|
5,56 |
5,43 |
5,47 |
5,47 |
5,33 |
5,37 |
5,43 |
5,54 |
5,61 |
|
5,33 |
5,43 |
5,61 |
5,11 |
5,43 |
5,33 |
5,54 |
5,33 |
5,11 |
|
5,54 |
5,43 |
5,33 |
5,54 |
5,43 |
5,43 |
5,43 |
5,33 |
5,11 |
|
5,43 |
5,43 |
5,43 |
5,33 |
5,4 |
5,43 |
5,47 |
5,68 |
5,47 |
|
5,43 |
5,68 |
5,21 |
5,33 |
5,58 |
5,47 |
5,47 |
5,21 |
5,54 |
|
5,64 |
5,47 |
5,27 |
5,27 |
5,37 |
5,33 |
5,47 |
5,47 |
5,54 |
|
5,4 |
5,58 |
5,47 |
5,27 |
5,05 |
5,79 |
5,79 |
5,64 |
5,64 |
|
5,71 |
5,85 |
5,47 |
5,47 |
5,43 |
5,47 |
5,54 |
5,64 |
5,64 |
|
5,79 |
5,03 |
5,33 |
5,68 |
5,43 |
5,61 |
5,54 |
5,64 |
5,54 |
|
5,39 |
5,33 |
5,21 |
5,68 |
5,54 |
5,33 |
5,21 |
5,21 |
5,81 |
|
5,27 |
5,64 |
5,27 |
5,27 |
5,33 |
5,37 |
5,27 |
5,54 |
5,54 |
|
5,47 |
Таблица.
.1
Пример. По
результатам выборочного исследования
100 однотипных предприятий получены
данные объема основных фондов
Построение
интервального вариационного ряда
распределения включает следующие этапы.
1. Определение
среди имеющихся наблюдений минимального
![]() и максимального
и максимального![]() значения признака. В данном примере это
значения признака. В данном примере это
будут![]() =5,03
=5,03
и![]() =5,85.
=5,85.
2. Определение
размаха варьирования признака
R=![]() –
–![]() =5,85-5,03=0,82
=5,85-5,03=0,82
3.Определение длины
интервала по формуле
![]() объем
объем
выборки. В данном примере![]()
4. Определение
граничных значений интервалов
![]() .
.
Так как![]() и
и![]() являются случайными величинами,
являются случайными величинами,
рекомендуется отступить влево от нижнего
предела варьирования (![]() ).
).
За нижнюю границу
первого интервала предлагается принимать
величину, равную
![]() .
.
Если окажется, что![]() ,
,
хотя по смыслу величина не отрицательная,
то можно принять![]() .
.
Верхняя граница
первого интервала
![]() .
.
Тогда, если![]() –верхняя
–верхняя
границаi-го
интервала (причём
![]() ),
),
то![]() ,
,![]() и т.д. Построение интервалов продолжается
и т.д. Построение интервалов продолжается
до тех пор, пока начало следующего по
порядку интервала не будет равным или
больше![]() .
.
В примере граничные
значения составят:
![]() ,
,
![]() ,
,![]() ,
,![]() и т.д.Границы последовательных интервалов
и т.д.Границы последовательных интервалов
записывают в графе 1 таблицы 1.2.
5. Группировка
результатов наблюдений.
П росматриваем
росматриваем
статистические данные в том порядке, в
каком они записаны в таблице 1.1, и значения
признака разносим по соответствующим
интервалам, обозначая их так
(по одному штриху для каждого
наблюдения). Так как граничные значения
признака могут совпадать с границами
интервалов, то условимся включать
варианты, большие, чем нижняя граница
интервала (![]() ),
),
и меньшие или равные верхней границе
(![]() ).
).
Общее количество штрихов, отмеченных
в интервале (табл. 1.2, графа 2) дает его
частоту (табл. 1.2, графа 3). В результате
получим статистический ряд распределения
частот (табл. 1.2, графа 1 и 3).
Примечание. Число
интервалов обычно берут равным от 7 до
11 в зависимости от числа наблюдений и
точности измерений с таким расчетом,
чтобы интервалы были достаточно наполнены
частотами. Если получают интервалы с
нулевыми частотами, то нужно увеличить
ширину интервала (особенно в середине
интервального ряда).
|
Интервалы
|
Подсчет |
Частота |
Накопленная |
|
4,97-5,08 5,08-5,19 5,19-5,30 5,30-5,41 5,41-5,52 5,52-5,63 5,63-5,74 5,74-5,85 |
|
2 3 12 19 29 18 13 4 |
2 5 17 36 65 83 96 100 |
|
100 |
Таблица 1.2.
Интервальный ряд распределения объемов
основных фондов 100 предприятий
2. Вычисление выборочных характеристик распределения (непосредственно)
Для вычисления
средней арифметической, дисперсии,
коэффициентов ассиметрии и эксцесса
рекомендуется следующий порядок
вычислений.
Заменяем интервальный
ряд дискретным, для чего все значения
признака в пределах интервала приравниваем
к его серединному значению, и считаем,
что частота относится к середине
интервала. Значения середин интервалов
равны
![]() .
.
Для удобства
вычислений целесообразно составить
вспомогательную таблицу 1.3. Заменяя
середины интервалов заносят в графу 1,
соответствующие частоты в графу и т.д.
|
Интервалы
|
|
|
|
|
|
|
|
1 |
2 |
3 |
4 |
5 |
6 |
7 |
|
4,97-5,08 5,08-5,19 5,19-5,30 5,30-5,41 5,41-5,52 5,52-5,63 5,63-5,74 5,74-5,85 |
5,03 5,14 5,25 5,36 5,47 5,58 5,69 5,80 |
2 3 12 19 29 18 13 4 |
2 5 17 36 65 83 96 100 |
10,06 15,42 63,00 101,84 158,63 100,44 73,97 23,20 |
50,60 79,26 330,75 545,86 867,71 560,46 420,89 134,56 |
-0,4356 -0,3256 -0,2156 -0,1056 0,0044 0,1144 0,2244 0,3344 |
|
100 |
546,56 |
2990,09 |
Таблица 1.3
Вспомогательная таблица для вычисления
выборочных характеристик
|
|
|
|
|
|
8 |
9 |
10 |
11 |
|
-0,8712 -0,9768 -2,5872 -2,0064 0,1276 2,0592 2,9172 1,3376 |
0,37949 0,31805 0,55780 0,21188 0,00056 0,23557 0,65462 0,44729 |
-0,1653 -0,10356 -0,12026 -0,02237 0,00000 0,02695 0,14690 0,14957 |
0,07201 0,03372 0,025928 0,00236 0,00000 0,00308 0,03296 0,05002 |
|
0 |
2,80526 |
0,08808 |
0,22008 |
В таблице
![]() .
.
Пользуясь таблицей
1.3, вычислим среднюю арифметическую: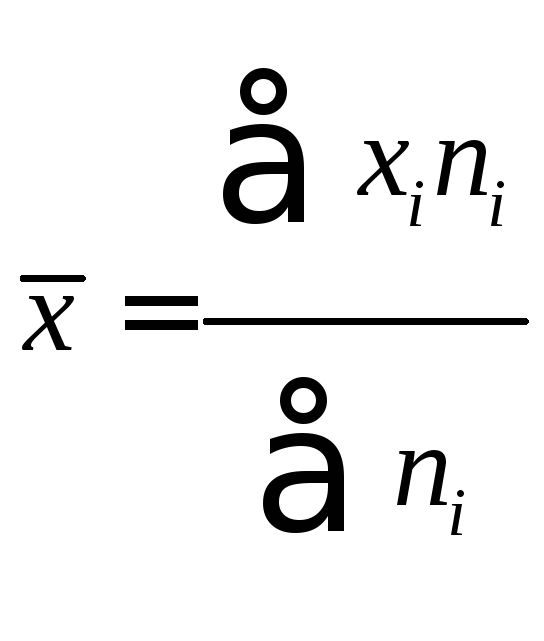 .
.
В нашем примере![]() млн.
млн.
руб. и характеризует среднее положение
наблюдаемых значений. Выборочный
центральный момент к-го порядка равен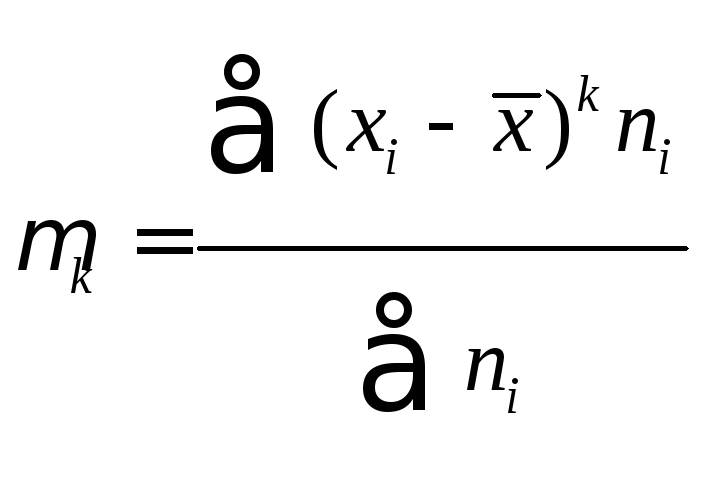 .
.
Для проверки правильности вычисления![]() и ввода в микрокалькулятор значений
и ввода в микрокалькулятор значений![]() ,
,![]() рассчитывают:
рассчитывают: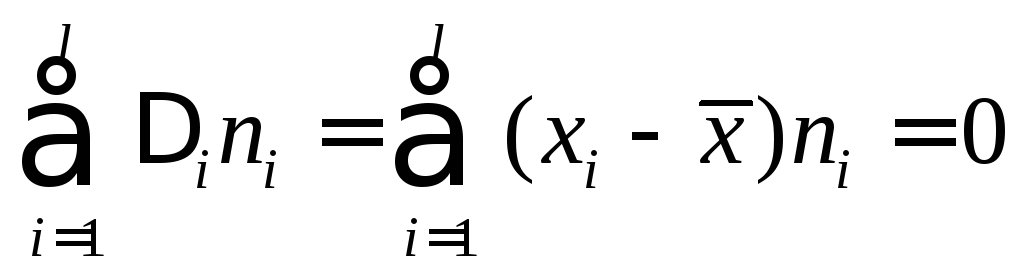
В нашем примере
тождество выполняется. В итоговой строке
столбца 4 табл. 1.3. имеем 0.
В данном примере
![]() .
.
Выборочная дисперсия
![]() равна
равна
центральному моменту второго порядка:
![]() =
=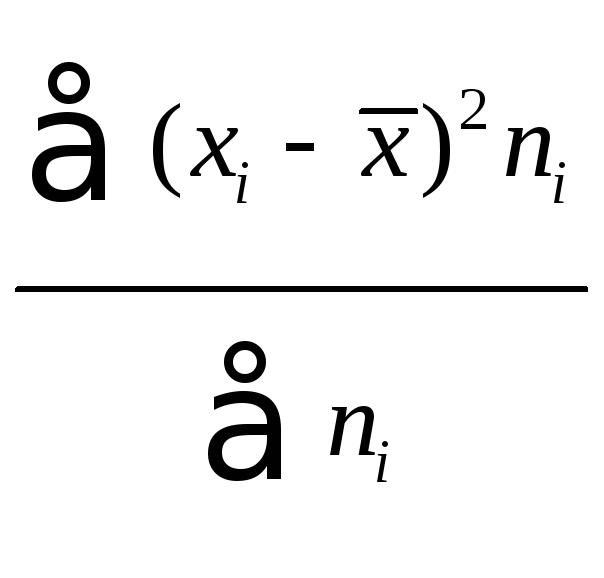 =
=![]() .
.
В нашем примере
![]() =0,028,
=0,028,
а выборочное среднее квадратичное
отклонение![]() млн.руб.
млн.руб.
Дисперсию можно
подсчитать и по-другому
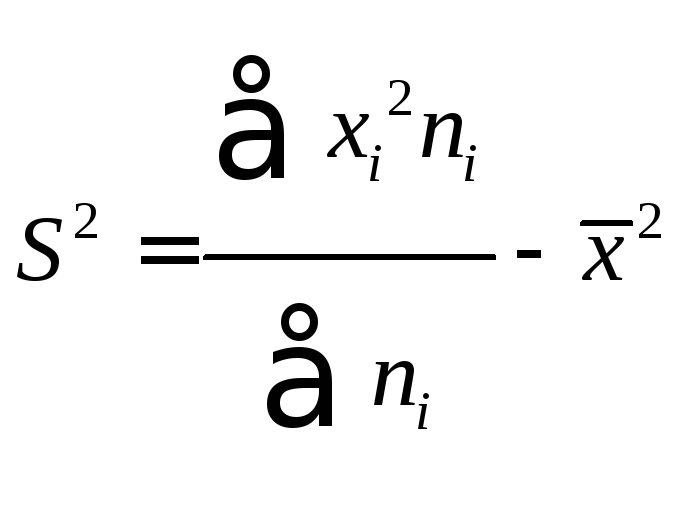
В нашем примере
![]()
Выборочные
коэффициенты асимметрии
![]() .
.![]()
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
Интервальный вариационный ряд и его характеристики
- Построение интервального вариационного ряда по данным эксперимента
- Гистограмма и полигон относительных частот, кумулята и эмпирическая функция распределения
- Выборочная средняя, мода и медиана. Симметрия ряда
- Выборочная дисперсия и СКО
- Исправленная выборочная дисперсия, стандартное отклонение выборки и коэффициент вариации
- Алгоритм исследования интервального вариационного ряда
- Примеры
п.1. Построение интервального вариационного ряда по данным эксперимента
Интервальный вариационный ряд – это ряд распределения, в котором однородные группы составлены по признаку, меняющемуся непрерывно или принимающему слишком много значений.
Общий вид интервального вариационного ряда
| Интервалы, (left.left[a_{i-1},a_iright.right)) | (left.left[a_{0},a_1right.right)) | (left.left[a_{1},a_2right.right)) | … | (left.left[a_{k-1},a_kright.right)) |
| Частоты, (f_i) | (f_1) | (f_2) | … | (f_k) |
Здесь k – число интервалов, на которые разбивается ряд.
Размах вариации – это длина интервала, в пределах которой изменяется исследуемый признак: $$ F=x_{max}-x_{min} $$
Правило Стерджеса
Эмпирическое правило определения оптимального количества интервалов k, на которые следует разбить ряд из N чисел: $$ k=1+lfloorlog_2 Nrfloor $$ или, через десятичный логарифм: $$ k=1+lfloor 3,322cdotlg Nrfloor $$
Скобка (lfloor rfloor) означает целую часть (округление вниз до целого числа).
Шаг интервального ряда – это отношение размаха вариации к количеству интервалов, округленное вверх до определенной точности: $$ h=leftlceilfrac Rkrightrceil $$
Скобка (lceil rceil) означает округление вверх, в данном случае не обязательно до целого числа.
Алгоритм построения интервального ряда
На входе: все значения признака (left{x_jright}, j=overline{1,N})
Шаг 1. Найти размах вариации (R=x_{max}-x_{min})
Шаг 2. Найти оптимальное количество интервалов (k=1+lfloorlog_2 Nrfloor)
Шаг 3. Найти шаг интервального ряда (h=leftlceilfrac{R}{k}rightrceil)
Шаг 4. Найти узлы ряда: $$ a_0=x_{min}, a_i=1_0+ih, i=overline{1,k} $$ Шаг 5. Найти частоты (f_i) – число попаданий значений признака в каждый из интервалов (left.left[a_{i-1},a_iright.right)).
На выходе: интервальный ряд с интервалами (left.left[a_{i-1},a_iright.right)) и частотами (f_i, i=overline{1,k})
Заметим, что поскольку шаг h находится с округлением вверх, последний узел (a_kgeq x_{max}).
Например:
Проведено 100 измерений роста учеников старших классов.
Минимальный рост составляет 142 см, максимальный – 197 см.
Найдем узлы для построения соответствующего интервального ряда.
По условию: (N=100, x_{min}=142 см, x_{max}=197 см).
Размах вариации: (R=197-142=55) (см)
Оптимальное число интервалов: (k=1+lfloor 3,322cdotlg 100rfloor=1+lfloor 6,644rfloor=1+6=7)
Шаг интервального ряда: (h=lceilfrac{55}{5}rceil=lceil 7,85rceil=8) (см)
Получаем узлы ряда: $$ a_0=x_{min}=142, a_i=142+icdot 8, i=overline{1,7} $$
| (left.left[a_{i-1},a_iright.right)) cм | (left.left[142;150right.right)) | (left.left[150;158right.right)) | (left.left[158;166right.right)) | (left.left[166;174right.right)) | (left.left[174;182right.right)) | (left.left[182;190right.right)) | (left[190;198right]) |
п.2. Гистограмма и полигон относительных частот, кумулята и эмпирическая функция распределения
Относительная частота интервала (left.left[a_{i-1},a_iright.right)) – это отношение частоты (f_i) к общему количеству исходов: $$ w_i=frac{f_i}{N}, i=overline{1,k} $$
Гистограмма относительных частот интервального ряда – это фигура, состоящая из прямоугольников, ширина которых равна шагу ряда, а высота – относительным частотам каждого из интервалов.
Площадь гистограммы равна 1 (с точностью до округлений), и она является эмпирическим законом распределения исследуемого признака.
Полигон относительных частот интервального ряда – это ломаная, соединяющая точки ((x_i,w_i)), где (x_i) – середины интервалов: (x_i=frac{a_{i-1}+a_i}{2}, i=overline{1,k}).
Накопленные относительные частоты – это суммы: $$ S_1=w_1, S_i=S_{i-1}+w_i, i=overline{2,k} $$ Ступенчатая кривая (F(x)), состоящая из прямоугольников, ширина которых равна шагу ряда, а высота – накопленным относительным частотам, является эмпирической функцией распределения исследуемого признака.
Кумулята – это ломаная, которая соединяет точки ((x_i,S_i)), где (x_i) – середины интервалов.
Например:
Продолжим анализ распределения учеников по росту.
Выше мы уже нашли узлы интервалов. Пусть, после распределения всех 100 измерений по этим интервалам, мы получили следующий интервальный ряд:
| i | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| (left.left[a_{i-1},a_iright.right)) cм | (left.left[142;150right.right)) | (left.left[150;158right.right)) | (left.left[158;166right.right)) | (left.left[166;174right.right)) | (left.left[174;182right.right)) | (left.left[182;190right.right)) | (left[190;198right]) |
| (f_i) | 4 | 7 | 11 | 34 | 33 | 8 | 3 |
Найдем середины интервалов, относительные частоты и накопленные относительные частоты:
| (x_i) | 146 | 154 | 162 | 170 | 178 | 186 | 194 |
| (w_i) | 0,04 | 0,07 | 0,11 | 0,34 | 0,33 | 0,08 | 0,03 |
| (S_i) | 0,04 | 0,11 | 0,22 | 0,56 | 0,89 | 0,97 | 1 |
Построим гистограмму и полигон:

Построим кумуляту и эмпирическую функцию распределения: 

Эмпирическая функция распределения (относительно середин интервалов): $$ F(x)= begin{cases} 0, xleq 146\ 0,04, 146lt xleq 154\ 0,11, 154lt xleq 162\ 0,22, 162lt xleq 170\ 0,56, 170lt xleq 178\ 0,89, 178lt xleq 186\ 0,97, 186lt xleq 194\ 1, xgt 194 end{cases} $$
п.3. Выборочная средняя, мода и медиана. Симметрия ряда
Выборочная средняя интервального вариационного ряда определяется как средняя взвешенная по частотам: $$ X_{cp}=frac{x_1f_1+x_2f_2+…+x_kf_k}{N}=frac1Nsum_{i=1}^k x_if_i $$ где (x_i) – середины интервалов: (x_i=frac{a_{i-1}+a_i}{2}, i=overline{1,k}).
Или, через относительные частоты: $$ X_{cp}=sum_{i=1}^k x_iw_i $$
Модальным интервалом называют интервал с максимальной частотой: $$ f_m=max f_i $$ Мода интервального вариационного ряда определяется по формуле: $$ M_o=x_o+frac{f_m-f_{m-1}}{(f_m-f_{m-1})+(f_m+f_{m+1})}h $$ где
(h) – шаг интервального ряда;
(x_o) – нижняя граница модального интервала;
(f_m,f_{m-1},f_{m+1}) – соответственно, частоты модального интервала, интервала слева от модального и интервала справа.
Медианным интервалом называют первый интервал слева, на котором кумулята превысила значение 0,5. Медиана интервального вариационного ряда определяется по формуле: $$ M_e=x_o+frac{0,5-S_{me-1}}{w_{me}}h $$ где
(h) – шаг интервального ряда;
(x_o) – нижняя граница медианного интервала;
(S_{me-1}) накопленная относительная частота для интервала слева от медианного;
(w_{me}) относительная частота медианного интервала.
Расположение выборочной средней, моды и медианы в зависимости от симметрии ряда аналогично их расположению в дискретном ряду (см. §65 данного справочника).
Например:
Для распределения учеников по росту получаем:
| (x_i) | 146 | 154 | 162 | 170 | 178 | 186 | 194 | ∑ |
| (w_i) | 0,04 | 0,07 | 0,11 | 0,34 | 0,33 | 0,08 | 0,03 | 1 |
| (x_iw_i) | 5,84 | 10,78 | 17,82 | 57,80 | 58,74 | 14,88 | 5,82 | 171,68 |
$$ X_{cp}=sum_{i=1}^k x_iw_i=171,68approx 171,7 text{(см)} $$ На гистограмме (или полигоне) относительных частот максимальная частота приходится на 4й интервал [166;174). Это модальный интервал.
Данные для расчета моды: begin{gather*} x_o=166, f_m=34, f_{m-1}=11, f_{m+1}=33, h=8\ M_o=x_o+frac{f_m-f_{m-1}}{(f_m-f_{m-1})+(f_m+f_{m+1})}h=\ =166+frac{34-11}{(34-11)+(34-33)}cdot 8approx 173,7 text{(см)} end{gather*} На кумуляте значение 0,5 пересекается на 4м интервале. Это – медианный интервал.
Данные для расчета медианы: begin{gather*} x_o=166, w_m=0,34, S_{me-1}=0,22, h=8\ \ M_e=x_o+frac{0,5-S_{me-1}}{w_me}h=166+frac{0,5-0,22}{0,34}cdot 8approx 172,6 text{(см)} end{gather*} begin{gather*} \ X_{cp}=171,7; M_o=173,7; M_e=172,6\ X_{cp}lt M_elt M_o end{gather*} Ряд асимметричный с левосторонней асимметрией.
При этом (frac{|M_o-X_{cp}|}{|M_e-X_{cp}|}=frac{2,0}{0,9}approx 2,2lt 3), т.е. распределение умеренно асимметрично.
п.4. Выборочная дисперсия и СКО
Выборочная дисперсия интервального вариационного ряда определяется как средняя взвешенная для квадрата отклонения от средней: begin{gather*} D=frac1Nsum_{i=1}^k(x_i-X_{cp})^2 f_i=frac1Nsum_{i=1}^k x_i^2 f_i-X_{cp}^2 end{gather*} где (x_i) – середины интервалов: (x_i=frac{a_{i-1}+a_i}{2}, i=overline{1,k}).
Или, через относительные частоты: $$ D=sum_{i=1}^k(x_i-X_{cp})^2 w_i=sum_{i=1}^k x_i^2 w_i-X_{cp}^2 $$
Выборочное среднее квадратичное отклонение (СКО) определяется как корень квадратный из выборочной дисперсии: $$ sigma=sqrt{D} $$
Например:
Для распределения учеников по росту получаем:
| $x_i$ | 146 | 154 | 162 | 170 | 178 | 186 | 194 | ∑ |
| (w_i) | 0,04 | 0,07 | 0,11 | 0,34 | 0,33 | 0,08 | 0,03 | 1 |
| (x_iw_i) | 5,84 | 10,78 | 17,82 | 57,80 | 58,74 | 14,88 | 5,82 | 171,68 |
| (x_i^2w_i) – результат | 852,64 | 1660,12 | 2886,84 | 9826 | 10455,72 | 2767,68 | 1129,08 | 29578,08 |
$$ D=sum_{i=1}^k x_i^2 w_i-X_{cp}^2=29578,08-171,7^2approx 104,1 $$ $$ sigma=sqrt{D}approx 10,2 $$
п.5. Исправленная выборочная дисперсия, стандартное отклонение выборки и коэффициент вариации
Исправленная выборочная дисперсия интервального вариационного ряда определяется как: begin{gather*} S^2=frac{N}{N-1}D end{gather*}
Стандартное отклонение выборки определяется как корень квадратный из исправленной выборочной дисперсии: $$ s=sqrt{S^2} $$
Коэффициент вариации это отношение стандартного отклонения выборки к выборочной средней, выраженное в процентах: $$ V=frac{s}{X_{cp}}cdot 100text{%} $$
Подробней о том, почему и когда нужно «исправлять» дисперсию, и для чего использовать коэффициент вариации – см. §65 данного справочника.
Например:
Для распределения учеников по росту получаем: begin{gather*} S^2=frac{100}{99}cdot 104,1approx 105,1\ sapprox 10,3 end{gather*} Коэффициент вариации: $$ V=frac{10,3}{171,7}cdot 100text{%}approx 6,0text{%}lt 33text{%} $$ Выборка однородна. Найденное значение среднего роста (X_{cp})=171,7 см можно распространить на всю генеральную совокупность (старшеклассников из других школ).
п.6. Алгоритм исследования интервального вариационного ряда
На входе: все значения признака (left{x_jright}, j=overline{1,N})
Шаг 1. Построить интервальный ряд с интервалами (left.right[a_{i-1}, a_ileft.right)) и частотами (f_i, i=overline{1,k}) (см. алгоритм выше).
Шаг 2. Составить расчетную таблицу. Найти (x_i,w_i,S_i,x_iw_i,x_i^2w_i)
Шаг 3. Построить гистограмму (и/или полигон) относительных частот, эмпирическую функцию распределения (и/или кумуляту). Записать эмпирическую функцию распределения.
Шаг 4. Найти выборочную среднюю, моду и медиану. Проанализировать симметрию распределения.
Шаг 5. Найти выборочную дисперсию и СКО.
Шаг 6. Найти исправленную выборочную дисперсию, стандартное отклонение и коэффициент вариации. Сделать вывод об однородности выборки.
п.7. Примеры
Пример 1. При изучении возраста пользователей коворкинга выбрали 30 человек.
Получили следующий набор данных:
18,38,28,29,26,38,34,22,28,30,22,23,35,33,27,24,30,32,28,25,29,26,31,24,29,27,32,24,29,29
Постройте интервальный ряд и исследуйте его.
1) Построим интервальный ряд. В наборе данных: $$ x_{min}=18, x_{max}=38, N=30 $$ Размах вариации: (R=38-18=20)
Оптимальное число интервалов: (k=1+lfloorlog_2 30rfloor=1+4=5)
Шаг интервального ряда: (h=lceilfrac{20}{5}rceil=4)
Получаем узлы ряда: $$ a_0=x_{min}=18, a_i=18+icdot 4, i=overline{1,5} $$
| (left.left[a_{i-1},a_iright.right)) лет | (left.left[18;22right.right)) | (left.left[22;26right.right)) | (left.left[26;30right.right)) | (left.left[30;34right.right)) | (left.left[34;38right.right)) |
Считаем частоты для каждого интервала. Получаем интервальный ряд:
| (left.left[a_{i-1},a_iright.right)) лет | (left.left[18;22right.right)) | (left.left[22;26right.right)) | (left.left[26;30right.right)) | (left.left[30;34right.right)) | (left.left[34;38right.right)) |
| (f_i) | 1 | 7 | 12 | 6 | 4 |
2) Составляем расчетную таблицу:
| (x_i) | 20 | 24 | 28 | 32 | 36 | ∑ |
| (f_i) | 1 | 7 | 12 | 6 | 4 | 30 |
| (w_i) | 0,033 | 0,233 | 0,4 | 0,2 | 0,133 | 1 |
| (S_i) | 0,033 | 0,267 | 0,667 | 0,867 | 1 | – |
| (x_iw_i) | 0,667 | 5,6 | 11,2 | 6,4 | 4,8 | 28,67 |
| (x_i^2w_i) | 13,333 | 134,4 | 313,6 | 204,8 | 172,8 | 838,93 |
3) Строим полигон и кумуляту

Эмпирическая функция распределения: $$ F(x)= begin{cases} 0, xleq 20\ 0,033, 20lt xleq 24\ 0,267, 24lt xleq 28\ 0,667, 28lt xleq 32\ 0,867, 32lt xleq 36\ 1, xgt 36 end{cases} $$ 4) Находим выборочную среднюю, моду и медиану $$ X_{cp}=sum_{i=1}^k x_iw_iapprox 28,7 text{(лет)} $$ На полигоне модальным является 3й интервал (самая высокая точка).
Данные для расчета моды: begin{gather*} x_0=26, f_m=12, f_{m-1}=7, f_{m+1}=6, h=4\ M_o=x_o+frac{f_m-f_{m-1}}{(f_m-f_{m-1})+(f_m+f_{m+1})}h=\ =26+frac{12-7}{(12-7)+(12-6)}cdot 4approx 27,8 text{(лет)} end{gather*}
На кумуляте медианным является 3й интервал (преодолевает уровень 0,5).
Данные для расчета медианы: begin{gather*} x_0=26, w_m=0,4, S_{me-1}=0,267, h=4\ M_e=x_o+frac{0,5-S_{me-1}}{w_{me}}h=26+frac{0,5-0,4}{0,267}cdot 4approx 28,3 text{(лет)} end{gather*} Получаем: begin{gather*} X_{cp}=28,7; M_o=27,8; M_e=28,6\ X_{cp}gt M_egt M_0 end{gather*} Ряд асимметричный с правосторонней асимметрией.
При этом (frac{|M_o-X_{cp}|}{|M_e-X_{cp}|} =frac{0,9}{0,1}=9gt 3), т.е. распределение сильно асимметрично.
5) Находим выборочную дисперсию и СКО: begin{gather*} D=sum_{i=1}^k x_i^2w_i-X_{cp}^2=838,93-28,7^2approx 17,2\ sigma=sqrt{D}approx 4,1 end{gather*}
6) Исправленная выборочная дисперсия: $$ S^2=frac{N}{N-1}D=frac{30}{29}cdot 17,2approx 17,7 $$ Стандартное отклонение (s=sqrt{S^2}approx 4,2)
Коэффициент вариации: (V=frac{4,2}{28,7}cdot 100text{%}approx 14,7text{%}lt 33text{%})
Выборка однородна. Найденное значение среднего возраста (X_{cp}=28,7) лет можно распространить на всю генеральную совокупность (пользователей коворкинга).
- Главная
- Полезные советы
- Построить интервальный статистический ряд и гистограмму распределения.
Построить интервальный статистический ряд и гистограмму распределения.
Для имеющейся совокупности опытных данных (выборки) требуется:
1) Построить интервальный статистический ряд и гистограмму распределения;
2) Вычислить выборочную среднюю, выборочную дисперсию, выборочное среднеквадратичное отклонение, коэффициент вариации;
3) Выбрать теоретический закон распределения.

Решение:
Для построения интервального ряда, определим по формуле Старджесса число интервалов: ![]()
Тогда величина интервала равна ![]() − разность между наибольшим и наименьшим значениями признака.
− разность между наибольшим и наименьшим значениями признака.
Отсюда имеем: ![]()
По этим данным составим интервальный статистический ряд:

Выборочное среднее определим по формуле среднего арифметического взвешенного:
![]()
Выборочная дисперсия равна:
![]()
Выборочное среднеквадратичное отклонение равно квадратному корню из дисперсии: ![]()
Коэффициент вариации равен: ![]()
Полученному статистическому ряду соответствует нормальное распределение. В качестве теоретического закона распределения используем нормальное распределение с математическим ожиданием 15,148 и дисперсией 19,79.
Если испытываете трудности в написании курсовой работы по статистике, оформите заявку и Вы узнаете сроки и стоимость работы. Цена – от 99 рублей.
Поможем решить контрольную, написать реферат, курсовую и диплом от 800р
Узнать стоимость
Статистическое распределение выборки
Содержание:
- Примеры использования формул и таблиц для решения практических задач
- Статистический интервальный ряд распределения
Предположим случай, когда из генеральной совокупности извлекается некоторая выборка, при этом каждому значению соответствует некоторый параметр, означающий количество раз, когда появлялось данное значение. Здесь $x_1$ было зафиксировано $n_1$ раз, $x_2$ было обнаружено $n_2$$x_k$ выявлено $n_k$. При этом
$sum_{i=1}^{k}n_i=n$
Где n — объём рассматриваемой выборки.
Определение 1
Используется следующая терминология: $x_k$ носят наименование вариантов, а последовательность таких вариантов, зафиксированный по возрастанию именуется вариационным рядом. Количество наблюдений каждого из вариантов носят название частот. При этом частное частот и выборки называют относительными частотами.
Определение 2
Статистическое распределение —это название всего набора вариантов и частот, которые с ними соотносятся. Чаще всего задаётся с помощью специальной таблицы, где представлены частоты, а также интервалы им соответствующие.
| $x_1$ | $x_2$ | … | $x_k$ |
| $n_1$ | $n_2$ | … | $n_k$ |
| $frac{n_1}{n}$ | $frac{n_2}{n}$ | $frac{n_k}{n}$ |
Здесь в первой строке представлены варианты, во второй частоты, в третьеq взяты относительные частоты.
Для определения размера интервала используется следующее выражение:
$d=frac{x_{max}- x_{min}}{1+3,332cdot lg n}$
Здесь $x_{max}$, $x_{min}$ наибольшее и наименьшее значения ряда вариантов, а n характеризуем объём выборки.
Примеры использования формул и таблиц для решения практических задач
Пример 1
В ходе проведения измерений в однородных группах, были определены следующие значения выборки: 71, 72, 74, 70, 70, 72, 71, 74, 71, 72, 71, 73, 72, 72, 72, 74, 72, 73, 72, 74. Необходимо использовать данные значения, что определить ряд распределения частот и ряд распределения относительных частот.
Решение.
1) Составим статистический ряд распределения частот:
| xi | 70 | 71 | 72 | 73 | 74 |
| ni | 2 | 4 | 8 | 2 | 4 |
2) Рассчитаем суммарный размер выборки: n=2+4+8+2+4=20. Определим относительные частоты, для этого используем формулы: ni/n=wi: wi=2/20=0.1; w2=4/20=0.2; w3=0.4; w4=4/20=0.1; w5=2/20=0.2. Теперь зафиксируем в таблице распределение относительных частот:
| xi | 70 | 71 | 72 | 73 | 74 |
| wi | 0.1 | 0.2 | 0.4 | 0.1 | 0.2 |
Контрольная сумма должна равняться единице: 0,1+0,2+0,4+0,1+0,2=1.
Полигон частот
Название «полигоном частот» применяют для обозначения ломаной линии, каждый отрезок, которой соединяют точки $(х_1,n_1),(х_2,n_2),…,(х_k,n_k)$. Для построения на графике полигона частот по оси абсцисс отмечают варианты $х_2$, при этом на оси ординат отсчитывают– соответствующие частоты $n_i$. Когда полученные точки $(х_i,n_i)$ соединяются с помощью отрезков, то автоматически получают полигон частот.
Статистический интервальный ряд распределения.
Статистическим дискретным рядом (или эмпирической функцией распределения) обычно пользуются, если число различающихся вариант в полученной выборке не слишком большое. Также применение возможно, когда дискретность имеет важное значение для экспериментатора. В тех случаях, когда важный для задачи признак генеральной совокупности Х распределяется непрерывным образом, либо его дискретность нет возможности учесть, то варианты предпочтительнее всего группировать, чтобы получить интервалы.
Статистическое распределение допустимо задавать в том числе в качестве последовательности интервалов и частот, соответствующих этим интервалам. При это за частоту какого-либо интервала принимается сумма всех частот, вошедших в данный интервал.
Особенно следует отметить ,что $h_i-h_{i-1}=h$ при всех i, т.е. группировка проводится с равным шагом h. Также в вопросе группировки можно ориентироваться на ряд полученных опытным путём рекомендацийу, касающихся таких параметров, как а, k и $h_i$:
1. $Rраз_{мах}=X_{max}-X_{min}$
2. $h=R/k$; k-число групп
3.$ kgeq 1+3.321lgn$ (формула Стерджеса)
4. $a=x_{min}, b=x_{max}$
5.$ h=a+h_i, i=0,1…k$
Определённую в ходе решения задачи группировку удобнее всего скомпоновать и перевести в вид специальной таблицы, которая также может именоваться — «статистический интервальный ряд распределения»:
| Интервалы группировки | [h0;h1) | [h1;h2) | … | [hk-2;hk-1) | [hk-1;hk) |
| Частоты | n1 | n2 | … | nk-1 | nk |
Таблицу подобного вида можно сделать, поменяв частоты $n_i$ на относительные частоты:
| Интервалы группировки | [h0;h1) | [h1;h2) | … | [hk-2;hk-1) | [hk-1;hk) |
| Отн. частоты | w1 | w2 | … | wk-1 | wk |

236
проверенных автора готовы помочь в написании работы любой сложности
Мы помогли уже 4 396 ученикам и студентам сдать работы от решения задач до дипломных на отлично! Узнай стоимость своей работы за 15 минут!
Пример 2
На склад пришла крупная партия деталей. Из них методом случайного отбора взято 50 экземпляров. Рассматривая изделия по одному, особенно интересующему признаку — размеру, определённому с точностью до 1 см, получим следующий вариационный ряд: 22, 47, 26, 26, 30, 28, 28, 31, 31, 31, 32, 32, 33, 33, 33, 33, 34, 34, 34, 34, 34, 35, 35, 36, 36, 36, 36, 36, 37, 37, 37, 37, 37, 37, 38, 38, 40, 40, 40, 40, 40, 41, 41, 43, 44, 44, 45, 45, 47, 50. Требуется произвести расчёт и определить статистический интервальный ряд распределения.
Решение
Найдём параметры выборки используя сведения из условия задачи.
$k geq1+3,321cdot lg50=1+3.32lg(5cdot10)=1+3.32(lg5+lg10)=6.6$
Получили a=22, k=7, h=(50-22)/7=4, hi=22+4i, i=0,1,…,7.
| Интервалы группировки | 22-26 | 26-30 | 30-34 | 34-38 | 38-42 | 42-46 | 46-50 |
| Частоты | 1 | 4 | 10 | 18 | 9 | 5 | 3 |
| Отн. частоты | 0.02 | 0.08 | 0.2 | 0.36 | 0.18 | 0.1 | 0.06 |
Десятичные логарифмы от 1 до 10
| n | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| lnn≈ | 0 | 0.3 | 0.48 | 0.6 | 0.7 | 0.78 | 0.85 | 0.9 | 0.95 | 1 |
Не получается написать работу самому?
Доверь это кандидату наук!
2.2. Интервальный вариационный ряд
Предпосылкой построения интервального вариационного ряда (ИВР) является тот факт, что исследуемая величина ![]() принимает слишком много различных значений
принимает слишком много различных значений ![]() . Зачастую ИВР появляется в результате
. Зачастую ИВР появляется в результате
изучения непрерывной характеристики объектов. Типично – это время, масса, размеры и другие физические величины.
Вспоминаем Константина, который замерял время на лабораторной работе и Фёдора, который взвешивал помидоры.
В таких ситуациях затруднительно либо невозможно применить тот же подход, что для дискретного ряда. Это связано с тем, что ВСЕ варианты ![]() различны (во многих случаях). И
различны (во многих случаях). И
даже если встречаются совпадающие значения, например, 50 грамм и 50 грамм, то связано это с округлением, а фактически значения
всё равно отличаются хоть какими-то микрограммами.
Поэтому здесь используется другой подход, а именно определяется интервал,
в пределах которого варьируются значения ![]() , затем этот интервал делится на частичные интервалы (обычно равной длины
, затем этот интервал делится на частичные интервалы (обычно равной длины
![]() ) и по каждому частичному интервалу
) и по каждому частичному интервалу
подсчитываются частоты ![]() (либо
(либо ![]() ) – количество вариант, которые в него попали.
) – количество вариант, которые в него попали.
Если варианта попала на «стык» интервалов, то её относят к старшему интервалу.
Интервальный вариационный ряд (ИВР) статистической совокупности – это
упорядоченное множество смежных интервалов и соответствующие им частоты, в сумме равные
объёму совокупности. Дабы не плодить лишних букв и индексов, я никак не обозначил эти
интервалы. Придирчивый читатель, к слову, наверняка заметил, что через ![]() я обозначаю как исходные варианты, так и значения сгруппированного
я обозначаю как исходные варианты, так и значения сгруппированного
ряда.
Следует отметить, что исследуемая характеристика не обязана быть непрерывной, и мы как раз начнём с такой задачи:
Пример 6
По результатам исследования цены некоторого товара в различных торговых точках города, получены следующие данные (в денежных
единицах):
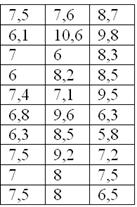
Составить вариационный ряд, построить гистограмму частот, гистограмму и полигон относительных частот + бонус:
эмпирическую функцию распределения.
Решение: очевидно, что перед нами выборочная совокупность
объема ![]() , и вопрос номер
, и вопрос номер
один: какой ряд составлять – дискретный или интервальный? Заметьте, что в
вопросе задачи ничего не сказано о характере ряда. Строго говоря, цены дискретны и среди них даже есть одинаковые. Однако они
могут быть округлены, да и разброс цен довольно велик. Поэтому здесь целесообразно провести интервальное разбиение.
Начнём с экстремальной ситуации, когда у вас под рукой нет Экселя или другого подходящего программного обеспечения. Только
ручка, карандаш, тетрадь и калькулятор.
Тактика действий похожа на работу с дискретным вариационным рядом. Сначала
окидываем взглядом предложенные числа и определяем примерный интервал, в который вписываются эти значения. «Навскидку» все
значения заключены в пределах от 5 до 11. Далее делим этот интервал на удобные подынтервалы, в данном случае
напрашиваются промежутки единичной длины. Записываем их на черновик:
![]()
Теперь начинаем вычёркивать числа из исходного списка и записываем их в соответствующие колонки нашей импровизированной
таблицы:
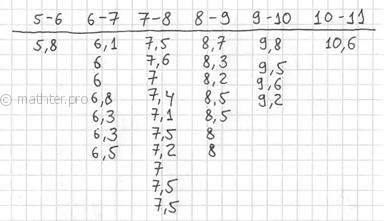
После этого находим самое маленькое число в левой колонке (минимальное значение) и самое большое число – в правой
(максимальное значение). Тут даже ничего искать не пришлось, честное слово, не нарочно получилось:)
![]() ден. ед. – не забываем указывать
ден. ед. – не забываем указывать
размерность!
Вычислим размах вариации:
![]() ден. ед. – длина общего
ден. ед. – длина общего
интервала, в пределах которого варьируется цена.
Теперь его нужно разбить на частичные интервалы. Сколько интервалов рассмотреть? По умолчанию на этот счёт
существует формула Стерджеса:
![]() , где
, где ![]() – десятичный логарифм* от объёма выборки и
– десятичный логарифм* от объёма выборки и
![]() – оптимальное количество
– оптимальное количество
интервалов, при этом результат округляют до ближайшего левого целого значения.
* есть на любом более или менее приличном калькуляторе.
В нашем случае получаем: ![]() интервалов.
интервалов.
Следует отметить, что правило Стерджеса носит рекомендательный, но не обязательный характер. Нередко в условии
задачи прямо сказано, на какое количество интервалов следует проводить разбиение (на 4, 5, 6, 10 и т.д.), и тогда следует
придерживаться именно этого указания.
Длины частичных интервалов могут быть различны, но в большинстве случаев использует равноинтервальную
группировку:
![]() – длина частичного интервала. В
– длина частичного интервала. В
принципе, здесь можно было не округлять и использовать длину 0,96, но удобнее, ясен день, 1.
И коль скоро мы прибавили 0,04, то по пяти частичным интервалам получается «перебор»: ![]() . Посему от самой малой варианты
. Посему от самой малой варианты ![]() отмеряем влево 0,1 влево (половину «перебора») и к
отмеряем влево 0,1 влево (половину «перебора») и к
значению 5,7 начинаем прибавлять по ![]() ,
,
получая тем самым частичные интервалы. При этом сразу рассчитываем их середины ![]() (например,
(например, ![]() ) – они требуются почти во всех тематических задачах:
) – они требуются почти во всех тематических задачах:
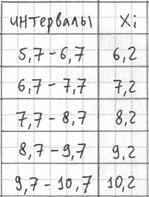
– убеждаемся в том, что самая большая варианта ![]() вписалась в последний частичный интервал и отстоит от его правого конца на
вписалась в последний частичный интервал и отстоит от его правого конца на
0,1.
Далее подсчитываем частоты по каждому интервалу. Для этого в черновой таблице обводим значения, попавшие в тот или
иной интервал, подсчитываем их количество и вычёркиваем:
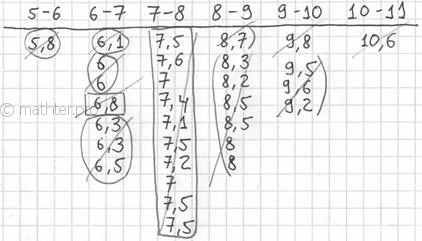
Так, значения из 1-го интервала я обвёл овалами (7 штук) и вычеркнул, значения из 2-го интервала – прямоугольниками (11
штук) и вычеркнул и так далее. Варианта ![]() попала на «стык» интервалов и, согласно озвученному выше правилу, её следует
попала на «стык» интервалов и, согласно озвученному выше правилу, её следует
отнести к последующему интервалу ![]() .
.
В результате получаем интервальный вариационный ряд:
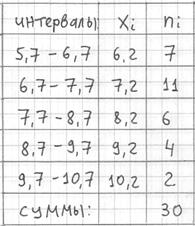
при этом обязательно убеждаемся в том, что ничего не потеряно:
![]() , ОК.
, ОК.
…Да, кстати, все ли представили свой любимый товар, чтобы было интереснее разбирать это длинное решение? J
Точно также как и в дискретном случае, интервальный вариационный ряд можно
(и нужно) изобразить графически. И здесь у нас весьма большое разнообразие. Но сначала добавим в таблицу дополнительные
столбцы и продолжим расчёты:
По каждому интервалу рассчитываем (не тушуемся): плотность частот ![]() , относительные частоты
, относительные частоты ![]() (округляем их до 2 знаков после запятой), а также плотность относительных
(округляем их до 2 знаков после запятой), а также плотность относительных
частот ![]() . Поскольку длина частичного
. Поскольку длина частичного
интервала ![]() , то вычисления заметно
, то вычисления заметно
упрощаются:
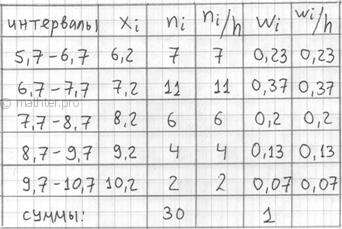
Если интервалы имеют разные длины ![]() , то
, то
при нахождении плотностей каждую частоту нужно разделить на длину своего интервала: ![]() . Но у нас группировка равноинтервальная, да не
. Но у нас группировка равноинтервальная, да не
абы какая, а с единичным частичным интервалом. Дело за чертежами. Один за другим:
 2.2.1. Гистограммы
2.2.1. Гистограммы
 2.1.2. Эмпирическая функция распределения
2.1.2. Эмпирическая функция распределения
| Оглавление |
