Семантическое ядро – как составить правильно?
Семантическое ядро – это страшное название, которое придумали SEOшники для обозначения довольно простой вещи. Нам надо просто подобрать ключевые запросы, по которым мы будем продвигать наш сайт.
И в этой статье я покажу вам, как правильно составить семантическое ядро, чтобы ваш сайт побыстрее вышел в ТОП, а не топтался месяцами на месте. Тут тоже есть свои “секретики”.
Содержание статьи:
- Что такое семантическое ядро простыми словами
- Как правильно составить семантическое ядро за 5 шагов
- #1 – Подбор базовых ключей
- #2 – Парсинг в SlovoEB
- #3 – Сбор точной частотности для ключей
- #4 – Проверка конкурентности запросов
- #5 – Подбор “хвоста” для каждого запроса
- Стоит ли заказывать СЯ у специалистов?
- Резюме
И прежде чем мы перейдем к составлению СЯ, давайте разберем, что это такое, и к чему мы в итоге должны прийти.
Что такое семантическое ядро простыми словами
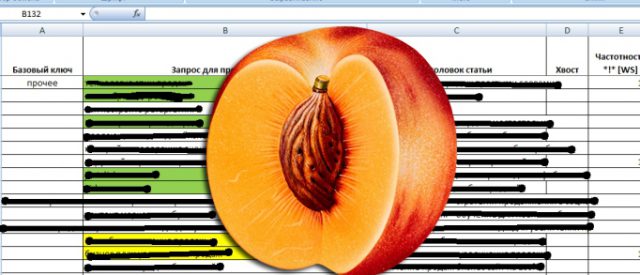
Как это ни странно, но семантическое ядро – это обычный excel файл, в котором списком представлены ключевые запросы, по которым вы (или ваш копирайтер) будете писать статьи для сайта.
Вот как, например, выглядит мое семантическое ядро:
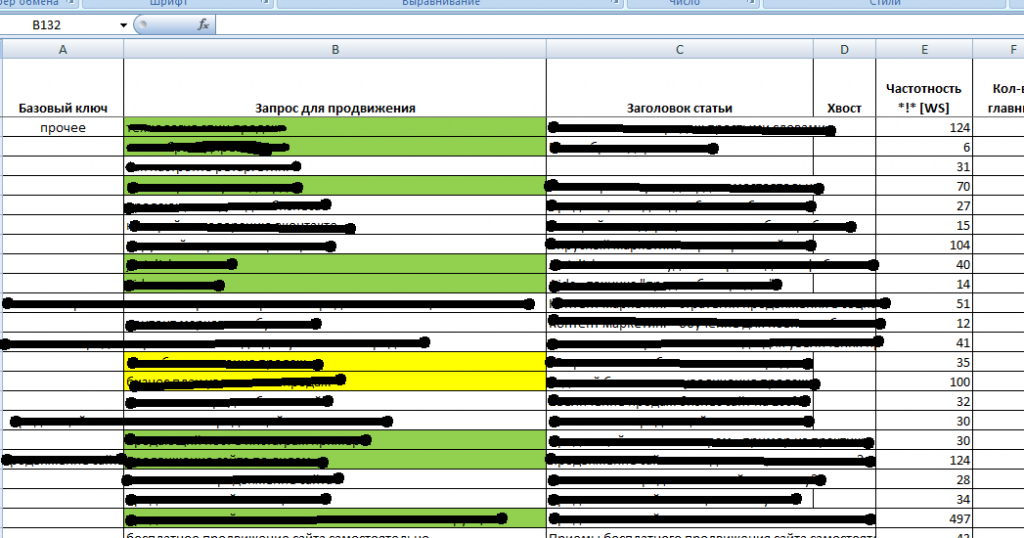
Зеленым цветом у меня помечены те ключевые запросы, по которым я уже написал статьи. Желтым – те, которым статьи собираюсь написать в ближайшее время. А бесцветные ячейки – это значит, что до этих запросов дело дойдет немного позже.
Для каждого ключевого запроса у меня определена частотность, конкурентность, и придуман “цепляющий” заголовок. Вот примерно такой же файл должен получиться и у вас. Сейчас у меня СЯ состоит из 150 ключевиков. Это значит, что я обеспечен “материалом” минимум на 5 месяцев вперед (если даже буду писать по одной статье в день).
Чуть ниже мы поговорим о том, к чему вам готовиться, если вы вдруг решите заказать сбор семантического ядра у специалистов. Здесь скажу кратко – вам дадут такой же список, но только на тысячи “ключей”. Однако, в СЯ важно не количество, а качество. И мы с вами будем ориентироваться именно на это.
Зачем вообще нужно семантическое ядро?
А в самом деле, зачем нам эти мучения? Можно же, в конце концов, просто так писать качественные статьи, и привлекать этим аудиторию, правильно? Да, писать можно, а вот привлекать не получится.
Главная ошибка 90% блогеров – это как раз написание просто качественных статей. Я не шучу, у них реально интересные и полезные материалы. Вот только поисковые системы об этом не знают. Они же не экстрасенсы, а всего лишь роботы. Соответственно они и не ставят вашу статью в ТОП.
Здесь есть еще один тонкий момент с заголовком. Например, у вас есть очень качественная статья на тему “Как правильно вести бизнес в “мордокниге”. Там вы очень подробно и профессионально расписываете все про фейсбук. В том числе и то, как там продвигать сообщества. Ваша статья – самая качественная, полезная и интересная в интернете на эту тему. Никто и рядом с вами не валялся. Но вам это все равно не поможет.
Почему качественные статьи вылетают из ТОПа
Представьте, что на ваш сайт зашел не робот, а живой проверяльщик (асессор) с Яндекса. Он понял, что у вас самая классная статья. И рукам поставил вас на первое место в выдаче по запросу “Продвижение сообщества в фейсбук”.
Знаете, что произойдет дальше? Вы оттуда все равно очень скоро вылетите. Потому что по вашей статье, даже на первом месте, никто не будет кликать. Люди вводят запрос “Продвижение сообщества в фейсбук”, а у вас заголовок – “Как правильно вести бизнес в “мордокниге”. Оригинально, свежо, забавно, но… не под запрос. Люди хотят видеть именно то, что они искали, а не ваш креатив.
Соответственно, ваша статья будет вхолостую занимать место в ТОП выдачи. И живой асессор, горячий поклонник вашего творчества, может сколько угодно умолять начальство оставить вас хотя бы в ТОП-10. Но не поможет. Все первые места займут пустые, как шелуха от семечек, статейки, которые друг у друга переписали вчерашние школьники.
Зато у этих статей будет правильный “релевантный” заголовок – “Продвижение сообщества в фейсбук с нуля” (по шагам, за 5 шагов, от А до Я, бесплатно и пр.) Обидно? Еще бы. Ну так боритесь против несправедливости. Давайте составим грамотное семантическое ядро, чтобы ваши статьи занимали заслуженные первые места.
Еще одна причина начать составлять СЯ прямо сейчас
Есть еще одна вещь, о которой почему-то люди мало задумываются. Вам надо писать статьи часто – как минимум каждую неделю, а лучше 2-3 раза в неделю, чтобы набрать побольше трафика и побыстрее.
Все это знают, но почти никто этого не делает. А все потому, что у них “творческий застой”, “никак не могут себя заставить”, “просто лень”. А на самом деле вся проблема именно в отсутствие конкретного семантического ядра.
Наше СЯ – это как контент-план для социальных сетей. То есть там написано конкретно, что мы будем делать в ближайшие 2-3 месяца. Нам не надо будет садиться с утра и начать выдумывать тему для нового поста. У нас все придумано, продумано и прочитано.
Именно это и спасет вас от так называемого “творческого кризиса”. Когда вы точно знаете, что вам делать – становится гораздо легче. Поэтому ни в коем случае не пропускайте этап создания семантического ядра (каким бы муторным вам это дело не показалось). Потом вам все равно придется подбирать темы и запросы, но только потратите вы на это в десять раз больше времени и сил.
А теперь. собственно, давайте разберем, как правильно составить семантическое ядро с нуля.
Как правильно составить семантическое ядро за 5 шагов
Шаг #1 – Подбор базовых “ключей”
Сначала мы займемся веселой и увлекательной штукой – будем собирать базовые ключевые запросы. Это очень широкие ключи, которые набирают десятки и сотни тысяч просмотров в месяц. Вам надо определиться, на какие темы вообще вы хотите писать, и просто взять названия этих тем в качестве ключей.
А увлекательное это занятие потому, что уже на этом этапе вы сможете понять – правильную вы выбрали тему для своего сайта или нет. Может так оказаться, что вы придумаете 1-2 широких базовых ключа, и на этом все закончится.
То есть тут вы поймете, что буквально через месяц-два вам уже не о чем будет писать. А это значит, что вам надо срочно менять свой маркетинговый план и думать в сторону другой ниши.
Для примера, вот какие базовые ключевые слова я взял для своего блога, на котором вы сейчас находитесь:
- копирайтинг
- вебинары
- smm
- seo
- яндекс-директ
- лендинг
- продвижение сайтов
- свой бизнес
- интернет маркетинг
- продажи
- …
Таких базовых ключей у меня набралось три десятка. А это значит, что без тем для статей я точно не останусь. Если в вашей нише то же самое – значит все нормально. И пусть вас не смущает, если в вашей теме есть уже сотни сильных сайтов, которые раскручиваются десятилетиями, и плотно заняли весь ТОП-10 (как вам кажется).
Если в нише много конкурентов – значит там есть деньги. А если много широких ключей – значит вы в любом случае сможете “зацепить” хотя бы часть этого трафика. Тем более, что мы сейчас будем учиться правильно подбирать ключевые запросы, которые позволят вам быстро выйти в ТОП в обход всех конкурентов.
Где найти базовые ключевые запросы
Начните с поиска в своей голове. Выпишите на листочек хотя бы 3-5 тем, по которым вы могли бы выдавать интересную и полезную информацию. Дальше идите в Яндекс-Вордстат, и смотрите подсказки.
Подсказки он вам будет показывать в правом столбце – “Запросы, похожие на…”
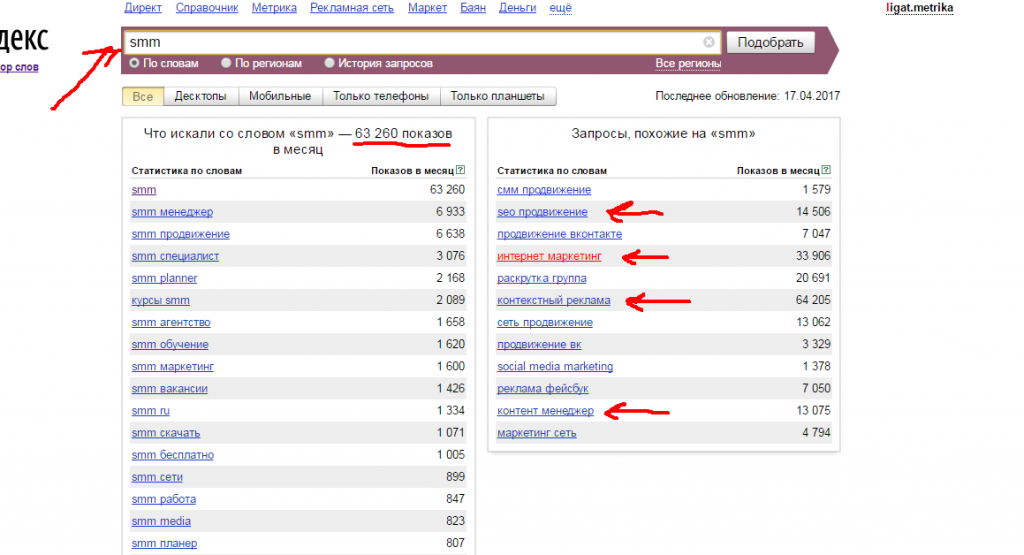
Я ввел в поле поиска один из своих базовых ключей – “smm”, и Яндекс тут же выдал мне с десяток подсказок, что еще может быть интересно людям, которым интересно “smm”. Мне остается только скопировать эти ключи в блокнотик. Потом я точно так же проверю каждый из них, и соберу подсказки еще и по ним.
После первого этапа сбора СЯ у вас должен получиться текстовый документ, в котором будет 10-30 широких базовых ключей, с которыми мы и будем работать дальше.
Шаг #2 – Парсинг базовых ключей в SlovoEB
Конечно, если вы напишите статью под запрос “вебинар” или “smm”, то чуда не произойдет. Вы никогда не сможете выйти в ТОП по такому широкому запросу. Нам надо разбить базовый ключ на множество мелких запросов по этой теме. И делать это мы будем с помощью специальной программы.
Я использую KeyCollector, но он платный. Вы можете воспользоваться бесплатным аналогом – программой SlovoEB. Скачать её вы можете с официального сайта.
Самое сложное в работе с этой программой – это её правильно настроить. Как правильно настроить и использовать Словоеб я показываю вот здесь. Но в той статье я упор делаю на подбор ключей для Яндекс-Директа.
А тут давайте по шагам посмотрим особенности использования это программы для составления семантического ядра под SEO.
Сначала создаем новый проект, и называем его по тому широкому ключу, который хотите парсить.
Я обычно даю такое же название проекту, как и мой базовый ключ, чтобы потом не запутаться. И да, предупрежу вас еще от одной ошибки. Не пытайтесь парсить все базовые ключи одновременно. Вам потом будет очень сложно отфильтровать “пустые” ключевые запросы от золотых крупиц. Давайте парсить по одному ключу.
После создания проекта – проводим базовую операцию. То есть мы собственно парсим ключ через Яндекс Вордстат. Для этого нажмите на кнопку “Ворстат” в интерфейсе программы, впишите ваш базовый ключ, и нажмите “Начать сбор”.
Для примера, давайте распарсим базовый ключ для моего блога “контекстная реклама”.
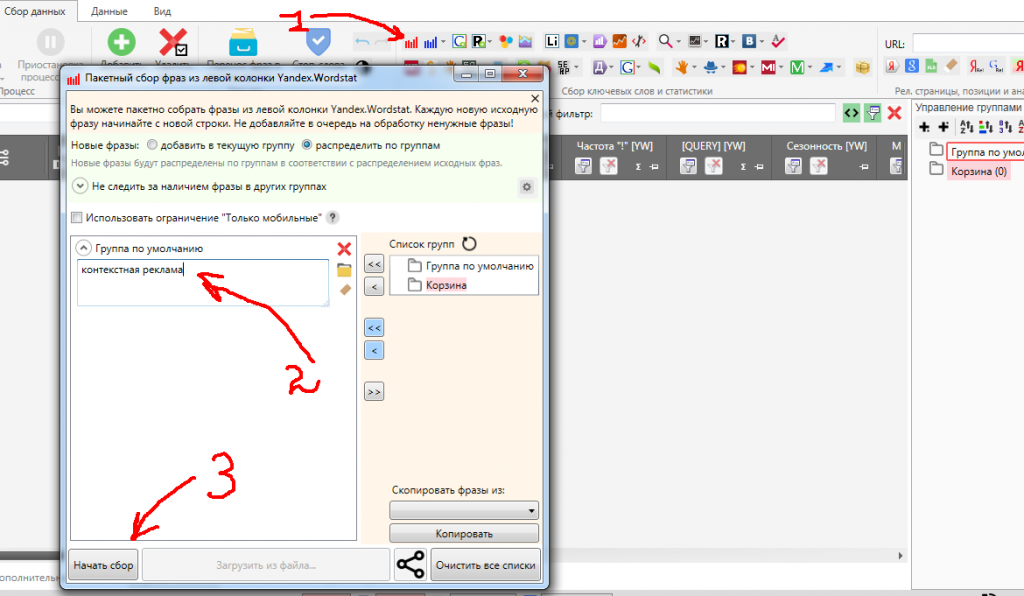
После этого запустится процесс, и через некоторое время программа нам выдаст результат – до 2000 ключевых запросов, в которых содержится “контекстная реклама”.
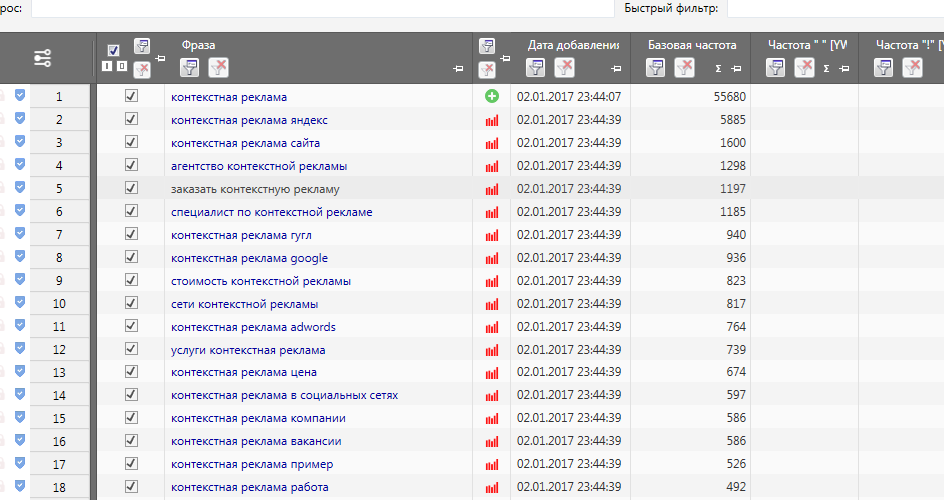
Так же рядом с каждым запросом будет стоять “грязная” частотность – сколько раз этот ключ (+ его словоформы и хвосты) искали в месяц через яндекс. Но не советую делать никаких выводов из этих цифр.
Шаг #3 – Сбор точной частотности для ключей
Грязная частотность нам ничего не покажет. Если вы будете на неё ориентироваться, то не удивляйтесь потом, когда ваш ключ на 1000 запросов не приносит ни одного клика в месяц.
Нам надо выявить чистую частотность. И для этого мы сначала выделяем все найденные ключи галочками, а потом нажимаем на кнопочку “Яндекс Директ” и снова запускаем процесс. Теперь Словоеб будет нам искать точную частоту запроса в месяц для каждого ключа.
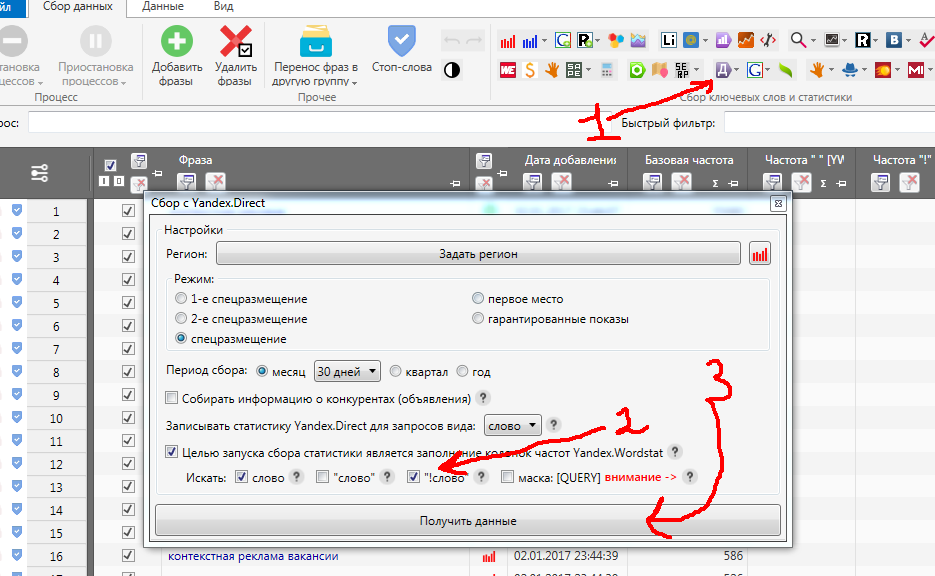
Программа опять некоторое время подумает, и выдаст нам результат. Кстати, сколько именно она будет думать – зависит от правильности настроек программы. Может 15 минут, а может и несколько часов. Поэтому обязательно посмотрите правильные настройки в этой моей статье.
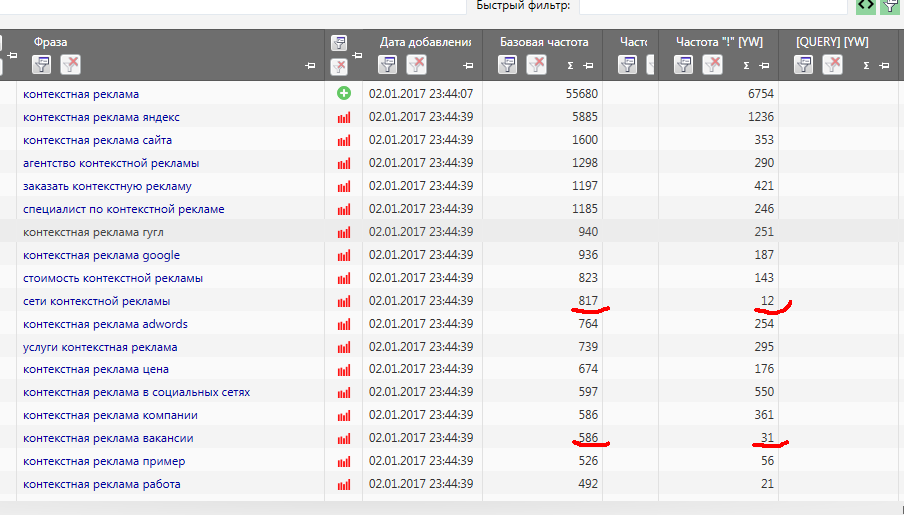
Теперь у нас есть объективная картина – сколько раз какой запрос вводили пользователи интернета за последний месяц. Предлагаю теперь сгруппировать все ключевые запросы по частотности, чтобы с ними было удобнее работать.
Для этого нажимаем на значок “фильтр” в столбце “Частота “!” [YW]”, и указываем – отфильтровать ключи со значением “меньше или равно 10”.
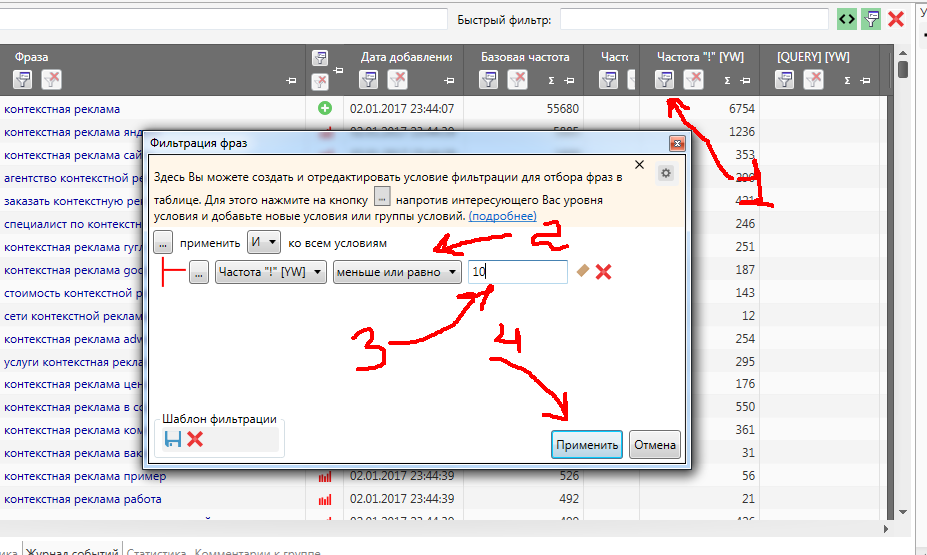
Теперь программа покажет вам только те запросы, частотность которых меньше или равна значению “10”. Эти запросы вы можете удалить или скопировать на будущее в другую группу ключевых запросов. Меньше 10 – это очень мало. Писать статьи под эти запросы – пустая трата времени.
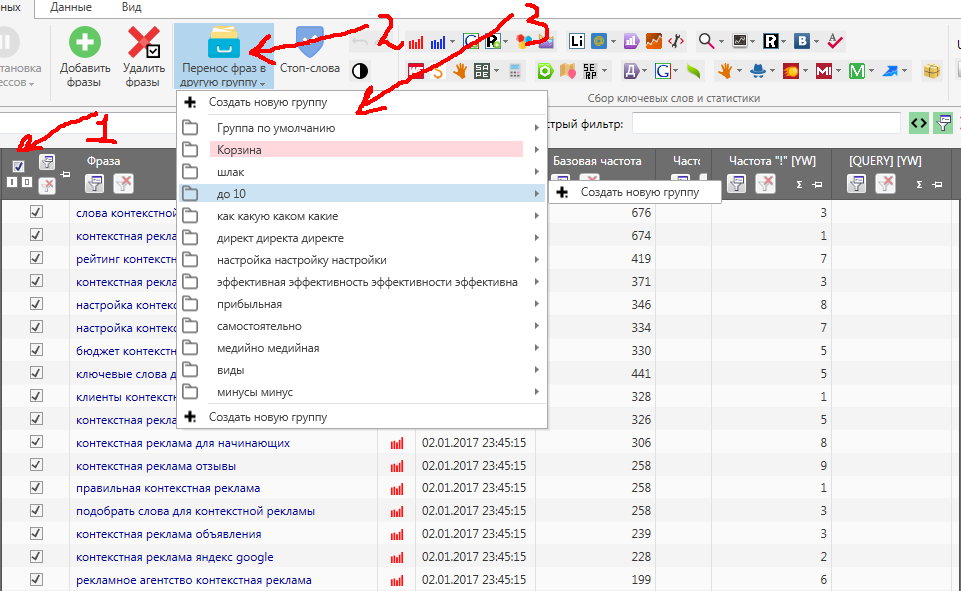
Сейчас нам надо выбрать те ключевые запросы, которые принесут нам более или менее хороший трафик. И для этого нам надо выяснить еще один параметр – уровень конкурентности запроса.
Шаг #4 – Проверка конкурентности запросов
Все “ключи” в этом мире делятся на 3 типа: высокочастотные (ВЧ), среднечастотные (СЧ), низкочастотные (НЧ). А еще они могут быть выосококонкурнетными (ВК), среднеконкурентными (СК) и низкоконкурентными (НК).
Как правило, ВЧ запросы являются одновременно и ВК. То есть если запрос часто ищут в интернете, то и сайтов, которые хотят по нему продвигаться – очень много. Но это не всегда так, бывают счастливые исключения.
Искусство составления семантического ядра как раз и заключается в том, чтобы найти такие запросы, которые имеют высокую частотность, а уровень конкуренции у них низкий. Вручную определить уровень конкуренции очень сложно.
Можно ориентироваться на такие показатели, как количество главных страниц в ТОП-10, длина и качество текстов. уровень траста и тиц сайтов в ТОП выдачи по запросу. Все это даст вам некоторое представление о том, насколько жесткая борьба за позиции для этого конкретного запроса.
Но я рекомендую вам воспользоваться сервисом Мутаген. Он учитывает все парметры, о которых я сказал выше, плюс еще с десяток, о которых ни вы, ни я наверное даже не слышали. После анализа сервис выдает точное значение – какой уровень конкуренции у данного запроса.
Вот как это выглядит:
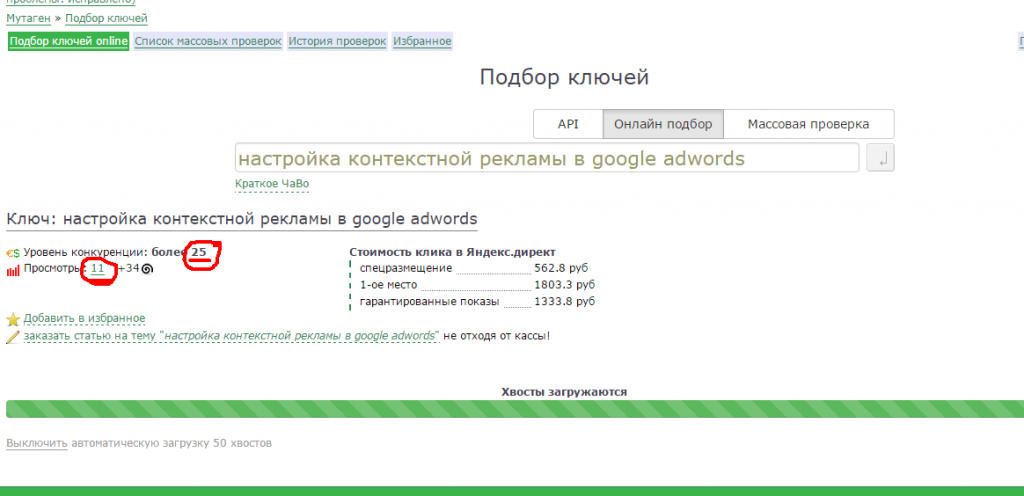
Здесь я проверил запрос “настройка контекстной рекламы в google adwords”. Мутаген показал нам, что у этого ключа конкурентность “более 25” – это максимальное значение, которое он показывает. А просмотров у этого запроса всего 11 в месяц. Значит нам он точно не подходит.
Мы можем скопировать все ключи, которые подобрали в Словоеб, и сделать массовую проверку в Мутаген. После этого нам останется только просмотреть список и взять те запросы, у которых много запросов и низкий уровень конкуренции.
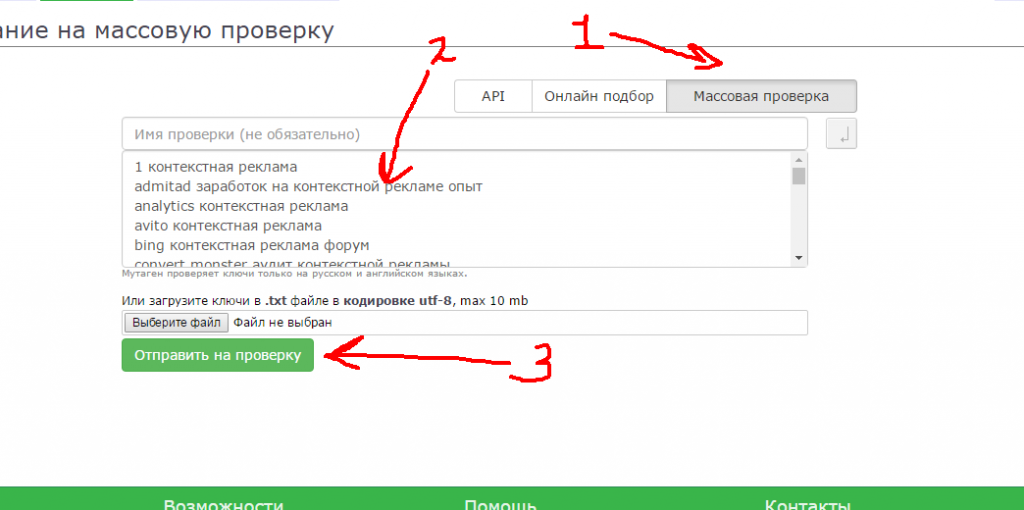
Мутаген – это платный сервис. Но 10 проверок в сутки вы можете сделать бесплатно. Кроме того, стоимость проверки очень низкая. За все время работы с ним я еще не истратил и 300 рублей.
Кстати, на счет уровня конкуренции. Если у вас молодой сайт, то лучше выбирать запросы с уровнем конкуренции 3-5. А если вы раскручиваетесь уже более года, то можно брать и 10-15.
Кстати, на счет частотности запросов. Нам сейчас надо сделать заключительный шаг, который позволит вам привлекать достаточно много трафика даже по низкочастотным запросам.
Шаг #5 – Сбор “хвостов” для выбранных ключей
Как уже много раз было доказано и проверено, основной объем трафика ваш сайт будет получать не от основных ключей, а от так называемых “хвостов”. Это когда человек вводит в поисковую строку странные ключевые запросы, с частотностью 1-2 в месяц, но таких запросов очень много.
Чтобы увидеть “хвост” – просто зайдите в Яндекс и введите выбранный вами ключевой запрос в строку поиска. Вот что вы примерно увидите.
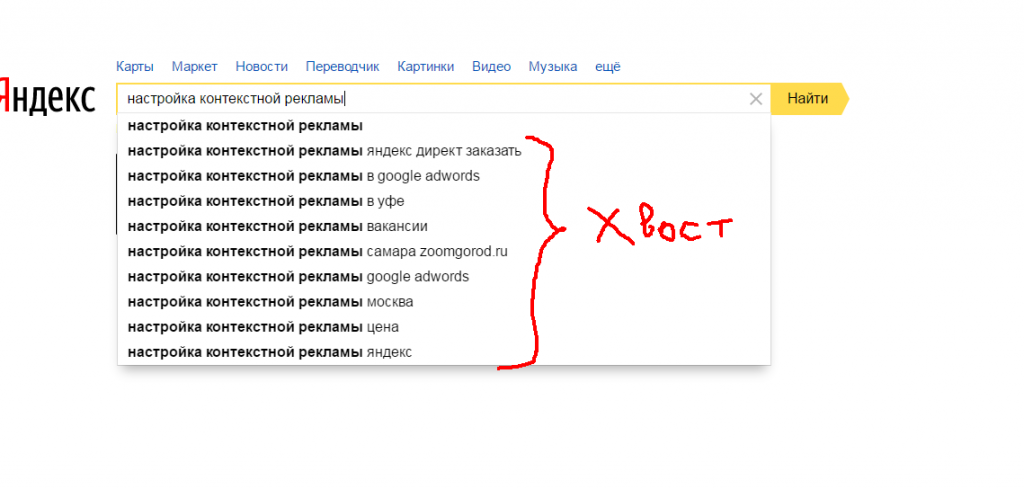
Теперь вам надо просто выписать эти дополнительные слова в отдельный документ, и использовать их в своей статье. При чем не надо ставить их всегда рядом с основным ключом. Иначе поисковые системы увидят “переоптимизацию” и ваши статьи упадут в выдаче.
Просто используйте их в разных местах вашей статьи, и тогда вы будете получать дополнительный трафик еще и по ним. Еще бы я вам рекомендовал постараться использовать как можно больше словоформ и синонимов для вашего основного ключевого запроса.
Например, у нас есть запрос – “Настройка контекстной рекламы”. Вот как можно его переформулировать:
- Настройка = настроить, сделать, создать, запустить, запуск, включить, разместить…
- Контекстная реклама = контекст, директ, тизер, РСЯ, адвордс, кмс. direct, adwords…
Никогда не знаешь, как именно люди будут искать информацию. Добавьте все эти дополнительные слова к себе в семантическое ядро, и используйте при написании текстов.
Вот так, мы собираем список из 100 – 150 ключевых запросов. Если вы составляете семантическое ядро впервые, то у вас может уйти на это несколько недель.
А может ну его, глаза ломать? Может есть возможность делегировать составления СЯ специалистам, которые сделают это лучше и быстрее? Да, такие специалисты есть, но пользоваться их услугами нужно не всегда.
Стоит ли заказывать СЯ у специалистов?
По большому счету специалисты по составлению семантического ядра сделают вам только шаги 1 – 3 из нашей схемы. Иногда, за большую дополнительную плату, сделают и шаги 4-5 – (сбор хвостов и проверку конкурентности запросов).
После этого они выдадут вам несколько тысяч ключевых запросов, с которыми вам дальше надо будет работать.
И вопрос тут в том, собираетесь ли вы писать статьи самостоятельно, или наймете для этого копирайтеров. Если вы хотите делать упор на качество, а не на количество – то надо писать самим. Но тогда вам будет недостаточно просто получить список ключей. Вам надо будет выбрать те темы, в которых вы разбираетесь достаточно хорошо, чтобы написать качественную статью.
И вот тут встает вопрос – а зачем тогда собственно нужны специалисты по СЯ? Согласитесь, распарсить базовый ключ и собрать точные частотности (шаги #1-3) – это совсем не сложно. У вас уйдет на это буквально полчаса времени.
Самое сложное – это именно выбрать ВЧ запросы, у которых низкая конкуренция. А теперь еще, как выясняется, надо ВЧ-НК, на которые вы можете написать хорошую статью. Вот именно это займет у вас 99% времени работы над семантическим ядром. И этого вам не сделает ни один специалист. Ну и стОит ли тратиться на заказ таких услуг?
Когда услуги специалистов по СЯ полезны
Другое дело, если вы изначально планируете привлекать копирайтеров. Тогда вам необязательно разбираться в теме запроса. Копирайтеры ваши тоже не будут в ней разбираться. Они просто возьмут несколько статей по этой теме, и скомпилируют из них “свой” текст.
Такие статьи будут пустыми, убогими, почти бесполезными. Но их будет много. Самостоятельно вы сможете писать максимум 2-3 качественные статьи в неделю. А армия копирайтеров обеспечит вам 2-3 говнотекста в день. При этом они будут оптимизированы под запросы, а значит будут привлекать какой-то трафик.
В этом случае – да, спокойно нанимайте специалистов по СЯ. Пусть они вам еще и ТЗ для копирайтеров составят заодно. Но сами понимаете, это тоже будет стоить отдельных денег.
Резюме
Давайте еще раз пробежимся по основным мыслям в статье для закрепления информации.
- Семантическое ядро – это просто список ключевых запросов, под которые вы будете писать статьи на сайт для продвижения.
- Необходимо оптимизировать тексты под точные ключевые запросы, иначе ваши даже самые качественные статьи никогда не выйдут в ТОП.
- СЯ – это как контент-план для социальных сетей. Он помогает вам не впадать в “творческий кризис”, и всегда точно знать, о чем вы будете писать завтра, послезавтра и через месяц.
- Для составления семантического ядра удобно использовать бесплатную программу Словоеб, надо только её правильно настроить.
- Вот пять шагов составления СЯ: 1 – Подбор базовых ключей; 2 – Парсинг базовых ключей; 3 – Сбор точной частотности для запросов; 4 – Проверка конкурентости ключей; 5 – Сбор “хвостов”.
- Если вы хотите сами писать статьи, то лучше сделайте семантическое ядро самостоятельно, под себя. Специалисты по составлению СЯ не смогут здесь вам помочь.
- Если вы хотите работать на количество и использовать копирайтеров для написания статей, то вполне можно привлечь делегировать и составления семантического ядра. Лишь бы на все хватило денег.
Надеюсь, эта инструкция была вам полезна. Сохраняйте её в избранное, чтобы не потерять, и поделитесь с друзьями. Не забудьте скачать мою книгу «Автостопом к миллиону». Там я показываю вам самый быстрый путь с нуля до первого миллиона в интернете (выжимка из личного опыта за 10 лет = )
До скорого!
Ваш Дмитрий Новосёлов

Хотели бы вы составить список ключевых фраз для сайта, который уже через 3-4 недели продвижения дал бы стабильный рост посещаемости и обращений? Сейчас мы поговорим о том, как это сделать максимально просто, быстро и правильно.
И для начала давайте посмотрим, какие проблемы в составлении семантического ядра вообще существуют. Очень часто список ключевых фраз составляется некорректно. По самым разным критериям.
В результате получаются слабые результаты продвижения. То есть, высокая стоимость посетителя и обращения с сайта. И рекламный бюджет, который вкладывается в сайт, расходуется практически впустую. Или с очень низкой степенью эффективности.
И почему так важно составить семантическое ядро эффективно и корректно?
Во-первых, чтобы увеличить количество посетителей на сайте.
Во-вторых, чтобы сократить время его выхода в ТОП.
Потому что если вы правильно составили семантическое ядро, то рост посещаемости будет уже в среднем через 3-4 недели. Говоря о какой-то средней температуре по больнице. Естественно, это сильно зависит и от сайта, и от списка ключевых фраз.
В-третьих, чтобы снизить стоимость посетителя и, соответственно, обращения с сайта. То есть, привлечение потенциального клиента с помощью сайта. И настроить стабильный рост как позиций, посещаемости, так и всего, что из этого вытекает.
Потому что, когда семантическое ядро составлено правильно, то позиции и метрики сайта постепенно растут. Это просто неизбежно. Правильно составленное семантическое ядро – это фундамент всего дальнейшего поискового продвижения. И поэтому от него очень сильно зависит успех сайта в дальнейшей выдаче.
Как правильно составить семантическое ядро сайта
Нужно учесть следующие моменты.
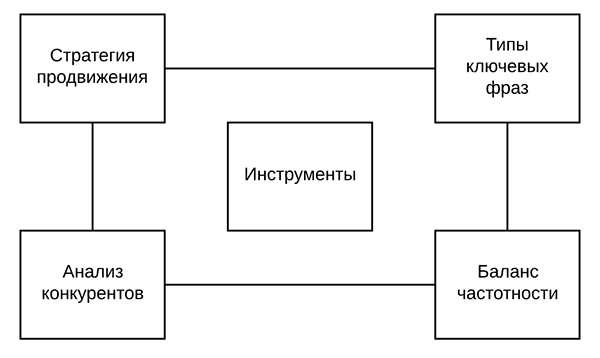
Стратегию продвижения сайта. Типы ключевых фраз. Соблюсти баланс частотности. Проанализировать конкурентов.
И все это завести на инструменты. С помощью которых, соответственно, и подобрать правильные ключевые фразы. Потому что семантическое ядро – это, по сути, список правильных ключевых фраз, по которым вас будут находить посетители в поиске.
Давайте разберем каждый из этих моментов более подробно.
1) Стратегия продвижения
Мы в работе часто сталкиваемся с тем, что при продвижении сайта у многих компаний вообще нет никакой стратегии. То есть, те компании по продвижению, к которым они обращаются, часто начинают с того, что просто открывают сайт. И примерно, «на глазок» подбирают фразы.
Очень часто с помощью автоматического сборщика или роботов. И в итоге получается не только не эффективное семантическое ядро, а практически неработающее. Именно поэтому так важно, чтобы вначале шла стратегия.
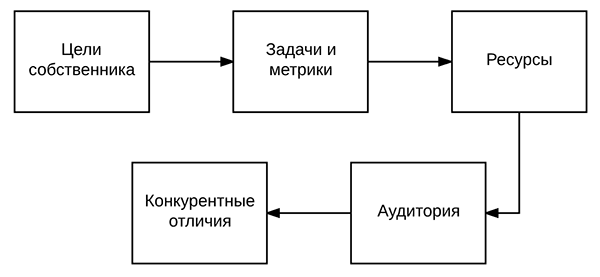
Из чего состоит стратегия? Что важно учесть перед тем, как составить семантическое ядро? В первую очередь — цели собственника или наемного руководителя. Которых они хотят достигнуть с помощью от сайта. Например, увеличить продажи в 2 раза, увеличить оборот компании или что-то подобное.
Потому что сайт – это точно такой же инструмент, как и все остальные в бизнесе. Он создан, как правило, в помощь бизнесу для увеличения количества продаж, прибыли.
У целей должно быть ограничение по времени. И какие-то цифры. При чем те, которые кажутся правда реальными. На том рынке и для того собственника, который это все просчитывает.
Дальше задачи и метрики. Они вытекают из целей. Например, цель – увеличить количество продаж. Задача – это, соответственно, посещаемость, позиции и т. д. Метрики – то, чем будет измеряться результат. То есть, KPI-показатели для сайта.
Следующий момент — это ресурсы. Что тоже очень важно. О них зачастую забывают, и это довольно распространенная ошибка. Потому что может быть так, что не хватает рекламного бюджета или людей в команде. И при этом ставятся какие-то наполеоновские планы. Стоит ли говорить, что вряд ли что-то получится?
Нужно обязательно быть реалистами в этом деле. И подбирать семантическое ядро, исходя из имеющихся ресурсов. Естественно, при достижении этих реалистичных планов, список фраз можно всегда расширить.
Также очень важно хорошо знать целевую аудиторию. И, в том числе, это отражается и на семантическом ядре.
Конкурентные отличия — то, чем компания выделяется. Чем она отличается от конкурентов? В чем ее сильные стороны? Почему клиенты должны покупать именно у нее? Обращаться в эту компанию, сайт которой продвигается.
Формулировки, количество и сложность ключевых фраз сильно зависят от стратегии. Например, компания позиционируется как элитная. Соответственно, для нее вряд ли нужно подбирать ключевые фразы в духе: “услуга дешево”. Потому что будут привлекаться не те люди.
То же самое можно отнести к любому из этих пунктов. Поэтому стратегия продвижения – это то, что в первую очередь должно рассматриваться при формировании семантического ядра.
2) Типы ключевых фраз
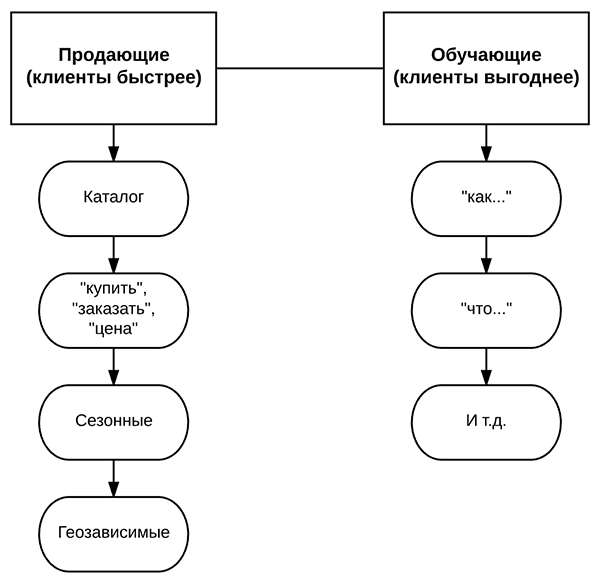
Условно говоря, можно выделить 2 основных типа. Первый – это продающие фразы. Второй – обучающие.
— Продающие
Это как раз те ключевые фразы, которые ориентированы на быстрые продажи в лоб. Например, какие-то формулировки наименований продукции или услуг в каталоге. Или к ним еще можно добавлять такие слова, как “купить”, “заказать”, “цена”, “стоимость” и т. д. Или, например, “аренда”.
Также существуют еще определенные сезонные фразы. Есть бизнесы, которые сильно зависят от сезонности. Это могут быть загородное строительство или же туризм. Например, туры в какую-то страну на Новый год.
И есть геозависимые и геонезависимые запросы. Это тоже важно. Грубо говоря, запросы, у которых выдача отличается в разных регионах. И у которых выдача одинаковая. Это если сильно упрощать. Потому что сейчас на выдачу влияют еще и другие факторы.
Тем не менее, это тоже стоит учесть. По сути, привлечение по таким запросам потенциального клиента стоит дороже. Нужно будет вложиться больше по бюджету. Но при этом цикл сделки более быстрый.
То есть тут человек уже выбирает, у кого заказать. И он видит вас. И если его устраивают какие-то ваши ключевые конкурентные преимущества, то он делает обращение. И дальше вы его доводите до сделки. Или он сразу делает заказ с сайта.
— Обучающие
Это фразы информационного плана. Когда человек еще не ищет, у кого купить. Он находится в поиске, как решить свою проблему. Поэтому может набирать запросы в духе: “как…” — и дальше решение проблемы. Или — “что…”. Или еще каким-то образом.
То есть обозначать именно такую информационную направленность. Когда он еще только подыскивает решение проблемы. И в этом случае, если у вас настроена вся цепочка привлечения клиента, то сначала он у вас обучается. И через какое-то время делает заказ.
В этом случае клиенты получаются выгоднее. Они к вам более лояльны, потому что вы их обучили. Вы им дали ценность перед тем, как что-то продать. Вы научили их пользоваться вашим товаром или услугой. И они в первую очередь будут рассматривать именно вас как кандидата, у которого купить.
Но здесь нужно выстраивать эту цепочку взаимодействия с клиентами. И если она построена, то да, будет более длительный цикл сделки. Но при этом стоимость привлечения клиента получается гораздо дешевле.
По-хорошему, желательно включить оба типа ключевых фраз в свое семантическое ядро. А стандартно берут именно продающие фразы. Но сейчас на перспективу лучше брать и обучающие тоже. И развивать свой блог.
3) Баланс частотности
Очень важно соблюдать баланс частотности ключевых фраз. Тут имеется в виду, сколько показов было в месяц. Условно говоря, фразы разделяются на низкочастотные (НЧ), среднечастотные (СЧ) и высокочастотные (ВЧ). Это такая старая терминология оптимизаторов.
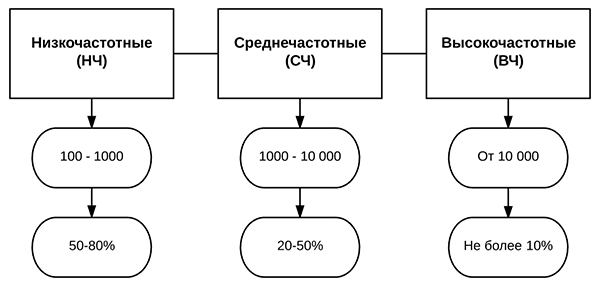
— Низкочастотные (НЧ)
Лучше составлять семантическое ядро именно из низкочастотных ключевых фраз. Сейчас это особенно актуально. Они более точные и несут более качественных клиентов. Вернее посетителей, которых проще потом превратить в клиентов.
Считается, что низкочастотные – это от 100 до 1000 показов. Или есть еще сверхнизкочастотные фразы – это когда меньше 100 показов. Как правило, лучше брать из этого диапазона и составлять из них 50-80% семантического ядра.
Пусть их будет больше. То есть, вы возьмете массой. Вывести их в ТОП гораздо проще, чем высокочастотные или среднечастотные запросы.
— Среднечастотные (СЧ)
Это фразы с частотностью примерно от 100 до 10 000 показов в месяц. И таких лучше брать от 20 до максимум 50%.
— Высокочастотные (ВЧ)
Это фразы от 10 000 показов в месяц. Иногда от 100 000 или даже выше — так называемые сверхвысокочастотники. ВЧ лучше брать не более 10%. Потому что положение таких фраз в ТОПе очень нестабильно. Приходит любой новый алгоритм — и выдача по высокочастотникам очень сильно перетасовывается. Потому вывести их в ТОП гораздо сложнее.
Естественно, это соотношение надо смотреть по ситуации и по тематике. Опять же исходить из вашей стратегии. Но в целом, если говорить о какой-то средней температуре по больнице, то порядок примерно такой.
4) Анализ конкурентов
Список ключевых фраз имеет смысл создавать, проанализировав конкурентов. Таким образом можно найти много интересных идей, как составить семантическое ядро сайта.
Каким способом это можно сделать?
Первое – просто взять те компании-лидеры, на кого вы равняетесь. Если такие есть в вашей сфере. А когда сфера достаточно конкурентная, то такие компании-флагманы все-таки есть. Может, они не во всем идеально походят, но они точно вкладываются в продвижение своих сайтов. И стоит посмотреть, по каким ключам они продвигаются.
Следующий момент – это набрать поисковую выдачу по наиболее актуальным для вашей сферы ключам. И посмотреть, кто находится в первой десятке. Какие ключевые фразы они используют для продвижения.
Также можно использовать дополнительные аналитические сервисы. Их в интернет-пространстве довольно много:
— Similarweb.com
Это зарубежный сервис. В нем можно бесплатно посмотреть некоторое количество данных. А все остальное уже платно.
Это сервис, который анализирует весь массив трафика, который дается на сайт. Не только поисковое продвижение, но и контекстную рекламу, и другие. На нем можно смотреть разные статистические выкладки, графики и т. д.
— Advse.ru
Произносится как “адвсё”. В нем тоже есть часть данных бесплатно. Можно смотреть по конкретному конкуренту. И за небольшие деньги вам выдается по нему полный отчет. Он рассчитывается, исходя из объема информации.
— Spywords.ru
Этот сервис тоже для анализа — и поискового, и контекстной рекламы. Оплата в нем помесячно и с определенными параметрами.
Естественно, таких сервисов гораздо больше. Я просто привожу здесь примеры. Вы можете использовать то, что вам больше понравится. Но конкурентов имеет смысл проанализировать.
5) Инструменты
И вот вы сделали все предыдущие шаги. Давайте посмотрим, какие инструменты можно использовать для составления семантического ядра.
Для подбора вручную используется главный классический инструмент оптимизатора — Яндекс. Вордстат. В нем помимо того, что вы вбиваете в основную графу, можно смотреть дополнительный блок. То есть, что еще ищут те люди, которые искали то же самое, что и вы.
Даже одного этого инструмента вполне достаточно для старта, чтобы набросать основные ключевые направления.
А если вас интересует массовый подбор, то можно использовать и дополнительные инструменты. Например, Key-collector.ru. Вы оплачиваете лицензию и устанавливаете эту программу на компьютер. Она анализирует фразы на основе Вордстата, но уже оптом.
Причем не только частотность, но и может учитывать другие дополнительные характеристики. Такие, например, как востребованность. Насколько эта фраза эффективна в плане трафика. И так далее.
И еще есть один инструмент от Google. Для автоматического подбора на основе контента, который есть на сайте. Это Keyword Planner.
Формально он создан для того, чтобы вы могли запустить контекстную рекламу в системе Google AdWords. Но его можно использовать для составления семантического ядра и в продвижении сайта.
Или, например, для Яндекс. Директа. Хотя у него тоже есть свои инструменты. Но в принципе, Keyword Planner подходит в качестве дополнения.
Итоговый результат
Как же формировать итоговый результат? Должна получиться некая табличка. Вы можете делать ее в чем угодно.
Это электронная таблица. И вы можете сделать в ней гораздо больше вкладок. Здесь я очень упростил для наглядности. И сделал всего 2 вкладки. Одна – каталог, другая – блог.
Каталог — туда идут как раз коммерческие фразы. Которые продают в лоб. Привлекают горячий трафик, готовых к совершению действия посетителей.
Блог — тут те фразы, где люди еще не дошли до покупки, их нужно разогревать. Вести по воронке.
На каждой вкладке можно сделать такие колонки, как — ключевая фраза, частотность, комментарий. Это не эталон, а некая стандартная разбивка. Вы можете добавить что-то свое.
Какой комментарий может быть? Например, поставлена ли эта ключевая фраза в заголовок страницы title? Или что по этой фразе включили помимо продвижения еще и Яндекс. Директ. Или то, что вы хотите дополнительно отметить по поводу этой ключевой фразы. Как правило, эта колонка нужна.
Рекомендую для старта подобрать не менее 50 ключевых фраз. Слишком много тоже не надо. Не стоит гнаться за тысячами фраз и собирать весь массив. Другое дело, если вы уже давно продвигаетесь. Знаете, как правильно составить семантическое ядро. И хотите его расширить. Но начинать лучше с не очень большого, но и не очень маленького количества ключевых фраз.
Естественно, это сильно зависит от темы и от стратегии. Потому что, напоминаю, в основе лежит стратегия. Какие у вас на данный момент есть ресурсы? Какой бюджет? Какая команда? Какие инструменты для того, чтобы обработать тот поток трафика, который вы хотите?
Просто следуйте этим советам, и вы сможете составить эффективное семантическое ядро буквально в пределах часа.
Подробная инструкция от руководителя оптимизаторов в «Ашманов и партнёры» Никиты Тарасова.
Семантическое ядро — основа поискового продвижения. Если допустить ошибки на этом этапе, дальнейшая работа по SEO пойдёт под откос. Это руководство поможет собрать семантику для проекта любого масштаба и ничего не упустить.
Этапы работы
Сбор семантического ядра состоит из четырёх последовательных этапов:
-
получение маркеров* и работа с ними;
-
парсинг запросов;
- чистка запросов;
- распределение запросов и кластеризация .
*Маркером (или маркерным запросом) называют слово или словосочетание наиболее точно отражающее суть конкретной страницы сайта. Обычно в качестве основного «маркерного» запроса для страницы берётся содержимое заголовка h1. У одной страницы может быть несколько маркерных запросов.
Получение маркеров и работа с ними
На рисунке изображена последовательность действий по подбору и обработке маркеров:
Собираем список заголовков h1
Собирать заголовки вручную долго и муторно, особенно если сайт состоит из тысяч страниц. Процесс можно автоматизировать и ускорить с помощью «пауков».
«Пауки» — программы, которые эмулируют роботов поисковых систем: обходят все страницы на сайте, получают список URL-адресов и заголовков h1. Список экспортируется в любой удобный формат, например, в Excel. Вот ссылки на наиболее популярные программы:
- Screaming Frog;
- Netpeak Spider;
- Xenu’s Link Sleuth.
Корректируем заголовки
Убедитесь, что собранные маркерные запросы обладают частотностью. Если частотность вызывает сомнения, сверьтесь с «Вордстатом», а потом скорректируйте запрос или найдите более частотный.
Не используйте несколько интентов (потребностей пользователей) для продвижения на одной странице. Например, на сайте магазина мебели есть раздел «Кресла и стулья». Но пользователи так не ищут, поэтому эффективней создать два отдельных раздела «Кресла» и «Стулья».
Не проектируйте структуру сайта так, чтобы в разных разделах дублировались одинаковые страницы, как на скриншоте ниже.
В примере выше для раздела «Душ» можно оставить ссылку на раздел «Смесители для ванны и душа», но она должна вести на страницу: http://www.domain.ru/catalog/vannaya/smesiteli-dlya-vanny-i-dusha/.
Не создавайте отдельные страницы под синонимичные группы запросов вроде «дешевые матрасы», «недорогие матрасы». Они могут быть восприняты поисковыми системами как нечёткие дубли. Это может привести к проблемам с индексацией сайта: часть страниц будет исключена из поиска.
Чтобы определить, какие запросы можно продвигать на одной странице, а какие — нет, воспользуйтесь сервисом кластеризации*.
*Кластеризация — принцип группировки запросов на основании общего числа URL в поисковой выдаче.
Суть кластеризации в том, чтобы изучить, как распределены запросы у сайтов, уже находящихся в верхней десятке поисковых систем. Для определения совместимости интентов идеально подойдёт такой сервис. А про методы кластеризации подробнее расскажу ниже.
Расширяем заголовки за счёт интентов и дополнительных слов
Когда мы получили маркеры, дальше собираем ключевые слова с помощью «Вордстата». Стоит учесть, что «Вордстат» отображает только 41 страницу со статистикой по запросу.
Если мы имеем дело с частотным маркером (например, «Диван»), то есть вероятность, что весь пул запросов мы не охватим.
Как видно, запросы ещё есть, но на следующей странице результаты не отображаются
Поэтому стоит подготовить список уточняющих запросов, характерных для конкретной тематики: например, «диван купить», «диван цена» и так далее.
Готовые тематические подборки можно найти на этой странице.
Получить маркеры, сцепленные с дополнительными словами, можно при помощи формулы =СЦЕПИТЬ(A1;” “;$E$1).
Маркеры не должны содержать символы .,”?!()- и другие знаки. Замените символы в Excel на пробел, используя сочетание клавиш Ctrl и H, а затем проверьте список маркерных запросов на орфографию.
Собираем заголовки с сайтов конкурентов
Проанализируйте сайты конкурентов, находящиеся в топе выдачи по интересующим вас запросам. В ходе анализа особенно интересно получить заголовки «теговых страниц», которые заточены под конкретный пользовательский интент.
Заголовки сайтов-конкурентов можно просканировать «пауками», о которых говорилось выше (например, Screaming frog SEO spider).
Этот подход поможет расширить структуру сайта и подобрать новые запросы для семантического ядра.
Нормализуем запросы
Под нормализацией понимается определение наиболее частотной формы запроса. Это нужно, чтобы не упустить запросы с высокой частотой, приносящие больше трафика на сайт.
Если запросов немного, они состоят из двух слов, то определить наиболее частотный запрос можно в «Вордстате» при помощи операторов: “[!поисковый !запрос]”.
Например:
Если запрос состоит из трех и более слов, а запросов больше ста, проверка вручную займёт много времени. Чтобы автоматически выявлять наиболее частотную словоформу, я сделал специальный парсер на базе А-parser.
Логика работы парсера в следующем:
- в «Вордстате» запросы выводятся в порядке убывания частоты;
- каждый запрос, подаваемый на вход, заключается в кавычки, тем самым анализируются все словоформы запроса;
- в качестве результата берётся первый запрос из левой колонки, то есть наиболее частотная из словоформ.
Как видно из примера ниже, наиболее частотной словоформой является «купить диван», что подтверждается точной частотой запросов из примеров выше.
Когда мы провели работы, описанные в разделе, у нас получается список маркерных запросов, удовлетворяющий следующим критериям:
- нет опечаток;
- нет символов и знаков препинания;
- все маркерные запросы частотные;
- часть маркеров содержит дополнительные слова и словосочетания, характерные для конкретной тематики;
- в списке присутствуют наиболее частотные словоформы запросов;
Парсинг запросов
Список маркеров, который мы получили, нужно расширить дополнительными словами — «хвостами». Это поможет нам максимально охватить семантику в поисковой нише, в которой продвигается сайт. Дополнительные слова можно взять из источников, указанных на схеме ниже.
Коротко разберу особенности некоторых источников.
Поисковые подсказки «Яндекса» и Google
Основное преимущество подсказок в том, что их база намного больше, чем база того же «Вордстата».
В подсказки попадают запросы, обладающие частотой, которые реально запрашивают пользователи. В «Вордстате» же есть доля мусорных и автосгенерированных запросов, не обладающих реальным поисковым спросом.
Подсказки в «Яндексе» можно получать в формате json. В этом случае каждой поисковой подсказке присваивается определенный тип.
Ниже приведены наиболее часто встречающиеся типы подсказок:
- B и T обозначают «обычные» подсказки;
- W — это перестановка слов;
- In — автодополнение;
- Pb — порно-подсказка;
- Nav — навигационный запрос;
- Rich — расширенная подсказка-сниппет, появляется для «Википедии»;
- Tail_word — как правило, означает, что подсказка дополняется не с конца, а с начала;
- Art, Fast_w, Fresh_console, Fast — неизвестные типы.
Например, после сбора можно сразу удалить все подсказки с типом «In», что существенно уменьшит число мусорных запросов. Для сбора подсказок с указанием типов я использую парсер.
«Яндекс.Вебмастер»
В «Вебмастере» есть раздел, в котором можно получить рекомендованные поисковые запросы. Достаточно нажать на кнопку и через некоторое время список будет доступен для скачивания.
«Яндекс.Метрика» и Google Analytics
Часть запросов можно выгрузить из отчёта «Яндекс.Метрики»: «Стандартные отчеты» → «Источники» → «Поисковые запросы».
В Google Analytics также есть данные о запросах, но с 2011 года Google начал шифровать запросы пользователей, поэтому собрать большой объём информации из данного источника не получится.
Готовые базы ключевых слов
На рынке есть готовые базы ключевых слов для различных тематик. Например:
- «Букварикс»;
- pastukhov.com.
У готовых баз есть два недостатка: они обновляются нерегулярно и содержат много мусорной и автосгенерированной семантики.
Тем не менее предпочтительнее использовать базу «Букварикс». Как показали исследования коллег из Rush Analytics, она содержит минимум мусорных запросов и к тому же бесплатная.
SaaS-решения
SaaS-решения (software as a service) помогают выгружать списки запросов, по которым находится в выдаче ваш сайт или сайты конкурентов. Ниже список наиболее популярных сервисов:
- keys.so;
- «Букварикс»;
- Spywords;
- Serpstat;
- Megaindex;
- Moab.tools.
Когда получим «хвосты» для маркерных запросов, нужно объединить данные из всех источников в один список и избавиться от дублей.
Для автоматизации сбора запросов можно воспользоваться программами:
- Key collector;
- A-parser.
И сервисами:
- Rush analytics;
- «Топвизор»;
- SE Ranking.
Чистка запросов
Удаляем мусорные фразы
В процессе сбора хвостов в списки неизбежно попадают мусорные запросы. Избавится от них можно с помощью функции «Стоп слова» программы Key collector.
В качестве стоп-слов можно использовать готовые тематические подборки.
С помощью функции «Анализ групп» можно найти и удалить нецелевую семантику.
Удаление низкочастотных запросов
Часть собранных запросов может быть автосгенерированными или низкочастотными (менее трех запросов). Если такие запросы попадут в семантическое ядро, то с высокой вероятностью для них будут созданы отдельные страницы на сайте. Значимого объема трафика они не принесут, но будут отнимать краулинговый бюджет.
Краулинговый бюджет — количество страниц, которые поисковый бот может обойти за период времени.
Нижний порог частоты запроса определяется отдельно для каждой тематики. Брать в работу микро- и низкочастотные запросы стоит лишь в исключительных ситуациях (например, если продукт супермаржинальный). Пример: разработка и внедрение ERP-систем, продажа нефтеперерабатывающего оборудования и так далее.
Для определения точной частоты запросов можно воспользоваться одной из программ — Key collector или A-parser, либо сервисами:
- Spyserp;
- Rush analytics;
- «Топвизор».
После чистки вы получите список целевых запросов, обладающих достаточной частотой.
Распределение запросов и кластеризация
Основная идея кластеризации — выяснить, как распределены запросы у сайтов, находящихся в первой десятке поисковой выдачи.
Наиболее широкое распространение данная методология получила около четырёх лет назад. Правда, некоторые оптимизаторы до сих пор предпочитают распределять запросы вручную, а зря.
Кластеризация позволяет решить ряд проблем при распределении запросов по страницам сайта. Она особенно полезна на больших объемах — от 1000 запросов и более.
Определяем тип запроса (коммерческий, информационный)
Запросы «пудра» и «пудра купить» на первый взгляд про одно и тоже. Но в первом случае поисковая выдача заполнена преимущественно информационными сайтами.
Исключение составляют два сайта: pudra.ru и «Подружка»: https://www.podrygka.ru/catalog/makiyazh/litso-1/pudra/. Их в расчет не берем, так как первый ранжируется за счет вхождения запроса в домен. А второй — за счёт своей популярности и больших объёмов прямого трафика на сайт.
По запросу «пудра купить» десятку результатов поисковой выдачи занимают в основном интернет-магазины.
Можно сделать вывод, что продвинуть оба запроса на одной странице не получится. Для продвижения запроса «пудра» нужна информационная статья с достаточным объемом текста и иллюстрациями. А для продвижения запроса «пудра купить» — небольшой текст и каталог товаров с ценами.
Результаты выдачи поисковых систем — особенно «Яндекса» — достаточно сильно типизированы. Выдача состоит либо преимущественно из коммерческих сайтов, либо из информационных. Кластеризация позволяет с большой точностью отделить коммерческие запросы от информационных.
Определяем типы страниц (главная, внутренняя)
Теперь проанализируем выдачу по запросы «люстры купить» и «люстры интернет-магазин», которые также похожи. Видно, что по запросу «люстры купить» топ занимают внутренние страницы сайтов, а по запросу «люстры интернет-магазин» — главные страницы.
Следовательно, по запросу «люстра купить» продвигаем внутренние страницы с каталогом люстр, а по запросу «люстры интернет магазин» — главную страницу сайта.
Определяем совместимость продвижения запросов на одной странице
На скриншоте ниже видно, что запросы «угловые диваны» и «недорогие диваны» не имеют между собой ни одного общего URL. Для достижения лучших результатов эти запросы стоит продвигать на отдельных страницах.
Кластеризация — инструмент аналитики, который не даёт готового решения. Он собирает данные в удобном отображении для дальнейшей постобработки и анализа.
Существует два метода кластеризации:
- Hard — используется для продвижения по позициям, а также для продвижения в конкурентных тематиках. Количество запросов в кластере меньше, но точность выше.
Условие, соблюдаемое при hard-кластеризации, — у всех запросов в кластере должен быть общий набор URL.
- Soft — в основном используется для трафикового продвижения. Количество запросов в кластере больше, но точность ниже.
Условие, соблюдаемое при soft-кластеризации, — запросы сравниваются на предмет общих URL у всех запросов в группе. Например, у запроса А есть общий набор URL с запросом В, у запроса В есть общий набор URL с запросом С.
Приведу несколько популярных сервисов кластеризации:
- Spyserp — сервис, платный;
- Rush analytics — сервис, платный;
- «Топвизор» — сервис, платный;
- coolakov.ru/tools/razbivka/ — сервис, бесплатный;
- Keyassort — программа, платная.
Для постобработки кластеризованной семантики можно воспользоваться бесплатной надстройкой для Excel.
Сбор семантики для больших проектов
Если проект содержит тысячи посадочных страниц, лучше собирать семантику отдельно для каждого раздела, учитывая приоритеты бизнеса и сезонность. А затем последовательно собирать семантическое ядро для двух–трёх разделов за каждую итерацию. Такой подход позволит собрать качественное семантическое ядро и не упустить целевые запросы
Если же собирать семантическое ядро сразу под весь проект, то на выходе получатся тысячи или даже десятки тысяч кластеров запросов, которые будет сложно обработать.
Как сохранить наследственность «Маркерный запрос — URL»
На первом шаге, описанном в статье, мы выгружали табличный список «Маркерный запрос — URL». Если сохранить URL после всех корректировок с маркерными запросами, то с помощью функции ВПР в Excel можно привязать часть URL-адресов к уже раскластеризованной семантике.
То есть — если маркерный запрос находится в кластере с другими запросами и у маркерного запроса уже известен URL, то можно считать, что все запросы кластера принадлежат к этому URL.
Не стоит бояться развивать структуру сайта. Если по результатам сбора запросов и их кластеризации вы понимаете, что под часть запросов не хватает посадочных страниц, лучше создать их или в крайнем случае отказаться от продвижения части запросов. Это будет эффективнее, чем вести несколько групп запросов (часто с несовместимыми интентами) на одну страницу сайта.

Советы
Как составить семантическое ядро сайта
Руководство с комментариями опытного сеошника
Семантическое ядро — список поисковых запросов, по которым пользователь может найти сайт. Его собирают для того чтобы понять интересы целевой аудитории, продумать структуру сайта и добавить ключи в текст.
В этом материале подробно разберемся с семантикой. В начале статьи будет теоретическая часть — что это такое, для чего нужно и когда сбор семантики лучше доверить специалисту. Во второй части будет пошаговая инструкция по сбору семантики. Если вам интересна именно эта часть — кликайте: пошаговая инструкция как составить семантическое ядро.
Статья написана под надзором Lead SEO в Unisender — Сергея Лукашевича. Если после статьи у вас останутся вопросы— задайте их в комментариях Сергею 🙂
Что такое семантическое ядро
Семантическое ядро — набор слов, фраз и запросов, которые характеризуют сайт, услугу или страницу в интернете. Использование таких слов на сайте позволит нам попасть в выдачу поисковика, хотя у самой семантики функции шире — о них чуть ниже.
Например, для интернет-магазина, который продает головные уборы, в семантическое ядро будут входить слова «купить шапку», «купить кепку», «шляпы дешево», «все ли шапки одного размера» и так далее.
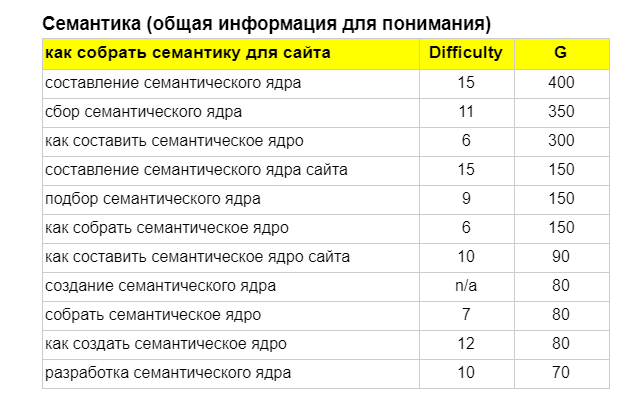
Вот так выглядит семантика для статьи, которую вы читаете. Скорее всего, если вы нашли эту статью в поиске, вы писали что-то подобное. Difficulty означает сложность запроса — чем выше, тем труднее попасть в топ выдачи. G означает частность — сколько таких запросов ищут в месяц
Для чего собирать семантическое ядро
Вот основные причины:
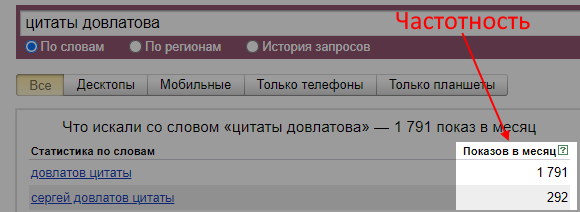
1. Исследовать интересы целевой аудитории. Анализ поисковых фраз — простой и достоверный способ узнать, как и что ищет человек: в поиске он не стесняется своих желаний. Более того, можно количественно отследить интерес людей к теме — в этом помогает частотность запросов в месяц:
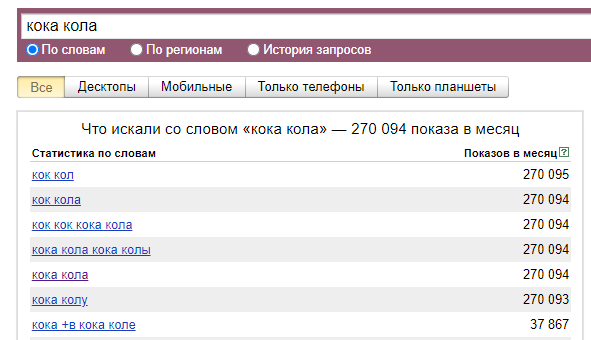
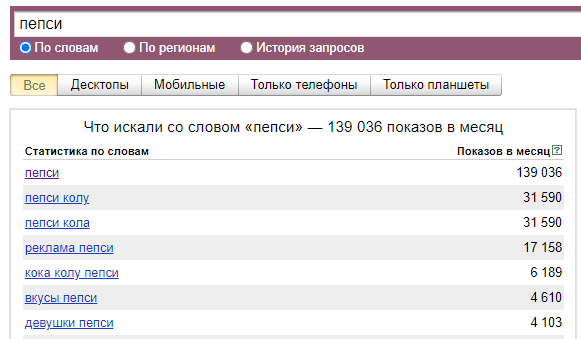
Кока кола популярнее Пепси. По данным Wordstat, запросов, связанных с ней, больше чем в два раза
Анализ семантического ядра дает подсказки в развитии бизнеса: закрыть непопулярные направления (их люди не ищут), открыть популярные — их часто ищут, а это потенциальный источник трафика и оплат.
Глобальная цель сбора семантики — понять, что хочет целевая аудитория, что ищут люди и как часто. Возможно, продукт который мы планируем выпустить или который уже есть — никому не нужен. В этом случае стоит сместить вектор развития в сторону популярных запросов.
2. Создать или доработать структуру сайта. Собранное семантическое ядро разбивается на кластеры. Кластер — группа запросов, которые поисковик считает одной темой и показывает по ней похожие результаты.
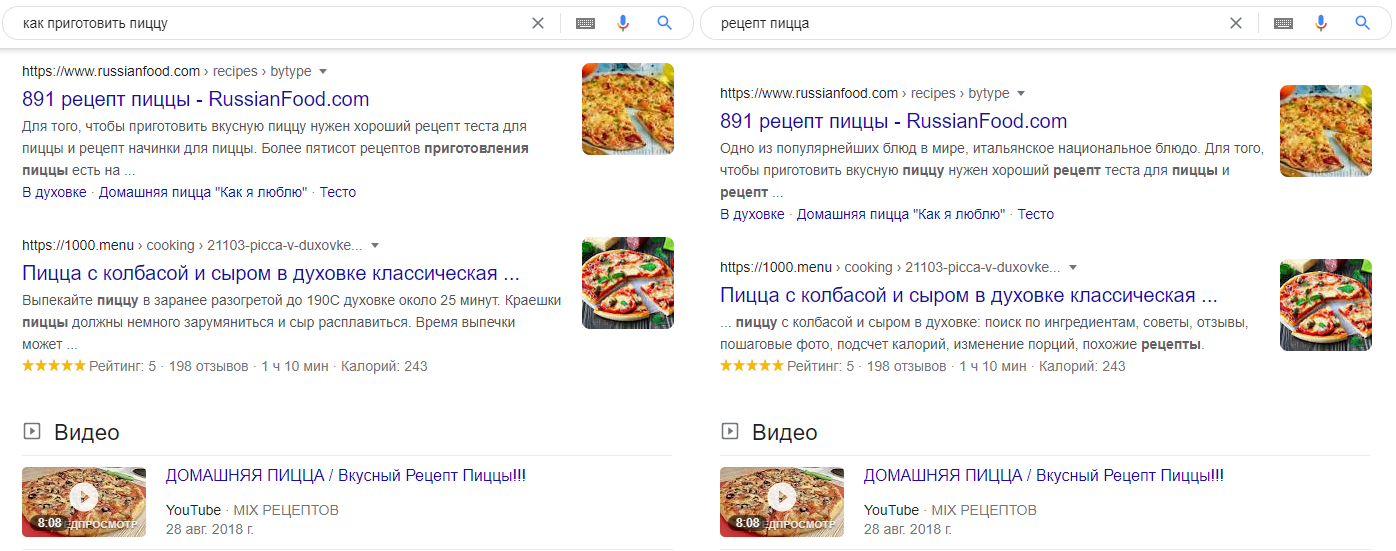
«Как приготовить пиццу» и «Рецепт пицца» — один кластер. Google выдает по этим запросам пересекающие результаты. Первые позиции совпадают полностью
Кластер — готовая идея для страницы в интернете или статьи. Разбив семантическое ядро на кластеры, мы получим грубую структуру сайта, основанную на интересах аудитории. Следуя этой структуре, мы становимся клиентоориентированными.
Семантика — практически неисчерпаемый источник идей для статей. Причем не просто статей, а статей по темам, на которые есть спрос. В блоге Unisender больше половины всех статей seo-оптимизированные. Эта статья тоже оптимизирована.
3. Оптимизировать текст под поиск. На основе семантического ядра к страницам прописывают заголовок, метатеги, описание статьи, структуру с H2 и H3 подзаголовками. А сама семантика — промежуточный этап в формировании ключевых слов (ключей). А глобально все это нужно для пассивного продвижения сайта в поиске.
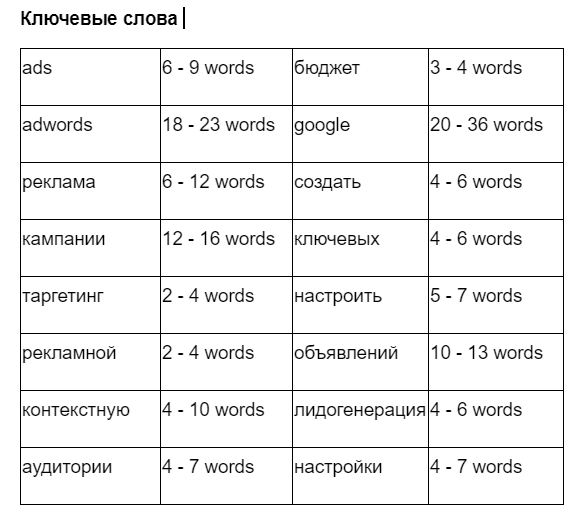
Ключи для статьи про контекстную рекламу. Справа от слова написано его рекомендуемое вхождение — сколько раз за статью оно должно быть использовано
Подбор ключей — совсем другой процесс, в котором сеошник анализирует текст конкурентов в выдаче по определенному кластеру. Через SEO-сервисы можно оценить, какие ключи и в каком количестве используются в их статьях. Если целиться на ключи конкурентов из первых мест выдачи, есть шанс, что и наш материал тоже попадет в топ.
Этап подбора ключей возможен только после составления семантического ядра и кластеризации — благодаря им, мы ищем конкурентов.
4. Отслеживать динамику страниц в поисковике. После того как собрано семантическое ядро мы можем следить за движением сайта в выдаче по определенным запросам. Например, в семантику попал запрос «как поставить мат двумя конями в шахматах». Мы написали статью на эту тему и теперь следим, как поисковик ранжирует ее.
Сначала статья будет выше сотой страницы в интернете, потом постепенно будет подниматься до тех пор, пока не достигнет первой страницы и высших строчек — это показатель того, что SEO-стратегия работает. Если же сайт застрял дальше второй-третьей страницы выдачи, мы что-то делаем неправильно. Возможно, неправильно подобраны ключи или есть другие фундаментальные проблемы. Кстати говоря, на пустой доске мат двумя конями поставить невозможно 🙂
А еще может выясниться, что по другим запросам из кластера сайт продвигается медленнее. Это повод докрутить текст, добавить ключей, оптимизировать некоторые предложения под отстающий запрос.
Семантика — это еще не все
Сбор семантики относится к SEO — оптимизации сайта под поисковую выдачу. Чем сайт оптимизированнее, тем выше вероятность, что он окажется на первой странице по ключевому запросу. Соответственно, тем больше переходов на сайт и целевых действий.
Кроме того, органика (люди, которые перешли на сайт по запросу из поисковика) бесплатна и пассивно приносит людей годами. Например, нашу статью про сокращаторы ссылок за полтора года прочитали 120 000 человек. При этом, мы не вкладывали денег в продвижение — просто правильно оптимизировали текст под поиск.
Сбор семантики — это только маленькая часть работы по SEO. На позицию сайта влияют его быстродействие, гигиена страниц, внешняя оптимизация, текстовая оптимизация и активность пользователей. Про все это подробнее можно почитать в нашем гиде по SEO. Если вы плохо ориентируетесь в поисковой оптимизации, рекомендую сначала изучать гид.
Когда семантическое ядро собирать самому, а когда лучше звать сеошника
Составление семантики — не самый сложный в мире процесс, однако в нем легко запутаться (особенно без опыта):
- Собрать много повторяющихся запросов.
- Упустить перспективные низкочастотные запросы.
- Неправильно отсеять нерелевантные запросы.
- Еще выше вероятность ошибиться на следующих этапах — кластеризации, анализе, формировании страниц в интернете.
Чем больше проект, тем выше вероятность ошибок.
Чем больше проект, тем больше нужд в специальном инструментарии
Я пользуюсь Ahrefs, SEMrush и другими. Они достаточно сложные и новичку в них будет сложно разобраться. В большом проекте может потребоваться сбор семантического ядра из 10 тысяч запросов (например, для крупного интернет-магазина) и развитая структура сайта с тысячами страниц.
Если ваш проект до 50 страниц, смело можете собирать семантику самостоятельно. Как минимум, это поможет определиться со структурой сайта и понять, на каких продуктах или услугах стоит сосредоточиться. А более тонкую работу можно оставить сеошнику, которого наймете позже.
Составление семантики — работа и она требует времени. Если вы плохо с этим знакомы, вам придется тратить время на изучение. Иногда целесообразнее сразу взять сеошника — пусть даже в рамках разового проекта.
На что обратить внимание при подборе ядра
Прежде чем собирать семантическое ядро, нужно синхронизироваться по некоторым терминам. Это теоретическая часть, чтобы лучше понимать инструкцию.
Частотность
Частотность показывает количество запросов в месяц. Запросы в семантическом ядре разделяются на высокочастотные, среднечастотные и низкочастотные. Высокочастотные ищут чаще, чем низкочастотные, а среднечастотные — что-то промежуточное между ними. Деление запросов на эти группы относительное и зависит от сферы. В каких-то сферах, 100 относится к низкочастотным, а в других — к высокочастотным.
Ранжирование
Ранжирование — сортировка сайтов в выдаче в зависимости от их рейтинга, который подсчитывают алгоритмы поисковика. Чем выше рейтинг сайта, тем лучше он ранжируется — занимает верхние строчки выдачи.
На рейтинг влияют текстовая оптимизация, адаптивность, скорость загрузки, внешние ссылки и другие параметры. Запущенный сайт с идеальными семантическим ядром не попадет в топ — поэтому не фокусируйтесь лишь на одном сборе семантики.
Конкурентность
Конкурентность запроса — величина, которая показывает сложность попасть в топ выдачи. Она зависит от конкурентов — чем их больше и чем качественные их сайты, тем сложнее будет идти продвижение.
Подробнее про конкуретность можете почитать здесь.
Опытные сеошники при сборе семантики указывают сложность (Difficulty). Если вы новичок — не парьтесь. Но если ваша ниша сильно конкурентная, опять же, нужен опытный сеошник.

Чем выше значение Difficulty, тем сложнее попасть в топ выдачи по этому запросу
Интент
Интент — это потребность пользователя, которую он хочет решить, когда вводит запрос. Некоторые запросы размыты, например, запрос «что такое осень» — пользователь хочет узнать, что такое осень или он ищет песню группы ДДТ?
Поисковики научились угадывать интент пользователя и даже по обобщенным запросам выдают нужное. И по запросу «что такое осень» все имеют в виду песню — это и показывает поисковик.
Учитывайте интент, иначе в ваше семантическое ядро попадут запросы, к которым вы не имеете отношения. Для этого просто внимательно просматривайте семантику на этапе чистки.
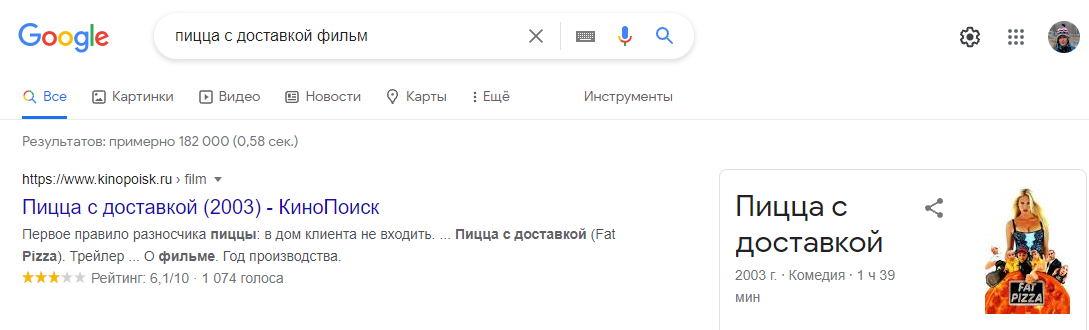
В мою семантику попал запрос «пицца с доставкой фильм». Не знал, что такой есть и поэтому было ощущение что запрос можно оставить. Но потом загуглил и вот — под пиццерию это не подходит
Геозависимость
Геозависимость — фича поисковиков, чтобы адаптировать выдачу под место проживания пользователя. Если вести «макдональдс адрес» — мне не покажут адреса фастфудов в Сыктывкаре, а покажут в моем городе.
Если у вас локальный бизнес, семантику нужно составлять с учетом геозависимости. Для этого в Яндекс Вордстат есть настройка по региону — информация будет выводиться только по нему. А если у вас онлайн бизнес, то на геозависимость можно не обращать внимания — в Вордстат по умолчанию выбраны все регионы. Но при желании можно добавить еще и страны СНГ.
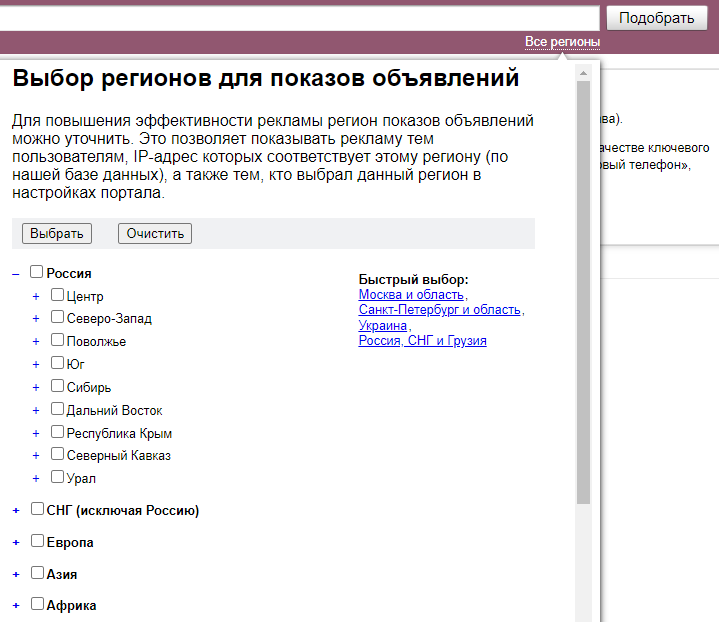
Можно выбрать как всю Россию, так и конкретный город или регион
Пошаговая инструкция как составить семантическое ядро
Подумайте, какие запросы характеризуют ваш сайт
Составление семантического ядра начинается с мозгового штурма. Ответьте на вопрос: если бы вы искали свой сайт в поисковике, то по каким запросам? Все идеи, которые придут в голову, записывайте в таблицу или текстовый документ.
Несколько советов, как охватить все интересные запросы:
- Созвонитесь с командой, особенно с теми, кто участвует в разработке продукта и делает сайт. Попросите их ответить на вопрос выше. Записывайте все идеи и фразы, которые придут в голову.
- Нужны запросы не только в рамках сайта в общем, но и в разрезе конкретных продуктов и частных вопросов клиентов. Например, сайт продает и устанавливает пластиковые окна. В семантику можно записать запросы «сколько стоит установка пластиковых окон» и «чем отличаются пластиковые окна». Такие запросы напрямую не связаны с нашими услугами, но все равно могут принести трафик, который позже конвертируется в клиентов.
- Забавный источник идей — отдел продаж и служба поддержки. Им всегда задают кучу вопросов и практически всегда эти вопросы популярны в поисковике.
Блог покроет информационные запросы и увеличит трафик на сайт
Даже если ваш сайт предполагается чисто коммерческим, я все равно рекомендую обратить внимание на информационные запросы, сделать под них специальные страницы или даже вынести в блог. Это в несколько раз ускорит продвижение и существенно увеличит трафик на сайт.
Блог ощутимо ест бюджет, особенно если организовывать собственную редакцию и налаживать регулярный выпуск материалов. Но это и не нужно — достаточно нескольких статей, которые бы отвечали на популярные запросы в поиске.
Производство статей можно отдать на аутсорс, а технически реализовать блог внутри домена несложно и недорого. В таком случае это будет лишь единовременным вложением, а не ежемесячной статьей расходов.
Теперь покажу на примере, что у вас должно получиться на этом этапе. В моем примере я собираю семантику для интернет-магазина пиццы в Оренбурге. Я сгенерировал такие запросы:
Сбор базовых ключевых слов
Все запросы, которые мы получили на прошлом этапе, поочередно вбиваем в Яндекс Wordstat или Букварикс. Все сервисы интуитивно понятны.
У Букварикс база Google и Яндекса, но я в нем не нашел функции фильтра по местности. У Яндекса это и есть, однако он раздражает вводом капчи после каждого запроса.
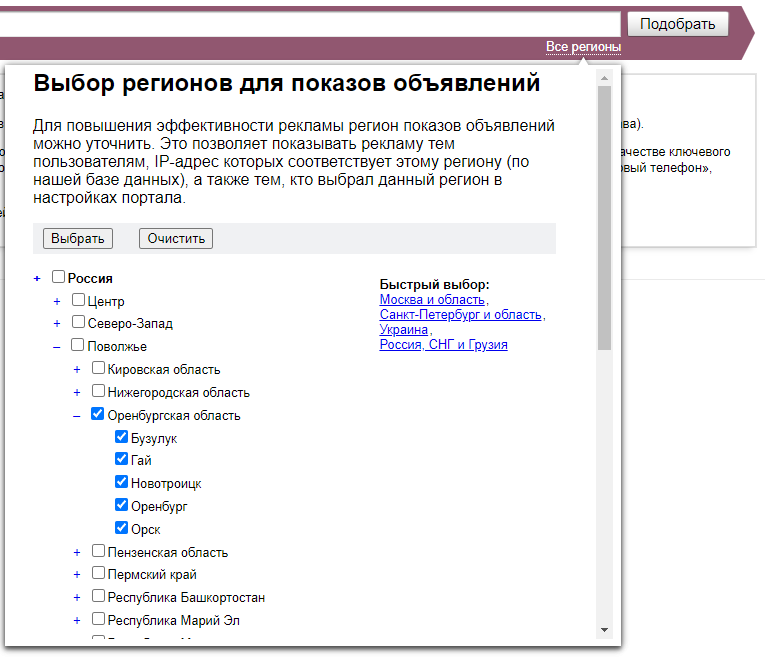
Выбор региона в Яндекс Вордстат
Поглядите, какая мне смешная капча попалась 🙂
Показываю на примере, как работаю с Яндекс Вордстат. Беру первый запрос из своего документа и ввожу его. Всю статистику из обоих столбцов копирую в Google Таблицы.
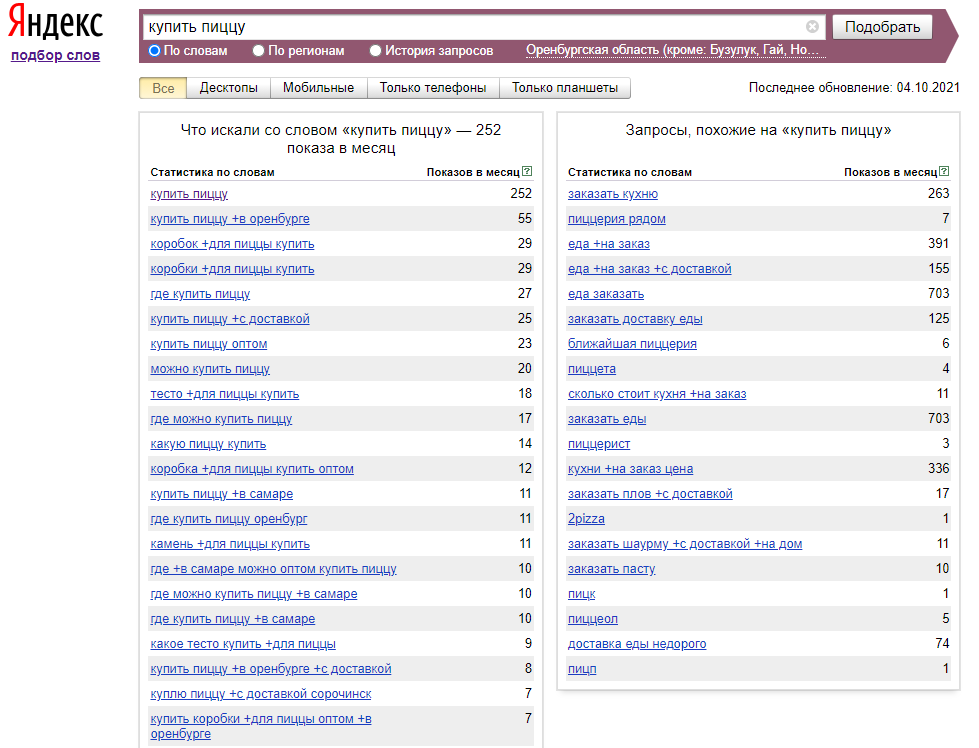
Статистика Яндекс Вордстат по запросу «купить пиццу» для Оренбурга
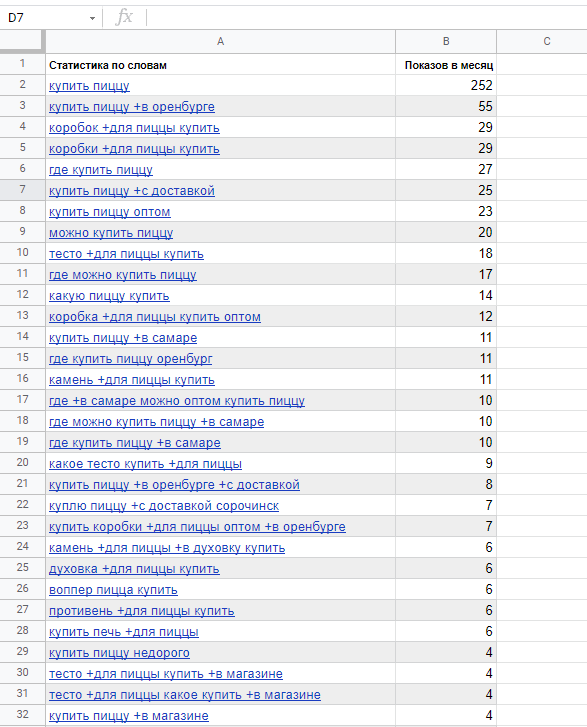
А вот так это выглядит в Google Таблицах
Располагайте запросы в один столбец. Пройдитесь по всем запросам из своего документа. Самые общие высокочастотные запросы пробейте дополнительно через Букварикс — в нем можно подсмотреть запросы, которые стоит поискать. Например:
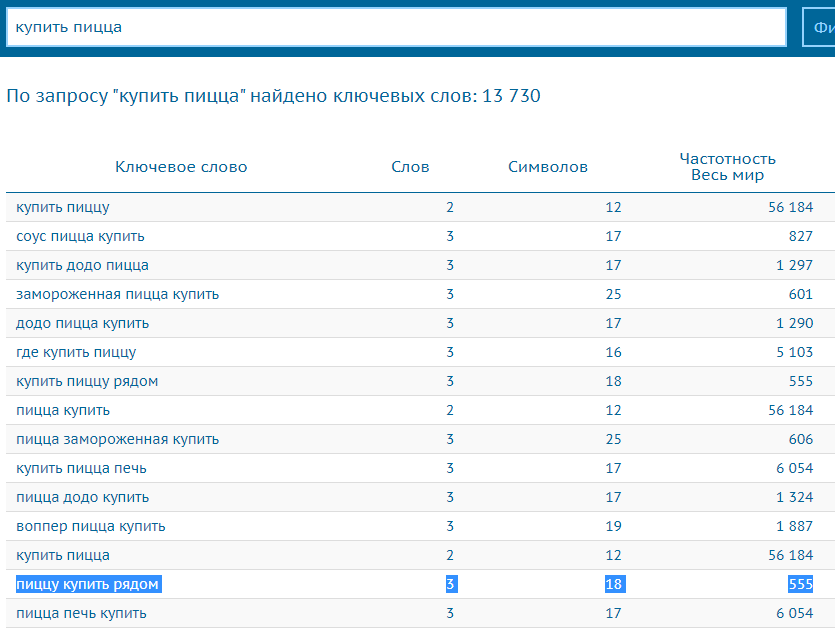
Я вбил общий запрос «купить пицца» и мне приглянулись фразы «пиццу купить рядом» и «воппер пицца купить» — последнюю часто ищут, видимо, какой-то тренд. В этот раз меня интуиция подвела: в Оренбурге «воппер пиццу» ищут 6 раз в месяц, что очень мало, а «купить пиццу рядом» не ищут вообще. Но тем не менее используйте Букварикс — это поможет вам отыскать другие перспективные запросы
Важно в процессе подбора запросов не переусердствовать. В какой-то момент это утратит смысл — в таблицу будут попадать фразы-синонимы, странная низкочастотка и другой мусор. Соблюдайте баланс — если расслабитесь слишком рано, не дойдете до перспективных среднечастотных запросов.
Как понять, что пора заканчивать собирать семантическое ядро — вопрос опыта. Тут нет идеального правила. По идее, вы сами почувствуете, что уже перебираете одно и то же — это сигнал, что вы финишировали.
Когда я только начал заниматься SEO, то любил собрать тонну запросов и копаться в них. Потом понимаешь, что это бессмыслица. Пускай лучше запросов будет меньше для каждой страницы, но они будут качественные и понятные.
Если сомневаетесь, можете собирать много запросов — мы все равно их удалим при чистке: просто это лишняя работа.
Анализ конкурентов
В интернете полно конкурентов — мы можем просканировать их через специальные сервисы и получить почти готовую семантику: важно отбирать только качественные страницы, которые высоко ранжируются в выдаче. Такие сервисы платные и разбирать в статье их функционал мы не будем. Если вам интересно, присмотритесь к следующим сервисам и изучите их самостоятельно:
- SEMRush
- Ahrefs
- Serpstat.
Почерпнуть идеи у конкурентов можно и без специализированных сервисов. Заходите на их сайт и внимательно изучайте — пощелкайте страницы в интернете и посмотрите, что пишут. Вы, скорее всего, отыщете запрос, который стоило бы включить в семантическое ядро, но который сами упустили из виду — обращайте внимание на заголовки страниц.
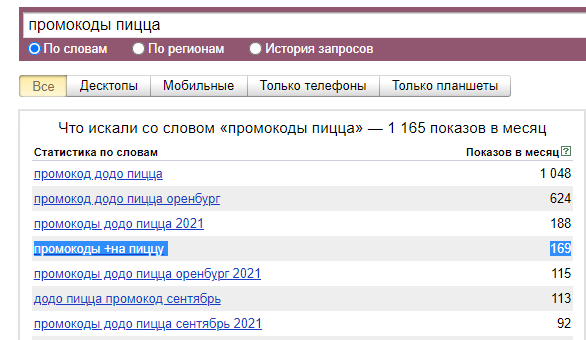
На одном сайте пиццерии я увидел раздел с акциями и стал копать в этом направлении. Попробовал запросы «пицца скидки» и «промокоды пицца». По последнему запросу неплохой результат — 169 запросов для Оренбурга, точно нужно взять. А по скидкам частотность меньше, но тоже можно использовать
Шлифуем семантику — сортируем, удаляем дубликаты и лишние символы
Удаление дубликатов. Некоторые запросы будут пересекаться. Нам они не нужны, поэтому удалим дубликаты через все тот же раздел «Данные»:
Выделяем таблицу и нажимаем вкладку «Данные», а в ней «Удалить повторы». Оставляем только столбец A — в котором содержатся сами запросы
Удалить плюсы. Они будут мешать на этапе кластеризации.
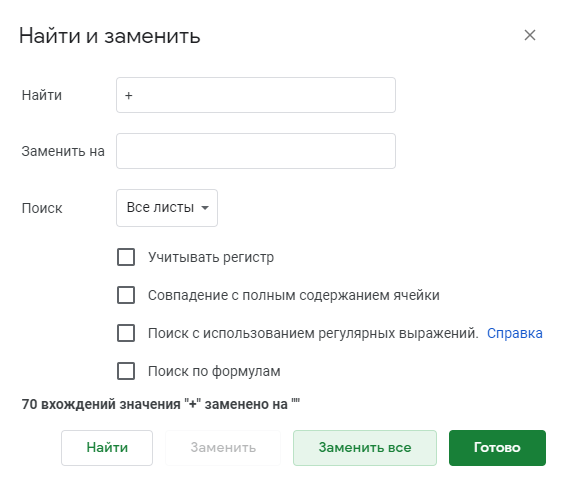
Нажмите Ctrl + F или Command + F на MacBook. В выпадающем меню выберите три точки. Либо в разделе «Правки» кликните «Найти и заменить». В поле «Найти» напишите «+», остальное оставьте без изменений. Нажмите на кнопку «Заменить все». Google удалит все плюсы из таблицы
Сортировка. Теперь всю таблицу отсортируем по убыванию частности. Отсортировать можно функционалом Google Таблиц. Этот шаг нужно повторить после следующего пункта «чистка нерелевантных запросов». При удалении запросов у нас появятся в случайных местах таблицы, а сортировка снова сведет всю семантику воедино.
Сортировка запросов по убыванию частотности. Выделяем таблицу, нажимаем «Данные» и кликаем по «Сортировать диапазон по столбцу B, Я → А». Если у вас частность не в столбце B, то сортируйте по другому столбцу
Чистка нерелевантных запросов
В семантическое ядро так или иначе попадут нерелевантные запросы — такие запросы не характеризуют наш сайт, а люди, когда их вводят, ищут совсем другое. От таких запросов нужно избавляться — трафика они не принесут.
Удаляем такие запросы:
- С упоминаниями конкурентов.
- С товарами или услугами, которые не оказываем.
- С упоминанием города, районов и улиц в которых не работаем.
- Запросы с ошибками. Даже если человек сделает ошибку в запросе, поисковик все равно переведет его на верный запрос.
- Фразы, которые вы не понимаете. С большой вероятностью это не имеет отношения к вашей компании.
- Запросы-синонимы, например, «купить смартфон» и «смартфон купить»
- Микрозапросы — их ищут ничтожно мало, такая сеошная погрешность. Зависит от сферы: например, если наша среднечастотка 200 запросов, то все запросы меньше 10 можно удалять. Тем более, если они похожи на уточнение основного запроса.
Давайте почистим ненужные ключи для нашего примера с пиццерией. Их получилось много:
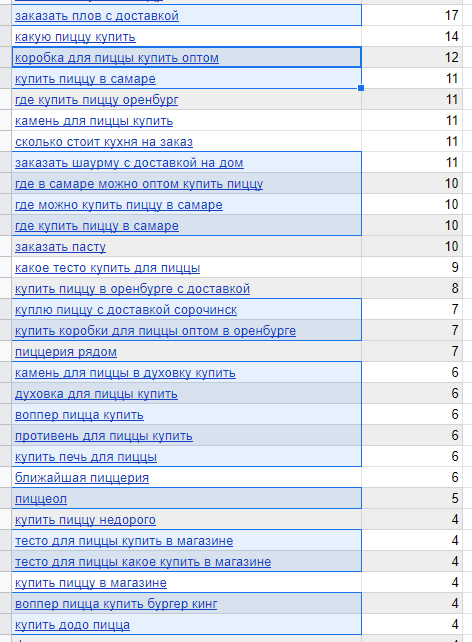
Плов и шаурму я не продаю. Печку, камень, противень, тесто и коробки для пиццы тоже. Воппер-пиццы нет в моем ассортименте. Удаляем.
Несмотря на то, что я смотрел запросы только по Оренбургу, в результаты Яндекс Вордстата подмешались левые запросы — пицца Сорочинск и Самара. Удаляем.
«Пиццеол» — непонятный запрос, который не прояснился даже после того, как я проверил в Google — удаляем. Еще на этот скриншот попала «Додо пицца» — конкурент. Конкурентов, гораздо больше, все они выше. Конкурентов удаляем, либо переносим их в другой документ: если планируете запускать контекстную рекламу — там пригодится такая семантика.
Еще встретился запрос «чудо пицца». Я сначала не понял, потом оказалось что это местная пиццерия. Поэтому важно удалять запросы, которые вы не понимаете. Для верности можете загуглить их.
Несколько примеров с запросами под удаление. Они выделены синим:



Если запрос перспективный, но у вас нет таких услуг — переносите его в скоринг-документ
При сборе семантики часто всплывают запросы, которые близки нашему бизнесу, но таких услуг у нас еще нет. Если эти запросы перспективны и их часто ищут люди — не удаляйте их, а перенесите в скоринг-документ. Это документ с идеями развития и масштабирования бизнеса с точки зрения SEO.
В нашем примере про пиццу такие запросы — суши и роллы. Люди часто ищут их вместе с пиццей, но если мы занимаемся одной только пиццей — нам они не подходят.
Чистка — рутинный процесс, который может занять много времени. Проверять семантическое ядро нужно вручную, а иногда запросов много — больше тысячи. Ну тут ничего не поделать.
Не игнорируйте информационные запросы
При чистке важно сохранять осознанность и не делать это действие на автомате — можете пропустить интересные запросы, которые стоило бы внедрить.
В примере про пиццерию я выяснил, что люди часто ищут рецепты для пиццы — это информационный запрос. Пиццерия вполне может запустить небольшой блог, в котором будет раскрывать похожие темы. Так мы привлечем больше трафика и познакомим аудиторию со своим брендом. Бизнесу ведь нужно повышать узнаваемость — это один из инструментов.
Конечно, если человек ищет рецепт пиццы, он хочет сам ее приготовить, но в конце статьи мы можем предложить человеку купить нашу пиццу, по рецепту который он искал. У человека уже появится лояльность к нашему бренду, а когда его пицца не получится, он закажет ее у нас 😁.
Другой интересный запрос, который я увидел — «рейтинг пиццерий». Мы можем на поддомене написать статью с рейтингом популярных оренбургских пиццерий. Похожую механику мы используем в Unisender: объективно сравниваем себя с конкурентами в статьях из базы знаний.
Если вы видите, что низкочастотные запросы повторяют основные запросы, только в них содержится странный хвост — их тоже можно удалять. В нашем примере про пиццу выяснилось что все запросы с частотой 10 и меньше можно убрать — они так или иначе копируют запросы, которые уже есть.
Также удаляйте запросы-синонимы, в которых слова из запроса одни и те же, но в другой последовательности. Например, «пицца доставка» и «доставка пицца. Их можно искать вручную, но удобнее делать через программу Key Collector (платная) — там есть функция «анализ неявных дублей».
Ссылка на Google-таблицу с семантикой сайта пиццы
На этом сбор семантики закончен. Теперь ее нужно разбить на кластеры.
Кластеризация
Напомню, кластеризация — деление семантического ядра на кластеры. Кластер — группа запросов, которую поисковик считает одной темой и выдает по ней пересекающиеся результаты.
Проверить кластеры можно вручную. В режиме инкогнито вбейте запросы и проверьте выдачу. Например, «заказать пиццу» и «купить пиццу» один кластер, выдача похожа.
Проще всего кластеризовать семантику через специальные сервисы. Советуем KeyAssort — он платный, но с мощным функционалом. Еще можете присмотреться к KeyClusterer, этот уже бесплатный.
Далее будем кластеризовать семантическое ядро на примере KeyAssort. Принцип работы следующий: вы отдаете сервису свою семантику, он в зависимости от заданных параметров, проверяет пересечения, объединяет похожие запросы в кластеры и отдает вам. Вы можете посмотреть видео-инструкцию по работе с программой на официальном сайте, а я здесь кратко перескажу основные действия.
Приведенный ниже пример кластеризации — упрощенная схема. Более сложный и точный подход — когда мы берем частотность и сложность ключевого слова из платных сервисов.
Импорт. Чтобы программа все загрузила верно, лучше работать через шаблон. Скачать шаблон.
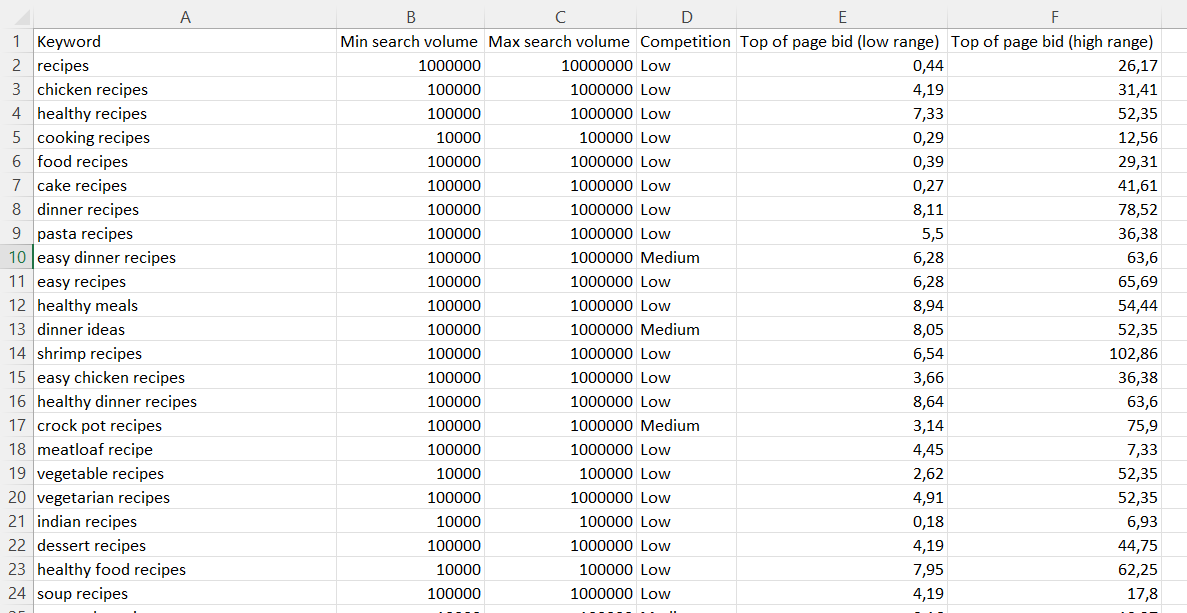
В первый столбец копируем запросы, а частотность копируем во второй и третий столбец (Mix search volume и Max search volume) — то есть их нужно продублировать. Поставьте значение «0» во всех остальных ячейках и «low» в Сompetition. Теперь импортируем:
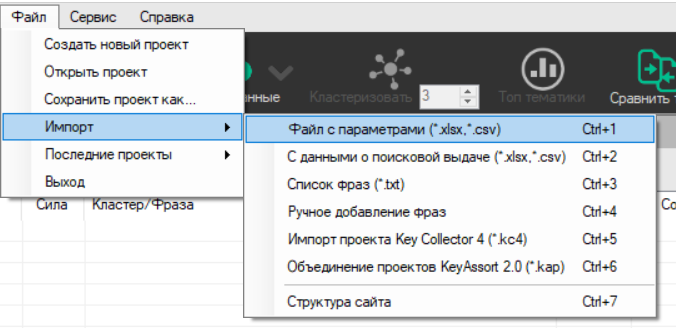
В меню нажимаем «Файл» — «Импорт» — «Файл с параметрами»
Следующие окна оставляем без изменений:
Сбор данных. Теперь нужно, чтобы программа проанализировала запросы и выявила среди них кластеры. Нажимаем «Собрать данные» в верхнем меню:
Так как мы работали с Яндекс Вордстат, то собираем по Яндексу
У нас около 200 запросов и сбор данных займет несколько минут. Чем больше семантика — тем больше времени.
Кластеризация. Нажимаем в верхнем меню «Кластеризация» и начинаем эксперименты с настройками. Цель — получить адекватную сборку кластеров . Мы можем менять вид кластеризации, силу группировки и другие параметры — подробнее об этом читайте в справке KeyAssort.
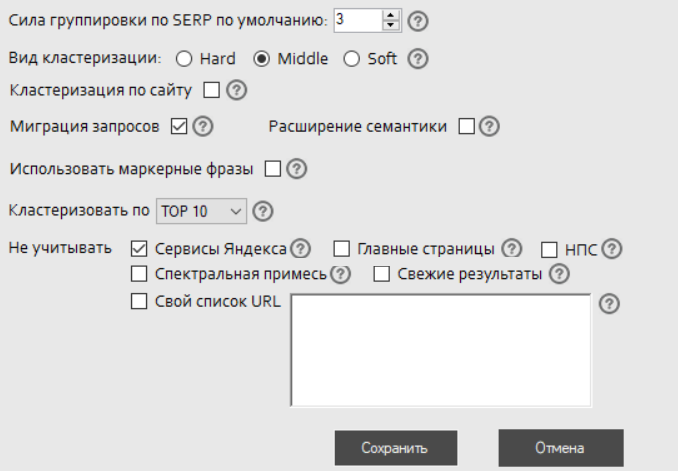
Настройка кластеризации
Меняйте настройки пока не увидите адекватную сборку кластеров. Иногда приходится вручную перебрасывать запросы из одного кластера в другой чтобы получить лучший результат.
В нашем примере получился такой результат:

В последнем кластере ошибка — это не статья в блоге, а страницы пиццы
Структура будущего сайта получилась точной, но большая часть запросов попала на главную страницу — это особенность региональных проектов.
Что дальше
Теперь у вас есть собранная и кластеризованная семантика. Можно:
- Продумать структуру сайта. Под каждый кластер — своя страница.
- Отслеживать движение сайта в выдаче по ключевым запросам.
- Подумать над созданием продуктов, которые близки нашему бизнесу.
- Писать технические задания с ключевыми словами и вставлять их в страницу — но это уже совсем другая тема, в этой статье мы ее касаться не будем.
Заключение
Статья получилась большой, пробежимся по основным выводам.
Что касается базовой теории:
- Семантика — набор запросов и фраз, которые характеризуют наш сайт или конкретную страницу.
- Семантика помогает продумать структура сайта, отслеживать продвижение сайта по ключевым запросам в поиске, а также это необходимый этап перед формированием сео-ключей. Собранное ядро — отличный советник по бизнес-идеям: на разработке каких продуктов и страниц, нужно сосредоточить внимание, а от каких наоборот отказаться.
- Если у вас не очень крупный проект, есть желание и время погрузиться в SEO — собрать семантику можно самостоятельно. В остальных случаях нужен сеошник хотя бы на разовый проект.
- Собранное семантическое ядро открывает путь к текстовой оптимизации страниц — добавлению SEO-ключей и метатегов, проработке структуры статьи, ее объема и другое. Это сложнее сбора семантики и тут нужные более глубокие знания. Скорее всего, придется звать сеошника и не факт, что его устроит собранная вами семантика.
Как собрать семантику за 6 шагов:
- Обсудите с коллегами и сотрудниками, какие запросы характеризуют ваш сайт. Ответьте на вопрос: «если бы вы искали свой сайт в поисковике, то по каким запросам?»
- Вбейте все фразы из предыдущего этапа в Яндекс Вордстат и скопируйте все предложенные запросы в Google Таблицы. Дополнительно используйте Букварикс.
- Посмотрите конкурентов — изучите их разделы, вам наверняка придет идея, как расширить свою семантику.
- Шлифовка и сортировка. Удаляем дубли, микрозапросы, символы «+» из Яндекс Вордстат.
- Чистка. Удаляем непонятные фразы и все, что наш сайт дать пользователю не может. Перспективные запросы, но которые сейчас не описывают наши услуги, переносим в скоринг-документ.
- Кластеризируем семантику через KeyClusterer.
SEO-продвижение не ограничивается одной лишь семантикой и текстовой оптимизацией — это более многогранный процесс, который охватывает работу с технической и контентной частью сайта. А еще желательно публиковаться на внешних ресурсах — блогах и каталогах. Подробности про всё SEO читайте в нашем гиде.
ЭКСКЛЮЗИВЫ ⚡️
Читайте только в блоге
Unisender
Поделиться
СВЕЖИЕ СТАТЬИ
Другие материалы из этой рубрики
![]()
![]()
Не пропускайте новые статьи
Подписывайтесь на соцсети
Делимся новостями и свежими статьями, рассказываем о новинках сервиса
«Честно» — авторская рассылка от редакции Unisender
Искренние письма о работе и жизни. Свежие статьи из блога. Эксклюзивные кейсы
и интервью с экспертами диджитала.
Семантическое ядро (СЯ) — это библиотека поисковых слов, их морфологических форм и словосочетаний, которые наиболее точно характеризуют вид деятельности, товар или услугу, предлагаемые сайтом. Данное определение в целом абсолютно правильно, но в нем нет и слова о том, что правильно подобранное семантическое ядро сайта — это половина успеха в поисковом продвижении ресурса.
Как сделать семантическое ядро?
Существует два способа подбора СЯ для ресурса: автоматический и ручной.
1. Как автоматически собрать семантическое ядро
Это подбор СЯ с помощью ссылочных агрегаторов, к примеру, сервиса ROOKEE, либо специализированных программ.
В сервисе Rookee СЯ можно подобрать следующим образом: после входа в свой аккаунт вводим url сайта в поле с надписью «(Введите адрес сайта)».

Далее нажимаем «Создать автоматически». После этого загружается страница с выбором региона продвижения, тематики, поисковой системы и системы сбора статистики.

Все данные на этой странице формируются автоматически, но их можно отредактировать в зависимости от ваших потребностей.
Нажимаем на кнопку «Далее», и система начинает автоматически создавать семантическое ядро сайта. Оно собирается на основании контента вашего ресурса и поиска по собственной большой базе (более 230 млн. запросов), причем не только по точному соответствию, но и с учетом морфологии. Также Rookee показывают спрогнозированные затраты на продвижение каждого конкретного ключа и количество приведенного по нему трафика на ваш ресурс.
Из функционала на данной странице стоит обратить внимание на возможность подобрать «еще запросы» и добавить их вручную.

Безусловно, автоматический способ подбора семантического ядра является самым быстрым.
2. Как вручную собрать семантическое ядро
Это анализ множества факторов и параметров, на основании которых можно оценить, является ли тот или иной ключевой запрос рентабельным (т.е. отношение цена/количество приведенного трафика на ресурс является оптимальным). Рассмотрим подробнее именно ручной способ подбора поисковых запросов.
Ручной способ составления семантического ядра сайта: с чего начать?
В первую очередь необходимо отбросить все предрассудки, которые связаны с высокочастотными запросами (ВЧ). Частотность не является синонимом конкурентности. Такое суждение можно вынести исключительно на основании анализа ТОП 10 по каждому конкретному запросу.
Во вторую очередь необходимо тщательно изучить все направления деятельности компании. Вот именно, все направления деятельности, а не весь контент, представленный на сайте. В большинстве случаев на сайте описано далеко не все.
Изучив направления деятельности компании, можно составить список ключевых слов, по которым будет осуществляться продвижение. В большинстве случаев это будут высокочастотные запросы. К примеру, возьмем фирму, занимающуюся продажей сантехники.

В нашем семантическом ядре могут оказаться такие запросы, как шаровые краны, радиаторы отопления, смесители для ванной и т.д.
Теперь нам потребуется узнать, к какому сектору бизнеса относится компания, работает ли она в сфере B2B или B2C. У вас может возникнуть логичный вопрос: «Зачем мне это знать?» Ответ прост: это знание позволит вам подобрать более эффективный шлейф (менее частотные запросы для продвижения). Если фирма работает на рынке B2B, то её, скорее всего, будут интересовать оптовые продажи. Таким образом, к ключевым запросам можно добавить слова: «оптом», «опт», а также названия компаний—производителей, неизвестных обычному пользователю.
Добавлять в шлейф запросы для частных лиц B2B-компании не имеет смысла по двум причинам:
- Это не целевой посетитель, он не сделает заказ;
- Это не целевой посетитель, и, скорее всего, он достаточно быстро уйдет, повысив тем самым показатель отказов вашего ресурса, что отрицательно скажется на пользовательских факторах и в дальнейшем повлияет на позиции.
Теперь представим, что компанию интересуют продажи частным лицам (т.е. сектор B2C). «Какой запрос может ввести человек, чтобы уточнить, что ему нужно?», — первое, что стоит спросить у самого себя. Для нашего СЯ самыми очевидными являются:
- Купить шаровые краны
- Радиаторы отопления цена
- Стоимость смесителей для ванной
Также рекомендуется добавлять в семантическое ядро запросы, связанные с регионом продвижения, т.е. «Шаровые краны в Москве» либо «Радиаторы отопления Подольск». Также будет не лишним использовать транзакционные слова, т.е. слова, побуждающие к действию: «заказать», «с доставкой» и т.д.
Следующим этапом при подборе шлейфа запросов для продвижения является сервис Яндекс ВордСтат. Для получения более общей картины пользовательских запросов рекомендуется в поисковой строке указывать не шлейф, а ВЧ запросы.
Изучив пользовательские запросы, добавим следующие:
- Биметаллические радиаторы отопления
- Краны шаровые фланцевые
- Смесители для ванной с душем
Во время добавления запросов из ВордСтата следует обратить внимание не только на их спрос, но и на то, подходят ли они компании. Также не рекомендуется добавлять «неправильные запросы», т.е. запросы, написанные с ошибкой, например: стеллажи. Яндекс автоматически заменяет их на правильные, и вам уже нужно будет продвигаться не по запросу со спросом «1989», а по запросу со спросом «149820».
Итак, у нас уже получилось семантическое ядро из 12 запросов:
- шаровые краны
- радиаторы отопления
- смесители для ванной
- купить шаровые краны
- радиаторы отопления цена
- стоимость смесителей для ванной
- биметаллические радиаторы отопления
- краны шаровые фланцевые
- смесители для ванной с душем
- шаровые краны в Москве
- радиаторы отопления Подольск
- заказать смесители для ванной
Следующим этапом является отсев запросов, по которым продвижение будет неоправданно затянуто, чрезмерно дорого и крайне неэффективно.
Первым шагом отсева является изучение простейших «пузомерок» ресурса, который вы собираетесь продвигать:
- Возраст сайта. Можно посмотреть на сервисе ROOKEE:
- Число страниц. Число проиндексированных страниц в Яндексе можно увидеть, введя в поисковую строку следующее значение: url:www.url_сайта.ru* | url:url_сайта.ru*
- тИЦ. Можно посмотреть, введя в адресную строку следующий запрос: http://yaca.yandex.ru/yca/cy/ch/url_сайта/, где «url_сайта» — это доменное имя вашего ресурса. Там же вы можете узнать, находится ли ваш ресурс в Яндекс.Каталоге (http://yaca.yandex.ru/) или нет.
- PR (и все предыдущие параметры) также можно узнать, проведя бесплатный аудит в сервисе ROOKEE.


Если вы не знаете главного зеркала своего ресурса (прочитать подробнее), то рекомендуется вводить доменное имя без www и с www.
Также все эти значения вы можете увидеть в тулбарах (плагинах для браузеров). К примеру: http://www.recipdonor.com/bar.
На втором шаге необходимо провести сравнительный анализ пузомерок вашего ресурса и пузомерок сайтов в ТОПе. Если они приблизительно одинаковы, их прирост не будет особенно трудозатратным — такой запрос можно смело брать в продвижение. Это не значит, что новым сайтам стоит забыть о поисковом продвижении по высококонкурентным (ВК) ВЧ запросам. Более правильно составить семантическое ядро, которое позволит приводить на ваш ресурс целевой трафик, и постепенно, вместе с повышением показателей трастовости (читать «пузомерки») можно подключать к рекламной кампании дополнительные конкурентные запросы. Предположим, что на первоначальном этапе для нашего ресурса не подходят следующие запросы: радиаторы отопления цена, смесители для ванной, краны шаровые фланцевые.
В результате мы получили следующее СЯ:
- шаровые краны
- радиаторы отопления
- купить шаровые краны
- стоимость смесителей для ванной
- биметаллические радиаторы отопления
- смесители для ванной с душем
- шаровые краны в Москве
- радиаторы отопления Подольск
- заказать смесители для ванной
Безусловно, при работе с СЯ необходимо учитывать еще множество параметров: геозависимость или геонезависимость (информационность) запроса, кликабельность позиций в ТОП 10 и т.д. Но на начальном этапе всего того, что перечислено выше, будет вполне достаточно.
