Здравствуйте, уважаемые посетители моего скромного блога для начинающих вебразработчиков и web мастеров ZametkiNaPolyah.ru. Продолжаем рубрику Заметки о MySQL, в которой уже были публикации: Нормальные формы и транзитивная зависимость, избыточность данных в базе данных, типы и виды баз данных, настройка MySQL сервера и файл my.ini, MySQL сервер, установка и настройка, Архитектура СУБД и архитектура баз данных, Сетевая база данных, сетевая модель данных. Я продолжаю рассматривать различные модели данных, и сегодня мы поговорим про иерархическую модель данных или иначе – иерархическую базу данных.
Стоит сказать, что иерархическая база данных является частным случаем сетевой модели данных, о которой мы говорили в предыдущей публикации. Но дело все в том, что и иерархическая модель данных, и сетевые базы данных являются мало эффективными, и постепенно от их использования отказываются. Иерархические и сетевые СУБД остались только в некоторых крупных фирмах, которые наполняли такие базы годами. И сейчас основной проблемой для таких фирм является проблема совместимости иерархических и сетевых баз данных с реляционными базами данных. Ну а сегодня мы просто поговорим про иерархическую базу данных.
Не забываем подписываться на RSS-ленту и на публичную страницу Вконтакте.
Иерархическая модель данных
Иерархическая модель данных является частным случаем сетевой модели данных, структура иерархической базы данных немного проще сетевой и, соответственно, иерархические базы данных даже менее эффективны, чем сетевые. Иерархическая модель данных, как и сетевые БД опирается на теорию графов.

Иерархическая база данных. Иерархическая модель данных.
В основе иерархической модели данных лежит один главный элемент (главный узел), с которого все и начинается, такой элемент называет корневым элементом, в теории графов это называется корнем дерева. Вообще, по сути, что сетевая база данных, что иерархическая база данных имеет древовидную структуру. Все элементы или узлы, которые находятся ниже корневого узла иерархической модели, являются потомками корня. Стоит сказать, что и иерархическая база данных, и сетевая база данных оптимизированы на чтение информации из БД, но не на запись информации в базу данных, эта особенность обусловлена самой моделью данных.
Узлы дерева, которые находятся на одном уровне, обычно называются братьями. Узлы, которые находятся ниже какого-то определенного уровня, являются дочерними узлами по отношению к нему. Иерархическую модель данных можно сравнить с файловой системой компьютера. Компьютер умеет очень быстро работать с отдельными файлами: удалять конкретный файл, редактировать файл, копировать или перемещать файл. Но операция проверки компьютера антивирусом может происходить достаточно длительное время.
Точно такие же особенности присуще иерархической СУБД, то есть базы данных, имеющие иерархическую структуру, умеют очень быстро находить и выбирать информацию и отдавать ее пользователю. Но структура иерархической модели данных не позволяет столь же быстро перебирать информацию. Ну, это видно из рисунка, представленного выше. Допустим, что нам необходимо найти все записи, содержащие слово «сотрудник». Как будет поступать иерархическая СУБД в этом случае? А поступать она будет следующим образом: свой поиск она начнет с корневого элемента иерархической модели данных, проверив его, она начнет проверять его связи, если связей будет несколько, то она пойдет проверять в крайний левый дочерний элемент, расположенный на уровень ниже.
Затем иерархическая СУБД проверит содержимое этого элемента и его связи, если связей опять будет несколько, то она отправится опять-таки в крайний левый дочерний элемент, чтобы проверить его содержимое, проверив его содержимое она увидит, что у этого узла нет дочерних элементов и вернется в родительский узел этого узла, чтобы проверить, есть ли у него еще дочерние элементы. И так постепенно, узел за узлом, спуская и поднимаясь по иерархии узлов СУБД переберет все узлы и выдаст нам все записи, в которых есть слово «сотрудник». Ну, думаю, что с иерархической моделью данных мы более-менее разобрались (если не разобрались, то пишите в комментарии), можно приступить к рассмотрению структуры иерархической базы данных.
Структура иерархической базы данных
Самые первые в мире СУБД использовали иерархическую модель данных, иерархические базы данных появились даже раньше, чем сетевая модель хранения данных. Поэтому структура иерархической базы данных немного проще, чем структура сетевой БД. И так, основными информационными единицами иерархической модели данных являются сегмент и поле. Поле данных является наименьшей неделимой информационной единицей иерархической базы данных, доступной пользователю. У сегмента данных можно определить его тип и экземпляр сегмента.

Иерархическая база данных. Иерархическая модель данных.
Экземпляр сегмента образуется из конкретных значений полей данных. Тип сегмента – это именованная совокупность всех типов полей данных, входящих в данный сегмент. Если ориентироваться по рисунку выше, то тип сегмента – это родительский элемент и все его дочерние элементы. Как я уже говорил: иерархическая модель данных базируется на теории графов, но если структура сетевой БД описывается ориентированным графом (графом со стрелочками), то структура иерархической базы данных описывается неориентированным графом. Характерной особенностью структуры иерархической модели данных является то, что у любого потомка или дочернего элемента может быть только один предок или родительский элемент.
Каждый узел иерархического дерева или каждый элемент иерархической базы данных является сегментом данных. Линии, соединяющие сегменты – это связи между информационными объектами иерархической базы данных. Рисунок должен внести дополнительную ясность:
На концептуальном уровне иерархическая база данных является частным случаем сетевой модели данных.
Преобразование концептуальной модели в иерархическую модель данных
Преобразование концептуальной модели в иерархическую модель данных происходит аналогично преобразованию в сетевую модель данных, но существую некоторые тонкости, о которых мы и поговорим. Эти тонкости связаны с тем, что структура иерархической базы данных должна быть представлена в виде дерева, то есть данные иерархической модели должны быть организованы в виде дерева.
Как вы помните: дуги, соединяющие узлы между собой, – это связи. Связи бывают один к одному и один ко многим. Преобразование связей один ко многим происходит автоматически в том случае, если потомок иерархического дерева имеет только одного предка. Происходит это следующим образом: Каждый объект с его атрибутами, участвующий в такой связи, становится логическим сегментом. Между двумя логическими сегментами устанавливается связь типа «один ко многим». Сегмент со стороны «много» становится потомком, а сегмент со стороны «один» становится предком. Согласитесь, что преобразование в иерархическую модель данных похоже на преобразование в сетевую модель.
Ситуация значительно усложняется, если потомок в связи имеет не одного, а двух и более предков. Так как подобное положение является невозможным для иерархической модели, то отражаемая структура данных нуждается в преобразованиях, которые сводятся к замене одного дерева, например, двумя (если имеется два предка). В результате такого преобразования в базе данных появляется избыточность, так как единственно возможный выход из этой ситуации — дублирование данных.
Управление иерархическими данными
У иерархической модели данных существует два средства управления данными: языковые средства описания данных (ЯОД) и языковые средства манипулирования данными (ЯМД). Физическая структура иерархической базы данных описывает: логическую структуру иерархической модели данных и саму структуру хранения базы данных.
При этом способ доступа устанавливает способ организации взаимосвязи физических записей. Определены следующие способы доступа:
- иерархически последовательный;
- иерархически индексно-последовательный;
- иерархически прямой;
- иерархически индексно-прямой;
- индексный.
Помимо того, что обязательно должно быть задано имя иерархической базы данных и способа доступа к каждому элементу иерархической модели данных, описание иерархической БД должно содержать определение типов каждого сегмента данных, входящих в базу данных, в соответствие с выстроенной иерархией. Описание типов сегмента следует начинать с корня иерархической модели. Особенностью иерархических баз данных является то, что каждая физическая база данных может содержать только один корень, но в одной иерархической системе может находиться несколько физических баз данных.
Среди операторов манипулирования данными для иерархической базы данных можно выделить операторы поиска данных, операторы поиска данных с возможностью модификации, операторы модификации данных. Набор операций манипулирования данными в иерархической модели данных не так уж обширен, но этого набора вполне достаточно для управления и поддержания иерархических баз данных. Примеры типичных операторов поиска данных:
- найти указанное дерево БД;
- перейти от одного дерева к другому;
- найти экземпляр сегмента, удовлетворяющий условию поиска;
- перейти от одного сегмента к другому внутри дерева;
- перейти от одного сегмента к другому в порядке обхода иерархии.
Примеры типичных операторов поиска данных с возможностью модификации:
- найти и удержать для дальнейшей модификации единственный экземпляр сегмента, удовлетворяющий условию поиска;
- найти и удержать для дальнейшей модификации следующий экземпляр сегмента с теми же условиями поиска;
- найти и удержать для дальнейшей модификации следующий экземпляр для того же родителя.
Примеры типичных операторов модификации иерархически организованных данных, которые выполняются после выполнения одного из операторов второй группы (поиска данных с возможностью модификации):
- вставить новый экземпляр сегмента в указанную позицию;
- обновить текущий экземпляр сегмента;
- удалить текущий экземпляр сегмента.
В иерархической модели автоматически поддерживается целостность ссылок между предками и потомками. Основное правило: никакой потомок не может существовать без своего родителя. Надеюсь, что я достаточно просто и понятно описал структуру иерархической базы данных, как обычно, если что-то не понятно, то, пожалуйста, задавайте вопросы в комментариях под записью. На этом всё, спасибо за внимание, надеюсь, что был хоть чем-то полезен и до скорых встреч на страницах блога для начинающих вебразработчиков и вебмастеров ZametkiNaPolyah.ru. Не забываем комментировать и делиться с друзьями;)
Иерархическая модель базы данных
Иерархические базы данных — самая
ранняя модель представления сложной
структуры данных. Информация в
иерархической базе организована по
принципу древовидной структуры, в виде
отношений «предок-потомок». Каждая
запись может иметь не более одной
родительской записи и несколько
подчиненных. Связи записей реализуются
в виде физических указателей с одной
записи на другую. Основной недостаток
иерархической структуры базы данных —
невозможность реализовать отношения
«много-ко-многим», а также ситуации,
когда запись имеет несколько предков.
Иерархические базы данных.
Иерархические базы данных графически
могут быть представлены как перевернутое
дерево, состоящее из объектов различных
уровней. Верхний уровень (корень дерева)
занимает один объект, второй – объекты
второго уровня и так далее.
Между объектами существуют
связи, каждый объект может включать в
себя несколько объектов
более низкого уровня. Такие объекты
находятся в отношении предка (объект,
более близкий к корню) к потомку (объект
более низкого уровня), при этом
объект-предок может не иметь потомков
или иметь их несколько, тогда как
объект-потомок обязательно имеет только
одного предка. Объекты, имеющие общего
предка, называются
близнецами.
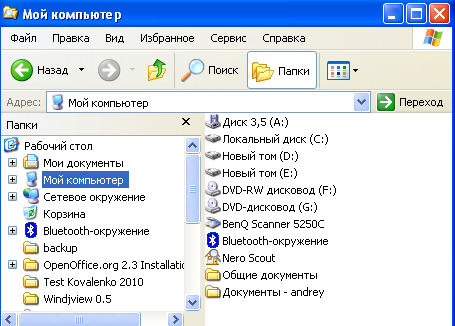
Иерархической базой данных
является Каталог папок Windows, с которым
можно работать, запустив Проводник.
Верхний уровень занимает папка Рабочий
стол. На втором уровне находятся папки
Мой компьютер, Мои документы, Сетевое
окружение и Корзина, которые являются
потомками папки Рабочий стол, а между
собой является близнецами. В свою
очередь, папка Мой компьютер является
предком по отношению к папкам третьего
уровня -папкам дисков (Диск 3,5(А:), (С:),
(D:), (Е:), (F:)) и системным папкам (сканер,
bluetooth
и.т.д.) – рис. 4.1.
Организация данных в СУБД
иерархического типа определяется в
терминах: элемент,
агрегат, запись (группа), групповое
отношение, база данных.
-
А

Рисунок 4.1
Иерархическая база данных Каталог
папок Windowsтрибут (элемент
данных) – наименьшая единица структуры
данных. Обычно каждому элементу при
описании базы данных присваивается
уникальное имя. По этому имени к нему
обращаются при обработке. Элемент
данных также часто называют полем. -
Запись –
именованная совокупность атрибутов.
Использование записей позволяет за
одно обращение к базе получить некоторую
логически связанную совокупность
данных. Именно записи изменяются,
добавляются и удаляются. Тип записи
определяется составом ее атрибутов.
Экземпляр
записи – конкретная
запись с конкретным значением элементов -
Групповое отношение
– иерархическое отношение между записями
двух типов. Родительская запись (владелец
группового отношения) называется
исходной записью, а дочерние записи
(члены группового отношения) – подчиненными.
Иерархическая база данных может хранить
только такие древовидные структуры.
Корневая запись
каждого дерева обязательно должна
содержать ключ с уникальным значением.
Ключи некорневых записей должны иметь
уникальное значение только в рамках
группового отношения. Каждая запись
идентифицируется полным сцепленным
ключом, под которым понимается совокупность
ключей всех записей от корневой по
иерархическому пути.
При графическом изображении групповые
отношения изображают дугами ориентированного
графа, а типы записей – вершинами
(диаграмма Бахмана).
Для групповых отношений в иерархической
модели обеспечивается автоматический
режим включения и фиксированное членство.
Это означает, что для запоминания любой
некорневой записи в БД должна существовать
ее родительская запись.
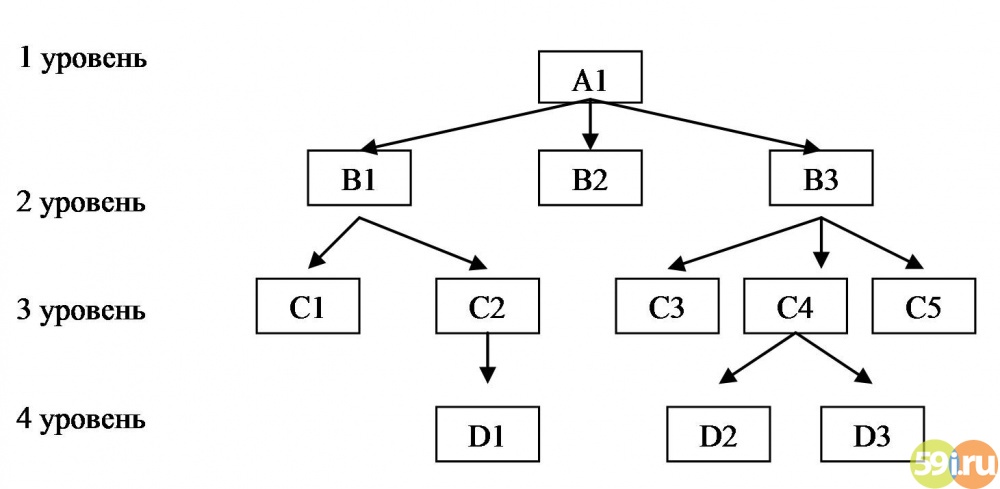
Пример:
Рассмотрим следующую модель данных
предприятия (см. рис.4.2): предприятие
состоит из отделов, в которых работают
сотрудники. В каждом отделе может
работать несколько сотрудников, но
сотрудник не может работать более чем
в одном отделе.
Поэтому, для информационной системы
управления персоналом необходимо
создать групповое отношение, состоящее
из родительской записи ОТДЕЛ
(НАИМЕНОВАНИЕ_ОТДЕЛА, ЧИСЛО_РАБОТНИКОВ)
и дочерней записи СОТРУДНИК (ФАМИЛИЯ,
ДОЛЖНОСТЬ, ОКЛАД). Это отношение показано
на рис. 4.2 (а) (Для простоты полагается,
что имеются только две дочерние записи).
Для автоматизации учета контрактов с
заказчиками необходимо создание еще
одной иерархической структуры: заказчик
– контракты с ним – сотрудники,
задействованные в работе над контрактом.
Это дерево будет включать записи ЗАКАЗЧИК
(НАИМЕНОВАНИЕ_ЗАКАЗЧИКА, АДРЕС),
КОНТРАКТ(НОМЕР, ДАТА,СУММА), ИСПОЛНИТЕЛЬ
(ФАМИЛИЯ, ДОЛЖНОСТЬ, НАИМЕНОВАНИЕ_ОТДЕЛА)
(рис. 4.2 b).
Из этого примера видны недостатки
иерархических БД:
Ч

Рисунок 4.2. Пример
иерархической базы данных
астично дублируется
информация между записями СОТРУДНИК и
ИСПОЛНИТЕЛЬ (такие записи называют
парными), причем в иерархической модели
данных не предусмотрена поддержка
соответствия между парными записями.
Иерархическая модель реализует отношение
между исходной и дочерней записью по
схеме 1:N, то есть одной родительской
записи может соответствовать любое
число дочерних.
Допустим теперь, что исполнитель может
принимать участие более чем в одном
контракте (т.е. возникает связь типа
M:N). В этом случае в базу данных необходимо
ввести еще одно групповое отношение, в
котором ИСПОЛНИТЕЛЬ будет являться
исходной записью, а КОНТРАКТ – дочерней
(рис. 4.2 c). Таким образом, мы опять вынуждены
дублировать информацию.
Операции над данными, определенные в
иерархической модели:
-
ДОБАВИТЬ
в базу данных новую запись. Для корневой
записи обязательно формирование
значения ключа. -
ИЗМЕНИТЬ
значение данных предварительно
извлеченной записи. Ключевые данные
не должны подвергаться изменениям. -
УДАЛИТЬ
некоторую запись и все подчиненные ей
записи. -
ИЗВЛЕЧЬ:
извлечь корневую запись по ключевому
значению, допускается также последовательный
просмотр корневых записей
извлечь следующую запись (следующая
запись извлекается в порядке левостороннего
обхода дерева)
В операции ИЗВЛЕЧЬ допускается задание
условий выборки (например, извлечь
сотрудников с окладом более 10 тысяч
руб.)
Как видим, все операции изменения
применяются только к одной “текущей”
записи (которая предварительно извлечена
из базы данных). Такой подход к
манипулированию данных получил название
“навигационного”.
Ограничения целостности.
Поддерживается только целостность
связей между владельцами и членами
группового отношения (никакой потомок
не может существовать без предка). Как
уже отмечалось, не обеспечивается
автоматическое поддержание соответствия
парных записей, входящих в разные
иерархии.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
Иерархическая модель данных — это модель данных, где используется представление базы данных в виде древовидной (иерархической) структуры, состоящей из объектов (данных) различных уровней.
Между объектами существуют связи, каждый объект может включать в себя несколько объектов более низкого уровня. Такие объекты находятся в отношении предка (объект более близкий к корню) к потомку (объект более низкого уровня), при этом возможна ситуация, когда объект-предок имеет несколько потомков, тогда как у объекта-потомка обязателен только один предок. Объекты, имеющие общего предка, называются близнецами (в программировании применительно к структуре данных дерево устоялось название братья).
Базы данных с иерархической моделью одни из самых старых, и стали первыми системами управления базами данных для мейнфреймов. Разрабатывались в 1950-х и 1960-х, например, Information Management System (IMS)[1] фирмы IBM.
Примеры[править | править код]
Например, если иерархическая база данных содержала информацию о покупателях и их заказах, то будет существовать объект «покупатель» (родитель) и объект «заказ» (дочерний). Объект «покупатель» будет иметь указатели от каждого заказчика к физическому расположению заказов покупателя в объект «заказ».
В этой модели запрос, направленный вниз по иерархии, прост (например, какие заказы принадлежат этому покупателю). Однако запрос, направленный вверх по иерархии, более сложен (например, какой покупатель поместил этот заказ). Также, трудно представить не-иерархические данные при использовании этой модели.
Иерархической базой данных является файловая система, состоящая из корневого каталога, в котором имеется иерархия подкаталогов и файлов.
Структурная часть иерархической модели[править | править код]
Основными информационными единицами в иерархической модели данных являются сегмент и поле. Поле данных определяется как наименьшая неделимая единица данных, доступная пользователю. Для сегмента определяются тип сегмента и экземпляр сегмента. Экземпляр сегмента образуется из конкретных значений полей данных. Тип сегмента — это поименованная совокупность входящих в него типов полей данных.
Как и сетевая, иерархическая модель данных базируется на графовой форме построения данных, и на концептуальном уровне она является просто частным случаем сетевой модели данных. В иерархической модели данных вершине графа соответствует тип сегмента или просто сегмент, а дугам — типы связей предок — потомок. В иерархических структуpax сегмент — потомок должен иметь в точности одного предка.
Иерархическая модель представляет собой связный неориентированный граф древовидной структуры, объединяющий сегменты. Иерархическая БД состоит из упорядоченного набора деревьев.
Управляющая часть иерархической модели[править | править код]
В рамках иерархической модели выделяют языковые средства описания данных (ЯОД) и средства манипулирования данными (ЯМД). Каждая физическая база описывается набором операторов, обусловливающих как её логическую структуру, так и структуру хранения БД. При этом способ доступа устанавливает способ организации взаимосвязи физических записей.
Определены следующие способы доступа:
- иерархически последовательный;
- иерархически индексно-последовательный;
- иерархически прямой;
- иерархически индексно-прямой;
- индексный.
Помимо задания имени БД и способа доступа описания должны содержать определения типов сегментов, составляющих БД, в соответствии с иерархией, начиная с корневого сегмента. Каждая физическая БД содержит только один корневой сегмент, но в системе может быть несколько физических БД.
Среди операторов манипулирования данными можно выделить операторы поиска данных, операторы поиска данных с возможностью модификации, операторы модификации данных. Набор операций манипулирования данными в иерархической БД невелик, но вполне достаточен.
Примеры типичных операторов поиска данных[править | править код]
- найти указанное дерево БД;
- перейти от одного дерева к другому;
- найти экземпляр сегмента, удовлетворяющий условию поиска;
- перейти от одного сегмента к другому внутри дерева;
- перейти от одного сегмента к другому в порядке обхода иерархии.
Примеры типичных операторов поиска данных с возможностью модификации:
- найти и удержать для дальнейшей модификации единственный экземпляр сегмента, удовлетворяющий условию поиска;
- найти и удержать для дальнейшей модификации следующий экземпляр сегмента с теми же условиями поиска;
- найти и удержать для дальнейшей модификации следующий экземпляр для того же родителя.
Примеры типичных операторов модификации иерархически организованных данных, которые выполняются после выполнения одного из операторов второй группы (поиска данных с возможностью модификации):
- вставить новый экземпляр сегмента в указанную позицию;
- обновить текущий экземпляр сегмента;
- удалить текущий экземпляр сегмента.
В иерархической модели автоматически поддерживается целостность ссылок между предками и потомками. Основное правило: никакой потомок не может существовать без своего родителя.
Известные иерархические СУБД[править | править код]
Примерами баз данных с иерархической моделью являются[2]:
- IBM DBOMP — ранняя иерархическая БД.
- Типичным представителем (наиболее известным и распространенным) является Information Management System (IMS)[1] фирмы IBM (1966—1968 г.).
- Time-Shared Date Management System (TDMS)[3] компании System Development Corporation;
- Mark IV MultiAccess Retrieval System компании Control Data Corporation;
- System 2000 разработки SAS Institute[1];
- InterSystems Caché[4].
Преобразование концептуальной модели в иерархическую модель данных[править | править код]
Преобразование концептуальной модели в иерархическую структуру данных во многом схоже с преобразованием её в сетевую модель, но и имеет некоторые отличия в связи с тем, что иерархическая модель требует организации всех данных в виде дерева.
Преобразование связи типа «один ко многим» между предком и потомком осуществляется практически автоматически в том случае, если потомок имеет одного предка, и происходит это следующим образом. Каждый объект с его атрибутами, участвующий в такой связи, становится логическим сегментом. Между двумя логическими сегментами устанавливается связь типа «один ко многим». Сегмент со стороны «много» становится потомком, а сегмент со стороны «один» становится предком.
Ситуация значительно усложняется, если потомок в связи имеет не одного, а двух и более предков. Так как подобное положение является невозможным для иерархической модели, то отражаемая структура данных нуждается в преобразованиях, которые сводятся к замене одного дерева, например, двумя (если имеется два предка). В результате такого преобразования в базе данных появляется избыточность, так как единственно возможный выход из этой ситуации — дублирование данных.
Примечания[править | править код]
- ↑ 1 2 3 Database Management System Concepts (неопр.). — FK Publications. — С. 32—. — ISBN 978-93-80006-33-8.
- ↑ Introduction to Database Management System (англ.). — Laxmi Publications. — P. 77—. — ISBN 978-93-81159-31-6.
- ↑ Setrag Khoshafian. Object-oriented databases (неопр.). — John Wiley, 1993. — ISBN 978-0-471-57058-5.
- ↑ Prakash M. Nadkarni. Metadata-driven Software Systems in Biomedicine: Designing Systems that can adapt to Changing Knowledge (англ.). — Springer Science & Business Media, 2011. — P. 72—. — ISBN 978-0-85729-510-1.
Иерархическая база данных – это сложная многокомпонентная система, в основе которой лежит древовидная структура. Она состоит из комплекса объектов разных уровней (рангов), расположенных по принципу их подчинения от общего к частному. Это один из самых распространенных типов сетевой модели данных, отличающийся целостностью и простотой концепции. Благодаря этому, его активно используют в современных информационных системах: при разработке структур в формате XML, а также в процессе передачи интернет-данных.
При этом стоит учитывать, что для полноценной работы с иерархическими БД требуется немало ресурсов, в первую очередь, основной и дисковой памяти. Эту особенность обязательно необходимо учитывать в работе, поскольку от нее напрямую зависит скорость обработки информации.
Иерархическая БД: суть и принципы работы
Иерархическая модель данных – это огромный комплекс взаимосвязанных объектов высшего и низшего уровня. Все они пребывают в теснейшем взаимодействии, обеспечивая целостное и автономное функционирование системы.
Каждый элемент системы способен одновременно состоять из десятков, а иногда и сотен объектов низшего уровня, и параллельно с этим находиться в подчинении вышестоящего объекта. На вершине иерархии находится только один объект, который принято называть «корнем дерева». От него исходят объекты следующего уровня, и так далее в четкой последовательности, вплоть до бесконечности.
Связи между структурными элементами одного уровня отсутствуют. Из этого следует, что объекты в иерархической базе данных не являются равноправными. Поскольку все они в той или иной степени зависят друг от друга. Если из двух элементов один находится ближе к вершине, его принято называть «предком». Если ниже уровнем – «потомком». Также следует отметить, что «потомков», находящихся на одном уровне иерархии, и исходящих от одного и того же предка, принято называть «близнецами» или «братьями».
Принцип работы иерархической БЗ основывается на вертикальном взаимодействии, начиная с вершины. Другой формат взаимодействия в данном случае не предусмотрен. Это обусловлено тем, что каждый компонент иерархии связан только с одним объектом на верхнем уровне и несколькими объектами на нижнем.
Иерархическая модель БД: основные понятия и специфика построения
На курсах Power Bi https://kemerovo.videoforme.ru/computer-programming-school/power_bi говорят о том, что в стандартном виде иерархическая модель данных состоит из следующих компонентов:
-
Атрибут. Минимальный неделимый элемент, к которому пользователь имеет доступ. В процессе использования каждый атрибут получает имя, по которому к нему можно обратиться из программного кода.
-
Запись. Комплекс логически взаимосвязанных элементов (атрибутов) с уникальным именем. Обращаясь к «Записи», можно за считаные секунды отправить в обработку огромный массив информации. При этом записи могут добавляться, преобразовываться и удаляться. В зависимости от специфики атрибутов, входящих в состав «Записи», ее можно представить в разных форматах.
-
Экземпляр записи. Состоит из записи с четко обозначенным количеством и значением атрибутов.
-
Групповое отношение. Иерархия данных между элементами двух разных типов. Например: между «предками» и «потомками», родительскими записями (расположены на вершине дерева) и дочерними (расположены ниже по иерархии).
В целом, иерархическая БД представляет собой упорядоченную совокупность «Атрибутов», соединяющихся в «Записи». Их главная задача – хранение чисел или символов. Визуально модель иерархической БД можно представить в виде дерева, состоящего из элементов различных уровней. Обход всех компонентов иерархической базы данных в большинстве случаев производится сверху вниз или слева направо.
Управляющая часть
Иерархическая бд имеет структуру, включающую управляющую и структурную части. В составе управляющей части входит набор профильных языковых средств, использующихся для обозначения атрибутов и непосредственной работы с ними. Кроме того, они применяются для представления логики построения базы данных и особенностей хранения ее сегментов. Для обеспечения взаимодействия между элементами иерархической БД и определения способа доступа к ним используются различные виды связей, в частности:
-
Прямые.
-
Индексные.
-
Последовательные.
-
Индексно-прямые.
-
Индексно-последовательные.
Тип выбранной связи зависит от специфики иерархической модели базы данных. Управляющая часть позволяет производить поиск необходимых объектов и их модификацию. Несмотря на довольно узкий спектр функциональных возможностей, подобные модели способны обеспечить корректное и продуктивное управление различными процессами.
Структурная часть
В качестве ключевых функциональных единиц в этом случае используются «Поле» и «Сегмент». «Поле» («Атрибут») представляет собой минимальный неделимый элемент, который находится в доступности у пользователя. Это крошечный винтик в гигантской многофункциональной системе.
«Сегмент» — это комплекс полей данных с указанием их видов. Из этого следует, что иерархическая база данных – это БД, в которой все объекты пребывают в тесной взаимосвязи друг с другом. При этом вне зависимости от количества все они строго систематизированы и упорядочены.
Трансформация концептуальной модели БД в иерархическую
Процесс трансформации концептуальной модели БД в древовидную осуществляется аналогично преобразованию в сетевую модель. Однако в этой ситуации все же есть ряд нюансов, которые обязательно необходимо учитывать. Преобразование связей между «предком» и «потомком» происходит практически автоматически при условии, если у потомка есть только один предок. В этом случае каждый компонент, задействованный в подобном формате связи, превращается в логистический сегмент. Впоследствии между логистическими сегментами налаживается мощная взаимосвязь типа – «1 ко многим», в рамках которой элемент со стороны «1» превращается в «предка», а элемент со стороны «много» превращается в потомка. В этом заключается принципиальное отличие иерархической модели организации данных от сетевой.
Преобразование существенно затрудняется, если в рассматриваемой связи потомок имеет больше одного предка. Такая ситуация является недопустимой для древовидной модели базы данных. Решить эту проблему можно только посредством дублирования объектов и создания нового дерева.
Специфика управления иерархиями
В процессе управления иерархической БД используются две группы языковых средств, в частности: средства описания и средства манипуляции. Каждая из представленных групп имеет свой спектр функциональных возможностей. Одно из ключевых условий корректного функционирования субд иерархической модели данных — определение ее имени и организация доступа ко всем объектам. Стоит учесть, что описание базы данных такого формата, как правило, включает в себя определение типов элементов, входящих в БД с учетом построенной иерархии. В классической схеме описание начинается с корневых элементов.
Какие операции можно выполнять с помощью иерархических БД
Иерархические модели БД имеют широкую сферу применения. С их помощью можно выполнять следующие типы операций:
-
Находить конкретное дерево.
-
Осуществлять переход от одной древовидной структуры к другой.
-
Находить требуемый объект, соответствующий условиям поиска.
-
Осуществлять переход от одного объекта к другому непосредственно внутри иерархии.
-
Осуществлять переход от одного объекта к другому в обход иерархической БД,
-
Добавлять новый атрибут.
-
Представлять, удалять и обновлять текущие сегменты БД.
-
Находить и удерживать атрибут с целью его модификации с учетом условий поиска.
Независимо от количества элементов, функционирование иерархической базы данных основывается на принципе целостности и автономности связей между «предками» и «потомками». При этом неукоснительно должно соблюдаться правило, ни один потомок не может полноценно функционировать, не имея предка.
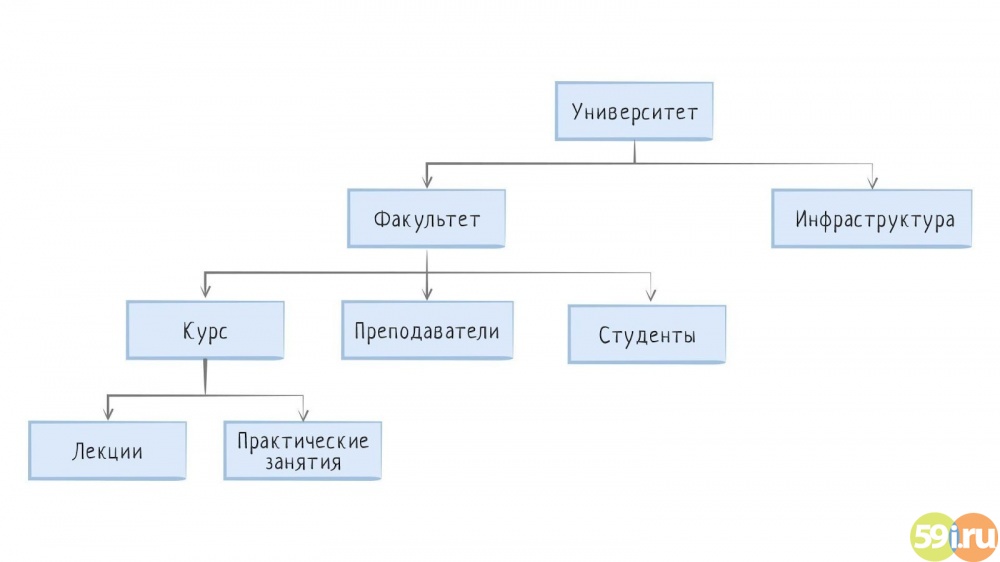
Где используются иерархические структуры данных
Иерархическая структура базы данных – это основа функционирования семейства ОС Windows. Для того чтобы убедиться в этом, достаточно воспользоваться традиционной опцией «Проводник». Кликнув по ней, вы попадает в корень операционной системы, в которой расположены крупнейшие структурные компоненты – «Этот компьютер», «Загрузки», «Изображения», «Музыка», «Рабочий стол» и др. Двигаясь в направлении от корня до других структурных единиц, вы будете переходить от одного уровня гигантской иерархической системы до другого.
На практике это выглядит примерно так: «Этот компьютер»→«Локальный диск (С)»→«Пользователи»→«User»→«Документы»→«Файл». Таким образом, переходя от одной папки к другой, вы, наконец, находите необходимую вам информацию. В данном случае иерархический вид базы данных выступает в качестве вашего путеводителя, обеспечивающего быстрый и удобный доступ ко всем компонентам системы.
Помимо сферы программирования иерархические БД повсеместно используются в биологии, географии и анатомии. Ключевая роль при этом отводится ветвящейся структуре, с помощью которой производится классификация живых организмов, клеток, органов и систем жизнедеятельности. Все они основываются на выстраивании иерархических взаимосвязей. Особое распространение в биологии получила система «доминирования-подчинения», которая считается основополагающим принципом иерархической модели СУБД.
В географии иерархия отчетливо прослеживается в административно-территориальном делении, которое идет от большего к меньшему (от континентов к странам, от стран к областям, штатам и т. д.). Кроме того, порядок подчинения низших элементов высшим встречается в обществе. Иерархия может быть: социальной, классовой, государственной, профессиональной, этнической, церковной и пр. Помимо науки и социальной сферы иерархическая модель используется при проектировании и эксплуатации строительных и технических объектов, при архитектурном планировании в качестве метода детализации планов.
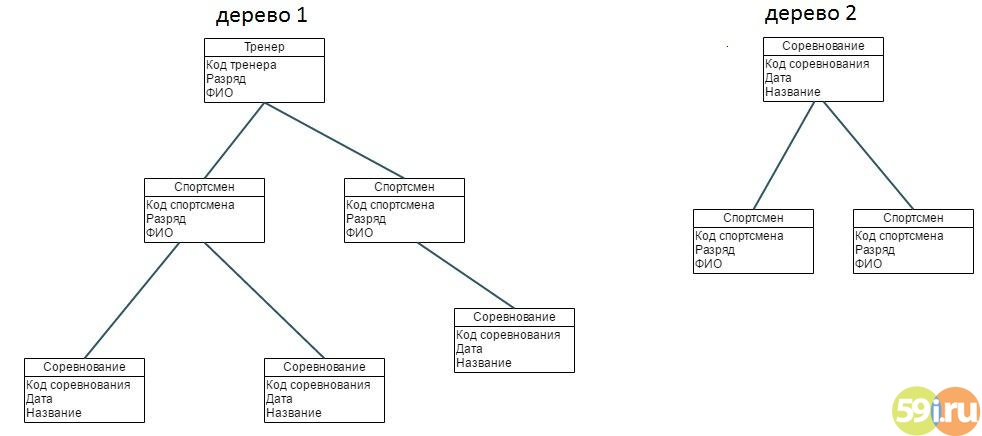
Пример иерархической базы данных
Рассмотрим иерархическую модель базы данных пример.
Предположим, что есть некий спортклуб, в котором за каждым атлетом закреплен свой тренер. У самого тренера может быть не один спортсмен. При этом каждый из них в теории может участвовать в неограниченном количестве соревнований. Для того чтобы упорядочить все эти данные целесообразно воспользоваться иерархической моделью базы данных. В качестве объектов в этом случае будут использоваться данные о:
-
Спортсмене (Ф. И. О., разряд).
-
Тренере (Ф. И. О.).
-
Соревновании (Название, дата проведения).
В процессе определения связей между записями нужно учитывать объективные факторы окружающей среды. В этой ситуации иерархическая СУБД будет иметь тип связи «1 ко многим». Это обусловлено тем, что запись «Спортсмен» будет «потомком» по отношению к записи «Тренер», которая будет представлена в роли «Предка». При этом стоит учитывать, что атрибуты «Спортсмен» и «Соревнование» будет связывать уже совершенно другой тип связи – «много ко многим», поскольку один и тот же спортсмен может участвовать сразу в нескольких соревнованиях, а в одном соревновании может принимать участие множество спортсменов.
Однако в данной ситуации возникает противоречие. Поскольку построение иерархии предусматривает исключительно прямое подчинение, построить дерево, компоненты которого объединены связью «много ко многим», невозможно. Для этого отдельные атрибуты иерархии необходимо продублировать, создав новое дерево. Как видите, в этом случае понятие иерархической базы данных (пример) используется для систематизации имеющихся данных.
Преимущества иерархической модели БД
Иерархическая модель базы данных обладает широким спектром безоговорочных преимуществ, в числе прочих выделяют:
-
Эффективное использование памяти электронно-вычислительных машин.
-
Простота концепции.
-
Автономность и независимость всех компонентов системы.
-
Высокая скорость обработки операций: от подачи команды до ее выполнения проходит минимум времени.
-
Целостность представленных данных.
-
Выполнение широкого спектра узкопрофильных задач.
-
Высокий уровень безопасности системы.
-
Удобство работы с большими массивами информации.
Иерархическая модель данных основана на большом количестве компонентов с различным уровнем подчинения, что обеспечивает упрощенный доступ к информации.
Недостатки иерархической базы данных
Несмотря на универсальность использования иерархические модели БД имеют некоторые недостатки, в частности:
-
Громоздкость. Наличие большого количества логических взаимосвязей значительно усложняет применение моделей данного формата.
-
Трудность в восприятии обычным пользователем. Сложность управления и реализации СУБД зачастую ставит в тупик среднестатистических пользователей. Даже опытному специалисту будет трудно освоить ранее неизвестную базу.
-
Трудность в применении. Работа с иерархической моделью БД требует задействования серьезных ресурсов. Причем не только материальных, но и временных и человеческих.
Кроме того, применение объемных разветвленных систем часто приводит к утрудненному доступу к файлам. Это обусловлено тем, что большинство имеющихся связей базируются на принципе навигационности.
Заключение
Структура иерархической базы данных позволяет эффективно, а главное — практически беспроблемно выполнять широкий спектр узкопрофильных задач. Эффективность ее применения напрямую зависит от навыков и опыта специалиста, который занимается ее наполнением и последующей реализацией. Как видите, иерархическая бд это не просто тип взаимосвязи между элементами. Это хранилище, которое может использоваться по отношению к тем системам, для которых свойственна древовидная структура. При этом, любая иерархическая БД имеет корневую папку, которая постепенно разветвляется вниз.
Учитывая, что аналогичный принцип используется в процессе создания операционных систем, неудивительно, что такие базы успешно применяются для выполнения различных операций с данными. Их использование позволяет рационально распределить имеющиеся компоненты, продумав их логические взаимосвязи. Данная закономерность четко прослеживается в иерархической СУБД, пример которой мы рассматривали ранее.
Подпишитесь на наш Telegram-канал и на наш паблик в соцсети Вконтакте, следите за актуальными новостями Перми и Пермского края..
Основные понятия иерархической модели базы данных
Содержание:
- Иерархическая модель базы данных — что это такое в информатике
- Основные понятия, принцип построения
- Структурная часть
- Управляющая часть
- Характерные особенности, какие операции можно производить
- Применение иерархической структуры данных на практике
Иерархическая модель базы данных — что это такое в информатике
Иерархическая модель базы данных — это древовидная структура, состоящая из данных или объектов разных уровней.
Преимуществами модели являются:
- простота концепции;
- независимость данных;
- целостность данных;
- безопасность базы;
- облегченный доступ к информации.
Среди несовершенств выделяют:
Осторожно! Если преподаватель обнаружит плагиат в работе, не избежать крупных проблем (вплоть до отчисления). Если нет возможности написать самому, закажите тут.
- недостаток структурной зависимости;
- сложность управления СУБД;
- сложность реализации СУБД;
- ограничение стандартизации.
Работа с иерархическими базами данных требует значительных ресурсов основной и дисковой памяти вычислительной машины. А это заметно понижает скорость считывания параметров, обработки информации.
Основные понятия, принцип построения
Между объектами иерархической базы присутствуют связи. Каждый из них может включать в себя объекты низшего уровня, быть зависимым от стоящего выше.
Если из двух объектов один расположен ближе к корню, его называют предком. Если дальше — потомком. Потомок всегда имеет только одного предка. А у предка может быть несколько потомков. При этом потомки одного уровня, имеющие единого предка, именуются близнецами или братьями.
Структурная часть
Основными элементами, информационными единицами выступают:
- поле — наименьшая из доступных пользователю неделимая единица;
- сегмент, для которого определяют экземпляр и тип.
Экземпляр — это образование из определенных значений полей данных. Тип — поименованная совокупность составляющих сегмент типов полей.
Иерархическая модель основана на графовой форме построения: вершине графа соответствует сегмент или тип сегмента, дугам — связи «предок-потомок». Модель представляет собой связный неориентированный граф объединяющей сегменты древовидной структуры. База данных состоит из строго упорядоченного набора деревьев.
Управляющая часть
Для рассматриваемой модели разработаны языковые средства описания данных и манипулирования ими. База описывается набором операторов, определяющих структуру хранения и логику построения. При этом вариант создания связей между физическими записями определяется способом доступа, который может быть:
- индексным;
- индексно-прямым;
- прямым;
- последовательным;
- индексно-последовательным.
Описание должно содержать имя БД, способ доступа, уточнение типа сегмента в соответствии с иерархией.
Каждая база имеет один корневой сегмент. А система может включать несколько физических баз.
Операций манипулирования данными в рассматриваемой модели немного. Это поиск данных, их модификация и поиск с возможностью модификации. Но, несмотря на сравнительно небольшой набор, его вполне достаточно для корректного и эффективного управления.
Характерные особенности, какие операции можно производить
В качестве примера операций по поиску данных можно привести такие задачи, как:
- найти определенное дерево;
- совершить переход от одного дерева к другому;
- найти нужный экземпляр сегмента;
- совершить переход между сегментами в рамках одного дерева;
- совершить такой же переход посредством обхода иерархии.
Типичные операторы модификации:
- добавить новый экземпляр сегмента в определенную позицию;
- удалить текущий экземпляр;
- обновить текущий экземпляр.
Примеры поиска данных с возможностью модификации:
- найти и зафиксировать для изменения единственный экземпляр сегмента;
- найти и зафиксировать для изменения следующий экземпляр.
Особенной характеристикой иерархической базы данных является то, что она оптимизирована на чтение, а не запись. Система быстро производит поиск, выбор и представление информации пользователю, но не позволяет оперативно обновлять и заменять ее.
В сравнении с базами, построенными на основе цикла, иерархическая структура более функциональна: одна циклическая база хранит только один неизменный набор данных.
Применение иерархической структуры данных на практике
Самым простым практическим применением структуры является традиционная файловая система ОС Windows. Зайдя в знакомый всем Проводник, мы попадаем в корень и видим крупные структурные единицы: «Этот компьютер», «Сеть» и другие. Продвигаясь в направлении от корня и выбирая одну из единиц, мы переходим к папкам, затем к файлам и находим нужную информацию.
Широко известными иерархическими базами данных считаются:
- Mark IV MultiAccess Retrieval System;
- InterSystems Caché;
- IMS.
К этой же категории принадлежит System 2000 от американской частной компании SAS Institute.
Если отойти от информатики, то практическое применение можно обнаружить в биологии, географии, анатомии. По принципу нисходящей ветвящейся структуры организована классификация живых организмов, выстроены объекты гидросферы, отображены разветвления нервов и кровеносных сосудов.
Прямым аналогом, отображающим свойства и основы построения иерархических баз данных, является генеалогическое дерево.
Насколько полезной была для вас статья?
Рейтинг: 5.00 (Голосов: 1)
Выделите текст и нажмите одновременно клавиши «Ctrl» и «Enter»
Текст с ошибкой:
Расскажите, что не так
