 Краткая теория вопроса
Краткая теория вопроса
Информационная система (ИС) — программно-аппаратный комплекс, предназначенный для хранения и обработки информации о какой-либо предметной области.
Процесс создания ИС делится на ряд этапов. Обычно выделяют следующие этапы создания ИС:
- формирование требований к системе (анализ),
- проектирование,
- реализация,
- тестирование,
- ввод в действие,
- эксплуатация и сопровождение.
Важнейшим компонентом любой информационной системы является База данных (БД). База данных (Data Base) – структурированный, организованный набор данных, объединенный в соответствии с некоторой выбранной моделью и описывающий характеристики какой-либо физической или виртуальной системы.
Именно БД позволяет эксплуатировать ИС, выполнять ее текущее обслуживание, модифицировать и развивать её при модернизации предприятия (организации) или изменении информационных потоков, законодательства и форм отчетности предприятия (организации).
Согласно современной методологии, процесс создания ИС представляет собой процесс построения и последовательного преобразования ряда согласованных моделей на всех этапах жизненного цикла (ЖЦ) ИС. На каждом этапе ЖЦ создаются модели: организации, требований к ИС, проекта ИС, требований к приложениям и т. д.
Проектирование ИС охватывает три основные области:
- проектирование объектов данных (создание моделей данных), которые будут реализованы в базе данных;
- проектирование программ, экранных форм, отчетов, которые будут обеспечивать выполнение запросов к данным;
- учет конкретной среды или технологии, а именно: топологии сети, конфигурации аппаратных средств, используемой архитектуры (файл-сервер или клиент-сервер), параллельной обработки, распределенной обработки данных и т. п.
Модель – искусственный объект,представляющий собой отображение (образ) системы и её компонентов.
Модель данных (Data Model) – это графическое или текстовое представление анализа, который выявляет данные, необходимые организации с целью достижения ее миссии, функций, целей, стратегий, для управления и оценки деятельности организации. Модель данных выявляет сущности, домены (атрибуты) и связи с другими данными, а также предоставляет концептуальное представление данных и связи между данными.
Цель создания модели данных состоит в обеспечении разработчика ИС концептуальной схемой базы данных в форме одной модели или нескольких локальных моделей, которые относительно легко могут быть интегрированы в любую базу данных.
При создании моделей данных используется метод семантического моделирования. Семантическое моделирование основывается на значении структурных компонентов или характеристик данных, что способствует правильности их интерпретации (понимания, разъяснения). В качестве инструмента семантического моделирования используются различные варианты диаграмм сущность-связь (ER — Entity-Relationship) — ERD.
Существуют различные варианты отображения ERD, но все варианты диаграмм сущность-связь исходят из одной идеи — рисунок всегда нагляднее текстового описания. ER -диаграммы используют графическое изображение сущностей предметной области, их свойств (атрибутов), и взаимосвязей между сущностями.
Базовые понятия ERD
Сущность (таблица, отношение) — это представление набора реальных или абстрактных объектов (людей, вещей, мест, событий, идей, комбинаций и т. д.), которые можно выделить в одну группу, потому что они имеют одинаковые характеристики и могут принимать участие в похожих связях. Каждая сущность должна иметь наименование, выраженное существительным в единственном числе. Каждая сущность в модели изображается в виде прямоугольника с наименованием.
Можно сказать, что Сущности представляют собой множество реальных или абстрактных вещей (людей, объектов, событий, идей и т. д.), которые имеют общие атрибуты или характеристики.
Экземпляр сущности (запись, кортеж)- это конкретный представитель данной сущности.
Атрибут сущности (поле, домен) — это именованная характеристика, являющаяся некоторым свойством сущности.
Связь — это некоторая ассоциация между двумя сущностями. Одна сущность может быть связана с другой сущностью или сама с собою. Связи позволяют по одной сущности находить другие сущности, связанные с ней.
Каждая связь может иметь один из следующих типов связи:
Один-к-одному, многое-ко-многим, один-ко-многим.
Связь типа один-к-одному означает, что один экземпляр первой сущности (левой) связан с одним экземпляром второй сущности (правой). Связь один-к-одному чаще всего свидетельствует о том, что на самом деле мы имеем всего одну сущность, неправильно разделенную на две.
Связь типа многое-ко-многим означает, что каждый экземпляр первой сущности может быть связан с несколькими экземплярами второй сущности, и каждый экземпляр второй сущности может быть связан с несколькими экземплярами первой сущности. Тип связи много-ко-многим является временным типом связи, допустимым на ранних этапах разработки модели. В дальнейшем этот тип связи должен быть заменен двумя связями типа один-ко-многим путем создания промежуточной сущности.
Связь типа один-ко-многим означает, что один экземпляр первой сущности (левой) связан с несколькими экземплярами второй сущности (правой). Это наиболее часто используемый тип связи. Левая сущность (со стороны «один») называется родительской, правая (со стороны «много») — дочерней.
При разработке ER-моделей необходимо обследовать предметную область (организацию, предприятие) и выявить:
1) Сущности, о которых хранятся данные в организации (предприятии), например, люди, места, идеи, события и т.д., (будут представлены в виде блоков);
2) Связи между этими сущностями (будут представлены в виде линий, соединяющих эти блоки);
3) Свойства этих сущностей (будут представлены в виде имен атрибутов в этих блоках).
Задача: разработать информационную систему «Контингент студентов института».
Необходимо: изучить предметную область (образовательное учреждение) и процессы, происходящие в ней.
Для этого обследуем объект: знакомимся с нормативной документацией, опрашиваем работников института, изучаем существующий документооборот института, анализируем ситуацию и т.п.
В результате обследования определяем цель и задачи системы и формулируем постановку задачи.
Краткая постановка задачи: главная задача системы – сбор и обработка информации об основных участниках учебного процесса: студентах и преподавателях, формирование необходимых печатных форм (документов), используемых преподавателями в период зачётной недели и экзаменационной сессии, генерация сводных отчётов по результатам сессии для работников деканатов, института. При разработке системы следует учитывать, что она основывается на документации, поступающей из приёмной комиссии, деканатов и других подразделений института. Информация об успеваемости студентов должна накапливаться и храниться в течение всего периода обучения. В системе должен использоваться справочник специальностей и дисциплин (предметов), изучаемых студентами.
Таким образом, проектируемая система должна выполнять следующие действия:
- Хранить информацию о студентах и их успеваемости.
- На факультетах по определённой специальности печатать экзаменационные ведомости и другие документы.
Выделим все существительные в этих предложениях — это предполагаемые сущности и проанализируем их:
- Студент — явная сущность.
- Успеваемость — явная сущность.
- ? Факультет — нужно выяснить один или несколько факультетов в институте? Если несколько, то это — предполагаемая новая сущность.
- ? Специальность — нужно выяснить одна или несколько специальностей на факультете? Если несколько, то это — ещё одна сущность.
- Предмет — предполагаемая сущность.
На первоначальном этапе моделирования данных информационной системы явно выделены две основные сущности: Студент и Успеваемость.
Критерием успеваемости является наличие отметки о сдачи экзаменов.
Сразу возникает очевидная связь между сущностями — «студент сдаёт несколько экзаменов » и «экзамены сдаются каждым студентом». Явная связь Один-ко-многим. Первый вариант диаграммы выглядит так:
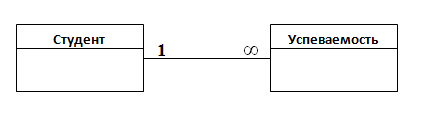
Мы знаем, что студенты учатся на факультетах, на определённой специальности и сдают экзамены по дисциплинам (предметам). Анализ предметной области показал, что студенты учатся на нескольких факультетах института по нескольким специальностях и сдают экзамены по определённому перечню предметов.
Исходя из этого, мы добавляем в ER-модель ещё несколько сущностей. В результате она будет выглядеть так:

На следующей стадии проектирования модели вносим атрибуты сущностей в диаграмму (предполагаем, что атрибуты выявлены на стадии обследования объекта и при анализе аналогов существующих систем) и получаем окончательный вариант ER— диаграммы:

Отметим, что предложенные этапы моделирования являются условными и нацелены на формирование общих представлений о процессе моделирования.
Разработанный выше пример ER-диаграммы является примером концептуальной диаграммы, не учитывающей особенности конкретной СУБД. На основе данной концептуальной диаграммы можно построить физическую диаграмму, которая будут учитывать такие особенности СУБД, как допустимые типы, наименования полей и таблиц, ограничения целостности и т.п.
Для преобразования концептуальной модели в физическую необходимо знать, что:
Каждая сущность в ER-диаграмме представляет собой таблицу базы данных.
Каждый атрибут становится колонкой (полем) соответствующей таблицы.
В некоторых таблицах необходимо вставить новые атрибуты (поля), которых не было в концептуальной модели — это ключевые атрибуты родительских таблиц, перемещённых в дочерние таблицы для того, чтобы обеспечить связь между таблицами посредством внешних ключей.
Выводы:
Семантическое моделирование данных основывается на технологии определения значения данных через их взаимосвязи с другими данными.
В качестве инструмента семантического моделирования используются различные варианты (нотации) диаграмм сущность-связь — (Entity-Relationship). Нотация — система условных обозначений, принятая в какой-либо области знаний или деятельности.
ER- диаграммы позволяют использовать наглядные графические обозначения для моделирования сущностей и их взаимосвязей. Основное достоинство метода состоит в том, модель строится методом последовательного уточнения и дополнения первоначальных диаграмм.
После создания концептуальной модели данных переходим к созданию физической модели средствами конкретной СУБД, а именно СУБД ACCESS. Для этого переходим к выполнению Практического задания №2
Приглашайте друзей на мой сайт
Чтобы помочь начинающим аналитикам разобраться с основами SQL и реляционных баз данных, сегодня рассмотрим практический пример построения модели данных, заполнения таблиц значениями и генерации запросов к полученной базе. DDL-запросы для создания таблиц и примеры DML-запросов для наполнения их данными, а также выборки с условиями WHERE, GROUP BY, HAVING, операторы работы с датами и временем.
Проектирование реляционной модели (схемы базы данных)
Как я уже рассказывала здесь, системные и бизнес-аналитики часто сталкиваются с моделированием данных в рамках задачи разработки требований к ИС. Однако, зачастую простого концептуального моделирования, которое переводит ключевые сущности домена (предметной области) в плоскость программной системы, бывает недостаточно для разработки или более детального проектирования базы данных на физическом уровне. Основным фактором, определяющим ценность концептуальной модели, является возможность ее использования для дальнейшей работы. И чтобы повысить эту ценность, аналитику полезно понимать, какие именно потребности бизнеса позволит обеспечить разработанная им модель. Применительно к моделированию данных это примеры SQL-запросов.
Предположим, учебный центр, который предлагает курсы по 3-м направлениям: системный и бизнес-анализ, технологии Big Data, а также менеджмент, имеет данные о заявках слушателей на разные курсы.
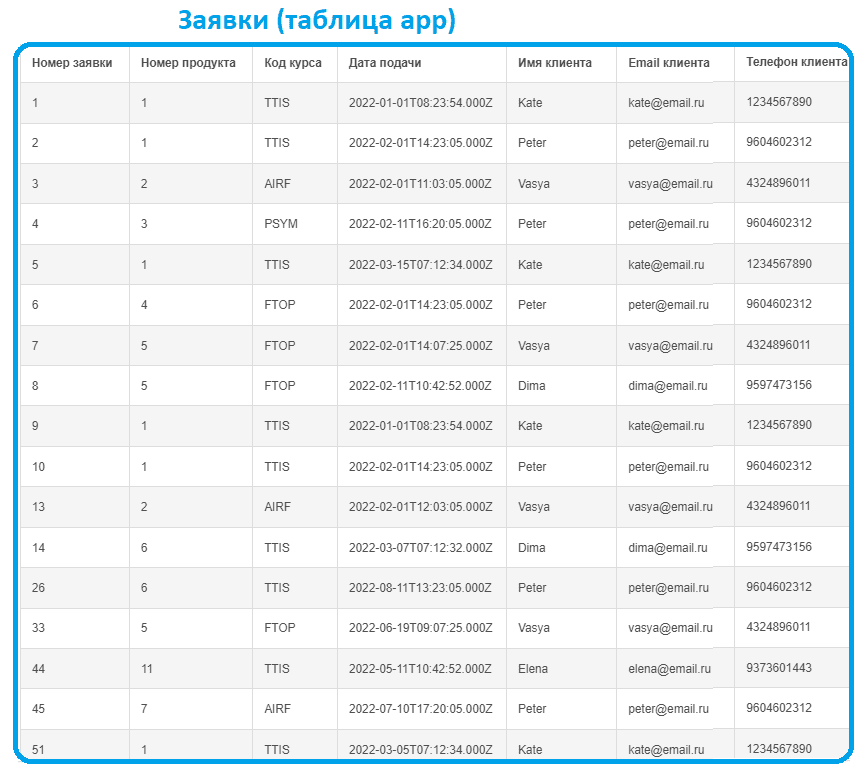
Имеется каталог курсов и расписание их проведение, а также данные по потенциальным клиентам, подавшим заявки и тренерам, которые проводят курсы.
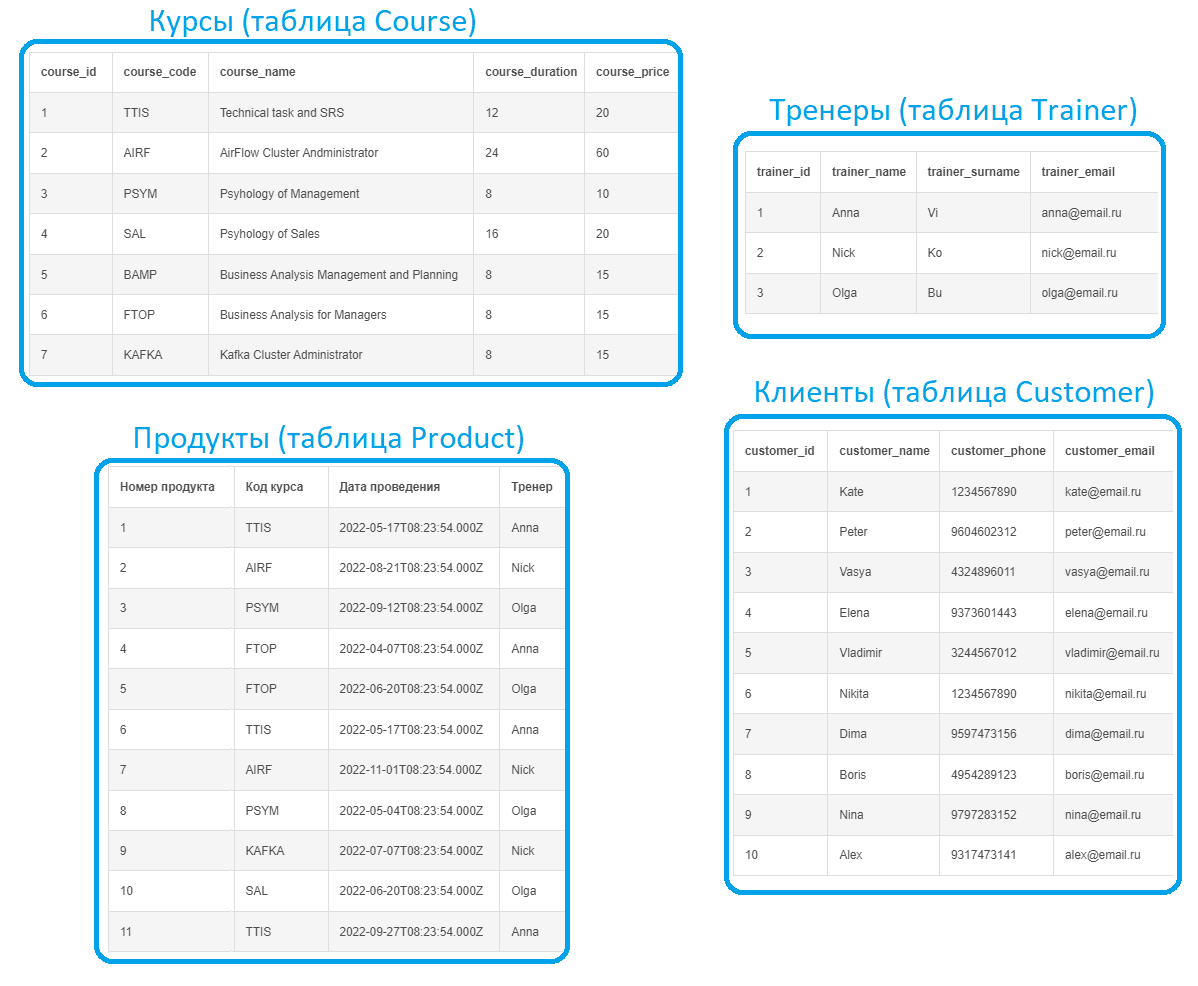
Реляционная модель данных, спроектированная для рассматриваемого случая, будет выглядеть следующим образом:
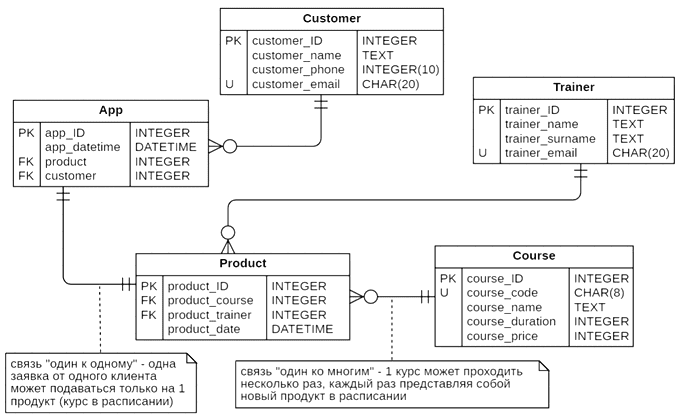
Выделено 5 сущностей, которые связаны между собой разными типами отношений. Каждая сущность в итоге представляет собой таблицу реляционной базы данных с набором столбцов, т.е. атрибутов или полей, каждое из которых содержит данные определенного типа. Поскольку база данных является реляционной, таблицы связаны между собой по ключам. Например, один тренер может вести несколько курсов. Таблица Course представляет собой каталог курсов, каждый из которых может проводиться несколько раз в разное время разными тренерами, что хранится в таблице Product. Один клиент (Customer) может подать много заявок, но каждая заявка может быть только по одному продукту.
Чтобы сократить избыточность данных в разных таблицах, проведена нормализация, т.е. приведение структуры данных к нормальной форме. В частности, данные клиентов хранятся не в таблице заявки, а выделены в отдельную таблицу Customer. Аналогичным образом данные о курсах и тренерах, которые их проводят содержатся не в таблице с расписанием (Product), а в отдельных таблицах. Это исключает транзитивную зависимость полей друг от друга. Чаще всего ER-модель приводят к 3-ей нормальной форме, когда каждая таблица атомарна и любой не ключевой атрибут в ней зависит только от первичного ключа.
В каждой таблице определен первичный ключ (Primary Key, PK),– столбец, каждое значение которого уникально и однозначно идентифицирует запись (строку) этой таблицы. Для ускорения работы базы данных в качестве первичного ключа обычно принимается целочисленный идентификатор, который реализуется автоматической генерацией поля ID с автоинкрементом, т.е. увеличением на 1 при создании новой записи. Большинство современных СУБД сами следят за этим, т.е. на уровне концептуального проектирования при описании модели предметной области, этот атрибут не обязательно добавлять в словарь данных.
Связи между таблицами реализованы с помощью внешних ключей (Foreign Key, FK). Внешний (ссылочный) ключ показывает, что поведение записи в одной таблице (зависимой сущности) меняется при изменении или удалении записей из другой связанной таблицы (независимой сущности). Внешний ключ также нужен для объединения двух таблиц. Можно сказать, FK в одной таблице – это один или несколько столбцов, значения которых соответствуют PK в другой таблице. Связь между двумя таблицами задается через соответствие PK в одной таблице FK во второй. Например, в таблице App внешними ключами будут поля product и customer, соответствующие первичным ключам (id) в таблицах Product и Customer соответственно.
После проектирования схемы модели данных в редакторе StarUML, который я часто использую для разработки UML-диаграмм, с помощью расширения Postgresql DDL Extension for StarUML 2 для создания DDL-запросов к СУБД PostgreSQL, я получила набор SQL-команд по созданию таблиц:
CREATE TABLE public.course (
course_id integer NOT NULL,
course_code char(8) NOT NULL,
course_name text NOT NULL,
course_duration integer NOT NULL,
course_price integer NOT NULL,
PRIMARY KEY (course_id)
);
ALTER TABLE public.course
ADD UNIQUE (course_code);
CREATE TABLE public.customer (
customer_id integer NOT NULL,
customer_name text NOT NULL,
customer_phone char(10) NOT NULL,
customer_email char(20) NOT NULL,
PRIMARY KEY (customer_id)
);
ALTER TABLE public.customer
ADD UNIQUE (customer_email);
CREATE TABLE public.app (
app_id integer NOT NULL,
app_datetime timestamp with time zone NOT NULL,
product integer NOT NULL,
customer integer NOT NULL,
PRIMARY KEY (app_id)
);
CREATE INDEX ON public.app
(product);
CREATE INDEX ON public.app
(customer);
CREATE TABLE public.trainer (
trainer_id integer NOT NULL,
trainer_name text NOT NULL,
trainer_surname text NOT NULL,
trainer_email char(20) NOT NULL,
PRIMARY KEY (trainer_id)
);
ALTER TABLE public.trainer
ADD UNIQUE (trainer_email);
CREATE TABLE public.product (
product_id integer NOT NULL,
product_course integer NOT NULL,
product_trainer integer NOT NULL,
product_date timestamp with time zone NOT NULL,
PRIMARY KEY (product_id)
);
CREATE INDEX ON public.product
(product_course);
CREATE INDEX ON public.product
(product_trainer);
Автоматическая генерация DDL-запросов по спроектированной схеме сэкономила мне время на прописывание SQL-команд вручную, чтобы создать нужные таблицы, определить их атрибуты и связи между таблицами. Полученный код я внесла в бесплатный веб-движок тестирования SQL-запросов https://www.db-fiddle.com/, определив схему SQL. Там же внесла данные в мои таблицы с помощью следующих DML-запросов:
INSERT INTO app VALUES (1, '2022-01-01 10:23:54', 1, 1); INSERT INTO app VALUES (2, '2022-02-01 16:23:05', 1, 2); INSERT INTO app VALUES (3, '2022-02-01 13:03:05', 2, 3); INSERT INTO app VALUES (4, '2022-02-11 18:20:05', 3, 2); INSERT INTO app VALUES (5, '2022-03-15 09:12:34', 1, 1); INSERT INTO app VALUES (6, '2022-02-01 16:23:05', 4, 2); INSERT INTO app VALUES (7, '2022-02-01 16:07:25', 5, 3); INSERT INTO app VALUES (8, '2022-02-11 12:42:52', 5, 7); INSERT INTO app VALUES (9, '2022-01-01 10:23:54', 1, 1); INSERT INTO app VALUES (10, '2022-02-01 16:23:05', 1, 2); INSERT INTO app VALUES (13, '2022-02-01 14:03:05', 2, 3); INSERT INTO app VALUES (45, '2022-07-10 19:20:05', 7, 2); INSERT INTO app VALUES (51, '2022-03-05 09:12:34', 1, 1); INSERT INTO app VALUES (26, '2022-08-11 15:23:05', 6, 2); INSERT INTO app VALUES (33, '2022-06-19 11:07:25', 5, 3); INSERT INTO app VALUES (44, '2022-05-11 12:42:52', 11, 4); INSERT INTO app VALUES (14, '2022-03-07 09:12:32', 6, 7); INSERT INTO customer VALUES (1, 'Kate', 1234567890, 'kate@email.ru'); INSERT INTO customer VALUES (2, 'Peter', 9604602312, 'peter@email.ru'); INSERT INTO customer VALUES (3, 'Vasya', 4324896011, 'vasya@email.ru'); INSERT INTO customer VALUES (4, 'Elena', 9373601443, 'elena@email.ru'); INSERT INTO customer VALUES (5, 'Vladimir', 3244567012, 'vladimir@email.ru'); INSERT INTO customer VALUES (6, 'Nikita', 1234567890, 'nikita@email.ru'); INSERT INTO customer VALUES (7, 'Dima', 9597473156, 'dima@email.ru'); INSERT INTO customer VALUES (8, 'Boris', 4954289123, 'boris@email.ru'); INSERT INTO customer VALUES (9, 'Nina', 9797283152, 'nina@email.ru'); INSERT INTO customer VALUES (10, 'Alex', 9317473141, 'alex@email.ru'); INSERT INTO trainer VALUES (1, 'Anna', 'Vi', 'anna@email.ru'); INSERT INTO trainer VALUES (2, 'Nick', 'Ko', 'nick@email.ru'); INSERT INTO trainer VALUES (3, 'Olga', 'Bu', 'olga@email.ru'); INSERT INTO course VALUES (1, 'TTIS', 'Technical task and SRS', 12, 20); INSERT INTO course VALUES (2, 'AIRF', 'AirFlow Cluster Andministrator', 24, 60); INSERT INTO course VALUES (3, 'PSYM', 'Psyhology of Management', 8, 10); INSERT INTO course VALUES (4, 'SAL', 'Psyhology of Sales', 16, 20); INSERT INTO course VALUES (5, 'BAMP', 'Business Analysis Management and Planning', 8, 15); INSERT INTO course VALUES (6, 'FTOP', 'Business Analysis for Managers', 8, 15); INSERT INTO course VALUES (7, 'KAFKA', 'Kafka Cluster Administrator', 8, 15); INSERT INTO product VALUES (1, 1, 1, '2022-05-17 10:23:54'); INSERT INTO product VALUES (2, 2, 2, '2022-08-21 10:23:54'); INSERT INTO product VALUES (3, 3, 3, '2022-09-12 10:23:54'); INSERT INTO product VALUES (4, 6, 1, '2022-04-07 10:23:54'); INSERT INTO product VALUES (5, 6, 3, '2022-06-20 10:23:54'); INSERT INTO product VALUES (6, 1, 1, '2022-05-17 10:23:54'); INSERT INTO product VALUES (7, 2, 2, '2022-11-01 10:23:54'); INSERT INTO product VALUES (8, 3, 3, '2022-05-04 10:23:54'); INSERT INTO product VALUES (9, 7, 2, '2022-07-07 10:23:54'); INSERT INTO product VALUES (10, 4, 3, '2022-06-20 10:23:54'); INSERT INTO product VALUES (11, 1, 1, '2022-09-27 10:23:54');
Когда схема данных создана и таблицы наполнены, можно приступить к самому интересному: SQL-запросам на выборку нужных данных.
Разработка ТЗ на информационную систему по ГОСТ и SRS
Код курса
TTIS
Ближайшая дата курса
24 июля, 2023
Длительность обучения
12 ак.часов
Стоимость обучения
20 000 руб.
SQL-запросы для анализа данных
Напомню, для доступа к данным в реляционных СУБД используется язык структурированных запросов SQL (Structured Query Language) – декларативный язык программирования. Он содержит операторы определения данных (DDL), манипулирования данными (DML), определения доступа к данным (DCL) и управления транзакциями (TCL). Все эти операторы реализуют не только базовые CRUDL-операции, но и обеспечивают целостность и непротиворечивость информации. В рамках этой статьи мы рассматриваем только самые распространенные DDL- и DML-запросы. Например, следующий запрос покажет, сколько заявок подано на каждый курс:
SELECT course.course_code AS "Код курса",
course.course_name AS "Название курса",
count(*) AS aps_number
FROM app
JOIN product ON product.product_id=app.product
JOIN course ON course.course_id=product.product_course
GROUP BY app.product,
course.course_code,
course.course_name
ORDER BY aps_number DESC;
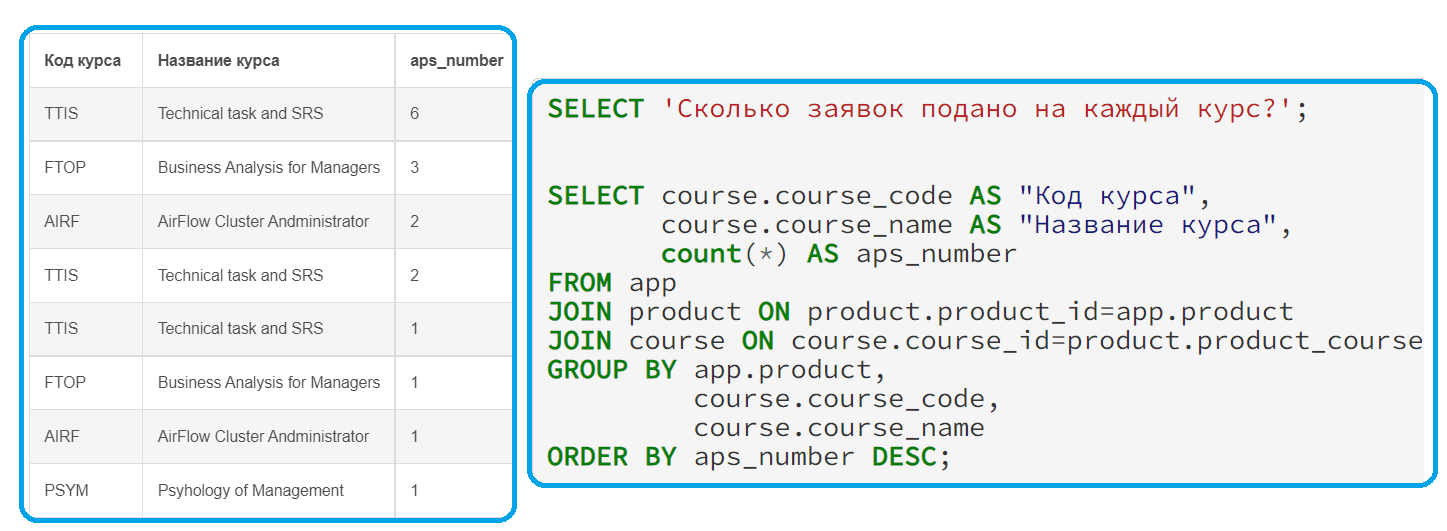
В этом запросе выполнено несколько соединений таблиц через оператор JOIN. Например, чтобы получить код и название курса, таблицу с заявками app нужно было соединить с таблицей продуктов, где указаны внешние ключи курсов, а не сами курсы. А чтобы получить название и код курса, пришлось выполнять соединение с таблицей курсов по внешним ключам, что указывается после ключевого слова ON. Для группировки заявок, поданных по одному и тому же курсу, в конце запроса добавлено выражение GROUP BY, в котором указаны поля группировки. В нашем случае некоторые из них совпадают с теми, что указаны в выборке после ключевого слова SELECT. Оператор COUNT(*) считает все строки таблицы с заявками. За сортировку по убыванию отвечает оператор ORDER BY с уточнением DESC.
Рассмотрим другой бизнес-запрос. Например, нужно определить, сколько денег на каком курсе заработает каждый тренер. На это ответит следующий SQL-запрос:
SELECT course.course_code AS "Код курса",
trainer.trainer_name AS "Тренер",
count(*)*(course.course_price) AS income
FROM product
JOIN app ON app.product=product.product_id
JOIN course ON course.course_id=product.product_course
JOIN trainer ON trainer.trainer_id=product.product_trainer
GROUP BY course.course_code,
trainer.trainer_name,
course.course_price
ORDER BY income DESC;

В этом SQL-запросе тоже появилась группировка, поскольку здесь выполняется агрегация строк по курсу. Поэтому встречается оператор GROUP BY с указанием полей, по которым выполняется группировка. Агрегатные функции, такие как расчет суммы, среднего или количества строк, выполняют вычисление на наборе ненулевых значений и возвращают одиночное значение. Исключением из этого правила является функция подсчета количества значений COUNT().
Также в запрос добавлен оператор сортировки по убыванию дохода от проведения курса, который вычисляется как произведение стоимости курса на количество поданных заявок. В свою очередь, количество заявок по определенному продукту, с которым связан курс, определяется через соединение с таблицей заявок.
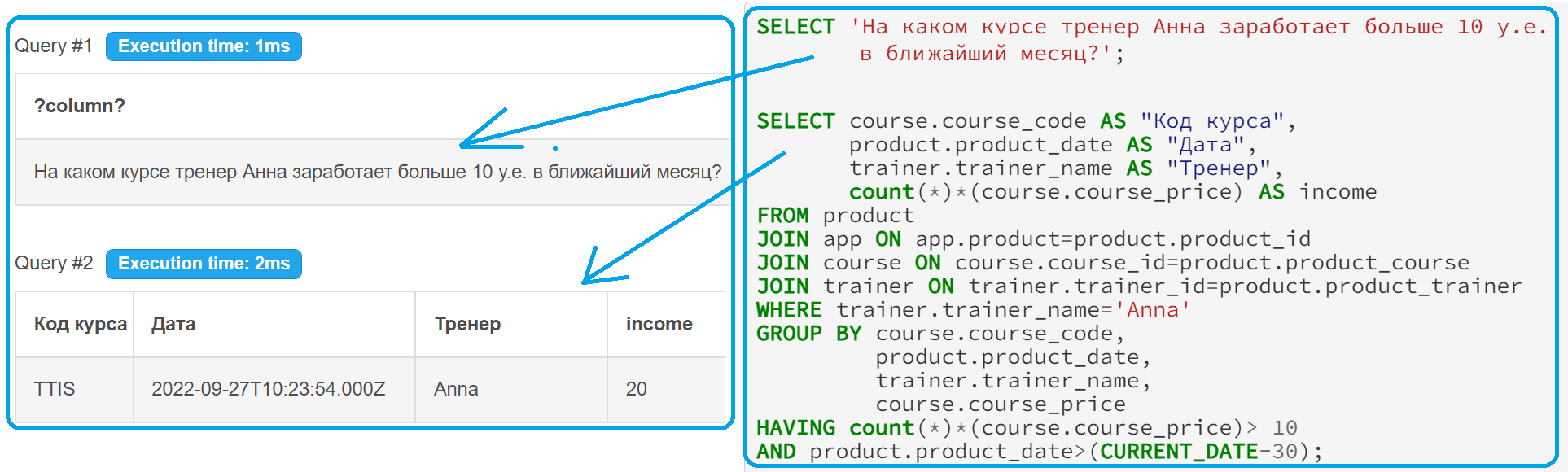
В заключение рассмотрим еще один пример с использованием группировки и фильтрации значений по агрегатным функциям через добавление HAVING после GROUP BY. Например, на каком курсе тренер Anna заработает больше 10 в ближайший месяц от текущей даты? Для этого используем следующий SQL-запрос:
SELECT 'На каком курсе тренер Анна заработает больше 10 у.е. в ближайший месяц?';
SELECT course.course_code AS "Код курса",
product.product_date AS "Дата",
trainer.trainer_name AS "Тренер",
count(*)*(course.course_price) AS income
FROM product
JOIN app ON app.product=product.product_id
JOIN course ON course.course_id=product.product_course
JOIN trainer ON trainer.trainer_id=product.product_trainer
WHERE trainer.trainer_name='Anna'
GROUP BY course.course_code,
product.product_date,
trainer.trainer_name,
course.course_price
HAVING count(*)*(course.course_price)> 10
AND product.product_date>(CURRENT_DATE-30);
Основы архитектуры и интеграции информационных систем
Код курса
OAIS
Ближайшая дата курса
29 июня, 2023
Длительность обучения
8 ак.часов
Стоимость обучения
15 000 руб.
Разумеется, в рамках это статьи не рассматривались все типы SQL-запросов и возможности этого языка. Наиболее эффективным способом освоить их будет самостоятельная работа с выполнением упражнений. Для этого есть множество открытых ресурсов, платных и бесплатных курсов, а также свободных и проприетарных инструментов. В частности, очень советую следующие онлайн-учебники и тренажеры:
- https://sql-academy.org/ru/guide
- https://learndb.ru/articles
- https://www.sql-ex.ru/
- https://stepik.org/course/63054/promo?search=882582677
Чтобы освоить все нюансы проектирования реляционных моделей и написания SQL-запросов к ним, также необходимо читать документацию и выполнять упражнения в соответствующей среде, развернув ее на своем компьютере. Например, для MySQL отлично подходит платформа MySQL Workbench (>https://www.mysql.com/products/workbench/), а для PostgreSQL можно использовать pgAdmin (>https://www.pgadmin.org/). Эти инструменты поддерживают как визуальное проектирование ER-модели, так и выполнение SQL-запросов. Они способны заменить целый набор инструментов, которые использовались при подготовке этой статьи:
- StarUML – среда разработки UML и ER-диаграмм;
- расширение Postgresql DDL Extension for StarUML 2 для создания DDL-запросов к СУБД PostgreSQL по спроектированной диаграмме;
- https://www.db-fiddle.com/ – онлайн-движок реляционных баз данных для тестирования, отладки и обмена фрагментами SQL-запросов;
- https://sqlformat.org/ – онлайн-форматер для операторов SQL, который делает код более читаемым;
- https://postgrespro.ru/docs/postgrespro/14/index – документация по Postgres Pro Standard, популярной объектно-реляционной СУБД.
В заключение отмечу, что проверить, как вы усвоили материал этой статьи можно бесплатно прямо на нашем сайте, выполнив интерактивный тест по основам баз данных и языку запросов SQL.
10 вопросов по основам теории баз данных и SQL: тест для начинающих
А подробнее познакомиться с основами реляционных СУБД и моделированием данных вам помогут курсы Школы прикладного бизнес-анализа в нашем лицензированном учебном центре обучения и повышения квалификации системных и бизнес-аналитиков в Москве:
- Основы архитектуры и интеграции информационных систем
- Разработка ТЗ на информационную систему по ГОСТ и SRS
This artcle will show you how to create a diagram for existing MySQL or MariaDB database using MySQL Workbench.
Reverse engineer a database
To create a diagram from existing database you need to use reverse engineering functionality to create a model.
Learn about reverse engineering and models in MySQL Workbench
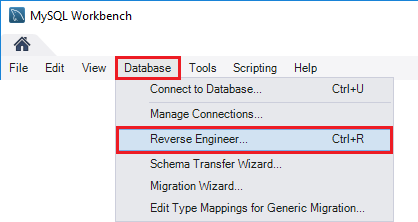
To reverse engineer database go to menu Database and choose Reverse Engineer… option.
Provide connection details to your database and click Next. Wait for the connection and click Next again.
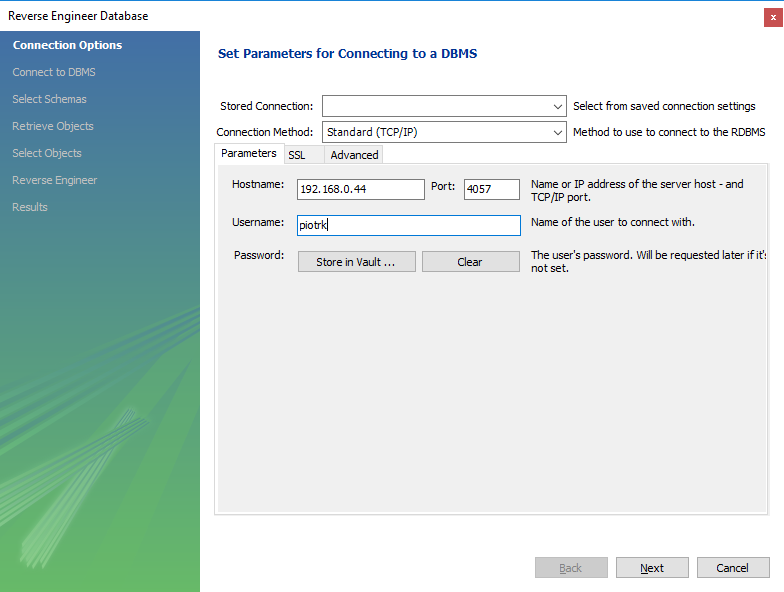
When successfully connected wizard will show you list of available schemas on the server. Select the ones you want to reverse engineer.
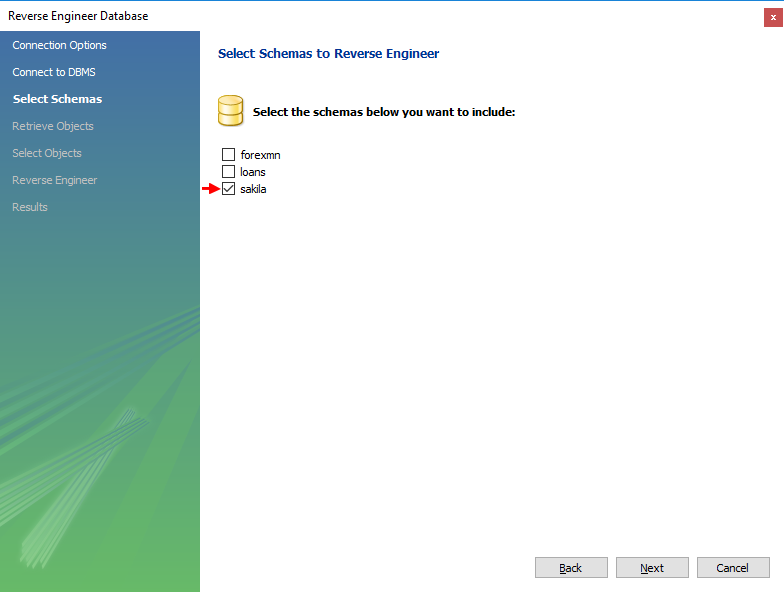
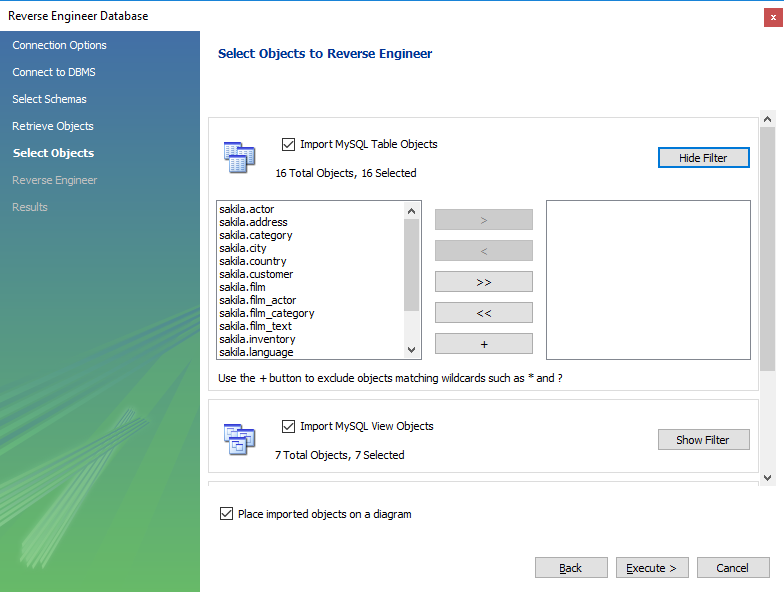
Wait for the schemas being read and continue with Next. On next screen you have an option to select object types and filter specific objects. Let’s ignore it and import all objects. Click Execute >.
Wait for reverse engineering to take place and when done continue with Next. Final screen shows you a summary of the import. Close with Finish.
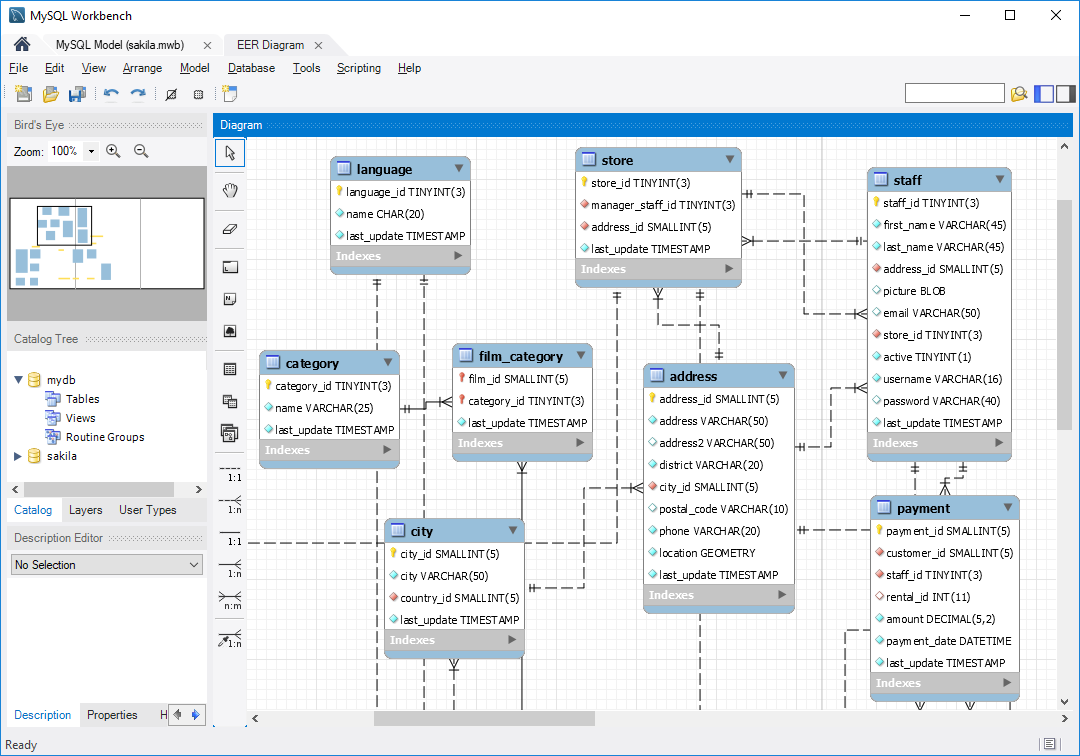
Default diagram
When the process ends with success you get a new model (more about models here) with default diagram with all tables and views.
Clean out diagram
What you probably want to do right after you created a default diagram is to remove unnecessary tables and views and arrange tables to make it easier to grasp.
To remove table from diagram select it, right click and choose Remove Figure option.
Be careful not to choose Delete option as it will remove table not only form diagram but also your model catalog. Without a warning!
Arrange tables
To arrange tables you can try autoarrange option, but you’ll need some manual work on top of that.
To use autoarrange go to menu, select Arrange and Autolayout.
To manually arrange tables simply select them and move around when you feel they fit best. Good luck.
Save model
Once you have completed your diagram make sure to save it. It is saved in a MySQL Workbench model in a .mwb file in Documents folder.
Export diagram
When your diagram is complete and safe it you can export it to png, pdf, ps or svg.
To export diagram go to menu, select File, then Export, select one of the available formats and provide folder and filename.
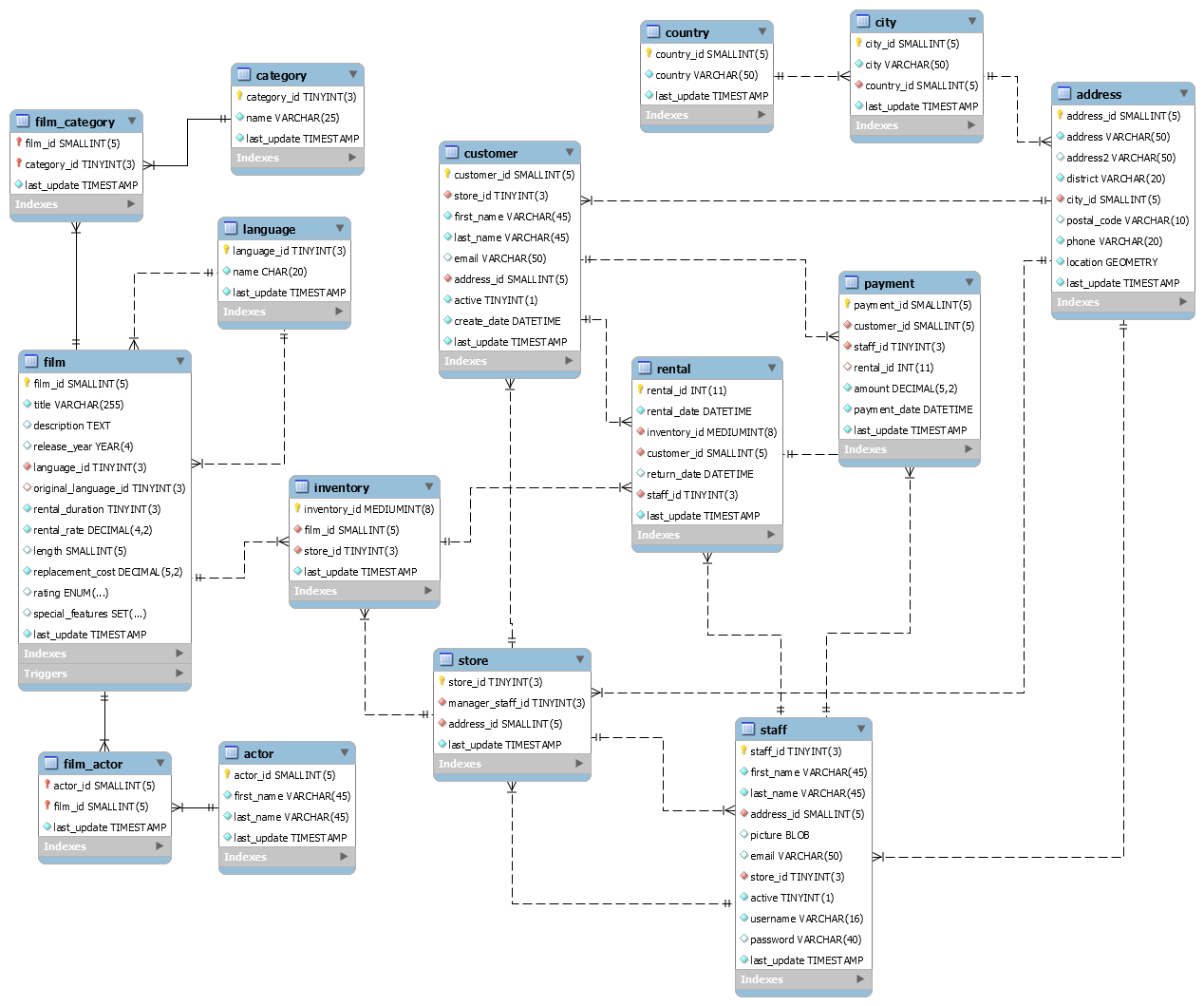
Here is my diagram:
See it in other formats:
- Sample PDF export
- Sample SVG export
A better way to share diagrams: Dataedo
There is a better way to create and share diagrams for existing databases – Dataedo. Here is a sample export of complete database documentation with diagrams:
See live HTML database documentaion sample
A few of the benefits:
- Easy and convenient sharing in interactive HTML
- Draw diagrams for databases with no FK constraints
- Attach complete data dicionary
Try for free now
Базы данных играют важнейшую роль в организации и сохранении данных компании, и базы данных должны надлежащим образом обслуживаться и быть спроектированы так, чтобы требовать незначительного обслуживания. Процесс проектирования модели базы данных включает в себя этапы архитектуры, программирования, установки и обслуживания.
Вы хотите создать диаграмму базы данных? Диаграммы являются наиболее эффективным инструментом для проектирования модели базы данных. Создание сложных структур данных с использованием двухфазного или бескриптового подхода может быть упрощено с помощью одного из многочисленных инструментов для создания диаграмм баз данных.
В этой статье мы обсудим схему проектирования базы данных, важность моделирования данных, процесс проектирования базы данных и его цель, а также объясним, как создать эффективный дизайн.
Что такое диаграмм////а проектирования базы данных?
Использование главных и внешних ключей для создания связей между структурами данных. Диаграммы баз данных графически изображают схемы баз данных и связи между объектами баз данных. Диаграмма базы данных может быть создана для источника данных и диаграммы. Созданные диаграммы баз данных можно сохранить в форматах UML и PNG. Внутренний формат UML был разработан специально для PhpStorm, и другие элементы его не принимают. Подумайте об использовании PNG, если вы хотите распространять готовые диаграммы баз данных.
Для получения данных, хранящихся в модели базы данных, использовалась серия процедур, известная как план действий. Вы также можете создать план действий. Существует два различных типа схем баз данных, которые поддерживает PhpStorm.
План объяснения: Результат отображается в виде комбинированного графика и таблицы на отдельной вкладке “План”. Выберите опцию Показать визуализацию, чтобы создать диаграмму базы данных, показывающую процесс выполнения запроса.
Explain Plan (Raw): Отображается таблица, показывающая результат.
Основой любой эффективной диаграммы базы данных должен быть список материала, который вы хотите включить, и предполагаемые цели модели базы данных. Что мне необходимо знать?”, а не “На какие столбцы или строки я должен обратить внимание в этом процессе?”. Все это может быть выполнено на вашем родном языке без использования SQL. Отнеситесь к этому серьезно, так как если вы позже обнаружите, что что-то упустили, вам, как правило, придется начинать все заново. Обычно требуется много работы, чтобы добавить что-то в вашу модель базы данных.
Почему моделирование данных важно?
Любой сложный процесс разработки программного обеспечения должен начинаться с моделирования данных. Модели данных помогают программистам понять область и правильно спланировать свою работу.
Более высокое качество
Неправильное кодирование является основной причиной неудач в проектах по разработке программного обеспечения, которые в среднем проваливаются примерно в 70% случаев. Вы должны думать о данных перед разработкой приложения, так же как архитекторы думают о данных перед строительством. Проектирование базы данных помогает в устранении неполадок, позволяя взвесить варианты и выбрать оптимальную стратегию.
Экономия затрат
Модели данных позволяют создавать приложения по более низкой цене. Модели баз данных занимают менее 5-10% от плана затрат и могут сократить 65-75% от лимита стоимости, который обычно отводится на кодирование. Моделирование данных обнаруживает ошибки и упущения несколько раньше, что упрощает их исправление, а это предпочтительнее, чем исправление ошибок после документирования приложений.
Улучшенная документация
Модели баз данных обеспечивают основу для долгосрочного сопровождения, документируя ключевые идеи и технический язык. Несмотря на кадровые изменения, материал по-прежнему будет полезен для вас.
Большая прозрачность
Модели данных придают определению масштаба точку фокуса. Модель базы данных предлагает что-то конкретное, чтобы финансовые спонсоры и программисты могли прийти к консенсусу относительно конкретных особенностей программы, которые будут включены и исключены. Пользователи предприятия могут получить доступ к тому, что создают программисты, чтобы соответствовать тому, что они знают. Модели баз данных способствуют достижению согласия между потребителями и программистами.
Модели данных также способствуют жаргону и лингвистическому консенсусу. Парадигма подчеркивает выбранные фразы, чтобы облегчить их включение в компоненты приложения. Программу, которая получается в результате, проще поддерживать и расширять.
Высокая эффективность
Хорошо построенная модель базы данных часто работает быстро, часто быстрее, чем предполагалось. Принципы, заложенные в модели данных, должны быть четкими и согласованными, чтобы работать наилучшим образом. После этого модель базы данных должна быть преобразована в проект базы данных с использованием правильных принципов.
Чаще всего неправильное использование модели базы данных является ошибкой, чем неисправностью приложения базы данных (SQL Server). Когда этот вопрос решен, исполнение становится превосходным. База данных может быть понята с помощью моделирования, что позволяет оптимизировать ее для быстрой эффективности.
Попробуйте no-code платформу AppMaster
AppMaster поможет создать любое веб, мобильное или серверное приложение в 10 раз быстрее и 3 раза дешевле
Начать бесплатно![]()
Снижение количества ошибок в приложении
Модель базы данных помогает людям прояснить идеи и устранить двусмысленность. Таким образом, сильное направление устанавливается еще до начала разработки приложения. Хотя вероятность этого меньше, программисты все равно могут допускать мелкие ошибки в процессе создания программного кода.
Процесс проектирования
Следующие шаги ведут к процессу проектирования:
- Определите цели модели базы данных
Определите цели, которые вы хотите достичь, поскольку это поможет вам подготовиться к последующим действиям. - Найдите и соберите необходимые данные
Соберите все данные, которые вы можете хранить в модели базы данных. Этими данными могут быть идентификатор заказа или название товара. - Поместите данные в табличную форму
Отсортируйте данные по широким категориям, таким как заказы или продукты. Затем свяжите таблицу с каждой темой. - Поместите информацию в виде столбцов
Выберите данные, которые вы хотите включить в каждую таблицу. Каждое значение преобразуется в поле и отображается в виде столбца таблицы. Например, в таблице “Работник” могут быть поля для даты приема на работу и фамилии. - Назовите первичные ключи
Выберите первичный ключ для каждой таблицы. Столбец, используемый для определения каждой строки, называется первичным ключом. Номер заказа D или номер продукта – это два первичных ключа, и значение всегда должно быть связано с первичным ключом.
Значение столбца не может быть использовано в качестве элемента первичного ключа, если оно может быть невостребованным или незнакомым. Всегда выбирайте первичный ключ, значение которого не будет меняться. Если первичный ключ изменится, это изменение должно быть отражено везде, где этот ключ используется. - Установите связи между таблицами
Рассмотрите каждую таблицу и определите связи между информацией в каждой таблице. Если для понимания связей требуется больше информации, добавьте столбцы в те же таблицы или создайте новые. - Разработайте свою концепцию
Проверьте, нет ли ошибок в вашем макете. Сделайте таблицы базы данных, затем добавьте в них несколько примеров записей данных. Проверьте статистику, чтобы узнать, можете ли вы получить необходимые результаты. При необходимости внесите изменения в дизайн. - Используйте рекомендации по нормализации
Проверьте правильность оформления таблиц вашей базы данных с помощью правил нормализации данных. При необходимости следует внести изменения в таблицы. Одна из ее форм запрещает сохранять производные данные из таблицы.
Анализ требований: определение назначения базы данных
Основная цель анализа требований – собрать все сведения, необходимые для создания модели базы данных, удовлетворяющей потребности компании в данных. Анализ требований преследует следующие цели:
- Установить информационные потребности базы данных в терминах примитивных объектов
- Категоризация и определение фактов об этих объектах
- Выявить и классифицировать отношения между сущностями
- Продемонстрировать виды платежей, которые будут выполняться над моделью базы данных
- Распознать руководящие принципы, которые регулируют надежность
Эти цели могут быть достигнуты путем выполнения ряда взаимосвязанных действий:
- Ознакомиться с текущей базой данных
- Необходимо провести интервью с потребителями
- Составить схему потока данных (при необходимости)
- Выяснить мнения пользователей
- Все наблюдения должны быть задокументированы
Разработчик программного обеспечения сотрудничает с конечными пользователями компании для уникального определения информационных потребностей базы данных. Существуют различные методы сбора данных, необходимых для анализа требований:
Изучение существующих документов
Определенные роли и выводы, письменные правила, должностные требования и истории являются примерами таких документов. Бумажная документация – отличный метод знакомства с компанией или действием, которое вы моделируете.
Интервьюирование конечных пользователей
Они могут включать как личные, так и групповые встречи. Постарайтесь ограничить групповые встречи не более чем пятью людьми. Постарайтесь собрать всех, кто выполняет одну и ту же роль, на одном занятии. Делайте записи во время интервью, используя доску или проекторы.
Обзор уже существующих автоматизированных систем
Изучите документацию и руководство по проектированию системы, если в компании есть процесс автоматизации. Обычно анализ требований и моделирование данных происходят одновременно. Объекты данных распознаются и классифицируются как сущности, свойства или отношения по мере сбора данных. Затем им присваиваются имена и они описываются с помощью слов, понятных конечным пользователям.
Затем для представления и анализа объектов используются диаграммы отношений сущностей. Разработчик и конечные пользователи могут оценить диаграммы базы данных отношений сущностей, чтобы убедиться в их точности и полноте. Если модель базы данных неверна, она пересматривается, что иногда требует сбора дополнительных данных. Процесс анализа и редактирования повторяется до тех пор, пока модель базы данных не будет признана точной.
Что такое схемы баз данных и экземпляры баз данных?
Система управления базами данных позволяет схемам и экземплярам баз данных взаимодействовать. Система управления базами данных гарантирует, что каждый экземпляр базы данных будет придерживаться ограничений, установленных в схеме базы данных разработчиками модели базы данных. Экземпляр базы данных – это копия модели базы данных, сделанная в определенный момент времени. В то же время схемы баз данных, как правило, статичны.
Попробуйте no-code платформу AppMaster
AppMaster поможет создать любое веб, мобильное или серверное приложение в 10 раз быстрее и 3 раза дешевле
Начать бесплатно![]()
Структура базы данных
Модель базы данных демонстрирует следующие структурные атрибуты:
- В структуре базы данных присутствует несколько таблиц
- Каждая таблица содержит информацию об одной теме
- Данные, детализирующие тему таблицы, содержатся в полях
- Записи являются конкретными примерами темы таблицы
- Явная область первичного ключа идентифицирует каждую запись в таблицах структуры базы данных.
Пример
Следующий пример таблицы объясняет, как структурируется таблица базы данных.
| Идентификатор клиента | Имя | Фамилия | Дата покупки |
| 26710 | Эндрю | Джобель | 14-10-2022 |
| 26711 | Энтони | Митчелл | 15-10-2022 |
| 26712 | Джими | Нишам | 15-10-2022 |
| 26713 | Кори | Андерсон | 16-10-2022 |
Таблица клиентов состоит из
- Идентификатор клиента
- Имя
- Фамилия
- Дата покупки
В таблице можно найти следующие аспекты:
- Заголовок раскрывает конкретную тему таблицы: Клиент
- Фамилия, имя и дата покупки – это поля, описывающие клиентов.
- Идентификатор клиента – это первичный ключ таблицы, который идентифицирует конкретный счет.
Создание взаимосвязей
Теперь вы готовы к исследованию взаимосвязей между таблицами, которые вы создали в своей базе данных. Количество записей, которые взаимодействуют между двумя связанными таблицами, является их кардинальностью. Определив кардинальность, вы можете убедиться, что данные были правильно разделены по таблицам.
Хотя отношения между сущностями теоретически возможны, они часто попадают в одну из трех категорий:
- отношения один-к-одному
- Отношения “один-ко-многим
- отношения “многие-ко-многим”.
Отношения “один на один” редко встречаются в финансовом мире, в то время как отношения между одним и многими людьми широко распространены. Отношения “многие-ко-многим” не поддерживаются в диаграммах баз данных и должны быть преобразованы в отношения “один-ко-многим”. Схемы баз данных почти полностью состоят из таблиц с отношениями “один-ко-многим”.
Один-к-одному
Когда ноль или одна модель сущности А может быть связана с нолем или одной моделью сущности В, и когда ноль или одна модель сущности В может быть связана с нолем или одной моделью сущности А, в схеме диаграммы базы данных существует связь один-к-одному (1:1). Например, на традиционной американской свадьбе мужчине разрешается жениться только на одной женщине; женщине также разрешается выйти замуж только за одного мужчину.
Один-ко-многим
Отношение один-ко-многим (1:N) возникает при проектировании диаграммы базы данных, когда на каждый пример сущности B приходится ноль, один или несколько случаев сущности A. Тем не менее, на каждую точку сущности B приходится ноль или один случай сущности A. Например, у ребенка один отец; у отца может быть несколько биологических детей.
Многие-ко-многим
Отношение “многие ко многим” (M: N) существует в схеме реляционной базы данных, когда для одной точки сущности B существует ноль, один или несколько случаев сущности A и ноль, один или несколько случаев сущности A для одного случая сущности B. Например, студент может записаться в несколько классов; в классе может быть несколько студентов.
SQL и UML
SQL – это стандартный язык программирования, известный как язык структурированных запросов, используемый для навигации и модификации баз данных. Вы можете использовать SQL для навигации и управления базами данных. В 1986 году Американский национальный институт стандартов и Международная организация по стандартизации признали SQL в качестве стандарта.
SQL позволяет выполнять запросы к базам данных. С помощью SQL разработчики могут получать информацию из базы данных. В любую модель базы данных можно добавлять данные с помощью SQL.
С помощью SQL можно помещать и удалять информацию из модели базы данных. Кроме того, можно создавать новые таблицы и устанавливать на них права доступа.
Другим визуальным стилем для определения больших систем, написанных в объектно-ориентированной парадигме, является унифицированный язык моделирования (UML). Сегодня UML используется менее широко, чем раньше. В наши дни он часто используется в школьных контекстах и в переписке между разработчиками программного обеспечения и их клиентами.
Попробуйте no-code платформу AppMaster
AppMaster поможет создать любое веб, мобильное или серверное приложение в 10 раз быстрее и 3 раза дешевле
Начать бесплатно![]()
Как создать диаграмму базы данных?
- Перейдите в проводник объектов, а затем щелкните правой кнопкой мыши по каталогу Database Diagrams.
- В контекстном меню вы сможете создать новую диаграмму базы данных
- В списке Таблицы выберите необходимые таблицы, затем нажмите кнопку добавить
Топ-5 инструментов для проектирования диаграмм баз данных
Схема базы данных
Database Schema – это инструмент администрирования для программистов SQL, MongoDB, NoSQL и облачных систем. Благодаря возможности динамического проектирования вы можете создавать модели баз данных с помощью диаграмм.
Вы можете перетаскивать объекты, включая таблицы и внешние ключи, на поверхность. Ссылка на первичный ключ другой таблицы называется внешним ключом. В столбцах внешнего ключа разрешено использовать только те элементы, которые присутствуют в столбце первичного ключа, к которому они подключаются. Внешние ключи обозначаются как FK.
С помощью инструмента drag-and-drop можно создавать модели баз данных без использования кода. Кроме того, вы можете создать несколько макетов для различных компонентов схемы базы данных. Когда макет базы данных будет завершен, вы сможете загрузить его в формате HTML5 или PDF.
Особенности
- Позволяет создавать и поддерживать модели баз данных
- Использует MongoDB, NoSQL и SQL
- коллективные возможности
Плюсы:
- Работает с региональными и веб-данными
- Предоставляет встроенные средства коллективной работы
- Позволяет отлаживать схемы
Минусы:
- Требуется более длительный пробный период
Smart Draw
Вы можете использовать облачное приложение SmartDraw для динамического построения диаграмм баз данных. Для создания диаграммы базы данных достаточно импортировать двоичные данные, например, CSV-файл. После построения модель базы данных можно редактировать с помощью drag-and-drop.
Особенности
- Веб-система
- Возможность перетаскивания
- Генерирует файлы CSV
Плюсы
- Простое в использовании приложение для построения диаграмм для базы данных
- Доступно из любого браузера
- Простота создания стильных диаграмм данных
Минусы
- Не предоставляет никакой функциональности, предназначенной для баз данных
DB Designer
DB Designer – это веб-инструмент для создания диаграмм баз данных. Он обладает возможностями прямого и обратного проектирования. Он может переключать и отправлять инженерные базы данных. Вы можете отправлять данные в MySQL, PostgreSQL, MS SQL и SQLite или получать данные из MySQL, PostgreSQL и Oracle. Файлы дампа SQL также сохраняются в MS SQL. Базы данных можно экспортировать в файлы типов PDF и PNG.
Особенности
- Этот инструмент для построения диаграмм баз данных поддерживает MySQL, SQL Server, Oracle и PostgreSQL
- Импорт и экспорт баз данных
Плюсы
- Поддерживает широкий спектр форм баз данных SQL
- Возможен экспорт изображений или документов
- Помогает получить доступ к данным и мониторингу
Минусы
- Инфографика является базовой и лучше всего подходит для относительно небольших баз данных
SQL DBM
Вы можете создавать и интегрировать базы данных с помощью SQL-диаграмм и инструмента моделирования баз данных, известного как SQL DBM. Snowflake, MySQL, PostgreSQL и SQL функционируют с SQL DBM. Такие объекты базы данных, как столбцы, модули и соединения, могут быть созданы с помощью удобного графического интерфейса пользователя.
Особенности
- Предлагается бесплатная версия
- Функционирует с SQL Server, PostgreSQL, MySQL, Snowflake
Плюсы
- Разработана для массовых баз данных и предприятий
- Поддерживает различные базы данных, такие как MySQL, Redshift и PostgreSQL
- Предлагает сложный пользовательский интерфейс, который использует цвет для поддержания организации
Инструмент для проектирования баз данных AppMaster
Надеетесь ли вы когда-нибудь, что кто-нибудь создаст инструмент для использования любых систем баз данных по вашему желанию? AppMaster database designer делает это возможным. Это лучший инструмент no-code для проектирования баз данных PostgreSQL. Он поможет вам решить множество задач, включая:
- Создание схем любой сложности.
- Создание любых моделей баз данных без написания SQL-скриптов
- Быстрое создание и изменение дизайна базы данных
- Оценивать и добавлять первичные ключи в модель отношений
С помощью конструктора баз данных AppMaster вы можете автоматически создать базу данных, а также автоматизировать процедуру модификации базы данных и повысить качество жизни и безопасность каждого. Хотя если ваш ручной метод был эффективен на протяжении многих лет, кто-то, скорее всего, страдает от беспокойства или тратит больше времени на отладку в результате. Сделайте так, чтобы это исчезло с помощью автоматизации.
Заключительные слова
Попробуйте использовать инструмент проектирования баз данных AppMaster, когда вы собираетесь создать свою модель базы данных. Предприятия должны изучить бизнес-данные, которые они хранят в различных источниках данных, и для получения глубокого понимания данных необходимо поместить их в хранилище данных. AppMaster – это no-code решение для конвейера данных для передачи ваших данных в соответствующее хранилище данных. Не создавая ни одной строчки кода, он упрощает процесс преобразования и передачи данных в нужное место. Начните бесплатную пробную версию прямо сейчас!
