе можно найти множество датасетов с фотографиями улиц с нужными для вашей нейросети объектами. Более того, подобные изображения можно легко спарсить, подобрав релевантные запросы.
С более специфичными данными придется проявить смекалку. Например, в моей компании был кейс, когда мы собирали датасет с мусорными свалками в РФ. Для того, чтобы собраться достаточное количество данных, мы обратились к комьюнити Пикабу и люди делились фотографиями мусорных свалок в своих городах.
Собрать “Мусорный датасет” можно было бы и с помощью краудсорсинга. В Яндекс.Толоке предусмотрен функционал для “сбора в полях”. Хотя создание заданий, ТЗ и инструкций для толокеров требует опыта. Без него есть вероятность получить много нерелевантных данных.
Конечно, можно и просто обратиться в компанию, которая оказывает услуги сбора и разметки данных под ключ. Это сэкономит время, но нужно закладывать бюджет, что для личных разработок или стартапов будет достаточно проблематично.

В качестве примера для статьи мы воспользуемся общедоступным датасетом aerial-home-images, в котором собраны аэрофотографии домов. Будем считать, что данные собраны. Переходим к разметке.
Шаг 2: Разметка данных
Предположим, что наша задача подразумевает детекцию различных классов объектов для кадастрового учета. Например, модель будет определять на снимках дома, бассейны, заборы, навесы, подъездные пути и так далее. Работать будем в Label Studio. Если вы прежде его не устанавливали, в этой статье есть подробная инструкция по установке и первом запуску.

После запуска Label Studio переходим в настройки проекта разметки. Импортируйте свои данные и настройте интерфейс маркировки. Для нашей задаче по детекции нам лучше всего подходит шаблон «Object Detection with Bounding Boxes» или, проще говоря, разметка прямоугольниками.

Далее в настройках меняем значение классов на необходимые под нашу задачу, а именно:
– Home
– Pool
– Fence
– Driveway
– Other
Далее приступаем к разметке. Если вы работаете самостоятельно – запаситесь терпением и включите медитативную музыку. Если у вас есть команда – разделить весь объем данных поровну. Благо Label Studio даёт такой функционал из коробки.

Принцип разметки прост: выбираем нужный класс и помещаем объект в рамку. Так до тех пор, пока не будут все важные для задачи классы на каждом изображении.
Совет: для создания ограничительной рамки не обязательно зажимать ПКМ и выделять объект. Просто щелкните один раз в том левом углу от объекта и затем еще раз с противоположной стороны.
При разметке данных для модели обнаружения объектов помните о следующих нюансах:
– Следите за тем, чтобы было примерно равное количество примеров по каждому классу. Например, убедитесь, что домов с бассейнами столько же сколько домов без бассейнов, если вы хотите, чтобы модель точнее обнаруживала бассейны.
– Следите за тем, чтобы ограничивающая рамка была не слишком далеко от объектов, но и не пролегала через них. Старайтесь размечать прямо по контуру объекта.
– Отметьте не менее 50 изображений домов, чтобы обучить модель.
– Ограничьте количество объектов, которые вы хотите обнаружить, чтобы повысить точность модели для обнаружения этих объектов. Если вы решите сразу обучить нейронку на детекцию 15 классов, результаты будут далеки от идеальных.
Разметили весь датасет? Тогда импортируем данные.
Шаг 3: Экспорт датасета в формате YOLO и обучение модели
Убедитесь, что все изображения и объекты размечены, а затем кликайте на экспорт и выбирайте YOLO. После этого начнется загрузка zip-архива. Экспортированные данные имеют следующую структуру:
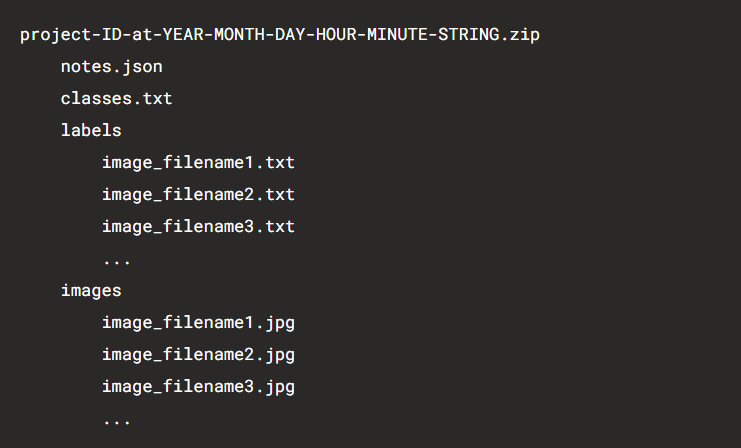
Чтобы обучить вашу модель YOLO с помощью созданного набора данных, вам необходимо указать имена классов и количество классов, а также URL-адреса файлов со списком всех изображений, которые вы будете использовать для обучения. Подробнее об этом можно прочитать в официальной документации для YOLOv3 и YOLOv4.
Экспортированная разметка в формате YOLO из Label Studio включает в себя файл classes.txt. Он уже содержит имена классов, которые использовались при аннотировании изображений, а также каталоги, включающие исходные изображения в каталоге images и файлы .txt с координатами ограничительных рамок для каждого изображения. Выглядит это вот так:

После того, как вы настроите среду модели YOLO для обучения, вы можете тренировать модель с помощью своего датасета. С помощью обученной модели вы можете анализировать новые аэрофотоснимки домов и определять важные объекты, имеющие отношение к вашему варианту использования нейросети.
Заключение
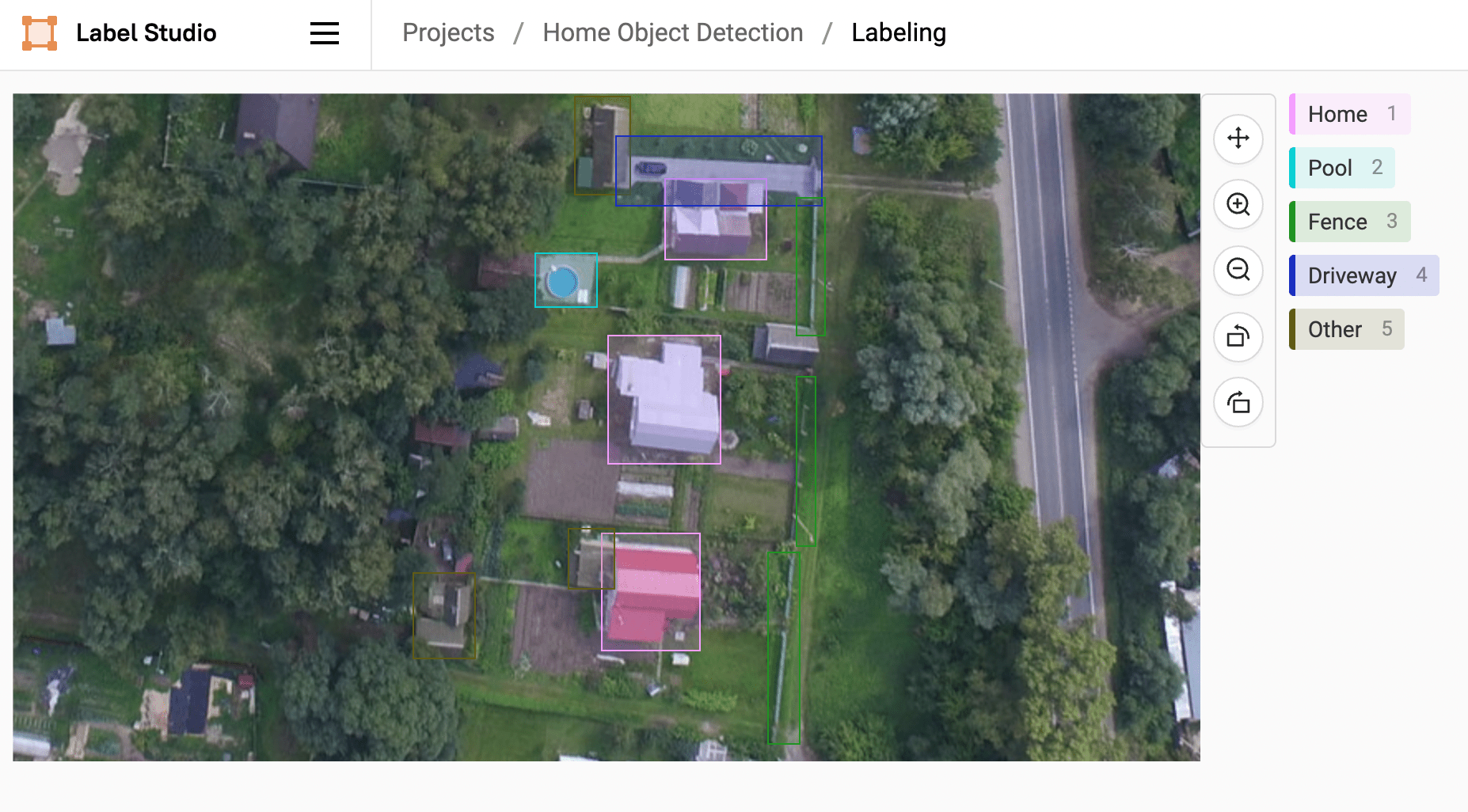
Создание набора данных и обучение пользовательской модели детекции объектов в YOLO – может занимать много времени и быть очень трудоемким. Но в связке с разметкой данных в Label Studio процесс становится намного проще.
Во-первых, у Label Studio удобный и понятный интерфейс. Есть горячие клавиши, позволяют ускорить процесс разметки.
Во-вторых, есть возможность разделить весь набор данных между несколькими разметчиками. Это тоже оптимизирует работу.
В-третьих, экспортный файл уже содержит всю информацию в нужном виде для того, чтобы использовать его YOLO v3 и v4.
Надеюсь, эта туториал был полезен и интересен. Всем хорошей разметки!
Ранее статья опубликована на моем сайте
