Автор: Сергей Драгун
Технический эксперт: Сергей Бондаренко
Какой бы надежной ни была IT-инфраструктура, невозможно на 100% застраховаться от отказов в работе ПО или оборудования. Поэтому каждая организация должна иметь план действий, помогающий как можно быстрей восстановить работу ресурсов.
Disaster Recovery plan (DRP) — это системный подход, который последовательно описывает действия по восстановлению работоспособности IT-инфраструктуры организации в случае аварийной ситуации.
Для составления плана в организации проводится анализ бизнес-процессов и формулируются цели Disaster Recovery.
Типы аварий
План аварийного восстановления должен учитывать три основных вида событий, приводящих к катастрофическим последствиям.
Природные бедствия
-
Пожары.
-
Наводнения.
-
Землетрясения.
-
Пандемия.
Инфраструктурные катастрофы
-
Отключение электричества.
-
Пожар или прорыв водопровода.
-
Обрушение здания.
-
Проникновение злоумышленников на объект и нанесение физического ущерба.
Технологические аварии
-
Авария сервера.
-
Сбой ПО на локальном сервере.
-
Сбой SaaS-приложения в облаке.
-
Потеря данных из-за сбоя или вируса.
-
Сбой сетевой инфраструктуры.
-
Выход из строя инфраструктуры интернет-провайдера.
Стратегии DRP
Правильно составленная стратегия включает расчет времени, которое понадобится на восстановление ключевых сервисов. Стратегия поможет предприятию быстрее справиться с инцидентами, сократить время простоя и уменьшить финансовый и репутационный ущерб. Существует четыре основных стратегии DRP.
Локальное восстановление
Так как приложения, системы и данные развернуты on-premise, стратегия восстановления должна предусматривать потерю одного или нескольких компонентов системы.
Для восстановления данных и приложений крупные компании могут использовать два географически распределенных корпоративных дата-центра. Небольшие организации используют для резервного копирования отдельный сервер.
Аварийное восстановление в облаке провайдера
Такой подход сокращает расходы организации, так как избавляет от необходимости вкладывать средства в резервное оборудование. Важно добавить, что за счет сильной конкуренции на рынке облачных услуг, пользователи получают недорогое и надежное решение. Вдобавок провайдеры обладают опытом и экспертизой в реализации DRP и могут проконсультировать и предложить свои варианты решения.
Аварийное восстановление как услуга (DRaaS)
Облачные провайдеры предлагают Disaster Recovery как услугу. По сути, она является горячей резервной площадкой для аварийного восстановления ресурсов. DRaaS использует облако для предоставления пользователям копий приложений из корпоративного дата-центра. За счет этого организации быстрее реагируют и восстанавливают критически важные приложения.
Аварийное восстановление за счет виртуализации ресурсов
Виртуализация позволяет быстро развернуть копию виртуальной машины из облака или резервного сервера.
Что включить в Disaster Recovery Plan
Он должен содержать несколько разделов:
-
описание и цели DRP;
-
периодичность тестирования на резервных ресурсах;
-
процедуры восстановления и перечень персонала, ответственного за реализацию плана.
Цели и параметры плана аварийного восстановления
Цель DRP — свести к минимуму негативное влияние аварии на работу организации. План может предусматривать как восстановление только базовых параметров, так и полное восстановление работоспособности.
Перед составлением плана оценивается потенциальное влияние аварии на бизнес. Исходя из этого, определяются приоритеты и задаются параметры для ключевых показателей аварийного восстановления: RTO и RPO.
RTO (целевое время восстановления) задает период, в течение которого система недоступна после аварии. Он указывается в минутах, часах или сутках. RTO относится к допустимому времени простоя от сбоя до восстановления. Например, организация должна вернуться к работе в течение 4 часов, чтобы избежать ущерба.
Для определения RTO нужно ответить на вопрос: «Сколько времени займет восстановление после сообщения о сбое бизнес-процесса?»
RPO (целевая точка восстановления) определяет максимальный период, за который данные могут быть утеряны. Например, RPO допускает потерю данных в пределах одного часа. Для достижения этой цели резервное копирование должно выполняться не реже одного раза в час.
Для определения RPO нужно ответить на вопрос: «Какой объем данных может быть потерян без существенного негативного влияния на бизнес организации?»
Затем разрабатываются стратегии восстановления приложений и данных.
Персонал
В плане аварийного восстановления должен быть указан персонал, ответственный за реализацию DRP. Кроме того, должны быть предусмотрены меры на случай отсутствия на рабочем месте кого-либо из ключевых сотрудников во время аварии.
IT-оборудование
При разработке DRP организации проводят инвентаризацию и составляют перечень аппаратных и программных активов, а также всех облачных сервисов, необходимых для функционирования организации. Оценивается важность каждого актива для бизнеса, находится ли он в собственности, аренде или используется по модели SaaS. Также важно сделать инвентаризацию лицензий и проверить их работу на измененных системах, чтобы понять нужна ли повторная активация или физическое перемещение лицензионных ключей.
Кроме того, все прошлые аварии необходимо задокументировать и описать, как они устранялись.
Процедуры резервного копирования и восстановления
В DRP указывается, как создается резервная копия каждого ресурса данных — где именно, на каких устройствах и в каких папках, а также как IT-отдел должен восстанавливать их из резервных копий.
Размещение ресурсов для аварийного восстановления
Надежный план Disaster Recovery должен предусматривать горячую площадку для аварийного восстановления. По сути, это резервный ЦОД, хранящий копии всех критически важных систем. Организация переключается на него после отказа основного ЦОДа.
Тестирование плана
Мало составить план — его надо протестировать, чтобы подтвердить соответствие заданным параметрам RTO и RPO, выявить и исправить возможные недостатки. Тестирование необходимо проводить с определенной периодичностью.
Существуют следующие типы тестирования:
-
кабинетные учения;
-
проверка отказоустойчивости приложений;
-
проверка отказоустойчивости инфраструктуры;
-
симуляция нарушения работы в тестовой среде;
-
симуляция нарушения работы в среде продакшн.
Важно понимать, что DRP не составляется раз и навсегда. Технологии быстро меняются, поэтому необходим регулярный аудит и корректировка плана в соответствии с текущими задачами организации.
Решения «Корп Софт» для аварийного восстановления
«Корп Софт» предлагает услугу DRaaS — аварийное восстановление как сервис.
В нее входит составление плана аварийного восстановления и его тестирование. Клиент получает резервную инфраструктуру в облаке с настройкой репликации виртуальных серверов и круглосуточной техподдержкой. Кроме DRaaS, «Корп Софт» предоставляет клиентам площадку с вычислительными ресурсами для Disaster Recovery.
Отказы и сбои IT-инфраструктуры нельзя исключить полностью. После катастрофы работу сервисов нужно восстановить как можно быстрее — тогда убытки бизнеса будут минимальны. Чтобы сотрудники знали, как действовать, и нужные меры были приняты вовремя, разрабатывают план аварийного восстановления (DRP): выбирают технологии Disaster Recovery с учетом потребностей бизнеса и бюджета, назначают ответственных, прописывают порядок действий для предупреждения катастрофы и устранения ее последствий.
Мы составили руководство по разработке плана аварийного восстановления с общими рекомендациями по восстановлению IT-инфраструктуры.
Что такое план аварийного восстановления
План аварийного восстановления — документ, который содержит шаги по устранению последствий аварии и восстановлению данных; список ответственных сотрудников, их роли и обязанности; последовательность действий по защите и восстановлению IT-инфраструктуры.
Главные цель разработки такого документа — четкая пошаговая инструкция с таймингом для определенных ролей, ее выполнение помогает решить следующие задачи:
- восстановить IT-инфраструктуру бизнеса после аварии в приемлемые сроки;
- обеспечить работу критически важных функций IT-инфраструктуры во время простоя основного ЦОД;
- сохранить данные компании в нужном объеме.
Для реализации плана аварийного восстановления нужна параллельная IT-инфраструктура — она может использоваться для хранения данных и шаблонов виртуальных машин либо быть второй боевой системой, которая возьмет на себя рабочие задачи на время катастрофы.
Чтобы обеспечить катастрофоустойчивость бизнеса и непрерывность его работы, компания может дублировать IT-сервисы в собственный дата-центр или использовать облачные сервисы, когда Disaster Recovery предоставляется провайдером как услуга.
Что должно быть в плане аварийного восстановления (Disaster Recovery Plan)
Цели плана аварийного восстановления
В качестве целей DRP могут быть указаны:
- Обучение сотрудников, чтобы они четко понимали порядок действий для быстрого восстановления IT-инфраструктуры — это ключевая цель DRP.
- Восстановление работы IT-инфраструктуры в нужное время, максимальное сохранение данных.
- Необходимость соблюдения корпоративных стандартов организации в ходе мероприятий DR.
- Необходимость финансового контроля, чтобы все принятые меры были рентабельными.
- Взаимодействие с ключевыми клиентами и прессой в момент катастрофы.
Конкретные цели зависят от целей компании и утверждаются лицами, принимающими решения, то есть руководящим составом.
Факторы риска
В DRP прописывают основные факторы риска для IT-инфраструктуры и те угрозы, что могут возникнуть в процессе аварийного восстановления. Также планируют мероприятия, которые помогут минимизировать риски или исключить их полностью.
Такие мероприятия, как правило, проводят регулярно для оценки состояния IT-инфраструктуры и ее готовности к процедурам аварийного восстановления в случае катастрофы. Это могут быть:
- проверка корректности создания резервных копий;
- проверка качества работы каналов резервной связи;
- контроль наличия нужного оборудования;
- периодическая проверка DRP на соответствие реальному положению дел;
- тестирование резервных инфраструктур.
Отдельно могут быть вынесены распространенные угрозы, которые могут вывести инфраструктуру из строя. Каждую возможную катастрофу оценивают по степени ущерба для бизнеса, также может быть предусмотрен порядок действий для наиболее вероятных угроз.
| Потенциальная угроза | Вероятность | Оценка угрозы | Важно |
| Отключение электричества | 50% | 2 из 5 | Проверять работу резервного генератора 1 раз в месяц. Ответственный: …. |
| Пожар в ЦОД | 10% | 5 из 5 | Проверять работу детекторов дыма. Проверка на соблюдение норм пожарной безопасности с инструктажем сотрудников раз в 3 месяца. Ответственный: … |
Так может выглядеть список потенциальных угроз для IT-инфраструктуры в DRP
Список критически важных сервисов
В каждом бизнесе есть список систем и приложений, работа которых будет критически важной для компании. Отказы в их работе приведут к сбою пользовательских сервисов.
Например, в интернет-магазине нельзя потерять данные о заказах, а в банке недопустима потеря данных о транзакциях, также пользователь должен в любой момент получать доступ к своему счету и проводить денежные операции.
Чем критичнее для бизнеса приложение или сервис, тем раньше должно быть начато аварийное восстановление его работы.
Для критически важных сервисов, которые не могут простаивать даже несколько минут, резервная инфраструктура должна сразу же заменить основную. Для тех сервисов, где допускается время простоя, работы по аварийному восстановлению начинают в определенный срок, чтобы система успела заработать до того, как бизнес понесет значительные убытки.
В плане DRP могут быть предусмотрены разные сценарии действия для критических и некритических сервисов, в том числе разное время реагирования на проблему и разные решения резервирования данных.
Система реагирования на сбои
Чтобы работы по аварийному восстановлению системы были начаты вовремя, нужно быстро обнаружить сбой в работе IT-инфраструктуры. Должны быть разработаны процедуры проверки работы пользовательских сервисов. В план может быть внесена периодическая диагностика систем и мониторинг точек отказа важных сервисов и приложений, сообщающий о проблеме раньше пользователей.
В плане аварийного восстановления указывают, что считать катастрофическим событием, какие действия и за какой период времени должны предпринимать сотрудники, если поступил сигнал о сбое. Сотрудников обучают так, чтобы они четко знали порядок действий в тех или иных случаях.
Распределение ролей и обязанностей между сотрудниками
Как правило, реализация плана аварийного восстановления требует участия двух групп: руководящей, то есть людей, которые принимают ключевые решения и контролируют процессы DR, и рабочей — специалистов, разрабатывающих, внедряющих и реализующих планы восстановления.
Для всех сотрудников, которые имеют отношение к работе IT-инфраструктуры, должны быть назначены роли и определены обязанности. Выбирают ответственных, чтобы сотрудники знали, к кому обращаться в момент катастрофы. Также назначают заместителей ответственных на случай, если нужные люди не доступны. Важно прописать в плане конкретные данные конкретных людей, а не только названия должностей.
Процесс реализации плана и реагирования на технический сбой
В плане DRP нужно прописать действия команды для восстановления IT-инфраструктуры после катастрофы. Сотрудники должны заниматься восстановлением работы сервисов, оповестить о случившемся нужных членов команды, добиться запуска системы в нужное время.
Например, системный администратор должен сообщить о сбое группе аварийного восстановления в течение 20 минут. Команда аварийного восстановления обязана восстановить ключевые услуги в течение четырех рабочих часов после инцидента, восстановить обычный режим работы инфраструктуры в течение суток после происшествия.
Также в плане прописывают всю важную дополнительную информацию: где хранится документация; что происходит в случае обновления плана; куда обращаться в страховых случаях; кто и как общается с прессой; что делает юридическая группа компании и когда она подключается; когда нужна оценка финансовых рисков и другое.
Каждая задача должна быть максимально конкретной, то есть состоять из точных команд или действий. Например, не просто позвонить ответственному, а позвонить менеджеру Юлии по телефону 8-965-123-45-64 в течение трех минут.

Типовая схема действий после катастрофы
Проконсультироваться по плану аварийного восстановления и решениям для Disaster Recovery
Тестирование плана
Готовый план аварийного восстановления тестируют, чтобы выяснить, сработает он в реальной ситуации аварии или нет.
Существуют различные типы тестов:
- Проработка действий с командой. Сотрудники устно проходят шаги, указанные в плане, выявляют пробелы и трудные места. Этот вид тестирования помогает команде ознакомиться с планом DR, но его недостаточно для проверки работоспособности плана.
- Моделирование аварийного сбоя. Имитация катастрофы без прерывания работы IT-инфраструктуры. Включает тестирование оборудования и программного обеспечения, работы персонала, коммуникаций, процедур, резервных сервисов. Результаты анализируют, при необходимости план корректируют.
- Тестирование в рабочем режиме. Полное прохождение процедур плана аварийного восстановления с отключением основной IT-инфраструктуры. Может быть дорогостоящим и представлять риск для текущих операций.
План DRP — не статичный документ, его нужно регулярно проверять и приводить в соответствие с реальными потребностями бизнеса. Составить план могут специалисты компании или провайдера, оказывающего услуги по резервированию IT-инфраструктуры в облаке. Если вы разрабатываете план аварийного восстановления самостоятельно, можете воспользоваться нашим шаблоном.
Проконсультироваться о выборе решения.
26 Апреля 2023 12:00
26 Апр 2023 12:00
|
В информационных технологиях чрезвычайная ситуация определяется как событие любого типа, которое влияет на сеть, подвергает риску данные, замедляет или останавливает нормальную работу. План аварийного восстановления (DRP) создается для устранения рисков и вероятностей таких событий и минимизации причиняемого ими ущерба.
План аварийного восстановления ИТ (DRP) — это формализованный документ, который организация создает для установления политики и процедуры реагирования на аварийные ситуации. DRP считается важным, поскольку он минимизирует риски, сокращает сбои и обеспечивает экономическую стабильность. Потенциальная экономия может быть значительной, если вы осознаете финансовый риск отсутствия плана на случай непредвиденных обстоятельств.
Аудит ИТ-процессов
В зависимости от типа ИТ-аудита анализируется текущее состояние ИТ-среды на основе соответствующих требований к правильности и безопасности или проводится сравнение первоначальной цели с фактически достигнутой.
Соответствующие требования к правильности и безопасности ИТ-систем вытекают из общих требований национального и международного законодательства, принципов и мнений, основанных на них, отраслевых и надзорных правил, а также соответствующих стандартов для проектирования ИТ-процессов и ландшафтов ИТ-систем.
Анализ рисков
Анализ рисков, или оценка рисков — это оценка всех потенциальных рисков и последствий, с которыми может столкнуться компания. Риски могут сильно различаться в зависимости от отрасли и географического положения компании. Оценка должна выявить потенциальные опасности, чтобы определить, кому или чему эти опасности могут причинить вред, и использовать результаты для разработки процедур, направленных на устранение этих рисков.
Определение критически важных приложений для активов и серверов, а также их ценности для компании — важный этап в создании плана. Выясните уязвимые места, нуждающиеся в защите, и ознакомьтесь с особенностями развертывания этой защиты. Проанализируйте угрозы, которым подвержены данные активы, и определитесь с действиями, необходимыми при возникновении каждой угрозы.
Если компания обслуживает клиентов, нужно проанализировать, какую часть из них затронет авария в вашей системе. Кроме того, нужно рассмотреть финансовые потери потенциальной опасности. Наилучшим показателем станут потери бизнеса за минуту времени, когда бизнес остановится по причине возникновения аварии на сервере или в приложении.
Разработка DRaaS-решения
DRaaS (аварийное восстановление как услуга) обеспечивает быстрое восстановление инфраструктуры и всех данных при отказе локального ЦОД. В технологическом аспекте это достигается за счет дублирования данных с серверов компании на серверы облачного провайдера. В большинстве случаев данная услуга предоставляется по подписке на основании плана аварийного восстановления, в который внесены персональные настройки.
Каждый хороший план восстановления сопровождается ключевыми цифрами, которые можно использовать для проверки его эффективности. Две самые важные метрики, которые вам нужно знать, — это целевое время восстановления (RTO) и целевая точка восстановления (RPO).
Одной из двух наиболее важных метрик плана восстановления является RPO. Она фокусируется на устойчивости компании к потерям своих данных. Это означает, что вы пытаетесь выяснить, как долго ваш бизнес может обходиться без этих данных, не неся при этом экономического ущерба. RPO определяется временем между резервными копиями и объемом данных, которые создаются между резервными копиями и могут быть потеряны.
Второй ключевой показатель в плане восстановления — RTO. Он описывает целевое время, когда должно быть завершено восстановление данных после аварии. Ваша цель — рассчитать, как быстро система будет снова работать. Это определяет максимально возможный объем потери данных.
Значения RPO и RTO определяются каждой компанией индивидуально. Например, для одной компании отсутствие доступа к электронной почте на несколько часов (RTO) не повлечет за собой серьезных убытков, а вот падение сайта ее интернет-магазина даже на полчаса (RPO) обойдется дорого.
Минимальные значения RTO и RPO имеют банковские организации, для которых даже 5 минут простоя системы означают нанесение прямого финансового ущерба.
Внедрение
Решение DRaaS внедряется достаточно просто. Для этого не нужно нанимать квалифицированный персонал. Эту услугу готовы предоставить облачные провайдеры. Их сотрудники владеют достаточным опытом внедрения подобных решений, поэтому исключается возможность влияния человеческого фактора при обслуживании системы и работы серверов в момент аварии.
Тестирование
Для подтверждения работоспособности и надежности выбранной стратегии аварийного восстановления она должна пройти многоуровневое тестирование. В частности, должны быть рассмотрены следующие задачи:
- проверка работоспособности и эффективности созданного плана DRP;
- анализ и сохранение шагов восстановления;
- проверка путем симуляции аварийной ситуации с фиксацией показателей, когда система снова будет работать и вы сможете оперировать восстановленными данными;
- регулярное обновление плана DRP, особенно в условиях масштабирования бизнеса;
- обновление и тестирование плана аварийного восстановления DRP при обновлении ИТ-инфраструктуры.
Запуск в эксплуатацию
Использование плана аварийного восстановления DRP позволит вам получить систему, которая работает должным образом не только сегодня, но и при изменении потребностей в бизнесе и технологиях.
По этой причине тренд на предоставление услуг внедрения DRaaS с каждым годом поддерживает все больше провайдеров.
Выводы
Создание плана аварийного восстановления жизненно важно для любого бизнеса, использующего информационные технологии. Успешное планирование означает поиск решений аварийного восстановления, отвечающих вашим уникальным ИТ-потребностям. При этом выбранные решения должны быть удобными в управлении и тестировании.
Согласно исследованию Uptime Institute, 44% организаций сталкивались с аварийными ситуациями, которые повлияли на бизнес.
Помимо аварий и поломок оборудования, ИТ инфраструктуре угрожают:
– природные катастрофы;
– политические конфликты;
– срыв поставок;
– сбои в каналах связи;
– одностороннее расторжение договорённостей;
– санкции;
– кибератаки;
и многое другое.
Для обеспечения отказоустойчивости, непрерывности работы и сокращения рисков потери данных, используют Disaster Recovery(DR), или аварийное восстановление — инструмент для восстановления ИТ инфраструктуры, данных и приложений.
Этапы аварийного восстановления
1 этап – выбор бизнес-критичных систем, комплексов, которые будут подвергаться защите с помощью DR. Определение RTO(Recovery Time Objective) и RPO(Recovery Point Objective).
2 этап – анализ ИТ-инфраструктуры предприятия. Разработка стратегии DR. Выбор технических решений.
3 этап – внедрение решений и формирование документации.
4 этап – тестирование, корректировка.
1 этап – выбор бизнес-критичных систем, комплексов, которые будут подвергаться защите с помощью DR. Определение RTO и RPO.
Бизнес требует от ИТ департамента непрерывной работы критичных приложений и недопущения потерь данных.
Хорошо, если и бизнес и ИТ команда понимают друг друга и воспринимают непрерывность равнозначно. Восстановленная виртуальная машина или “поднятый с колен” сервер совсем не равны работающему приложению или целому бизнес-процессу.
Поэтому начинают с вопроса – а какие системы и приложения вообще являются бизнес-критичными?
Для некоторых предприятий это 1С, для других – веб-приложение с интернет-магазином, а для третьих – биллинговая система. Для каждого приложения определяем допустимый уровень доступности. Для этого используем метод BIA (Business Impact Analysis).
Он находит взаимосвязи между процессами, внутренними и внешними сторонами, цепочками поставок, активами, персоналом, технологиями, и т.д. По результатам BIA бизнес получает требования к непрерывности работы бизнес-процессов. При этом, стоимость решения не должна превышать ущерб от потерь. Для этого определяем показатели RTO и RPO.
RTO (Recovery Time Objective) – это промежуток времени, в течение которого система может оставаться недоступной в случае аварии.
RTO помогает оценить, какой урон будет нанесён бизнесу, если система будет стоять час, сутки, неделю и, исходя из этого, понять, какое время является приемлемым, а какое – нет. Выбираем наиболее высоконагруженный период (например, чёрная пятница, новогодняя распродажа и т.д.), считаем потери за промежуток времени и определяем RTO. Если он равен 2 часам, значит, система должна возобновить работу за 2 часа.
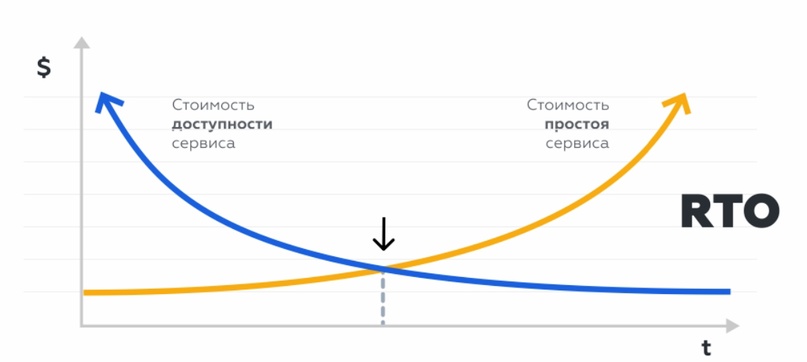
RPO (Recovery Point Objective) – это максимальный период времени, за который могут быть потеряны данные. На точке пересечения графиков стоимости потерь и доступности получаем время восстановления и лучшую стоимость.
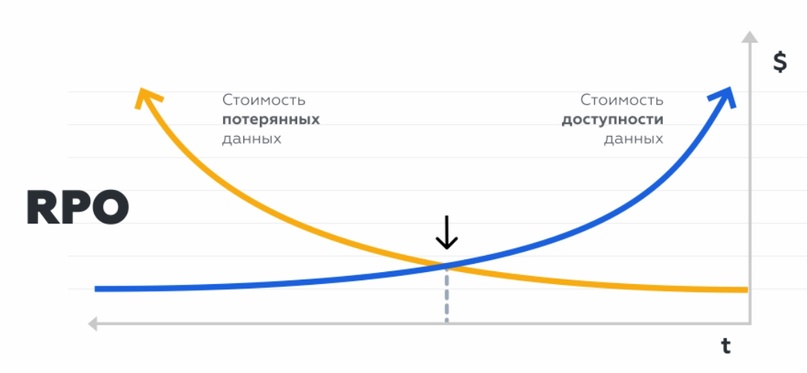
RPO определяет частоту резервного копирования.
— Если он равен суткам – будем записывать бэкап с периодичностью раз в 24 часа.
— Если максимальное время, за которое бизнес может потерять данные – 5 минут, то разрабатываем дополнительную стратегию обеспечения сохранности данных – например, подключаем инструменты репликации, кластеризации и т.д.
Универсальных значений показателей RTO и RPO не существует. В случае небольшого обувного магазина простой в сутки не даст ощутимых потерь, но совершенно другая история – операционная деятельность банков.
2 этап – анализ ИТ-инфраструктуры предприятия. Разработка стратегии DR. Выбор технических решений.
Выясняем, может ли ИТ-инфраструктура обеспечить нужный уровень RTO. Для этого:
– Соотносим все компоненты с ИТ-системами, участвующими в организации непрерывной работы;
– Проверяем архитектуру резервирования;
– Выявляем специфические особенности ИТ-ландшафта организации.
Определение бизнес-критичных систем, оценка потерь в случае аварии и результаты аудита существующей ИТ-инфраструктуры помогают договориться бизнесу и ИТ-отделу и определиться, какой уровень DR подойдет под конкретный бизнес-процесс и бюджет.
Варианты:
– в рамках одного ЦОДа между разными серверами;
– между ЦОДами;
– между “землёй” и облаком;
– между облаками.
2 наиболее популярных схемы:
1. Бэкапы и быстрое восстановление из облака (DRaaS Backup & Restore).
Относительно бюджетный вариант, поскольку нет затрат на дублирующую инфраструктуру. Бизнес платит за объём данных в облаке и временное использование виртуальных машин в случае аварии. RPO и RTO в данном случае составляют несколько часов.
Порядок действий:
Делаем бэкап в облако. В случае наступления локальной аварии, приложения переключаются на виртуальные машины, которые берут на себя нагрузку. В это время восстанавливаем инфраструктуру, возобновляем работу и делаем новые бэкапы.
2. Параллельная инфраструктура
Метод кратно дороже, чем первый, время аварийного восстановления занимает от двух-трёх секунд до нескольких минут. Механизм работы подробно описали в материале о синхронной и асинхронной репликации.
Стоимость выбранного решения сравниваем с ущербом от простоя и корректируем показатели.
3 этап – внедрение решений и формирование документации.
Как правило, в комплект входит 4 документа:
1. SLA (Service-Level Agreement) – это договор между поставщиком и клиентом, в котором закрепляем:
– требования бизнеса;
– перечень и объём услуг;
– обязанности;
– ожидания сторон;
– ключевые показатели эффективности.
Метрики SLA (цифры, которым должен соответствовать бизнес-процесс)
![]()
Благодаря SLA бизнес получает гарантированную доступность сервисов в соответствии с заявленными характеристиками.
2. Результаты аудита ИТ-инфраструктуры и проект новой архитектуры. Описание методов и технологий в стратегии DR. Данный документ можно назвать чек-листом для построения отказоустойчивой ИТ-инфраструктуры.
2.1. План резервирования и резервного копирования. Определяет способы, время восстановления по каждому элементу, а также частоту и глубину бэкапов.
3. RunBook (книга запуска) — пошаговая инструкция по восстановлению. Документ, в котором фиксируют последовательность действий для каждого участника ответственной команды в момент аварии.
4. DRP (Disaster Recovery Plan) – подробный план аварийного восстановления. Отвечает на вопрос: что делать в момент аварии?
– Описывает порядок действий – что делаем на каждом конкретном этапе;
– Регламентирует зоны ответственности;
Например, ответственность за закупку оборудования, согласно DRP, лежит на директоре департамента информационных технологий. Если нужно приобрести новый сервер, сотрудник обращается к нему.
– Закрепляет состав команд по аварийному восстановлению
В DRP распределяем обязанности – по людям, по группам, по их взаимодействию в различных вариантах развития событий.
Например, в для штатного случая способ связи между командой – стационарный телефон. На случай отключения электроэнергии в DRP прописываем альтернативный вариант связи.
Все подобные организационные нюансы учитываются в плане аварийного восстановления.
4 этап – проведение тестирования, корректировка
Чтобы убедиться, что реальные показатели не отличаются от требуемых и довести действия команды до автоматизма, проводим репетиции аварийных ситуаций и восстановлений.
Аварийные работы по восстановлению проводим отдельно для каждого риска, например DR-команда:
– Отключает сетевой кабель и тестирует падение интернет-провайдера.
– Оценивает влияние человеческого фактора, когда системный администратор не выходит на связь.
– Имитирует кибератаки и вмешательства.
Важно учесть, что единоразового тестирования режима аварийного восстановления недостаточно. Ответственная группа должна регулярно проводить учения (например, раз в 6 месяцев) и поддерживать актуальное состояние DRP.
Все недочёты и допущенные ошибки фиксируем в план и совершенствуем его до тех пор, пока реальное время восстановления не будет совпадать с запланированным.
Зачем нужен план аварийного восстановления (DRP)? Почему бэкапов недостаточно?
Резервное копирование данных — обязательная часть Disaster Recovery, но это лишь часть. Даже методика “3-2-1” не сможет обеспечить быстрое восстановление и защитить от риска потери критически важных данных.
Если проводить аналогию, то бэкап – это подушки безопасности в автомобиле. В случае аварии, до того, как они сработают, есть ещё несколько линий обороны – ремни безопасности, система тормозов, реакция водителя, специальный вывод из строя некоторых систем.
Резервное копирование – последний рубеж. А DRP предусматривает, какие системы и в каком порядке будут срабатывать перед восстановлением из бэкапов.
Дата публикации: 1 января 2020 г.

* * *
Процесс планирования аварийного восстановления включает в себя не просто создание документа (плана), это комплекс заранее согласованных действий направленных на снижение последствий аварии. Disaster Recovery Plan включает в себя следующие этапы разработки:

- установление сфер/объектов защиты при аварийных инцидентах
- сбор документации о процессах и инфраструктуре
- расстановка приоритетов: выявление критических угроз, уязвимостей и наиболее важных активов
- оценка и анализ аварийных инцидентов / сбоев, а также последовательность их решения
- определение стратегии аварийного восстановления
- определение ролей и обязанностей в чрезвычайных ситуациях
- разбор и утверждение плана аварийного восстановления с группой
- тестирование и испытание плана
- обновление плана
- аудит Disaster Recovery Plan
Commvault Disaster Recovery
Контрольный список целей аварийного восстановления включает в себя определение критически важных объектов защиты: ИТ-сервисов, сетей и данных, а так же расчет значений основных показателей BIA, RA, RTO и RPO для разработки стратегии восстановления работоспособности (перезапуск, установка, настройка и восстановление систем, данных и сетей) по каждому объекту. Перед составлением детального плана, необходимо выполнить расчет основных показателей:
- Анализ воздействия на бизнес (business impact analysis – BIA)
- Анализ рисков (Risk Analysis – RA)
- Допустимое время восстановления (recovery time objective – RTO)
- Допустимая (критическая) точка восстановления (recovery point objective – RPO)
| Значение RTO / RPO | Объекты воздействия | Стратегия |
| От нескольких секунд до минут | Критически важные системы и базы данных высокой доступности | Репликация и кластеризация с мгновенным переключением на резервный узел (failover) |
| От нескольких минут до пары часов | Виртуальные машины, базы данных, системы обмена сообщениями. | Горячее резервное копирование с оперативным восстановлением работы системы или базы данных на новом или том же устройстве |
| От нескольких часов до дней | Файловые сервера, рабочие станции | Холодное резервное копирование редко изменяющихся данных, поиск и восстановление отдельных файлов, почтовых сообщений |
BIA: АНАЛИЗ ВОЗДЕЙСТВИЯ НА БИЗНЕС
В рамках плана аварийного восстановления показатель BIA, определяет затраты (убытки, ущерб) вызванные последствием сбоя. В расчете BIA дается количественная оценка важности бизнес-процессов и распределение средств для принятия мер по их защите и устранению. Последствия сбоев будут оцениваться с точки зрения их воздействия на безопасность, финансы, маркетинг, деловую репутация, уголовную или административную ответственность перед законом. Все возможные воздействия выражаются в денежном исчислении для сравнения и ранжирования. Например, бизнес может потратить в три раза больше средств на маркетинг после инцидента, чтобы восстановить доверие клиентов и репутацию. BIA должен помогать в создании стратегий аварийного восстановления, выбору приоритетов, требований к ресурсам и времени.
RA: АНАЛИЗ РИСКОВ
Анализ рисков – это процесс выявления и анализа потенциальных проблем, которые могут негативно повлиять на ключевые бизнес-процессы или критически важные функции системы, чтобы помочь организациям избежать или смягчить эти риски. Организации используют анализ рисков для:
- Предупреждения и уменьшения последствий от вредных результатов неблагоприятных событий
- Планирования решения в случаи отказа или потери сервиса, выхода из строя оборудования в результате неблагоприятных явлений, как природных, так и человеческих
- Оценки сбалансированности потенциальных рисков
RTO: ДОПУСТИМОЕ ВРЕМЯ ВОССТАНОВЛЕНИЯ
Допустимое время восстановления – это максимально допустимый период времени, в течение которого сервис, сеть или информационная система могут оставаться неработоспособными. Несоблюдение RTO приводит к критическому нарушению рабочего процесса и потери доходов в единицу времени в зависимости от затронутого оборудования и систем в результате катастрофы. RTO измеряется в секундах, минутах, часах или днях и является важным показателем при планировании аварийного восстановления. Многочисленные исследования были проведены в попытке определить стоимость простоя для различных систем на предприятиях. Эти исследования показывают, что стоимость зависит от долгосрочных и нематериальных эффектов, а также от непосредственных, краткосрочных или ощутимых факторов. Как только RTO для определенной системы будет рассчитан, технические специалисты смогут предложить решения аварийного восстановления лучше всего подходящее для данной ситуации.
Например, если RTO для информационной системы равно одному часу, то выполнение и хранение резервной копии на внешних жестких дисках будет являться оптимальным решением. Если RTO составляет 2-3 дня, может быть более практичным использование ленточных носителей или внешнего хранилища на удаленном сервере или в облаке.
RPO: ДОПУСТИМАЯ ТОЧКА ВОССТАНОВЛЕНИЯ (допустимые потери данных)
Допустимая точка восстановления – это максимальный период времени, за который могут быть потеряны данные из-за сбоя. RPO выражается во времени с момента, когда происходит сбой, и может рассчитываться в секундах, минутах, часах или днях. Это важный параметр при планировании аварийного восстановления (DRP). Как только RPO определен, можно рассчитать с какой минимальной частотой необходимо делать резервные копии.
Заранее выполненный анализ рисков и влияния на бизнес помогают определить, где сосредоточить ресурсы в процессе планирования аварийного восстановления. BIA идентифицирует воздействие аварийных инцидентов и является отправной точкой для определения риска в контексте аварийного восстановления. Он также генерирует RTO и RPO. RA идентифицирует угрозы и уязвимости, которые могут нарушить работу систем и процессов, выделенных в BIA.
Стратегия аварийного восстановления
Стратегия восстановления является основой для формирования плана реагирования на инцидент. При определении стратегии восстановления следует учитывать:
- бюджет
- ресурсы – люди и объекты инфраструктуры
- позиция руководства по рискам
- технологии резервного копирования и восстановления
- данные
ПЛАН АВАРИЙНОГО ВОССТАНОВЛЕНИЯ
План аварийного восстановления (Disaster Recovery Plan – DRP) это документ с инструкциями для решения аварийных ситуаций, выполняя которые организация может оперативно продолжить работу в информационных системах или быстро восстановить критически важные функции. В плане должны быть определены роли и обязанности всех членов команды ответственных за аварийное восстановление, а так же намечены условия для запуска плана в действие. План должен содержать подробное описание действий по реагированию на инциденты для восстановления. План аварийного восстановления может варьироваться в зависимости от степени сложности ситуации, от базового до всеобъемлющего. Для создания DRP можно воспользоваться бесплатными ресурсами, например:
https://www.template.net/business/plan-templates/sample-disaster-recovery-plan-examples/
https://www.ibm.com/support/knowledgecenter/ru/ssw_ibm_i_73/rzarm/rzarmdisastr.htm
Рассмотрим несколько примеров плана аварийного восстановления адаптированных для определенной среды.
План аварийного восстановления виртуальных систем
Виртуализация предоставляет возможности для ускорения процесса восстановления после сбоев более эффективным и простым способом. Виртуальная среда может создать новые экземпляры виртуальной машины (VM) в течение нескольких минут и обеспечить восстановление приложений с высокой доступностью. Тестирование также может быть легко выполнено, но план должен включать возможность проверки того, что приложения могут быть запущены в режиме аварийного восстановления и возвращены к нормальной работе в RPO и RTO.
