Время на прочтение
10 мин
Количество просмотров 57K
Для кого эта статья

Данная статья составлена по материалам практики по курсу операционных систем в Академическом университете . Материал готовился для студентов, и ничего сложного здесь не будет, достаточно базового знания командной строки, языка C, Makefile и общих теоретических знаний о файловых системах.
Весь материал разбит на несколько частей, в данной статье будет описана вводная часть. Я коротко расскажу о том, что понадобится для разработки в ядре Linux, затем мы напишем простейший загружаемый модуль ядра, и наконец напишем каркас будущей файловой системы — модуль, который зарегистрирует довольно бесполезную (пока) файловую систему в ядре. Люди уже знакомые (пусть и поверхностно) с разработкой в ядре Linux не найдут здесь ничего интересного.
Введение
Файловая система является одной из центральных подсистем ОС. Развитие файловых систем шло вместе с развитием ОС. На настоящий момент мы имеем целый зоопарк самых разнообразных файловых систем от старой «классической» UFS , до новых интересных NILFS (хотя идея совсем не новая, посмотрите на LFS ) и BTRFS . Так что, можно сказать, теория и практика создания файловых систем вполне проработаны. Мы не будем пытаться свергнуть монстров вроде ext3/4 и BTRFS, наша файловая система будет носить исключительно образовательный характер, на ее примере мы будем знакомиться с ядром Linux.
Настройка окружения
Перед тем как лезть в ядро, подготовим все необходимое для сборки нашего модуля файловой системы. У каждого свои предпочтения в дистрибутивах Linux, но мне привычнее использовать Ubutnu, поэтому настройку окружения я буду показывать на ее примере, к счастью это совсем не трудно. Для начала нам понадобятся компилятор и средства для сборки:
sudo apt-get install gcc build-essential
Дальше нам понадобятся исходники ядра, или не понадобятся. Мы пойдем простым путем — не будем пересобирать ядро из исходников, просто установим себе заголовки ядра, этого будет достаточно, чтобы написать загружаемый модуль. Установить заголовки можно так:
sudo apt-get install linux-headers-`uname -r`
Тут я должен сделать небольшое лирическое отступление. Ковыряться в ядре на рабочей машине не самая удачная идея, поэтому настоятельно советую проделывать это все в виртуальной машине. Мы не будем делать ничего опасного, так что сохраненные данные в безопасности, но если
что-то пойдет не так, вероятно придется перезагружать систему, а это довольно быстро надоедает. Кроме того отлаживать модули ядра удобнее в виртуальной машине (такой как QEMU), хотя этот вопрос не будет рассмотрена в этой статье.
Проверяем окружение
Чтобы проверить окружение напишем и запустим модуль ядра, который не будет делать ничего полезного (Hello, World!). Посмотрим на код модуля, я его назвал super.c (не подумайте ничего, super это от superblock):
#include <linux/init.h>
#include <linux/module.h>
static int __init aufs_init(void)
{
pr_debug("aufs module loadedn");
return 0;
}
static void __exit aufs_fini(void)
{
pr_debug("aufs module unloadedn");
}
module_init(aufs_init);
module_exit(aufs_fini);
MODULE_LICENSE("GPL");
MODULE_AUTHOR("kmu");
В самом начале идут два заголовка, считайте, что они обязательная часть любого загружаемого модуля ядра, ничего интересного в них нет. Далее идут две функции aufs_init и aufs_fini — они будут вызваны после загрузки и перед выгрузкой модуля соответственно.
Некоторых из вас может смутить метка __init. __init это подсказка ядру, что функция используется только во время инициализации модуля, а значит, после инициализации модуля эту функцию можно выгрузить из памяти. Аналогичный маркер есть и для данных, впрочем, ядро вполне может игнорировать эти подсказки. Обращение к __init функциям и данным из основного кода модуля это потенциальная ошибка, поэтому во время сборки модуля проверяется, что таких обращений нет. Если же такое обращение найдено, система сборки ядра выдаст предупреждение. Аналогично проверка делается для __exit функций и данных. Если вам интересны детали того, что из себя представляют __init и __exit, то можете обратиться к исходникам .
Обратите внимание, что aufs_init возвращает int. Таким образом ядро узнает, что во время инициализации модуля что-то пошло не так — если модуль вернул не нулевое значение, значит во время инициализация произошла ошибка.
Чтобы указать какие именно функции нужно вызвать при загрузке и выгрузке модуля используются два макроса module_init и module_exit. Они раскрываются в некоторое количество компиляторной магии, но мы не будем углубляться в детали, интересующиеся могут обратиться к lxr и походить по ссылкам (надо сказать, для освоения ядра очень удобная штука).
pr_debug — это функция (на самом деле это макрос, но пока нам это не важно) вывода в лог ядра, очень похожа семейство функций printf с некоторыми расширениями, например, для печати IP и MAC адресов. Полный список модификаторов можно найти в документации к ядру. Вместе с pr_debug, есть целое семейство макросов: pr_info, pr_warn, pr_err и другие. Те кто немного знаком с разработкой модулей Linux наверняка знают про функцию printk, в принципе, макросы pr_* раскрываются в вызовы printk, так что вместо них можно использовать напрямую printk.
Далее идут макросы с информацией для потомков — лицензия и автор. Есть и другие макросы позволяющие сохранить самую разнообразную информацию о модуле, например, MODULE_VERSION, MODULE_INFO, MODULE_SUPPORTED_DEVICE и другие. Кстати, забавный факт, если вы используете лицензию отличную от GPL, то некоторые функции доступные GPL модулям вы использовать не сможете.
Теперь соберем и загрузим наш модуль. Для этого напишем Makefile, который будет собирать наш модуль:
obj-m := aufs.o
aufs-objs := super.o
CFLAGS_super.o := -DDEBUG
all:
make -C /lib/modules/$(shell uname -r)/build M=$(PWD) modules
clean:
make -C /lib/modules/$(shell uname -r)/build M=$(PWD) clean
По факту, этот Makefile для сборки вызывает Makefile ядра, который должен находиться в каталоге /lib/modules/$(shell uname -r)/build (uname -r — команда, которая возвращает версию запущенного ядра), если у вас заголовки (или исходники) ядра находятся в другом каталоге, то нужно поправить.
obj-m — позволяет указать имя будущего модуля, в нашем случае модуль будет называться aufs.ko (именно ko — от kernel object). А aufs-objs позволяет указать из каких исходных файлов собирать модуль aufs, в нашем случае будет использоваться всего один файл super.c. Кроме того, можно указать различные флаги компилятора, которые будут использоваться (в дополнение к тем, которые использует Makefile ядра) при сборке объектных файлов, в нашем случае я передаю флаг -DDEBUG при сборке super.c. Если не передавать флаг -DDEBUG, то мы не увидим вывод pr_debug в системном логе.
Чтобы собрать модуль нужно выполнить команду make. Если все хорошо, то в каталоге должен будет появится файл aufs.ko — это наш загружаемый модуль. Загрузить модуль довольно просто:
sudo insmod ./aufs.ko
Чтобы убедиться, что модуль загрузился можно посмотреть на вывод команды lsmod:
lsmod | grep aufs
Чтобы посмотреть системный лог нужно вызвать команду dmesg, и там мы должны увидеть сообщения от нашего модуля. Выгрузить модуль тоже не сложно:
sudo rmmod aufs
Возвращаемся к файловой системе
Итак окружение настроено и работает, мы научились собирать простейший модуль, загружать и выгружать его, пора взяться за файловую систему. Проектирование файловой системы должно начинаться «на бумажке», с основательного продумывания используемых структур данных и прочего. Но мы пойдем простым путем и отложим детали хранения файлов и папок (и много чего другого) на диске на следующий раз, а сейчас напишем каркас нашей будущей файловой системы.
Жизнь файловой системы начинается с регистрации. Зарегистрировать файловую систему можно с помощью вызова register_filesystem . Мы будем регистрировать файловую систему в функции инициализации модуля. Чтобы разрегистрировать файловую систему есть функция unregister_filesystem , и вызывать мы ее будем в функции aufs_fini нашего модуля.
Обе функции принимают как параметр указатель на структуру file_system_type — она будет «описывать» файловую систему, считайте, что это класс файловой системы. Полей в этой структуре хватает, но нас интересуют лишь некоторые из них:
static struct file_system_type aufs_type = {
.owner = THIS_MODULE,
.name = "aufs",
.mount = aufs_mount,
.kill_sb = kill_block_super,
.fs_flags = FS_REQUIRES_DEV,
};
В первую очередь нас интересует поле name, оно хранит название файловой системы, именно это название будет использоваться при монтировании, но об этом позже, просто запомните его.
mount и kill_sb — два поля хранящие указатели на функции. Первая функция будет вызвана при монтировании файловой системы, а вторая при размонтировании. Нам достаточно реализовать всего одну, а вместо второй будем использовать kill_block_super, которую любезно предоставляет ядро.
Поле fs_flags — хранит различные флаги, в нашем случае оно хранит флаг FS_REQUIRES_DEV, который говорит, что нашей файловой системе для работы нужен диск (хотя пока это не так). Можно этот флаг не указывать, все будет прекрасно работать и без него.
Наконец, поле owner нужно для организации счетчика ссылок на модуль. Счетчик ссылок нужен, чтобы модуль не выгрузили раньше времени, например, если файловая система была примонтирована, то выгрузка модуля может привести к краху, счетчик ссылок не позволит выгрузить модуль, пока он используется, т. е. пока мы не размонтируем файловую систему.
Теперь рассмотрим функцию aufs_mount. Она должна примонтировать устройство и вернуть структуру описывающую корневой каталог файловой системы. Звучит довольно сложно, но, к счастью, и тут ядро почти все сделает за нас:
static struct dentry *aufs_mount(struct file_system_type *type, int flags,
char const *dev, void *data)
{
struct dentry *const entry = mount_bdev(type, flags, dev,
data, aufs_fill_sb);
if (IS_ERR(entry))
pr_err("aufs mounting failedn");
else
pr_debug("aufs mountedn");
return entry;
}
По факту, большая часть работы происходит внутри функции moun_bdev, нас интересует лишь ее параметр aufs_fill_sb — это указатель на функцию (опять), которая будет вызвана из mount_bdev чтобы инициализировать суперблок. Но перед тем как мы перейдем к ней остановимся на важной для файловой подсистемы ядра структуре dentry . Эта структура представляет участок пути в имени файла, например, если мы обращаемся к файлу /usr/bin/vim, то у нас будут экземпляры структуры dirent представляющие участки пути / (корневой каталог), bin/ и vim. Ядро поддерживает кеш этих структур, что позволяет быстро искать inode (еще одна центровая структура) по имени (пути) файла. Так вот, функция aufs_mount должна вернуть dentry представляющую корневой каталог нашей файловой системы, а создаст его функция aufs_fill_sb.
Итак, aufs_fill_sb пока что самая важная функция в нашем модуле, и выглядит она так:
static int aufs_fill_sb(struct super_block *sb, void *data, int silent)
{
struct inode *root = NULL;
sb->s_magic = AUFS_MAGIC_NUMBER;
sb->s_op = &aufs_super_ops;
root = new_inode(sb);
if (!root)
{
pr_err("inode allocation failedn");
return -ENOMEM;
}
root->i_ino = 0;
root->i_sb = sb;
root->i_atime = root->i_mtime = root->i_ctime = CURRENT_TIME;
inode_init_owner(root, NULL, S_IFDIR);
sb->s_root = d_make_root(root);
if (!sb->s_root)
{
pr_err("root creation failedn");
return -ENOMEM;
}
return 0;
}
В первую очередь мы заполняем структуру super_block . Что это за структура такая? Обычно, файловые системы хранят в специальном месте раздела диска (это место выбирает файловая система) набор параметров файловой системы, таких как размер блока, количество свободных/занятых блоков, версию файловой системы, «указатель» на корневой каталог, магическое число, по которому драйвер файловой системы может проверить, что на диске хранится именно та самая файловая система, а не что-то еще, ну и прочие данные. Эта структура называется суперблоком (см. картинку ниже). Структура super_block в ядре Linux, в целом, предназначен для схожих целей, мы сохраняем в нем магическое число и dentry для корневого каталога (ту самую, которую возвращает mount_bdev).
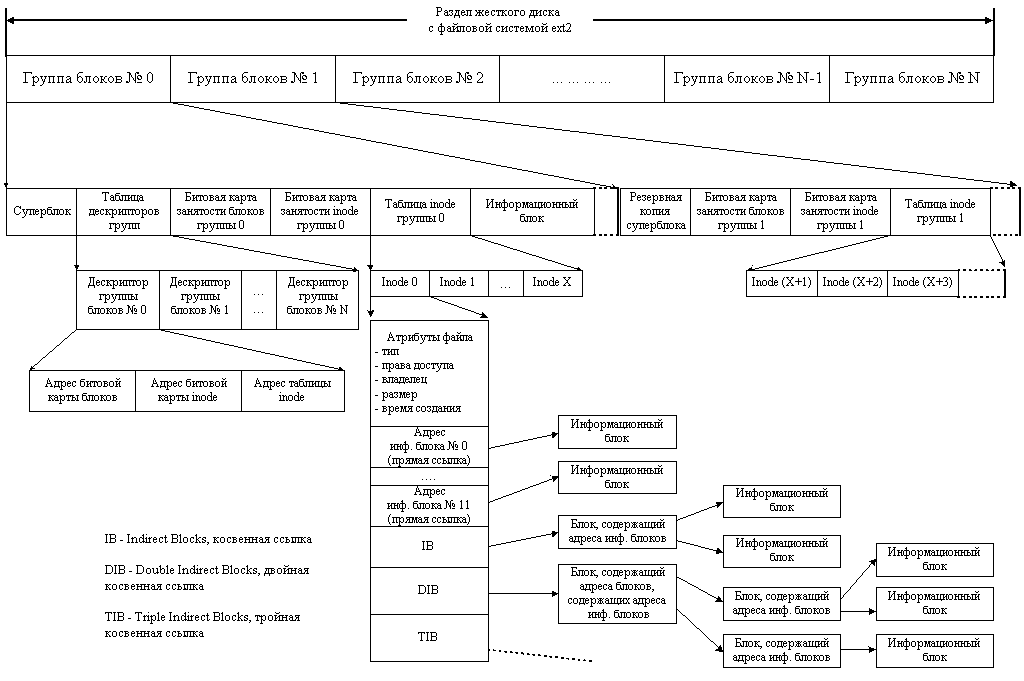
Кроме того, в поле s_op структуры super_block мы сохраняем указатель на структуру super_operations — это «методы класса» super_block, т. е. еще одна структура, которая хранит кучу указателей на функции.
Тут я сделаю еще одно отступление, ядро Linux написано на C, т. е. без поддержки различных ООП фич со стороны языка, но структурировать программу следуя идеям ООП можно и без поддержки со стороны языка, поэтому структуры содержащие кучу указателей на функции довольно часто встречаются в ядре — это такой способ реализации полиморфизма подтипов (aka виртуальных функций) имеющимися средствами.
Но вернемся к структуре super_block и ее «методам», мы не будем сейчас углубляться в детали структуры super_operations, нас будет интересовать только одно ее поле — put_super. В put_super мы сохраним «деструктор» нашего суперблока:
static void aufs_put_super(struct super_block *sb)
{
pr_debug("aufs super block destroyedn");
}
static struct super_operations const aufs_super_ops = {
.put_super = aufs_put_super,
};
Пока функция aufs_put_super ни делает ничего полезного, мы используем ее исключительно чтобы напечатать в системный лог еще одну строчку. Функция aufs_put_super будет вызвана внутри kill_block_super (см. выше) перед уничтожением структуры super_block, т. е. при размонтировании файловой системы.
Теперь вернемся к нашей самой важной функции aufs_fill_sb. Перед созданием dentry для корневого каталога мы должны создать inode корневого каталога. Структура inode является, пожалуй, самой важной в файловой подсистеме, каждый объект файловой системы (файл, папка, специальный файл, журнал и пр) идентифицируется inode. Как и с super_block, структура inode отражает то, как файловые системы хранятся на диске. Название inode происходит от index node, т. е. он индексирует файлы и папки на диске. Обычно внутри inode на диске хранится указание на то, где хранятся данные файла на диске (в каких блоках сохранено содержимое файла), различные флаги доступа (доступен для чтения/записи/исполнения), информация о владельце файла, время создания/модификации/доступа и прочие подобные вещи (см. картинку выше).
Пока мы не умеем читать с диска, так что заполняем inode фиктивными данными. В качестве времени создания/модификации/доступа используем текущее время, а назначение владельца и прав доступа делегируем ядру (вызываем функцию inode_init_owner). Ну наконец создаем dentry связанную с корневым inode.
Проверяем каркас
Каркас нашей файловой системы готов, пора его проверить. Сборка и загрузка драйвера файловой системы ничем не отличается от сборки и загрузки обычного модуля. Вместо реального диска для экспериментов мы будем использовать loop устройство. Это такой драйвер «диска», который пишет данные не на физическое устройство, а в файл (образ диска). Создадим образ диска, пока он не хранит никаких данных, поэтому все просто:
touch image
Кроме того, нам нужно создать каталог, который будет точкой монтирования (корнем) нашей файловой системы:
mkdir dir
Теперь используя этот образ примонтируем нашу файловую систему:
sudo mount -o loop -t aufs ./image ./dir
Если операция завершилась удачно, то в системном логе мы должны увидеть сообщения от нашего модуля. Чтобы размонтировать файловую систему делаем так:
sudo umount ./dir
И опять проверяем системный лог.
Итог
Мы поверхностно познакомились с созданием загружаемых модулей ядра и основными структурами файловой подсистемы. Мы также написали настоящую файловую систему, которая умеет только монтироваться и размонтироваться, пока она довольно глупая, даже сделать cd в корень файловой системы не получится, но мы собираемся исправить это в будущем.
Далее мы планируем рассмотреть чтение данных с диска, для начала мы определим, как мы будем хранить данные на дисках, и научимся читать суперблок и иноды с диска.
Список литературы и ссылки
- Код к статье лежит на github
- Не так давно, один индиец уже писал простую файловую систему с нуля в образовательных целях, он проделал очень большую работу
- Я понимаю, что отправлять новичков к исходникам ядра не очень педагогично (хотя исходники читать полезно), но тем не менее советую всем интересующимся посмотреть на исходники очень простой файловой системы ramfs . Кроме того, в отличие от нашей файловой системы ramfs не использует диск, а хранит все в памяти.
Исходные данные и результаты работы программ должны где-то храниться для дальнейшего использования. Их хранение нужно организовать так, чтобы мы могли быстро получить нужную информацию. За эту задачу отвечает Файловая система (FS): она предоставляет абстракцию для устройств, на которых физически хранятся данные.
В этом посте мы больше узнаем о концепциях, используемых файловыми системами, и о том, как, зная их, можно написать свою файловую систему на языке Rust.

Файловая система и диск
Когда данные нужно сохранить на жестком диске (HDD) или твёрдотельном накопителе (SSD), они записываются небольшими секторами (или страницами в случае SSD). Диски не знают о том, что представляет собой тот или иной фрагмент данных. Диск всего лишь хранит массив секторов. А управлять и взаимодействовать с ними должна файловая система.
Файловая система делит диск на блоки фиксированного размера. FS использует большинство этих блоков для хранения пользовательских данных, но некоторые блоки используются для хранения метаданных, которые необходимы для работы файловой системы.
На следующем рисунке приведен пример того, как файловая система структурирует информацию на диске:

Далее мы разберёмся, какие бывают типы блоков.
Суперблоки и битовые карты (bitmaps)
Суперблок хранит большую часть метаданных о файловой системе: размер блока, временные метки, сколько блоков и файлов используется, сколько свободно и так далее.
Битовые карты являются одним из способов отслеживания того, какие блоки данных и индексные дескрипторы (иноды) являются свободными. Каждому сектору в файловой системе соответствует один бит карты. Если сектор занят, то значение соответствующего бита в битовой карте устанавливается в 1, если свободен — в 0.
Инод
Инод — это структура, в которой хранятся метаданные о файле: разрешения, размер, расположение блоков данных, из которых состоит файл и многое другое.
Иноды хранятся вместе с блоками, которые вместе образуют таблицу инодов, как показано на следующем рисунке.

Для каждого сектора в битовой карте инодов с индексом, установленным в 1, в таблице будет соответствующий инод. Индекс сектора совпадает с индексом в таблице.
Блоки данных
Как следует из названия, блоки данных — это блоки, в которые записаны данные, принадлежащие файлу. Эти блоки также используются для других целей, о которых мы поговорим ниже.
Указатели на блоки данных
Инод должен иметь возможность хранить указатели на блоки данных, из которых состоит файл. Самый простой способ — хранить прямые указатели. В этом случае каждому блоку соответствует указатель на тот или иной блок файла. Проблема в том, что с большими файлами (количество блоков превышает число прямых указателей, которые может иметь инод) эта схема не работает. Одним из способов решения проблемы является использование косвенных указателей. Они указывают не на данные, а на другие указатели на блоки, содержащие пользовательские данные. Для больших файлов добавляется ещё один уровень косвенности с двойными косвенными указателями и так далее.

Чтобы получить представление о максимальном размере файла для каждого уровня, давайте возьмём фиксированный размер блока в 4 КиБ. Большинство файлов имеют небольшой размер, поэтому 12 прямых указателей позволят хранить файлы размером до 48 КиБ. Учитывая, что каждый указатель занимает 4 байта, один косвенный указатель позволит увеличить размер файла до 4 МиБ:
(12 + 1024) * 4 KiBС введением двойных косвенных указателей размер файла вырастает до 4 ГиБ:
(12 + 1024 + 1024<sup>2</sup>) * 4 KiBС добавлением тройных косвенных указателей мы получаем 4 TиБ:
(12 + 1024 + 1024<sup>2</sup> + 1024<sup>3</sup>) * 4 KiBПоэтому такой подход может быть не очень эффективным для обработки больших файлов.
Например, файл размером 100 МБ потребует 25600 блоков. В случае фрагментации блоков на диске производительность может сильно пострадать.
Некоторые файловые системы используют экстенты, которые позволяют объединить несколько логических блоков. В этом случае мы используем один указатель и задаём длину диапазона объединённых блоков. В нашем примере выше для описания файла будет использован один экстент размером 100 МБ. Для работы с более крупными файлами можно использовать несколько экстентов.
Каталоги
Возможно, вы заметили, что у каталогов нет собственной структуры. Дело в том, что инод представляет как файлы, так и каталоги. Разница заключается в том, что именно хранится в соответствующих блоках данных. Каталог — это по сути список всех файлов, которые он включает. Каждая запись имеет вид (имя, порядковый номер), поэтому при поиске определённого файла (или другого каталога) система использует имя для поиска соответствующего инода.
Поиск файла может быть медленным, если каталог содержит большое количество файлов. Эту проблему можно решить, поддерживая отсортированный список и используя бинарный поиск. Или вместо списка, можно также использовать хеш-таблицу или сбалансированное дерево поиска.
Чтение и запись
Чтение
Для чтения из файла файловой системе необходимо перебрать все иноды, которые встретятся на пути к нужному файлу. Предполагая, что пользователь имеет разрешение на доступ к файлу, файловая система проверяет, какие блоки связаны с ним, а затем считывает из них запрошенные данные.
Запись
Для записи в файл нужно выполнить тот же поиск, чтобы найти соответствующий инод. Если для записи требуется новый блок, файловая система должна выделить этот блок, обновить соответствующую информацию (битовую карту и инод) и выполнить запись в него. Таким образом, для одной операции записи требуется пять операций ввода-вывода: одна операция чтения в битовую карту, одна запись, чтобы пометить новый блок как занятый, две операции чтения и записи в инод и одна запись данных в блок. А при создании нового файла это количество может увеличиться, поскольку теперь понадобится обновление данных его каталога и создание новых инодов.
Моя файловая система (GotenksFS)
Я некоторое время изучал язык Rust и решил написать на нём свою собственную файловую систему. Я во многом опирался на ext4, а также использовал FUSE, свободный модуль для ядер UNIX-подобных ОС. Вместо диска я использовал обычный файл. Размер блока можно выставить в 1 КиБ, 2 КиБ или 4 КиБ. Файлы могут иметь размер до 4 ГиБ для блоков размером 4 КиБ. Потенциально файловая система может занимать до 16 ТиБ.
Начинаем
Первым шагом стало создание образа со значениями конфигурации для файловой системы. Это достигается с помощью команды mkfs:
$ ./gotenksfs mkfs disk.img -s "10 GiB" -b 4096После выполнения команды создаётся образ с общим размером 10 ГиБ, а каждый блок в файловой системе имеет размер 4 КиБ.
На этом этапе значения конфигурации и другие структуры, такие как корневой каталог, записываются в образ в первом блоке — то есть в суперблоке. Кроме того, заполняется битовая карта и записываются данные. Эти значения будут необходимы для следующего шага — монтирование файловой системы.
Монтирование
После создания образа нам нужно смонтировать его, чтобы мы могли начать его использовать. Для этого используем команду mount:
$ ./gotenksfs mount disk.img gotenks
Основные структуры
Суперблок записывается в первых 1024 байтах и содержит значения конфигурации, указанные в команде mkfs.
pub struct Superblock {
pub magic: u32,
pub block_size: u32,
pub created_at: u64,
pub modified_at: Option<u64>,
pub last_mounted_at: Option<u64>,
pub block_count: u32,
pub inode_count: u32,
pub free_blocks: u32,
pub free_inodes: u32,
pub groups: u32,
pub data_blocks_per_group: u32,
pub uid: u32,
pub gid: u32,
pub checksum: u32,
}Следующие два блока — это битовые карты для данных и для инода. Для таблицы инодов используется набор из n блоков. А в последующие блоки будут записываться пользовательские данные.
Инод я сформировал так:
pub struct Inode {
pub mode: libc::mode_t,
pub hard_links: u16,
pub user_id: libc::uid_t,
pub group_id: libc::gid_t,
pub block_count: u32, // should be in 512 bytes blocks
pub size: u64,
pub created_at: u64,
pub accessed_at: Option<i64>,
pub modified_at: Option<i64>,
pub changed_at: Option<i64>,
pub direct_blocks: [u32; DIRECT_POINTERS as usize],
pub indirect_block: u32,
pub double_indirect_block: u32,
pub checksum: u32,
}
Я реализовал поддержку двойных косвенных указателей — то есть, для диска с размером блока 4 КиБ максимальная ёмкость файла составит 4 ГиБ. Количество прямых указателей я ограничил двенадцатью:
pub const DIRECT_POINTERS: u64 = 12;При первом запуске FS она создаёт корневой каталог:
pub struct Directory {
pub entries: BTreeMap<OsString, u32>,
checksum: u32,
}Формируем группы блоков
Размер битовой карты для инода равен 4 КиБ, то есть в каждом блоке можно разместить 32768 инодов. Округлим это число до 128 байт: соответствующая таблица инодов потребует 4 МБ свободного места. Один из способов их структурирования выглядит так: есть множество блоков, выделенных для битовых карт, затем соответствующие числовые блоки для хранения инодов и оставшиеся блоки для пользовательских данных.
Но вместо этого мы можем создать группы блоков, которые всегда будут иметь один блок для битовой карты данных и один для битовой карты инода. Следующие 1024 блока содержат таблицу инодов, а затем идут 32768 блоков, которые используются для пользовательских данных.

Реализуем чтение и запись
Когда наш «диск» создан, можно заняться файловыми операциями. Создадим новый каталог с помощью mkdir:

Процесс создания каталога выглядит так: система ищет инод корневого каталога, затем ищет, в какой блок данных записывается содержимое, выделяет новый инод и блок данных для нового каталога, делает запись в корневой каталог и, наконец, записывает новый каталог в свой блок данных.
Создание нового файла происходит аналогичным способом: система бежит по заданному пути, пока не будет достигнут конечный каталог, и добавляет запись для нового файла.
Аргументами функции записи служат путь, буфер с данными, смещение и структура с информацией о файле, которая может содержать дескриптор файла вместе с другой, дополнительной, информацией о нём:
fn write(&mut self, path: &Path, buf: &[u8], offset: u64, file_info: &mut fuse_rs::fs::WriteFileInfo)В этом случае вместо повторного обхода пути для поиска инода система использует дескриптор файла (FS предварительно инициализирует его при создании файла). И тогда FS сможет собрать структуру, вычислив точный адрес инода:
fn inode_offsets(&self, index: u32) -> (u64, u64) {
let inodes_per_group = self.superblock().data_blocks_per_group as u64;
let inode_bg = (index as u64 - 1) / inodes_per_group;
let bitmap_index = (index as u64 - 1) & (inodes_per_group - 1);
(inode_bg, bitmap_index)
}
fn inode_seek_position(&self, index: u32) -> u64 {
let (group_index, bitmap_index) = self.inode_offsets(index);
let block_size = self.superblock().block_size;
group_index * util::block_group_size(block_size)
+ 2 * block_size as u64
+ bitmap_index * INODE_SIZE
+ SUPERBLOCK_SIZE
}Теперь, когда FS имеет информацию о том, какие блоки данных выделены для инода, она может использовать их для поиска точного адреса, чтобы записать туда данные. Новые блоки сначала добавляются в массив прямых указателей, и если размер файла превышает (12 * BLOCK_SIZE), FS выдаёт косвенный указатель (поле indirect_block). Для очень больших файлов система добавляет двойной косвенный указатель, используя поле double_indirect_block. Чтение из файла реализуется аналогично.
Ниже вы можете увидеть, как у меня работают чтение и запись:

Вывод
Главная идея, лежащая в основе реализации собственной файловой системы состоит в том, чтобы определить свою структуру содержимого на «диске», которая затем позволит системе работать с этой структурой при создании, записи и чтении из файлов и каталогов.
Важный момент — реализация косвенных указателей для хранения больших файлов. Если вам интересно узнать о файловых системах больше, я бы рекомендовал почитать о таких вещах, как журналирование, копирование при записи (Copy-On-Write), Лог-структурированные файловые системы.
Код для моего проекта файловой системы GotenksFS находится по адресу https://github.com/carlosgaldino/gotenksfs
На правах рекламы
Эпичные серверы — это надёжные серверы на Linux или Windows с мощными процессорами семейства AMD EPYC и очень быстрой файловой системой, используем исключительно NVMe диски от Intel. Попробуйте как можно быстрее!

Информатика
7 класс
Урок № 8
Файл и файловая система
Перечень вопросов, рассматриваемых в теме:
- Что такое файл, каталог.
- Виды файлов.
- Имена файлов.
- Каталоги, файловая структура.
- Графические изображения иерархической файловой структуры.
Тезаурус:
Файл – это поименованная область внешней памяти.
Операции над файлами:
- Копирование
- Перемещение
- Переименование
- Удаление
- Поиск
Маска представляет собой последовательность букв, цифр и прочих допустимых символов, среди которых также могут встречаться следующие символы:
? – означает ровно один произвольный символ
* – означает любую последовательность символов, в том числе, и пустую.
Каталог – это поименованная совокупность файлов и подкаталогов.
Файловая структура – это совокупность файлов на диске и взаимосвязей между ними.
Простые файловые структуры могут использоваться для дисков с небольшим (до нескольких десятков) количеством файлов.
Иерархические файловые структуры используются для хранения большого (сотни и тысячи) количества файлов.
Графическое изображение иерархической файловой структуры называется деревом.
Последовательно записанные: путь к файлу и имя файла, составляют полное имя файла.
Основная литература:
1. Босова Л. Л. Информатика: 7 класс. // Босова Л. Л., Босова А. Ю. – М.: БИНОМ, 2017. – 226 с.
Дополнительная литература:
- Босова Л. Л. Информатика: 7–9 классы. Методическое пособие. // Босова Л. Л., Босова А. Ю., Анатольев А. В., Аквилянов Н.А. – М.: БИНОМ, 2019. – 512 с.
- Босова Л. Л. Информатика. Рабочая тетрадь для 7 класса. Ч 1. // Босова Л. Л., Босова А. Ю. – М.: БИНОМ, 2019. – 160 с.
- Босова Л. Л. Информатика. Рабочая тетрадь для 7 класса. Ч 2. // Босова Л. Л., Босова А. Ю. – М.: БИНОМ, 2019. – 160 с.
- Гейн А. Г. Информатика: 7 класс. // Гейн А. Г., Юнерман Н. А., Гейн А.А. – М.: Просвещение, 2012. – 198 с.
Теоретический материал для самостоятельного изучения.
Компьютер человеку даёт большие возможности: создавать, копировать, передавать, хранить информацию различного рода. Данные в компьютере могут быть разными, это и документы, и рисунки, и программы, и музыка и многое другое. Так вот, все данные и программы в компьютере хранятся в виде файлов. Сегодня на уроке мы и узнаем, что такое файл.
Вам уже известно, что все программы и данные хранятся во внешней памяти компьютера в виде файлов. Файл – это поименованная область внешней памяти.
Файл характеризуется набором параметров: именем, размером, датой создания, датой последней модификации и атрибутами, которые используются операционной системой для его обработки: является ли файл системным, скрытым или предназначен только для чтения. Размер файла выражается в байтах.
Файлы, которые содержат данные – графические, текстовые называются документами, а файлы, содержащие прикладные программы, – файлами-приложениями.
Причём, файлы-документы создаются и обрабатываются с помощью файлов-приложений.
Имя файла состоит из двух частей, разделённых точкой: собственно имени файла и расширения. Имя файлу даёт пользователь, делать это нужно осмысленно, отражая в имени содержание файла. Имя файла может содержать до 255 символов национальных алфавитов и пробелы. Но в имени файлов есть и запрещённые символы, например, знак вопроса, звёздочка. Расширение имени файла задаётся программой автоматически, оно содержит 3–4 символа, которые записываются после точки.
Над файлами можно выполнять следующие действия: копирование, перемещение, переименование, удаление, поиск.
Если имя файла указано неточно, то можно использовать маску имени файла. Маска представляет собой последовательность букв, цифр и прочих допустимых символов.
На каждом компьютерном носителе информации может храниться большое количество файлов. Для удобства поиска информации файлы объединяют в группы, называемые каталогами или папками. Каталогам, как и файлам, дают собственные имена. Каждый каталог может содержать множество файлов и вложенных каталогов, может входить в состав другого каталога, тем самым, образуя определённую структуру хранения файлов. Её называют файловой структурой. Файловая структура – это совокупность файлов на диске и взаимосвязей между ними.
Любой информационный носитель операционной системы Windowsимеет корневой каталог, который создаётся без участия человека. Корневые каталоги имеют специальное обозначение с указанием имени соответствующего устройства и знака «» (обратный слэш).
Простые файловые структуры могут использоваться для дисков с небольшим количеством файлов. В этом случае оглавление диска представляет собой линейную последовательность имён файлов.
Иерархические файловые структуры используются для хранения большого количества файлов. Иерархия – это расположение частей целого в порядке от высшего к низшим. Корневой каталог содержит файлы и вложенные каталоги первого уровня.
Графическое изображение иерархической файловой структуры называется деревом, его можно изображать вертикально и горизонтально.
Чтобы обратиться к нужному файлу, который хранится, например, на жёстком диске, можно указать путь к файлу. То есть имена всех каталогов от корневого до того, в котором находится файл. Такую запись называют полным именем файла.
Разберём задачу:
Учитель работал в каталоге Д:Уроки7 класс Практические работы. Затем перешёл в дереве каталогов на уровень выше, спустился в подкаталог Презентации и удалил из него файл Введение.ppt. Каково полное имя файла, который удалил учитель?
Решение:
Учитель работал с каталогом: Д:Уроки7 классПрактические работы. Поднявшись на один уровень вверх, он оказался в каталоге Д:Уроки7 класс. После этого учитель спустился в каталог Презентации, путь к файлам которого имеет вид: D:Уроки7 класс Презентации. В этом каталоге он удалил файл Введение.ppt, полное имя которого Д:Уроки7 класс Презентации Введение.ppt.
Итак, сегодня мы узнали, что такое файл, какое имя он может иметь, какие операции можно выполнять над файлами. Также познакомились с понятиями каталог, файловая структура диска.
Материал для углубленного изучения темы.
Файловый менеджер Double Commander.
Double Commander‑ бесплатный файловый менеджер с двухоконным интерфейсом. Программа работает на разных операционных системах: Windows, Linux, MAC OS.
В программу встроены инструменты для группового переименования файлов и синхронизации, все операции выполняются в фоновом режиме, реализована поддержка вкладок, встроен просмотр файлов, эскизов, работа с архивами, расширенный поиск файлов, функция приостановки файловых операций, имеется поддержка некоторых плагинов для TotalCommander и т. д.

Внешний вид DoubleCommader является традиционным для программ подобного типа. Сверху расположены панели инструментов, список дисков, вкладки, собственно, список файлов, внизу находится командная строка и кнопки для тех, кто еще не запомнил наиболее часто используемые файловые операции, но можно скрыть эту панель,
DoubleCommander имеет огромное количество настроек. Настроить можно практически каждый элемент окна, главное найти нужные галочки или поля ввода.
Работа с избранными папками осуществляется с помощью меню, выпадающего при нажатии на кнопку «*». Выглядит оно следующим образом:

Сверху перечислены папки, добавленные в избранные, а снизу два пункта меню для добавления/удаления папки из выбранной панели в список.
Что касается группового переименования, то интерфейс для него выглядит следующим образом:

При переименовании можно использовать регулярные выражения и различные поля вроде счетчика (чтобы добавлять к каждому последующему файлу свой номер), даты, времени создания файла.
В DoubleCommander есть возможность с помощью горячих клавиш (или пункта меню) копировать в буфер обмена имя файла или полный путь до него, Правда, это решается двумя горячими клавишами: сначала переходим к «редактированию пути» в заголовке панели, затем выделенный путь можно скопировать с помощью стандартной комбинации Ctrl+C. Панель быстрого фильтра, позволяет искать файлы/папки в текущей папке, а при необходимости скрыть все файлы и папки, не удовлетворяющие критерию поиска.

Для поиска файлов в DoubleCommander довольно удобный интерфейс. Есть возможность вынесения результатов поиска на панель.
Программа DoubleCommander создана коллективом разработчиков из России, которые стремятся создать файловый менеджер, аналогичный по функциональности TotalCommander. Программа активно развивается.
Разбор решения заданий тренировочного модуля.
№1.Тип задания: выделение цветом.
Укажите, какое из указанных ниже имён файлов удовлетворяет маске ?ese*ie.?t*
Варианты ответов:
seseie.ttx
esenie.ttx
eseie.xt
sesenie.txt
Решение:
Так как маска – это последовательность букв, цифр и других, допустимых в именах файлов символов, среди которых встречаются следующие: «?» – означает ровно один последовательный символ, «*» – означает любую (в том числе и пустую) последовательность символов произвольной длины. Рассмотрев маску?ese*ie.?t*, вопросительный знак – это один символ, т.е. s, * – это последовательность символов произвольной длины, т.е. может подойти ответ первый и последний, т.к. * – это ещё и пустой символ. Но, рассматривая расширение, и также рассуждая, последний вариант ответа не подходит, потому что на втором месте стоит буква t. Следовательно, выделяем цветом первый вариант ответа.
Ответ: seseie.ttx
№2.Тип задания: восстановление последовательности элементов.
Восстановите полное имя файла.
Файл Онегин.doc хранится на жёстком диске в каталоге ПОЭЗИЯ, который является подкаталогом каталога ЛИТЕРАТУРА. В таблице приведены фрагменты полного имени файла:
|
А |
Б |
В |
Д |
Е |
|
ЛИТЕРАТУРА |
С: |
Онегин |
.doc |
ПОЭЗИЯ |
Решение:
Так как, полное имя файла начинается с корневого каталога, то на первом месте будет С:, далее идёт. Так как, каталог ПОЭЗИЯ является подкаталогом каталога ЛИТЕРАТУРА, то далее пойдёт ЛИТЕРАТУРА, затем ПОЭЗИЯ и разделяются каталоги также обратным слэшем. Ну и, учитывая, что файл Онегин.doc хранится на жёстком диске в каталоге ПОЭЗИЯ, получаем С:ЛИТЕРАТУРАПОЭЗИЯОнегин.doc.
Ответ: С:ЛИТЕРАТУРАПОЭЗИЯОнегин.doc.
Цели:
- Cформировать у учащихся навыки создания папок и
файлов. - Познакомить с операциями над файлами и папками.
Учащиеся должны знать:
- этапы создания папок;
- назначение и использование контекстного меню.
Учащиеся должны уметь:
- создавать папки и простые текстовые и
графические файлы; - передвигаться по файловой системе в любом
направлении.
ХОД УРОКА
К уроку подготовлена презентация, на первом
слайде изображена открытая папка Мои документы.
В ней имеются другие папки и файлы.
Внимание на экран:
– Что вы видите на экране?
– Как вы различаете файлы и папки?
– Назовите из них папки? Файлы?
– Что такое файл?
Вы знаете, что и программы и данные в компьютере
хранятся на жестком диске в виде файлов. Их очень
много. Очевидно, что если не навести порядок в их
хранении, то нужную информацию найти практически
невозможно. Нужна какая-то организация, а у
всякой организации есть структура.
Так вот вы знакомы с видами структур данных.
Назовите их.
- линейная (пример);
- табличная (пример);
- иерархическая (пример).
Ребята, сейчас я вам раздам файлы – это
листочки с информацией; папки – это согнутые
пополам листочки.
Найдите ответ на следующий вопрос: “Что уронил
Алеша?” (Утюг)
(Пауза)
– Почему вы потратили так много времени на поиск
ответа? (Листочки не подписаны, их много, надо их
всех прочитать, найти ответ на заданный вопрос)
– Значит нужно навести порядок! А как это
сделать? (Дать название каждому листочку (файлу),
по которому можно определить содержание,
распределить их на группы (по папкам), а
полученные папки снова положить в большую папку).
Теперь ответьте на второй вопрос:
“Сколько килограмм картофеля собрали в
течении дня?” (1650 кг)
Времени на поиск информации потратили меньше,
значит порядок навели не зря.
А теперь, самый важный вопрос: “Структуру
какого вида мы получили?” (Иерархический)
Молодцы! Вы смогли навести порядок с
листочками. А можно ли это сделать на компьютере?
А хотите научиться?
Тогда давайте запишем тему урока – “Создание
файловой структуры. Операции с файлами,
папками”.
Устали? Сделаем физкультминутку:
– скрестили пальцы рук, вывернули ладонями
наружу и подтянулись;
– плечи сжимаем, разжимаем.
Теперь давайте конкретно выясним, что мы должны
сделать за компьютером.
Мы должны научиться создавать папки, задавать
им названия, создавать, перемещать и
переименовывать файлы. Также научиться удалять и
восстанавливать файлы.
Все эти действия будем делать с помощью
контекстного меню, который появляется на экране
нажатием правой кнопки мыши.
Итак, приступаем к практической части урока.
Перед вами инструкция к практической работе.
Пользуйтесь по мере необходимости.
1. Переименовать файлы и папки.
Выделить нужный файл (папку), вызвать
контекстное меню с помощью правой кнопки мыши,
выбрать команду Переименовать, набрать
имя файла (папки).
2. Переместить файлы по соответствующим папкам.
Выделить нужный файл, не отпуская левую кнопку
мыши, переместить файл в нужную папку.
3. Создать папку Школьные предметы.
Вызвать контекстное меню с помощью правой
кнопки мыши на свободном месте рабочей области.
Выбрать команду Создать/Папку. После этого
будет создана папка под именем Новая папка.
Вести имя папки Школьные предметы и
нажать Enter.
4. Открыть папку Школьные предметы.
Перенести в нее папки математика, литература и
рисование.
5. Создать недостающие файлы в соответствующих
папках.
Давайте теперь проверим. Можно проверить с
помощью программы проводник:
– на левой панели Проводника отображаются папки
и диски;
– на правой панели отображаются содержание
открытой папки-файла и вложенных папок.
Оцените свою работу. Оценивает учитель.
А теперь мы научимся удалять и восстанавливать
файлы и папки.
- Удалим файл Яблоко.
- Восстановим его.
- Удалим папку Математика.
- Восстановим папку Математика.
Вывод: файл или папка восстанавливается на то
же место (или по тому же адресу).
Итак, ребята, чему мы с вами научились?
- Пользоваться контекстным меню.
- Создавать папку.
- Создавать файл.
- Переименовывать файл и папки.
- Перемещать файлы и папки.
- Удалять и восстанавливать файлы и папки.
В тетрадях у вас ничего не записано, поэтому эту
инструкцию вы забираете домой, приклеите его в
свою тетрадь.
Запишите домашнее задание: стр. 168, 172, 176 “Общая
информатика”.
В учебнике вы также можете найти другие способы
создания, удаления, перемещения файлов и папок.
Ознакомьтесь и на следующем уроке мы с вами
попробуем это сделать.
– Поняли ли вы тему урока?
– Что было самым трудным на уроке?
– Что больше всего запомнилось?
Приложение 1
Приложение 2
Приложение 3
Как создать удобную файловую структуру для ваших документов
После того как вы очистили компьютер от лишних файлов, пора привести в порядок все остальные1. Как должны храниться файлы в вашем компьютере? Нужно создать такие файловые структуры, которые содержат папки с названиями часто используемых вами файлов. Примерами таких папок могут быть: акты, письма, приказы, счета и т. д. Мы расскажем, как создать такую файловую структуру для вашего компьютера, чтобы все документы были у вас под рукой.
Как правильно сортировать файлы

Еще по этой теме
«Как секретарю создать электронный архив документов»
Пишите дату в названии файла. Если вам важно отслеживать дату редактирования файла, используйте ее прямо в названии файла. Дату пишите следующим образом: год в четырехзначном формате – пробел – месяц в двухзначном формате – пробел – день в двухзначном формате. Например: 2017 03 02. Тогда проводник будет упорядочивать файлы одновременно по дате создания и по имени файла (рис. 1 ниже).
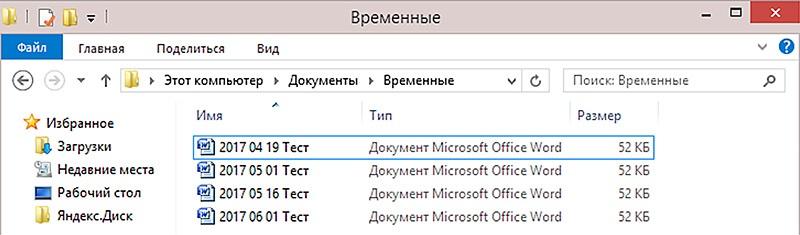
Рис. 1. Пример правильной сортировки файлов
Еще по этой теме
«Хранение электронной почты»
Не используйте дату, которая начинается с календарного дня. При сортировке по названию файла проводник выстроит ваши файлы в неправильном порядке: после июня будет идти май, затем апрель (рис. 2 ниже). Это происходит потому, что проводник рассматривает цифры не как дату, а как последовательность знаков в цифровом выражении. Правило здесь такое: сначала файлы выстраиваются по первому знаку – причем первыми идут названия с цифрами, а потом с буквами, потом по второму знаку и т. д.
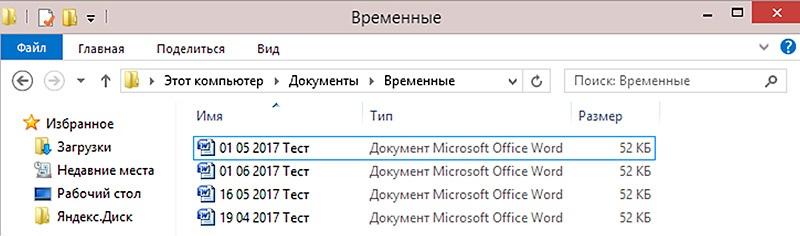
Рис. 2. Пример неправильной сортировки файлов
256
символов –
максимальная длина названия файла и пути к нему в файловой системе Windows
Дробите название файла на смысловые блоки. Помещайте названия важных для вас смысловых блоков ближе к началу названия файла. Например, если вы много работаете с согласованием документов, используйте сокращенные метки для виз согласования: «Сглсн» для «Согласовано», «СглснСЗ» для «Согласовано с замечаниями» и «НСглсн» для «Не согласовано» (рис. 3 ниже).
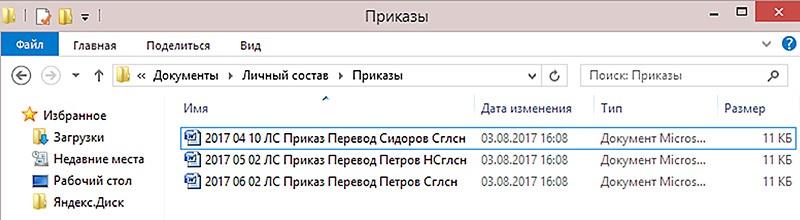
Рис. 3. Пример названий файлов с включением смысловых меток

Полезный совет
Заведите файл, в котором вы будете записывать метки и их сокращенные варианты. Так вам будет проще запомнить их
Неважно, какое сокращение вы выберете, главное, чтобы оно было понятным для вас и не слишком длинным. В файловой системе Windows есть ограничение на суммарную длину названия файла и пути к нему. Максимальная длина названия файла и пути – 256 символов. Чем грозит превышение этой длины? Если вы захотите переписать файлы на другой носитель, их нельзя будет перенести с оригинальными названиями – из понятных названий получится смесь латинских букв и символов.
Смысловые метки всегда должны идти в одной и той же последовательности и соответствовать той классификации документов, которая отражает работу вашей организации. Образец расширенной классификации документов в виде наглядной интеллект-карты.
Как организовать файлы в иерархическую структуру
Когда мы храним информацию на цифровых носителях, часто не утруждаем себя ее правильной организацией, надеясь на функцию поиска. Этот процесс бывает достаточно длительным и трудоемким. Иногда поиск может не принести результата – например, если вы не сохранили нужную версию документа или заменили ее новой, сильно отличающейся версией. Чтобы этого не произошло, организуйте ваши файлы в иерархическую структуру. Построить идеальную структуру для ваших файлов невозможно, особенно если вы только начали разрабатывать документацию. Вы можете создать ее постепенно, знакомясь с документооборотом компании. Если же вы унаследовали большой объем информации, то сможете определить по тем файлам, которые его составляют, какие именно вам нужны папки и подпапки.
Например, на одном из компьютеров хранилась информация по сотням компаний и вопросов. Все файлы секретарь распределила по следующим папкам: клиент, субподрядчик, смежник, конкурент, гос. организации, ЖКХ, связь, ремонт и обслуживание офиса, регулирующий орган, персонал и др. Внутри каждой папки сделала подпапки одного или двух уровней. Папки и подпапки отсортировала по алфавиту (рис. 4 ниже). Для более наглядного представления иерархической структуры файлов рекомендуем сделать интеллект-карту. Образец интеллект-карты здесь.
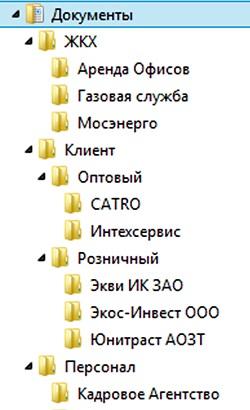
Рис. 4. Пример иерархической структуры файлов
Как структурировать файлы с помощью ярлыков и гиперссылок
Мыслить в иерархиях – это умение. Для того чтобы привыкнуть, требуется время. Однако проблема появляется тогда, когда один файл по логике принадлежит к двум и более категориям.
Пример. Вы хотите, чтобы один документ был в папке «Конкурент» и в папке «Субподрядчик», а другой – в папке «Личный состав / Заявление» и в папке «Срочные». Если вы просто скопируете документ из одной папки в другую, то неизбежен тот момент, когда вы отредактируете одну копию, а во второй забудете сделать правки. Это нарушит целостность информации и внесет неразбериху в документацию.
Выходов из ситуации может быть два: воспользуйтесь ярлыками или гиперссылками.
Используйте ярлыки. Если вам нужно поместить документ во вторую по счету папку, поместите в нее не сам документ, а его ярлык – указатель на первоначальный файл. Для этого щелкните правой кнопкой мыши на нужном файле и в выпадающем меню нажмите кнопку «Создать ярлык». Появится файл типа «Ярлык». Теперь переместите его в нужную папку – для этого используйте команды «Вырезать» и «Вставить». Вы можете копировать ярлык неограниченное число раз и помещать копии ярлыка в нужные вам папки. Теперь в какой бы папке вы не открыли оригинальный файл или один из его ярлыков, вы будете работать только с первым и уникальным документом.
Полезный совет
Когда вы рассортировываете фото по папкам, можете дать им название с использованием даты и места, где они были сделаны. Например, «2017 08 12 Питер». Для изображений из Интернета создайте отдельную папку
Используйте гиперссылки. В этом случае вы можете даже не создавать разветвленную иерархию папок и подпапок – создайте несколько самых необходимых. Вы будете упорядочивать документы в специальном файле, который можете создать в MS Word, MS Excel или в любом другом документе, который поддерживает работу с гиперссылками, – например, в интеллект-карте. Приведем пример регистрационного документа, созданного в Excel. Этот документ, в терминологии Excel – книга, должен содержать некоторое количество листов, которые будут носить названия основных категорий файлов, хранящихся на вашем компьютере. Варианты категоризации мы обсуждали выше. Приведем пример простой категоризации для рабочего места секретаря отдела кадров.
Далее на ячейке, в которую вы хотите поместить гиперссылку, щелкните правой кнопкой мыши и выберите пункт «Гиперссылка…». В открывшемся окне выберите путь к нужному файлу (1) и при необходимости добавьте подсказку к вашей гиперссылке (2), которая будет появляться при наведении курсора мышки на ячейку с гиперссылкой (рис. 5 ниже).
Полезный совет
Используйте наглядные и запоминающиеся значки для ваших папок. Щелкните правой кнопкой мыши по папке, перейдите на вкладку «Настройка» и нажмите кнопку «Сменить значок…»
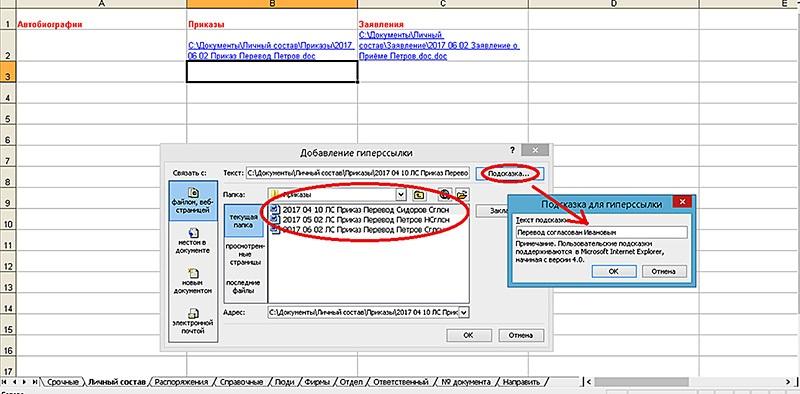
Рис. 5. Добавление гиперссылки и подсказки для нее
